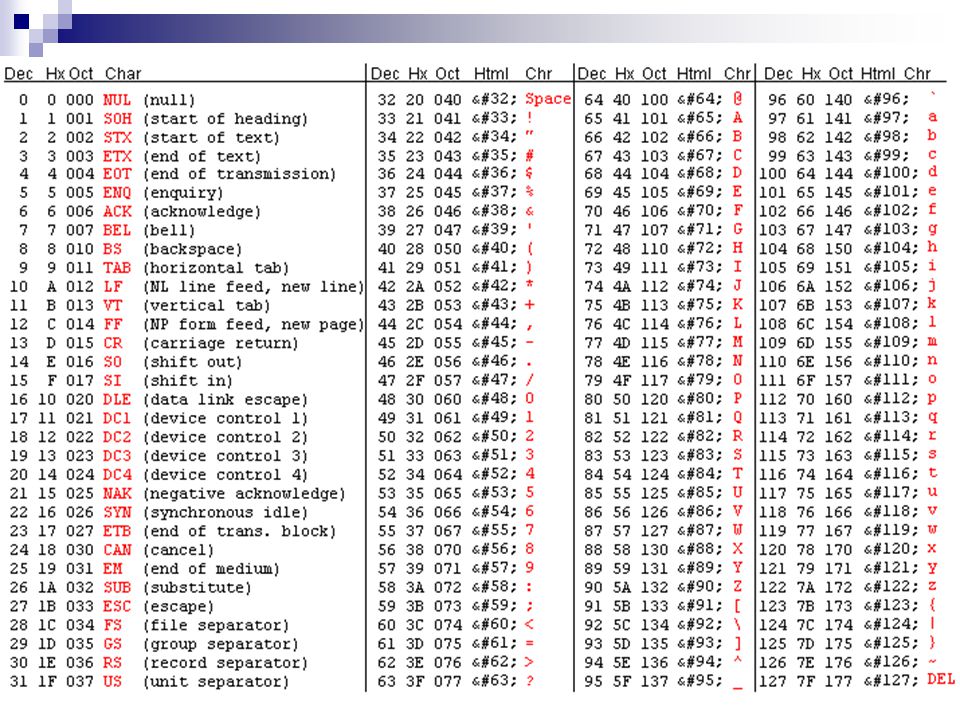
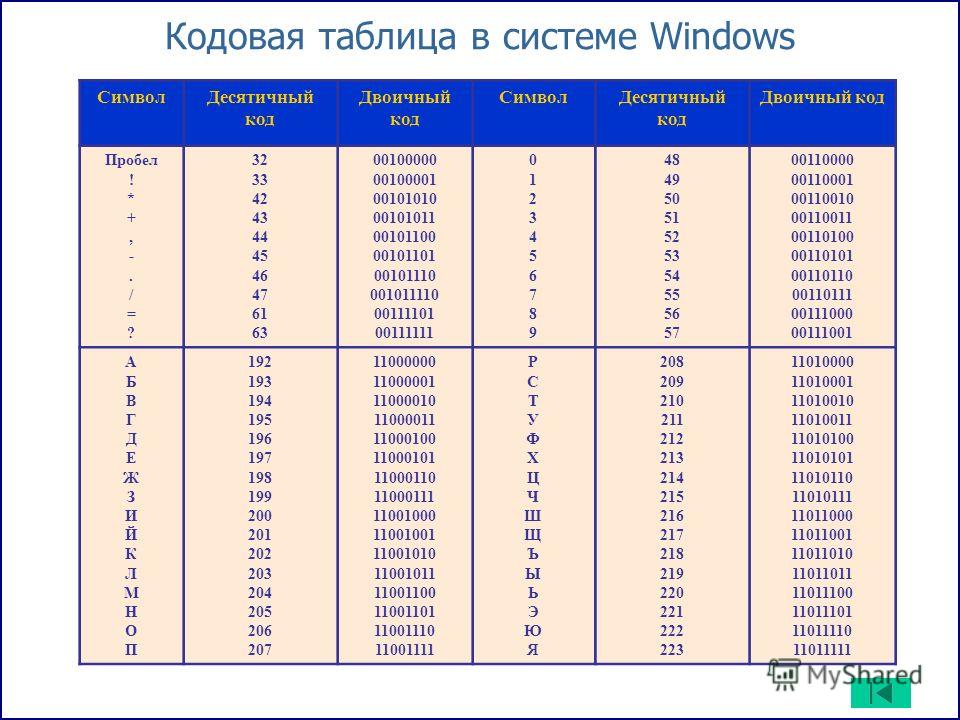
c — Что есть ANSI и ASCII
Я бы хотел, наконец, разобраться, как правильно называть строки 8-ми битных символов.
Что такое строка символов UTF-8 мне хорошо понятно — это строка, каждый символ которой представлен переменным количеством 8-ми битных блоков (байтов).
Что такое строки UTF-16/UTF-32 мне тоже ясно.
Но я не могу понять, как корректно называть восьмибитные кодировки, где первые 128 знаков строго определены, а последующие — меняются в зависимости от используемой кодовой страницы.
Кто-то их называет ascii, кто-то ansi, или просто CP1251, если подразумевается конкретная кодировка.
Помогите разобраться. Гугл только запутал.
- c
- utf-8
- ascii
- ansi
ASCII (читается аски́) — это первая кодировка применявшаяся еще в пору когда 99% юзеров SO еще даже не родились (1963 год).
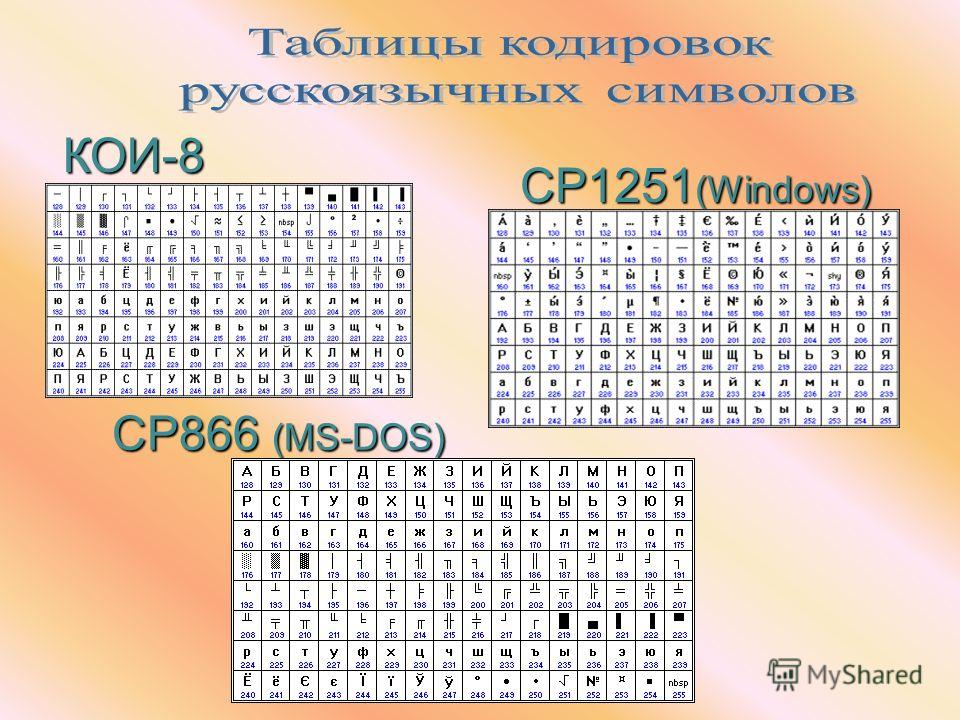
Далее со временем стало понятно, что для других языков можно использовать 8-й бит для отображения национальных символов — то есть использовать 256 символов. Эту расширенную 8-битовую кодировку условно называют ANSI (читается анси́) по названию американского института стандартов в рамках которого и была предложена 8-битовая кодировка. Соответственно, для каждого национального языка была предложена своя раскладка второй половины таблицы (от 128 до 255 символа), а первая половина таблицы от 0 до 127 — изначальные символы ASCII. KOI-8, CP-1251, 1252 и проч. — это различные инкарнации ANSI
Далее когда дело дошло до иероглифов стало понятно, что в 256 символов не уместиться и появилась UNICODE (читается юникод
) — где на 1 символ отводится 2 байта, то есть 65536 символов, где таблица была жестко поделена между национальными символами, например таблица ASCII осталась в интервалеU+0000 до U+007F, а наша с вами кириллица в интервале U+A640 до U+A69F ну и т. д.
д.С нарастанием угара стало ясно что 65536 символов также не хватает, потому что появились эмодзи, стали поднимать голову другие национальные символы справедливо указывавшие на нехватку места в таблице UNICODE, тогда был предложен UTF-8 (читается ютиэф 8), где количество байтов в символе имеет разную длину и может быть от 1-го до 4 байт, что дает 1 112 064 символов.
Вот, как то так.
3
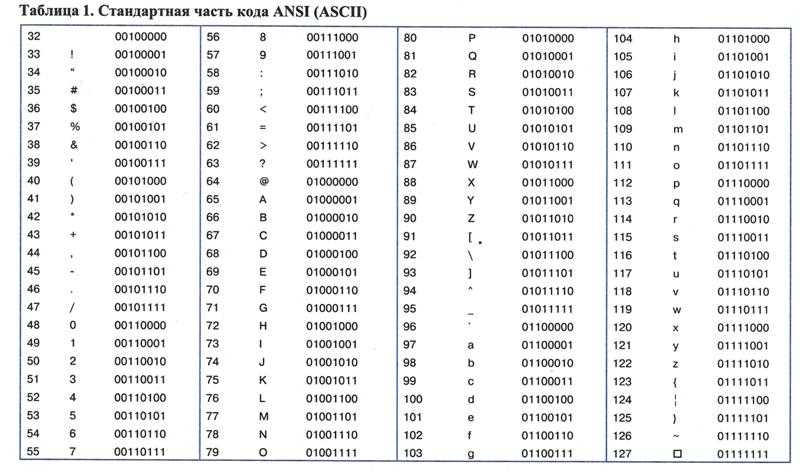
ASCII (American Standard Code for Information Interchange) — первый вариант кодировки.
Потом появились CP866, KOI8-R, Windows 1251 и вот это всё.
Так что, CP1251 — это расширенная версия ASCII.
ANSI — это расширения ASCII, в которых были удалены псевдографические элементы и добавлены символы типографики.
CP1251 — это пример ANSI кодировки.
Если на диаграмме Эйлера показать:
2
Считаю название «восьмибитные» или «однобайтовые кодировки» вполне корректным общим названием для подобных вещей.
Само собой, если подразумевается какая-то конкретная кодовая страница/кодировка, то она и указывается: «KOI8-R», «CP1251» «CP1250», «ISO8859-5».
ASCII как стандарт (а это действительно стандарт — American standard code for information interchange) определяет, если я правильно помню, только первые 127 кодов символов. Поэтому формально символы типа «я», «č», «њ», «Ḱ» не принадлежат ASCII.
«ANSI» — это вообще исключительно русскоязычный (sic!) термин для CP1251, т.к. вообще-то это сокращение обозначает американский национальный институт стандартизации (а «OEM» — original equipment manufacturer).
Зарегистрируйтесь или войдите
Регистрация через Google
Регистрация через Facebook
Регистрация через почту
Отправить без регистрации
Почта
Необходима, но никому не показывается
Отправить без регистрации
Почта
Необходима, но никому не показывается
Нажимая на кнопку «Отправить ответ», вы соглашаетесь с нашими пользовательским соглашением, политикой конфиденциальности и политикой о куки
Unicode.
 Краткий обзор—ArcMap | Документация
Краткий обзор—ArcMap | Документация- Кодовые знаки
- Кодирование символов
Unicode представляет собой систему кодирования символов, которая используется компьютерами для хранения и обмена текстовыми данными. В Unicode имеется уникальный номер (или кодовый знак) для каждого символа основных мировых систем письменности. В эту систему также включены технические символы, знаки пунктуации и многие другие символы, используемые в письменности.
Помимо того что Unicode является таблицей кодов символов, он также включает в себя алгоритмы для сопоставления и кодирования двусторонней письменности, например, арабской, а также спецификации для нормализации текстовых форм.
В данном разделе приводится общее описание Unicode. Для получения более полной информации и списка поддерживаемых языков, символы которых могут быть закодированы с помощью Unicode, см.Веб-сайт Unicode Consortium.
Кодовые знаки
Символы представляют собой единицы информации, которые приблизительно соответствуют единице текста в письменной форме естественного языка. Unicode определяет то, каким образом символы будут интерпретироваться, а не отображаться.
Unicode определяет то, каким образом символы будут интерпретироваться, а не отображаться.
Образ символа (глиф), который отображается, или визуальное представление символа, является знаком, который выводится на экране монитора или распечатанной странице. В некоторых системах записи один символ может соответствовать нескольким глифам, или несколько символов может соответствовать одному глифу. Например, «ll» в испанском языке является одним глифом, но двумя символами: «l» и «l».
В Unicode символы преобразуются в кодовые знаки. Кодовые знаки представляют собой числа, которые назначаются Unicode Consortium для каждого символа в каждой системе записи. Кодовые знаки представляются в виде записи «U+» и четырех чисел и/или букв. Ниже приводятся примеры кодовых знаков для четырех разных символов: строчная l, строчная u с умляутом, бета и строчной e с акутом.
l = U+006C
u = U+00FC
= U+0392
e = U+00E9
Unicode содержит 1,114,112 кодовых значений; на настоящий момент времени, для них назначено более 96,000 символов.
Уровни
Кодовое пространство Unicode для символов разделено на 17 уровней, каждый из которых содержит 65,536 кодовых знаков.
Первым уровнем (plane) – plane 0 – является Basic Multilingual Plane (BMP). Большая часть наиболее используемых символов кодируются с помощью BMP, и на сегодняшний день это уровень, на котором закодировано больше всего символов. BMP содержит кодовые знаки для почти всех символов современных языков и многих специальных символов. В BMP существует порядка 6,300 неиспользуемых кодовых знаков. Они будут использованы для добавления большего числа символов в будущем.
Следующим уровнем (plane) – plane 1 – является Supplementary Multilingual Plane (SMP). SMP используется для кодирования древних символов, а также музыкальных и математических символов.
Кодирование символов
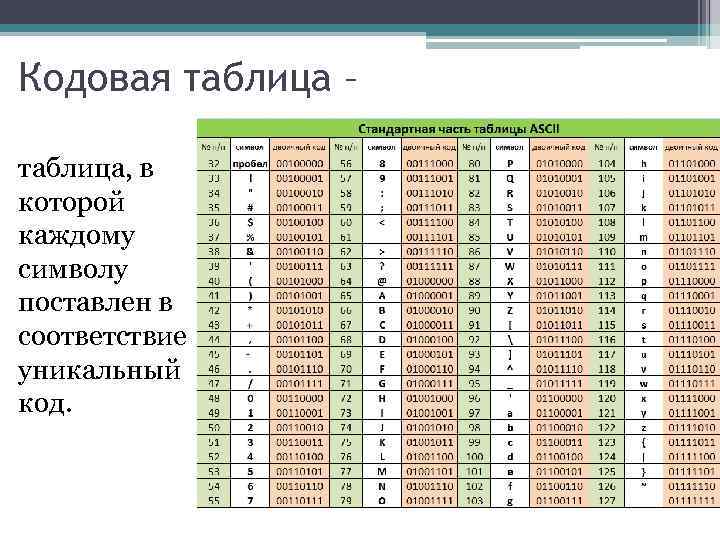
Кодирование символов определяет каждый символ, его кодовый знак и то, как кодовый знак будет представлен в битах. Не зная, какое кодирование использовалось, вы не сможете интерпретировать строку символов корректно.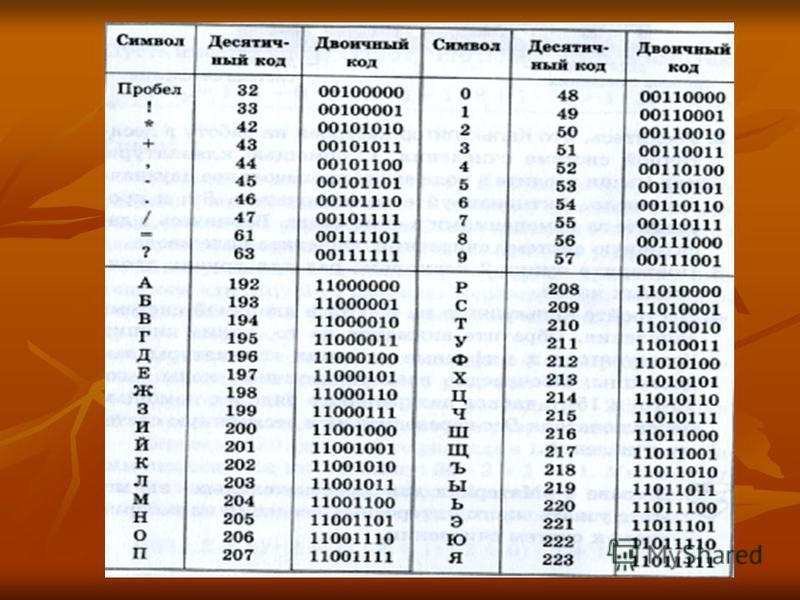
Существует очень большое количество схем кодирования, но конвертировать их данные между ними очень трудно, причем немногие из них могут учесть наличие символов более двух-трех разных языков. Например, если ваш ПК по умолчанию настроен на использование OEM-Latin II и вы просматриваете Веб-сайт, который использует IBM EBCDIC-Cyrillic, то все символы, которые будут представлены в Cyrillic, который не будет закодирован в схеме Latin II, не будут отображаться корректно. Такие символы будут замещены другими символами, например, знаками вопроса и квадратами.
Поскольку Unicode содержит кодовые знаки для большинства символов во всех современных языках, то использование кодировки символов Unicode позволит вашему компьютеру интерпретировать практически каждый известный символ.
Существует три основных схемы Юникод для кодирования символов: UTF-8, UTF-16 и UTF-32. UTF означает Unicode Transformation Format. Числа, которые идут за UTF, означают размер единиц (в байтах), используемых для кодирования.
- UTF-8 использует 8-битовую кодовую единицу переменной ширины. UTF-8 использует от 1 до 6 байт для кодирования символа; она может использовать меньше, столько же или больше байт, чем UTF-16 для кодирования одного и того же символа. В windows-1251, каждый код от 0 до 127 (U+0000 to U+0127) хранится в одном байте. Только кодовые знаки от 128 (U+0128) и выше хранятся с использованием от 2 до 6 байт.
- UTF-16 использует одну 16-битовую кодовую единицу фиксированной ширины. Он сравнительно компактен и все наиболее часто используемые символы могут быть закодированы с помощью одной 16-битовой кодовой единицы. Другие символы могут быть доступны при использовании пар 16-битовых кодовых единиц.
- UTF-32 требуется 4 байта для кодирования любого символа. В большинстве случаев документ, закодированный с помощью UTF-32, будет примерно в два раза больше, чем такой же документ, закодированный с помощью UTF-16. Каждый символ в нем кодируется с помощью одной 32-битовой единицы кодирования фиксированной ширины.
 Вы можете использовать UTF-32, если вы не ограничены в дисковом пространстве и хотите использовать одну кодовую единицу для каждого символа.
Вы можете использовать UTF-32, если вы не ограничены в дисковом пространстве и хотите использовать одну кодовую единицу для каждого символа.
Все три формы кодирования могут кодировать одни и те же символы и могут быть переведены из одной в другую без потери данных.
Существуют и другие кодировки: например, UTF-7 и UTF-EBCDIC. Существует также кодировка GB18030, которая является китайским эквивалентом кодировки UTF-8 и поддерживает упрощенные и традиционные китайские символы. Для русского языка удобно пользоваться windows-1251.
Является ли CP-1251 расширением для ASCII?
спросил
Изменено 9 лет, 10 месяцев назад
Просмотрено 818 раз
Если мне нужны символы кириллицы в формате ASCII, это будет означать, что мне понадобится расширенная таблица ASCII, верно? Я хочу знать, является ли cp-1251 расширением ASCII, и если нет, то чем оно считается.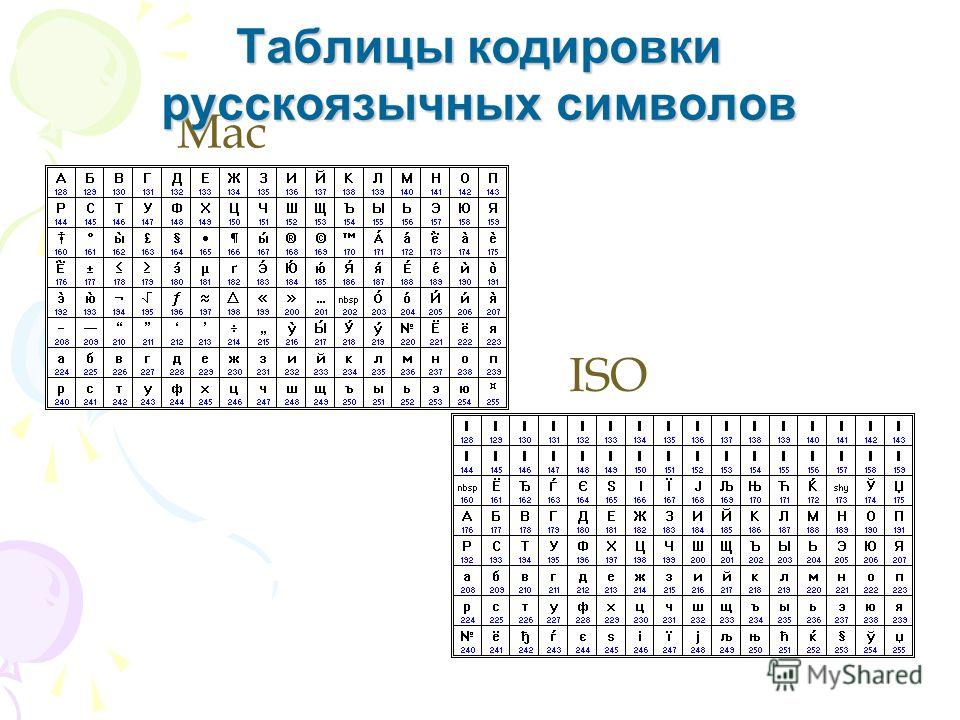
Также, если у меня есть символ O cp-1251 с кодом 206, тогда значение UTF-8 того же символа будет 041E, верно?
«Расширенный ASCII» — неоднозначный термин.
US-ASCII поддерживает 128 значений (8-й бит зарезервирован) и не поддерживает коды кириллицы. Первая половина Windows 1251 сопоставляет кодовые точки с одним и тем же диапазоном значений. То же самое верно и для UTF-8. Таким образом, любые документы, закодированные как ASCII, являются допустимыми для Windows 1252, Windows 1251, UTF-8, ISO-8859-1, и некоторых других кодировок .
U+004F (ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА O), закодированные как ASCII, Windows-1251 или UTF-8, будут иметь одно и то же значение октета ( 4F ) при просмотре с помощью шестнадцатеричного редактора.
Для данных на естественном языке большинство кодировок, отличных от Unicode, следует считать устаревшими.
ASCII является стандартом. Это 7-битный код. Он содержит значения в диапазоне 0 .. 127. Все остальное не ASCII.
На ПК можно работать с кодовыми страницами. Вы можете выбрать кодовую страницу, содержащую интересующие вас символы.
Может оказаться полезным взглянуть на Unicode, который может поддерживать ASCII и практически любой другой когда-либо изобретенный символ.
Технически ASCII — это 7-битный формат, не содержащий символов кириллицы. Учитывая это, нельзя иметь кириллические символы в подлинном формате ASCII.
CP-1251 — это 8-битная кодировка, включающая символы кириллицы. Первые 128 символов CP-1251 совпадают с ASCII, поэтому в этом смысле это расширение ASCII. Однако в конечном итоге CP-1251 — это просто кодировка символов, т. е. сопоставление между символами и числовыми значениями.
В настоящее время семейство кодировок Unicode имеет наибольшую популярность для современных интернационализированных приложений, при этом UTF-8 является наиболее популярным благодаря компактному представлению основных символов ASCII. Полное использование Unicode требует возможности обработки многобайтовых символов, включая использование более сложных алгоритмов для задач обработки текста, таких как сортировка, поиск и сравнение текста.
Полное использование Unicode требует возможности обработки многобайтовых символов, включая использование более сложных алгоритмов для задач обработки текста, таких как сортировка, поиск и сравнение текста.
К сожалению, кодировка символов уже не так проста, как во времена правления US-ASCII. Конечно, даже тогда конкуренты, такие как EBCDIC, мутили воду.
Несколько полезных ссылок:
http://www.unicode.org/
http://msdn.microsoft.com/en-us/goglobal/cc305144
http://en.wikipedia. org/wiki/Windows-1251
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью GoogleЗарегистрироваться через Facebook
Зарегистрируйтесь, используя адрес электронной почты и пароль
Опубликовать как гость
Электронная почта
Требуется, но никогда не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Кодирование: Однобайтовый декодер
Кодирование: Однобайтовый декодер Эти тесты кодирования теперь заменены копиями, которые хранятся в репозитории тестов веб-платформ.
Целевая аудитория: пользователи, кодировщики HTML (использующие редакторы или скрипты), разработчики скриптов (PHP, JSP и т. д.), кодировщики CSS, менеджеры веб-проектов и все, кто хочет знать о кодировках в современных браузерах.
Эти тесты проверяют, декодируют ли пользовательские агенты символы для данной кодировки, как указано в спецификации кодировки, когда используются предпочтительные метки и псевдонимы, указанные в спецификации.
Чтобы увидеть тест, нажмите на ссылку в крайнем левом столбце. Чтобы увидеть подробные результаты для одного теста, щелкните строку и посмотрите чуть выше таблицы. В подробных результатах указаны даты, когда были записаны результаты теста, и версия протестированного браузера.
Любые зависимости показаны в примечаниях над таблицей, а примечания под таблицей обычно содержат любую дополнительную полезную информацию, включая объяснение, почему результат был помечен как «частично успешный».
Ключ:
| пропуск | сбой | частично успешно |
Обратите внимание, что эти результаты тестов относятся к выпущенным версиям протестированных браузеров. Версии, которые все еще находятся в разработке, могут обеспечить лучшую поддержку этих функций. В тестах не используются префиксы поставщиков.
В верхней строке каждой таблицы показана поддержка предпочтительного имени для кодировки.
IBM866
- Если тест ibm866 не пройден, то результаты остальных тестов в этом разделе, скорее всего, также не пройдут, так как они являются псевдонимами для той же кодировки.
исо-8859-2
- Если тест iso-8859-2 не пройден, то результаты остальных тестов в этом разделе, скорее всего, также не пройдут, так как они являются псевдонимами для одной и той же кодировки.
исо-8859-3
- Если тест iso-8859-3 не проходит, то и результаты остальных тестов в этом разделе, скорее всего, тоже не пройдут, так как они являются псевдонимами для одной и той же кодировки.
- Edge : для частично поддерживаемых меток выдает 7 символов вместо U+FFFD для всех поддерживаемых меток кодирования.
исо-8859-4
- Если тест iso-8859-4 не пройдет, то и результаты остальных тестов в этом разделе, скорее всего, тоже не пройдут, так как они являются псевдонимами для той же кодировки.
исо-8859-5
- Если тест iso-8859-5 не пройден, то результаты остальных тестов в этом разделе, скорее всего, также не пройдут, так как они являются псевдонимами для одной и той же кодировки.
исо-8859-6
- Если тест iso-8859-6 не пройден, то результаты остальных тестов в этом разделе, скорее всего, также не пройдут, так как они являются псевдонимами для одной и той же кодировки.
- Edge : для частично поддерживаемых меток создает 45 символов PUA вместо ожидаемого U+FFFD и создает дополнительные 28 неожиданных символов для asmo-708.
исо-8859-7
- Если тест iso-8859-7 не пройден, то результаты остальных тестов в этом разделе, скорее всего, также не пройдут, так как они являются псевдонимами для одной и той же кодировки.
- Edge : для частично поддерживаемых меток выдает 3 символа PUA вместо ожидаемого U+FFFD, а также еще 5 неожиданных символов.
исо-8859-8
- Если тест iso-8859-8 не пройден, то результаты остальных тестов в этом разделе, скорее всего, также не пройдут, так как они являются псевдонимами для одной и той же кодировки.
- Edge : для частично поддерживаемых меток выдает 36 символов PUA вместо ожидаемых U+FFFD и выдает еще 3 неожиданных символа.
исо-8859-8-и
- Если тест iso-8859-8-i не проходит, то и результаты остальных тестов в этом разделе, скорее всего, тоже не пройдут, так как они являются псевдонимами для той же кодировки.
- Edge : для частично поддерживаемых меток выдает 36 символов PUA вместо ожидаемых U+FFFD и выдает еще 3 неожиданных символа.
исо-8859-10
- Если тест iso-8859-10 не пройден, то результаты остальных тестов в этом разделе, скорее всего, также не пройдут, так как они являются псевдонимами для той же кодировки.
исо-8859-13
- Если тест iso-8859-13 не пройден, то результаты остальных тестов в этом разделе, скорее всего, также не пройдут, так как они являются псевдонимами для той же кодировки.
исо-8859-14
- Если тест iso-8859-14 не пройдет, то и результаты остальных тестов в этом разделе, скорее всего, тоже не пройдут, так как они являются псевдонимами для одной и той же кодировки.

исо-8859-15
- Если тест iso-8859-15 не проходит, то и результаты остальных тестов в этом разделе, скорее всего, тоже не пройдут, так как они являются псевдонимами для той же кодировки.
исо-8859-16
кои8-р
- Если тест koi8-r не пройден, то результаты остальных тестов в этом разделе, скорее всего, также не пройдут, так как они являются псевдонимами для той же кодировки.
кои8-у
- Если тест koi8-u не пройден, то результаты остальных тестов в этом разделе, скорее всего, также не пройдут, так как они являются псевдонимами для одной и той же кодировки.
- Firefox, Chrome, Safari, Opera : для частично поддерживаемых меток все терпят неудачу только из-за двух белорусских символов, введенных в спецификации кодировки для соответствия поведению Internet Explorer.

Макинтош
- Если тест macintosh не проходит, то и результаты остальных тестов в этом разделе, скорее всего, тоже не пройдут, так как они являются псевдонимами для той же кодировки.
- Edge : для частично поддерживаемой метки выдает 1 неожиданный символ.
окна-1250
- Если тест windows-1250 не пройден, то и результаты остальных тестов в этом разделе, скорее всего, тоже не пройдут, так как они являются псевдонимами для одной и той же кодировки.
окна-1251
- Если тест windows-1251 не проходит, то и результаты остальных тестов в этом разделе, скорее всего, тоже не пройдут, так как они являются псевдонимами для одной и той же кодировки.
окна-1252
- Если тест windows-1252 не пройден, то и результаты остальных тестов в этом разделе, скорее всего, тоже не пройдут, так как они являются псевдонимами для одной и той же кодировки.

окна-1253
- Если тест windows-1253 не пройден, то и результаты остальных тестов в этом разделе, скорее всего, тоже не пройдут, так как они являются псевдонимами для одной и той же кодировки.
- Edge : для частично поддерживаемой метки выдает 3 символа PUA вместо ожидаемого U+FFFD.
- Safari : проходит через один символ в строке A, который имеет неопределенное сопоставление в сопоставлении Unicode, где ожидалось U+FFFD. Это похоже на ошибку, поскольку неопределенные отображения в строках D и F, как и ожидалось, дают U+FFFD.
окна-1254
- Если тест windows-1254 не пройден, то и результаты остальных тестов в этом разделе, скорее всего, тоже не пройдут, так как они являются псевдонимами для одной и той же кодировки.
окна-1255
- Если тест windows-1255 не пройден, то и результаты остальных тестов в этом разделе, скорее всего, тоже не пройдут, так как они являются псевдонимами для одной и той же кодировки.

- Edge : для частично поддерживаемой метки выдает 3 символа PUA вместо ожидаемого U+FFFD.
окна-1256
- Если тест windows-1256 не пройден, то результаты остальных тестов в этом разделе, скорее всего, тоже не пройдут, так как они являются псевдонимами для одной и той же кодировки.
окна-1257
- Если тест windows-1257 не пройден, то и результаты остальных тестов в этом разделе, скорее всего, тоже не пройдут, так как они являются псевдонимами для одной и той же кодировки.
- Edge : для частично поддерживаемой метки выдает 2 символа PUA вместо ожидаемого U+FFFD.
окна-1258
- Если тест windows-1258 не пройден, то и результаты остальных тестов в этом разделе, скорее всего, тоже не пройдут, так как они являются псевдонимами для одной и той же кодировки.