DISTINCT SQL Server — Oracle PL/SQL •MySQL •MariaDB •SQL Server •SQLite
В этом учебном пособии вы узнаете, как использовать DISTINCT в SQL Server (Transact-SQL) с синтаксисом и примерами.
Описание
Оператор DISTINCT SQL Server (Transact-SQL) используется для удаления дубликатов из набора результатов. DISTINCT может использоваться только с операторами SELECT.
Синтаксис
Синтаксис оператора DISTINCT в SQL Server (Transact-SQL):
SELECT DISTINCT expressions
FROM tables
[WHERE conditions];
Параметры или аргументы
expressions — столбцы или вычисления, которые вы хотите получить.
tables — таблицы, из которых вы хотите получить записи. Должна быть хотя бы одна таблица, перечисленная в предложении FROM.
WHERE conditions — необязательный. Условия, которые должны быть выполнены для выбранных записей.
Примечание
- Когда в DISTINCT предусмотрено только одно expressions, запрос возвращает уникальные значения для этого expressions.
- Если в DISTINCT представлено более одного expressions, запрос будет получать уникальные комбинации для указанных expressions.
- В SQL Server оператор DISTINCT не игнорирует значения NULL. Поэтому при использовании DISTINCT в вашем SQL-предложении ваш результирующий набор будет включен NULL в качестве отдельного значения.
Пример с одним выражением
Рассмотрим простейший пример SQL Server DISTINCT. Мы можем использовать SQL Server DISTINCT, чтобы вернуть одно поле, которое удаляет дубликаты из набора результатов.
Например:
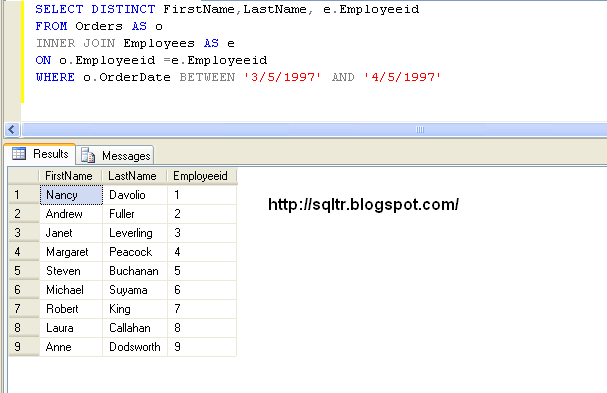
SELECT DISTINCT last_name FROM employees WHERE employee_id >= 90;
SELECT DISTINCT last_name FROM employees WHERE employee_id >= 90; |
Этот пример SQL Server DISTINCT возвращает все уникальные значения last_name из таблицы employees, где employee_id больше или равно 90.
Пример с несколькими выражениями
Рассмотрим, как вы можете использовать SQL Server DISTINCT для удаления дубликатов из нескольких полей в предложении SELECT.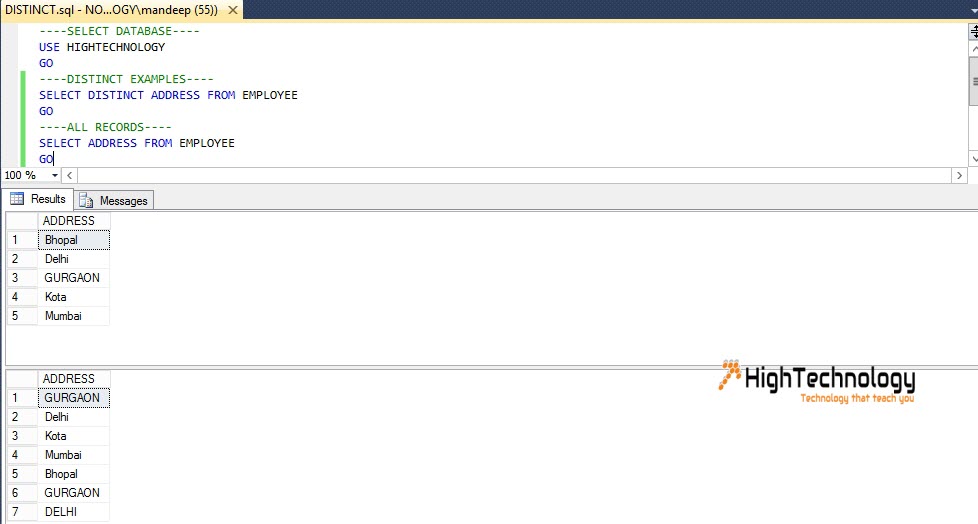
Например:
SELECT DISTINCT first_name, last_name FROM employees WHERE employee_id >=30 ORDER BY last_name;
SELECT DISTINCT first_name, last_name FROM employees WHERE employee_id >=30 ORDER BY last_name; |
Этот пример SQL Server DISTINCT возвращает каждую уникальную комбинацию first_name и last_name из таблицы employees, где employee_id больше или равно 30. Результаты сортируются в порядке возрастания по полю last_name.
В этом случае DISTINCT применяется к каждому полю, указанному после ключевого слова DISTINCT, и, следовательно, возвращает различные комбинации.
Команда IN — выборка по конкретным значениям
Команда IN выбирает записи из базы данных по определенным значениям поля.
К примеру, можно выбрать записи, у которых id имеет значение 1, 3, 7, 14, 28. Это будет выглядеть так: WHERE id IN (1, 3, 7, 14, 28).
Или же
все записи, у которых поле name имеет значение ‘Дима’, ‘Вася’ или ‘Коля’. Это будет выглядеть так: WHERE id IN (‘Дима’, ‘Вася’, ‘Коля’).
Это будет выглядеть так: WHERE id IN (‘Дима’, ‘Вася’, ‘Коля’).
См. также команду NOT, которая делает отрицание (к примеру, так: NOT IN).
См. также команду BETWEEN, которая выбирает записи по диапазону значений.
Синтаксис
SELECT * FROM имя_таблицы WHERE поле IN (значение1, значение2...)Примеры
Все примеры будут по этой таблице workers, если не сказано иное:
| id айди | name имя | age возраст | salary зарплата |
|---|---|---|---|
| 1 | Дима | 23 | 400 |
| 2 | Петя | 25 | 500 |
| 3 | Вася | 23 | 500 |
| 4 | Коля | 30 | 1000 |
| 5 | 27 | 500 | |
| 6 | Кирилл | 28 | 1000 |
Пример
Давайте выберем записи с id, равным 1, 3 и 5:
SELECT * FROM workers WHERE id IN (1, 3, 5)SQL запрос выберет следующие строки:
| id айди | name имя | age возраст | salary зарплата |
|---|---|---|---|
| 1 | Дима | 23 | 400 |
| 3 | Вася | 23 | 500 |
| 5 | Иван | 27 | 500 |
Пример
Давайте выберем записи с именами ‘Дима’, ‘Коля’, ‘Кирилл’:
SELECT * FROM workers WHERE id IN ('Дима', 'Коля', 'Кирилл')SQL запрос выберет следующие строки:
| id айди | name имя | age возраст | salary зарплата |
|---|---|---|---|
| 1 | Дима | 23 | 400 |
| 4 | Коля | 30 | 1000 |
| 6 | Кирилл | 28 | 1000 |
| Ключевые слова | Описание |
|---|---|
| ADD | Добавляет столбец в существующую таблицу |
| ADD CONSTRAINT | Добавляет ограничение после того, как таблица уже создана |
| ALTER | Добавляет, удаляет или изменяет столбцы в таблице, а также изменяет данные тип столбца в таблице |
| ALTER COLUMN | Изменяет тип данных столбца в таблице |
| ALTER TABLE | Добавляет, удаляет или изменяет столбцы в таблице |
| ALL | Возвращает true, если все значения подзапроса соответствуют состояние |
| AND | Включает только строки, где оба условия истинны |
| ANY | Возвращает true, если какое-либо из значений подзапроса соответствует состоянию |
| AS | Переименовывает столбец или таблицу с помощью псевдонима |
| ASC | Сортировка результирующего набора в порядке возрастания |
| BACKUP DATABASE | Создает резервную копию существующей базы данных |
| BETWEEN | Выбор значений в заданном диапазоне |
| CASE | Создает различные выходные данные в зависимости от условий |
| CHECK | Ограничение, ограничивающее значение, которое может быть помещено в колонка |
| COLUMN | Изменяет тип данных столбца или удаляет столбец в таблице |
| CONSTRAINT | Добавляет или удаляет ограничение |
| CREATE | Создает базу данных, индекс, представление, таблицу или процедуру |
| CREATE DATABASE | Создает новую базу данных SQL |
| CREATE INDEX | Создает индекс в таблице (позволяет дублировать значения) |
| CREATE OR REPLACE VIEW | Обновление представления |
| CREATE TABLE | Создает новую таблицу в базе данных |
| CREATE PROCEDURE | Создает хранимую процедуру |
| CREATE UNIQUE INDEX | Создает уникальный индекс в таблице (без повторяющихся значений) |
| CREATE VIEW | Создает представление на основе результирующего набора инструкции SELECT |
| DATABASE | Создает или удаляет базу данных SQL |
| DEFAULT | Ограничение, предоставляющее значение по умолчанию для столбца |
| DELETE | Удаляет строки из таблицы |
| DESC | Сортировка результирующего набора в порядке убывания |
| DISTINCT | Выбирает только отдельные (разные) значения |
| DROP | Удаляет столбец, ограничение, базу данных, индекс, таблицу или представление |
| DROP COLUMN | Удаляет столбец в таблице |
| DROP CONSTRAINT | Удаляет UNIQUE, PRIMARY KEY, FOREIGN KEY, или ограничение CHECK |
| DROP DATABASE | Удаляет существующую базу данных SQL |
| DROP DEFAULT | Удаляет ограничение по умолчанию |
| DROP INDEX | Удаление индекса в таблице |
| DROP TABLE | Удаляет существующую таблицу в базе данных |
| DROP VIEW | Удаление представления |
| EXEC | Выполняет хранимую процедуру |
| EXISTS | Тесты на наличие любой записи в подзапросе |
| FOREIGN KEY | Ограничение, которое является ключом, используемым для связывания двух таблиц вместе |
| FROM | Указывает, из какой таблицы следует выбрать или удалить данные |
| FULL OUTER JOIN | Возвращает все строки при наличии совпадения в левой или правой таблице |
| GROUP BY | Группирует результирующий набор (используется с агрегатными функциями: COUNT, MAX, MIN, SUM, AVG) |
| HAVING | Используется вместо WHERE с агрегатными функциями |
| IN | Позволяет указать несколько значений в предложении WHERE |
| INDEX | Создает или удаляет индекс в таблице |
| INNER JOIN | Возвращает строки, имеющие совпадающие значения в обеих таблицах |
| INSERT INTO | Вставка новых строк в таблицу |
| INSERT INTO SELECT | Копирует данные из одной таблицы в другую |
| IS NULL | Тесты для пустых значений |
| IS NOT NULL | Тесты для непустых значений |
| JOIN | Для объединения таблиц |
| LEFT JOIN | Возвращает все строки из левой таблицы и соответствующие строки из правой таблицы |
| LIKE | Поиск указанного шаблона в столбце |
| LIMIT | Задает количество записей, возвращаемых в результирующем наборе |
| NOT | Включает только строки, в которых условие не является истинным |
| NOT NULL | Ограничение, которое заставляет столбец не принимать нулевые значения |
| OR | Включает строки, в которых выполняется любое из условий |
| ORDER BY | Сортировка результирующего набора в порядке возрастания или убывания |
| OUTER JOIN | Возвращает все строки при наличии совпадения в левой или правой таблице |
| PRIMARY KEY | Ограничение, которое однозначно идентифицирует каждую запись в таблице базы данных |
| PROCEDURE | Хранимая процедура |
| RIGHT JOIN | Возвращает все строки из правой таблицы и соответствующие строки из левой таблицы |
| ROWNUM | Задает количество записей, возвращаемых в результирующем наборе |
| SELECT | Выбор данных из базы данных |
| SELECT DISTINCT | Выбирает только отдельные (разные) значения |
| SELECT INTO | Копирует данные из одной таблицы в новую таблицу |
| SELECT TOP | Задает количество записей, возвращаемых в результирующем наборе |
| SET | Указывает, какие столбцы и значения должны быть обновлены в таблице |
| TABLE | Создает таблицу, добавляет, удаляет или изменяет столбцы в таблице, а также удаляет таблицу или данные внутри таблицы |
| TOP | Задает количество записей, возвращаемых в результирующем наборе |
| TRUNCATE TABLE | Удаляет данные внутри таблицы, но не саму таблицу |
| UNION | Объединяет результирующий набор из двух или более операторов SELECT (только отдельные значения) |
| UNION ALL | Объединяет результирующий набор из двух или более операторов SELECT (позволяет дублировать значения) |
| UNIQUE | Ограничение, обеспечивающее уникальность всех значений в столбце |
| UPDATE | Обновление существующих строк в таблице |
| VALUES | Задает значения инструкции INSERT INTO |
| VIEW | Создает, обновляет или удаляет представление |
| WHERE | Фильтрует результирующий набор для включения только тех записей, которые удовлетворяют заданному условию |
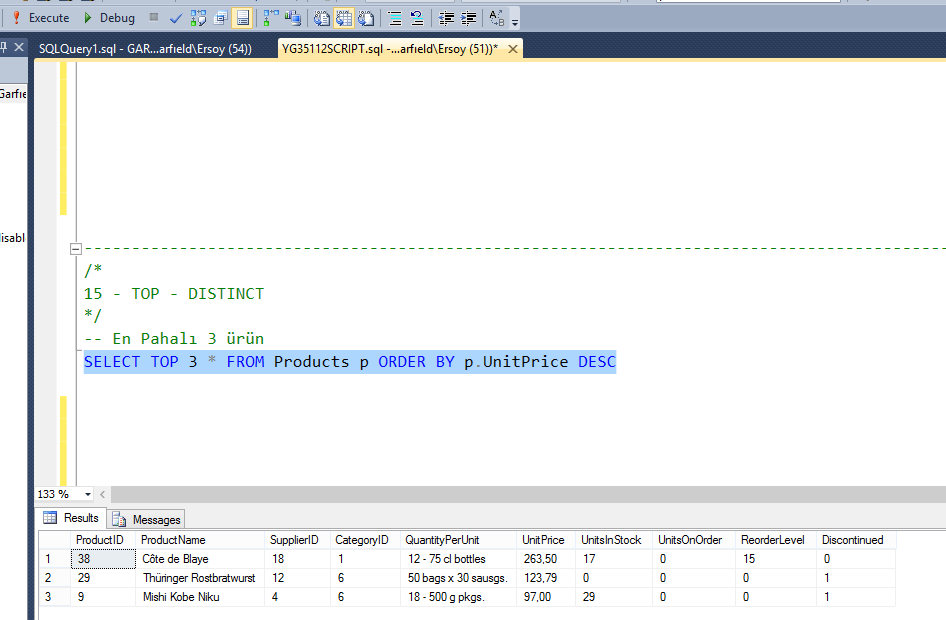
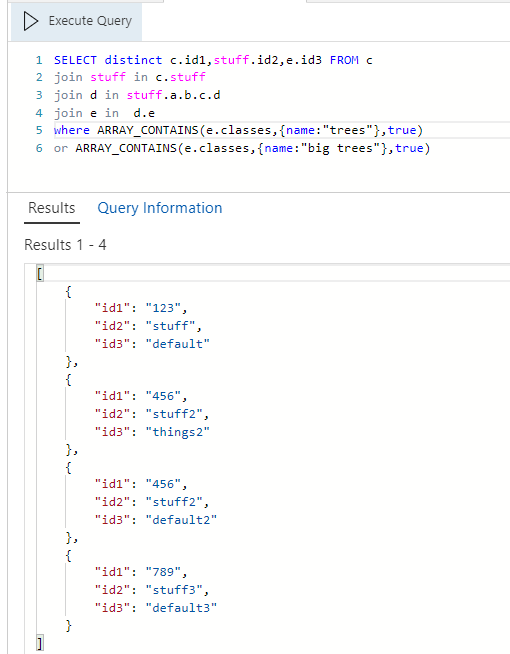
SQL-Урок 11. Выборка уникальных данных (SELECT DISTINCT)
Выборка уникальных данных (SELECT DISTINCT)
Оператор SQL DISTINCT используется для указания на то, что следует работать только с уникальными значениями столбца.
Оператор SQL DISTINCT нашел широкое применение в операторе SQL SELECT, для выборки уникальных значений. Так же используется в агрегатных функциях.
Синтаксис
При выборке:
SELECT DISTINCT поле FROM имя_таблицы WHERE условие
При подсчете:
SELECT COUNT(DISTINCT поле) FROM имя_таблицы WHERE условие
При суммировании:
SELECT SUM(DISTINCT поле) FROM имя_таблицы WHERE условие
Примеры
Все примеры будут по этой таблице workers, если не сказано иное:
| id | name | age | salary |
|---|---|---|---|
| 1 | Дима | 23 | 400 |
| 2 | Петя | 25 | 500 |
| 3 | Вася | 23 | 500 |
| 4 | Коля | 30 | 1000 |
| 5 | Иван | 27 | 500 |
| 6 | Кирилл | 28 | 1000 |
Пример
Давайте выберем все уникальные значения зарплат из таблицы workers:
SELECT DISTINCT salary FROM workers
SQL запрос выберет следующие строки:
Пример
Давайте подсчитаем все уникальные значения зарплат из таблицы workers (их будет 3 штуки: 400, 500 и 1000):
SELECT COUNT(DISTINCT salary) as count FROM workers
SQL запрос выберет следующие строки:
Пример
Давайте подсчитаем одновременно все уникальные значения зарплат и уникальные значения возрастов и запишем их в разные поля:
SELECT COUNT(DISTINCT salary) as salary_count, COUNT(DISTINCT age) as age_count FROM workers
SQL запрос выберет следующие строки:
Пример
Давайте просуммируем все уникальные значения зарплат из таблицы workers:
SELECT SUM(DISTINCT salary) as sum FROM workers
SQL запрос выберет следующие строки:
ВСЕ, DISTINCT, DISTINCTROW, ВЕРХНие предикаты (Microsoft Access SQL)
- Чтение занимает 3 мин
В этой статье
Область применения: Access 2013 | Access 2016Applies to: Access 2013 | Access 2016
Указывает записи, выбранные с запросами SQL.Specifies records selected with SQL queries.
СинтаксисSyntax
ВЫБЕРИТЕ [ALL | DISTINCT | DISTINCTROW | [TOP n [percent]]] ИЗ таблицыSELECT [ALL | DISTINCT | DISTINCTROW | [TOP n [PERCENT]]] FROM table
Инструкция SELECT, содержащая эти предикаты, состоит из следующих частей.A SELECT statement containing these predicates has the following parts.
ALL: предполагается, если не включен один из предикатов.ALL: Assumed if you do not include one of the predicates. Ядро СУБД Microsoft Access выбирает все записи, которые удовлетворяют условиям оператора SQL.
 The Microsoft Access database engine selects all of the records that meet the conditions in the SQL statement.
The Microsoft Access database engine selects all of the records that meet the conditions in the SQL statement.Два приведенных ниже примера эквивалентны и возвращают все записи из таблицы Employees:The following two examples are equivalent and return all records from the Employees table:
SELECT ALL * FROM Employees ORDER BY EmployeeID;SELECT * FROM Employees ORDER BY EmployeeID;DISTINCT: исключает записи, содержащие повторяющиеся данные в выбранных полях.DISTINCT: Omits records that contain duplicate data in the selected fields. Для включения в результаты запроса значения для каждого поля, указанного в операторе SELECT, должны быть уникальными.To be included in the results of the query, the values for each field listed in the SELECT statement must be unique. Например, несколько сотрудников, перечисленных в таблице Employees, могут иметь одно и то же фамилию.For example, several employees listed in an Employees table may have the same last name.
 Если две записи содержат Smith в поле LastName, приведенная ниже инструкция SQL возвращает только одну запись, содержащую Smith:If two records contain Smith in the LastName field, the following SQL statement returns only one record that contains Smith:
Если две записи содержат Smith в поле LastName, приведенная ниже инструкция SQL возвращает только одну запись, содержащую Smith:If two records contain Smith in the LastName field, the following SQL statement returns only one record that contains Smith:SELECT DISTINCT LastName FROM Employees;Если опустить DISTINCT, этот запрос возвращает обе записи Smith.If you omit DISTINCT, this query returns both Smith records. Если предложение SELECT содержит более одного поля, сочетание значений из всех полей должно быть уникальным для включения записи в результаты.If the SELECT clause contains more than one field, the combination of values from all fields must be unique for a given record to be included in the results. Выходные данные запроса, использующего DISTINCT, не обновляются и не отражают последующие изменения, внесенные другими пользователями.The output of a query that uses DISTINCT is not updatable and does not reflect subsequent changes made by other users.

DISTINCTROW: пропускает данные на основе всех повторяющихся записей, а не только на повторяющихся полях.DISTINCTROW: Omits data based on entire duplicate records, not just duplicate fields. Например, вы можете создать запрос, который присоединяет таблицы Customers и Orders в поле CustomerID.For example, you could create a query that joins the Customers and Orders tables on the CustomerID field. Таблица Customers не содержит дублирующихся полей CustomerID, но таблица Orders, так как каждый клиент может иметь много заказов.The Customers table contains no duplicate CustomerID fields, but the Orders table does because each customer can have many orders. Приведенная ниже инструкция SQL показывает, как можно использовать DISTINCTROW для создания списка компаний, у которых есть по крайней мере один заказ, но без дополнительных сведений об этих заказах:The following SQL statement shows how you can use DISTINCTROW to produce a list of companies that have at least one order but without any details about those orders:
SELECT DISTINCTROW CompanyName FROM Customers INNER JOIN Orders ON Customers. CustomerID = Orders.CustomerID
ORDER BY CompanyName;
CustomerID = Orders.CustomerID
ORDER BY CompanyName;
Если опустить DISTINCTROW, этот запрос создает несколько строк для каждой компании, имеющей более одного заказа.If you omit DISTINCTROW, this query produces multiple rows for each company that has more than one order. DISTINCTROW действует только в том случае, если выбраны поля из одних, но не всех таблиц, используемых в запросе.DISTINCTROW has an effect only when you select fields from some, but not all, of the tables used in the query. DISTINCTROW игнорируется, если запрос содержит только одну таблицу или если вы выводите поля из всех таблиц.DISTINCTROW is ignored if your query includes only one table, or if you output fields from all tables.
Top n [percent]: возвращает определенное количество записей, которые попадают в верхнюю или нижнюю часть диапазона, УКАЗАННОГО предложением ORDER BY.TOP n [PERCENT]: Returns a certain number of records that fall at the top or the bottom of a range specified by an ORDER BY clause.
 Предположим, что вы хотите, чтобы имена первых 25 студентов из класса 1994:Suppose you want the names of the top 25 students from the class of 1994:
Предположим, что вы хотите, чтобы имена первых 25 студентов из класса 1994:Suppose you want the names of the top 25 students from the class of 1994:SELECT TOP 25 FirstName, LastName FROM Students WHERE GraduationYear = 1994 ORDER BY GradePointAverage DESC;Если не включить предложение ORDER BY, запрос возвратит произвольный набор из 25 записей из таблицы Students, удовлетворяющих предложению WHERE.If you do not include the ORDER BY clause, the query will return an arbitrary set of 25 records from the Students table that satisfy the WHERE clause. Предикат TOP не выбирает между равными значениями.The TOP predicate does not choose between equal values. В предыдущем примере, если двадцать пятый и двадцать шестой средние значения среднего уровня одинаковы, запрос возвратит 26 записей.In the preceding example, if the twenty-fifth and twenty-sixth highest grade point averages are the same, the query will return 26 records. Вы также можете использовать зарезервированное слово PERCENT, чтобы получить определенный процент записей, которые попадают в верхнюю или нижнюю часть диапазона, указанного предложением ORDER BY.
 You can also use the PERCENT reserved word to return a certain percentage of records that fall at the top or the bottom of a range specified by an ORDER BY clause. Предположим, что вместо 25 лучших студентов вы хотите 10 самых нижних студентов:Suppose that, instead of the top 25 students, you want the bottom 10 percent of the class:
You can also use the PERCENT reserved word to return a certain percentage of records that fall at the top or the bottom of a range specified by an ORDER BY clause. Предположим, что вместо 25 лучших студентов вы хотите 10 самых нижних студентов:Suppose that, instead of the top 25 students, you want the bottom 10 percent of the class:SELECT TOP 10 PERCENT FirstName, LastName FROM Students WHERE GraduationYear = 1994 ORDER BY GradePointAverage ASC;Предикат ASC задает возвращение значений из нижней части.The ASC predicate specifies a return of bottom values. Значение, которое следует за знаком TOP, должно быть целым числом.The value that follows TOP must be an unsigned Integer. TOP не влияет на то, является ли запрос обновляемым.TOP does not affect whether or not the query is updatable.
Таблица: имя таблицы, из которой извлекаются записи.table: The name of the table from which records are retrieved.

ПримерExample
В этом примере создается запрос, который присоединяет таблицы Customers и Orders в поле CustomerID.This example creates a query that joins the Customers and Orders tables on the CustomerID field. Таблица Customers не содержит дублирующихся полей CustomerID, но таблица Orders, так как каждый клиент может иметь много заказов.The Customers table contains no duplicate CustomerID fields, but the Orders table does because each customer can have many orders. С помощью DISTINCTROW создается список компаний, у которых есть по крайней мере один заказ, но без дополнительных сведений об этих заказах.Using DISTINCTROW produces a list of companies that have at least one order but without any details about those orders.
Sub AllDistinctX()
Dim dbs As Database, rst As Recordset
' Modify this line to include the path to Northwind
' on your computer.
Set dbs = OpenDatabase("Northwind.mdb")
' Join the Customers and Orders tables on the
' CustomerID field.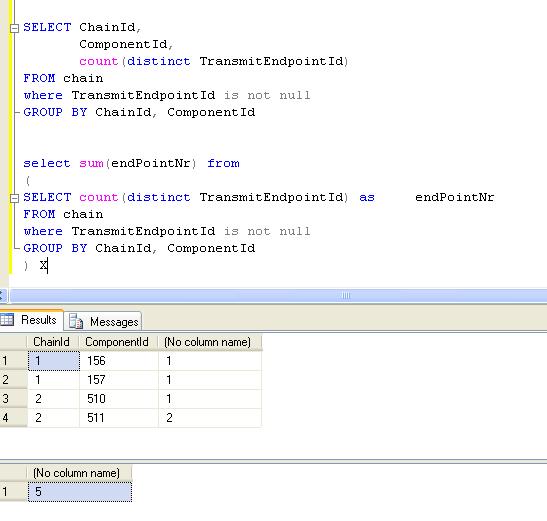 Select a list of companies
' that have at least one order.
Set rst = dbs.OpenRecordset("SELECT DISTINCTROW " _
& "CompanyName FROM Customers " _
& "INNER JOIN Orders " _
& "ON Customers.CustomerID = " _
& "Orders.CustomerID " _
& "ORDER BY CompanyName;")
' Populate the Recordset.
rst.MoveLast
' Call EnumFields to print the contents of the
' Recordset. Pass the Recordset object and desired
' field width.
EnumFields rst, 25
dbs.Close
End Sub
Select a list of companies
' that have at least one order.
Set rst = dbs.OpenRecordset("SELECT DISTINCTROW " _
& "CompanyName FROM Customers " _
& "INNER JOIN Orders " _
& "ON Customers.CustomerID = " _
& "Orders.CustomerID " _
& "ORDER BY CompanyName;")
' Populate the Recordset.
rst.MoveLast
' Call EnumFields to print the contents of the
' Recordset. Pass the Recordset object and desired
' field width.
EnumFields rst, 25
dbs.Close
End Sub
См. такжеSee also
Поддержка и обратная связьSupport and feedback
Есть вопросы или отзывы, касающиеся Office VBA или этой статьи?Have questions or feedback about Office VBA or this documentation? Руководство по другим способам получения поддержки и отправки отзывов см. в статье Поддержка Office VBA и обратная связь.Please see Office VBA support and feedback for guidance about the ways you can receive support and provide feedback.
SQL — ключевое слово Distinct
Ключевое слово DISTINCT используется в сочетании с SELECT, чтобы устранить все дубликаты записей и выборку только уникальных записей.Там может быть ситуация, когда у вас есть несколько дублирующих записей в таблице. Выборка таких записей, имеет смысл, чтобы показать только уникальные записи вместо выборки повторяющихся записей.
Синтаксис
Базовый синтаксис ключевого слова DISTINCT, чтобы устранить дублирующие записи выглядят следующим образом:
SELECT DISTINCT column1, column2,.....columnN FROM table_name WHERE [condition]
Примеры
Рассмотрим таблицу клиентов, имеющих следующие записи:
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Maxim | 35 | Moscow | 21000.00 | | 2 | AndreyEx | 38 | Krasnodar | 55500.00 | | 3 | Oleg | 33 | Rostov | 34000.00 | | 4 | Masha | 35 | Moscow | 34000.00 | | 5 | Ruslan | 34 | Omsk | 45000.00 | | 6 | Dima | 32 | SP | 45000.00 | | 7 | Roma | 34 | SP | 10000.00 | +----+----------+-----+-----------+----------+
Во-первых, давайте посмотрим, как следующий запрос SELECT возвращает повторяющиеся записи заработной платы.
SQL> SELECT SALARY FROM CUSTOMERS ORDER BY SALARY;
Это произведет следующий результат, где зарплата (34000 и 45000) приходит дважды, дублирует записи из исходной таблицы.
+----------+ | SALARY | +----------+ | 21000.00 | | 55000.00 | | 34000.00 | | 34000.00 | | 45000.00 | | 45000.00 | | 10000.00 | +----------+
Теперь, давайте используем ключевое слово DISTINCT с указанным запросом SELECT, а затем увидим результат.
SQL> SELECT DISTINCT SALARY FROM CUSTOMERS ORDER BY SALARY;
Это произведет следующий результат, где у нас нет каких-либо повторяющихся записей.
+----------+ | SALARY | +----------+ | 21000.00 | | 55000.00 | | 34000.00 | | 45000.00 | | 10000.00 | +----------+
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
SQL Server: пункт DISTINCT
В этом руководстве по SQL Server объясняется, как использовать предложение DISTINCT в SQL Server (Transact-SQL) с синтаксисом и примерами.
Описание
Предложение DISTINCT SQL Server (Transact-SQL) используется для удаления дубликатов из набора результатов. Предложение DISTINCT можно использовать только с операторами SELECT.
Синтаксис
Синтаксис предложения DISTINCT в SQL Server (Transact-SQL):
ВЫБРАТЬ РАЗЛИЧНЫЕ выражения ИЗ таблиц [ГДЕ условия];
Параметры или аргументы
- выражений
- Столбцы или вычисления, которые вы хотите получить.
- столов
- Таблицы, из которых вы хотите получить записи. В предложении FROM должна быть хотя бы одна таблица.
- ГДЕ условия
- Необязательно. Условия, которые должны быть выполнены для выбора записей.
Примечание
- Если в предложении DISTINCT указано только одно выражение, запрос вернет уникальные значения для этого выражения.
- Если в предложении DISTINCT указано более одного выражения, запрос будет извлекать уникальные комбинации для перечисленных выражений.
- В SQL Server предложение DISTINCT не игнорирует значения NULL. Поэтому при использовании предложения DISTINCT в вашем операторе SQL ваш набор результатов будет включать NULL как отдельное значение.
Пример — с одним выражением
Давайте посмотрим на простейший пример предложения SQL Server DISTINCT. Мы можем использовать предложение SQL Server DISTINCT, чтобы вернуть одно поле, которое удаляет дубликаты из набора результатов.
Например:
ВЫБРАТЬ DISTINCT last_name ОТ сотрудников ГДЕ employee_id> = 50;
Этот пример SQL Server DISTINCT вернет все уникальные значения last_name из таблицы employee , где employee_id больше или равно 50.
Пример — с несколькими выражениями
Давайте посмотрим, как можно использовать предложение SQL Server DISTINCT для удаления дубликатов из более чем одного поля в операторе SELECT.
Например:
ВЫБРАТЬ DISTINCT имя, фамилия ОТ сотрудников ГДЕ employee_id> = 50 ЗАКАЗАТЬ ПО last_name;
Этот пример предложения SQL Server DISTINCT будет возвращать каждую уникальную комбинацию first_name и last_name из таблицы employee , где employee_id больше или равно 50.Результаты отсортированы в порядке возрастания по last_name .
В этом случае DISTINCT применяется к каждому полю, указанному после ключевого слова DISTINCT, и, следовательно, возвращает различные комбинации.
Устранение дубликатов с помощью оператора SQL DISTINCT
Резюме : в этом руководстве вы узнаете, как использовать оператор SQL DISTINCT для удаления повторяющихся строк в наборе результатов.
Набор результатов оператора SELECT может содержать повторяющиеся строки.Чтобы удалить дубликаты, используйте оператор DISTINCT следующим образом:
SELECT DISTINCT column_1, column2 FROM table; |
Обратите внимание: оператор DISTINCT можно использовать только в операторе SELECT .
Механизм базы данных использует значения столбцов, указанных после оператора DISTINCT , для оценки уникальности строки в наборе результатов.Если вы укажете один столбец, ядро базы данных будет использовать значения в столбце для оценки уникальности. Если вы указываете несколько столбцов, ядро базы данных оценивает уникальность строк на основе комбинации значений в этих столбцах.
Примеры оператора SQL DISTINCT
Давайте рассмотрим несколько примеров использования оператора DISTINCT в операторе SELECT .
SQL DISTINCT, пример одного столбца
Следующий запрос получает город сотрудника в таблице сотрудников :
ВЫБРАТЬ город ИЗ сотрудников |
Набор результатов содержит повторяющийся город i.e., London встречается четыре раза, что указывает на то, что некоторые сотрудники находятся в одном городе.
Чтобы удалить повторяющиеся города, вы можете использовать оператор DISTINCT в виде следующего запроса:
SELECT DISTINCT city FROM сотрудников; |
Пример нескольких столбцов SQL DISTINCT
Чтобы найти список уникальных городов и стран сотрудников, вы можете указать столбцы city и country после оператора DISTINCT в виде следующего запроса:
SELECT DISTINCT город, страна ИЗ сотрудников; |
Комбинация значений в столбцах города и страны используется для определения уникальности строк в наборе результатов.
SQL DISTINCT со значениями NULL
Оператор DISTINCT обрабатывает значения NULL как дублирующие друг друга, поэтому, если оператор SELECT возвращает значения NULL , при использовании возвращается только одно значение NULL оператор DISTINCT .
Давайте посмотрим на следующий пример:
SELECT region FROM сотрудников |
Запрос возвращает повторяющиеся регионы, в результате которых значение NULL появляется 4 раза набор.Давайте применим в запросе оператор DISTINCT следующим образом:
SELECT DISTINCT область ИЗ сотрудников; |
Теперь у нас есть только одно значение NULL , включенное в набор результатов.
SQL DISTINCT с агрегатными функциями
Помимо удаления дубликатов, вы можете использовать оператор DISTINCT в сочетании с агрегатной функцией, например:
- COUNT:
COUNT (столбец DISTINCT)для подсчета различных значений в наборе результатов .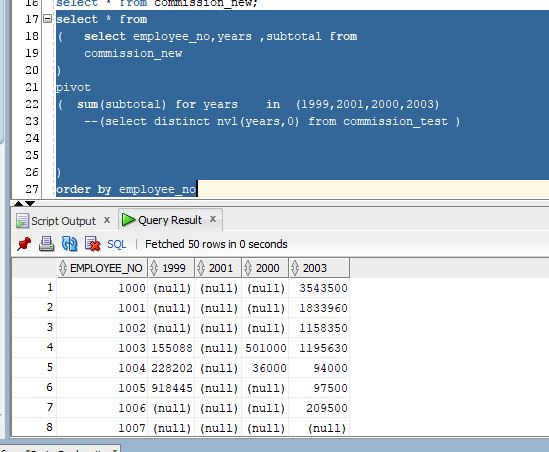
- SUM:
SUM (столбец DISTINCT)для вычисления суммы различных значений.
Например, чтобы подсчитать отдельные города сотрудников, вы используете оператор DISTINCT с функцией COUNT в качестве следующего запроса:
SELECT COUNT (DISTINCT city) FROM сотрудников; |
Для вычисления суммы отдельных цен за единицу продуктов в таблице продукты используйте оператор DISTINCT с функцией SUM следующим образом:
SELECT SUM ( DISTINCT unitprice) ИЗ товаров; |
DISTINCT vs.ALL
В этом руководстве стоит упомянуть оператор ALL . В отличие от оператора DISTINCT , оператор ALL используется для включения всех строк, содержащих повторяющиеся строки, в набор результатов. Следующие запросы возвращают тот же набор результатов.
Следующие запросы возвращают тот же набор результатов.
ВЫБРАТЬ ВСЕ column_1, column_2 FROM table; |
ВЫБРАТЬ столбец_1, столбец_2 ИЗ таблица; |
Оператор SELECT по умолчанию использует оператор ALL , поэтому вам не нужно явно указывать его в операторе.
В этом руководстве мы показали вам, как использовать оператор DISTINCT в операторе SELECT для удаления повторяющихся строк в наборе результатов.
- Было ли это руководство полезным?
- Да Нет
SQL SELECT DISTINCT Заявление
Чайтанья Сингх | Файл: SQL
SELECT DISTINCT Оператор используется для выборки уникальных записей из таблицы. Он возвращает только отдельные значения в результате.
Допустим, у нас есть таблица «Сотрудник», имеющая поле «Отделение сотрудника».Поскольку в каждом отделе может быть несколько сотрудников, это поле таблицы будет иметь повторяющиеся значения. Предположим, мы хотим получить только названия отделов из этой таблицы. В этом случае было бы разумно использовать ключевое слово DISTINCT, так как мы не хотим иметь кучу повторяющихся значений.
Есть несколько случаев, когда ключевое слово DISTINCT может быть очень полезным. Чтобы лучше понять, давайте посмотрим синтаксис и пример оператора SQL SELECT DISTINCT.
SELECT DISTINCT Синтаксис
ВЫБРАТЬ DISTINCT имя_столбца1, имя_столбца2 ,... ОТ TableName;
SELECT DISTINCT Пример
У нас есть таблица STUDENT со следующими записями:
+ --------- + ---------- + ----- + ----------- + --------- - + | ROLL_NO | ИМЯ | ВОЗРАСТ | ФИЛИАЛ | ГОРОД | + --------- + ---------- + ----- + ----------- + ---------- + | 10001 | Кейт | 22 | CSE | Мумбаи | | 10002 | Ричард | 21 | ЕЭК | Дели | | 10003 | Рик | 33 | ME | Ченнаи | | 10004 | Питер | 26 | CSE | Дели | | 10005 | Стив | 22 | CSE | Нойда | | 10006 | Марк | 22 | ЕЭК | Джайпур | | 10007 | Брэд | 23 | ME | Рампур | + --------- + ---------- + ----- + ----------- + ---------- +
Получить уникальные «Ветви» из таблицы СТУДЕНТ —
ВЫБРАТЬ ОТЛИЧИТЕЛЬНОЕ ОТДЕЛЕНИЕ У СТУДЕНТА;
Результат:
+ ---------- + | ФИЛИАЛ | + ---------- + | CSE | | ЕЭК | | ME | + ---------- +
Допустим, вы хотите отсортировать результат.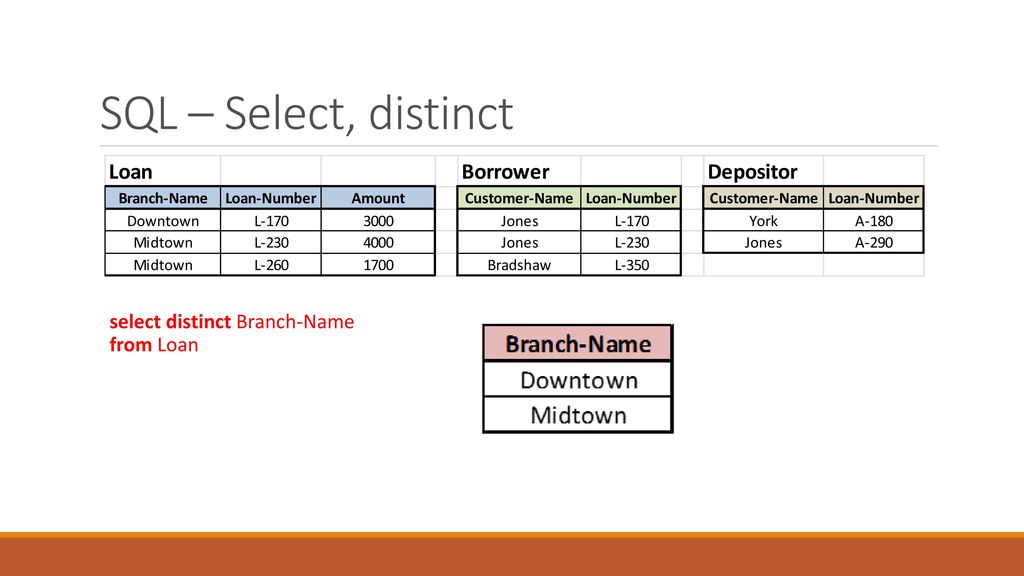 Вы можете сделать это, используя предложение Order by (мы обсуждали предложение ORDER BY в отдельном руководстве) вместе с Distinct —
Вы можете сделать это, используя предложение Order by (мы обсуждали предложение ORDER BY в отдельном руководстве) вместе с Distinct —
ВЫБРАТЬ ОТЛИЧИТЕЛЬНОЕ ОТДЕЛЕНИЕ У СТУДЕНТА
ЗАКАЗ ОТ ФИЛИАЛОВ ПО УДАЛЕНИЮ; Результат:
+ ---------- + | ФИЛИАЛ | + ---------- + | ME | | ЕЭК | | CSE | + ---------- +
ВЫБРАТЬ РАЗЛИЧНЫЕ несколько столбцов
В приведенном выше примере мы получили данные только одного столбца из таблицы.Давайте посмотрим, что произойдет, когда мы используем оператор SELECT DISTINCT с несколькими столбцами —
Рассмотрим эту таблицу ЗАКАЗА:
CUSTOMER_NAME BILL_AMOUNT ORD_NUM ---------- ----------- ------- Рик 2000 1901 Рик 2000 1902 Рик 3000 1903 Рик 3000 1904 Рик 4500 1905 Стив 2000 1906
Заявление SQL:
ВЫБЕРИТЕ DISTINCT CUSTOMER_NAME, BILL_AMOUNT ОТ ЗАКАЗА;
Вывод:
Когда мы выбираем несколько столбцов с помощью оператора SELECT DISTINCT, данные этих столбцов вместе обрабатываются как отдельное значение. Как вы можете видеть в этом примере, строки Rick 2000 и Rick 3000 несколько раз присутствовали в таблице ORDER, поэтому, когда мы DISTINCT выбираем эти строки на основе этих столбцов, мы получили эти строки только один раз в выводе.
Как вы можете видеть в этом примере, строки Rick 2000 и Rick 3000 несколько раз присутствовали в таблице ORDER, поэтому, когда мы DISTINCT выбираем эти строки на основе этих столбцов, мы получили эти строки только один раз в выводе.
CUSTOMER_NAME BILL_AMOUNT ---------- ----------- Рик 2000 Рик 3000 Рик 4500 Стив 2000
Использование MySQL DISTINCT для исключения дубликатов
Резюме : в этом руководстве вы узнаете, как использовать предложение MySQL DISTINCT в операторе SELECT для устранения повторяющихся строк в наборе результатов.
Введение в MySQL DISTINCT clause
При запросе данных из таблицы вы можете получить повторяющиеся строки. Чтобы удалить эти повторяющиеся строки, используйте предложение DISTINCT в инструкции SELECT .
Вот синтаксис предложения DISTINCT :
SELECT DISTINCT select_list ИЗ table_name;
MySQL DISTINCT примеры
Давайте взглянем на простой пример использования предложения DISTINCT для выбора уникальных фамилий сотрудников из таблицы сотрудников .
Сначала запросите фамилии сотрудников из таблицы сотрудников , используя следующий оператор SELECT :
SELECT фамилия ИЗ сотрудники СОРТИРОВАТЬ ПО фамилия;
Попробовать
Как ясно видно из выходных данных, у некоторых сотрудников одинаковая фамилия, например, Bondur, Firrelli .
Этот оператор использует предложение DISTINCT для выбора уникальных фамилий из таблицы сотрудников :
SELECT ОТЛИЧИТЕЛЬНАЯ фамилия ИЗ сотрудники СОРТИРОВАТЬ ПО фамилия;
Попробовать
Как видно из выходных данных, повторяющиеся фамилии были удалены из набора результатов.
MySQL DISTINCT и NULL Значения
Если столбец имеет значения NULL и вы используете предложение DISTINCT для этого столбца, MySQL сохраняет только одно значение NULL , потому что DISTINCT обрабатывает все значения NULL как то же значение.
Например, в таблице клиентов у нас есть много строк, в которых столбец состояния имеет значений NULL .
При использовании предложения DISTINCT для запроса состояний клиентов вы увидите уникальные состояния и NULL в виде следующего запроса:
SELECT DISTINCT state ОТ клиентов;
Попробовать
MySQL DISTINCT с несколькими столбцами
Вы можете использовать предложение DISTINCT с несколькими столбцами.В этом случае MySQL использует комбинацию значений в этих столбцах для определения уникальности строки в наборе результатов.
Например, чтобы получить уникальную комбинацию города и штата из таблицы клиентов , вы используете следующий запрос:
SELECT DISTINCT город-государство ИЗ клиенты ГДЕ состояние НЕ ПУСТО СОРТИРОВАТЬ ПО штат, город;
Попробовать
Без предложения DISTINCT вы получите повторяющуюся комбинацию штата и города следующим образом:
SELECT город-государство ИЗ клиенты ГДЕ состояние НЕ ПУСТО СОРТИРОВАТЬ ПО штат , город;
Попробовать
Предложение DISTINCT vs.
Предложение GROUP BY
Если вы используете предложение GROUP BY в инструкции SELECT без использования агрегатных функций, предложение GROUP BY ведет себя так же, как предложение DISTINCT .
Следующий оператор использует предложение GROUP BY для выбора уникальных состояний клиентов из таблицы клиентов .
ВЫБРАТЬ штат ИЗ клиенты GROUP BY состояние;
Попробовать
Вы можете получить аналогичный результат, используя предложение DISTINCT :
SELECT DISTINCT штат ИЗ клиенты;
Попробовать
Вообще говоря, предложение DISTINCT является частным случаем предложения GROUP BY .Разница между предложением DISTINCT и предложением GROUP BY состоит в том, что предложение GROUP BY сортирует набор результатов, а предложение DISTINCT — нет.
Обратите внимание, что MySQL 8.0 удалил неявную сортировку для предложения GROUP BY . Поэтому, если вы используете MySQL 8.0+, вы обнаружите, что набор результатов вышеуказанного запроса с предложением GROUP BY не отсортирован.
Если вы добавите предложение ORDER BY к оператору, в котором используется предложение DISTINCT , набор результатов будет отсортирован и будет таким же, как тот, который возвращается оператором, использующим предложение GROUP BY .
ВЫБРАТЬ ОТЛИЧИТЕЛЬНЫЙ штат ИЗ клиенты СОРТИРОВАТЬ ПО штат;
Попробовать
MySQL DISTINCT и агрегатные функции
Вы можете использовать предложение DISTINCT с агрегатной функцией, например SUM, AVG и COUNT, чтобы удалить повторяющиеся строки перед применением агрегатных функций к набор результатов.
Например, для подсчета уникальных состояний клиентов в США вы используете следующий запрос:
SELECT СЧЁТ (ОТЛИЧНОЕ состояние) ИЗ клиенты ГДЕ country = 'США';
Попробовать
MySQL DISTINCT с предложением LIMIT
Если вы используете предложение DISTINCT с предложением LIMIT , MySQL немедленно прекращает поиск, когда находит количество уникальных строк, указанное в пункт LIMIT .
Следующий запрос выбирает первые пять непустых уникальных состояний в таблице клиентов .
ВЫБРАТЬ ОТЛИЧИТЕЛЬНЫЙ штат ИЗ клиенты ГДЕ состояние НЕ ПУСТО LIMIT 5;
Попробовать
В этом руководстве мы показали вам различные способы использования предложения MySQL DISTINCT , например, удаление повторяющихся строк и подсчет значений, отличных от NULL.
- Было ли это руководство полезным?
- Да Нет
7 примеров, объясняющих SQL SELECT DISTINCT (MySQL и SQL Server)
Ваша таблица может содержать повторяющиеся значения в столбце, и в определенных сценариях вам может потребоваться выборка только уникальных записей из таблицы.
Чтобы удалить повторяющиеся записи для данных, полученных с помощью оператора SELECT, вы можете использовать предложение DISTINCT, как показано в примерах ниже.
Демонстрация простого SELECT — DISTINCT
В первом примере я использовал предложение DISTINCT с оператором SELECT, чтобы получить только уникальные имена из нашей демонстрационной таблицы, sto_emp_salary_paid . В этой таблице хранятся зарплаты сотрудников вместе с их именами. Таким образом, повторение имен сотрудников происходит в таблице.
В этой таблице хранятся зарплаты сотрудников вместе с их именами. Таким образом, повторение имен сотрудников происходит в таблице.
Используя предложение DISTINCT, мы получаем только уникальные имена сотрудников:
Запрос:
ВЫБРАТЬ DISTINCT (emp_name) FROM sto_emp_salary_paid;
(применимо к базам данных SQL Server и MySQL)
Использование предложения WHERE с DISTINCT
В этом примере я использовал предложение WHERE с оператором SELECT / DISTINCT, чтобы получить только тех уникальных сотрудников, которым выплаченная зарплата больше или равна 4500.См. Запрос и набор результатов:
Запрос:
ВЫБЕРИТЕ DISTINCT (emp_name) FROM sto_emp_salary_paid WHERE emp_sal_paid> = 4500; |
Пример функции COUNT с DISTINCT
Вы также можете использовать функцию COUNT SQL для получения количества записей, используя предложение DISTINCT.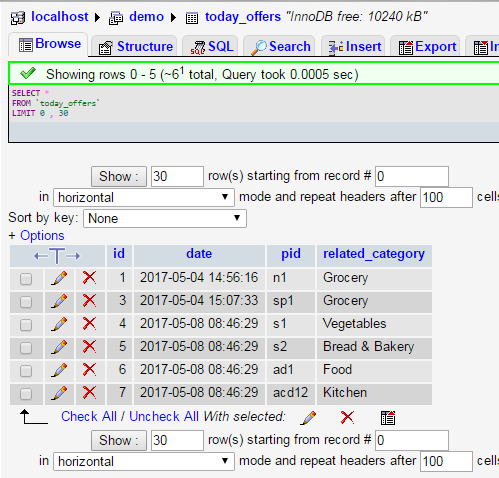 Функция возвращает только количество строк, возвращенных после предложения DISTINCT.
Функция возвращает только количество строк, возвращенных после предложения DISTINCT.
Для демонстрации я использую таблицу сотрудников, в которой хранится информация о сотрудниках. В демонстрации используются следующие три запроса:
- Первый запрос возвращает полную запись из таблицы
- Второй запрос получает количество сотрудников по идентификатору (COUNT и DISTINCT)
- В то время как третий возвращает уникальные имена сотрудников с использованием столбца emp_name .
Три запроса:
ВЫБРАТЬ * ИЗ sto_employees; SELECT COUNT (DISTINCT id) AS «Всего сотрудников» FROM sto_employees SELECT COUNT (DISTINCT emp_name) AS «Уникальные имена сотрудников» FROM sto_employees |
Предложение DISTINCT с примером GROUP BY
Следующий запрос извлекает записи из той же таблицы, что и в приведенных выше примерах, и группирует зарплату сотрудников. Для этого предложения GROUP BY и DISTINCT используются следующим образом:
Для этого предложения GROUP BY и DISTINCT используются следующим образом:
Запрос:
ВЫБЕРИТЕ DISTINCT (emp_name), emp_id, SUM (emp_sal_paid) как «Всего выплачено» FROM sto_emp_salary_paid ГРУППА ПО emp_name, emp_id; |
Рекорд для «Джимми» появляется дважды, так как имеет два разных идентификатора.
Использование предложения HAVING с DISTINCT
Как и при использовании предложения GROUP BY с DISTINCT, вы также можете добавить предложение HAVING для выборки записей.В следующем запросе в приведенном выше примере добавлено предложение HAVING, и мы получим записи, сумма которых превышает 5000.
Запрос:
ВЫБЕРИТЕ DISTINCT (emp_name), emp_id, SUM (emp_sal_paid) Как «Всего выплачено» FROM sto_emp_salary_paid ГРУППА ПО emp_name, emp_id HAVING SUM (emp_sal_paid)> |
Предложение DISTINCT с ORDER BY, пример
Предложение SQL ORDER BY можно использовать с предложением DISTINCT для сортировки результатов после удаления повторяющихся значений. См. Запрос и вывод ниже:
См. Запрос и вывод ниже:
ВЫБРАТЬ DISTINCT (emp_name) FROM sto_emp_salary_paid ORDER BY emp_name; |
Результат:
Использование нескольких столбцов в предложении DISTINCT
Вы также можете указать два или более столбца, используя предложение SELECT — DISTINCT. Таким образом, наша таблица в качестве примера содержит повторяющиеся значения для сотрудников и их идентификаторов, поэтому было бы неплохо узнать, как предложение DISTINCT возвращает записи при использовании обоих этих столбцов в одном запросе.
Чтобы увидеть разницу, я сначала написал запрос с DISTINCT (emp_name), за которым следуют оба столбца:
Запрос:
ВЫБРАТЬ DISTINCT emp_name FROM sto_emp_salary_paid ЗАКАЗАТЬ ПО emp_name; ВЫБРАТЬ DISTINCT emp_name, emp_id FROM sto_emp_salary_paid ЗАКАЗАТЬ ПО emp_name; |
Результаты для полной таблицы, запросов DISTINCT emp_name и DISTINCT emp_name, emp_id:
IS DISTINCT FROM — оператор сравнения, который рассматривает два значения NULL как одно и то же.
В SQL null не равно ( = ) чему-либо — даже другому null .Согласно трехзначной логике SQL, результат null = null будет не истинным , а неизвестным . SQL имеет предикат is [not] null для проверки, является ли конкретное значение null .
С [не] отличным от SQL также предоставляет оператор сравнения, который обрабатывает два значения null как одно и то же.
<выражение> НЕ ОТЛИЧИТСЯ ОТ <выражения> Обратите внимание, что вам нужно использовать инвертированную форму с , а не , чтобы прийти к логике, аналогичной оператору равенства ( = ).
Следующая таблица истинности подчеркивает различия между знаком равенства ( = ) и не отличается от .
A | B | A = B | A НЕ ОТЛИЧАЕТСЯ ОТ B |
|---|---|---|---|
0 | 0 | true | true|
0 | 1 | ложно | ложно |
0 | null | неизвестно | ложно |
null | null | unknown | true |
Результат с равно ( = ) равен unknown , если один оператор null .
не отличается от . Сравнение: истинно , если оба значения null или false , если только одно из них null .
Соответствующие альтернативы
Примечание
Хотя существуют стандартные альтернативы , которые не отличаются от , использование проприетарной альтернативы часто является лучшим выбором.
Из-за трехзначной логики SQL полностью эквивалентная замена для A не отличается от B , которая работает во всех базах данных SQL, на удивление сложна — даже если мы ограничиваем требование случаями, когда вычисление выражений A и B детерминирован и не имеет побочных эффектов.
СЛУЧАЙ, КОГДА (a = b) или (a IS NULL AND b IS NULL)
ТО 0
ЕЩЕ 1
END = 0 Результат выражения в предложении when равен true , если оба аргумента равны или оба имеют значение null .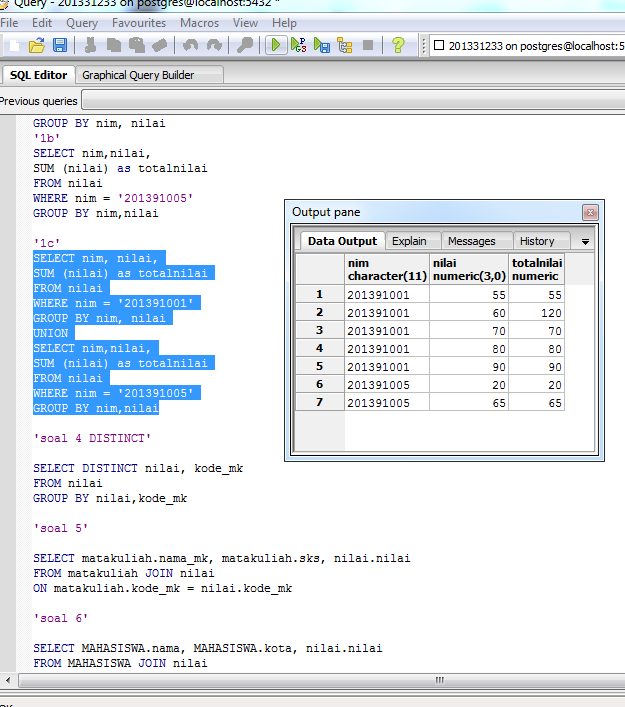 Если только один аргумент —
Если только один аргумент — null , результатом будет unknown , а не false . Часто это не проблема, потому что SQL обычно обрабатывает unknown как false при принятии бинарных решений, таких как принятие или отклонение строки для предложения where .
Чтобы получить полностью эквивалентную функциональность, не отличается от — т.е. либо истинно , либо ложно , но никогда не неизвестно — выражение case сокращает трехзначный результат до двух двузначного. В некоторых базах данных не является ложным может использоваться вместо выражения case . Этот метод объясняется в « Бинарные решения, основанные на трехзначных результатах ».
Другой вариант — использовать операторы таблиц, которые используют отдельные сравнения внутри.В следующем фрагменте кода пересекается с для определения общего подмножества. Два сравниваемых набора представляют собой только одно значение каждый (одна строка с одним столбцом). Если это дважды одно и то же значение, то это значение будет общим подмножеством. В противном случае общее подмножество будет пустым. Эту логику можно легко проверить в
Два сравниваемых набора представляют собой только одно значение каждый (одна строка с одним столбцом). Если это дважды одно и то же значение, то это значение будет общим подмножеством. В противном случае общее подмножество будет пустым. Эту логику можно легко проверить в , где существует предложение с предикатом :
СУЩЕСТВУЕТ (ЗНАЧЕНИЯ (A)
ПЕРЕСЕЧЕНИЕ
ЗНАЧЕНИЯ (B)
) Это имеет то преимущество, что не повторяет никаких выражений.К сожалению, он не работает со всеми базами данных из-за использования предложения values . Выбор из однострочной фиктивной таблицы может использоваться для получения соответствующего и широко поддерживаемого решения.
Совместимость
Предикат [не] отличен от был введен в два этапа: SQL: 1999 добавил T151, «предикат DISTINCT». Необязательное отрицание с , а не с было добавлено SQL: 2003 как функция T152, «Предикат DISTINCT с отрицанием».
Собственные альтернативы
Большинство баз данных, которые не предлагают , неотличимы от , предлагают частную альтернативу, которая более удобна, чем соответствующая альтернатива, описанная выше.Следующие фирменные функции полностью совместимы, т. Е. они имеют двузначный результат и никогда не возвращают неизвестно .
Существует , выберите без из , пересекается
Стандартное решение с использованием существует , значения и пересекаются можно легко изменить для работы с большим количеством баз данных, используя выберите без из вместо значений Предложение :
СУЩЕСТВУЕТ (SELECT c1
ПЕРЕСЕЧЕНИЕ
ВЫБРАТЬ c2
) decode — Db2, Oracle, h3
Db2, база данных Oracle и h3 имеют проприетарную функцию decode , которая использует , внутренне не отличается от семантики .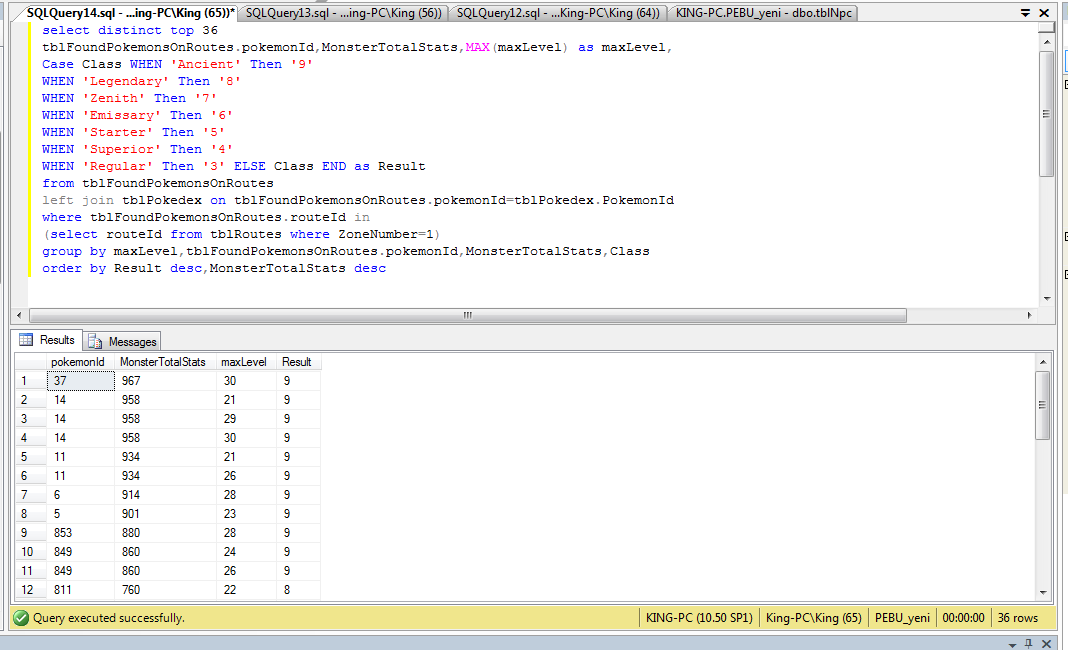 Следующий пример имеет тот же эффект, что и
Следующий пример имеет тот же эффект, что и A не отличается от B :
DECODE (A, B, 0, 1) = 0 is — SQLite, h3
Оператор is SQLite (документация) и h3 (документация) могут сравнивать два выражения (не только is [not] null ), и он имеет ту же семантику, что и не отличается от .
<=> — MySQL, MariaDB
MySQL предлагает собственный оператор сравнения <=> , который работает так, как будто не отличается от .
ANSI_NULLS — SQL Server
Устаревший параметр ANSI_NULLS в SQL Server заставляет некоторое сравнение на равные ( = ) действовать так, как если бы это было , не отличное от сравнения .
Предупреждение
ANSI_NULLS OFF не рекомендуется: его использование может вызвать ошибки в будущих версиях SQL Server.
Также обратите внимание, что это влияет не на все знаки равенства, а только на те, где одна сторона сравнения является переменной или литералом null .