что это: Системы Управления Базами Данных
СУБД — это система управления базами данных. Так называют сложное программное обеспечение, которое требуется, чтобы создавать базы данных, изменять их, получать из них информацию и контролировать версии.
База данных — это хранилище, где находится информация. База может принадлежать сайту, приложению, любой программе: там будут находиться сведения, связанные с работой проекта. А СУБД — это программный комплекс, который позволяет администрировать базу, защищает ее целостность и конфиденциальность сведений.
Зачем нужна СУБДСистемы управления бывают разными: различаются типы баз данных, особенности представления информации внутри базы, методы управления и языки, на которых пишутся запросы. Существуют платные и бесплатные СУБД, системы для локального или распределенного использования, предназначенные для крупных, средних или мелких проектов.
Кто пользуется СУБД
- Бэкенд-разработчики, которые часто взаимодействуют с базой, чтобы получать данные для сайта или приложения.

- Разработчики локальных приложений, которые тоже могут хранить собственные данные.
- Администраторы баз данных — если продукт сложный, то для обслуживания базы, как правило, необходим собственный администратор. Такие сотрудники обычно специализируются на конкретной СУБД.
- Другие IT-специалисты — в разных ситуациях работать с БД могут аналитики, DevOps-инженеры или специалисты по Big Data.

Для чего нужны СУБД
- Создание и хранение базы данных нужного типа — он зависит от того, к какому виду относится система.
- Управление базой — сюда относится создание новых записей, модификация существующих или удаление данных, которые уже не нужны.
- Получение нужных сведений из базы в удобной форме с помощью запросов, обычно на специальном языке SQL. Запросы фильтруют данные и выдают только нужную информациЮ, так как в базе могут быть миллионы записей. СУБД обязана поддерживать хотя бы один язык запросов.
- Администрирование и контроль доступа к базе данных, выдача разным пользователям различных прав и поддержка конфиденциальности сведений.

- Обеспечение безопасности и целостности данных, чтобы какая-либо проблема не привела к потере информации из базы.
- Защита от возможных атак и сбоев.
- Отслеживание изменений, резервное копирование и восстановление базы в случае падения.
Как информация хранится в БД
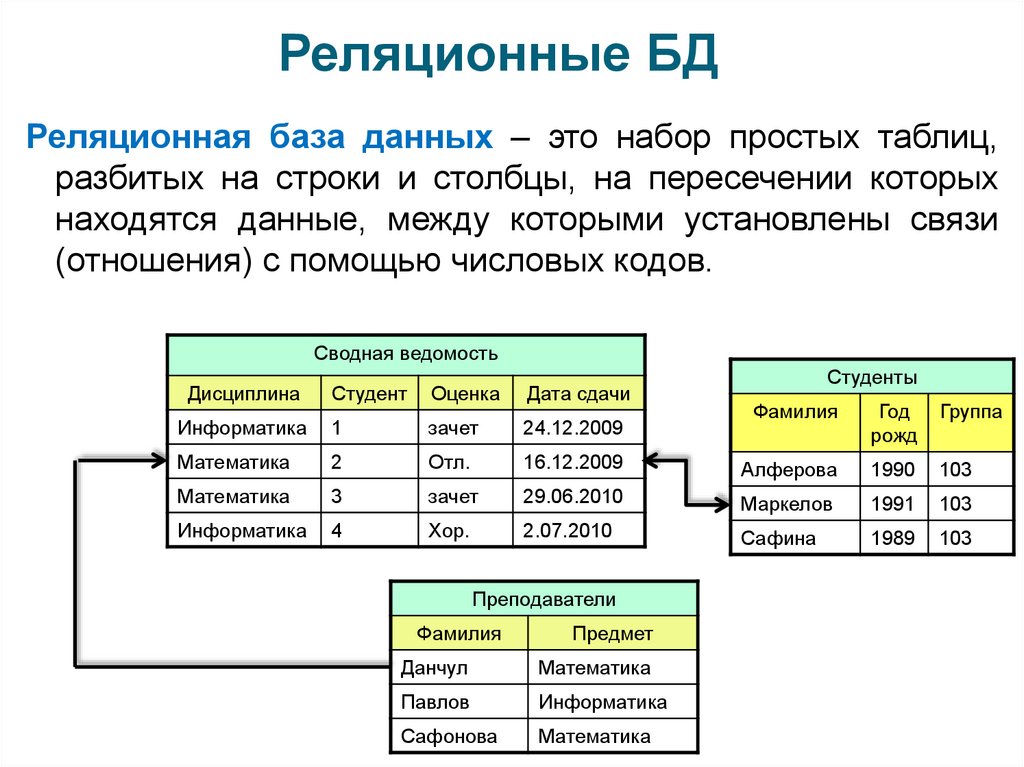
Связанные таблицы. Данные могут быть организованы по-разному в зависимости от типа базы. Чаще всего речь идет о реляционных БД — базах данных, где информация представлена в виде связанных друг с другом таблиц. Такие СУБД управляются с помощью языка запросов SQL и обычно хранят структурированные данные, между которыми есть жесткие связи.
Объекты. Объектные и объектно-реляционные БД представляют блоки информации как объект — сложную сущность с рядом свойств и методов. Объектная модель дает больше возможностей при работе с данными: у объектов есть наследование и другие свойства, которых нет у реляционных таблиц. Подробнее об этом можно прочесть в статье про объектно-ориентированный подход.
Древовидные структуры. Еще один вариант системы хранения информации — иерархический. В нем данные хранятся в виде древовидной структуры. Его расширение — сетевой тип: он отличается от иерархического тем, что данные могут иметь больше одного «предка».
Иногда частным подвидом иеархического типа называют документно-ориентированную модель, при которой данные представлены в виде JSON-подобных документов. Она более гибкая и хорошо подходит для информации, не связанной между собой. Но для жестко связанных данных такой способ не подойдет.
Из чего состоят системы управления базами данных
Если база — это хранилище, то СУБД — комплекс средств для обслуживания хранилища. СУБД имеет сложное устройство.
Ядро СУБД отвечает за главные операции: хранение базы, ее обслуживание, документирование изменений. Это основная часть системы.
Процессор языка или компилятор обрабатывает запросы. Обычно СУБД реляционного, объектно-ориентированного и объектно-реляционного типа поддерживают язык SQL и внутренние языки запросов.
Набор утилит предназначен для различных сервисных функций: их может быть очень много, а некоторые СУБД могут расширяться с помощью пользовательских модулей.
Устройство СУБДВиды СУБД по способу доступа
База данных хранится на так называемом сервере — это не обязательно отдельный компьютер, некоторые системы позволяют «поднять» сервер на конечном устройстве. Если база и все части системы находятся на одном компьютере, и ими пользуются с того же устройства, СУБД называется локальной. Если части системы находятся на разных устройствах — это распределенная СУБД.
Системы по-разному обеспечивают хранение и доступ к данным. Существуют три вида архитектуры.
Клиент-серверная. База данных находится на сервере, СУБД располагается там же. К базе могут обращаться различные клиенты — конечные устройства. Например, пользователи запрашивают информацию на конкретном сайте.
Клиент-серверная архитектура подразумевает, что прямой доступ к базе есть только у сервера — он обрабатывает обращения клиентов. Сами клиенты не обязаны иметь специальное ПО для взаимодействия с базами данных. Так для доступа к сайту не нужно устанавливать программы, которые будут обрабатывать запросы, — все сделает сервер, жестко отделенный от клиентской части.
Сами клиенты не обязаны иметь специальное ПО для взаимодействия с базами данных. Так для доступа к сайту не нужно устанавливать программы, которые будут обрабатывать запросы, — все сделает сервер, жестко отделенный от клиентской части.
Такие базы надежны и обычно имеют высокую доступность. Ими пользуются чаще всего.
Файл-серверная. Тут все иначе: база хранится на файл-сервере, вот СУБД — на каждом клиентском компьютере. Доступ к базе данных могут получить только устройства, на которых установлена и настроена система.
Сейчас такие системы используются очень редко, в основном во внутренних приложениях, которые работают в локальных сетях. В крупных проектах файл-серверные СУБД не применяют.
Встраиваемая. Это маленькая локальная СУБД, которая используется для хранения данных отдельной программы. Такие системы не функционируют как самостоятельные единицы, а встраиваются в программный продукт как модуль. Они нужны при разработке локальных приложений, целиком размещаются на одном устройстве и обычно очень мало весят.
Что такое NoSQL-системы
Большинство баз данных управляется специальным языком запросов SQL. Но из этого правила есть исключения — системы, которые не подразумевают использования SQL. Их называют NoSQL.
К СУБД NoSQL относят любые нереляционные системы — те, где не поддерживается реляционная модель представления информации. Некоторые нужны для хранения больших данных, другие — для ведения логов, третьи — для хранения данных с огромным количеством связей. Например, документно-ориентированные СУБД тоже относятся к NoSQL.
Вместо SQL применяются внутренние языки запросов, часто основанные на тех или иных языках программирования. Иногда они схожи с SQL, а иногда вместо внутреннего языка система использует JavaScript или иной ЯП.
Примеры современных СУБД
- Oracle Database — объектно-реляционная клиент-серверная СУБД, одна из первых и самых популярных в мире. Платная, сложная, подходит для больших проектов.
- PostgreSQL — объектно-реляционная СУБД клиент-серверного типа, которую иногда называют бесплатным аналогом Oracle.
 Масштабная, рассчитана на высоконагруженные проекты, содержит огромное количество функций и распространяется бесплатно.
Масштабная, рассчитана на высоконагруженные проекты, содержит огромное количество функций и распространяется бесплатно. - MySQL — реляционная клиент-серверная СУБД. Популярный выбор для проектов небольшого и среднего размера. Легкая, гибкая и довольно простая в использовании. Она бесплатная, хорошо подходит для обучения и веб-проектов.
- MongoDB — документно-ориентированная NoSQL-СУБД, где данные хранятся в JSON-подобных файлах. Тоже бесплатная, а внутренний язык запросов основан на JavaScript.
- SQLite — маленькая и легкая встраиваемая СУБД, которая активно применяется в локальных проектах.
Особенности построения баз данных, тонкости работы с запросами, поддержку целостности и другие важные темы можно изучить самостоятельно с помощью учебников и мануалов, а также на курсах SkillFactory.
Информатика
Информатика| Информатика |
Глава 11.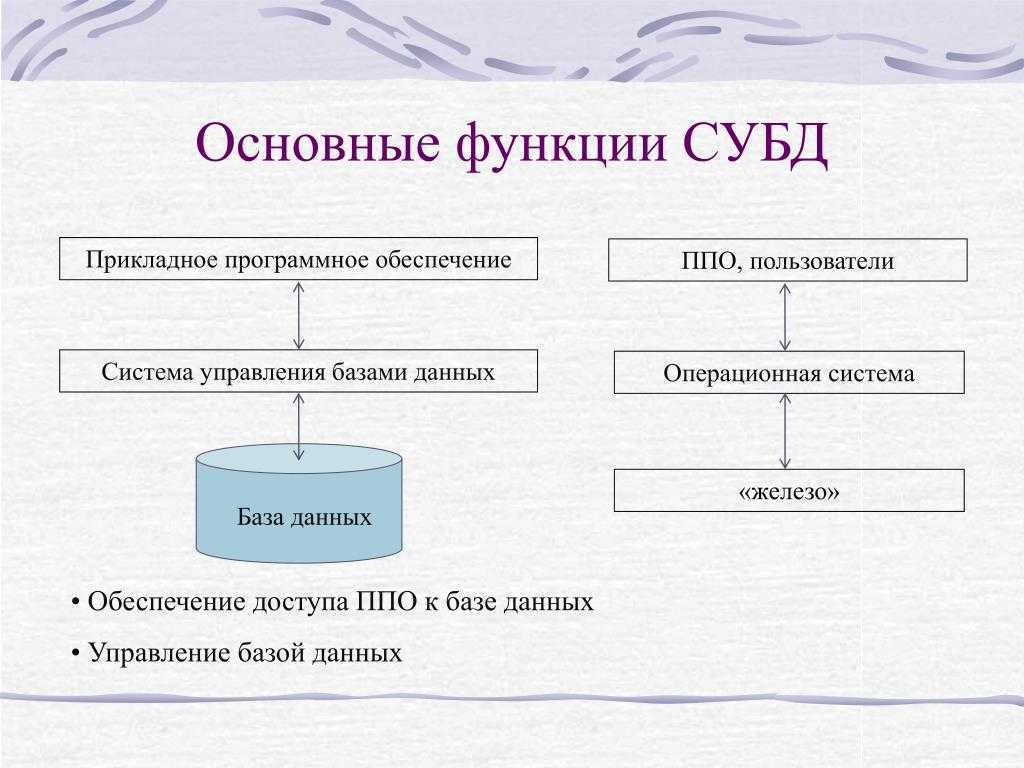 Работа
с базами данных Работа
с базами данных | назад оглавление вперед |
11.1. Основные понятия баз данных
11.1.1. Базы данных и системы управления базами данных
База
данных — это организованная структура, предназначенная для хранения информации.
Поскольку данные и информация — понятия взаимосвязанные, но не тождественные,
то следует заметить некоторое несоответствие в этом определении. Его причины
чисто исторические. В те годы, когда формировалось понятие баз данных, в них
действительно хранились только данные. Однако сегодня большинство систем управления
базами данных (СУБД) позволяют размещать в своих структурах не только данные,
но и методы (то есть программный код), с помощью которых происходит взаимодействие
с потребителем или с другими программно-аппаратными комплексами. Таким образом,
мы можем говорить, что в современных базах данных хранятся отнюдь не только
данные, но и информация.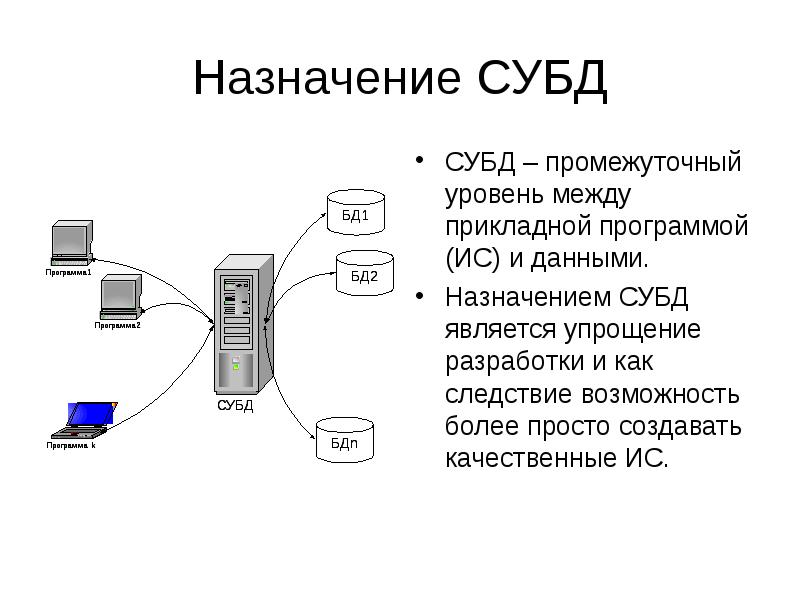
Это утверждение легко пояснить, если, например, рассмотреть базу данных крупного банка. В ней есть все необходимые сведения о клиентах, об их адресах, кредитной истории, состоянии расчетных счетов, финансовых операциях и т. д. Доступ к этой базе имеется у достаточно большого количества сотрудников банка, но среди них вряд ли найдется такое лицо, которое имеет доступ ко всей базе полностью и при этом способно единолично вносить в нее произвольные изменения. Кроме данных, база содержит методы, и средства, позволяющие каждому из сотрудников оперировать только с теми данными, которые входят в его компетенцию. В результате взаимодействия данных, содержащихся в базе, с методами, доступными конкретным сотрудникам, образуется информация, которую они потребляют и на основании которой в пределах собственной компетенции производят ввод и редактирование данных.
С понятием
базы данных тесно связано понятие системы управления базой данных. Это
комплекс программных средств, предназначенных для создания структуры новой базы,
наполнения ее содержимым, редактирования содержимого и визуализации информации.
Под визуализацией информации базы понимается отбор отображаемых данных
в соответствии с заданным критерием, их упорядочение, оформление и последующая
выдача на устройство вывода или передача по каналам связи.
Это
комплекс программных средств, предназначенных для создания структуры новой базы,
наполнения ее содержимым, редактирования содержимого и визуализации информации.
Под визуализацией информации базы понимается отбор отображаемых данных
в соответствии с заданным критерием, их упорядочение, оформление и последующая
выдача на устройство вывода или передача по каналам связи.
Сразу поясним, что если в базе нет никаких данных (пустая база), то это все равно полноценная база данных. Этот факт имеет методическое значение. Хотя данных в базе и нет, но информация в ней все-таки есть — это структура базы. Она определяет методы занесения данных и хранения их в базе. Простейший “некомпьютерный” вариант базы данных — деловой ежедневник, в котором каждому календарному дню выделено по странице. Даже если в нем не записано ни строки, он не перестает быть ежедневником, поскольку имеет структуру, четко отличающую его от записных книжек, рабочих тетрадей и прочей писчебумажной продукции.
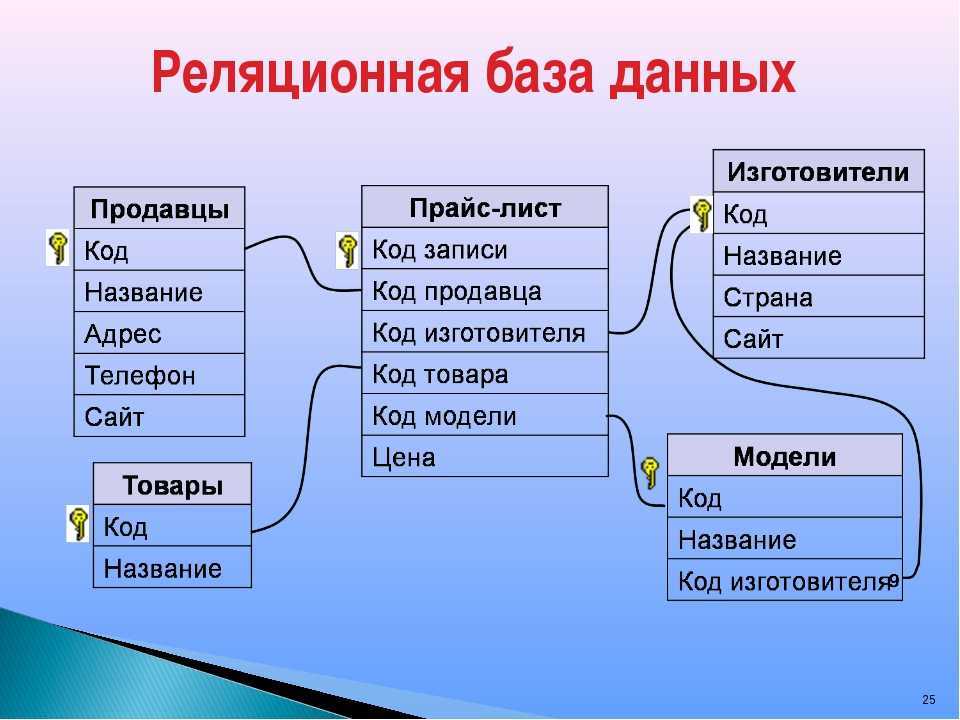
Базы данных
могут содержать различные объекты, но, забегая вперед, скажем, что основными
объектами любой базы данных являются ее таблицы. Простейшая база данных имеет
хотя бы одну таблицу. Соответственно, структура простейшей базы данных тождественно
равна структуре ее таблицы, рис.
Мы знаем, что структуру двумерной таблицы образуют столбцы и строки. Их аналогами в структуре простейшей базы данных являются поля и записи. Если записей в таблице пока нет, значит, ее структура образована только набором полей. Изменив состав полей базовой таблицы (или их свойства), мы изменяем структуру базы данных и, соответственно, получаем новую базу данных.
Рис. 11.1. Простая таблица базы данных
11.1.3. Свойства полей базы данных
Поля базы данных не просто определяют структуру базы — они еще определяют групповые свойства данных, записываемых в ячейки, принадлежащие каждому из полей. Ниже перечислены основные свойства полей таблиц баз данных на примере СУБД Microsoft Access.
- Имя поля — определяет,
как следует обращаться к данным этого поля при автоматических операциях с
базой (по умолчанию имена полей используются в качестве заголовков столбцов
таблиц).
- Тип поля — определяет тип данных, которые могут содержаться в данном поле.
- Размер поля — определяет предельную длину (в символах) данных, которые могут размещаться в данном поле.
- Формат поля — определяет способ форматирования данных в ячейках, принадлежащих полю.
- Маска ввода — определяет форму, в которой вводятся данные в поле (средство автоматизации ввода данных).
- Подпись — определяет заголовок столбца таблицы для данного поля (если подпись не указана, то в качестве заголовка столбца используется свойство Имя поля).
- Значение по умолчанию — то значение, которое вводится в ячейки поля автоматически (средство автоматизации ввода данных).
- Условие на значение — ограничение, используемое для проверки правильности ввода данных (средство
автоматизации ввода, которое используется, как правило, для данных, имеющих
числовой тип, денежный тип или тип даты).

- Сообщение об ошибке — текстовое сообщение, которое выдается автоматически при попытке ввода в поле ошибочных данных (проверка ошибочности выполняется автоматически, если задано свойство Условие на значение).
- Обязательное поле — свойство, определяющее обязательность заполнения данного поля при наполнении базы;
- Пустые строки — свойство, разрешающее ввод пустых строковых данных (от свойства Обязательное поле отличается тем, что относится не ко всем типам данных, а лишь к некоторым, например к текстовым).
- Индексированное поле — если поле обладает этим свойством, все операции, связанные с поиском или
сортировкой записей по значению, хранящемуся в данном поле, существенно ускоряются.
Кроме того, для индексированных полей можно сделать так, что значения в записях
будут проверяться по этому полю на наличие повторов, что позволяет автоматически
исключить дублирование данных.

Здесь мы должны обратить особое внимание читателя на то, что поскольку в разных полях могут содержаться данные разного типа, то и свойства у полей могут различаться в зависимости от типа данных. Так, например, список вышеуказанные свойств полей относится в основном к полям текстового типа. Поля других типов могут иметь или не иметь эти свойства, но могут добавлять к ним и свои. Например для данных, представляющих действительные числа, важным свойством является количество знаков после десятичной запятой. С другой стороны, для полей, используемых для хранения рисунков, звукозаписей, видеоклипов и других объектов OLE, большинство вышеуказанных свойств не имеют смысла.
11.1.4. Типы данных
- Таблицы баз данных, как правило, допускают работу с большим количеством разных типов данных. Так, например, базы данных Microsoft Access работают со следующими типами данных.
- Текстовый — тип
данных, используемый для хранения обычного неформатированного текста ограниченного
размера (до 255 символов).
- Мемо — специальный тип данных для хранения больших объемов текста (до 65 535 символов). Физически текст не хранится в поле. Он хранится в другом месте базы данных, а в поле хранится указатель на него, но для пользователя такое разделение заметно не всегда.
- Числовой — тип данных для хранения действительных чисел.
- Дата/время — тип данных для хранения календарных дат и текущего времени.
- Денежный — тип данных для хранения денежных сумм. Теоретически, для их записи можно было бы пользоваться и полями числового типа, но для денежных сумм есть некоторые особенности (например, связанные с правилами округления), которые делают более удобным использование специального типа данных, а не настройку числового типа.
- Счетчик — специальный тип данных для уникальных (не повторяющихся в поле) натуральных чисел с автоматическим наращиванием. Естественное использование — для порядковой нумерации записей
- Логический — тип для хранения логических
данных (могут принимать только два значения, например Да или Нет).
- Поле объекта OLE — специальный тип данных, предназначенный для хранения объектов OLE, например мультимедийных. Реально, конечно, такие объекты в таблице не хранятся. Как и в случае полей МЕМО, они хранятся в другом месте внутренней структуры файла базы данных, а в таблице хранятся только указатели на них (иначе работа с таблицами была бы чрезвычайно замедленной).
- Гиперссылка — специальное поле для хранения адресов URL Web-объектов Интернета. При щелчке на ссылке автоматически происходит запуск браузера и воспроизведение объекта в его окне.
- Мастер подстановок — это не специальный тип данных. Это объект, настройкой которого можно автоматизировать ввод в данных поле так, чтобы не вводить их вручную, а выбирать из раскрывающегося списка.
11.1.5. Безопасность баз данных
Базы данных
— это тоже файлы, но работа с ними отличается от работы с файлами других типов,
создаваемых прочими приложениями. Выше мы видели, что всю работу по обслуживанию
файловой структуры берет на себя операционная система. Для баз данных предъявляются
особые требования с точки зрения безопасности, поэтому в них реализован другой
подход к сохранению данных.
Выше мы видели, что всю работу по обслуживанию
файловой структуры берет на себя операционная система. Для баз данных предъявляются
особые требования с точки зрения безопасности, поэтому в них реализован другой
подход к сохранению данных.
При работе с обычными приложениями для сохранения данных мы выдаем соответствующую команду, задаем имя файла и доверяемся операционной системе. Если мы закроем файл, не сохранив его, то вся работа по созданию или редактированию файла пропадет безвозвратно.
Базы данных
— это особые структуры. Информация, которая в них содержится, очень часто имеет
общественную ценность. Нередко с одной и той же базой (например, с базой регистрации
автомобилей в ГИБДД) работают тысячи людей по всей стране. От информации, которая
содержится в некоторых базах, может зависеть
благополучие множества людей. Поэтому целостность содержимого базы не может
и не должна зависеть ни от конкретных действий некоего пользователя, забывшего
сохранить файл перед выключением компьютера, ни от перебоев в электросети.
Проблема безопасности баз данных решается тем, что в СУБД для сохранения информации используется двойной подход. В части операций, как обычно, участвует операционная система компьютера, но некоторые операции сохранения происходят в обход операционной системы.
Операции изменения структуры базы данных, создания новых таблиц или иных объектов происходят при сохранении файла базы данных. Об этих операциях СУБД предупреждает пользователя. Это, так сказать, глобальные операции. Их никогда не проводят с базой данных, находящейся в коммерческой эксплуатации, — только с ее копией. В этом случае любые сбои в работе вычислительных систем не страшны.
С другой
стороны, операции по изменению содержания данных, не затрагивающие структуру
базы, максимально автоматизированы и выполняются без предупреждения. Если работая
с таблицей данных мы что-то в ней меняем в составе данных, то изменения сохраняются
немедленно и автоматически.
Обычно, решив отказаться от изменений в документе, его просто закрывают без сохранения и вновь открывают предыдущую копию. Этот прием работает почти во всех приложениях, но только не в СУБД. Все изменения, вносимые в таблицы базы, сохраняются на диске без нашего ведома, поэтому попытка закрыть базу “без сохранения” ничего не даст, так как все уже сохранено. Таким образом, редактируя таблицы баз данных, создавая новые записи и удаляя старые, мы как бы работаем с жестким диском напрямую, минуя операционную систему.
Предупреждение. По указанным выше причинам нельзя заниматься учебными экспериментами на базах данных, находящихся в эксплуатации. Для этого следует создавать специальные учебные базы или выполнять копии структуры реальных баз (без фактического наполнения данными).
назад оглавление вперед
Моделирование подразделений
Создано 31 марта 2011 г.
 , 15:17.
, 15:17.Моделирование подразделения — это метод цифрового 3D-моделирования, используемый для создания чистых моделей с масштабируемой детализацией, которые хорошо выглядят при визуализации. Он в той или иной степени используется почти во всех отраслях, в которых работают цифровые художники. Говоря это, часто на усмотрение художника или инструмента, какую технику моделирования они предпочитают использовать. Другими популярными методами являются моделирование по полигонам, nurb-моделирование и цифровая скульптура.
Техника и последующее искусство моделирования подразделений возникли более или менее естественным образом из-за нескольких аспектов или явлений в том, как обычно визуализируется цифровое искусство. Двумя основными примерами этого являются метод по умолчанию, с помощью которого вычисляются нормали вершин, и способ, которым работает подразделение Кэтмулла – Кларка (в честь которого назван метод).
Пример модели подразделения
Вершина — это точка в пространстве, где встречаются различные линии (или ребра).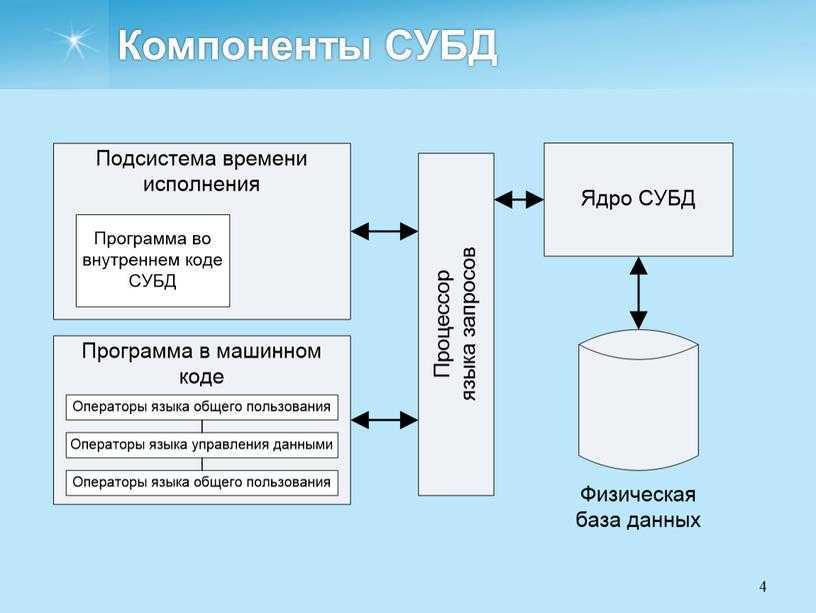 Их можно рассматривать как углы геометрических фигур. Когда компьютер отображает форму на экране, есть два варианта. Либо он может визуализировать каждый многоугольник (или грань) этой формы как плоскую поверхность и выполнять расчеты освещения на основе этого, либо он может попытаться визуализировать некоторую сглаженную версию той же формы. Этот второй вариант часто является тем, что нам нужно, и именно здесь используются нормали вершин.
Их можно рассматривать как углы геометрических фигур. Когда компьютер отображает форму на экране, есть два варианта. Либо он может визуализировать каждый многоугольник (или грань) этой формы как плоскую поверхность и выполнять расчеты освещения на основе этого, либо он может попытаться визуализировать некоторую сглаженную версию той же формы. Этот второй вариант часто является тем, что нам нужно, и именно здесь используются нормали вершин.
Если вместо того, чтобы смотреть на нормали грани (направление, на которое указывает грань), визуализатор смотрит на нормали вершин (направление, на которое указывает угол), то он может интерполировать (своего рода усреднение) это направление по треугольной грани. рендеринг, придающий ему плавный вид. На самом деле, для любого треугольника графические карты специально разработаны так, чтобы иметь возможность очень быстро интерполировать нормали от трех вершин в каждом углу. Это то, что происходит во всей трехмерной компьютерной графике, от «Властелина колец» до Quake II.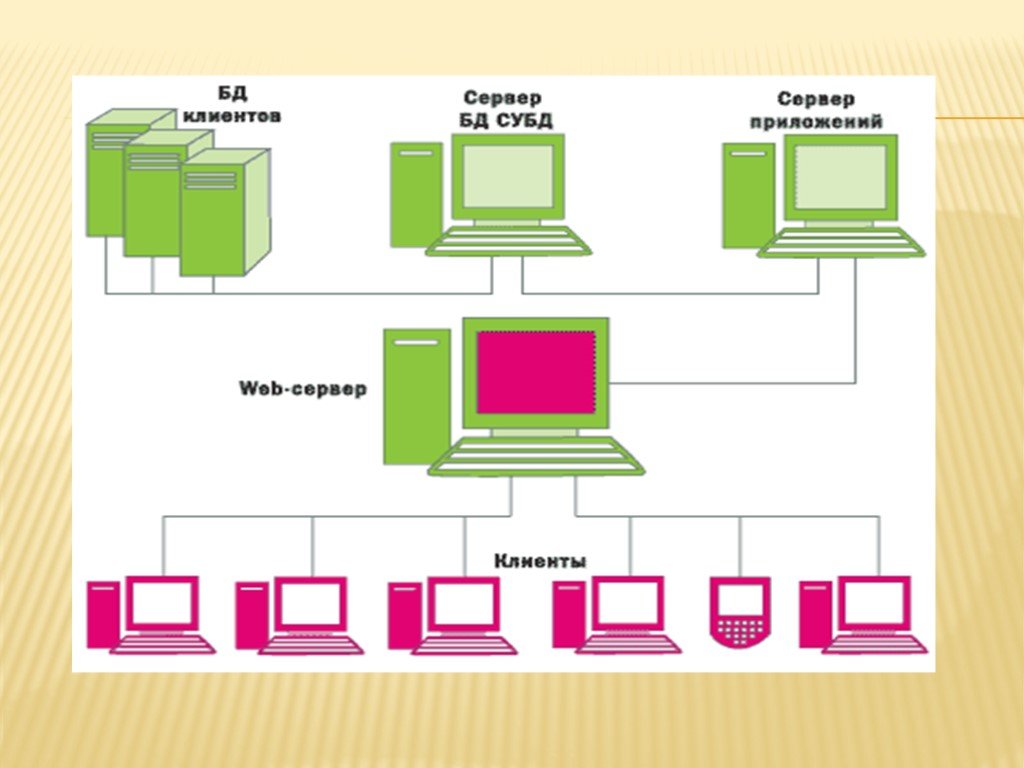
Но, прежде чем мы сможем сделать эту интерполяцию, мы должны разработать фактические нормали вершин для использования. На самом деле найти направление, на которое указывает вершина, невозможно (у нее нет поверхности, поэтому нет и нормали), но обычно мы просто усредняем нормали граней для всех граней, прикрепленных к этой вершине, и используем это как приближение к нормальному.
Это позволяет нам рендерить гладкие поверхности с использованием угловой геометрии (и фиксированного количества полигонов), но за это приходится платить. Во многих случаях это работает не совсем так, как ожидалось, и может привести к визуальным артефактам или участкам освещения, которые выглядят странно. Они возникают из-за проблем с аппроксимацией нормалей вершин, а также с интерполяционными вычислениями по треугольникам. Но с хорошей сеткой эти артефакты можно свести к минимуму или даже преодолеть, и именно здесь вступает в действие моделирование подразделения.0005
В компьютерной графике практически для всего используются новые термины. Я, вероятно, уже бросил вам несколько новых, которые я буду пересматривать здесь, но как только вы освоитесь с ними, все станет намного проще объяснить. Причина, по которой некоторые из этих вещей имеют имена, также станет очевидной позже.
Я, вероятно, уже бросил вам несколько новых, которые я буду пересматривать здесь, но как только вы освоитесь с ними, все станет намного проще объяснить. Причина, по которой некоторые из этих вещей имеют имена, также станет очевидной позже.
- Вершина — Точка в пространстве, где встречаются ребра, угол фигуры.
- Ребро — Соединение между двумя вершинами.
- Многоугольник — Грань трехмерной формы, соединяющая несколько вершин через ребра.
- Сетка — Набор полигонов, фигура в 3D пространстве. Также упоминается как модель или тело.
- Треугольник — Многоугольник ровно с тремя вершинами.
- Quad — Многоугольник с ровно четырьмя вершинами.
- N-Gon — Многоугольник с пятью и более вершинами.
- Полюс — Вершина, из которой выходят три ребра.
- N-Pole — Вершина, из которой выходит пять или более ребер.

Спрашивать, что делает хорошую сетку, почти то же самое, что спрашивать, что делает хорошую картину. Как и в большинстве случаев в жизни, здесь нет простого ответа, и, по правде говоря, хорошее моделирование действительно требует практики. Когда вы хорошо разбираетесь в подразделении, вы можете почувствовать, что делает хорошую сетку, и это будет видно при рендеринге. Тем не менее, безусловно, есть некоторые рекомендации, которым вы можете следовать, чтобы свести к минимуму визуальные артефакты и сделать вашу жизнь намного проще. Вот некоторые из основных. (Стоит отметить, что эти рекомендации также применимы почти ко всем моделям создания сеток и никоим образом не относятся к моделированию подразделений.)
Избегайте треугольников и полюсов
Треугольники и полюса можно рассматривать как две стороны одной медали. Они часто являются причиной странных артефактов сглаживания, поэтому их следует избегать, когда это возможно. Однако полностью избежать их просто невозможно; любая сетка потребует их некоторого количества. Часто их размещают с попыткой минимизировать их эффект. Есть два основных способа сделать это: либо разместить их на относительно плоской поверхности, либо «спрятать» их в плотно закрытых областях сетки. У человеческих персонажей это часто делается в подмышках, паху, суставах или вообще в любом месте с естественными складками на поверхности.
Однако полностью избежать их просто невозможно; любая сетка потребует их некоторого количества. Часто их размещают с попыткой минимизировать их эффект. Есть два основных способа сделать это: либо разместить их на относительно плоской поверхности, либо «спрятать» их в плотно закрытых областях сетки. У человеческих персонажей это часто делается в подмышках, паху, суставах или вообще в любом месте с естественными складками на поверхности.
Полюса и треугольники, «спрятанные» на плоской части ключа
Избегайте N-угольников и N-полюсов
с использованием тех же приемов. Обычно люди стараются избегать их больше, чем треугольников или полюсов. В основном это связано с тем, что их сложнее моделировать, и с тем фактом, что чем больше количество ребер, входящих в полюс, или количество сторон лица, тем более странными становятся проблемы сглаживания.
Старайтесь строить свою сетку в основном из четырехугольников
Этот пункт часто кажется немного неверным для новичков.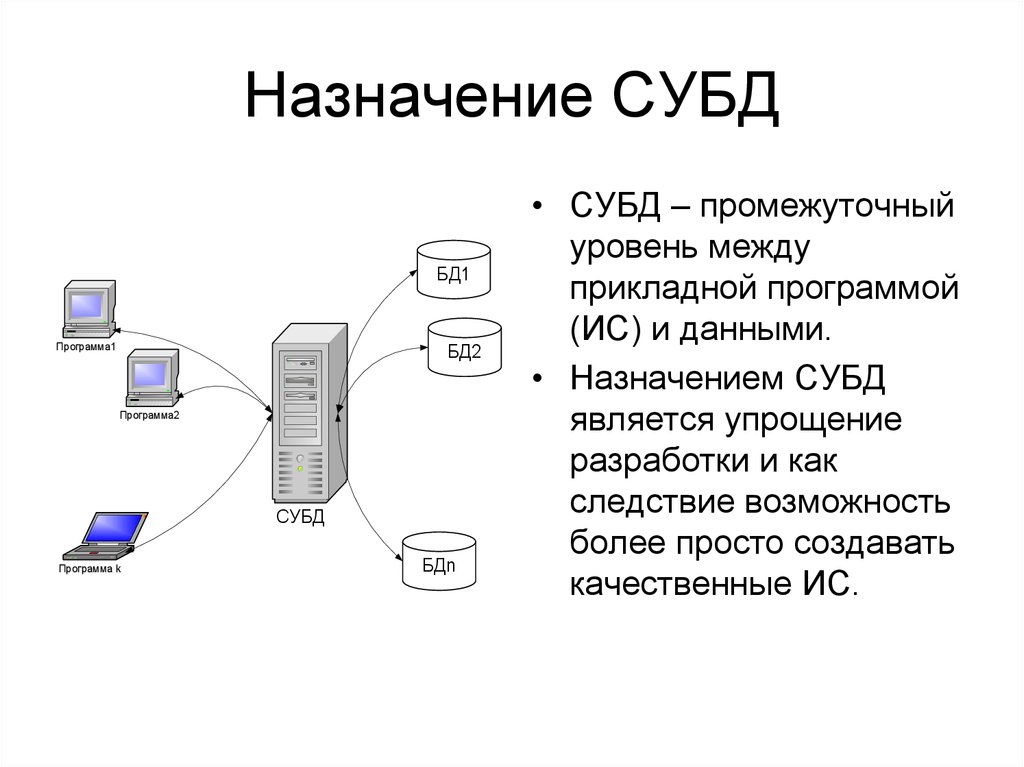 Например, если у вас есть некоторые знания о графике, вы знаете, что модели в любом случае всегда визуализируются только с использованием треугольников — все четырехугольники превращаются в треугольники перед визуализацией, обычно путем соединения ребра между двумя ближайшими вершинами. Таким образом, попытка построить свою сетку в основном из четырехугольников может показаться довольно избыточной и глупой. Но, по правде говоря, построение сетки с учетом четырехугольников — это самый простой способ избежать всех других плохих вещей, которые могут вызвать визуальные артефакты.
Например, если у вас есть некоторые знания о графике, вы знаете, что модели в любом случае всегда визуализируются только с использованием треугольников — все четырехугольники превращаются в треугольники перед визуализацией, обычно путем соединения ребра между двумя ближайшими вершинами. Таким образом, попытка построить свою сетку в основном из четырехугольников может показаться довольно избыточной и глупой. Но, по правде говоря, построение сетки с учетом четырехугольников — это самый простой способ избежать всех других плохих вещей, которые могут вызвать визуальные артефакты.
Не только это, но есть много-много причин, по которым работать с квадратными сетками проще, чем с другими запутанными и запутанными сетками. Их легче анимировать, легче смонтировать и проще практически с любой другой задачей, которую вы можете с ними выполнять.
Видео, показывающее наглядные примеры артефактов подразделения
Равномерное размещение вершин , вершины и детали.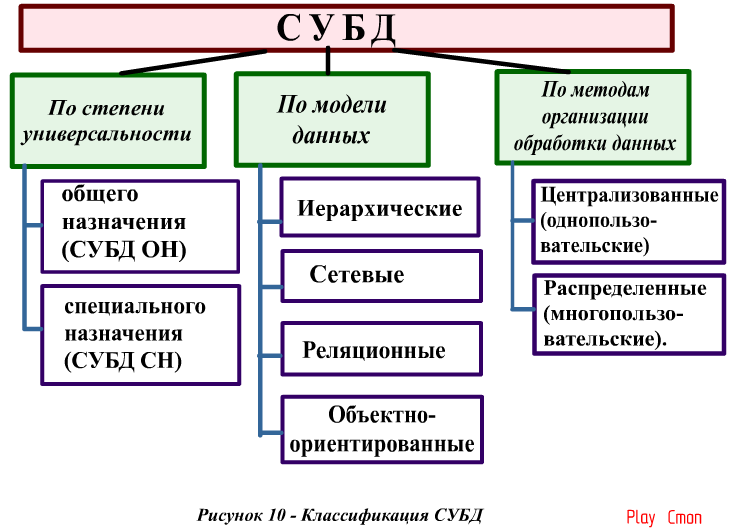 Это не нужно, и это не будет хорошо выглядеть, когда дело доходит до времени рендеринга. Что происходит, когда у вас есть сетка, полная продолгов, а не квадратов, вы получаете множество длинных тонких треугольников во время рендеринга. Это вызовет проблемы с интерполяцией и, как правило, будет выглядеть плохо. Слишком тонкие связки образуют на сетке что-то похожее на жесткие швы, что во многих случаях нежелательно.
Это не нужно, и это не будет хорошо выглядеть, когда дело доходит до времени рендеринга. Что происходит, когда у вас есть сетка, полная продолгов, а не квадратов, вы получаете множество длинных тонких треугольников во время рендеринга. Это вызовет проблемы с интерполяцией и, как правило, будет выглядеть плохо. Слишком тонкие связки образуют на сетке что-то похожее на жесткие швы, что во многих случаях нежелательно.
Также идея состоит в том, чтобы расположить вершины так, чтобы плотность увеличивалась в областях с большим количеством деталей. Это придаст вашей сетке дополнительное определение там, где это необходимо, и не будет тратить полигоны в другом месте.
Хорошо расположенная голова
Фокус на теле, форме и потоке это не совсем соответствует моделируемому объекту. При моделировании вы должны представлять края, которые вы размещаете, следуя контурам объекта. Если вы моделируете что-то органическое, например человеческое тело, края должны следовать за движением мышц, выпуклостей, изгибов и складок. Это поможет с анимацией, манипуляциями и настройкой вашей сетки.
Это поможет с анимацией, манипуляциями и настройкой вашей сетки.
Форма над квадроциклом
Стоит также отметить, что этот пункт является наиболее важным. В то время как другие рекомендации уменьшают некоторые артефакты, они обычно рассматриваются как эстетический выбор и облегчают создание модели, а не исправляют ее окончательный вид.
Начинайте медленно, получайте удовольствие
Моделирование подразделений — это передовая техника. Это не та вещь, которую можно освоить за один сеанс. Если вы чувствуете, что ведете битву против моделирования подразделений, значит, вы делаете это неправильно. Начните с малого, получайте удовольствие и гордитесь тем, что вы создаете! Гораздо легче научиться моделировать подразделения, когда вы чувствуете, что вам это нравится.
Подразделение — это процесс, который сглаживает сетку, добавляя больше полигонов и вершин, сохраняя при этом форму. Четырехугольник будет сглажен в четыре четырехугольника, которые продолжат следовать контуру сетки.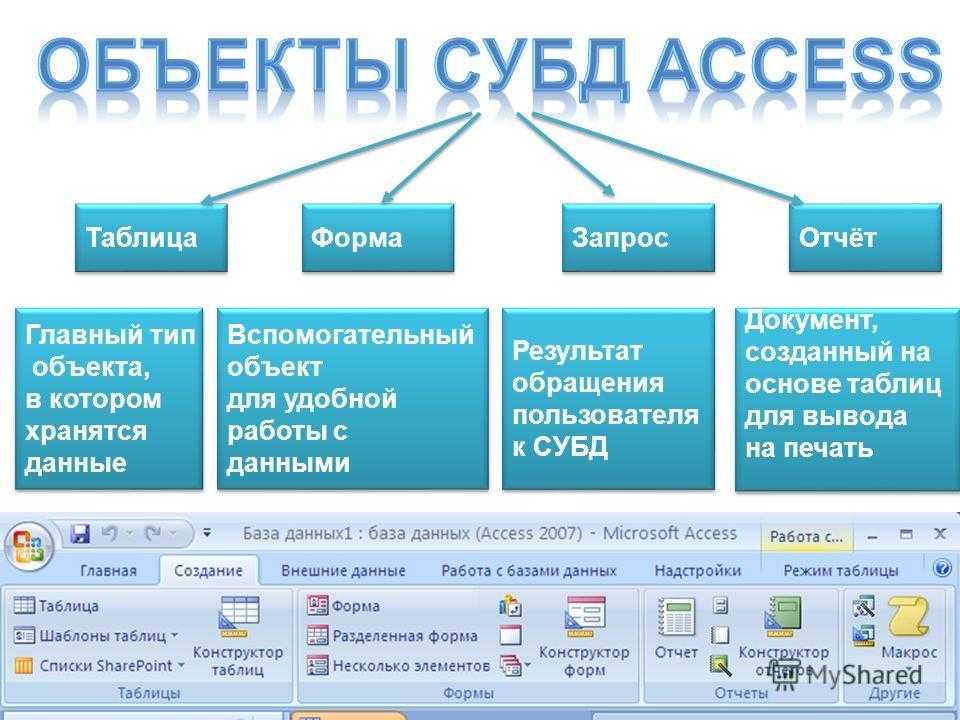 Этот процесс используется во многих вещах, от рендеринга до цифровой скульптуры. По сути, это то, что позволяет вам создавать сетки с управляемым количеством полигонов, прежде чем использовать подразделение, чтобы сделать их настолько гладкими, насколько это необходимо визуально.
Этот процесс используется во многих вещах, от рендеринга до цифровой скульптуры. По сути, это то, что позволяет вам создавать сетки с управляемым количеством полигонов, прежде чем использовать подразделение, чтобы сделать их настолько гладкими, насколько это необходимо визуально.
Boots Mesh
Boots Smoothed
Subdivision, как и расчет нормалей вершин, не совершенен. Вы получаете артефакты одними и теми же способами. Кроме того, любые артефакты от нормалей вершин в исходной сетке (на одном уровне подразделения) останутся после разделения (на следующем уровне подразделения). В том, как это работает, есть прекрасная симметрия. При подразделении треугольники становятся полюсами, а N-угольники становятся N-полюсами. Обратное тоже верно. Полюса становятся треугольниками, а N-полюса становятся N-угольниками. Из-за этого четырехугольники — это единственное, что разделяет «идеально», поэтому важно иметь четырехугольники в вашей сетке во всех ключевых местах, которые определяют форму и гладкость поверхности.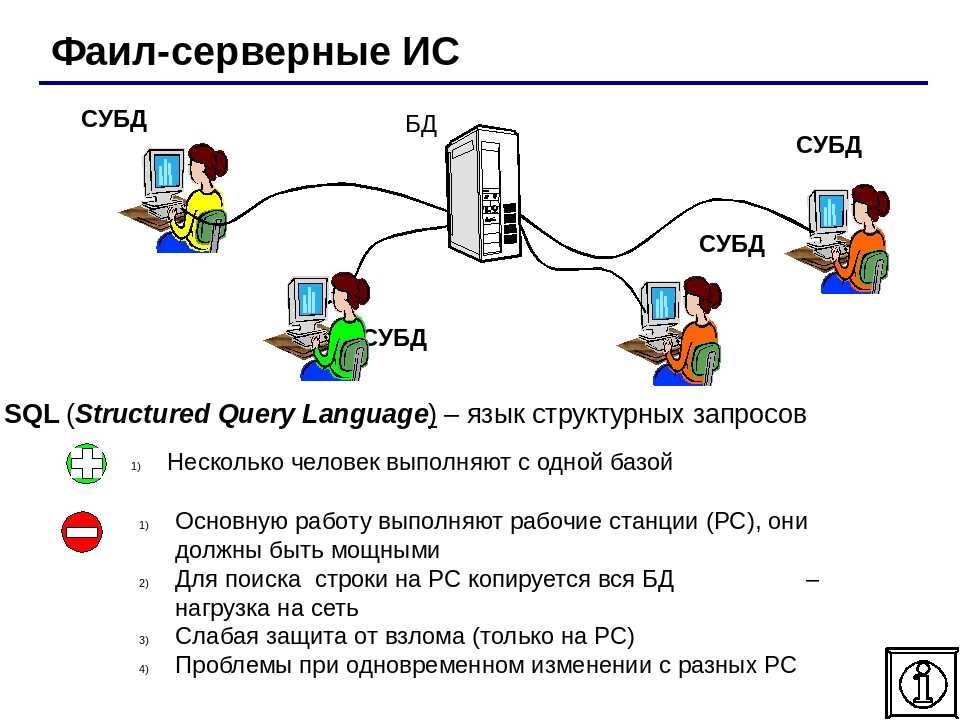
Видео, объясняющее, как работает подразделение.
Все, что я сказал выше, применимо практически к любой технике моделирования. Они могут показаться о рендеринге в целом. Но на самом деле моделирование подразделения можно рассматривать как процесс моделирования со всеми этими идеями на переднем плане вашего разума. Идея состоит в том, что вы придерживаетесь этих правил и моделируете соответственно. На форумах подразделений вы не увидите конца разговорам о поляках, н-гонах и прочих. Сторонники других методов, как правило, просто смиряются с этим.
Второй частью моделирования подразделений как техники являются инструменты. Часто программы моделирования, классифицируемые как «разработчики моделей подразделений», предоставляют вам множество продвинутых инструментов, помогающих в моделировании подразделений.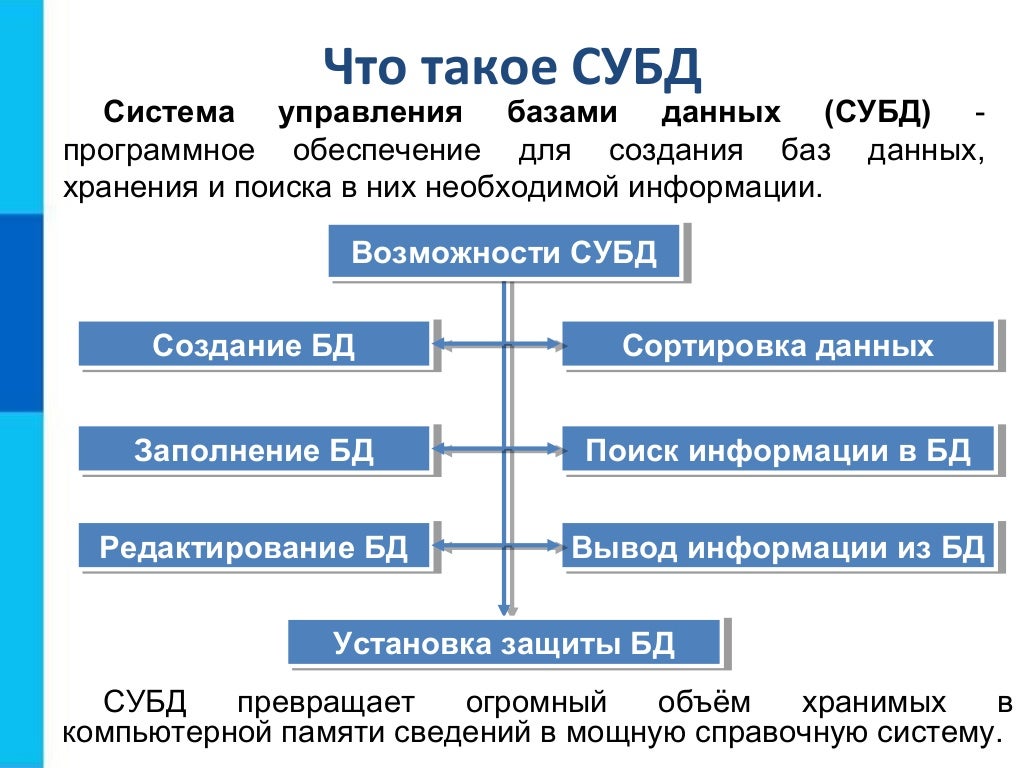 Они часто позволяют вам быстро переключаться между уровнями подразделения, позволяя вам предварительно просмотреть вашу сетку и увидеть, как она выглядит после сглаживания.
Они часто позволяют вам быстро переключаться между уровнями подразделения, позволяя вам предварительно просмотреть вашу сетку и увидеть, как она выглядит после сглаживания.
Они также используют понятие «петли ребер» и «кольца ребер», которые представляют собой наборы ребер, соединенных либо в линию (для петель), либо параллельно (для колец). Как правило, существует простой способ их выбора, добавления, удаления и изменения. Эти две вещи являются важной концепцией в моделировании подразделений, поскольку они в конечном итоге определяют поток и форму вашей модели.
Наконец, при моделировании с разделением часто бывает принято фокусироваться сначала на определении формы и тела, а затем на подразделении и использовании дополнительных полигонов для добавления большего количества деталей и глубины. Это чем-то похоже на метод обычной живописи, когда вначале используются крупные мазки кисти, задолго до того, как будут добавлены какие-либо реальные детали. Как и в обычной живописи, это имеет почти те же преимущества и часто приводит к лучшему восприятию тела, формы и пропорций.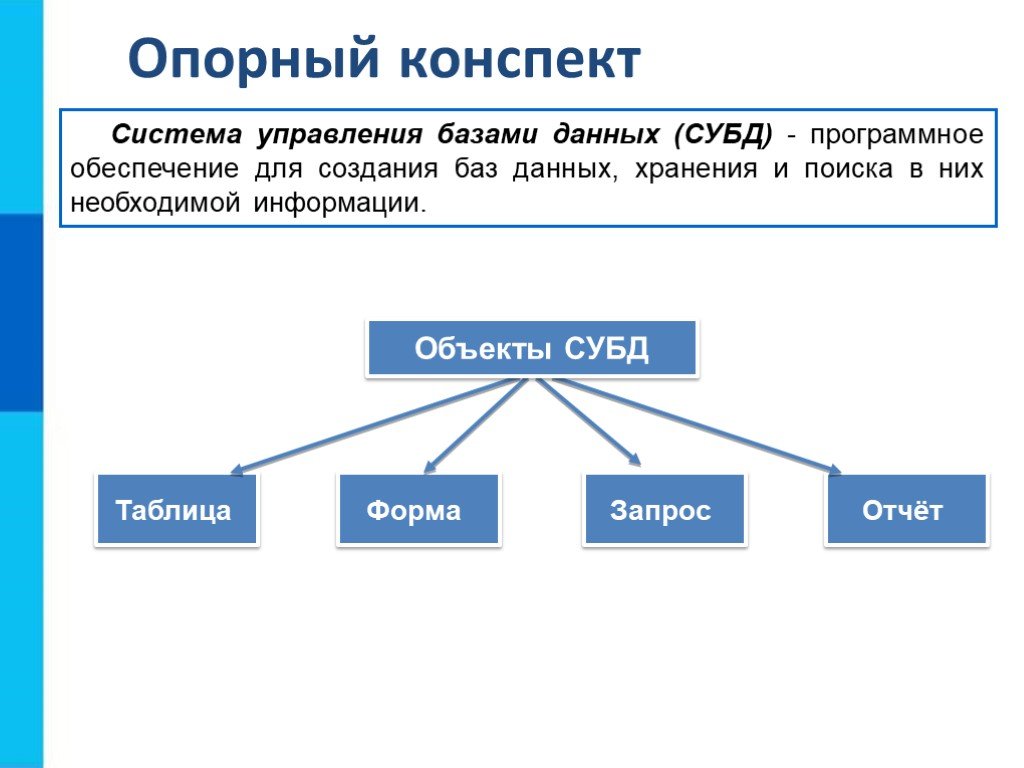
Блочное моделирование
Хорошие ресурсы по моделированию подразделений сократились, но хороший список можно найти здесь:
Вы начинаете здесь
Здесь вы узнаете все, что я вам рассказал, и даже больше .
Хотя на самом деле, если вы новичок в 3D-моделировании в целом, лучший способ действий — просто загрузить пакет моделирования и немного повеселиться. Мой любимый (и один из самых простых в освоении) — Wings3d. Это бесплатное, легкое приложение с открытым исходным кодом, поэтому, если вы хотите поиграть со своими недавно приобретенными знаниями, загрузите его и попробуйте. Удачного моделирования!
Компьютерная графика — Алгоритм разделения области в 3D (удаление скрытых поверхностей)
Улучшить статью
Сохранить статью
Нравится Статья
madhav_mohan
профессиональный
45 опубликованных статей
Улучшить статью
Сохранить статью
Нравится Статья
Г-н Джон Уорнок предложил алгоритм разделения области, поэтому он также известен как алгоритм Уорнока. Этот алгоритм широко использует концепцию когерентности областей при вычислении видимой поверхности в сцене, которая находится ближе к плоскости просмотра, когерентность областей позволяет избежать вычисления обнаружения видимости общей поверхности, которая уже была вычислена на предыдущем шаге. так что не надо пересчитывать. Это все, что делает территориальная когерентность.
Этот алгоритм широко использует концепцию когерентности областей при вычислении видимой поверхности в сцене, которая находится ближе к плоскости просмотра, когерентность областей позволяет избежать вычисления обнаружения видимости общей поверхности, которая уже была вычислена на предыдущем шаге. так что не надо пересчитывать. Это все, что делает территориальная когерентность.
Алгоритм разделения области основан на методе «разделяй и властвуй», когда видимая (просматриваемая) область последовательно делится на все меньшие и меньшие прямоугольники, пока не будет обнаружена упрощенная область. Рассмотрим данные с панелью окна, куда будет проецироваться многоугольник, следующим образом:
Рис.1
Когда мы разделяем панель окна относительно многоугольника, мы можем столкнуться со следующими случаями, которые заключаются в следующем:
1. Окружающая поверхность: Это случай, когда полигональная поверхность обзора полностью окружает всю оконную панель.
Рис.2
2. Перекрывающаяся (пересекающаяся) поверхность: Это случай, когда панель окна (окно просмотра) и полигональная поверхность обзора пересекаются друг с другом.
Рис.3
3. Внутренняя (содержащая) поверхность: В этом случае вся поверхность многоугольника вписана внутрь оконной панели. Этот случай прямо противоположен первому (окружающая поверхность) случаю.
Рис.4
4. Внешняя (непересекающаяся) поверхность : В этом случае вся поверхность полигона находится полностью за пределами оконной панели.
Рис.5
Алгоритм:- Инициализировать размер области просмотра или оконной панели.
- Зачислите все полигоны и отсортируйте их по Z min (значение глубины) по отношению к оконной панели (порту просмотра).
- Классифицируйте все многоугольники в соответствии с их соответствующими случаями, в которые они попадают.
