Яндекс.Документы: как использовать онлайн, создавать и сохранять файлы
Яндекс.Документы – это бесплатный российский онлайн сервис, запущенный в апреле 2021 года. Является достойной альтернативой Google Docs и офисному пакету Microsoft Office, не уступает им по удобству использования и функциональным возможностям.
Сегодня мы разберемся, как работать с документами, таблицами и презентациями в Яндекс.Документах.
Реклама: 2Vtzqxi7Yrq
Читайте также: ТОП-10 курсов по копирайтингу для начинающих
Как зайти в Яндекс.Документы
Чтобы попасть в Яндекс.Документы, нужно авторизоваться и нажать на пункт «Диск» в правом верхнем углу своего профиля.
Далее выбираем в верхнем меню «Документы».
Второй вариант попасть в Яндекс.Документы – ввести в адресную строку браузера «docs.yandex.ru» (без кавычек).
Откроется окно со списком папок с левой стороны и пятью значками в основном поле, для создания, открытия и загрузки файлов трех видов – текстовых документов, электронных таблиц и презентаций мультимедиа.
Как работать в Яндекс Документах
Редактор документов предназначен для работы с текстовыми файлами – их можно создавать, загружать, скачивать, править, сохранять и распечатывать, открывать к ним общий доступ.
Как создать или загрузить документ
Чтобы создать документ, нужно нажать на значок «Документ» в белом поле окна (такой вид окно имеет только на начальном этапе работы, позже там появятся значки созданных и загруженных документов).
Или нажать на кнопку «Создать» и в раскрывшемся списке выбрать «Документ»:
Откроется окно с предложением указать название нового документа. После ввода названия, нажимаем на кнопку «Создать».
Созданный документ откроется в другой вкладке браузера, а в главном окне отобразится значок созданного документа.
Для загрузки уже существующего документа с компьютера нажмите на кнопку загрузки – она располагается в верхней части окна и выглядит как короткая черная стрелка, направленная вверх. Или нажать кнопку «Создать» и в открывшемся списке выбрать пункт «Загрузить».
Находим на компьютере нужный файл и нажимаем кнопку «Открыть».
Далее нажимаем на кнопку «Загрузить». В нижнем правом углу появилось окно загрузки, а значок файла отобразился в списке документов.
Отображение файлов можно настраивать как в обычной папке, щелкнув по кнопке настройки и выбрав из списка нужный вид. Существует три доступных варианта – плитка (по умолчанию), крупная плитка и список.
При нажатии на три вертикальные точки в верхнем правом углу открывается меню, в котором можно выбирать, какие файлы будут отображаться в папке: все существующие на данный момент, только те, которые созданы или загружены владельцем Яндекс-аккаунта, или только чужие файлы, которыми с ним поделились другие пользователи.
Аналогичные опции доступны для таблиц, презентаций и сканов.
Как редактировать документы
Окно документа имеет структуру, схожую с MS Word, содержит в своем составе рабочее поле (1), меню в виде ленты (2), горизонтальную (3) и вертикальную (4) линейки, строку состояния (5).
Но есть и отличия – по бокам располагаются вертикальные панели инструментов, которые в Word отсутствуют.
В левой части верхней строки размещены несколько кнопок: «Документы» – для быстрого выхода в главное окно документов на Яндекс.Диске (1), «Сохранить» (2), «Напечатать файл» (3), «Отменить» (4) и «Вернуть» (5). Посередине отображается название документа (6), а справа – имя владельца (7).
Инструменты «Копировать» и «Вставить» выделены в отдельный блок, примыкающий к ленте с левой стороны.
Под именем автора расположена кнопка «Параметры вида», позволяющая настраивать вид окна редактора, включать и выключать отдельные элементы.
При нажатии на кнопку открывается меню, разделенное на три части. В первой части – команды для скрытия горизонтальной панели инструментов (под верхним меню), строки состояния и линеек. Используя опцию «Масштаб» можно менять масштаб отображения документа вручную (с шагом 10%), нажимая на «–» (уменьшение) или «+» (увеличение). При выборе «По размеру документа» автоматически уменьшится масштаб страницы (до 33%) и она полностью отобразится на экране. «По ширине» – документ растянется по ширине рабочего окна.
При выборе «По размеру документа» автоматически уменьшится масштаб страницы (до 33%) и она полностью отобразится на экране. «По ширине» – документ растянется по ширине рабочего окна.
Главное меню
Главное меню состоит из 5 вкладок, в каждой из который сгруппированы рабочие инструменты.
При наведении курсора на инструмент появляется всплывающая подсказка с его названием.
Вкладка «Главная»
Панель разделена на 3 блока, в соответствии с функциональным назначением инструментов. Первый блок предназначен для работы со шрифтами: с его помощью можно задавать тип, размер, начертание и цвет шрифта, добавлять верхние и нижние символы. Здесь же находятся инструменты для быстрого увеличения / уменьшения размера шрифта (с шагом – 2 пт.), изменения регистра и выделения цветом выбранных фрагментов.
Инструменты второго блока позволяют работать со списками (маркированными, нумерованными и многоуровневыми), выравнивать текст на странице (по левому краю / по центру / по правому краю / по ширине), уменьшать и увеличивать отступ, задавать значение межстрочного интервала. Присутствуют кнопка для включения / отключения непечатных символов и инструмент для задания фонового цвета абзаца.
Присутствуют кнопка для включения / отключения непечатных символов и инструмент для задания фонового цвета абзаца.
В левой части третьего блока располагаются 4 инструмента: «Очистить стиль», «Скопировать стиль», «Изменение цветовой схемы» и «Слияние» (из файла и по URL), правую часть занимают стили.
При нажатии на стрелку раскрывается список доступных стилей. С их помощью можно добавлять заголовки разного уровня (от 1 до 9), выбирать стиль названий, цитат, верхних и нижних колонтитулов, сносок.
Вкладка «Вставка»
Инструменты разбиты на 9 групп – по типам объектов, доступных для вставки в документ. Они обеспечивают вставку пустых страниц и разрывов (1), таблиц (2), изображений, диаграмм и фигур (3), комментариев и гиперссылок (4), колонтитулов, даты и времени (5), надписей и элементов Text Art (6), уравнений и символов (7), буквиц (8), элементов управления с содержимым (9).
Вкладка «Макет»
Первый блок содержит инструменты для задания параметров документа – полей, ориентации (книжная / альбомная) и размера (формат А4, А5 и др. ) страницы, а также для добавления в документ колонок, разрывов (страниц, колонок, разделов) и нумерации строк, с возможностью выбора вариантов.
) страницы, а также для добавления в документ колонок, разрывов (страниц, колонок, разделов) и нумерации строк, с возможностью выбора вариантов.
Второй блок позволяет работать с объектами – выравнивать их (по центру страницы, середине документа, верхнему / нижнему /правому /левому краю), группировать, переносить на передний / задний план, задавать положение относительно текста (в тексте, за текстом, по контуру и т. д.).
Третий блок представлен одним инструментом, предназначенным для задания текстовой или графической подложки – фона документа.
Вкладка «Ссылки»
Позволяет получать ссылки на заголовки и подзаголовки с их автоматическим размещением в начале документа (1), делать вставку обычных и концевых сносок (2), добавлять гиперссылки и закладки (3), вставлять названия таблиц, рисунков и уравнений, перекрестных ссылок на страницы и абзацы, ссылок на иллюстрации (4).
В первом блоке содержится также кнопка «Обновить» – документа целиком или отдельной страницы.
Вкладка «Совместная работа»
Инструмент (1) позволяет задавать режим совместного редактирования документа – быстрый (все изменения сохраняются автоматически в режиме реального времени) или строгий (изменения сохраняются только после нажатия кнопки «Сохранить»).
Присутствуют инструменты добавления, удаления и решения комментариев (2), отслеживания и отображения происходящих изменений, перехода к предыдущему и следующему изменению, принятия и отклонение текущих изменений (3), сравнения документов из файла или с URL-адреса (4).
Вкладка «Файл»
Открывает доступ к списку команд («Закрыть меню», «Сохранить», «Скачать как», «Печатать») и ряду опций. По умолчанию открывается на разделе «Дополнительные параметры», где путем установки / снятия галочки можно включать и отключать отображение комментариев, изменение при рецензировании, проверку орфографии и др.
В разделе «Сведения о документе» содержатся: статистика (количество страниц, абзацев, слов, символов с пробелами и без), сведения об авторе и времени последнего изменения, данные о версии редактора и месте размещения документа.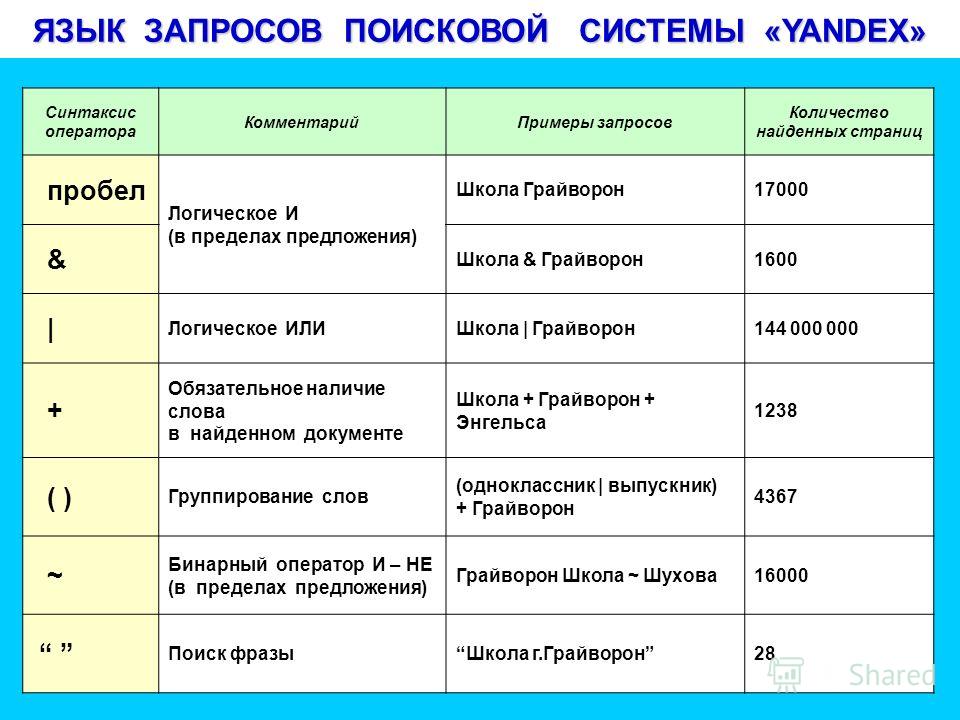
Раздел «Справка» содержит материалы по работе с редактором.
Контекстное меню
Быстрый доступ к основным командам можно получить из контекстного меню. Для доступа к нему нужно нажать на правую кнопку мыши.
Контекстное меню доступно также при работе с объектами. Набор команд зависит от типа выделенного объекта.
Левая боковая панель
Содержит пять элементов: «Поиск» (1), Комментарии» (2), «Навигация» (3), «Обратная связь и поддержка» (4), «О программе» (5).
Инструмент «Поиск» позволяет производить внутренний поиск в документе, с выделением полученного результата. Можно искать слова и выражения с учетом регистра (значок шестеренки слева от текстового поля – доступ к настройкам поиска) и делать замену, щелкнув по пункту «Заменить».
Под полем поиска откроется поле замены. Заменять можно все найденные фрагменты («Заменить все») или по отдельности («Заменить»), осуществляя переход между ними (стрелки вправо и влево).
Инструмент «Комментарий» служит для открытия формы «Комментарии».
При нажатии на пункт, расположенный в нижней части формы «Добавить комментарий к документу» откроется текстовое поле. Чтобы добавить комментарий, нужно ввести его в текстовое поле и нажать на кнопку «Добавить».
Инструмент «Навигация» открывает окно со списком существующих в документе заголовков, для быстрого перехода между ними.
Посмотрим, как это работает на примере загруженного документа, в котором есть один заголовок первого уровня и два заголовка – второго уровня. При нажатии на заголовок в списке осуществляется быстрый переход к нему в тексте. Чтобы закрыть окно, нужно повторно нажать на инструмент.
«Обратная связь и поддержка» – открывает в отдельном окне форму обратной связи для запросов в службу поддержки.
«О программе» – справочная информация о компании-разработчике редактора – адрес и контактные данные.
Правая вертикальная панель
Содержит 8 иконок, которые становятся активными в момент работы с элементом определенного типа: абзацами (1), таблицами (2), рисунками (3), колонтитулами (4), фигурами (5), диаграммами (5), буквицами (7) и файлами при их слиянии (8). При этом слева от панели открывается окно с полным набором инструментов, предназначенных для работы с текущим элементом.
При наборе и редактировании текста отображается окно для работы с абзацами (оно же появляется по умолчанию при открытии документа).
Если, например, добавить таблицу, включится вторая иконка, а слева от панели откроется окно для редактирования таблиц. Аналогично – с другими объектами, будут открываться окна редактирования, соответственно их типу.
Строка состояния
Располагается в нижней части, указывает номер текущей страницы и информирует о сохранении изменений. В правой части содержит несколько инструментов – некоторые из них дублируются из главного меню.
Рассмотрим их поближе. Слева отображается информация о текущем языке документа (1), а значок в виде глобуса открывает список доступных языков (2). Далее располагаются инструменты для проверки орфографии (3) и отслеживания изменений (4). В правой части инструменты размещены настройки вида документа: по размеру страницы (5), по ширине (6) и масштаб (7).
Слева отображается информация о текущем языке документа (1), а значок в виде глобуса открывает список доступных языков (2). Далее располагаются инструменты для проверки орфографии (3) и отслеживания изменений (4). В правой части инструменты размещены настройки вида документа: по размеру страницы (5), по ширине (6) и масштаб (7).
Как скачать документ
Чтобы скачать документ, нужно подвести курсор к правому верхнему углу и нажать на появившиеся три вертикальные точки (либо правой кнопкой мыши кликнуть по значку). В открывшемся меню выбрать пункт «Скачать». Начнется скачивание файла в соответствии с настройками браузера – в папку «Загрузки» либо в папку, назначенную пользователем.
Чтобы поделиться ссылкой на файл, нужно подвести курсор к файлу и щелкнуть по появившемуся значку.
Откроется окно настройки доступа, где можно скопировать ссылку на загруженный файл, предварительно указав права доступа – «Просмотр» или «Редактирование». В первом случае другие пользователи смогут только просматривать файл, а во втором – получат возможность вносить в него изменения.
В том же окне можно задавать настройки безопасности (устанавливать срок действия ссылки и/или запрещать скачивание), но они доступны только на платном тарифе.
Пользователь может делиться файлом сразу после его загрузки с компьютера на Яндекс.Диск – кнопка «Поделиться» появляется в окне загрузки.
Таблицы
Яндекс.Документы позволяют работать с электронными таблицами. Доступно большинство операций, предусмотренных в MS Excel.
Как создать или загрузить таблицу
Чтобы создать таблицу, нужно нажать на кнопку «Создать» и выбрать пункт «Таблицу» либо кликнуть по значку «Таблица» справа, если создается первый файл в папке.
Откроется окно с предложение указать название таблицы, вписываем и нажимаем кнопку «Создать».
Окно редактора открывается в новой вкладке. В папке появляется значок созданного файла.
Появилась кнопка «Новая таблица» в верхней правой части окна, которую также можно использовать для создания новых файлов.
Чтобы загрузить таблицу с компьютера, нужно нажать на кнопку «Создать» и выбрать пункт «Загрузить» либо по кликнуть по кнопке загрузки в правой части окна.
Для загрузки в редактор файлов xlsx с Яндекс.Диска нужно последовательно нажать на кнопку «Создать» и выбрать пункт «Загрузить» или кликнуть на «Открыть из Диска».
Как работать в таблицах
Структура Яндекс.Таблицы напоминает структуру таблицы в Excel и содержит почти все инструменты последней: разбитую на ячейки рабочую область, с нумерацией строк и столбцов (6), меню ленточного типа (2), верхнюю панель инструментов (3), поле имени (7), строку формул (8) и строку состояния (12).
По аналогии с текстовым редактором, инструменты «Копировать» и «Вставить» вынесены в отдельный блок (4), присутствуют кнопка настройки вида (5), вертикальные левая (9) и правая (10) панели инструментов, окно редактирования текущего элемента (11).
Верхняя строка (1) таблицы по структуре полностью копирует верхнюю строку текстового документа, на левой вертикальной панели (9) инструмент «Навигация» заменен на «Проверку орфографии», состав правой вертикальной панели (10) изменен в соответствии с типами элементов, с которыми можно работать в среде электронной таблицы.
Главное меню
Рассмотрим основные инструменты главного меню.
Вкладка «Главная»
Содержит инструменты для редактирования ячеек: работа со шрифтами (1), задание положение текста в ячейке (2), суммирование содержимого ячеек и задание диапазонов (3), сортировка элементов по возрастанию / убыванию и с помощью фильтра (4). С использованием блока 5 можно задавать формат данных (числовой, процентный, финансовый и т. д.) и увеличивать / уменьшать разрядность чисел. Блок 6 предназначен для быстрой вставки и удаления ячеек. В 7 блоке содержатся инструменты для очистки формата, копирования стиля, условного форматирования и форматирования по шаблону таблицы. Здесь же располагается список стилей ячеек, который раскрывается при нажатии стрелки справа.
Вкладка «Вставка»
Содержит список объектов, которые можно добавлять в таблицу – сводные таблицы, таблицы, изображения, фигуры и т. д.
В нижней правой части некоторых значков присутствуют стрелки – это означает, что есть выбор вариантов. Например, при добавлении изображения можно выбирать источник: из файла или по URL.
Например, при добавлении изображения можно выбирать источник: из файла или по URL.
А при нажатии на инструмент «Диаграмма» открывается список, где можно выбрать вид графического представления данных – графики, линейные и круговые диаграммы, гистограммы и пр.
Вкладка «Макет»
Позволяет задавать вид таблицы (поля, ориентацию и пр.), добавлять колонтитулы и указывать параметры печати. Содержит инструменты для работы с группами объектов и список цветовых схем.
Вкладка «Формулы»
Содержит инструменты для работы с функциями и формулами – математическими, финансовыми и др.
Каждый инструмент содержит список доступных вариантов. Например, при нажатии на стрелку под значком «Автосумма» открывается список, в котором можно выбрать функции для вычисления суммы элементов выбранного диапазона (СУММ), их среднего значения (СРЗНАЧ), минимального элемента (МИН) и т. д.
Вкладка «Данные»
Служит для получения данных из локальных файлов и по URL, позволяет настраивать сортировку, делить текст ячейки по столбцам, удалять дубликаты строк, проверять данные по указанным параметрам, делать группировку / разгруппировку строк и столбцов.
Вкладка «Сводная таблица» – объединяет инструменты, предназначенные для работы со сводными таблицами.
Вкладка «Совместный доступ» – позволяет устанавливать режим совместной работы с таблицей (быстрый или строгий), добавлять, удалять и решать комментарии.
Вкладка «Защита» – позволяет задавать пароль для доступа к документу («Шифровка»), защищать структуру книги и листов от изменений, определять диапазоны, доступные для совместного редактирования.
Вкладка «Вид» – определяет внешний вид документа, позволяет задавать масштаб, включать и отключать рабочие элементы окна (строку формул и линии сетки), заголовки и отображение нулей.
Вкладка «Файл»
По умолчанию открывается на пункте «Сохранить как…», где можно выбирать формат при сохранении таблицы на компьютер.
При нажатии на пункт «Печатать» появляется окно для задания параметров печати (диапазона, размера листа и пр. )
)
«Защитить» дублирует инструмент «Шифровать», позволяет задавать пароль для доступа к таблице.
Пункт «Дополнительные параметры» открывает доступ к общим настройкам и настройкам параметров страницы.
«Справка» – это справочная информация по работе с Яндекс.Таблицами.
Контекстное меню
При нажатии на правую кнопку мыши вызывается контекстное меню, в котором дублируются наиболее важные команды из меню. С его помощью можно вырезать, копировать и вставлять выделенные фрагменты, вставлять и удалять строки, столбцы и ячейки (со сдвигом вправо или влево), производить очистку ячеек, сортировать данные, устанавливать фильтры, добавлять комментарии, выбирать форматы ячеек, применять функции.
Добавление ячеек, строк и столбцов:
Примечание. В контекстном меню отсутствует пункт «Объединить ячейки». Воспользоваться данной опцией можно только из панели инструментов главного меню (вкладка «Главная»). При выделении фрагмента из нескольких строк и столбцов можно выбирать вариант объединения ячеек.
Инструмент «Очистить» позволяет удалять из выделенного диапазона всю информацию полностью либо только данные определенного типа – текст, комментарии или гиперссылки. При очистке форматирования данные сохранятся, будет удалено только пользовательское форматирование.
Сортировка элементов выделенного диапазона по возрастанию или убыванию, с возможностью задания приоритета для ячеек с выделенным шрифтом или цветом.
Вставка функции.
При нажатии на пункт контекстного меню «Вставить функцию» появляется окно для выбора нужной функции.
Чтобы добавить лист, нужно нажать на значок «+» в нижней левой части листа (строка состояния).
В книге появится еще один лист, его ярлык разместится справа от других ярлыков.
При нажатии правой кнопкой мыши по ярлыку вызывается контекстное меню со списком доступных команд. Лист можно удалять, переименовывать, копировать, перемещать, скрывать, защищать паролем, выбирать цвет его ярлыка.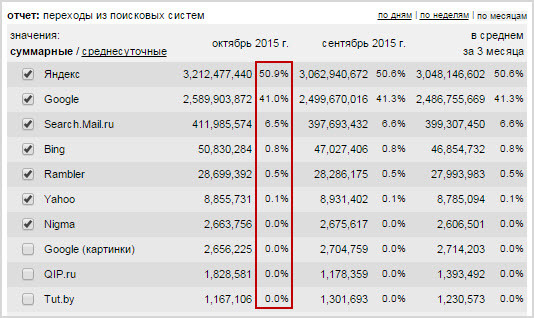 При выборе команды «Вставить» создается новый лист, ярлык которого разместится слева от текущего.
При выборе команды «Вставить» создается новый лист, ярлык которого разместится слева от текущего.
Как скачать таблицу
Чтобы скачать таблицу на компьютер, нужно вызвать контекстное меню к файлу и выбрать пункт «Скачать».
Для получения ссылки следует подвести курсор к файлу и нажать на появившийся значок.
Откроется окно, в котором нужно задать права доступа для других пользователей («Просмотр» или «Редактирование») и нажать на кнопку «Скопировать ссылку». Настройка безопасности доступна только на платных тарифах.
Чтобы удалить ссылку, нужно выбрать в контекстном меню «Удалить ссылку на файл» – этот пункт добавляется в меню сразу после создания ссылки.
Презентации
Как создать или загрузить презентацию
Чтобы создать презентацию, нужно нажать на кнопку «Создать» и выбрать пункт «Презентацию» в раскрывшемся списке. Второй способ: нажать на значок «Презентация» (при создании первого файла).
Далее по аналогии с документами и таблицами, пишем название и создаём файл.
Чтобы загрузить презентацию с компьютера, нужно щелкнуть на кнопку с короткой черной стрелкой, расположенной в верхней правой части папки, либо нажать на кнопку «Создать» и выбрать пункт «Загрузить».
Чтобы открыть презентацию с Яндекс.Диска, нужно нажать на кнопку «Открыть из Диска» или на кнопку «Создать», а потом выбрать пункт «Открыть».
Как работать в презентациях
По внешнему виду редактор напоминает PowerPoint, содержит строку заголовка (1), меню ленточного типа (2), каждому пункту из которого соответствует своя панель инструментов (3), рабочего поля (6), поля для заметок, открытого по умолчанию (7), списка слайдов (8) и строки состояния (12).
По аналогии с Яндекс.Документами и Яндекс.Таблицами, команды «Копировать» и «Вставить» вынесены в отдельный блок (5), присутствуют кнопка задания вида (4), вертикальная левая (9) и вертикальная правая (10) панели, а также окно редактирования текущего элемента (11).
Главное меню
Вкладка «Главная»
Слева содержит кнопку добавления слайда, инструменты для задания макета и установки времени начала показа слайдов. Далее идут средства для работы с текстом и вставки наиболее часто используемых объектов – надписей, изображений и фигур. С правой стороны располагаются инструменты для очистки и копирования стиля, выбора цветовой схемы и размеров слайдов. Крайнюю правую часть занимают шаблоны слайдов, полностью список раскрывается после нажатия на стрелку рядом.
Далее идут средства для работы с текстом и вставки наиболее часто используемых объектов – надписей, изображений и фигур. С правой стороны располагаются инструменты для очистки и копирования стиля, выбора цветовой схемы и размеров слайдов. Крайнюю правую часть занимают шаблоны слайдов, полностью список раскрывается после нажатия на стрелку рядом.
Вкладка «Вставка» – содержит инструменты для создания таблиц, надписей, элементов TextArt, изображений, фигур, диаграмм, комментариев, гиперссылок, колонтитулов, даты и времени, номеров слайдов, уравнений и символов. С левой стороны дублируется кнопка «Добавить слайд».
Вкладка «Переходы» – позволяет задать параметры перехода между слайдами: тип переходов, их длительность, способ запуска и пр. Можно задать одинаковые переходы для всех слайдов либо делать настройки для каждого слайда по отдельности.
Вкладки «Совместная работа», «Файл», «Дополнительные Параметры» и «Справка» содержат инструменты аналогичные таблицам и документам.
Контекстное меню
В контекстном меню дублируются некоторые наиболее часто используемые команды. Например, для текстовых фрагментов: сверху – команды «Вырезать», «Копировать» и «Вставить», далее за ними – пункты «Вертикальное выравнивание» (по верхнему / нижнему краю или по середине), «Направление текста» (горизонтальное или с поворотом вверх / вниз) и «Дополнительные параметры абзаца» (открывается окно редактирования абзацев). В нижней части меню – команды для добавления комментариев и гиперссылок.
В контекстном меню к объекту (например, к фигуре) повторяться будут только общие команды верхнего блока. При редактировании фигур и других графических объектов с использованием пункта «Порядок» можно задавать их положение (переносить вперед / назад, на передний / задний план), группировать / разгруппировать. «Выравнивание» обеспечивает выравнивание по центру, середине, верхнему / нижнему / правому /левому краю. «Поворот» позволяет повернуть объект на 90 градусов по или против часовой стрелки, отразить его слева направо или сверху вниз.
При нажатии на пункт «Дополнительные параметры фигуры» открывается окно редактирования фигур. К фигурам можно добавлять комментарии.
Чтобы добавить новый слайд, нужно воспользоваться инструментом «Добавить слайд» либо щелкнуть правой кнопкой мыши в окне слайдов и из контекстного меню выбрать «Новый слайд».
Слайды можно дублировать, удалять, скрывать, изменять макет (структуру) и цветовую схему оформления, задавать другие параметры.
Макет определяет содержимое слайда: титульный лист (с большим заголовком посередине), заголовок и объект, два объекта и т. д.
Тема определяет цветовое оформление слайда.
Как скачать презентацию
Чтобы скачать презентацию, нужно вызвать контекстное меню к файлу и выбрать пункт «Скачать».
Для получения ссылки на файл наведите на него курсор мыши и нажмите на появившийся снизу серый значок. Задайте параметры доступа в открывшемся окне («Просмотр» или «Редактирование») и нажмите на кнопку «Скопировать ссылку».
Онлайн-сервис Яндекс.Документы позволяет полноценно работать с текстовыми документами, электронными таблицами и презентациями. В отличие от офисных пакетов, он не требует покупки лицензии и установки приложений на компьютер, что позволяет экономить деньги и время.
Дополнительное преимущество сервиса – он российский и на него не распространяются санкции.
Полезные ссылки:
- Как составить пресс-релиз
- Как пользоваться Гугл Документами
- Как сделать и добавить Яндекс.Карту на сайт
Войти в Яндекс Диск и начать обмениваться файлами
Войдите в свой аккаунт Яндекс Диска, чтобы начать работать с файлами из облака.
Скачать для Windows
Скачать для macOS
С Диск-О: все действия с файлами из хранилища будут занимать в 2 раза меньше времени, чем в браузере
Вы сможете работать с файлами офлайн, а при подключении к интернету они будут автоматически обновляться
Ваши файлы из Яндекс Диска на компьютере будут моментально синхронизироваться с облаком Яндекс в браузере
Вам не придется устанавливать приложение Яндекс Диск на ваше устройство – достаточно скачать Диск-О: для MacOS или Windows
Яндекс Диск — облачный сервис, позволяющий пользователям хранить и передавать файлы на любое устройство, подключенное к Сети.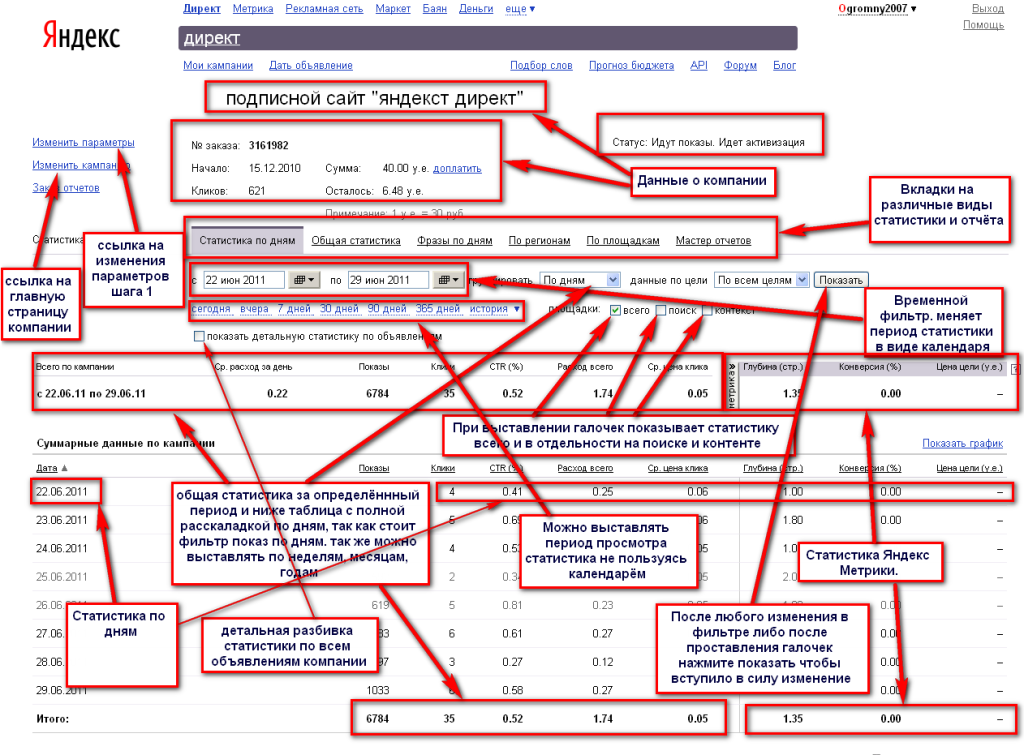 Яндекс Диск поддерживает разные форматы документов таблиц и презентаций, также в облаке можно хранить фото и видео, группируя их в альбомы.
Яндекс Диск поддерживает разные форматы документов таблиц и презентаций, также в облаке можно хранить фото и видео, группируя их в альбомы.
Всеми файлами и папками можно делиться с другими пользователями, настроив совместный доступ.
При установке Диска пользователи бесплатно получают хранилище объемом 10 ГБ.
Сохраняйте фото и видео и делитесь ими
После подключения вашего аккаунта на Яндекс Диске к Диск-О: ваша коллекция фото и видео будет храниться на устройстве, не занимая его память, и вы сможете:
Просматривать медиафайлы из облака на компьютере;
Редактировать свои снимки в Photoshop и других фоторедакторах;
Сохранять скриншоты в свой аккаунт на Яндекс Диске;
Отправлять оригиналы изображений и видео другим пользователям в мессенджерах, соцсетях или по электронной почте;
Делать PDF-документы из ваших фотографий;
Архивировать свои фото и видео;
Создавать новые папки и добавлять в них медиафайлы, объединенные одной темой.
Работайте с файлами в Word, Excel, PowerPoint
Создавать и редактировать файлы онлайн в облаке не всегда удобно. Диск-О: упростит вашу работу с документами, и вы сможете:
Редактировать тексты в Word, создавать таблицы в Excel или презентации в PowerPoint, не скачивая файлы из облака;
Отправлять ссылки на документы вашим коллегам для совместной работы – файлы будут доступны только тем, кому вы отправите ссылку;
Создавать документы на компьютере, а затем просматривать их на Яндекс Диске через браузер – синхронизация будет происходить моментально;
Хранить все файлы из облака на вашем устройстве – они не будут занимать его память.
Как пользоваться Яндекс Диск и Диск-О:
1
В приложении Диск-О: нажмите кнопку «Добавить диск»
2
Выберите Яндекс Диск в списке сервисов
3
Введите ваш логин и пароль для входа в аккаунт Яндекс Диска
4
После завершения синхронизации на компьютере появится новый диск, где будут храниться файлы из вашего облака. Они готовы к работе!
Они готовы к работе!
Поддерживает 13 сервисов
Диск-О: можно подключить к Облаку Mail.ru бесплатно (только 1 диск), возможность подключения Яндекс.Диска и других сторонних облачных хранилищ является частью подписки
Как подключить?
Яндекс.ДискOneDriveDropboxGoogle Drive
Облако Mail.ru
Яндекс.Диск
Google Drive
Dropbox
OneDrive
VK WorkDisk
Huawei
Box
pCloud
WebDAV
MCS S3
Amazon S3
S3
Что может?
Резервное копированиеОбъединение облаков
Приложение Диск-О:
доступно для MacOS и Windows
Оно позволяет бесплатно подключать все доступные облачные сервисы. При этом из Облака Mail.ru загружать файлы можно безлимитно, а из других облачных хранилищ (в том числе из Yandex Disk) не более 10 раз в сутки.
Скачать для Windows
Скачать для macOS
Тарифы
Для Облака Mail.ru (только 1 аккаунт) в Диск-О: нет ограничений по количеству загрузок, но в другие сервисы можно добавлять не более 10 файлов в сутки. Снятие этого лимита является частью подписки.
Снятие этого лимита является частью подписки.
YTsaurus: Эксабайтная система хранения и обработки теперь с открытым исходным кодом | Максим Бабенко | Яндекс | март 2023
Здравствуйте, меня зовут Максим Бабенко, я руководитель отдела технологий распределенных вычислений в Яндексе. Сегодня мы рады сообщить, что выпустили платформу YTsaurus с открытым исходным кодом. YTsaurus — одна из ключевых инфраструктурных систем больших данных, разработанная в Яндексе и ранее известная как YT.
После почти десятилетия напряженной работы мы хотим поделиться YTsaurus со всем миром. В этой статье мы познакомим вас с историей развития YT, объясним, зачем нужен YTsaurus, опишем его основные возможности и наметим области, для которых он лучше всего подходит.
Репозиторий GitHub содержит код сервера для YTsaurus, инфраструктуру развертывания с использованием k8s, веб-интерфейс для системы и клиентские SDK для популярных языков программирования, таких как C++, Java, Go и Python. Все распространяется под лицензией Apache 2.0, что означает, что каждый может загрузить и модифицировать его в соответствии со своими потребностями.
Все распространяется под лицензией Apache 2.0, что означает, что каждый может загрузить и модифицировать его в соответствии со своими потребностями.
История начинается в 2006 году. К тому времени Яндекс стал достаточно крупной компанией. Вопрос о том, где хранить и как обрабатывать данные компании, перестал быть простым. В то время основное внимание уделялось журналам из нескольких сервисов. Обработка журналов включала в себя множество аналитических средств, которые могли решать широкий спектр задач, от улучшения моделей машинного обучения до анализа поведения пользователей при внесении функциональных или интерфейсных изменений в сервисы.
Идея масштабируемой и эластичной системы хранения данных, которая могла бы выполнять параллельные вычисления, не заботясь о физическом расположении данных и отказоустойчивости физических компонентов кластера, уже витала в воздухе.
В 2004 году Джеффри Дин и Санджай Гемават из Google опубликовали книгу MapReduce: Simplified Data Processing on Large Clusters. Он во многом предсказал эволюцию индустрии распределенных вычислений на следующее десятилетие. Неудивительно, что похожая реализация парадигмы MapReduce появилась в Яндексе под названием YAMR — Yet Another MapReduce.
Он во многом предсказал эволюцию индустрии распределенных вычислений на следующее десятилетие. Неудивительно, что похожая реализация парадигмы MapReduce появилась в Яндексе под названием YAMR — Yet Another MapReduce.
ЯМР был построен с нуля в рекордно короткие сроки и, несомненно, оказал огромное влияние на развитие внутренней инфраструктуры компании. Однако со временем стало ясно, что многие варианты дизайна, первоначально сделанные в YAMR, не позволяли системе эффективно развиваться и масштабироваться. Например, главный сервер YAMR был единственной точкой отказа и не масштабировался.
На первый взгляд может показаться, что решение построить собственную инфраструктуру — типичный случай синдрома НИЗ, а вариант использования готового решения вроде Apache Hadoop даже не рассматривался. Но это не совсем так. В сентябре 2015 года группа инженеров Яндекса отправилась в Калифорнию, чтобы встретиться с теми, кто использует стек Hadoop в продакшене. Они задавали вопросы об ограничениях, особенностях работы и ожидаемом развитии Hadoop.
Но потом стало ясно, что стек Hadoop значительно отстает, даже по сравнению с YAMR, который уже поддерживал кодирование с затиранием и подключение по IPv6. Это были далеко не единственные проблемы.
Все проанализировав, мы решили отказаться от использования Hadoop. При этом нам пришлось выбирать между эволюционным развитием ЯМР и революционным написанием новой системы, и мы выбрали последнее решение. За пять лет до этих событий небольшая группа энтузиастов, частью которой мне посчастливилось быть, начала работу над проектом под кодовым названием YT. При должной доработке YT имел все шансы заменить YAMR.
Важно понимать, что не было возможности немедленно заменить YAMR. На пике своего развития эта система управляла кластерами, насчитывающими в общей сложности тысячи узлов, и большое количество кода приложений было основано на API YAMR. В результате процесс доработки YT и миграции с YAMR занял много лет. Подробности этой истории интересны сами по себе и, вероятно, заслуживают отдельного поста.
С 2017 года в Яндексе действует единая система MapReduce, развитие которой как по масштабам, так и по возможностям продолжается и по сей день. Сегодня компания управляет несколькими кластерами YT размером от нескольких машин до десятков тысяч серверов. Крупнейшие установки хранят эксабайты данных, используя миллионы ядер ЦП и тысячи видеокарт для круглосуточных вычислений.
Нам потребовалось почти семь лет, чтобы ответить на вопрос: «Будет ли YT открытым исходным кодом?» Но вот оно: YT не будет с открытым исходным кодом, но YTsaurus будет!
Первоначально разработанная нами система называлась «YT». Та же аббревиатура появляется во многих частях кодовой базы. Из уст в уста в Яндексе говорят, что аббревиатура «YT» предназначалась для обозначения «Яндекс-таблицы», возможно, вдохновленной известной системой Google Big Table, но мы не смогли найти никаких надежных доказательств в поддержку этой теории. .
Когда мы решили выпустить систему с открытым исходным кодом, нам было сложно сохранить исходное название. Проблема заключалась не только в том, что это двухбуквенное сочетание часто ассоциируется с определенной популярной видеохостинговой платформой, но и в том, что сложно найти короткие названия для продуктов, которые выставлены на продажу.
Проблема заключалась не только в том, что это двухбуквенное сочетание часто ассоциируется с определенной популярной видеохостинговой платформой, но и в том, что сложно найти короткие названия для продуктов, которые выставлены на продажу.
В конце концов мы остановились на имени YTsaurus. У него такая же родная и знакомая приставка «YT», и наша команда всегда относилась к проекту как к живому существу. Теперь мы наконец-то знаем его расу!
В нашей кодовой базе и текстах мы часто сокращаем «YTsaurus» до «YT». Сами пока привыкаем к полному названию 🙂
Мы сделали систему гибкой и масштабируемой, и на данный момент ее возможности не ограничиваются классической технологией MapReduce. В этом разделе я опишу основные технические возможности, доступные в версии YTsaurus с открытым исходным кодом, от низкоуровневого хранилища до высокоуровневых вычислительных примитивов.
Cypress: надежное и эффективное хранилище данных
Ядром любой системы больших данных является хранилище различных журналов, статистики, индексов и других структурированных или неструктурированных данных. YTsaurus построен на основе Cypress, отказоустойчивого хранилища на основе дерева, возможности которого можно кратко описать следующим образом: данные) в виде узлов
YTsaurus построен на основе Cypress, отказоустойчивого хранилища на основе дерева, возможности которого можно кратко описать следующим образом: данные) в виде узлов
В основе Cypress лежит реплицированный и масштабируемый по горизонтали главный сервер, на котором хранятся метаданные о древовидной структуре Cypress, а также о составе и расположении реплик фрагментов для всех таблиц в кластере.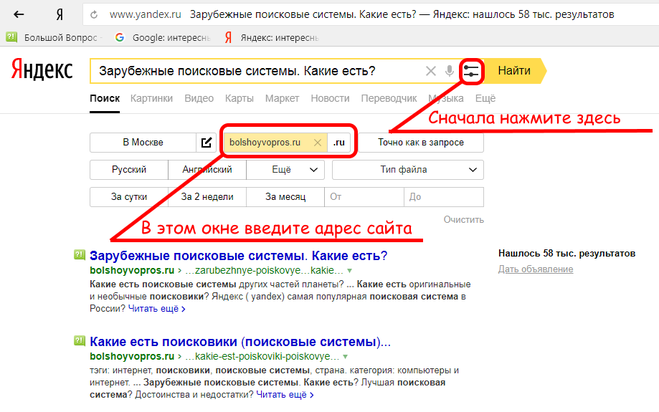 Главные серверы реализованы как реплицированные конечные автоматы на основе Hydra, проприетарного алгоритма консенсуса, похожего на Raft.
Главные серверы реализованы как реплицированные конечные автоматы на основе Hydra, проприетарного алгоритма консенсуса, похожего на Raft.
Cypress реализует отказоустойчивый эластичный уровень данных, который используется практически во всех аспектах системы, описанных ниже.
Вычисления MapReduce и планировщик общего назначения
Несмотря на то, что технология MapReduce уже не считается новой и необычной, ее реализация в нашей системе заслуживает внимания. Мы по-прежнему используем его для вычислений с петабайтами данных, где требуется высокая пропускная способность.
MapReduce в YTsaurus имеет следующие особенности:
- Богатая базовая модель операций: классический MapReduce (с различными стратегиями перетасовки и поддержкой многоэтапного разбиения), Map, Erase, Sort и некоторые расширения классической модели, учитывающие «сортированность» входных данных
- Горизонтальная масштабируемость вычислений: операции разбиты на задания, которые выполняются на отдельных серверах
- Поддержка сотен тысяч заданий в одной операции
- Гибкая модель иерархических вычислительных пулов с мгновенными и целостными гарантиями, а также справедливой долевое распределение недоиспользованных ресурсов между потребителями без гарантий
- Модель векторных ресурсов, позволяющая запрашивать различные вычислительные ресурсы (ЦП, ОЗУ, ГП) в разных пропорциях
- Выполнение заданий на вычислительных узлах в контейнерах, изолированных ЦП, ОЗУ, файловой системой и пространством имен процессов с использованием механизма контейнеризации Porto
- Масштабируемый планировщик, который может обслуживать кластеры с миллионом одновременных задач
- Практически весь ход вычислений сохраняется в случае обновлений или отказов узлов планировщика
YT поддерживает не только выполнение операций MapReduce, но и развертывание в кластере произвольного пользовательского кода.
В терминологии YT выполнение произвольного кода с неопределенными побочными эффектами достигается с помощью «ванильных» операций. Мы используем эту возможность для ряда других компонентов нашей платформы, о которых я расскажу ниже.
Динамические таблицы хранения k-v
Парадигма MapReduce практически не подходит для создания конвейеров интерактивных вычислений с временем отклика менее секунды. Проблема заключается не только в том, как данные обрабатываются, но и в том, как они хранятся.
Статические таблицы YT, как и набор файлов в HDFS, могут служить входными и выходными данными для вычислений MapReduce. Однако их нельзя использовать в интерактивном сценарии, поскольку они привязаны к медленному постоянному носителю данных. Для интерактивных сценариев приложения обычно используют хранилища ключей и значений. Они могут масштабироваться горизонтально, обеспечивая доступ для чтения и записи с малой задержкой.
К счастью, в 2014 году мы начали работать над динамическими таблицами в рамках YT. Они частично основаны на модели Apache HBase. Они масштабируются горизонтально и используют нашу распределенную файловую систему в качестве базового хранилища. Однако, в отличие от Apache HBase, динамические таблицы органично интегрированы в общую экосистему: они представляют собой узлы Cypress и могут использоваться во многих сценариях, где ожидаются статические таблицы.
Они частично основаны на модели Apache HBase. Они масштабируются горизонтально и используют нашу распределенную файловую систему в качестве базового хранилища. Однако, в отличие от Apache HBase, динамические таблицы органично интегрированы в общую экосистему: они представляют собой узлы Cypress и могут использоваться во многих сценариях, где ожидаются статические таблицы.
Например, в YT можно создать динамическую таблицу в результате операции MapReduce и использовать ее для быстрого поиска и вставки на основе ключа. В то же время вы можете создать фоновый процесс MapReduce, который обрабатывает выборку данных из динамической таблицы и вычисляет по ней некоторую статистику.
- Хранение данных в модели MVCC. Пользователи могут искать значения по ключу или по метке времени
- Масштабируемость: динамические таблицы разбиты на планшеты (сегменты по диапазонам ключей), которые обслуживаются отдельными серверами
- Транзакционность: динамические таблицы представляют собой хранилище OLTP, которое может изменять множество строк в разных сегментах из разных таблиц
- Отказоустойчивость: отказ одного узла, обслуживающего планшет, приводит к перемещению этого планшета на другой узел без потери данных
- Изоляция : узлы, обслуживающие планшеты, сгруппированы в пакеты, расположенные на отдельных машинах, что обеспечивает изоляцию нагрузки
- Проверка конфликтов на уровне отдельных ключей или даже отдельных значений
- Горячие ответы данных из ОЗУ
- Встроенный SQL-подобный язык для сканирования и анализа запросов
Помимо динамических таблиц с интерфейсом хранилища k-v, система поддерживает динамические таблицы, реализующие абстракцию очереди сообщений, а именно темы и потоки. Эти очереди также можно считать таблицами, поскольку они состоят из строк и имеют собственную схему. В транзакции вы можете одновременно изменять строки как в динамической таблице k-v, так и в очереди. Это позволяет вам строить потоковую обработку поверх динамических таблиц YT с семантикой ровно один раз.
Эти очереди также можно считать таблицами, поскольку они состоят из строк и имеют собственную схему. В транзакции вы можете одновременно изменять строки как в динамической таблице k-v, так и в очереди. Это позволяет вам строить потоковую обработку поверх динамических таблиц YT с семантикой ровно один раз.
YQL
YQL — это язык запросов на основе SQL; это первый высокоуровневый примитив, созданный поверх YT. YQL занимает примерно такое же положение по отношению к YT, как Hive по отношению к Hadoop. Эта технология позволяет пользователям писать простые запросы на языке SQL, а не создавать последовательность операций MapReduce с помощью пользовательского кода. Вот пример такого запроса:
SELECT
region,
AVG(age) AS avg_age_in_region,
COUNT(DISTINCT ip) AS ips_count
FROM `//home/production/users`
СГРУППИРОВАТЬ ПО РЕГИОНУ
ORDER BY avg_age_in_region;
Сегодня многие задачи с большими данными можно кратко сформулировать в виде SQL-запросов. Без YQL наша экосистема была бы неполной. Это один из самых популярных инструментов как для специального анализа больших наборов данных, так и для регулярных производственных расчетов.
Без YQL наша экосистема была бы неполной. Это один из самых популярных инструментов как для специального анализа больших наборов данных, так и для регулярных производственных расчетов.
Преимущества YQL включают:
- Мощный механизм выполнения графов, который может создавать конвейеры MapReduce с сотнями узлов и адаптироваться во время вычислений
- Возможность построения сложных конвейеров обработки данных с использованием SQL путем сохранения подзапросов в переменных в виде цепочек зависимых запросов и транзакций
- Предсказуемое параллельное выполнение запросов любой сложности
- Эффективная реализация объединений, подзапросов и оконных функций без ограничений по их топологии или вложенности
- Обширная библиотека функций
- Поддержка пользовательских функций на C++, Python и JavaScript
- Поддержка использования моделей машинного обучения через CatBoost и TensorFlow
- Автоматическое выполнение небольших частей запросов на подготовленных вычислительных экземплярах в обход MapReduce для уменьшения задержки
CHYT
Само собой разумеется, что большинство моих читателей слышали о ClickHouse. В 2016 году эта СУБД стала пионером среди открытых технологий Яндекса и оказалась настолько успешной, что в 2021 году была выделена в отдельную компанию под названием ClickHouse Inc. исполнительный движок и множество интеграций с системами BI. Одной из приятных особенностей ClickHouse является хорошее разделение частей хранения и вычислений в исходном коде, что позволило нам построить CHYT в 2018 году — интеграцию вычислительного движка ClickHouse с YTsaurus в качестве хранилища.
В 2016 году эта СУБД стала пионером среди открытых технологий Яндекса и оказалась настолько успешной, что в 2021 году была выделена в отдельную компанию под названием ClickHouse Inc. исполнительный движок и множество интеграций с системами BI. Одной из приятных особенностей ClickHouse является хорошее разделение частей хранения и вычислений в исходном коде, что позволило нам построить CHYT в 2018 году — интеграцию вычислительного движка ClickHouse с YTsaurus в качестве хранилища.
В экосистеме YTsaurus CHYT предоставляет следующие возможности
- Быстрые аналитические запросы к статическим таблицам в YT с задержкой менее секунды
- Повторное использование существующих данных в кластере YTsaurus без необходимости их копирования в отдельный кластер ClickHouse
- Возможность для интеграции (например, со сторонними системами визуализации) через собственные драйверы ODBC и JDBC ClickHouse
Отмечу, что интеграция выполнена на достаточно низком уровне.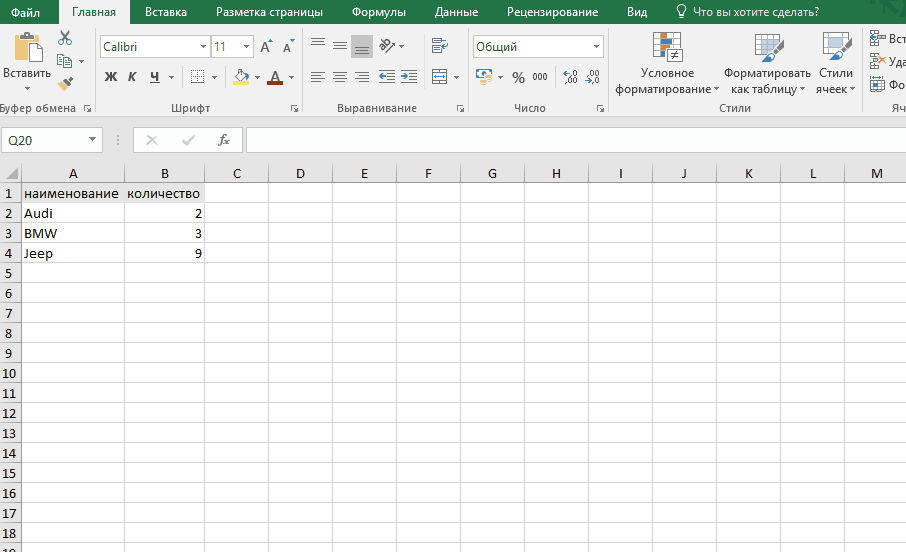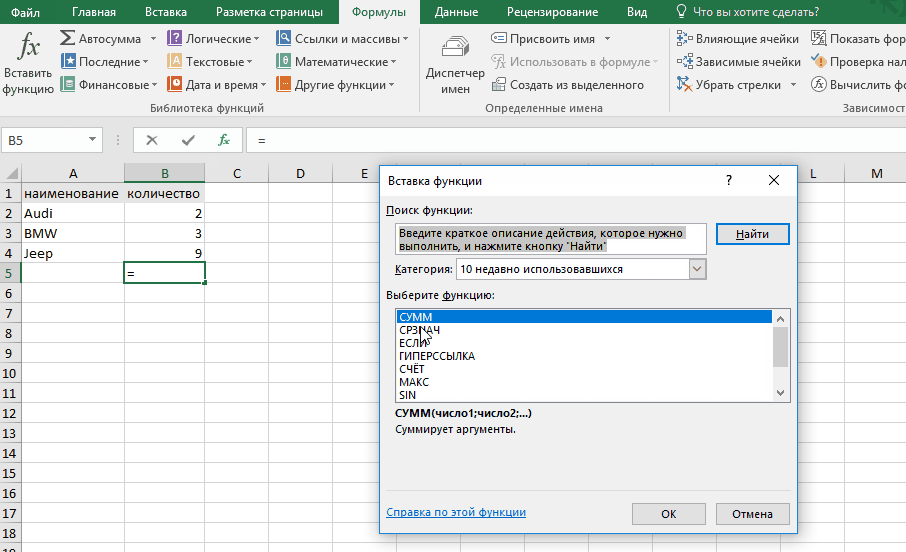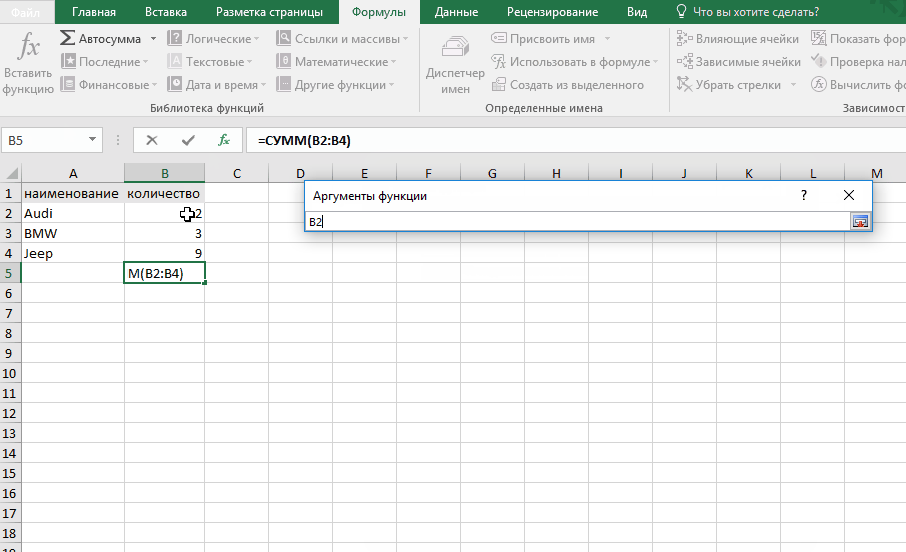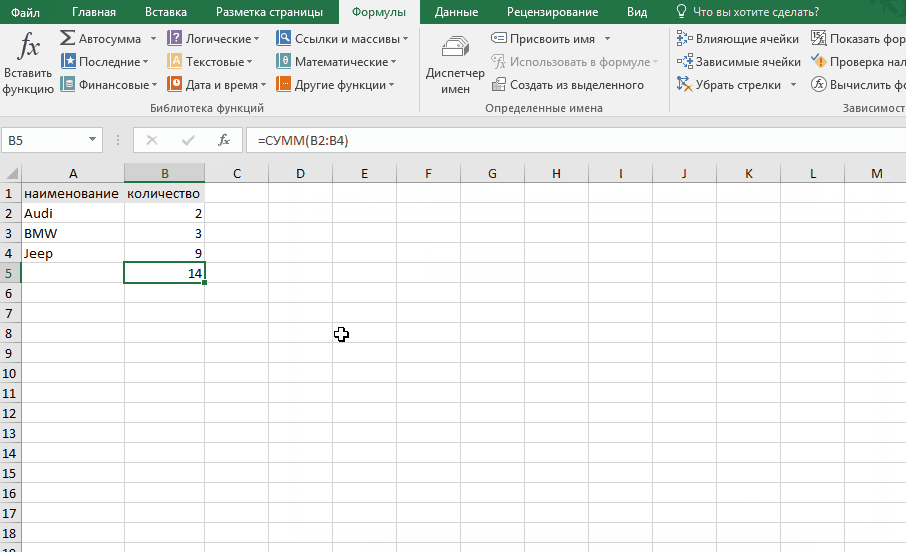 Это позволяет нам использовать весь потенциал как YTsaurus, так и ClickHouse, а именно:
Это позволяет нам использовать весь потенциал как YTsaurus, так и ClickHouse, а именно:
- Поддержка чтения как статических, так и динамических таблиц
- Частичная поддержка транзакционной модели YTsaurus
- Поддержка распределенных вставок
- Эффективное преобразование столбцовых данных из внутреннего формата YTsaurus в представление ClickHouse в памяти
- Агрессивный кэширование данных, которое в некоторых случаях позволяет считывать данные выполнения запроса исключительно из памяти экземпляра
Код сервера ClickHouse выполняется в вышеупомянутых ванильных операциях, используя те же вычислительные ресурсы, которые могут использоваться для вычислений MapReduce. В этом смысле кластер YTsaurus действует как вычислительное облако по отношению к кластерам CHYT внутри.
Это позволяет разным пользователям или командам пользователей запускать несколько кластеров CHYT в одном кластере YT, полностью изолированных друг от друга, решая проблему разделения ресурсов облачным способом.
SPYT
В 2019 году Яндекс представил SPYT, систему, которая интегрирует Apache Spark в качестве вычислительного механизма для данных, хранящихся в YT. Подобно CHYT, ванильные операции YTsaurus предоставляют вычислительные ресурсы для кластера Spark. Apache Spark изначально был разработан для упрощения подключения к стороннему хранилищу в качестве источника данных.
SPYT также хорошо зарекомендовал себя в экосистеме YTsaurus. Это один из основных способов написания процессов ETL благодаря его богатым возможностям интеграции со сторонними системами. Под капотом Spark используется гибкий оптимизатор распределенных вычислений, который максимально увеличивает объем памяти для хранения промежуточных данных и может реализовывать вычислительные конвейеры с несколькими соединениями.
Различные SDK
Часто SDK для системы на определенном языке автоматически генерируются или пишутся кем-то из сообщества пользователей и давно не поддерживаются. В нашем случае мы сами разрабатываем все API на популярных языках (C++, Python, Java, Go). В каждом случае учитываются и продуманы все нюансы взаимодействия с системой.
В каждом случае учитываются и продуманы все нюансы взаимодействия с системой.
Наши клиентские библиотеки, написанные на разных языках, могут повторять запросы, включая чтение или запись больших объемов данных, несмотря на возможные сбои сети и другие ошибки. При создании каждой библиотеки мы учитывали особенности языков и использовали их, чтобы сделать взаимодействие с системой максимально удобным и простым.
Веб-интерфейс
Удобный веб-интерфейс является обязательным условием для системы, используемой тысячами пользователей. Более того, мы намеренно не стали создавать отдельные веб-интерфейсы для пользователей и администраторов, что уберегло нас от распространенной ситуации, когда административный веб-интерфейс делается наспех энтузиастами: ведь пользовательская сторона важнее, и не нужно стыдно перед админами 🙂
Вот что вы можете делать с веб-интерфейсом YTsaurus:
- Навигация по Cypress для просмотра файлов, таблиц и других объектов
- Создание, переименование или удаление объектов Cypress и изменение их атрибутов
- Выполнение и просмотр MapReduce вычисления
- Выполнение и просмотр истории SQL-запросов по всем механизмам — YQL, CHYT, динамические таблицы SQL
- Администрирование системы: мониторинг работоспособности компонентов кластера, создание, удаление или блокировка пользователей, управление правами доступа и квотами, просмотр компонентов кластера версии и многое другое
Большая часть серверного кода написана на C++. Мы любим этот язык за его богатую функциональность и эффективный код. После выпуска YTsaurus с открытым исходным кодом мы надеемся поделиться большим количеством разработок, которые могут быть полезны в виде отдельных примитивов C++.
Мы любим этот язык за его богатую функциональность и эффективный код. После выпуска YTsaurus с открытым исходным кодом мы надеемся поделиться большим количеством разработок, которые могут быть полезны в виде отдельных примитивов C++.
Серверный код создается с помощью компилятора clang и системы сборки CMake.
Отдельные части системы написаны на Go, Python и Java. Существует также API для разработки приложений, которые работают с YTsaurus на четырех упомянутых выше языках программирования.
База кода автоматически синхронизируется с внутренним хранилищем. Таким образом, актуальная версия YTsaurus всегда доступна извне.
YTsaurus работает на Linux x86–64.
Развертывание и администрирование
Внутри Яндекса установлено более 20 установок YTsaurus. Они сильно различаются по размеру и конфигурации: от 5 до 20 000+ хостов в одном кластере. YTsaurus также интегрирован с несколькими внутренними системами Яндекса, включая аутентификацию, контроль доступа, аудит, мониторинг, управление оборудованием и оркестрацию контейнеров. Все эти системы позволяют нам управлять кластерами с минимальными усилиями.
Все эти системы позволяют нам управлять кластерами с минимальными усилиями.
Для удобства пользователей мы вложили средства в разработку нашего оператора второго уровня для автоматизированного развертывания кластера YTsaurus в Kubernetes с поддержкой стандартных механизмов обновления до новой версии с даунтаймом. Оператор позволяет за несколько минут развернуть ваш кластер YTsaurus на локальной машине в миникубе, общедоступном облаке или собственной локальной установке Kubernetes.
Конфигурацией кластера можно управлять «на лету», изменяя системные узлы в дереве метаданных (Cypress). Используя основные команды Cypress, такие как list, get, set и remove, вы можете создать учетную запись, добавить пользователя или вычислительный пул, предоставить доступ к каталогу или удалить узлы кластера.
Особо следует отметить возможность динамической настройки отдельных компонентов: изменяя специальные атрибуты, вы можете настраивать размеры кэша, периоды такта или параметры ведения журналов на узлах.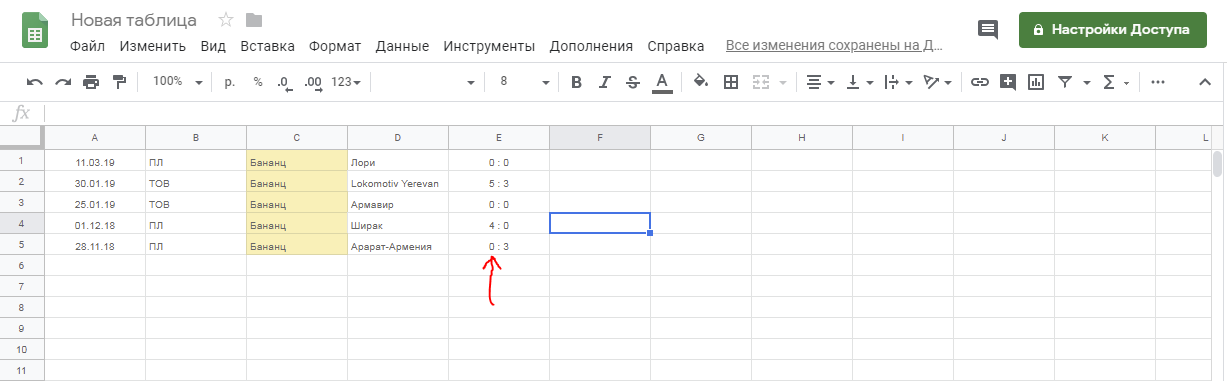
YTsaurus — это вычислительная платформа, поэтому подразумевается выполнение пользовательского кода. Для запуска и изоляции ненадежного кода YTsaurus использует Porto — систему контейнеризации, разработанную в Яндексе. Для полной изоляции пользователей в мультитенантном кластере рекомендуется установить Porto в качестве CRI Kubernetes. Это откроет весь спектр возможностей YTsaurus для изоляции заданий и использования настраиваемых сред в различных операциях.
И, конечно же, работа большой распределенной системы невозможна без инструментов наблюдаемости — логирования, количественного мониторинга и трассировки. YTsaurus ведет структурированные журналы для аудита и мониторинга действий пользователей, а также подробные журналы отладки для более глубокой диагностики проблем. Кроме того, система поддерживает экспорт метрик в формате Prometheus и доставку трассировки по протоколу Jaeger gRPC.
Давайте рассмотрим несколько вариантов использования нашей системы в Яндексе.
Одним из наиболее показательных и типичных вариантов использования YTsaurus является создание DWH. Например, заказы от Яндекс Такси, Яндекс Еда, Яндекс Гастроном и Яндекс Доставка поступают в динамические таблицы YTsaurus в необработанном виде с минимальной задержкой. Объем данных достигает сотен терабайт в месяц.
Затем заказы обрабатываются с помощью различных инструментов: например, большинство аналитических витрин данных готовятся с использованием YQL и SPYT. Общий объем данных превышает 6 ПБ. CHYT используется для специального анализа, а в Yandex DataLens создаются различные визуализации. Аналогичные варианты использования существуют и для других сервисов Яндекса, таких как Яндекс Маркет, Яндекс Музыка и Яндекс Путешествия.
Существуют также очень специфические варианты использования. Например, все три суперкомпьютера Яндекса управляются планировщиком YTsaurus. Многие узлы с различными типами графических процессоров подключены к YT и распределены по разным деревьям пулов.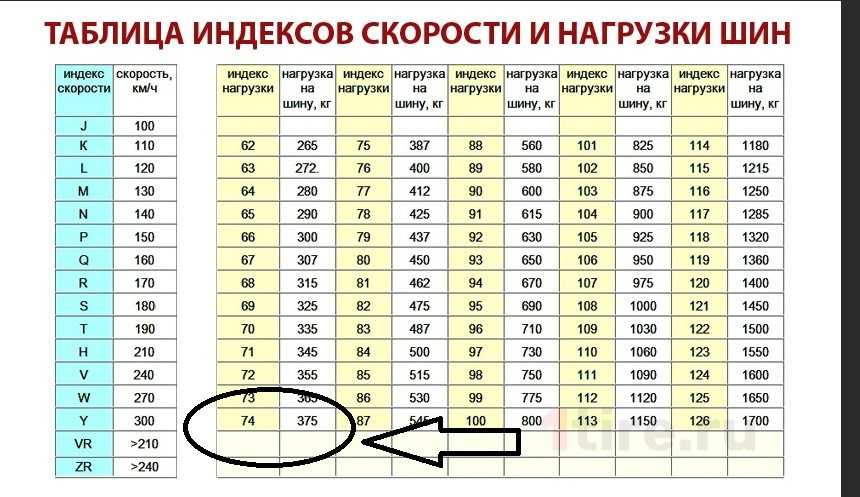 Это позволяет пользователям явно указывать требуемую модель графического процессора и использовать данные, хранящиеся в YTsaurus.
Это позволяет пользователям явно указывать требуемую модель графического процессора и использовать данные, хранящиеся в YTsaurus.
В настоящее время динамические таблицы в YTsaurus хранят петабайты данных, и на их основе построено большое количество интерактивных сервисов. Один из крупнейших внутренних заказчиков — рекламная команда Яндекса. На конференции HighLoad++ 2022 мои коллеги рассказали о своем подходе к построению интерактивной потоковой обработки на основе YTsaurus.
YTsaurus — большой проект с богатой историей. Приглашаем всех любознательных взглянуть на YTsaurus и найти для себя что-то полезное. Возможно, вы оцените технические решения, которые мы реализовали в коде, или найдете возможность развернуть установку YTsaurus и опробовать ее на практике.
Если вы заинтересованы и хотите помочь нам в разработке системы, это было бы здорово. Поделитесь своим отзывом в Telegram-чате, а еще лучше — присылайте пулл-реквесты.
Яндекс Школа анализа данных | Результаты учреждения
Исследования
Диапазон дат: 1 декабря 2021 г. — 30 ноября 2022 г.
— 30 ноября 2022 г.
Регион: Весь мир
Тема/группа журнала: Все
В таблице справа приведены подсчеты всех результатов исследований для Школы анализа данных Яндекса. опубликовано в период с 1 декабря 2021 г. по 30 ноября 2022 г., отслеживается журналом Nature. Индекс.
Наведите указатель мыши на круговую диаграмму, чтобы просмотреть общий доступ для каждой темы. Ниже то же самое результаты исследований сгруппированы по темам. Нажмите на тему, чтобы перейти к списку статей, организованных по журналам, а затем по заголовкам.
Примечание. Статьи могут быть отнесены к более чем одной предметной области.
| Счет | Поделиться |
|---|---|
| 31 | 0,20 |
Результаты по темам (Поделиться)
| Субъект | Граф | Поделиться |
|---|---|---|
| Физические науки | 31 | 0,20 |
Доля выпуска за последние 5 лет
| 2017 | 2018 | 2019 | 2020 | 2021 |
|---|---|---|---|---|
| 0,52 | 0,53 | 0,30 | 0,26 | 0,37 |
Сравните Школу анализа данных Яндекса с другими вузами
Отчеты о природоохранной стратегии
Отчеты о стратегии Nature дают вам простые идеи для поддержки решений, влияющих на вашу организацию.
Отчеты, созданные для вас нашими экспертами в предметной области, сочетают убедительные идеи с доверием и авторитетом Nature. Получите углубленный анализ результатов исследований, проведенных вами и вашими коллегами, включая анализ относительных сильных и слабых сторон. Все это создано с использованием данных и инструментов компании Nature Research Intelligence, охватывающей все основные дисциплины и все регионы мира.
Начало работы
Сотрудничество
Диапазон дат: 1 декабря 2021 г. — 30 ноября 2022 г.
Международное и внутреннее сотрудничество по доле
- 7,41% Одомашненный
- 92,59% Международный
Наведите указатель мыши на график, чтобы просмотреть процент совместной работы.
Топ-10 отечественных сотрудников Школы анализа данных Яндекса по доле (всего 11)
- Школа анализа данных Яндекса и Национальный исследовательский центр «Курчатовский институт» (НИЦКИ)
(1,77) Школа анализа данных Яндекса0,23
Национальный исследовательский центр «Курчатовский институт» (НИЦКИ)1,54
- Школа анализа данных Яндекса и Национальный исследовательский технологический университет (МИСиС)
(0,90)
Школа анализа данных Яндекса0,23
Национальный исследовательский технологический университет (МИСиС)0,67
- Школа анализа данных Яндекса и Российская академия наук (РАН)
(0,64)
Школа анализа данных Яндекса0,23
Российская академия наук (РАН)0,41
- Школа анализа данных Яндекса и Московский государственный университет им.
 М.В. Ломоносова (МГУ)
(0,50)
М.В. Ломоносова (МГУ)
(0,50)Школа анализа данных Яндекса0,23
Московский государственный университет им. М.В. Ломоносова (МГУ)0,27
Школа анализа данных Яндекса0,22
Национальный исследовательский университет «Высшая школа экономики» (НИУ ВШЭ)0,26
- Школа анализа данных Яндекса и Томский политехнический университет (ТПУ)
(0,32) Школа анализа данных Яндекса 0,22
Томский политехнический университет (ТПУ) 0,10
- Школа анализа данных Яндекса и Новосибирский государственный университет (НГУ)
(0,22)
Школа анализа данных Яндекса 0,15
Новосибирский государственный университет (НГУ) 0,07
- Школа анализа данных Яндекса и Национальный исследовательский ядерный университет МИФИ (Московский инженерно-физический институт)
(0,05)
Яндекс Школа анализа данных0,01
Национальный исследовательский ядерный университет МИФИ (Московский инженерно-физический институт)0,04
- Школа анализа данных Яндекса и Объединенный институт ядерных исследований (ОИЯИ)
(0,03)
Яндекс Школа анализа данных0,01
Объединенный институт ядерных исследований (ОИЯИ)0,01
- Школа анализа данных Яндекса и Санкт-Петербургский политехнический университет Петра Великого (СПбПУ)
(0,02)
Яндекс Школа анализа данных 0,01
Санкт-Петербургский политехнический университет Петра Великого (СПбПУ)0,01
Топ-10 международных сотрудников Школы анализа данных Яндекса по акции (всего 177)
- Школа анализа данных Яндекса и Национальный институт ядерной физики (ИНЯФ)
(4.
 08)
08)Яндекс Школа анализа данных0,23
Национальный институт ядерной физики (ИНЯФ)3,85
- Школа анализа данных Яндекса и Европейская организация ядерных исследований (ЦЕРН)
(3.47)
Яндекс Школа анализа данных0,23
Европейская организация ядерных исследований (ЦЕРН)3,24
- Школа анализа данных Яндекса и Швейцарский федеральный технологический институт Лозанны (EPFL)
(1.
 30)
30)Школа анализа данных Яндекса0,23
Швейцарский федеральный технологический институт Лозанны (EPFL)1,07
- Школа анализа данных Яндекса и Манчестерский университет (UoM)
(1.29)
Школа анализа данных Яндекса0,22
Манчестерский университет (UoM)1,07
- Школа анализа данных Яндекса и Национальный институт субатомной физики (Нихеф)
(1.
 19)
19)Яндекс Школа анализа данных0,22
Национальный институт субатомной физики (Нихеф)0,97
- Школа анализа данных Яндекса и Instituto Galego de Física de Altas Enerxías (IGFAE)
(1.18)
Школа анализа данных Яндекса0,22
Instituto Galego de Física de Altas Enerxías (IGFAE)0,97
- Школа анализа данных Яндекса и Французский национальный центр научных исследований (CNRS)
(1.
 18)
18)Школа анализа данных Яндекса0,23
Французский национальный центр научных исследований (CNRS)0,95
- Школа анализа данных Яндекса и Технический университет Дортмунда
(1.07)
Яндекс Школа анализа данных 0,21
ТУ Дортмундский университет 0,85
- Школа анализа данных Яндекса и Уорикский университет (Warwick)
(1.
