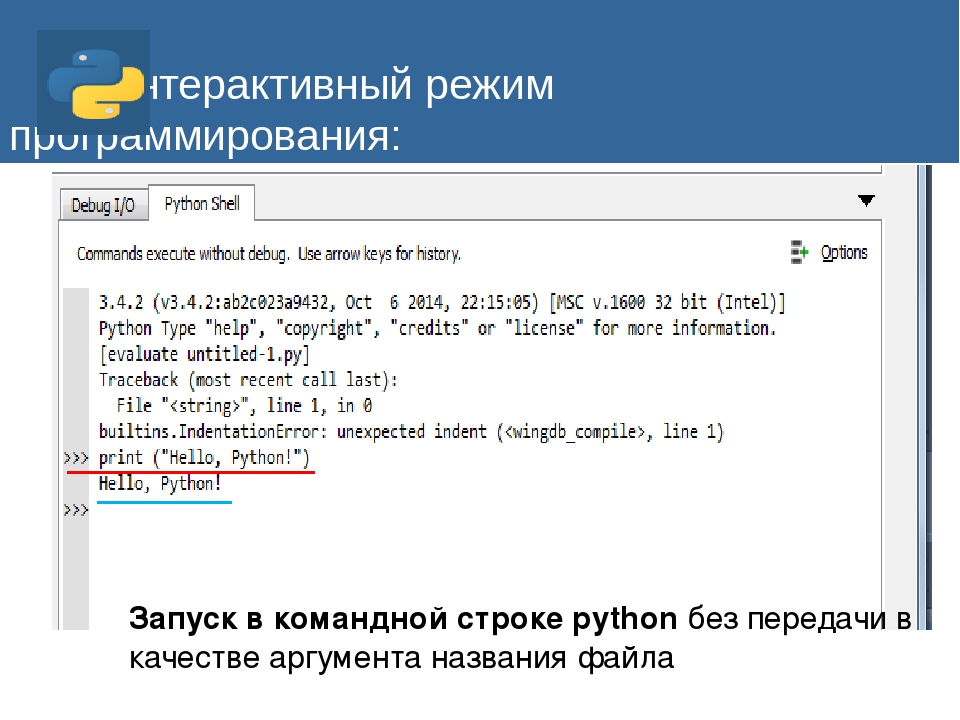
Как разбить строку на символы в Python
Сейчас мы разберем, как в Python можно разбить строку на символы. В общем, все что нам нужно, это создать такую функцию (назовем ее, например, split() ), которая будет решать эту задачу. Если вы новичок в функциях, то можете ознакомиться с базовыми принципами их создания на нашем сайте.
Чтобы понять, о чем речь, возьмем конкретный пример. Допустим, у нас есть следующая строка: «Hdfs Tutorial». И мы хотим разбить ее на отдельные символы, используя язык Python. Давайте поищем способы, как лучше это сделать.
Вход: “Hdfs Tutorial” Результат: [‘H’, ‘d’, ‘f’, ‘s’, ‘ ‘, ‘T’, ‘u’, ‘t’, ‘o’, ‘r’, ‘i’, ‘a’, ‘l’]
Что же, начнем!
1. Определяемая пользователем функция
Здесь я создам функцию под названием split(), которая принимает на вход один аргумент, например, нашу строку, и возвращает список всех символов, имеющихся в этой строке.
def split(s):
return [char for char in s]Сейчас мы создали собственную функцию под названием split(), принимающую один аргумент — строку, которую мы хотим разбить на символы.
Теперь нам надо задать строку, которую мы хотим разбить на символы.
s = 'Hdfs Tutorial' print(s)
Результат
Hdfs Tutorial
Теперь просто вызовем нашу функцию, передав в нее только что определенную нами строку.
split(s)
Результат
[‘H’, ‘d’, ‘f’, ‘s’, ‘ ‘, ‘T’, ‘u’, ‘t’, ‘o’, ‘r’, ‘i’, ‘a’, ‘l’]
Вот и все! Это простейший способ разбить строку на символы в языке Python. Однако, как это обычно бывает в Python, есть еще несколько способов сделать то же самое. И сейчас мы по-быстрому разберем пару таких примеров.
2. Функция list()
Мы можем использовать встроенную функцию list(), которая сделает ровно то же самое.
s = 'Hdfs Tutorial' list(s)
Резльтат
[‘H’, ‘d’, ‘f’, ‘s’, ‘ ‘, ‘T’, ‘u’, ‘t’, ‘o’, ‘r’, ‘i’, ‘a’, ‘l’]
3. Разбиение строки на символы с использованием цикла
Разбиение строки на символы с использованием цикла for
Также можно разбить строку на символы при помощи цикла for, который мы использовали в теле функции split(), не определяя самой функции. Этот способ рекомендован лишь для специального использования и, как правило, не подходит для промышленного применения.
s = 'Hdfs Tutorial' [c for c in s]
Результат
[‘H’, ‘d’, ‘f’, ‘s’, ‘ ‘, ‘T’, ‘u’, ‘t’, ‘o’, ‘r’, ‘i’, ‘a’, ‘l’]
Заключение
Это было очень краткое руководство о том, как разбить строку на символы в Python. Мы обсудили три простых способа, как это сделать. Лично я предпочитаю первый метод, так как он дает гораздо больше гибкости.
Мы обсудили три простых способа, как это сделать. Лично я предпочитаю первый метод, так как он дает гораздо больше гибкости.
Разделение строки на списки в Python
В этой статье мы расскажем, как можно разбивать строки на списки. Вы узнаете, как при этом использовать разделители (в частности — как отделять часть строки только по первому разделителю и как быть с последовательно идущими разделителями) и регулярные выражения. Безусловно, эта информация будет особенно полезна начинающим питонистам, но, возможно, и более опытные найдут для себя кое-что интересное.
Простое разделение строки и получение списка ее составляющих
Если вы хотите разбить любую строку на подстроки и составить из них список, вы можете просто воспользоваться методом split(sep=None, maxsplit=-1). Этот метод принимает два параметра (опционально). Остановимся пока на первом из них — разделителе (sep).
Разделитель можно задать явно в
качестве параметра, но можно и не
задавать: в этом случае в его роли
выступает пробел.
Пример использования метода split() без указания разделителя:
print("Python2 Python3 Python Numpy".split())
print("Python2, Python3, Python, Numpy".split())Результат:
['Python2', 'Python3', 'Python', 'Numpy'] ['Python2,', 'Python3,', 'Python,', 'Numpy']
Разделение строки с использованием разделителя
Python может разбивать строки по любому разделителю, указанному в качестве параметра метода split(). Таким разделителем может быть, например, запятая, точка или любой другой символ (или даже несколько символов).
Давайте рассмотрим пример, где в качестве разделителя выступает запятая и точка с запятой (это можно использовать для работы с CSV-файлами).
print("Python2, Python3, Python, Numpy". split(',')) print("Python2; Python3; Python; Numpy".split(';'))
Результат:
['Python2', ' Python3', ' Python', ' Numpy'] ['Python2', ' Python3', ' Python', ' Numpy']
Как видите, в результирующих списках отсутствуют сами разделители.
Если вам нужно получить список, в который войдут и разделители (в качестве отдельных элементов), можно разбить строку по шаблону, с использованием регулярных выражений (см. документацию re.split). Когда вы берете шаблон в захватывающие круглые скобки, группа в шаблоне также возвращается как часть результирующего списка.
import re
sep = re.split(',', 'Python2, Python3, Python, Numpy')
print(sep)
sep = re.split('(,)', 'Python2, Python3, Python, Numpy')
print(sep)Результат:
['Python2', ' Python3', ' Python', ' Numpy'] ['Python2', ',', ' Python3', ',', ' Python', ',', ' Numpy']
Если вы хотите, чтобы разделитель был частью каждой подстроки в списке, можно обойтись без регулярных выражений и использовать list comprehensions:
text = 'Python2, Python3, Python, Numpy' sep = ',' result = [x+sep for x in text.split(sep)] print(result)
Результат:
['Python2,', ' Python3,', ' Python,', ' Numpy,']
Разделение многострочной
строки (построчно)
Создать список из отдельных строчек многострочной строки можно при помощи того же метода split(), указав в качестве разделителя символ новой строки \n. Если текст содержит лишние пробелы, их можно удалить при помощи методов strip() или lstrip():
str = """
Python is cool
Python is easy
Python is mighty
"""
list = []
for line in str.split("\n"):
if not line.strip():
continue
list.append(line.lstrip())
print(list)Результат:
['Python is cool', 'Python is easy', 'Python is mighty']
Разделение строки-словаря и преобразование ее в списки или словарь
Допустим, у нас есть строка, по сути являющаяся словарем и содержащая пары ключ-значение в виде key => value. Мы хотим получить эти пары в виде списков или настоящего словаря. Вот простой пример, как получить словарь и два списка:
Мы хотим получить эти пары в виде списков или настоящего словаря. Вот простой пример, как получить словарь и два списка:
dictionary = """\
key1 => value1
key2 => value2
key3 => value3
"""
mydict = {}
listKey = []
listValue = []
for line in dictionary.split("\n"):
if not line.strip():
continue
k, v = [word.strip() for word in line.split("=>")]
mydict[k] = v
listKey.append(k)
listValue.append(v)
print(mydict)
print(listKey)
print(listValue)Результат:
{'key3': 'value3', 'key2': 'value2', 'key1': 'value1'}
['key1', 'key2', 'key3']
['value1', 'value2', 'value3']Отделение указанного количества элементов
Метод split() имеет еще один опциональный параметр — maxsplit. С его помощью можно указать, какое максимальное число «разрезов» нужно сделать. По умолчанию
С его помощью можно указать, какое максимальное число «разрезов» нужно сделать. По умолчанию maxsplit=-1, это означает, что число разбиений не ограничено.
Если вам нужно отделить от строки несколько первых подстрок, это можно сделать, указав нужное значение maxsplit. В этом примере мы «отрежем» от строки первые три элемента, отделенные запятыми:
str = "Python2, Python3, Python, Numpy, Python2, Python3, Python, Numpy"
data = str.split(", ",3)
for temp in data:
print(temp)Результат:
Python2 Python3 Python Numpy, Python2, Python3, Python, Numpy
Разделение строки при помощи последовательно идущих разделителей
Если вы для разделения строки используете метод split() и не указываете разделитель, то разделителем считается пробел. При этом последовательно идущие пробелы трактуются как один разделитель.
При этом последовательно идущие пробелы трактуются как один разделитель.
Но если вы указываете определенный разделитель, ситуация меняется. При работе метода будет считаться, что последовательно идущие разделители разделяют пустые строки. Например, '1,,2'.split(',') вернет ['1', '', '2'].
Если вам нужно, чтобы последовательно идущие разделители все-таки трактовались как один разделитель, нужно воспользоваться регулярными выражениями. Разницу можно видеть в примере:
import re
print('Hello1111World'.split('1'))
print(re.split('1+', 'Hello1111World' ))Результат:
['Hello', '', '', '', 'World'] ['Hello', 'World']
Как разбить строку по символу split Python
Как разбить строку по символу. Существует несколько способов как это сделать. Есть как минимум 2 пути: регулярные выражения, метод split. В старых версиях python метод split был запрятан в модуль string. Сейчас в 3 версии Python метод доступен без подключения модуля. В этой статье я покажу как разбить строку при помощи split. Давайте рассмотрим мой пример. Он довольно простой. Есть три блока с текстом. По символу ; будем разбивать строку.
Существует несколько способов как это сделать. Есть как минимум 2 пути: регулярные выражения, метод split. В старых версиях python метод split был запрятан в модуль string. Сейчас в 3 версии Python метод доступен без подключения модуля. В этой статье я покажу как разбить строку при помощи split. Давайте рассмотрим мой пример. Он довольно простой. Есть три блока с текстом. По символу ; будем разбивать строку.
text = 'тут некий текст для первого блока ; тут некий текст для второго блока ;\
тут некий текст для третьего блока'
res1_new = []
# разбиваем по символу
res1 = text.split(";")
for val in res1:
#срезаю пробелы
val = val.strip()
#формирую новый массив
res1_new.append(val)
print(res1_new)
'''
вывод:
['тут некий текст для первого блока', 'тут некий текст для второго блока',\
'тут некий текст для третьего блока']
'''
У функции strip есть интересная особенность. Если вы вызовите функцию без данных для входных параметров, то она отработает как trim в PHP. Произойдёт срезание пробелов слева и справа. Это довольно приятная особенность. Вам не надо делать лишних действий.
Произойдёт срезание пробелов слева и справа. Это довольно приятная особенность. Вам не надо делать лишних действий.
Функции split может отрабатывать заданное число раз. Если передадите число в качестве второго входного параметра, то функция отработает определённое количество раз. Мне трудно понять когда это используется.
text = 'тут некий текст для первого блока ;\
тут некий текст для второго блока ; тут некий текст для третьего блока'
res2 = text.split(";", maxsplit=1)
'''
Тут 2 значения в списке, а не три.
вывод:
['тут некий текст для первого блока ',\
' тут некий текст для второго блока ; тут некий текст для третьего блока']
'''
Если вы хотите обработать строки, то существуют функции для работы со строками Python. Например, вы сможете заменить разделитель другим символом.
просмотры: 15695, уровень: лёгкий уровень, рейтинг: 4, дата: 2017-12-11 12:48:17
Комментарии:
Python | Разделить несколько символов из строки
При кодировании или импровизации своих навыков программирования вы наверняка сталкивались со многими сценариями, в которых вы хотели бы использовать . в Python, чтобы не разделять только один символ, а несколько символов одновременно. Рассмотрим это для примера: split()
split()
"GeeksforGeeks, is an-awesome! website"
Использование .split() для приведенного выше приведет к
['GeeksforGeeks, ', 'is', 'an-awesome!', 'website']
тогда как желаемый результат должен быть
['GeeksforGeeks', 'is', 'an', 'awesome', 'website']
В этой статье мы рассмотрим некоторые способы, с помощью которых мы можем достичь того же.
Использование re.split ()
Это наиболее эффективный и часто используемый метод разделения нескольких символов одновременно. Для этого используется регулярное выражение (регулярные выражения).
|
 split(
split(Выход:
The original string is : GeeksforGeeks, is_an-awesome ! website
The list after performing split functionality : [‘GeeksforGeeks’, ‘is’, ‘an’, ‘awesome ‘, ‘ website’]
Линия re.split(', |_|-|!', data) говорит Python разделить данные переменной на символы: или _ или — или! , Символ « | Представляет или.
В регулярном выражении есть несколько символов, которые рассматриваются как специальные символы и имеют разные функции. Если вы хотите разделить такой символ, вам нужно экранировать его, используя « / » (обратная косая черта). Список специальных символов, которые необходимо экранировать перед их использованием:
.] $ ( ) { } = ! | : -
Например:
|
Выход:
['GeeksforGeeks', ' is', 'an', 'awesome', ' app', 'too']
Примечание. Чтобы узнать больше о регулярных выражениях, нажмите здесь .
Использование re.findall ()
Это немного более загадочная форма, но экономит время. Он также использует регулярное выражение, как описано выше, но вместо метода .split() он использует метод с именем .findall() . Этот метод находит все совпадающие экземпляры и возвращает каждый из них в списке. Этот способ разделения лучше всего использовать, когда вы не знаете, какие именно символы вы хотите разделить.
|
Выход:
The original string is : This, is – another : example?!
The list after performing split functionality : [‘This’, ‘is’, ‘another’, ‘example’]
Здесь ключевое слово [/w']+ указывает, что оно найдет все экземпляры алфавитов или подчеркнет (_) один или несколько и вернет их в списке.
Примечание: [/w']+ не разделяется на подчеркивание ( _ ), так как оно ищет алфавиты и подчеркивания.
Например:
|
Выход:
['This', 'is', 'underscored', '_', 'example']
Использование replace () и split ()
Это очень новый способ расколоть. Он не использует регулярные выражения и неэффективен, но все же стоит попробовать. Если вы знаете символы, на которые хотите разбить символы, просто замените их пробелом, а затем используйте .split() :
|
 replace(
replace(Выход:
The original string is : Let’s_try, this now
The list after performing split functionality : [“Let’s”, ‘try’, ‘this’, ‘now’]
Классы персонажей
Шпаргалка Regex на описание персонажа
| Shorthand character class | Represents |
|---|---|
| \d | Any numeric digit from 0 to 9 |
| \D | Any character that is not a numeric digit from 0 to 9 |
| \w | Any letter, numeric digit, or the underscore character |
| \W | Any character that is not a letter, numeric digit, or the underscore character |
| \s | Any space, tab, or newline character |
| \S | Any character that is not a space, tab, or newline |
Рекомендуемые посты:
Python | Разделить несколько символов из строки
0. 00 (0%) 0 votes
00 (0%) 0 votes
41 вопрос о работе со строками в Python / RUVDS.com / Хабр
Я начал вести список наиболее часто используемых функций, решая алгоритмические задачи на LeetCode и HackerRank.
Быть хорошим программистом — это не значит помнить все встроенные функции некоего языка. Но это не означает и того, что их запоминание — бесполезное дело. Особенно — если речь идёт о подготовке к собеседованию.
Хочу сегодня поделиться со всеми желающими моей шпаргалкой по работе со строками в Python. Я оформил её в виде списка вопросов, который использую для самопроверки. Хотя эти вопросы и не тянут на полноценные задачи, которые предлагаются на собеседованиях, их освоение поможет вам в решении реальных задач по программированию.
1. Как проверить два объекта на идентичность?
Оператор
isвозвращает
True в том случае, если в две переменные записана ссылка на одну и ту же область памяти. Именно об этом идёт речь при разговоре об «идентичности объектов».
Не стоит путать is и ==. Оператор == проверяет лишь равенство объектов.
animals = ['python','gopher']
more_animals = animals
print(animals == more_animals) #=> True
print(animals is more_animals) #=> True
even_more_animals = ['python','gopher']
print(animals == even_more_animals) #=> True
print(animals is even_more_animals) #=> False
Обратите внимание на то, что
animalsи
even_more_animalsне идентичны, хотя и равны друг другу.
Кроме того, существует функция id(), которая возвращает идентификатор адреса памяти, связанного с именем переменной. При вызове этой функции для двух идентичных объектов будет выдан один и тот же идентификатор.
name = 'object'
id(name)
#=> 4408718312
2. Как проверить то, что каждое слово в строке начинается с заглавной буквы?
Существует строковый метод
istitle(), который проверяет, начинается ли каждое слово в строке с заглавной буквы.
print( 'The Hilton'.istitle() ) #=> True
print( 'The dog'.istitle() ) #=> False
print( 'sticky rice'.istitle() ) #=> False
3. Как проверить строку на вхождение в неё другой строки?
Существует оператор
in, который вернёт
Trueв том случае, если строка содержит искомую подстроку.
print( 'plane' in 'The worlds fastest plane' ) #=> True
print( 'car' in 'The worlds fastest plane' ) #=> False
4. Как найти индекс первого вхождения подстроки в строку?
Есть два метода, возвращающих индекс первого вхождения подстроки в строку. Это —
find()и
index(). У каждого из них есть определённые особенности.
Метод find() возвращает -1 в том случае, если искомая подстрока в строке не найдена.
'The worlds fastest plane'.find('plane') #=> 19
'The worlds fastest plane'.find('car') #=> -1
Метод
index()в подобной ситуации выбрасывает ошибку
ValueError.
'The worlds fastest plane'.index('plane') #=> 19
'The worlds fastest plane'.index('car') #=> ValueError: substring not found
5. Как подсчитать количество символов в строке?
Функция
len()возвращает длину строки.
len('The first president of the organization..') #=> 41
6. Как подсчитать то, сколько раз определённый символ встречается в строке?
Ответить на этот вопрос нам поможет метод
count(), который возвращает количество вхождений в строку заданного символа.
'The first president of the organization..'.count('o') #=> 3
7. Как сделать первый символ строки заглавной буквой?
Для того чтобы это сделать, можно воспользоваться методом
capitalize().
'florida dolphins'.capitalize() #=> 'Florida dolphins'
8. Что такое f-строки и как ими пользоваться?
В Python 3. 6 появилась новая возможность — так называемые «f-строки». Их применение чрезвычайно упрощает интерполяцию строк. Использование f-строк напоминает применение метода
6 появилась новая возможность — так называемые «f-строки». Их применение чрезвычайно упрощает интерполяцию строк. Использование f-строк напоминает применение метода
format().
При объявлении f-строк перед открывающей кавычкой пишется буква f.
name = 'Chris'
food = 'creme brulee'
f'Hello. My name is {name} and I like {food}.'
#=> 'Hello. My name is Chris and I like creme brulee'
9. Как найти подстроку в заданной части строки?
Метод
index()можно вызывать, передавая ему необязательные аргументы, представляющие индекс начального и конечного фрагмента строки, в пределах которых и нужно осуществлять поиск подстроки.
'the happiest person in the whole wide world.'.index('the',10,44)
#=> 23
Обратите внимание на то, что вышеприведённая конструкция возвращает
23, а не
0, как было бы, не ограничь мы поиск.
'the happiest person in the whole wide world.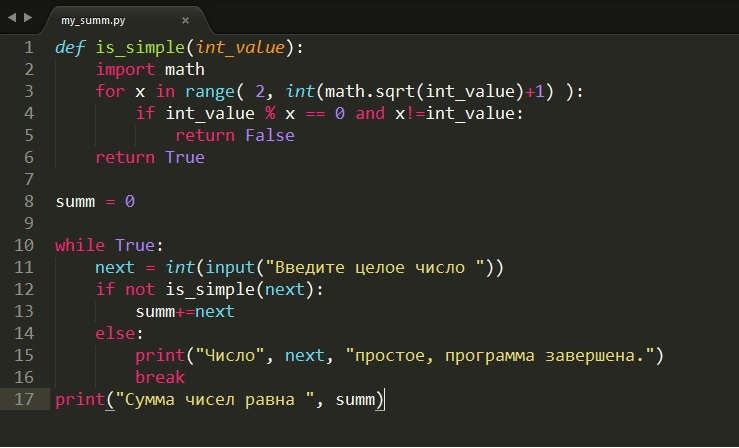 '.index('the')
#=> 0
'.index('the')
#=> 0
10. Как вставить содержимое переменной в строку, воспользовавшись методом format()?
Метод
format()позволяет добиваться результатов, сходных с теми, которые можно получить, применяя f-строки. Правда, я полагаю, что использовать
format()не так удобно, так как все переменные приходится указывать в качестве аргументов
format().
difficulty = 'easy'
thing = 'exam'
'That {} was {}!'.format(thing, difficulty)
#=> 'That exam was easy!'
11. Как узнать о том, что в строке содержатся только цифры?
Существует метод
isnumeric(), который возвращает
Trueв том случае, если все символы, входящие в строку, являются цифрами.
'80000'.isnumeric() #=> True
Используя этот метод, учитывайте то, что знаки препинания он цифрами не считает.
'1.0'.isnumeric() #=> False
12. Как разделить строку по заданному символу?
Как разделить строку по заданному символу?
Здесь нам поможет метод
split(), который разбивает строку по заданному символу или по нескольким символам.
'This is great'.split(' ')
#=> ['This', 'is', 'great']
'not--so--great'.split('--')
#=> ['not', 'so', 'great']
13. Как проверить строку на то, что она составлена только из строчных букв?
Метод
islower()возвращает
Trueтолько в том случае, если строка составлена исключительно из строчных букв.
'all lower case'.islower() #=> True
'not aLL lowercase'.islower() # False
14. Как проверить то, что строка начинается со строчной буквы?
Сделать это можно, вызвав вышеописанный метод
islower()для первого символа строки.
'aPPLE'[0].islower() #=> True
15. Можно ли в Python прибавить целое число к строке?
В некоторых языках это возможно, но Python при попытке выполнения подобной операции будет выдана ошибка
TypeError.
'Ten' + 10 #=> TypeError
16. Как «перевернуть» строку?
Для того чтобы «перевернуть» строку, её можно разбить, представив в виде списка символов, «перевернуть» список, и, объединив его элементы, сформировать новую строку.
''.join(reversed("hello world"))
#=> 'dlrow olleh'
17. Как объединить список строк в одну строку, элементы которой разделены дефисами?
Метод
join()умеет объединять элементы списков в строки, разделяя отдельные строки с использованием заданного символа.
'-'.join(['a','b','c'])
#=> 'a-b-c'
18. Как узнать о том, что все символы строки входят в ASCII?
Метод
isascii()возвращает
Trueв том случае, если все символы, имеющиеся в строке, входят в ASCII.
print( 'Â'.isascii() ) #=> False
print( 'A'.isascii() ) #=> True
19. Как привести всю строку к верхнему или нижнему регистру?
Для решения этих задач можно воспользоваться методами
upper()и
lower(), которые, соответственно, приводят все символы строк к верхнему и нижнему регистрам.
sentence = 'The Cat in the Hat'
sentence.upper() #=> 'THE CAT IN THE HAT'
sentence.lower() #=> 'the cat in the hat'
20. Как преобразовать первый и последний символы строки к верхнему регистру?
Тут, как и в одном из предыдущих примеров, мы будем обращаться к символам строки по индексам. Строки в Python иммутабельны, поэтому мы будем заниматься сборкой новой строки на основе существующей.
animal = 'fish'
animal[0].upper() + animal[1:-1] + animal[-1].upper()
#=> 'FisH'
21. Как проверить строку на то, что она составлена только из прописных букв?
Имеется метод
isupper(), который похож на уже рассмотренный
islower(). Но
isupper()возвращает
Trueтолько в том случае, если вся строка состоит из прописных букв.
'Toronto'.isupper() #=> False
'TORONTO'.isupper() #= True
22. В какой ситуации вы воспользовались бы методом splitlines()?
Метод
splitlines()разделяет строки по символам разрыва строки.
sentence = "It was a stormy night\nThe house creeked\nThe wind blew."
sentence.splitlines()
#=> ['It was a stormy night', 'The house creeked', 'The wind blew.']
23. Как получить срез строки?
Для получения среза строки используется синтаксическая конструкция следующего вида:
string[start_index:end_index:step]
Здесь
step— это шаг, с которым будут возвращаться символы строки из диапазона
start_index:end_index. Значение
step, равное 3, указывает на то, что возвращён будет каждый третий символ.
string = 'I like to eat apples'
string[:6] #=> 'I like'
string[7:13] #=> 'to eat'
string[0:-1:2] #=> 'Ilk oetape' (каждый 2-й символ)
24. Как преобразовать целое число в строку?
Для преобразования числа в строку можно воспользоваться конструктором
str().
str(5) #=> '5'
25. Как узнать о том, что строка содержит только алфавитные символы?
Метод
isalpha()возвращает
Trueв том случае, если все символы в строке являются буквами.
'One1'.isalpha() #=> False
'One'.isalpha() #=> True
26. Как в заданной строке заменить на что-либо все вхождения некоей подстроки?
Если обойтись без экспорта модуля, позволяющего работать с регулярными выражениями, то для решения этой задачи можно воспользоваться методом
replace().
sentence = 'Sally sells sea shells by the sea shore'
sentence.replace('sea', 'mountain')
#=> 'Sally sells mountain shells by the mountain shore'
27. Как вернуть символ строки с минимальным ASCII-кодом?
Если взглянуть на ASCII-коды элементов, то окажется, например, что прописные буквы имеют меньшие коды, чем строчные. Функция
min()возвращает символ строки, имеющий наименьший код.
min('strings') #=> 'g'
28. Как проверить строку на то, что в ней содержатся только алфавитно-цифровые символы?
В состав алфавитно-цифровых символов входят буквы и цифры. Для ответа на этот вопрос можно воспользоваться методом
isalnum().
'Ten10'.isalnum() #=> True
'Ten10.'.isalnum() #=> False
29. Как удалить пробелы из начала строки (из её левой части), из её конца (из правой части), или с обеих сторон строки?
Здесь нам пригодятся, соответственно, методы
lstrip(),
rstrip()и
strip().
string = ' string of whitespace '
string.lstrip() #=> 'string of whitespace '
string.rstrip() #=> ' string of whitespace'
string.strip() #=> 'string of whitespace'
30. Как проверить то, что строка начинается с заданной последовательности символов, или заканчивается заданной последовательностью символов?
Для ответа на этот вопрос можно прибегнуть, соответственно, к методам
startswith()и
endswith().
city = 'New York'
city.startswith('New') #=> True
city.endswith('N') #=> False
31. Как закодировать строку в ASCII?
Метод
encode()позволяет кодировать строки с использованием заданной кодировки. По умолчанию используется кодировка
utf-8. Если некий символ не может быть представлен с использованием заданной кодировки, будет выдана ошибка
UnicodeEncodeError.
'Fresh Tuna'.encode('ascii')
#=> b'Fresh Tuna'
'Fresh Tuna Â'.encode('ascii')
#=> UnicodeEncodeError: 'ascii' codec can't encode character '\xc2' in position 11: ordinal not in range(128)
32. Как узнать о том, что строка включает в себя только пробелы?
Есть метод
isspace(), который возвращает
Trueтолько в том случае, если строка состоит исключительно из пробелов.
''.isspace() #=> False
' '.isspace() #=> True
' '.isspace() #=> True
' the '.isspace() #=> False
33. Что случится, если умножить некую строку на 3?
Будет создана новая строка, представляющая собой исходную строку, повторённую три раза.
'dog' * 3
# 'dogdogdog'
34. Как привести к верхнему регистру первый символ каждого слова в строке?
Существует метод
title(), приводящий к верхнему регистру первую букву каждого слова в строке.
'once upon a time'.title() #=> 'Once Upon A Time'
35. Как объединить две строки?
Для объединения строк можно воспользоваться оператором
+.
'string one' + ' ' + 'string two'
#=> 'string one string two'
36. Как пользоваться методом partition()?
Метод
partition()разбивает строку по заданной подстроке. После этого результат возвращается в виде кортежа. При этом подстрока, по которой осуществлялась разбивка, тоже входит в кортеж.
sentence = "If you want to be a ninja"
print(sentence.partition(' want '))
#=> ('If you', ' want ', 'to be a ninja')
37. Строки в Python иммутабельны. Что это значит?
То, что строки иммутабельны, говорит о том, что после того, как создан объект строки, он не может быть изменён. При «модификации» строк исходные строки не меняются. Вместо этого в памяти создаются совершенно новые объекты. Доказать это можно, воспользовавшись функцией
id().
proverb = 'Rise each day before the sun'
print( id(proverb) )
#=> 4441962336
proverb_two = 'Rise each day before the sun' + ' if its a weekday'
print( id(proverb_two) )
#=> 4442287440
При конкатенации
'Rise each day before the sun'и
' if its a weekday'в памяти создаётся новый объект, имеющий новый идентификатор. Если бы исходный объект менялся бы, тогда у объектов был бы один и тот же идентификатор.
38. Если объявить одну и ту же строку дважды (записав её в 2 разные переменные) — сколько объектов будет создано в памяти? 1 или 2?
В качестве примера подобной работы со строками можно привести такой фрагмент кода:
animal = 'dog'
pet = 'dog'
При таком подходе в памяти создаётся лишь один объект. Когда я столкнулся с этим в первый раз, мне это не показалось интуитивно понятным. Но этот механизм помогает Python экономить память при работе с длинными строками.
Доказать это можно, прибегнув к функции id().
animal = 'dog'
print( id(animal) )
#=> 4441985688
pet = 'dog'
print( id(pet) )
#=> 4441985688
39. Как пользоваться методами maketrans() и translate()?
Метод
maketrans()позволяет описать отображение одних символов на другие, возвращая таблицу преобразования.
Метод translate() позволяет применить заданную таблицу для преобразования строки.
# создаём отображение
mapping = str.maketrans("abcs", "123S")
# преобразуем строку
"abc are the first three letters".translate(mapping)
#=> '123 1re the firSt three letterS'
Обратите внимание на то, что в строке произведена замена символов
a,
b,
cи
s, соответственно, на символы
1,
2,
3и
S.
40. Как убрать из строки гласные буквы?
Один из ответов на этот вопрос заключается в том, что символы строки перебирают, пользуясь механизмом List Comprehension. Символы проверяют, сравнивая с кортежем, содержащим гласные буквы. Если символ не входит в кортеж — он присоединяется к новой строке.
string = 'Hello 1 World 2'
vowels = ('a','e','i','o','u')
''.join([c for c in string if c not in vowels])
#=> 'Hll 1 Wrld 2'
41. В каких ситуациях пользуются методом rfind()?
Метод
rfind()похож на метод
find(), но он, в отличие от
find(), просматривает строку не слева направо, а справа налево, возвращая индекс первого найденного вхождения искомой подстроки.
story = 'The price is right said Bob. The price is right.'
story.rfind('is')
#=> 39
Итоги
Я часто объясняю одному продакт-менеджеру, человеку в возрасте, что разработчики — это не словари, хранящие описания методов объектов. Но чем больше методов помнит разработчик — тем меньше ему придётся гуглить, и тем быстрее и приятнее ему будет работаться. Надеюсь, теперь вы без труда ответите на рассмотренные здесь вопросы.
Уважаемые читатели! Что, касающееся обработки строк в Python, вы посоветовали бы изучить тем, кто готовится к собеседованию?
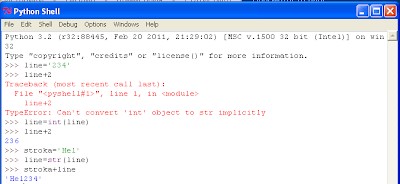
Метод str.split() в Python, делит строку по подстроке.
Разделить строку на список подстрок по разделителю.
Синтаксис:
str.split(sep=None, maxsplit=-1)
Параметры:
sep=None—str, разделитель. Может содержать как один, так и несколько символов;maxsplit=-1—int, сколько раз делить строку. По умолчанию-1— неограниченно.
Возвращаемое значение:
list, список подстрок.
Описание:
Метод str.split() возвращает список слов (подстрок) в строке, используя sep в качестве разделителя строки str. Если задан maxsplit, то выполняется не более maxsplit разбиений, таким образом, список будет иметь не более maxsplit+1 элементов. Если maxsplit не указан или равен -1, то делаются все возможные разделения строки str.
Если указан разделитель sep, то последовательные разделители в обрабатываемой строке не группируются вместе, а считаются разделителями пустых подстрок. Аргумент sep может состоять из нескольких символов. Разбиение пустой строки str с указанным разделителем возвращает значение ["]. Например:
# Последовательные разделители не группируются вместе.
# и считаются разделителями пустых строк
>>> '1,,2'.split (',')
# ['1', ", '2'])
#Аргумент 'sep' может состоять из нескольких символов.
>>> '1<>2<>3'.split ('<>')
# ['1', '2', '3'])
# Разбиение пустой строки с указанным разделителем.
>>> ''.split(';')
['']
Если sep не указан или задан None, применяется другой алгоритм разбиения:
Последовательности пробелов рассматриваются как один разделитель и если строка имеет начальные или конечные пробелы, то результат не будет содержать пустых строк в начале или конце. Следовательно, разбиение пустой строки или строки, состоящей только из пробела с разделителем None, возвращает пустой список [].
Если необходимо разделить строку на список подстрок по регулярному выражению, то обратите внимание на функцию re.split().
Примеры деления строки по подстроке/символу.
>>> '1,2,3'.split(',')
# ['1', '2', '3']
>>> '1,2,3'.split(',', maxsplit=1)
# ['1', '2,3']
>>> '1,2,,3,'.split(',')
# ['1', '2', '', '3', '']
>>> '1 2 3'.split()
# ['1', '2', '3']
>>> '1 2 3'.split(maxsplit=1)
# ['1', '2 3']
>>> ' 1 2 3 '.split()
# ['1', '2', '3']
>>> '--1-3--2'.split('-')
# ['', '', '1', '3', '', '2']
Python | Разделение строки на список символов
Python | Разделение строки на список символов
Иногда мы получаем строку, и нам нужно разбить ее на отдельную обработку. Это довольно распространенная утилита, которая применяется во многих областях, будь то машинное обучение или веб-разработка. Сокращения к нему могут быть полезны. Давайте обсудим некоторые способы, которыми это можно сделать.
Метод №1: Использование list ()
Это простейший способ решения данной конкретной задачи с использованием внутренней реализации встроенной функции списка, которая помогает разбить строку на ее символьные компоненты.
редактировать
закрыть
play_arrow
ссылка
яркость_4
код
|
Исходная строка: GeeksforGeeks
Список разделенных символов: [‘G’, ‘e’, ’e’, ’k’, ‘s’, ‘f’, ‘o’, ‘r’, ‘G’, ‘e’, ‘e’, ’k’, ‘s’]
Метод № 2: Использование map ()
Функция карты также может использоваться для выполнения этой конкретной задачи.В функцию карты необходимо добавить значение None для выполнения этой задачи в качестве первого аргумента и целевой строки в качестве последнего аргумента. Работает только для Python2.
редактировать
закрыть
play_arrow
ссылка
яркость_4
код
|
Исходная строка: GeeksforGeeks
Список разделенных символов: [‘G’, ‘e’, ’e’, ’k’, ‘s’, ‘f’, ‘o’, ‘r’, ‘G’, ‘e’, ‘e’, ’k’, ‘s’]
Внимание компьютерщик! Укрепите свои основы с помощью курса Python Programming Foundation и изучите основы.
Для начала подготовьтесь к собеседованию. Расширьте свои концепции структур данных с помощью курса Python DS .
Мои личные заметки arrow_drop_up
Голосуйте за сложность
Легко Обычный Средняя Жесткий Эксперт
Python Разделить строку по пробелу
Python — Разделить строку по пробелу
Вы можете разделить строку с помощью пробела в качестве разделителя в Python, используя String.split () метод.
В этом руководстве мы узнаем, как разделить строку пробелом и пробелами в целом в Python с помощью методов String.split () и re.split () .
Обратитесь к Python Split String, чтобы узнать синтаксис и основы использования метода String.split ().
Пример 1: Разделить строку пробелом
В этом примере мы возьмем строку, которая содержит слова / элементы / блоки, разделенные пробелом. Затем мы разделим строку по пробелу с помощью String.split () метод. Метод split () возвращает список чанков.
Программа Python
str = '63 41 92 81 69 70 '
# разделить строку на один пробел
chunks = str.split ('')
print (chunks) RunOutput
['63', '41', '92', '81', '69', '70'] Пример 2: Разделить строку на одну или Дополнительные смежные пробелы
В этом примере мы возьмем строку с фрагментами, разделенными одним или несколькими одиночными пробелами.Затем мы разделим строку с помощью функции re.split (). re.split () возвращает фрагменты в списке.
Мы будем использовать пакет python re в следующей программе. re.split (regular_expression, string) возвращает список фрагментов, разделенных из строки на основе regular_expression .
Программа Python
импорт
str = '63 41 92 81 69 70 '
# разделить строку на один пробел
chunks = re.split ('+', строка)
print (chunks) Run Регулярное выражение + представляет один или несколько немедленно возникающих пробелов.Таким образом, один или несколько одиночных пробелов считаются разделителями.
Выходные данные
['63', '41', '92', '81', '69', '70'] Один или несколько смежных пробелов считаются одним разделителем из-за регулярное выражение.
Пример 3: Разделить строку любым символом пробела
В этом примере мы разделим строку на части с любым символом пробела в качестве разделителя.
Ниже приведен список символов пробела из таблицы ASCII.
| Шестнадцатеричный код ASCII | Описание | ||
| 09 | горизонтальный язычок | ||
| 0A | Подача новой строки | ||
| 0B | вертикальный язычок | Возврат каретки / Подача формы | |
| 20 | Пробел |
По умолчанию String.split (), без переданного аргумента, разбивает строку на фрагменты со всеми пробелами в качестве разделителей.
Программа Python
импорт
str = '63 41 \ t92 \ n81 \ r69 70 '
# разделить строку на один пробел
chunks = str.split ()
print (chunks) RunOutput
['63', '41', '92', '81', '69', '70'] Summary
В этом руководстве по Python На примерах мы узнали, как разбить строку по пробелу с помощью методов String.split () и re.split (). Кроме того, мы узнали, как разбить строку, рассматривая все пробельные символы как разделители.
Как разбить строку в Python?
Python Split String
Чтобы разделить строку в Python с помощью разделителя, вы можете использовать метод split () класса String для этой строки.
В этом руководстве мы узнаем, как разбить строку в Python, с помощью хорошо подробных примеров программ Python.
Синтаксис
Синтаксис метода String.split ():
str.split (separator, maxsplit) , где
- str — это строка, которая должна быть разделена
- 10 separator разделитель, в котором разделяется строка.Если не указан, вся строка рассматривается как один фрагмент и возвращается как элемент в списке.
- maxsplit — максимальное количество разделений, которое может быть выполнено. Если не предусмотрено, выполняется максимально возможное разбиение.
Пример 1: Разделить строку
В этом примере мы берем строку, в которой есть фрагменты, разделенные запятой. Мы разделим эту строку, используя запятую в качестве разделителя, и сохраним результат в переменной.
Программа Python
str = 'Python, Примеры, Программы, Код, Программирование'
chunks = str.Трещина(',')
print (chunks) RunOutput
['Python', 'Примеры', 'Программы', 'Код', 'Программирование'] Пример 2: Разделение строки с ограниченным количеством разделений
В этом примере мы берем строку, в которой есть фрагменты, разделенные запятой. Мы разделим эту строку, используя запятую в качестве разделителя и максимальное количество фрагментов: 3 .
Программа Python
str = 'Python, Примеры, Программы, Код, Программирование'
chunks = str.сплит (',', 3)
print (chunks) RunOutput
['Python', 'Примеры', 'Программы', 'Код, Программирование'] Строка разбивается на три части и, следовательно, на 4 части.
Пример 3: Разделить строку без аргументов
Если для функции split () не предоставлены аргументы, один или несколько пробелов рассматриваются как разделители, и входная строка разделяется.
В этом примере мы разделим строку на произвольное количество пробелов между частями.
Программа Python
str = 'hello World! Добро пожаловать в примеры Python. '
# разделить функцию без аргументов
splits = str.split ()
print (splits) RunOutput
['hello', 'World!', 'Welcome', 'to', 'Python', 'Примеры.'] Summary
В этом руководстве Примеров Python мы рассмотрели разные сценарии, в которых мы разбивали строку с помощью разных типов разделителей, контролировали количество разбиений и т. д.
Разделение строк в Python (разделитель, разрыв строки, регулярное выражение и т. Д.)
В этой статье описывается, как разделить строки по разделителям, разрывам строк, регулярным выражениям и количеству символов в Python.
- Разделить по разделителю:
split ()- Укажите разделитель:
sep - Укажите максимальное количество split:
maxsplit
- Укажите разделитель:
- Разделить справа по разделителю:
rsplit () - Разделить по разрыву строки:
разделенных строк () - Разделить по регулярному выражению:
re.split ()- Разделить на несколько разных разделителей
- Конкатенационный список строк
- Разделение по количеству символов: срез
Подробнее о конкатенации строк см. В следующей статье.
Разделить по разделителю: разделить ()
Используйте метод split () для разделения по одному разделителю.
Если аргумент не указан, он будет разделен пробелом. Пробелы включают пробелы, символы новой строки \ n и табуляции \ t , а следующие друг за другом пробелы обрабатываются вместе.
Возвращается список слов.
s_blank = 'один, два, три \ nfour \ tfive'
печать (s_blank)
# один два три
# четыре пять
печать (s_blank.split ())
# ['один два три четыре пять']
печать (тип (s_blank.split ()))
# <список классов>
Используйте join () , описанный ниже, для объединения списка в строку.
Укажите разделитель: сен
Задайте разделитель для первого параметра сен .
s_comma = 'один, два, три, четыре, пять'
печать (s_comma.split (','))
# ['один два три четыре пять']
print (s_comma.split ('три'))
# ['один, два,', ', четыре, пять']
Если вы хотите указать несколько разделителей, используйте регулярные выражения, как описано ниже.
Укажите максимальное количество сплитов: maxsplit
Укажите максимальное количество разбиений для второго параметра maxsplit .
Если задано maxsplit , будет выполнено не более maxsplit разбиений.
печать (s_comma.split (',', 2))
# ['один два три четыре пять']
Например, это полезно, когда вы хотите удалить первую строку из строки.
Если sep = '\ n' , maxsplit = 1 , вы можете получить список строк, разделенных первым символом новой строки \ n . Второй элемент [1] этого списка представляет собой строку, исключая первую строку. Поскольку это последний элемент, его можно указать как [-1] .
s_lines = 'один \ nдва \ nтри \ nfour'
печать (s_lines)
# один
# два
# три
# четыре
печать (s_lines.split ('\ n', 1))
# ['один', 'два \ nтри \ nfour']
print (s_lines.split ('\ n', 1) [0])
# один
print (s_lines.split ('\ n', 1) [1])
# два
# три
# четыре
print (s_lines.split ('\ n', 1) [- 1])
# два
# три
# четыре
Аналогично, чтобы удалить первые две строки:
print (s_lines.split ('\ n', 2) [- 1])
# три
# четыре
Разделить справа по разделителю: rsplit ()
rsplit () разделяется справа от строки.
Результат отличается от split () только тогда, когда задан второй параметр maxsplit .
Так же, как split () , если вы хотите удалить последнюю строку, используйте rsplit () .
печать (s_lines.rsplit ('\ n', 1))
# ['один \ nдва \ nтри', 'четыре']
print (s_lines.rsplit ('\ n', 1) [0])
# один
# два
# три
print (s_lines.rsplit ('\ n', 1) [1])
# четыре
Чтобы удалить две последние строки:
печать (s_lines.rsplit ('\ n', 2) [0])
# один
# два
Разделить по разрыву строки: разделенных строк ()
Также есть splitlines () для разделения по границам строк.
Как и в предыдущих примерах, split () и rsplit () по умолчанию разделяются пробелами, включая разрыв строки, и вы также можете указать разрыв строки с помощью параметра sep .
Однако часто лучше использовать splitlines () .
Например, разделенная строка, которая содержит \ n (LF), используемое ОС Unix, включая Mac, и \ r \ n (CR + LF), используемое ОС WIndows.
s_lines_multi = '1 один \ n2 два \ r \ n3 три \ n'
печать (s_lines_multi)
# 1 один
# 2 два
# 3 три
Когда split () применяется по умолчанию, он разбивается не только по разрывам строк, но и по пробелам.
печать (s_lines_multi.split ())
# ['1', 'один', '2', 'два', '3', 'три']
Поскольку в sep можно указать только один символ новой строки, он не может быть разделен, если есть смешанные символы новой строки. Он также разделяется в конце символа новой строки.
печать (s_lines_multi.split ('\ n'))
# ['1 один', '2 два \ r', '3 три', '']
splitlines () разделяется на различные символы новой строки, но не на другие пробелы.
печать (s_lines_multi.splitlines ())
# ['1 один', '2 два', '3 три']
Если для первого аргумента keepends установлено значение True , результат будет содержать символ новой строки в конце строки.
печать (s_lines_multi.splitlines (True))
# ['1 один \ n', '2 два \ r \ n', '3 три \ n']
О других операциях с переносом строки см. В следующей статье.
Разделить по регулярному выражению: re.split ()
split () и rsplit () разделяются только тогда, когда sep полностью совпадает.
Если вы хотите разбить строку, которая соответствует регулярному выражению, а не точному совпадению, используйте split () модуля re.
В рэ.split () укажите шаблон регулярного выражения в первом параметре и целевую строку символов во втором параметре.
Ниже приведен пример разбивки по порядковым номерам.
импорт ре
s_nums = 'one1two22three333four'
печать (re.split ('\ d +', s_nums))
# ['один два три четыре']
Максимальное количество разбиений можно указать в третьем параметре maxsplit .
печать (re.split ('\ d +', s_nums, 2))
# ['one', 'two', 'three333four']
Разделить на несколько разных разделителей
Следующие два полезно запомнить, даже если вы не знакомы с регулярными выражениями.
Заключите строку с [] , чтобы соответствовать любому одиночному символу в ней. Его можно использовать для разделения на несколько разных символов.
s_marks = 'один-два + три # четыре'
print (re.split ('[- + #]', s_marks))
# ['один два три четыре']
Если шаблоны разделены символом | , соответствует любому шаблону. Конечно, можно использовать специальные символы регулярного выражения для каждого шаблона, но это нормально, даже если обычная строка указана как есть.Его можно использовать для разделения нескольких разных строк.
s_strs = 'oneXXXtwoYYYthreeZZZfour'
print (re.split ('XXX | YYY | ZZZ', s_strs))
# ['один два три четыре']
Конкатенационный список строк
В предыдущих примерах мы разделили строку и получили список.
Если вы хотите объединить список строк в одну строку, используйте строковый метод join () .
Вызвать метод join () из 'separator' , передать в аргумент список строк, которые нужно объединить.
l = ["один", "два", "три"]
print (','. join (l))
# один два три
print ('\ n'.join (l))
# один
# два
# три
печать (''. join (l))
# один два три
Подробнее о конкатенации строк см. В следующей статье.
Разделение по количеству символов: срез
Используйте срез для разделения строк по количеству символов.
s = 'abcdefghij'
печать (s [: 5])
# abcde
печать (s [5:])
# fghij
Его можно получить как кортеж или присвоить переменной соответственно.
s_tuple = s [: 5], s [5:]
печать (s_tuple)
# ('abcde', 'fghij')
печать (тип (s_tuple))
# <класс 'кортеж'>
s_first, s_last = s [: 5], s [5:]
печать (s_first)
# abcde
печать (s_last)
# fghij
Разделить на три:
s_first, s_second, s_last = s [: 3], s [3: 6], s [6:]
печать (s_first)
# abc
печать (s_second)
# def
печать (s_last)
# ghij
Количество символов можно получить с помощью встроенной функции len () . Его также можно разделить на две части.
половина = длина (с) // 2
печать (половина)
# 5
s_first, s_last = s [: половина], s [половина:]
печать (s_first)
# abcde
печать (s_last)
# fghij
Если вы хотите объединить строки, используйте оператор + .
печать (s_first + s_last)
# abcdefghij
Python String split — JournalDev
Python String split () функция используется для разделения строки на список строк на основе разделителя.
Python String split
Синтаксис функции Python string split ():
ул.split (sep = None, maxsplit = -1)
sep аргумент используется в качестве разделителя. Если строка содержит последовательные разделители, возвращается пустая строка. Аргумент-разделитель также может состоять из нескольких символов.
Если разделитель не указан или Нет , то в качестве разделителя рассматриваются пробелы. В этом случае пустая строка не будет возвращена, если в начале или в конце есть пробелы. Кроме того, несколько пробелов будут рассматриваться как один разделитель.
Если предоставляется maxsplit, выполняется не более maxsplit разбиений (таким образом, список будет содержать не более maxsplit + 1 элементов). Если maxsplit не указан или -1, то количество разделений не ограничено, и все возможные разделения возвращаются в списке.
Python String split (), пример
Давайте посмотрим на простой пример, где строка будет разбита на список на основе указанного разделителя.
s = 'Python хорош'
# простой пример разделения строки
str_list = s.разделить (sep = '')
печать (str_list)
Выход:
['Python', 'is', 'Nice']
Разделение строки () с примером maxsplit
s = 'Python хорош'
str_list = s.split (sep = '', maxsplit = 1)
печать (str_list)
Вывод: ['Python', 'is Nice']
Обратите внимание, что возвращенный список содержит только 2 элемента, строка была разделена только один раз.
sep не предоставляется или отсутствует
s = 'Java Python iOS Android'
str_list = s.Трещина()
печать (str_list)
Вывод: ['Java', 'Python', 'iOS', 'Android']
Начальные и конечные пробелы игнорируются в возвращаемом списке. Кроме того, последовательные пробелы также считаются одним разделителем.
Пример разделения многострочной строки
multiline_str = 'Привет \ nКак дела? \ nЯ в порядке'
multiline_str_split_list = multiline_str.split (sep = '\ n')
для s в multiline_str_split_list:
печать (и)
Выход:
Всем привет
Как поживаете?
У меня все нормально
Пример многосимвольного разделителя
s = 'Привет || Привет || Прощай'
str_list = s.сплит ('||')
печать (str_list)
Вывод: ['Hi', 'Hello', 'Adios']
Пример функции str.split ()
Мы также можем использовать функцию split () непосредственно из класса str.
печать (str.split ('ABACAD', sep = 'A'))
print (str.split ('ABACAD', sep = 'A', maxsplit = 2))
Выход:
['', 'B', 'C', 'D']
['', 'B', 'CAD']
Обратите внимание, что пустая строка возвращается, когда первый символ соответствует разделителю.
Пример разделения строки CSV с пользовательским вводом
Наконец, давайте посмотрим на реальный пример, где пользователь вводит данные CSV, а мы разделим их на список строк.
input_csv = input ('Пожалуйста, введите данные CSV \ n')
input_csv_split_list = input_csv.split (sep = ',')
print ('Длина входных данных =', len (input_csv_split_list))
print ('Список входов =', input_csv_split_list)
Выход:
Пожалуйста, введите данные CSV
Java, Android, Python, iOS, jQuery
Длина входных данных = 5
Список входов = ['Java', 'Android', 'Python', 'iOS', 'jQuery']
Вот и все, что касается примеров функции split () строки Python.Это очень полезная функция для разделения строки в список на основе некоторого разделителя.
Python String rsplit ()
Python String Функция rsplit () очень похожа на функцию split (). Единственная разница в том, что разделение выполняется, начиная с конца струны и двигаясь вперед.
Давайте посмотрим на некоторые примеры функции rsplit ().
# пример rsplit ()
s = 'Python - это круто'
str_list = s.rsplit (sep = '')
печать (str_list)
str_list = s.rsplit (sep = '', maxsplit = 1)
печать (str_list)
s = 'Java Python iOS Android'
str_list = s.rsplit ()
печать (str_list)
multiline_str = 'Привет \ nКак дела? \ nЯ в порядке'
multiline_str_split_list = multiline_str.rsplit (sep = '\ n')
для s в multiline_str_split_list:
печать (и)
s = 'Привет || Привет || Прощай'
str_list = s.rsplit ('||')
печать (str_list)
# использование split () с классом str
печать (str.rsplit ('ABACAD', sep = 'A'))
print (str.rsplit ('ABACAD', sep = 'A', maxsplit = 2))
# csv и пример пользовательского ввода
input_csv = input ('Пожалуйста, введите данные CSV \ n')
input_csv_split_list = input_csv.rsplit (сеп = ',')
print ('Длина входных данных =', len (input_csv_split_list))
print ('Список входов =', input_csv_split_list)
Выход:
['Python', 'is', 'Awesome']
['Python is', 'Awesome']
['Java', 'Python', 'iOS', 'Android']
Всем привет
Как поживаете?
У меня все нормально
[«Привет», «Привет», «Прощай»]
['', 'B', 'C', 'D']
['AB', 'C', 'D']
Пожалуйста, введите данные CSV
х, у, г
Длина входных данных = 3
Список входов = ['x', 'y', 'z']
Обратите внимание, что разница видна, если указан аргумент maxsplit.В противном случае выходные данные функций split () и rsplit () одинаковы.
Вы можете получить полный скрипт Python и другие примеры Python в нашем репозитории GitHub.Ссылка: API Doc
Разделение строки символов на основе изменения символа
Разделение строки символов на основе изменения символаВам предлагается решить эту задачу в соответствии с описанием задачи, используя любой язык, который вы знаете.
- Задача
Разделить (символьную) строку на запятую (плюс пробел) с разделителями строки, основанные на изменении символа (слева направо).
Показать вывод здесь (используйте пример 1 st ниже).
Пробелы следует рассматривать как любой другой символ (кроме
их проблематично отобразить четко). То же самое относится
до запятых.
Например, строка:
gHHH5YY ++ /// \
следует разделить и показать:
г, ЧЧЧ, 5, ГГ, ++, ///, \
- Связанная задача
/ * ARM сборка AARCH64 Raspberry PI 3B * /
/ * программа splitcar64.s * /
/ ****************************************** /
/ * Файл констант * /
/ **************************************** ** /
/ * для этого файла см. Задачу включить файл на языке сборки AArch64 * /
.include "../includeConstantesARM64.inc"
/ **************** ***************** /
/ * Инициализированные данные * /
/ *********************** ********** /
.data
szCarriageReturn: .asciz "\ n"
szString1:.asciz "gHHH5YY ++ /// \\"
/ * ВАЖНОЕ ЗАМЕЧАНИЕ для компилятора как
. Чтобы добавить специальные символы в строку, нужно экранировать эти символы: перед ними
поставьте символ обратной косой черты ‘\’. Например, «\\» представляет одну обратную косую черту: первый \ - это
escape, который сообщает as интерпретировать второй символ буквально как обратную косую черту (что
не позволяет as распознать второй \ как escape-символ).
* /
/ ******************************** /
/ * Неинициализированные данные * /
/ * ******************************** /
.bss
sBuffer: .skip 100
/ ******************************** /
/ * раздел кода * /
/ ******************************** /
.text
.global main
main: // entry программы
ldr x0, qAdrszString1 // адрес входной строки
ldr x1, qAdrsBuffer // адрес выходного буфера
bl split
ldr x0, qAdrsBuffer
bl affichageMess // отображать сообщение
ldr x0, qAdrszCarriageReturn
bl affic 100: // стандартный конец программы
mov x0,0 // код возврата
mov x8, EXIT // запрос на выход из программы
svc 0 // выполнение системного вызова
qAdrszString1:.quad szString1
qAdrszCarriageReturn: .quad szCarriageReturn
qAdrsBuffer: .quad sBuffer
/ ******************************** ******************************** /
/ * генерировать значение * /
/ ******* ************************************************* ********* /
/ * x0 содержит адрес входной строки * /
/ * x1 содержит адрес выходного буфера * /
split:
stp x1, lr, [sp, -16] ! // сохраняем регистры
mov x4,0 // входная строка цикла индекса
mov x5,0 // буфер индекса
ldrb w2, [x0, x4] // читаем первый символ в регистре x2
cbz x2,4f // если ноль -> end
strb w2, [x1, x5] // сохраняем char в буфере
add x5, x5,1 // увеличиваем буфер местоположения
1:
ldrb w3, [x0, x4] // читаем char [x4] в reg x3
cbz x3,4f // если null end
cmp x2, x3 // сравнить два символа
bne 2f
strb w3, [x1, x5] // = -> сохранить символ в буфере
b 3f // цикл
2:
mov x2, ',' // иначе сохраняем запятую в буфере
strb w2, [x1, x5] // сохраняем char в буфере
добавляем x5, x5,1
mov x2, '' // и сохраняем пространство в буфер
strb w2, [x1, x5]
add x5, x5,1
strb w3, [x1, x5] // и сохраните входной char в буфере
mov x2, x3 // и maj x2 с новым char
3:
add x5, x5,1 // увеличиваем индексы
add x4, x4,1
b 1b // и цикл
4:
strb w3, [x1, x5] // сохранить нулевой финал в буфере
100:
ldp x1, lr, [sp], 16 // восстановить 2 регистра
ret // вернуться по адресу lr x30
/ **** ************************************************* ** /
/ * Файл включает функции * /
/ ************************************ ******************* /
/ * для этого файла см. Задачу включить файл на языке сборки AArch64 * /
.включить "../includeARM64.inc"
гг., ЧЧЧ, 5, ГГ, ++, ///, \
с Ada.Text_IO;
разделение процедур
процедура Print_Tokens (s: String) равно
i, j: Integer: = s'First;
начать
цикл
, пока j <= s'Last, а затем s (j) = s (i) loop j: = j + 1; конец петли;
, если i / = s'first, то Ada.Text_IO.Put (","); конец, если;
Ada.Text_IO.Put (s (i..j-1));
i: = j;
выйти, когда j> s'last;
конец петли;
end Print_Tokens;
begin
Print_Tokens ("gHHH5YY +++");
концевой разрез;
BEGIN
# возвращает s с ",", добавляемым между каждым изменением символа #
PROC, разделенный на символы = (STRING s) STRING:
IF s = "" THEN
# пустая строка #
""
ELSE
# разрешить В 3 раза больше символов, чем в строке #
# это обработает строку уникальных символов #
[3 * ((UPB s - LWB s) + 1)] CHAR result;
INT r pos: = результат LWB;
INT s pos: = LWB s;
CHAR s char: = s [LWB s];
FOR s pos ОТ LWB до UPB s DO
IF s char / = s [s pos] THEN
# изменение символа - вставить "," #
result [r pos]: = ",";
результат [r pos + 1]: = "";
r pos +: = 2;
s char: = s [s pos]
FI;
результат [r pos]: = s [s pos];
r pos +: = 1
OD;
# вернуть использованную часть результата #
result [1: r pos - 1]
FI; # разделить по символам #
print ((разделить по символам ("gHHH5YY ++ /// \"), новая строка))
END
г, ЧЧЧ, 5, ГГ, ++, ///, \
REM> split
ОБЪЯВИТЬ ВНЕШНЮЮ ФУНКЦИЮ FN_split $
ПЕЧАТЬ FN_split $ ("gHHH5YY ++ /// \")
END
ВНЕШНЯЯ ФУНКЦИЯ FN_split $ (s $)
LET c $ = s11 (1: 1) split $ = ""
FOR i = 1 TO LEN (s $)
LET d $ = s $ (i: i)
IF d $ <> c $ THEN
LET split $ = split $ & ","
LET c $ = d $
END IF
LET split $ = split $ & d $
NEXT i
LET FN_split $ = split $
END FUNCTION
г, ЧЧЧ, 5, ГГ, ++, ///, \
Функциональный [править]
intercalate (",", ¬
map (curry (intercalate) 's | λ | (""), ¬
group ("gHHH5YY ++ /// \\")))
-> "g, HHH, 5, YY, ++, ///, \\ "
- ОБЩИЕ ФУНКЦИИ ----------------------------- -----------------------------
- curry :: (Скрипт | Обработчик) -> Скрипт
на карри (f)
скрипт
на | λ | (a)
скрипт
на | λ | (b)
| λ | (a, b) из mReturn (f)
end | λ |
конец скрипта
конец | λ |
конец скрипта
конец карри
- foldl :: (a -> b -> a) -> a -> [b] -> a
на foldl (f, startValue, xs)
сказать mReturn (f)
установить v на startValue
установить lng на длину xs
повторить с i от 1 до lng
установить v на | λ | (v, элемент i xs, i, xs)
end repeat
return v
end tell
end foldl
- group :: Eq a => [a] -> [[a]]
on group (xs)
script eq
on | λ | (a, b)
a = b
end | λ |
конец скрипта
groupBy (eq, xs)
end group
- groupBy :: (a -> a -> Bool) -> [a] -> [[a]]
на groupBy (f, xs)
установить mf на mReturn (f)
script enGroup
on | λ | (a, x)
if length of (active of a)> 0 then
set h to item 1 of active of a
else
set h to пропущенное значение
конец, если
, если h не является пропущенным значением и mf | λ | (h, x), то
{active: (active из a) & x, sofar: sofar of a}
else
{active: {x }, sofar: (sofar of a) & {active of a}}
end if
end | λ |
конец скрипта
, если длина xs> 0, тогда
скажите foldl (enGroup, {active: {item 1 of xs}, sofar: {}}, tail (xs))
, если длина (его active)> 0, тогда
его софар и его активный
else
{}
end if
end tell
else
{}
end if
end groupBy
- intercalate :: Text -> [Text] -> Text
on intercalate (strText, lstText)
установить {dlm, мои разделители текстовых элементов} в {мои разделители текстовых элементов, strText}
установить strJoined в lstText как текст
установить мои разделители текстовых элементов в dlm
вернуть strJoined
end intercalate
- map :: ( a -> b) -> [a] -> [b]
на карте (f, xs)
сказать mReturn (f)
установить lng на длину xs
установить lst на {}
повторить с i от 1 до lng
установить конец lst в | λ | (элемент i xs, i, xs)
end repeat
return lst
end tell
end map
- Перенести функцию обработчика 2-го класса в оболочку сценария 1-го класса
- mReturn: : Обработчик -> Скрипт 900 11 на mReturn (f)
, если класс f является сценарием, тогда
f
иначе
сценарий
свойство | λ | : f
end script
end if
end mReturn
- tail :: [a] -> [a]
on tail (xs)
если длина xs> 1, то
элементы 2 через -1 из xs
иначе
{}
конец если
конец хвост г, ЧЧЧ, 5, ГГ, ++, ///, \
Straightforward [править]
(Также с учетом регистра.)
на splitAtCharacterChanges (ввод)
установить len на (ввод счетчика)
if (len <2) затем вернуть ввод
установить chrs на символы ввода
установить currentChr на начало chrs
с учетом случая
повторить с i от 2 до len
установить thisChr для элемента i chrs
, если (thisChr не currentChr), то
устанавливает элемент i для chrs на "," и thisChr
устанавливает currentChr на thisChr
end if
end repeat
end с учетом
, установленного astid для разделителей текстовых элементов AppleScript
установить разделители текстовых элементов AppleScript в «»
установить для вывода chrs как текст
установить разделители текстовых элементов AppleScript в astid
вернуть выходные данные
end splitAtCharacterChanges
- Тестовый код:
splitAtCharacterChanges («gHHH5YY ++ /// \\»)
"г, ЧЧЧ, 5, ГГ, ++, ///, \\"
ASObjC [править]
использовать AppleScript версии "2.4 "- OS X 10.10 (Yosemite) или более поздняя версия
использует фреймворк" Foundation "
на splitAtCharacterChanges (вход)
tell (текущий класс приложения NSMutableString 's stringWithString: (вход)) к ¬
return (его stringByReplacingOccurrencesOfString: ("(.) \\ 1 * + (?! $)") WithString :( "$ 0,") ¬
параметры: (NSRegularExpressionSearch текущего приложения) диапазон: ({0, его | длина | ()})) как текст
конец splitAtCharacterChanges
- Тестовый код:
splitAtCharacterChanges ("gHHH5YY ++ /// \\")
"г, ЧЧЧ, 5, ГГ, ++, ///, \\"
/ * ARM сборка Raspberry PI * /
/ * программа splitcar.s * /
/ *********************************** /
/ * Константы * /
/ *********************************** /
.equ STDOUT, 1 @ консоль вывода Linux
. equ EXIT, 1 @ системный вызов Linux
.equ WRITE, 4 @ системный вызов Linux
/ ****************************** ** /
/ * Инициализированные данные * /
/ ********************************* /
. Data
szCarriageReturn. обратная косая черта '\'.Например, «\\» представляет одну обратную косую черту: первый \ - это
escape, который сообщает as интерпретировать второй символ буквально как обратную косую черту (что
не позволяет as распознать второй \ как escape-символ).
* /
/ ******************************** /
/ * Неинициализированные данные * /
/ * ******************************* /
.bss
sBuffer: .skip 100
/ ***** **************************** /
/ * раздел кода * /
/ ************ ********************* /
.текст
.global main
main: @ запись программы
ldr r0, iAdrszString1 @ адрес входной строки
ldr r1, iAdrsBuffer @ адрес выходного буфера
bl split
ldr r0, iAdrsBuffer
bl affichageMess @ display message
ldr r0, iAdrszCarriageReturn
bl affichageMess
100: @ стандартный конец программы
mov r0, # 0 @ код возврата
mov r7, #EXIT @ запрос на выход из программы
svc # 0 @ выполнить системный вызов
iAdrszString1:.int szString1
iAdrszCarriageReturn: .int szCarriageReturn
iAdrsBuffer: .int sBuffer
/ ******************************** ******************************** /
/ * генерировать значение * /
/ ******* ************************************************* ********* /
/ * r0 содержит адрес входной строки * /
/ * r1 содержит адрес выходного буфера * /
split:
push {r1-r5, lr} @ save registers
mov r4, # 0 @ входная строка цикла индекса
mov r5, # 0 @ буфер индекса
ldrb r2, [r0, r4] @ чтение первого символа в reg r2
cmp r2, # 0 @ if null -> конец
beq 3f
strb r2, [r1, r5] @ сохранить символ в буфере
добавить r5, # 1 @ увеличить буфер местоположения
1:
ldrb r3, [r0, r4] @read char [r4] в reg r3
cmp r3, # 0 @ if null end
beq 3f
cmp r2, r3 @ сравнить два символа
streqb r3, [r1, r5] @ = -> сохранить char в буфере
beq 2f @ loop
mov r2, # ',' @ else сохранить запятую в буфере
strb r2, [r1, r5] @ сохранить char в буфере
добавить r5, # 1
mov r2, # '' @ и сохранить место в буфер
strb r2, [r1, r5]
добавить r5, # 1
strb r3, [r1, r5] @ и сохранить входной char в буфере
mov r2, r3 @ и maj r2 с новым char
2:
добавить r5 , # 1 @ приращение индексов
добавить r4, # 1
b 1b @ и цикл
3:
strb r3, [r1, r5] @ сохранить ноль fi окончание в буфере
100:
pop {r1-r5, lr}
bx lr @ return
/ ************************** ************************************** /
/ * отображение текста с вычислением размера * /
/ *********************************************** ****************** /
/ * r0 содержит адрес сообщения * /
affichageMess:
push {r0, r1, r2, r7, lr} @ save registres
mov r2, # 0 @ длина счетчика
1: @ вычисление длины цикла
ldrb r1, [r0, r2] @ чтение стартовой позиции октета + индекс
cmp r1, # 0 @ если 0 больше
addne r2, r2, # 1 @ else добавить 1 к длине
bne 1b @ и зациклить
@, так что здесь r2 содержит длину сообщения 900 11 mov r1, r0 @ адрес сообщение в r1
mov r0, # STDOUT @ код для записи на стандартный вывод Linux
mov r7, #WRITE @ code call system "write"
svc # 0 @ call systeme
pop {r0, r1, r2, r7, lr} @ restaur des 2 registres * /
bx lr @ return
вывод: gg, HHH, 5, YY, ++, ///, \
Split_Change (str) {
для i, v в StrSplit (str)
res.= (v = предыдущая)? v: (res? ",": "") v, prev: = v
return res
} Примеры:str: = "gHHH5YY ++ /// \"Выходы:
MsgBox% Split_Change (str)
г, ЧЧЧ, 5, ГГ, ++, ///, \
RegEx Version [править]
Split_Change (str) {
return RegExReplace (str, "(.) \ 1 * (?! $)", "$ 0,")
} Примеры:str: = "gHHH5YY ++ /// \"Выходы:
MsgBox% Split_Change (str)
г, ЧЧЧ, 5, ГГ, ++, ///, \
# синтаксис: GAWK -f SPLIT_A_CHARACTER_STRING_BASED_ON_CHANGE_OF_CHARACTER.AWK
BEGIN {
str = "gHHH5YY ++ /// \\"
printf ("old:% s \ n", str)
printf ("new:% s \ n", split_on_change (str))
exit (0 )
}
function split_on_change (str, c, i, new_str) {
new_str = substr (str, 1,1)
for (i = 2; i <= length (str); i ++) {
c = substr ( str, i, 1)
if (substr (str, i-1,1)! = c) {
new_str = new_str ","
}
new_str = new_str c
}
return (new_str)
}
старый: gHHH5YY ++ /// \ новое: g, ЧЧЧ, 5, ГГ, ++, ///, \
Литеральные строки в BaCon передаются компилятору C как есть; поэтому необходимо избежать обратной косой черты.
txt $ = "gHHH5YY ++ /// \\"
c $ = LEFT $ (txt $, 1)
FOR x = 1 TO LEN (txt $)
d $ = MID $ (txt $, x, 1 )
IF d $ <> c $ THEN
PRINT ",";
c $ = d $
END IF
PRINT d $;
СЛЕДУЮЩИЙ
г, ЧЧЧ, 5, ГГ, ++, ///, \
REM> split
PRINT FN_split ("gHHH5YY ++ /// \")
END
DEF FN_split (s $)
LOCAL c $, split $, d $, i%
c $ = LEFT $ (s $, 1 )
split $ = ""
FOR i% = 1 TO LEN s $
LET d $ = MID $ (s $, i%, 1)
IF d $ <> c $ THEN
split $ + = ","
c $ = d
ENDIF
разделить $ + = d
NEXT
= разделить 90 339 долларовг, ЧЧЧ, 5, ГГ, ++, ///, \#include.
#include
#include
char * split (char * str);
int main (int argc, char ** argv)
{
char input [13] = "gHHH5YY ++ /// \\";
printf ("% s \ n", разделить (ввод));
}
char * split (char * str)
{