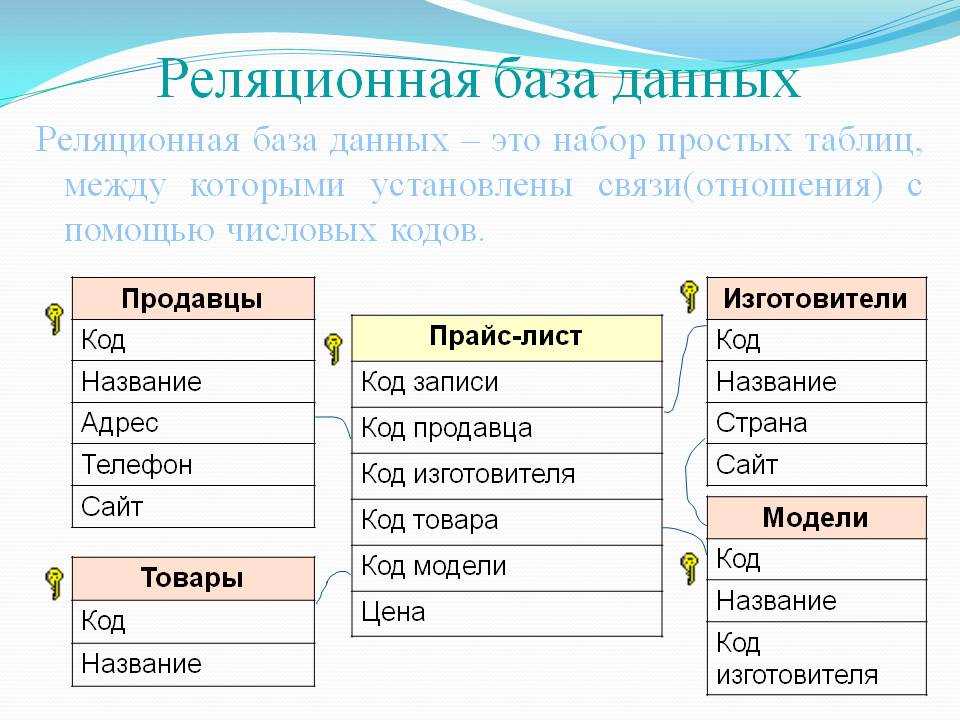
Структура реляционной базы данных | Основы реляционных баз данных
Зарегистрируйтесь для доступа к 15+ бесплатным курсам по программированию с тренажером
PostgreSQL — это СУБД, созданная для работы с реляционными базами данных. Что такое «реляционная», мы рассмотрим в будущем уроке. А в этом разберем, как устроены такие базы данных.
Структура реляционной базы данных
Данные в реляционных базах данных хранятся в таблицах. Их структура напоминает Microsoft Excel. Каждая строка в таблице — это связанный набор данных, который относится к одному предмету. Например, в таблице можно посмотреть все детали об одном сотруднике — его фамилию, имя, номер, отдел, зарплату, год рождения, адрес и телефон:
Разные таблицы предназначены для хранения информации о различных сущностях, например, пользователи, статьи или заказы в интернет-магазине. В типичных веб-приложениях таблиц десятки и сотни, в больших — тысячи. Например, в Хекслете их несколько сотен.
У таблиц в базе данных есть определенная структура. Она включает:
Она включает:
- Название таблицы — уникально в рамках одной базы данных. Имя таблицы и ее структура задаются при создании, но их можно изменить впоследствии
- Столбцы или поля — располагаются в строго определенном порядке, и у каждого поля уникальное имя в рамках одной таблицы
- Тип данных — сопоставляется каждому столбцу. Тип данных ограничивает набор допустимых значений, которые можно присвоить столбцу, и определяет смысловое значение данных для вычислений. Например, в столбец числового типа нельзя записать обычные текстовые строки, но его данные можно использовать в математических вычислениях, и наоборот
- Строки — их число переменно и отражает текущий объем данных. В отличие от таблиц в Exсel, в таблицах реляционных баз данных нет никаких гарантий относительно порядка строк в таблице. Он может быть любым, и его можно задать с помощью языка SQL, который рассмотрим позже.
 Объем данных в разных таблицах сильно отличается — от нескольких штук до миллиардов записей
Объем данных в разных таблицах сильно отличается — от нескольких штук до миллиардов записей
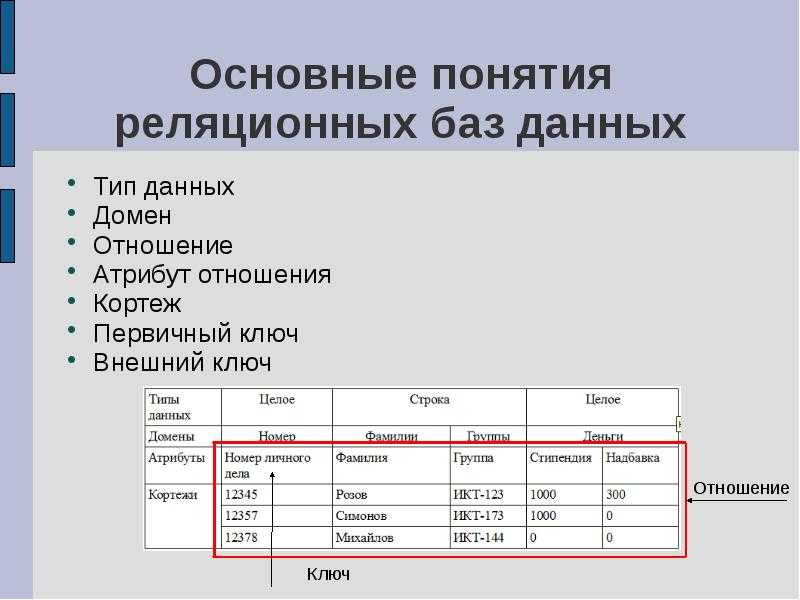
Пример таблицы с именем users:
Структура
Включает в себя имена полей и их типы. Структура определяет столбцы:
first_name string last_name string email string created_at datetime
Содержание
Включает в себя данные. Содержание определяет строки:
| first_name | last_name | email | created_at | |------------|-----------|-------------------|------------| | Сергей | Петров | [email protected] | 11.10.2005 | | Иван | Сидоров | [email protected] | 03.08.2000 | | Виктор | Курганов | [email protected] | 23.12.2011 |
first_name, last_name, email и created_at — это имена столбцов. Строки содержат данные по каждому столбцу, а в поле created_at установлен тип данных datetime, поэтому туда нельзя записать текст.
В дальнейшем эту структуру можно модифицировать: удалять и добавлять поля, менять типы данных.
Правила именования сущностей базы данных
Именование таблиц и полей в базе не фиксировано и зависит от программиста. Например, в проектах, где используют ORM — название группы фреймворков или библиотек, которые помогают моделировать предметную область и связывать ее с базой данных, — имена определяются соглашениями конкретной экосистемы.
В этом курсе мы используем именование, принятое во фреймворке Rails и его ORM (ActiveRecord). Оно состоит из нескольких правил:
- Все имена в нижнем регистре
- Для имен из нескольких слов используется snake_case — когда слова разделяются подчеркиванием
_без пробелов - Имя таблицы во множественном числе
В отличие от Excel, где ввод данных и отображение визуальные, в СУБД у данных нет никакого представления. Они вводятся и выбираются с помощью команд. При этом существуют специальные клиенты, которые используются, чтобы визуализировать управление базами данных.
Рекомендуем поставить его и поэкспериментировать внутри.
Управлять структурой базы данных и данными внутри таблиц — две разные задачи. При этом они выполняются одним инструментом — языком SQL.
Язык SQL
SQL (Structured Query Language) — специализированный язык, который разработали, чтобы управлять данными в реляционных СУБД.
-- Пример запроса, который извлекает -- информацию о пользователях из таблицы users SELECT * FROM users;
SQL разрабатывается независимо от баз данных и имеет собственный стандарт, который реализуют конкретные базы данных. Поэтому на базовом уровне все реляционные базы работают примерно одинаково.
Когда вы научитесь работать с одной базой, сможете спокойно переключиться на другую. Базы данных поддерживают основной SQL и дополняют его своими возможностями. На протяжение курса мы будем использовать только стандартные возможности SQL, например, управлять ролями и их правами, создавать базы данных, обновлять данные.
Выводы
Реляционная база данных: принцип работы, перспективы использования
Что это? Реляционная база данных – современная форма хранения и упорядочения информации в интуитивно понятной таблице. Блоки в ней связаны и соотносятся между собой по заранее определенным правилам.
Где используется? Это стандарт сегодняшнего дня, гарантирующий целостность данных, поэтому используется во многих сферах, в том числе, в веб-разработке. Официальный язык реляционных баз данных – SQL.
В статье рассказывается:
- Суть реляционных баз данных
- Важные составляющие реляционной базы данных
- Преимущества и недостатки реляционных баз данных
- 3 популярных реляционных базы данных для веб-разработки
- Перспективы реляционных баз данных
-
Пройди тест и узнай, какая сфера тебе подходит:
айти, дизайн или маркетинг.
Бесплатно от Geekbrains
Суть реляционных баз данных
Реляционные базы данных — это система хранения и организации информации, имеющей установленные отношения, что обеспечивает возможность для быстро доступа. В этом случае данные упорядочиваются с использованием табличных форм, содержащих сведения об их сущности. Строки и столбцы в таких таблицах представляют заранее установленные категории данных.
Такой способ структурирования информации делает процедуру доступа к ней более гибкой и быстрой. Именно это обстоятельство способствовало тому, что такой тип баз данных получил наибольшее распространение. Они поддерживают стандартный язык программирования – SQL. Это популярная система для хранения и обработки информации. В рамках SQL используются также встроенные языки реляционных баз данных: DDL для таблиц (применяют для описания данных) и DML для работы с данными.
Суть реляционных баз данныхРассмотрим понятие «реляционный». Этот термин указывает на наличие связей в информационных базах. К примеру, клиентская база предприятия может включать сведения по каждой транзакции, связанной с отдельным счетом. Особое внимание здесь уделяется предустановленным отношениям между хранящимися блоками данных.
К примеру, клиентская база предприятия может включать сведения по каждой транзакции, связанной с отдельным счетом. Особое внимание здесь уделяется предустановленным отношениям между хранящимися блоками данных.
В качестве примера реляционной базы данных рассмотрим таблицы, используемые небольшой фирмой для обработки заявок на продукцию. В первой табличной форме представлены сведения о заказчиках. Здесь в каждой записи представлена информация о названии и адресе клиента, его платежных реквизитах, контактном номере телефона и т.д.
Каждый атрибут данных (элемент информации) размещается в отдельном столбце информационной базы. Все столбцы имеют свой неповторяющийся идентификатор для каждой строки (ключ). Вторая табличная форма содержит отдельные записи с идентификатором клиента, подавшего заявку, наименование заказанного товара, его количество и характеристики. Как мы видим, в этой таблице отсутствуют данные клиента (название, телефон, адрес и т.д.).
В представленных табличных формах, являющихся основными объектами реляционной базы данных, присутствует лишь один общий компонент.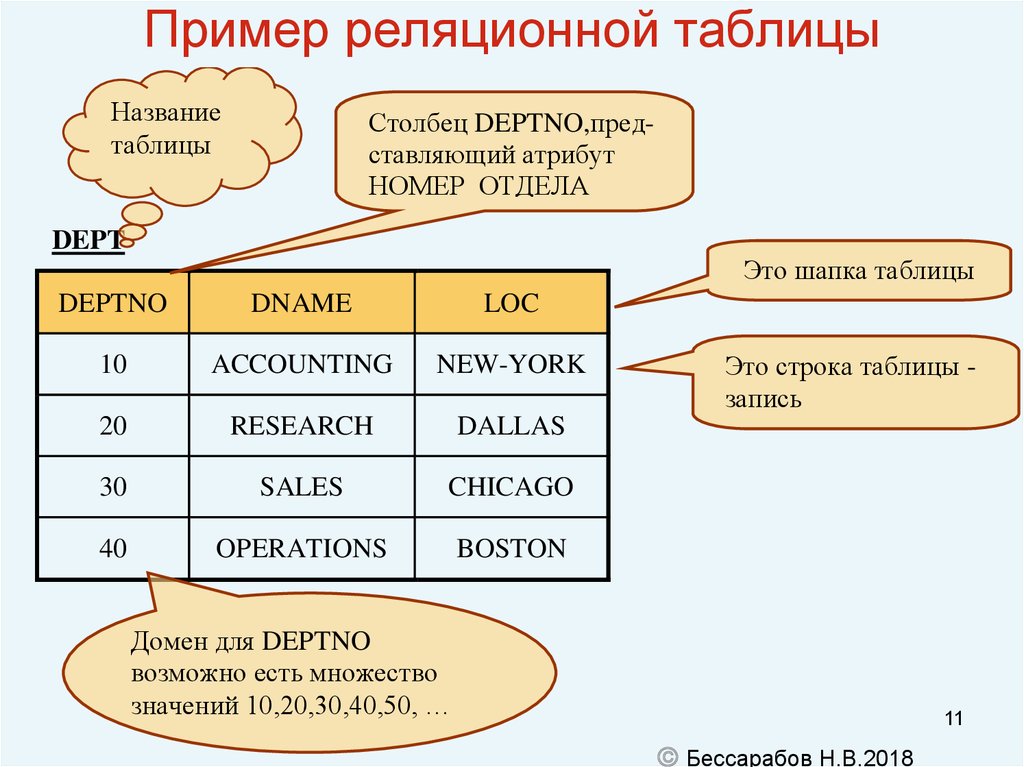 Им является идентификатор столбца. Он устанавливает взаимосвязи в двух таблицах. Теперь рассмотрим, что происходит, когда приложение, используемое компанией для обработки заявок клиентов, передает заказ в базу данных.
Им является идентификатор столбца. Он устанавливает взаимосвязи в двух таблицах. Теперь рассмотрим, что происходит, когда приложение, используемое компанией для обработки заявок клиентов, передает заказ в базу данных.
В этом случае база, обрабатывая табличную форму с информацией о заявках, выбирает данные о продукции и с помощью ключа клиента получает сведения об оплате и доставке. После этого работники склада находят необходимый товар, клиент получает его и оплачивает.
Важные составляющие реляционной базы данных
SQL
Structured Query Language (язык программирования SQL) является основой интерфейса для реляционных баз данных. Он в 1986 г. стал стандартом ANSI (Национальный институт стандартов Соединенных Штатов). Сейчас этот стандарт поддерживают все самые распространенные ядра реляционных баз данных. Существуют также расширения стандарта ANSI SQL.
Они поддерживаются некоторыми ядрами реляционных баз данных. В реляционных базах данных SQL применяют для работы со строками данных (удаление, добавление, обновление), отбора блоков данных для приложений аналитики и обработки транзакций.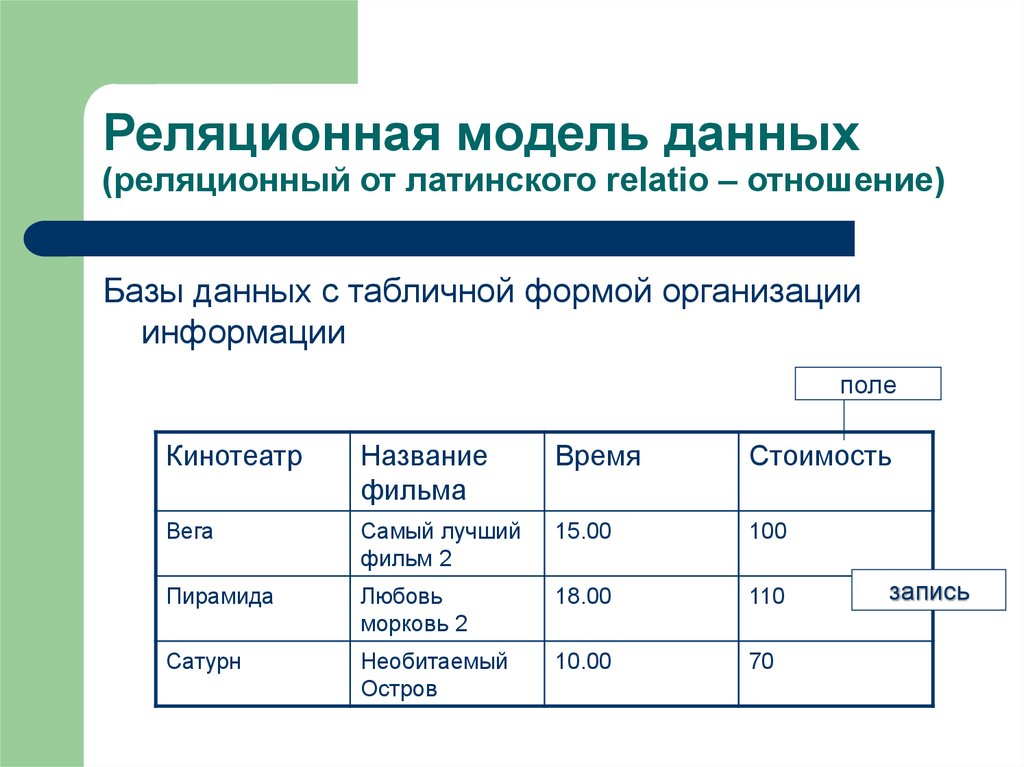 Кроме того, этот язык программирования используется для управления всеми видами работы реляционных баз данных.
Кроме того, этот язык программирования используется для управления всеми видами работы реляционных баз данных.
Целостность данных
Под целостностью данных понимают обеспечение их точности, полноты и единообразия. Для решения этой задачи в контексте реляционных баз данных применяется определенный комплекс инструментов, включающий первичные и внешние ключи, а также ограничители «Not NULL», «Unique», «Default» и «Check».
С помощью инструментов обеспечения целостности данных решаются вопросы применения практических правил к табличной информации, а также гарантируется точность данных и их надежность. Многие ядра реляционных БД поддерживают внедрение пользовательского кода, который выполняется при конкретных операция в базах данных.
Транзакции
Транзакций в базе данных называют комплекс последовательных операций, являющихся единой логической задачей и применением одного или ряда операторов SQL. Это неделимое действие. Транзакция должна выполняться как единая операция, поэтому она должна записываться в БД полностью, или ни один из ее элементов не должен записываться.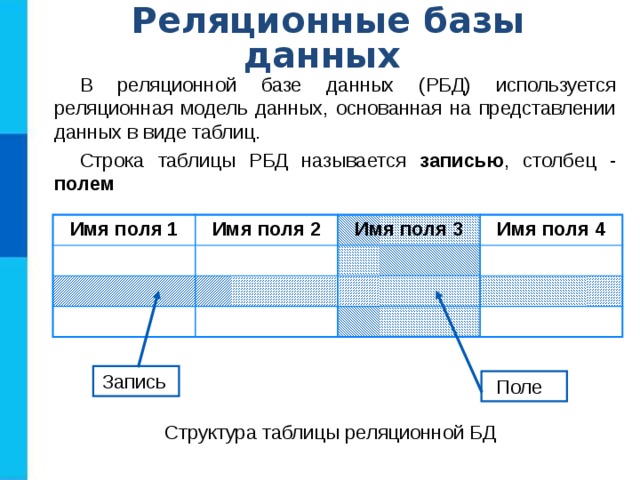
Транзакции в реляционных базах данных завершают действия COMMIT или ROLLBACK. Любой комплекс транзакционных операций следует рассматривать как надежный, имеющий внутренние связи элемент, не зависящий от остальных транзакций.
Соответствие требованиям ACID
Чтобы обеспечить требование по целостности реляционных баз данных, все транзакции в них должны удовлетворять требованиям ACID (они должны быть атомарными, единообразными, изолированными, надежными).
Топ-30 самых востребованных и высокооплачиваемых профессий 2022
Поможет разобраться в актуальной ситуации на рынке труда
Подборка 50+ ресурсов об IT-сфере
Только лучшие телеграм-каналы, каналы Youtube, подкасты, форумы и многое другое для того, чтобы узнавать новое про IT
ТОП 50+ сервисов и приложений от Geekbrains
Безопасные и надежные программы для работы в наши дни
pdf 3,7mb
doc 1,7mb
Уже скачали 16865
Первое условие – «атомарность».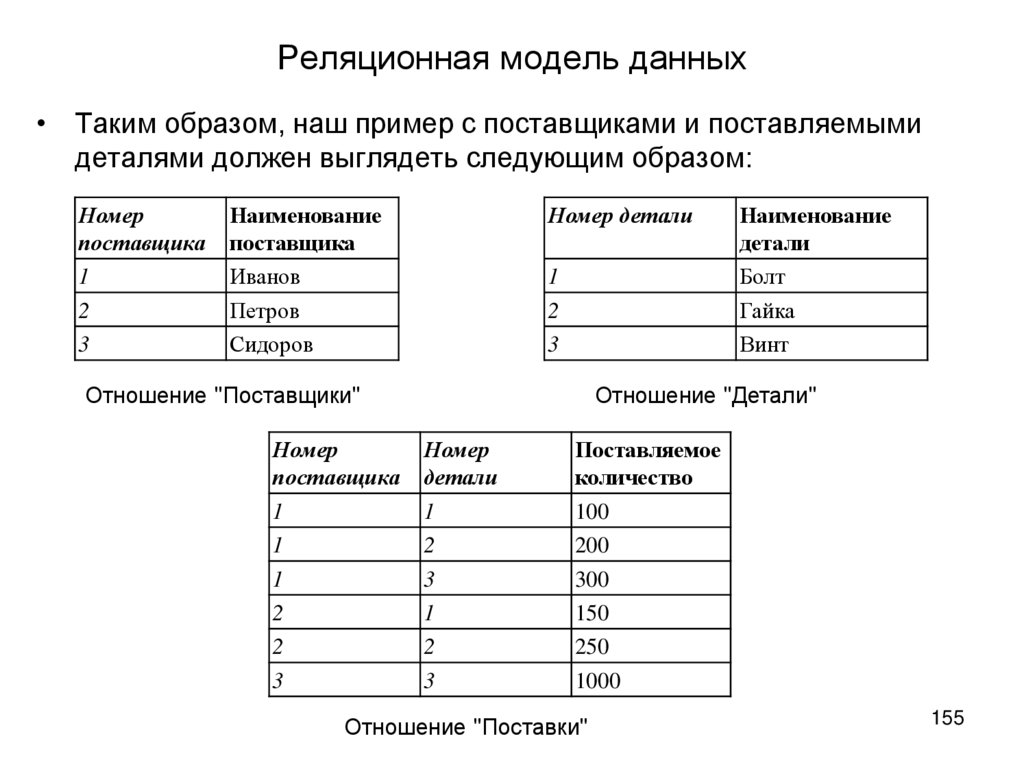 Оно указывает, что любая транзакция должна быть выполнена полностью. Если хоть один из ее элементов не выполняется, то должна отменяться вся транзакция. В соответствии с условием «единообразие», все элементы, записываемые в поля реляционной базы данных по транзакции, должны удовлетворять комплексу правил и ограничений, в том числе по целостности, каскадам и триггерам.
Оно указывает, что любая транзакция должна быть выполнена полностью. Если хоть один из ее элементов не выполняется, то должна отменяться вся транзакция. В соответствии с условием «единообразие», все элементы, записываемые в поля реляционной базы данных по транзакции, должны удовлетворять комплексу правил и ограничений, в том числе по целостности, каскадам и триггерам.
Условие «изолированность» важно для контроля согласованности данных. Кроме того, его выполнение необходимо для гарантии базовой независимости всех транзакций. В соответствии с условием «надежность», все изменения, которые внесены в реляционную базу данных до момента завершения транзакции, получают статус постоянных.
Преимущества и недостатки реляционных баз данных
Основные плюсы и минусы мы будем рассматривать с учетом организационной структуры реляционной базы данных.
Современные модели БД, построенные на языке программирования SQL, в некоторой степени отходят от логической реляционной модели, созданной математиком Э.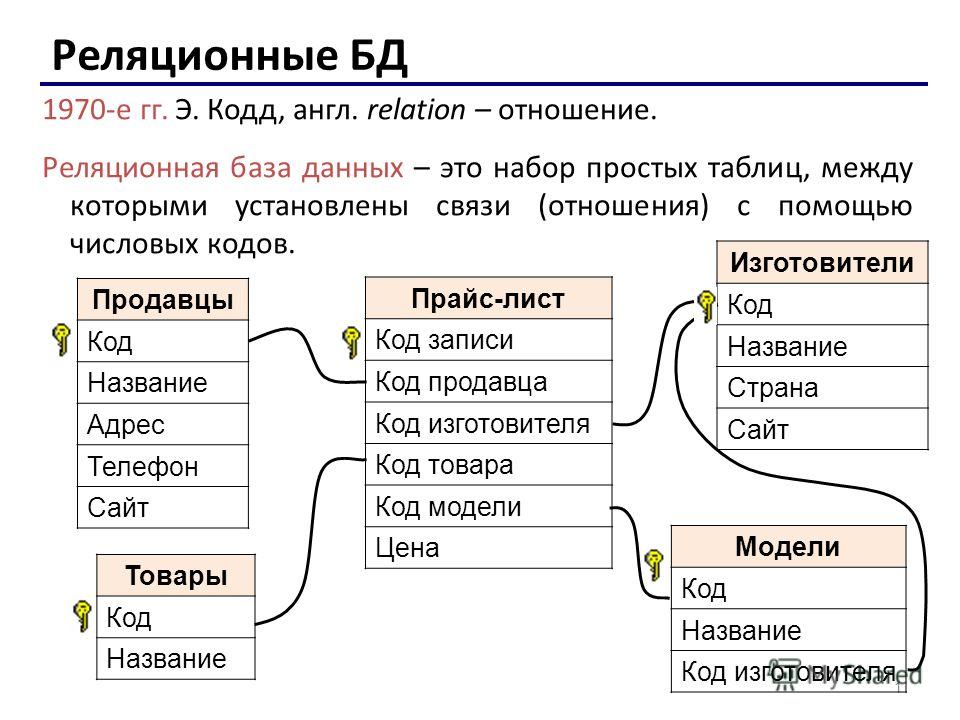 Коддом. К примеру, изначально основатель системы предусматривал необходимость обеспечения уникальности каждой новой строки. Это было предписано в модели Кодда, но многие новые реляционные базы данных допускают повторение строк, что вызвано практической целесообразностью.
Коддом. К примеру, изначально основатель системы предусматривал необходимость обеспечения уникальности каждой новой строки. Это было предписано в модели Кодда, но многие новые реляционные базы данных допускают повторение строк, что вызвано практической целесообразностью.
При этом некоторые исследователи считают, что если БД на основе SQL не полностью соответствуют набору критериев модели Кодда, то их нельзя называть реляционными базами данных. В реальности ситуация несколько отличается. Все СУБД, созданные на основе SQL и в некоторой степени, соответствующие сути реляционной базы данных, могут считаться реляционными системами.
Параллельно с растущей популярностью реляционной модели базы данных на фоне увеличения размеров и ценности хранящейся и обрабатываемой информации, стали проявляться и ее слабые стороны. Так, возникают существенные сложности с горизонтальным масштабированием таких БД. Возможность масштабировать базу данных горизонтально является стандартной практикой при добавлении большого числа машин к имеющемуся стеку.
Это способствует рациональному распределению нагрузки, ускорению обработки и увеличению трафика. Нередко горизонтальное масштабирование является альтернативой вертикальному, при котором проводится усовершенствование аппаратного обеспечения имеющегося сервера (обычно для этого добавляют оперативную память или центральный процессор).
Трудности с горизонтальным масштабированием записи в реляционной базе данных возникают из-за того, что она создается в соответствии с условием «целостности» (пользователи, которые отправляют запросы в одну и ту же реляционную БД, всегда получают похожие данные). Выполняя масштабирование горизонтально, сложно будет обеспечить целостность данных, поскольку пользователи имеют возможность вносить информацию лишь в один узел, а не во все имеющиеся одновременно.
Скорее всего, будет происходить задержка между моментом начальной записи и обновлением других узлов, которое позволит отобразить изменения. В результате будет нарушена целостность данных между узлами системы.
Еще один недостаток реляционной СУБД обусловлен тем, что такая модель создавалась для обработки структурированной информации (данные реляционной базы должны соответствовать определенному типу, или их необходимо изначально организовать определенным образом). Увеличение количества ПК и развитие Всемирной паутины способствовали тому, что в начале девяностых стали появляться большие объемы неструктурированных данных (электронные сообщения, фото, видео и т.д.).
Интенсив «Путь в IT» поможет:
- За 3 часа разбираться в IT лучше, чем 90% новичков.
- Понять, что действительно ждет IT-индустрию в ближайшие 10 лет.
- Узнать как по шагам c нуля выйти на доход в 200 000 ₽ в IT.
При регистрации вы получите в подарок:
«Колесо компетенций»
Тест, в котором вы оцениваете свои качества и узнаете, какая профессия в IT подходит именно вам
«Критические ошибки, которые могут разрушить карьеру»
Собрали 7 типичных ошибок, четвертую должен знать каждый!
Тест «Есть ли у вас синдром самозванца?»
Мини-тест из 11 вопросов поможет вам увидеть своего внутреннего критика
Хотите сделать первый шаг и погрузиться в мир информационных технологий? Регистрируйтесь и смотрите интенсив:
Только до 22 декабря
Осталось 17 мест
Тем не менее, реляционные базы данных и в условиях развития интернет-технологий остаются актуальными. Эта модель все еще остается доминирующей для СУБД. Ее широкое применение и длительный срок «жизни» говорит о том, что мы имеем дело с вполне зрелой технологий, что уже само по себе является весомым достоинством. Создано большое количество приложений для организации работы с реляционными базами данных.
Эта модель все еще остается доминирующей для СУБД. Ее широкое применение и длительный срок «жизни» говорит о том, что мы имеем дело с вполне зрелой технологий, что уже само по себе является весомым достоинством. Создано большое количество приложений для организации работы с реляционными базами данных.
Кроме того, существует множество карьерных администраторов БД, имеющих экспертные знания в области реляционной модели. Тем новичкам, которые стремятся получить знания и навыки работы с реляционными базами данных, доступен широкий выбор интернет-ресурсов, книг и учебников по этой теме.
К достоинствам данной модели можно отнести и тот факт, что практически все системы управления реляционными базами данных обеспечивают поддержку транзакций. Транзакции – одно или несколько уникальных выражений SQL, которые выполняются последовательно, как единый рабочий блок. Они работают по принципу «все или ничего».
Другими словами, каждый из операторов SQL в одной транзакции должен быть действительным. Если такое условие не соблюдается, транзакция не выполняется. Данный момент важен в контексте целостности данных в момент внесения изменений в таблицы или в ряд строк.
Если такое условие не соблюдается, транзакция не выполняется. Данный момент важен в контексте целостности данных в момент внесения изменений в таблицы или в ряд строк.
Если сравнить реляционные и нереляционные базы данных, то первые будут отличаться высокой степенью гибкости. Их применяют для создания самых разных приложений. При этом, реляционные БД все также эффективны для работы с объемными базами информации. В этой связи стоит отметить большой потенциал языка программирования. Он обеспечивает высокую скорость внесения и изменения данных, а также корректировки структуры схем БД и табличных форм, без воздействия на имеющиеся данные.
3 популярных реляционных базы данных для веб-разработки
MySQL
Данную открытую систему управления базами данных американская корпорация Oracle приобрела в комплекте с Sun Microsystems. Опрос, проведенный порталом StackOverflow.com два года назад, в котором приняли участие 65 000 пользователей, показал, что около 55,6 % разработчиков работают с MySQL.
Такая популярность обусловлена высокой скоростью управления данными и возможностью бесплатного использования. MySQL изначально разрабатывалась, чтобы обрабатывать огромные информационные базы в промышленных объемах. Впоследствии, когда разработчики оценили ее быстродействие и бесплатность, эта СУБД покорила мировой Интернет. Пока MySQL остается наиболее удобной системой управления данными для работы и веб-приложениями, и страницами.
При этом, данная СУБД получает серьезную поддержку от разработчиков языков программирования. Сегодня практически все популярные языки имеют интерфейс для работы с MySQL.
SQLite
В этой системе управления реляционными базами данных применяется много всего, что входит в стандартный язык SQL.
Основным ее достоинством считается встраиваемость, которая обусловлена тем, что SQlight в отличие от остальных СУБД является не приложением на подобие «клиент-сервер», а подключаемой библиотекой.
О популярности SQLite может говорить тот факт, что она присутствует во всех смартфонах. В гаджетах на Андроид в этой базе данных хранятся медиафайлы и контакты. В смартфонах на iOS СУБД SQLite используется большинством приложений.
В гаджетах на Андроид в этой базе данных хранятся медиафайлы и контакты. В смартфонах на iOS СУБД SQLite используется большинством приложений.
PostgreSQL
Это наиболее продвинутая система управления реляционными базами данных. PostgreSQL является свободной объектно-реляционной СУБД.
Уникальность данной СУБД состоит в том, что кроме стандартных типов данных, поддерживаемых другими реляционными системами, она может работать с финансовой информацией, сетевыми адресами, JSON, XML и геометрическими данными. Более того, PostgreSQL может создавать свои типы данных.
Перспективы реляционных баз данных
Существующие виды реляционных баз данных уже длительное время развиваются в плане повышения производительности, безопасности и надежности. Они стали более удобными в обслуживании, но при этом структура их сильно усложнилась. Сегодня администрирование реляционных баз данных связано с существенными затратами времени и ресурсов в плане администрирования.
В результате разработчики вынуждены направлять свои силы на управление СУБД и их оптимизацию вместо того, чтобы работать над созданием новых приложений, способных приносить высокую прибыль бизнесу.
Автономные технологии сейчас больше применяются для расширения функционала реляционной модели базы данных, разработки облачных хранилищ, машинного обучения и информационных баз нового типа. Автономные БД обладают всеми преимуществами реляционных систем, поддерживают те же функции, но плюс к этому способны использовать средства машинного обучения и искусственного интеллекта для контроля и повышения скорости ответа на запросы и эффективности управления.
К примеру, чтобы запросы выполнялись быстрее, самоуправляемые базы данных осуществляют прогнозирование и проверяют индексы. После этого более высокие результаты находят практическое применение. Примечательно, что все эти процессы происходят без вмешательства администратора. Другими словами, автономные БД на постоянной основе могут обеспечивать улучшения в своей работе без участия человека.
Автономные технологии освобождают разработчиков от рутинной работы по обслуживанию СУБД. В отличие от реляционных баз данных, примеры которых мы рассматривали в этом материале, самоуправляемые БД избавляют от необходимости предварительно выяснять все требования к инфраструктуре.
Автономные базы позволят расширять хранилища данных и увеличивать вычислительные мощности при появлении такой необходимости. Их создание может происходить намного быстрее, чем проектирование реляционных баз данных, что значительно сократит время, необходимое для разработки приложений.
Рейтинг: 5
( голосов 1 )
Поделиться статьей
Что такое реляционная база данных? {Примеры, преимущества и недостатки}
Введение
С таким количеством доступных вариантов может быть сложно выбрать решение для базы данных, которое идеально соответствует вашим потребностям. Когда дело доходит до типов баз данных, одним из популярных вариантов является реляционная база данных.
Когда дело доходит до типов баз данных, одним из популярных вариантов является реляционная база данных.
В этой статье мы расскажем о структуре реляционных баз данных, о том, как они работают, а также о преимуществах и недостатках их использования. Мы также будем использовать примеры, чтобы проиллюстрировать, как реляционные базы данных организуют данные.
Определение реляционной базы данных
Реляционная база данных — это тип базы данных, который фокусируется на отношениях между сохраненными элементами данных. Это позволяет пользователям устанавливать связи между различными наборами данных в базе данных и использовать эти связи для управления и ссылки на связанные данные.
Многие реляционные базы данных используют SQL (язык структурированных запросов) для выполнения запросов и обслуживания данных.
Реляционные и нереляционные базы данных
Реляционные базы данных сосредоточены на отношениях между данными. Следовательно, база данных отношений должна хранить данные строго структурированным образом. Это обеспечивает более быстрое индексирование и время ответа на запросы, а также делает данные более безопасными и согласованными.
Следовательно, база данных отношений должна хранить данные строго структурированным образом. Это обеспечивает более быстрое индексирование и время ответа на запросы, а также делает данные более безопасными и согласованными.
С другой стороны, базам данных NoSQL не нужно так сильно полагаться на структуру, что позволяет им хранить большие объемы данных, оставаться гибкими и легко масштабировать хранилище и производительность.
Примечание: Для более подробного изучения различий между реляционными и нереляционными базами данных ознакомьтесь с нашей статьей, посвященной сравнению SQL и NoSQL.
Как организованы данные в реляционной базе данных?
Системы реляционной базы данных Используйте модель, которая организует данные в таблицы из строк (также называется Записи или CURPLE ) и колонны (также вызвали атрибуты 877777777878787878788887887878888888888888888 года 8888888888888 гг.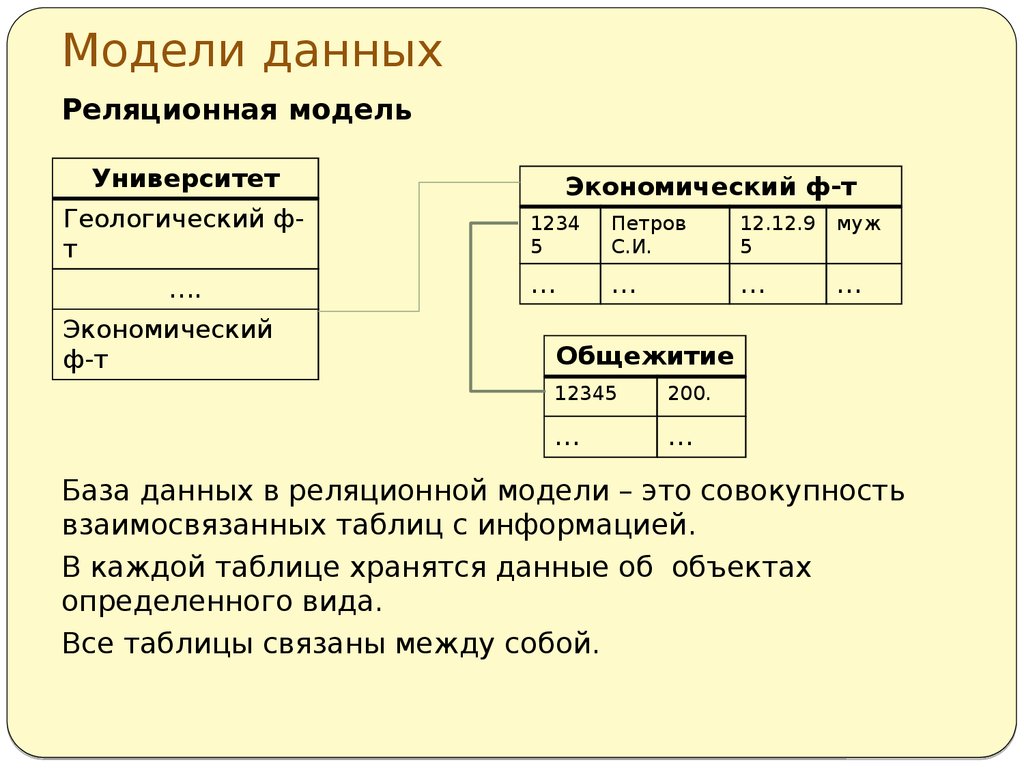 полей ). Как правило, столбцы представляют категории данных, а строки представляют отдельные экземпляры.
полей ). Как правило, столбцы представляют категории данных, а строки представляют отдельные экземпляры.
В качестве примера возьмем цифровую витрину. В нашей базе данных может быть таблица, содержащая информацию о клиентах, со столбцами, представляющими имена или адреса клиентов, а каждая строка содержит данные для одного отдельного клиента.
Эти таблицы могут быть связаны или связаны с помощью ключей . Каждая строка в таблице идентифицируется с помощью уникального ключа, называемого первичным ключом . Этот первичный ключ можно добавить в другую таблицу, став внешним ключом . Отношения первичный/внешний ключ составляют основу работы реляционных баз данных.
Возвращаясь к нашему примеру, если у нас есть таблица, представляющая заказы на продукты, один из столбцов может содержать информацию о клиентах. Здесь мы можем импортировать первичный ключ, который ссылается на строку с информацией для конкретного клиента.
Таким образом, мы можем ссылаться на данные или дублировать данные из таблицы информации о клиентах. Это также означает, что эти две таблицы теперь связаны.
Примечание: Если вы новичок в базах данных, наш пост «Что такое база данных» — хорошая отправная точка для изучения всего, что вам нужно знать.
Примеры реляционных баз данных
Теперь, когда мы рассмотрели, как они работают, вот некоторые из наиболее популярных примеров реляционных баз данных:
MySQL
приобретена Sun Microsystems (теперь Oracle Corporation). Он по-прежнему доступен под лицензией с открытым исходным кодом с добавлением различных проприетарных лицензий.
MySQL имеет встроенную поддержку репликации с соответствием ACID, кластеризацию без совместного использования и поддерживает несколько механизмов хранения. Однако использование некоторых механизмов хранения может привести к некорректной работе SQL.
MySQL отличается быстрым вводом данных и масштабируемостью, сохраняя при этом высокую доступность и производительность. Это делает его чрезвычайно полезным для веб-разработки и разработки приложений.
Это делает его чрезвычайно полезным для веб-разработки и разработки приложений.
PostgreSQL
PostgreSQL — это бесплатный менеджер реляционных баз данных, доступный по лицензии с открытым исходным кодом. Он разделяет некоторые функции с MySQL, с заметным добавлением MVCC (контроль параллелизма нескольких версий), что делает его совместимым с ACID.
PostgreSQL сохраняет высокий уровень производительности и гибкости даже при работе с большими базами данных. Это правильный выбор для пользователей, которым требуется высокая скорость чтения/записи и обширный анализ данных.
Некоторые известные пользователи PostgreSQL включают Reddit, Skype и Instagram.
MariaDB
MariaDB начиналась как форк MySQL, управляемый сообществом, после того, как последний был куплен Oracle. Он по-прежнему с открытым исходным кодом и доступен по лицензии GNU General Public License.
MariaDB основывается на базе MySQL, добавляя поддержку еще большего количества механизмов хранения и устраняя ограничения механизмов хранения.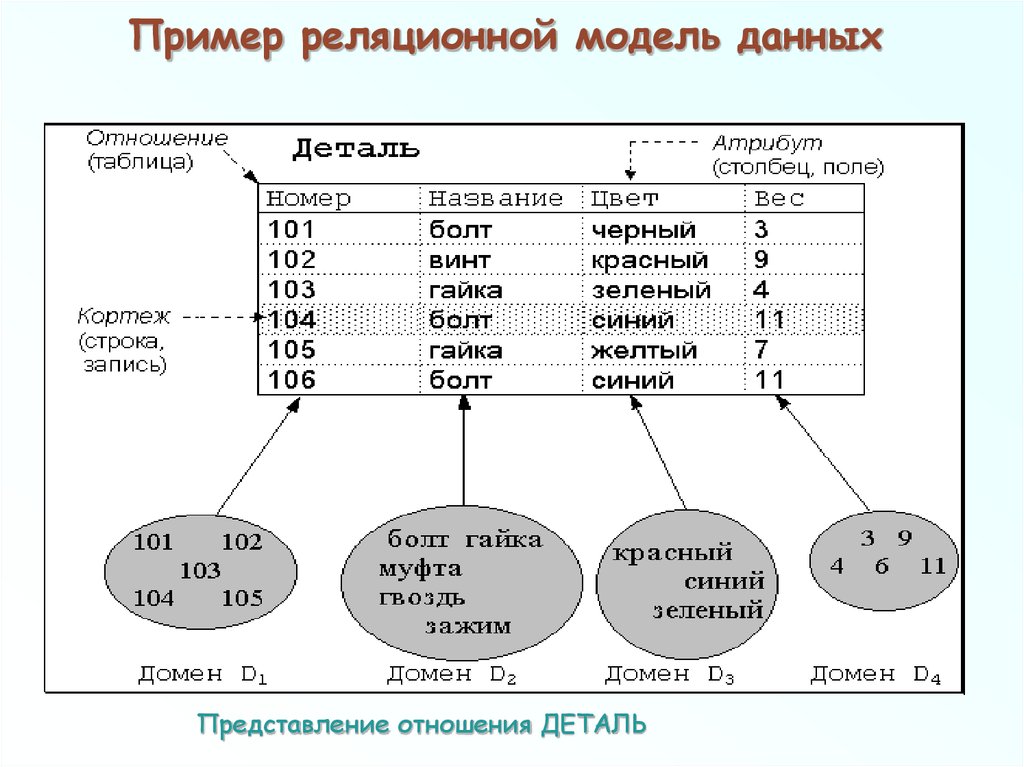 Это позволяет ему работать даже быстрее, чем MySQL, и запускать как SQL, так и NoSQL в одной базе данных.
Это позволяет ему работать даже быстрее, чем MySQL, и запускать как SQL, так и NoSQL в одной базе данных.
Известные пользователи MariaDB включают Google, Mozilla и Фонд Викимедиа.
SQLite
В отличие от других записей в этом списке, SQLite не является менеджером базы данных клиент-сервер, а скорее встроен в конечное приложение. Это делает его легким и способным работать с широким спектром систем и платформ.
Это также вызывает некоторые ограничения, так как SQLite лишь частично предоставляет триггеры, имеет ограниченную функцию ALTER TABLE и не может записывать в представления. Он также ограничивает максимальный размер базы данных до 32 000 столбцов и 140 ТБ.
Поэтому SQLite лучше всего использовать в качестве компонента базы данных для других приложений. Известное использование включает популярные браузеры, такие как Google Chrome, Mozilla Firefox, Opera и Safari.
Что такое система управления реляционными базами данных?
Система управления базами данных (СУБД) — это программное решение, которое помогает пользователям просматривать, запрашивать и управлять базами данных.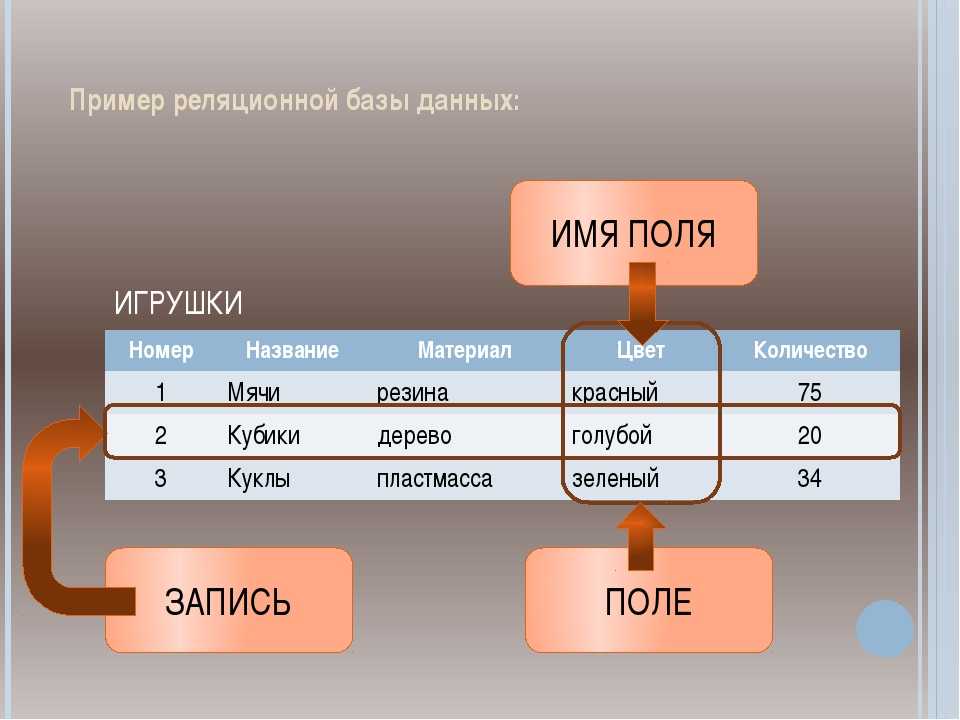
Системы управления реляционными базами данных (RDBMS) являются более продвинутым подмножеством СУБД, обрабатывающим реляционные базы данных.
дБм против RDBMS
Вот некоторые из различий между более общими решениями DBMS и RDBMS:
| DBMS | RDBMS | RDBMS | . | Хранит большие объемы данных в виде связанных друг с другом таблиц. |
| Одновременно возможен доступ только к одному элементу данных. | Может обращаться к нескольким элементам данных одновременно. |
| Работа с большими объемами данных замедляет выборку. | Реляционный подход позволяет быстро получать данные даже для больших баз данных. |
| Нет нормализации базы данных. | Разрешает нормализацию базы данных. |
| Не поддерживает распределенные базы данных. | Поддерживает распределенные базы данных.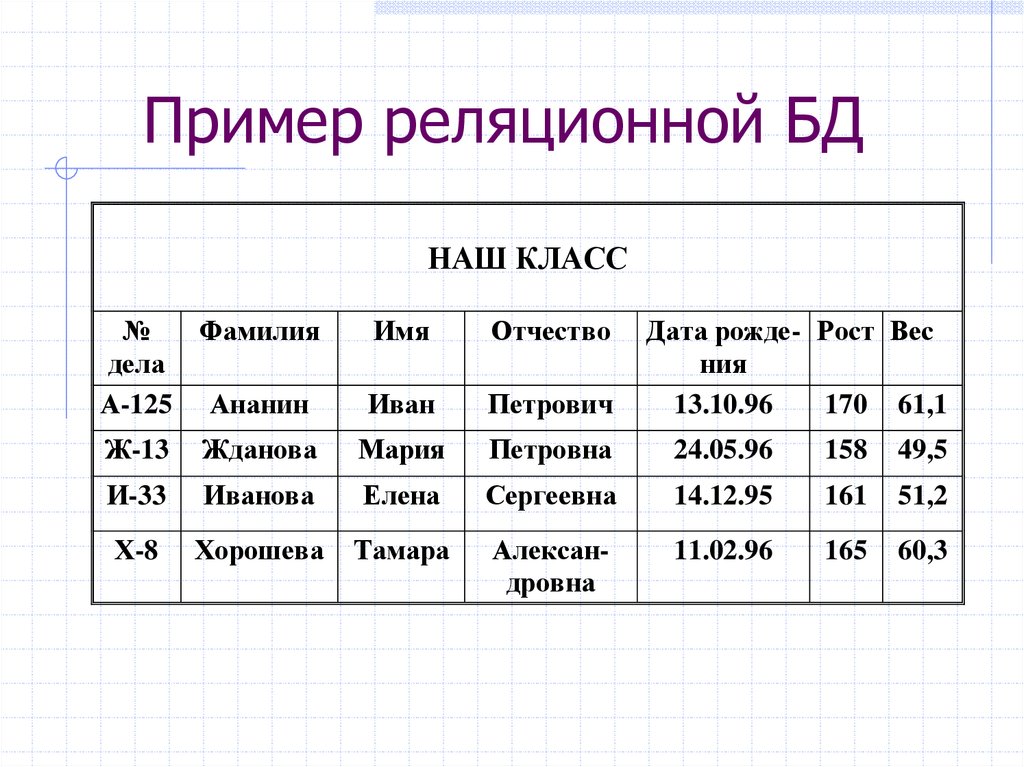 |
| Поддерживает одного пользователя. | Поддерживает несколько пользователей. |
| Низкий уровень безопасности. | Несколько уровней безопасности. |
| Низкие требования к программному и аппаратному обеспечению. | Высокие требования к программному и аппаратному обеспечению. |
Преимущества и недостатки реляционных баз данных
Как и любая другая модель базы данных, использование реляционных баз данных имеет свои преимущества и недостатки: другие типы баз данных, что упрощает их использование.
Эта табличная структура смещает акцент на обработку данных, что позволяет повысить производительность и использовать сложные высокоуровневые запросы.
Наконец, реляционные базы данных позволяют легко масштабировать данные, просто добавляя строки, столбцы или целые таблицы без изменения общей структуры базы данных.
Недостатки
Существуют пределы масштабируемости реляционных баз данных. Что касается размера, некоторые базы данных имеют фиксированные ограничения на длину столбцов. Если ваша база данных построена на одном выделенном сервере, масштабирование требует покупки дополнительного места на сервере, что в долгосрочной перспективе обходится дорого.
Что касается размера, некоторые базы данных имеют фиксированные ограничения на длину столбцов. Если ваша база данных построена на одном выделенном сервере, масштабирование требует покупки дополнительного места на сервере, что в долгосрочной перспективе обходится дорого.
Кроме того, постоянное добавление новых элементов в базу данных может сделать ее настолько сложной, что становится трудно установить отношения между новыми фрагментами данных. Сложные отношения данных также замедляют выполнение запросов и отрицательно сказываются на производительности.
Заключение
Прочитав эту статью, вы должны иметь четкое представление о том, как работают реляционные базы данных. Вы также должны быть знакомы с некоторыми наиболее известными примерами систем управления реляционными базами данных.
Объяснение реляционных баз данных — примеры, варианты использования и многое другое
Реляционная база данных — это именно то, что следует из ее названия: инструмент для хранения различных типов информации, которые связаны друг с другом различными способами. Например, реляционная база данных для интернет-магазина может содержать данные о клиентах, а также соответствующую информацию, такую как их различные адреса, списки пожеланий, заказы и т. д.
Например, реляционная база данных для интернет-магазина может содержать данные о клиентах, а также соответствующую информацию, такую как их различные адреса, списки пожеланий, заказы и т. д.
Реляционные базы данных существуют уже давно, использовались в широкий спектр вариантов использования и остаются популярным выбором даже сегодня, поскольку они предлагают зрелую, стабильную, проверенную технологию, которая становится все более надежной и простой в использовании. Вы можете ожидать, что они будут управлять данными для приложений электронной коммерции, управления запасами, расчета заработной платы, данных о клиентах и многого другого.
В этой статье мы объясним, как работают реляционные базы данных, обсудим их преимущества, сравним и сопоставим альтернативные системы, а также опишем некоторые более популярные сегодня системы, которые могут работать с реляционными базами данных.
Как работают реляционные базы данных
На заре вычислительной техники каждое приложение обычно хранило свои данные в собственном уникальном формате. Хранение данных столь разными способами усложняло обслуживание систем и их интеграцию по мере необходимости. Модель реляционной базы данных возникла как способ стандартизировать, как разработчики могут последовательно работать с данными на высоком уровне, оставляя детали базовых операций и форматов хранения программному обеспечению.
Хранение данных столь разными способами усложняло обслуживание систем и их интеграцию по мере необходимости. Модель реляционной базы данных возникла как способ стандартизировать, как разработчики могут последовательно работать с данными на высоком уровне, оставляя детали базовых операций и форматов хранения программному обеспечению.
Реляционные модели, как правило, организуют данные в таблицы, состоящие из строк и столбцов, подобно программам для работы с электронными таблицами. Ниже показано, как реляционная база данных может отслеживать детей в летнем лагере. Каждая строка содержит информацию о конкретном туристе, включая уникальный идентификационный номер, а также имя ребенка, возраст и любимую еду.
| ID | Наименование | Возраст | Любимая еда |
| 1 | Лиза | 11 | Пицца |
| 2 | Сара | 8 | Мороженое |
| 3 | Дженна | 9 | Пицца |
Назначение уникального идентификатора может быть неочевидным, но это позволяет другим таблицам в базе данных отслеживать любые связанные данные, такие как даты посещения, назначения в каютах, мероприятия, сертификаты, награды и т.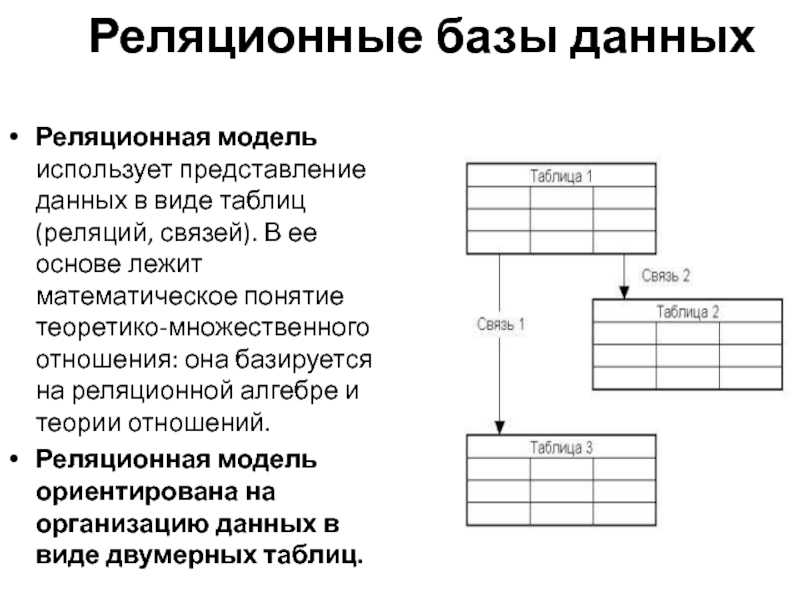 д. — путем включения идентификационного номера кемпера в подчиненные таблицы . Возможность объединять множество разных таблиц по таким идентификаторам делает реляционные базы данных… ну, реляционными .
д. — путем включения идентификационного номера кемпера в подчиненные таблицы . Возможность объединять множество разных таблиц по таким идентификаторам делает реляционные базы данных… ну, реляционными .
Напротив, системы управления реляционными базами данных (сокращенно РСУБД) представляют собой программные системы, которые управляют реляционными базами данных. В то время как реляционная база данных сама по себе представляет собой набор концептуальных таблиц, которые хранятся на носителях в различных форматах, РСУБД — это то, что позволяет взаимодействовать с данными, не зная деталей. Например, СУБД позволяют администрировать несколько реляционных баз данных на одном или нескольких серверах и принимать команды для создания, чтения, обновления или удаления данных (так называемые операции «CRUD») в таблицах.
Реляционные базы данных абстрагируют операции с помощью так называемого языка структурированных запросов (SQL). SQL был стандартизирован для систем СУБД для согласованного выполнения операций CRUD (и других), поэтому одни и те же операторы SQL могут выполняться _любой _RDBMS, которая поддерживает этот стандарт. Возвращаясь к нашему примеру, можно выполнить элементарные операторы SQL, чтобы вставить новую строку для Тома, которому 13 лет и он любит спагетти, или изменить любимую еду Лизы на мороженое. SQL также может получить все строки в таблице или отфильтрованное и отсортированное подмножество только детей в определенных возрастных диапазонах, которые разделяют любимую еду.
Возвращаясь к нашему примеру, можно выполнить элементарные операторы SQL, чтобы вставить новую строку для Тома, которому 13 лет и он любит спагетти, или изменить любимую еду Лизы на мороженое. SQL также может получить все строки в таблице или отфильтрованное и отсортированное подмножество только детей в определенных возрастных диапазонах, которые разделяют любимую еду.
Тем не менее, SQL не является обязательным требованием для классификации системы как реляционной. Современные реляционные базы данных, такие как Fauna, предлагают все свойства реляционной базы данных без использования SQL в качестве основного языка запросов. Новые языки, такие как GraphQL, могут предложить аналогичную (или даже большую) выразительность и иногда лучше вписываются в среду программирования разработчика.
Преимущества реляционных баз данных
Реляционные базы данных приносят много преимуществ таблице, что делает их популярным выбором для баз данных.
С точки зрения разработки реляционные базы данных представляют собой более структурированное представление о мире.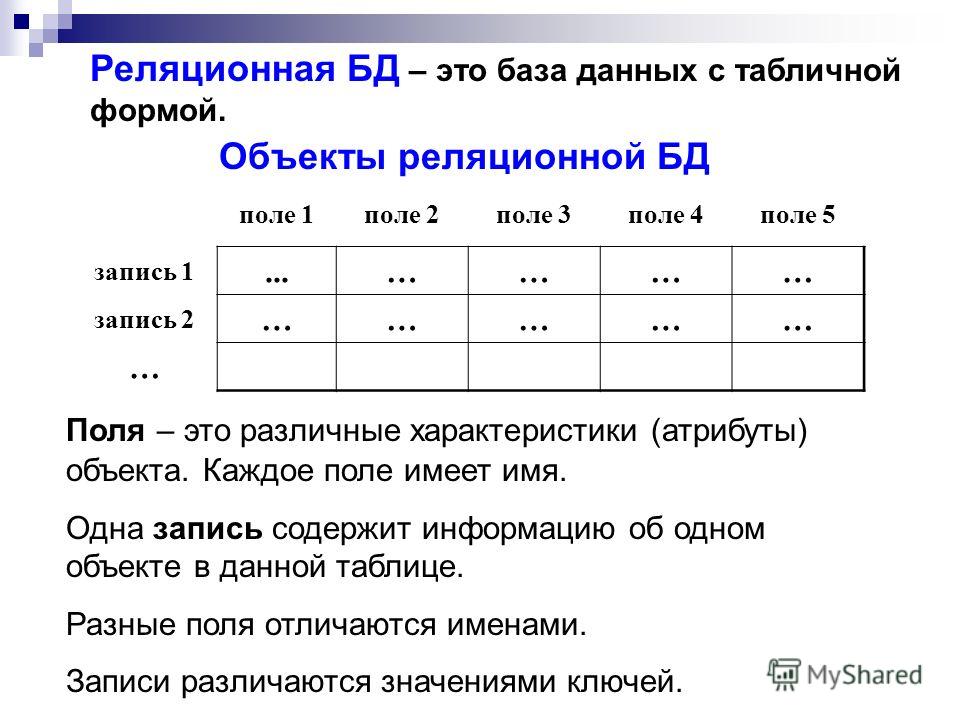 Реляционная структура хорошо подходит для моделирования реальных бизнес-сущностей (например, клиентов, заказов, каталогов, товаров и т. д.) и деловых отношений, существующих между ними.
Реляционная структура хорошо подходит для моделирования реальных бизнес-сущностей (например, клиентов, заказов, каталогов, товаров и т. д.) и деловых отношений, существующих между ними.
Сами операторы SQL часто достаточно просты, чтобы их можно было прочитать человеку, и они снижают входной барьер для разработчиков приложений. . Учитывая свой возраст, SQL стал обычным языком, знакомым многим разработчикам.
Тем не менее, одним из наиболее заметных преимуществ, предоставляемых реляционными базами данных, являются гарантии «ACID », что является важным преимуществом для критически важных для бизнеса операций. «ACID» означает «атомарность», «непротиворечивость», «изоляция» и «долговечность», все из которых относятся к важным свойствам транзакции , термин , используемый для описания единицы работы с базой данных. Реляционные базы данных процветали при рабочих нагрузках, требующих ACID, точно так же, как сегодня это делают некоторые нереляционные системы. Давайте объясним это по одному.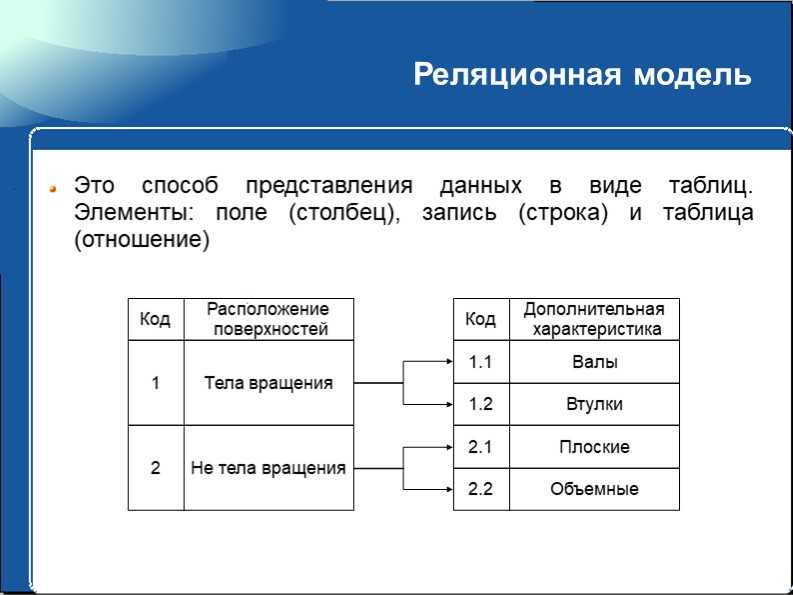
Атомарность — это свойство транзакции, которое гарантирует, что это «все или ничего». То есть транзакция либо успешно завершается как завершенная единица работы, выполняя различные операции CRUD (и другие), и регистрируется как единая фиксация в реляционной базе данных, либо аналогично завершается сбоем. В случае сбоя атомарность требует полного отката любых частей уже выполненной транзакции, оставляя реляционную базу данных точно такой, какой она была до начала транзакции.
Легко понять, почему это важно. Рассмотрим пользователя, размещающего заказ на товар в интернет-магазине. Покупка сложного предмета может означать, что, хотя пользователь заказывает «одну» вещь, это приводит к тому, что три разных предмета извлекаются из внутреннего инвентаря. Первые два могут не быть проблемой, но если третьего нет в наличии, вся транзакция должна завершиться неудачей и быть отменена. Реляционная модель поддерживает этот тип общей бизнес-логики.
Консистенция идет рука об руку с атомарностью, поскольку требует, чтобы данные всегда находились в согласованном внутреннем состоянии, когда транзакция начинается и когда она заканчивается. Все изменения базовых данных для таблиц и других структур должны быть полными и правильными, чтобы каждая успешная транзакция «перемещала» данные базы данных из одного четко определенного допустимого состояния в другое, при этом ничего не оставалось или еще не было сделано.
Все изменения базовых данных для таблиц и других структур должны быть полными и правильными, чтобы каждая успешная транзакция «перемещала» данные базы данных из одного четко определенного допустимого состояния в другое, при этом ничего не оставалось или еще не было сделано.
Это может звучать как атомарность, но это несколько иное, что демонстрируют многие нереляционные системы, которые вместо этого обеспечивают частичную или окончательную согласованность. Такие системы часто отвечают на команды быстрее, потому что фактические данные о хранении данных могут быть неполными, когда они отвечают кодом успеха. Это может быть большим преимуществом при создании высокопроизводительных веб-сайтов, масштабируемых для одновременного обслуживания большого количества пользователей.
Полное обсуждение согласованности выходит за рамки этой статьи, но достаточно сказать, что различные подходы могут создать или разрушить систему в зависимости от вариантов использования, которые она обслуживает. Многие критически важные бизнес-операции требуют согласованности, поэтому важно тщательно продумать все детали.
Многие критически важные бизнес-операции требуют согласованности, поэтому важно тщательно продумать все детали.
Теперь мы подошли к изоляции и долговечности, которые, пожалуй, проще понять. Когда множество разных пользователей взаимодействуют с одной и той же реляционной базой данных в одно и то же время, каждый из которых предпринимает различные транзакции с потенциально одним и тем же набором таблиц, важно, чтобы каждый пользователь видел только его вид данных. Чтение данных из таблицы, в которую одновременно пытается записать другой пользователь, должно отображать существующие данные, а не изменения, чтобы избежать «утечки» информации из транзакции, которая еще может потерпеть неудачу. Изоляция гарантирует, что «представление» во всей системе остается согласованным и неизменным для других операций, пока данная транзакция находится в процессе, как если бы она выполнялась сама по себе. Чтобы глубже погрузиться в уровни изоляции и их значение, ознакомьтесь с этой серией 9. 0285 блогов известного эксперта по базам данных доктора Даниэля Абади.
0285 блогов известного эксперта по базам данных доктора Даниэля Абади.
Долговечность просто требует, чтобы детали любой успешно совершенной транзакции постоянно записывались после ее завершения. Базовые изменения представления данных должны применяться полностью, чтобы не было потерь — даже в случае кэширования, жесткого диска или других сбоев системы. Обычно это включает неизменное ведение журнала сведений о том, что было изменено, когда и кем, а также для будущих нужд аудита.
Реляционные и нереляционные базы данных
После подробного обсуждения реляционных баз данных стоит уделить время важной альтернативе, о которой уже упоминалось: нереляционным базам данных (или иногда называемым базами данных «NoSQL », потому что они не используют SQL в качестве языка запросов). В отличие от строго структурированных таблиц СУБД, системы NoSQL вместо этого предлагают множество механизмов хранения, оптимизированных для конкретных случаев использования, и могут не предлагать гарантии ACID.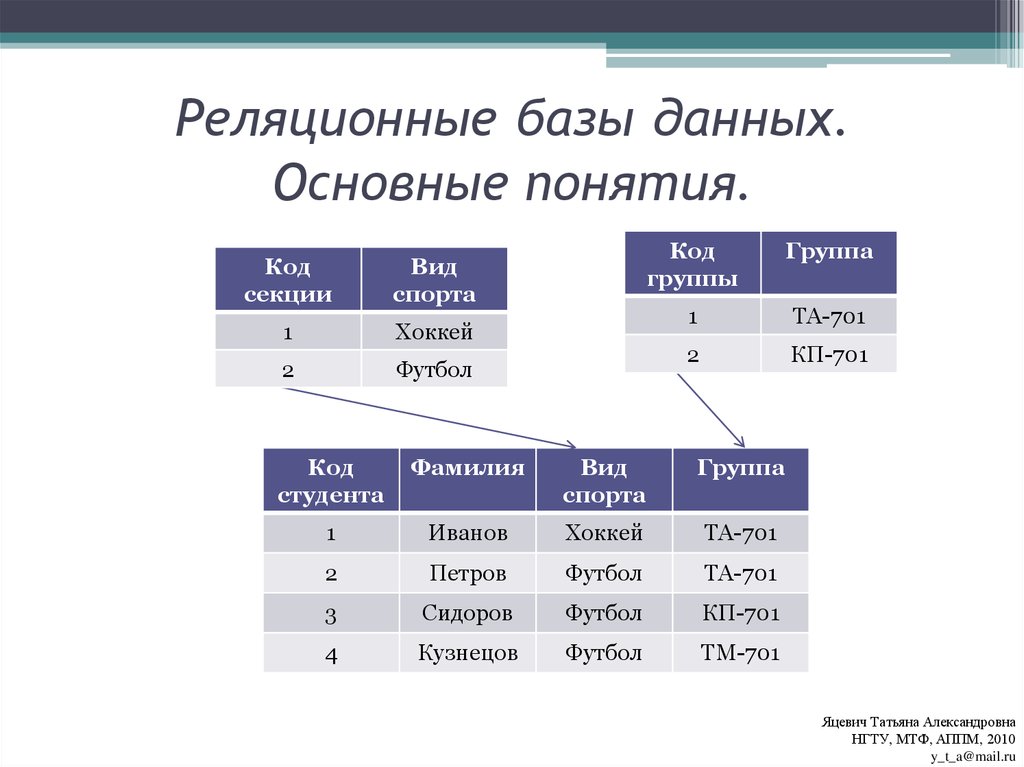
Существует четыре основных категории хранения, предлагаемые нереляционными базами данных: (1) документ, (2) пары ключ-значение, (3) широкий столбец и (4) граф. Рассмотрим каждый из них по очереди.
Так называемые «документные» базы данных, возможно, представляют собой нереляционное предложение в наиболее свободной форме, поскольку в их документах хранятся потенциально иерархические наборы объектов со свойствами. Вернемся к нашему предыдущему примеру: в то время как в реляционной базе данных данные об одном автофургоне будут храниться в ряде связанных таблиц, в базе данных документов могут храниться все сведения об этом автофургоне 9.0039 в одном документе . Указанный документ может содержать «Личные данные», включая свойства, которые мы видели ранее (например, имя, возраст и любимая еда), в то время как другие объекты, возможно, называемые «Посещаемость», «Назначения салона», «Действия» и т. д., могут содержать другие данные. характеристики.
Таким образом, формат базы данных документов хорошо подходит для хранения менее структурированной информации в более свободной форме.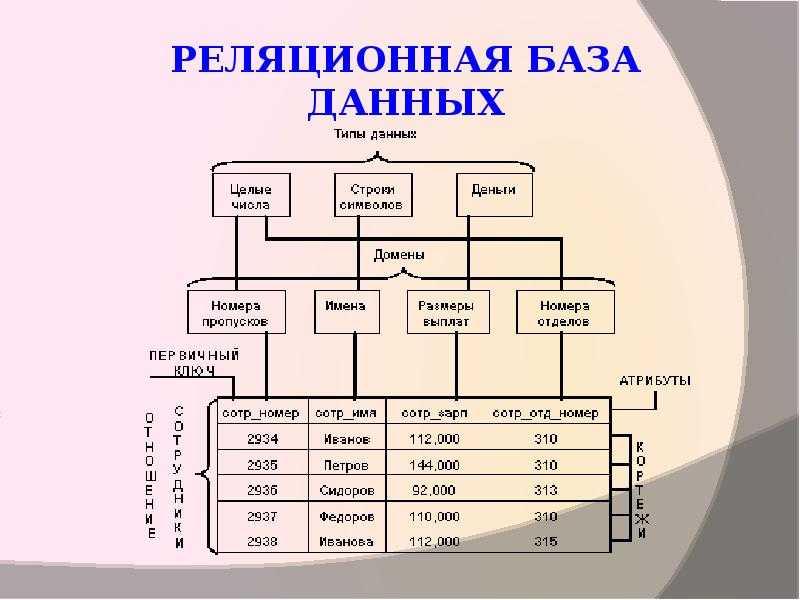 Это отличный стартовый выбор для любого нового проекта разработки, если вы не уверены, какими будут модели данных. Нереляционные базы данных хранят практически все и позволяют схемам легко изменяться с течением времени без особой структуры.
Это отличный стартовый выбор для любого нового проекта разработки, если вы не уверены, какими будут модели данных. Нереляционные базы данных хранят практически все и позволяют схемам легко изменяться с течением времени без особой структуры.
Как следует из их названия, «базы данных ключ-значение » хранят пары ключ-значение или KVP для краткости. KVP может быть любой простой информационной диадой; т. е. какой-то элемент служит ключом, который связан с каким-то другим элементом как значение. В то время как версия базы данных документов из нашего предыдущего примера могла бы хранить информацию для одного дочернего элемента в одном документе, это было бы намного сложнее в базе данных «ключ-значение». Например, вы можете хранить самую основную информацию о Лизе с помощью следующего KVP:
| Ключ | Значение |
| Лиза.Имя | Лиза |
Лиза.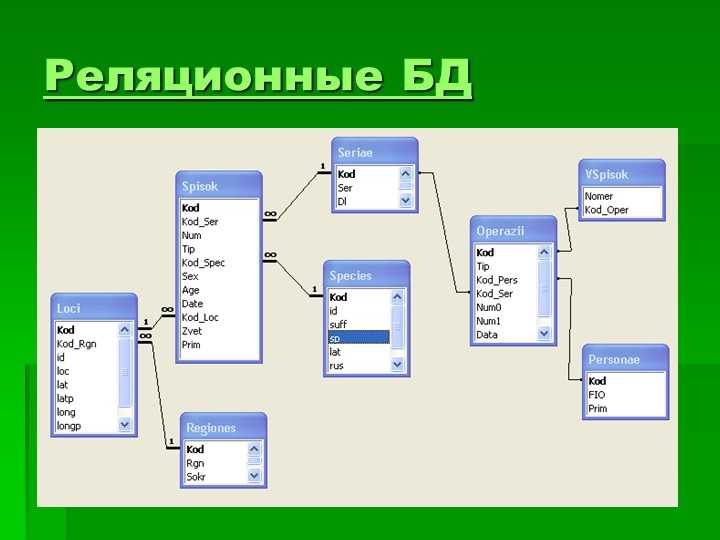 Возраст Возраст | 11 |
| Лиза.Любимая | Пицца |
Но вы бы впихнули базу данных NoSQL типа «ключ-значение» в вариант использования, для которого она в лучшем случае не подходит. Такие базы данных предназначены для более простых целей, таких как кэширование временных данных для веб-сеансов, сбор простых точек телеметрии с устройств в полевых условиях и т. д. Если вам интересно, почему кто-то может принять такую ограниченную модель данных, ответ — ее основное преимущество. : молниеносная производительность. Хеширование и другие алгоритмы позволяют считывать и записывать простые структуры KVP намного быстрее, чем многие альтернативы.
«Хранилища с широкими столбцами», иногда называемые «базами данных столбцов», занимают интересное место между базами данных документов и реляционными базами данных. Они не являются документными базами данных в том смысле, что они не поддерживают неопределенные иерархии объектов со свойствами, но они и не реляционные базы данных в том смысле, что они не требуют, чтобы все строки в таблице имели одинаковые столбцы.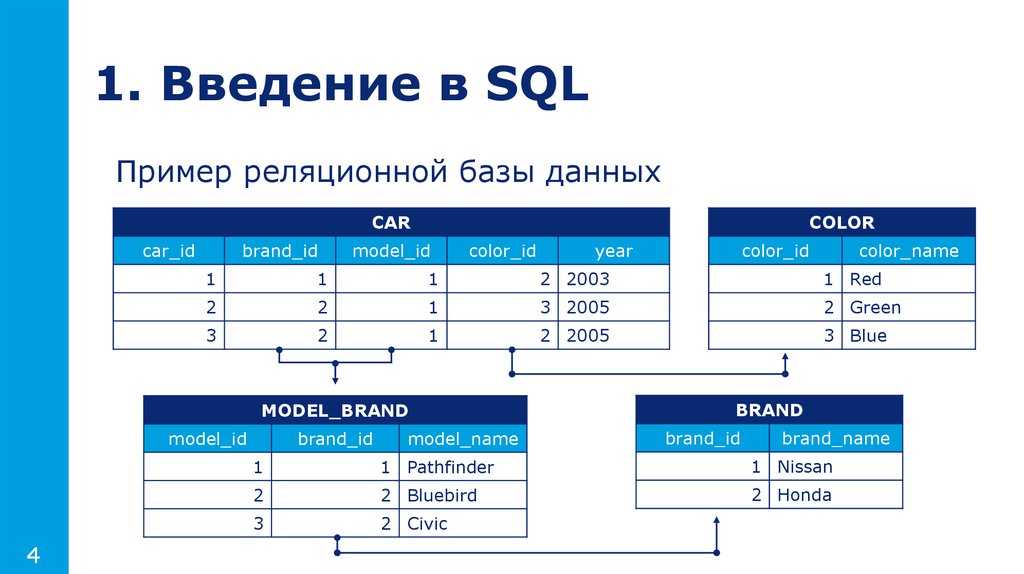 И, несмотря на свое название, такие базы данных часто могут быть ориентированы на строки, а не на столбцы.
И, несмотря на свое название, такие базы данных часто могут быть ориентированы на строки, а не на столбцы.
Ключевым фактором для понимания модели данных с широкими столбцами является keyspace , которое, по сути, представляет собой набор различных структур квазитаблиц, обычно называемых «семействами столбцов». Каждое семейство столбцов может иметь любое количество строк, но каждая строка (1) должна иметь уникальный ключ строки, который отличает ее от всех остальных, и (2) может иметь любое количество столбцов информации, каждый из которых обычно содержит KVP и отметка времени, указывающая на его последнее обновление.
Например, наша база данных летнего лагеря может иметь несколько пространств ключей для хранения той же информации, что и раньше, в то время как специальное пространство ключей для личной информации может иметь одну строку для каждого ребенка со столбцами для имени, возраста, любимой еды и т. д. Проблема хранения таких данных в хранилище столбцов состоит в том, чтобы найти правильный подход к разделению информации на разные пространства ключей и выбрать значения, которые действительно индивидуализируют строки.
Наконец, мы подошли к «графовым базам данных», которые легче всего понять с точки зрения их узлов и отношений. Узлы — это то, что хранит значения данных, часто в виде небольших «мини-документов» аля базы данных документов или «мешков» KVP и т. д. Отношения соединяют узлы и, как таковые, фактически являются гражданами первого класса в модели данных графа. В то время как реляционная база данных объединяет различные типы данных в таблицах с общими уникальными идентификаторами, графовая база данных связывает один узел с другими через явные отношения различных типов.
Было бы тривиально просто хранить примерные данные, которые мы обсуждали, в базе данных графа, где личная информация каждого туриста представляет собой единый узел, а любая связанная информация хранится в других узлах, связанных соответствующими отношениями. Кроме того, было бы просто хранить отношения между детьми, отслеживая, кто с кем дружит, какие участники не ладят с другими участниками лагеря и т. д.
Сама структура графовых баз данных делает их идеально подходящими для многих целей.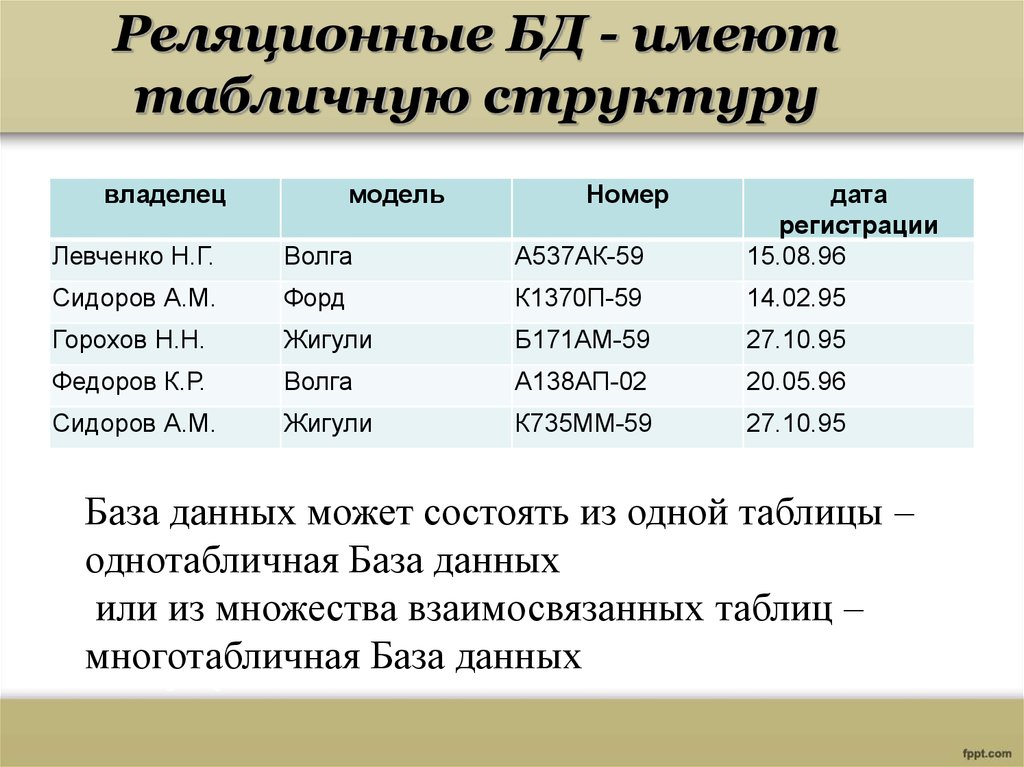 случаи, когда другие типы баз данных не справляются с легкостью. Примеры включают организационные схемы, социальные сети, сетевое оборудование и схемы маршрутизации, дорожные и другие карты, маршруты проезда и т. д.
случаи, когда другие типы баз данных не справляются с легкостью. Примеры включают организационные схемы, социальные сети, сетевое оборудование и схемы маршрутизации, дорожные и другие карты, маршруты проезда и т. д.
Примеры реляционных баз данных
Сегодня на рынке доступно множество различных предложений реляционных баз данных. Некоторым требуется локальное оборудование, а это означает, что вы несете ответственность за всю подготовку, обслуживание и поддержку. Другие предлагают варианты облачного хостинга, но фактически предоставляют вам удаленные базы данных, к которым вы можете подключаться, но при этом должны самостоятельно администрировать и управлять ими. Третьи устраняют всю административную нагрузку, поставщик выполняет всю «черную работу», так что вы можете сосредоточиться на создании своих приложений.
При проектировании вашей базы данных важно не только рассмотреть ваши варианты на данный момент, но и предоставить дорожную карту для легкого масштабирования в будущем. В следующей таблице сравниваются некоторые распространенные примеры в свете различных факторов, которые мы обсуждали.
| [PostgreSQL] | [Аврора] (виртуальные машины PostgreSQL) | [Фауна] | |
| КИСЛОТА | Да, но с более слабой изоляцией транзакций | Да, но с обычными предостережениями PostgreSQL | Да |
| Масштабируемость | Масштабируется по вертикали, но по горизонтали ограничивается записью только в первичный узел. Нет автоматической эластичности. | Масштабируется по вертикали, но с теми же ограничениями для PostgreSQL. Автоматизированная эластичность, ограниченная «короткой» детализацией на уровне виртуальных машин. | Вертикальное и горизонтальное масштабирование с полностью автоматизированной эластичностью.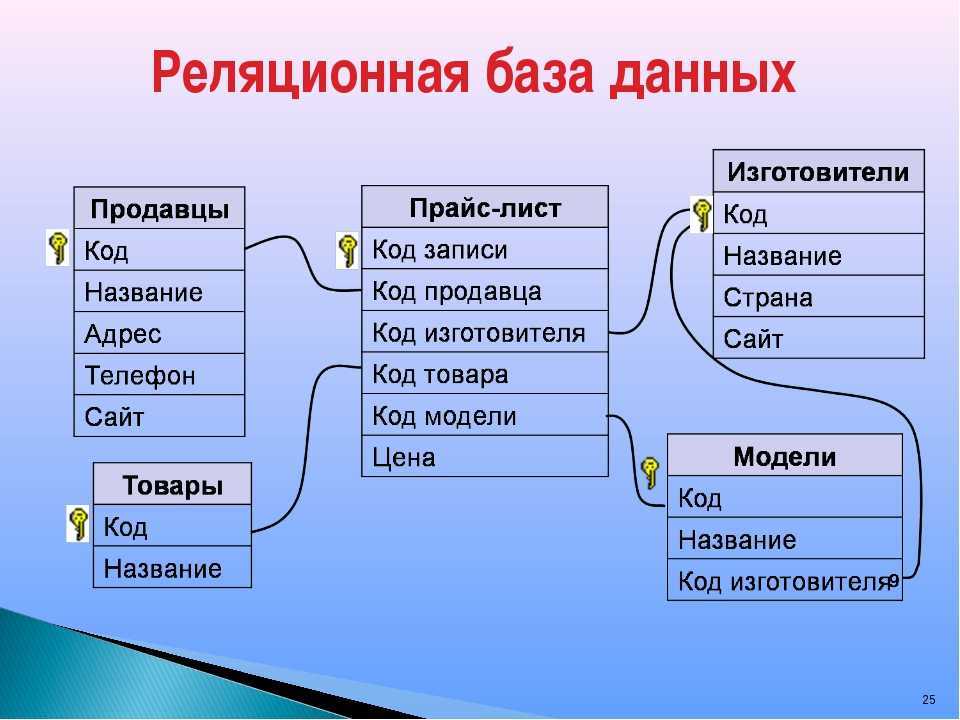 |
| Биллинг | Гибкие цены на сервер в Azure | Аврора Прайс | Цены на фауну |
| Модели данных | Относительный | Относительный | Реляционный и Нереляционный |
| Заключение | Хорошо | Лучше | Лучший |
Развернуть реляционную базу данных за считанные минуты
В этой статье мы обсудили, как реляционные базы данных и нереляционные предложения могут удовлетворить различные варианты использования, а также их сильные и слабые стороны. Подводя итог, можно сказать, что реляционные базы данных лучше всего обеспечивают реляционную целостность, предлагая гарантии ACID и простоту программирования с помощью SQL. Но все это происходит за счет ограниченной гибкости и производительности.