Многотабличные запросы, оператор JOIN
Многотабличные запросы
В предыдущих статьях описывалась работа только с одной таблицей базы данных. В реальности же очень часто приходится делать выборку из нескольких таблиц, каким-то образом объединяя их. В данной статье вы узнаете основные способы соединения таблиц.
Общая структура многотабличного запроса
SELECT поля_таблиц
FROM таблица_1
[INNER] | [[LEFT | RIGHT | FULL][OUTER]] JOIN таблица_2
ON условие_соединения
[[INNER] | [[LEFT | RIGHT | FULL][OUTER]] JOIN таблица_n
ON условие_соединения]Эту же структуру можно переписать следующим образом:
SELECT поля_таблиц
FROM таблица_1
[INNER] | [[LEFT | RIGHT | FULL][OUTER]] JOIN таблица_2[ JOIN таблица_n]
ON условие_соединения [AND условие_соединения]В большинстве случаев условием соединения является равенство столбцов таблиц (таблица_1.поле = таблица_2.поле), однако точно так же можно использовать и другие операторы сравнения.
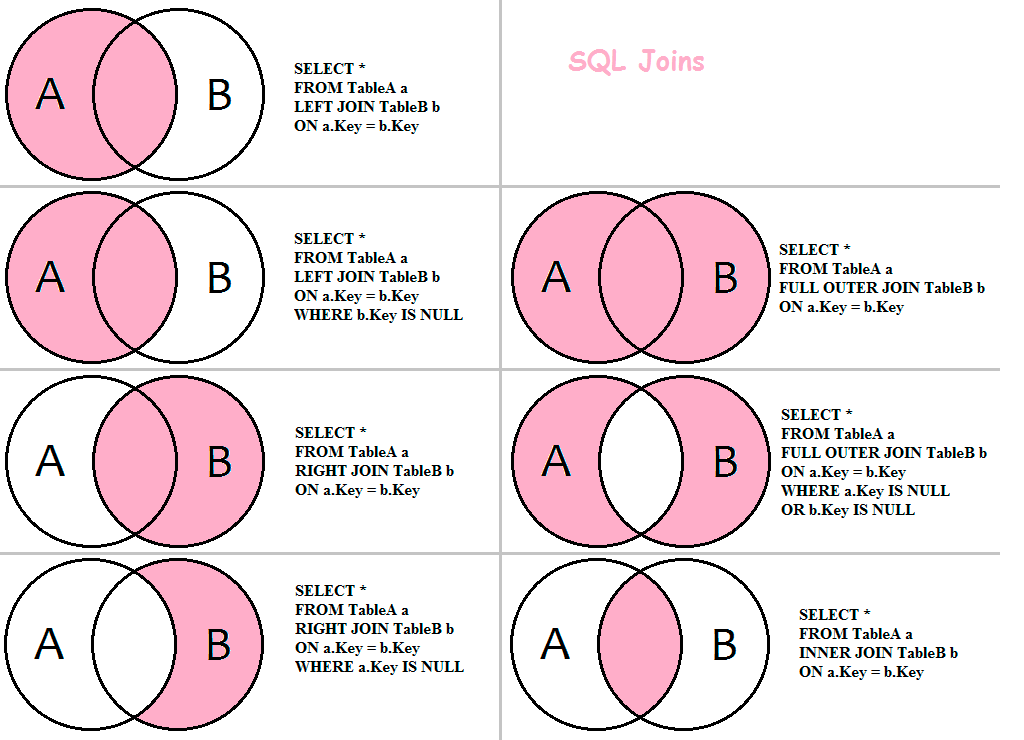
Соединение бывает внутренним (INNER) или внешним (OUTER), при этом внешнее соединение делится на левое (LEFT), правое (RIGHT) и полное (FULL).
INNER JOIN
По умолчанию, если не указаны какие-либо параметры, JOIN выполняется как INNER JOIN, то есть как внутреннее (перекрёстное) соединение таблиц.
Внутреннее соединение — соединение двух таблиц, при котором каждая запись из первой таблицы соединяется с каждой записью второй таблицы, создавая тем самым все возможные комбинации записей обеих таблиц (декартово произведение).
Например, объединим таблицы покупок (Payments) и членов семьи (FamilyMembers) таким образом, чтобы дополнить каждую покупку данными о том, кто её совершил.
Данные в таблице Payments:
Данные в таблице FamilyMembers:
Для того, чтобы решить поставленную задачу выполним запрос, который объединяет поля строки из одной таблицы с полями другой, если выполняется условие, что покупатель товара (family_member) совпадает с идентификатором члена семьи (member_id):
SELECT *
FROM Payments
JOIN FamilyMembers ON family_member = member_id;В результате вы можете видеть, что каждая строка из таблицы Payments дополнилась данными о члене семьи, который совершил покупку.
Использование WHERE для соединения таблиц
Для внутреннего соединения таблиц также можно использовать оператор WHERE. Например, вышеприведённый запрос, написанный с помощью INNER JOIN, будет выглядеть так:
SELECT * FROM Payments, FamilyMembers WHERE family_member = member_id;
OUTER JOIN
Внешнее соединение может быть трёх типов: левое (LEFT), правое (RIGHT) и полное (FULL). По умолчанию оно является полным.
Главным отличием внешнего соединения от внутреннего является то, что оно обязательно возвращает все строки одной (LEFT, RIGHT) или двух таблиц (FULL).
Внешнее левое соединение (LEFT OUTER JOIN)
Соединение, которое возвращает все значения из левой таблицы, соединённые с соответствующими значениями из правой таблицы если они удовлетворяют условию соединения, или заменяет их на NULL в обратном случае.
Для примера получим из базы данных расписание звонков объединённых с соответствующими занятиями в расписании занятий:
SELECT *
FROM Timepair
LEFT JOIN Schedule ON Schedule.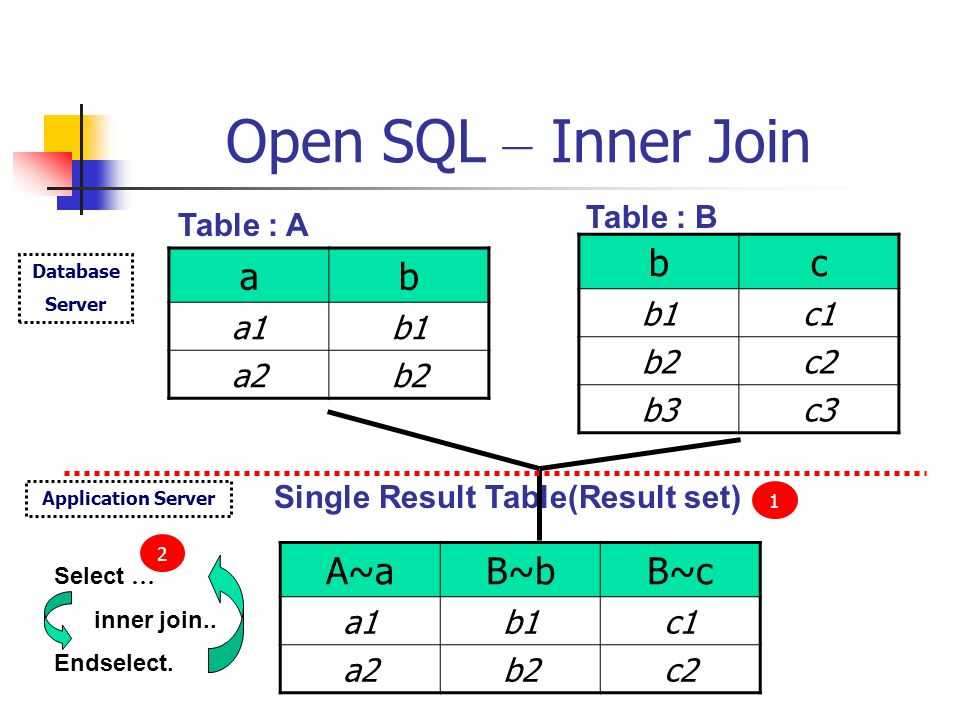 number_pair = Timepair.id;
number_pair = Timepair.id;Данные в таблице Timepair (расписание звонков):
Данные в таблице Schedule (расписание занятий):
В выборку попали все строки из левой таблицы, дополненные данными о занятиях. Примечательно, что в конце таблицы есть строки с полями, заполненными NULL. Это те строки, для которых не нашлось соответствующих занятий, однако они присутствуют в левой таблице, поэтому тоже были выведены.
Внешнее правое соединение (RIGHT OUTER JOIN)
Соединение, которое возвращает все значения из правой таблицы, соединённые с соответствующими значениями из левой таблицы если они удовлетворяют условию соединения, или заменяет их на NULL в обратном случае.
Внешнее полное соединение (FULL OUTER JOIN)
Соединение, которое выполняет внутреннее соединение записей и дополняет их левым внешним соединением и правым внешним соединением.
Алгоритм работы полного соединения:
- Формируется таблица на основе внутреннего соединения (INNER JOIN).

- В таблицу добавляются значения не вошедшие в результат формирования из левой таблицы (LEFT OUTER JOIN).
- В таблицу добавляются значения не вошедшие в результат формирования из правой таблицы (RIGHT OUTER JOIN).
Соединение FULL JOIN реализовано не во всех СУБД. Например, в MySQL оно отсутствует, однако его можно очень просто эмулировать:
SELECT *
FROM левая_таблица
LEFT JOIN правая_таблица
ON правая_таблица.ключ = левая_таблица.ключ
UNION ALL
SELECT *
FROM левая_таблица
RIGHT JOIN правая_таблица
ON правая_таблица.ключ = левая_таблица.ключ
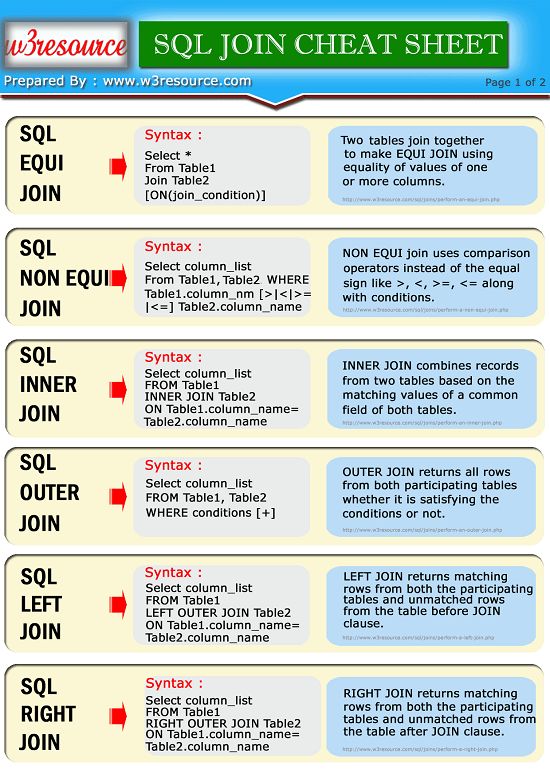
WHERE левая_таблица.key IS NULLБазовые запросы для разных вариантов объединения таблиц
| Схема | Запрос с JOIN |
|---|---|
Получение всех данных из левой таблицы, соединённых с соответствующими данными из правой:SELECT поля_таблиц
FROM левая_таблица LEFT JOIN правая_таблица
ON правая_таблица.ключ = левая_таблица. | |
Получение всех данных из правой таблицы, соединённых с соответствующими данными из левой:SELECT поля_таблиц
FROM левая_таблица RIGHT JOIN правая_таблица
ON правая_таблица.ключ = левая_таблица.ключ | |
Получение данных, относящихся только к левой таблице:SELECT поля_таблиц
FROM левая_таблица LEFT JOIN правая_таблица
ON правая_таблица.ключ = левая_таблица.ключ
WHERE правая_таблица.ключ IS NULL | |
Получение данных, относящихся только к правой таблице:SELECT поля_таблиц
FROM левая_таблица RIGHT JOIN правая_таблица
ON правая_таблица.ключ = левая_таблица.ключ
WHERE левая_таблица.ключ IS NULL | |
Получение данных, относящихся как к левой, так и к правой таблице:SELECT поля_таблиц
FROM левая_таблица INNER JOIN правая_таблица
ON правая_таблица.ключ = левая_таблица.ключ | |
Получение всех данных, относящихся к левой и правой таблицам, а также их внутреннему соединению:SELECT поля_таблиц
FROM левая_таблица
FULL OUTER JOIN правая_таблица
ON правая_таблица. | |
Получение данных, не относящихся к левой и правой таблицам одновременно (обратное INNER JOIN):SELECT поля_таблиц
FROM левая_таблица
FULL OUTER JOIN правая_таблица
ON правая_таблица.ключ = левая_таблица.ключ
WHERE левая_таблица.ключ IS NULL
OR правая_таблица.ключ IS NULL |
 ключ
ключ ключ = левая_таблица.ключ
ключ = левая_таблица.ключОбъединение таблиц при запросе (JOIN) в SQL
С помощью команды SELECT можно выбрать данные не только из одной таблицы, но и нескольких. Такая задача появляется довольно часто, потому что принято разносить данные по разным таблицам в зависимости от хранимой в них информации. К примеру, в одной таблице хранится информация о пользователях, во второй таблице о должностях компании, а в третьей и четвёртой о поставщиках и клиентах. Данные разбивают на таблицы так, чтобы с одной стороны получить самую высокую скорость выполнения запроса, а с другой стороны избежать ненужных объединений, которые снижают производительность.
Чем больше столбцов в таблице — тем сильнее падает скорость выборки из неё. Поэтому стараются делать в каждой таблице не больше 5-10 столбцов. Но чем сильнее данные разбиваются на разные таблицы, тем больше придётся делать объединений внутри запросов, что тоже снизит скорость получения выборки и увеличит нагрузку на базу.
Приведём пример запроса с объединением данных из двух таблиц. Для этого предположим, что существует две таблицы. Первая таблица будет иметь название USERS и будет иметь два столбца: ID и именами пользователей:
+-----------+ | USERS | +-----------+ | ID | NAME | +----+------+ | 1 | Мышь | +----+------+ | 2 | Кот | +----+------+Вторая таблица будет называться FOOD и будет содержать два столбца: USER_ID и NAME. В этой таблице будет содержаться список любимых блюд пользователей из первой таблицы.
 В столбце USER_ID содержится ID пользователя, а в столбце PRODUCT находится название любимого блюда.
В столбце USER_ID содержится ID пользователя, а в столбце PRODUCT находится название любимого блюда.
+-------------------+ | FOOD | +-------------------+ | USER_ID | PRODUCT | +---------+---------+ | 1 | Сыр | +---------+---------+ | 2 | Молоко | +---------+---------+
Условимся что поле ID в таблице USERS и поле USER_ID в таблице FOOD являются первичными ключами (то есть имеют уникальные значения, которые не повторяются). Теперь попробуем использовать логику и найти любимое блюдо пользователя «Мышь», используя обе таблицы. Для этого мы сначала посмотрим в первую таблицу и найдём ID пользователя под именем «Мышь», а затем найдём название продукта под таким же ID во второй таблице. Объединяющие SQL запросы работают по такой же логике: нужен столбец, в по которому таблицы могут быть объединены.
Продемонстрируем запрос, объединяющий таблицы по столбцам ID и USER_ID:
SELECT * FROM `USERS` INNER JOIN `FOOD` ON `USERS`.`ID`=`FOOD`.`USER_ID`;
Разберём команду по словам. Начинается она как обычная выборка из одной таблицы со слов «SELECT * FROM USERS». Но затем идёт слово INNER, которое означает тип объединения. Существует три типа объединения таблиц: INNER, LEFT, RIGHT. Все они связаны с тем, что некоторым строкам в одной таблице может не найтись соответствующей строки во второй таблице. В таком случае при использовании «INNER» из результатов запроса будет удалены все строки, которым не нашлась соответствующая пара в другой таблице. Если же использовать вместо «INNER» слово «LEFT» или «RIGHT», то будут удалены строки, которые не нашли совпадение из первой (левой) или второй (правой) таблицы.
После слова «INNER» стоит слово «JOIN» (которое переводится с английского как «ПРИСОЕДИНИТЬ»). После слова «JOIN» стоит название таблицы, которая будет присоединена. В нашем случае это таблица FOOD. После названия таблицы стоит слово «ON» и равенство USERS. ID=FOOD.USER_ID, которое задаёт правило присоединения. При выполнении выборки будут объединены две таблицы так, чтобы значения в столбце ID таблицы USERS равнялось значению USER_ID таблицы FOOD.
ID=FOOD.USER_ID, которое задаёт правило присоединения. При выполнении выборки будут объединены две таблицы так, чтобы значения в столбце ID таблицы USERS равнялось значению USER_ID таблицы FOOD.
В результате выполнения этого SQL запроса мы получим таблицу с четырьмя столбцами:
+----+------+---------+---------+ | ID | NAME | USER_ID | PRODUCT | +----+------+---------+---------+ | 1 | Мышь | 1 | Сыр | +----+------+---------+---------+ | 2 | Кот | 2 | Молоко | +----+------+---------+---------+
Предлагаем модифицировать запрос, потому что нам не нужны все четыре столбца. Уберём столбцы ID и USER_ID. Для этого вместо * в команде SELECT поставим название столбцов. Но необходимо сделать это, ставя сначала название таблицы и через точку название столбца. Чтобы получилось так:
SELECT `USERS`.`NAME`, `FOOD`.`PRODUCT` FROM `USERS` INNER JOIN `FOOD` ON `USERS`.`ID`=`FOOD`.`USER_ID`;
Теперь результат будет компактнее. И благодаря уменьшенному количеству запрашиваемых данных, результат будет получаться из базы быстрее:
+------+---------+ | NAME | PRODUCT | +------+---------+ | Мышь | Сыр | +------+---------+ | Кот | Молоко | +------+---------+
Если в двух таблицах имеются столбцы с одинаковыми названиями, то будет показан только последний столбце с таким названием. Чтобы этого не происходило, выбирайте определённый столбцы и используйте команду «AS» с помощью которой можно переименовать столбец в результатах выборки.
Давайте теперь решим логическую задачу, которую поставили в начале статьи. Попробуем выбрать в этой объединённой таблице только одну строку, которая соответствует пользователю «Мышь». Для этого используем условие WHERE в SQL запросе:
SELECT `USERS`.`NAME`, `FOOD`.`PRODUCT` FROM `USERS` INNER JOIN `FOOD` ON `USERS`.`ID`=`FOOD`.`USER_ID` WHERE `USERS`.`NAME` LIKE 'Мышь';
Обратите внимание, что в условии WHERE название полей так же необходимо ставить вместе с названием таблицы через точку: USERS.NAME. В результате выполнения этого запроса появится такой результат:
+------+---------+ | NAME | PRODUCT | +------+---------+ | Мышь | Сыр | +------+---------+
Отлично! Теперь мы знаем, как делать объединение таблиц.
Была ли эта статья полезна? Есть вопрос?
Закажите недорогой хостинг Заказать
всего от 290 руб
Работа с запросами в SQL Server
В этой статье вы увидите, как использовать различные типы запросов таблиц SQL JOIN для выбора данных из двух или более связанных таблиц.
В реляционной базе данных несколько таблиц связаны друг с другом с помощью ограничений внешнего ключа.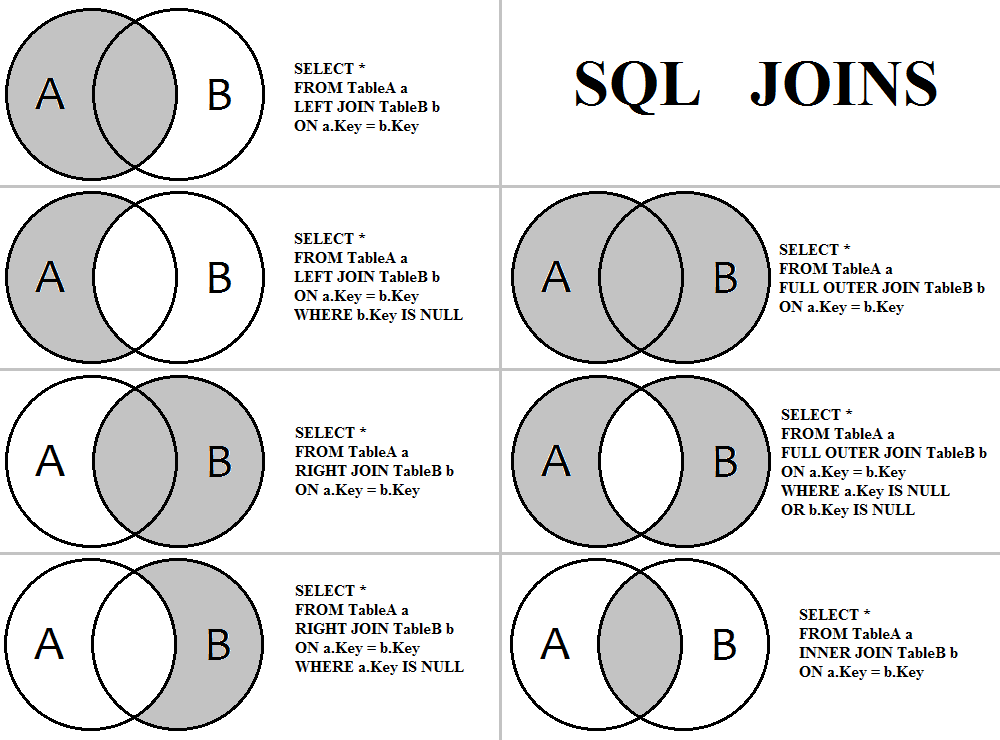 Если вы хотите одновременно получать данные из связанных таблиц, будут полезны SQL-запросы таблиц JOIN.
Если вы хотите одновременно получать данные из связанных таблиц, будут полезны SQL-запросы таблиц JOIN.
Запросы таблиц SQL JOIN можно разделить на четыре основных типа:
- ВНУТРЕННЕЕ СОЕДИНЕНИЕ
- ЛЕВОЕ СОЕДИНЕНИЕ
- ПРАВОЕ ПРИСОЕДИНЕНИЕ
- ПОЛНОЕ СОЕДИНЕНИЕ
Прежде чем мы увидим запросы таблиц SQL JOIN в действии, давайте создадим фиктивную базу данных.
Создание фиктивной базы данных
В этом разделе мы создадим простую базу данных для воображаемого книжного магазина. Имя базы данных будет BookStore. Следующий скрипт создает нашу базу данных:
СОЗДАТЬ БАЗУ ДАННЫХ BookStore |
База данных будет содержать три таблицы: Книги, Категории и Авторы. Следующий скрипт создает таблицу Books:
1 2 3 4 5 6 7 8 9 | USE BookStore CREATE TABLE Books ( Id INT PRIMARY KEY IDENTITY(1,1), Name VARCHAR (50) NOT NULL, Price INT, CategoryId INT, AuthorId 0 3 3 90) |
Таблица Books содержит четыре столбца: Id, Name, Price CategoryId и AuthorId.
Аналогичным образом выполните следующий скрипт, чтобы создать таблицы категорий и авторов:
1 2 3 4 5 6 7 8 9 10 11 12 13 | Используйте книжный магазин Категории создания таблиц ( ID Primary Key, Имя VARCHAR (50) Не нулевой, ) Использование книжного магазина Создание авторов таблицы ( ID ID ID. ПЕРВИЧНЫЙ КЛЮЧ, Имя VARCHAR (50) НЕ NULL, ) |
Давайте теперь вставим несколько фиктивных записей в таблицу «Категории»:
1 2 3 4 5 6 7 8 10 3 9 3 | ВСТАВИТЬ В Категории ЗНАЧЕНИЯ (1, ‘Категория-A’), (2, ‘Категория-B’), (3, ‘Категория-C’), (7, ‘Категория- Д’), (8, «Кат-Е»), (4, кат-F), (10, кат-G), (12, кат-H), (6, кат-I) |
Аналогичным образом запустите следующий скрипт, чтобы вставить записи в таблицу авторов:
1 2 3 4 5 6 | ВСТАВИТЬ В Авторы ЗНАЧЕНИЯ (1, ‘Автор-А’), (2, ‘Автор-Б’), (3, ‘Автор-С’), (10, «Автор-D»), (12, «Автор-E») |
Наконец, чтобы добавить фиктивные записи в таблицу Books, запустите следующий скрипт:
1 2 3 4 5 6 7 8 10 3 9 3 | ВСТАВИТЬ В Книги ЗНАЧЕНИЯ («Книга-A», 100, 1, 2), («Книга-B», 200, 2, 2), («Книга-C», 150, 3, 2), («Книга-D», 100, 3,1), («Книга-E», 200, 3,1), (‘Книга-F’, 150, 4,1), (‘Книга-G’, 100, 5,5), (‘Книга-H’, 200, 5,6), (‘ Книга I’, 150, 7,8) |
Примечание. Поскольку столбец Id книги имеет свойство Identity, нам не нужно указывать значение для столбца Id.
Поскольку столбец Id книги имеет свойство Identity, нам не нужно указывать значение для столбца Id.
Давайте теперь подробно рассмотрим каждый из запросов таблиц SQL JOIN.
Тип запроса таблиц SQL JOIN 1 — INNER JOIN
Запрос INNER JOIN извлекает записи только из тех строк обеих таблиц в запросе JOIN, где найдено совпадение между значениями столбцов, к которым применяется INNER JOIN.
Это может показаться сложным, но не волнуйтесь, на практике все довольно просто.
Давайте получим значения столбцов CategoryId и Name из таблицы Books, а также столбцов Id и Name из таблицы Categories, где значения столбца CateogryId таблицы Books и столбца Id таблицы Categories совпадают:
SELECT Books.CategoryId, Books.Name, Categories.Id, Categories.Name FROM Books INNER JOIN Categories ON Books.CategoryId = Categories.Id |
Вот набор результатов:
Вы можете видеть, что из таблицы «Книги» записи для книг с идентификатором категории 5 не отображаются, поскольку столбец «Идентификатор» таблицы «Категории» не содержит 5. Аналогично, из таблиц «Категории» категории со значением идентификатора 8 , 10, 12 и 16 не отображаются, так как столбец CateogryId из таблицы Books не содержит этих значений.
Аналогично, из таблиц «Категории» категории со значением идентификатора 8 , 10, 12 и 16 не отображаются, так как столбец CateogryId из таблицы Books не содержит этих значений.
Следовательно, для ВНУТРЕННЕГО СОЕДИНЕНИЯ из обеих таблиц выбираются только те строки, в которых значения столбцов, задействованных в запросе ВНУТРЕННЕЕ СОЕДИНЕНИЕ, совпадают.
Тип запроса таблиц SQL JOIN 2 — LEFT JOIN
В LEFT JOIN извлекаются все записи из таблицы слева от предложения LEFT JOIN.
Напротив, из таблицы справа от предложения LEFT JOIN выбираются только те строки, в которых значения столбцов, задействованных в запросе LEFT JOIN, совпадают.
Например, если вы применяете LEFT JOIN к столбцу CategoryId таблицы Books и столбцу Id таблицы Categories. Все записи из таблицы Books (таблица слева) будут извлечены, тогда как из таблицы Categories (таблица справа) будут извлечены только те записи, где столбец CategoryId таблицы Books и столбец Id таблицы Таблица категорий имеет те же значения.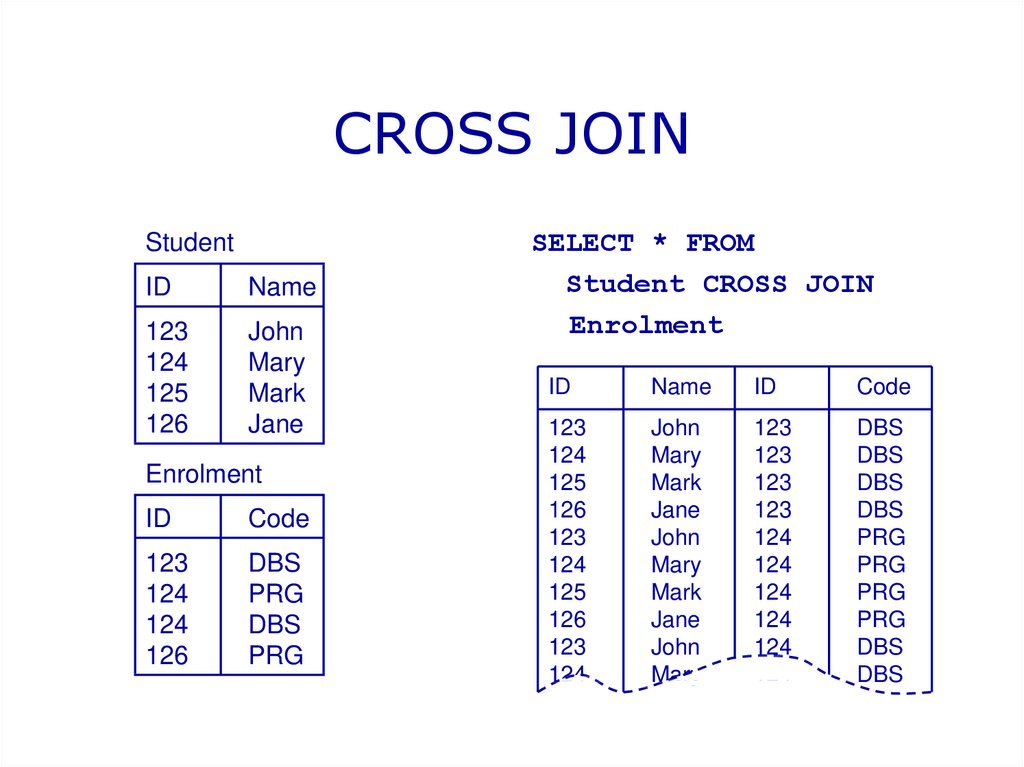
Посмотрите на следующий скрипт:
SELECT Books.CategoryId, Books.Name, Categories.id, Categories.Name FROM Books LEFT JOIN Categories ON Books.CategoryId = Categories.Id |
Вот набор результатов:
Из результата видно, что отображаются все записи из таблицы books. Для столбцов id и Name таблицы Categories отображаются только совпадающие записи. Поскольку таблица «Категории» не содержит 5 в столбце «Идентификатор», значения NULL были добавлены в столбцы таблицы «Категории».
Тип запроса таблиц SQL JOIN 3 — RIGHT JOIN
Предложение RIGHT JOIN полностью противоположно предложению LEFT JOIN.
В RIGHT JOIN извлекаются все записи из таблицы справа от предложения RIGHT JOIN. И наоборот, из таблицы слева от предложения RIGHT JOIN выбираются только те строки, в которых значения столбцов, задействованных в запросе RIGHT JOIN, совпадают.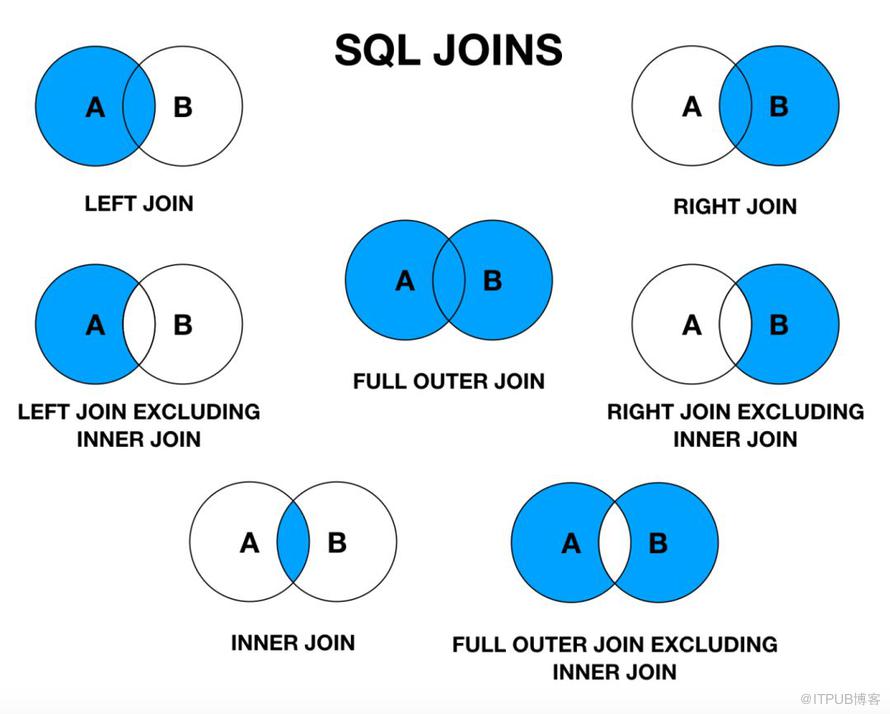
Например, если вы применяете ПРАВОЕ СОЕДИНЕНИЕ к столбцу CategoryId таблицы Books и столбцу Id таблицы Categories. Все записи из таблицы «Категории» (таблица справа) будут извлечены, тогда как из таблицы «Книги» (таблица слева) будут извлечены только те записи, в которых столбец «Идентификатор категории» таблицы «Книги» и столбец «Идентификатор» Таблица категорий имеет те же значения.
Посмотрите на следующий скрипт:
ВЫБЕРИТЕ Books.CategoryId, Books.Name, Categories.id, Categories.Name FROM Books RIGHT JOIN Categories ON Books.CategoryId = Categories.Id |
Вот набор результатов:
Из вывода видно, что отображаются все записи из столбцов таблицы «Категории». Для столбцов CategoryId и Name таблицы Books отображаются только совпадающие записи. Поскольку в таблице Books нет записей со значениями 6, 8, 10 или 12, в столбце CategoryId в столбцах из таблицы Books были добавлены значения NULL.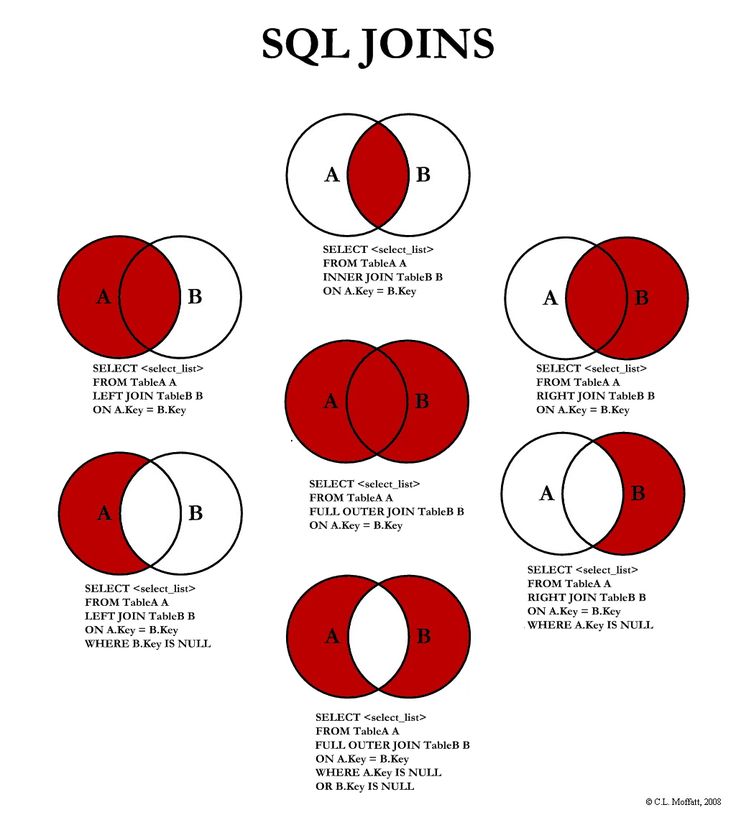
Запрос таблиц SQL JOIN 4 — ПОЛНОЕ СОЕДИНЕНИЕ
Предложение FULL JOIN извлекает все записи из обеих таблиц независимо от совпадения значений в столбцах, используемых в предложении FULL JOIN.
Следующий скрипт применяет ПОЛНОЕ соединение к столбцу CategoryId таблицы Books и столбцу Id таблицы Categories:
SELECT Books.CategoryId, Books.Name, Categories.id, Categories.Name FROM Books FULL JOIN Categories ON Books.CategoryId = Categories.Id |
Вот набор результатов:
Вывод показывает, что все записи были извлечены из таблиц «Книги» и «Категории». Значения NULL были добавлены для строк, в которых не найдено совпадения между столбцом CategoryId таблицы Books и столбцом Id таблицы Categories.
Заключение
Запросы таблиц SQL JOIN используются для извлечения связанных данных из нескольких таблиц.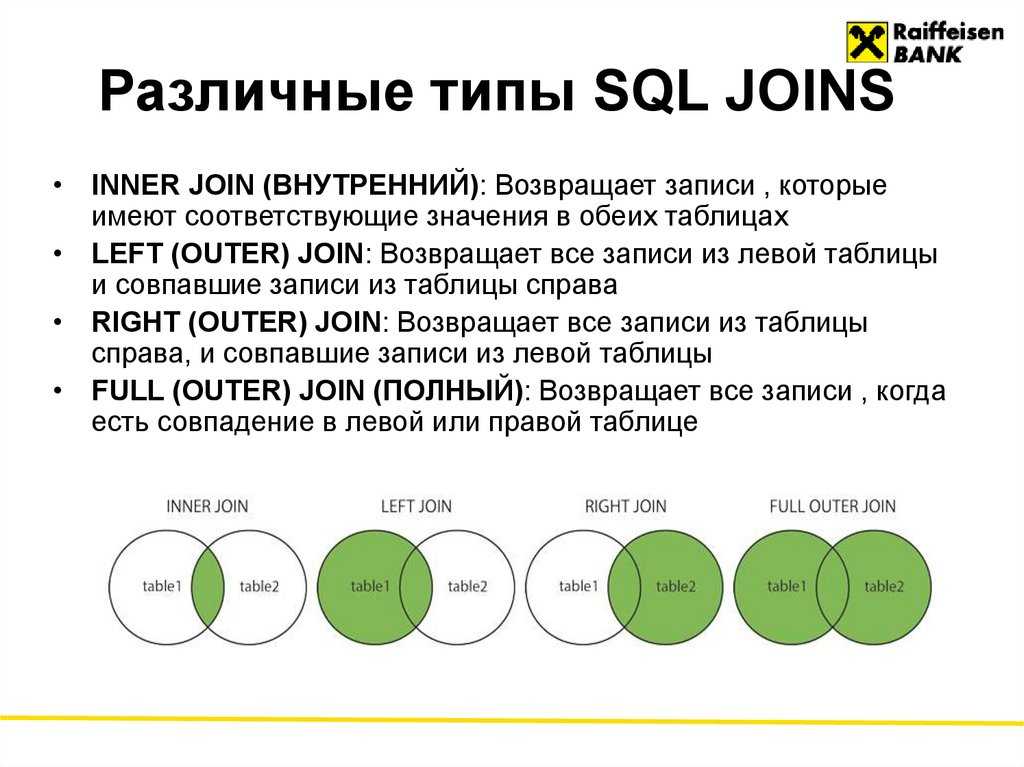 В этой статье вы увидели, как реализовать различные типы запросов таблиц SQL JOIN в Microsoft SQL Server с помощью различных примеров.
В этой статье вы увидели, как реализовать различные типы запросов таблиц SQL JOIN в Microsoft SQL Server с помощью различных примеров.
- Автор
- Последние сообщения
Бен Ричардсон
Бен Ричардсон управляет Acuity Training, ведущим поставщиком обучения SQL в Великобритании. Он предлагает полный спектр обучения SQL от вводных курсов до продвинутого обучения администрированию и работе с хранилищами данных — см. здесь для получения более подробной информации. Acuity имеет офисы в Лондоне и Гилфорде, графство Суррей. Он также иногда пишет в блоге Acuity 9.0003
Просмотреть все сообщения Бена Ричардсона
Последние сообщения Бена Ричардсона (посмотреть все)
PostgreSQL: Документация: 15: 2.6. Соединения между таблицами
До сих пор наши запросы обращались только к одной таблице за раз. Запросы могут обращаться к нескольким таблицам одновременно или обращаться к одной и той же таблице таким образом, что несколько строк таблицы обрабатываются одновременно. Запросы, которые обращаются к нескольким таблицам (или к нескольким экземплярам одной и той же таблицы) одновременно, называются присоединяются к запросам. Они объединяют строки из одной таблицы со строками из второй таблицы с выражением, указывающим, какие строки должны быть объединены в пары. Например, чтобы вернуть все записи о погоде вместе с местоположением соответствующего города, база данных должна сравнить столбец
Запросы, которые обращаются к нескольким таблицам (или к нескольким экземплярам одной и той же таблицы) одновременно, называются присоединяются к запросам. Они объединяют строки из одной таблицы со строками из второй таблицы с выражением, указывающим, какие строки должны быть объединены в пары. Например, чтобы вернуть все записи о погоде вместе с местоположением соответствующего города, база данных должна сравнить столбец city каждой строки таблицы Weather со столбцом name всех строк в городах. и выберите пары строк, в которых эти значения совпадают. [4] Это можно сделать с помощью следующего запроса:
ВЫБЕРИТЕ * ИЗ ПОГОДЫ ПРИСОЕДИНЯЙТЕСЬ к городам ON city = name;
город | temp_lo | temp_hi | пркп | дата | имя | место нахождения
---------------+---------+----------+------+------- -----+---------------+-----------
Сан-Франциско | 46 | 50 | 0,25 | 1994-11-27 | Сан-Франциско | (-194,53)
Сан-Франциско | 43 | 57 | 0 | 1994-11-29 | Сан-Франциско | (-194,53)
(2 ряда)
Обратите внимание на две особенности результирующего набора:
Нет строки результатов для города Хейворд.
 Это связано с тем, что в таблице
Это связано с тем, что в таблице городовдля Хейворда нет соответствующей записи, поэтому объединение игнорирует несопоставленные строки в таблицепогоды. Вскоре мы увидим, как это можно исправить.Есть две колонки, содержащие название города. Это правильно, потому что списки столбцов из таблиц
Weatherигородовобъединены. На практике это нежелательно, поэтому вы, вероятно, захотите указать выходные столбцы явно, а не использовать*:ВЫБЕРИТЕ город, temp_lo, temp_hi, prcp, дату, местоположение ОТ ПОГОДЫ ПРИСОЕДИНЯЙТЕСЬ к городам ПО city = name;
Поскольку все столбцы имели разные имена, синтаксический анализатор автоматически нашел, к какой таблице они принадлежат. Если бы в двух таблицах были повторяющиеся имена столбцов, вам нужно было бы квалифицировать имена столбцов, чтобы показать, какой из них вы имели в виду, например:
ВЫБЕРИТЕ погода.город, погода.temp_lo, погода.temp_hi, погода.prcp, погода.дата, города.местоположение ИЗ ПОГОДЫ ПРИСОЕДИНЯЙТЕСЬ к городам ПО Weather.city = city.name;
Считается хорошим стилем уточнять все имена столбцов в запросе на соединение, чтобы запрос не завершился ошибкой, если позже в одну из таблиц будет добавлено повторяющееся имя столбца.
Запросы на соединение того вида, который мы видели до сих пор, также можно записать в такой форме:
ВЫБРАТЬ *
ОТ погоды, городов
ГДЕ город = имя;
Этот синтаксис предшествует синтаксису JOIN / ON , который был представлен в SQL-92. Таблицы просто перечислены в ОТ , а выражение сравнения добавляется к предложению WHERE . Результаты этого старого неявного синтаксиса и нового явного синтаксиса JOIN / ON идентичны. Но для читателя запроса явный синтаксис облегчает понимание его смысла: условие соединения вводится собственным ключевым словом, тогда как ранее условие было смешано с предложением WHERE вместе с другими условиями.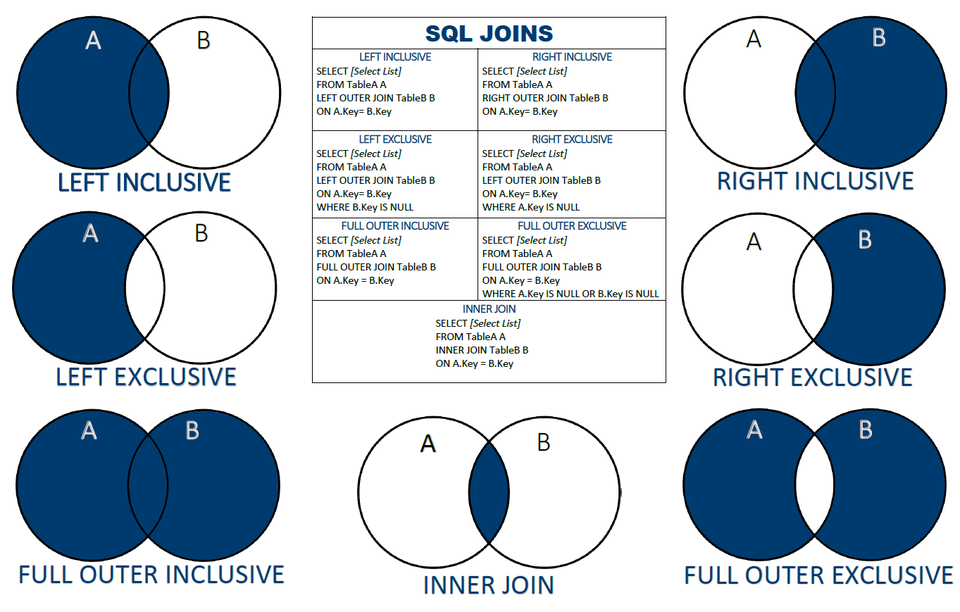
Теперь мы выясним, как вернуть записи Хейворда. Мы хотим, чтобы запрос сканировал погода таблицы и для каждой строки, чтобы найти соответствие городов строк. Если подходящая строка не найдена, мы хотим, чтобы некоторые «пустые значения» были заменены на столбцы таблицы городов . Такой запрос называется внешним соединением . (Соединения, которые мы видели до сих пор, это внутренних соединений .) Команда выглядит так:
ВЫБРАТЬ *
ОТ погоды ЛЕВЫЙ ВНЕШНИЙ СОЕДИНЯЙТЕ города НА Weather.city = city.name;
город | temp_lo | temp_hi | пркп | дата | имя | место нахождения
---------------+---------+----------+------+------- -----+---------------+-----------
Хейворд | 37 | 54 | | 1994-11-29 | |
Сан-Франциско | 46 | 50 | 0,25 | 1994-11-27 | Сан-Франциско | (-194,53)
Сан-Франциско | 43 | 57 | 0 | 1994-11-29 | Сан-Франциско | (-194,53)
(3 ряда)
Этот запрос называется левым внешним соединением , потому что таблица, указанная слева от оператора соединения, будет иметь каждую из своих строк в выходных данных по крайней мере один раз, тогда как таблица справа будет иметь только те строки, которые соответствуют некоторую строку левой таблицы. При выводе строки левой таблицы, для которой нет совпадения с правой таблицей, столбцы правой таблицы заменяются пустыми (нулевыми) значениями.
При выводе строки левой таблицы, для которой нет совпадения с правой таблицей, столбцы правой таблицы заменяются пустыми (нулевыми) значениями.
Упражнение: Существуют также правые внешние соединения и полные внешние соединения. Попробуйте узнать, что они делают.
Мы также можем объединить таблицу против себя. Это называется самосоединением . В качестве примера предположим, что мы хотим найти все записи о погоде, которые находятся в температурном диапазоне других записей о погоде. Поэтому нам нужно сравнить столбцы temp_lo и temp_hi каждой строки Weather с temp_lo и temp_hi 9.0432 столбца всех остальных погода строки. Мы можем сделать это с помощью следующего запроса:
ВЫБЕРИТЕ w1.city, w1.temp_lo как низкий, w1.temp_hi как высокий, w2.city, w2.temp_lo низкий уровень AS, w2.temp_hi высокий уровень AS ОТ погоды w1 ПРИСОЕДИНЯЙТЕСЬ к погоде w2 ON w1.