как с ними работать — гайд для новичков / Skillbox Media
#статьи- 0
Расскажем о самом популярном: дублировании, сложении, подсчёте длины, замене символов и работе с индексом.
Vkontakte Twitter Telegram Скопировать ссылкуМарина Демидова
Программист, консультант, специалист по документированию. Легко и доступно рассказывает о сложных вещах в программировании и дизайне.
Легко и доступно рассказывает о сложных вещах в программировании и дизайне.
Строковый тип данных — один из основных типов данных в Python. Он используется для хранения символьной информации: букв, чисел, знаков препинания и других символов. Например, отлично подходит для записи ФИО или адресов клиентов в базах данных.
В этой статье разберём полезные методы работы со строкам и узнаем, как их складывать, умножать, научимся считать индексы в строковых переменных попрактикуемся с кодом. Приступим!
Содержание
- Вспомним, что такое строки
- Работа со строками в Python: базовые операции
- Сложение (конкатенация)
- Вычитание
- Дублирование (умножение)
- Принадлежность строки
- Определение длины строки
- Доступ по индексу
- Срез строки
- Шаг извлечения среза
- Таблица методов и функций строк
- Примеры кода
Строковый тип данных — это последовательности символов Unicode любой длины, заключённые в одинарные, двойные или тройные кавычки.
Например, создадим три переменных, используя разное число кавычек:
s1 = 'Hello, world!'
s2 = "Hello, world2"
s3 = '''Используем тройные
кавычки для вывода
многострочного текста'''
Проверим, действительно ли мы создали переменные нужного типа. Для этого воспользуемся функцией type:
# Выведем на печать типы переменных s1, s2, s3
s1 = 'Hello, world!'
print(type(s1))
s2 = "Hello, world2"
print(type(s2))
s3 = '''Используем тройные
кавычки для вывода
многострочного текста'''
print(type(s3))
Запустим код и посмотрим на результат:
<class 'str'>
<class 'str'>
<class 'str'>
Да. Все три переменные имеют тип str, то есть являются строковыми.
Все три переменные имеют тип str, то есть являются строковыми.
Разберём подробнее, какие операции можно производить над строками, и поговорим про функции и методы этого типа данных.
Перед тем как перейти к конкретным действиям, напомним что строки в Python — неизменяемый тип данных. Это означает, что строковую переменную нельзя изменить с помощью операторов, функций и методов. Если мы хотим сохранить результат изменения существующей строки, то надо создать новую переменную.
Начнём! Разберём основные виды операций над строками. Запускайте любимый редактор кода и повторяйте действия за нами.
Строки, как и числа, можно складывать, проще говоря, склеивать между собой с помощью оператора +. Эту операцию иногда называют «сцеплением».
Например:
s1 = 'Skill'
s2 = 'box'
s3 = s1 + s2
print(s3)
Результат:
Skillbox
Здесь, в отличие от сложения чисел, перестановка мест слагаемых меняет результат:
s3 = s2 + s1
print(s3)
Результат
boxSkill
Это важно помнить, не путая сложение строк со сложением чисел. В математическом плане это разные действия.
В математическом плане это разные действия.
Настоящей операции вычитания строк, по аналогии с числами, в Python не существует — мы не сможем отнять символы из строки с помощью операции −. Но можно использовать метод replace().
Он создаёт новую строку путём замены частей исходной строки. Лучше всего показать это на примере. Попробуем удалить часть слова, заменив её пустой строкой:
# Вычтем часть "box" из строки "Skillbox"
s1 = 'Skillbox'
s2 = 'box'
s3 = s1.replace(s2, '') # Передаём методу два аргумента — то, что хотим убрать из строки, и то, на что планируем заменить удалённый фрагмент
print(s3)
В результате получим:
Skill
В языке Python строки можно умножать на целые числа. Операция работает просто — повторяет содержимое переменной указанное количество раз. Например:
Например:
st = 'ab ' * 6
print(st)
В результате получим:
ab ab ab ab ab ab
Операцию умножения удобно использовать, если строку нужно продублировать много раз без ручного ввода. Например:
st = 35 * '*'
print(st)
Результат:
***********************************
Иногда разработчикам приходится проверять, есть ли в составе строки определённый фрагмент, который называют подстрокой. Например, мы хотим подтвердить наличие пользователя с определённым именем в нашей базе данных, где имя хранится вместе с фамилией — Иван Иванов. Строка здесь — это Иван Иванов, а нужная нам подстрока — Иван. Как это проверить? Воспользуемся проверкой принадлежности строки.
Для этого воспользуемся оператором in. Он возвращает True, если одна подстрока входит в состав строки, в противном случае возвращает False.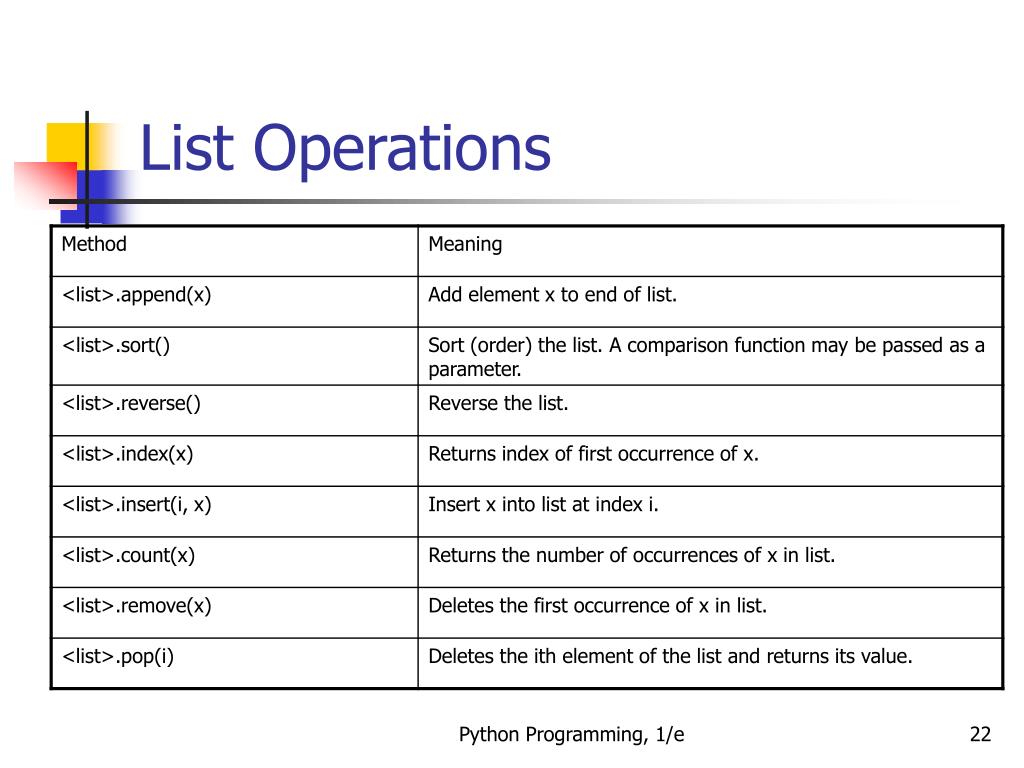
Например:
s1 = 'Иван Иванов'
s2 = 'Иван'
if s2 in s1: # Проверяем, есть ли «содержимое» строки s2 в s1
print('Пользователь Иван есть в нашей базе данных')
else:
print('Пользователь Иван в базе данных отсутствует')С помощью оператора in можно упростить поиск строк в разных переменных. Например, нам необходимо проверить наличие символа в четырёх строковых переменных. Мы можем написать такой код:
st = 'a'
if st == 'a' or st == 'b' or st == 'c' or st == 'd':
print('YES')Выглядит сложно. Упростим его, объединив содержимое переменных в одну строку:
st = 'a'
if st in 'abcd':
print('YES')Не забывайте, что регистр символов имеет значение. Например, буквы «A» и «a» компьютер воспринимает как разные.
Это количество содержащихся в строке символов, включая пробелы. Чтобы определить длину строки, используется функция len() (от англ. length — длина). Например:
Чтобы определить длину строки, используется функция len() (от англ. length — длина). Например:
ln = len('Skillbox')
print(ln)
s1 = 'skill'
print(len(s1))Результат выполнения:
8
5
Чтобы выделить один символ строки, используют индексацию. Нумерация символов начинается с нуля и заканчивается длиной строки −1.
Например, посмотрим на индексацию строковой переменной, значение которой равно ‘Skillbox’:
| s | k | i | l | l | b | o | x |
| 0 | 1 | 2 | 3 | 4 | 5 | 6 |
Мы видим, что нумерация начинается с нуля, а заканчивается числом 7, то есть равна количеству символов в строке с вычетом единицы.
Чтобы распечатать символы по их индексу, его необходимо указать в квадратных скобках. Вот так:
st = 'Skillbox'
print(st[0])
print(st[1])
print(st[2])
print(st[3])
print(st[4])
print(st[5])
print(st[6])
print(st[7])
В результате выполнения кода получим:
S
k
i
l
l
b
o
x
Если мы попытаемся использовать индекс больший, чем количество символов в строке, то получим ошибку. Проверим:
st = 'Skillbox'
print(st[8])
Результат выполнения:
IndexError: string index out of range
Индексацию также можно начинать с конца строки. В таком случае последний символ будет иметь индекс, равный −1, а индекс первого символа будет равен длине строки со знаком −. Посмотрим на такую индексацию на нашем примере:
| s | k | i | l | l | b | o | x |
| -8 | -7 | -6 | -5 | -4 | -3 | -2 | -1 |
Если мы используем индекс меньше отрицательного значения длины строки, программа также выдаст ошибку IndexError, например:
st = 'Skillbox'
print(st[−9])
В результате получим:
IndexError: string index out of range
Если нам нужно получить не один символ, а часть строки, используются срезы. Срез с двумя параметрами выглядит так:
Срез с двумя параметрами выглядит так:
st[начальный индекс:конечный индекс]
Срез извлекает подстроку, начиная c начального индекса (включительно) и заканчивая последним индексом (не включая его), то есть символ с конечным индексом в срез не входит. Не забывайте, что индексация строки начинается с 0.
Например:
st = 'Skillbox'
print(st[0:3])
print(st[2:5])
print(st[4:7])
Результат выполнения кода:
Ski
ill
lbo
Если не указывать начальный индекс, то срез берётся с начала строки. Если не указывать конечный — то до конца строки. Если опустить оба параметра, то срез возвращает всю строку. Попробуем несколько вариантов:
st = 'Skillbox'
print(st[:6]) # Срез с начала строки
print(st[5:]) # Срез до конца строки
print(st[:]) # Целая строка
Получаем срезы:
Skillb
box
Skillbox
Если мы зададим конечный индекс среза больше, чем количество символов в строке, то ошибки не будет. В этом случае программа возвращает срез до конца строки.
В этом случае программа возвращает срез до конца строки.
Например:
st = 'Skillbox'
print(st[:10])
Получим срез:
Skillbox
Срез, в котором начальный индекс больше или равен конечному, возвращает пустую строку, например:
st = 'Skillbox'
print(st[2:2]) # Конечный индекс равен начальному
print(st[5:3]) # Конечный индекс меньше начального
Этот код вернёт пустые строки, но ошибки не будет. Можете проверить в своём редакторе кода.
Индексы могут быть не только положительными, но и отрицательными. В этом случае отсчёт начинается с конца строки. Главное условие — начальный индекс должен быть меньше конечного или пропущен, иначе результатом будет пустая строка.
Например, программный код:
st = 'Skillbox'
print(st[−7:−4]) # Срез с отрицательными индексами
print(st[−4:−4]) # Начальный индекс равен конечному
print(st[−4:]) # Срез до конца строки
print(st[:−3]) # Срез с начала строки
print(st[−7:4]) # Срез с положительным и отрицательным индексами
Полученный результат:
kil # Всё сработало как надо
# Возврат пустой строки, так как начальный индекс равен конечному
lbox # Всё сработало как надо
Skill # Всё сработало как надо
kil # Всё сработало как надо
В срез можно добавить третий параметр, который будет означать шаг извлечения символов.
Например, если мы возьмём срез st[0:6:2] строки st = ‘Python’, то получим строку ‘Pto’:
| P | y | t | h | o | n |
|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 |
Рассмотрим пример с отрицательными индексами. Например, срез st[-6:-1:2] строки st = ‘Python’ тоже будет равен ‘Pto’:
Например, срез st[-6:-1:2] строки st = ‘Python’ тоже будет равен ‘Pto’:
| P | y | t | h | o | n |
|---|---|---|---|---|---|
| −6 | −5 | −4 | −3 | −2 | −1 |
Шаг среза может быть отрицательным. В этом случае начальный индекс должен быть больше конечного. Символы будут включаться в срез в обратном порядке.
В этом случае начальный индекс должен быть больше конечного. Символы будут включаться в срез в обратном порядке.
Например, срез st[-3:-7:-2] возвращает строку ‘hy’. Как видим, правая граница здесь не включается в срез.
| P | y | t | h | o | n |
|---|---|---|---|---|---|
| −6 | −5 | −4 | −3 | −2 | −1 |
Отрицательный шаг можно использовать с положительными индексами, например:
st = 'Skillbox'
print(st[6:1:−2])
Результат выполнения:
oli
Чтобы вывести символы строки в обратном порядке, удобно использовать срез [::−1], например:
st = 'шорох'
print(st[::−1])
st = 'город'
print(st[::−1])
st = 'топор'
print(st[::−1])
В результате выполнения получим:
хорош
дорог
ропот
Работа со срезами может казаться сложной — надо правильно задавать интервал, шаг или даже использовать отрицательные индексы. Попробуйте попрактиковаться на разных примерах, меняя параметры среза. Через пару десятков слов точно получится разобраться.
Попробуйте попрактиковаться на разных примерах, меняя параметры среза. Через пару десятков слов точно получится разобраться.
Для строк существует несколько десятков полезных методов и функций, позволяющих преобразовывать текстовые переменные. Подробнее с ними можно ознакомиться в официальной документации. Собрали в таблицу наиболее популярные из них:
| S.find(str, [start], [end]) | Поиск подстроки str в строке S в интервале индексов (start, end). Возвращает индекс первого совпавшего значения подстроки. Если подстрока не найдена, возвращает −1. Здесь start и end — необязательные аргументы. |
| S.rfind(str, [start], [end]) | Поиск подстроки str в строке S в интервале индексов (start, end). Возвращает индекс последнего совпавшего значения подстроки. Если подстрока не найдена, возвращает −1. Здесь start и end — необязательные аргументы. Если они не заданы, поиск ведётся во всей строке |
| S.count(t) | Возвращает количество непересекающихся вхождений подстроки t в строку S. То есть метод начинает искать следующую подстроку строго после окончания предыдущей. Например, в строке s = ‘ababab’ есть два пересекающихся вхождения ‘abab’, но непересекающееся вхождение одно. Метод вернёт единицу |
| S.isdigit() | Проверяет, состоит ли строка из цифр. Если да, возвращает True, иначе — False |
S. upper() upper() | Преобразует символы строки к верхнему регистру. Заглавные буквы и символы, которые не относятся к буквам, не меняются |
| S.lower() | Преобразует символы строки к нижнему регистру. Строчные буквы и символы, которые не относятся к буквам, не меняются |
| S.lstrip([символ]) | Удаляет определённые символы в начале строки. Здесь [символ] — необязательный аргумент. Если он не задан, метод удаляет пробелы |
| S.rstrip([символ]) | Удаляет определённые символы в конце строки. Здесь [символ] — необязательный аргумент. Если он не задан, метод удаляет пробелы |
| S.split([разделитель [, maxsplit]]) | Разбивает строку по разделителю и возвращает список, содержащий подстроки. Если разделитель не задан, то строка разбивается по пробелу, символу перевода строки или табуляции. Если разделитель не задан, то строка разбивается по пробелу, символу перевода строки или табуляции.maxsplit — необязательный аргумент, определяет максимальное количество частей, на которые разбивается строка. Если он не задан, то количество фрагментов не ограничивается. При заданном maxsplit максимальное количество элементов в списке равно maxsplit+1 |
| chr(число) | Преобразует код ASCII в символ |
| ord(символ) | Преобразует символ в его код ASCII |
| sorted(строка) | Сортирует символы строки в порядке возрастания их номеров в таблице ASCII |
| list(строка) | Возвращает список, состоящий из символов строки |
 Если они не заданы, поиск ведётся во всей строке
Если они не заданы, поиск ведётся во всей строкеРассмотрим несколько практических примеров использования функций и методов.
К ним относятся два метода: S.find(str, [start], [end]) и S.rfind(str, [start], [end]).
s = 'SkillboxSkillbox'
str = 'box'
print(s.find(str)) # Возвращает индекс первого совпавшего значения подстроки
print(s.rfind(str)) # Возвращает индекс последнего совпавшего значения подстроки
Результат выполнения кода:
5
13
Если подстроки в строке нет, Python возвращает −1:
S = 'SkillboxSkillbox'
print(S.rfind('abc'))Результат:
-1
Поиск в срезе:
S = 'Skillbox'
str = 'box'
print(S.find(str,0,7))
Результат:
-1
Здесь подстрока str ищется в срезе S[0:7]. Так как правая граница в срез не включается, Python не находит подстроку и выдаёт −1.
Так как правая граница в срез не включается, Python не находит подстроку и выдаёт −1.
Для преобразования используются два метода:
- S.upper() — преобразование всех символов строки S в верхний регистр.
- S.lower() — преобразование всех символов строки S в нижний регистр.
И тот и другой метод возвращают новую строку, а исходная остаётся прежней.
Например:
S = 'Skillbox 23'
print(S.upper()) # Переводит все символы в верхний регистр
print(S.lower()) # Переводит все символы в нижний регистр
print(S) # Проверяем значение исходной строки
В результате получим:
SKILLBOX 23
skillbox 23
Skillbox 23
Если мы хотим сохранить результат, то результат выполнения метода надо присвоить новой переменной.
Для разбиения строки по разделителю используется метод S.split([разделитель [, maxsplit]]). Посмотрим на него в коде:
S = 'Cat, Dog,Hamster Rabbit, Pig'
print(S.split()) # Разделитель не задан. Метод разбивает строку по пробельным символам — пробелу и знаку табуляции
print(S.split(',')) # Разбивает строку по заданному разделителю ','
print(S.split(',', 2)) # Задаёт максимальное количество разбиений, равное 3Результат:
['Cat,', 'Dog,Hamster', 'Rabbit,', 'Pig']
['Cat', ' Dog', 'Hamster Rabbit', ' Pig']
['Cat', ' Dog', 'Hamster Rabbit, Pig']
Методы rjust() и ljust():
S = 'Hi!'
print(S.rjust(10,'*')) # Увеличивает длину строки до 10 и заполняет пробелы слева символами '*'
print(S.ljust(10,'*')) # Увеличивает длину строки до 10 и заполняет пробелы справа символами '*'
В результате выполнения получим:
*******Hi!
Hi!*******
Мы рассмотрели понятия строки и текстового типа данных в Python. Подробно со всеми методами и функциями строк можно ознакомиться в документации.
Подробно со всеми методами и функциями строк можно ознакомиться в документации.
Читайте также:
Vkontakte Twitter Telegram Скопировать ссылкуЛистая дальше, вы перейдете на страницу курса
Как зарабатывать больше с помощью нейросетей?Большой вебинар: 15 экспертов, 7 топ-нейросетей.
 Научитесь использовать ИИ в своей работе и увеличьте доход.
Узнать больше
Научитесь использовать ИИ в своей работе и увеличьте доход.
Узнать большеПонравилась статья?
ДаStr Python. Строки в Python .
Одним из самых распространённых типов данных является строковый. Вопреки расхожему мнению, программист чаще сталкивается не с числами, а с текстом. В Python, как известно, всё является объектами. Не исключение и строки – это объекты, состоящие из набора символов. Естественно, в языке существует широкий набор инструментов для работы с этим типом данных.
Содержание
- Строковые операторы
- Оператор сложения строк +
- Оператор умножения строк *
- Оператор принадлежности подстроки in
- Встроенные функции строк в python
- Индексация строк
- Форматирование строки
- Изменение строк
- Встроенные методы строк в Python
- Изменение регистра строки
- Найти и заменить подстроку в строке
- Классификация строк
- Выравнивание строк, отступы
- Методы преобразования строки в список
Строковые операторы
Операторы «+» и «*» в Питоне применимы не только к числам, но и к строкам.
Оператор сложения строк +
Оператор «+» выполняет операцию, называемую конкатенацией, — объединение строк.
Пример:
Копировать Скопировано Use a different Browser
var_1 = 'Привет,' var_2 = 'Python!' print(var_1 + ' ' + var_2) # Вывод: Привет, Python!
Можно и так:
Копировать Скопировано Use a different Browser
var_1 = 'Привет, ' var_2 = 'Python!' var_1 += var_2 print(var_1) # Вывод: Привет, Python!
Оператор умножения строк *
Оператор «*» дублирует строку указанное количество раз.
Пример:
Копировать Скопировано Use a different Browser
var_1 = 'O_o ' var_2 = 10 print(var_1 * var_2) # Вывод: O_o O_o O_o O_o O_o O_o O_o O_o O_o O_o
Это работает только с целочисленными множителями. Если умножить на ноль или отрицательное число, результатом будет пустая строка. Но лучше так не делать.
Но лучше так не делать.
Копировать Скопировано Use a different Browser
var_1 = 'O_o'
[print('При множителе', i, 'получаем строку: "' + var_1 * i + '"') for i in range(-1, 2)]
# Вывод:
При множителе -1 получаем строку: ""
При множителе 0 получаем строку: ""
При множителе 1 получаем строку: "O_o"Оператор принадлежности подстроки in
Если надо проверить, содержится ли подстрока в строке, удобно пользоваться оператором “in”
Копировать Скопировано Use a different Browser
var_1 = '''Lorem ipsum dolor sit amet, consectetur adipisicing elit. Id,
fuga, earum consequuntur magni accusamus nihil ipsum qui. Facere,
error velit possimus qui dolorum dolorem illum voluptates nemo pariatur ea. Temporibus.
'''
print('ipsum' in var_1)
# Вывод:
TrueТак же можно использовать этот оператор с «not» для инвертирования результата.
Копировать Скопировано Use a different Browser
var_1 = '''Lorem ipsum dolor sit amet, consectetur adipisicing elit. Id,
fuga, earum consequuntur magni accusamus nihil ipsum qui. Facere,
error velit possimus qui dolorum dolorem illum voluptates nemo pariatur ea. Temporibus.
'''
print('тру-ля-ля' not in var_1)
# Вывод:
TrueВстроенные функции строк в python
Пайтон содержит ряд удобных встроенных функций для работы со строками.
Функция ord() возвращает числовое значение символа, при чём, как для кодировки ASCII, так и для UNICODE.
Копировать Скопировано Use a different Browser
print('A', ord('A'))
print('А русская', ord('А'))
print('~', ord('~'))
print('1', ord('1')) # Обратите внимание, что здесь единица является именно строкой
# Вывод:
A 65
А русская 1040
~ 126
1 49Функция chr(n) возвращает символьное значение для данного целого числа, то есть выполняет действие обратное ord().
Копировать Скопировано Use a different Browser
from random import randint
for i in range(10):
[print(chr(randint(0, 8000)), end=' ') for i in range(10)]
print('')
# Вывод:
ச ઘ ᔝ ዱ છ ᐝ § ֹ
ၹ ሌ ᔭ ཋ ٺ ຝ ྅ ᒊ ֚ ᴠ
д ߀ Ỽ Ů ጼ ̼ ᅌ ᶥ ḿ ᇶ
ᴗ ȹ ཱི ᥈ Ҥ Р ᇑ
ސ ϯ ኊ ᠻ ដ ᄖ ᓣ ᆧ
ଯ ᑟ ߂ ൢ ԝ ᤵ ඡ ᴼ ႊ
ᥒ ᜭ ˽ ä ؑ ૧ ᅈ ഉ ौ ଦ
ᔚ ॓ ௵ ᥰ ɵ ຘ Ἵ ᨃ ང
ᬇ ᳓ ᕈ ᳖ ࣝ ˼ ʋ ં გ
? ᓀ ځ ื ᚢ Ӌ ဃ ႔Функция len() возвращает количество символов в строке.
Копировать Скопировано Use a different Browser
from random import randint
for i in range(10):
var = [chr(randint(500, 800)) for i in range(randint(10, 20))]
print(len(''.join(var)), ''.join(var))
# Вывод:
11 ˫ʸɹʄˈȺȨȪȍʮ˴
16 ȷ˝ȁɚ˷Ⱥʾ̂ʨʗȍɺɹ˫̓ȼ
13 əʼɒȞʪɗʍ̍ˡɮɫȉʙ
10 ʜ˧ˬɆ˃əȃ̚ʰ̏
12 ˤ˾ʀɨȷˌɏʿɴȨ˲ȟ
13 ˌʡ˝ȭʪɈ˾ʵȋɎʋ˿ʍ
13 ˜̃ȱ̇ˋ˂ʡȞȍ̄ʭȌʣ
14 ̙ɸɎˈ̀ȾȠ˞ȒɇʀɈȁȫ
20 ȞȎʯɐʪəʔȆʳȨɦʚ˾Ǵȁɕˋ˘̈˭
12 ʷɱ̄˺ʽʤɳȂȗʍˉɦ Функция str() возвращает строковое представление объекта.
Копировать Скопировано Use a different Browser
from math import inf, e, pi print(str(...)) print(str(inf)) print(str(e)) print(str(pi)) print(str(10 + 11)) print(str(10 + 11j)) print(str(None)) print(str(1 == 1)) # Вывод: Ellipsis inf 2.718281828459045 3.141592653589793 21 (10+11j) None True
Индексация строк
Строка является упорядоченной последовательностью символов. Другими словами, она состоит из символов, стоящих в определённом порядке. Благодаря этому, к символу можно обратиться по его порядковому номеру. Для этого надо указать номер символа в квадратных скобках. Нумерация начинается с нуля (0 – это первый символ).
Копировать Скопировано Use a different Browser
var = '''Lorem ipsum dolor sit amet, consectetur adipisicing elit. Consequuntur, eligendi, aperiam, consequatur, perferendis non sequi voluptates asperiores soluta quam ad id beatae facere aut quod libero dignissimos inventore nesciunt commodi.''' print(var[0]) print(var[10]) print(var[33]) # Вывод: L m c
Попытка обращения по индексу большему чем длина строки вызовет исключение IndexError:
Копировать Скопировано Use a different Browser
var = '''Lorem ipsum dolor sit amet, consectetur adipisicing elit. Consequuntur, eligendi, aperiam, consequatur, perferendis non sequi voluptates asperiores soluta quam ad id beatae facere aut quod libero dignissimos inventore nesciunt commodi.''' print(var[330]) # Вывод: Traceback (most recent call last): File "C:\Users\ivand\AppData\Roaming\JetBrains\PyCharm2021.2\scratches\scratch.py", line 7, in <module> print(var[330]) IndexError: string index out of range Process finished with exit code 1
В качестве индекса может быть использовано отрицательное число. В этом случае индексирование начинается с конца строки: -1 относится к последнему символу, -2 к предпоследнему и так далее.
Копировать Скопировано Use a different Browser
var = '''Lorem ipsum dolor sit amet, consectetur adipisicing elit. Consequuntur, eligendi, aperiam, consequatur, perferendis non sequi voluptates asperiores soluta quam ad id beatae facere aut quod libero dignissimos inventore nesciunt commodi.''' print(var[-1]) print(var[-10]) print(var[-33]) # Вывод: . t s
Срезы строк
В Python существует механизм срезов коллекций. Срезы позволяют обратиться к подстроке используя индексы. Для этого надо в квадратных скобках указать: [начальный индекс : конечный индекс : шаг]. Каждый из параметров является необязательным. Поскольку строка это коллекция, срезы применимы и к ней.
Копировать Скопировано Use a different Browser
Форматирование строкиvar = '''Lorem ipsum dolor sit amet, consectetur adipisicing elit. Consequuntur, eligendi, aperiam, consequatur, perferendis non sequi voluptates asperiores soluta quam ad id beatae facere aut quod libero dignissimos inventore nesciunt commodi.''' print(var[-1: 50: -3]) print(var[10:-160]) print(var[::-33]) # Вывод: .ootieetv msg elo ara ea ual rrssauvuso snee,tqn ae dgernqn i m dolor sit amet, consectetur adipisicing elit. Consequuntur, eligendi, aperiam, co .s r a n
В Python есть функция форматирования строки, которая официально названа литералом отформатированной строки, но обычно упоминается как f-string.
Главной особенностью этой функции является возможность подстановки значения переменной в строку.
Чтобы это сделать с помощью f-строки необходимо:
- Указать f или F перед кавычками строки (что сообщит интерпретатору, что это f-строка).
- В любом месте внутри строки вставить имя переменной в фигурных скобках ({ }).
Копировать Скопировано Use a different Browser
var = 10 * 254 // 77 % 5 ** 5
var_2 = f'Вот что получилось {var}'
print(var_2)
# Вывод:
Вот что получилось 32
Изменение строкТип данных строка в Python относится к неизменяемым (immutable), но это почти не влияет на удобство их использования, ведь можно создать изменённую копию. Для этого есть два возможных пути:
Для этого есть два возможных пути:
- Использовать перезапись значения переменной
Копировать Скопировано Use a different Browser
var = 'Что-то ' var += 'и что-то ещё' print(var) var = var[:16] + 'новое' print(var) # Вывод: Что-то и что-то ещё Что-то и что-то новое
- Использовать встроенный метод replace(x, y):
Копировать Скопировано Use a different Browser
var = 'Что-то '
print(var.replace('то ', 'нибудь'))
print(var)
# Вывод:
Что-нибудь
Что-то
Как Вы можете видеть, данный метод не меняет строку, а возвращает изменённую копию.
Встроенные методы строк в PythonПоскольку строка в Пайтон – это объект, у него есть свои методы. Методы – это те же самые функции, просто они «закреплены» за объектами определённого класса.
Изменение регистра строкиЕсли Вам надо изменить регистр строки, удобно использовать один из следующих методов
capitalize() переводит первую букву строки в верхний регистр, остальные в нижний.
Копировать Скопировано Use a different Browser
var = 'abracadabra' print(var.capitalize()) print(var) # Вывод: Abracadabra abracadabra
Не алфавитные символы не изменяются:
Копировать Скопировано Use a different Browser
var = '_abracadabra' print(var.capitalize()) print(var) # Вывод: _abracadabra _abracadabra
lower() преобразует все буквенные символы в строчные.
Копировать Скопировано Use a different Browser
var = 'AbRaCAdAbRa' print(var.lower()) print(var) # Вывод: abracadabra AbRaCAdAbRa
swapcase() меняет регистр на противоположный.
Копировать Скопировано Use a different Browser
var = 'AbRaCAdAbRa' print(var.swapcase()) print(var) # Вывод: aBrAcaDaBrA AbRaCAdAbRa
title() преобразует первые буквы всех слов в заглавные
Копировать Скопировано Use a different Browser
var = 'я пРосТо ПРИМЕР' print(var.title()) var = 'я @странный _ПРИМЕР' print(var.title()) print(var) # Вывод: Я Просто Пример Я @Странный _Пример я @странный _ПРИМЕР
upper() преобразует все буквенные символы в заглавные.
Копировать Скопировано Use a different Browser
Найти и заменить подстроку в строкеvar = 'я пРосТо ПРИМЕР' print(var.upper()) var = 'я @странный _ПРИМЕР' print(var.upper()) print(var) # Вывод: Я ПРОСТО ПРИМЕР Я @СТРАННЫЙ _ПРИМЕР я @странный _ПРИМЕР
Эти методы предоставляют различные способы поиска в целевой строке указанной подстроки.
Каждый метод в этой группе поддерживает необязательные аргументы start и end. Они задают диапазон поиска: действие метода ограничено частью целевой строки, начинающейся в позиции символа start и продолжающейся вплоть до позиции символа end, но не включая его. Если start указано, а end нет, метод применяется к части строки от start до конца.
Если start указано, а end нет, метод применяется к части строки от start до конца.
count() подсчитывает количество точных вхождений подстроки в строку.
Копировать Скопировано Use a different Browser
var = 'Ололо'
print(var.count('ол'))
# Вывод:
1
endswith() определяет, заканчивается ли строка заданной подстрокой.
Копировать Скопировано Use a different Browser
var = 'Олололололо'
print(var.endswith('оло'))
print(var.endswith('ол', 5, 10))
# Вывод:
True
True
find() ищет в строке заданную подстроку. Возвращает первый индекс который соответствует началу подстроки. Если указанная подстрока не найдена, возвращает -1.
Копировать Скопировано Use a different Browser
var = 'Олололололо'
print(var.find('оло'))
print(var.find('лОл'))
# Вывод:
2
-1
index() ищет в строке заданную подстроку.
Этот метод идентичен find(), за исключением того, что он вызывает исключение ValueError, если подстрока не найдена.
Копировать Скопировано Use a different Browser
var = 'Олололололо'
print(var.index('лОл'))
# Вывод:
Traceback (most recent call last):
File "C:\Users\ivand\AppData\Roaming\JetBrains\PyCharm2021.2\scratches\scratch.py", line 3, in <module>
print(var.index('лОл'))
ValueError: substring not found
Process finished with exit code 1
rfind() ищет в строке заданную подстроку, начиная с конца.
Возвращает индекс последнего вхождения подстроки, который соответствует её началу.
Копировать Скопировано Use a different Browser
var = 'Олололололо'
print(var.rfind('оло'))
# Вывод:
8
rindex() ищет в строке заданную подстроку, начиная с конца.
Этот метод идентичен rfind(), за исключением того, что он вызывает исключение ValueError, если подстрока не найдена.
startswith() определяет, начинается ли строка с заданной подстроки.
Копировать Скопировано Use a different Browser
var = 'Олололололо'
print(var.startswith('Оло'))
# Вывод:
True
Классификация строкМетоды в этой группе классифицируют строку на основе символов, которые она содержит.
isalnum() возвращает True, если строка не пустая, а все ее символы буквенно-цифровые (либо буква, либо цифра).
Копировать Скопировано Use a different Browser
var = 'Олололололо' print(var.isalnum()) # Вывод: True
isalpha() определяет, состоит ли строка только из букв.
isdigit() определяет, состоит ли строка из цифр.
isidentifier() определяет, является ли строка допустимым идентификатором (название переменной, функции, класса и т.д.) Python.
Копировать Скопировано Use a different Browser
var = 'print' print(var.isidentifier()) # Вывод: True
isidentifier() вернет True для строки, которая соответствует зарезервированному ключевому слову Пайтон, даже если его нельзя использовать.
Вы можете проверить, является ли строка ключевым словом Python, используя функцию iskeyword(), которая находится в модуле keyword.
Если вы действительно хотите убедиться, что строку можно использовать как идентификатор Питон, вы должны проверить, что isidentifier() = True и iskeyword() = False.
islower() определяет, являются ли буквенные символы строки строчными.
isprintable() определяет, состоит ли строка только из печатаемых символов.
Копировать Скопировано Use a different Browser
print('qwerty'. isidentifier())
print(chr(7).isidentifier())
# Вывод:
True
False
isidentifier())
print(chr(7).isidentifier())
# Вывод:
True
FalseЭто единственный метод данной группы, который возвращает True, если строка не содержит символов. Все остальные возвращаются False.
isspace() определяет, состоит ли строка только из пробельных символов.
Тем не менее есть несколько символов ASCII, которые считаются пробелами. И если учитывать символы Юникода, их еще больше:
‘\f’ и ‘\r’ являются escape-последовательностями для символов ASCII; ‘\u2005’ это escape-последовательность для Unicode.
istitle() определяет, начинаются ли слова строки с заглавной буквы.
isupper() определяет, являются ли буквенные символы строки заглавными.
Выравнивание строк, отступыМетоды из данной группы управляют отображением строки.
center() выравнивает строку по центру.
Копировать Скопировано Use a different Browser
print('qwerty'. center(50))
print((' ' * 22 + 'qwerty' + ' ' * 22))
print((' ' * (25 - int(len('qwerty') / 2)) + 'qwerty' + ' ' * (25 - int(len('qwerty') / 2)) == ('qwerty'.center(50))))
# Вывод:
qwerty
qwerty
True
center(50))
print((' ' * 22 + 'qwerty' + ' ' * 22))
print((' ' * (25 - int(len('qwerty') / 2)) + 'qwerty' + ' ' * (25 - int(len('qwerty') / 2)) == ('qwerty'.center(50))))
# Вывод:
qwerty
qwerty
True
Если указан необязательный аргумент fill, он используется как символ заполнения:
Копировать Скопировано Use a different Browser
print('qwerty'.center(50, '='))
# Вывод:
======================qwerty======================
Если строка больше или равна указанной ширине, строка возвращается без изменений:
Копировать Скопировано Use a different Browser
print('qwerty'.center(6, '='))
# Вывод:
qwerty
expandtabs() заменяет каждый символ табуляции (‘\t’) пробелами. По умолчанию табуляция заменяются на 8 пробелов.
По умолчанию табуляция заменяются на 8 пробелов.
tabsize необязательный параметр, задающий количество пробелов.
ljust() выравнивание по левому краю.
lstrip() удаляет переданные в качестве аргумента символы слева. По умолчанию это пробелы.
Копировать Скопировано Use a different Browser
print('__init__.py'.lstrip('_'))
# Вывод:
init__.py
replace() заменяет вхождения подстроки в строке.
Копировать Скопировано Use a different Browser
var = 'Hello, C! Hello, JS! Hello, Python!'
print(var.replace('C', 'PHP'))
# Вывод:
Hello, PHP! Hello, JS! Hello, Python!
Необязательный аргумент count, указывает количество замен, которое нужно осуществить:
Копировать Скопировано Use a different Browser
var = 'Hello, C! Hello, JS! Hello, Python!' print(var.replace('Hello', 'Bye', 2)) # Вывод: Bye, C! Bye, JS! Hello, Python!
rjust() выравнивание по правому краю строки в поле.
rstrip() обрезает пробельные символы.
strip() удаляет символы с левого и правого края строки.
Когда возвращаемое значение метода является другой строкой, как это часто бывает, методы можно вызывать последовательно:
Копировать Скопировано Use a different Browser
var = 'Hello, C! Hello, JS! Hello, Python!'
print(var.replace('Hello', 'Buy', 2).center(60).swapcase())
# Вывод:
bUY, c! bUY, js! hELLO, pYTHON!
zfill() возвращает копию строки дополненную нулями слева для достижения длины строки указанной в параметре width:
Копировать Скопировано Use a different Browser
var = 12/100*(-0.5) print(str(var).zfill(7)) # Вывод: -000.06
Если строка короче или равна параметру width, строка возвращается без изменений:
Копировать Скопировано Use a different Browser
Методы преобразования строки в списокvar = 10/3 print(str(var).zfill(7)) # Вывод: 3.3333333333333335
Методы в данной группе превращают строку в другой тип данных и наоборот. Эти методы возвращают или принимают коллекции (чаще всего это список).
join() возвращает строку, которая является результатом конкатенации элементов коллекции и разделителя.
Копировать Скопировано Use a different Browser
var: list[str] = ['1', '2', '3']
print('+'.join(var))
var: tuple[str, str, str] = ('1', '2', '3')
print(' & '.join(var))
var: set[str, str, str] = {'1', '2', '3'}
print(' и '. join(var))
var: dict[str, int] = {'1': 4, '2': 5, '3': 6}
print('->'.join(var))
# Вывод:
1+2+3
1 & 2 & 3
3 и 2 и 1
1->2->3
join(var))
var: dict[str, int] = {'1': 4, '2': 5, '3': 6}
print('->'.join(var))
# Вывод:
1+2+3
1 & 2 & 3
3 и 2 и 1
1->2->3
Стоит обратить внимание что все элементы итерируемого объекта должны быть строкового типа. Так же Вы могли заметить в последнем примере, что для объединения словаря в строку метод join() использует не значения, а ключи. Если Вам нужны именно ключи, то делается это так:
Копировать Скопировано Use a different Browser
var: dict[str, str] = {'1': '4', '2': '5', '3': '6'}
print('->'.join(var.values()))
# Вывод:
4->5->6
Сложнее ситуация, когда нужны пары ключ-значение. Здесь придётся сперва распаковать кортежи.
Копировать Скопировано Use a different Browser
var: dict[str, str] = {'1': '4', '2': '5', '3': '6'}
print('->'. join([str(a+':'+b) for a, b in var.items()]))
# Вывод:
1:4->2:5->3:6
join([str(a+':'+b) for a, b in var.items()]))
# Вывод:
1:4->2:5->3:6
partition() делит строку на основе разделителя (действие, обратное join). Возвращаемое значение представляет собой кортеж из трех частей:
- Часть строки до разделителя
- Разделитель
- Часть строки после разделителя
Копировать Скопировано Use a different Browser
print('1:4->2:5->3:6'.partition(':'))
# Вывод:
('1', ':', '4->2:5->3:6')
Если разделитель не найден, возвращаемый кортеж содержит строку и ещё две пустые строки:
Копировать Скопировано Use a different Browser
print('1:4->2:5->3:6'.partition('7'))
# Вывод:
('1:4->2:5->3:6', '', '')rpartition() делит строку на основе разделителя, начиная с конца.
rsplit() делит строку на список из подстрок. По умолчанию разделителем является пробел.
По умолчанию разделителем является пробел.
Копировать Скопировано Use a different Browser
print('1:4->2:5->3:6'.rsplit('->'))
# Вывод:
['1:4', '2:5', '3:6']
split() делит строку на список из подстрок.
Ведет себя как rsplit(), за исключением того, что при указании maxsplit – максимального количества разбиений, деление начинается с левого края строки:
Копировать Скопировано Use a different Browser
print('1:4->2:5->3:6'.rsplit('->', 1))
print('1:4->2:5->3:6'.split('->', 1))
# Вывод:
['1:4->2:5', '3:6']
['1:4', '2:5->3:6']
Если параметр maxsplit не указан, между rsplit() и split() разницы нет.
splitlines() делит текст на список строк и возвращает их в списке. Любой из следующих символов или последовательностей символов считается границей строки:
| Разделитель | Значение |
| \n | Новая строка |
| \r | Возврат каретки |
| \r\n | Возврат каретки + перевод строки |
| \v или же \x0b | Таблицы строк |
| \f или же \x0c | Подача формы |
| \x1c | Разделитель файлов |
| \x1d | Разделитель групп |
| \x1e | Разделитель записей |
| \x85 | Следующая строка |
| \u2028 | Новая строка (Unicode) |
| \u2029 | Новый абзац (Unicode) |
Заключение
В этом уроке мы рассмотрели основные инструменты для работы со строками в Python. Как видите, они удобны и гибки. Есть встроенные функции и методы объекта «строка», строковые литералы. Ещё больше возможностей даёт нерассмотренный в этом уроке метод format и модуль re. Так же отдельного разговора заслуживает работа с кодировками. Следует отметить для тех, кто уже знаком с другими языками программирования: в отличие от некоторых из них, один символ в Пайтоне тоже является строкой. И изюминка напоследок. Поскольку в Питоне всё является объектом, у каждой строки тоже есть атрибуты.
Как видите, они удобны и гибки. Есть встроенные функции и методы объекта «строка», строковые литералы. Ещё больше возможностей даёт нерассмотренный в этом уроке метод format и модуль re. Так же отдельного разговора заслуживает работа с кодировками. Следует отметить для тех, кто уже знаком с другими языками программирования: в отличие от некоторых из них, один символ в Пайтоне тоже является строкой. И изюминка напоследок. Поскольку в Питоне всё является объектом, у каждой строки тоже есть атрибуты.
Копировать Скопировано Use a different Browser
from pprint import pprint
pprint('Строка'.__dir__())
# Вывод:
['__repr__',
'__hash__',
'__str__',
'__getattribute__',
'__lt__',
'__le__',
'__eq__',
'__ne__',
'__gt__',
'__ge__',
'__iter__',
'__mod__',
'__rmod__',
'__len__',
'__getitem__',
'__add__',
'__mul__',
'__rmul__',
'__contains__',
'__new__',
'encode',
'replace',
'split',
'rsplit',
'join',
'capitalize',
'casefold',
'title',
'center',
'count',
'expandtabs',
'find',
'partition',
'index',
'ljust',
'lower',
'lstrip',
'rfind',
'rindex',
'rjust',
'rstrip',
'rpartition',
'splitlines',
'strip',
'swapcase',
'translate',
'upper',
'startswith',
'endswith',
'removeprefix',
'removesuffix',
'isascii',
'islower',
'isupper',
'istitle',
'isspace',
'isdecimal',
'isdigit',
'isnumeric',
'isalpha',
'isalnum',
'isidentifier',
'isprintable',
'zfill',
'format',
'format_map',
'__format__',
'maketrans',
'__sizeof__',
'__getnewargs__',
'__doc__',
'__setattr__',
'__delattr__',
'__init__',
'__reduce_ex__',
'__reduce__',
'__subclasshook__',
'__init_subclass__',
'__dir__',
'__class__']Работа со строками — Памятка по Python
Экранирующие символы
Экранирующий символ создается путем ввода обратной косой черты \ , за которой следует символ, который вы хотите вставить.
| Экранирующий символ | Печатает как |
|---|---|
\' | Одинарная кавычка | 900 15
\" | Двойная кавычка |
\t | Закладка |
\n | Новая строка (разрыв строки) |
\\ | Обратная косая черта |
| Backspace | |
\ooo | Восьмеричное значение |
\r 9000 6 | Возврат каретки |
>>> print("Привет!\nКак дела?\nУ меня все хорошо.")
# Привет!
# Как вы?
# У меня все хорошо.
Необработанные строки
Необработанная строка полностью игнорирует все escape-символы и печатает любую обратную косую черту, которая появляется в строке.
>>> print(r"Привет!\nКак дела?\nУ меня все хорошо.") # Привет!\nКак дела?\nУ меня все хорошо.
Необработанные строки в основном используются для определения регулярных выражений.
Многострочные строки
>>> print( ..."""Дорогая Алиса, ... ... Кот Евы был арестован за кошачий сон, ... кража со взломом и вымогательство. ... ... Искренне, ... Боб""" ... ) # Дорогая Алиса, # Кот Евы был арестован за кошачий сон, # кража со взломом и вымогательство. # Искренне, # Боб
Индексация и нарезка строк
Черт возьми! 0 1 2 3 4 5 6 7 8 9 10 11
Индексирование
>>> spam = 'Привет, мир!' >>> спам[0] # 'Н' >>> спам[4] # 'о' >>> спам[-1] # '!'
Нарезка
>>> spam = 'Привет, мир!' >>> спам[0:5] # 'Привет' >>> спам[:5] # 'Привет' >>> спам[6:] # 'мир!' >>> спам[6:-1] # 'мир' >>> спам[:-1] # 'Привет, мир' >>> спам[::-1] # '!dlrow olleH' >>> шипение = спам[0:5] >>> шипение # 'Привет'
Входящие и не входящие операторы
>>> 'Hello' в 'Hello World' # Истинный >>> «Привет» в «Привет» # Истинный >>> «HELLO» в «Hello World» # ЛОЖЬ >>> '' в 'спам' # Истинный >>> "кошки" не в "кошках и собаках" # ЛОЖЬ
верхний(), нижний() и заголовок()
Преобразует строку в верхний, нижний и заглавный регистр:
>>> приветствие = 'Привет, мир!' >>> приветствие.upper() # 'ПРИВЕТ, МИР!' >>> приветствовать.ниже() # 'Привет, мир!' >>> приветствовать.название() # 'Привет, мир!'
Методы isupper() и islower()
Возвращает True или False после оценки того, находится ли строка в верхнем или нижнем регистре:
>>> spam = 'Hello world!' >>> spam.islower() # ЛОЖЬ >>> spam.isupper() # ЛОЖЬ >>> 'ПРИВЕТ'.isupper() # Истинный >>> 'abc12345'.islower() # Истинный >>> '12345'.islower() # ЛОЖЬ >>> '12345'.isupper() # ЛОЖЬ
Строковые методы isX
| Метод | Описание |
|---|---|
| isalpha() | возвращает True , если строка состоит только из букв. |
| isalnum() | возвращает True , если строка состоит только из букв и цифр. |
| isdecimal() | возвращает True , если строка состоит только из чисел. |
| isspace() | возвращает True , если строка состоит только из пробелов, табуляции и новых строк. |
| istitle() | возвращает True , если строка состоит только из слов, начинающихся с прописной буквы, за которой следуют только строчные символы. |
начинает с() и заканчивает с()
>>> 'Привет, мир!'.startswith('Привет')
# Истинный
>>> 'Привет, мир!'.endswith('мир!')
# Истинный
>>> 'abc123'.startswith('abcdef')
# ЛОЖЬ
>>> 'abc123'.endswith('12')
# ЛОЖЬ
>>> 'Привет, мир!'.startswith('Привет, мир!')
# Истинный
>>> 'Привет, мир!'.endswith('Привет, мир!')
# Истинный
join() и split()
join()
Метод join() берет все элементы итерируемого объекта, такого как список, словарь, кортеж или набор, и объединяет их в строку. Вы также можете указать разделитель.
>>> ''.join(['Мой', 'имя', 'есть', 'Саймон']) 'Мое имяСаймон' >>> ', '.join(['кошки', 'крысы', 'летучие мыши']) # 'кошки, крысы, летучие мыши' >>> ' '.join(['Мой', 'имя', 'есть', 'Саймон']) # 'Меня зовут Саймон' >>> 'ABC'.join(['Мой', 'имя', 'есть', 'Саймон']) # 'MyABCnameABCisABCSimon'
split()
Метод split() разбивает строку на список . По умолчанию для разделения элементов используются пробелы, но вы также можете установить другой символ по выбору:
>>> 'Меня зовут Саймон'.split()
# ['Мой', 'имя', 'есть', 'Саймон']
>>> 'MyABCnameABCisABCSimon'.split('ABC')
# ['Мой', 'имя', 'есть', 'Саймон']
>>> 'Меня зовут Саймон'.split('m')
# ['My na', 'e is Si', 'on']
>>> 'Меня зовут Саймон'.split()
# ['Мой', 'имя', 'есть', 'Саймон']
>>> 'Меня зовут Саймон'.split(' ')
# ['', 'Мой', '', 'имя', 'есть', '', 'Саймон']
Выравнивание текста с помощью rjust(), ljust() и center()
>>> 'Привет'.rjust(10) # ' Привет' >>> 'Привет'.rjust(20) # ' Привет' >>> 'Привет, мир'.rjust(20) # ' Привет, мир' >>> 'Привет'.ljust(10) # 'Привет ' >>> 'Привет'.center(20) # ' Привет '
Необязательный второй аргумент для rjust() и ljust() задает символ заполнения, кроме символа пробела:
>>> 'Привет'.rjust(20, '*') # '***************Привет' >>> 'Привет'.ljust(20, '-') # 'Привет---------------' >>> 'Здравствуйте'.center(20, '=') # '=======Привет========='
Удаление пробелов с помощью strip(), rstrip() и lstrip()
>>> spam = 'Hello World'
>>> спам.strip()
# 'Привет, мир'
>>> спам.lstrip()
# 'Привет, мир '
>>> спам.rstrip()
# ' Привет, мир'
>>> spam = 'SpamSpamBaconSpamEggsSpamSpam'
>>> spam.strip('ampS')
# 'BaconSpamEggs'
Общие операции со строками в Python
Введение
Python — это высокоуровневый, динамически типизированный, мультипарадигменный язык программирования, который, в частности, поставляется с множеством встроенных инструментов для различных задач, снижая объем усилий, необходимых для быстрого прототипирования и проверки идей. Строки — одна из наиболее часто используемых структур данных в информатике, и, естественно, манипулирование строками — распространенная процедура.
В этом руководстве вы узнаете, как выполнять манипуляции со строками в Python.

Строки и операции со строками
Строки представляют собой последовательности (или, скорее... строки ) символов. Обычно они реализуются в виде массива 90 239 90 240 символов, которые вместе действуют как единый объект в большинстве языков программирования. При этом манипуляции со строками сводятся к изменению символов в массиве в любой форме.
Примечание: В большинстве языков, включая Python, строки являются неизменяемыми — однажды созданная строка не может быть изменена. Если вы хотите изменить строку, под капотом создается новая строка, состоящая из оригинала и изменения, которое вы хотите внести. Это связано с тем, что строки используются очень часто и могут быть «объединены» в общий пул, из которого объекты могут повторно использоваться для одинаковых строк (что происходит довольно часто). В большинстве случаев это снижает нагрузку на инициализацию объектов в системной памяти и повышает производительность языка. Это также известно как Интернирование строки .
Это также известно как Интернирование строки .
В Python — для объявления строки вы заключаете последовательность символов в одинарные, двойные или тройные кавычки (с конструктором str() или без него):
# Одинарная кавычка welcome = 'Доброе утро, Марк!' # Двойная кавычка note = "У вас есть 7 новых уведомлений." # Тройная кавычка позволяет использовать многострочные строки больше_текст = """ Бы ты нравиться к читать их? """
Вы также можете явно инициализировать строковый объект, используя str() конструктор:
welcome1 = 'Доброе утро, Марк!'
welcome2 = str('Доброе утро, Марк!')
В зависимости от версии Python, которую вы используете, а также от компилятора, вторая строка либо интернирует , либо не интернирует строку. Для проверки этого можно использовать встроенную функцию id() , которая возвращает идентификатор объекта в памяти:
print(id(welcome1)) # 1941232459688 печать (id (добро пожаловать2)) # 1941232459328
С практической точки зрения вам не нужно беспокоиться об интернировании строк или их производительности в вашем приложении.
Примечание: Другое замечание по реализации заключается в том, что Python не поддерживает тип из символов, в отличие от других языков, которые превращают массивы из символов типа в строку из строк типа . В Python символ — это строка длиной 1 .
Если вы проверите тип любого из объектов, которые мы создали, вас встретит str :
print(type(welcome1)) # class <'str'>
Класс string предоставляет довольно длинный список методов, которые можно использовать для манипулирования/изменения строк (все они возвращают измененную копию, поскольку строки неизменяемы). Кроме того, стандартные операторы были переопределены для использования в конкретных строках, поэтому вы можете «складывать» строки вместе, используя такие операторы, как 9.0005 + !
Операторы для работы со строками
Операторы являются краеугольным камнем всех языков, и они обычно округляются до арифметических операторов ( + , - , * , / ), операторов отношения ( < , > , <= , >= , = , == ) и логические операторы ( и или И 9000 6 , | или ИЛИ ) и т. д. Чтобы сделать работу со строками интуитивно понятной, операторы Python были переопределены, чтобы разрешить прямое использование строк!
д. Чтобы сделать работу со строками интуитивно понятной, операторы Python были переопределены, чтобы разрешить прямое использование строк!
Добавление строки
Помимо добавления целых чисел, оператор + может использоваться для объединения/объединения двух строк:
string_1 = "Hello" string_2 = "Мир!" print(string_1 + string_2) # Привет, мир!
Умножение строк
Оператор умножения часто недооценивают — * . Его можно использовать для создания нескольких строк или последовательностей как части одной строки:
string = 'Recursion...' * 5 print(string) # Рекурсия...Рекурсия...Рекурсия...Рекурсия...Рекурсия...
Так как выражения оцениваются справа налево, вы можете умножить строку, а затем добавить ее к другой строке:
string = "Кажется, я застрял в цикле " + "..." * 5 print(string) # Кажется, я застрял в петле... петля... петля... петля... петля...
Присвоение строки с дополнением
Оператор += , известный как оператор "на месте", является сокращенным оператором. Это сокращает добавление двух операндов, вставляя назначенную ссылочную переменную в качестве первого операнда в добавление:
Это сокращает добавление двух операндов, вставляя назначенную ссылочную переменную в качестве первого операнда в добавление:
с = 'Привет' # Эквивалентно: # s = s + 'Мир' s += 'Мир' print(s) # HelloWorld
Функции для работы со строками
len() Функция len() встроена в пространство имен Python и поэтому может вызываться как глобальная вспомогательная функция. Он используется для оценки длины последовательности — списка, кортежа и т. д. Поскольку строки — это списки, их длину также можно оценить с помощью функции len() !
print(len("Прошло 84 года...")) # 21
В качестве входных данных принимает любую итерируемую последовательность и возвращает ее длину в виде целого числа.
find() Метод find() ищет вхождение шаблона в строку и возвращает его начальную позицию (индекс, с которого он начинается), в противном случае возвращает -1 :
text = "Писать на Python довольно весело".print(text.find("довольно")) # 18 print(text.find("at")) # -1
Метод find() принимает два дополнительных необязательных аргумента - начало и конец . str определяет строку для поиска, beg — это начальный индекс ( 0 по умолчанию), а end — это конечный индекс строки, который по умолчанию установлен на длину строки. Изменяя их, вы можете изменить область поиска для шаблона:
text = "Я не был так задыхался с тех пор, как кусок мусаки застрял у меня в горле! - Аид." текст2 = "Я" печать(текст.найти(текст2)) # 0 печать(текст.найти(текст2, 10)) # 36 печать(текст.найти(текст2, 40)) # -1
Примечание: Метод rfind() находит последнее вхождение.
count()
Метод count() ищет предоставленную подстроку в заданном тексте (с учетом регистра) и возвращает целое число, обозначающее количество вхождений этого шаблона в строку:
text = "Цветок, распустившийся в невзгодах, самый редкий и красивый из всех - Мулан." text_count = text.count('i') print("Счетчик 'i' равен", text_count) # Счетчик 'i' равен 4
По умолчанию отсчет начинается с 0 и продолжается до конца строки, но можно указать начальный и конечный индексы:
text = "Цветок, который расцветает в невзгодах, самый редкий и красивый из всех - Мулан."
# ул, начало, конец
text_count = text.count('i', 0, 5)
print("Счетчик 'i' равен", text_count) # Счетчик 'i' равен 0
Нарезка
Нарезка — это мощная и универсальная система обозначений, которую можно использовать для нарезки последовательностей! Используя нотацию скобок, как при доступе к элементам из итерируемой последовательности, вы также можете получить доступ к срезу элементов между начальным и конечным индексом:
текст = "Привет, мир!" print(text[6:12]) # Мир
Нотация среза принимает три входа: iterable[start:stop:step] . start — это начальный индекс (включительно), stop — это конечный индекс (не включая), а step — это приращение (которое также может быть отрицательным числом). Попробуем разрезать строку между 2-м (включительно) и 7-м (исключительно) индексом с шагом
Попробуем разрезать строку между 2-м (включительно) и 7-м (исключительно) индексом с шагом 2 :
text = 'Код работает быстро' print(text[2:7:2]) # ecd
openswith() и endwith()
Метод openswith() в Python определяет, начинается ли строка с предоставленной подстроки, в то время как метод endwith() проверяет, заканчивается ли строка подстрокой, и оба возвращают логическое значение:
text = "hello world"
print(text.startswith("H")) # Ложь
print(text.endswith("d")) # Истинно
Примечание: И openswith() , и endwith() чувствительны к регистру.
Форматирование строк
Добавление и удаление пробелов
Метод strip() удаляет пробелы в начале и конце строки, что упрощает удаление завершающих пустых символов. Чтобы удалить просто пробел справа или слева, используйте rstrip() или lstrip() :
text = 'a short break' text.strip() # 'короткий перерыв' text.rstrip() #' короткий перерыв' text.lstrip() #'короткий перерыв'
Специальное руководство по удалению пробелов из строк — прочтите наше руководство по методу strip() в Python!
Изменение регистра строки — upper(), lower(), Capitalize(), title(), swapcase()
Изменить регистр строки довольно просто! Методы upper() , lower() , capitalize() , title() и swapcase() могут использоваться для изменения регистра строки: что делать? Просто продолжай плыть! – В поисках Немо»
print(text.upper()) # Все символы в верхнем регистре
print(text.lower()) # Переводит все символы в нижний регистр
print(text.title()) # Заглавный регистр
print(text.capitalize()) # Делает первый символ заглавным
print(text.swapcase()) # Меняет местами любой регистр для каждого символа
В результате получается:
КОГДА ЖИЗНЬ ЗАНИМАЕТ ТЕБЯ, ВЫ ЗНАЕТЕ, ЧТО НУЖНО ДЕЛАТЬ? ПРОСТО ПРОДОЛЖАЙ ПЛАВАТЬ! - В ПОИСКАХ НЕМО когда жизнь сводит тебя с ума, ты знаешь, что ты должен делать? Просто продолжай плавать! - в поисках Немо Когда жизнь подводит вас, вы знаете, что вам нужно делать? Просто продолжай плавать! - В поисках Немо Когда жизнь подводит тебя, ты знаешь, что ты должен делать? Просто продолжай плавать! - в поисках Немо КОГДА ЖИЗНЬ ПОДНИМАЕТ ТЕБЯ, ТЫ ЗНАЕШЬ, ЧТО ТЫ ДОЛЖЕН ДЕЛАТЬ? Просто продолжай плавать! - в поисках Немо
Разбиение и разбиение строк с помощью split() и partition()
Чтобы найти подстроку, а затем разбить строку на основе ее местоположения, вам понадобятся методы partition() и split() . Оба вернут список строк с примененным разделением. Оба чувствительны к регистру.
Оба вернут список строк с примененным разделением. Оба чувствительны к регистру.
Метод partition() возвращает подстроку до первого вхождения точки разделения, саму точку разделения и подстроку после нее:
text = "Быть или не быть, вот в чем вопрос"
print(text.partition('to be')) # ('Быть или не быть', 'быть', ', вот в чем вопрос')
Между тем, split() по умолчанию разбивает строку по каждому пробелу, получая список отдельных слов в строке:
text = "Быть или не быть, вот в чем вопрос" print(text.split()) # ['Кому', 'быть', 'или', 'не', 'чтобы', 'быть', 'что', 'есть', 'то', 'вопрос']
Естественно, вы также можете разделить любой другой символ, указанный в вызове split() :
text = "Быть или не быть, вот в чем вопрос"
print(text.split(',')) # ['Быть или не быть', ' вот в чем вопрос']
Соединение строк с помощью join()
Метод join() работает с итерируемыми объектами, содержащими исключительно экземпляры строк, объединяя все элементы вместе в строку.