Как определить шрифт: 7 популярных сервисов
Для печати логотипов и надписей на сублимационной продукции (чашках, футболках, тарелках и т. д.) необходимо уметь определять шрифт. Если вы встретили на картинке привлекательный шрифт и хотели бы использовать его для своих изделий, воспользуйтесь описанными в этой статье инструментами.
7 способов распознать шрифт
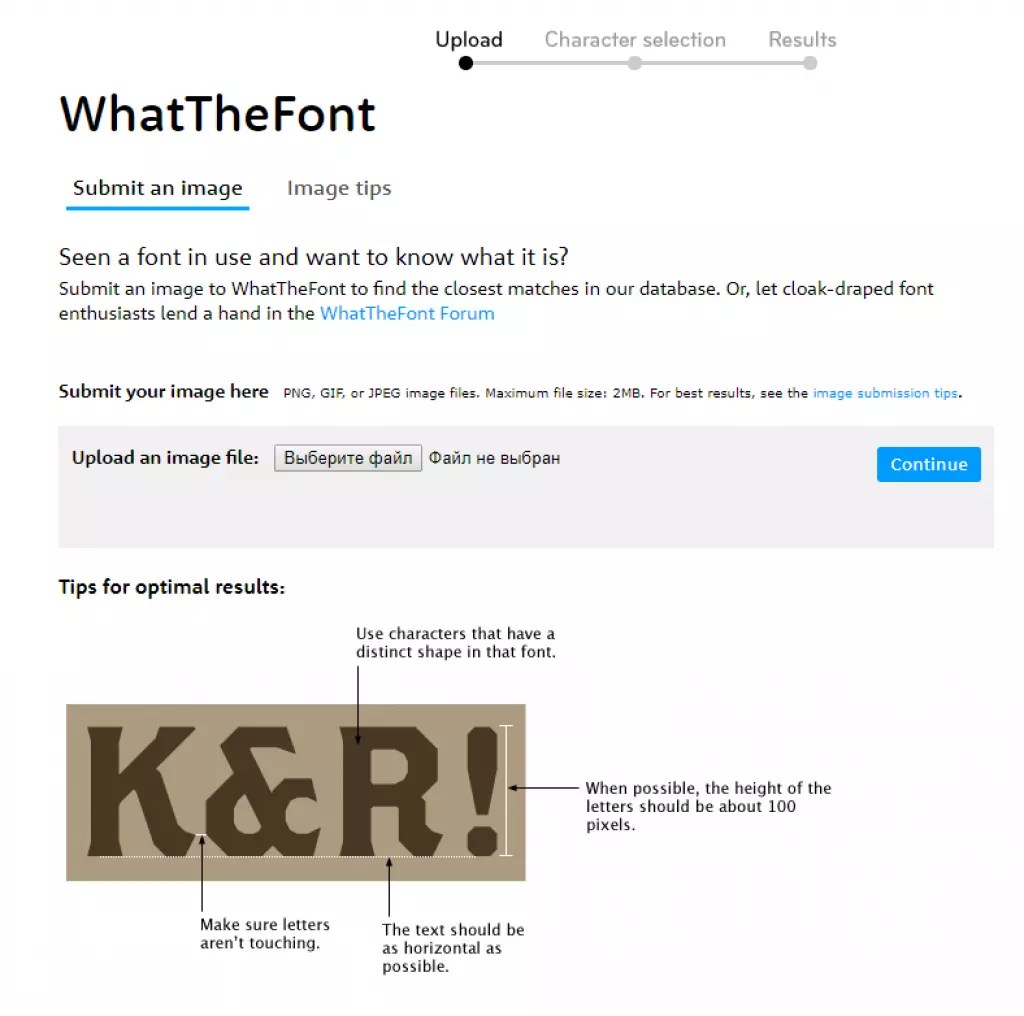
1. WhatTheFont
Один из самых популярных сервисов для определения шрифта. Нужно загрузить картинку размером не менее 360 x 275 пикселей в программу, и запустить процесс распознавания. Чем выше качество изображения, тем точнее определение. Допустимые форматы изображений: GIF, JPEG, TIFF, BMP.
Важно, чтобы символы были разделены друг от друга. Под каждой буквой есть строка, в которую можно ввести ее вручную. Интерфейс на английском языке, но достаточно прост и понятен.
2. What Font is
В программе доступен широкий выбор шрифтов, выполненных латиницей. Распознать интересующий можно тремя путями: загрузить изображение, указать адрес картинки, искать по названию.
3. Identifont
Сервис определяет шрифт путем задавания ряда вопросов. Наши результаты были неточными, но вы можете проверить эффективность его работы на своих примерах.
4. Bowfin Printworks
Программа работает аналогично предыдущей. Принцип: поиск шрифта на основе вопросов о форме букв и т. д. Работает немного быстрее Identifont, но поиск также может стать утомительным.
5. Typophile
Форум, на котором общается сообщество экспертов по шрифтам. Если вы не найдете подходящий вариант в обсуждениях, создайте свой топик и загрузите изображение. Высока вероятность, что вам помогут определить название.
6. Плагин для Google Chrome
Он определяет шрифт путем сканирования html-кода страниц. При наведении курсора всплывает подсказка. Чем больше шрифт, тем выше точность распознавания.
7. Мобильное приложение WhatTheFont
Если под рукой нет компьютера, для распознавания шрифта можно воспользоваться мобильным приложением.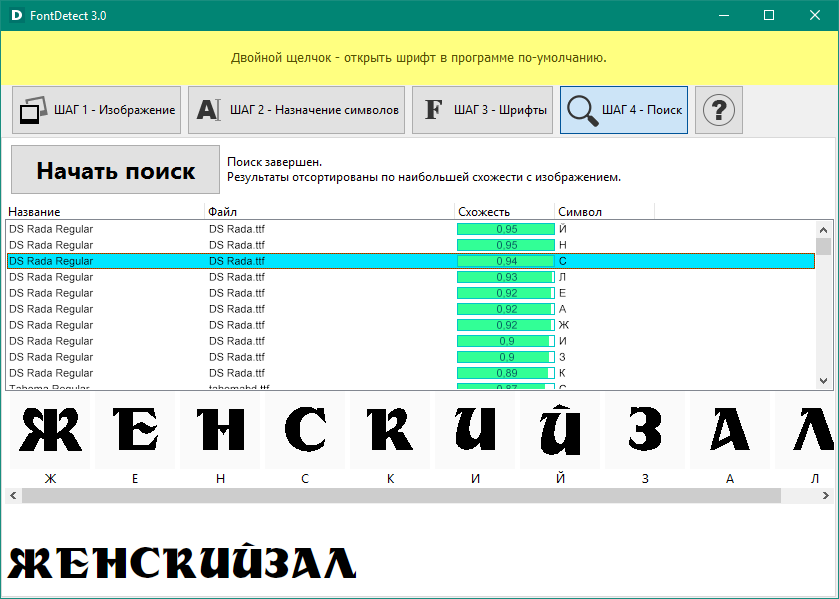 Для этого понадобится доступ к Интернету.
Для этого понадобится доступ к Интернету.
Кроме вышеперечисленных, вы также можете воспользоваться группами на фотохостинге Flickr или списками популярных шрифтов. К сожалению, все эти сервисы определяют только латиницу.
Для распознавания кириллических шрифтов (на русском языке) специальных сервисов нет. Можно попробовать оставить на изображении только такие символы, которые дублируются в латинице: A, B, C, E, H, K, M, O, P, T и попробовать распознать с помощью вышеуказанных сервисов. Иначе, помогут только списки или советы специалистов на форумах.
делаем распознавалку текста за полчаса / Хабр
Привет Хабр.После экспериментов с многим известной базой из 60000 рукописных цифр MNIST возник логичный вопрос, есть ли что-то похожее, но с поддержкой не только цифр, но и букв. Как оказалось, есть, и называется такая база, как можно догадаться, Extended MNIST (EMNIST).
Если кому интересно, как с помощью этой базы можно сделать несложную распознавалку текста, добро пожаловать под кат.
Примечание: данный пример экспериментальный и учебный, мне было просто интересно посмотреть, что из этого получится. Делать второй FineReader я не планировал и не планирую, так что многие вещи тут, разумеется, не реализованы. Поэтому претензии в стиле «зачем», «уже есть лучше» и пр, не принимаются. Наверно готовые OCR-библиотеки для Python уже есть, но было интересно сделать самому. Кстати, для тех кто хочет посмотреть, как делался настоящий FineReader, есть две статьи в их блоге на Хабре за 2014 год: 1 и 2 (но разумеется, без исходников и подробностей, как и в любом корпоративном блоге). Ну а мы приступим, здесь все открыто и все open source.
Для примера мы возьмем простой текст. Вот такой:
HELLO WORLD
И посмотрим что с ним можно сделать.
Разбиение текста на буквы
Первым шагом разобьем текст на отдельные буквы. Для этого пригодится OpenCV, точнее его функция findContours.
 cvtColor + cv2.threshold), слегка увеличим (cv2.erode) и найдем контуры.
cvtColor + cv2.threshold), слегка увеличим (cv2.erode) и найдем контуры.image_file = "text.png"
img = cv2.imread(image_file)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
ret, thresh = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY)
img_erode = cv2.erode(thresh, np.ones((3, 3), np.uint8), iterations=1)
# Get contours
contours, hierarchy = cv2.findContours(img_erode, cv2.RETR_TREE, cv2.CHAIN_APPROX_NONE)
output = img.copy()
for idx, contour in enumerate(contours):
(x, y, w, h) = cv2.boundingRect(contour)
# print("R", idx, x, y, w, h, cv2.contourArea(contour), hierarchy[0][idx])
# hierarchy[i][0]: the index of the next contour of the same level
# hierarchy[i][1]: the index of the previous contour of the same level
# hierarchy[i][2]: the index of the first child
# hierarchy[i][3]: the index of the parent
if hierarchy[0][idx][3] == 0:
cv2.rectangle(output, (x, y), (x + w, y + h), (70, 0, 0), 1)
cv2.imshow("Input", img)
cv2.imshow("Enlarged", img_erode)
cv2. imshow("Output", output)
cv2.waitKey(0)
imshow("Output", output)
cv2.waitKey(0)
Мы получаем иерархическое дерево контуров (параметр cv2.RETR_TREE). Первым идет общий контур картинки, затем контуры букв, затем внутренние контуры. Нам нужны только контуры букв, поэтому я проверяю что «родительским» является общий контур. Это упрощенный подход, и для реальных сканов это может не сработать, хотя для распознавания скриншотов это некритично.
Результат:
Следующим шагом сохраним каждую букву, предварительно отмасштабировав её до квадрата 28х28 (именно в таком формате хранится база MNIST). OpenCV построен на базе numpy, так что мы можем использовать функции работы с массивами для кропа и масштабирования.
def letters_extract(image_file: str, out_size=28) -> List[Any]:
img = cv2.imread(image_file)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
ret, thresh = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY)
img_erode = cv2.erode(thresh, np.ones((3, 3), np.uint8), iterations=1)
# Get contours
contours, hierarchy = cv2.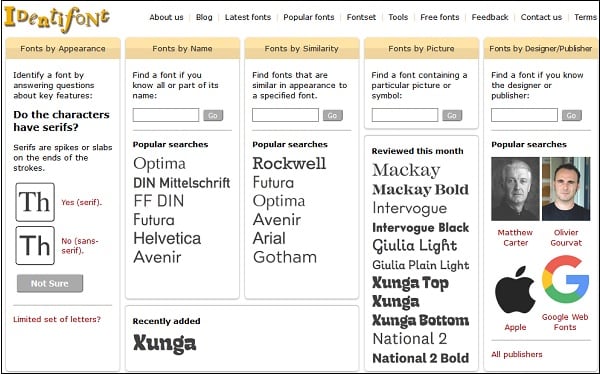 findContours(img_erode, cv2.RETR_TREE, cv2.CHAIN_APPROX_NONE)
output = img.copy()
letters = []
for idx, contour in enumerate(contours):
(x, y, w, h) = cv2.boundingRect(contour)
# print("R", idx, x, y, w, h, cv2.contourArea(contour), hierarchy[0][idx])
# hierarchy[i][0]: the index of the next contour of the same level
# hierarchy[i][1]: the index of the previous contour of the same level
# hierarchy[i][2]: the index of the first child
# hierarchy[i][3]: the index of the parent
if hierarchy[0][idx][3] == 0:
cv2.rectangle(output, (x, y), (x + w, y + h), (70, 0, 0), 1)
letter_crop = gray[y:y + h, x:x + w]
# print(letter_crop.shape)
# Resize letter canvas to square
size_max = max(w, h)
letter_square = 255 * np.ones(shape=[size_max, size_max], dtype=np.uint8)
if w > h:
# Enlarge image top-bottom
# ------
# ======
# ------
y_pos = size_max//2 - h//2
letter_square[y_pos:y_pos + h, 0:w] = letter_crop
elif w < h:
# Enlarge image left-right
# --||--
x_pos = size_max//2 - w//2
letter_square[0:h, x_pos:x_pos + w] = letter_crop
else:
letter_square = letter_crop
# Resize letter to 28x28 and add letter and its X-coordinate
letters.
findContours(img_erode, cv2.RETR_TREE, cv2.CHAIN_APPROX_NONE)
output = img.copy()
letters = []
for idx, contour in enumerate(contours):
(x, y, w, h) = cv2.boundingRect(contour)
# print("R", idx, x, y, w, h, cv2.contourArea(contour), hierarchy[0][idx])
# hierarchy[i][0]: the index of the next contour of the same level
# hierarchy[i][1]: the index of the previous contour of the same level
# hierarchy[i][2]: the index of the first child
# hierarchy[i][3]: the index of the parent
if hierarchy[0][idx][3] == 0:
cv2.rectangle(output, (x, y), (x + w, y + h), (70, 0, 0), 1)
letter_crop = gray[y:y + h, x:x + w]
# print(letter_crop.shape)
# Resize letter canvas to square
size_max = max(w, h)
letter_square = 255 * np.ones(shape=[size_max, size_max], dtype=np.uint8)
if w > h:
# Enlarge image top-bottom
# ------
# ======
# ------
y_pos = size_max//2 - h//2
letter_square[y_pos:y_pos + h, 0:w] = letter_crop
elif w < h:
# Enlarge image left-right
# --||--
x_pos = size_max//2 - w//2
letter_square[0:h, x_pos:x_pos + w] = letter_crop
else:
letter_square = letter_crop
# Resize letter to 28x28 and add letter and its X-coordinate
letters.
append((x, w, cv2.resize(letter_square, (out_size, out_size), interpolation=cv2.INTER_AREA)))
# Sort array in place by X-coordinate
letters.sort(key=lambda x: x[0], reverse=False)
return letters
В конце мы сортируем буквы по Х-координате, также как можно видеть, мы сохраняем результаты в виде tuple (x, w, letter), чтобы из промежутков между буквами потом выделить пробелы.
Убеждаемся что все работает:
cv2.imshow("0", letters[0][2])
cv2.imshow("1", letters[1][2])
cv2.imshow("2", letters[2][2])
cv2.imshow("3", letters[3][2])
cv2.imshow("4", letters[4][2])
cv2.waitKey(0)Буквы готовы для распознавания, распознавать их мы будем с помощью сверточной сети — этот тип сетей неплохо подходит для таких задач.
Нейронная сеть (CNN) для распознавания
Исходный датасет EMNIST имеет 62 разных символа (A..Z, 0..9 и пр):
emnist_labels = [48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 97, 98, 99, 100, 101, 102, 103, 104, 105, 106, 107, 108, 109, 110, 111, 112, 113, 114, 115, 116, 117, 118, 119, 120, 121, 122] Нейронная сеть соответственно, имеет 62 выхода, на входе она будет получать изображения 28х28, после распознавания «1» будет на соответствующем выходе сети.
Создаем модель сети.
from tensorflow import keras from keras.models import Sequential from keras import optimizers from keras.layers import Convolution2D, MaxPooling2D, Dropout, Flatten, Dense, Reshape, LSTM, BatchNormalization from keras.optimizers import SGD, RMSprop, Adam from keras import backend as K from keras.constraints import maxnorm import tensorflow as tf def emnist_model(): model = Sequential() model.add(Convolution2D(filters=32, kernel_size=(3, 3), padding='valid', input_shape=(28, 28, 1), activation='relu')) model.add(Convolution2D(filters=64, kernel_size=(3, 3), activation='relu')) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Dropout(0.25)) model.add(Flatten()) model.add(Dense(512, activation='relu')) model.add(Dropout(0.5)) model.add(Dense(len(emnist_labels), activation='softmax')) model.compile(loss='categorical_crossentropy', optimizer='adadelta', metrics=['accuracy']) return model
Как можно видеть, это классическая сверточная сеть, выделяющая определенные признаки изображения (количество фильтров 32 и 64), к «выходу» которой подсоединена «линейная» сеть MLP, формирующая окончательный результат.
Обучение нейронной сети
Переходим к самому продолжительному этапу — обучению сети. Для этого мы возьмем базу EMNIST, скачать которую можно по ссылке (размер архива 536Мб).
Для чтения базы воспользуемся библиотекой idx2numpy. Подготовим данные для обучения и валидации.
import idx2numpy emnist_path = '/home/Documents/TestApps/keras/emnist/' X_train = idx2numpy.convert_from_file(emnist_path + 'emnist-byclass-train-images-idx3-ubyte') y_train = idx2numpy.convert_from_file(emnist_path + 'emnist-byclass-train-labels-idx1-ubyte') X_test = idx2numpy.convert_from_file(emnist_path + 'emnist-byclass-test-images-idx3-ubyte') y_test = idx2numpy.convert_from_file(emnist_path + 'emnist-byclass-test-labels-idx1-ubyte') X_train = np.reshape(X_train, (X_train.shape[0], 28, 28, 1)) X_test = np.reshape(X_test, (X_test.shape[0], 28, 28, 1)) print(X_train.shape, y_train.shape, X_test.shape, y_test.shape, len(emnist_labels)) k = 10 X_train = X_train[:X_train.shape[0] // k] y_train = y_train[:y_train.shape[0] // k] X_test = X_test[:X_test.shape[0] // k] y_test = y_test[:y_test.shape[0] // k] # Normalize X_train = X_train.astype(np.float32) X_train /= 255.0 X_test = X_test.astype(np.float32) X_test /= 255.0 x_train_cat = keras.utils.to_categorical(y_train, len(emnist_labels)) y_test_cat = keras.utils.to_categorical(y_test, len(emnist_labels))
Мы подготовили два набора, для обучения и валидации. Сами символы представляют собой обычные массивы, которые несложно вывести на экран:
Также мы используем лишь 1/10 датасета для обучения (параметр k), в противном случае процесс займет не менее 10 часов.
Запускаем обучение сети, в конце процесса сохраняем обученную модель на диск.
# Set a learning rate reduction
learning_rate_reduction = keras.callbacks.ReduceLROnPlateau(monitor='val_acc', patience=3, verbose=1, factor=0.5, min_lr=0.00001)
# Required for learning_rate_reduction:
keras.backend.get_session().run(tf.global_variables_initializer())
model. fit(X_train, x_train_cat, validation_data=(X_test, y_test_cat), callbacks=[learning_rate_reduction], batch_size=64, epochs=30)
model.save('emnist_letters.h5')
fit(X_train, x_train_cat, validation_data=(X_test, y_test_cat), callbacks=[learning_rate_reduction], batch_size=64, epochs=30)
model.save('emnist_letters.h5')Сам процесс обучения занимает около получаса:
Это нужно сделать только один раз, дальше мы будем пользоваться уже сохраненным файлом модели. Когда обучение закончено, все готово, можно распознавать текст.
Распознавание
Для распознавания мы загружаем модель и вызываем функцию predict_classes.
model = keras.models.load_model('emnist_letters.h5')
def emnist_predict_img(model, img):
img_arr = np.expand_dims(img, axis=0)
img_arr = 1 - img_arr/255.0
img_arr[0] = np.rot90(img_arr[0], 3)
img_arr[0] = np.fliplr(img_arr[0])
img_arr = img_arr.reshape((1, 28, 28, 1))
result = model.predict_classes([img_arr])
return chr(emnist_labels[result[0]])Как оказалось, изображения в датасете изначально были повернуты, так что нам приходится повернуть картинку перед распознаванием.
Окончательная функция, которая на входе получает файл с изображением, а на выходе дает строку, занимает всего 10 строк кода:
def img_to_str(model: Any, image_file: str):
letters = letters_extract(image_file)
s_out = ""
for i in range(len(letters)):
dn = letters[i+1][0] - letters[i][0] - letters[i][1] if i < len(letters) - 1 else 0
s_out += emnist_predict_img(model, letters[i][2])
if (dn > letters[i][1]/4):
s_out += ' '
return s_outЗдесь мы используем сохраненную ранее ширину символа, чтобы добавлять пробелы, если промежуток между буквами более 1/4 символа.
Пример использования:
model = keras.models.load_model('emnist_letters.h5')
s_out = img_to_str(model, "hello_world.png")
print(s_out)
Результат:
Забавная особенность — нейронная сеть «перепутала» букву «О» и цифру «0», что впрочем, неудивительно т.к. исходный набор EMNIST содержит рукописные буквы и цифры, которые не совсем похожи на печатные. В идеале, для распознавания экранных текстов нужно подготовить отдельный набор на базе экранных шрифтов, и уже на нем обучать нейросеть.
В идеале, для распознавания экранных текстов нужно подготовить отдельный набор на базе экранных шрифтов, и уже на нем обучать нейросеть.
Заключение
Как можно видеть, не боги горшки обжигают, и то что казалось когда-то «магией», с помощью современных библиотек делается вполне несложно.
Поскольку Python является кроссплатформенным, работать код будет везде, на Windows, Linux и OSX. Вроде Keras портирован и на iOS/Android, так что теоретически, обученную модель можно использовать и на мобильных устройствах.
Для желающих поэкспериментировать самостоятельно, исходный код под спойлером.
keras_emnist.py# Code source: [email protected]
import os
# Force CPU
# os.environ["CUDA_VISIBLE_DEVICES"] = "-1"
# Debug messages
# 0 = all messages are logged (default behavior)
# 1 = INFO messages are not printed
# 2 = INFO and WARNING messages are not printed
# 3 = INFO, WARNING, and ERROR messages are not printed
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3'
import cv2
import imghdr
import numpy as np
import pathlib
from tensorflow import keras
from keras. models import Sequential
from keras import optimizers
from keras.layers import Convolution2D, MaxPooling2D, Dropout, Flatten, Dense, Reshape, LSTM, BatchNormalization
from keras.optimizers import SGD, RMSprop, Adam
from keras import backend as K
from keras.constraints import maxnorm
import tensorflow as tf
from scipy import io as spio
import idx2numpy # sudo pip3 install idx2numpy
from matplotlib import pyplot as plt
from typing import *
import time
# Dataset:
# https://www.nist.gov/node/1298471/emnist-dataset
# https://www.itl.nist.gov/iaui/vip/cs_links/EMNIST/gzip.zip
def cnn_print_digit(d):
print(d.shape)
for x in range(28):
s = ""
for y in range(28):
s += "{0:.1f} ".format(d[28*y + x])
print(s)
def cnn_print_digit_2d(d):
print(d.shape)
for y in range(d.shape[0]):
s = ""
for x in range(d.shape[1]):
s += "{0:.1f} ".format(d[x][y])
print(s)
emnist_labels = [48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 97, 98, 99, 100, 101, 102, 103, 104, 105, 106, 107, 108, 109, 110, 111, 112, 113, 114, 115, 116, 117, 118, 119, 120, 121, 122]
def emnist_model():
model = Sequential()
model.
models import Sequential
from keras import optimizers
from keras.layers import Convolution2D, MaxPooling2D, Dropout, Flatten, Dense, Reshape, LSTM, BatchNormalization
from keras.optimizers import SGD, RMSprop, Adam
from keras import backend as K
from keras.constraints import maxnorm
import tensorflow as tf
from scipy import io as spio
import idx2numpy # sudo pip3 install idx2numpy
from matplotlib import pyplot as plt
from typing import *
import time
# Dataset:
# https://www.nist.gov/node/1298471/emnist-dataset
# https://www.itl.nist.gov/iaui/vip/cs_links/EMNIST/gzip.zip
def cnn_print_digit(d):
print(d.shape)
for x in range(28):
s = ""
for y in range(28):
s += "{0:.1f} ".format(d[28*y + x])
print(s)
def cnn_print_digit_2d(d):
print(d.shape)
for y in range(d.shape[0]):
s = ""
for x in range(d.shape[1]):
s += "{0:.1f} ".format(d[x][y])
print(s)
emnist_labels = [48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 97, 98, 99, 100, 101, 102, 103, 104, 105, 106, 107, 108, 109, 110, 111, 112, 113, 114, 115, 116, 117, 118, 119, 120, 121, 122]
def emnist_model():
model = Sequential()
model. add(Convolution2D(filters=32, kernel_size=(3, 3), padding='valid', input_shape=(28, 28, 1), activation='relu'))
model.add(Convolution2D(filters=64, kernel_size=(3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(len(emnist_labels), activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adadelta', metrics=['accuracy'])
return model
def emnist_model2():
model = Sequential()
# In Keras there are two options for padding: same or valid. Same means we pad with the number on the edge and valid means no padding.
model.add(Convolution2D(filters=32, kernel_size=(3, 3), activation='relu', padding='same', input_shape=(28, 28, 1)))
model.add(MaxPooling2D((2, 2)))
model.add(Convolution2D(64, (3, 3), activation='relu', padding='same'))
model.add(MaxPooling2D((2, 2)))
model.
add(Convolution2D(filters=32, kernel_size=(3, 3), padding='valid', input_shape=(28, 28, 1), activation='relu'))
model.add(Convolution2D(filters=64, kernel_size=(3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(len(emnist_labels), activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adadelta', metrics=['accuracy'])
return model
def emnist_model2():
model = Sequential()
# In Keras there are two options for padding: same or valid. Same means we pad with the number on the edge and valid means no padding.
model.add(Convolution2D(filters=32, kernel_size=(3, 3), activation='relu', padding='same', input_shape=(28, 28, 1)))
model.add(MaxPooling2D((2, 2)))
model.add(Convolution2D(64, (3, 3), activation='relu', padding='same'))
model.add(MaxPooling2D((2, 2)))
model. add(Convolution2D(128, (3, 3), activation='relu', padding='same'))
model.add(MaxPooling2D((2, 2)))
# model.add(Conv2D(128, (3, 3), activation='relu', padding='same'))
# model.add(MaxPooling2D((2, 2)))
## model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(len(emnist_labels), activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adadelta', metrics=['accuracy'])
return model
def emnist_model3():
model = Sequential()
model.add(Convolution2D(filters=32, kernel_size=(3, 3), padding='same', input_shape=(28, 28, 1), activation='relu'))
model.add(Convolution2D(filters=32, kernel_size=(3, 3), padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Convolution2D(filters=64, kernel_size=(3, 3), padding='same', activation='relu'))
model.add(Convolution2D(filters=64, kernel_size=(3, 3), padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512, activation="relu"))
model.add(Dropout(0.5))
model.add(Dense(len(emnist_labels), activation="softmax"))
model.compile(loss='categorical_crossentropy', optimizer=RMSprop(lr=0.001, rho=0.9, epsilon=1e-08, decay=0.0), metrics=['accuracy'])
return model
def emnist_train(model):
t_start = time.time()
emnist_path = 'D:\\Temp\\1\\'
X_train = idx2numpy.convert_from_file(emnist_path + 'emnist-byclass-train-images-idx3-ubyte')
y_train = idx2numpy.convert_from_file(emnist_path + 'emnist-byclass-train-labels-idx1-ubyte')
X_test = idx2numpy.convert_from_file(emnist_path + 'emnist-byclass-test-images-idx3-ubyte')
y_test = idx2numpy.convert_from_file(emnist_path + 'emnist-byclass-test-labels-idx1-ubyte')
X_train = np.reshape(X_train, (X_train.shape[0], 28, 28, 1))
X_test = np.reshape(X_test, (X_test.shape[0], 28, 28, 1))
print(X_train.shape, y_train.shape, X_test.shape, y_test.shape, len(emnist_labels))
# Test:
k = 10
X_train = X_train[:X_train.shape[0] // k]
y_train = y_train[:y_train.shape[0] // k]
X_test = X_test[:X_test.shape[0] // k]
y_test = y_test[:y_test.shape[0] // k]
# Normalize
X_train = X_train.astype(np.float32)
X_train /= 255.0
X_test = X_test.astype(np.float32)
X_test /= 255.0
x_train_cat = keras.utils.to_categorical(y_train, len(emnist_labels))
y_test_cat = keras.utils.to_categorical(y_test, len(emnist_labels))
# Set a learning rate reduction
learning_rate_reduction = keras.callbacks.ReduceLROnPlateau(monitor='val_acc', patience=3, verbose=1, factor=0.5, min_lr=0.00001)
# Required for learning_rate_reduction:
keras.backend.get_session().run(tf.global_variables_initializer())
model.fit(X_train, x_train_cat, validation_data=(X_test, y_test_cat), callbacks=[learning_rate_reduction], batch_size=64, epochs=30)
print("Training done, dT:", time.time() - t_start)
def emnist_predict(model, image_file):
img = keras.preprocessing.image.load_img(image_file, target_size=(28, 28), color_mode='grayscale')
emnist_predict_img(model, img)
def emnist_predict_img(model, img):
img_arr = np.expand_dims(img, axis=0)
img_arr = 1 - img_arr/255.0
img_arr[0] = np.rot90(img_arr[0], 3)
img_arr[0] = np.fliplr(img_arr[0])
img_arr = img_arr.reshape((1, 28, 28, 1))
result = model.predict_classes([img_arr])
return chr(emnist_labels[result[0]])
def letters_extract(image_file: str, out_size=28):
img = cv2.imread(image_file)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
ret, thresh = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY)
img_erode = cv2.erode(thresh, np.ones((3, 3), np.uint8), iterations=1)
# Get contours
contours, hierarchy = cv2.findContours(img_erode, cv2.RETR_TREE, cv2.CHAIN_APPROX_NONE)
output = img.copy()
letters = []
for idx, contour in enumerate(contours):
(x, y, w, h) = cv2.boundingRect(contour)
# print("R", idx, x, y, w, h, cv2.contourArea(contour), hierarchy[0][idx])
# hierarchy[i][0]: the index of the next contour of the same level
# hierarchy[i][1]: the index of the previous contour of the same level
# hierarchy[i][2]: the index of the first child
# hierarchy[i][3]: the index of the parent
if hierarchy[0][idx][3] == 0:
cv2.rectangle(output, (x, y), (x + w, y + h), (70, 0, 0), 1)
letter_crop = gray[y:y + h, x:x + w]
# print(letter_crop.shape)
# Resize letter canvas to square
size_max = max(w, h)
letter_square = 255 * np.ones(shape=[size_max, size_max], dtype=np.uint8)
if w > h:
# Enlarge image top-bottom
# ------
# ======
# ------
y_pos = size_max//2 - h//2
letter_square[y_pos:y_pos + h, 0:w] = letter_crop
elif w < h:
# Enlarge image left-right
# --||--
x_pos = size_max//2 - w//2
letter_square[0:h, x_pos:x_pos + w] = letter_crop
else:
letter_square = letter_crop
# Resize letter to 28x28 and add letter and its X-coordinate
letters.append((x, w, cv2.resize(letter_square, (out_size, out_size), interpolation=cv2.INTER_AREA)))
# Sort array in place by X-coordinate
letters.sort(key=lambda x: x[0], reverse=False)
# cv2.imshow("Input", img)
# # cv2.imshow("Gray", thresh)
# cv2.imshow("Enlarged", img_erode)
# cv2.imshow("Output", output)
# cv2.imshow("0", letters[0][2])
# cv2.imshow("1", letters[1][2])
# cv2.imshow("2", letters[2][2])
# cv2.imshow("3", letters[3][2])
# cv2.imshow("4", letters[4][2])
# cv2.waitKey(0)
return letters
def img_to_str(model: Any, image_file: str):
letters = letters_extract(image_file)
s_out = ""
for i in range(len(letters)):
dn = letters[i+1][0] - letters[i][0] - letters[i][1] if i < len(letters) - 1 else 0
s_out += emnist_predict_img(model, letters[i][2])
if (dn > letters[i][1]/4):
s_out += ' '
return s_out
if __name__ == "__main__":
# model = emnist_model()
# emnist_train(model)
# model.save('emnist_letters.h5')
model = keras.models.load_model('emnist_letters.h5')
s_out = img_to_str(model, "hello_world.png")
print(s_out)
add(Convolution2D(128, (3, 3), activation='relu', padding='same'))
model.add(MaxPooling2D((2, 2)))
# model.add(Conv2D(128, (3, 3), activation='relu', padding='same'))
# model.add(MaxPooling2D((2, 2)))
## model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(len(emnist_labels), activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adadelta', metrics=['accuracy'])
return model
def emnist_model3():
model = Sequential()
model.add(Convolution2D(filters=32, kernel_size=(3, 3), padding='same', input_shape=(28, 28, 1), activation='relu'))
model.add(Convolution2D(filters=32, kernel_size=(3, 3), padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Convolution2D(filters=64, kernel_size=(3, 3), padding='same', activation='relu'))
model.add(Convolution2D(filters=64, kernel_size=(3, 3), padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512, activation="relu"))
model.add(Dropout(0.5))
model.add(Dense(len(emnist_labels), activation="softmax"))
model.compile(loss='categorical_crossentropy', optimizer=RMSprop(lr=0.001, rho=0.9, epsilon=1e-08, decay=0.0), metrics=['accuracy'])
return model
def emnist_train(model):
t_start = time.time()
emnist_path = 'D:\\Temp\\1\\'
X_train = idx2numpy.convert_from_file(emnist_path + 'emnist-byclass-train-images-idx3-ubyte')
y_train = idx2numpy.convert_from_file(emnist_path + 'emnist-byclass-train-labels-idx1-ubyte')
X_test = idx2numpy.convert_from_file(emnist_path + 'emnist-byclass-test-images-idx3-ubyte')
y_test = idx2numpy.convert_from_file(emnist_path + 'emnist-byclass-test-labels-idx1-ubyte')
X_train = np.reshape(X_train, (X_train.shape[0], 28, 28, 1))
X_test = np.reshape(X_test, (X_test.shape[0], 28, 28, 1))
print(X_train.shape, y_train.shape, X_test.shape, y_test.shape, len(emnist_labels))
# Test:
k = 10
X_train = X_train[:X_train.shape[0] // k]
y_train = y_train[:y_train.shape[0] // k]
X_test = X_test[:X_test.shape[0] // k]
y_test = y_test[:y_test.shape[0] // k]
# Normalize
X_train = X_train.astype(np.float32)
X_train /= 255.0
X_test = X_test.astype(np.float32)
X_test /= 255.0
x_train_cat = keras.utils.to_categorical(y_train, len(emnist_labels))
y_test_cat = keras.utils.to_categorical(y_test, len(emnist_labels))
# Set a learning rate reduction
learning_rate_reduction = keras.callbacks.ReduceLROnPlateau(monitor='val_acc', patience=3, verbose=1, factor=0.5, min_lr=0.00001)
# Required for learning_rate_reduction:
keras.backend.get_session().run(tf.global_variables_initializer())
model.fit(X_train, x_train_cat, validation_data=(X_test, y_test_cat), callbacks=[learning_rate_reduction], batch_size=64, epochs=30)
print("Training done, dT:", time.time() - t_start)
def emnist_predict(model, image_file):
img = keras.preprocessing.image.load_img(image_file, target_size=(28, 28), color_mode='grayscale')
emnist_predict_img(model, img)
def emnist_predict_img(model, img):
img_arr = np.expand_dims(img, axis=0)
img_arr = 1 - img_arr/255.0
img_arr[0] = np.rot90(img_arr[0], 3)
img_arr[0] = np.fliplr(img_arr[0])
img_arr = img_arr.reshape((1, 28, 28, 1))
result = model.predict_classes([img_arr])
return chr(emnist_labels[result[0]])
def letters_extract(image_file: str, out_size=28):
img = cv2.imread(image_file)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
ret, thresh = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY)
img_erode = cv2.erode(thresh, np.ones((3, 3), np.uint8), iterations=1)
# Get contours
contours, hierarchy = cv2.findContours(img_erode, cv2.RETR_TREE, cv2.CHAIN_APPROX_NONE)
output = img.copy()
letters = []
for idx, contour in enumerate(contours):
(x, y, w, h) = cv2.boundingRect(contour)
# print("R", idx, x, y, w, h, cv2.contourArea(contour), hierarchy[0][idx])
# hierarchy[i][0]: the index of the next contour of the same level
# hierarchy[i][1]: the index of the previous contour of the same level
# hierarchy[i][2]: the index of the first child
# hierarchy[i][3]: the index of the parent
if hierarchy[0][idx][3] == 0:
cv2.rectangle(output, (x, y), (x + w, y + h), (70, 0, 0), 1)
letter_crop = gray[y:y + h, x:x + w]
# print(letter_crop.shape)
# Resize letter canvas to square
size_max = max(w, h)
letter_square = 255 * np.ones(shape=[size_max, size_max], dtype=np.uint8)
if w > h:
# Enlarge image top-bottom
# ------
# ======
# ------
y_pos = size_max//2 - h//2
letter_square[y_pos:y_pos + h, 0:w] = letter_crop
elif w < h:
# Enlarge image left-right
# --||--
x_pos = size_max//2 - w//2
letter_square[0:h, x_pos:x_pos + w] = letter_crop
else:
letter_square = letter_crop
# Resize letter to 28x28 and add letter and its X-coordinate
letters.append((x, w, cv2.resize(letter_square, (out_size, out_size), interpolation=cv2.INTER_AREA)))
# Sort array in place by X-coordinate
letters.sort(key=lambda x: x[0], reverse=False)
# cv2.imshow("Input", img)
# # cv2.imshow("Gray", thresh)
# cv2.imshow("Enlarged", img_erode)
# cv2.imshow("Output", output)
# cv2.imshow("0", letters[0][2])
# cv2.imshow("1", letters[1][2])
# cv2.imshow("2", letters[2][2])
# cv2.imshow("3", letters[3][2])
# cv2.imshow("4", letters[4][2])
# cv2.waitKey(0)
return letters
def img_to_str(model: Any, image_file: str):
letters = letters_extract(image_file)
s_out = ""
for i in range(len(letters)):
dn = letters[i+1][0] - letters[i][0] - letters[i][1] if i < len(letters) - 1 else 0
s_out += emnist_predict_img(model, letters[i][2])
if (dn > letters[i][1]/4):
s_out += ' '
return s_out
if __name__ == "__main__":
# model = emnist_model()
# emnist_train(model)
# model.save('emnist_letters.h5')
model = keras.models.load_model('emnist_letters.h5')
s_out = img_to_str(model, "hello_world.png")
print(s_out)
Как обычно, всем удачных экспериментов.
Как определить шрифт по картинке и не только. Обзор лучших сервисов
Любому дизайнер сталкивается с проблемой выбора подходящего шрифта. Иногда необходимо найти шрифт по картинке, определить шрифт по образцу. Особенно это актуально для веб-разработчиков при подборе шрифтов для будущего сайта. В этом случае на помощь приходят специальные сервисы, о которых будет подробно рассказано в этой статье.
Итак, проведем эксперимент. Для этого я написала в фотошопе тест с помощью выбранного шрифта и буду определять в различных сервисах, какой шрифт я использовала. Таким образом, определю, какой сервис лучший.
Вы можете вместе со мной пройтись по сервисам, а для тестирования использовать мою картинку. Возможно, что вы придете к другим выводам
.Вот это надпись:
Вам же я рекомендую перед тем, как определить шрифт, немного обработайте изображение – отсеките ненужные поля, добавьте контрастность или вовсе избавьтесь от фона.
Первый сервис, с помощью которого мы будет определять шрифт —
- WhatFontIs, адрес — http://www.whatfontis.com/
Нажмите на кнопку “Browse” для выбора картинки с текстом. Далее вам предстоит выбрать один пункт и даух:
- The background color is lighter than the characters color – означает, что цвет фона светлее цвета букв и символов,
- The background color is dark, please invert colors – светлый текст на темном фоне.
Теперь нажмите на кнопку “Continue” для продолжения.
В новом окне вам предстоит идентифицировать буквы – введите каждую букву в соответствующую для нее поле.
Снова кнопка “Continue” и перед нами список наиболее похожих шрифтов. Кстати, сервис правильно определил шрифт. Первый вариант – правильный.
Оценка сервиса – 5 баллов.
- What The Font, адрес http://www.myfonts.com/WhatTheFont/
xdfЗдесь вам тоже нужно загрузить картинку с текстом на сервис или вставить прямую ссылку на изображение. На рисунке-схеме показано,какая должны быть картинка для правильной работы сервиса. Буквы и символы должны быть четкими, не должны сливаться, размер шрифта не менее 100 пикчелей и текст должен быть выровнен по горизонтальной линии.
После выбора картинки с текстом нажмите “Continue”. Приятно, что сервис частично сам идентифицирует символы и лишь сомнительные вам придется ввести вручную.
Я добавила букву f, исправила S на i и дописала точку в свободное поле. Снова “Continue”.
И этот сервис отлично справился с заданием, правильно угадав шрифт. Единственный недостаток сайта What The Font это меньшее количество шрифтов по сравнению с WhatFontIs.
Оценка сервиса – 5 баллов.
- Это были сервисы, которые определяют шрифт по картинке. Однако, есть сайты, где работает поиск шрифта по отдельным отличительным элементам.
Identifont адрес http://www.identifont.com/index.htmlЕсли вы знаете точно, как выглядит шрифт, если у вас есть образцы букв, то вы можете выполнить небольшой тест по внешнему виду шрифта и найти его название.
Примеры вопросов, на которые вам предстоит ответить:
- есть ли у шрифта засечки,
- название: просто введите название шрифта или его часть,
- похожие шрифты – введите название похожих шрифтов, на тот который вы ищите,
- дизайнер шрифта. Если известен дизайнер, или издетель шрифта, то вы можете включить его в поиск.
Примечание: сервис англоязычный, но даже бе нания языка в нем легко разобраться, так как вопросы подкреплены рисунками с обозначениями.
Мне не удалось с помощью этого сервиса найти нужный шрифт. Тест на пройден.
- Font Finder Firefox Add-On — дополнения для Firefox, которое определяет какой шрифт используется на сайте. Просто выделите слово на сайте, и дополнение определит шрифт и стиль CSS.
Ссылка на дополнение https://addons.mozilla.org/en-US/firefox/addon/font-finder/ - Bowfin Print Works — http://www.bowfinprintworks.com/SerifGuide/serifsearch.php
Сервис, который основан на вашем представлении о том, как выглядит шрифт, вам нужно провести детальный анализ букв и их элементов.
С помощью данного сервиса также не удалось определить шрифт.
Надеюсь, что теперь найти нужный шрифт, узнать его название не будет для вас проблемой.
7 лучших бесплатных программ для оптического распознавания текста для преобразования изображений в текст
Хотите бесплатное программное обеспечение для распознавания текста? В этой статье собраны семь лучших программ, которые ничего не стоят.
Что такое OCR?
Программа оптического распознавания символов (OCR) преобразует изображения или даже рукописный текст в текст.Программное обеспечение OCR анализирует документ и сравнивает его со шрифтами, хранящимися в их базе данных, и / или отмечая особенности, характерные для символов. Некоторые программы OCR также используют программу проверки правописания, чтобы «угадывать» нераспознанные слова. Трудно добиться 100% точности, но большая часть программного обеспечения стремится к точному приближению.
Программное обеспечение OCR может помочь студентам, исследователям и офисным работникам повысить производительность труда.Итак, давайте поиграем еще с несколькими и найдем лучшее программное обеспечение для распознавания текста, соответствующее вашим потребностям.
1.OCR с использованием Microsoft OneNote
Microsoft OneNote имеет расширенные функции распознавания текста, которые работают как с изображениями, так и с рукописными заметками.
- Перетащите отсканированное изображение или сохраненное изображение в OneNote.Вы также можете использовать OneNote для вырезания части экрана или изображения в OneNote.
- Щелкните правой кнопкой мыши вставленное изображение и выберите Копировать текст с изображения . Скопированный оптически распознанный текст попадает в буфер обмена, и теперь вы можете вставить его обратно в OneNote или в любую программу, например Word или Блокнот.
OneNote также может извлекать текст из многостраничной распечатки одним щелчком мыши.Вставьте распечатку нескольких страниц в OneNote, а затем щелкните правой кнопкой мыши текущую выбранную страницу.
- Щелкните Копировать текст с этой страницы распечатки , чтобы получить текст только с этой выбранной страницы.
- Щелкните Копировать текст со всех страниц распечатки , чтобы скопировать текст со всех страниц одним снимком, как вы можете видеть ниже.
Обратите внимание, что точность OCR зависит также от качества фотографии.Вот почему оптическое распознавание почерка все еще немного нечеткое для OneNote и другого программного обеспечения для распознавания текста на рынке. Тем не менее, это одна из ключевых функций OneNote, которую вы должны использовать при каждой возможности.
Хотите узнать, как OneNote сравнивается с платным программным обеспечением OCR? Прочтите наше сравнение OneNote и OmniPage.
2.SimpleOCR
Трудность, с которой я столкнулся с распознаванием рукописного ввода с помощью инструментов MS, могла найти решение в SimpleOCR.Но программа предлагает распознавание рукописного ввода только в виде 14-дневной бесплатной пробной версии. Распознавание машинной печати, хотя не имеет никаких ограничений для .
Программное обеспечение выглядит устаревшим, так как не обновлялось с версии 3.1, но вы все равно можете попробовать его из-за простоты.
- Настройте его на чтение прямо со сканера или добавив страницу (форматы JPG, TIFF, BMP).
- SimpleOCR предлагает некоторый контроль над преобразованием с помощью функций выделения текста, выбора изображения и игнорирования текста.
- Преобразование в текст переводит процесс с на этап проверки ; пользователь может исправить неточности в преобразованном тексте с помощью встроенной проверки орфографии.
- Конвертированный файл можно сохранить в формате DOC или TXT.
SimpleOCR отлично справлялся с обычным текстом, но его обработка многоколоночных макетов разочаровывала. На мой взгляд, точность преобразования инструментов Microsoft была значительно лучше, чем SimpleOCR.
Загрузить: SimpleOCR для Windows (бесплатно, платно)
3.Сканирование фотографий
Photo Scan — это бесплатное приложение для распознавания текста для Windows 10, которое можно загрузить из Microsoft Store.Приложение, созданное Define Studios, поддерживается рекламой, но это не мешает работе. Приложение представляет собой сканер OCR и считыватель QR-кода в одном флаконе.
Наведите приложение на изображение или распечатку файла.Вы также можете использовать веб-камеру вашего ПК, чтобы дать ему изображение. Распознанный текст отображается в соседнем окне.
Функция преобразования текста в речь выделяется. Щелкните значок динамика, и приложение прочитает вслух то, что только что отсканировало.
С рукописным текстом не очень хорошо, но распознания печатного текста было достаточно.Когда все будет сделано, вы можете сохранить текст OCR в нескольких форматах, таких как текст, HTML, Rich Text, XML, формат журнала и т. Д.
Загрузить: Photo Scan (Бесплатная покупка в приложении)
4.(a9t9) Бесплатное приложение OCR для Windows
(a9t9) Бесплатное программное обеспечение для распознавания текста — это приложение для универсальной платформы Windows.Таким образом, вы можете использовать его с любым устройством Windows, которое у вас есть. Существует также онлайн-эквивалент OCR, работающий на том же API.
(a9t9) поддерживает 21 язык для преобразования изображений и PDF в текст.Приложение также можно использовать бесплатно, а поддержку рекламы можно удалить с помощью покупки в приложении. Как и большинство бесплатных программ OCR, это идея для печатных документов, а не для рукописного текста.
Загрузить: a9t9 Free OCR (бесплатно, покупка в приложении)
5.Capture2Text
Capture2Text — это бесплатное программное обеспечение для распознавания текста для Windows 10, которое дает вам сочетания клавиш для быстрого распознавания текста на экране.Также не требует установки.
Используйте комбинацию клавиш по умолчанию WinKey + Q , чтобы активировать процесс распознавания текста.Затем вы можете использовать мышь, чтобы выбрать часть, которую хотите захватить. Нажмите Enter, и выделение будет оптически распознано. Захваченный и преобразованный текст появится во всплывающем окне и также будет скопирован в буфер обмена.
Capture2Text использует движок Google OCR и поддерживает более 100 языков.Он использует Google Translate для преобразования захваченного текста на другие языки. Загляните внутрь Settings , чтобы настроить различные параметры, предоставляемые программным обеспечением.
Загрузить: Capture2Text (бесплатно)
6.Easy Screen OCR
Capture2Text
Capture2TextСодержание
Что такое Capture2Text?
Capture2Text позволяет пользователям быстро распознавать текст на части экрана с помощью Сочетание клавиш.Полученный текст по умолчанию будет сохранен в буфер обмена.
Концептуальная иллюстрация:
Capture2Text распространяется бесплатно и под лицензией GNU General Public License.
Скачать
Последнюю версию можно найти на странице загрузки Capture2Text, размещенной на SourceForge.
Системные требования
Поддерживаемые операционные системы:
- Окна 7
- Windows 8/8.1
- Windows 10
Примечание. Поддержка Windows XP была прекращена с версии Capture2Text v4.0.
Как запустить Capture2Text (установка не требуется)
- Распакуйте содержимое ZIP-файла.
- Дважды щелкните файл Capture2Text.exe. Вы должны увидеть значок Capture2Text на в правом нижнем углу экрана (хотя он может быть скрыт, и в этом случае вы придется нажать на стрелку «Показать скрытые значки»).
Установка дополнительных языков OCR
По умолчанию Capture2Text поставляется со следующими языками: английский, французский, немецкий, японский, корейский, русский и испанский.
Выполните следующие действия, если вы хотите установить дополнительные языки OCR:
- Загрузите словарь соответствующего языка OCR.
- Откройте файл .zip, который вы только что загрузили, с помощью 7-Zip или аналогичной программы для распаковки.
- Перетащите все файлы, содержащиеся в zip-файле, в папку tessdata:
- Перезапустите Capture2Text.
Поддерживаются следующие языки OCR:
| африкаанс (африкаанс) | греческий (элл) | одия (ори) | ||
| албанский (sqi) | гуджарати (гудж) | панджаби (9017 amhari) | гаитянский (шляпа) | персидский (fas) |
| древнегреческий (grc) | иврит (иврит) | польский (польский) | ||
| арабский (ара) | хинди (хин португальский) | 9017 por)|||
| Ассамский (asm) | Венгерский (hun) | Пушту (pus) | ||
| Азербайджанский (aze) | Исландский (isl) | Румынский (ron) | ||
| Баскский (eus) | Индийский (inc) | Русский (rus) | ||
| Белорусский (bel) | Индонезийский (ind) | Санскрит (san) | ||
| Бенгальский (ben) | (iku)сербский (srp) | |||
| боснийский (bos) | ирландский (gle) | сингальский (sin) | ||
| болгарский (bul) | итальянский (ita) | словацкий (sl) | ||
| бирманский (mya) | японский (jpn) | словенский (slv) | ||
| каталонский (cat) | яванский (jav) | испанский (спа) | ||
| Себуано (ceb) | Каннада (кан) | Суахили (swa) | ||
| Центральный кхмерский (khm) | Казахский (kaz) | Шведский (swe) | ||
| Чероки ( | ) Чероки ( | ) kir) | Сирийский (syr) | |
| Китайский — упрощенный (chi_sim) | Корейский (kor) | Тагальский (tgl) | ||
| Китайский традиционный (chi_tra) | (kru) tgk) | |||
| Хорватский (hrv) | Лаосский (lao) | Тамильский (tam) | ||
| Чешский (ces) | Latin (lat) | Telugu (tel) | латышский (lav) | тайский (tha) |
| голландский (nld) | литовский (lit) | тибетский (bod) | ||
| дзонгха (dzo) | македонский | Тигринья (tir) | ||
| Английский (eng) | Малайский (msa) | Турецкий (tur) | ||
| Эсперанто (epo) | Малаялам (mal) | Мальтийский (mlt) | Украинский (ukr) | |
| Финский (фин) | Marathi (mar) | Урду (urd) | ||
| Frankish (frk) | Математика / уравнения (equ) | Узбекский (uzb) | ||
| Французский (fra) | Среднеанглийский (1100-1500) (enm) | Вьетнамский (vie) | ||
| Галицкий (glg) | Среднефранцузский (1400-1600) (frm) | валлийский (cym) | ||
| грузинский (kat) | непальский (nep) | идиш (yid) | ||
| немецкий (deu) | норвежский (норвежский) |
Как выполнить стандартное распознавание текста
Выполните следующие действия, чтобы выполнить стандартный захват OCR с помощью окна захвата:
- Поместите указатель мыши в верхний левый угол текста, который нужно OCR.
- Нажмите горячую клавишу OCR (Windows Key + Q), чтобы начать захват OCR.
- Переместите указатель мыши, чтобы изменить размер синего поля захвата над текстом, который нужно OCR. Вы можете удерживать правую кнопку мыши и перетаскивать, чтобы переместить весь блок захвата.
- Нажмите горячую клавишу OCR еще раз (или щелкните левой кнопкой мыши или нажмите ENTER), чтобы завершить захват OCR. Текст OCR будет помещен в буфер обмена, и появится всплывающее окно, показывающее захваченный текст (всплывающее окно может быть отключено в настройках).
Как и для всех снимков OCR, вы должны вручную выбрать язык, который вы хотите OCR, в настройках.
Чтобы изменить язык оптического распознавания текста, щелкните правой кнопкой мыши значок Capture2Text на панели задач, выберите параметр «Язык оптического распознавания текста», а затем выберите нужный язык.
Для быстрого переключения между 3 языками используйте клавиши быстрого доступа к языку OCR: Клавиша Windows + 1, Клавиша Windows + 2 и Клавиша Windows + 3. Языки быстрого доступа можно указать в настройках.
Если выбран китайский или японский язык, необходимо указать текст направление (вертикальное / горизонтальное / авто) с использованием направления текста горячая клавиша: Windows Key + O. Если выбрано авто, то при ширина захвата более чем вдвое превышает высоту, в противном случае вертикальная будет используемый. Направление текста также влияет на то, как фуригана удаляется из японского текста.
(для японского) Capture2Text попытается автоматически удалить фуригану.
Как выполнить оптическое распознавание текста строки
Capture2Text может автоматически захватывать строку текста, ближайшую к указателю мыши.
Выполните следующие действия, чтобы выполнить оптическое распознавание текста строки:
- Наведите указатель мыши на строку текста, которую нужно захватить, или рядом с ней.
- Нажмите горячую клавишу Text Line OCR Capture (Windows Key + E).
- Capture2Text выделит захваченный текст и сохранит результат распознавания текста в буфер обмена.
Пример:
Как выполнить захват OCR прямой текстовой строки
Capture2Text может автоматически захватывать строку текста, начиная с символа, ближайшего к указателю мыши, и продвигаясь вперед.
Выполните следующие действия для выполнения прямого распознавания текста строки:
- Наведите указатель мыши на символ, с которого нужно начать, или рядом с ним.
- Нажмите горячую клавишу Захват OCR вперед текстовой строки (Windows + W).
- Capture2Text выделит захваченный текст и сохранит результат распознавания текста в буфер обмена.
Пример:
Как выполнить захват OCR пузырьков
Capture2Text может автоматически захватывать текст, содержащийся в пузыре речи / мысли комиксов, если пузырь полностью закрыт.
Выполните следующие действия, чтобы выполнить захват OCR в виде пузырьков:
- Поместите указатель мыши в пустую часть пузыря (не на текст).
- Нажмите горячую клавишу «Захват OCR» (Клавиша Windows + S).
- Capture2Text выделит захваченный текст и сохранит результат распознавания текста в буфер обмена.
Пример:
Как указать активный язык OCR
Чтобы указать активный язык OCR, щелкните правой кнопкой мыши значок в области уведомлений, выберите Язык OCR и выберите языки OCR из списка:
Перевод
Чтобы включить функцию перевода, сначала откройте диалоговое окно настроек (щелкните правой кнопкой мыши значок в области уведомлений и выберите «Настройки… «) и щелкнув вкладку» Перевести «.
Установите флажок «Добавить перевод в буфер обмена», чтобы добавить переведенный текст в буфер обмена с помощью предоставленного разделителя. Установите флажок «Показать перевод во всплывающем окне», чтобы отображать переведенный текст рядом с текстом OCR во всплывающем окне. Например:.Каждый установленный язык OCR может быть переведен на другой язык.
Примечание 1: Некоторые языки OCR не поддерживают перевод.Неподдерживаемые языки отображаться не будут.
Примечание 2: Для перевода требуется доступ в Интернет.
Настройки
Щелкните правой кнопкой мыши значок Capture2Text на панели задач в правом нижнем углу экрана, а затем выберите параметр «Настройки …», чтобы открыть диалоговое окно «Настройки». Вы можете навести указатель мыши на многие метки параметров, чтобы отобразить полезную подсказку, объясняющую этот параметр.
На вкладке «Горячие клавиши» можно указать, какие клавиши и модификаторы использовать для каждой горячей клавиши.Чтобы отключить горячую клавишу, выберите «
Текущий язык OCR: укажите используемый активный язык OCR. Вы также можете указать активный язык OCR в меню значка на панели задач.
Quick-Access Languages: языки, используемые для каждой из горячих клавиш быстрого доступа.
Белый список. Сообщите механизму распознавания текста, что захваченный текст будет содержать только указанные символы.
Черный список: Сообщите механизму OCR, что захваченный текст никогда не будет содержать указанные символы.
Ориентация текста: ориентация текста, который будет записан. Этот параметр используется только в том случае, если в качестве активного языка распознавания выбран китайский или японский. Если выбран параметр «Авто», будет использоваться горизонтальное положение, когда ширина захвата более чем в два раза превышает высоту, в противном случае будет использоваться вертикальное. Направление текста также влияет на то, как фуригана удаляется из японского текста. Вы также можете указать ориентацию текста в меню значка на панели задач или с помощью горячей клавиши «Ориентация текста».
Файл конфигурации Tesseract: расширенная функция, позволяющая указать файл конфигурации Tesseract.
Trim Capture: во время предварительной обработки OCR обрезайте захваченное изображение до пикселей переднего плана и добавьте тонкую границу. Точность распознавания текста будет более стабильной и даже может быть улучшена.
Deskew Capture: во время предварительной обработки OCR попытайтесь компенсировать наклон текста, обнаруженный при захвате OCR.
Содержит параметры для настройки автоматических захватов. Чтобы получить дополнительную информацию, наведите указатель мыши на метки параметров.
Позволяет указать цвета поля захвата OCR.Прозрачность можно изменить, настроив значение «Альфа-канал» в диалоговом окне выбора цвета.
Позволяет указать положение, цвет и шрифт предварительного просмотра. Вы можете отключить предварительный просмотр, сняв флажок «Показать окно предварительного просмотра».
Сохранить в буфер обмена: сохранить захваченный текст OCR в буфер обмена.
Показать всплывающее окно: Показать захваченный текст OCR во всплывающем окне:
Сохранять разрывы строк: установите этот флажок, если вы не хотите, чтобы символы возврата каретки и перевода строки удалялись из захваченного текста.
Logging: позволяет сохранять все записи в указанный файл в указанном формате. В формате могут использоваться следующие токены: $ {capture}, $ {translation}, $ {timestamp}, $ {linebreak}, $ {tab}. Формат по умолчанию: «$ {capture} $ {linebreak}».
Вызов исполняемого файла: расширенная функция, позволяющая вызывать исполняемый файл после завершения распознавания текста. Могут использоваться следующие токены: $ {capture}, $ {translation}, $ {timestamp}. Пример:
C: \ Anaconda3 \ python.exe "C: \ Scripts \ test.py" "$ {capture}" "$ {translation}"
Позволяет выполнять замену текста. Поддерживает регулярные выражения. Текст слева будет заменен текстом справа. Для каждого языка OCR могут быть указаны разные замены.
См. Раздел перевода.
Эта страница позволяет вам включить функцию преобразования текста в речь, установить громкость и выбрать параметры (голос, скорость, высота тона) для использования для каждого языка OCR.
Включить преобразование текста в речь: включить преобразование текста в речь при захвате текста.
Если этот параметр отмечен и голос не установлен на «
Громкость: основная громкость функции преобразования текста в речь. Применимо ко всем языкам.
Язык OCR: укажите параметры речи для выбранного языка OCR.
- Скорость: Скорость преобразования текста в речь.
- Pitch: Высота голоса для преобразования текста в речь.
- Голос: голос для преобразования текста в речь. Установите значение «
», чтобы отключить функцию преобразования текста в речь только для выбранного языка OCR.
Предварительный просмотр: предварительный просмотр текущей скорости, высоты тона и голоса.
Параметры командной строки
Использование: Capture2Text_CLI.exe [параметры]
Capture2Text можно использовать для распознавания файлов изображений или части экрана.Примеры:
Capture2Text_CLI.exe --screen-rect "400 200 600 300"
Capture2Text_CLI.exe --vertical -l "Китайский - упрощенный" -i img1.png
Capture2Text_CLI.exe -i img1.png -i img2.jpg -o result.txt
Capture2Text_CLI.exe -l японский -f "C: \ Temp \ image_files.txt"
Capture2Text_CLI.exe --show-languages
Параметры:
- ?, -h, --help Отображает эту справку.
-v, --version Отображает информацию о версии.
-b, --line-breaks Не удалять разрывы строк из текста OCR.-d, --debug Выводить захваченное изображение и предварительно обработанное
изображение для отладки.
--debug-timestamp Добавить метку времени для отладки изображений, когда
используя опцию -d.
-f, --images-file <файл> Файл, содержащий пути файлов изображений к
OCR. Один путь на строку.
-i, --image <файл> Файл изображения для OCR.Вы можете OCR несколько
файлы изображений, например: "-i -i
-i "
-l, --language <язык> используемый язык распознавания текста. Чувствительный к регистру.
По умолчанию "английский". Использовать
--show-languages для вывода списка установленных
Языки OCR.
-o, --output-file <файл> Выводить текст OCR в этот файл.Если не
указано, будет использоваться стандартный вывод.
--output-file-append Добавить в файл при использовании опции -o.
-s, --screen-rect <"x1 y1 x2 y2"> Координаты прямоугольника, определяющего область
экрана в OCR.
-t, --vertical OCR вертикальный текст. Если не указано,
предполагается горизонтальный текст.
-w, --show-languages Показать установленные языки, которые можно использовать
с опцией "--language".--output-format Формат для использования при выводе текста OCR.
Вы можете использовать эти токены:
$ {capture}: текст OCR.
$ {linebreak}: разрыв строки (\ r \ n).
$ {tab}: символ табуляции.
$ {timestamp}: время этого экрана или каждого
файл был обработан.$ {file}: файл, который был обработан или
экран прямоугольник.
Формат по умолчанию - «$ {capture} $ {linebreak}».
--whitelist <символы> Распознавать только указанные символы.
Пример: «0123456789».
--blacklist <символы> Не распознавать указанные символы.
Пример: «0123456789».--clipboard Выводить текст OCR в буфер обмена.
--trim-capture Во время предварительной обработки OCR выполняется обрезка
изображение в пиксели переднего плана и добавьте тонкий
граница.
--deskew Во время предварительной обработки OCR попытаться
компенсировать наклон текста.
--scale-factor Коэффициент масштабирования для использования во время предварительной обработки.Диапазон: [0,71, 5,0]. По умолчанию - 3,5.
--tess-config-file <файл> (Дополнительно) Путь к конфигурации Tesseract
файл.
------
Для Capture2Text.exe (в отличие от Capture2Text_CLI.exe) вы можете указать дополнительную опцию:
--portable Хранить файл настроек .ini в том же каталоге
как.EXE файл.
Устранение неполадок и часто задаваемые вопросы
- Я получаю сообщение об отсутствии файла DLL, когда дважды щелкаю Capture2Text.exe.
Решение: установите распространяемый пакет Visual Studio 2015.
- Capture2Text вообще не работает. Что я могу сделать?
Возможные решения:
Убедитесь, что вы разархивировали Capture2Text.Поищите в Google, если не знаете, как разархивировать файл.
Убедитесь, что ваше антивирусное программное обеспечение не блокирует Capture2Text. Обратитесь к документации, прилагаемой к вашему антивирусному программному обеспечению.
Убедитесь, что вы скачали последнюю версию с SourceForge.
Перезагрузите компьютер.
Попросите внука помочь вам 🙂
- Я обнаружил ошибку!
Отлично! Создайте заявку и опишите ошибку.
- Я хочу сделать предложение.
Отлично! Создайте заявку и опишите свое предложение.
- Capture2Text выводит символы мусора.
Решение: укажите правильный язык распознавания текста.
- Интересующий меня язык не отображается в меню языка OCR.
Прочтите Установка дополнительных языков распознавания текста.
- Я не вижу значок Capture2Text на панели задач.персонаж).
- Я щелкнул значок Capture2Text в трее, но он ничего не сделал.
Вместо этого щелкните его правой кнопкой мыши.
- Capture2Text не работает на моем Mac.
Capture2Text — это программное обеспечение только для Windows. Если у вас есть технический опыт, не стесняйтесь портировать его (но не просите меня помочь).
- Где деинсталлятор?
Нет ни одного. Capture2Text также не имеет установщика.Удалять Capture2Text со своего компьютера, просто удалите каталог Capture2Text.
- Где находится файл настроек .ini?
Введите «% appdata% \ Capture2Text» в проводнике Windows.
Вы можете удалить его, чтобы восстановить настройки по умолчанию.
- Как сделать Capture2Text портативным?
Вызовите Capture2Text.exe с параметром —portable. Вы можете создать для этого ярлык.Установка этого параметра заставит Capture2Text хранить файл настроек .ini в том же каталоге, что и Capture2Text.exe (в отличие от «% appdata% \ Capture2Text», которое является обычным местом).
- Где находится исходный код?
Исходный код находится на SourceForge.
Сопутствующие инструменты для изучающих японский язык
- JGlossator (Windows)
Автоматический поиск японских слов, распознаваемых вами с помощью Capture2Text.Поддерживает искаженные выражения, чтения, звуковое произношение, примеры предложений, ударный тон, частота слов, информация о кандзи и грамматический анализ. Поддерживает словари EDICT и EPWING.
- OCR Manga Reader (Android)
Бесплатное приложение для чтения манги для Android с открытым исходным кодом, которое позволяет быстро распознавать текст и выполнять поиск Японские слова в реальном времени. Нет никакой рекламы и никаких загадочных сетевых разрешений. Поддерживает словари EDICT и EPWING.
Recognition Font — скачать бесплатно, онлайн-генератор
Информация
Подробная информация о шрифте Recognition.
Дата добавления шрифта: 2018-03-29
Лицензия: бесплатно для личного использования
Размер: 23 КБ
Формат: ttf
Просмотров: 79
Загрузок: 21
Для операционных систем: Windows , Mac, Linux
Для программ: Microsoft Word, Corel Draw, Adobe Photoshop, Autocad, Adobe Illustrator, Sony Vegas, Adobe Reader
Персонажи
Буква алфавита (a-z) и специальные символы шрифта Recognition.
Генератор шрифтов для предварительного просмотра онлайн
Генератор шрифтов для предварительного просмотра в Интернете — это инструмент для предварительного просмотра шрифтов, который позволяет просматривать в Интернете, как будет выглядеть текст шрифта.
Чтобы просмотреть шрифт распознавания, просто введите желаемый текст или символы в поле ниже:
Полученный результат:
Примечание: , если результат сгенерированного шрифта отличается от орфографии, отображаемой на изображениях, то этот шрифт не может быть оптимизирован для Интернета.По этой причине просмотр шрифта в Интернете невозможен.
Размеры
Соотношение размеров шрифта в абсолютных единицах: 72 pt = 1 дюйм = 2,54 см = 25,4 мм = 6 шт. = 96 пикселей.
Как установить шрифт распознавания
для Windows
Для установки шрифта они должны быть на компакт-диске, съемном носителе или жестком диске.
Чтобы установить шрифт распознавания, выполните следующие действия:
- Выберите «Мой компьютер» / «Компьютер» / «Этот компьютер».
- В поле «Устройства и диски» выберите диск, на котором установлено Распознавание.ttf загруженный для установки шрифт.
- В окне «Папки» выберите папку, в которой находится шрифт для установки.
- В окне «Список файлов» выберите нужный шрифт.
- Дважды щелкните или нажмите клавишу Enter, чтобы открыть файл шрифта.
- Нажмите кнопку «Установить» и дождитесь установки шрифта.
Для macOS
Для установки шрифта они должны быть на компакт-диске, съемном носителе или жестком диске.
Чтобы установить шрифт распознавания, выполните следующие действия:
- Дважды щелкните файл шрифта (Recognition.ttf) — откроется окно с обзором шрифта.
- Для установки шрифта нажмите кнопку «Установить шрифт» в открывшемся окне предварительного просмотра.
- После того как Mac проверит шрифт и откроет программу «Fonts», шрифт установлен и доступен для использования.
Другие шрифты
Лицензия: бесплатно для личного использования
Размер: 105 КБ Просмотров: 105 Скачиваний: 16
Лицензия: бесплатно для личного пользования
Размер: 21 КБ Просмотров: 105 Скачиваний: 15
Лицензия: бесплатно для личного пользования
Размер: 54 КБ Просмотров: 87 Скачиваний: 17 9077 Скачиваний: 17
Размер: 50 КБ Просмотры: 98 Загрузки: 14
Лицензия: бесплатно для личного использования
Размер: 85 КБ Просмотры : 106 Загрузки: 14
Программы признания сотрудников | UpCounsel 2020
Программы признания сотрудников важны для организаций, потому что они позволяют сотрудникам оставаться вовлеченными и чувствовать, что их ценят.Читать 8 мин.
1. Что такое программы признания сотрудников?2. Психология признания
3. Способы признания сотрудников
4. Премии
5. Типы признания
6. Частота признания
7. Разработка программы признания
8. Повышение вовлеченности и производительности
9. Ресурсы для улучшения помолвка
Программы признания сотрудников важны для организаций, потому что они позволяют сотрудникам оставаться вовлеченными и чувствовать, что их ценят.В свою очередь, компании имеют меньшую текучесть кадров и получают лучшую производительность от сотрудников. Признание может быть получено на всех уровнях компании от менеджеров и руководителей, коллег, высшего руководства и клиентов. Поэтому компании надлежит создать программу признания сотрудников, чтобы повысить вовлеченность и создать благоприятную рабочую среду.
Примерно 1-2% фонда заработной платы компании тратится на предметы признания, такие как награды, значки, таблички и другие знаки признательности. История признания восходит к началу 20-го века, когда профсоюзы заставляли руководителей компаний награждать сотрудников за их услуги и повышать их почасовую ставку.
Реализация программы признательности не требует значительных затрат или ненужного бремени для руководства. Выделить время на разработку программы с помощью небольших жестов, чтобы показать, что сотрудники ценятся, — это разумное вложение. Сотрудники, которых ценят, мотивированы работать лучше и делать больше работы. Они также будут оставаться вовлеченными и работать в компании в течение более длительного периода времени.
Психология узнавания
На рабочем месте получение зарплаты и пособий отвечает основным человеческим потребностям.Но этого недостаточно. Признание вдохновляет людей делать больше для организации и заставляет их чувствовать, что их ценят. Лучшее ощущение выполняемой работы ведет к повышению ее производительности и повышению доверия. Организации, которые регулярно благодарят своих сотрудников, имеют более высокую общую производительность, чем организации, которые не применяют регулярную практику признания сотрудников.
Повышенная производительность отражается как внутри, так и снаружи. Клиенты, которые контактируют с более довольными сотрудниками, с большей вероятностью вернутся.Лучшие 20 процентов компаний, которые предпочитают отдавать предпочтение сотрудникам, снижают вероятность текучести кадров на 32 процента.
Регулярное признание и обратная связь дают сотруднику лучшее представление о своей работе и указывают, где ему нужно улучшить и как они могут продолжать приносить пользу организации в целом. Это также поднимает моральный дух в организации.
Но признание бесполезно, если сотрудники получают его только от своих коллег. Без признания со стороны руководства вовлеченность сотрудников резко падает, как и производительность.
Способы узнать сотрудников
Система признания сотрудников, которая начинается с руководства вниз, является одним из способов сохранить заинтересованность сотрудников и ощущение того, что их ценят на рабочем месте. В этой системе руководство наблюдает за вкладом сотрудника и вознаграждает его.
Сотрудники, которые постоянно вносят свой вклад в компанию на протяжении многих лет работы, могут по достоинству оценить награды за годы работы. Компания может выдавать их, когда сотрудники достигают таких вех, как 20 лет службы, или раз в 5 лет.Идеи наград за годы службы включают:
- Сертификаты
- Открытки фирмы
- Гравированный предмет, например ручки, статуэтки или безделушки
Известно, что организации посвящают день тому, чтобы ценить своих сотрудников. Такие дни включают в себя корпоративный обед, посещение тематического парка или угощение для сотрудников, например кофе, массаж в офисе, выступления и другие.
1 марта — официальный День признательности сотрудников.Это полуформальный праздник, который открыл человек по имени Боб Нельсон, член правления компании Recognition Professional. С тех пор, как начался День благодарности сотрудников, другие организации использовали этот день как способ оценить сотрудников.
Бонусов
Компании также могут использовать денежную премию как способ выразить признательность за работу своих сотрудников. Бонус выплачивается сотруднику в дополнение к его обычной годовой зарплате или графику выплат. Есть три типа бонусов:
- Ежегодно
- Ежеквартально
- Место
Годовые бонусы обычно выплачиваются в четвертом квартале в конце финансового года.Бонус выдается сотруднику как отражение его вклада или работы в течение года. Организация также может выбрать выплату бонуса в зависимости от ее результатов.
Ежеквартальные бонусы выплачиваются чаще, как правило, 4 раза в год по сравнению с годовыми. Организации, специализирующиеся на продажах, часто выплачивают ежеквартальные бонусы, чтобы стимулировать продажи своим сотрудникам.
Спотовые бонусы меньше по размеру и вознаграждают сотрудников за такие вещи, как продуктивность, своевременная сдача товаров или исключительная производительность.Эти бонусы также могут быть предоставлены менеджером или руководителем сотруднику в качестве прямого признания работы сотрудника.
Типы распознавания
Одноранговые системы позволяют каждому в организации признавать вклад и достижения коллег. Сюда входят менеджеры и коллеги. Эти системы позволяют менеджерам, руководителям и сотрудникам выражать признательность по своему желанию. Пример такой системы может включать вручение небольшого предмета, такого как золотая звезда, который, в свою очередь, обменивается на ценные предметы.Еще один пример — вербальное признание. Это давний и эффективный способ распознать коллегу за работой без особых усилий. Обычно его дают коллеги, чтобы выделить недавние усилия.
Микробонусы — это молниеносный способ дать денежный бонус. Как и в случае спотового бонуса, микробонусы начисляются за вклад в момент. Они передаются другим коллегам, от менеджеров до подчиненных и наоборот. Поскольку микробонусы — это небольшие выплаты физическим лицам, их можно делать несколько раз, не изменяя регулярные выплаты сотрудникам из организации.
Частота признания
Распознавание зависит от времени. Когда предлагается сразу, он сразу же ассоциируется с вкладом, который его побудил. Без немедленного признания сотрудники будут тратить больше времени, чем необходимо, полагая, что их вклад не был оценен. Или они думают, что не внесли значительного вклада в проект.
Чем чаще кто-то получает признание, тем оно эффективнее, тем более что сотрудники вносят свой вклад различными способами в течение рабочей недели.При использовании в сочетании с обратной связью признание осуществляется и вознаграждается немедленно, а не ожиданием. Регулярность также имеет решающее значение. Без регулярной обратной связи и признания достижений сотрудник чувствует себя недооцененным в той роли, которую он выполняет. Например:
«Спасибо, что позвонили клиенту Джейн. Без вашей помощи этот проект остался бы открытым и незавершенным».
Признавая навыки, которые использовал сотрудник, компании мотивируют его искать новые способы использования этих навыков, что приносит пользу всем.Коллеги также с большей вероятностью признают этот вклад в следующий раз и будут готовы внести свой вклад
Разработка программы признательности
Программа признательности дает возможность для общественного признания. Это часто увеличивает влияние вклада и дает коллегам возможность участвовать в признании. Более вероятно, что другие будут вносить свой вклад в организацию после того, как увидят признание другого человека. Советы по разработке эффективной программы распознавания:
- Расширьте структуру программы, чтобы вовлечь в организацию самые разные слои населения.
- Обеспечьте прозрачность, чтобы увеличить вероятность участия и вызвать интерес.
- Максимально вовлеките в разработку программы, где вы можете вовлечь разнообразную группу в разработку проекта.
- Сделайте возможным участие всех, независимо от уровня или отдела.
- Упростите процесс присуждения наград и сделайте их доступными.
- Выдвижение кандидатов должно быть простым с использованием установленного процесса.
- Объясните программу лично перед ее реализацией.
- Сделайте программы спотовых премий простыми, неформальными и доступными.
- Пусть сотрудники составят собственную программу вознаграждений.
- Расскажите о программе на собраниях команды.
Расскажите о своей программе признательности новым сотрудникам, когда они присоединятся к компании. Постоянно продвигайте достижения и признание, чтобы побудить сотрудников использовать новую программу и использовать предметы или мероприятия в качестве стимула.
Повышение вовлеченности и производительности
Помимо создания программы признания, есть и другие способы удержать сотрудников и заставить их чувствовать себя узнаваемыми.Пусть сотрудники сами выбирают проекты и работают как можно больше.
Поддержка их непрерывного образования тоже важна. Для компаний, у которых есть средства, предлагайте стипендии или компенсацию за обучение. Недорогие идеи включают в себя поиск и распространение бесплатных курсов, предложение наставничества со стороны руководителей более высокого уровня и предоставление сотрудникам возможности руководить офисом без отрыва от производства или курсом для повышения вовлеченности и роста.
Встречи, выездные встречи и веселые дни компании должны включать идеи сотрудников.Повысьте вовлеченность и веселье, разместив доску объявлений, где люди могут размещать информацию о продаже, уходе за детьми или домашними животными, а также тех, кто арендует или нуждается в жилье.
Отметьте дни рождения и годовщины компании в офисе или отправьте уведомления в Интернете по электронной почте.
Проведите ежегодное мероприятие по награждению, на котором сотрудники могут получить признание за свои годичные действия в компании. Комитет по наградам должен быть представлен каждой частью компании на всех уровнях, и комитет должен меняться каждый год.Обязательно укажите бывших победителей. Ежегодные награды должны быть празднованием всего, что произошло в течение года.
Используйте творческие возможности, такие как логотипы или дизайн, для проведения конкурса дизайна и повышения вовлеченности компании.
Проведите обучение сотрудников компании, чтобы они могли распознавать, когда их коллеги вносят свой вклад. Если это что-то вроде передовой практики, поощряйте сотрудников передавать их руководству для рассмотрения в качестве улучшения в масштабах всей компании.
Сообщайте сотрудникам о признаниях, чтобы руководители и менеджеры групп знали о достижениях своей команды. Постоянно продвигайте достижения и признание, чтобы побудить сотрудников использовать новую программу и использовать предметы или мероприятия в качестве стимула.
Ресурсы для улучшения взаимодействия
Многие приложения предназначены для облегчения общения, совместной работы и распознавания в компании. Выберите один из них или любую их комбинацию, чтобы облегчить процесс признания сотрудников.
Bonusly Analytics дает работодателям возможность определять, какие сотрудники вносят свой вклад и выделяются из толпы. Кроме того, он также выявляет сотрудников, которым требуется дополнительная помощь. Он использует социальные данные, созданные путем предоставления микробонусов.
УBonusly есть блог, который охватывает:
- Идеи вознаграждения сотрудников
- Вовлеченность сотрудников
- Вдохновляющая лояльность сотрудников
Он также предлагает интервью с отраслевыми экспертами и статьи.Другие публикации охватывают все, что нужно знать о HR и сотрудниках, в том числе о том, как распознать вклад.
Slack, командное приложение для обмена сообщениями, делает общение между отдельными людьми и группами намного проще, чем электронная почта. К счастью, внутри Slack работает руководство по признанию сотрудников. Он отправляет действия команде и позволяет присуждать микробонусы без остановки работы.
HipChat — еще одно приложение для обмена сообщениями и видео, которое также предлагает общение и включает в себя возможность обмена файлами и поиска.У него есть возможность транслировать благодарность со стороны сотрудников, а микробонусы могут передаваться непосредственно сотруднику внутри приложения.
Социальная сетьYammer создана для использования в бизнесе. Это поощряет связи и обмен информацией. В Yammer есть общий доступ к файлам, профили пользователей и канал. Его Bonusly-интеграция использует функции однорангового распознавания, чтобы транслировать их в компанию.
Small Improvements упрощает обратную связь и обзоры, предлагая и то, и другое в программе. Он также предлагает общение и отслеживание целей.Его бонусные функции показывают вклад сотрудника во время обзоров, поэтому их не нужно искать.
Office Vibe работает со Slack и имеет бота Leo, который поддерживает общение, не прерывая работу. Он также рассылает сотрудникам опросы, в которых спрашивают, насколько они удовлетворены, и поощряют участие. Он даже дает советы!
When I Work — это приложение для планирования и общения. Это помогает в общении между руководством и почасовыми сотрудниками.Он предлагает советы по найму новых сотрудников, помогает их принять на работу и дает советы о том, как лучше управлять людьми.
TLNT — это публикация, в которой представлены HR-новости и информация от основ управления персоналом до более сложных вопросов, таких как приемы на работу, сокращение пробелов в навыках персонала и повышение удержания сотрудников.
TalentCulture охватывает HR, технологии, рекрутинг, лидерство, социальный бизнес и т. Д. Это отличный источник, чтобы быть в курсе последних новостей и технологий HR.Гостевые посты часто добавляют на сайт эксперты в сфере HR. На сайте также проводится еженедельный Twitter-чат с «#TChat»
.Switch & Shift — это веб-сайт, посвященный человеческому аспекту человеческих отношений. Он дает советы и рекомендации по управлению и вовлечению. Подкаст «Работа, который имеет значение» основан на идее работы со смыслом и включает лидеров мнений по этой теме.
Признать вклад сотрудников можно разными способами. Наличие плана и через определенные промежутки времени обеспечивает приятную рабочую среду.
Вам нужна помощь с программами признания сотрудников? Вы можете опубликовать свою юридическую потребность на торговой площадке UpCounsel. UpCounsel принимает на свой сайт только 5% лучших юристов. Юристы UpCounsel являются выпускниками юридических школ, таких как Harvard Law и Yale Law, и имеют в среднем 14 лет юридического опыта, включая работу с такими компаниями, как Google, Menlo Ventures и Airbnb, или от их имени.