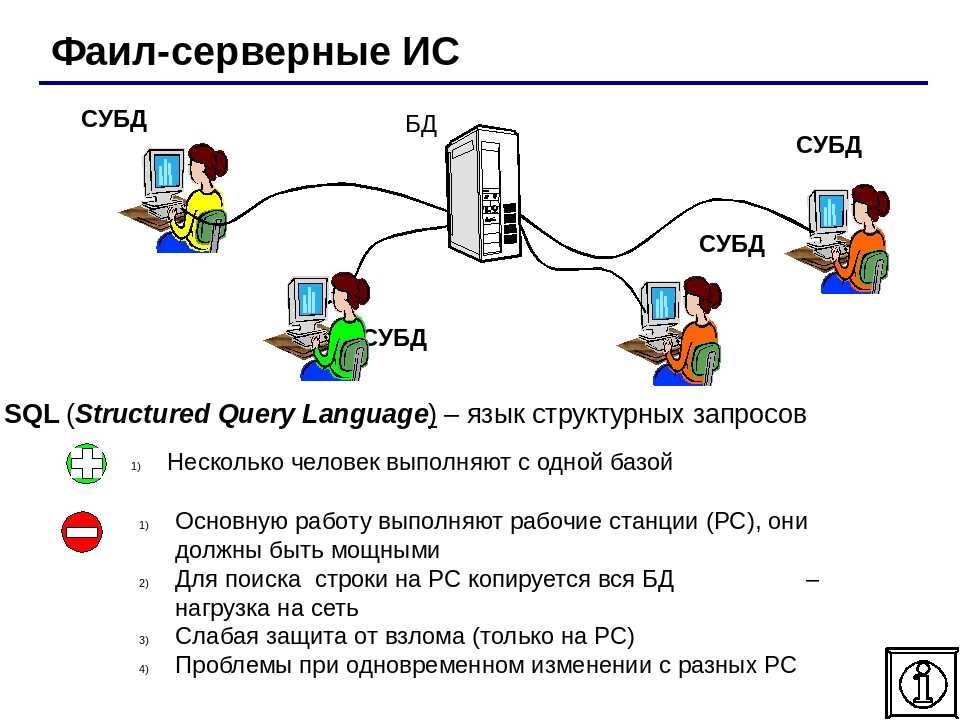
1. Понятие информации и данных. База данных (бд). Определение, назначение.
Информация – это сведения о чём-либо, независимо от формы их представления.
В
настоящее время не существует единого
определения информации как научного термина.
С точки зрения различных областей знания
данное понятие описывается своим
специфическим набором признаков.
Например, понятие «информация» является
базовым в курсе информатики,
и невозможно дать его определение через
другие, более «простые» понятия (так
же, в геометрии, например, невозможно
выразить содержание базовых понятий
«точка», «прямая», «плоскость» через
более простые понятия). Содержание
основных, базовых понятий в любой науке
должно быть пояснено на примерах или
выявлено путём их сопоставления с
содержанием других понятий. В случае с
понятием «информация» проблема его
определения ещё более сложная, так как
оно является общенаучным понятием.
Данное понятие используется в различных
науках (информатике, кибернетике,
биологии, физике и др.
База данных — это информационная модель, позволяющая упорядоченно хранить данные о группе объектов, обладающих одинаковым набором свойств. Базами данных являются, например, различные справочники, энциклопедии и т. п. Информация в базах данных хранится в упорядоченном виде. Так, в записной книжке все записи упорядочены по алфавиту, а в библиотечном каталоге либо по алфавиту (алфавитный каталог), либо в соответствии с областью знания (предметный каталог). Существует несколько различных типов баз данных: табличные, иерархические и сетевые. Табличные базы данных. Табличная база данных содержит перечень объектов одного типа, т. е. объектов с одинаковым набором свойств. Такую базу данных удобно представлять в виде двумерной таблицы.
a) ИЕРАРХИЧЕСКАЯ БАЗА ДАННЫХ.
Каждый
объект при таком хранение информации
представляется в виде определенной
сущности, то есть, у этой сущности могут
быть дочерние элементы, родительские
элементы, а у тех дочерних могут быть
еще дочерние элементы, но есть один
объект, с которого все начинается.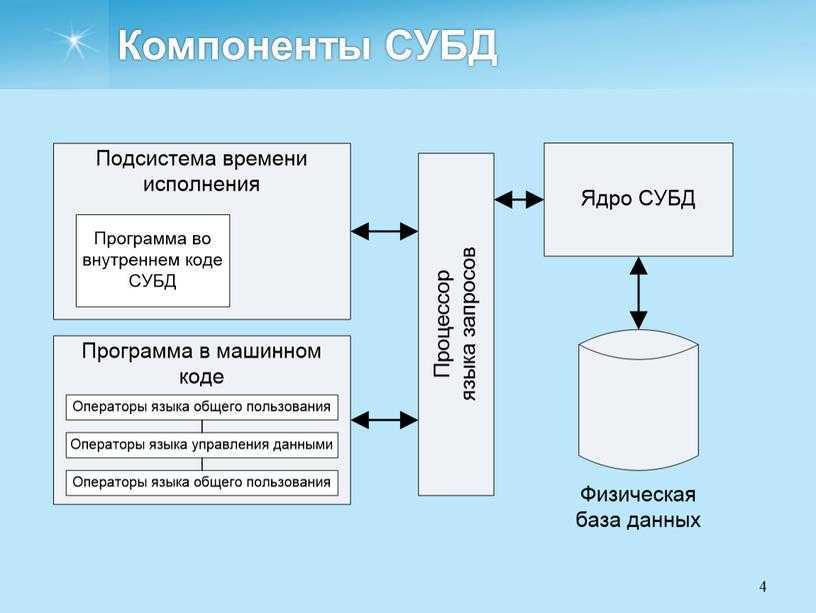
Следует сказать, что базы данных подобного вида оптимизированы под чтение информации, то есть, базы данных, имеющие иерархическую структуру умеют очень быстро выбирать, запрашиваемую информацию и отдавать ее пользователям. Но такая структура не позволяет столь же быстро перебирать информацию, тут можно привести пример из жизни, компьютер может легко работать с каким-либо конкретным файлом или папкой (которые, по сути являются объектами иерархической структуры) но проверка компьютера антивирусам осуществляется очень долго.
Б) СЕТЕВАЯ БАЗА ДАННЫХ
Сетевые
базы данных, являются своеобразной
модификацией иерархических баз данных.
Если вы внимательно смотрели на рисунок
выше, то наверное обратили внимание,
что к каждому нижнему элементу идет
только одна стрелочка от верхнего
элемента. То есть у иерархических баз
данных у каждого дочернего элемента
может быть только один потомок. Сетевые
базы данных отличаются от иерархических
тем, что у дочернего элемента может быть
несколько предков, то есть, элементов
стоящих выше него.
То есть у иерархических баз
данных у каждого дочернего элемента
может быть только один потомок. Сетевые
базы данных отличаются от иерархических
тем, что у дочернего элемента может быть
несколько предков, то есть, элементов
стоящих выше него.
В) РЕЛЯЦИОННЫЕ БАЗЫ ДАННЫХ
Реляционные базы данных получили очень широкое распространение и многие пытаются писать огромные статьи, посвященные вопросу – почему реляционные базы данных получили такое широкое распространение, делают глубокомысленные выводы и замечания. Но на самом деле все очень просто – реляционные базы данных очень легко описываются в математике, то есть, под них очень хорошо написана математика.
Был
когда-то такой математик – Эдгар Франк
Кодд, умерший в 2003 году, который в
восьмидесятых годах очень подробно
описал структуру реляционных баз данных
математическим языком. А если есть
хорошо написанная математика, то
соответственно есть и программная
реализация.
Именно благодаря Кодду реляционные базы данных стали активно развиваться. Поэтому-то, когда мы говорим базы данных, чаще всего мы подразумеваем именно реляционные базы данных.
Системы управления базами данных. Типы баз данных 9 класс онлайн-подготовка на Ростелеком Лицей
Тема: Технологии поиска и хранения информации
Урок: Системы управления базами данных. Типы баз данных
1. Выгоды внедрения баз данных
Обобщая опыт использования информационных систем, можно перечислить основные выгоды от их внедрения:
Получение быстрого результата при поиске нужной информации
Освобождение сотрудников от рутинной работы
Обеспечение достоверности получаемой информации
Уменьшение затрат на производство товаров и услуг
2. Определение баз данных
В основе современной информационной системы лежит база данных, которая являет собой совокупность структурированных данных, предназначенных для хранения, накопления и обработки с помощью компьютеров.
Структурирование – это способ систематизации данных: выбор однотипных объектов, определение общих характеристик, их описывающих, и связей между ними.
Комплекс программ, обеспечивающих хранение и обработку таких данных (например, обновление или сортировку) и быстрый доступ к информации по запросу, называется СУБД – системой управления базой данных.
3. Основные типы баз данных, их структуры
Основные типы (модели) баз данных:
Реляционные – используют табличное представление данных;
Иерархические – используют структуру данных в виде деревьев;
Сетевые – используют структуру в виде сети с множественными связями между данными, т. е. в виде графа.
4. Этапы развития моделей баз данных
В реляционной модели базы данных все данные можно представить в виде множества записей, которые, в свою очередь, организованы в виде электронных таблиц. Получить представление о структуре модели можно, если мы представим себе организацию информации об учащихся образовательного учреждения. Такую информацию можно представить в виде нескольких таблиц.
Такую информацию можно представить в виде нескольких таблиц.
Допустим, в одной таблице столбцами будут фамилия, имя, отчество, далее может быть адрес, телефон, сведения о родителях. Это была первая таблица. В другой таблице могут храниться данные об успеваемости ученика, например, столбцами такой таблицы будут фамилия, имя, а дальше названия предметов – математика, русский язык, химия, физика и т. д. В третьей таблице можно хранить информацию для медицинского кабинета, например, ФИО ученика, год рождения, рост, вес, сведения о прививках и т. д. Между всеми этими таблицами можно организовать связи. Например, если ученик переводится в другую школу, то данные о нем удаляются из одной таблицы, но, поскольку между таблицами организованы связи, то автоматически произойдет удаление информации из всех других таблиц.
Теоретические разработки моделей баз данных начались в 50-е годы. В 60-е годы они получили новое развитие, в связи с появлением таких устройств внешней памяти, как жесткий диск, на которых стало возможным хранить большие объемы информации. В 70-е, 80-е годы эти разработки продолжались, и такие фирмы, как Oracle, IBM выпустили свои системы управления базами данных.
В 70-е, 80-е годы эти разработки продолжались, и такие фирмы, как Oracle, IBM выпустили свои системы управления базами данных.
В 90-х годах прошлого столетия особое распространение получила реляционная модель баз данных. Она оказалась очень удобной для приложений, построенных на архитектуре клиент-сервер, которые используются в компьютерных сетях.
Вся система управления базами данных подразделяется на две части: клиентскую и серверную. Клиентская часть отвечает за ввод данных и представление информации для пользователя, а серверная часть отвечает за обработку запросов, идущих от пользователя и обработку информации, выдачу результата обработки.
5. Логическая структура иерархической модели
Логическая структура иерархической модели базы данных может быть представлена в виде дерева (рис. 1). Все объекты такой модели существуют на разных уровнях, причем, есть понятия предок и потомок.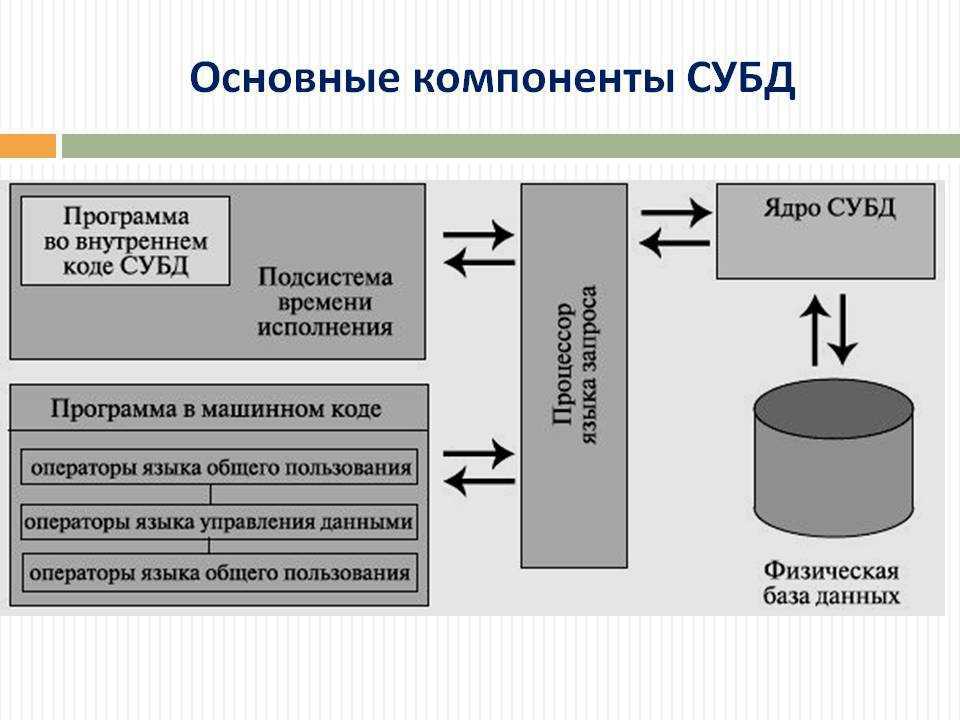 Объект предок находится ближе к корню, у каждого предка может быть один или несколько потомков, так же как их может не быть вовсе (объект 3 уровня справа). Но у каждого потомка обязательно есть предок. Те объекты, которые находятся на одном уровне и имеют общего предка, принято называть близнецами (рис. 2).
Объект предок находится ближе к корню, у каждого предка может быть один или несколько потомков, так же как их может не быть вовсе (объект 3 уровня справа). Но у каждого потомка обязательно есть предок. Те объекты, которые находятся на одном уровне и имеют общего предка, принято называть близнецами (рис. 2).
Рис. 1
Рис. 2
Для того чтобы наглядно представить себе такую вот логическую модель, представим себе электронный каталог библиотеки (рис. 3). В библиотеке есть разделы, например, детская литература, художественная, научно-техническая литература. Это все объекты одного уровня (рис. 4). Следующий уровень – это авторы (рис. 5) и самый низкий уровень – это названия книг данных авторов.
Рис. 3
Рис. 4
Рис. 5
Иерархия (от греч. – «священный» и «власть») – это расположение частей или элементов целого в порядке от высшего к низшему.
6. Сетевая модель баз данных
Сетевая модель базы данных – это самая сложная модель, поскольку допускает множественные связи между объектами.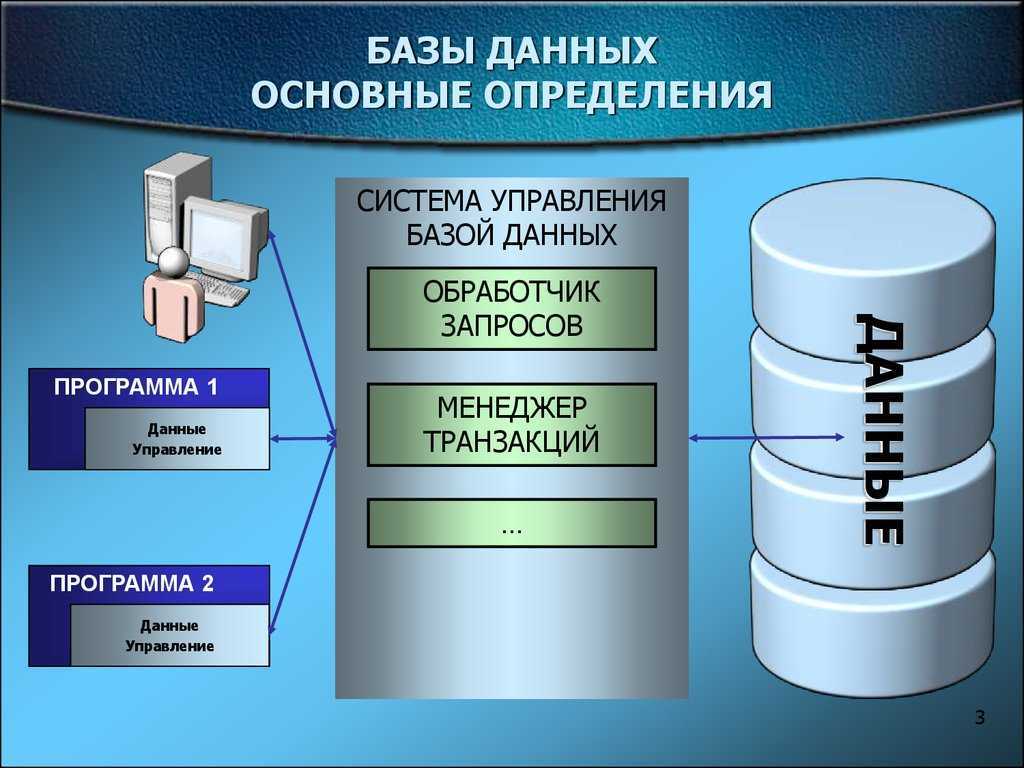 Если в иерархической модели у каждого объекта может быть один предок, то у сетевой модели каждый объект может быть связан с любым количеством других объектов.
Если в иерархической модели у каждого объекта может быть один предок, то у сетевой модели каждый объект может быть связан с любым количеством других объектов.
Такую модель можно себе представить на примере базы данных школы (рис. 6).
Рис. 6
Объектами одного уровня являются такие объекты, как Преподаватель начальной школы, Преподаватель старшей школы, Классный руководитель. На следующем уровне находится Преподаватель. Преподаватель может быть связан со всеми объектами, которые мы только что перечислили, поскольку он может быть и преподавателем начальной школы, и преподавателем средней школы, и классным руководителем, например, учитель музыки.
7. Приложения для создания баз данных и работы с ними
Существуют специальные приложения для создания баз данных такие, как:
Paradox
Oracle
dBase
FoxPro
OpenOffice.org Base
Microsoft Office Access и т. д.
Они постоянно развиваются, появляются новые версии этих приложений, например, приложение FoxPro девятой версии работает под операционной системой Windows 7.
8. Заключение
Существуют также специальные языки программирования для создания баз данных. К таким языкам относится
Список литературы
- Угринович Н.Д. Информатика-9. – М.: БИНОМ. Лаборатория знаний, 2012.
- Гейн А.Г., Юнерман Н.А. Информатика-9. – М.: Просвещение, 2012.
- Соловьёва Л.Ф. Информатика и ИКТ. Учебник для 9 класса. – СПб.: БХВ-Петербург, 2007.
Дополнительные рекомендованные ссылки на ресурсы сети Интернет
- Site-do.ru (Источник).
- 5byte.ru (Источник).
Домашнее задание
- Что такое СУБД? Какие виды баз данных существуют?
- В чем заключается различие между иерархическими и сетевыми моделями баз данных?
- Что такое структурирование?
- На сколько частей подразделяется современная система управления базами данных? Назовите каждую из них.

Моделирование подразделений
Создано 31 марта 2011 г., 15:17.
Моделирование подразделения — это метод цифрового 3D-моделирования, используемый для создания чистых моделей с масштабируемой детализацией, которые хорошо выглядят при визуализации. Он в той или иной степени используется почти во всех отраслях, в которых работают цифровые художники. Говоря это, часто на усмотрение художника или инструмента, какую технику моделирования они предпочитают использовать. Другими популярными методами являются моделирование по полигонам, nurb-моделирование и цифровая скульптура.
Техника и последующее искусство моделирования подразделений возникли более или менее естественным образом из-за нескольких аспектов или явлений в том, как обычно визуализируется цифровое искусство. Двумя основными примерами этого являются метод по умолчанию, с помощью которого вычисляются нормали вершин, и способ, которым работает подразделение Кэтмулла – Кларка (в честь которого назван метод).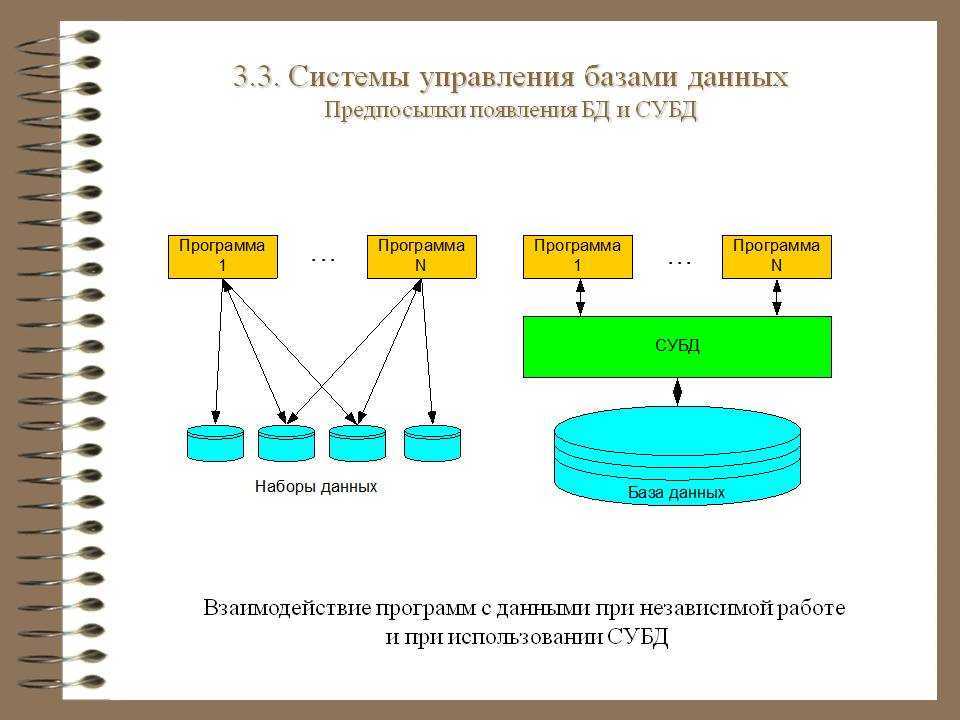
Пример модели подразделения
Вершина — это точка в пространстве, где встречаются различные линии (или ребра). Их можно рассматривать как углы геометрических фигур. Когда компьютер отображает форму на экране, есть два варианта. Либо он может визуализировать каждый многоугольник (или грань) этой формы как плоскую поверхность и выполнять расчеты освещения на основе этого, либо он может попытаться визуализировать некоторую сглаженную версию той же формы. Этот второй вариант часто является тем, что нам нужно, и именно здесь используются нормали вершин.
Если вместо того, чтобы смотреть на нормали грани (направление, на которое указывает грань), визуализатор смотрит на нормали вершин (направление, на которое указывает угол), то он может интерполировать (своего рода усреднение) это направление по треугольной грани. рендеринг, придающий ему плавный вид. На самом деле, для любого треугольника графические карты специально разработаны так, чтобы иметь возможность очень быстро интерполировать нормали от трех вершин в каждом углу.
Но, прежде чем мы сможем сделать эту интерполяцию, мы должны разработать фактические нормали вершин для использования. На самом деле найти направление, на которое указывает вершина, невозможно (у нее нет поверхности, поэтому нет и нормали), но обычно мы просто усредняем нормали граней для всех граней, прикрепленных к этой вершине, и используем это как приближение к нормальному.
Это позволяет нам рендерить гладкие поверхности с использованием угловой геометрии (и фиксированного количества полигонов), но за это приходится платить. Во многих случаях это работает не совсем так, как ожидалось, и может привести к визуальным артефактам или участкам освещения, которые выглядят странно. Они возникают из-за проблем с аппроксимацией нормалей вершин, а также с интерполяционными вычислениями по треугольникам. Но с хорошей сеткой эти артефакты можно свести к минимуму или даже преодолеть, и именно здесь вступает в действие моделирование подразделения.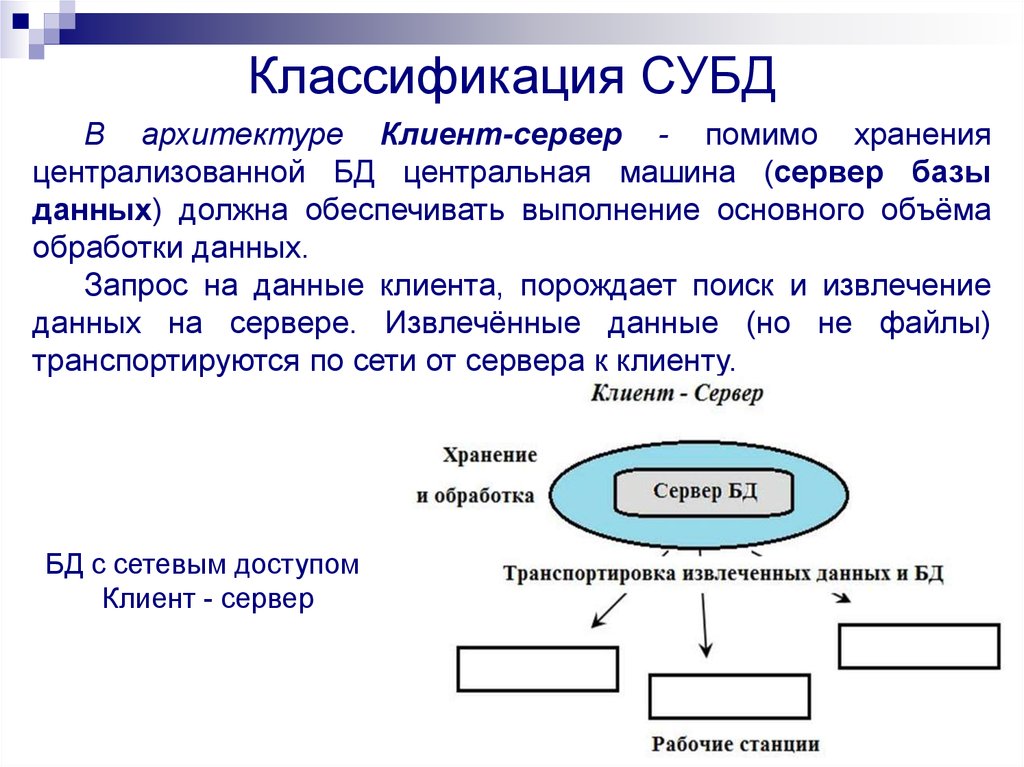 0005
0005
В компьютерной графике практически для всего используются новые термины. Я, вероятно, уже бросил вам несколько новых, которые я буду пересматривать здесь, но как только вы освоитесь с ними, все станет намного проще объяснить. Причина, по которой некоторые из этих вещей имеют имена, также станет очевидной позже.
- Вершина — Точка в пространстве, где встречаются ребра, угол фигуры.
- Ребро — Соединение между двумя вершинами.
- Многоугольник — Грань трехмерной формы, соединяющая несколько вершин через ребра.
- Сетка — Набор полигонов, фигура в 3D пространстве. Также упоминается как модель или тело.
- Треугольник — Многоугольник ровно с тремя вершинами.
- Quad — Многоугольник с ровно четырьмя вершинами.
- N-Gon — Многоугольник с пятью и более вершинами.

- Полюс — Вершина, из которой выходят три ребра.
Спрашивать, что делает хорошую сетку, почти то же самое, что спрашивать, что делает хорошую картину. Как и в большинстве случаев в жизни, здесь нет простого ответа, и, по правде говоря, хорошее моделирование действительно требует практики. Когда вы хорошо разбираетесь в подразделении, вы можете почувствовать, что делает хорошую сетку, и это будет видно при рендеринге. Тем не менее, безусловно, есть некоторые рекомендации, которым вы можете следовать, чтобы свести к минимуму визуальные артефакты и сделать вашу жизнь намного проще. Вот некоторые из основных. (Здесь стоит отметить, что эти рекомендации также применимы почти ко всем видам создания мешей и никоим образом не относятся к моделированию подразделений.)
Избегайте треугольников и полюсов
Треугольники и полюса можно рассматривать как две стороны одной медали. Они часто являются причиной странных артефактов сглаживания, поэтому их следует избегать, когда это возможно. Однако полностью избежать их просто невозможно; любая сетка потребует их некоторого количества. Часто их размещают с попыткой минимизировать их эффект. Есть два основных способа сделать это: либо разместить их на относительно плоской поверхности, либо «спрятать» их в плотно закрытых областях сетки. У человеческих персонажей это часто делается в подмышках, паху, суставах или вообще в любом месте с естественными складками на поверхности.
Они часто являются причиной странных артефактов сглаживания, поэтому их следует избегать, когда это возможно. Однако полностью избежать их просто невозможно; любая сетка потребует их некоторого количества. Часто их размещают с попыткой минимизировать их эффект. Есть два основных способа сделать это: либо разместить их на относительно плоской поверхности, либо «спрятать» их в плотно закрытых областях сетки. У человеческих персонажей это часто делается в подмышках, паху, суставах или вообще в любом месте с естественными складками на поверхности.
Полюса и треугольники, «спрятанные» на плоской части ключа
Избегайте N-угольников и N-полюсов
с использованием тех же приемов. Обычно люди стараются избегать их больше, чем треугольников или полюсов. В основном это связано с тем, что их сложнее моделировать, и с тем фактом, что чем больше количество ребер, входящих в полюс, или количество сторон лица, тем более странными становятся проблемы сглаживания.
Старайтесь строить свою сетку в основном из четырехугольников
Этот пункт часто кажется немного неверным для новичков. Например, если у вас есть некоторые знания о графике, вы знаете, что модели в любом случае всегда визуализируются только с использованием треугольников — все четырехугольники превращаются в треугольники перед визуализацией, обычно путем соединения ребра между двумя ближайшими вершинами. Таким образом, попытка построить свою сетку в основном из четырехугольников может показаться довольно избыточной и глупой. Но, по правде говоря, построение сетки с учетом четырехугольников — это самый простой способ избежать всех других плохих вещей, которые могут вызвать визуальные артефакты.
Не только это, но есть много-много причин, по которым работать с квадратными сетками проще, чем с другими запутанными и запутанными сетками. Их легче анимировать, легче смонтировать и проще практически с любой другой задачей, которую вы можете с ними выполнять.
Видео, показывающее наглядные примеры артефактов подразделения
Равномерное размещение вершин , вершины и детали. Это не нужно, и это не будет хорошо выглядеть, когда дело доходит до времени рендеринга. Что происходит, когда у вас есть сетка, полная продолгов, а не квадратов, вы получаете множество длинных тонких треугольников во время рендеринга. Это вызовет проблемы с интерполяцией и, как правило, будет выглядеть плохо. Слишком тонкие связки образуют на сетке что-то похожее на жесткие швы, что во многих случаях нежелательно.
Также идея состоит в том, чтобы расположить вершины так, чтобы плотность увеличивалась в областях с большим количеством деталей. Это придаст вашей сетке дополнительное определение там, где это необходимо, и не будет тратить полигоны в другом месте.
Хорошо расположенная голова
Фокус на теле, форме и потоке это не совсем соответствует моделируемому объекту.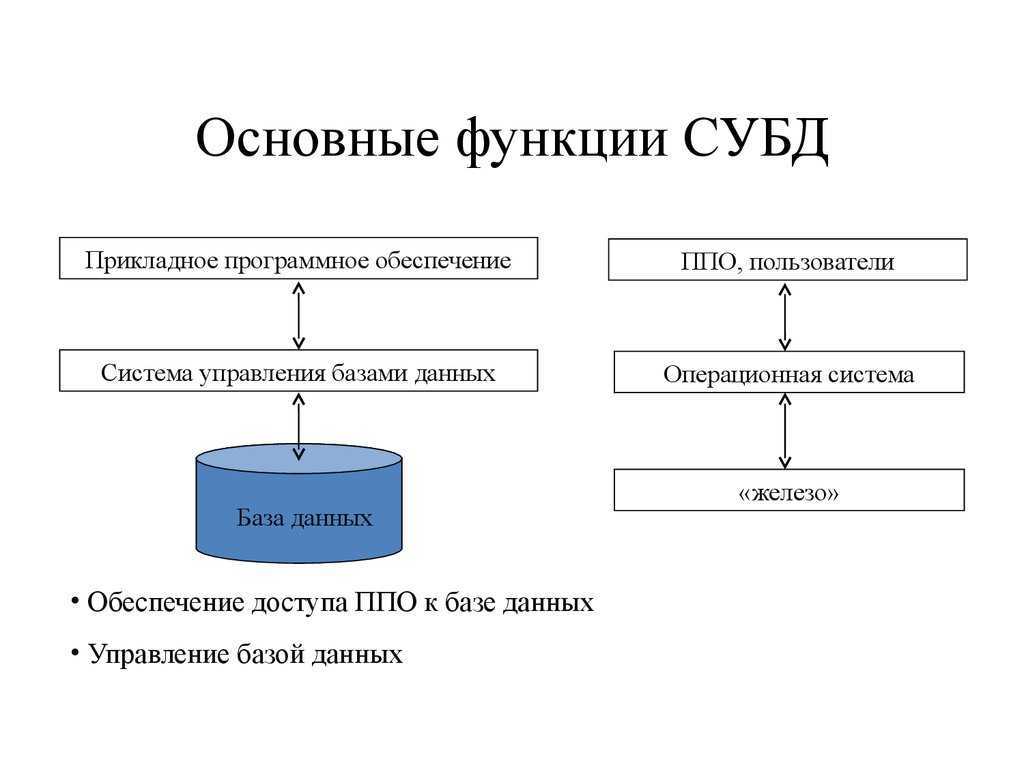 При моделировании вы должны представлять края, которые вы размещаете, следуя контурам объекта. Если вы моделируете что-то органическое, например человеческое тело, края должны следовать за движением мышц, выпуклостей, изгибов и складок. Это поможет с анимацией, манипуляциями и настройкой вашей сетки.
При моделировании вы должны представлять края, которые вы размещаете, следуя контурам объекта. Если вы моделируете что-то органическое, например человеческое тело, края должны следовать за движением мышц, выпуклостей, изгибов и складок. Это поможет с анимацией, манипуляциями и настройкой вашей сетки.
Форма над квадроциклом
Стоит также отметить, что этот пункт является наиболее важным. В то время как другие рекомендации уменьшают некоторые артефакты, они обычно рассматриваются как эстетический выбор и облегчают создание модели, а не исправляют ее окончательный вид.
Начинайте медленно, получайте удовольствие
Моделирование подразделений — это передовая техника. Это не та вещь, которую можно освоить за один сеанс. Если вы чувствуете, что ведете битву против моделирования подразделений, значит, вы делаете это неправильно. Начните с малого, получайте удовольствие и гордитесь тем, что вы создаете! Гораздо легче научиться моделировать подразделения, когда вы чувствуете, что вам это нравится.
Подразделение — это процесс, который сглаживает сетку, добавляя больше полигонов и вершин, сохраняя при этом форму. Четырехугольник будет сглажен в четыре четырехугольника, которые продолжат следовать контуру сетки. Этот процесс используется во многих вещах, от рендеринга до цифровой скульптуры. По сути, это то, что позволяет вам создавать сетки с управляемым количеством полигонов, прежде чем использовать подразделение, чтобы сделать их настолько гладкими, насколько это необходимо визуально.
Boots Mesh
Boots Smoothed
Subdivision, как и расчет нормалей вершин, не совершенен. Вы получаете артефакты одними и теми же способами. Кроме того, любые артефакты от нормалей вершин в исходной сетке (на одном уровне подразделения) останутся после разделения (на следующем уровне подразделения). В том, как это работает, есть прекрасная симметрия. При подразделении треугольники становятся полюсами, а N-угольники становятся N-полюсами. Обратное тоже верно. Полюса становятся треугольниками, а N-полюса становятся N-угольниками. Из-за этого четырехугольники — это единственное, что разделяет «идеально», поэтому важно иметь четырехугольники в вашей сетке во всех ключевых местах, которые определяют форму и гладкость поверхности.
Обратное тоже верно. Полюса становятся треугольниками, а N-полюса становятся N-угольниками. Из-за этого четырехугольники — это единственное, что разделяет «идеально», поэтому важно иметь четырехугольники в вашей сетке во всех ключевых местах, которые определяют форму и гладкость поверхности.
Видео, объясняющее, как работает подразделение.
Все, что я сказал выше, применимо практически к любой технике моделирования. Они могут показаться о рендеринге в целом. Но на самом деле моделирование подразделения можно рассматривать как процесс моделирования со всеми этими идеями на переднем плане вашего разума. Идея состоит в том, что вы придерживаетесь этих правил и моделируете соответственно. На форумах подразделений вы не увидите конца разговорам о поляках, н-гонах и прочих. Сторонники других методов, как правило, просто смиряются с этим.
Сторонники других методов, как правило, просто смиряются с этим.
Второй частью моделирования подразделений как техники являются инструменты. Часто программы моделирования, классифицируемые как «разработчики моделей подразделений», предоставляют вам множество продвинутых инструментов, помогающих в моделировании подразделений. Они часто позволяют вам быстро переключаться между уровнями подразделения, позволяя вам предварительно просмотреть вашу сетку и увидеть, как она выглядит после сглаживания.
Они также используют понятие «петли ребер» и «кольца ребер», которые представляют собой наборы ребер, соединенных либо в линию (для петель), либо параллельно (для колец). Как правило, существует простой способ их выбора, добавления, удаления и изменения. Эти две вещи являются важной концепцией в моделировании подразделений, поскольку они в конечном итоге определяют поток и форму вашей модели.
Наконец, при моделировании подразделений часто бывает принято сначала фокусироваться на определении формы и тела, прежде чем подразделять и использовать дополнительные полигоны, чтобы добавить больше деталей и глубины. Это чем-то похоже на метод обычной живописи, когда вначале используются крупные мазки кисти, задолго до того, как будут добавлены какие-либо реальные детали. Как и в обычной живописи, это имеет почти те же преимущества и часто приводит к лучшему восприятию тела, формы и пропорций.
Это чем-то похоже на метод обычной живописи, когда вначале используются крупные мазки кисти, задолго до того, как будут добавлены какие-либо реальные детали. Как и в обычной живописи, это имеет почти те же преимущества и часто приводит к лучшему восприятию тела, формы и пропорций.
Блочное моделирование
Хорошие ресурсы по моделированию подразделений сократились, но хороший список можно найти здесь:
Вы начинаете здесь
Здесь вы узнаете все, что я вам рассказал, и даже больше .
Хотя на самом деле, если вы новичок в 3D-моделировании в целом, лучший способ действий — просто загрузить пакет моделирования и немного повеселиться. Мой любимый (и один из самых простых в освоении) — Wings3d. Это бесплатное, легкое приложение с открытым исходным кодом, поэтому, если вы хотите поиграть со своими недавно приобретенными знаниями, загрузите его и попробуйте. Удачного моделирования!
Что такое нисходящий дизайн?
Последнее обновление: 13 октября 2014 г.
Дизайн «сверху вниз» — это декомпозиция системы на более мелкие части, чтобы понять ее композиционные подсистемы.
При нисходящем проектировании обзор системы разрабатывается с указанием, но без детализации каких-либо подсистем первого уровня. Затем каждую подсистему уточняют более подробно, например, иногда разбивая на множество различных уровней подсистемы, так что вся спецификация разлагается на базовые элементы.
Как только эти базовые элементы будут идентифицированы, их будет легче собрать в виде компьютерных модулей. После того, как модули построены, их легко собрать вместе, создав целую систему из этих отдельных элементов.
Схема «сверху вниз» также известна как ступенчатая схема.
Реклама
Нисходящий дизайн обычно представляет собой план, составленный на простом английском языке для программы. Очень важно отметить, что нисходящий дизайн должен быть независимым от любого языка программирования. Нисходящий дизайн никогда не должен включать ссылки на библиотечные функции или синтаксические элементы, характерные для конкретного языка.
Именно поэтому проекты сверху вниз написаны простым английским языком. Концепция нисходящего проектирования состоит в том, чтобы разбить задачу, которую выполняет программа, на очень небольшое количество обширных подзадач.
Высший уровень известен как основной модуль, верхний уровень или уровень 0. На этом этапе объем подзадач должен быть небольшим. Большинство программ этого уровня обычно включают от трех до семи подзадач. Для небольших программ объем подзадач должен быть в нижней части указанного диапазона.
Разделение задач на подзадачи, по сути, разбивает задачу на несколько более мелких программ, что помогает разработчикам легко кодировать эти более простые части. Обычно возможно, что многие из этих подзадач настолько просты, что могут сразу определить, как написать код для выполнения этой части.
Однако на верхнем уровне это обычно не так. Если подзадача занимает больше нескольких строк кода, рекомендуется повторить процесс подразделения.