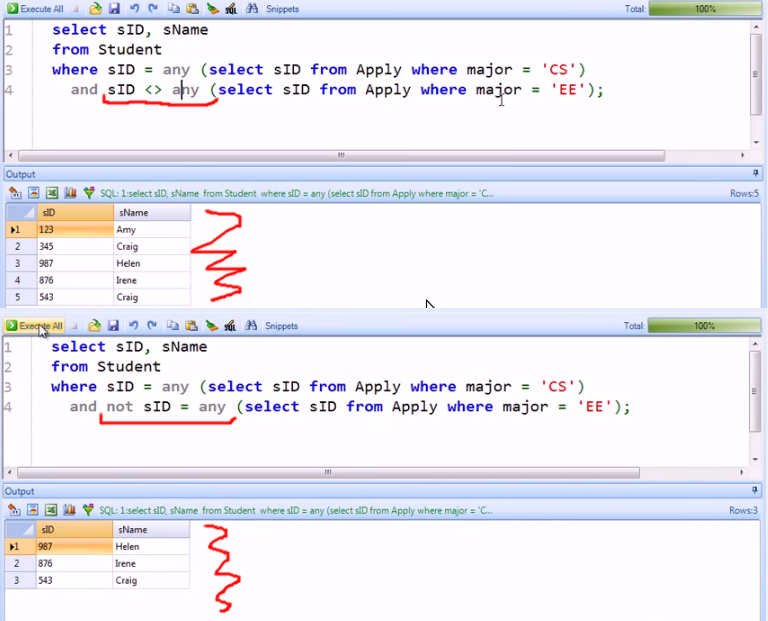
Оператор SQL WHERE: примеры, синтаксис
Оператор SQL WHERE служит для задания дополнительного условия выборки, операций вставки, редактирования и удаления записей.
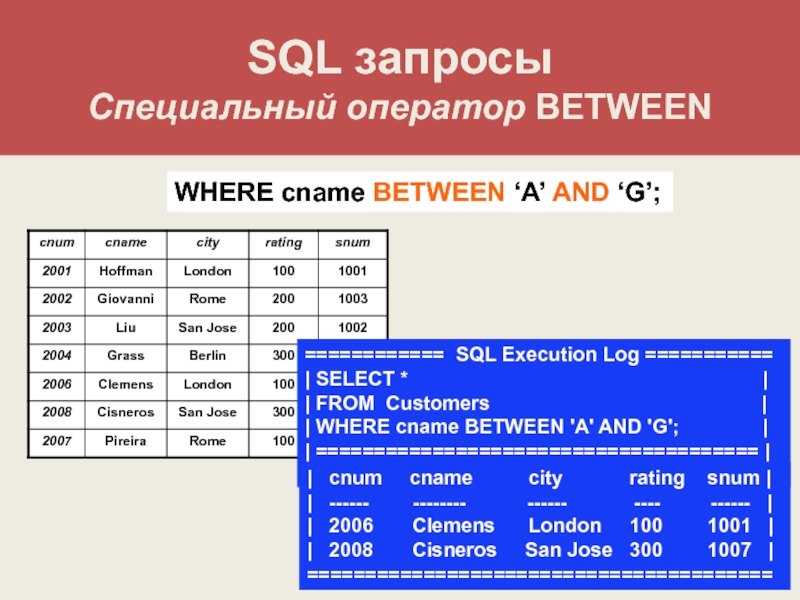
Оператор SQL WHERE имеет следующий синтаксис:
WHERE condition
Условие (condition) может включать в себя предикаты AND, OR, NOT, LIKE, BETWEEN, IS, IN, ключевое слово NULL, операторы сравнения и равенства (<, >, =).
Примеры оператора SQL WHERE. Имеется следующая таблица Planets:
| ID | PlanetName | Radius | SunSeason | OpeningYear | HavingRings | Opener |
| 1 | Mars | 3396 | 687 | 1659 | No | Christiaan Huygens |
| 2 | Saturn | 60268 | 10759. 22 22 | — | Yes | — |
| 3 | Neptune | 24764 | 60190 | 1846 | Yes | John Couch Adams |
| 4 | Mercury | 2439 | 115.88 | 1631 | No | Nicolaus Copernicus |
| 5 | Venus | 6051 | 243 | 1610 | No | Galileo Galilei |
Пример 1. Используя оператор SQL WHERE вывести записи, значение радиуса (Radius) которых находится в пределах от 3000 до 9000:
SELECT * FROM Planets WHERE Radius BETWEEN 3000 AND 9000
Результат:
| ID | PlanetName | Radius | SunSeason | OpeningYear | HavingRings | Opener |
| 1 | Mars | 3396 | 687 | 1659 | No | Christiaan Huygens |
| 5 | Venus | 6051 | 243 | 1610 | No | Galileo Galilei |
Пример 2. Используя оператор SQL WHERE вывести название планеты (PlanetName), год ее открытия (OpeningYear) и имя первооткрывателя (Opener), планет, чье название не начинается или не заканчивается на букву «s»:
Используя оператор SQL WHERE вывести название планеты (PlanetName), год ее открытия (OpeningYear) и имя первооткрывателя (Opener), планет, чье название не начинается или не заканчивается на букву «s»:
SELECT PlanetName, OpeningYear, Opener FROM Planets WHERE PlanetName NOT LIKE '%s' AND PlanetName NOT LIKE 'S%'
Результат:
| PlanetName | OpeningYear | Opener |
| Neptune | 1846 | John Couch Adams |
| Mercury | 1631 | Nicolaus Copernicus |
Конструкция WHERE в SQL
Вы здесь: Главная — MySQL — SQL — Конструкция WHERE в SQL
При выборке записей из таблицы практически всегда требуется задавать определённые условия, по которым мы определяем, какие записи нам нужны, а какие — нет. И именно эти условия можно задавать с помощью конструкции WHERE в SQL. Я уже знакомил Вас с ней, но в этой статье решил познакомить с WHERE немного поближе.
И именно эти условия можно задавать с помощью конструкции WHERE в SQL. Я уже знакомил Вас с ней, но в этой статье решил познакомить с WHERE немного поближе.
Начну с простого примера выборки с использованием конструции WHERE в SQL:
SELECT * FROM table WHERE count=5
Вернутся записи, в которых поле «count» имеет значение 5. Теперь усложним запрос:
SELECT * FROM table WHERE count=5 AND id < 100
Таким образом, вернутся записи, у которых поле «count» имеет значение 5 И поле «id» имеет значение меньше 100.
Разумеется, Вы можете использовать и другие логические операции. Их полный список:
- ! (отрицание)
- AND (И)
- OR (ИЛИ)
- XOR (ИСКЛЮЧАЮЩЕЕ ИЛИ, иногда ещё называют МОНТАЖНОЕ ИЛИ, но такое название встречается в основном в микропроцессорной литературе)
Пример с использованием нескольких логических операторов:
SELECT * FROM table WHERE !(id <= 120 AND (count=10 OR date > "10/11/1980"))Вот такой, на первый взгляд, сложный SQL-запрос. Постарайтесь в нём разобраться самостоятельно.
Постарайтесь в нём разобраться самостоятельно.
Также конструкция WHERE в SQL может содержать LIKE. LIKE позволяет определить, совпадает ли указанная строка с определённым шаблоном. Чтобы стало немного понятнее, приведу пример:
SELECT * FROM table WHERE text LIKE "%some text%"
Данный SQL-запрос вернёт result_set, содержащий записи, в которых поле «text» имеет такой текст: «some text«. Обратите внимание, что это не проверка на равенство. Текст может быть огромным, но если в нём содержитася строка: «some text«, то LIKE вернёт true.
Давайте напишу, как задаётся шаблон для LIKE:
- % — это то, что мы с Вами использовали. Используется он чаще всего и означает он любую строку любой длины. Фактически, строкой «%some text%» мы говорим, что сначала идёт любая строка любой длины, затем «some text«, а затем вновь любая строка любой длины.
 az]some_«. Данный шаблон означает, что вначале идёт любой символ, но только НЕ «a» и НЕ «z«. Далее должна идти строка «some«, а после только один одиночный символ.
az]some_«. Данный шаблон означает, что вначале идёт любой символ, но только НЕ «a» и НЕ «z«. Далее должна идти строка «some«, а после только один одиночный символ.
Знание и умение использования LIKE очень важно, поверьте моему опыту. Самый простой пример использования LIKE — это поиск по сайту. Ведь контент находится в базе данных, и необходимо вытащить только те записи, в которых содержится строка, заданная в строке поиска. И тут приходит на помощь LIKE. Именно так реализован поиск мною на этом сайте.
Вот, пожалуй, всё, что необходимо знать для успешной выборки записей с использованием конструкции WHERE в SQL
Полный курс по PHP и MySQL: http://srs.myrusakov.ru/php
- Создано 22.01.2011 16:41:50
- Михаил Русаков
Копирование материалов разрешается только с указанием автора (Михаил Русаков) и индексируемой прямой ссылкой на сайт (http://myrusakov. ru)!
ru)!
Добавляйтесь ко мне в друзья ВКонтакте: http://vk.com/myrusakov.
Если Вы хотите дать оценку мне и моей работе, то напишите её в моей группе: http://vk.com/rusakovmy.
Если Вы не хотите пропустить новые материалы на сайте,
то Вы можете подписаться на обновления: Подписаться на обновления
Если у Вас остались какие-либо вопросы, либо у Вас есть желание высказаться по поводу этой статьи, то Вы можете оставить свой комментарий внизу страницы.
Порекомендуйте эту статью друзьям:
Если Вам понравился сайт, то разместите ссылку на него (у себя на сайте, на форуме, в контакте):
-
Кнопка:
<a href=»https://myrusakov.ru» target=»_blank»><img src=»https://myrusakov.ru/images/button.gif» alt=»Как создать свой сайт» /></a>Она выглядит вот так:
-
Текстовая ссылка:
<a href=»https://myrusakov.ru» target=»_blank»>Как создать свой сайт</a>Она выглядит вот так: Как создать свой сайт
- BB-код ссылки для форумов (например, можете поставить её в подписи):
[URL=»https://myrusakov. ru»]Как создать свой сайт[/URL]
ru»]Как создать свой сайт[/URL]
MS SQL Server и T-SQL
Фильтрация. WHERE
Последнее обновление: 13.07.2017
WHERE условие
Если условие истинно, то строка попадает в результирующую выборку. В качестве можно использовать операции сравнения. Эти операции сравнивают два выражения. В T-SQL можно применять следующие операции сравнения:
=: сравнение на равенство (в отличие от си-подобных языков в T-SQL для сравнения на равенство используется один знак равно)
<>: сравнение на неравенство
<: меньше чем
>: больше чем
!<: не меньше чем
!>: не больше чем
<=: меньше чем или равно
>=: больше чем или равно
Например, найдем всех товары, производителем которых является компания Samsung:
SELECT * FROM Products WHERE Manufacturer = 'Samsung'
Стоит отметить, что в данном случае регистр не имеет значение, и мы могли бы использовать для поиска и строку «Samsung», и «SAMSUNG», и «samsung». Все эти варианты давали бы эквивалентный результат выборки.
Все эти варианты давали бы эквивалентный результат выборки.
Другой пример — найдем все товары, у которых цена больше 45000:
SELECT * FROM Products WHERE Price > 45000
В качестве условия могут использоваться и более сложные выражения. Например, найдем все товары, у которых совокупная стоимость больше 200 000:
SELECT * FROM Products WHERE Price * ProductCount > 200000
Логические операторы
Для объединения нескольких условий в одно могут использоваться логические операторы. В T-SQL имеются следующие логические операторы:
AND: операция логического И. Она объединяет два выражения:
выражение1 AND выражение2
Только если оба этих выражения одновременно истинны, то и общее условие оператора AND также будет истинно. То есть если и первое условие истинно, и второе.
OR: операция логического ИЛИ. Она также объединяет два выражения:
выражение1 OR выражение2
Если хотя бы одно из этих выражений истинно, то общее условие оператора OR также будет истинно.
 То есть если или первое условие истинно, или второе.
То есть если или первое условие истинно, или второе.NOT: операция логического отрицания. Если выражение в этой операции ложно, то общее условие истинно.
NOT выражение
Если эти операторы встречаются в одном выражении, то сначала выполняется NOT, потом AND и в конце OR.
Например, выберем все товары, у которых производитель Samsung и одновременно цена больше 50000:
SELECT * FROM Products WHERE Manufacturer = 'Samsung' AND Price > 50000
Теперь изменим оператор на OR. То есть выберем все товары, у которых либо производитель Samsung, либо цена больше 50000:
SELECT * FROM Products WHERE Manufacturer = 'Samsung' OR Price > 50000
Применение оператора NOT — выберем все товары, у которых производитель не Samsung:
SELECT * FROM Products WHERE NOT Manufacturer = 'Samsung'
Но в большинстве случае вполне можно обойтись без оператора NOT. Так, в предыдущий пример мы можем переписать следующим образом:
Так, в предыдущий пример мы можем переписать следующим образом:
SELECT * FROM Products WHERE Manufacturer <> 'Samsung'
Также в одной команде SELECT можно использовать сразу несколько операторов:
SELECT * FROM Products WHERE Manufacturer = 'Samsung' OR Price > 30000 AND ProductCount > 2
Так как оператор AND имеет более высокий приоритет, то сначала будет выполняться подвыражение
Price > 30000 AND ProductCount > 2, и только потом оператор OR.
То есть здесь выбираются товары, которыех на складе больше 2 и у которых одновременно цена больше 30000, либо те товары,
производителем которых является Samsung.
С помощью скобок мы также можем переопределить порядок операций:
SELECT * FROM Products WHERE (Manufacturer = 'Samsung' OR Price > 30000) AND ProductCount > 2
IS NULL
Ряд столбцов может допускать значение NULL. Это значение не эквивалентно пустой строке ». NULL представляет полное отсутствие какого-либо значения.
И для проверки на наличие подобного значения применяется оператор IS NULL.
NULL представляет полное отсутствие какого-либо значения.
И для проверки на наличие подобного значения применяется оператор IS NULL.
Например, выберем все товары, у которых не установлено поле ProductCount:
SELECT * FROM Products WHERE ProductCount IS NULL
Если, наоборот, необходимо получить строки, у которых поле ProductCount не равно NULL, то можно использовать оператор NOT:
SELECT * FROM Products WHERE ProductCount IS NOT NULL
Оператор case в предложении where SQL
Я пытаюсь извлечь данные из таблицы, где я использую условие CASE в предложении WHERE , и в настоящее время я использую следующий запрос:-
SELECT count(enq_id) AS total, sum(purchase_amount) AS purchase
FROM temp_stock
WHERE purchase_date <> '0000-00-00'
AND purchase_date < '2012-08-01'
AND (
STATUS = 'Sold'
OR STATUS = 'In Stock'
OR STATUS = 'Ref'
)
AND CASE WHEN (
STATUS = 'Sold'
)
THEN delivery_date >= '2012-08-01'
END
Но он возвращает 0 для total и NULL для purchase .
Поделиться Источник guri 13 сентября 2012 в 06:26
2 ответа
- PL/SQL использование CASE в предложении WHERE
Добрый день Stackoverflow! У меня есть запрос, который выдает мне ошибку: отсутствует правая скобка , по крайней мере, так говорит разработчик SQL. Мой запрос содержит оператор CASE в предложении WHERE, который принимает параметр, а затем выполняет условие на основе введенного значения. Я читал,…
- оператор use case в предложении where
Я пытаюсь использовать оператор case в предложении where в sql server и получаю сообщение об ошибке. WHERE (PRCA.EDLType = ‘E’) AND ( NOT ( PRCA.EDLCode IN ( SELECT EarnCode FROM dbo.udECforUnionRpt WHERE (EDL = ‘E’) ) ) ) AND (PRCM.udMasterCraft IS NOT NULL) AND (PRCA.PREndDate BETWEEN…
17
Из вашего комментария .
Я хочу использовать Case Statement, не могли бы Вы уточнить меня о case statament в предложении where
Вы можете использовать оператор CASE в WHERE следующим образом:
SELECT count(enq_id) AS total, sum(purchase_amount) AS purchase
FROM temp_stock
WHERE purchase_date <> '0000-00-00'
AND purchase_date < '2012-08-01'
AND ( STATUS = 'Sold'
OR STATUS = 'In Stock'
OR STATUS = 'Ref')
AND CASE STATUS
WHEN 'Sold'
THEN delivery_date >= '2012-08-01'
ELSE 1=1
END
Здесь вам нужно использовать ELSE 1=1. иначе вы не получите желаемого результата. Для получения более подробных объяснений см. Этот SQLFiddle
Поделиться hims056 13 сентября 2012 в 07:09
3
Я не думаю, что CASE может работать таким образом. То, что вам нужно, — это немного более сложное выражение, как ваше предложение WHERE. Вероятно, что-то вроде этого:
То, что вам нужно, — это немного более сложное выражение, как ваше предложение WHERE. Вероятно, что-то вроде этого:
SELECT count(enq_id) AS total, sum(purchase_amount) AS purchase
FROM temp_stock
WHERE purchase_date <> '0000-00-00'
AND purchase_date < '2012-08-01'
AND (
(STATUS = 'Sold' AND delivery_date >= '2012-08-01')
OR STATUS = 'In Stock'
OR STATUS = 'Ref'
)
Поделиться Ian Clelland 13 сентября 2012 в 06:30
Похожие вопросы:
Можно ли использовать оператор Case в предложении sql From
Можно ли использовать оператор Case в предложении sql From с использованием SQL 2005? Например, я пытаюсь сделать что-то вроде: SELECT Md5 FROM CASE WHEN @ClientType = ‘Employee’ THEN @Source = ‘HR’…
Перепишите оператор case в предложении Where
Как переписать следующий оператор sql server case, используемый в предложении where. Это приводит к снижению производительности. SELECT mode,m_name from mst_mode a WHERE CASE @mode WHEN ‘K’ THEN ‘Y’…
Это приводит к снижению производительности. SELECT mode,m_name from mst_mode a WHERE CASE @mode WHEN ‘K’ THEN ‘Y’…
Оператор Case параметра в предложении Where
Нужно разделить заказы, если они ‘Millwork’ или ‘Not Millwork’. Параметр позволяет пользователю выбрать тип заказа при создании отчета. Переместил оператор Parameter Case из Select в предложение…
PL/SQL использование CASE в предложении WHERE
Добрый день Stackoverflow! У меня есть запрос, который выдает мне ошибку: отсутствует правая скобка , по крайней мере, так говорит разработчик SQL. Мой запрос содержит оператор CASE в предложении…
оператор use case в предложении where
Я пытаюсь использовать оператор case в предложении where в sql server и получаю сообщение об ошибке. WHERE (PRCA.EDLType = ‘E’) AND ( NOT ( PRCA.EDLCode IN ( SELECT EarnCode FROM dbo.udECforUnionRpt…
Оператор case в SQL в предложении where с другом, как всегда верно
Я использовал оператор always true, например 1 = 1 in case оператор where в предложении MYSQL со следующим синтаксисом: select * from tablename where (case when tablefield is not null then then. ..
..
SQL Server: CASE оператор в предложении where
Я использую SQL Server, как я могу использовать оператор CASE в предложении where в операторе SQL? Я хочу переписать этот запрос: select * from Persons P where P.Age = 20 and P.FamilyName in (select…
Оператор CASE в предложении WHERE : Teradata
Ниже вставлен пример кода SQL, который использует оператор case в предложении where, но выдает синтаксическую ошибку: ожидая Ключевое слово типа END между mrktng_pckge_typ_cd и ключевым словом NOT….
Оператор CASE в предложении WHERE с условием !=
Я пытаюсь понять, как использовать оператор case в предложении where (with !=), вот идея того, что я пытаюсь сделать: SELECT * FROM Table1 JOIN Table2 JOIN Table3 WHERE CASE @fruit WHEN ‘Apples’…
Оператор CASE в предложении WHERE с условием IN
Могу ли я иметь оператор CASE с условием IN в предложении WHERE запроса SQL Server? Я пытаюсь вернуть все события UK, когда @DivisionCode = ‘UK’ еще все события для US и CA. Я уже пробовал это…
Я уже пробовал это…
sql-server — Несколько таблиц в предложении where SQL
У меня есть 2 таблицы: —
Table_1
GetID UnitID
1 1,2,3
2 4,5
3 5,6
4 6
Table_2
ID UnitID UserID
1 1 1
1 2 1
1 3 1
1 4 1
1 5 2
1 6 3
Мне нужен GetID ‘, основанный на ‘ UserID ‘.
Позвольте мне объяснить вам пример. Например,
Я хочу все GetID, где UserID равен 1. Результирующий набор должен быть 1 и 2. 2 включен, потому что один из блоков 2 имеет UserID 1.
Я хочу все GetID, где UserID равен 2 Результирующий набор должен быть 2 и 3. 2 включен, потому что один из блоков 2 имеет UserID 2.
Я хочу добиться этого.
Заранее спасибо.
0
Rlogical techsoft 4 Апр 2018 в 16:55
3 ответа
Лучший ответ
Попробуй это:
declare @Table_1 table(GetID INT, UnitId VARCHAR(10))
declare @Table_2 table(ID INT, UnitId INT,UserId INT)
INSERT INTO @Table_1
SELECT 1,'1,2,3'
union
SELECT 2,'4,5'
union
SELECT 3,'5,6'
union
SELECT 4,'6'
INSERT INTO @Table_2
SELECT 1,1,1
union
SELECT 1,2,1
union
SELECT 1,3,1
union
SELECT 1,4,1
union
SELECT 1,5,2
union
SELECT 1,6,3
declare @UserId INT = 2
DECLARE @UnitId VARCHAR(10)
SELECT @UnitId=COALESCE(@UnitId + ',', '') + CAST(UnitId AS VARCHAR(5)) from @Table_2 WHERE UserId=@UserId
select distinct t. GetId
from @Table_1 t
CROSS APPLY [dbo].[Split](UnitId,',') AS AA
CROSS APPLY [dbo].[Split](@UnitId,',') AS BB
WHERE AA.Value=BB.Value
GetId
from @Table_1 t
CROSS APPLY [dbo].[Split](UnitId,',') AS AA
CROSS APPLY [dbo].[Split](@UnitId,',') AS BB
WHERE AA.Value=BB.Value
Функция разделения:
CREATE FUNCTION [dbo].Split(@input AS Varchar(4000) )
RETURNS
@Result TABLE(Value BIGINT)
AS
BEGIN
DECLARE @str VARCHAR(20)
DECLARE @ind Int
IF(@input is not null)
BEGIN
SET @ind = CharIndex(',',@input)
WHILE @ind > 0
BEGIN
SET @str = SUBSTRING(@input,1,@ind-1)
SET @input = SUBSTRING(@input,@ind+1,LEN(@input)-@ind)
INSERT INTO @Result values (@str)
SET @ind = CharIndex(',',@input)
END
SET @str = @input
INSERT INTO @Result values (@str)
END
RETURN
END
0
Sahi 5 Апр 2018 в 04:36
Запрос для этого будет относительно уродливым, потому что вы допустили ошибку при сохранении данных CSV в столбце UnitID (или, возможно, кто-то еще сделал, и вы застряли с этим).
SELECT DISTINCT
t1.GetID
FROM Table_1 t1
INNER JOIN Table_2 t2
ON ',' + t1.UnitID + ',' LIKE '%,' + CONVERT(varchar(10), t2.UnitID) + ',%'
WHERE
t2.UserID = 1;
Демо
Чтобы понять используемый здесь трюк соединения, для первой строки Table_1 мы сравниваем ,1,2,3, с другими одиночными UnitID значениями из Table_2, например, %,1,% . Надеюсь, ясно, что моя логика будет соответствовать одному значению UnitID в строке CSV в любой позиции, включая первую и последнюю.
Но гораздо лучшим долгосрочным подходом было бы разделить эти значения CSV между отдельными записями. Затем, в дополнение к требованию гораздо более простого запроса, вы можете воспользоваться такими вещами, как индексы.
1
Tim Biegeleisen 4 Апр 2018 в 14:07
Оконные функции – то, что должен знать каждый T-SQL программист.
 Часть 1.
Часть 1.
Еще в Microsoft SQL Server 2005 появился интересный функционал – оконные функции. Это функции, которые позволяют осуществлять вычисления в заданном диапазоне строк внутри предложения Select. Для тех, кто не сталкивался с этими функциями возникает вопрос – «Что значит оконные?». Окно – значит набор строк, в рамках которого происходит вычисление. Оконная функция позволяет разбивать весь набор данных на такие окна.
Конечно, все что могут оконные функции возможно реализовать и без них. Однако оконные функции обладают большим преимуществом перед регулярными агрегатными функциями: нет нужды группировать набор данных для расчетов., что позволяет сохранить все строки набора с их уникальными идентификаторами. При этом результаты работы оконных функций просто добавляются к результирующей выборке как еще одно поле.
Основное преимущество использования оконных функций над регулярными агрегатными функциями заключается в следующем: оконные функции не приводят к группированию строк в одну строку вывода, строки сохраняют свои отдельные идентификаторы, а агрегированное значение добавляется к каждой строке.
Окно определяется с помощью инструкции OVER(). Давайте рассмотрим синтаксис этой инструкции:
Оконная функция (столбец для вычислений) OVER ([PARTITION BY столбец для группировки] [ORDER BY столбец для сортировки] [ROWS или RANGE выражение для ограничения строк в пределах группы])
Ассортимент функций мы рассмотрим во второй части статьи. Скажу лишь, что они разделяются на: агрегирующие, ранжирующие, смещения.
Для демонстрации работы оконных функций предлагаю на тестовой таблице:
1 2 3 4 5 6 7 |
CREATE TABLE ForWindowFunc (ID INT, GroupId INT, Amount INT) GO INSERT INTO ForWindowFunc (ID, GroupId, Amount) VALUES(1, 1, 100), (1, 1, 200), (1, 2, 150), (2, 1, 100), (2, 1, 300), (2, 2, 200), (2, 2, 50), (3, 1, 150), (3, 2, 200), (3, 2, 10); |
|
ID |
GroupId |
Amount |
|
1 |
1 |
100 |
|
1 |
1 |
200 |
|
1 |
2 |
150 |
|
2 |
1 |
100 |
|
2 |
1 |
300 |
|
2 |
2 |
200 |
|
2 |
2 |
50 |
|
3 |
1 |
150 |
|
3 |
2 |
200 |
Как видно, здесь три группы в колонке ID и две подгруппы в колонке GroupId с разным количеством элементов в группе.
Чаще всего используется функция суммирования, поэтому демонстрацию проведем именно на ней. Давайте посмотрим, как работает инструкция OVER:
1 2 3 |
SELECT ID, Amount, SUM(Amount) OVER() AS SUM FROM ForWindowFunc |
|
ID |
Amount |
Sum |
|
1 |
100 |
1310 |
|
1 |
200 |
1310 |
|
2 |
100 |
1310 |
|
2 |
300 |
1310 |
|
2 |
200 |
1310 |
|
2 |
50 |
1310 |
|
3 |
150 |
1310 |
|
3 |
200 |
1310 |
|
3 |
10 |
1310 |
Мы использовали инструкцию OVER() без предложений. В таком варианте окном будет весь набор данных и никакая сортировка не применяется. Нам просто повезло, что данные вывелись в том же порядке, в котором были вставлены в таблицу, но SQL Server может поменять порядок отображения, если нет явно заданной сортировки. Поэтому инструкцию OVER() практически никогда не применяют без предложений. Но, обратим наше внимание на новый столбец SUM. Для каждой строки выводится одно и то же значение 1310. Это сквозная сумма всех значений колонки Amount.
В таком варианте окном будет весь набор данных и никакая сортировка не применяется. Нам просто повезло, что данные вывелись в том же порядке, в котором были вставлены в таблицу, но SQL Server может поменять порядок отображения, если нет явно заданной сортировки. Поэтому инструкцию OVER() практически никогда не применяют без предложений. Но, обратим наше внимание на новый столбец SUM. Для каждой строки выводится одно и то же значение 1310. Это сквозная сумма всех значений колонки Amount.
Предложение PARTITION BY
Предложение PARTITION BY определяет столбец, по которому будет производиться группировка, и он является ключевым в разбиении набора строк на окна.
Изменим наш запрос, написанный ранее, так:
1 2 3 |
SELECT ID, Amount, SUM(Amount) OVER(PARTITION BY ID) AS SUM FROM ForWindowFunc |
|
ID |
Amount |
Sum |
|
1 |
100 |
300 |
|
1 |
200 |
300 |
|
2 |
100 |
650 |
|
2 |
300 |
650 |
|
2 |
200 |
650 |
|
2 |
50 |
650 |
|
3 |
150 |
360 |
|
3 |
200 |
360 |
|
3 |
10 |
360 |
Предложение PARTITION BY сгруппировало строки по полю ID. Теперь для каждой группы рассчитывается своя сумма значений Amount. Вы можете создавать окна по нескольким полям. Тогда в PARTITION BY нужно писать поля для группировки через запятую (например, PARTITION BY ID, Amount).
Теперь для каждой группы рассчитывается своя сумма значений Amount. Вы можете создавать окна по нескольким полям. Тогда в PARTITION BY нужно писать поля для группировки через запятую (например, PARTITION BY ID, Amount).
Предложение ORDER BY
Вместе с PARTITION BY может применяться предложение ORDER BY, которое определяет порядок сортировки внутри окна. Порядок сортировки очень важен, ведь оконная функция будет обрабатывать данные согласно этому порядку. Если вы не используете предложение PARTITION BY, а только ORDER BY, то окном будет весь набор данных.
1 2 3 4 |
SELECT ID, GroupId, Amount, SUM(Amount) OVER(PARTITION BY id ORDER BY Amount) AS SUM FROM ForWindowFunc |
|
ID |
GroupId |
Amount |
Sum |
|
1 |
1 |
100 |
100 |
|
1 |
2 |
150 |
250 |
|
1 |
1 |
200 |
450 |
|
2 |
2 |
50 |
50 |
|
2 |
1 |
100 |
150 |
|
2 |
2 |
200 |
350 |
|
2 |
1 |
300 |
650 |
|
3 |
2 |
10 |
10 |
|
3 |
1 |
150 |
160 |
|
3 |
2 |
200 |
360 |
К предложению PARTITION BY добавилось ORDER BY по полю Amount. Таким образом мы указали, что хотим видеть сумму не всех значений Amount в окне, а для каждого значения Amount сумму со всеми предыдущими. Такое суммирование часто называют нарастающий итог или накопительный итог.
Таким образом мы указали, что хотим видеть сумму не всех значений Amount в окне, а для каждого значения Amount сумму со всеми предыдущими. Такое суммирование часто называют нарастающий итог или накопительный итог.
Вы заметили, что в выборке появилось поле GpoupId. Это поле позволит показать, как изменится нарастающий итог, в зависимости от сортировки. Изменим запрос:
1 2 3 4 |
SELECT ID, GroupId, Amount, SUM(Amount) OVER(Partition BY id ORDER BY GroupId, Amount) AS SUM FROM ForWindowFunc |
|
ID |
GroupId |
Amount |
Sum |
|
1 |
1 |
100 |
100 |
|
1 |
1 |
200 |
300 |
|
1 |
2 |
150 |
450 |
|
2 |
1 |
100 |
100 |
|
2 |
1 |
300 |
400 |
|
2 |
2 |
50 |
450 |
|
2 |
2 |
200 |
650 |
|
3 |
1 |
150 |
150 |
|
3 |
2 |
10 |
160 |
|
3 |
2 |
200 |
360 |
И мы получаем совсем другое поведение. И хоть в итоге для последнего значения в окне значения сходятся с предыдущим примером, но сумма для всех остальных отличается. Поэтому важно четко понимать, что вы хотите получить в итоге.
И хоть в итоге для последнего значения в окне значения сходятся с предыдущим примером, но сумма для всех остальных отличается. Поэтому важно четко понимать, что вы хотите получить в итоге.
Предложение ROWS/RANG
Еще два предложения ROWS и RANGE применяются в инструкции OVER. Этот функционал появился в MS SQL Server 2012.
Предложение ROWS ограничивает строки в окне, указывая фиксированное количество строк, предшествующих или следующих за текущей. Оба предложения ROWS и RANGE используются вместе с ORDER BY.
Предложение ROWS может быть задано с помощью методов:
- CURRENT ROW – отображение текущей строки;
- UNBOUNDED FOLLOWING – все записи после текущей;
- UNBOUNDED PRECEDING – все предыдущие записи;
- <целое число> PRECEDING – заданное число предыдущих строк;
- <целое число> FOLLOWING – заданное число последующих записей.

Вы можете комбинировать эти функции для достижения желаемого результата, например:
- ROWS BETWEEN CURRENT ROW AND 1 FOLLOWING – в окно попадут текущая и одна следующая запись;
1 2 3 4 |
SELECT ID, GroupId, Amount, SUM(Amount) OVER(Partition BY id ORDER BY GroupId, Amount ROWS BETWEEN CURRENT ROW AND 1 FOLLOWING ) AS SUM FROM ForWindowFunc |
|
ID |
GroupId |
Amount |
Sum |
|
1 |
1 |
100 |
300 |
|
1 |
1 |
200 |
350 |
|
1 |
2 |
150 |
150 |
|
2 |
1 |
100 |
400 |
|
2 |
1 |
300 |
350 |
|
2 |
2 |
50 |
250 |
|
2 |
2 |
200 |
200 |
|
3 |
1 |
150 |
160 |
|
3 |
2 |
10 |
210 |
|
3 |
2 |
200 |
200 |
Здесь, сумма рассчитывается по текущей и следующей ячейке в окне. А последняя в окне строка имеет то же значение, что и Amount. Посмотрим на первое окно, выделенное голубым цветом. Сумма 300 рассчитана сложением 100 и 200. Для следующего значения ситуация аналогичная. А последняя в окне сумма имеет значение 150, потому что текущий Amount больше не с чем складывать.
А последняя в окне строка имеет то же значение, что и Amount. Посмотрим на первое окно, выделенное голубым цветом. Сумма 300 рассчитана сложением 100 и 200. Для следующего значения ситуация аналогичная. А последняя в окне сумма имеет значение 150, потому что текущий Amount больше не с чем складывать.
- ROWS BETWEEN 1 PRECEDING AND CURRENT ROW – одна предыдущая и текущая запись
1 2 3 4 |
SELECT ID, GroupId, Amount, SUM(Amount) OVER(Partition BY id ORDER BY GroupId, Amount ROWS BETWEEN 1 PRECEDING AND CURRENT ROW) AS SUM FROM ForWindowFunc |
|
ID |
GroupId |
Amount |
Sum |
|
1 |
1 |
100 |
100 |
|
1 |
1 |
200 |
300 |
|
1 |
2 |
150 |
350 |
|
2 |
1 |
100 |
100 |
|
2 |
1 |
300 |
400 |
|
2 |
2 |
50 |
350 |
|
2 |
2 |
200 |
250 |
|
3 |
1 |
150 |
150 |
|
3 |
2 |
10 |
160 |
|
3 |
2 |
200 |
210 |
В этом запросе мы получаем сумму путем сложения текущего значения Amount и предыдущего.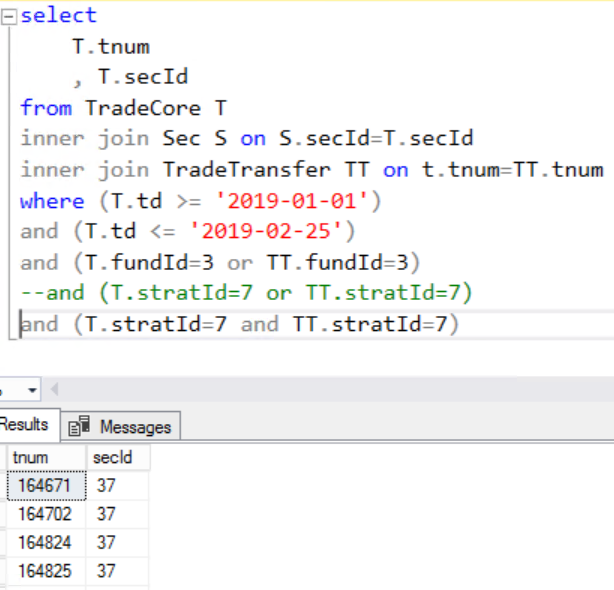 Первая строка имеет значение 100, т.к. предыдущего значения Amount не существует.
Первая строка имеет значение 100, т.к. предыдущего значения Amount не существует.
Предложение RANGE предназначено также для ограничения набора строк. В отличие от ROWS, оно работает не с физическими строками, а с диапазоном строк в предложении ORDER BY. Это означает, что одинаковые по рангу строки в контексте предложения ORDER BY будут считаться как одна текущая строка для функции CURRENT ROW. А в предложении ROWS текущая строка – это одна, текущая строка набора данных.
Предложение RANGE может использоваться только с опциями CURRENT ROW, UNBOUNDED PRECEDING и UNBOUNDED FOLLOWING.
Предложение RANGE может использовать опции:
- CURRENT ROW – отображение текущей строки;
- UNBOUNDED FOLLOWING – все записи после текущей;
- UNBOUNDED PRECEDING – все предыдущие записи.
И не может:
- <целое число> PRECEDING – заданное число предыдущих строк;
- <целое число> FOLLOWING – заданное число последующих записей.
Примеры:
1 2 3 4 |
SELECT ID, GroupId, Amount, SUM(Amount) OVER(Partition BY id ORDER BY GroupId RANGE CURRENT ROW) AS SUM FROM ForWindowFunc |
|
ID |
GroupId |
Amount |
Sum |
|
1 |
1 |
100 |
300 |
|
1 |
1 |
200 |
300 |
|
1 |
2 |
150 |
150 |
|
2 |
1 |
100 |
400 |
|
2 |
1 |
300 |
400 |
|
2 |
2 |
200 |
250 |
|
2 |
2 |
50 |
250 |
|
3 |
1 |
150 |
150 |
|
3 |
2 |
200 |
210 |
|
3 |
2 |
10 |
210 |
Предложение Range настроено на текущую строку. Но, как мы помним, для Range текущая строка, это все строки, соответствующие одному значению сортировки. Сортировка в данном случае по полю GroupId. Первые две строки первого окна имеют значение GroupId равное 1 – следовательно оба эти значения удовлетворяют ограничению RANGE CURRENT ROW. Поэтому Sum для каждой из этих строк равна общей сумме Amount по ним — 300.
Но, как мы помним, для Range текущая строка, это все строки, соответствующие одному значению сортировки. Сортировка в данном случае по полю GroupId. Первые две строки первого окна имеют значение GroupId равное 1 – следовательно оба эти значения удовлетворяют ограничению RANGE CURRENT ROW. Поэтому Sum для каждой из этих строк равна общей сумме Amount по ним — 300.
- RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW;
1 2 3 4 |
SELECT ID, GroupId, Amount, SUM(Amount) OVER(Partition BY id ORDER BY GroupId RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS SUM FROM ForWindowFunc |
|
ID |
GroupId |
Amount |
Sum |
|
1 |
1 |
100 |
300 |
|
1 |
1 |
200 |
300 |
|
1 |
2 |
150 |
450 |
|
2 |
1 |
100 |
400 |
|
2 |
1 |
300 |
400 |
|
2 |
2 |
200 |
650 |
|
2 |
2 |
50 |
650 |
|
3 |
1 |
150 |
150 |
|
3 |
2 |
200 |
360 |
|
3 |
2 |
10 |
360 |
В этом случае ограничение по всем предыдущим строкам и текущей. Для первой и второй строки это правило работает как предыдущее (вспоминаем CURRENT ROW), а для третьей как сумма Amount предыдущих строк с текущей.
Для первой и второй строки это правило работает как предыдущее (вспоминаем CURRENT ROW), а для третьей как сумма Amount предыдущих строк с текущей.
- RANGE BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING.
1 2 3 4 |
SELECT ID, GroupId, Amount, SUM(Amount) OVER(Partition BY id ORDER BY GroupId RANGE BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS SUM FROM ForWindowFunc |
|
ID |
GroupId |
Amount |
Sum |
|
1 |
2 |
150 |
150 |
|
1 |
1 |
100 |
450 |
|
1 |
1 |
200 |
450 |
|
2 |
2 |
200 |
250 |
|
2 |
2 |
50 |
250 |
|
2 |
1 |
100 |
650 |
|
2 |
1 |
300 |
650 |
|
3 |
2 |
200 |
210 |
|
3 |
2 |
10 |
210 |
|
3 |
1 |
150 |
360 |
Это ограничение позволило нам получить сумму из текущей строки и всех предыдущих в рамках одного окна. Так как вторая и третья строка у нас в одной GroupId, то эти значения и есть Current Row. Поэтому они просуммированы сразу.
Так как вторая и третья строка у нас в одной GroupId, то эти значения и есть Current Row. Поэтому они просуммированы сразу.
На этом закончим первую часть статьи. А напоследок — пример использования оконной функции из реальной практики.
Лучше всего понять суть оконных функций можно на примере. Допустим у вас есть данные о платежах абонентов. Платеж поступает на договор. Но у этого договора есть дочерние договора, на которых отрицательный баланс. И мы хотим распределить поступившие средства на погашение долга дочерних договоров.
Таким образом, нам нужно определить сколько же денег мы спишем со счета основного договора и сколько переведем на дочерний. Давайте посмотрим на таблицу:
|
ContractId |
ChildContractId |
PayId |
CustAccount |
PayAmount |
|
1000000000 |
1000000002 |
1000000752 |
-200,00 |
800,00 |
|
1000000000 |
1000000003 |
1000000753 |
-1000,00 |
800,00 |
Где, ContractId – идентификатор основного договора,
ChildContractId – идентификатор дочернего договора,
PayId – идентификатор платежа,
CustAccount – баланс дочернего договора,
PayAmount – платеж.
Из таблицы видно, что для каждого дочернего договора сумма платежа 800. Это из-за того, что платеж на родительском договоре.
Так что наша задача рассчитать суммы переносов денег с родительского на дочерние договора.
Для этого суммируем CustAccount и PayAmount. Однако, простая сумма баланса и платежа нас не устраивает. Ведь на погашение долга на втором дочернем договоре мы должны учитывать остаток от суммы баланса первого договора и платежа.
Как мы можем действовать в этой ситуации? Мы могли бы выбрать:
1 2 3 4 5 6 7 8 |
SELECT ContractId, ChildContractId, PayId, CustAccount, PayAmount, PayAmount + (SELECT SUM(CustAccount) FROM dbo.Pays p2 WHERE p1.PayId = p2.PayId AND p2.ChildContractId <= p1.ChildContractId) AS [SUM] FROM dbo.Pays p1 |
Этот запрос решает поставленную задачу, но подзапрос портит всю картину – увеличивает время выполнения запроса.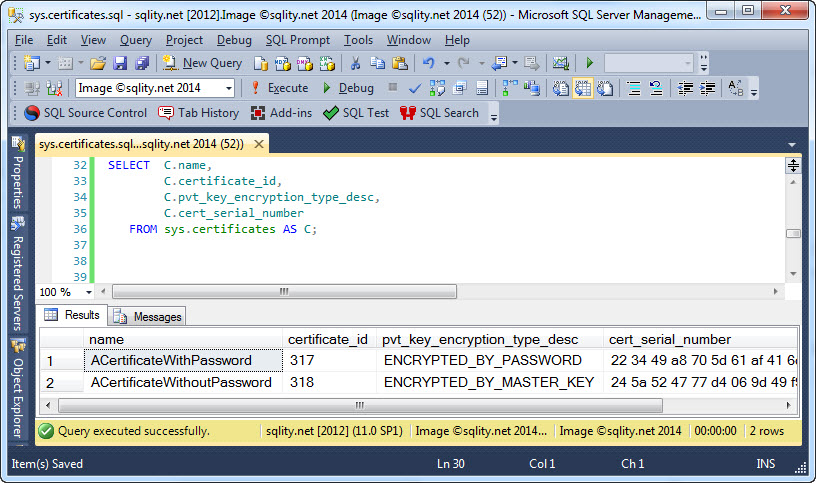 Применим оконную функцию сложения:
Применим оконную функцию сложения:
1 2 3 4 5 6 7 8 |
SELECT ContractId, ChildContractId, PayId, CustAccount, PayAmount, PayAmount + SUM(CustAccount) OVER (ORDER BY ChildContractId) AS [SUM] FROM dbo.Pays p1 |
Этот вариант работает быстрее и выглядит лаконичнее. В нашем случае мы получаем сумму по полю CustAccount в окне, которое формируется по полю ChildContractId.
Результатом этих запросов будет таблица:
|
ContractId |
ChildContractId |
PayId |
CustAccount |
PayAmount |
Sum |
|
1000000000 |
1000000002 |
1000000752 |
-200,00 |
800,00 |
600 |
|
1000000000 |
1000000003 |
1000000753 |
-1000,00 |
800,00 |
-400 |
Исходя из полученных данных в колонке Sum мы определяем сумму, которую нужно перенести с родительского договора на дочерний. Для договора 1000000002 мы погасили долг полностью, так что сумма платежа 200р. Для договора 1000000003 долг погашен частично – сумма платежа равна сумме баланса и остатка от платежа после расчета для первой записи (-1000 + 600 = -400р).
Для договора 1000000002 мы погасили долг полностью, так что сумма платежа 200р. Для договора 1000000003 долг погашен частично – сумма платежа равна сумме баланса и остатка от платежа после расчета для первой записи (-1000 + 600 = -400р).
Порядок операций SQL — В каком порядке MySQL выполняет запросы?
Знание порядка битов и байтов операций SQL-запроса может быть очень полезным, поскольку оно может упростить процесс написания новых запросов, а также очень полезно при попытке оптимизировать SQL-запрос.Если вы ищете короткую версию, это логический порядок операций, также известный как порядок выполнения, для SQL-запроса:
- FROM, включая JOINs
- WHERE
- GROUP BY
- HAVING
- Функции WINDOW
- SELECT
- DISTINCT
- UNION
- ORDER BY
- LIMIT и OFFSET
Но реальность не так проста и не прямолинейна. Как мы уже говорили, стандарт SQL определяет порядок выполнения для различных предложений SQL-запросов. Сказано, что современные базы данных уже проверяют этот порядок по умолчанию, применяя некоторые приемы оптимизации, которые могут изменить фактический порядок выполнения, хотя в конечном итоге они должны возвращать тот же результат, как если бы они выполняли запрос в порядке выполнения по умолчанию.
Сказано, что современные базы данных уже проверяют этот порядок по умолчанию, применяя некоторые приемы оптимизации, которые могут изменить фактический порядок выполнения, хотя в конечном итоге они должны возвращать тот же результат, как если бы они выполняли запрос в порядке выполнения по умолчанию.
Почему они это сделали? Что ж, может быть глупо, если база данных сначала извлечет все данные, упомянутые в предложении FROM (включая JOIN), прежде чем заглядывать в предложение WHERE и его индексы. Эти таблицы могут содержать большое количество данных, поэтому вы можете представить, что произойдет, если оптимизатор базы данных будет придерживаться традиционного порядка операций SQL-запроса.
Давайте рассмотрим каждую из частей SQL-запроса в соответствии с порядком их выполнения.
FROM и JOINs
Таблицы, указанные в предложении FROM (включая JOIN), будут оцениваться первыми, чтобы определить весь рабочий набор, который имеет отношение к запросу. База данных будет объединять данные из всех таблиц в соответствии с предложениями JOINs ON, а также извлекать данные из подзапросов и даже может создавать некоторые временные таблицы для хранения данных, возвращаемых из подзапросов в этом разделе.
Во многих случаях, тем не менее, оптимизатор базы данных сначала выберет оценку части WHERE, чтобы увидеть, какая часть рабочего набора может быть пропущена (предпочтительно с использованием индексов), поэтому он не будет слишком сильно раздувать набор данных, если он действительно не нужен.
Класс WHERE
Предложение WHERE будет вторым, который будет оценен после предложения FROM. У нас есть набор рабочих данных, и теперь мы можем фильтровать данные в соответствии с условиями в предложении WHERE.
Эти условия могут включать ссылки на данные и таблицы из условия FROM, но не могут включать ссылки на псевдонимы, определенные в предложении SELECT, поскольку эти данные и эти псевдонимы могут еще не «существовать» в этом контексте, так как это предложение не было пока оценивается базой данных.
Кроме того, распространенной ошибкой для предложения WHERE является попытка отфильтровать агрегированные значения в предложении WHERE, например, с помощью этого предложения: WHERE sum (available_stock)> 0. Этот оператор не выполнит запрос, потому что агрегаты будут оцениваться позже в процессе (см. Раздел GROUP BY ниже). Чтобы применить условие фильтрации к агрегированным данным, вы должны использовать предложение HAVING, а не предложение WHERE.
Предложение GROUP BY
Теперь, когда мы отфильтровали набор данных с помощью предложения WHERE, мы можем объединить данные в соответствии с одним или несколькими столбцами, появляющимися в предложении GROUP BY. Группировка данных фактически разбивает их на разные порции или сегменты, где каждый сегмент имеет один ключ и список строк, соответствующих этому ключу. Отсутствие предложения GROUP BY похоже на помещение всех строк в одно большое ведро.
После того как вы агрегируете данные, вы можете теперь использовать функции агрегации, чтобы возвращать значение для каждой группы для каждого сегмента. Такие функции агрегации включают COUNT, MIN, MAX, SUM и другие.
Класс HAVING
Теперь, когда мы сгруппировали данные с помощью предложения GROUP BY, мы можем использовать предложение HAVING, чтобы отфильтровать некоторые сегменты. Условия в предложении HAVING могут ссылаться на функции агрегирования, поэтому пример, который не работал в приведенном выше предложении WHERE, будет прекрасно работать в предложении HAVING:
Условия в предложении HAVING могут ссылаться на функции агрегирования, поэтому пример, который не работал в приведенном выше предложении WHERE, будет прекрасно работать в предложении HAVING: HAVING sum (available_stock)> 0.
Поскольку мы уже сгруппировали данные, мы больше не можем получить доступ к исходным строкам на этом этапе, поэтому мы можем применять условия только для фильтрации целых сегментов, а не отдельных строк в сегменте.
Кроме того, как мы упоминали в предыдущих разделах, псевдонимы, определенные в предложении SELECT, также не могут быть доступны в этом разделе, поскольку они еще не были оценены базой данных (это верно для большинства баз данных).
Функции Window
Если вы используете функции Window , это точка, где они будут выполняться. Подобно механизму группировки, оконные функции также выполняют вычисления для набора строк. Основное отличие состоит в том, что при использовании оконных функций каждая строка будет сохранять свою идентичность и не будет сгруппирована в группу других похожих строк.
Оконные функции могут использоваться только в предложении SELECT или ORDER BY. Вы можете использовать функции агрегирования внутри оконных функций, например:
SUM(COUNT(*)) OVER ()
Предложение SELECT
Теперь, когда мы закончили отбрасывать строки из набора данных и группировать данные, мы можем выбрать данные, которые мы хотим получить из запроса на стороне клиента. Вы можете использовать имена столбцов, агрегаты и подзапросы внутри предложения SELECT. Имейте в виду, что если вы используете ссылку на функцию агрегации, например COUNT (*) в предложении SELECT, это просто ссылка на агрегацию, которая уже произошла, когда произошла группировка, поэтому сама агрегация не произойдет в предложении SELECT, но это только ссылка на его набор результатов.
Ключевое слово DISTINCT
Синтаксис ключевого слова DISTINCT немного сбивает с толку, потому что ключевое слово занимает свое место перед именами столбцов в предложении SELECT. Но фактическая операция DISTINCT происходит после SELECT. При использовании ключевого слова DISTINCT база данных отбрасывает строки с повторяющимися значениями из оставшихся строк, оставшихся после фильтрации и агрегирования.
При использовании ключевого слова DISTINCT база данных отбрасывает строки с повторяющимися значениями из оставшихся строк, оставшихся после фильтрации и агрегирования.
Ключевое слово UNION
Ключевое слово UNION объединяет наборы результатов двух запросов в один набор результатов. В большинстве баз данных вы можете выбирать между UNION DISTINCT (который отбрасывает дублирующиеся строки из объединенного набора результатов) или UNION ALL (который просто объединяет наборы результатов без применения какой-либо проверки на дублирование).
Вы можете применить сортировку (ORDER BY) и ограничение (LIMIT) к набору результатов UNION, так же, как вы можете применить его к обычному запросу.
Предложение ORDER BY
Сортировка происходит после того, как в базе данных будет готов весь набор результатов (после фильтрации, группировки, удаления дубликатов). После этого база данных может теперь сортировать результирующий набор, используя столбцы, выбранные псевдонимы или функции агрегирования, даже если они не являются частью выбранных данных.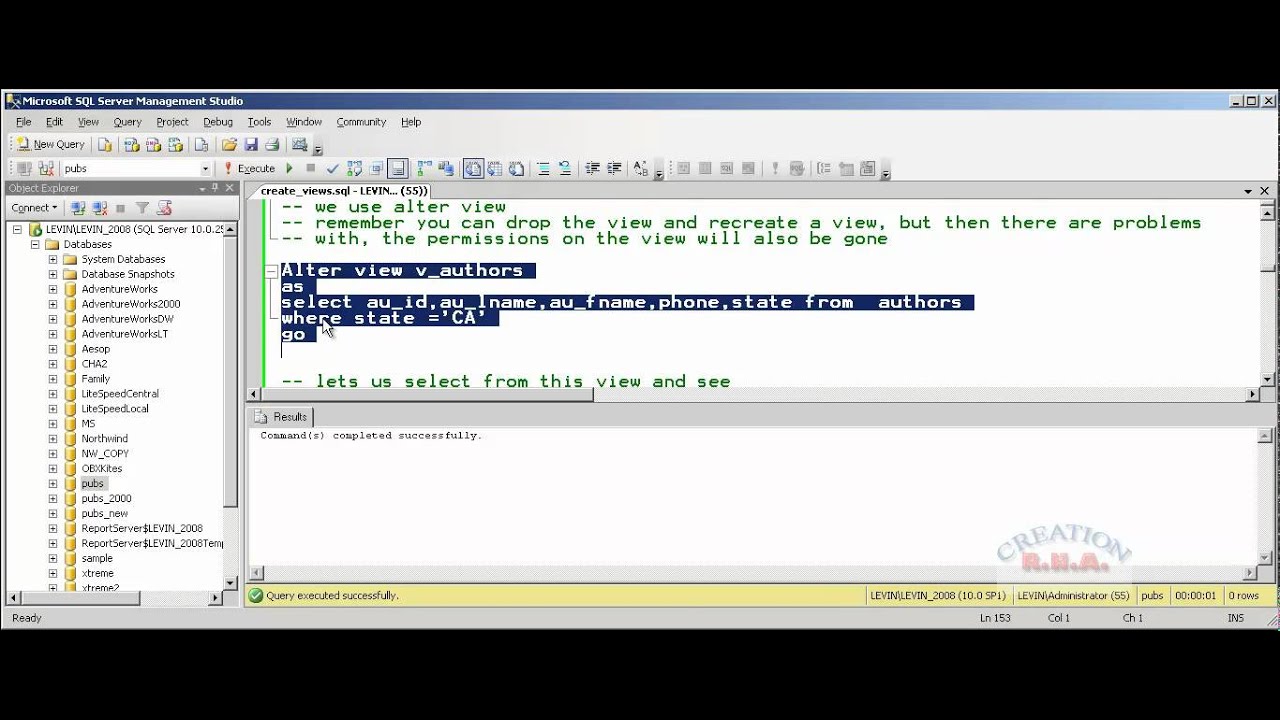 Единственным исключением является использование ключевого слова DISTINCT, которое предотвращает сортировку по не выбранному столбцу, так как в этом случае порядок набора результатов будет неопределенным.
Единственным исключением является использование ключевого слова DISTINCT, которое предотвращает сортировку по не выбранному столбцу, так как в этом случае порядок набора результатов будет неопределенным.
Вы можете выбрать сортировку данных по убыванию (DESC) или по возрастанию (ASC). Заказ может быть уникальным для каждой из частей заказа, поэтому действует следующее: ORDER BY firstname ASC, age DESC
LIMIT и OFFSET
В большинстве случаев использования (за исключением нескольких подобных отчетов) мы хотели бы отбросить все строки, кроме первых X строк результата запроса. Предложение LIMIT, которое выполняется после сортировки, позволяет нам сделать это. Кроме того, вы можете выбрать, с какой строки начинать извлекать данные и сколько исключать, используя комбинацию ключевых слов LIMIT и OFFSET. В следующем примере будет выбрано 50 строк, начиная с строки 100: LIMIT 50 OFFSET 100
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.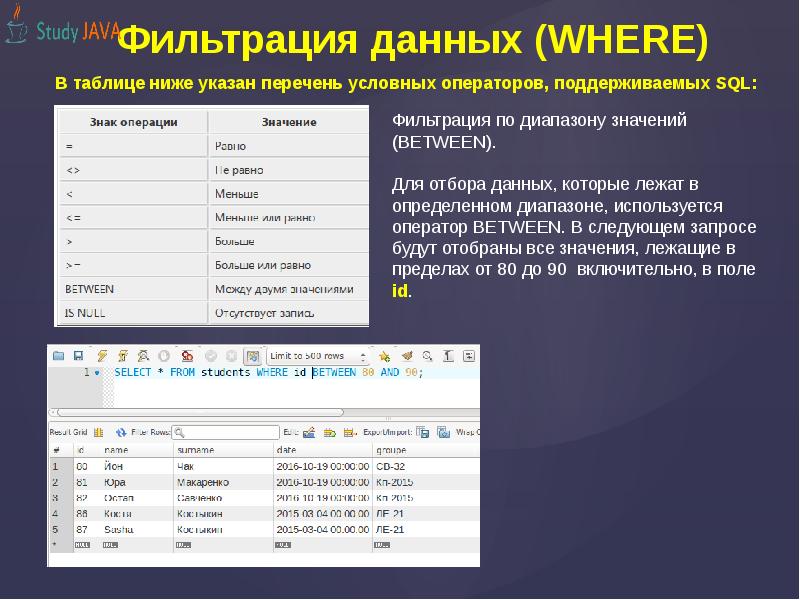
SQL WHERE, SQL SELECT WHERE — с примерами
Как использовать предложение SQL WHERE?
Предложение SQL WHERE фильтрует строки, соответствующие определенным критериям.
Это способ ограничить строки теми, которые вам интересны.
За WHERE следует условие, которое возвращает либо истину, либо ложь.
Предложение WHERE используется с SELECT, UPDATE и DELETE.
Синтаксис SQL WHERE
Вот инструкция SELECT с предложением WHERE:
ВЫБЕРИТЕ имена столбцов ОТ имя-таблицы ГДЕ условие
И вот ОБНОВЛЕНИЕ с предложением WHERE:
ОБНОВЛЕНИЕ имя-таблицы УСТАНОВИТЬ имя-столбца = значение ГДЕ условие
Наконец, оператор DELETE с предложением WHERE:
УДАЛИТЬ имя-таблицы ГДЕ условие
| КЛИЕНТ |
|---|
| Идентификатор |
| Имя |
| Фамилия |
| Город |
| Страна |
| Телефон |
Примеры предложения WHERE SQL
Задача: Список всех клиентов в Швеции
ВЫБЕРИТЕ Id, FirstName, LastName, City, Country, Phone ОТ Заказчика ГДЕ Страна = 'Швеция'
Результат: 2 записи
| Id | Имя | Фамилия | Город | Страна | Телефон |
|---|---|---|---|---|---|
| 5 | Кристина | Berglund | Лулео | Швеция | 0921-12 34 65 |
| 24 | Мария | Ларссон | Bräcke | Швеция | 0695-34 67 21 |
| ПОСТАВЩИК |
|---|
| Идентификатор |
| Название компании |
| Контактное имя |
| Город |
| Страна |
| Телефон |
| Факс |
Задача: Обновить город Сидней для поставщика Pavlova, Ltd.
ОБНОВЛЕНИЕ Поставщик SET City = 'Сидней' ГДЕ Name = 'Павлова, ООО'
Результат: Обновлена 1 запись.
| ПРОДУКТ |
|---|
| Идентификатор |
| Название продукта |
| Идентификатор поставщика |
| Цена за единицу |
| Упаковка |
| Снято с производства |
Проблема: Удалить все товары с ценой выше 50 долларов.
УДАЛИТЬ ИЗ ПРОДУКТА ГДЕ UnitPrice> 50
Результат: 7 записей удалены.
Примечание. Ссылочная целостность может предотвратить это удаление.
Лучшим подходом может быть прекращение выпуска продукта, то есть установка для столбца IsDiscontinued значения true.
1. Изучите SQL SELECT / FROM / WHERE
Если вы завершили загрузку QueryPie и уже подключились к базе данных, пора искать данные и управлять ими. Давайте рассмотрим, что мы можем сделать с запросами SELECT, FROM и WHERE.
Давайте рассмотрим, что мы можем сделать с запросами SELECT, FROM и WHERE.
📌Содержание
Запрос 1. Использование SELECT для ВСЕХ столбцов
SELECT * FROM film; Запрос 2. Использование SELECT для столбца SPECIFIC
SELECT film_id, title, rating, special_features FROM film; Запрос 3. Использование WHERE
SELECT film_id, title, rating, special_features FROM film WHERE rating = 'R'; # SELECT, FROM, WHERE
Самые основные «вопросы», которые мы можем задать в SQL: SELECT , FROM и WHERE .Они имеют интуитивное значение, поэтому их довольно легко угадать, прочитав их. Давайте быстро их рассмотрим.
📌 SELECT : вы сообщаете базе данных, что вам показать
📌 FROM : вы даете базе данных местоположение для поиска
📌 ГДЕ : вы сужаете / указываете местоположение
🔑 С этого момента мы будем называть наши «Вопросы»
запросами .
Итак, давайте рассмотрим наш первый запрос.
1 кв.Какие данные есть в таблице «фильм»? Покажи мне!
ВЫБРАТЬ (желаемые «столбцы») ИЗ (в конкретной «таблице»)
Это самый простой запрос. Мы можем начать разговор с любой базой данных
, просто используя это предложение.
В этом примере мы собираемся использовать данные из таблицы Film внутри Sample Database sakila .
Применяя эту идею к запросу 1, мы можем прочитать его как «ВЫБРАТЬ« столбцы »ИЗ таблицы« фильм ».«Нам не нужно слово« таблица »после названия таблицы. SQL уже знает, что слово, следующее за запросом FROM , будет именем таблицы. Так что напишите ИЗ пленки .
Если вы хотите увидеть сразу все доступные данные каждого столбца в указанной таблице, используйте символ звездочки ( * ). Символ * здесь означает все данные всех столбцов. Допустим, мы хотим, чтобы отображал все столбцы, содержащие информацию внутри таблицы фильма . В SQL это примерно переводится как «
В SQL это примерно переводится как « SELECT (показать) * (все столбцы, содержащие информацию) FROM (внутри) film (table) ». Удалите все круглые скобки, и вы получите простой SQL-запрос:
SELECT * FROM film; Обязательно используйте точку с запятой (; ) в конце предложения, чтобы SQL знал, что это конец вашего запроса и вы готовы увидеть результаты.
✦ Щелкните SQL Выполнить в левом верхнем углу, чтобы попробовать запрос
Вы должны увидеть что-то похожее на изображение, показанное ниже.
Результат — тонна столбцов, заполненных информацией о фильмах!
Но, допустим, мы хотим видеть только информацию о самом фильме, без лишнего шума, связанного с арендной ставкой или продолжительностью фильма.
2 кв. Здесь слишком много столбцов !! Давайте посмотрим только на идентификатор, название, рейтинг и особенности в таблице фильмов.
ВЫБРАТЬ (конкретный желаемый столбец) ИЗ (в конкретной таблице)
Для этого мы собираемся сосредоточиться на столбцах , идентификатор фильма , заголовок , рейтинг , и специальные функции . Просто введите точное имя нужного столбца после SELECT , чтобы отфильтровать информацию. В этом случае вы можете использовать это:
SELECT film_id, title, rating, special_features FROM film; 3 кв.Хорошо, теперь давайте сузим круг вопросов. Давайте посмотрим только на идентификатор фильма, название, рейтинг и особенности фильмов с рейтингом R.
SELECT (показать этот «столбец») FROM (конкретная «таблица») WHERE (соответствует условию)
If condition is number: WHERE film_id = 5
If condition is character: WHERE rating = ‘PG’ — ( Добавить одиночные кавычки !! )
Теперь, когда мы знаем, как находить конкретные данные, давайте сузим их еще немного. Допустим, нам нужна информация только о фильмах с определенным рейтингом (R, PG-13, PG и т. Д.). Для этого нам нужно начать использовать SQL-запрос
Допустим, нам нужна информация только о фильмах с определенным рейтингом (R, PG-13, PG и т. Д.). Для этого нам нужно начать использовать SQL-запрос WHERE .
Просто добавьте ГДЕ в конец запроса после желаемой оценки. В этом примере мы будем искать фильмы с рейтингом R. Почему бы и нет?
Плагин ГДЕ рейтинг = «R» в конце заявления. Обратите внимание, что мы добавили одинарные кавычки вокруг буквы R ( ‘’ ).Это потому, что SQL нуждается в этой дополнительной скобке, когда условие не является числом. Есть способы обойти это, но для новичков хорошо иметь прочный фундамент. Так что давайте использовать эти одиночные цитаты! Ваш окончательный запрос должен выглядеть примерно так:
SELECT film_id, title, rating, special_features FROM film WHERE rating = 'R'; ✦ Не забудьте нажать SQL Run в левом верхнем углу, чтобы выполнить запрос
# Время практики Попробуйте использовать SELECT , FROM и WHERE в этом примере сценария:
📰 К вам подходит покупатель вашего киномагазина и спрашивает список всех фильмов, срок проката которых составляет 3 дня.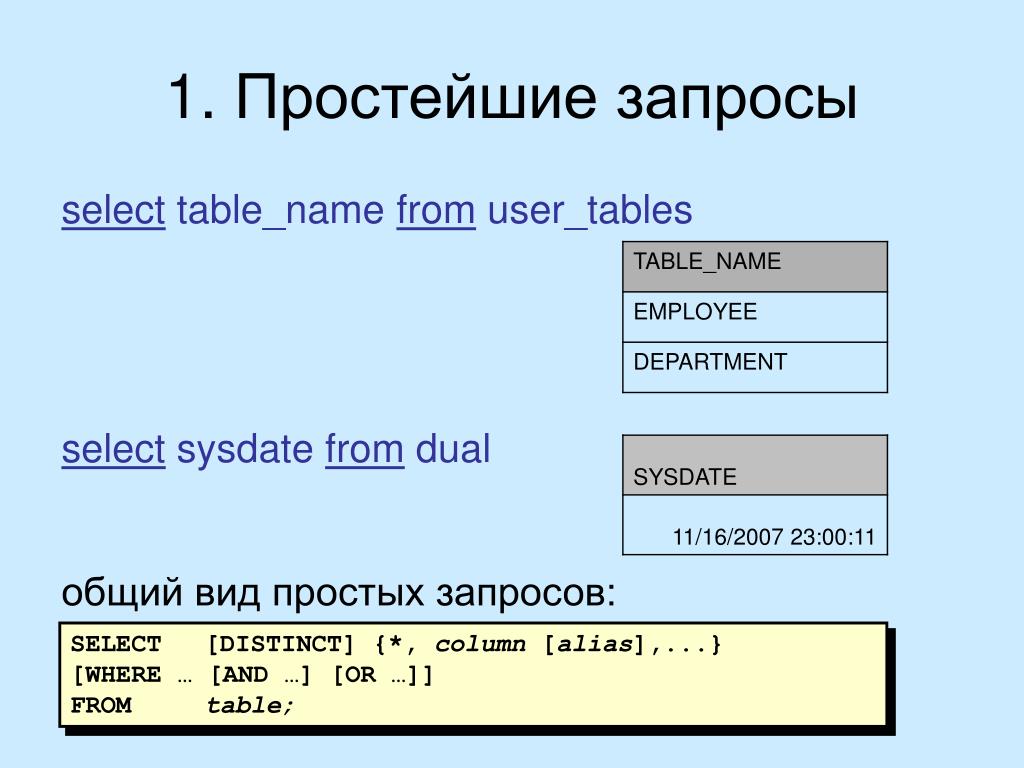 Она также интересуется ценой (арендной ставкой). Как вы можете найти эту информацию? Не забудьте также выполнить поиск по идентификационному номеру, чтобы вы могли легко найти фильмы на полках.
Она также интересуется ценой (арендной ставкой). Как вы можете найти эту информацию? Не забудьте также выполнить поиск по идентификационному номеру, чтобы вы могли легко найти фильмы на полках.
Вот ответ:
ВЫБЕРИТЕ film_id, title, rental_rate, rental_duration ИЗ фильма WHERE rental_duration = 3; SQL Server WHERE
Резюме : в этом руководстве вы узнаете, как использовать предложение SQL Server WHERE для фильтрации строк, возвращаемых запросом.
Введение в SQL Server
WHERE , пункт Когда вы используете оператор SELECT для запроса данных по таблице, вы получаете все строки этой таблицы, что не является необходимым, поскольку приложение может обрабатывать только набор строк в время.
Чтобы получить строки из таблицы, которые удовлетворяют одному или нескольким условиям, вы используете предложение WHERE следующим образом:
Язык кода: SQL (язык структурированных запросов) (sql)
SELECT select_list ИЗ table_name ГДЕ search_condition;
В предложении WHERE вы указываете условие поиска для фильтрации строк, возвращаемых предложением FROM . Предложение
Предложение WHERE возвращает только те строки, которые приводят к тому, что условие поиска оценивается как TRUE .
Условие поиска — это логическое выражение или комбинация нескольких логических выражений. В SQL логическое выражение часто называют предикатом .
Обратите внимание, что SQL Server использует логику трехзначного предиката, где логическое выражение может оцениваться как ИСТИНА , ЛОЖЬ или НЕИЗВЕСТНО . Предложение WHERE не вернет ни одной строки, из-за которой предикат оценивается как FALSE или UNKNOWN .
SQL Server
WHERE примеры Мы будем использовать таблицу production.products из образца базы данных для демонстрации
A) Поиск строк с помощью простого равенства
Следующая инструкция извлекает все продукты с идентификатором категории 1:
Язык кода: SQL (язык структурированных запросов) (sql)
ВЫБРАТЬ идантификационный номер продукта, наименование товара, category_id, год выпуска, список цен ИЗ production.products ГДЕ category_id = 1 СОРТИРОВАТЬ ПО list_price DESC;
B) Поиск строк, отвечающих двум условиям
В следующем примере возвращаются продукты, соответствующие двум условиям: идентификатор категории — 1 и модель — 2018.Он использует логический оператор И для объединения двух условий.
Язык кода: SQL (язык структурированных запросов) (sql)
ВЫБРАТЬ идантификационный номер продукта, наименование товара, category_id, год выпуска, список цен ИЗ production.products ГДЕ category_id = 1 AND model_year = 2018 СОРТИРОВАТЬ ПО list_price DESC;
C) Поиск строк с помощью оператора сравнения
Следующий оператор находит продукты, прейскурантная цена которых превышает 300, а модель — 2018.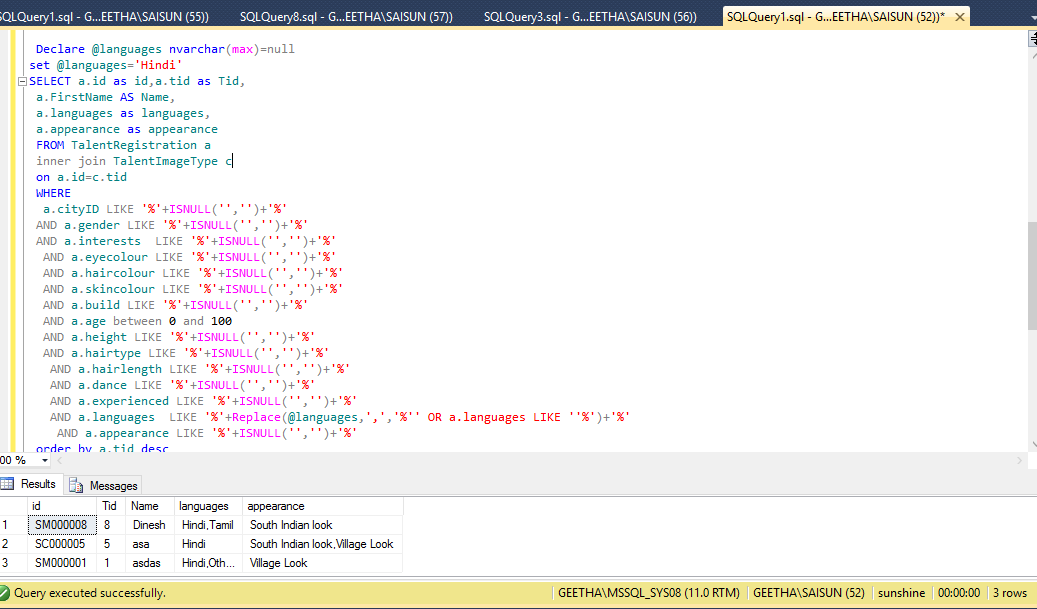
Язык кода: SQL (язык структурированных запросов) (sql)
ВЫБРАТЬ идантификационный номер продукта, наименование товара, category_id, год выпуска, список цен ИЗ production.products ГДЕ list_price> 300 И model_year = 2018 СОРТИРОВАТЬ ПО list_price DESC;
D) Поиск строк, удовлетворяющих любому из двух условий
Следующий запрос находит продукты, цена которых превышает 3000 или модель 2018 года. удовлетворяет одному из этих условий, включается в набор результатов.
Язык кода: SQL (язык структурированных запросов) (sql)
ВЫБРАТЬ идантификационный номер продукта, наименование товара, category_id, год выпуска, список цен ИЗ production.products ГДЕ list_price> 3000 ИЛИ model_year = 2018 СОРТИРОВАТЬ ПО list_price DESC;
Обратите внимание, что для объединения предикатов использовался оператор OR .
E) Поиск строк со значением между двумя значениями
Следующий оператор находит продукты, прейскурантные цены которых находятся в диапазоне от 1899 до 1999.99:
Язык кода: SQL (язык структурированных запросов) (sql)
ВЫБРАТЬ идантификационный номер продукта, наименование товара, category_id, год выпуска, список цен ИЗ production.products ГДЕ list_price МЕЖДУ 1899.00 И 1999.99 СОРТИРОВАТЬ ПО list_price DESC;
F) Поиск строк, имеющих значение в списке значений
В следующем примере оператор IN используется для поиска продуктов, прайс-лист которых 299.99 или 466,99 или 489,99.
Язык кода: SQL (язык структурированных запросов) (sql)
ВЫБРАТЬ идантификационный номер продукта, наименование товара, category_id, год выпуска, список цен ИЗ production.products ГДЕ list_price IN (299,99, 369,99, 489,99) СОРТИРОВАТЬ ПО list_price DESC;
G) Поиск строк, значения которых содержат строку
В следующем примере оператор LIKE используется для поиска продуктов, имя которых содержит строку Cruiser :
Язык кода: SQL (язык структурированных запросов) (sql)
ВЫБРАТЬ идантификационный номер продукта, наименование товара, category_id, год выпуска, список цен ИЗ производство.продукты ГДЕ product_name LIKE '% Cruiser%' СОРТИРОВАТЬ ПО список цен;
В этом руководстве вы узнали, как использовать предложение SQL Server WHERE для фильтрации строк на основе одного или нескольких условий.
SQL-соединений с использованием WHERE или ON | Средний уровень SQL
Начиная с этого места? Этот урок является частью полного руководства по использованию SQL для анализа данных. Проверьте начало.
В этом уроке мы рассмотрим:
Фильтрация в предложении ON
Обычно фильтрация обрабатывается в предложении WHERE после того, как две таблицы уже были объединены. Однако возможно, что вы захотите отфильтровать одну или обе таблицы , прежде чем присоединится к ним. Например, вы хотите создавать совпадения между таблицами только при определенных обстоятельствах.
Используя данные Crunchbase, давайте еще раз посмотрим на пример LEFT JOIN из предыдущего урока (на этот раз мы добавим предложение ORDER BY ):
ВЫБРАТЬ компании.постоянная ссылка AS companies_permalink,
имя_компании AS имя_компании,
acquisitions.company_permalink AS acquisitions_permalink,
acquisitions.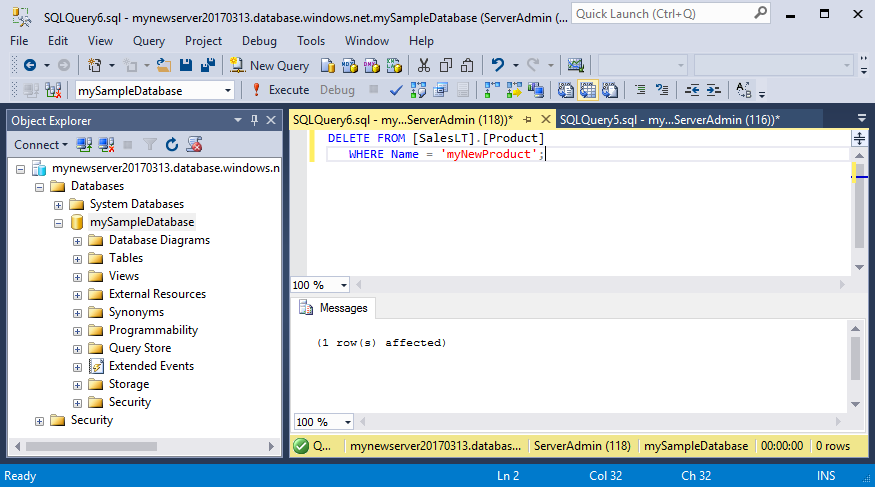 acquired_at AS Дата_ приобретения
ОТ tutorial.crunchbase_companies компании
LEFT JOIN tutorial.crunchbase_acquisitions acquisitions
ON companies.permalink = acquisitions.company_permalink
ЗАКАЗАТЬ ПО 1
acquired_at AS Дата_ приобретения
ОТ tutorial.crunchbase_companies компании
LEFT JOIN tutorial.crunchbase_acquisitions acquisitions
ON companies.permalink = acquisitions.company_permalink
ЗАКАЗАТЬ ПО 1
Сравните следующий запрос с предыдущим, и вы увидите, что все в таблице tutorial.crunchbase_acquisitions было объединено с , за исключением для строки, для которой company_permalink равно '/ company / 1000memories' :
ВЫБРАТЬ компании.постоянная ссылка AS companies_permalink,
имя_компании AS имя_компании,
acquisitions.company_permalink AS acquisitions_permalink,
acquisitions.acquired_at AS Дата_ приобретения
ОТ tutorial.crunchbase_companies компании
LEFT JOIN tutorial.crunchbase_acquisitions acquisitions
ON companies.permalink = acquisitions.company_permalink
И acquisitions.company_permalink! = '/ Company / 1000memories'
ЗАКАЗАТЬ ПО 1
Что происходит выше, так это то, что условный оператор AND. оценивается до того, как произойдет соединение. Вы можете думать об этом как о предложении 
WHERE , которое применяется только к одной из таблиц. Вы можете сказать, что это происходит только в одной из таблиц, потому что постоянная ссылка 1000memories все еще отображается в столбце, извлеченном из другой таблицы:
Фильтрация в предложении WHERE
Если вы переместите тот же фильтр в предложение WHERE , вы заметите, что фильтр применяется после объединения таблиц. В результате строка 1000memories присоединяется к исходной таблице, но затем она полностью отфильтровывается (в обеих таблицах) в предложении WHERE перед отображением результатов.
SELECT companies.permalink AS companies_permalink,
имя_компании AS имя_компании,
acquisitions.company_permalink AS acquisitions_permalink,
acquisitions.acquired_at AS Дата_ приобретения
ОТ tutorial.crunchbase_companies компании
LEFT JOIN tutorial. crunchbase_acquisitions acquisitions
ON companies.permalink = acquisitions.company_permalink
ГДЕ acquisitions.company_permalink! = '/ Company / 1000memories'
ИЛИ acquisitions.company_permalink ЕСТЬ NULL
ЗАКАЗАТЬ ПО 1
crunchbase_acquisitions acquisitions
ON companies.permalink = acquisitions.company_permalink
ГДЕ acquisitions.company_permalink! = '/ Company / 1000memories'
ИЛИ acquisitions.company_permalink ЕСТЬ NULL
ЗАКАЗАТЬ ПО 1
Вы можете видеть, что строка 1000memories не возвращается (она была бы между двумя выделенными строками ниже).Также обратите внимание, что фильтрация в предложении WHERE также может фильтровать нулевые значения, поэтому мы добавили дополнительную строку, чтобы обязательно включить нули.
Отточите свои навыки работы с SQL
Для этого набора практических задач мы собираемся представить новый набор данных: tutorial.crunchbase_investments . Эта таблица также получена из Crunchbase и содержит большую часть той же информации, что и данные tutorial.crunchbase_companies . Однако он имеет другую структуру: он содержит одну строку на инвестиций .В каждой компании может быть несколько инвестиций — даже возможно, что один инвестор может инвестировать в одну и ту же компанию несколько раз. Имена столбцов говорят сами за себя. Важно то, что
Имена столбцов говорят сами за себя. Важно то, что company_permalink в таблице tutorial.crunchbase_investments сопоставляется с постоянной ссылкой в таблице tutorial.crunchbase_companies . Имейте в виду, что некоторые случайные данные были удалены из этой таблицы для этого урока.
Очень вероятно, что вам нужно будет провести некоторый исследовательский анализ этой таблицы, чтобы понять, как вы можете решить следующие проблемы.
Практическая задача
Напишите запрос, который показывает название компании, «статус» (находится в таблице «Компании») и количество уникальных инвесторов в этой компании. Порядок по количеству инвесторов от наибольшего к наименьшему. Ограничение только для компаний в штате Нью-Йорк.
Попробуй это Посмотреть ответПрактическая задача
Напишите запрос, в котором будут перечислены инвесторы по количеству компаний, в которые они вложили средства. Включите строку для компаний без инвестора и закажите от большинства компаний до наименьшего.
Включите строку для компаний без инвестора и закажите от большинства компаний до наименьшего.
Разница между WHERE и ON в SQL для данных JOIN
Последнее изменение: 3 мая 2021 г.
Есть ли разница между предложением WHERE и ON?
Да. ON следует использовать для определения условия соединения, а WHERE следует использовать для фильтрации данных. Я использовал слово «должен», потому что это не жесткое правило.Разделение этих целей с соответствующими предложениями делает запрос наиболее читаемым, а также предотвращает получение неверных данных при использовании типов JOIN, отличных от INNER JOIN.
Чтобы углубиться в подробности, мы рассмотрим два варианта использования, которые могут поддерживать WHERE или ON:
- Объединение данных
- Фильтрация данных
Объединение данных
Оба этих предложения могут использоваться для объединения данных путем определения условия, при котором две таблицы объединяются. Чтобы продемонстрировать это, давайте воспользуемся примером набора данных друзей facebook и подключений linkedin.
Чтобы продемонстрировать это, давайте воспользуемся примером набора данных друзей facebook и подключений linkedin.
Мы хотим видеть людей, которые являются и нашими друзьями, и нашей связью. Так что в данном случае это будет только Мэтт. Теперь давайте сделаем запрос, используя различные определения условия JOIN.
Все три запроса дают одинаковый правильный результат:
ВЫБРАТЬ *
С Фейсбука
ПРИСОЕДИНЯЙТЕСЬ linkedin
НА facebook.name = linkedin.name
ВЫБРАТЬ *
С Фейсбука
ПРИСОЕДИНЯЙТЕСЬ linkedin
ГДЕ facebook.name = linkedin.name
ВЫБРАТЬ *
ИЗ facebook, linkedin
ГДЕ facebook.name = linkedin.name
Первые два — это типы явного соединения, а последний — неявное соединение. Явное JOIN явно сообщает вам, как присоединиться к данным, указав тип JOIN и условие соединения в предложении ON. Неявное JOIN не указывает тип JOIN и не использует предложение WHERE для определения условия соединения.
Читаемость
Основное различие между этими запросами заключается в том, насколько легко понять, что происходит. В первом запросе мы можем легко увидеть, как таблицы соединяются в предложениях FROM и JOIN. Мы также можем ясно видеть условие соединения в предложении ON. Во втором запросе это кажется столь же ясным, однако мы можем дважды взглянуть на предложение WHERE, поскольку оно обычно используется для фильтрации данных, а не для присоединения к ним. В последнем запросе мы должны внимательно посмотреть, как установить, к какой таблице присоединяются, и как они присоединяются.
В первом запросе мы можем легко увидеть, как таблицы соединяются в предложениях FROM и JOIN. Мы также можем ясно видеть условие соединения в предложении ON. Во втором запросе это кажется столь же ясным, однако мы можем дважды взглянуть на предложение WHERE, поскольку оно обычно используется для фильтрации данных, а не для присоединения к ним. В последнем запросе мы должны внимательно посмотреть, как установить, к какой таблице присоединяются, и как они присоединяются.
Последний запрос использует так называемое неявное СОЕДИНЕНИЕ (СОЕДИНЕНИЕ, которое явно не указано в запросе.В большинстве случаев неявные СОЕДИНЕНИЯ будут действовать как ВНУТРЕННИЕ СОЕДИНЕНИЯ. Если вы хотите использовать JOIN, отличное от INNER JOIN, заявив, что это явно проясняет, что происходит.
ПРИСОЕДИНЕНИЕ к предложению WHERE может вызвать путаницу, поскольку это не типичная цель. Чаще всего используется для фильтрации данных. Поэтому, когда к предложению WHERE добавляются дополнительные условия фильтрации, помимо его использования для определения того, как ПРИСОЕДИНЯТЬСЯ к данным, становится труднее понять.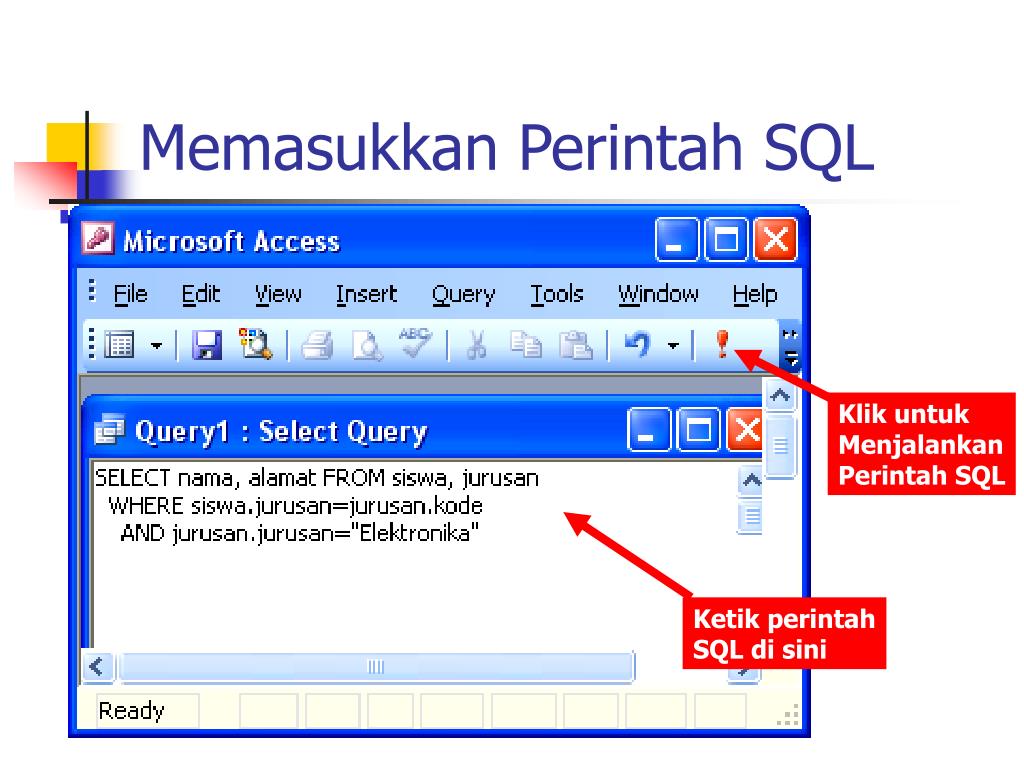
ВЫБРАТЬ *
ИЗ facebook, linkedin
ГДЕ facebook.name = linkedin.name И (facebook.name = Matt OR linkedin.city = "SF")
ВЫБРАТЬ *
С Фейсбука
ПРИСОЕДИНЯЙТЕСЬ linkedin
НА facebook.name = linkedin.name
ГДЕ facebook.name = Мэтт ИЛИ linkedin.city = "SF"
Хотя в первом запросе меньше символов, чем во втором, его не так легко понять.
Оптимизация
Иногда написание запроса другим способом может улучшить скорость. Однако в этом случае не должно быть преимуществ в скорости из-за того, что называется планом запроса.План запроса — это код, который SQL предлагает для выполнения запроса. Он принимает запрос, а затем создает оптимизированный способ поиска данных. Использование WHERE или ON для JOIN данных должно привести к тому же плану запроса.
Однако способ создания планов запросов может различаться в зависимости от языка и версии SQL, опять же, в этом случае все должно быть одинаковым, но вы можете протестировать его в своей базе данных, чтобы увидеть, повысится ли производительность. Будьте осторожны, чтобы кеширование не повлияло на результаты ваших запросов.
Будьте осторожны, чтобы кеширование не повлияло на результаты ваших запросов.
Фильтрация данных
И предложение ON, и предложение WHERE можно использовать для фильтрации данных в запросе. Есть проблемы с удобочитаемостью и точностью, которые нужно решить с помощью фильтрации в предложении ON. Давайте воспользуемся немного большим набором данных, чтобы продемонстрировать это.
На этот раз мы ищем людей, которые являются нашими друзьями и связями, но мы хотим видеть только тех, кто также живет в Сан-Франциско.
Читаемость
Давайте оценим, насколько удобочитаема каждая опция, эти два запроса дадут одинаковый результат:
ВЫБРАТЬ *
ПРИСОЕДИНЯЙТЕСЬ linkedin
На Фейсбуке.name = linkedin.name
ГДЕ facebook.city = 'SF'
ВЫБРАТЬ *
С Фейсбука
ПРИСОЕДИНЯЙТЕСЬ linkedin
НА facebook.name = linkedin.name И facebook.city = 'SF'
Первый запрос ясен, каждое предложение имеет свое назначение. Второй запрос труднее понять, потому что предложение ON используется как для СОЕДИНЕНИЯ данных, так и для их фильтрации.
Точность
Фильтрация в предложении ON может привести к неожиданным результатам при использовании LEFT, RIGHT или OUTER JOIN.Эти два запроса не дадут одинаковый результат:
ВЫБРАТЬ *
С Фейсбука
ЛЕВЫЙ ПРИСОЕДИНЯЙТЕСЬ linkedin
НА facebook.name = linkedin.name
ГДЕ facebook.city = 'SF'
В LEFT JOIN он вводит каждую строку из первой таблицы «facebook» и присоединяется везде, где истинно условие соединения (facebook.name = linkedin.name), это будет верно как для Мэтта, так и для Дэйва. Так и была бы промежуточная таблица.
Затем предложение WHERE фильтрует эти результаты в строки, где facebook.city = ‘SF’, оставив одну строку.
ВЫБРАТЬ *
С Фейсбука
ЛЕВЫЙ ПРИСОЕДИНЯЙТЕСЬ linkedin
НА facebook.name = linkedin.name И facebook.city = 'SF'
В этом запросе другое условие соединения. LEFT JOIN вводит каждую строку, а данные, которые присоединяются из linkedin, происходят только тогда, когда facebook. name = linkedin.name AND facebook.city = ‘SF’. Он не отфильтровывает все строки, в которых не было facebook.city = ‘SF’
name = linkedin.name AND facebook.city = ‘SF’. Он не отфильтровывает все строки, в которых не было facebook.city = ‘SF’
Оптимизация
Здесь есть потенциальные вариации в том, как строится план запроса, поэтому может быть полезно попробовать фильтрацию в ON.Некоторые языки SQL могут фильтровать при присоединении, а другие могут ждать, пока будет построена полная таблица, перед фильтрацией. Первый план будет быстрее.
Сводка
Разделяйте контекст между , объединяющим таблицы, и , фильтрующим объединенной таблицы. Он наиболее читаемый, с наименьшей вероятностью может быть неточным и не должен быть менее производительным.
- Данные JOIN в ON
- Данные фильтра в ГДЕ
- Напишите явные JOIN, чтобы сделать ваш запрос более читаемым
- Отфильтруйте данные в предложении WHERE вместо JOIN, чтобы убедиться, что они правильные и читаемые
- У разных языков SQL могут быть разные планы запросов на основе фильтрации в предложении ON и в предложении WHERE, поэтому проверьте производительность в своей базе данных.

Написано:
Мэтт Дэвид
Проверено:
Пошаговое руководство по SQL Inner Join
Организации генерируют и анализируют непревзойденные объемы данных каждую минуту.В этой статье мы продемонстрируем, как мы можем использовать SQL Inner Join для запроса и доступа к данным из нескольких таблиц, хранящих эти постоянно растущие данные в базах данных SQL.
SQL присоединяется к
Прежде чем мы начнем с SQL Inner Join, я хотел бы вызвать здесь SQL Join. Присоединение — это широко используемое предложение в SQL Server, по сути, для объединения и извлечения данных из двух или более таблиц. В реальной реляционной базе данных данные структурированы в виде большого количества таблиц, поэтому существует постоянная потребность в объединении этих нескольких таблиц на основе логических отношений между ними.В SQL Server существует четыре основных типа объединений — внутреннее, внешнее (левое, правое, полное), самостоятельное и перекрестное соединение. Чтобы получить краткий обзор всех этих объединений, я бы порекомендовал пройти по этой ссылке, обзору типов соединений SQL и руководству.
Чтобы получить краткий обзор всех этих объединений, я бы порекомендовал пройти по этой ссылке, обзору типов соединений SQL и руководству.
Эта статья посвящена внутреннему соединению в SQL Server, так что давайте перейдем к ней.
Определение внутреннего соединения SQL
Предложение Inner Join в SQL Server создает новую таблицу (не физическую) путем объединения строк, имеющих совпадающие значения в двух или более таблицах.Это соединение основано на логической связи (или общем поле) между таблицами и используется для извлечения данных, которые появляются в обеих таблицах.
Предположим, у нас есть две таблицы, Таблица A и Таблица B, которые мы хотели бы объединить с помощью SQL Inner Join. Результатом этого соединения будет новый набор результатов, который возвращает совпадающие строки в обеих этих таблицах. В части пересечения, выделенной черным цветом ниже, показаны данные, полученные с помощью внутреннего соединения в SQL Server.
Синтаксис внутреннего соединения SQL Server
Ниже приведен базовый синтаксис Inner Join.
SELECT Column_list
FROM TABLE1
INNER JOIN TABLE2
ON Table1.ColName = Table2.ColName
Синтаксис внутреннего соединения в основном сравнивает строки таблицы 1 с таблицей 2, чтобы проверить, совпадает ли что-либо, на основе условия, указанного в предложении ON. Когда условие соединения выполнено, оно возвращает совпадающие строки в обеих таблицах с выбранными столбцами в предложении SELECT.
Предложение SQL Inner Join аналогично предложению Join и работает таким же образом, если мы не указываем тип (INNER) при использовании предложения Join.Короче говоря, Inner Join — это ключевое слово по умолчанию для Join, и оба могут использоваться взаимозаменяемо.
Примечание. В этой статье мы будем использовать ключевое слово «внутреннее» присоединение для большей ясности. Вы можете опустить его при написании запросов, а также можете использовать только «Присоединиться».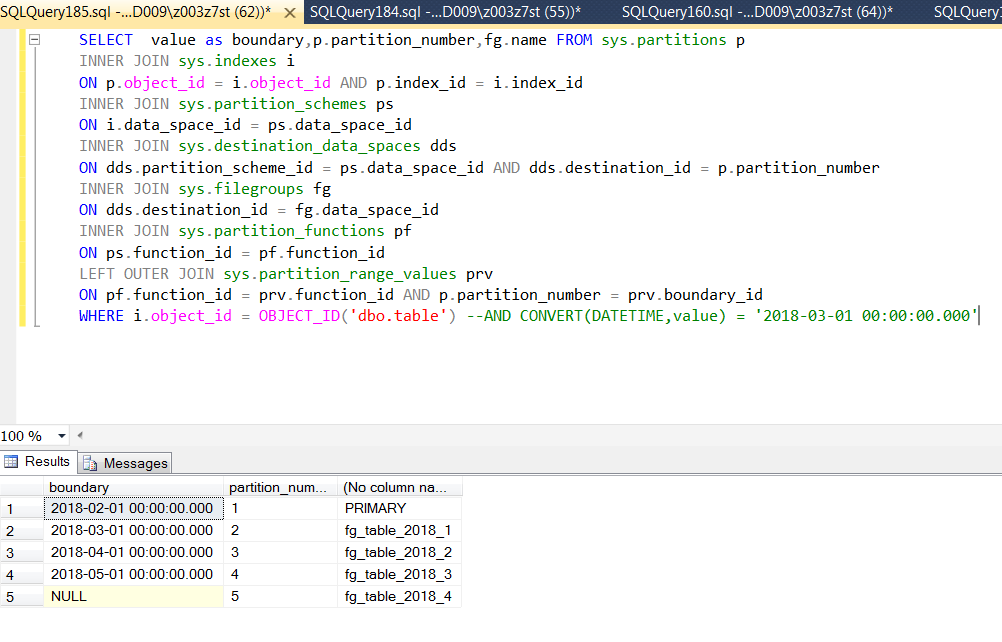
SQL Inner Join в действии
Давайте попробуем понять концепцию внутреннего объединения на примере интересной выборки данных, касающейся пиццерии и ее распределения.Сначала я собираюсь создать две таблицы — таблицу PizzaCompany, которая управляет различными филиалами пиццерий в нескольких городах, и таблицу Foods, в которой хранятся данные о распределении продуктов питания в этих компаниях. Вы можете выполнить приведенный ниже код, чтобы создать и заполнить данные в этих двух таблицах. Все эти данные являются гипотетическими, и их можно создать в любой из существующих баз данных.
СОЗДАТЬ ТАБЛИЦУ [dbo]. [PizzaCompany] ( [CompanyId] [int] IDENTITY (1,1) PRIMARY KEY CLUSTERED, [CompanyName] [varchar] (50), [CompanyCity] [ varchar] (30) ) SET IDENTITY_INSERT [dbo].[PizzaCompany] ВКЛ; ВСТАВИТЬ В [dbo]. [PizzaCompany] ([CompanyId], [CompanyName], [CompanyCity]) VALUES (1, ‘Dominos’, ‘Los Angeles’); INSERT INTO [dbo]. INSERT INTO [dbo]. [PizzaCompany] ([CompanyId], [CompanyName], [CompanyCity]) VALUES (3, ‘Papa johns’, ‘Сан-Диего’); ВСТАВИТЬ В [dbo]. [PizzaCompany] ([CompanyId], [CompanyName], [CompanyCity]) VALUES (4, ‘Ah Pizz’, ‘Fremont’); ВСТАВИТЬ В [dbo].[PizzaCompany] ([CompanyId], [CompanyName], [CompanyCity]) ЗНАЧЕНИЯ (5, «Нино Пицца», «Лас-Вегас»); ВСТАВИТЬ В [dbo]. [PizzaCompany] ([CompanyId], [CompanyName], [CompanyCity]) VALUES (6, ‘Пиццерия’, ‘Бостон’); ВСТАВИТЬ В [dbo]. [PizzaCompany] ([CompanyId], [CompanyName], [CompanyCity]) VALUES (7, ‘chuck e cheese’, ‘Chicago’); ВЫБРАТЬ * ОТ PizzaКомпания: |
 [PizzaCompany] ([CompanyId], [CompanyName], [CompanyCity]) VALUES (2, «Pizza Hut», «Сан-Франциско»);
[PizzaCompany] ([CompanyId], [CompanyName], [CompanyCity]) VALUES (2, «Pizza Hut», «Сан-Франциско»);Вот так выглядят данные в таблице PizzaCompany:
Давайте сейчас создадим и заполним таблицу Foods.CompanyID в этой таблице — это внешний ключ, который ссылается на первичный ключ таблицы PizzaCompany, созданной выше.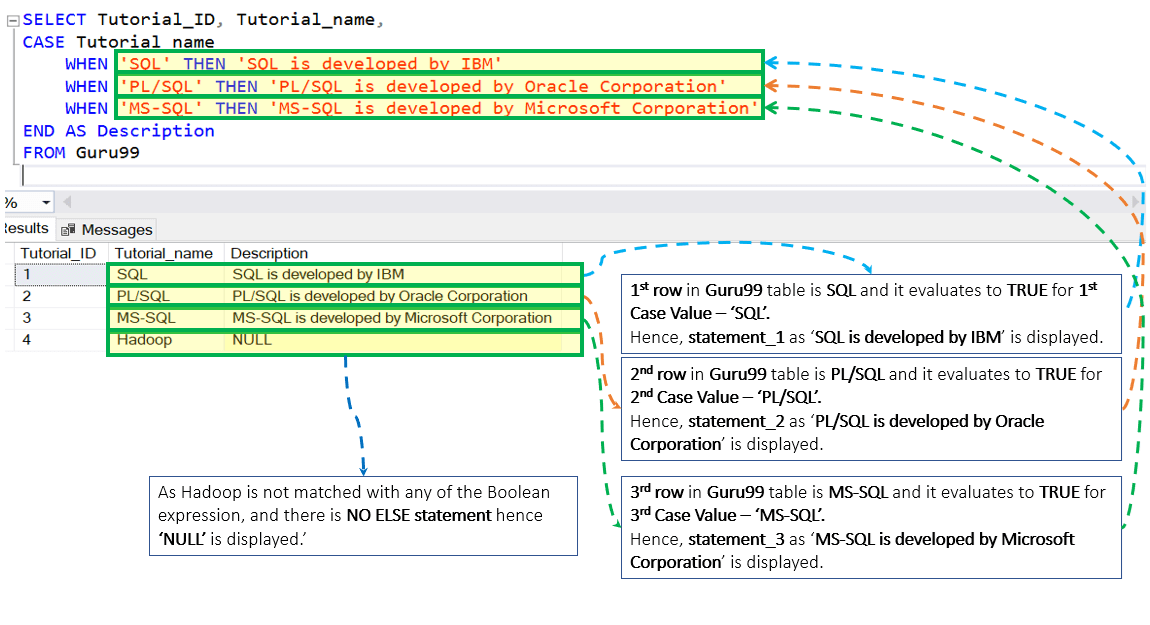
1 2 3 4 5 6 7 8 9 10 11 12 13 140004 14 18 | СОЗДАТЬ ТАБЛИЦУ [dbo].[Foods] ( [ItemId] INT PRIMARY KEY CLUSTERED, [ItemName] Varchar (50), [UnitsSold] int, CompanyID int, FOREIGN KEY (CompanyID) REFERENCES Pizza ) ВСТАВИТЬ [dbo]. [Foods] ([ItemId], [ItemName], [UnitsSold], [CompanyId]) ЗНАЧЕНИЯ (1, ‘Large Pizza’, 5,2) INSERT INTO [dbo ]. [Продукты] ([ItemId], [ItemName], [UnitsSold], [CompanyId]) VALUES (2, ‘Garlic Knots’, 6,3) ВСТАВИТЬ В [dbo].[Foods] ([ItemId], [ItemName], [UnitsSold], [CompanyId]) VALUES (3, ‘Large Pizza’, 3,3) INSERT INTO [dbo]. [Foods] ([ItemId], [ ItemName], [UnitsSold], [CompanyId]) VALUES (4, ‘Средняя пицца’, 8,4) INSERT INTO [dbo]. [Foods] ([ItemId], [ItemName], [UnitsSold], [CompanyId ]) VALUES (5, ‘Breadsticks’, 7,1) INSERT INTO [dbo]. INSERT INTO [dbo]. [Foods] ([ItemId], [ItemName], [UnitsSold], [CompanyId]) VALUES (7, ‘Маленькая пицца’, 9,6) INSERT INTO [dbo].[Еда] ([ItemId], [ItemName], [UnitsSold], [CompanyId]) ЗНАЧЕНИЯ (8, ‘Маленькая пицца’, 6,7) ВЫБРАТЬ * ИЗ Foods |
 [Foods] ([ItemId], [ItemName], [UnitsSold], [CompanyId] »VALUES (6, ‘Medium Pizza’) , 11,1)
[Foods] ([ItemId], [ItemName], [UnitsSold], [CompanyId] »VALUES (6, ‘Medium Pizza’) , 11,1)В следующей таблице показаны данные из таблицы «Продукты питания». В этой таблице хранится такая информация, как количество проданных единиц продукта питания, а также точка доставки пиццы (CompanyId), которая ее доставляет.
Теперь, если мы хотим увидеть предметы, а также единицы, продаваемые каждой пиццерией, мы можем объединить эти две таблицы с помощью предложения внутреннего соединения, используемого в поле CompanyId (в нашем случае это имеет отношение внешнего ключа ).
SELECT pz.CompanyCity, pz. FROM PizzaCompany pz INNER JOIN Foods ON f CompanyId |
 CompanyName, pz.CompanyId AS PizzaCompanyId, f.CompanyID AS FoodsCompanyId, f.ItemName, f.UnitsSold
CompanyName, pz.CompanyId AS PizzaCompanyId, f.CompanyID AS FoodsCompanyId, f.ItemName, f.UnitsSoldНиже приведен набор результатов указанного выше запроса SQL Inner Join. Для каждой строки в таблице PizzaCompany функция Inner Join сравнивает и находит совпадающие строки в таблице Foods и возвращает все совпадающие строки, как показано ниже.И если вы заметили, CompanyId = 5 исключается из результата запроса, так как он не соответствует в таблице Foods.
С помощью приведенного выше набора результатов мы можем различить товары, а также количество товаров, доставленных пиццериями в разных городах. Например, Dominos доставил в Лос-Анджелес 7 хлебных палочек и 11 средних пицц.
Внутреннее объединение SQL трех таблиц
Давайте подробнее рассмотрим это объединение и предположим, что в штате открываются три аквапарка (похоже, летом), и эти аквапарки передают еду на аутсорсинг в пиццерии, упомянутые в таблице PizzaCompany.
Я собираюсь быстро создать таблицу WaterPark и загрузить в нее произвольные данные, как показано ниже.
СОЗДАТЬ ТАБЛИЦУ [dbo]. [WaterPark] ( [WaterParkLocation] VARCHAR (50), [CompanyId] int, FOREIGN KEY (CompanyID) ССЫЛКИ PizzaSCompany (CompanyID4) IN [dbo]. [WaterPark] ([WaterParkLocation], [CompanyId]) ЗНАЧЕНИЯ (‘Улица 14’, 1)ВСТАВИТЬ В [dbo].[WaterPark] ([WaterParkLocation], [CompanyId]) ЗНАЧЕНИЯ (‘Boulevard 2’, 2) ВСТАВИТЬ [dbo]. [WaterPark] ([WaterParkLocation], [CompanyId]) ЗНАЧЕНИЯ (‘Rogers 54’, 4) ВСТАВИТЬ В [dbo]. [WaterPark] ([WaterParkLocation], [CompanyId]) ЗНАЧЕНИЯ (‘Street 14’, 3) ВСТАВИТЬ В [dbo]. [WaterPark] ([WaterParkLocation], [CompanyId]) ЗНАЧЕНИЯ (‘Rogers 54’, 5) ВСТАВИТЬ В [dbo]. [WaterPark] ([WaterParkLocation], [CompanyId]) ЗНАЧЕНИЯ (‘Boulevard 2’, 5) ВЫБРАТЬ * ИЗ WaterPark |
И ниже вывод этой таблицы.
Как говорится, картина стоит тысячи слов. Давайте быстро посмотрим на схему базы данных этих трех таблиц с их взаимосвязями, чтобы лучше понять их.
Теперь мы собираемся включить эту третью таблицу в предложение SQL Inner Join, чтобы увидеть, как это повлияет на набор результатов. Согласно данным в таблице «Аквапарк», три аквапарка передают еду на аутсорсинг всем пиццериям, кроме пиццерии (Id = 6) и Chuck e Cheese (Id = 7).Выполните приведенный ниже код, чтобы увидеть, как распределяется еда в аквапарках у точек Pizza.
SELECT pz.CompanyId, pz.CompanyCity, pz.CompanyName, f.ItemName, f.UnitsSold, w.WaterParkLocation ОТ PizzaCompany pz INNER JOIN Foodpanys f ON pz.CompanyId = ПРИСОЕДИНЯЙТЕСЬ к аквапарку w.CompanyId = pz.CompanyIdЗАКАЗАТЬ pz.CompanyId |
На основе CompanyId SQL Inner Join сопоставляет строки в обеих таблицах, PizzaCompany (Таблица 1) и Foods (Таблица 2), а затем ищет совпадение в WaterPark (Таблица 3), чтобы вернуть строки. Как показано ниже, с добавлением внутреннего соединения в WaterPark, CompanyId (6,7 (кроме 5)) также исключается из окончательного набора результатов, поскольку условие w.CompanyId = pz.CompanyId не выполняется для идентификаторов (6, 7). Вот как внутреннее соединение SQL помогает возвращать определенные строки данных из нескольких таблиц.
Как показано ниже, с добавлением внутреннего соединения в WaterPark, CompanyId (6,7 (кроме 5)) также исключается из окончательного набора результатов, поскольку условие w.CompanyId = pz.CompanyId не выполняется для идентификаторов (6, 7). Вот как внутреннее соединение SQL помогает возвращать определенные строки данных из нескольких таблиц.
Давайте углубимся в SQL Inner Join еще с несколькими предложениями T-SQL.
Использование WHERE с внутренним соединением
Мы можем фильтровать записи на основе указанного условия, когда внутреннее соединение SQL используется с предложением WHERE.Предположим, мы хотели бы получить строки, в которых проданных единиц было больше 6.
В следующем запросе предложение WHERE добавляется для извлечения результатов со значением более 6 для проданных единиц.
SELECT pz.CompanyId, pz.CompanyCity, pz.CompanyName, f.ItemName, f.UnitsSold FROM PizzaCompany pz INNER JOIN Foods f ON pz.CompanyId = f.CompanyId WHERE f.U ЗАКАЗАТЬ pz.КомпанияCity |
Выполните приведенный выше код в SSMS, чтобы увидеть результат ниже. Этот запрос возвращает четыре таких записи.
Использование Group By с внутренним соединением
SQL Inner Join позволяет нам использовать предложение Group by вместе с агрегатными функциями для группировки набора результатов по одному или нескольким столбцам. Группировка по обычно работает с внутренним объединением по окончательному результату, возвращаемому после объединения двух или более таблиц. Если вы не знакомы с предложением Group by в SQL, я бы посоветовал пройти через это, чтобы быстро понять эту концепцию.Ниже приведен код, в котором используется предложение Group By с внутренним соединением.
SELECT pz.CompanyCity, pz.CompanyName, SUM (f.UnitsSold) AS TotalQuantitySold FROM PizzaCompany pz INNER JOIN Foods f ON pz.CompanyId = f.CompanyId GROUP BY pz.CompanyCity ЗАКАЗАТЬ pz.CompanyCity |
Здесь мы собираемся получить общее количество товаров, проданных каждой пиццерией, присутствующей в городе.Как видно ниже, агрегированный результат в столбце «totalquantitysold» равен 18 (7 + 11) и 9 (6 + 3) для Лос-Анджелеса и Сан-Диего соответственно.
Краткое описание Equi и Theta Join
Прежде чем мы закончим эту статью, давайте быстро рассмотрим термины, которые разработчик SQL может время от времени слышать — Equi и Theta Join.
Equi Join
Как следует из названия, equi join содержит оператор равенства ‘=’ либо в предложении Join, либо в условии WHERE.SQL Inner, Left, Right — все равнозначные соединения, когда оператор «=» используется в качестве оператора сравнения. Обычно, когда упоминается внутреннее соединение SQL, оно рассматривается как внутреннее равное соединение, только в необычной ситуации оператор равенства не используется.
Чтобы упростить задачу, я собираюсь обратиться к образцу базы данных AdventureWorksDW2017 и запустить запрос к существующим таблицам, чтобы продемонстрировать, как выглядит равное соединение.
ВЫБРАТЬ e.EmployeeKey, e.FirstName, e.Title, e.HireDate, fs.SalesAmountQuota ОТ DimEmployee e INNER JOIN FactSalesQuota fs ON e.EmployeeKey = fs.Employee32Key |
Theta Join (Неравномерное соединение)
Неравномерное соединение в основном противоположно равнозначному соединению и используется, когда мы присоединяемся по условию, отличному от оператора «=». Этот тип редко используется на практике. Ниже приведен пример, в котором используется тета-соединение с оператором неравенства (<) для оценки прибыли путем оценки себестоимости и продажных цен в двух таблицах.
ВЫБРАТЬ * ИЗ Таблица1 T1, Таблица2 T2 ГДЕ T1.ProductCost |
Заключение
Я надеюсь, что эта статья о «Внутреннем соединении SQL» обеспечивает понятный подход к одному из важных и часто используемых предложений — «Внутреннее соединение» в SQL Server для объединения нескольких таблиц. Если у вас есть какие-либо вопросы, не стесняйтесь задавать их в разделе комментариев ниже.
Чтобы продолжить изучение SQL-соединений, вы можете обратиться к сообщениям ниже:
Гаури является специалистом по SQL Server и имеет более 6 лет опыта работы с международными международными консалтинговыми и технологическими организациями. Она очень увлечена работой над такими темами SQL Server, как База данных SQL Azure, Службы отчетов SQL Server, R, Python, Power BI, ядро базы данных и т. Д. Она имеет многолетний опыт работы с технической документацией и увлекается разработкой технологий.Она имеет большой опыт в разработке решений для данных и аналитики, а также в обеспечении их стабильности, надежности и производительности. Она также сертифицирована по SQL Server и прошла такие сертификаты, как 70-463: Внедрение хранилищ данных с Microsoft SQL Server.
Посмотреть все сообщения от Gauri Mahajan
Последние сообщения от Gauri Mahajan (посмотреть все)SQL Server Предложение WHERE | Рам Кедем
Это руководство по SQL представляет собой введение в предложение WHERE SQL Server с пояснениями, примерами и упражнениями.Для упражнений этого урока используйте эту ссылку.
Это руководство является частью нескольких сообщений, в которых описывается, как использовать предложение WHERE в SQL Server. Чтобы прочитать дополнительные сообщения по этой теме, воспользуйтесь следующими ссылками:
Введение — SQL Server WHERE, пункт
Предложение SQL Server WHERE используется для ограничения строк, возвращаемых из запроса. В то время как в предыдущей главе (Основные операторы SELECT) объяснялось, как извлечь имена всех сотрудников из таблицы Employees, используя предложение SQL Server WHERE, вы можете ограничить запрос строками, удовлетворяющими условию.Например: извлеките сотрудников, чья зарплата выше 5000, или сотрудников, которые работают в отделе кадров, и так далее.
- Предложение SQL Server WHERE должно быть записано после предложения SQL Server FROM (которое, в свою очередь, должно быть записано после предложения SQL Server SELECT), этот порядок нельзя изменить.
- В отличие от операторов SQL Server SELECT и FROM, которые необходимы для создания действительного SQL-запроса, предложение WHERE SQL Server является необязательным. SQL-запрос может правильно работать с предложением SQL Server WHERE или без него.
Синтаксис предложения WHERE SQL Server
Предложение WHERE SQL Server имеет следующую структуру:
WHERE column_name значение оператора
Например:
ВЫБРАТЬ * ОТ сотрудников ГДЕ зарплата = 3000
- Column_name — имя столбца. Вышеупомянутый запрос извлекает всех сотрудников, чья зарплата равна 3000, и поэтому был выбран столбец Salary. Если вы хотите отобразить всех сотрудников, чей город проживания совпадает с Лондоном, вам нужно выбрать столбец Город.
ВЫБРАТЬ * ОТ сотрудников ГДЕ city = 'Лондон'
- Оператор — есть два типа операторов:
- Операторы сравнения — представлены простыми операторами, такими как =, <,>, =>, = <, <>
- Логические операторы — представлены такими операторами, как IN, BETWEEN, LIKE.
- Значение для сравнения —
- Число — например, зарплата больше определенного числа.
ВЫБРАТЬ * ОТ сотрудников ГДЕ зарплата и gt; 6000
- Дата — например, дата транзакции больше определенной даты.
ВЫБРАТЬ * ОТ транзакций ГДЕ transaction_date & amp; gt; '2013-01-13'
- Строка — например, фамилия соответствует определенной фамилии.
ВЫБРАТЬ * ОТ сотрудников ГДЕ last_name = 'Баран'
Общие правила
- Тип данных значения должен соответствовать типу даты столбца (нет смысла пытаться отобразить сотрудников, имя которых больше 4503).
ВЫБРАТЬ * ОТ сотрудников ГДЕ first_name & amp; amp; gt; 6000 -- (ошибка)
- Если запрошенное сравнение не соответствует значениям таблицы (например, самая высокая зарплата в таблице составляет 12000, и вы хотите отобразить сотрудников, чья зарплата больше 200000), результат не будет получен, но не будет ошибок. либо сгенерировано (таблица не смогла получить значения, которые в соответствии с ее настройками не существуют).
ВЫБРАТЬ * ОТ сотрудников ГДЕ зарплата и gt; 200000 - (допустимый оператор SELECT SQL Server) - Как описано, не будет генерироваться ошибка и не будут извлечены строки..