Сайт, который показывает, как выглядели сайты и веб-страницы в прошлом
Сервис, который может показать, как выглядели сайты в прошлом, напоминает своеобразную машину времени в интернете. С его помощью можно перенестись на год, два или двадцать лет назад и увидеть, какими ресурсы были тогда. Зачем может понадобиться эта информация и как воспользоваться данным сервисом?
Для чего нужно искать старые версии сайтов
Причины, по которым может быть необходимо посмотреть сайт в прошлом времени, могут быть абсолютно разными. Часто это желание погрузиться в приятную ностальгию. Например, посмотреть, как раньше выглядели популярные площадки и соцсети. Или же посмотреть, как выглядел собственный сайт несколько лет назад. К счастью, существует инструмент, который позволяет это сделать, даже если сам ресурс уже давно не доступен.
Как это возможно? Если сайт существует в интернете хотя бы пару дней, он попадает в веб-архив. Инструмент сохраняет его код, благодаря чему, можно увидеть, как он выглядел даже много лет назад.
Причины, по которым возникает необходимость посмотреть порталы в прошлом времени:
- Отслеживание истории изменений. Такая потребность может возникать у копирайтеров или журналистов для подготовки нового контента. Также это может быть нужно для анализа конкурентов: можно проследить путь их развития и увидеть допущенные ошибки.
- Восстановление ресурса. Если пользователь забыл продлить домен или не сделал бэкап, веб-архив будет отличным вариантом восстановления.
- Поиск уникального контента. Если площадка больше не доступна, её контент становится уникальным. Можно использовать его полностью или частично, предварительно проверив уникальность.
- Увидеть необходимый контент, если страница уже недоступна. Например, пользователь добавил площадку в закладки, а через время оказалось, что её больше нет. Тогда посмотреть её содержимое можно только с помощью веб-архива.
Как узнать прошлое веб-ресурса с помощью archive.org
Чтобы узнать, как выглядел конкретный веб-ресурс ранее, можно воспользоваться сайтом для просмотра страниц в прошлом – archive.org. Для этого нужно выполнить следующее:
- Пройти по ссылке https://archive.org/.
- Ввести URL-адрес и нажать кнопку «Go».

- Выбрать интересующий период времени. Затем с помощью календаря найти нужную дату, навести на нее курсор мыши и выбрать время сохранения копии (в списке может быть как одна, так и несколько ссылок).
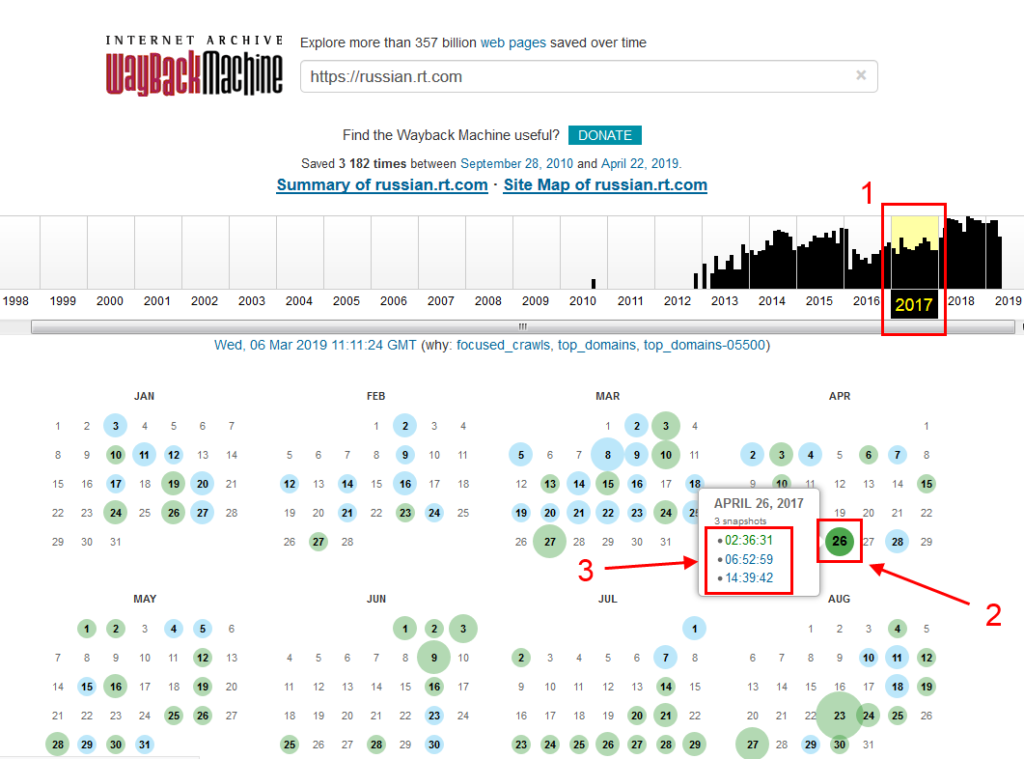
После этого откроется главная страница в том виде, какой она была в выбранный период.
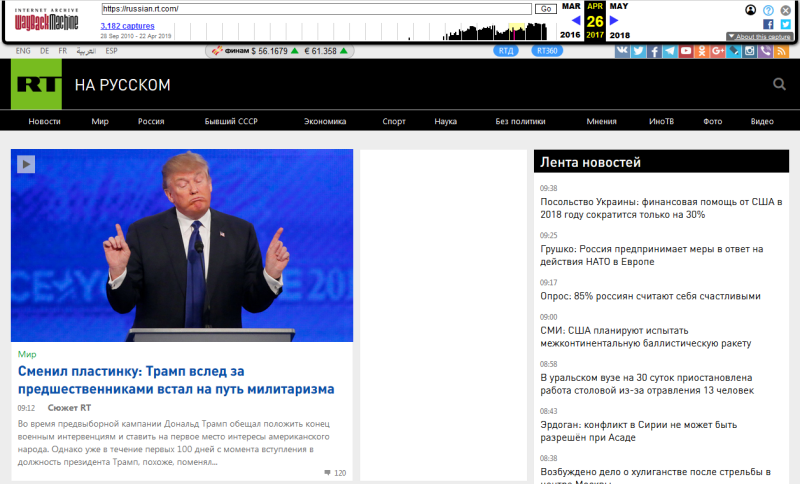
Учитывайте, что кликабельными в календаре являются только дни, помеченные синим или зеленым цветом. Посмотреть, как выглядел сайт в даты без подсветки, не получится.
Если это страница Вконтакте
Аналогичным образом можно узнать содержимое страницы ВКонтакте. Достаточно указать на нее ссылку в соответствующем поле.
По сравнению с новостными или другими веб-ресурсами здесь будет меньше подсвеченных дат с сохранённым содержимым. Количество дат зависит от популярности страницы: у обычных пользователей их будет немного, в то время как у известных медиа-личностей – на порядок больше.
Дальнейшие действия такие же: надо выбрать любую из подсвеченных дат и перейти по кликабельной ссылке. В этой же вкладке откроется страница в ВКонтакте с актуальным на тот момент содержимым.
Как выглядели культовые сайты раньше
Для примера посмотрим, как выглядели популярные ресурсы раньше, а именно Яндекс, Google, YouTube, Википедия и VK. Все из них с течением времени претерпели кардинальные изменения в дизайне.
Поисковик Яндекс
Поисковую систему Яндекс официально анонсировали 23 сентября 1997 года. С тех прошло более 20 лет, и сегодня это одна из самых популярных поисковых систем в мире.
В веб-архиве первая сохраненная копия датируется 6 декабря 1998 года.

На тот момент выглядел Яндекс вот так:

Поисковик Google
Поисковая система Google была основа чуть позже – в 1998 году. Сейчас это самая популярная поисковая система в мире.
Первые сохраненные копии появились в веб-архиве в конце 1998 года. Например, 2 декабря Гугл выглядел вот так:

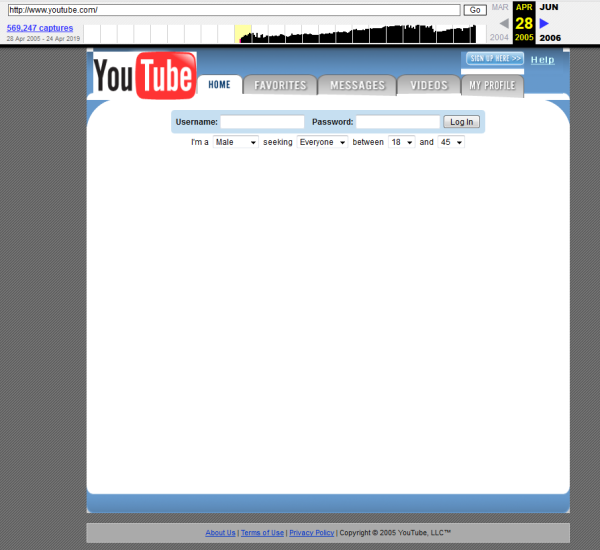
YouTube
Youtube начал свою работу в феврале 2005 года. Первые сохраненные в веб-архиве копии появились в конце апреля 2005 года. На то время сервис имел минималистичный дизайн, и видно, что он являлся не более, чем видеохостингом:
Википедия
Википедия появилась 15 января 2001 года. Сегодня она является наиболее крупным и популярным справочником в интернете и содержит более 40 миллионов статей, которые доступны на 301 языке.
В веб-архиве первая сохраненная копия Википедии датируется 27 июля 2001 года:

ВКонтакте
Популярная в России и других странах социальная сеть ВКонтакте была создана 10 октября 2006 года.
В веб-архиве первая сохраненная копия сайта датируется 8 ноября 2006 года. На нём видно, что сайт изначально был ориентирован на студентов и выпускников.

Можно ли восстановить сайт из вебархива?
При потере данных, восстановить свой сайт можно с помощью сайта https://webarchiveorg.ru/. Для этого нужно:
- ввести URL-адрес;
- выбрать нужный год, месяц и число;
- нажать кнопку «Восстановить сайт».

Услуга является платной, поэтому перед восстановлением рекомендуется ознакомиться с тарифами. Точная стоимость зависит от количества сайтов и его страниц.
Выводы
С помощью веб-архива можно посмотреть, какой дизайн и контент были у сайтов раньше, что может быть необходимо для восстановления данных, анализа конкурентов, поиска интересного контента с исчезнувших ресурсов или просто ради интереса.

altblog.ru
Как узнать вид сайта в прошлом через WebArchive
У 9 из 10 наших читателей есть свой сайт или интернет-магазин на 1C-UMI. Кто-то создал его недавно, а кому-то уже можно праздновать юбилей. За годы развития веб-ресурсы претерпевают множество изменений во внешнем виде и функционале. Иногда хочется вспомнить, каким же был ваш проект раньше, когда всё только начиналось. Или поднять какую-то утерянную информацию, которая была на сайте ранее. Сделать это легко при помощи чудо-сервиса Wayback Machine.
Как пользоваться веб-архивом
Откройте сервис, вбейте в строку поиска домен или полный адрес своего сайта. Сервис автоматически начнет поиск и через пару секунд покажет вам результаты в виде временной шкалы и календаря с датами, когда были сделаны снимки ресурса.
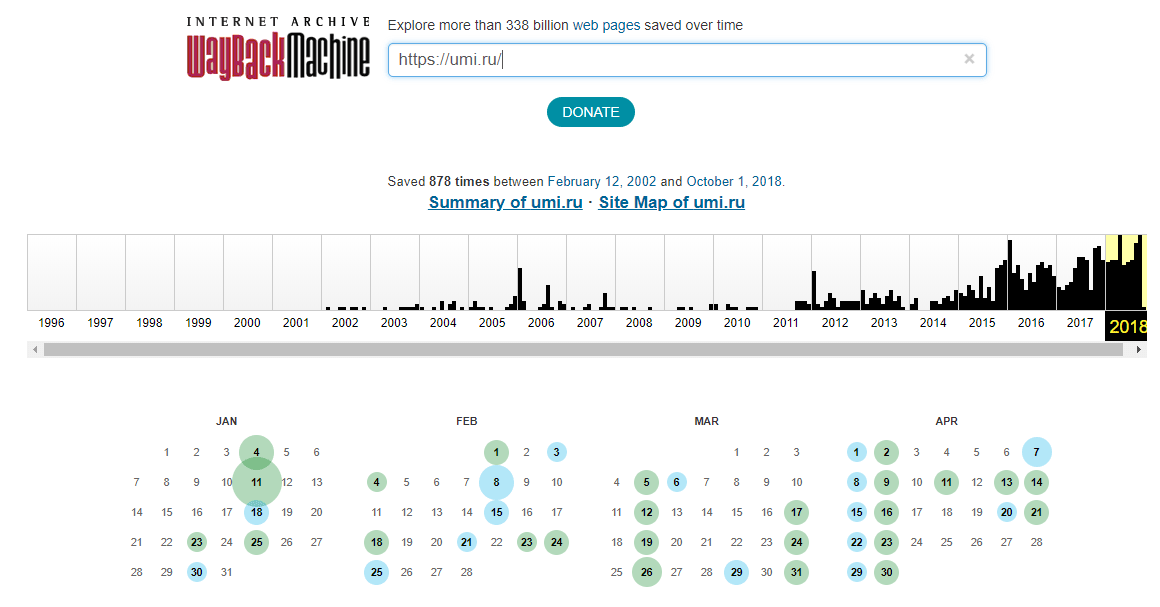
Чтобы перейти к конкретному году, кликните по соответствующему блоку на шкале. Затем в календаре ниже нажмите на одну из дат, выделенных голубым цветом. Если в тот день было сделано несколько снимков, при нажатии на дату вы увидите окно для выбора нужного вам времени. Если снимок был один, вы сразу попадете на сохраненную версию.
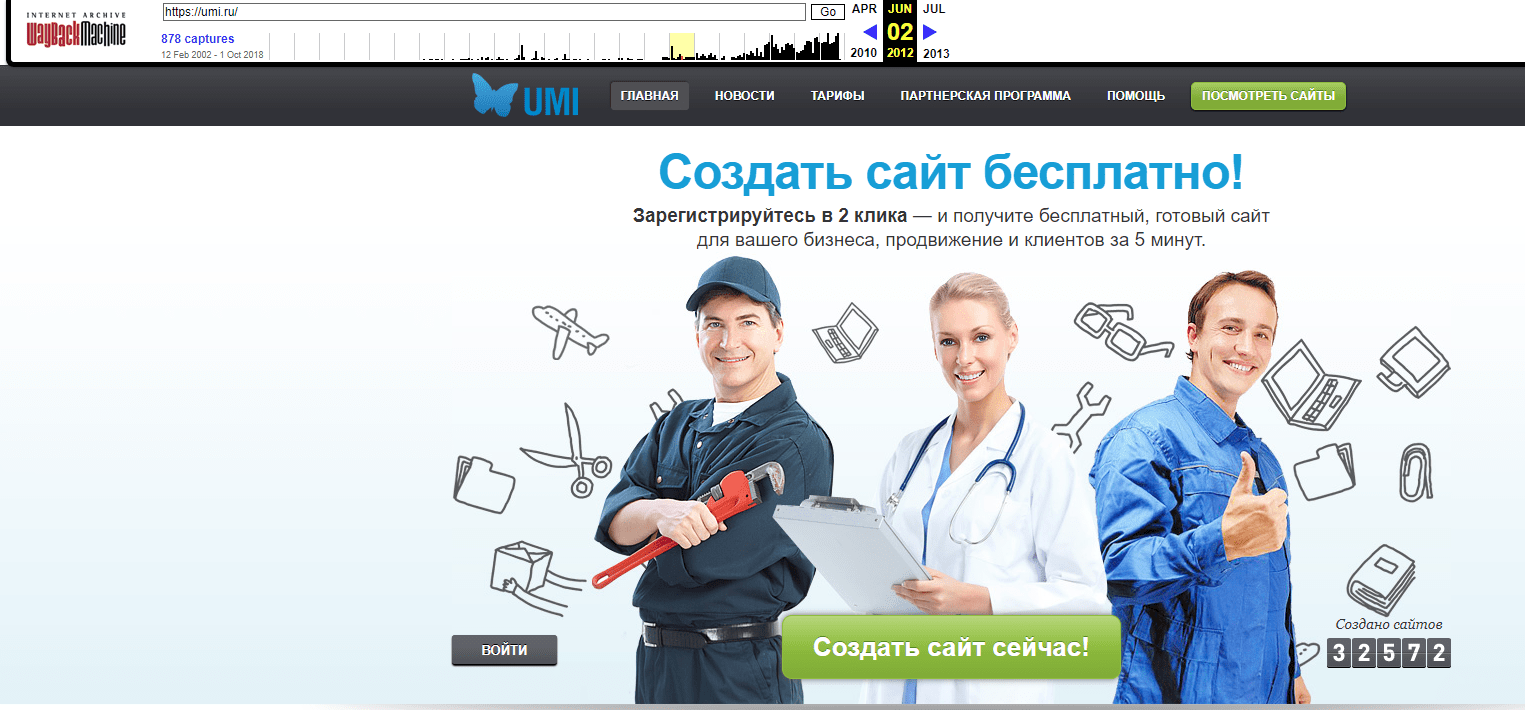
Вот так выглядел наш сайт 1C-UMI летом 2012 года:
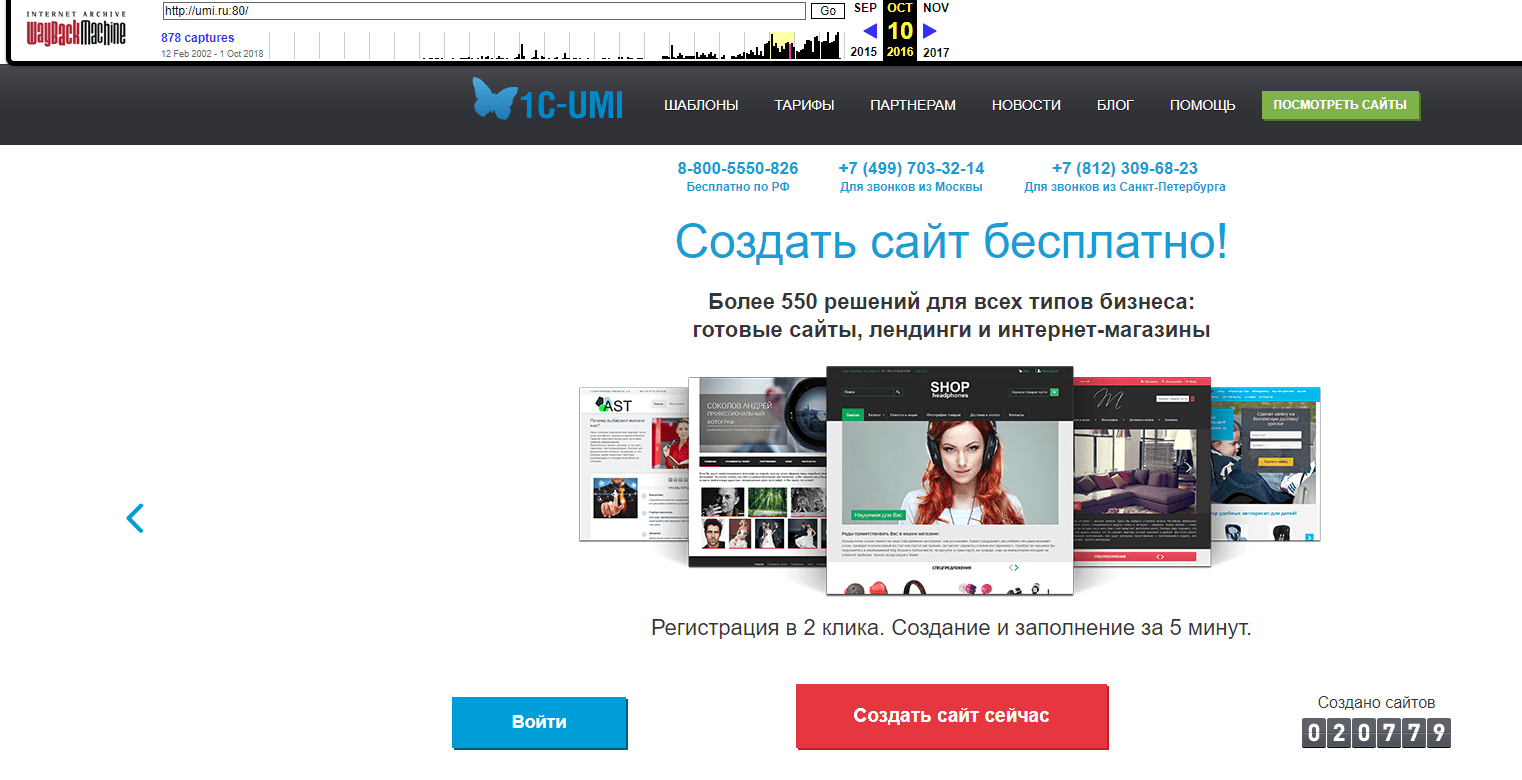
А вот так его видели наши пользователи осенью 2016 года:
Чем дольше ресурс работает, тем больше его снимков будет в WebArhive. Для путешествия в прошлое используйте временную шкалу и блок переключения месяцев и чисел справа от нее.
Самое классное — что данный сервис не делает скриншоты сайтов, а сохраняет их целиком. Таким образом, вы увидите версию 10-летней давности и, все разделы, формы, почитаете тексты, полистаете изображения и многое другое.
Какие сайты попадают в веб-архив
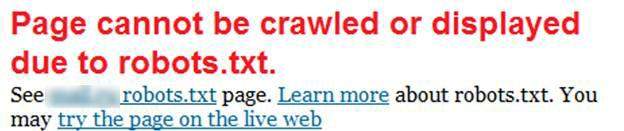
Оказаться в Wayback Machine может любой сайт. Особенно это касается тех веб-ресурсов, которые находятся в каталоге DMOZ. Но так как сейчас туда свое «детище» уже не добавить, будет достаточно того, что на вашу площадку ссылаются сайты, снимки которых уже присутствуют в веб-архиве. А даже если таких ссылок нет, ваш ресурс все равно может попасть в базу сервиса. Главное, чтобы в его файле Robots.txt не было запрета.
Как проверить? Для сайтов на 1С-UMI откройте раздел «Реклама/SEO → Управление robots.txt» в панели управления сайтом и проверьте, нет ли в нем следующей записи:
User-agent: ia_archiver
Disallow: /
Если такой записи (как выше) нет, все хорошо, ваш сайт имеет шанс на попадание в веб-архив. В противном случае, при поиске своего ресурса в сервисе вы увидите надпись, как на скриншоте ниже.
Если вы не хотите ждать, когда сервис соблаговолит сделать снимок вашего сайта, добавьте его в базу WebArchive вручную. Для этого найдите функцию «Save Page Now», которая находится в центральной части страницы справа.
Укажите ссылку на свой ресурс и нажмите на кнопку «SAVE PAGE». Сохранение начнется через несколько секунд и, спустя минуту или около того, будет закончено. За ходом выполнения вы можете наблюдать в небольшом окошке по центру экрана.
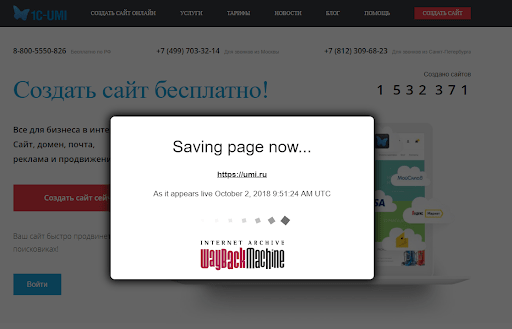
После сохранения снимка страницы начнет загружаться только что архивированная версия сайта.

По окончании процесса окно загрузки закроется, и вы сможете просмотреть сохраненный снимок, побродить по всем разделам сайта и т. д.
Чем будет полезен веб-архив для вас
Данный сервис годится не только для того, чтобы смотреть, в каком состоянии была ваша страничка или любой другой ресурс некоторое время назад. С его помощью вы можете восстановить свой сайт, его страницу, какой-то текст или элемент, если вдруг по какой-то причине данные были стерты. Чтобы этого не произошло, не забывайте почаще выполнять резервное копирование вашего сайта, ну, а на экстренный случай имейте в виду WebArchive. Но имейте в виду также, что WebArchive делает снимки по своему усмотрению с непредсказуемой частотой, поэтому нужной вам версии сайта в нем может и не оказаться.
Вручную восстанавливать ресурс из веб-архива очень долго и для этого нужно неплохо разбираться в сайтостроении и верстке. Однако при желании восстановление можно автоматизировать при помощи онлайн-инструмента ARCHIVARIX.
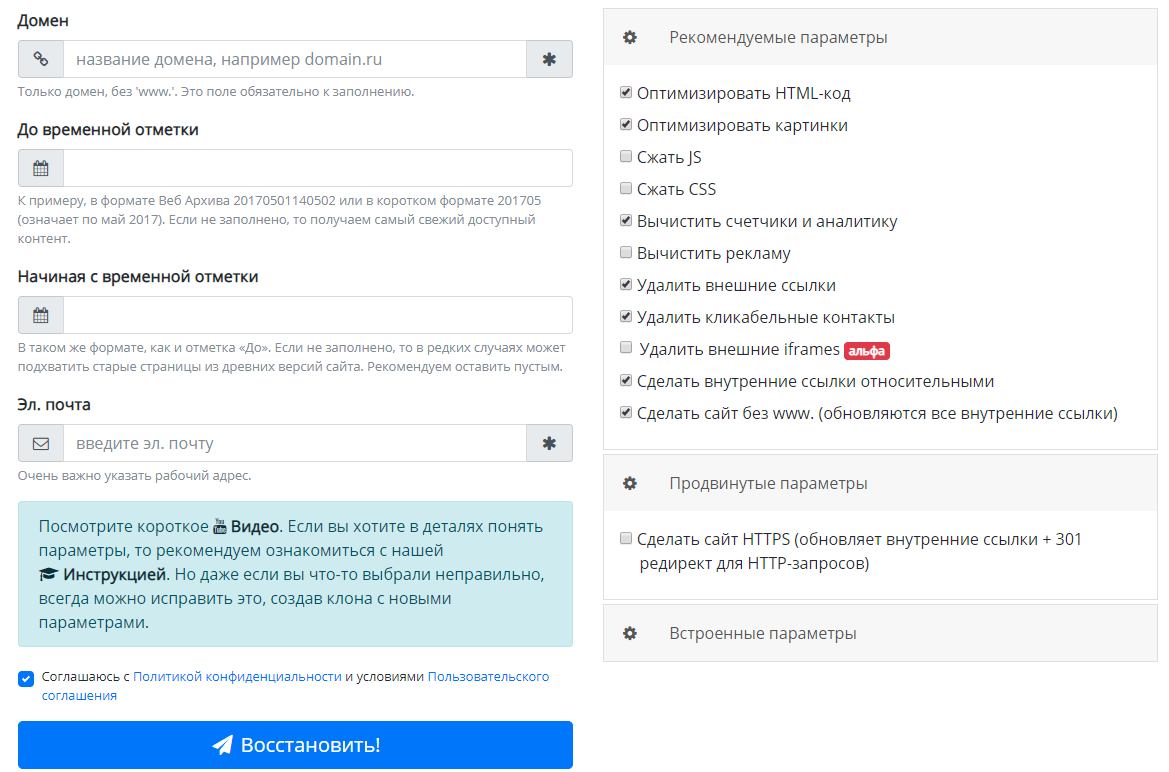
До 200 файлов сервис восстанавливает бесплатно, а при большем количестве взимает небольшую плату.
Веб-архив может быть вам полезен и тем, что он содержит колоссальное количество уникальных текстов, которые опубликованы на канувших в небытие ресурсах. Как это можно использовать с выгодой для своего бизнеса? Допустим, вы запускаете сайт. Сами писать тексты не можете из-за отсутствия времени, а на оплату услуг копирайтера денег нет. Чтобы не откладывать запуск проекта, попробуйте найти уникальный контент в Wayback Machine.
Найдите любой сайт, близкий вашему по тематике, откройте его содержимое, скопируйте тексты и прогоните их через софт или сервис проверки на плагиат. Статьи, которые окажутся уникальными (от 90% и выше), вы можете без зазрения совести опубликовать на своем сайте. Это не будет считаться хищением, так как тексты после удаления ресурсов стали ничейными.
Для поиска таких сайтов можно использовать базы хостинговых компаний. Обычно они публикуют список тех доменов, срок действия которых истек или вот-вот истечет. Существуют и специальные программы, которые ищут освободившиеся домены по нужным параметрам.
Несколько фактов о веб-архиве
Первый запуск сервиса WebArchive состоялся в 1996 году. С тех пор этот инструмент сумел накопить в своей базе более 338 миллиардов сайтов. Представьте, сколько это! А дисковое пространство, которое занято информацией в архиве, составляет 1015 Терабайт. Если перевести на математический язык, то это квадриллион.

На следующий год после основания сервиса WebArchive добавил в свою базу сам себя. Хотите посмотреть, как он выглядел на тот момент? Тогда взгляните на изображение ниже.
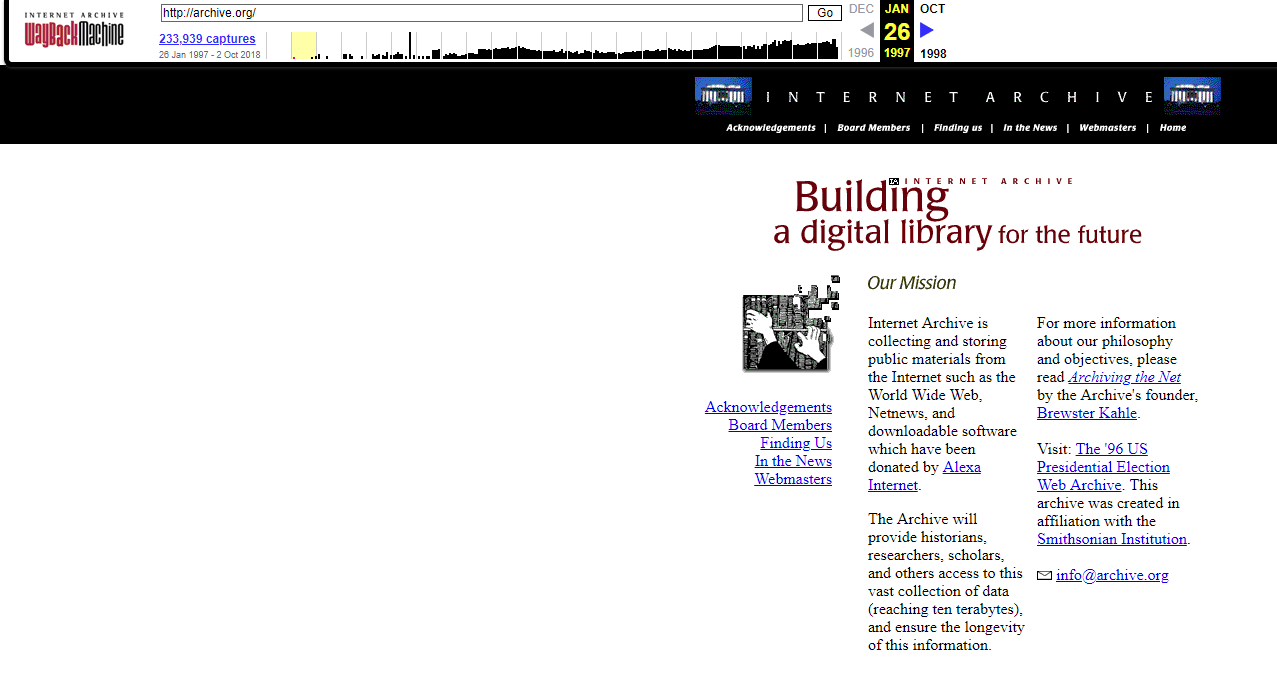
Это самый первый его снимок от 26 января 1997 года.
На данный момент веб-архив считается наилучшим способом из бесплатных для создания снимков интернет-ресурсов. Возьмите его на вооружение.
umi.ru
машина времени в любое место
Доброго дня, уважаемые посетители моего блога. Сегодня я не буду рассказывать о создании сайтов, заработке и других полезных штуках. Я решил немного поразвлечься. Конечно же, это мы будем делать с пользой.
Мы отправимся в прошлое интернета и посмотрим на то, как выглядел дизайн много лет назад. Я научу вас делать это в любое удобное для вас время. С этого момента машина времени будет для вас доступна по первому требованию.

Итак, как посмотреть сайт в прошлом? Сегодня я покажу, а заодно поведаю вам о некоторых интересных фактах из жизни популярных сайтов. Ну что ж, не будем тянуть.
Как смотреть в прошлое
В сожалению, вы не сможете увидеть как выглядел конкретно ваш сайт, но множество популярных ресурсов находится в базе archive.org/web/web.php. По словам самого сервиса, у них сохранилось 500 биллионов страниц.

Просто зайдите на этот портал, введите в поисковую строчку адрес сайта, который хотите увидеть, например Яндекс, и выбирайте Browse History.

Синим цветом на календаре отмечены дни, в которые добавлены скриншоты. Полоса сверху показывает годы. Черные полоски – количество изображений. Чем они выше, тем больше вы можете увидеть. Как вы видите, ближе к нашему времени скриншоты стали добавлять чаще.

Выбираете год, затем дату. Наводите на нее стрелкой, а затем кликаете на время добавления. В данном случае 03:42 или 03:44. Рекомендую последнее действие (с временем) производить через правую кнопку мыши, а в открывшемся меню выбирать «Открыть в новой вкладке». На мой взгляд так удобнее.

И вот перед вами скриншот того, как выглядел Яндекс 12 декабря 1998 года. Эта информация высвечивается в верхнем баре, который можно закрыть при желании. Или, через него же выбирать другую дату. Путешествие во времени осуществляется очень просто. Даже несмотря на то, что «машина» на английском.

Это Яндекс постарше, образец 2000 года.

Так он выглядел в 2005, 11 лет назад.

Ну а так эта поисковая система отображалась в прошлом году. Изменения есть!

Ну вот в принципе и все, но не спешите покидать мой блог. Мне бы хотелось показать вам еще несколько популярных проектов и рассказать интересные факты об этих сайтах.
Изначально, популярнейший поисковик Гугл назывался BackRub. И выглядел как-то стрёмно и совершенно непонятно.

Лишь в 1998 он принял более современный внешний вид. Тогда еще, в конце слова Google стоял восклицательный знак. Представляете, это бета версия, то есть тестовая. Тогда еще разработчики исправляли ошибки и проверяли как все работает. Эх, где мои 16 лет.

Уже тогда здесь было две кнопки. Одна со стандартным поиском, а вторая выбирает случайную страницу с информацией. Если бы администраторы убрали кнопку «Мне повезет», которая пользуется бешенной популярностью и по сей день, то смогли бы получать дополнительный доход с рекламы. Он составил бы примерно 100 миллионов долларов в год. Но, они не жадные.

Кстати о деньгах, компания Mozilla ежегодно получает от гугла 300 миллионов за то, что в их браузере по умолчанию стоит поисковая система от Google.

YouTube
Компания YouTube открылась 14 февраля, в день всех влюбленных. В России же его начали использовать лишь в 2007 году, а первым выложенным роликом стала песня Петра Налича «Гитар». С той поры прошло 10 лет.

Если бы ютуб был не видеохостингом, а кинокомпанией, то каждую неделю они смогли бы выпускать по 60 тысяч фильмов. Материала для этого предостаточно.
Кстати, сейчас у ютуба столько же посетителей, сколько было пользователей в интернете в целом в 2000 году. Ежедневно ролики набирают около 2 миллиарда просмотров.
YouTube не только стал одной из самых популярных компаний, но еще и делает знаменитыми простых людей. Многим россиянам известны такие люди как Макс Голопогосов (+100500), Рома Желудь, BadComedian, mrFreeman. А вот певица Адель и Джастин Бибер получили всемирную славу благодаря этой социальной сети. Я уже молчу о том, сколько людей благодаря ним смогли разбогатеть.
Вконтакте
Чего только не скрывалось под популярным ныне доменом vk.com. Кстати, использовать его стали не сразу, изначально в контакт можно было зайти только по URL: vkontakte.ru, но потом ситуация изменилась и администрация решила облегчить нашу с вами жизнь.

Кстати, само название социальной сети стало производным от фразы, которую Павел Дуров, создатель, постоянно слышал по радио «Эхо Москвы». Она звучала как «В полном контакте с информацией».
Изначально проект был создан как закрытый справочник студентов и выпускников. Об этом свидетельствует надпись на главной странице того периода.

Мог ли тогда представить Павел Дуров, насколько популярным станет его проект? Сейчас даже смешно смотреть на горделивую надпись: «Нас уже 350 000». Сейчас численность проекта насчитывает миллионы.

Интересных историй о этой социальной сети предостаточно, но на мой взгляд самая впечатляющая заключается в том, что вплоть до 2014 года через Одноклассники нельзя было послать ссылку на информацию, находящуюся Вконтакте. Система не блокировала их, а просто заменяла буквы в словах.
Еще один интересный факт, о котором многие пользователи помнят. В какой-то момент администрация сайта решила поменять дизайн личных страниц. Это вызвало бурю эмоций среди пользователей.
И тут и там кипели возгласы: «Верните стену, нет микроблогу». Павел Дуров был не преклонен. В моей памяти эти воспоминания все еще свежи, а тем не менее с той поры прошло 6 лет. Военные действия разворачивались в 2010 году. Согласитесь, сейчас смотришь на этот кошмар и думаешь, что там могло нравиться, за что воевали?

Интересный момент, но благодаря социальным сетям люди не только общаются между собой и зарабатывают, но и достигают других интересных целей. Хоть в свое время дизайн стены не вернули, зато деятельность пользователей на Facebook и Вконтакте вернула в мультсериал «Гриффины» умершего пса Брайна.
Мне очень понравилось, как они потом подшутили над этим фактом. После «воскрешения» в одной из серий они не показали ни единого кадра с псом, а в конце написали какую-то забавную фразу из серии: «Кто-нибудь вообще заметил, что в этой серии не было Брайана? Нам ждать возмущений по этому поводу в социальных сетях?».
Ну и на последок мне бы хотелось порекомендовать вам курс «Из зомби в интернет-предпринимателя». Становитесь популярными и вы, достигайте своих целей.

Если вы переживаете, что ничего не умеете и не знаете, просто посмотрите как изначально выглядел любой сайт, тот же Яндекс. Время решает многое. Мы растем, двигаемся вперед и учимся на своих ошибках.
Подписывайтесь на рассылку и я помогу вам справиться со сложностями. До новых встреч.
start-luck.ru
Как выглядел сайт раньше — пошаговая инструкция, как посмотреть
Как узнать, как сайт выглядел раньше?
Иногда хочется вспомнить те времена, когда по интернетам бродили динозавры, а одна песня загружалась 10 минут. Смотрим в прошлое и ностальгуем, спасибо за это онлайн-сервису: Wayback Machine – Internet Archive. Работает с 1996 года, за это время собрал в базе данных более 279 миллиардов веб-страниц.


Синими кругами на календаре обведены даты резервных копий. Выбираем нужный год, дату и заглядываем в прошлое веб-страницы.
Виртуальный хостинг сайтов для популярных CMS:
Где посмотреть, как выглядели страницы сайтов в разные годы.

Яндекс в это время открыл первый удаленный офис в Питере, запустил Яндекс.пробки и «словари». А майл.ру начали использовать поисковик на своем портале. Через год Яндекс купит разработчика мобильного софта «Смартком» и соц. сеть «Мой круг». Запустит «Календари», блого-сервис Я.ру, портал Яндекс.Mirror и откроет школу анализа данных — бесплатный образовательный курс.

Google запускают календарь, финансы и переводчик. Открывают бесплатный хостинг изображений Picasa и объявляют о покупке YouTube. В 2007 компания установит крупнейшую систему солнечных батарей (Сейчас она обеспечивает энергией 30% офисов) и объявит о появлении Android. А сотрудники начинают ездить по офисам на велосипедах gBikes.

История Facebook уникальна. Только в 2004 году сервис вышел за стены Гарварда, а уже в 2008 вырос так, что количество пользователей перевалило за 50 млн. человек, а состояние Марка Цукерберга уже оценивалось в 1.5 млдр. долларов.
Как раньше выглядел наш сайт.
А вот так менялся наш сайт с 2006 года:

www.ipipe.ru
Как узнать историю сайта? Пошаговая инструкция
Есть ли история у интернет-сайтов? Есть сервисы и инструменты, которые позволяют узнать историю для большинства сайтов.
Как же нам узнать и посмотреть своими глазами историю интересного нам сайта? Ответ вы узнаете из этой статьи.
Интернет – это динамическая среда, в которой все меняется очень быстро. Так, у доменных имен могут меняться их владельцы, обновляться или даже полностью меняться контент сайта, его дизайн, разметка, функциональность. Стоит пустить сайт на самотек – и он уже через пару лет сильно устареет.

Благодаря одному интересному инструменту мы можем узнать историю, отправившись в прошлое, будто бы на машине времени.
Вебархив – www.archive.org
Это интернет-сайт, который индексирует сайты, делает снимки их состояния в разное время и кладет их на свои полки архива, то есть на жесткие диски.
Перейдя по ссылке, мы узнаем его поближе: http://archive.org/web/web.php
Интересно узнать историю Google.com? Это сделать очень просто – заполняем и смотрим:

История поисковика Google уходит своими корнями в далекий по меркам интернета 1998 год. Посмотрим как он выглядел тогда:

Вот такой вид имела поисковая система Google в то время. Посмотрим еще на любимый Яндекс примерно в то же время:

Любой популярный сайт, как правило, архивируется подобным образом, так что любой желающий может пострадать ностальгией и вспомнить, как давным-давно выглядели его любимые сайты.
Разумеется, сохранить всю историю всех сайтов невозможно, но тем не менее, в базе данных веб архива насчитывается более 450 000 000 сайтов. Архив может быть полезен в самых разных случаях и, кроме того, он абсолютно бесплатен!
Если нужно узнать хронологию сайта, то сервис незаменим, так как можно:
1. Определить тематику усиленного имени и сайта
С помощью веб архива мы сможем увидеть контент, который был на сайте этого домена, а значит – распознать тематику ресурса.
2. Узнать историю сайта
Частно начинающие вебмастеры забрасывают свои сайты, недооценивая их потенциал. А опытные веб-мастеры просто охотятся на такие домены с хорошей историей, чтобы создать на них сайты. Одним из инструментов, который они используют для анализа истории и содержания старого сайта является веб архив.
Поэтому не стоит пренебрегать возможностями, которые нам предоставляет веб архив. Ведь применяя этот инструмент, можно извлечь достаточно много полезной информации о сайте, в том числе просмотреть контент старого сайта.
Читайте также:
apanshin.ru
Как узнать историю сайта | SeoProfy.ua
Если вы задумывались о том, есть ли история у сайтов? То она таки есть, и ее можно посмотреть.
Данная статья про то, как посмотреть и узнать историю сайта. Ведь дизайны сайта меняются постоянно, а так же у доменных имен появляются разные владельцы, и облик сайтов меняется.

В интернете существует сайт, который еще называют машина времени, только она работает только для прошлого. С помощью этого сайта мы и сможем узнать историю.
Принцип работы сайта заключается в том, что он индексирует сайты интернета, и сохраняет их в разное время.
Для начала переходим по ссылке: http://archive.org/web/web.php
Вводим адрес, например Google.com, и нажимаем смотреть:

Как мы видим, история для поисковой системы Гугл учитывается с 1998 года, дальше выбираем 1998 год, выбираем доступную дату и смотрим:

Дальше смотрим, как выглядел сайт поискового гиганта в то время.
А так выглядела поисковая система Яндекс в 1998 году:

Таким образом, мы сможем посмотреть любой нас интересующий сайт, особенно если сайт популярный, то его история записывалась постоянно.
В базе сервиса веб архива более 450 миллионов сайтов. Конечно, там не сохранены все сайты, но очень много. Сервис по просмотру истории сайтов абсолютно бесплатный и может пригодиться в разных случаях.
Основные моменты, когда нужно узнать историю сайта:
1. Узнать тематику сайта
С помощью веб архива мы сможем посмотреть содержание, которое было на домене, и узнать тематику ресурса.
2. Посмотреть каким сайт был в разные времена
Как я уже говорил, довольно таки часто люди забрасывают сайты, и многие seo оптимизаторы охотятся на такие домены, что бы сделать на них сайты. С помощью веб архива мы смотрим его содержание, его историю, и решаем, нужен ли нам такой домен.
Если вы хотите посмотреть и узнать историю сайта – используйте веб архив, это довольно таки полезный инструмент.
Помимо сайтов в веб архиве можно смотреть видео, музыку, картинки.
Оцените статью
 Загрузка…
Загрузка…
seoprofy.ua
Архив Интернета или как выглядел любой сайт в прошлом
Вам когда-нибудь хотелось посмотреть, как выглядел любой популярный ресурс в интернете 2-5 лет назад, а может и более? У вас есть такая возможность!
Привет, дорогие друзья!
Сегодня статья будет скорее развлекательная, но не менее познавательная и ценная.
Вам когда-нибудь хотелось посмотреть, как выглядел любой популярный ресурс в интернете 2-5 лет назад, а может и более? У вас есть такая возможность!
Вы можете изучить историю интернет-ресурсов с помощью архива Wayback Machine, который начал работать с 1996 г.
Ссылка на архив сайтов: https://archive.org/web/web.php
Данный архив собирает копии веб-страниц и даже целых сайтов. Архив обеспечивает долгосрочное архивирование собранного материала и бесплатный доступ к своим базам данных для широкой публики.
Содержание веб-страниц фиксируется с временным промежутком c помощью бота. Таким образом, можно посмотреть, как выглядела та или иная страница раньше, даже если она больше не существует.
Конечно, первое, что хочется проверить, это сайт Вконтакте) Просто впишите название сайта в поле и жмите «Take Me Back».

Вот так выглядела главная страница сайта Вконтакте 9 ноября 2006 года:

Для справки: Вконтакте начал работать с 10 октября 2006 года.
А вот так выглядел известный мегамаркет Ozon.ru 19 июня 2000 года:

Для справки: Российский интернет-магазин начал работать с 1998 года.
Остальные сайты, которые вас интересуют, можете проверить уже сами. Инструмент я вам показал. Возможно вы найдете какое-нибудь применение данному сервису.
Оставляйте отзывы к этой статье ниже. Если вы нашли интересный сайт в прошлом – поделитесь с нами ссылкой в комментариях.
Статьи по темеКомментарии
stasbykov.ru