Строковые функции Python: руководство | Timeweb Cloud
Как следует из названия, строковые функции Python 3 предназначены для совершения различных операций над строками. В языке программирования Python строковых функций несколько десятков, и в статье мы рассмотрим самые употребляемые, а также ряд специальных, которые не так популярны, зато полезны. Они могут пригодиться вам не только при форматировании, но и при проверке данных.
Список основных строковых функций для форматирования текстаВ первую очередь расскажем о функциях форматирования строк, а чтобы обучение шло веселее, в примерах будем использовать тексты, сгенерированные нейросетью «Порфирьевич» (если фраза состоит из двух предложений, то первое в каждом примере написано человеком, а второе — нейросетью, которую обучали на примерах из русской классики).
capitalize()— преобразует первый символ строки в верхний регистр, однако все остальные будут в нижнем:
>>> phrase = 'нехватка программистов повышает значимость DevOps.После презентации разработчики начинают наперебой предлагать свои услуги, конкурируя между собой за DevOps.'
>>> phrase.capitalize()
'Нехватка программистов повышает значимость devops. после презентации разработчики начинают наперебой предлагать свои услуги, конкурируя между собой за devops.'
 После презентации разработчики начинают наперебой предлагать свои услуги, конкурируя между собой за DevOps.'
После презентации разработчики начинают наперебой предлагать свои услуги, конкурируя между собой за DevOps.'casefold()— возвращает все элементы строки в нижнем регистре:
>>> phrase = 'Российский рынок облачных провайдеров имеет хорошие перспективы в плане импортозамещения. Как он будет развиваться, пока не ясно, но потенциал у него есть.'
>>> phrase.casefold()
'российский рынок облачных провайдеров имеет хорошие перспективы в плане импортозамещения. как он будет развиваться, пока не ясно, но потенциал у него есть.'
center()— с помощью этого метода можно выравнивать строки по центру:
>>> text = 'Python прекрасно подходит для написания ИИ'
>>> newtext = text.center(50,'*')
>>> print(newtext)
****Python прекрасно подходит для написания ИИ****
Небольшое пояснение. У функции center() два аргумента: первый (длина строки для центровки) обязательный, второй (заполнитель) — произвольный. В операции выше мы использовали оба. Наша строка состоит из 42 элементов, поэтому оставшиеся 8 были заполнены «звездочками». Если бы второго атрибута не было, на месте звездочек были бы пробелы.
upper()иlower()— преобразуют все символы в верхний и нижний регистр соответственно:
>>> text = 'Проекты с применением технологий Интернета вещей становятся в Европе всё более популярными.'
>>> text.lower()
'проекты с применением технологий интернета вещей становятся в европе всё более популярными.'
>>> text.upper()
'ПРОЕКТЫ С ПРИМЕНЕНИЕМ ТЕХНОЛОГИЙ ИНТЕРНЕТА ВЕЩЕЙ СТАНОВЯТСЯ В ЕВРОПЕ ВСЁ БОЛЕЕ ПОПУЛЯРНЫМИ.'
replace()— предназначен для замены части строки другим элементом:
>>> text.replace('Европе','России')
'Проекты с применением технологий Интернета вещей становятся в России всё более популярными.'У функции replace() есть и необязательный количественный атрибут, который обозначает максимальное количество замен, если заменяемый элемент встречается в тексте несколько раз. Он указывается на третьем месте:
>>> text = 'ура-ура-ура'
>>> text.replace('ура','гип',2)
'гип-гип-ура'
strip()— удаляет одинаковые символы по краям строки:
>>> text = 'оле-оле-оле'
>>> text.strip('оле')
'-оле-'
Если симметричных значений нет, будет удалено найденное слева или справа, а если указанные символы отсутствуют, вывод останется неизменным:
>>> text.strip('ол')
'е-оле-оле'
>>> text.strip('ле')
'оле-оле-о'
>>> text.strip('ура')
'оле-оле-оле'
title()— создает заголовки в соответствии с тем, как это принято в английском, то есть пишет каждое слово с заглавной буквы. Снова похулиганим с Порфирьевичем:
>>> texttitle = 'Респонденты разочарованы сетями 5G. Они ждали от телефона услуг VPN, но получили их от Google.'
>>> texttitle.title()
'Респонденты Разочарованы Сетями 5G. Они Ждали От Телефона Услуг Vpn, Но Получили Их От Google.'
Вы наверняка заметили, что метод title() делает и еще одну вещь: он переводит не начальные буквы в словах в нижний регистр, если они написаны в верхнем.
expandtabs()— меняет табуляцию в тексте, что помогает при форматировании:
>>> clublist = 'Милан\tРеал\tБавария\tАрсенал'Строковые функции для проверки значений
>>> print(clublist)
Милан Реал Бавария Арсенал
>>> clublist.expandtabs(1)
'Милан Реал Бавария Арсенал'
>>> clublist.expandtabs(5)
'Милан Реал Бавария Арсенал'
Иногда бывает необходимо подсчитать определенное количество элементов последовательности или проверить, встречается ли в тексте какое-то значение. Эти и другие задачи решают следующие строковые функции.
count()— подсчитывает подстроки (отдельные элементы), встречающиеся в строке. За примером снова обратимся к нашей нейросети:
>>> text = "Облачные технологии значительно ускоряют работу с нейросетями и ИИ. Особенно важны эти технологии для сотрудников крупной корпорации, работающей в любой области — от пилотирования космических кораблей до подготовки программистов."
>>> element = "о"
>>> number = text.count(element)
>>> print("Буква «о» встречается в тексте", number, "раз.(-а)")
Буква «о» встречается в тексте 29 раз(-а).
В качестве подстроки можно указать последовательность символов (будем использовать текст из примера выше):
>>> element = "об"
>>> number = text.count(element)
>>> print("Сочетание «об» встречается в тексте", number, "раз(-а).")
Сочетание «об» встречается в тексте 2 раз(-а).
Добавим, что у функции count() есть и два необязательных числовых атрибута, обозначающих границы поиска указанного элемента:
>>> element = "о"
>>> number = text.count(element,20,80)
>>> print("Буква «о» в указанном фрагменте текста встречается", number, "раз(-а).")
Буква «о» в указанном фрагменте текста встречается 6 раз(-а).
find()— выполняет поиск указанного в строке значения и возвращает наименьший индекс. Снова используем пример выше:
>>> print(text.find(element))
13
Этот вывод означает, что первая найденная буква «о» располагается на 13-й позиции в строке (на самом деле на 14-й, потому что счет в Python начинается с нуля). Заметьте, что интерпретатор проигнорировал заглавную букву «О», которая как раз и расположена на нулевой позиции.
Теперь давайте совместим две изученные функции в одном коде:>>> text = "Облачные технологии значительно ускоряют работу с нейросетями и ИИ. Особенно важны эти технологии для сотрудников крупной корпорации, работающей в любой области — от пилотирования космических кораблей до подготовки программистов."
>>> element = "о"
>>> number = text.count(element,20,80)
>>> print("Буква «о» в указанном фрагменте текста встречается", number, "раз(-а), а первый раз во всём тексте на", (text.find(element)), "месте.")
Буква «о» в указанном фрагменте текста встречается 6 раз(-а), а первый раз во всём тексте на 13 месте.
index()— по работе похож наfind(), однако при отсутствии введенного значения выдаст примерно такую ошибку:
Traceback (most recent call last):
File "C:\Python\text.py", line 4, in <module>
print(text.index(element))
ValueError: substring not found

А вот что выдал бы интерпретатор при использовании функции find() в этом случае:
-1
Это отрицательная позиция, то есть значение не найдено.
enumerate()— очень полезная функция, которая не только перебирает элементы списка или кортежа, возвращая их значения, но также возвращает и порядковый номер каждого элемента:
team_scores = [78, 74, 56, 53, 49, 47, 44]
for number, score in enumerate(team_scores,1):
print(str(number) + '-я команда набрала ' + str(score) + ' очков(-а)')
Для вывода значений с их порядковыми номерами мы ввели несколько переменных: number для порядковых номеров, score для значений списка, а str обозначает строку. И вот вывод:
1-я команда набрала 78 очков(-а)
2-я команда набрала 74 очков(-а)
3-я команда набрала 56 очков(-а)
4-я команда набрала 53 очков(-а)
5-я команда набрала 49 очков(-а)
6-я команда набрала 47 очков(-а)
7-я команда набрала 44 очков(-а)
Заметьте, что вторым атрибутом функции enumerate() указано число 1, поскольку иначе Python стал бы считать с нуля.
len()— подсчитывает длину объекта, то есть количество элементов, из которых состоит та или иная последовательность:
>>> len(team_scores)
7
Вот так мы посчитали количество элементов в списке из примера выше. А теперь снова повеселимся с Порфирьевичем, напишем строку и подсчитаем число символов в ней:
>>> porfirevich = 'Говорят, что искусственный интеллект исключает человеческий фактор. Но не забывайте, что человеческий фактор все еще присутствует в СМИ и в правительственных структурах.'Специальные строковые функции Python
>>> len(porfirevich)
169
join()— позволяет конвертировать списки в строки:
>>> cities = ['Москва','Санкт-Петербург','Нижний Новгород','Казань','Уфа','Самара','Ростов-на-Дону']
>>> cities_str = ', '.join(cities)
>>> print('Города в одну строчку:', cities_str)
Города в одну строчку: Москва, Санкт-Петербург, Нижний Новгород, Казань, Уфа, Самара, Ростов-на-Дону
print()— дает печатное представление любого объекта в Python:
>>> cities = ['Москва','Санкт-Петербург','Нижний Новгород','Казань','Уфа','Самара','Ростов-на-Дону']
>>> print(cities)
['Москва', 'Санкт-Петербург', 'Нижний Новгород', 'Казань', 'Уфа', 'Самара', 'Ростов-на-Дону']
type()— возвращает тип объекта:
>>> type(cities)
<class 'list'>
Выяснили, что объект из предыдущего примера — список. Полезно для новичков, ведь они могут поначалу путать, например, списки и кортежи, которые имеют разные функциональные возможности и обрабатываются интерпретатором тоже по-разному.
Полезно для новичков, ведь они могут поначалу путать, например, списки и кортежи, которые имеют разные функциональные возможности и обрабатываются интерпретатором тоже по-разному.
map()— является довольно эффективной заменой циклаfor, позволяя перебирать элементы какого-либо итерируемого объекта, применяя к каждому из них встроенную функцию. Для примера давайте преобразуем список строковых значений в целочисленные, для чего задействуем функциюint:
>>> numbers_list = ['4', '7', '11', '12', '17']
>>> list(map(int, numbers_list))
[4, 7, 11, 12, 17]
Как видим, мы использовали функцию list(), «обернув» в нее map() — это было необходимо, чтобы избежать вот такого вывода:
>>> numbers_list = ['4', '7', '11', '12', '17']
>>> map(int, numbers_list)
<map object at 0x0000000002E272B0>
Это не ошибка, просто получился вывод ID объекта, и программа продолжит работу. Но чтобы получить нужный вывод списка, полезно в таких случаях использовать метод
Но чтобы получить нужный вывод списка, полезно в таких случаях использовать метод list().
Разумеется, мы описали не все строковые функции Python, но уже этот набор поможет вам производить большое число операций со строками и выполнять различные преобразования (программные и математические). Желаем дальнейших успехов!
Справочник по PYTHON | Строки. Функции и методы строк
Базовые операции
Конкатенация (сложение)
>>>
>>> S1 = ‘spam’
>>> S2 = ‘eggs’
>>> print(S1 + S2)
‘spameggs’
Дублирование строки
>>>
>>> print(‘spam’ * 3)
spamspamspam
Длина строки (функция len)
>>>
>>> len(‘spam’)
4
Доступ по индексу
>>>
>>> S = ‘spam’
>>> S[0]
‘s’
>>> S[2]
‘a’
>>> S[-2]
‘a’
Как видно из примера, в Python возможен и доступ по отрицательному индексу, при этом отсчет идет от конца строки.
Извлечение среза
Оператор извлечения среза: [X:Y]. X – начало среза, а Y – окончание;
символ с номером Y в срез не входит. По умолчанию первый индекс равен 0, а второй — длине строки.
>>>
>>> s = ‘spameggs’
>>> s[3:5]
‘me’
>>> s[2:-2]
‘ameg’
>>> s[:6]
‘spameg’
>>> s[1:]
‘pameggs’
>>> s[:]
‘spameggs’
Кроме того, можно задать шаг, с которым нужно извлекать срез.
>>>
>>> s[::-1]
‘sggemaps’
>>> s[3:5:-1]
»
>>> s[2::2]
‘aeg’
Другие функции и методы строк
При вызове методов необходимо помнить, что строки в Python относятся к категории неизменяемых последовательностей, то есть все функции и методы могут лишь создавать новую строку.
>>>
>>> s = ‘spam’
>>> s[1] = ‘b’
Traceback (most recent call last):
File «», line 1, in
s[1] = ‘b’
TypeError: ‘str’ object does not support item assignment
>>> s = s[0] + ‘b’ + s[2:]
>>> s
‘sbam’
Поэтому все строковые методы возвращают новую строку, которую потом следует присвоить переменной.
Таблица «Функции и методы строк»
Функция или метод Назначение
S = ‘str’; S = «str»; S = »’str»’; S = «»»str»»» Литералы строк
S = «s\np\ta\nbbb» Экранированные последовательности
S = r»C:\temp\new» Неформатированные строки (подавляют экранирование)
S = b»byte» Строка байтов
S1 + S2 Конкатенация (сложение строк)
S1 * 3 Повторение строки
S[i] Обращение по индексу
S[i:j:step] Извлечение среза
len(S) Длина строки
S.find(str, [start],[end]) Поиск подстроки в строке. Возвращает номер первого вхождения или -1
S.rfind(str, [start],[end]) Поиск подстроки в строке. Возвращает номер последнего вхождения или -1
S.index(str, [start],[end]) Поиск подстроки в строке. Возвращает номер первого вхождения или вызывает ValueError
S.rindex(str, [start],[end]) Поиск подстроки в строке. Возвращает номер последнего вхождения или вызывает ValueError
S.replace(шаблон, замена[, maxcount]) Замена шаблона на замену. maxcount ограничивает количество замен
maxcount ограничивает количество замен
S.split(символ) Разбиение строки по разделителю
S.isdigit() Состоит ли строка из цифр
S.isalpha() Состоит ли строка из букв
S.isalnum() Состоит ли строка из цифр или букв
S.islower() Состоит ли строка из символов в нижнем регистре
S.isupper() Состоит ли строка из символов в верхнем регистре
S.isspace() Состоит ли строка из неотображаемых символов (пробел, символ перевода страницы (‘\f’), «новая строка» (‘\n’), «перевод каретки» (‘\r’), «горизонтальная табуляция» (‘\t’) и «вертикальная табуляция» (‘\v’))
S.istitle() Начинаются ли слова в строке с заглавной буквы
S.upper() Преобразование строки к верхнему регистру
S.lower() Преобразование строки к нижнему регистру
S.startswith(str) Начинается ли строка S с шаблона str
S.endswith(str) Заканчивается ли строка S шаблоном str
S.join(список) Сборка строки из списка с разделителем S
ord(символ) Символ в его код ASCII
chr(число) Код ASCII в символ
S. capitalize() Переводит первый символ строки в верхний регистр, а все остальные в нижний
capitalize() Переводит первый символ строки в верхний регистр, а все остальные в нижний
S.center(width, [fill]) Возвращает отцентрованную строку, по краям которой стоит символ fill (пробел по умолчанию)
S.count(str, [start],[end]) Возвращает количество непересекающихся вхождений подстроки в диапазоне [начало, конец] (0 и длина строки по умолчанию)
S.expandtabs([tabsize]) Возвращает копию строки, в которой все символы табуляции заменяются одним или несколькими пробелами, в зависимости от текущего столбца. Если TabSize не указан, размер табуляции полагается равным 8 пробелам
S.lstrip([chars]) Удаление пробельных символов в начале строки
S.rstrip([chars]) Удаление пробельных символов в конце строки
S.strip([chars]) Удаление пробельных символов в начале и в конце строки
S.partition(шаблон) Возвращает кортеж, содержащий часть перед первым шаблоном, сам шаблон, и часть после шаблона. Если шаблон не найден, возвращается кортеж, содержащий саму строку, а затем две пустых строки
S. rpartition(sep) Возвращает кортеж, содержащий часть перед последним шаблоном, сам шаблон, и часть после шаблона. Если шаблон не найден, возвращается кортеж, содержащий две пустых строки, а затем саму строку
rpartition(sep) Возвращает кортеж, содержащий часть перед последним шаблоном, сам шаблон, и часть после шаблона. Если шаблон не найден, возвращается кортеж, содержащий две пустых строки, а затем саму строку
S.swapcase() Переводит символы нижнего регистра в верхний, а верхнего – в нижний
S.title() Первую букву каждого слова переводит в верхний регистр, а все остальные в нижний
S.zfill(width) Делает длину строки не меньшей width, по необходимости заполняя первые символы нулями
S.ljust(width, fillchar=» «) Делает длину строки не меньшей width, по необходимости заполняя последние символы символом fillchar
S.rjust(width, fillchar=» «) Делает длину строки не меньшей width, по необходимости заполняя первые символы символом fillchar
S.format(*args, **kwargs) Форматирование строки
7 Полезные строковые функции в Python
Являясь одним из самых популярных языков программирования, Python позволяет разработчикам использовать строковые функции, которые помогают им выполнять различные операции.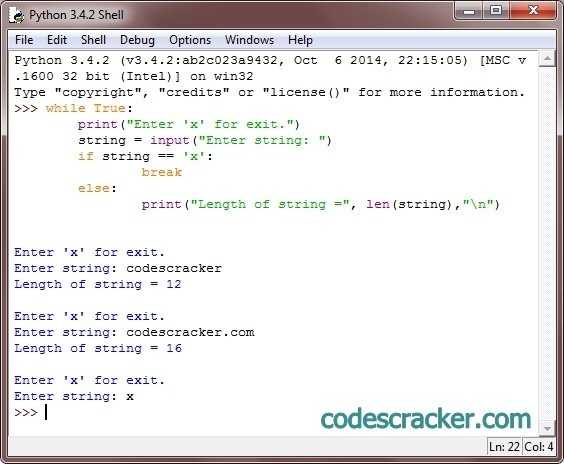 Для тех, кто не знает, строковые данные содержат значение 1 или 1> (это может быть любое число, уникальный символ и т. д.), а затем преобразуются в код ASCII, т. е. в американский стандартный код для обмена информацией и Unicode, чтобы машина могут понимать на своем языке.
Для тех, кто не знает, строковые данные содержат значение 1 или 1> (это может быть любое число, уникальный символ и т. д.), а затем преобразуются в код ASCII, т. е. в американский стандартный код для обмена информацией и Unicode, чтобы машина могут понимать на своем языке.
Python использует один и тот же шаблон для своих данных string , которые выполняют различные задачи, такие как сдвиг верхнего или нижнего регистра и т. д. Это делает разработчиков более полезными, чтобы сэкономить свое время на различных задачах, не беспокоясь о небольших опечатках. ошибок, и поэтому для вас искренне важно иметь технические знания о тех строковых функциях, которые были сужены в этой статье.
7 полезных строковых функций в Python
1. Заглавные буквы
Заглавные буквы () используются в Python, где первая буква строки преобразуется в ПРОПИСНЫЕ, а остальные символы остаются прежними. С другой стороны, если все символы написаны ПРОПИСНЫМИ буквами, строка вернет одно и то же значение (кроме первого символа).
Пример: мое имя Юврадж -> Меня зовут Юврадж
Python3
0 90 print 2 |
Вывод:
Имя предложения -> Myyuvrajuvrajuvrajuvrajuvrajuvrajuvrajuvrajuvraju 1 вывод Вывод предложения 2 -> Меня зовут ansul
2.
 Count
CountФункция count() используется в Python для подсчета количества вхождений отдельного элемента или подстроки в строке. count() выдает числовое значение, которое предоставляет подробную информацию о фактическом количестве данной строки.
Пример: GFG KARLO HO JAYEGA -> Количество 'G' = 3
Python3
|

|
Выход:
7
3
Примечание: 4 запутались в том, как начать изучение python, тогда должны обратиться к ссылкам ниже :
- Как выучить Python за 21 день?
- Python Programming Foundation - Self Paced
4. Нижний
Функция lower() используется в программировании на Python, чтобы гарантировать, что все символы в строке в верхнем регистре преобразуются в нижний регистр и извлекаются с помощью нового строка в нижнем регистре, а исходная копия строки остается нетронутой.
Пример: GEEKSFORGEEKS — ПОРТАЛ ПО КОМПЬЮТЕРНЫМ НАУКАМ -> 'geeksforgeeks — портал по информатике'
Python3
1 message =32 1 «GEEKSFORGEEKS — ПОРТАЛ ПО КОМПЬЮТЕРНЫМ НАУКАМ» Функция upper() используется в программировании на Python, чтобы гарантировать, что все символы нижнего регистра в строке преобразуются в БОЛЬШИЕ и извлекаются вместе с новой строкой, в то время как исходная копия строки остается нетронутой. Пример: geeksforgeeks — портал информатики -> GEEKSFORGEEKS — портал информатики 6. ЗаменитьИспользуется replace() в Python, чтобы заменить любой нежелательный символ или текст и заменить его новым желаемым выводом в строке. Заменить() можно использовать в Python с указанным ниже синтаксисом для выполнения действия: string.replace(old, new, count) Пример: subway Surfer -> Замените 's' на 't' = tubway turfer серфингист |
 upper())
upper()) Вывод:
Tubway turfer
7.
 Join
JoinМетод join() используется в программировании на Python для объединения каждого элемента итерируемого объекта, такого как список, набор и т. д., а позже вы можете использовать строку разделитель для разделения значений. Таким образом, join() возвращает объединенную строку и выдает исключение TypeError, если итерируемый объект содержит любой нестроковый элемент.
Python3
|
Вывод:
Аншул - мой единственный друг Если вы хотите узнать больше о строках Python, мы рекомендуем вам перейти по этой ссылке: Учебник по строкам Python .
Строковые функции в Python с примерами
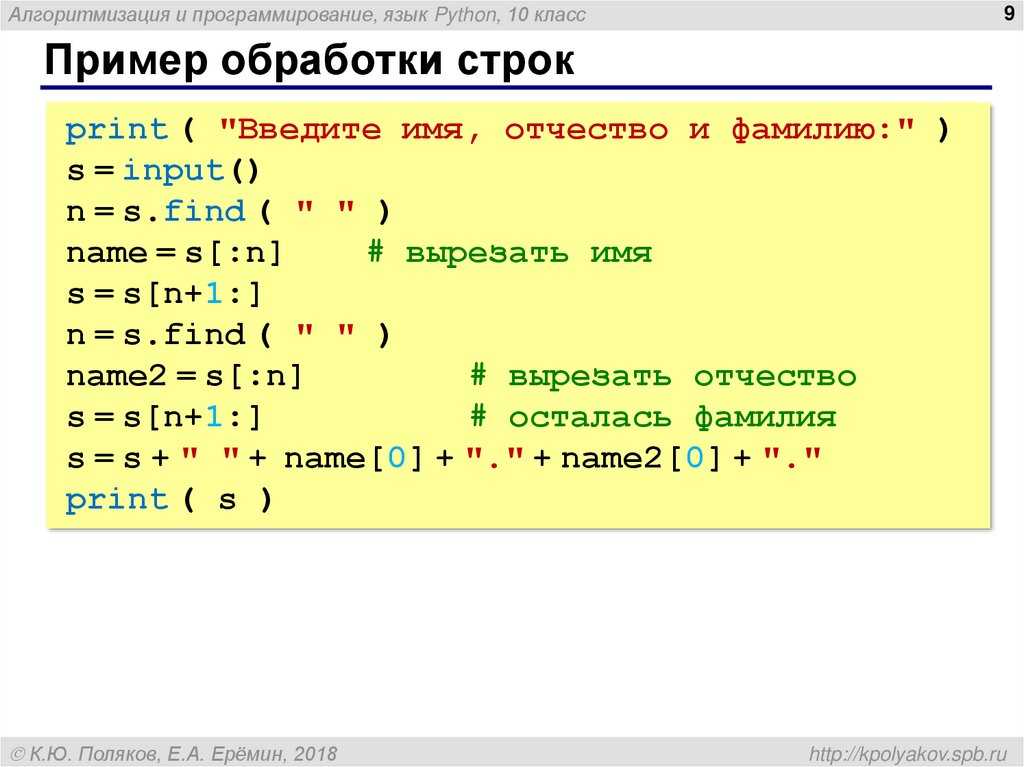
В этом руководстве описываются различные строковые (символьные) функции, используемые в Python. Для управления строками и символьными значениями в python есть несколько встроенных функций. Это означает, что вам не нужно импортировать или иметь зависимость от какого-либо внешнего пакета для работы со строковым типом данных в Python. Это одно из преимуществ использования Python по сравнению с другими инструментами обработки данных. Работа со строковыми значениями очень распространена в реальном мире. Предположим, у вас есть полное имя клиента, и ваш менеджер попросил вас извлечь имя и фамилию клиента. Или вы хотите получить информацию обо всех продуктах, код которых начинается с «QT».
Список часто используемых строковых функций
В таблице ниже показаны многие распространенные строковые функции вместе с описанием и эквивалентной функцией в MS Excel.
Мы все используем MS Excel на своем рабочем месте и знакомы с функциями, используемыми в MS Excel. Сравнение строковых функций в MS EXCEL и Python поможет вам быстро изучить функции и набраться опыта перед собеседованием.
| Функция | Описание | MS EXCEL ФУНКЦИЯ |
|---|---|---|
| моя строка[:N] | Извлечь N символов из начала строки. | ЛЕВЫЙ( ) |
| моя строка[-N:] | Извлечь N символов из конца строки | ПРАВО( ) |
| моя строка[X:Y] | Извлечь символы из середины строки, начиная с позиции X и заканчивая Y | СРЕДНИЙ( ) |
| ул.split(sep=' ') | Разделенные струны | - |
| ул.заменить (старая_подстрока, новая_подстрока) | Заменить часть текста другой подстрокой | ЗАМЕНИТЬ( ) |
| стр.нижний() | Преобразование символов в нижний регистр | НИЖНИЙ( ) |
стр. верхний() верхний() |
Преобразование символов в верхний регистр | ВЕРХНЯЯ( ) |
| str.contains('шаблон', case=False) | Проверка соответствия шаблону (функция Pandas) | Оператор SQL LIKE |
| ул.экстракт(regular_expression) | Возврат совпадающих значений (функция Pandas) | - |
| количество ул('sub_string') | Количество вхождений шаблона в строке | - |
| ул. найти() | Возврат позиции подстроки или шаблона | НАЙТИ() |
| улица isalnum() | Проверить, состоит ли строка только из буквенно-цифровых символов | - |
| улица islower() | Проверить, все ли символы в нижнем регистре | - |
| ул.исуппер() | Проверить, все ли символы в верхнем регистре | - |
| числовая строка() | Проверить, состоит ли строка только из цифр | - |
ул.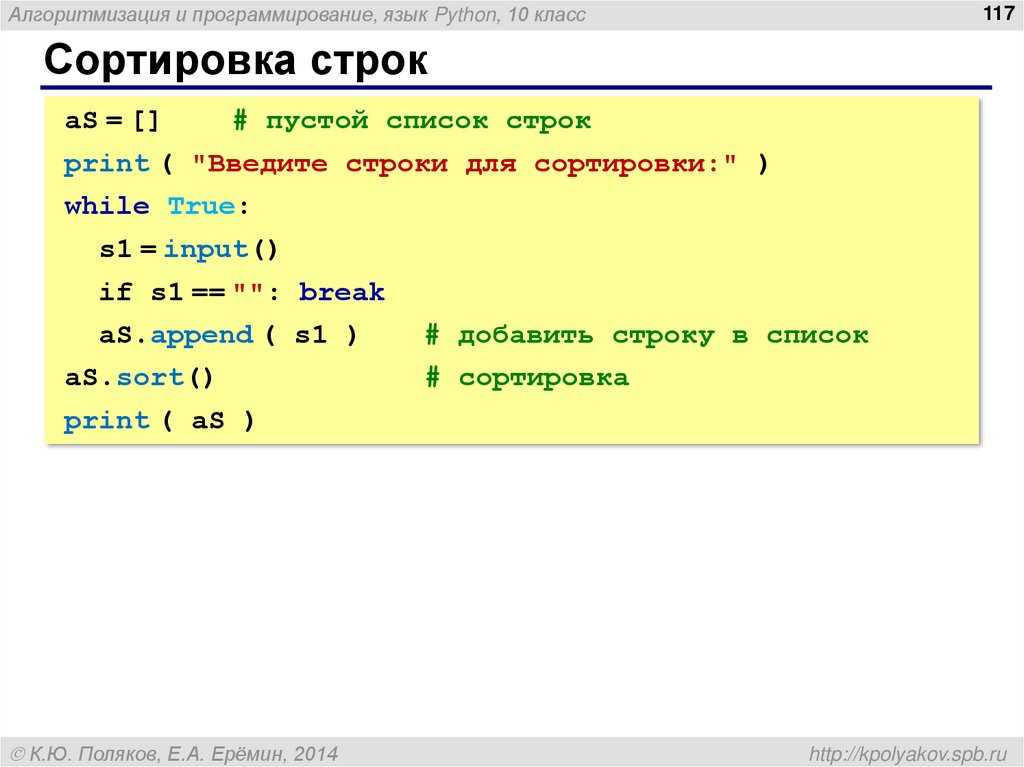 isspace() isspace() |
Проверить, состоит ли строка только из пробельных символов | - |
| лен( ) | Вычислить длину строки | ДЛИН( ) |
| кот( ) | Объединить строки (функция Pandas) | СЦЕПИТЬ( ) |
| separator.join(str) | Объединить строки | СЦЕПИТЬ( ) |
Функции LEFT, RIGHT и MID
Если вы являетесь средним пользователем MS Excel, вы должны использовать функции ВЛЕВО, ВПРАВО и СРЕДНЯЯ. Эти функции используются для извлечения N символов или букв из строки.
1. Извлечь первые два символа из начала строки
mystring = "Эй, приятель, как дела?" моя строка[:2]
Исходящий[1]: 'Он'
-
string[start:stop:step]означает начало элемента от 0 (по умолчанию) до (stop-1), шаг за шагом 1 (по умолчанию). -
mystring[:2]эквивалентноmystring[0:2] -
mystring[:2]сообщает Python, что необходимо извлечь первые 2 символа из строкового объектаmystring.
- Индексирование начинается с нуля, поэтому оно включает первый, второй элемент и исключает третий.
2. Найти два последних символа строки
mystring[-2:]
Приведенная выше команда возвращает p? . -2 начинает диапазон от предпоследней позиции до максимальной длины строки.
3. Найти символы из середины строки
mystring[1:3]
Исходящий[1]: 'эй'
mystring[1:3] возвращает второй и третий символы. 1 относится ко второму символу, так как индекс начинается с 0.
4. Как перевернуть строку?
моя строка[::-1]
Out[1]: '?pussaw ,yddub yeH'
-1 указывает Python начать с конца и увеличить его на 1 справа налево.
5. Как извлечь символы из строковой переменной в Pandas DataFrame?
Давайте создадим поддельный фрейм данных для иллюстрации. В приведенном ниже коде мы создаем фрейм данных с именем
В приведенном ниже коде мы создаем фрейм данных с именем df , содержащий только 1 переменную с именем var1
.
импортировать панд как pd
df = pd.DataFrame({"var1": ["A_2", "B_1", "C_2", "A_2"]})
переменная1
0 А_2
1 Б_1
2 С_2
3 А_2
Для обработки текстовых данных в Python Pandas Dataframe мы можем использовать атрибут str . Его можно использовать для нарезки значений символов.
df['var1'].str[0]
В этом случае мы получаем первый символ из var1 переменная. См. вывод, показанный ниже.
Выход 0 А 1 Б 2 С 3 А
Извлечение слов из строки
Предположим, вам нужно вынуть слово(а) вместо символов из строки. Обычно мы рассматриваем один пробел как разделитель для поиска слов из строки.
1. Найти первое слово строки
mystring.split()[0]
Исходящий[1]: 'Эй'
Как это работает?
-
функция split()разбивает строку, используя пробел в качестве разделителя по умолчанию -
mystring.возвращает split()
split() ['Эй', 'приятель', 'как дела?'] -
0возвращает первый элемент или словоHey
2. Запятая как разделитель слов
mystring.split(',')[0]
Исходящий[1]: 'Эй, приятель'
3. Как извлечь последнее слово
mystring.split()[-1]
Out[1]: 'как дела?'
4. Как извлечь слово из DataFrame
Давайте создадим фиктивный фрейм данных, состоящий из имен клиентов, и назовем его переменной 9.0031 имя пользователя
mydf = pd.DataFrame({"custname": ["Priya_Sehgal", "David_Stevart", "Kasia_Woja", "Sandy_Dave"]})
пользовательское имя
0 Прия_Сегал
1 Дэвид_Стеварт
2 Кася_Воя
3 Сэнди_Дэйв
#Первое слово
mydf['fname'] = mydf['custname'].str.split('_').str[0]
#Последнее слово
mydf['lname'] = mydf['custname'].str.split('_').str[1]
Подробное объяснение
-
str.аналогичен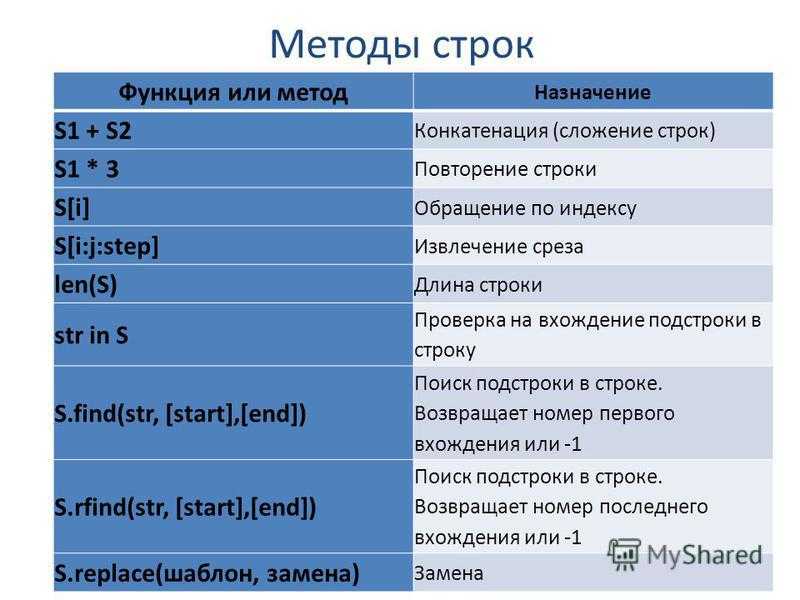 split()
split() split(). Он используется для активации функции разделения во фрейме данных pandas в Python. - В приведенном выше коде мы создали два новых столбца с именами
fnameиlname, в которых хранятся имя и фамилия.
Выход
имя пользователя fname lname
0 Priya_Sehgal Прия Сегал
1 David_Stevart Дэвид Стюарт
2 Kasia_Woja Кася Воя
3 Сэнди_Дэйв Сэнди Дэйв
Оператор SQL LIKE в Pandas DataFrame
В SQL оператор LIKE используется, чтобы узнать, соответствует ли строка символов шаблону или содержит ли он его. Мы можем реализовать аналогичную функциональность в python, используя str.contains() функция.
df2 = pd.DataFrame({"var1": ["AA_2", "B_1", "C_2", "a_2"],
"var2": ["X_2", "Y_1", "Z_2", "X2"]})
вар1 вар2 0 АА_2 Х_2 1 Б_1 Д_1 2 C_2 Z_2 3 а_2 Х2
Как найти строки, содержащие A или B в переменной var1?
df2['var1'].str.contains('A|B')
str.contains(pattern) используется для сопоставления шаблона в Pandas Dataframe.
Выход 0 Верно 1 правда 2 Ложь 3 Ложь
Приведенная выше команда возвращает FALSE для четвертой строки, поскольку функция чувствительна к регистру. Чтобы игнорировать чувствительность к регистру, мы можем использовать параметр case=False . См. рабочий пример ниже. df2['var1'].str.contains('A|B', case=False) Как фильтровать строки, содержащие определенный шаблон?
В следующей программе мы просим Python подмножить данные с условием — содержать символьные значения либо A, либо B. Это эквивалентно ключевому слову WHERE в SQL. 9 — это токен регулярного выражения, означающий начало с определенного элемента.
вар1 вар2 1 Б_1 Д_1 2 C_2 Z_2 3 а_2 Х2
Найти позицию определенного символа или ключевого слова
str. используется для поиска позиции подстроки. В этом случае подстрока '_'. find(pattern)
find(pattern)
df2['var1'].str.find('_')
0 2 1 1 2 1 3 1
Заменить подстроку
str.replace(old_text,new_text,case=False) используется для замены определенного символа (символов) или шаблона на какое-то новое значение или шаблон. В приведенном ниже коде мы заменяем _ на -- в переменной var1.
df2['var1'].str.replace('_', '--', case=False)
Выход 0 АА--2 1 Б--1 2 С--2 3 А--2
Мы также можем создавать сложные шаблоны, подобные следующей программе. + означает, что элемент встречается один или несколько раз. В этом случае алфавит встречается 1 или более раз.
df2['var1'].str.replace('[A-Z]+_', 'X', case=False)
0 х2 1 х 1 2 х 2 3 х 2
Найти длину строки
len(string) используется для вычисления длины строки. Во фрейме данных pandas вы можете применить
Во фрейме данных pandas вы можете применить str.len() для того же.
df2['var1'].str.len()
Выход 0 4 1 3 2 3 3 3
Чтобы найти количество вхождений определенного символа (скажем, сколько раз «A» появляется в каждой строке), вы можете использовать функцию str.count(pattern) .
df2['var1'].str.count('A') Преобразование в нижний и верхний регистр
str.lower() и str.upper() Функции используются для преобразования строки в нижний и верхний регистр. значения в верхнем регистре.
# Преобразовать в нижний регистр mydf['имя пользователя'].str.lower() # Преобразовать в верхний регистр mydf['имя пользователя'].str.upper()
Удалить начальные и конечные пробелы
-
str.strip()удаляет как начальные, так и конечные пробелы. -
ул.lstrip()удаляет начальные пробелы (в начале).
-
str.rstrip()удаляет конечные пробелы (в конце).
df1 = pd.DataFrame({'y1': ['Джек', 'Джилл', 'Джесси', 'Фрэнк']})
df1['оба']=df1['y1'].str.strip()
df1['left']=df1['y1'].str.lstrip()
df1['право']=df1['y1'].str.rstrip()
y1 оба слева направо
0 джек джек джек джек
1 Джилл Джилл Джилл Джилл
2 Джесси Джесси Джесси Джесси
3 Фрэнк Фрэнк Фрэнк Фрэнк
Преобразование числа в строку
С помощью функции str() вы можете преобразовать числовое значение в строку.
моя переменная = 4 mystr = str (моя переменная)
Объединение или объединение строк
Просто используя + , вы можете соединить два строковых значения.
х = "Дипаньшу" у = "Бхалла" х+у
ДипаншуБхалла
Если вы хотите добавить пробел между двумя строками, вы можете использовать это - x+' '+y возвращает Дипаншу Бхалла Предположим, у вас есть список, содержащий несколько строковых значений, и вы хотите их объединить. Вы можете использовать функцию join() .
Вы можете использовать функцию join() .
string0 = ['Рам', 'Кумар', 'Сингх'] ' .присоединиться (строка0)
Выход 'Рам Кумар Сингх'
Предположим, вы хотите объединить или объединить два столбца фрейма данных pandas.
mydf['полное имя'] = mydf['fname'] + ' ' + mydf['lname']
ИЛИ
mydf['полное имя'] = mydf[['fname', 'lname']].apply(лямбда x: ' '.join(x), ось=1)
пользовательское имя fname lname полное имя
0 Priya_Sehgal Прия Сегал Прия Сегал
1 David_Stevart Дэвид Стюарт Дэвид Стюарт
2 Kasia_Woja Kasia Woja Kasia Woja
3 Sandy_Dave Сэнди Дэйв Сэнди Дэйв
Оператор SQL IN в Pandas
Мы можем использовать функцию isin(list) , чтобы включить несколько значений в наши критерии фильтрации или подмножества.
mydata = pd.DataFrame({'продукт': ['A', 'B', 'B', 'C','C','D','A']})
мои данные[мои данные['продукт']. Оставить комментарий
Оставить комментарий