Linux, DevOps и системное администрирование
DevOops
Operating systems
main()
Scripting/coding
Самое читаемое
Архив месяца
| Пн | Вт | Ср | Чт | Пт | Сб | Вс |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | ||
Архивы по годам
Архивы по годам Выберите месяц Апрель 2021 (4) Март 2021 (8) Февраль 2021 (6) Январь 2021 (1) Декабрь 2020 (1) Ноябрь 2020 (9) Октябрь 2020 (9) Сентябрь 2020 (4) Август 2020 (8) Июль 2020 (4) Июнь 2020 (3) Май 2020 (5) Апрель 2020 (9) Март 2020 (8) Февраль 2020 (9) Январь 2020 (2) Декабрь 2019 (9) Ноябрь 2019 (9) Октябрь 2019 (11) Сентябрь 2019 (11) Август 2019 (10) Июль 2019 (2) Июнь 2019 (4) Май 2019 (9) Апрель 2019 (13) Март 2019 (32) Февраль 2019 (20) Январь 2019 (10) Декабрь 2018 (9) Ноябрь 2018 (12) Октябрь 2018 (15) Сентябрь 2018 (12) Август 2018 (14) Июль 2018 (17) Июнь 2018 (18) Май 2018 (21) Апрель 2018 (6) Март 2018 (18) Февраль 2018 (7) Январь 2018 (13) Декабрь 2017 (14) Ноябрь 2017 (6) Октябрь 2017 (24) Сентябрь 2017 (13) Август 2017 (15) Июль 2017 (11) Июнь 2017 (11) Май 2017 (11) Апрель 2017 (7) Март 2017 (18) Февраль 2017 (13) Январь 2017 (14) Декабрь 2016 (12) Ноябрь 2016 (15) Октябрь 2016 (13) Сентябрь 2016 (21) Август 2016 (19) Июль 2016 (14) Июнь 2016 (8) Май 2016 (24) Апрель 2016 (15) Март 2016 (19) Февраль 2016 (21) Январь 2016 (19) Декабрь 2015 (17) Ноябрь 2015 (17) Октябрь 2015 (14) Сентябрь 2015 (13) Август 2015 (1) Июль 2015 (20) Июнь 2015 (23) Май 2015 (26) Апрель 2015 (28) Март 2015 (30) Февраль 2015 (26) Январь 2015 (24) Декабрь 2014 (31) Ноябрь 2014 (21) Октябрь 2014 (28) Сентябрь 2014 (23) Август 2014 (31) Июль 2014 (23) Июнь 2014 (11) Май 2014 (14) Апрель 2014 (8) Март 2014 (11) Февраль 2014 (11) Январь 2014 (11) Декабрь 2013 (12) Ноябрь 2013 (23) Октябрь 2013 (20) Сентябрь 2013 (30) Август 2013 (20) Июль 2013 (6) Июнь 2013 (9) Май 2013 (5) Апрель 2013 (13) Март 2013 (22) Февраль 2013 (36) Январь 2013 (10) Декабрь 2012 (4) Ноябрь 2012 (8) Октябрь 2012 (13) Сентябрь 2012 (29) Август 2012 (24) Июль 2012 (18) Июнь 2012 (2) Май 2012 (4) Март 2012 (5) Февраль 2012 (5) Январь 2012 (25) Декабрь 2011 (15) Ноябрь 2011 (6) Август 2011 (13)Linux, DevOps и системное администрирование
Operating systems
main()
Scripting/coding
Самое читаемое
Архив месяца
| Пн | Вт | Ср | Чт | Пт | Сб | Вс |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | ||
Архивы по годам
Архивы по годам Выберите месяц Апрель 2021 (4) Март 2021 (8) Февраль 2021 (6) Январь 2021 (1) Декабрь 2020 (1) Ноябрь 2020 (9) Октябрь 2020 (9) Сентябрь 2020 (4) Август 2020 (8) Июль 2020 (4) Июнь 2020 (3) Май 2020 (5) Апрель 2020 (9) Март 2020 (8) Февраль 2020 (9) Январь 2020 (2) Декабрь 2019 (9) Ноябрь 2019 (9) Октябрь 2019 (11) Сентябрь 2019 (11) Август 2019 (10) Июль 2019 (2) Июнь 2019 (4) Май 2019 (9) Апрель 2019 (13) Март 2019 (32) Февраль 2019 (20) Январь 2019 (10) Декабрь 2018 (9) Ноябрь 2018 (12) Октябрь 2018 (15) Сентябрь 2018 (12) Август 2018 (14) Июль 2018 (17) Июнь 2018 (18) Май 2018 (21) Апрель 2018 (6) Март 2018 (18) Февраль 2018 (7) Январь 2018 (13) Декабрь 2017 (14) Ноябрь 2017 (6) Октябрь 2017 (24) Сентябрь 2017 (13) Август 2017 (15) Июль 2017 (11) Июнь 2017 (11) Май 2017 (11) Апрель 2017 (7) Март 2017 (18) Февраль 2017 (13) Январь 2017 (14) Декабрь 2016 (12) Ноябрь 2016 (15) Октябрь 2016 (13) Сентябрь 2016 (21) Август 2016 (19) Июль 2016 (14) Июнь 2016 (8) Май 2016 (24) Апрель 2016 (15) Март 2016 (19) Февраль 2016 (21) Январь 2016 (19) Декабрь 2015 (17) Ноябрь 2015 (17) Октябрь 2015 (14) Сентябрь 2015 (13) Август 2015 (1) Июль 2015 (20) Июнь 2015 (23) Май 2015 (26) Апрель 2015 (28) Март 2015 (30) Февраль 2015 (26) Январь 2015 (24) Декабрь 2014 (31) Ноябрь 2014 (21) Октябрь 2014 (28) Сентябрь 2014 (23) Август 2014 (31) Июль 2014 (23) Июнь 2014 (11) Май 2014 (14) Апрель 2014 (8) Март 2014 (11) Февраль 2014 (11) Январь 2014 (11) Декабрь 2013 (12) Ноябрь 2013 (23) Октябрь 2013 (20) Сентябрь 2013 (30) Август 2013 (20) Июль 2013 (6) Июнь 2013 (9) Май 2013 (5) Апрель 2013 (13) Март 2013 (22) Февраль 2013 (36) Январь 2013 (10) Декабрь 2012 (4) Ноябрь 2012 (8) Октябрь 2012 (13) Сентябрь 2012 (29) Август 2012 (24) Июль 2012 (18) Июнь 2012 (2) Май 2012 (4) Март 2012 (5) Февраль 2012 (5) Январь 2012 (25) Декабрь 2011 (15) Ноябрь 2011 (6) Август 2011 (13)struct (C++) | Microsoft Docs
- Чтение занимает 2 мин
В этой статье
struct Ключевое слово определяет тип структуры и (или) переменную типа структуры.The struct keyword defines a structure type and/or a variable of a structure type.
СинтаксисSyntax
[template-spec] struct [ms-decl-spec] [tag [: base-list ]] { member-list } [declarators]; [struct] tag declarators;
ПараметрыParameters
Спецификация шаблонаtemplate-spec
Необязательные спецификации шаблона.Optional template specifications. Дополнительные сведения см. в разделе спецификации шаблонов.For more information, refer to Template Specifications.
structstructstruct Ключевое слово.The struct keyword.
MS-decl-Specms-decl-spec
Необязательная спецификация класса хранения.Optional storage-class specification. Дополнительные сведения см. в разделе ключевое слово __declspec .For more information, refer to the __declspec keyword.
тегtag
Имя типа, присваиваемое структуре.The type name given to the structure. Тег становится зарезервированным ключевым словом в области структуры.The tag becomes a reserved word within the scope of the structure. Тег является необязательным.The tag is optional. Если он опущен, определяется анонимная структура.If omitted, an anonymous structure is defined. Дополнительные сведения см. в разделе типы анонимных классов.For more information, see Anonymous Class Types.
base-listbase-list
Необязательный список классов или структур, из которых эта структура будет наследовать члены.Optional list of classes or structures this structure will derive its members from. Дополнительные сведения см. в разделе базовые классы .See Base Classes for more information. Каждому базовому классу или имени структуры может предшествовать спецификатор доступа (открытый, частный, защищенный) и ключевое слово Virtual .Each base class or structure name can be preceded by an access specifier (public, private, protected) and the virtual keyword. Дополнительные сведения см. в таблице доступ к элементам в разделе Управление доступом к членам класса .See the member-access table in Controlling Access to Class Members for more information.
в разделе базовые классы .See Base Classes for more information. Каждому базовому классу или имени структуры может предшествовать спецификатор доступа (открытый, частный, защищенный) и ключевое слово Virtual .Each base class or structure name can be preceded by an access specifier (public, private, protected) and the virtual keyword. Дополнительные сведения см. в таблице доступ к элементам в разделе Управление доступом к членам класса .See the member-access table in Controlling Access to Class Members for more information.
Список участниковmember-list
Список членов структуры.List of structure members. Дополнительные сведения см. в разделе Обзор членов класса .Refer to Class Member Overview for more information. Единственное отличие заключается в том, что struct используется вместо class .The only difference here is that struct is used in place of class.
declaratorsdeclarators
Список деклараторов, указывающий имена структуры.Declarator list specifying the names of the structure. В списках деклараторов объявляются один или несколько экземпляров типа структуры.Declarator lists declare one or more instances of the structure type. Деклараторы могут включать списки инициализаторов, если все элементы данных структуры имеют значение public .Declarators may include initializer lists if all data members of the structure are public. Списки инициализаторов являются общими в структурах, так как элементы данных public по умолчанию имеют значение.Initializer lists are common in structures because data members are public by default. Дополнительные сведения см. в разделе Общие сведения об деклараторах .See Overview of Declarators for more information.
КомментарииRemarks
Тип структуры — это пользовательский составной тип. A structure type is a user-defined composite type. Он состоит из полей или членов, которые могут иметь разные типы.It is composed of fields or members that can have different types.
A structure type is a user-defined composite type. Он состоит из полей или членов, которые могут иметь разные типы.It is composed of fields or members that can have different types.
В C++ структура является такой же, как и класс, за исключением того, что ее члены по public умолчанию имеют значение.In C++, a structure is the same as a class except that its members are public by default.
Сведения об управляемых классах и структурах в C++/CLI см. в разделе классы и структуры.For information on managed classes and structs in C++/CLI, see Classes and Structs.
Использование структурыUsing a Structure
В языке C struct для объявления структуры необходимо явно использовать ключевое слово.In C, you must explicitly use the struct keyword to declare a structure. В C++ не нужно использовать struct ключевое слово после определения типа.In C++, you do not need to use the struct keyword after the type has been defined.
Если тип структуры определен путем размещения одной или нескольких разделенных запятыми имен переменных между закрывающей фигурной скобкой и точкой с запятой, имеется возможность объявления переменных.You have the option of declaring variables when the structure type is defined by placing one or more comma-separated variable names between the closing brace and the semicolon.
Переменные структуры можно инициализировать.Structure variables can be initialized. Инициализация каждой переменной должна быть заключена в скобки.The initialization for each variable must be enclosed in braces.
Связанные сведения см. в разделе класс, объединениеи перечисление.For related information, see class, union, and enum.
ПримерExample
#include <iostream>
using namespace std;
struct PERSON { // Declare PERSON struct type
int age; // Declare member types
long ss;
float weight;
char name[25];
} family_member; // Define object of type PERSON
struct CELL { // Declare CELL bit field
unsigned short character : 8; // 00000000 ????????
unsigned short foreground : 3; // 00000??? 00000000
unsigned short intensity : 1; // 0000?000 00000000
unsigned short background : 3; // 0???0000 00000000
unsigned short blink : 1; // ?0000000 00000000
} screen[25][80]; // Array of bit fields
int main() {
struct PERSON sister; // C style structure declaration
PERSON brother; // C++ style structure declaration
sister. age = 13; // assign values to members
brother.age = 7;
cout << "sister.age = " << sister.age << '\n';
cout << "brother.age = " << brother.age << '\n';
CELL my_cell;
my_cell.character = 1;
cout << "my_cell.character = " << my_cell.character;
}
// Output:
// sister.age = 13
// brother.age = 7
// my_cell.character = 1
age = 13; // assign values to members
brother.age = 7;
cout << "sister.age = " << sister.age << '\n';
cout << "brother.age = " << brother.age << '\n';
CELL my_cell;
my_cell.character = 1;
cout << "my_cell.character = " << my_cell.character;
}
// Output:
// sister.age = 13
// brother.age = 7
// my_cell.character = 1
Программирование на C и C++
Структура — это совокупность переменных, объединенных одним именем, предоставляющая общепринятый способ совместного хранения информации. Объявление структуры приводит к образованию шаблона, используемого для создания объектов структуры. Переменные, образующие структуру, называются членами структуры. (Члены структуры также часто называются элементами или полями.)
Обычно все члены структуры связаны друг с другом. Например, информация об имени и адресе, находящаяся в списке рассылки, обычно представляется в виде структуры. Следующий фрагмент кода объявляет шаблон структуры, определяющий имя и адрес. Ключевое слово struct сообщает компилятору об объявлении структуры.
struct addr {
char name[30];
char street [40]; char city[20];
char state[3];
unsigned long int zip;
};
Объявление завершается точкой с запятой, поскольку объявление структуры — это оператор. Имя структуры addr идентифицирует структуру данных и является спецификатором типа. Имя структуры часто используют как ярлык.
На данный момент на самом деле не создано никакой переменной. Определена только форма данных. Для объявления настоящей переменной, соответствующей данной структуре, следует написать:
struct addr addr_info;
В данной строке происходит объявление переменной addr_info типа addr. При объявлении структуры определяется переменная смешанного типа. До тех пор, пока не будет объявлена переменная данного типа, она не будет существовать.
Когда объявлена структурная переменная, компилятор автоматически выделяет необходимый участок памяти для размещения всех ее членов. Рис. показывает размещение addr_info в памяти.
Рис. показывает размещение addr_info в памяти.
При объявлении структуры можно одновременно объявить одну или несколько переменных.
Например:
struct addr {
char name[30];
char street[40];
char city[20];
char state[3];
unsigned long int zip;
} addr_info; binfo, cinfo;
объявляет структуру addr и объявляет переменные addr_info, binfo, cinfo данного типа.
Важно понять, что каждая вновь создаваемая структурная переменная содержит свои собственный копии переменных, образующих структуру. Например, поле zip переменной binfo отделено от поля zip переменной cinfo. Фактически, единственная связь между binfo и cinfo заключается в том, что они обе являются экземплярами одного типа структуры. Больше между ними нет связи.
Если необходима только одна структурная переменная, то нет необходимости в ярлыке структуры. Это означает, что
struct {
char name[30];
char street[40];
char city[20];
char state[3];
unsigned long int zip;
} addr_info;
объявляет одну переменную addr_info с типом, определенным предшествующей ей структурой. Стандартный вид объявления структуры следующий:
struct ярлык {
тип имя переменной;
тип имя переменной;
тип имя переменной;
} структурные переменные;
ярлык — это имя типа структуры, а не имя переменной. Структурные переменные — это разделенный запятыми список имен переменных. Следует помнить, что или ярлык, или структурные переменные могут отсутствовать, но не оба.
Искусство упаковки структур в C
От переводчика Объем памяти и скорость процессора стремительно растет. Старые техники оптимизации применяются все меньше, и, в конце концов, забываются. Однако иногда возникают ситуации, когда опыт прошлых лет становится бесценным.
Упаковка структур в C — старая, почти забытая, но все еще актуальная тема, если вы занимаетесь низкоуровневыми приложениями.
Кому предназначается данная статья
В этой статье я рассмотрю технику, с помощью которой можно уменьшить потребление памяти в программах на C путем реорганизации объявляемых структур. Вам потребуются базовые знания языка C.
Этот способ пригодится при написании программ для встроенных систем с ограниченным количеством памяти или компонентов ядра ОС. Также он полезен, если вы работаете с настолько большими структурами данных, что ваша программа постоянно упирается в лимит памяти. Кроме того, он пригодится в любом приложении, где действительно необходимо уменьшить промахи в кэше.
И, наконец, этот способ — первый шаг к некоторым магическим приемам в С. Вы не можете называть себя опытным C-программистом, если не овладели им. Вы не можете называться мастером C, пока не сможете написать подобную статью самостоятельно и грамотно ее критиковать.
Почему я написал эту статью
В 2013 мне пришлось использовать технику оптимизации, о которой я узнал более 20 лет назад и с тех пор практически не использовал. Мне понадобилось уменьшить потребление памяти программой, которая использовала тысячи, а иногда и десятки тысяч С-структур. Это был cvs-fast-export, и очень часто он рушился из-за недостатка памяти.
Существует способ значительно уменьшить потребление памяти в таких ситуациях путем грамотной реорганизации элементов структур. В моем случае программа стала потреблять на 40% меньше памяти и стала способна переработать бо́льшие репозитории без падений.
Однако в процессе работы я понял, что эта техника в наши дни почти забыта. Поиск в сети подтвердил мою догадку: сегодня в среде С-программистов мало кто пишет об этом, по крайней мере, в тех местах, которые индексируются поисковиком. Есть пара статей в Википедии, но нигде нет подробного разъяснения этой темы.
Этому есть вполне разумное объяснение. На всех курсах по информатике студентов приучают (и вполне обоснованно) избегать микрооптимизаций в пользу поиска лучшего алгоритма. Снижение цены на оборудование сделало охоту за байтами менее актуальной. И сегодня все реже встречается опыт глубокого погружения в различные архитектуры процессоров.
Снижение цены на оборудование сделало охоту за байтами менее актуальной. И сегодня все реже встречается опыт глубокого погружения в различные архитектуры процессоров.
Однако описываемый трюк все еще имеет ценность в некоторых ситуациях и будет иметь ее до тех пор, пока количество памяти на машине конечно. Эта статья убережет С-программистов от изобретения велосипеда и поможет сконцентрироваться на более важных вещах.
Выравнивание
Первое, что необходимо учесть: на современных процессорах ваш компилятор располагает базовые типы в памяти так, чтобы обеспечить наиболее быстрый доступ к ним.
На процессорах x86 и ARM примитивные типы не могут находиться в произвольной ячейке памяти. Каждый тип, кроме char, требует выравнивания. char может начинаться с любого адреса, однако двухбайтовый short должен начинаться только с четного адреса, четырехбайтный int или float — с адреса, кратного 4, восьмибайтные long или double — с адреса, кратного 8. Наличие или отсутствие знака значения не имеет. Указатели — 32-битные (4 байта) или 64-битные (8 байт) — также выравниваются.
Выравнивание ускоряет доступ к памяти за счет генерации кода, в котором на чтение и запись ячейки памяти требуется по одной инструкции. Без выравнивания мы можем столкнуться с ситуацией, когда процессору придется использовать две и более инструкции для доступа к данным, расположенным между адресами, кратными размеру машинного слова. char — особый случай, они занимают ровно одно машинное слово и всегда требуют одинакового количества инструкций для доступа. Поэтому для них нет предпочтительного выравнивания.
Я специально упомянул, что это происходит на современных процессорах, потому что на некоторых старых процессорах небезопасный код (например, приведение некратного адреса в указатель на int и его использование) не просто замедлит работу процессора, он упадет с ошибкой о невалидной инструкции. Так вел себя, например, Sun SPARK. На самом деле такое поведение можно воспроизвести на x86 с правильным флагом (
Так вел себя, например, Sun SPARK. На самом деле такое поведение можно воспроизвести на x86 с правильным флагом (e18) в детерминированной ситуации.
Иногда можно дать указание процессору не использовать выравнивание, к примеру, с помощью директивы #pragma pack. (Не делайте этого без серьезной необходимости, потому что результатом будет более ресурсоемкий и медленный код.) Обычно это позволяет сохранить почти столько же памяти, сколько и описываемый мной способ.
Единственная хорошая причина использования #pragma pack — если вы хотите, чтобы расположение данных в памяти точно соответствовало требованиям низкоуровневого протокола или оборудования, как, например, порт с прямым доступом к памяти, и нарушение соглашения необходимо для работы программы. Если вы с этим столкнулись и не знакомы с тем, что описано в этой статье, я вам сочувствую, вы действительно в трудной ситуации.
Заполнение
Давайте посмотрим на простой пример расположения переменных в памяти. Допустим, у нас есть следующие строки в C-коде:
char *p;
char c;
int x;Если вы не знакомы с выраниванием, вы можете предположить, что эти три значения располагаются в памяти последовательно. Таким образом, на 32-битной машине за четырьмя байтами указателя сразу расположится 1 байт char, а следом за ним четыре байта целого. На 64-битной машине отличие будет в размере указателя — 8 байт вместо 4.
А вот что происходит на самом деле (на x86, ARM или другом процессоре с выравниваением данных). Память для p начинается с адреса, кратного 4. Выравнивания указателя — самое строгое.
Следом за ним идет c. Но четырехбайтный x требует заполнения (padding) пустыми байтами. Происходит примерно то же самое, как если бы мы добавили еще одну переменную:
char *p /* 4 or 8 байт */
char c /* 1 байт */
char pad[3] /* 3 байт */
int x /* 4 байт */Массив символов pad[3] в данном случае указывает на то, что мы заполняем пространство тремя пустыми байтами. Раньше это называли «мусор» («slop»).
Раньше это называли «мусор» («slop»).
Если тип x будет short, который занимает 2 байта, данные будут располагаться так:
char *p /* 4 or 8 байт */
char c /* 1 байт */
char pad[1] /* 1 байт */
short x /* 2 байт */С другой стороны, на 64-битной машине эти данные расположатся в памяти следующим образом:
char *p /* 8 байт */
char c /* 1 байт */
char pad[7] /* 7 байт */
long x /* 8 байт */У вас наверняка уже возник вопрос: а что, если переменная с меньшим размером будет объявлена в начале:
char c;
char *p;
int x;Если мы представим расположение структуры в памяти как:
char c;
char pad1[M];
char *p;
char pad2[N];
int x;что мы можем сказать о M и N?
Для начала, N в данном случае будет равно 0. Адрес x гарантированно будет выравниваться по адресу указателя p, выравнивание которого, в свою очередь, более строгое.
Значение M менее предсказуемо. Если компилятор расположит c в последнем байте машинного слова, следующий за ним байт (первый байт p) будет находиться в начале следующего машинного слова. В этом случае M будет равен 0.
Более вероятно, что c расположится в первом байте машинного слова. В этом случае размер M будет таким, чтобы p был выровнен по началу следующего слова — 3 на 32-битной машине, 7 на 64-битной.
Возможны промежуточные ситуации. M может быть от 0 до 7 (от 0 до 3 на 32-битной машине), потому что char может начинаться на любом байте машинного слова.
Если вы хотите, чтобы эти переменные занимали меньше памяти, вы можете поменять местами x и c.
char *p /* 8 байт */
long x /* 8 байт */
char c /* 1 байт */Обычно, путем реорганизации скалярных величин можно сэкономить несколько байт памяти.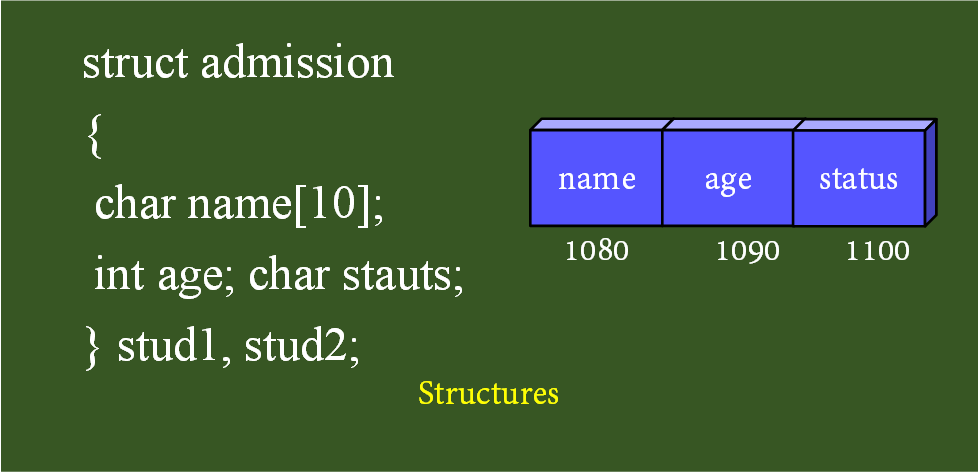 Но в случае использования нескалярных величин — особенно структур — мы можем получить более выдающиеся результаты.
Но в случае использования нескалярных величин — особенно структур — мы можем получить более выдающиеся результаты.
Прежде чем мы коснемся структур, следует упомянуть массивы скалярных величин. На платформе с выравниванием данных массивы char/short/int/long или указателей располагаются в памяти последовательно, без заполнения.
В следующем разделе мы увидим, что это не всегда выполняется для массивов структур.
Выравнивание и заполнение структур
В общем случае, экземпляр структуры будет выровнен по самому длинному элементу. Для компилятора это самый простой способ убедиться, что все поля структуры будут также выровнены для быстрого доступа.
Также, в C адрес структуры совпадает с адресом ее первого элемента, без сдвига в начале. Осторожно: в C++ классы, которые выглядят как структуры, могут нарушать это правило. (Это зависит от того, как устроен базовый класс и реализованы виртуальные методы, и может отличаться в различных компиляторах.)
(В случае сомнений вы можете использовать макрос offsetof() из ANSI C, с помощью которого можно рассмотреть расположение элементов струтур в памяти.)
Давайте рассмотрим следующую структуру:
struct foo1 {
char *p; /* 8 байт */
char c; /* 1 байт */
char pad[7]; /* 7 байт */
long x; /* 8 байт */
};На 64-битной машине любой экземпляр foo1 будет выравниваться по 8 байтам. Расположение в памяти идентично тому, которое мы получили бы, если бы в памяти находились скалярные величины. Однако, если мы перенесем c в начало, все поменяется:
struct foo2 {
char c; /* 1 байт */
char pad[7]; /* 7 байт */
char *p; /* 8 байт */
long x; /* 8 байт */
};Если бы мы рассматривали отдельные переменные, c мог бы начинаться с произвольного байта и размер заполнения мог бы варьироваться. Но выравнивание структуры
Но выравнивание структуры foo2 идет по указателю, c также должен быть выровнен по указателю. В итоге мы получаем фиксированное заполнение в 7 байт.
Рассмотрим теперь концевое заполнение структур. Общее правило такое: компилятор заполняет все место до адреса следующей структуры так, чтобы она была выровнена по самому длинному элементу структуры. sizeof() возвращает размер структуры с учетом заполнения.
Например, на 64-битном x86 процессоре или ARM:
struct foo3 {
char *p; /* 8 байт */
char c; /* 1 байт */
};
struct foo3 singleton;
struct foo3 quad[4];Вы можете подумать, что sizeof(struct foo3) вернет 9, однако верным ответом будет 16. Адрес следующей структуры будет (&p)[2]. Таким образом, в массиве из 4 элементов у каждого будет заполнение в 7 пустых байт, поскольку первые элементы каждой структуры должны быть выровнены в данном случае по 8 байтам. Расположение в памяти такое, какое было бы, если бы структура была объявлена следующим образом:
struct foo3 {
char *p; /* 8 байт */
char c; /* 1 байт */
char pad[7];
};Для сравнения, рассмотрим такой пример:
struct foo4 {
short s; /* 2 байт */
char c; /* 1 байт */
char pad[1];
};Поскольку s требует 2-байтового выравнивания, следующий адрес будет отстоять от c на один байт, вся структура foo4 будет заполнена одним пустым байтом в конце и sizeof(struct foo4) вернет 4.
Выравнивание битовых полей и вложенных структур
Битовые поля позволяют объявить переменные, занимающие меньшую, чем char память, вплоть до 1 бита. Например:
struct foo5 {
short s;
char c;
int flip:1;
int nybble:4;
int septet:7;
};Важно помнить, что они реализованы с помощью маски поверх байта или машинного слова и не могут выходить за его пределы.
С точки зрения компилятора битовые поля структуры foo5 выглядят как двухбайтовые значения, из 16 бит которых используются только 12. Место после них заполняется так, чтобы размер структуры был кратен sizeof(short) — размеру наибольшего элемента.
struct foo5 {
short s; /* 2 байт */
char c; /* 1 байт */
int flip:1; /* всего 1 бит */
int nybble:4; /* всего 5 бит */
int septet:7; /* всего 12 бит */
int pad1:4; /* всего 16 бит = 2 байт */
char pad2; /* 1 байт */
};Ограничения битового поля на выход за пределы машинного слова приведет к тому, что на 32-битной машине первые две структуры поместятся в одно или два слова, но третья (foo8) займет три слова, причем у последнего будет занят только первый бит. С другой стороны, структура foo8 поместится в одно 64-битное слово.
struct foo6 {
int bigfield:31; /* Начало первого 32-битного слова */
int licodelefield:1;
};
struct foo7 {
int bigfield1:31; /* Начало первого 32-битного слова */
int licodelefield1:1;
int bigfield2:31; /* Начало второго 32-битного слова */
int licodelefield2:1;
};
struct foo8 {
int bigfield1:31; /* Начало первого 32-битного слова */
int bigfield2:31; /* Начало второго 32-битного слова */
int licodelefield1:1;
int licodelefield2:1; /* Начало третьего 32-битного слова */
};Важная деталь: если элементом вашей структуры является структура, она также будет выравниваться по самому длинному скаляру. Например:
struct foo9 {
char c;
struct foo9_inner {
char *p;
short x;
} inner;
};char *p во внутренней структуре требует выравнивания по указателю как во внутренней, так и во внешней структуре. Реальное расположение в памяти на 64-битной машине будет примерно такое:
Реальное расположение в памяти на 64-битной машине будет примерно такое:
struct foo9 {
char c; /* 1 байт*/
char pad1[7]; /* 7 байт */
struct foo9_inner {
char *p; /* 8 байт */
short x; /* 2 байт */
char pad2[6]; /* 6 байт */
} inner;
};Эта структура дает нам подсказку, где и как мы можем сэкономить память переупаковкой. Из 24 байт 13 заполняющие. Это больше 50% потерянного места!
Реорганизация структур
Теперь, когда мы знаем как и зачем компилятор выравнивает данные в памяти, посмотрим, как мы можем уменьшить количество «мусора». Это и будет называться «искусство упаковки структур».
Первое, что можно заметить — мусор появляется в двух местах: когда данные большего размера расположены после данных меньшего размера и в конце структуры, заполняя место в памяти вплоть до адреса следующей структуры.
Наиболее простой способ избавиться от мусора — расположить элементы структуры по уменьшению размера. Таким образом, указатели будут располагаться в начале, поскольку на 64-битной машине они займут по 8 байт. Потом 4-битовые int; 2-байтовые short; затем char.
Рассмотрим, например, односвязный список:
struct foo10 {
char c;
struct foo10 *p;
short x;
};Или, если мы явно укажем заполняющие байты:
struct foo10 {
char c; /* 1 byte */
char pad1[7]; /* 7 bytes */
struct foo10 *p; /* 8 bytes */
short x; /* 2 bytes */
char pad2[6]; /* 6 bytes */
};Всего 24 байта. Однако, если мы перепишем следующим образом:
struct foo11 {
struct foo11 *p;
short x;
char c;
};то, посмотрев на расположение структуры в памяти, мы увидим, что теперь данные не требуют заполнения, поскольку начало адреса более короткого элемента следует сразу после конца адреса более длинного. Все, что нам теперь требуется — концевое заполнение для выравнивания следующей структуры:
Все, что нам теперь требуется — концевое заполнение для выравнивания следующей структуры:
struct foo11 {
struct foo11 *p; /* 8 bytes */
short x; /* 2 bytes */
char c; /* 1 byte */
char pad[5]; /* 5 bytes */
};Переупаовкой мы добились сокращения занимаемого места с 24 до 16 байт. Это может показаться незначительным, но что, если у вас односвязный список из 200 тысяч элементов? Эффект растет быстро, особенно на встроенных системах с ограниченым объемом памяти или в критических участках ядра ОС.
Замечу, что реорганизация не всегда позволяет сохранить память. Если мы применим этот прием к нашей структуре foo9, мы получим следующее:
struct foo12 {
struct foo12_inner {
char *p; /* 8 bytes */
int x; /* 4 bytes */
} inner;
char c; /* 1 byte*/
};Явно укажем заполнение:
struct foo12 {
struct foo12_inner {
char *p; /* 8 bytes */
int x; /* 4 bytes */
char pad[4]; /* 4 bytes */
} inner;
char c; /* 1 byte*/
char pad[7]; /* 7 bytes */
};Размер foo12 — также 24 байта, потому что c выравнивается по внутренней структуре. Для уменьшения занимаемой памяти нам придется изменить дизайн самой структуры данных.
Когда я выложил первый вариант этой статьи, меня спросили почему, если реогранизация для уменьшения «мусора» настолько проста, компилятор не делает ее автоматически. Ответ: C изначально разрабатывался для написания ОС и низкоуровневого кода. Автоматическая реорганизация структур будет мешать программисту организовать структуру с учетом требований оборудования к расположению битов и байтов в памяти.
Выравнивания перечислений и целочисленных типов
Использование перечислений («enumerated types») вместо директивы #define — отличная идея, если отладчик может их отличить от целых чисел. Перечисления гарантировано совместимы с целочисленным типом, однако стадарт C не специфицирует, с помощью какого именно типа они реализованы.
Перечисления гарантировано совместимы с целочисленным типом, однако стадарт C не специфицирует, с помощью какого именно типа они реализованы.
Будьте осторожны: несмотря на то, что обычно в перечислениях используется int, в некоторых компиляторах по умолчанию может использоваться short, long или char. Также в компиляторе может быть предусмотрена директива или опция для явного указания размера.
Тип long double также может создавать некоторые проблемы. Некоторые платформы реализуют его с помощью 80 бит, некоторые — 128 бит, некоторые 80-битные реализации заполняют место после данных до 96 или 128 бит.
В обоих случаях лучше использовать sizeof() для проверки занимаемого места.
Наконец, иногда на x86 Linux-машинах double может быть исключением: 8-байтный double может требовать выравнивания по 4 байтам в структуре, несмотря на то, что стоящий отдельно выравнивается по 8 байтам. Это зависит от компилятора и его опций.
Читаемость кода и локальность кэша
Несмотря на то, что реорганизация структур — самый простой способ избавиться от мусора в памяти, он не всегда будет оптимальным. Необходимо также учесть читаемость кода и локальность кэша («cache locality»).
Следует помнить, что программы пишутся не только для компьютера, но и для людей. Читаемый код важен даже тогда, когда единственный, кто его будет читать — это вы в будущем.
Бездумная механическая реструктуризация может серьезно снизить читаемость. Лучше оставлять семантически связанные поля структур вместе. В идеале, дизайн программы должен быть взаимосвязан с дизайном структур данных.
При написании программы, которой требуется частый доступ к данным или их части, стоит помнить, что произволительность будет выше, если запрашиваемые данные помещяются в кэш — блок памяти, целиком читаемый процессором при доступе к адресу в нем. На 64-битной машине он обычно занимает 64 байта, на других платформах — обычно 32 байта.
Группировка связанных данных не только улучшает читаемость, но и способствует локализации данных в кэше. Это дополнительная причина реорганизовывать структуры с учетом особенностей доступа к данным в вашей программе.
Если в вашем коде есть конкурентный (concurrent) доступ к данным, появляется третья проблема: «cache line bouncing». Для минимизации трафика в шине следует располагать данные так, чтобы чтение из одного кэша и запись в другой производились с меньшим промежутком.
Да, это противоречит предыдущему замечанию, однако многопоточный код — это всегда сложно. Оптимизация многопоточного кода — тема, заслуживающая отдельной большой статьи. Все, что я могу здесь сказать, такая проблема существует.
Другие способы упаковки
Реорганизация структур лучше всего работает вместе с другими способами уменьшения их размера. Например, если у вас есть несколько булевых флагов, вы можете привести их к битовым полям и упаковать их в структуру, которая в противном случае располагалась бы в памяти с зазорами.
Это освободит вам столько памяти, что эффект от уменьшения количества промахов в кэше перевесит увеличенное время доступа к данным.
В общем случае старайтесь уменьшить размер полей с данными. В cvs-fast-export, например, я воспользовался знанием от том, что CVS и RCS репозитории не существовали до 1982 года. Я заменил 64-битное Unix-время time_t (начинающееся с 1970) на 32-битное время с начальной точкой 1982-01-01T00:00:00; это должно покрыть даты до 2118 года. (Если вы применяете подобный трюк, не забудьте проверять границы устанавливаемого значения, чтобы избежать трудноуловимых багов.)
Каждое такое сокращение размера поля не только уменьшает размер структуры, но и уменьшает количество мусора или может создать дополнительные возможности для уменьшения структуры путем реорганизации элементов. Последовательно применяя эти шаги, мы можем добиться значительной экономии памяти.
Самый рискованый метод упаковки — использование union. Если вы уверены, что в вашей структуре данных поля никогда не будут использоваться совместно, можете рассмотреть этот вариант. Но будьте предельно осторожны, тщательно тестируйте свой код, потому что даже маленькая неточность может привести не только к трудноуловимым багам, но и к порче данных.
Если вы уверены, что в вашей структуре данных поля никогда не будут использоваться совместно, можете рассмотреть этот вариант. Но будьте предельно осторожны, тщательно тестируйте свой код, потому что даже маленькая неточность может привести не только к трудноуловимым багам, но и к порче данных.
Инструменты
Компилятор clang имеет опцию -Wpadded, которая будет генерировать сообщения о заполнении.
Я слышал много хороших отзывов о программе pahole, хотя сам ее не использовал. Она работает вместе с компилятором и позволяет генерировать отчет, описывающий реальное расположение данных в памяти.
Доказательства и исключения
Исходный код небольшой программы, которая иллюстрирует вышеописанное можно скачать здесь: packtest.c.
Если вы используете экзотические сочетания компилятора, опций и оборудования, вы, возможно, найдете исключения из правил, который я привожу. Причем, чем старше процессор, тем чаще вы с ними будете сталкиваться.
Следующий уровень владения данной техникой — знать, где и когда ожидать, что правила будут нарушены. В то время, когда я изучал ее (ранние 80-е), людей, которые не освоили эту технику называли «жертвами VAX» («all-the-world’s-a-VAX syndrome»). Помните, что не все компьютеры в мире — PC.
Полезные ссылки
Здесь я привожу ссылки на статьи и эссе, которые я считаю хорошим дополнением к данному материалу.
A Guide to Undefined Behavior in C and C++
Time, Clock, and Calendar Programming In C
Источник: The Lost Art of C Structure Packing (Eric S. Raymond, [email protected])
C# NET: Class vs Struct или в чём различия между Классом и Структурой
Просто о NET | created: 7/10/2011 | published: 7/10/2011 | updated: 4/12/2021 | view count: 79093 | comments: 0
Мне в последнее время очень часто встречаются программисты, которые не только используют в обычной “программной” жизни структуры (struct), но вообще, ничего не знают об этом объекте. И зачастую, для простоты своей «программной» жизни используют всегда классы (class). В этой статье я бы хотел в очередной раз остановиться на различиях между структурами и классами.
И зачастую, для простоты своей «программной» жизни используют всегда классы (class). В этой статье я бы хотел в очередной раз остановиться на различиях между структурами и классами.
Что такое struсture?
Структуры синтаксически очень похожи на классы, но существует принципиальное отличие, которое заключается в том, что класс – является ссылочным типом (reference type), а структуры – значимый класс (value type). А следовательно, классы всегда создаются в, так называемой, “куче” (heap), а структуры создаются в стеке (stack). Цитата из комментария: «Имхо, главное отличие структур и классов: структуры передаются по значению (то есть копируются), объекты классов — по ссылке. Именно это является существеннейшим различием в их поведении, а не то, где они хранятся. Примечание: структуру тоже можно передать по ссылке, используя модификаторы out и ref.»
Ключевой момент статьи: Чем больше Вы будете использовать структуры вместо небольших (наверное, правильнее будет сказать – маленьких) классов, тем менее затратным по ресурсам будет использование памяти. Смею предположить, что не требуется объяснения почему… “куча”, “сборщик мусора”, “неопределенные временные интервалы прохода”, сложность “ручного” управления кучей и сборщиком мусора. Все ключевые моменты уже перечислены.
Так же как и классы, структуры могут иметь поля, методы и конструкторы. Хотя про конструкторы надо поговорить подробнее (будет дальше по теме), ибо это есть очень важное понятие при сравнивании классов и структур.
Структуры всегда с ВамиНе хочется думать, что следующая информация, для Вас сюрпризом. В языке C# примитивные числовые типы int, long, float являются альясами для структур System.Int32, System.Int64 и System.Single соответственно. Эти структуры имеют поля и методы. Вы обычно вызываете методы у переменных данных типов. Например, каждая из перечисленных структур имеет метод ToString. Также у перечисленных структур есть статичные поля, например, Int32.MaxValue или Int32.MinValue. Получается, что Вы уже в повседневной «программной» жизни используете структуры, а значит знакомы с ними.
Также у перечисленных структур есть статичные поля, например, Int32.MaxValue или Int32.MinValue. Получается, что Вы уже в повседневной «программной» жизни используете структуры, а значит знакомы с ними.
Таблица классов и структур в Microsoft. NET Framework
В таблице указаны альясы и соответствующие им типы, а также дана информация о представляющем типе (структура или класс).
| Keyword | Type equivalent | Class or structure |
|---|---|---|
| bool | System.Boolean | Structure |
| byte | System.Byte | Structure |
| decimal | System.Decimal | Structure |
| double | System.Double | Structure |
| float | System.Single | Structure |
| int | System.Int32 | Structure |
| long | System.Int64 | Structure |
| object | System.Object | Class |
| sbyte | System.SByte | Structure |
| short | System.Int16 | Structure |
| string | System.String | Class |
| uint | System.UInt32 | Structure |
| ulong | System.UInt64 | Structure |
| ushort | System.UInt16 | Structure |
Объявление структур
Для объявления структуры используется зарезервированное слово struct, следом наименование структуры и фигурные скобки:
struct Time
{
public int hours, minites, seconds;
}В отличие от классов, использование публичных полей в структурах в большинстве случаев не рекомендуется, потому что не существует способа контролирования значений в них. Например, кто-либо может установит значение минут или секунд более 60. Более правильный вариант в данном случае — использовать свойства, а в конструкторе осуществить проверку:
Например, кто-либо может установит значение минут или секунд более 60. Более правильный вариант в данном случае — использовать свойства, а в конструкторе осуществить проверку:
struct Time
{
public Time(int hh, int mm, int ss)
{
hours = hh % 24;
minutes = mm % 60;
seconds = ss % 60;
}
public int Hours()
{
return hours;
}
...
private int hours, minutes, seconds;
}Кстати, …По умолчанию, Вы не можете использовать некоторые общие операторы в Ваших структурах. Например, Вы не можете использовать оператор сравнения (==) и противоположные ему (!=) на своих структурах. Однако, Вы можете явно объявить и реализовать операторы для своих структур.
И в чем же разница между структурами и классами
Давайте рассмотрим пример, в котором уже заложена ошибка:
struct Time
{
public Time() { ... } // compile-time error
...
}Причина возникновении ошибки в том, что Вы не можете использовать конструктор по умолчанию (без параметров) для структуры, потому что компилятор всегда генерирует его сам. Что же касается класса, то компилятор создает конструктор по умолчанию, только в том случае, если Вы его не создали. Сгенерированный конструктор для структуры всегда устанавливает поля в 0, false или null – как и для классов. Поэтому Вы можете быть уверенными в том, что созданная структура всегда будет вести себя “адекватно” в соответствии со значениями по умолчанию в используемых типах. Если Вы не хотите использовать значения по умолчанию, Вы можете инициализировать поля своими значениями в конструкторе с параметрами для инициализации. Однако, если в этом конструкторе не будет инициализировано какое-нибудь значение, компилятор не будет его инициализировать за Вас и покажет ошибку.
struct Time
{
private int hours, minutes, seconds;
...
public Time(int hh, int mm)
{
this.hours = hh;
this.minutes = mm;
} // compile-time error: seconds not initialized
}Первое правило Структуры: Всегда все переменные должны быть инициализированы!
В классах Вы можете инициализировать значение полей непосредственно в месте их объявления. В структурах такого сделать не получится, и поэтому данный код вызовет ошибку при компиляции:
struct Time
{
private int hours = 0; // compile-time error
private int minutes;
private int seconds;
...
}Второе правило Структуры: Нельзя инициализировать переменные в месте их объявления!
Данная таблица в некотором роде подытоживает всё вышесказанное и отображает основные отличия между классами и структурами.
| Вопрос | Структура | Класс |
| И какого же типа экземпляр объекта? | Структура значимый (value) тип | Класс ссылочный (reference) тип |
| А где “живут” экземпляры этих объектов? | Экземпляры структуры называют значениями и “живут” они в стеке (stack). | Экземпляры классов называют объектами и “живут” они в куче (heap). |
| Можно ли создать конструктор по умолчанию? | Нет | Да |
| Если создается свой конструктор будет ли компилятор генерировать конструктор по умолчанию? | Да | Нет |
| Если в своём конструкторе не будут инициализированы некоторые поля, будут ли они автоматически инициализированы компилятором? | Нет | Да |
| Разрешается ли инициализировать переменные в месте их объявления? | Нет | Да |
Использование структур как переменных
После того как Вы создали структуры, Вы можете использовать ее также как классы и другие типы. Например, создав структуру Time, я могу использовать ее в классе:
Например, создав структуру Time, я могу использовать ее в классе:
struct Time
{
private int hours, minutes, seconds;
...
}
class Example
{
private Time currentTime;
public void Method(Time parameter)
{
Time localVariable;
...
}
}Кстати, …
Вы можете создавать nullable версию переменной типа структуры использую модификатор “?” и потом присвоить ей значение null:
Time? currentTime = null;
Инициализация структур
В статье я не раз говорил, что поля структуры могут быть инициализированы при использования конструктора, причем не важно какого “собственного” или “по умолчанию”. К особенностям структур можно отнести еще и тот факт, что вследствие того, что структуры являются значимым типом, то можно создать структуру без использования конструктора, например:
Time now;
В таком случае, переменная создается, но поля не будут инициализированы в соответствии параметрами конструктора.
Заключение
Используйте структуры, это признак хорошего тона в программировании на C# и да прибудет с Вами сила… структур. Цитата из комментария: «С заключением тоже не согласен. Многие маститые западные авторы наоборот рекомендуют как можно меньше использовать структуры, предпочитая классы. Хотя, конечно, молиться на них и их мнение не стоит, лучше думать своей головой.»
продвинутых концепций в C — структурах | автор: Christian Walter
Сегодня я хотел бы поделиться с вами некоторыми передовыми концепциями языка Си. Я сталкиваюсь с этими концепциями, которые являются хорошими функциями, но используются редко или, по крайней мере, я не вижу их часто используемых. Сегодня мы обсудим…
Мне кажется, что очень немногие люди либо используют конструкции, либо знают, что они собой представляют и для чего годны.
Структура создает тип данных, который можно использовать для группировки элементов, возможно, разных типов в один тип.
Структуры больше ориентированы на удобочитаемость. Мы можем группировать переменные, которые принадлежат друг другу. Предположим, вам нужно обработать чей-то адрес. Вместо этого:
void main () {
char street [50] = "Somestreet";
int housenumber = 123;
int почтовый индекс [5] = {4,3, 2, 1, 0};
char city [20] = "SomeCity";
} Мы можем сгруппировать это в структуру. Во-первых, мы должны объявить структуру. Мы объявляем структуру, которая содержит название улицы, номер дома, пятизначный почтовый индекс и город.
структурный адрес {
char street [50];
int housenumber;
int почтовый индекс [5];
символ города [20];
}; Теперь мы можем определить переменную в нашей основной функции и инициализировать ее следующим образом:
void main () {
struct address myAddress = {
"SomeStreet",
123,
{1, 2, 3, 4, 5},
"SomeCity"
};
printf ("Номер дома:% u \ n", myAddress.housenumber)
} Что дает нам номер дома: 123 .
Со структурами можно работать как с любыми другими переменными.Вы можете передать его в функцию, построить массив структур или вложить структуры в структуры.
Структуры очень полезны для группировки данных. Если вам нужно работать с данными, например, memcpy , будет намного проще, если вы уже сгруппировали их в структуру. Но будьте осторожны: структуры могут быть больше в памяти из-за заполнения. Но как это работает?
Структура памяти «структур»
Когда мы используем структуры, нам нужно знать, как они выравниваются в памяти.Члены структуры данных хранятся в памяти последовательно, так что размер структуры будет равен количеству содержащихся в ней членов. Позвольте привести пример. Следующая структура
struct data {
uint8_t val1;
uint8_t val2;
uint8_t val3;
}; — ровно три байта.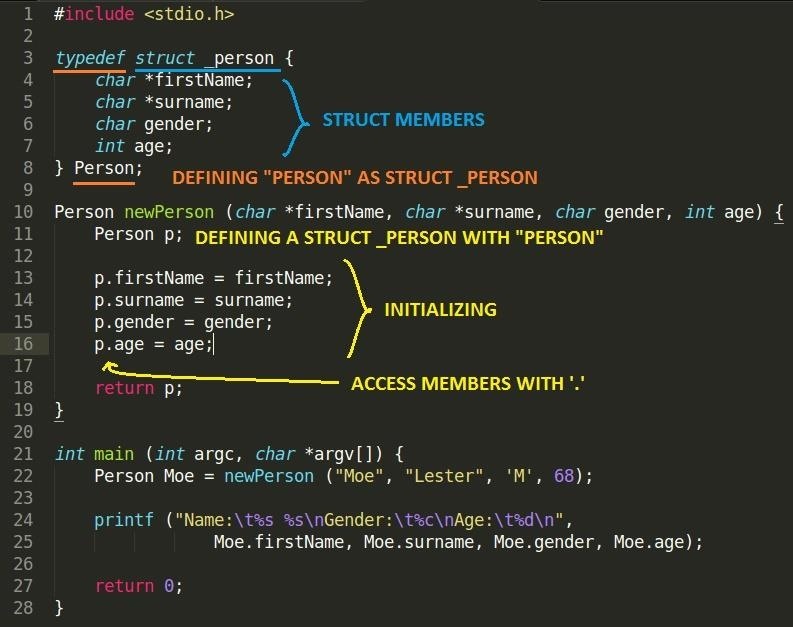 Выравнивание здесь составляет один байт, потому что каждый член — это
Выравнивание здесь составляет один байт, потому что каждый член — это uint8_t , то есть один байт, так что сама структура кратна своим членам, трем байтам.
Выравнивание структуры зависит от типов внутри структуры.
Когда мы используем структуры смешанного типа, выравнивание может быть немного сложнее. Следующая структура
struct data2 {
uint8_t val1;
uint32_t val2;
uint8_t val3;
}; технически шесть байт — правильно? У нас есть два однобайтовых значения, а одно четырехбайтовое значение составляет шесть. К сожалению, это неверно . Мы забыли обивку. Если мы создаем структуры со смешанным типом, заполнение будет , как правило, также будет равно самому большому типу, который мы использовали в структуре.Но учтите — это зависит от реализации! Давайте посмотрим, как структура struct data2 выглядит в памяти.
Как я уже сказал, выравнивание структуры в памяти будет соответствовать самому большому типу, используемому в нашей структуре — так что это будет uint32_t : 4 байта. Это означает, что структура будет помещена в память 4-байтовыми блоками. Если следующее значение больше не помещается в 4-байтовый фрагмент, текущий фрагмент будет заполнен нулями (дополнен) и будет использован новый фрагмент.На самом деле структура struct data2 является 12-байтовой большой в памяти.
Теперь, если мы изменим структуру как это
struct data3 {
uint8_t val1;
uint8_t val3;
uint32_t val2;
}; Структура памяти данных3 он по-прежнему содержит такое же количество значений, но в памяти он выглядит совершенно иначе.
Как видите, val1 и val3 помещаются в один блок. Очевидно, что val2 больше не подходит, поэтому фрагмент дополняется, и val2 переходит в следующий фрагмент. Порядок переменных в структуре имеет огромное влияние на размер структуры. Знание этого чрезвычайно важно, если вы думаете о том, что записывает данные непосредственно в структуру или наоборот.
Порядок переменных в структуре имеет огромное влияние на размер структуры. Знание этого чрезвычайно важно, если вы думаете о том, что записывает данные непосредственно в структуру или наоборот.
Изменить выравнивание
Есть несколько способов изменить выравнивание конструкции. Все они зависят от компилятора, но должны работать с большинством компиляторов. Если вы хотите установить однобайтовое выравнивание, чтобы в памяти структуры не было заполнения, вы можете использовать ключевое слово __packed .Определите вашу структуру, как это
struct __attribute __ ((__ pack__)) data {
uint8_t val1;
uint32_t val2;
uint8_t val3;
}; Структура памяти данных __packed__И ваш компилятор не будет добавлять заполнение в структуру. В памяти это выглядит так.
Размер структуры составляет ровно шесть байтов. Имейте в виду, что удаление заполнения приведет к замедлению кода. Это следует использовать только для сценариев, где размер действительно имеет значение или где вы хотите сохранить данные memcpy непосредственно из входного потока, например.грамм. серийный номер в структуру.
Вы можете получить тот же эффект, если используете прагму в C. Директива прагмы pack изменяет максимальное выравнивание. Всегда разумно устанавливать пакет прагмы только для той структуры, которой вы хотите, а не для всего проекта. Если вы хотите изменить выравнивание, это работает следующим образом:
#pragma pack (push)
#pragma pack (1) struct data {
uint8_t val1;
uint32_t val2;
uint8_t val3;
}; # pragma pack (pop)
#pragma pack (push) помещает фактические параметры выравнивания во внутренний стек, чтобы мы могли снова восстановить этот параметр позже. #pragma pack (1) устанавливает максимальное выравнивание в один байт, за которым следует определение структуры. После этого мы снова восстанавливаем предыдущие настройки выравнивания с помощью #pragma pack (pop) , снова выталкивая из внутреннего стека.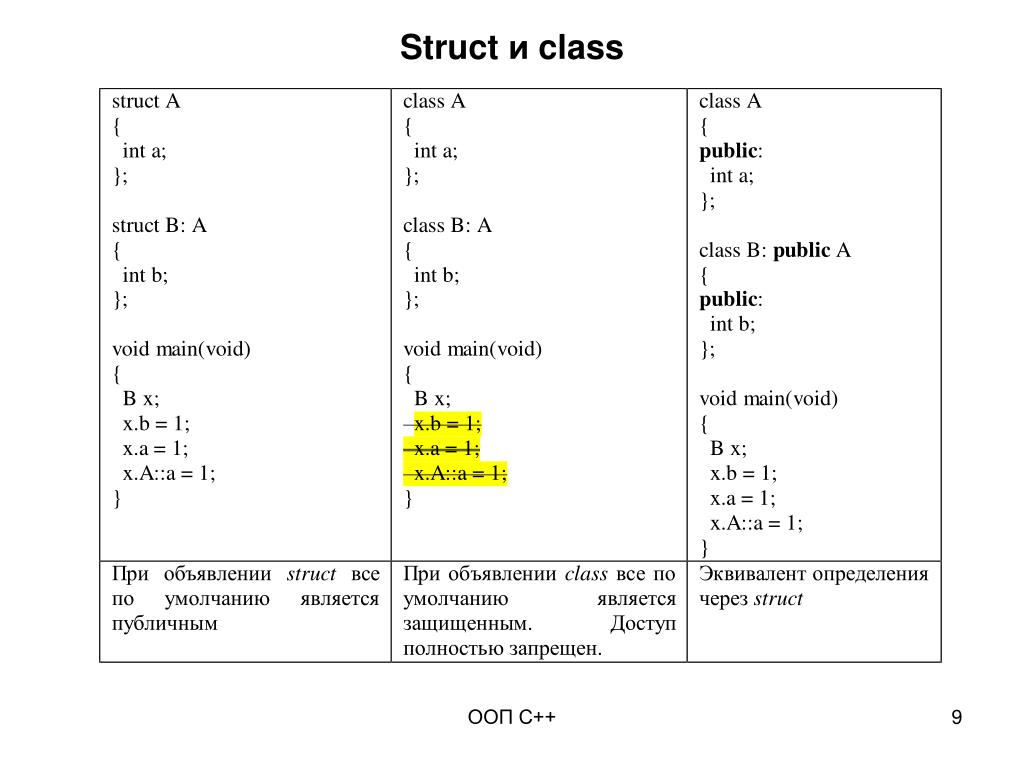
| Структуры в C | ||
Структура — это набор из одной или нескольких переменных, возможно, разных типов данных, сгруппированных вместе под одним именем для удобства обработки. | ||
| ||
| Объявление структуры | ||
Тип структуры обычно определяется рядом с началом файла с помощью оператора typedef.typedef определяет и дает имя новому типу, что позволяет использовать его во всей программе. typedef обычно появляется сразу после операторов #define и #include в файле. | ||
Вот пример определения структуры. | ||
1 typedef struct {
2 символа [64];
3-х символьный курс [128];
4 инт возраста;
5 в год;
6} студент;
Вы можете скачать файл struct.c здесь | ||
Это определяет новый тип студента. Переменные типа student могут быть объявлены следующим образом. | ||
студенческая ул. | ||
Обратите внимание, насколько это похоже на объявление типа int или float.Имя переменной — st_rec, у нее есть члены с именами name, course, age и year. | ||
| Вложенные структуры | ||
Конструкции могут содержать другие конструкции в качестве элементов; другими словами, структуры могут гнездиться. Рассмотрим следующие два типа структуры: | ||
1 struct first_structure_type {
2 int integer_member;
3 float float_member;
4};
5
6 struct second_structure_type {
7 двойных double_member;
8 struct first_structure_type struct_member;
9};
Вы можете скачать файл struct_nested.c здесь | ||
Первый структурный тип включен как член второго структурного типа. Вы можете инициализировать переменную второго типа следующим образом: | ||
1 демонстрация struct second_structure_type; 2 3 demo.double_member = 12345.6789; 4 демо.struct_member.integer_member = 5; 5 demo.struct_member.float_member = 1023.17;Вы можете скачать файл struct_nested1.c здесь | ||
Оператор-член. используется для доступа к элементам структур, которые сами являются членами более крупной структуры. Для принудительного выполнения особого порядка оценки скобки не требуются; выражение оператора-члена просто вычисляется слева направо. | ||
В принципе, структуры могут быть вложены неограниченное время. | ||
1 my_structure.member1.member2.member3.member4 = 5;Вы можете скачать файл struct_nested2.c здесь | ||
Но что произойдет, если структура содержит экземпляр своего собственного типа? Например: | ||
1 структурная регрессия {
2 int int_member;
3 структурная регрессия self_member;
4};
Вы можете скачать файл struct_nested3.c здесь | ||
Для компиляции оператора этого типа вашему компьютеру теоретически потребуется бесконечный объем памяти. На практике, однако, вы просто получите сообщение об ошибке следующего содержания: | ||
struct5.c: В функции `main ': struct5.c: 8: поле `self_member 'имеет неполный тип | ||
Компилятор сообщает вам, что self_member был объявлен до его типа данных, регрессия была полностью объявлена - естественно, поскольку вы объявляете self_member в середине объявления его собственного типа данных! | ||
| Массивы конструкций | ||
Так же, как массивы основных типов, таких как целые числа и числа с плавающей запятой, разрешены в C, так и массивы структур. | ||
1 struct personal_data my_struct_array [100];Вы можете скачать файл struct_array.c здесь | ||
Затем доступ к элементам структур в массиве осуществляется с помощью следующих операторов: | ||
Значение элемента структуры в массиве может быть присвоено другой переменной, или значение переменной может быть присвоено члену.Например, следующий код присваивает номер 1974 члену year_of_birth четвертого элемента my_struct_array: | ||
1 my_struct_array [3] .year_of_birth = 1974;Вы можете скачать файл struct_array1.c здесь | ||
(Как и все другие массивы в C, массивы структур начинают свою нумерацию с нуля.) | ||
Следующий код присваивает значение члена year_of_birth четвертого элемента my_struct_array переменной yob: | ||
1 год = my_struct_array [3] .year_of_birth;Вы можете скачать файл struct_array2.c здесь | ||
Наконец, следующий пример присваивает значения всех членов второго элемента my_struct_array, а именно my_struct_array [1], третьему элементу, поэтому my_struct_array [2] принимает общее значение my_struct_array [1]. | ||
1 my_struct_array [2] = my_struct_array [1];Вы можете скачать файл struct_array3.  c здесь c здесь | ||
| Указатели на строения | ||
Хотя структура не может содержать экземпляр своего собственного типа, она может содержать указатель на другую структуру своего собственного типа или даже на саму себя.Это связано с тем, что указатель на структуру сам по себе не является структурой, а просто переменной, которая содержит адрес структуры. Указатели на структуры фактически неоценимы для построения структур данных, таких как связанные списки и деревья. (См. Сложные структуры данных.) | ||
Указатель на переменную структурного типа объявляется с помощью следующего оператора: | ||
1 struct personal_data * my_struct_ptr;Вы можете скачать файл struct_ptr.c здесь | ||
Переменная my_struct_ptr является указателем на переменную типа struct personal_data. Этот указатель может быть назначен любому другому указателю того же типа и может использоваться для доступа к членам его структуры. Согласно правилам, которые мы изложили до сих пор, это должно быть сделано так: | ||
1 struct personal_data person1; 2 3 my_struct_ptr = & person1; 4 (* my_struct_ptr).day_of_birth = 23;Вы можете скачать файл struct_ptr1.c здесь | ||
Этот пример кода, по сути, говорит: «Пусть член day_of_birth структуры, на которую указывает my_struct_ptr, принимает значение 23.» Обратите внимание на использование круглых скобок, чтобы избежать путаницы в отношении приоритета * и. | ||
Однако есть лучший способ написать приведенный выше код, используя новый оператор: ->.Это стрелка, состоящая из знака «минус» и символа «больше», и используется следующим образом: | ||
1 my_struct_ptr-> day_of_birth = 23;Вы можете скачать файл struct_ptr2.c здесь | ||
Знак -> позволяет получить доступ к элементам структуры напрямую через ее указатель.Этот оператор означает то же самое, что и последняя строка в предыдущем примере кода, но значительно понятнее. Оператор -> очень удобен при работе со сложными структурами данных. (См. Сложные структуры данных.) | ||
| Структуры :: typedef | ||
Существует более простой способ определения структур или создание «псевдонимов» типов.Например: | ||
1 typedef struct {
2 символа * первые;
3 символа * последний;
4 символа SSN [9];
5 плавающих гПа;
6 символьных ** классов;
7} студент;
8
9 студент student_a;
Вы можете скачать файл type_defs_c.c здесь | ||
Теперь мы избавляемся от этих глупых структурных тегов.Вы можете использовать typedef для неструктур: | ||
1 typedef long int * pint32; 2 3 пинты32 x, y, z;Вы можете скачать файл type_defs1_c.c здесь | ||
x, y и z — все указатели на длинные целые числа. | ||
| Конструкции и функции | ||
Структура может передаваться как аргумент функции, как и любая другая переменная.Это поднимает несколько практических вопросов. | ||
Если мы хотим изменить значение членов структуры, мы должны передать указатель на эту структуру. Это похоже на передачу указателя на аргумент типа int, значение которого мы хотим изменить. | ||
Если нас интересует только один член структуры, вероятно, проще просто передать этот член.Это упростит функцию, которую будет легче использовать повторно. Конечно, если мы хотим изменить значение этого члена, мы должны передать на него указатель. | ||
Когда структура передается в качестве аргумента, каждый член структуры копируется. Это может оказаться дорогостоящим, если структуры большие или функции вызываются часто. В таких случаях передача указателей на большие структуры и работа с ними может быть более эффективной. | ||
| Структуры и союзы | ||
Объединения объявляются так же, как и структуры, но имеют фундаментальное отличие. В любое время можно использовать только один элемент в объединении, потому что память, выделенная для каждого элемента в объединении, находится в общей области памяти. Почему ты спрашиваешь? Пример первый: | ||
1 struct conditions {
2 температуры поплавка;
3 union feel_like {
4 float wind_chill;
5 float heat_index;
6}
7} сегодня;
Вы можете скачать файл struct_union_c. c здесь c здесь | ||
Как вы знаете, wind_chill вычисляется, только когда он «холодный», и heat_index, когда он «горячий». И то и другое не требуется. Поэтому, когда вы указываете temp в сегодня, feel_like имеет только одно значение: либо float для wind_chill, либо float для heat_index. Типы внутри объединений не ограничены, вы даже можете использовать структуры внутри объединений. | ||
 Такие утверждения, как следующие, синтаксически приемлемы, но плохой стиль. (См. Стиль.)
Такие утверждения, как следующие, синтаксически приемлемы, но плохой стиль. (См. Стиль.) Массив структур объявляется обычным образом:
Массив структур объявляется обычным образом: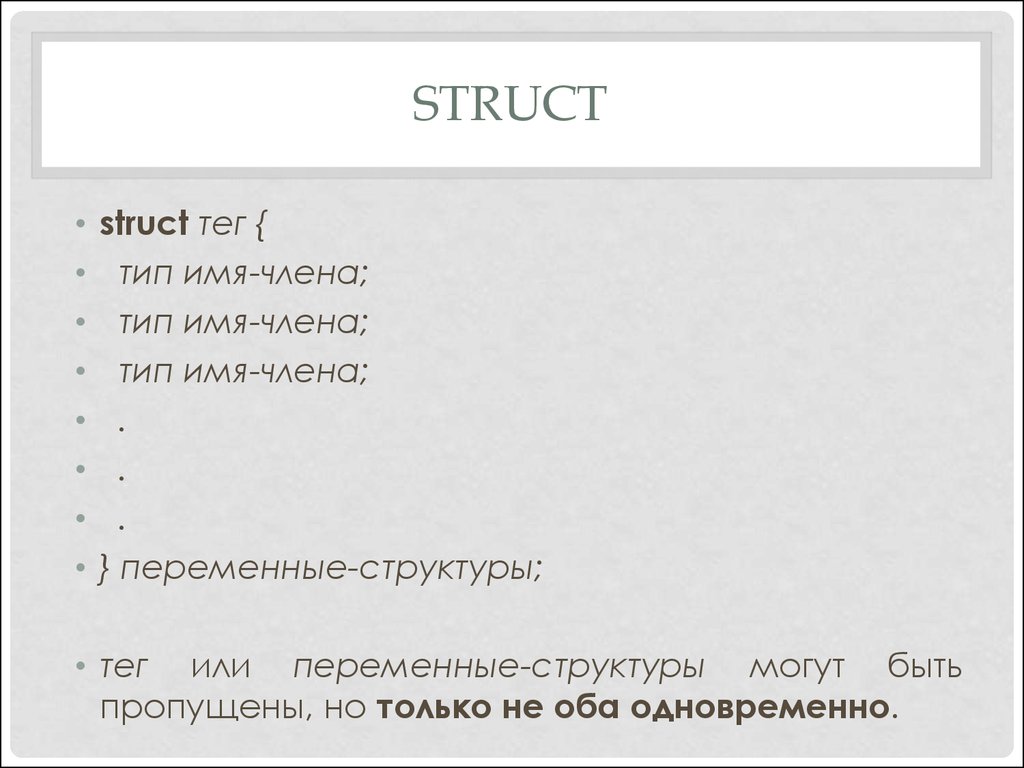 операторы.
операторы. typedef — ваш друг. Используй это.
typedef — ваш друг. Используй это.Сопоставление типов структур и объединений из C — учебник
Это второй пост в серии.Самым первым учебным курсом этой серии является Сопоставление примитивных типов данных из C. Есть также указатели функций сопоставления из C и Mapping Strings из руководств C.
В этом руководстве вы узнаете:
Сопоставление структур и объединений типов C
Лучший способ понять сопоставление между Kotlin и C — это попробовать небольшой пример. Мы объявим структуру и объединение на языке C, чтобы увидеть, как они отображаются в Kotlin.
Kotlin / Native поставляется с инструментом cinterop , инструмент генерирует привязки между языком C и Kotlin.Он использует файл .def , чтобы указать импортируемую библиотеку C. Более подробная информация обсуждается в учебнике «Взаимодействие с библиотеками C.
В предыдущем руководстве вы создали файл lib.h . На этот раз включите эти объявления непосредственно в файл interop.def после разделительной строки --- :
— typedef struct { int a; двойной б; } MyStruct; void struct_by_value (MyStruct s) {} void struct_by_pointer (MyStruct * s) {} typedef union { int a; MyStruct b; float c; } MyUnion; void union_by_value (MyUnion u) {} void union_by_pointer (MyUnion * u) {}
Взаимодействие . достаточно для компиляции и запуска приложения или открытия его в IDE. Пришло время создать файлы проекта, открыть проект в IntelliJ IDEA и запустить его. def
def
Проверка сгенерированных API-интерфейсов Kotlin для библиотеки C
Хотя можно использовать командную строку напрямую или путем объединения ее с файлом сценария (например, .sh или .bat файл), этот подход не работает. плохо масштабируется для больших проектов с сотнями файлов и библиотек. Тогда лучше использовать компилятор Kotlin / Native с системой сборки, поскольку он помогает загружать и кэшировать двоичные файлы и библиотеки компилятора Kotlin / Native с транзитивными зависимостями и запускать компилятор и тесты.Kotlin / Native может использовать систему сборки Gradle через плагин kotlin-multiplatform.
Мы рассмотрели основы настройки IDE-совместимого проекта с Gradle в учебнике «Базовое приложение Kotlin / Native Application». Пожалуйста, проверьте его, если вы ищете подробные первые шаги и инструкции о том, как запустить новый проект Kotlin / Native и открыть его в IntelliJ IDEA. В этом руководстве мы рассмотрим расширенные возможности взаимодействия с C для Kotlin / Native и мультиплатформенных сборок с Gradle.
Сначала создайте папку проекта. Все пути в этом руководстве будут относиться к этой папке. Иногда недостающие каталоги необходимо создать до того, как можно будет добавить какие-либо новые файлы.
Используйте следующий файл сборки build.gradle (.kts) Gradle:
plugins {
id ‘org.jetbrains.kotlin.multiplatform’ версия ‘1.4.32’
} репозитории {
mavenCentral ()
} kotlin {
linuxX64 (‘native’) {// в Linux
// macosX64 (‘native’) {// в macOS
// mingwX64 (‘native’) {// в Windows
сборники.main.cinterops {
взаимодействие
}
двоичные файлы {
исполняемый файл ()
}
}
} wrapper {
gradleVersion = ‘6. 7.1′
distributionType = ‘BIN’
}
7.1′
distributionType = ‘BIN’
}
плагины { котлин («мультиплатформенная») версия «1.4.32» } репозитории { mavenCentral () } kotlin { linuxX64 («native») {// в Linux // macosX64 («native») {// в macOS // mingwX64 («native») {// в Windows val main от compilations.getting val взаимодействие от main.cinterops.creating двоичные файлы { исполняемый файл () } } } задачи.wrapper { gradleVersion = «6.7.1» distributionType = Wrapper.DistributionType.BIN }
Подготовленные исходные коды проекта можно напрямую загрузить с Github:
Файл проекта настраивает взаимодействие C в качестве дополнительного шага сборки. Давайте переместим файл interop.def в каталог src / nativeInterop / cinterop . Gradle рекомендует использовать соглашения вместо конфигураций, например, исходные файлы должны находиться в папке src / nativeMain / kotlin .По умолчанию все символы из C импортируются в пакет interop , вы можете импортировать весь пакет в наши файлы .kt . Ознакомьтесь с документацией плагина kotlin-multiplatform, чтобы узнать обо всех различных способах его настройки.
Создайте файл-заглушку src / nativeMain / kotlin / hello.kt со следующим содержимым, чтобы увидеть, как объявления C видны из Kotlin:
import interop. * fun main () { println («Привет, Котлин / Родной!») struct_by_value (/ * исправь меня * /) struct_by_pointer (/ * исправь меня * /) union_by_value (/ * исправь меня * /) union_by_pointer (/ * исправь меня * /) }
Теперь вы готовы открыть проект в IntelliJ IDEA и посмотреть, как исправить пример проекта.При этом посмотрите, как примитивные типы C отображаются в Kotlin / Native.
Примитивные типы в Kotlin
С помощью IntelliJ IDEA Перейти к | Объявление или ошибки компилятора, вы видите следующий сгенерированный API для функций C, struct и union :
fun struct_by_value (s: CValue  Тип
} конструктор класса MyUnion (rawPtr: NativePtr / * = NativePtr * /): CStructVar {
var a: Int
val b: MyStruct
var c: Float
сопутствующий объект: CStructVar.Type
}
Тип
} конструктор класса MyUnion (rawPtr: NativePtr / * = NativePtr * /): CStructVar {
var a: Int
val b: MyStruct
var c: Float
сопутствующий объект: CStructVar.Type
}
Вы видите, что cinterop сгенерировал типы оболочки для наших типов struct и union . Для объявлений типов MyStruct и MyUnion в C создаются классы Kotlin MyStruct и MyUnion соответственно. Оболочки наследуются от базового класса CStructVar и объявляют все поля как свойства Kotlin.Он использует CValue для представления параметра структуры по значению и CValuesRef, чтобы представить передачу указателя на структуру или объединение.
Технически нет разницы между типами struct и union на стороне Kotlin. Обратите внимание, что свойства a , b и c класса MyUnion в Kotlin используют одно и то же место в памяти для чтения / записи своего значения, точно так же, как union на языке C.
Более подробная информация и расширенные варианты использования представлены в документации
C Interop
Используйте типы структур и объединений из Kotlin
Сгенерированные классы-оболочки для типов C struct и union из Kotlin легко использовать. Благодаря сгенерированным свойствам кажется естественным использовать их в коде Kotlin. Пока что единственный вопрос — как создать новый экземпляр для этих классов. Как видно из объявлений MyStruct и MyUnion , их конструкторам требуется NativePtr .Конечно, вы не хотите иметь дело с указателями вручную. Вместо этого вы можете использовать Kotlin API для создания экземпляров этих объектов для нас.
Давайте посмотрим на сгенерированные функции, которые принимают наши MyStruct и MyUnion в качестве параметров. Вы видите, что параметры по значению представлены как
Вы видите, что параметры по значению представлены как kotlinx.cinterop.CValue. А для параметров типизированного указателя вы видите kotlinx.cinterop.CValuesRef. Kotlin предоставляет нам API, чтобы легко работать с обоими типами, давайте попробуем и посмотрим.
Создать CValue
CValue используется для передачи параметров по значению в вызов функции C. Используйте функцию cValue для создания экземпляра объекта CValue. Функция требует лямбда-функции с приемником для инициализации базового типа C. Функция объявлена следующим образом:
fun
Теперь пора посмотреть, как использовать cValue и передавать параметры по значению:
fun callValue () { val cStruct = cValue
Создать структуру и объединение как CValuesRef
CValuesRef используется в Kotlin для передачи параметра типизированного указателя функции C. Во-первых, вам понадобится экземпляр классов MyStruct и MyUnion . Создавайте их прямо в родной памяти. Используйте
fun
функция расширения на kotlinx.cinterop.NativePlacement для этого.
NativePlacement представляет внутреннюю память с функциями, аналогичными malloc и free . Существует несколько реализаций NativePlacement . Глобальный вызывается с помощью kotlinx.cinterop.nativeHeap и не забудьте вызвать функцию nativeHeap., чтобы освободить память после использования. free (..)
free (..)
Другой вариант — использовать
fun
функция. Он создает кратковременную область выделения памяти, и все выделения будут очищены автоматически в конце блока .
Ваш код для вызова функций с указателями будет выглядеть так:
fun callRef () {
memScoped {
val cStruct = alloc
Обратите внимание, что этот код использует свойство расширения ptr , которое происходит от типа лямбда-приемника memScoped , чтобы превратить экземпляры MyStruct и MyUnion в собственные указатели.
Классы MyStruct и MyUnion имеют указатель на внутреннюю память внизу. Память будет освобождена, когда функция memScoped завершится, что равно концу ее блока .Убедитесь, что указатель не используется вне вызова memScoped . Вы можете использовать Arena () или nativeHeap для указателей, которые должны быть доступны дольше или кэшируются внутри библиотеки C.
Преобразование между CValue и CValuesRef
Конечно, бывают случаи использования, когда вам нужно передать структуру в качестве значения одному вызову, а затем передать ту же структуру в качестве ссылки на другой вызов. Это возможно и в Kotlin / Native. Здесь потребуется NativePlacement .
Давайте теперь посмотрим, CValue сначала превращается в указатель:
fun callMix_ref () {
val cStruct = cValue  ptr)
}
}
ptr)
}
}
Этот код использует свойство расширения ptr , которое происходит от типа лямбда-приемника memScoped , чтобы превратить экземпляры MyStruct и MyUnion в собственные указатели. Эти указатели действительны только внутри блока memScoped .
Для обратного преобразования, чтобы превратить указатель в переменную по значению, мы вызываем функцию расширения readValue () :
fun callMix_value () {
memScoped {
val cStruct = alloc
Выполните код
Теперь, когда вы узнали, как использовать объявления C в своем коде, вы готовы опробовать это на реальном примере. Давайте исправим код и посмотрим, как он работает, вызвав задачу runDebugExecutableNative Gradle в среде IDE или используя следующую консольную команду:
./ gradlew runDebugExecutableNative
Последний код в файле hello.kt может выглядеть следующим образом:
import interop. *
импорт kotlinx.cinterop.alloc
import kotlinx.cinterop.cValue
import kotlinx.cinterop.memScoped
импорт kotlinx.cinterop.ptr
import kotlinx.cinterop.readValue fun main () {
println («Привет, Котлин / Родной!») val cUnion = cValue
Следующие шаги
Продолжите изучение типов языков C и их представления в Kotlin / Native в соответствующих руководствах:
Документация C Interop охватывает более сложные сценарии взаимодействия.
Последнее изменение: 11 февраля 2021 г.
Вложенные структуры в C — DEV Community
Вложенные структуры
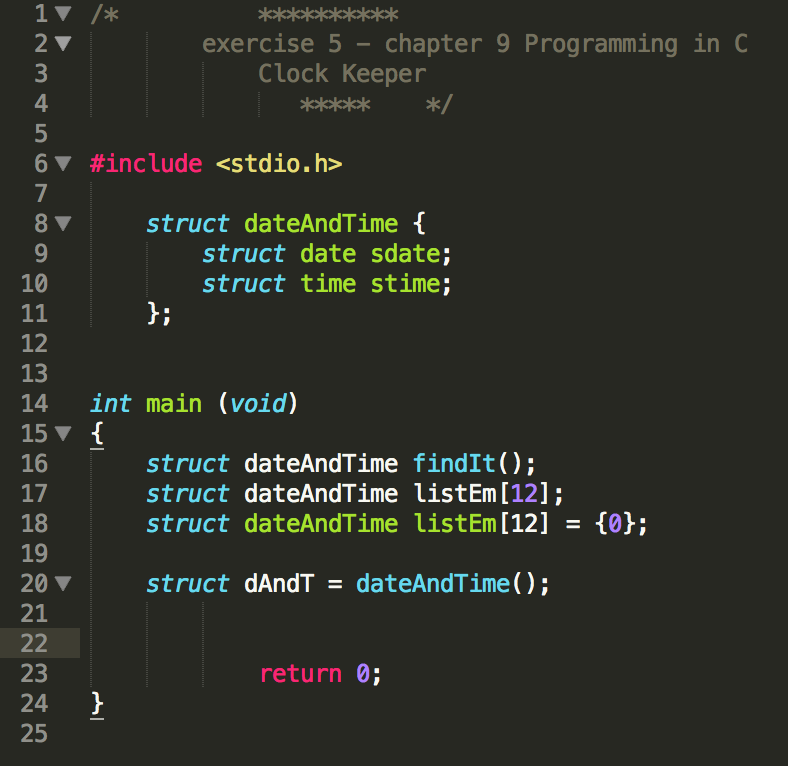
C также позволяет вам определять структуру, которая сама содержит другие структуры в качестве одного или нескольких своих членов.Если программе, над которой вы работаете, требуется метка времени, удобным способом связать их вместе было бы определение новой структуры, которая содержит как время, так и дату в качестве элементов-членов:
структура dateAndTime
{
struct date sDate;
struct time sTime;
};
Войти в полноэкранный режимВыйти из полноэкранного режима Теперь вы можете создать экземпляр dateAndTime, который содержит структуры даты и времени:
struct dateAndTime timestamp;
// для доступа к членам, как обычно, используется точечная нотация:
отметка времени.sDate;
// для ссылки на конкретный член внутри одной из этих структур используется тот же синтаксис:
timestamp.sDate.month = 10;
// увеличивает секунды внутри sTime члена dateAndTime
++ timestamp.sTime.seconds;
// инициализация даты и времени внутри метки времени
// устанавливает дату на 1 февраля 2018 г. в 3:30:00
struct dateAndTime timestamp = {{2, 1, 2018}, {3, 30, 0}};
// как и другие структуры, точечная нотация может использоваться для инициализации определенных переменных-членов
// и, хотя он более типизирован, более читабелен.Это не зависит от порядка:
struct dateAndTime timestamp = {
{.month = 2, .day = 1, .year = 2018},
{.hour = 3, .minutes = 30, .seconds = 0}
};
Войти в полноэкранный режимВыйти из полноэкранного режима Также возможно создать массив структур dateAndTime. Индекс массива вместе с точечной нотацией используются так же, как и с невложенной структурой внутри массива:
struct dateAndTime timestamp [100];
отметка времени [0] .sTime.hour = 3;
отметка времени [0].sTime.minutes = 30;
отметка времени [0] .sTime.seconds = 0;
Войти в полноэкранный режимВыйти из полноэкранного режима Можно объявить структуру внутри структуры в пределах фактического определения, он следует тому же синтаксису, что и объявление структурной переменной во время определения, но ИМО это не так читаемо, как более длинные способы их объявления, но, как и в большинстве случаев, это вопрос личных предпочтений:
время структуры
{
дата структуры
{
int день;
int месяц;
int год;
} Дата рождения;
int час;
int минута;
int секунды;
}
Войти в полноэкранный режимВыйти из полноэкранного режима Приведенное выше объявление заключено в область определения временной структуры и не существует вне ее. Вы не сможете объявить переменную даты, внешнюю по отношению к временной структуре.
Вы не сможете объявить переменную даты, внешнюю по отношению к временной структуре.
анонимных структур в C
анонимных структур в C«Анонимные» структуры в C
Определение / объявления структуры могут иметь «двойное назначение» в C. Они могут определять типы данных и они могут объявлять объекты данных, и они могут даже делать и то, и другое одновременно. (Большинство других языков не так гибки, как C в этом отношении, и, честно говоря, такая гибкость не является чем-то, что мне нравится в C.)
- Вот определение именованного структурированного типа, который не объявляет никаких объектов:
Пример структуры
{
int dumb;
плавать глупо;
};На самом деле мы не объявили никакой структуры пример объекты; но мы определили тип данных с именем struct пример, поэтому в будущем мы можем использовать его для объявления объектов или в качестве аргумента для sizeof и т. д.Например.,
пример структуры x, y [10], z; который создает в общей сложности 12 объектов типа struct example
- Вот объявление массива структурированных объектов:
структура
{
int x, y;
} баллы [50];Это пример анонимной структуры типа .Поскольку мы не назвали тип структуры, мы никогда не сможем ссылаться на нее в другом месте нашего кода; этот массив назван points содержит единственные объекты этого типа, которые когда-либо будут существовать.
- Вот пример, который делает и то, и другое:
структурная точка
{
int x, y;
} points_on_a_plane [50];
- А вот пример совершенно бессмысленного, но неэтичного юридического кода на C:
структура
{
int x, y;
};
Примеры исходного кода для наших учебных модулей
Компоненты веб-решения Пример из учебного курса Well House ConsultantsПодробнее о компонентах веб-решения [ссылка]
Исходный код: примеры. txt Модуль: A100
txt Модуль: A100
Эта страница является только примером — вы запустили сценарий «Пример исходного кода
» на веб-сайте Well House Consultants, но
вы не сказали нам, какой пример вам нужен. Пожалуйста, перейдите по
по приведенным ссылкам, чтобы найти конкретный пример
, который вы ищете.
Узнать об этом предмете
Книги по этой теме
Да. В нашей библиотеке более 700 книг. Книги Прикрывающее развертывание лампы перечислены здесь, и когда вы выбрали соответствующую книгу мы свяжем вас с Amazon для заказа.Другие примеры
Этот пример взят из нашего учебного модуля «Компоненты веб-решения». Вы найдете описание темы и некоторые другие тесно связанные примеры на индексной странице модуля «Компоненты веб-решения».Полное описание исходного кода
Вы можете узнать больше об этом примере на учебных курсах, перечисленных на этой странице, на котором вы получите полный набор обучающих заметок.Многие другие учебные модули доступны для загрузки (для ограниченного использования) с наш центр загрузки под Лицензия Open Training Notes.
Другие ресурсы
• В нашем центре решений есть ряд более длинных технических статей.• В нашем архиве форумов Opentalk есть центр вопросов и ответов.
• Лошадиный рот дает ежедневные подсказки или мысли.
• Дополнительные ресурсы доступны через ресурсный центр.
• Все эти ресурсы можно искать с помощью нашей поисковой системы
• И здесь есть глобальный индекс.
Назначение этого сайта
Это образец программы, демонстрация класса или ответ от учебный курс.Это основная цель заключается в предоставлении послекурсовых услуг клиентам, которые посещали наши общественное частное или на сайте курсы, но примеры сделаны обычно доступны при условиях, описанных ниже.Автор веб-сайта
Этот веб-сайт написан и поддерживается Консультанты Well House.Условия использования
Прошедшие участники наших учебных курсов могут использовать индивидуальные примеры в процессе их программирования, но необходимо проверить примеры, которые они используют, чтобы убедиться, что они подходят для их работа.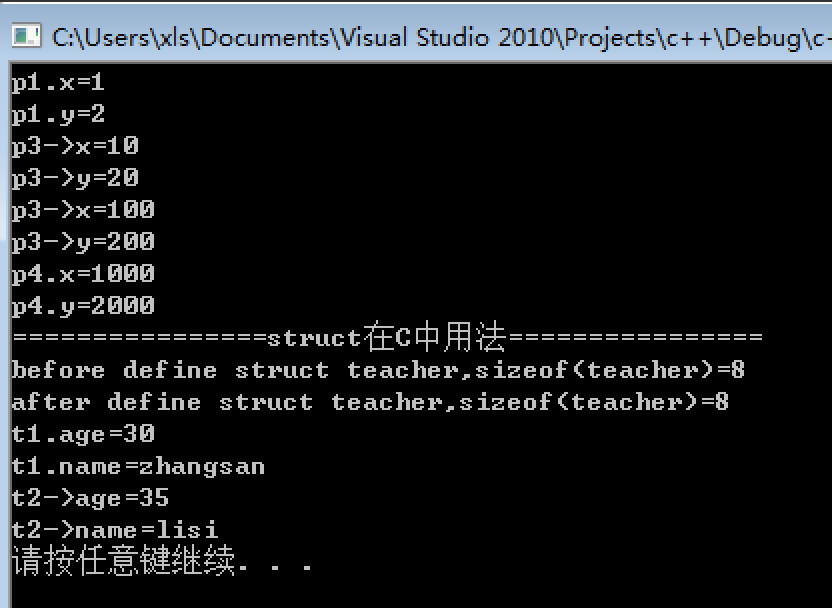 Помните, что некоторые из наших примеров показывают вам, как , а не делать
вещи — проверяйте в своих заметках. Well House Consultants не несет ответственности
на предмет соответствия этих примеров программ потребностям клиентов.
Помните, что некоторые из наших примеров показывают вам, как , а не делать
вещи — проверяйте в своих заметках. Well House Consultants не несет ответственности
на предмет соответствия этих примеров программ потребностям клиентов.Авторские права на эту программу принадлежат Well House Consultants Ltd. запрещено использовать его для проведения собственных учебных курсов без нашего предварительного письменного разрешения. Смотрите наши страницу о предоставлении учебных программ для получения более подробной информации.
Любое из наших изображений в этом коде ЗАПРЕЩАЕТСЯ повторно использовать в общедоступном URL-адресе без нашего предварительное разрешение.Для добросовестного личного использования мы часто предоставляем вам разрешение. что вы предоставляете обратную ссылку. За коммерческое использование веб-сайта взимается лицензионный сбор за каждое использованное изображение — детали по запросу.
Взаимозависимые структуры — Учебники по Си
Вопрос: Что такое взаимозависимые структуры в C?Ответ: Две структуры, например, A и B, называются взаимозависимыми, если один из членов каждой относится к другой структуре. Например,
struct A {
struct B b;
значение int;
};
struct B {
struct A a;
плавучая шерсть;
}; Могут ли эти объявления структур быть достаточным условием для взаимозависимых структур?
Конечно, член «b» структуры A относится к структуре B, а член «a» структуры B относится к структуре A.Но что произойдет, когда вы скомпилируете приведенный выше фрагмент кода. Компилятор выдает ошибку при обработке строки
, а ошибка — структура B не известна до этой строки. Итак, мы пытаемся перевернуть объявления как,
struct B {
struct A a;
плавучая шерсть;
};
struct A {
struct B b;
значение int;
}; Теперь мы поместили объявление структуры B перед объявлением структуры A и скомпилировали фрагмент кода.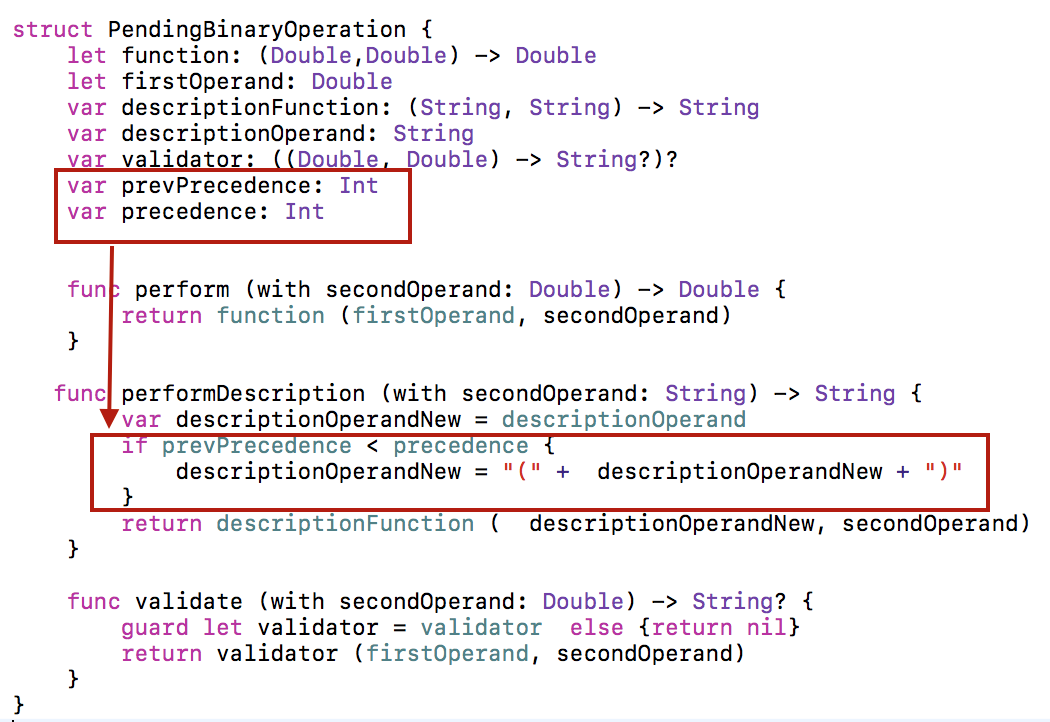 Опять же, тот же тип ошибки, и это структура A, неизвестна при компиляции строки
Опять же, тот же тип ошибки, и это структура A, неизвестна при компиляции строки
Должны ли мы использовать указатель как член первой структуры для ссылки на вторую структуру
и наоборот? Давайте попробуем и это,
struct B {
struct A * a;
плавучая шерсть;
};
struct A {
struct B * b;
значение int;
}; А теперь? Для компилятора не составляет труда решить, сколько памяти выделить
для члена «a» структуры B i.е. в строках
, потому что «a» — указатель. Но «a» — это указатель на структуру A, а структура A не известна компилятору до этой строки. Хотя объявление struct A дается после объявления struct B, компилятор требует его до строки
Это делается с использованием концепции неполного или частичного объявления. Давайте посмотрим на простую программу для понимания взаимозависимых структур.
/ * * mutuallydependant.c - программа объявляет взаимозависимые структуры * и получить доступ к членам первого, используя член второго, который является указателем * к первому * / / * в программе используется концепция неполных объявлений * / # включитьstruct A; / * Частичное объявление структуры A * / struct B {/ * НОВЫЙ тег для списка памяти * / int roll_no; плавающие знаки; struct A * p2A; / * 'p2A' - это ptr-to-struct типа A * / }; struct A { поплавок дождя [5]; struct B * p2B; / * 'p2B' - это ptr-to-struct типа B * / начальный символ; }; int main (пусто) { int я = 0; struct B u; struct A a = {{1.1, 2.43, 2.01, 3.34, 2.213}, & u, 'A'}; структура B b = {44, 58.0, & a}; put ("Позволяет получить доступ к элементам структуры \ 'a \' с помощью элемента-указателя" "\ 'p2A \', указатель на структуру \ 'a \', а также член" "структура \ 'б \' \ п"); / * первый член структуры 'a' - это массив 'rain [5]' * / printf ("Первый член \ 'a \' - это массив \ 'дождя из 5 поплавков \':"); для (я = 0; я <5; я ++) printf ("%. 2f", (b.p2A) -> дождь [i]); кладет ("\ п"); / * второй член структуры 'a' - указатель на структуру B * / printf ("Второй член структуры \ 'a \' - указатель на структуру" "\ 'u \' типа struct B, \ n"); printf ("Посмотрим адрес структуры \ 'u \':"); printf ("% p", (b.p2A) -> p2B); кладет ("\ п"); printf ("Последний член структуры \ 'a \' - это символ:"); printf ("% c", (b.p2A) -> начальный); кладет ("\ п"); возврат 0; }
Вывод программы следующим образом:
Позволяет получить доступ к элементам структуры 'a', используя член-указатель 'p2A', указатель на структуру 'a', а также член структуры 'b' Первый член 'a' - это массив 'rain of 5 float': 1,10 2,43 2,01 3,34 2,21 Второй член структуры 'a' - указатель на структуру 'u' типа struct B, посмотрим адрес структуры 'u': 0x7fff9ce0c020 Последний член структуры 'a' - символ: A
Обратите внимание, что в приведенной выше программе мы объявили неполное объявление структуры A перед объявлением структуры B, чтобы компилятор знал, что где-то в программе существует объявление структуры A. И компилятор теперь знает, сколько памяти выделить члену-указателю структуры B, относящемуся к структуре A, и члену-указателю структуры A, относящемуся к структуре B. Можете ли вы догадаться, что бы произошло, если бы мы использовали переменные вместо элементов-указателей в декларации? Хотя все просто, лучше попробуй!
Далее, мы получили доступ к элементам структуры «a», используя элемент-указатель «p2A» структуры «b», который ссылается на структуру «a».
Sanfoundry Global Education & Learning Series — Учебники по 1000 C.
Если вы хотите просмотреть все учебные пособия по C, перейдите к учебным пособиям по C. Примите участие в конкурсе сертификации Sanfoundry, чтобы получить бесплатную Почетную грамоту. Присоединяйтесь к нашим социальным сетям ниже и будьте в курсе последних конкурсов, видео, стажировок и вакансий!.