Ассемблер ARM64 | Первая программа на ассемблере ARM64 на Linux
Последнее обновление: 27.12.2022
Пакет gcc-aarch64-linux-gnu
Наиболее популярным способом компиляции программ на языке ассемблера ARM64 представляет применение компилятора GAS от проекта GNU. Под Linux есть ряд различных пакетов, в рамках которых распространяется этот компилятор. Выбор конкретного пакета зависит от того, под какую архитектуру мы собираемся компилировать приложение.
Если мы собираемся компилировать приложение непосредственно под Linux (в том числе под Android), то самым простым вариантом является использование пакета gcc-aarch64-linux-gnu. Рассмотрим его использование. Вначале установим пакет командой:
sudo apt-get install gcc-aarch64-linux-gnu
После установки нам станет доступно приложение aarch64-linux-gnu-as, которое представляет компилятор GAS для ARM64 под Linux. Кроме того, также будет доступен линкер
в виде приложения aarch64-linux-gnu-ld. Например, проверим версию компилятора gas:
Например, проверим версию компилятора gas:
eugene@Eugene:~$ aarch64-linux-gnu-as --version GNU assembler (GNU Binutils for Ubuntu) 2.38 Copyright (C) 2022 Free Software Foundation, Inc. This program is free software; you may redistribute it under the terms of the GNU General Public License version 3 or later. This program has absolutely no warranty. This assembler was configured for a target of `aarch64-linux-gnu`. eugene@Eugene:~$
В системе можно также найти компилятор и линкер в папке usr\aarch64-linux-gnu\bin, где они называются соответственно as и ld.
Создание первой программы
Теперь напишем первую простейшую программу, которая просто будет выводить на консоль некоторую строку. Для этого создадим в каталоге пользователя какой-нибудь каталог, например, arm.
Создадим в этого каталоге новый файл hello.s (обычно файлы с кодом ассемблера arm имеют расширение .
.global _start // устанавливаем стартовый адрес программы _start: mov X0, #1 // 1 = StdOut - поток вывода ldr X1, =hello // строка для вывода на экран mov X2, #19 // длина строки mov X8, #64 // устанавливаем функцию Linux svc 0 // вызываем функцию Linux для вывода строки mov X0, #0 // Устанавливаем 0 как код возврата mov X8, #93 // код 93 представляет завершение программы svc 0 // вызываем функцию Linux для выхода из программы .data hello: .ascii "Hello METANIT.COM!\n" // данные для вывода
Для большего понимания я снабдил программу комментариями. GNU Assembler использует тот же самый синтаксис комментариев, что и C/C++ и другие си-подобные
языки: одиночный комментарий начинается с двойного слеша //.
/* текст комментария */Вначале надо указать линкеру (в нашем случае программа ld) стартовую точку программы. В данной программе стартовая точка программы проецируется
на метку _start. И чтобы линкер получил к ней доступ, определяет _start в качестве глобальной переменной с помощью оператора global.
.global _start
Одна программа может состоять из множества файлов, но только один из них может иметь точку входа в программу _start
Далее идут собственно действия программы. Вначале вызывается инструкция mov, которая помещает данные в регистр.
mov X0, #1
Значения X0-X2 представляют регистры для параметров функции в Linux. В данном случае помещаем в регистр X0 значение «#1». Операнды начинаются со знака «#»
Число 1 представляет номер стандартного потока вывода «StdOut».
Далее загружаем в регистр X1 адрес строки для вывода на экран с помощью инструкции ldr
ldr X1, =hello
Затем также с помощью инструкции mov помещаем в регистр X2 длину выводимой строки
mov X2, #19
Для любого системного вызова в Linux параметры помещаются в регистры X0–X7 в зависимости от количества. Затем в регистр X0 помещается код возврата. А сам системный вызов
определяется номером функции из регистра X8. Здесь помещаем в X8 функцию с номеро 64 (функция write)
mov X8, #64
Далее выполняем системный вызов с помощью оператора svc
svc 0
Операционная система, используя параметры в регистрах и номер функции, выведет строку на экран.
После этого нам надо выйти из программы. Для этого помещаем в регистр X0 число 0
mov X0, #0
А в регистр X8 передаем число 93 — номер функции для выхода из программы (функция exit)
mov X8, #93
И с помощью svc также выполняем функции. После этого программа должна завершить выполнение.
После этого программа должна завершить выполнение.
В самом конце программы размещена секция данных
.data hello: .ascii "Hello METANIT.COM!\n" // данные для вывода
Оператор .data указывает, что дальше идет секция данных. Выражение .ascii выделяет память и помещает в нее указанную далее строку.
Строка завершается символом перевода строки «\n», чтобы не надо было нажимать на Return, чтобы увидеть текст в окне терминала.
Компиляция приложения
Для компиляции приложения откроем терминал/командную строку и командой cd перейдем к папке, где расположен файл hello.s с исходным кодом программы. И для компиляции выполним команду:
aarch64-linux-gnu-as hello.s -o hello.o
Компилятору aarch64-none-elf-as в качестве параметра передается файл с исходным кодом hello.s. А параметр -o указывает, в какой файл будет компилироваться
программа — в данном случае в файл hello.o. Соответственно в папке программы появится файл hello.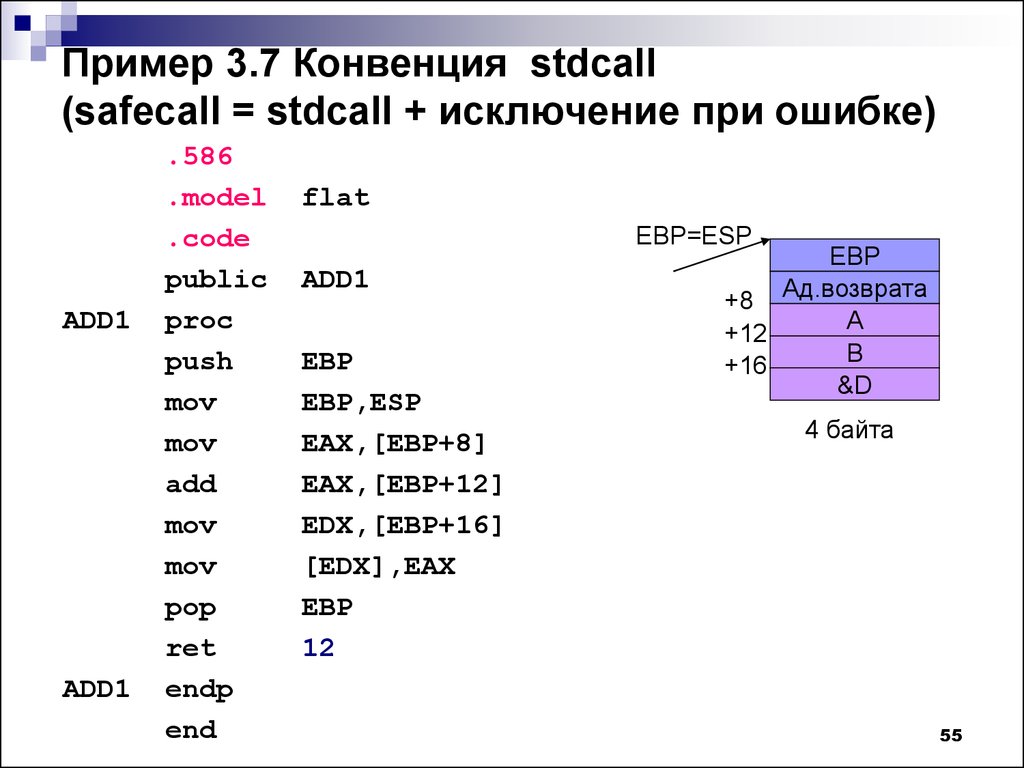 o
o
Затем нам нужно скомпоновать программу с исполняемый файл с помощью линкера aarch64-none-elf-ld командой:
aarch64-linux-gnu-ld hello.o -o hello
После этого в папке программы появится исполняемый файл hello, который мы можем запускать на устройстве с архитектурой ARM64 под управлением Linux.
Установка Arm GNU Toolchain
Выше рассматривалась компиляция с помощью компилятора и линкера из пакета gcc-aarch64-linux-gnu
bare metall).
Одним из наиболее популярных подобных пакетов является комплект инструметов Arm GNU Toolchain, который можно найти на странице
https://developer.arm.com/downloads/-/arm-gnu-toolchain-downloads.
Здесь представлены поседние версии Arm GNU Toolchain для разных архитектур.
Каждая версия Arm GNU Toolchain привязана к определенной версии компиляторов GCC. Например, версия Arm GNU Toolchain 12.2.Rel1
привязан к версии 12.2 набора компиляторов gcc.
Для Linux есть пакеты, которые можно использовать как на архитектуре x86-64, так и на ARM64. Доступно несколько групп пакетов под различные архитектуры. Так, для архитектуры x86-64 доступны следующие пакеты:
AArch42 bare-metal target (arm-none-eabi): для компиляции программ под 32-битные архитектуры без привязки к конкретной операционной системеAArch42 GNU/Linux target with hard float (arm-none-linux-gnueabihf): для компиляции программ под 32-битную ОС LinuxAArch64 bare-metal target (aarch64-none-elf): для компиляции программ под 64-битные архитектуры без привязки к конкретной операционной системеAArch64 GNU/Linux target (aarch64-none-linux-gnu): для компиляции программ под 64-битную ОС LinuxAArch64 GNU/Linux big-endian target (aarch64_be-none-linux-gnu): то же самое, что и предыдущий пункт, только с использованием порядка байтов Big Indian
Для архитектуры AArch64 (ARM64) доступны следующие пакеты:
AArch42 bare-metal target (arm-none-eabi)AArch42 GNU/Linux target with hard float (arm-none-linux-gnueabihf): для компиляции программ под 32-битную ОС LinuxAArch64 bare-metal target (aarch64-none-elf): для компиляции программ под 64-битные архитектуры без привязки к конкретной операционной системе
Поскольку в нашем случае мы работаем с ARM64, то нас интересуют прежде всего пакеты AArch64 bare-metal target (aarch64-none-elf) и AArch64 GNU/Linux target (aarch64-none-linux-gnu). Второй пакет —
Второй пакет — AArch64 GNU/Linux target (aarch64-none-linux-gnu) в принципе аналогичен выше рассмотренному пакету gcc-aarch64-linux-gnu — используется только для компиляции под Linux.
А первый пакет AArch64 bare-metal target (aarch64-none-elf) не привязан к определенной ОС, поэтому выберем его. Например, у меня архитектура
х86-64, поэтому в млоем случае это архивный пакет arm-gnu-toolchain-12.2.rel1-x86_64-aarch64-none-elf.tar.xz. Загрузим данный архив.
После загрузки сначала создадим папку, где будут располагаться все загруженные инструменты:
sudo mkdir /opt/aarch64-none-elf
Далее для распаковки архива в созданный каталог «opt/aarch64-none-elf» выполним следующую команду:
sudo tar -xvf ~/Загрузки/arm-gnu-toolchain-12.2.rel1-x86_64-aarch64-none-elf.tar.xz --strip-components=1 -C /opt/aarch64-none-elf
В данном случае предполагается, что архив загружен в папку «Загрузки» в папке текущего пользователя. После этого в папке текущего пользователя в каталоге
После этого в папке текущего пользователя в каталоге
aarch64-none-elf-as и aarch64-none-elf-ld — компилятор и линкер соответственно.
Добавим в переменную PATH путь к компилятору и линкеру в папке bin. Для этого откроем выполним следующую команду:
echo 'export PATH=$PATH:/opt/aarch64-none-elf/bin' | sudo tee -a /etc/profile.d/aarch64-none-elf.sh
Чтобы изменения вступили в силу без необходимости перезагрузки, выполним команду
source /etc/profile
Проверим установку, выведя на консоль версию с помощью следующей команды:
aarch64-none-elf-as --version
Весь остальной процесс будет аналогичен то, что был описан ранее. Так, переходим в папку с файлом с исходным кодом и для создания объектного файла выполняем команду
aarch64-none-elf-as hello.s -o hello.o
Затем нам нужно скомпновать программу с исполняемый файл с помощью линкера aarch64-none-elf-ld командой:
aarch64-none-elf-ld hello.o -o hello
Тестирование на Android
Итак, у нас есть исполняемый файл программы. Мы ее можем протестировать. Для этого нам нужен Linux на устройстве с архитектурой ARM. В качестве такого устройства я возьму самый распространенный вариант — смартфон под управлением Android. Поскольку Android построен на базе Linux и как правило устанавливается на устройства с arm архитектурой.
Для установки файла на Android нам понадобится консольная утилита adb (Android Debug Bridge), которая используется для отладки приложений под Android и которая устанавливается в рамках Android SDK. Android SDK обычно устанавливается вместе с Android Studio. Но мы также можем установить ADB отдельно. Для этого выполним команду
sudo apt-get install adb
Теперь переместим скомпилированный файл hello на устройство под Android. Для этого прежде всего подключим к компьютеру смартфон с Android. Перейдем в консоли с помощью команды cd к папке с файлом hello и выполним следующую команду
adb push hello /data/local/tmp/hello
То есть в данном случае используем команду push для помещения копии файла hello на смартфон в папку /data/local/tmp/
Далее перейдем к консоли устройства Android с помощью команды:
adb shell
Далее перейдем к папке /data/local/tmp с помощью команды
cd /data/local/tmp
Затем изменим режим файла, чтобы его можно было запустить:
chmod +x hello
и в конце выполним файл hello
./hello
И на консоль должна быть выведена строка «Hello METANIT.COM!»
НазадСодержаниеВперед
Assembler. Установка интерпретатора и запуск первой программы через DOSBox / Хабр
В данной статье разбирается способ установки интерпретатора и запуск файла EXE через DOSBox. Планировалось погрузить читателя в особенности программирования на TASM, но я согласился с комментаторами. Есть много учебников по Ассемблер и нет смысла перепечатывать эти знания вновь. Лично мне в изучении очень помог сайт av-assembler.ru. Рекомендую. В комментариях также вы найдёте много другой литературы по Assembler. А теперь перейдём к основной теме статьи.
Для начала давайте установим наш старенький интерпретатор.
Ссылка
Я прекрасно понимаю, что это ещё тот колхоз делиться файлами через обсуждения VK, но кто знает, во что может превратиться эта маленькая группа в будущем.
После распаковки файлов, советую сохранить их в папке Asm на диск C, чтобы иметь меньше расхождений с представленным тут материалом. Если вы разместите директорию в другое место, изменится лишь путь до файлов, когда вы будете использовать команду mount.
Если вы разместите директорию в другое место, изменится лишь путь до файлов, когда вы будете использовать команду mount.
Для запуска интерпретатора нам так же потребуется эмулятор DOSBox. Он и оживит все наши компоненты. Скачаем и установим его!
Ссылка
В папке Asm я специально оставил файл code.asm. Именно на нём мы и потренируемся запускать нашу программу. Советую сохранить его копию, ибо там хранится весь код, который в 99% случаев будет присутствовать в каждом вашем проекте.
code.asms_s segment s_s ends d_s segment d_s ends c_s segment assume ss:s_s, ds:d_s, cs:c_s begin: mov ax, d_s mov ds, ax mov ax, 0 ; Your code needs to be here mov ah, 4ch int 21h c_s ends end begin
Итак. Запускаем наш DOSBox и видим следующее:
Для простоты сопоставим имя пути, по которому лежит наша папка Asm. Чтобы это сделать, пропишем следующую команду:
mount d: c:\asm
Здесь вместо d: мы можем использовать любую другую букву. Например назвать i или s. А C это наш реальный диск. Мы прописываем путь до наших файлов ассемблера.
А C это наш реальный диск. Мы прописываем путь до наших файлов ассемблера.
Теперь, откроем смонтированный диск:
d:
Прописав команду dir, мы сможем увидеть все файлы, которые там хранятся. Здесь можно заметить и наш файл CODE с расширением ASM, а также дату его создания.
И только теперь мы начинаем запускать наш файл! Бедные программисты 20 века, как они только терпели всё это? Пропишем следующую команду:
tasm code.asm
После мы увидим следующее сообщение, а наша директория пополнится новым файлом с расширением OBJ.
Теперь пропишем ещё одну команду:
tlink code.obj
В нашей папке появилась ещё пара файлов – CODE.MAP и CODE.EXE. Последний как раз и есть исполняемый файл нашего кода assembler.
Если он появился, значит, мы можем запустить режим отладки нашей программы, введя последнюю команду. Обратите внимание, теперь мы не указываем расширение файла, который запускаем.
td code
Этот старинный интерфейс насквозь пропитан духом ушедшей эпохи старых операционных систем. Тем не менее…
Тем не менее…
Нажав F7 или fn + F7 вы сможете совершить 1 шаг по коду. Синяя строка начнёт движение вниз, изменяя значения регистров и флагов. Пока это всего лишь шаблон, на котором мы потренировались запускать нашу программу в режиме дебага. Реальное “волшебство” мы увидим лишь с полноценным кодом на asm.
Небольшой пример для запускаПрога проверяет, было ли передано верное число открывающих и закрывающих скобок:
s_s segment
dw 20 dup('$')
s_s ends
d_s segment
string db '()','$';
result db 0
d_s ends
c_s segment
assume ss:s_s,ds:d_s,cs:c_s
begin: ; начало программы
mov ax,d_s
mov ds,ax
xor ax,ax
lea si, string
;Ищем в строке скобку
search:
lodsb
;Проверка, это конец строки?
cmp al, '$'
je endString
;Это открывающая или закрывающая скобка?
;Это открывающие скобки?
cmp al, '('
je inStack
cmp al, '{'
je inStack
cmp al, '['
je inStack
;Это закрывающие скобки?
cmp al, ')'
je outStack
cmp al, '}'
je outStack
cmp al, ']'
je outStack
jmp search
;Помещаем скобку в Stack, увеличиваем счётчик
inStack:
inc cx
push ax
jmp search
;Выниманием из Stack скобку, проверяем пару
outStack:
;Была передана лишняя закрыв. скобка?
cmp cx, 0
je error3
dec cx
pop bx
;Вскрытая скобка закрыта верно?
cmp bl, '('
jne close1
cmp al, ')'
jne error1
jmp search
close1:
cmp bl, '['
jne close2
cmp al, ']'
jne error1
jmp search
close2:
cmp bl, '{'
cmp al, '}'
jne error1
jmp search
;Остались ли незакрытые скобки?
endString:
cmp cx, 0
jne error2
jmp exit
;Скобки остались, это ошибка №2
error2:
mov result, 2
jmp exit
;Лишняя скобка передана, ошибка №3
error3:
mov result, 3
jmp exit
;Закрывающая скобка несоответствует открывающей, ош №1
error1:
mov result, 1
jmp exit
;Пред-завершение. Каков результат программы?
exit:
cmp result, 1
jne enough
;Ищем нужную скобку для исправления ошибки №1
cmp bl, '('
jne next1
mov bl, ')'
jmp enough
next1:
cmp bl, '{'
jne next2
mov bl, '}'
jmp enough
next2:
cmp bl, '['
mov bl, ']'
jmp enough
enough:
mov dl, result
xor dx, dx
mov dl, bl
mov ah,4ch
int 21h
c_s ends
end begin
скобка?
cmp cx, 0
je error3
dec cx
pop bx
;Вскрытая скобка закрыта верно?
cmp bl, '('
jne close1
cmp al, ')'
jne error1
jmp search
close1:
cmp bl, '['
jne close2
cmp al, ']'
jne error1
jmp search
close2:
cmp bl, '{'
cmp al, '}'
jne error1
jmp search
;Остались ли незакрытые скобки?
endString:
cmp cx, 0
jne error2
jmp exit
;Скобки остались, это ошибка №2
error2:
mov result, 2
jmp exit
;Лишняя скобка передана, ошибка №3
error3:
mov result, 3
jmp exit
;Закрывающая скобка несоответствует открывающей, ош №1
error1:
mov result, 1
jmp exit
;Пред-завершение. Каков результат программы?
exit:
cmp result, 1
jne enough
;Ищем нужную скобку для исправления ошибки №1
cmp bl, '('
jne next1
mov bl, ')'
jmp enough
next1:
cmp bl, '{'
jne next2
mov bl, '}'
jmp enough
next2:
cmp bl, '['
mov bl, ']'
jmp enough
enough:
mov dl, result
xor dx, dx
mov dl, bl
mov ah,4ch
int 21h
c_s ends
end beginДавайте ознакомимся с имеющимися разделами.
CS
Code segment – место, где turbo debug отражает все найденные строки кода. Важное замечание – все данные отражаются в TD в виде 16-ричной системы. А значит какая-нибудь ‘12’ это на самом деле 18, а реальное 12 это ‘C’. CS аналогичен разделу “Begin end.” на Pascal или функции main.
DS
Data segment, отражает данные, которые TD обнаружил в d_s. Справа мы видим их символьную (char) интерпретацию. В будущем мы сможем увидеть здесь наш “Hello, world”, интерпретируемый компилятором в числа, по таблице ASCII. Хорошей аналогией DS является раздел VAR, как в Pascal. Для простоты можно сказать, что это одно и тоже.
SS
Stack segment – место хранения данных нашего стека.
Регистры
Все эти ax, bx, cx, si, di, ss, cs и т. д. – это наши регистры, которые используются как переменные для хранения данных. Да, это очень грубое упрощение. Переменные из Pascal и регистры Assembler это не одно и тоже, но надеюсь, такая аналогия даёт более чёткую картину. Здесь мы сможем хранить данные о циклах, арифметических операциях, системных прерываниях и т. д.
Здесь мы сможем хранить данные о циклах, арифметических операциях, системных прерываниях и т. д.
Флаги
Все эти c, z, s, o, p и т.д. это и есть наши флаги. В них хранится промежуточная информация о том, например, было ли полученное число чётным, произошло ранее переполнение или нет. Они могут хранить результат побитого сдвига. По опыту, могу сказать, на них обращаешь внимание лишь при отладке программы, а не во время штатного исполнения.
Ещё одно замечание. Если вы измените данные исходного файла с расширением .ASM, то вам придётся совершить все ранее описанные операции вновь, ибо обновив например code.asm вы не меняете code.obj или code.exe.
Маленькая шпаргалка для заметок:
mount d: c:\asm – создаём виртуальный диск, где корень –папка asm
d: — открываем созданный диск
tasm code.asm – компилируем исходный код
tlink code.obj – создаём исполняемый файл
td code – запускаем debug
F7 – делаем шаг в программе
Буду ждать комментарии от всех, кому интересен Assembler. Чувствую, я где-то мог накосячить в терминологии или обозначении того или иного элемента. Но статья на Habr отличный повод всё повторить.
Чувствую, я где-то мог накосячить в терминологии или обозначении того или иного элемента. Но статья на Habr отличный повод всё повторить.
— Были ли первые ассемблеры написаны на машинном коде?
спросил
Изменено 4 года, 5 месяцев назад
Просмотрено 32к раз
Я читаю книгу «Элементы вычислительных систем: создание современного компьютера из первых принципов», в которой содержатся проекты, охватывающие сборку компьютера от логических элементов до приложений высокого уровня (именно в таком порядке). Текущий проект, над которым я работаю, — это написание ассемблера с использованием языка высокого уровня по моему выбору для перевода ассемблерного кода Hack в машинный код Hack (Hack — это название аппаратной платформы, созданной в предыдущих главах). Хотя все аппаратное обеспечение было построено в симуляторе, я попытался сделать вид, что на самом деле конструирую каждый уровень, используя только инструменты, доступные мне на тот момент в реальном процессе.
Хотя все аппаратное обеспечение было построено в симуляторе, я попытался сделать вид, что на самом деле конструирую каждый уровень, используя только инструменты, доступные мне на тот момент в реальном процессе.
Тем не менее, это заставило меня задуматься. Использование языка высокого уровня для написания моего ассемблера, безусловно, удобно, но для самого первого ассемблера, когда-либо написанного (т.е. в истории), не нужно ли было писать его в машинном коде, поскольку это все, что существовало в то время?
И связанный с этим вопрос… как насчет сегодняшнего дня? Если появится совершенно новая архитектура ЦП с совершенно новым набором инструкций и совершенно новым синтаксисом ассемблера, как будет построен ассемблер? Я предполагаю, что вы все еще можете использовать существующий язык высокого уровня для создания двоичных файлов для программы на ассемблере, поскольку, если вы знаете синтаксис как ассемблера, так и машинного языка для вашей новой платформы, то задача написания ассемблера на самом деле просто задача анализа текста и не связана по своей сути с этой платформой (т. е. должна быть написана на машинном языке этой платформы)… что является той самой причиной, по которой я могу «обмануть» при написании моего ассемблера Hack в 2012 году и использовать некоторые ранее существовавшие язык высокого уровня, чтобы помочь мне.
е. должна быть написана на машинном языке этой платформы)… что является той самой причиной, по которой я могу «обмануть» при написании моего ассемблера Hack в 2012 году и использовать некоторые ранее существовавшие язык высокого уровня, чтобы помочь мне.
- сборка
- низкоуровневая
6
для самого первого ассемблера, когда-либо написанного (т.е. в истории), разве его не нужно было бы писать в машинном коде
Не обязательно. Конечно, самая первая версия ассемблера v0.00 должна была быть написана на машинном коде, но она не была бы достаточно мощной, чтобы называться ассемблером. Он не будет поддерживать и половины функций «настоящего» ассемблера, но его будет достаточно, чтобы написать следующую версию самого себя. Затем вы можете переписать v0.00 на подмножестве языка ассемблера, назвать его v0.01, использовать его для создания следующего набора функций вашего ассемблера v0. 02, затем использовать v0.02 для сборки v0.03, и так далее, пока не доберетесь до версии 1.00. В результате в машинном коде будет только первая версия; первые выпущенная версия будет на ассемблере.
02, затем использовать v0.02 для сборки v0.03, и так далее, пока не доберетесь до версии 1.00. В результате в машинном коде будет только первая версия; первые выпущенная версия будет на ассемблере.
Используя этот прием, я запустил разработку компилятора языка шаблонов. Моя первоначальная версия использовала операторы printf , но первая версия, которую я применил в своей компании, использовала тот самый обработчик шаблонов, который он обрабатывал. Фаза начальной загрузки длилась менее четырех часов: как только мой процессор мог выдавать едва ли полезный вывод, я переписал его на его родном языке, скомпилировал и выбросил версию без шаблона.
6
Согласно Википедии, первый в истории ассемблер/язык ассемблера был реализован для IBM 701 Натаниэлем Рочестером. (Даты немного неопределенны из статьи в Википедии. В ней говорится, что Рочестер присоединился к IBM в 1948 году, но на другой странице Википедии говорится, что 701 был публично анонсирован в 1952 году. А на этой странице IBM говорится, что «настоящая разработка началась 1 февраля 1951 г. и завершено через год» .)
А на этой странице IBM говорится, что «настоящая разработка началась 1 февраля 1951 г. и завершено через год» .)
Однако в «Ассемблере и загрузчиках» Дэвида Саломона говорится (на стр. 7), что у EDSAC также был ассемблер:
«Одним из первых компьютеров с хранимой программой был EDSAC (автоматический калькулятор электронного хранения с задержкой), разработанный в Кембриджском университете в 1949 году Морис Уилкс и В. Ренвик. С первых дней существования EDSAC был ассемблер под названием Initial Orders. Он был реализован в постоянной памяти, сформированной из набора поворотных телефонных селекторов, и принимал символические инструкции. Каждая инструкция состояла из мнемоники из одной буквы, десятичного адреса и третьего поля, которое было буквой. Третье поле вызывало добавление к адресу во время сборки одной из 12 предустановленных программистом констант».0030 (Ссылки опущены… см. оригинал.)
Предполагая, что мы согласны с тем, что «Первоначальные заказы» имеют приоритет, у нас есть четкие доказательства того, что первый ассемблер был реализован в машинном коде.
Этот шаблон (написание начальных ассемблеров в машинном коде) был бы нормой еще в 1950-х годах. Однако, согласно Википедии, «[a] ассемблеры были первыми языковыми инструментами, которые самозагрузились». См. также этот раздел, в котором объясняется, как изначальный машинный код, написанный на ассемблере, использовался для начальной загрузки более продвинутого ассемблера, написанного на языке ассемблера.
В наши дни ассемблеры и компиляторы пишутся на языках более высокого уровня, а ассемблер или компилятор для новой машинной архитектуры обычно разрабатывается на другой архитектуре и подвергается кросс-компиляции.
(FWIW — написание и отладка нетривиальных программ в машинном коде — чрезвычайно трудоемкий процесс. Кто-то, разрабатывающий ассемблер в машинном коде, скорее всего, как можно скорее загрузится на ассемблер, написанный на ассемблере.)
Эта страница Википедии на загрузку компиляторов и ассемблеров стоит прочитать… если все это вас сбивает с толку.
0
Я предполагаю, что первые ассемблеры были написаны на машинном коде, потому что, как вы говорите, тогда ничего другого не было.
Однако сегодня, когда выходит совершенно новая архитектура ЦП, мы используем так называемый кросс-компилятор, который представляет собой компилятор, создающий машинный код не для той архитектуры, на которой он работает, а для другой архитектуры.
(На самом деле, как я уверен, вы узнаете позже из книги, которую читаете, нет абсолютно ничего, что делало бы компилятор более подходящим для создания машинного кода для архитектуры, на которой он работает, чем на любой другой архитектуре.Вопрос только в том, на какую архитектуру вы, как создатель компилятора, собираетесь ориентироваться.)
Итак, сегодня даже возможно (по крайней мере, в теории) создать совершенно новую архитектуру и использовать компиляторы языка высокого уровня, работающие на ней (скомпилированные на других архитектурах с использованием кросс-компиляторов), прежде чем у вас будет даже ассемблер для этого. архитектура.
архитектура.
Сначала «сборка» писалась на бумаге, а потом вручную «собиралась» на перфокарты.
Мой дедушка работал с ZRA1 (извините, страница существует только на немецком языке, но с переводом Google все в порядке, и вы действительно можете подобрать самые важные факты :D).
Метод работы заключался в том, чтобы записать ваш код на бумаге на языке ассемблера, а секретарь фактически сделал транскрипцию на перфокарты, затем передал их оператору, и результат был возвращен на следующее утро.
Все это было, по сути, до того, как программисты смогли позволить себе роскошь вводить данные с клавиатуры и просматривать их на экране.
1
Трудно быть уверенным в самый первый ассемблер (трудно даже определить, что это было). Много лет назад, когда я написал несколько ассемблеров для машин, на которых не было ассемблеров, я все еще писал код на ассемблере. Затем, когда у меня был достаточно законченный участок кода, я вручную перевел его в машинный код. Тем не менее, это были две совершенно разные фазы — когда я писал код, я вообще не работал и не думал на уровне машинного кода.
Тем не менее, это были две совершенно разные фазы — когда я писал код, я вообще не работал и не думал на уровне машинного кода.
Должен добавить, что в нескольких случаях я пошел еще дальше: я написал большую часть кода на языке ассемблера, который мне показался более простым в использовании, затем написал крошечное ядро (более или менее то, что мы сейчас называем виртуальным машине) для интерпретации этого на целевом процессоре. Это было смертельно медленно (особенно на 8-разрядном процессоре с тактовой частотой 1 МГц), но это не имело большого значения, поскольку обычно оно запускалось только один раз (или, самое большее, несколько раз).
Вам не нужен ассемблер, чтобы вручную ассемблировать код на языке ассемблера в машинный код. Так же, как вам не нужен редактор для написания кода на ассемблере.
Исторический взгляд
Первые ассемблеры, вероятно, были написаны на языке ассемблера, а затем вручную собраны в машинный код. Даже если у процессора не было официального «языка ассемблера», программисты, вероятно, выполняли большую часть работы по программированию, используя какой-то псевдокод, прежде чем переводить этот код в машинные инструкции.
Даже на заре вычислительной техники программисты писали программы в своего рода символической записи и переводили их в машинный код перед тем, как ввести его в свой компьютер. В случае с Августой Адой Кинг ей пришлось бы перевести их в перфокарты для аналитической машины Бэббиджа, но, увы, она так и не была построена.
Личный опыт
Первым моим компьютером был Sinclair ZX81 (Timex 1000 в США). На обратной стороне руководства была вся информация, необходимая для перевода языка ассемблера Z80 в машинный код (даже включая все странные коды операций индексного режима, которые были у Z80).
Я бы написал программу (на бумаге) на ассемблере и прогнал код. Когда я был счастлив, что в моей программе нет ошибок, я искал каждую инструкцию в конце руководства, переводил ее в машинный код и тоже записывал машинный код на бумаге. Наконец, я набирал все инструкции машинного кода в свой ZX81, прежде чем сохранять его на ленту и пытаться запустить.
Если бы это не сработало, я бы перепроверил свою ручную сборку и, если бы какой-либо перевод был неправильным, я бы исправил байты, загруженные с ленты, перед повторным сохранением и повторной попыткой запустить программу.
По своему опыту могу сказать, что гораздо легче отлаживать свой код, если он написан на ассемблере, чем на машинном коде — отсюда и популярность дизассемблеров. Даже если у вас нет ассемблера, ручная сборка менее подвержена ошибкам, чем попытка написать машинный код напрямую, хотя я думаю, что настоящий программист, такой как Мел, может не согласиться. *8′)
Нет никакой разницы тогда или сейчас. Вы хотите изобрести новый язык программирования, вы выбираете один из языков, доступных вам сегодня, чтобы сделать первый компилятор. в течение некоторого периода времени, если это цель проекта, вы создаете компилятор на этом языке, и затем он может размещаться самостоятельно.
Если все, что у вас было, это карандаш, бумага и несколько переключателей или перфокарт в качестве пользовательского интерфейса для первого или следующего нового набора инструкций, вы использовали один или все доступные вам предметы. Вы вполне могли бы написать язык ассемблера на бумаге, а затем использовать ассемблер, вы, чтобы преобразовать его в машинный код, может быть, в восьмеричный, а затем в какой-то момент это вошло в интерфейс к машине.
Когда сегодня изобретается совершенно новый набор инструкций, ничем не отличается, в зависимости от компании/отдельных лиц, практики и т. д. вполне вероятно, что инженер по аппаратному обеспечению, вероятно, программирует на verilog или vhdl, пишет первые несколько тестовых программ вручную на машинный код (вероятно, в шестнадцатеричном или двоичном формате). в зависимости от прогресса разработчиков программного обеспечения они могут очень быстро или не очень долго переходить на язык ассемблера, а затем на компилятор.
Первые вычислительные машины не были машинами общего назначения, которые можно было использовать для создания ассемблеров и компиляторов. Вы запрограммировали их, переместив несколько проводов между выходом предыдущего алюминиевого сплава и входом следующего. В конце концов у вас появился процессор общего назначения, так что вы могли написать ассемблер на ассемблере, собрать его вручную, передать как машинный код, затем использовать его для разбора ebcdic, ascii и т. д., а затем самостоятельно разместить. сохраните двоичный файл на каком-либо носителе, который вы могли бы позже прочитать / загрузить, не переключая переключатели на машинный код с ручной подачей.
д., а затем самостоятельно разместить. сохраните двоичный файл на каком-либо носителе, который вы могли бы позже прочитать / загрузить, не переключая переключатели на машинный код с ручной подачей.
Подумайте о перфокартах и бумажной ленте. Вместо того, чтобы переключать переключатели, вы определенно могли бы сделать полностью механическую машину, устройство для экономии труда, которое создавало бы носитель, который компьютер читал. Вместо того, чтобы вводить биты машинного кода с помощью переключателей, таких как Altair, вы могли вместо этого подавать бумажную ленту или перфокарты (используя что-то механическое, не управляемое процессором, которое питало память или процессор, ИЛИ используя небольшой загрузчик, написанный машинным кодом). Это была неплохая идея, потому что вы могли сделать что-то под управлением компьютера, который также мог бы механически производить бумажные ленты или перфокарты, а затем подавать их обратно. Два источника перфокарт, механическое устройство для экономии труда, не основанное на компьютере. , и машина с компьютерным управлением. оба производят «двоичные файлы» для компьютера.
, и машина с компьютерным управлением. оба производят «двоичные файлы» для компьютера.
2
В компьютерном зоопарке Брука есть один или два случая, когда он сказал что-то вроде «мнемоника — это наше изобретение, дизайнер просто использовал числовой код операции или символ, код которого был кодом операции», так что там, где машины, для которых не было даже не язык ассемблера.
Ввод программ завершает отладку на передней панели (для тех, кто не делал, это был способ настройки памяти, одни переключатели устанавливаешь на адрес, какие-то на значение и нажимаешь кнопку, или другое кнопку, чтобы прочитать значение) было распространено намного позже. Некоторые старожилы хвастаются, что они по-прежнему смогут вводить загрузочный код для машин, которые они активно использовали.
Сложность написания непосредственно машинного кода и чтения программ из дампа памяти сильно зависит от машинного языка, некоторые из них относительно просты (самая сложная часть — отслеживание адресов), x86 — один из худших.
1
Анекдот:
Когда я изучал язык ассемблера, на Apple ][ в ПЗУ была включена программа под названием микроассемблер. Он делал немедленный перевод ассемблерной инструкции в байты, как только вы их вводили. Это означает, что не было меток — если вы хотите прыгнуть или загрузиться, вам нужно было рассчитать смещения самостоятельно. Это было намного проще, чем искать схемы инструкций и вводить шестнадцатеричные значения.
Несомненно, настоящие ассемблеры сначала писались на микроассемблере или какой-то другой не совсем полной среде.
Я построил компьютер в 1975 году. Он был намного продвинутее своего современника Altair, потому что у него был «монитор ПЗУ», который позволял мне вводить программы, вводя машинный код в шестнадцатеричном формате и просматривая этот код на видеомониторе, где как в Altair каждую машинную инструкцию нужно было вводить понемногу с помощью ряда переключателей.
Так что да, на заре компьютеров, а затем снова на заре персональных компьютеров люди писали приложения в машинном коде.
сборка — Как собирается первый ассемблер? (без кросс-компиляции)
Задавать вопрос
спросил
Изменено 3 года, 11 месяцев назад
Просмотрено 757 раз
Я знаю, что есть много тем по этой теме, но я не могу найти ответ именно на эту тему:
Во-первых, под «первым ассемблером» я имею в виду программу, которая переводит, скажем, инструкцию «mov» на конкретный машинный код, понятный АЛУ, 1100111 или любое другое двоичное число. Между этими двумя шагами есть некоторый разрыв, на который я не могу найти ответы.
Я понимаю, что процесс выглядит примерно так: у вас есть чип процессора, построенный с определенной микроархитектурой, которая реализует N инструкций. Доступ к каждой инструкции осуществляется внутри ALU с помощью двоичного числа или кода операции (000 mov, 001 add и т. д.).
В какой-то исторический момент инструкции загружались в ЦП с помощью перфокарт, лент и т. д.
Доступ к каждой инструкции осуществляется внутри ALU с помощью двоичного числа или кода операции (000 mov, 001 add и т. д.).
В какой-то исторический момент инструкции загружались в ЦП с помощью перфокарт, лент и т. д.
Но тогда вы хотите поднять уровень абстракции и вам нужен ассемблер для программирования на более высоком языке вместо опкодов, и это именно то, где я что-то упускаю.
На данный момент, я думаю, для перехода от кодов операций к ассемблеру используется некоторая начальная загрузка, но как? Как вы пишете ассемблер v0.00 для данного нового процессора? Есть ли какой-либо чип, жестко кодирующий эти инструкции, может быть, первый ассемблер аппаратный?
В «Ассемблере и загрузчиках» кажется, что первый ассемблер был создан с использованием ПЗУ, жестко связывающего телефонные селекторы с адресами памяти.
«Одним из первых компьютеров с хранимой программой был EDSAC (автоматический калькулятор электронного хранения с задержкой), разработанный в Кембриджском университете в 1949 году Морисом Уилксом и У.
Ренвиком. С первых дней своего существования EDSAC имел ассемблер под названием Initial Orders. была реализована в постоянной памяти, сформированной из набора поворотных телефонных селекторов, и принимала символьные инструкции.Каждая инструкция состояла из одной буквенной мнемоники, десятичного адреса и третьего поля, которое было буквой.Третье поле вызывало одно из 12 предустановленных программистом констант, которые будут добавлены к адресу во время сборки.»
- в сборе
4
Вы пишете программу на ассемблере в машинном коде, то есть в виде ряда чисел. Может быть, вы пишете код на ассемблере на листе бумаги, а затем вручную переводите каждую инструкцию в соответствующий номер машинного кода.
1
Вопрос напоминает мне анекдот, рассказанный о Джоне фон Неймане:
Дональд Жиль, один из учеников фон Неймана в Принстоне, преподаватель Иллинойского университета, вспоминал, что аспирантов «использовали» для ручной сборки программ в двоичный файл для их ранней машины (вероятно, машины IAS).
Он взял время для создания ассемблера, но когда фон Нейман узнал о это он был очень зол, говоря (перефразируя): «Это пустая трата ценный научный вычислительный инструмент, чтобы использовать его для канцелярских работа»
Таким образом, на заре вычислительной техники ручное преобразование машинного кода было настолько рутинной практикой, что оспаривалась даже потребность в инструментах.
Точно так же на заре микрокомпьютеров программисты нередко запоминали шестнадцатеричные значения для большинства инструкций (даже в тех случаях, когда у них были ассемблеры, доступные отладчики не всегда имели дизассемблеры).
В настоящее время, как правило, нет причин не использовать кросс-ассемблер.
2
Примитивный ассемблер написать не так уж сложно. Например, я написал простой ассемблер/дизассемблер в Excel — на самом деле просто набор операций поиска.
Все, что вам нужно, это очень простой синтаксический анализатор для каждой строки, простой словарь для меток и список прямых ссылок, которые требуют последующих исправлений.
Существует также много возможностей для сокращений, т. е. требование, чтобы имя кода операции однозначно определяло ожидаемые аргументы, минимальное количество псевдоинструкций или их отсутствие, отсутствие арифметических выражений и т. д.
Упрощением является то, что ранние машины имели меньше инструкций и более простые режимы адресации. В случае, который вы цитируете, используются даже однобуквенные коды операций с тем, что выглядит как фиксированный набор аргументов.
Исходный код ассемблера даже не должен быть эффективным или устойчивым к размеру входных данных, поэтому он может использовать массивы фиксированного размера (в которых не хватило бы места при слишком больших входных данных) и линейный поиск (вместо хэш-таблиц или даже связанные списки), например. Обработка ошибок и сообщения также не должны быть хорошими. Как только вы освоите основные мнемоники, вы, по сути, загрузите ассемблер.
Как написать ассемблер v0.00 для данного нового процессора?
Это относительно просто, вы просто используете более старую машину, на которой уже есть язык программирования.
2
Написание ассемблера в любой момент времени аналогично написанию любой другой программы. Если бы вы имели дело с новым чипом с совершенно новой архитектурой, которая не была бинарно совместима ни с одним другим чипом, то вы бы использовали спецификацию этого чипа для создания отображения строк языка высокого уровня в строки машинного кода. . В противном случае вы бы основывали свою программу на ассемблере для какого-то подобного чипа.
Эта картографическая программа может быть реализована на любом языке на любом компьютере. Люди сделали это в Excel, а я сделал это в Python, используя регулярные выражения. В прошлом они написали бы это перфокартами, переключателями, молотком и зубилом или чем-то еще.
В руководстве по архитектуре чипа описаны регистры процессора, поддерживаемые операции, коды операций и т. д. Задачи написания ассемблера — это задача перевода высокоуровневого описания алгоритма в описание, совместимое с тем, что описано в руководство.