Что нужно знать каждому разработчику о кодировках и наборах символов для работы с текстом / Хабр
Это первая часть перевода статьи What Every Programmer Absolutely, Positively Needs To Know About Encodings And Character Sets To Work With Text
Если вы работаете с текстом в компьютере, вам обязательно нужно знать про кодировки. Даже если вы посылаете электронные письма. Даже если вы их только получаете. Необязательно понимать каждую деталь, но надо хотя бы знать, что из себя представляют кодировки. И вот первая хорошая новость: статья может быть немного запутанной, но основная идея очень и очень простая.
Эта статья о кодировках и наборах символов.
Статья Джоеэля Спольски под названием «Абсолютный минимум о Unicode и наборе символов для каждого разработчика(без исключений!)» будет хорошей вводной и мне доставляет большое удовольствие перечитывать ее время от времени. Я стесняюсь отсылать к ней тех людей, которые испытывают трудности с пониманием проблем с кодировкам, хотя она довольно легкая в плане технических деталей. Я надеюсь, эта статья прольет немного света на то, чем именно являются кодировки, и почему все ваши тексты оказываются испорченными в самый ненужный момент. Статья предназначена для разработчиков(главным образом, на PHP), но пользу от нее может получить любой пользователь компьютера.
Я надеюсь, эта статья прольет немного света на то, чем именно являются кодировки, и почему все ваши тексты оказываются испорченными в самый ненужный момент. Статья предназначена для разработчиков(главным образом, на PHP), но пользу от нее может получить любой пользователь компьютера.
Основы
Все более или менее слышали об этом, но каким-то образом знание испаряется, когда дело доходит до обсуждения, так что вот вам: компьютер не может хранить буквы, числа, картинки или что-либо еще. Он может запомнить только биты. Бит имеет только два значения: ДА или НЕТ, ПРАВДА или ЛОЖЬ, 1 или 0 или любую другую пару, которую вы можете вообразить. Раз уж компьютер работает с электричеством, бит представлен электрическим зарядом: он либо есть, либо его нет. Людям проще представлять это в виде 1 и 0, так что я буду придерживаться этих обозначений.
Чтобы с помощью битов представлять нечно полезное, нам нужны правила. Надо сконвертировать последовательность бит в что-то похожее на буквы, числа и изображения, используя схему кодирования, или, коротко, кодировку.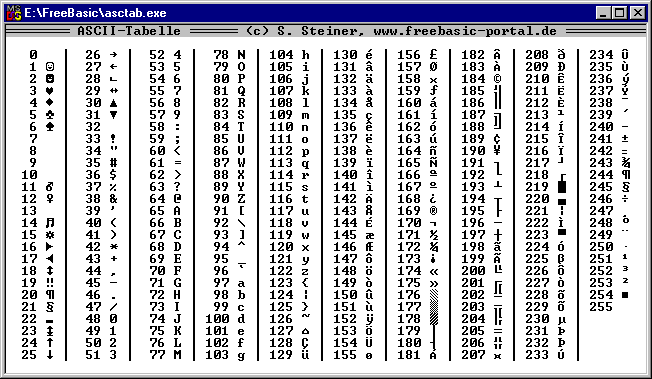 Вот так, например:
Вот так, например:
01100010 01101001 01110100 01110011
b i t s
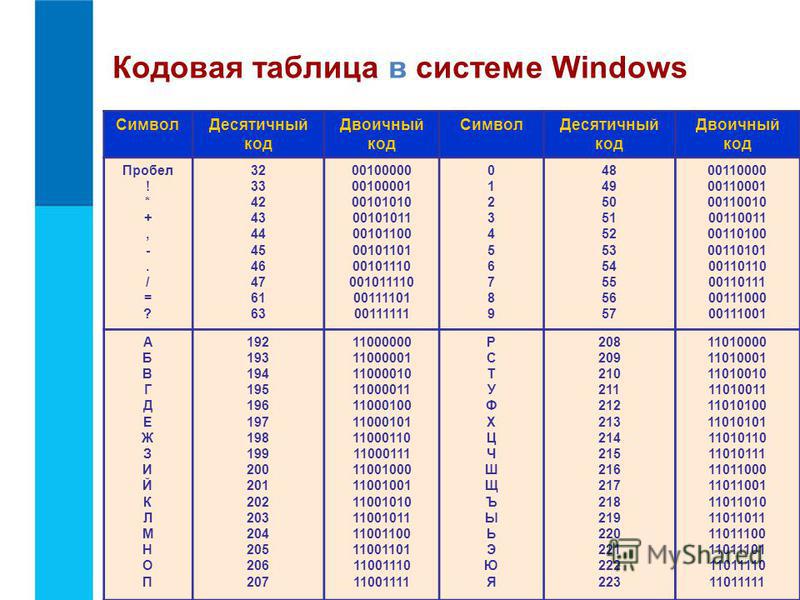
Упомянутая схема носит название ASCII. Строка с нолями и единицами разбивается на части по 8 бит(по байтам). Кодировка ASCII определяет таблицу перевода байтов в человеческие буквы. Вот небольшой кусочек этой таблицы:
bits character01000001 A
01000010 B
01000011 C
01000100 D
01000101 E
01000110 F
В ней 95 символов, включая буквы от A до Z, в нижнем и верхнем регистре, цифры от 0 до 9, с десяток знаков препинания, амперсанд, знак доллара и прочие.
Вот вам способ представить человеческую строку, используя только единицы и нули:
01001000 01100101 01101100 01101100 01101111 00100000
01010111 01101111 01110010 01101100 01100100«Hello World»
Важные термины
Для кодирования чего-либо в ASCII двигайтесь справа налево, подменяя буквы на биты. Для декодирования битов в символы, следуйте по таблице слева направо, подменяя биты на буквы.
encode |enˈkōd|
verb [ with obj. ]
convert into a coded formcode |kōd|
noun
a system of words, letters, figures, or other symbols substituted for other words, letters, etc.

Кодирование – это представление чего-либо чем-нибудь другим. Кодировка – это набор правил, описывающий способ перевода одного представления в другое.
Прочие термины, заслуживающие прояснения:
Набор символов, чарсет, charset – Набор символов, который может быть закодирован. «Кодировка ASCII включает набор из 128 символов». Синоним к кодировке.
Кодовая страница – страница кодов, закрепляюшая за символом набор битов. Таблица. Синоним к кодировке.
Строка – пачка чего-нибудь, объединенных вместе. Битовая строка – это пачка бит, такая как 00011011. Символьная строка – это пачка символов, например «Вот эта». Синоним к последовательности.
Двоичный, восьмеричный, десятичный, шестнадцатеричный
Существует множество способов записывать числа. 10011111 – это бинарная запись для 237 в восьмеричной, 159 в десятичной и 9F в шестнадцатиричной системах. Значения у всех этих чисел одинаково, но шестнадцатиричная система короче и проще для понимания, чем двоичная. Я буду придерживаться двоичной системы в этой статье, чтобы улучшить понимание и убрать лишний уровень абстракции. Не пугайтесь, встречая коды символов в других нотациях, все значения эквиваленты.
Я буду придерживаться двоичной системы в этой статье, чтобы улучшить понимание и убрать лишний уровень абстракции. Не пугайтесь, встречая коды символов в других нотациях, все значения эквиваленты.
Excusez-Moi?
Раз уж мы теперь знаем, о чем говорим, заметим: 95 символов – это совсем немного, когда речь идет о языках. Этот набор покрывает базовый английский, но как насчет французских символов? А вот это Straßen¬übergangs¬änderungs¬gesetz из немецкого языка? А приглашение на smörgåsbord в шведском? В-общем, не получится. Не в ASCII. Спецификация на представление é, ß, ü, ä, ö просто отсутствует.
“Постойте-ка”, скажут европейцы, “в обычных компьютерах с 8 битами в байте, ASCII никак не использует бит, который всегда равен 0! Мы можем использовать его, чтобы расширить таблицу еще на 128 значений”. И было так. Но способов обозначить звучание гласных еще слишком много. Не все сочетания букв и значений, используемые в европейских языках, влезают в таблицу из 256 записей. Так мир пришел к изобилию кодировок, стандартов, стандартов де-факто и недостандартов, которые покрывают все субнаборы символов. Кому-то понадобилось написать документ на шведском или чешском, и, не найдя нужной кодировки, просто изобрел еще одну. Или я думаю, что все так и произошло.
Кому-то понадобилось написать документ на шведском или чешском, и, не найдя нужной кодировки, просто изобрел еще одну. Или я думаю, что все так и произошло.
Не забывайте о русском, хинди, арабском, корейском и множестве других живых языков планеты. Про мертвые уж молчим. Как только вы найдете способ писать документ, использующий несколько языков, попробуйте добавить китайский. Или японский. Оба содержат тысячи символов. И у вас всего 256 значений. Вперед!
Многобайтные кодировки
Для создания таблиц, которые содержат более 256 символов, одного байта просто недостаточно. Двух байтов (16 бит) хватит для кодировки 65536 различных значений. Big-5 например, кодировка двухбайтная. Вместо разбиения последовательности битов в блоки по 8, она использует блоки по 16 битов и содержит большую(я имею ввиду БОЛЬШУЮ) таблицу с соответствием. Big-5 в своем основном виде покрывает большинство символов традиционного китайского. GB18030 – это похожая кодировка, но она включает как традиционный, так и упрощенный китайский.
Вот кусок таблицы GB18030:
bits character
10000001 01000000 丂
10000001 01000001 丄
10000001 01000010 丅
10000001 01000011 丆
10000001 01000100 丏
Путаница с Unicode
В итоге тем, кому больше всех надоела эта каша, пришла в голову идея разработать единый стандарт, объединяющий все кодировки. Этим стандартом стал Unicode. Он определяет невероятную таблицу из 1 114 112 пунктов, используемую для всех вариантов букв и символов. Этого хватит для кодирования всех европейских, средне-азиатских, дальневосточных, южных, северных, западных, доисторических и будущих символов, о которых человечеству известно. Unicode позволяет создать документ на любом языке любыми символами, которые можно ввести в компьютер. Это было невозможно, или очень затруднительно до эры Unicode. В стандарте есть даже неофициальная секция под клингонский. Вы поняли, Unicode настолько большой, чтобы допускает неофициальные секции.
Это было невозможно, или очень затруднительно до эры Unicode. В стандарте есть даже неофициальная секция под клингонский. Вы поняли, Unicode настолько большой, чтобы допускает неофициальные секции.
Итак, и сколько же байт использует Unicode для кодирования? Нисколько. Потому что Unicode – это не кодировка.
Смущены? Не вы одни. Unicode в первую и главную очередь определяет таблицу пунктов для символов. Это такой способ сказать «65 – A, 66 – B, 9731 – »(я не шучу, так и есть). Как эти пункты кодируются в байты является предметом другого разговора. Для представления 1 114 112 значений двух байт недостаточно. Трех достаточно, но 3 – странное число, так что 4 является комфортным минимумом. Но, пока вы не используете китайский, или другой язык со множеством символов, которые требуют большого количества битов для кодирования, вам никогда не придет в голову использовать толстую колбасу из 4х байт. Если “A” всегда кодируется в 00000000 00000000 00000000 01000001, а “B” – в 00000000 00000000 00000000 01000010, то документ, использующий такую кодировку, распухнет в 4 раза.
Существует несколько способов решения этой проблемы. UTF-32 – это кодировка, которая переводит все символы в наборы из 32 бит. Это простой алгоритм, но изводящий много места впустую. UTF-16 и UTF-8 являются кодировками с переменной длиной кодирования. Если символ может быть закодирован одним байтом(потому что номер пункта символа очень маленький), UTF-8 закодирует его одним байтом. Если нужно 2 байта, то используется 2 байта. Кодировка сообщает старшими битами, сколькими битами кодируется текущий символ. Такой способ экономит место, но так же и тратит его в случае, если эти сигнальные биты часто используются. UTF-16 является компромиссом: все символы как минимум двухбайтные, но их размер может увеличиваться до 4 байт, если нужно.
character encoding bits
A UTF-8 01000001
A UTF-16 00000000 01000001
A UTF-32 00000000 00000000 00000000 01000001
あ UTF-8 11100011 10000001 10000010
あ UTF-16 00110000 01000010
あ UTF-32 00000000 00000000 00110000 01000010
И все.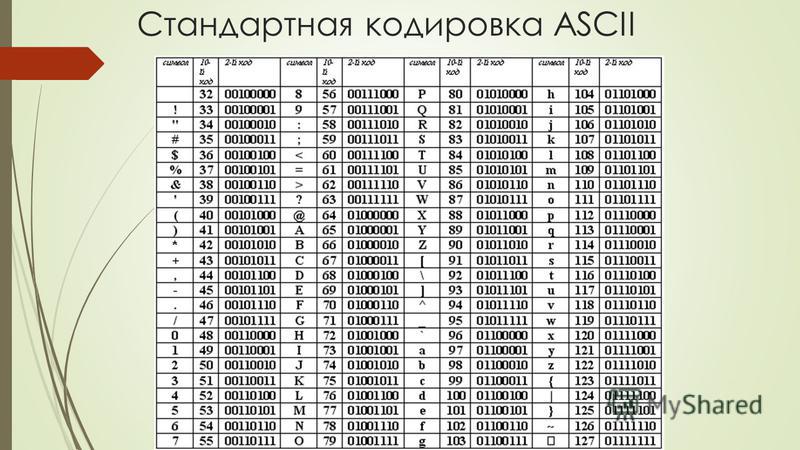 Unicode – это огромная таблица соответствия символов и чисел, а различные UTF кодировки определяют, как эти числа переводятся в биты. В-общем, Unicode – это просто еще одна схема. Ничего особенного, она просто пытается покрыть все, что можно, оставаясь эффективной. И это хорошо.
Unicode – это огромная таблица соответствия символов и чисел, а различные UTF кодировки определяют, как эти числа переводятся в биты. В-общем, Unicode – это просто еще одна схема. Ничего особенного, она просто пытается покрыть все, что можно, оставаясь эффективной. И это хорошо.
Пункты
Символы определяются по их Unicode-пунктам. Эти пункты записаны в шестнадцатеричной системе и предварены “ U+” (просто для удобство, не значит ничего, кроме “Это пункт Unicode”). Символ Ḁ имеет пункт U+1E00. Иными(десятичными) словами, это 7680й символ таблицы Unicode. Он официально называется “ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА А С КОЛЬЦОМ СНИЗУ”.
Ниасилил
Суть вышесказанного: любой символ может быть закодирован множеством разных последовательностей бит, и любая последовательность бит может представлять разные символы, в зависимости от используемой кодировки. Причина в том, что разные кодировки используют разное число бит на символ и разные значения для кодирования разных символов.
bits encoding characters11000100 01000010 Windows Latin 1 ÄB
11000100 01000010 Mac Roman ƒB
11000100 01000010 GB18030 腂characters encoding bits
Føö Windows Latin 1 01000110 11111000 11110110
Føö Mac Roman 01000110 10111111 10011010
Føö UTF-8 01000110 11000011 10111000 11000011 10110110
Заблуждения, смущения и проблемы
Имея все вышесказанное, мы приходим к насущным проблемам, которые испытывают множество пользователей и разработчиков каждый день, как они соотносятся с указанным выше, и каковы пути решения. Сама большая проблема – это
Сама большая проблема – это
Какого черта мой текст нечитаем?
ÉGÉìÉRÅ[ÉfÉBÉìÉOÇÕìÔǵÇ≠ǻǢ
Если вы откроете документ, и он выглядит так, как текст выше, то причина у этого одна: ваша программа ошиблась с кодировкой. И все. Документ не испорчен(по крайней мере, пока), и не нужно никакое волшебство. Вместо него надо просто выбрать правильную кодировку для отображения текста. Предполагаемый документ выше содержит биты:
10000011 01000111 10000011 10010011 10000011 01010010 10000001 01011011
10000011 01100110 10000011 01000010 10000011 10010011 10000011 01001111
10000010 11001101 10010011 11101111 10000010 10110101 10000010 10101101
10000010 11001000 10000010 10100010
Так, быстренько угадали кодировку? Если вы пожали плечами, то вы правы. Да кто знает?
Попробуем с ASCII. Большая часть этих байтов начинается с 1. Если вы правильно помните, ASCII вообще-то не использует этот бит. Так что ASCII не вариант.
Конечно, это полный бред. Правильный ответ таков: текст закодирован в Japanes Shift-JIS и должен выглядеть как エンコーディングは難しくない. Кто бы мог подумать?
Первая причина нечитаемости текста в том, что кто-то пытается прочитать последовательность байт в неверной кодировке. Компьютеру всегда нужно подсказывать. Сам он не догадается. Некоторые типы документов определяют кодировку своего содержимого, но последовательность байт всегда остается черным ящиком.
 Иные программы тоже имеют аналогичные пункты.
Иные программы тоже имеют аналогичные пункты.У автора нет разбиения на части, но статья и так длинна. Продолжение будет через пару дней.
[Перевод] Символы Unicode: о чём должен знать каждый разработчик
Если вы пишете международное приложение, использующее несколько языков, то вам нужно кое-что знать о кодировке. Она отвечает за то, как текст отображается на экране. Я вкратце расскажу об истории кодировки и о её стандартизации, а затем мы поговорим о её использовании. Затронем немного и теорию информатики.
Введение в кодировку
Компьютеры понимают лишь двоичные числа — нули и единицы, это их язык. Больше ничего. Одно число называется битом, каждый бит состоит из восьми байтов. То есть восемь нулей и единиц составляют один байт. Внутри компьютеров всё сводится к двоичности — языки программирования, движений мыши, нажатия клавиш и все слова на экране. Но если статья, которую вы читаете, раньше была набором нулей и единиц, то как двоичные числа превратились в текст? Давайте разберёмся.
Краткая история кодировки
На заре своего развития интернет был исключительно англоязычным. Его авторам и пользователям не нужно было заботиться о символах других языков, и все нужды полностью покрывала кодировка American Standard Code for Information Interchange (ASCII).
ASCII — это таблица сопоставления бинарных обозначений знакам алфавита. Когда компьютер получает такую запись:
01001000 01100101 01101100 01101100 01101111 00100000 01110111 01101111 01110010 01101100 01100100
то с помощью ASCII он преобразует её во фразу «Hello world».
Один байт (восемь бит) был достаточно велик, чтобы вместить в себя любую англоязычную букву, как и управляющие символы, часть из которых использовалась телепринтерами, так что в те годы они были полезны (сегодня уже не особо). К управляющим символам относился, например 7 (0111 в двоичном представлении), который заставлял компьютер издавать сигнал; 8 (1000 в двоичном представлении) — выводил последний напечатанный символ; или 12 (1100 в двоичном представлении) — стирал весь написанный на видеотерминале текст.
В те времена компьютеры считали 8 бит за один байт (так было не всегда), так что проблем не возникало. Мы могли хранить все управляющие символы, все числа и англоязычные буквы, и даже ещё оставалось место, поскольку один байт может кодировать 255 символов, а для ASCII нужно только 127. То есть неиспользованными оставалось ещё 128 позиций в кодировке.
Вот как выглядит таблица ASCII. Двоичными числами кодируются все строчные и прописные буквы от A до Z и числа от 0 до 9. Первые 32 позиции отведены для непечатаемых управляющих символов.
Проблемы с ASCII
Позиции со 128 по 255 были пустыми. Общественность задумалась, чем их заполнить. Но у всех были разные идеи. Американский национальный институт стандартов (American National Standards Institute, ANSI) формулирует стандарты для разных отраслей. Там утвердили позиции ASCII с 0 по 127. Их никто не оспаривал. Проблема была с остальными позициями.
Вот чем были заполнены позиции 128–255 в первых компьютерах IBM:
Какие-то загогулины, фоновые иконки, математические операторы и символы с диакретическим знаком вроде é. Но разработчики других компьютерных архитектур не поддержали инициативу. Всем хотелось внедрить свою собственную кодировку во второй половине ASCII.
Но разработчики других компьютерных архитектур не поддержали инициативу. Всем хотелось внедрить свою собственную кодировку во второй половине ASCII.
Все эти различные концовки назвали кодовыми страницами.
Что такое кодовые страницы ASCII?
Здесь собрана коллекция из более чем 465 разных кодовых страниц! Существовали разные страницы даже в рамках какого-то одного языка, например, для греческого и китайского. Как можно было стандартизировать этот бардак? Или хотя бы заставить его работать между разными языками? Или между разными кодовыми страницами для одного языка? В языках, отличающихся от английского? У китайцев больше 100 000 иероглифов. ASCII даже не может всех их вместить, даже если бы решили отдать все пустые позиции под китайские символы.
Эта проблема даже получила название Mojibake (бнопня, кракозябры). Так говорят про искажённый текст, который получается при использовании некорректной кодировки. В переводе с японского mojibake означает «преобразование символов».
В переводе с японского mojibake означает «преобразование символов».
Пример бнопни (кракозябров).
Безумие какое-то…
Именно! Не было ни единого шанса надёжно преобразовывать данные. Интернет — это лишь монструозное соединение компьютеров по всему миру. Представьте, что все страны решили использовать собственные стандарты. Например, греческие компьютеры принимают только греческий язык, а английские отправляют только английский. Это как кричать в пустой пещере, тебя никто не услышит.
ASCII уже не удовлетворял жизненным требованиям. Для всемирного интернета нужно было создать что-то другое, либо пришлось бы иметь дело с сотнями кодовых страниц.
��� Если только ������ вы не хотели ��� бы ��� читать подобные параграфы. �֎֏0590��׀ׁׂ׃ׅׄ׆ׇ
Так появился Unicode
Unicode расшифровывают как Universal Coded Character Set (UCS), и у него есть официальное обозначение ISO/IEC 10646. Но обычно все используют название Unicode.
Но обычно все используют название Unicode.
Этот стандарт помог решить проблемы, возникавшие из-за кодировки и кодовых страниц. Он содержит множество кодовых пунктов (кодовых точек), присвоенных символам из языков и культур со всего мира. То есть Unicode — это набор символов. С его помощью можно сопоставить некую абстракцию с буквой, на которую мы хотим ссылаться. И так сделано для каждого символа, даже египетских иероглифов.
Кто-то проделал огромную работу, сопоставляя каждый символ во всех языках с уникальными кодами. Вот как это выглядит:
«Hello World» U+0048 : латинская прописная H U+0065 : латинская строчная E U+006C : латинская строчная L U+006C : латинская строчная L U+006F : латинская строчная O U+0020 : пробел U+0057 : латинская прописная W U+006F : латинская строчная O U+0072 : латинская строчная R U+006C : латинская строчная L U+0064 : латинская строчная D
Префикс U+ говорит о том, что это стандарт Unicode, а число — это результат преобразования двоичных чисел. Стандарт использует шестнадцатеричную нотацию, которая является упрощённым представлением двоичных чисел. Здесь вы можете ввести в поле что угодно и посмотреть, как это будет преобразовано в Unicode. А здесь можно полюбоваться на все 143 859 кодовых пунктов.
Стандарт использует шестнадцатеричную нотацию, которая является упрощённым представлением двоичных чисел. Здесь вы можете ввести в поле что угодно и посмотреть, как это будет преобразовано в Unicode. А здесь можно полюбоваться на все 143 859 кодовых пунктов.
Уточню на всякий случай: речь идёт о большом словаре кодовых пунктов, присвоенных всевозможным символам. Это очень большой набор символов, не более того.
Осталось добавить последний ингредиент.
Unicode Transform Protocol (UTF)
UTF — протокол кодирования кодовых пунктов в Unicode. Он прописан в стандарте и позволяет кодировать любой кодовый пункт. Однако существуют разные типы UTF. Они различаются количеством байтов, используемых для кодировки одного пункта. В UTF-8 используется один байт на пункт, в UTF-16 — два байта, в UTF-32 — четыре байта.
Но если у нас есть три разные кодировки, то как узнать, какая из них применяется в конкретном файле? Для этого используют маркер последовательности байтов (Byte Order Mark, BOM), который ещё называют сигнатурой кодировки (Encoding Signature).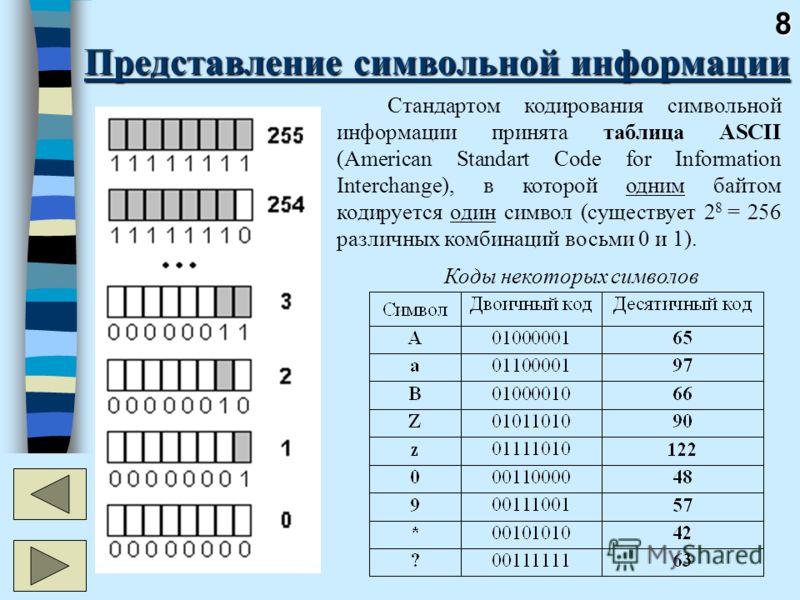 BOM — это двухбайтный маркер в начале файл, который говорит о том, какая именно кодировка тут применена.
BOM — это двухбайтный маркер в начале файл, который говорит о том, какая именно кодировка тут применена.
В интернете чаще всего используют UTF-8, она также прописана как предпочтительная в стандарте HTML5, так что уделю ей больше всего внимания.
Этот график построен в 2012-м, UTF-8 становилась доминирующей кодировкой. И всё ещё ею является.
График показывает распространённость UTF-8.
Что такое UTF-8 и как она работает?
UTF-8 кодирует с помощью одного байта каждый кодовый пункт Unicode с 0 по 127 (как в ASCII). То есть если вы писали программу с использованием ASCII, а ваши пользователи применяют UTF-8, они не заметят ничего необычного. Всё будет работать как задумано. Обратите внимание, как это важно. Нам нужно было сохранить обратную совместимость с ASCII в ходе массового внедрения UTF-8. И эта кодировка ничего не ломает.
Как следует из названия, кодовый пункт состоит из 8 битов (один байт). В Unicode есть символы, которые занимают несколько байтов (вплоть до 6). Это называют переменной длиной. В разных языках удельное количество байтов разное. В английском — 1, европейские языки (с латинским алфавитом), иврит и арабский представлены с помощью двух байтов на кодовый пункт. Для китайского, японского, корейского и других азиатских языков используют по три байта.
Если нужно, чтобы символ занимал больше одного байта, то применяется битовая комбинация, обозначающая переход — он говорит о том, что символ продолжается в нескольких следующих байтах.
И теперь мы, как по волшебству, пришли к соглашению, как закодировать шумерскую клинопись (Хабр её не отображает), а также значки emoji!
Подытожив сказанное: сначала читаем BOM, чтобы определить версию кодировки, затем преобразуем файл в кодовые пункты Unicode, а потом выводим на экран символы из набора Unicode.
Напоследок про UTF
Коды являются ключами. Если я отправлю ошибочную кодировку, вы не сможете ничего прочесть. Не забывайте об этом при отправке и получении данных. В наших повседневных инструментах это часто абстрагировано, но нам, программистам, важно понимать, что происходит под капотом.
Если я отправлю ошибочную кодировку, вы не сможете ничего прочесть. Не забывайте об этом при отправке и получении данных. В наших повседневных инструментах это часто абстрагировано, но нам, программистам, важно понимать, что происходит под капотом.
Как нам задавать кодировку? Поскольку HTML пишется на английском, и почти все кодировки прекрасно работают с английским, мы можем указать кодировку в начале раздела .
Важно сделать это в самом начале , поскольку парсинг HTML может начаться заново, если в данный момент используется неправильная кодировка. Также узнать версию кодировки можно из заголовка Content-Type HTTP-запроса/ответа.
Если HTML-документ не содержит упоминания кодировки, спецификация HTML5 предлагает такое интересное решение, как BOM-сниффинг. С его помощью мы по маркеру порядка байтов (BOM) можем определить используемую кодировку.
Это всё?
Unicode ещё не завершён. Как и в случае с любым стандартом, мы что-то добавляем, убираем, предлагаем новое. Никакие спецификации нельзя назвать «завершёнными». Обычно в год бывает 1–2 релиза, найти их описание можно здесь.
Как и в случае с любым стандартом, мы что-то добавляем, убираем, предлагаем новое. Никакие спецификации нельзя назвать «завершёнными». Обычно в год бывает 1–2 релиза, найти их описание можно здесь.
Недавно я прочитал об очень интересном баге, связанном с некорректным отображением в Twitter русских Unicode-символов.
Если вы дочитали до конца, то вы молодцы. Предлагаю сделать домашнюю работу. Посмотрите, как могут ломаться сайты при использовании неправильной кодировки. Я воспользовался этим расширением для Google Chrome, поменял кодировку и попытался открывать разные страницы. Информация была совершенно нечитаемой. Попробуйте сами, как выглядит бнопня. Это поможет понять, насколько важна кодировка.
Заключение
При написании этой статьи я узнал о Майкле Эверсоне. С 1993 года он предложил больше 200 изменений в Unicode, добавил в стандарт тысячи символов. По состоянию на 2003 год он считался самым продуктивным участником. Он один очень сильно повлиял на облик Unicode.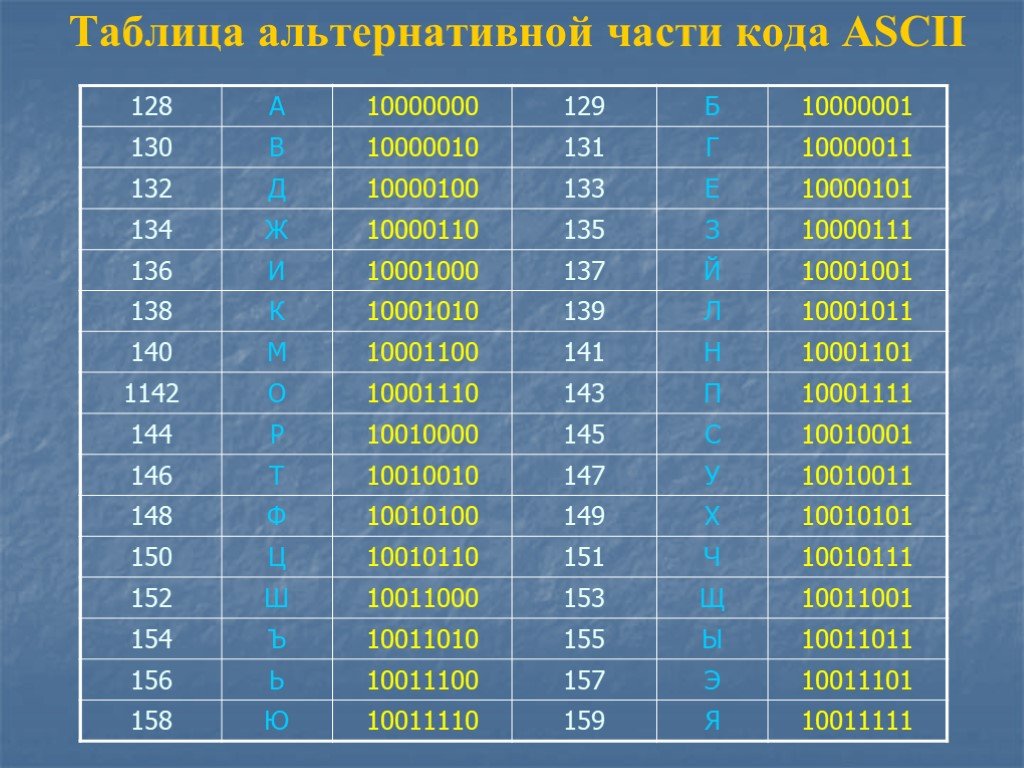 Майкл — один из тех, кто сделал интернет таким, каким мы его сегодня знаем. Очень впечатляет.
Майкл — один из тех, кто сделал интернет таким, каким мы его сегодня знаем. Очень впечатляет.
Надеюсь, мне удалось показать вам, для чего нужны кодировки, какие проблемы они решают, и что происходит при их сбоях.
символов — преобразование/кодирование перевода | Текст | Датакадамиа
Содержание
Преобразование символов/кодирование перевода
О нас
Статьи по теме
Сопоставление набора символов в разных кодовых страницах
Документация/справка
О
Строка — это последовательность байтов, которая может представлять собой символы. Все символы в строке имеют общее кодовое представление. В некоторых случаях, например, кодовые представления могут различаться в отправляющей и принимающей системах, может потребоваться преобразовать эти символы в другое кодовое представление.
Этот процесс известен как преобразование символов. Преобразование символов при необходимости выполняется автоматически, а в случае успеха оно прозрачно для приложения.
Преобразование символов при необходимости выполняется автоматически, а в случае успеха оно прозрачно для приложения.
В результате использования множества методов кодирования символов (и необходимости обратной совместимости с архивными данными) было разработано множество компьютерных программ для преобразования данных между схемами кодирования. Например, в Firefox 3 см. подменю View/Character Encoding (здесь на голландском языке).
Ослабление ограничения кодовой страницы (или проверки) означает, что этот процесс не должен быть полностью успешным, и тогда вы можете потерять данные во время преобразования.
Сопоставление набора символов в разных кодовых страницах
На следующем рисунке показано, как типичный набор символов может сопоставляться с разными кодовыми точками на двух разных кодовых страницах.
Даже при одной и той же схеме кодирования существует много разных кодовых страниц, и одна и та же кодовая точка может представлять разные символы в разных кодовых страницах.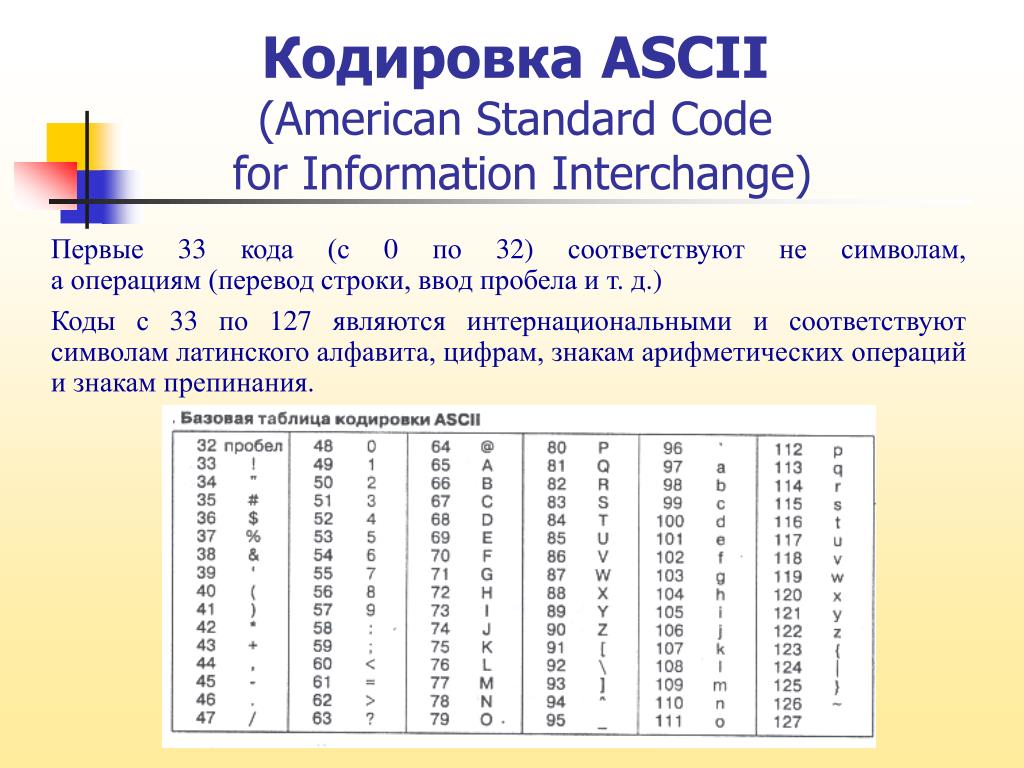
Кроме того, байт в строке символов не обязательно представляет символ из набора однобайтовых символов (SBCS). Строки символов также используются для смешанных и битовых данных. Смешанные данные представляют собой смесь однобайтовых, двухбайтовых или многобайтовых символов. Битовые данные (столбцы, определенные как FOR BIT DATA, или BLOB, или двоичные строки) не связаны ни с каким набором символов.
Документация / Справочник
Преобразование символов
Рекомендуемые страницы
Текст — Кодировка (Набор символов|кодировка|кодовая страница)
Текст — Кодировка (Набор символов|кодировка|кодовая страница) О Набор символов — это набор символов, в котором каждый символ (назначен|закодирован) в числовой кодовой точке. Набор символов (как «…
Набор символов — Кодовая страница
Кодовая страница — это числовой идентификатор для набора символов.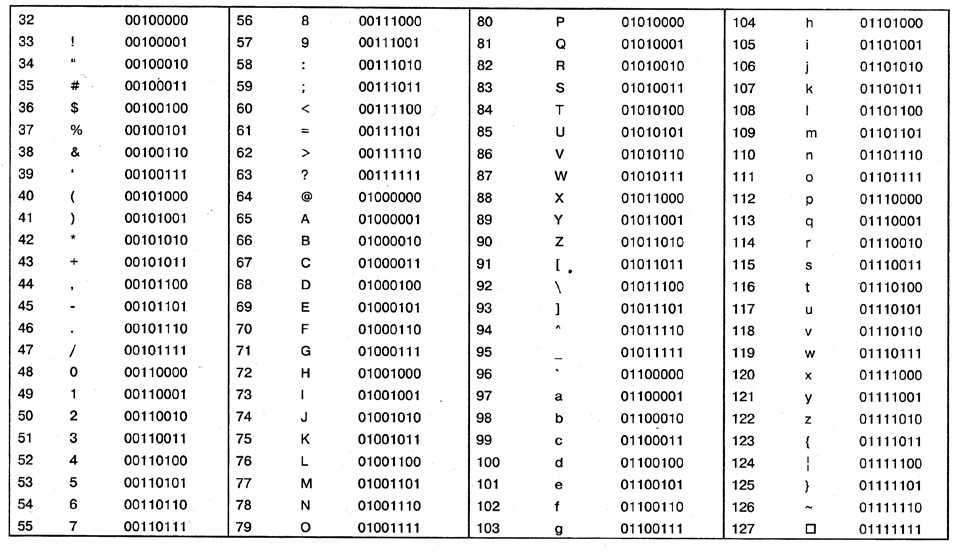 Термин «кодовая страница» возник в системах мэйнфреймов IBM на основе EBCDIC, но многие поставщики используют этот термин, включая Microsoft, SAP и Oracle Corpo «…
Термин «кодовая страница» возник в системах мэйнфреймов IBM на основе EBCDIC, но многие поставщики используют этот термин, включая Microsoft, SAP и Oracle Corpo «…
FTP — Тип
FTP Задать тип передачи файлов. Тип передачи по умолчанию — . Статьи по теме Синтаксис где: TypeName is : binary Тип ASCII ASCII Команду ascii следует использовать при передаче текстовых файлов. В «…
OBIA — версия установки 7.9.6 с EBS, PowerCenter, базой данных Oracle в Windows
Roadmap
Roadmap Чтобы установить и настроить приложения Oracle BI, выполните следующие действия: предустановочные шаги для «…OWB — Плоский файл
Плоский файл заметок в OWB. Статьи по теме Импорт Чтобы сэкономить время на шаге примера, вы можете выбрать То же, что и
из раскрывающегося списка «Так же как». (Вы должны использовать параметр «То же, что и», когда файл «…База данных Oracle — длинный (текст) и длинный необработанный тип данных
Предупреждение LOB Oracle также рекомендует преобразовать существующие столбцы LONG в столбцы LOB. меньше ограничений, чем столбцы LONG. Кроме того, функциональность LOB расширена в «…
меньше ограничений, чем столбцы LONG. Кроме того, функциональность LOB расширена в «…
Oracle Database — NLS_LANG (LOCALE)
NLS_LANG — это параметр среды, используемый для установки языкового стандарта клиентского приложения. Установка параметра среды NLS_LANG — это простейший способ указать поведение локали для базы данных Oracle SOF «…
База данных Oracle — протокол Two-Task Common (TTC)
Протокол, который используется в типичном соединении Oracle Net для обеспечения преобразования наборов символов и типов данных между различными наборами символов или форматами на клиенте и сервере. Статьи, связанные с документом «…
PowerCenter — Кодовая страница
, кодовая страница в Powercenter Статьи, связанные с кодовой страницей службы интеграции Ослабление кодовой страницы Вы можете настроить службу интеграции, чтобы ослабить проверку кодовой страницы при запуске службы интеграции в Unico». ..
..
SQL — Большой символьный объект (CLOB)
Большой символьный объект (CLOB) — это тип данных SQL, используемый для хранения большого количества символьных данных. Это специализированный вариант большого объекта (LOB), где данные хранятся в файле в локальном файле sy «…
Поделиться этой страницей:
Подписывайтесь на нас:
Преобразование вектора символов между кодировками
| iconv | R Документация |
Описание
При этом используются системные средства для преобразования вектора символов между кодировки: «i» означает «интернационализация».
Использование
iconv(x, from = "", to = "", sub = NA, mark = TRUE, toRaw = FALSE) список иконок()
Аргументы
x | Вектор символов или объект, который нужно преобразовать в символ
вектор на |
из | Строка символов, описывающая текущую кодировку. |
до | Строка символов, описывающая целевую кодировку. |
вспомогательный | Строка из символов. Если не |
знак | логический, для экспертного использования. Должны ли кодировки быть отмечены? |
toRaw | логический. |
 character
character  Должен ли возвращаться список необработанных векторов, а не
чем вектор символов?
Должен ли возвращаться список необработанных векторов, а не
чем вектор символов?Детали
Названия кодировок и доступные
зависит от платформы. Все платформы R поддерживают "" (для
кодировка текущей локали), "latin1" и "UTF-8" .
Обычно регистр игнорируется при указании кодировки.
На большинстве платформ iconvlist предоставляет алфавитный список
поддерживаемые кодировки. На других информация о человеке
страницу для iconv(5) или где-либо еще на справочных страницах (но будьте осторожны
что системная команда iconv может не поддерживать тот же набор
кодирования как функции C R звонки). К сожалению, имена
редко поддерживается на всех платформах.
Элементы размером x , которые невозможно преобразовать (возможно, потому, что они
недействительны или потому что они не могут быть представлены в целевом
кодировка) будет возвращено как NA , если не указано sub .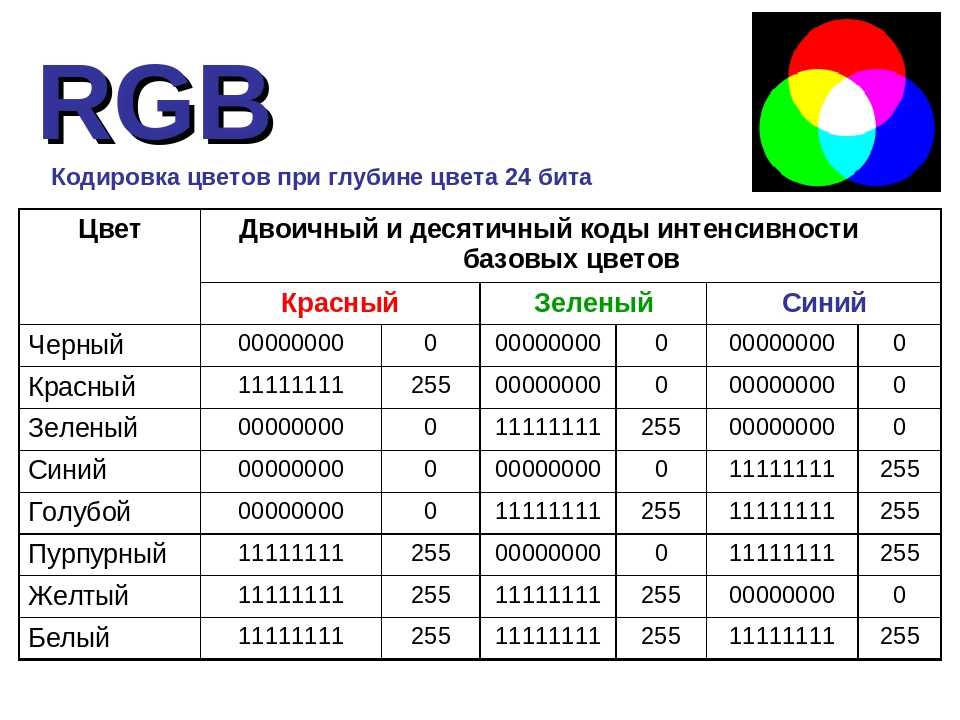
Большинство версий iconv допускают транслитерацию путем добавления
//ПЕРЕВОД в кодировку от до : см. примеры.
Кодировка "ASCII" принимается, а на большинстве систем "C" и "POSIX" являются синонимами ASCII.
Любые биты кодирования (см. Кодирование ) на элементах размером x игнорируются: они всегда будут транслироваться как из кодировки из , даже если указано иное. enc2native и enc2utf8 предоставляют альтернативы, которые принимают объявленные
кодировки с учетом.
Обратите внимание, что реализации iconv обычно мало что делают
проверка достоверности и часто неправильно преобразует входные данные, которые недействительны
в кодировке из .
Если sub = "Unicode" используется для ввода не-UTF-8, это то же самое
как sub = "byte" .
Значение
Если toRaw = FALSE (значение по умолчанию), значение представляет собой вектор символов
той же длины и тех же атрибутов, что и x (после
преобразование в вектор символов).
Если метка = TRUE (по умолчанию), элементы результата имеют
объявленная кодировка, если от до равна "latin1" или "УТФ-8" ,
или если to = "" и кодировка текущей локали определяется как
Latin-1 (или его расширенный набор CP1252 в Windows) или UTF-8.
Если toRaw = TRUE , значение представляет собой список той же длины и
те же атрибуты, что и x , элементы которых равны NULL (если преобразование не удалось) или необработанный вектор.
Для iconvlist() вектор символов (обычно из нескольких сотен
элементы) известных имен кодировок.
Сведения о реализации
Существует три основных реализации iconv . Linux
наиболее распространенная среда выполнения C, glibc, содержит один. Несколько платформ
поставлять GNU libiconv, включая macOS, FreeBSD и Cygwin, в
некоторые случаи с дополнительными кодировками. В Windows мы используем версию
Win_iconv Юкихиро Накадайры, основанный на Windows
кодовые страницы. (Мы добавили много имен кодировок для совместимости с
другие системы.) Все три имеют
(Мы добавили много имен кодировок для совместимости с
другие системы.) Все три имеют iconvlist , игнорировать регистр
названия кодировок и поддержка //ТРАНСЛИТ (но с разными
результаты, а для win_iconv в настоящее время «наиболее подходящий»
стратегия используется за исключением to = "ASCII" ).
Большинство коммерческих Unix содержат реализацию iconv , но
ни один из тех, с которыми мы сталкивались, не поддерживал нужные нам имена кодировок:
руководство «Установка и администрирование R» рекомендует
установка GNU libiconv, например, на Solaris и AIX.
Некоторые дистрибутивы Linux используют musl в качестве среды выполнения C. Это менее полный, чем glibc: он не поддерживает //ТРАНСЛИТИРУЕТ, но делает неточные преобразования (в настоящее время используется *).
Существуют и другие реализации, например. NetBSD использовала один из
проект Citrus (который не поддерживает //ТРАНСЛИТ) и есть
более старый порт FreeBSD (там обычно используется libiconv): он
не сообщалось, работают ли они с R .
Обратите внимание, что нельзя полагаться на обнаружение недопустимых входных данных, особенно
для to = "ASCII" , где некоторые реализации допускают 8-битный
символов и передавать их без изменений или с транслитерацией или
замена.
Некоторые реализации имеют интересные дополнительные кодировки: для
пример GNU libiconv позволяет использовать to = "C99" \uxxxx экранирует символы, отличные от ASCII.
Знаки порядка байтов
, наиболее известные как «спецификации».
Кодирование с использованием символьных единиц размером более одного байта
могут быть записаны в файле либо в прямом, либо в обратном порядке:
чаще всего это относится к UCS-2, UTF-16 и UTF-32/UCS-4.
кодировки. Некоторые системы будут записывать символ Unicode U+FEFF в начале файла в этих кодировках и
возможно также в UTF-8. В этом использовании символ известен как спецификация,
и должны обрабатываться во время ввода (см. раздел «Кодировки»
под соединение : перекодированные соединения имеют некоторые
специальная обработка спецификаций). Остальная часть этого раздела применяется, когда это
не было сделано, поэтому
Остальная часть этого раздела применяется, когда это
не было сделано, поэтому x начинается со спецификации.
Реализации обычно интерпретируют спецификацию для из заданного как один из "UCS-2" , "УТФ-16" и "УТФ-32" . Реализации различаются тем, как они обрабатывают спецификации в x в других кодировках из : они могут быть отброшены,
возвращается как символ U+FEFF или считается недопустимым.
Примечание
Единственное разумно переносимое имя для кодировки ISO 8859-15,
обычно известный как «Latin 9», это «latin-9» : некоторые
платформы поддерживают "latin9" , а GNU libiconv — нет.
Кодировка имен "utf8" , "mac" и "macroman" являются
не портативный. "utf8" преобразуется в "UTF-8" для от и до по iconv , но не
например fileEncoding аргументов.