Использование кодовых страниц UTF-8 в приложениях Windows — Windows apps
Twitter LinkedIn Facebook Адрес электронной почты- Статья
Используйте кодировку символов UTF-8 для оптимальной совместимости между веб-приложениями и другими платформами на основе nix (Unix, Linux и варианты), минимизируйте ошибки локализации и сократите затраты на тестирование.
UTF-8 — это универсальная кодовая страница для интернационализации и может кодировать весь набор символов Юникода. Он используется повсеместно в Интернете и используется по умолчанию для платформ на основе *nix.
Установка кодовой страницы процесса на UTF-8
Начиная с Windows версии 1903 (обновление за май 2019 г.), можно использовать свойство ActiveCodePage в appxmanifest для упакованных приложений или манифест слияния для непакованных приложений, чтобы принудительно использовать UTF-8 в качестве кодовой страницы процесса.
Вы можете объявить это свойство и целевой объект или запустить в более ранних Windows сборках, но необходимо обрабатывать обнаружение и преобразование устаревшей кодовой страницы как обычно. С минимальной целевой версией Windows версии 1903 кодовая страница процесса всегда будет иметь значение UTF-8, поэтому обнаружение и преобразование устаревшей кодовой страницы можно избежать.
Примечание
Закодированный символ занимает от 1 до 4 байт. Кодировка UTF-8 поддерживает более длинные последовательности байтов, до 6 байт, но самая большая кодовая точка Юникода 6.0 (U+10FFFF) занимает только 4 байта.
Кодировка UTF-8 поддерживает более длинные последовательности байтов, до 6 байт, но самая большая кодовая точка Юникода 6.0 (U+10FFFF) занимает только 4 байта.
Примеры
Манифест Appx для упаковаемого приложения:
<?xml version="1.0" encoding="utf-8"?>
<Package xmlns="http://schemas.microsoft.com/appx/manifest/foundation/windows10"
...
xmlns:uap7="http://schemas.microsoft.com/appx/manifest/uap/windows10/7"
xmlns:uap8="http://schemas.microsoft.com/appx/manifest/uap/windows10/8"
...
IgnorableNamespaces="... uap7 uap8 ...">
<Applications>
<Application ...>
<uap7:Properties>
<uap8:ActiveCodePage>UTF-8</uap8:ActiveCodePage>
</uap7:Properties>
</Application>
</Applications>
</Package>
Манифест Fusion для распаковки приложения Win32:
<?xml version="1.0" encoding="UTF-8" standalone="yes"?> <assembly manifestVersion="1.0" xmlns="urn:schemas-microsoft-com:asm.v1"> <assemblyIdentity type="win32" name="..." version="6.0.0.0"/> <application> <windowsSettings> <activeCodePage xmlns="http://schemas.microsoft.com/SMI/2019/WindowsSettings">UTF-8</activeCodePage> </windowsSettings> </application> </assembly>
Примечание
Добавление манифеста в существующий исполняемый файл из командной строки с помощью команды mt.exe -manifest <MANIFEST> -outputresource:<EXE>;#1
-A и API-интерфейсы -W
API Win32 часто поддерживают варианты -A и -W.
-Варианты распознают кодовую страницу ANSI, настроенную в системе и поддержку char*, а варианты -W работают в UTF-16 и поддерживают WCHAR.
До недавнего времени Windows подчеркнули варианты Юникода -W по сравнению с API-интерфейсами -A. Однако последние выпуски использовали кодовую страницу ANSI и API-интерфейсы A в качестве средства для внедрения поддержки UTF-8 для приложений. Если кодовая страница ANSI настроена для UTF-8, API-интерфейсы A обычно работают в UTF-8. Эта модель имеет преимущество поддержки существующего кода, созданного с помощью API-интерфейсов -A без каких-либо изменений кода.
Если кодовая страница ANSI настроена для UTF-8, API-интерфейсы A обычно работают в UTF-8. Эта модель имеет преимущество поддержки существующего кода, созданного с помощью API-интерфейсов -A без каких-либо изменений кода.
Преобразование кодовой страницы
Так как Windows работает изначально в UTF-16 (WCHAR), может потребоваться преобразовать данные UTF-8 в UTF-16 (или наоборот), чтобы взаимодействовать с Windows API.
MultiByteToWideChar и WideCharToMultiByte позволяют выполнять преобразование между UTF-8 и UTF-16 () (WCHARи другими кодовых страницами). Это особенно полезно, если устаревший API Win32 может быть понятен WCHARтолько . Эти функции позволяют преобразовывать входные данные UTF-8 для WCHAR передачи в API -W, а затем при необходимости преобразовывать все результаты.
При использовании этих функций с CodePage заданным значением CP_UTF8, использование dwFlags любого 0 из них или MB_ERR_INVALID_CHARSиным образом ERROR_INVALID_FLAGS происходит.
Примечание
CP_ACPПриравнивается только к CP_UTF8 тому, что в Windows версии 1903 (обновление за май 2019 г.) или более поздней версии, а для свойства ActiveCodePage, описанного выше, задано значение UTF-8. В противном случае она учитывает устаревшую системную кодовую страницу. Рекомендуется использовать CP_UTF8 явно.
- Кодовые страницы
- Идентификаторы кодовой страницы
UTF — универсальная кодировка для всего
В прошлый раз мы рассказали про Юникод — универсальную таблицу символов, в которой есть знаки почти всех языков. Вот краткое содержание:
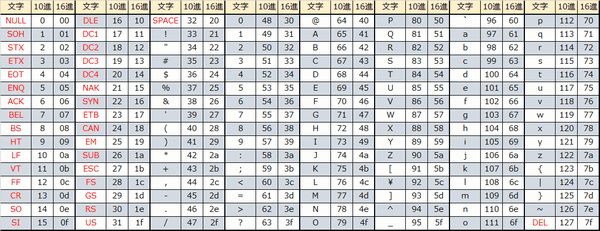
- Когда компьютеры только появились, у них была кодировка только для букв латинского алфавита и некоторых знаков — всего 7 бит и 128 символов.
- С развитием технологий многие страны сделали себе альтернативные восьмибитные кодировки — в них можно было хранить уже 256 символов.
- Кроме латиницы, в таких кодировках записывали буквы национальных алфавитов и другие нужные символы.

- Это сработало в тех странах, где алфавит состоит из небольшого числа букв (20—40), но не решило проблему с иероглифами. Тогда страны Азии сделали свои кодировки.
- В итоге всё это привело к тому, что файл с одного компьютера мог не прочитаться на другом компьютере, если там не было нужной кодировки.
- Для решения этих проблем сделали Юникод — универсальную таблицу, в которую можно поместить 1 112 064 символа.
- Сейчас в Юникоде записаны символы почти всех языков мира, но свободных позиций там осталось ещё около 80%.
Получается, что Юникод — универсальное решение проблемы совместимости текста. Текстовый файл, записанный в таком формате, можно прочитать на любом современном компьютере. Поддержка Юникода есть во всех новых операционных системах последних лет.
Кодирование и шифрование — в чём разница?
Чтобы пользоваться Юникодом, нужна была новая кодировка, которая бы определяла правила хранения информации о каждом символе. Такой кодировкой стала UTF — про неё и поговорим. Она сложно устроена: будет интересно всем, кто интересуется компьютерами.
Она сложно устроена: будет интересно всем, кто интересуется компьютерами.
UTF — универсальная кодировка для хранения символов
Юникод как таковой отвечает на вопрос «Как мы храним символы?». Он объясняет, каким символам мы присваиваем какие коды; по какому принципу выделяем эти коды; какие символы используем, а какие нет.
Но также нам нужно знать, как хранить и передавать данные о символах Юникода. Вот это и есть UTF.
UTF (Unicode Transformation Format) — это стандарт кодирования символов Unicode. Разберём на куски:
- Стандарт — то есть всеобщая договорённость. Разработчик в России и Мексике открывают одну и ту же документацию и одинаково понимают, как им работать с данными. Договорились такие.
- Кодирование — то есть как мы представляем эти данные на компьютере. Это одно большое число? Несколько чисел поменьше? Сколько байтов выделять на эти символы? Нужно ли специально говорить компьютеру, что сейчас будут символы Юникода?
Что такое UTF-8?
Сейчас самая популярная разновидность UTF-кодировки — это UTF-8.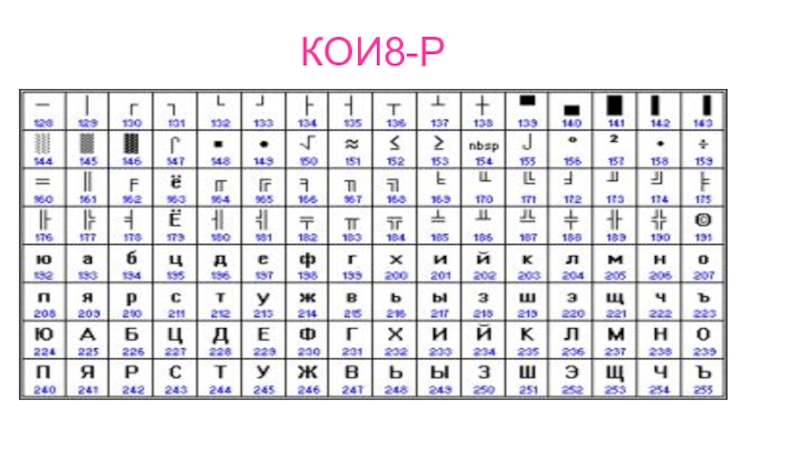
Чаще всего упоминание UTF-8 можно встретить в самом начале HTML-кода, когда мы объявляем кодировку в заголовке страницы. Строчка <meta charset=»utf-8″> как раз говорит браузеру, что всё текстовое содержимое страницы нужно отображать по формату UTF-8.
Число 8 означает, что для хранения данных используются 8 бит информации. Ещё есть 16- и 32-битные кодировки: UTF-16 и UTF-32.
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <meta name="viewport" content="width=device-width, initial-scale=1"> <title></title> </head> <body> </body> </html>
Проблема нулевых байтов
Сейчас немного информатики, потерпите.
Компьютер кодирует числа с помощью единиц и нулей в двоичной системе счисления. Она позволяет закодировать любое число, если дать ей достаточно места в памяти. Эти места измеряются в битах. Одним битом можно закодировать 0 или 1; двумя битами — числа от 0 до 3; восемью битами — от 0 до 255 и так далее. Биты слишком мелкие, поэтому для удобства хранения и обработки компьютеры группируют их по 8 бит, это называется байтом. В памяти можно выделять только байты, а не отдельные биты.
Биты слишком мелкие, поэтому для удобства хранения и обработки компьютеры группируют их по 8 бит, это называется байтом. В памяти можно выделять только байты, а не отдельные биты.
Максимальное количество символов в Юникоде — 1 112 064. Для хранения числа такого размера нам нужен 21 бит. Получается, что кодировка должна уметь работать с 21-битными числами.
Самое простое решение — выделить на каждый символ по 3 байта, то есть 24 бита. Например, символ с номером 998 536 в двоичной системе счисления выглядит так:
Двоичное счисление на пальцах
11110011110010001000
Если мы разобьём это на три байта и добавим впереди нужное количество нулей до трёх байтов, то получится такое:
00001111 00111100 10001000
Кажется, что мы сразу нашли способ кодирования: просто выделяй на все символы по три байта и кайфуй.
Но что, если нам нужен, например, символ под номером 150?
150₁₀ = 10010110₂
Разобьем снова на три байта:
00000000 00000000 10010110
У нас получилось в самом начале два нулевых байта. Проблема в том, что многие системы передачи данных воспринимают нулевые байты как конец передачи. Если они встретят такую последовательность, то решат, что передача окончена, а всё, что идёт дальше, — лишний шум, который обрабатывать не нужно. Если в нашем Юникод-тексте много символов из начала таблицы (например, всё на английском), то с чтением такого файла возникнут проблемы.
Проблема в том, что многие системы передачи данных воспринимают нулевые байты как конец передачи. Если они встретят такую последовательность, то решат, что передача окончена, а всё, что идёт дальше, — лишний шум, который обрабатывать не нужно. Если в нашем Юникод-тексте много символов из начала таблицы (например, всё на английском), то с чтением такого файла возникнут проблемы.
Чтобы выйти из этой ситуации, придумали UTF-8 — кодировку с плавающим количеством символов.
Как устроена кодировка UTF-8
В UTF-8 каждый символ кодируется разным количеством байтов — всё зависит от того, какой длины исходное число. Сначала расскажем теорию, потом нарисуем, как это работает.
До 7 бит — выделяется один байт, первый бит всегда ноль: 0xxxxxxxx. Иксы — это биты нашего числа. Например, буква A стоит на 65-м месте в таблице, а если перевести 65 в двоичный код, получится 1000001. Ставим эти 7 бит в наш шаблон и получаем нужный юникод-байт: 01000001.
Ноль здесь — признак того, что перед нами символ из первых 128 символов таблицы. Они совпадают с таблицей ASCII, поэтому одним байтом можно закодировать все стандартные математические символы, знаки препинания и буквы латинского алфавита.
Если первым в символе идёт ноль, кодировка понимает, что перед нами — один восьмибитный символ. Двух-, трёх- и четырёхбайтные символы всегда начинаются с единицы.
8—11 бит: выделяется два байта — 110xxxxx 10xxxxxx. Две единицы в начале говорят, что перед нами символ из двух байтов. Последовательность 10 в начале второго байта — признак того, что это продолжение предыдущего байта.
12—16 бит: тут уже три байта — 1110xxxx 10xxxxxx 10xxxxxx. Три единицы в начале — признак трёхбайтного символа. Каждый байт продолжения начинается с 10.
17—21 бит: для кодирования нужно четыре байта: 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx.
Короче: в кодировке UTF договорились, что много байтов выделяют только на те символы, которые стоят где-то в глубине таблицы, то есть всякие сложные национальные кодировки, эмодзи и иконки. Чем ближе к началу таблицы символ, тем меньше байтов на него выделяют. А чтобы компьютер понимал, сколько байтов выделено на каждый конкретный символ, сначала ставят специальные маркеры-подсказки.
Чем ближе к началу таблицы символ, тем меньше байтов на него выделяют. А чтобы компьютер понимал, сколько байтов выделено на каждый конкретный символ, сначала ставят специальные маркеры-подсказки.
Практика: кодируем символы в UTF-8
Закодируем в UTF-8 такой Юникод-символ — 𐍈 с порядковым номером 66376.
Для этого сначала переведём число 66376 в двоичный формат:
66376 = 10000001101001000
Здесь 17 бит, поэтому для кодирования в UTF-8 нам понадобится 4 байта. Вот шаблон, который нам нужно будет заполнить:
Подготовим наше двоичное число к заполнению по этому шаблону. Для этого разобьем его справа налево на те же группы: 3—6—6—6 символов:
Теперь подставим эти значения в наш четырёхбитный шаблон:
И переведём в шестнадцатеричную систему счисления:
Получается, что символ 𐍈 закодируется в четырёх байтах как F0 90 8D 88.
Почему нельзя просто всё кодировать одинаковым количеством бит
Можно, причём так часто делают в некоторых системах. Для этого там используют кодировки UTF-16 и UTF-32 — в них на каждый символ отводится сразу 2 или 4 байта.
Для этого там используют кодировки UTF-16 и UTF-32 — в них на каждый символ отводится сразу 2 или 4 байта.
Проблема такого подхода в том, что это увеличивает объём памяти, нужный для хранения данных. Проще говоря, те символы, на которых в UTF-8 хватило бы одного байта, здесь занимают в 2–4 раза больше.
С другой стороны, такие кодировки иногда проще в обработке, поэтому их, например, используют как штатные кодировки операционных систем. Так, UTF-16 — стандартная кодировка файловой системы NTFS в Windows.
У меня большая флешка, но на неё не влезают большие файлы. Почему?
Проблемы с безопасностью
Так как Юникод с помощью UTF-8 сам преобразует символы в последовательность байтов и наоборот, есть ситуации, когда это может навредить системе и привести к взлому.
Например, пользователю могут прислать файл, который называется otchetexe. txt — кажется, что это обычный текстовый файл, который можно смело открывать. Но на самом деле файл называется otchet[U+202E]txt. exe, а U+202E — это специальный юникод-символ, который включает написание справа налево. После того как Юникод встречает этот символ, он выводит всё написанное после него в обратном порядке. Так простой текстовый файл превращается в исполняемый .exe-файл для Windows. Если его запустить с правами администратора, он может натворить много всякого.
exe, а U+202E — это специальный юникод-символ, который включает написание справа налево. После того как Юникод встречает этот символ, он выводит всё написанное после него в обратном порядке. Так простой текстовый файл превращается в исполняемый .exe-файл для Windows. Если его запустить с правами администратора, он может натворить много всякого.
Как устроены файлы
Ещё пример — использование Юникода в разных SQL- и PHP-запросах. Из-за сложных преобразований может произойти переполнение стека — а этим уже могут воспользоваться злоумышленники, чтобы внедрить нужный код для выполнения.
На самом деле Юникод с этой точки зрения — большая дыра в безопасности любой системы, поэтому при работе с ним в критичных ситуациях используют белые списки, то есть те символы, которые использовать безопасно.
Текст:
Михаил Полянин
Редактор:
Максим Ильяхов
Художник:
Алексей Сухов
Корректор:
Ирина Михеева
Вёрстка:
Кирилл Климентьев
Соцсети:
Виталий Вебер
Использовать кодовые страницы UTF-8 в приложениях для Windows — Приложения для Windows
Редактировать Твиттер LinkedIn Фейсбук Электронная почта- Статья
Используйте кодировку символов UTF-8 для оптимальной совместимости между веб-приложениями и другими платформами на основе *nix (Unix, Linux и варианты), минимизируйте ошибки локализации и уменьшите затраты на тестирование.
UTF-8 — это универсальная кодовая страница для интернационализации, которая может кодировать весь набор символов Unicode. Он широко используется в Интернете и используется по умолчанию для платформ на основе * nix.
Установите для кодовой страницы процесса значение UTF-8
Начиная с версии Windows 1903 (обновление за май 2019 г.) вы можете использовать свойство ActiveCodePage в appxmanifest для упакованных приложений или манифест fusion для неупакованных приложений, чтобы заставить процесс используйте UTF-8 в качестве кодовой страницы процесса.
Вы можете объявить это свойство и использовать его в более ранних сборках Windows, но вы должны выполнять обнаружение и преобразование устаревших кодовых страниц как обычно. С минимальной целевой версией Windows версии 1903, кодовая страница процесса всегда будет UTF-8, поэтому можно избежать обнаружения и преобразования устаревшей кодовой страницы.
С минимальной целевой версией Windows версии 1903, кодовая страница процесса всегда будет UTF-8, поэтому можно избежать обнаружения и преобразования устаревшей кодовой страницы.
Примечание
Закодированный символ занимает от 1 до 4 байтов. Кодировка UTF-8 поддерживает более длинные последовательности байтов, до 6 байтов, но самая большая кодовая точка Unicode 6.0 (U+10FFFF) занимает всего 4 байта.
Примеры
Манифест Appx для упакованного приложения:
<Пакет xmlns="http://schemas.microsoft.com/appx/manifest/foundation/windows10"
...
xmlns:uap7="http://schemas.microsoft.com/appx/manifest/uap/windows10/7"
xmlns:uap8="http://schemas.microsoft.com/appx/manifest/uap/windows10/8"
...
IgnorableNamespaces="... uap7 uap8 ...">
<Приложения>
<Приложение...>
UTF-8
Манифест Fusion для неупакованного приложения Win32:
0" encoding="UTF-8" standalone="yes"?>
<приложение> <настройки окна> UTF-8
Примечание
Добавьте манифест к существующему исполняемому файлу из командной строки с помощью mt.exe -manifest
-A vs. -W APIs
API Win32 часто поддерживают варианты -A и -W.
Варианты -A распознают кодовую страницу ANSI, настроенную в системе, и поддерживают char* , а варианты -W работают в UTF-16 и поддерживают WCHAR .
До недавнего времени Windows делала упор на варианты «Unicode» -W, а не на -A API. Однако в недавних выпусках использовалась кодовая страница ANSI и API-интерфейсы -A в качестве средства внедрения поддержки UTF-8 в приложения. Если кодовая страница ANSI настроена для UTF-8, API-интерфейсы -A обычно работают в UTF-8. Преимущество этой модели заключается в поддержке существующего кода, созданного с помощью API-интерфейсов -A, без каких-либо изменений кода.
Если кодовая страница ANSI настроена для UTF-8, API-интерфейсы -A обычно работают в UTF-8. Преимущество этой модели заключается в поддержке существующего кода, созданного с помощью API-интерфейсов -A, без каких-либо изменений кода.
Преобразование кодовой страницы
Поскольку Windows изначально работает в UTF-16 ( WCHAR ), вам может потребоваться преобразовать данные UTF-8 в UTF-16 (или наоборот) для взаимодействия с Windows API.
MultiByteToWideChar и WideCharToMultiByte позволяют выполнять преобразование между UTF-8 и UTF-16 ( WCHAR ) (и другими кодовыми страницами). Это особенно полезно, когда устаревший API Win32 может понимать только WCHAR . Эти функции позволяют преобразовать ввод UTF-8 в WCHAR 9.0048 для передачи в -W API, а затем, при необходимости, обратного преобразования любых результатов.
При использовании этих функций с CP_UTF8 , используйте dwFlags из 0 или MB_ERR_INVALID_CHARS , иначе ERROR_INVALID_FL Возникает ошибка AGS .
Примечание
CP_ACP соответствует CP_UTF8 только при работе в Windows версии 1903 (обновление за май 2019 г.) или более поздней версии, а для описанного выше свойства ActiveCodePage установлено значение UTF-8. В противном случае он учитывает кодовую страницу устаревшей системы. Мы рекомендуем использовать CP_UTF8 явно.
- Кодовые страницы
- Идентификаторы кодовых страниц
Обратная связь
Просмотреть все отзывы о странице
asp classic — Кодовая страница 65001 и utf-8 — это одно и то же?
спросил
Изменено 2 года, 11 месяцев назад
Просмотрено 118 тысяч раз
<%@LANGUAGE="VBSCRIPT" CODEPAGE="65001"%> <голова>
Верен ли приведенный выше код?
- asp-classic
- кодовые страницы
Да.
UTF-8 — это CP65001 в Windows (это просто способ указать UTF-8 в устаревшей кодовой странице). Насколько я читал, ASP может обрабатывать UTF-8, если указано таким образом.
9Ваш код правильный, хотя я предпочитаю устанавливать CharSet в коде, а не использовать метатег: -
<% Response.CharSet = "UTF-8" %>
Кодовая страница 65001 относится к набору символов UTF-8. Вам нужно будет убедиться, что ваша страница asp (и любые включения) сохранены как UTF-8, если они содержат какие-либо символы за пределами стандартного набора символов ASCII.
Указав атрибут CODEPAGE в блоке <%@, вы указываете, что все, что пишется с помощью Response. Write, должно быть закодировано с указанной кодовой страницей, в данном случае 65001 (utf-8). Стоит иметь в виду, что это не влияет на статический контент, который дословно отправляется байт за байтом в ответ. Следовательно, причина, по которой файл должен быть фактически сохранен с использованием указанной кодовой страницы.
Write, должно быть закодировано с указанной кодовой страницей, в данном случае 65001 (utf-8). Стоит иметь в виду, что это не влияет на статический контент, который дословно отправляется байт за байтом в ответ. Следовательно, причина, по которой файл должен быть фактически сохранен с использованием указанной кодовой страницы.
Свойство CharSet ответа устанавливает значение CharSet заголовка Content-Type. Это не влияет на то, как контент может быть закодирован, он просто сообщает клиенту, какая кодировка принимается. Опять же важно, чтобы его значение соответствовало фактической отправленной кодировке.
3Да, 65001 — это идентификатор кодовой страницы Windows для UTF-8, как указано на веб-сайте Microsoft. Википедия предполагает, что кодовая страница IBM 128 и кодовая страница SAP 4110 также являются индикаторами для UTF-8.
1ответ.кодовая страница = 65001
, кажется, дает плохой результат, когда физический файл сохраняется как utf-8
В противном случае он работает так, как должен.