Нереляционные данные и базы данных NoSQL — Azure Architecture Center
Нереляционная база данных — это база данных, в которой в отличие от большинства традиционных систем баз данных не используется табличная схема строк и столбцов. В этих базах данных применяется модель хранения, оптимизированная под конкретные требования типа хранимых данных. Например, данные могут храниться как простые пары «ключ — значение», документы JSON или граф, состоящий из ребер и вершин.
Все эти хранилища данных не используют реляционную модель. Кроме того, они, как правило, поддерживают определенные типы данных. Процесс запроса данных также специфический. Например, хранилища данных временных рядов рассчитаны на запросы к последовательностям данных, упорядоченных по времени. В свою очередь хранилища данных графов рассчитаны на анализ взвешенных связей между сущностями. Ни один из форматов не подходит в полней мере при выполнении задач управления данными о транзакциях.
Термин NoSQL применяется к хранилищам данных, которые не используют язык запросов SQL. Вместо этого они запрашивают данные с помощью других языков программирования и конструкций. На практике NoSQL означает «нереляционная база данных», даже несмотря на то, что многие из этих баз данных под держивают запросы, совместимые с SQL. Однако базовая стратегия выполнения запросов SQL обычно значительно отличается от применяемой в системе управления реляционной базой данных (реляционная СУБД).
Вместо этого они запрашивают данные с помощью других языков программирования и конструкций. На практике NoSQL означает «нереляционная база данных», даже несмотря на то, что многие из этих баз данных под держивают запросы, совместимые с SQL. Однако базовая стратегия выполнения запросов SQL обычно значительно отличается от применяемой в системе управления реляционной базой данных (реляционная СУБД).
В разделах ниже описаны основные категории нереляционных баз данных или баз данных NoSQL.
Хранилища данных документов
Хранилище данных документов управляет набором значений именованных строковых полей и данных объекта в сущности, которая называется документом. Обычно данные в этих хранилищах содержатся в виде документов JSON. Каждое значение поля может представлять собой скалярный элемент, например число, или сложный объект, например список или коллекция типа «родитель — потомок». Данные в полях документа можно закодировать разными способами, например в формате XML, YAML, JSON, BSON, или хранить в виде обычного текста.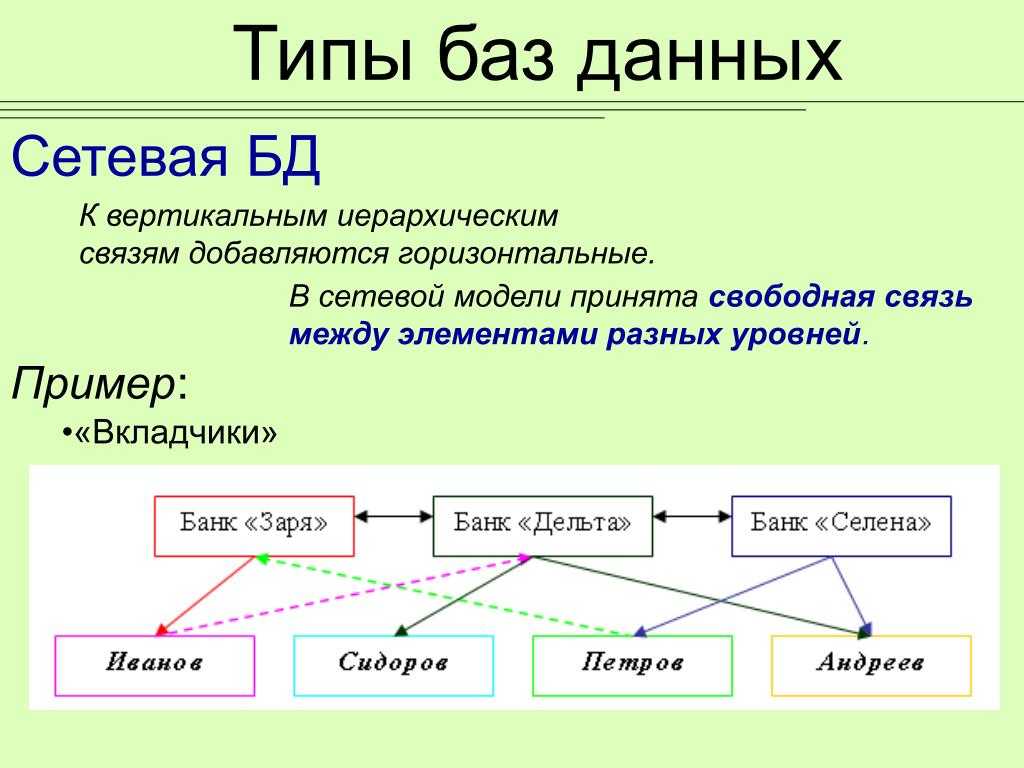 Поля документов доступны системе управления хранилищем, что позволяет приложению выполнять запросы и применять фильтры, основанные на значениях этих полей.
Поля документов доступны системе управления хранилищем, что позволяет приложению выполнять запросы и применять фильтры, основанные на значениях этих полей.
Как правило, документ содержит все данные для сущности. Элементы, составляющие сущность, зависят от конкретного приложения. Например, сущность может содержать сведения о клиенте, заказе или их сочетание. Один документ может содержать сведения, которые в реляционной СУБД обычно распределяются по нескольким реляционным таблицам. Хранилище документов не требует, чтобы все документы имели одинаковую структуру. Такой свободный подход к форме обеспечивает большую гибкость. Например, приложения могут хранить в документах разные данные в соответствии с текущими требованиями компании.
Приложение может получать документы по ключу документа. Ключ — это уникальный идентификатор документа. Часто к нему применяется хэширование для равномерного распределения данных. Некоторые базы данных документов автоматически создают ключ документа. Другие позволяют указать атрибут документа, который будет использоваться в качестве ключа. Приложение также может запрашивать документы на основе значения одного или нескольких полей. Некоторые базы данных документов поддерживают индексирование, чтобы облегчить быстрый поиск документов по одному или нескольким индексированным полям.
Другие позволяют указать атрибут документа, который будет использоваться в качестве ключа. Приложение также может запрашивать документы на основе значения одного или нескольких полей. Некоторые базы данных документов поддерживают индексирование, чтобы облегчить быстрый поиск документов по одному или нескольким индексированным полям.
Многие базы данных документов поддерживают обновления «на месте», то есть позволяют приложению изменять значения отдельных полей без перезаписи всего документа. Операции чтения и записи в нескольких полях одного документа обычно являются атомарными.
Соответствующие службы Azure:
- Azure Cosmos DB
Столбчатые хранилища данных
Столбчатое хранилище данных или хранилище семейств столбцов упорядочивает данные по столбцам и строкам. Столбчатое хранилище данных в простейшей форме почти неотличимо от реляционной базы данных, по крайней мере организационно. Настоящее преимущество столбчатого хранилища данных заключается в способности денормализованно структурировать разреженные данные, что связано со столбцово-ориентированным методом хранения данных.
Столбчатое хранилище данных можно представить как набор табличных данных со строками и столбцами, в которых столбцы разделяются на определенные группы или семейства столбцов. Каждое семейство столбцов включает набор логически связанных столбцов, которые обычно извлекаются или управляются как единое целое. Другие данные, которые используются в других процессах, хранятся отдельно в других семействах столбцов. В семейство столбцов можно динамически добавить новые столбцы, а строки могут быть разреженными (то есть строки не обязаны иметь значение для каждого столбца).
На следующей диаграмме представлен пример таблицы с двумя семействами столбцов: Identity и Contact Info. Данные одной сущности имеют одинаковые ключи строк во всех семействах столбцов. Такая структура, в которой строки любого объекта в семействе столбцов могут динамически изменяться, определяет важное преимущество этой категории хранилищ. Семейства столбцов очень хорошо подходят для хранения данных с различными схемами.
В отличие от хранилища пар «ключ — значение» и баз данных документов, большинство столбчатых баз данных упорядочивают хранимые данные с помощью самих значений ключей, а не хэш-кодов от них. Ключ строки рассматривается как первичный индекс и обеспечивает доступ на основе определенного ключа или их диапазона. Некоторые реализации позволяют создавать вторичные индексы по определенным столбцам в семействе столбцов. Вторичные индексы позволяют получать данные по значениям столбцов, а не ключам строки.
Все столбцы одного семейства хранятся на диске в одном файле. Каждый файл содержит определенное число строк. При использовании больших наборов данных этот подход позволяет повысить производительность за счет снижения объема данных, которые необходимо считывать с диска, когда отправляется запрос на получение нескольких столбцов за раз.
Чтение и запись строки из одного семейства столбцов — это обычно атомарные операции. Однако некоторые реализации поддерживают атомарность всей строки, распределенной по нескольким семействам столбцов.
Соответствующие службы Azure:
- Azure Cosmos DB для Apache Cassandra
- Использование HBase в HDInsight
Хранилище пар «ключ — значение»
Хранилище пар «ключ — значение» по сути представляет собой большую хэш-таблицу. Каждое значение сопоставляется с уникальным ключом, и хранилище ключей использует этот ключ для хранения данных, применяя к нему некоторую функцию хэширования. Выбор функции хэширования должен обеспечить равномерное распределение хэшированных ключей по хранилищу данных.
Большинство хранилищ пар «ключ — значение» поддерживают только самые простые операции запроса, вставки и удаления. Чтобы частично или полностью изменить значение, приложение всегда перезаписывает существующее значение целиком. В большинстве реализаций атомарной операцией считается чтение или запись одного значения. Запись больших значений занимает относительно долгое время.
Приложение может хранить в наборе значений произвольные данные, но некоторые хранилища пар «ключ — значение» накладывают ограничения на максимальный размер значений.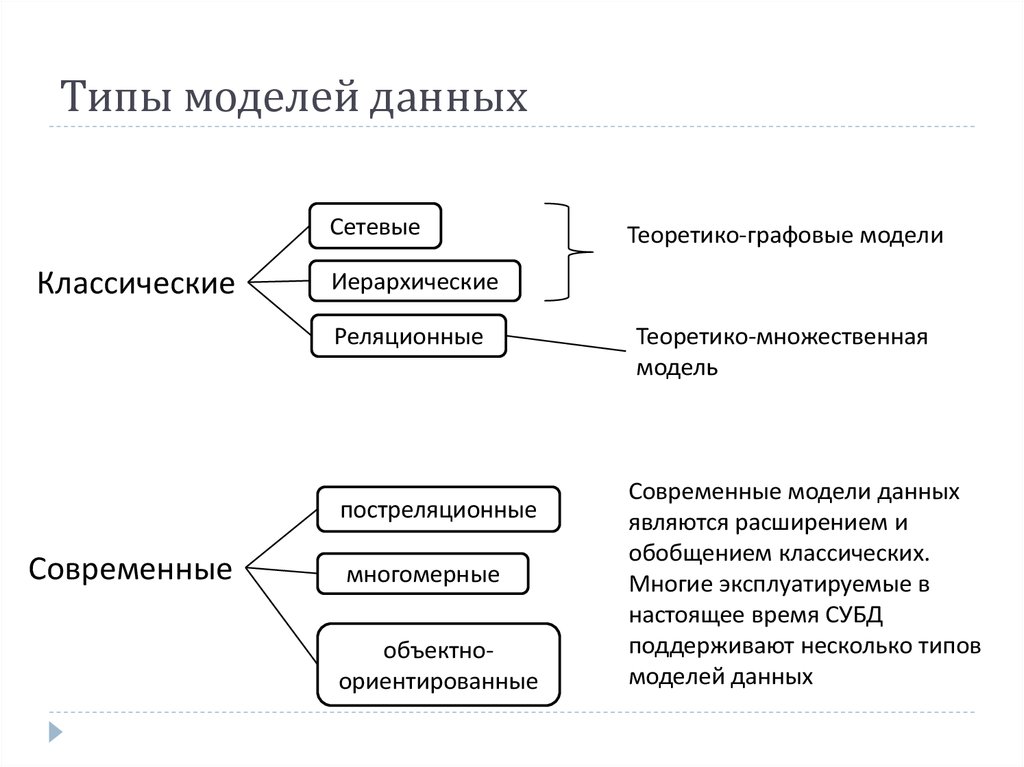 Программное обеспечение хранилища ничего не знает о значениях, которые в нем хранятся. Все сведения о схеме поддерживаются и применяются на уровне приложения. Эти значения по существу являются большими двоичными объектами, которые хранилище извлекает и сохраняет по соответствующему ключу.
Программное обеспечение хранилища ничего не знает о значениях, которые в нем хранятся. Все сведения о схеме поддерживаются и применяются на уровне приложения. Эти значения по существу являются большими двоичными объектами, которые хранилище извлекает и сохраняет по соответствующему ключу.
Хранилища пар «ключ — значение» рассчитаны на приложения, выполняющие простые операции поиска на основе значения ключа или диапазона ключей, но не очень подходят для систем, которым нужно запрашивать данные из нескольких таблиц хранилищ пар «ключ — значение», например присоединенные данные в нескольких таблицах.
Кроме того, хранилища пар «ключ — значение» неудобны в сценариях, где могут выполняться запросы или фильтрация по значению, а не только по ключам. Например, в реляционной базе данных вы можете найти определенную запись с помощью предложения WHERE и отфильтровать ее по неключевым столбцам, но хранилища пар «ключ-значение» обычно не поддерживают такую возможность поиска значений или же этот процесс выполняется медленно.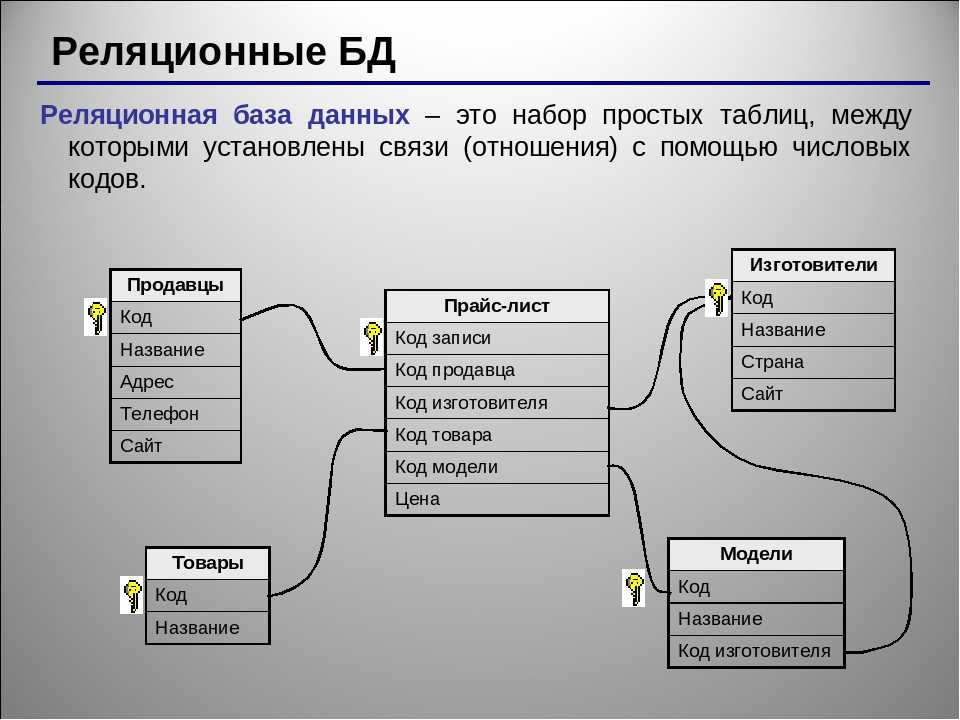
Одно хранилище пар «ключ — значение» очень легко масштабируется, поскольку позволяет удобно распределить данные среди нескольких узлов на разных компьютерах.
Соответствующие службы Azure:
- Azure Cosmos DB для таблицы
- Кэш Azure для Redis
- хранилище таблиц Azure
Хранилища данных графов
Хранилища данных графов управляют сведениями двух типов: узлами и ребрами. Узлы в этом случае представляют сущности, а ребра определяют связи между ними. Узлы и грани имеют свойства, которые предоставляют сведения о конкретном узле или грани, примерно как столбцы в реляционной таблице. Грани могут иметь направление, указывающее на характер связи.
Хранилища данных графов позволяют приложениям эффективно выполнять запросы, которые проходят через сеть узлов и ребер, а также анализировать связи между сущностями. На схеме ниже представлены данные персонала организации, структурированные в виде графа. Сущностями здесь являются сотрудники и отделы, а грани определяют отношения подчинения и отдел, в котором работает каждый сотрудник. Стрелки на ребрах этого графа показывают направление связей.
Стрелки на ребрах этого графа показывают направление связей.
Такая структура позволяет легко выполнять такие запросы, как «найти всех сотрудников, которые прямо или косвенно подчиняются Светлане» или «найти всех, кто работает в одном отделе с Дмитрием». Процессы сложного анализа выполняются быстро даже на больших графах с большим количеством сущностей и связей. Многие базы данных графов предоставляют язык запросов, который можно использовать для эффективного обхода сети связей.
Соответствующие службы Azure:
- API Graph в Azure Cosmos DB
Хранилища данных временных рядов
Данными временных рядов называются наборы значений, которые упорядочены по времени. Соответственно хранилища данных временных рядов оптимизированы для хранения данных именно такого типа. Хранилища данных временных рядов должны поддерживать очень большое число операций записи, так как обычно в них в режиме реального времени собирается большой объем данных из большого количества источников. Эти хранилища также хорошо подходят для хранения данных телеметрии. Например, для сбора данных от датчиков Интернета вещей или счетчиков в приложениях или системах. Обновления в таких базах данных выполняются редко, а удаление чаще всего является массовой операцией.
Эти хранилища также хорошо подходят для хранения данных телеметрии. Например, для сбора данных от датчиков Интернета вещей или счетчиков в приложениях или системах. Обновления в таких базах данных выполняются редко, а удаление чаще всего является массовой операцией.
Размер отдельных записей в базе данных временных рядов обычно невелик, но их очень много, а значит общий размер данных быстро увеличивается. Хранилища данных временных рядов также обрабатывают данные, полученные вне очереди или несвоевременно, автоматически индексируют точки данных и оптимизируют запросы, полученные в течение определенного промежутка времени. Эта последняя возможность позволяет быстро выполнять запросы к миллионам точек данных и нескольким потокам данных, что, в свою очередь, обеспечивает поддержку визуализации временных рядов (стандартный способ потребления данных временных рядов).
Дополнительные сведения см. в статье Решения для временных рядов.
Соответствующие службы Azure:
- Аналитика временных рядов Azure
- OpenTSDB с HBase в HDInsight
Хранилище данных объектов
Хранилища данных объектов оптимизированы для хранения и извлечения больших двоичных объектов, например изображений, текстовых файлов, видео- и аудиопотоков, объектов данных и документов приложений большого размера, образы дисков виртуальных машин.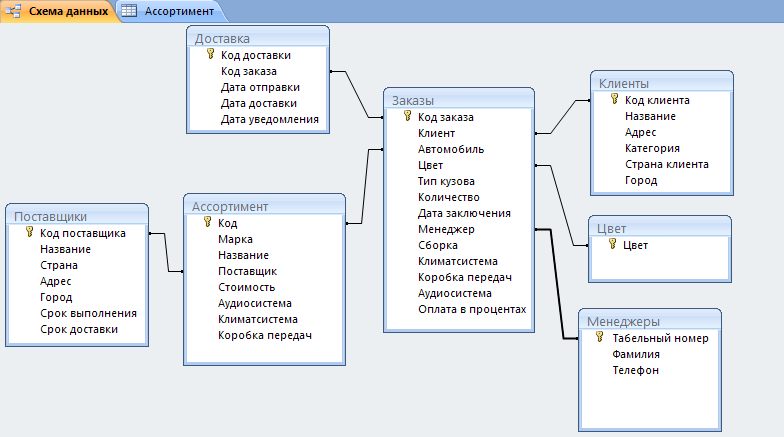 Объект состоит из сохраненных данных, метаданных и уникального идентификатора доступа к объекту. Хранилища объектов поддерживают отдельные большие файлы, а также позволяют управлять всеми файлами за счет внушительного общего объема хранилища.
Объект состоит из сохраненных данных, метаданных и уникального идентификатора доступа к объекту. Хранилища объектов поддерживают отдельные большие файлы, а также позволяют управлять всеми файлами за счет внушительного общего объема хранилища.
Некоторые хранилища данных объектов реплицируют определенный большой двоичный объект между несколькими узлами кластера, что обеспечивает быстрое параллельное чтение. Этот процесс, в свою очередь, позволяет реализовать масштабируемую архитектуру запроса данных, хранящихся в больших файлах, так как несколько процессов, обычно выполняющихся на разных серверах, могут одновременно запрашивать большие файлы данных.
Часто хранилища данных объектов используют как сетевые общие папки. Доступ к файлам, хранящимся в этих папках, можно получить через компьютерную сеть с использованием стандартных сетевых протоколов, например SMB. Если созданы необходимые механизмы поддержки безопасности и одновременного доступа, такое совместное использование данных позволяет распределенным службам с высокой степенью масштабируемости предоставлять доступ к данным для базовых низкоуровневых операций, то есть для простых запросов на чтение и запись.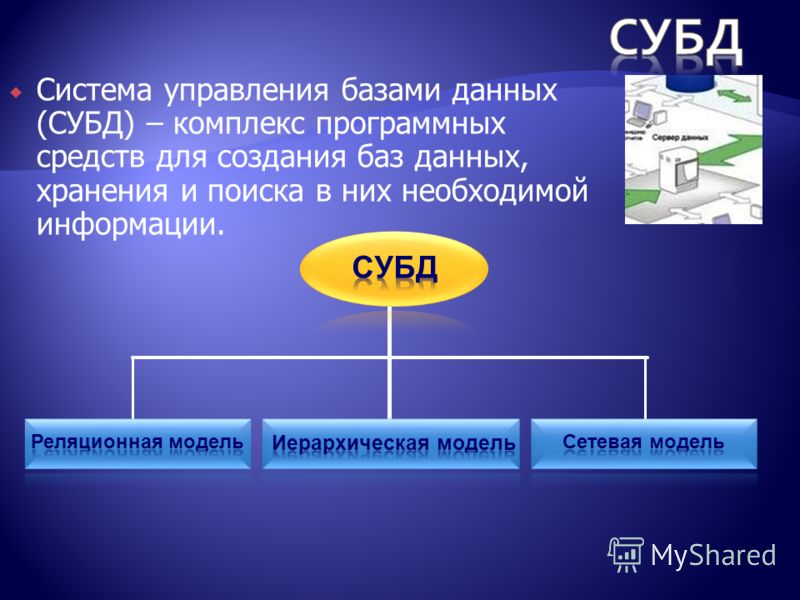
Соответствующие службы Azure:
- Хранилище BLOB-объектов Azure
- Azure Data Lake Storage
- Хранилище файлов Azure
Хранилища данных внешних индексов
Хранилища данных внешних индексов позволяют искать информацию, содержащуюся в других хранилищах данных и службах. Внешний индекс выступает в роли вторичного индекса любого хранилища данных. Кроме того, с его помощью можно индексировать большие объемы данных и предоставлять доступ к этим индексам почти в реальном времени.
Например, в файловой системе могут храниться текстовые файлы. По пути файл можно найти быстро, но поиск на основе содержимого выполняется медленно, так как сканируются все файлы. Внешний индекс позволяет создавать вторичные индексы, а затем быстро искать путь к файлам, соответствующим заданным условиям. Рассмотрим еще один пример использования внешнего индекса. Предположим, что хранилища пар «ключ — значение» поддерживают индексирование только по ключу. Вы можете создать вторичный индекс на основе значений данных и быстро найти ключ, однозначно определяющий каждый соответствующий элемент.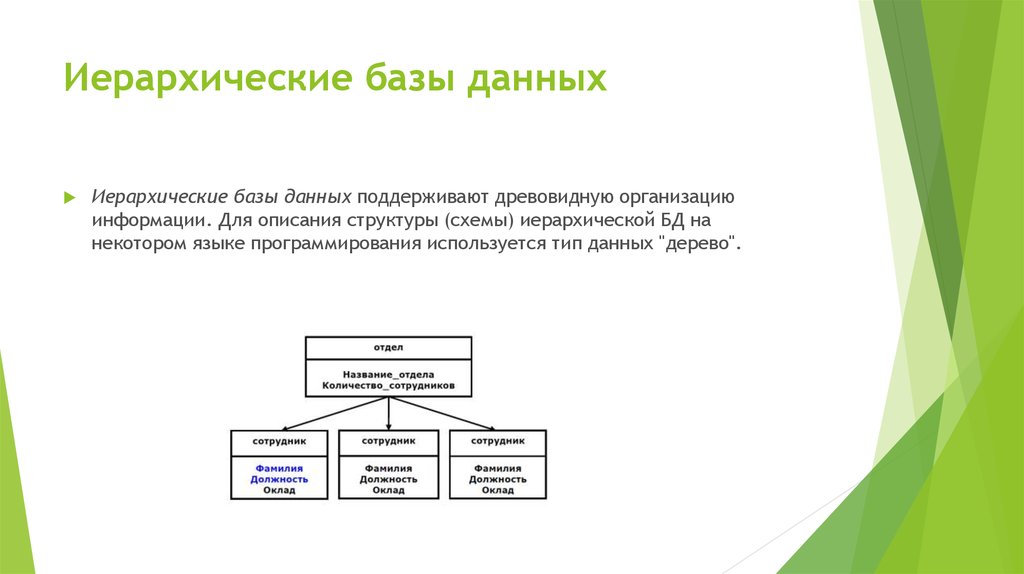
Индексы создаются в процессе индексирования, который может выполняться по модели извлечения, то есть по требованию хранилища данных, или по модели передачи, то есть по команде из кода приложения. В некоторых системах поддерживаются многомерные индексы и полнотекстовый поиск по большим объемам текстовых данных.
Часто хранилища данных внешних индексов используют для реализации полнотекстового поиска и поиска в Интернете. В этих случаях поддерживается точный или нечеткий поиск. Нечеткий поиск находит документы, которые соответствуют набору условий, и вычисляет для них коэффициент совпадения с этим набором. Некоторые внешние индексы также поддерживают лингвистический анализ, который возвращает соответствия с учетом синонимов, категорий (например, при поиске по запросу «собаки» соответствием считается «питомцы») и морфологии (например, при поиске по запросу «бег» соответствием считается «бегущий»).
Соответствующие службы Azure:
- Поиск Azure
Стандартные требования
Часто архитектура нереляционных хранилищ данных отличается от архитектуры реляционных баз данных. В частности эти хранилища, как правило, не имеют фиксированной схемы, а также не поддерживают транзакции или ограничивают их область. Из соображений масштабируемости они обычно не включают вторичные индексы.
В частности эти хранилища, как правило, не имеют фиксированной схемы, а также не поддерживают транзакции или ограничивают их область. Из соображений масштабируемости они обычно не включают вторичные индексы.
В таблице ниже приведено сравнение требований каждого нереляционного хранилища данных.
| Требование | Хранилище данных документов | Столбчатое хранилище данных | Хранилище данных пар «ключ — значение» | Хранилище данных графов |
|---|---|---|---|---|
| Нормализация | Денормализированные данные | Денормализированные данные | Денормализированные данные | Нормализированные данные |
| схема | Схема при чтении | Семейства столбцов, определенные при записи, схема столбца при чтении | Схема при чтении | Схема при чтении |
| Согласованность (между параллельными транзакциями) | Настраиваемый уровень согласованности, гарантии на уровне документа | Гарантии на уровне семейства столбцов | Гарантии на уровне ключей | Гарантии на уровне графа |
| Атомарность (область транзакции) | Коллекция | Таблица | Таблица | График |
| Стратегия блокировки | Оптимистичная (без блокировки) | Пессимистичная (блокировка строк) | Оптимистичная (ETag) | |
| Шаблон доступа | Прямой доступ | Статистические выражения на основе данных большого формата | Прямой доступ | Прямой доступ |
| Индексация | Первичный и вторичные индексы | Первичный и вторичные индексы | Только первичный индекс | Первичный и вторичные индексы |
| Форма представления данных | Документ | Таблица с семействами столбцов | Ключ и значение | Граф с ребрами и вершинами |
| разреженные; | Да | Да | Да | Нет |
| Масштабность (большое количество столбцов и атрибутов) | Да | Да | Нет | Нет |
| Размер данных | От малого (КБ) до среднего (несколько МБ) | От среднего (МБ) до большого (несколько ГБ) | Небольшой (КБ) | Небольшой (КБ) |
| Общий максимальный масштаб | Очень большой (ПБ) | Очень большой (ПБ) | Очень большой (ПБ) | Большой (ТБ) |
| Требование | Данные временных рядов | Хранилище данных объектов | Хранилище данных внешних индексов |
|---|---|---|---|
| Нормализация | Нормализированные данные | Денормализированные данные | Денормализированные данные |
| схема | Схема при чтении | Схема при чтении | Схема при записи |
| Согласованность (между параллельными транзакциями) | Н/Д | Н/Д | Н/Д |
| Атомарность (область транзакции) | Н/Д | Объект | Н/Д |
| Стратегия блокировки | Н/Д | Пессимистичная (блокировка больших двоичных объектов) | Н/Д |
| Шаблон доступа | Прямой доступ и агрегирование | Последовательный доступ | Прямой доступ |
| Индексация | Первичный и вторичные индексы | Только первичный индекс | Н/Д |
| Форма представления данных | Таблица | Большой двоичный объект и метаданные | Документ |
| разреженные; | нет | Н/Д | Нет |
| Масштабность (большое количество столбцов и атрибутов) | Нет | Да | Да |
| Размер данных | Небольшой (КБ) | От большого (ГБ) до очень большого (ТБ) | Небольшой (КБ) |
| Общий максимальный масштаб | Большой (несколько ТБ) | Очень большой (ПБ) | Большой (несколько ТБ) |
Соавторы
Эта статья поддерживается Майкрософт.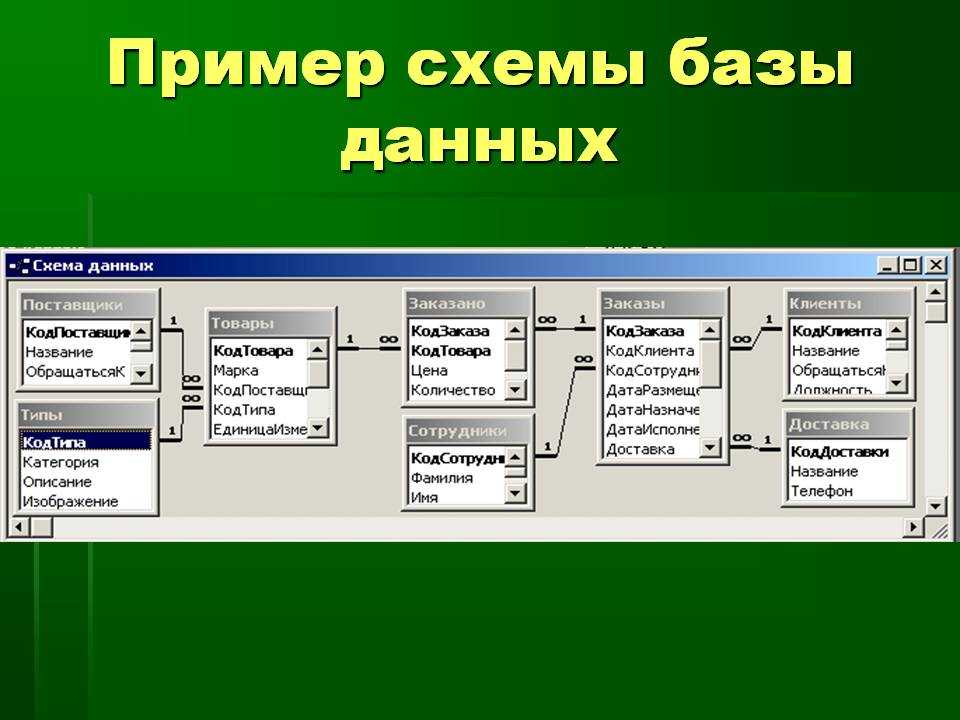 Первоначально она была написана следующими авторами.
Первоначально она была написана следующими авторами.
Основной автор:
- | Зойнер Теджада Генеральный директор и архитектор
Дальнейшие действия
- Реляционные и Данные NoSQL
- Общие сведения о распределенных базах данных NoSQL
- Основы данных в Microsoft Azure: изучение нереляционных данных в Azure
- Реализация нереляционной модели данных
- Разработка архитектуры баз данных
- Основные сведения о моделях хранилищ данных
- Масштабируемая обработка заказов
- Обработка данных Lakehouse практически в реальном времени
что это такое, виды, как хранятся
Автор Сергей Тимофеев На чтение 10 мин Просмотров 1.7к. Опубликовано Обновлено
Термин «база данных» (БД, database) попадается на глаза всем, кто пользуется компьютером: и инженеру-программисту, и студенту, и тому, кто просто читает новости в интернете.
БД — это хранилище информации, которую можно быстро вносить и редактировать. Например, оформленные в интернет-магазине заказы, даты, имена клиентов, цены, формулы для математических вычислений.
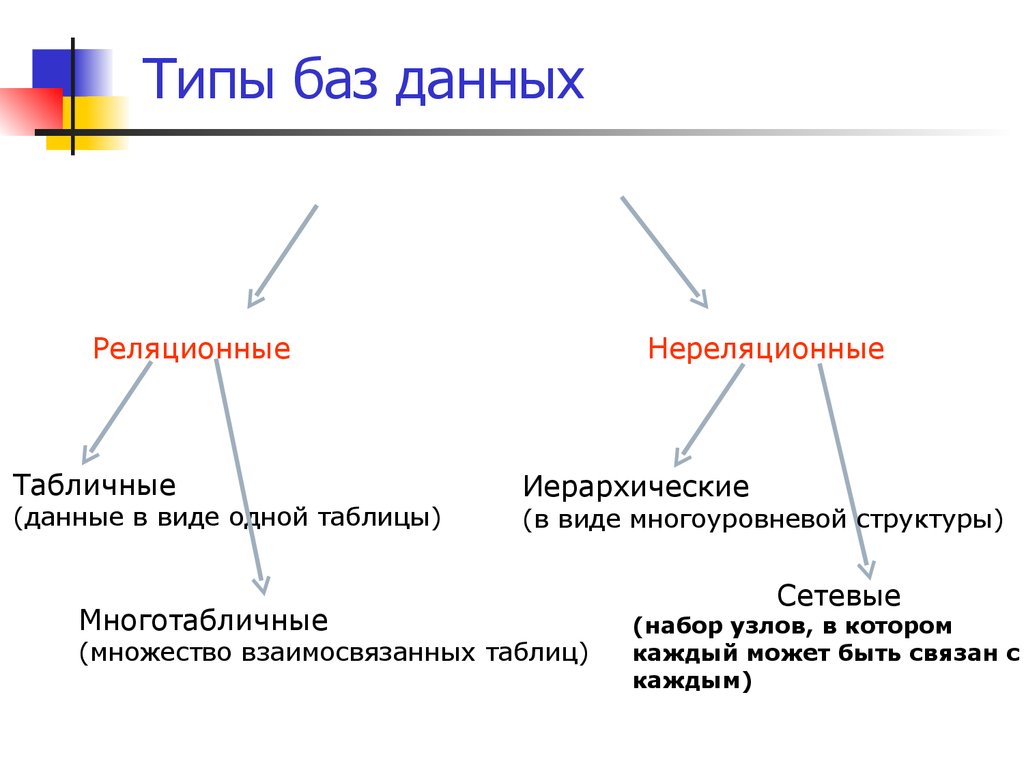
Базами данных управляют через специальные системы управления. Сами БД — простейшие, реляционные, NoSQL, комбинированные — строятся по разным принципам. В статье мы расскажем, для чего предназначены базы, какие они бывают, и как иметь с ними дело.
В БД указаны имена таблиц, типы данных, типы отношений между полями и ключевые поляСодержание
- Что такое База Данных
- Как работают базы данных
- Как хранится информация в БД
- Типы баз данных
- Простейшие типы баз данных
- Простые структуры данных
- Иерархические
- Сетевые
- Реляционные БД
- NoSQL базы данных
- Документные
- Колоночные
- Графовые
- «Ключ-значение»
- Комбинированные типы
- NewSQL
- Многомодельные
- Преимущество разных типов баз данных
- Популярные системы управления базами данных (СУБД)
- Как работают с базой данных: упрощенная инструкция
- Выводы
Что такое База Данных
База данных — структурированные электронные сведения.
Пользователи манипулируют ими согласно правилам моделирования данных. В визуальном представлении это выглядит как книжный шкаф с документами, которые можно передвигать, сортировать, «прореживать», дополнять новыми бумагами.
Если человек делает проект, в котором обращается к структурированному хранилищу информации — например, пишет программу для учета клиентов банка или собирает сайт — ему нужно знать, какие бывают базы данных, чтобы правильно выбрать их тип. Они различаются по свойствам и ограничениям, которые важно учитывать в работе.
Как работают базы данных
БД — это среда, которая представляет собой таблицы с информацией. Самый наглядный пример базы данных — таблицы в программе MS Excel. Их заполняют цифрами и словами вручную, составляют формулы для управления содержимым ячеек, перетаскивают это содержимое мышью для замены или копирования.
База данных выглядит как таблица и хранится в отдельном файле.
Если БД «прикреплена» к сайту, увидеть ее в виде таблицы не получится, зато получится написать в строке поиска текстовый запрос и увидеть в списке результатов соответствующую выборку. Еще можно составить запрос на специальном языке Structured Query Language (SQL), чтобы вывести из базы интересующий массив строк.
Еще можно составить запрос на специальном языке Structured Query Language (SQL), чтобы вывести из базы интересующий массив строк.
Структура базы данных представляет собой набор таблиц, которые состоят из строк (записей) и столбцов (полей). У столбцов есть уникальные имена, типы хранимых данных (текст, число, логический тип «Да/Нет», гиперссылка и др.), списки свойств и описания.
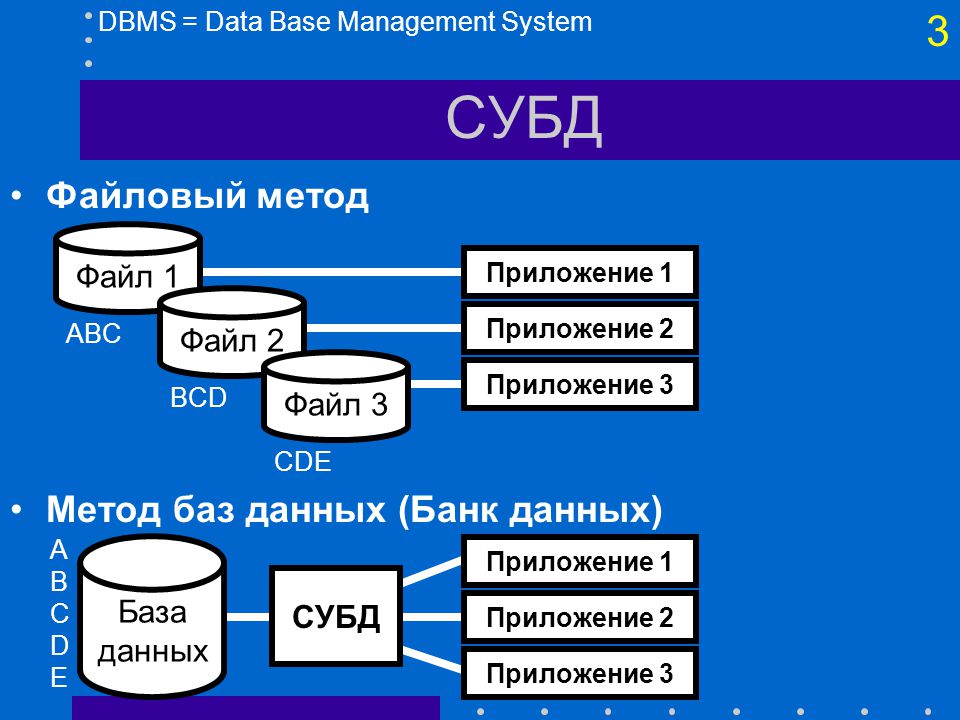
Базы данных бывают централизованными и распределенными.
Централизованная БД хранится на одном компьютере, распределенная — на нескольких. Для локального и удаленного доступа к распределенным базам применяют системы управления базами данных (СУБД).
Если БД однопользовательская, в один момент времени с её содержимым может работать один человек, если многопользовательская — несколько человек одновременно манипулируют данными.
БД в программе MS Excel — набор таблиц с уникальными номерами строк и столбцовТипы баз данных
Базы данных бывают простейшими, реляционными, NoSQL и комбинированными.
Простейшие типы баз данных
Эту группу делят на простые структуры данных, иерархические и сетевые БД.
Простые структуры данных
Самый простой способ хранить информацию — записать ее в текстовый файл. Если информации немного, этот вариант вполне подходит. Поля разделяют запятой, точкой с запятой, двоеточием или пробелом.
У текстовых файлов есть такие проблемы:
- ограничения по типу и уровню сложности данных;
- сложности с установкой связи между компонентами;
- невозможность параллельной работы с информацией.
Из-за этих проблем текстовые файлы используют при небольших требованиях к чтению и записи и в случаях, когда нет возможности писать запросы в сторонних программах.
Иерархические
Такие БД выглядят как деревья. «Дерево» начинается с «родителя», а от него тянутся связи-ветки к «потомкам». «Родитель» всегда один, а «потомков» может быть сколько угодно. Такого рода отношения называют «один ко многим». Для связи элементов иерархической базы данных применяют физические указатели.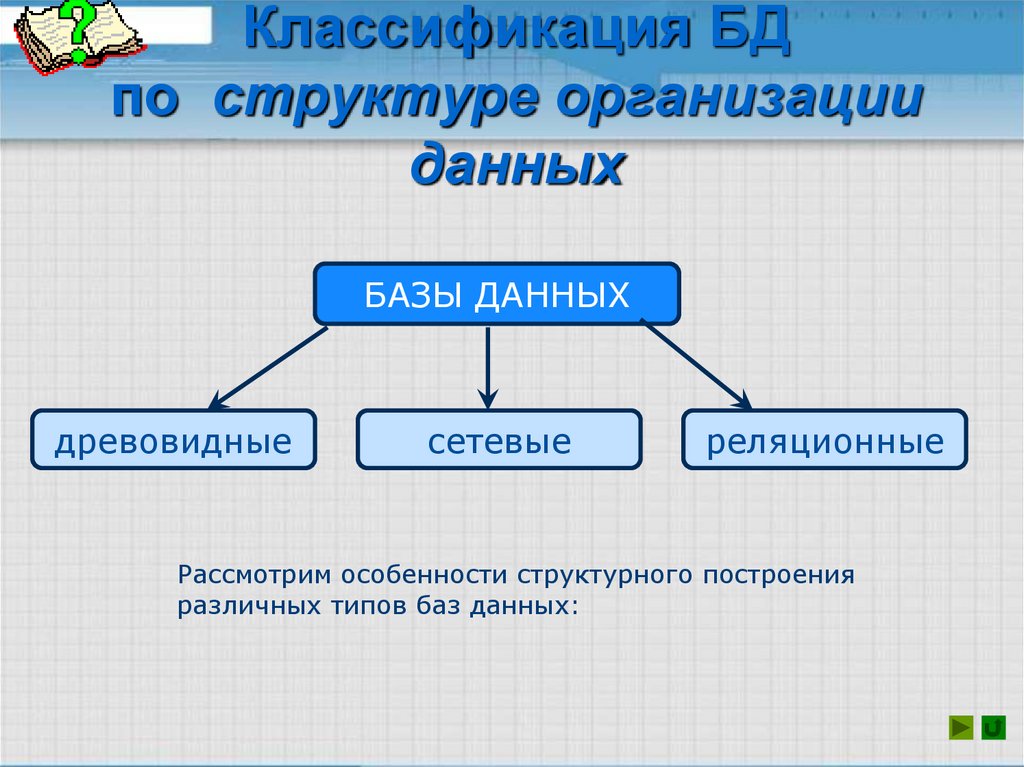 Самый близкий к пользователю пример — файловая система компьютера.
Самый близкий к пользователю пример — файловая система компьютера.
Проблема иерархической базы данных — невозможность создавать отношения «многие к многим» между объектами.
Пример БД с отношениями «один ко многим»Сетевые
Сетевая БД — это иерархическая база данных с отношениями «многие ко многим». То есть, не дерево, а граф. Для доступа к информации в сетевой базе применяют те же шаблоны, что и в работе с иерархической БД.
Реляционные БД
Такие базы данных выглядят как связанные таблицы со структурированной информацией. Для составления выборки из реляционной БД используют язык запросов SQL. Схема такой базы определяется до внесения данных.
Столбцам присваивают уникальные имена и определяют тип хранимой информации. Еще у каждой таблицы есть специальное поле «внешний ключ». Это поле хранит ссылки на столбцы в соседних таблицах с информацией. Благодаря внешнему ключу столбцы и таблицы соединяются по принципу «многие ко многим».
Реляционные базы данных — высокоорганизованные и гибкие.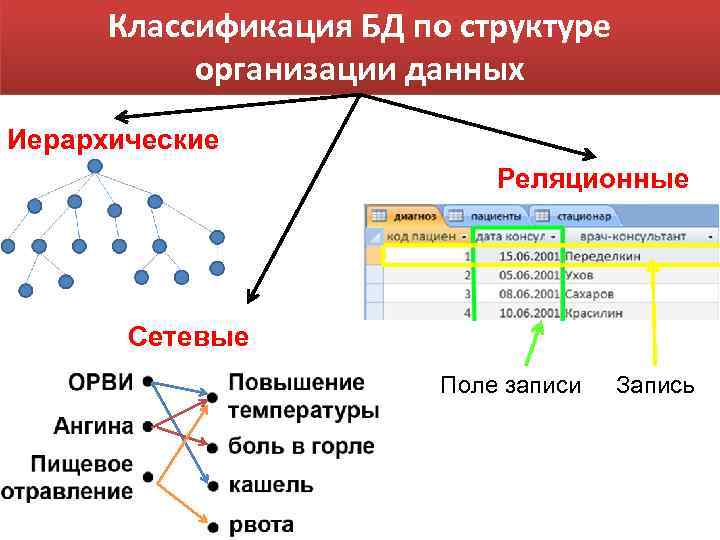 Они подходят для хранения разных типов информации в разных приложениях: на сайтах, в десктопных программах.
Они подходят для хранения разных типов информации в разных приложениях: на сайтах, в десктопных программах.
NoSQL базы данных
Реляционные БД хранят информацию разбитой по колонкам и столбцам. Чтобы сделать выборку данных, составляют SQL-запросы. В случае с NoSQL-базами запросы не пишут: такая база данных может содержать информацию в виде записей в формате JSON (JavaScript Object Notation), изображений или текста. Для доступа к этим объектам используют другие методы.
NoSQL БД бывают документными, колоночными, графовыми и типа «ключ-значение».
Документные
Документные БД, или архивы документов, хранят информацию в структурированных форматах: JSON, BSON или XML. Они не предписывают конкретные форматы и могут содержать документы с разной структурой. Пользователь вправе поменять свойства данных, когда вздумается, и это не скажется на структуре БД или самой записанной информации.
Документные БД применяют там, где нужно занимать параллельными вычислениями и манипулировать большим объемом информации.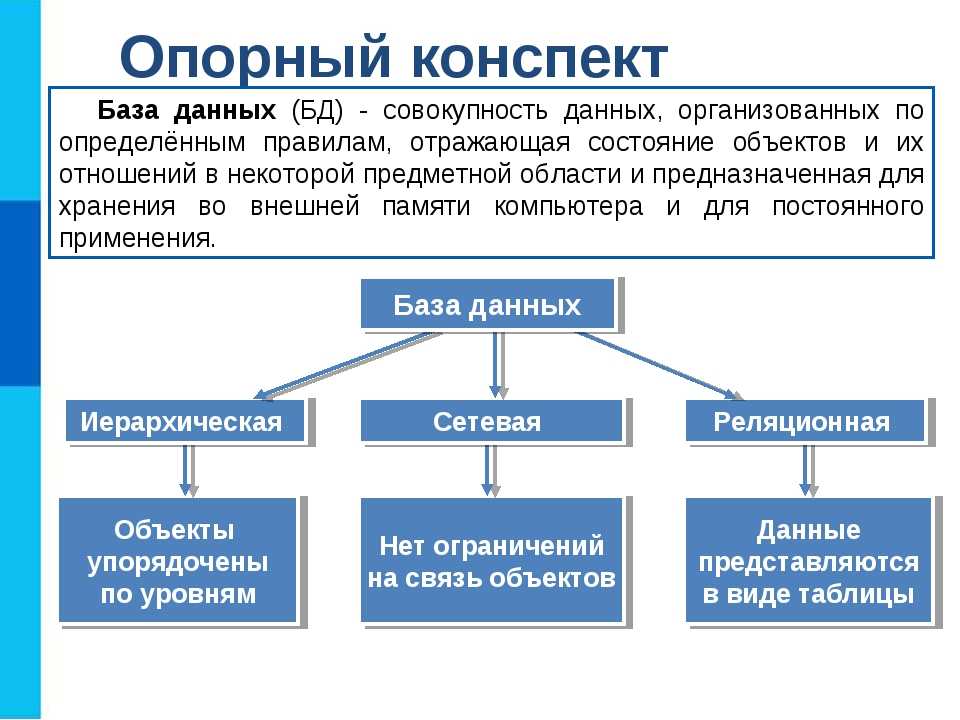
Колоночные
Эти БД сохраняют информацию столбец за столбцом. Информация в каждом из столбцов однородная, поэтому хорошо сжимается.
Колоночные БД быстро обрабатывают запросы к подмножеству столбцов, потому что считывают конкретные столбцы, а не все строки подряд, как это происходит с реляционными БД. Из-за такой особенности их прикрепляют к приложениям, от которых требуется высокая скорость обработки информации.
В колоночной БД данные и метаданные записи хранятся под общим идентификаторомГрафовые
Они могут состоять из узлов, которые отображают объекты, и взаимоотношений между этими объектами. Каждый объект может быть связан с любым количеством других объектов Примеры графовой БД — социальные сети и wiki базы знаний.
Графовые БД явно показывают связи между типами данных и не предполагают пошаговый обход для доступа к тому или иному элементу.
«Ключ-значение»
Пользователь запрашивает ключ, программа выдает значение ключа: JSON-объект, изображение или текст.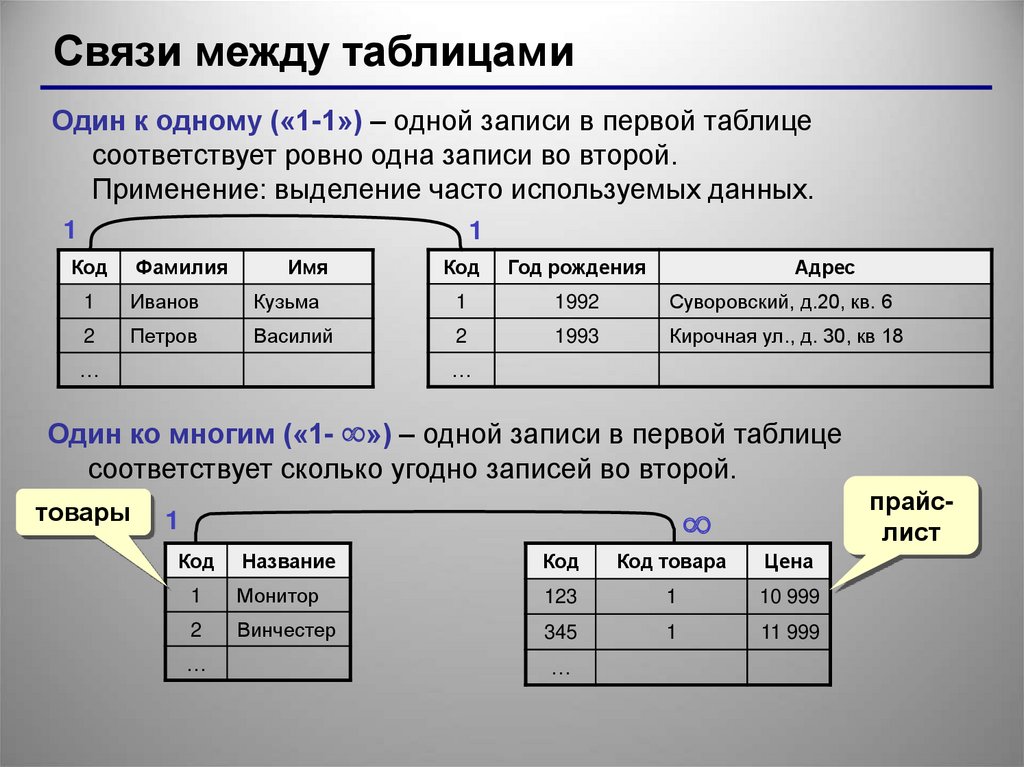 БД «ключ-значение» лишены жестких схем взаимоотношений между данными, поэтому подходят для одновременного хранения разной информации. Если программист выбирает такую БД, он берет на себя ответственность за присвоение имен ключам и за соответствие значению ключа типу или формату.
БД «ключ-значение» лишены жестких схем взаимоотношений между данными, поэтому подходят для одновременного хранения разной информации. Если программист выбирает такую БД, он берет на себя ответственность за присвоение имен ключам и за соответствие значению ключа типу или формату.
Комбинированные типы
Комбинированные БД делят на NewSQL и многомодельные. Принципы их устройства различаются, но могут быть объединены для решения проблем, связанных со специфическими ограничениями SQL и NoSQL баз.
NewSQL
Устроены как реляционные БД, но гораздо лучше масштабируются по горизонтали. У NoSQL-баз они выигрывают по согласованности. Результат — баланс согласованности и простоты доступа.
NewSQL базы обладают высокой производительностью и репликацией. Они не самые гибкие, требуют большого запаса вычислительной мощности и специальных знаний для манипулирования хранимой информацией.
Многомодельные
Соединяют плюсы разных типов баз данных. Например, пользователи получают доступ к информации, записанной в разные базы.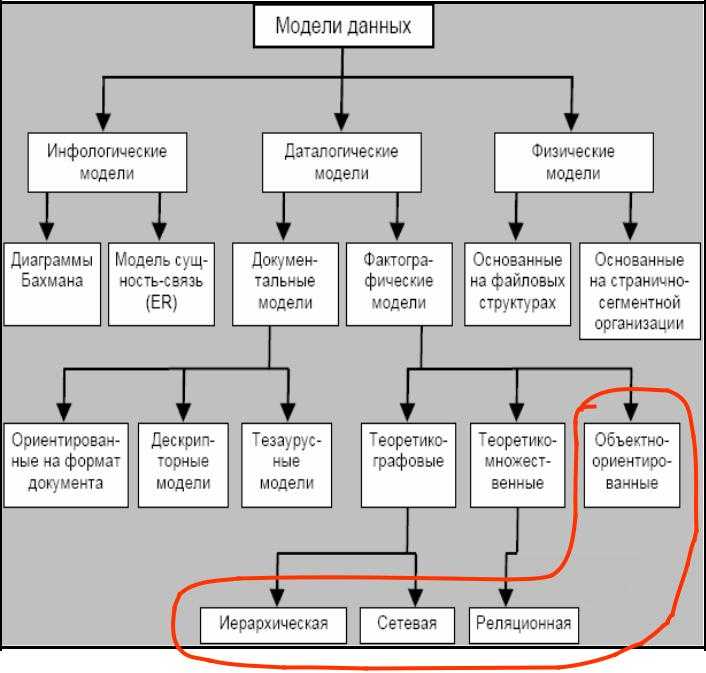 Для доступа к ней они пишут один запрос. Еще пользователи могут менять информацию сразу в нескольких базах, и эти операции будут согласованными.
Для доступа к ней они пишут один запрос. Еще пользователи могут менять информацию сразу в нескольких базах, и эти операции будут согласованными.
Многомодельные базы снижают нагрузку на СУБД, быстро и просто распределяют хранимую информацию, дают пользователям непрерывный доступ, масштабируются по горизонтали.
Преимущество разных типов баз данных
При разработке программ обычно пользуются реляционными и документными БД.
Реляционные базы:
- устроены просто, подходят для хранения 9 из 10 типов данных;
- выдают выборки в ответ на SQL-запросы — простые и знакомые каждому разработчику;
- позволяют обновить одну строку и автоматически обновляют все связанные с ней строки;
- защищены от ошибок при сбоях, так как «пропускают» все действия пользователя или не пропускают ни одного.
Документные базы:
- хранят объекты с разной структурой — в том числе, объекты из объектно-ориентированных программ, перечни, словари;
- поддерживают параллельность и быстро отвечают на запросы, потому что строки в них независимы друг от друга;
- поддерживают горизонтальное масштабирование — то есть, добавление компьютеров и распределение архивов между ними.
Популярные системы управления базами данных (СУБД)
СУБД — программа для управления информацией, которая хранится в базе данных. Эти программы предназначены для работы с реляционными и объектно-реляционными БД с использованием языка запросов SQL. Запросы предназначены для определения данных, управления и манипулирования ими. Самые распространенные СУБД — MySQL, PostgreSQL, SQLite и Oracle.
MySQL — самая простая и быстрая многопользовательская СУБД, способная обрабатывать таблицы с 50+ млн. строк. Система доступна в текстовом и графическом режимах. Последний удобен для тех, кто плохо знает язык запросов SQL.
PostgreSQL — лишена ограничений по размеру БД. Обеспечивает надежность транзакций, легко масштабируется, подробно документирована разработчиками.
SQLite — компактная и быстрая СУБД, которая позволяет хранить всю информацию в одном файле.
Oracle — стабильная система, которая быстро и полноценно восстанавливается после сбоев. Она безопасная, надежно защищает хранимую информацию.
Она безопасная, надежно защищает хранимую информацию.
Как работают с базой данных: упрощенная инструкция
- Формируют новые таблицы, чтобы задать структуру. На начальном этапе определяют поля, из которых состоит каждая строка таблицы, и задают им формат. Если в базе данных будет несколько таблиц со связями «многие ко многим», задают еще и внешние ключи. Формирование структуры и ввод данных — не связанные друг с другом понятия. Сначала составляют структуру, потом вписывают в таблицу все нужное.
- Заполняют таблицы информацией. Это делают вручную или пишут программный код, чтобы автоматически разнести по строкам большой объем информации.
- Обрабатывают информацию в таблицах. Обрабатывать можно с помощью запросов или программ. Главное — составить «инструкцию» для отбора записей. Когда компьютер обработает запрос, он выдаст таблицу с временным набором информации. Этот набор можно отправить в отчет или выстроить в виде формы.
- Выводят информацию на экран и принтер. Отсортированные запросом данные распечатывают на принтере, прикрепляют к электронному письму, выдают пользователю сайта или программы.
Выводы
08. Что такое базы данных? — Информационная грамотность
Что такое библиотечная база данных? (видео)
Узнайте, какую информацию можно найти в библиотечных базах данных и когда их использовать для исследований
(видео CSU, продолжительность 1:52 мин.)
ЧТО ТАКОЕ БАЗЫ ДАННЫХ?
Базы данных представляют собой организованные наборы связанной информации или данных. Коллекции обычно охватывают определенную область исследований, такую как история, биология или музыка. Большинство баз данных онлайн-библиотек состоят из письменных работ, опубликованных в журналах, журналах или газетах, но другие состоят из данных, изображений или специализированной информации, такой как правительственные документы.
Коллекции обычно охватывают определенную область исследований, такую как история, биология или музыка. Большинство баз данных онлайн-библиотек состоят из письменных работ, опубликованных в журналах, журналах или газетах, но другие состоят из данных, изображений или специализированной информации, такой как правительственные документы.
Просмотрите наши базы данных по типу документа или по учебной единице .
КОГДА ИСПОЛЬЗОВАТЬ БАЗУ ДАННЫХ?
Вам следует использовать базу данных библиотеки, если вы:
- Ищете статьи в журнале, газете или научном журнале.
- Проведение научного исследования по заданию.
- Поиск информации по определенной теме.
- Поиск рецензируемых или профессионально отредактированных работ.
ЧТО СОДЕРЖИТСЯ В БИБЛИОТЕЧНОЙ БАЗЕ ДАННЫХ? (БЕСПЛАТНЫЙ ВЕБ ПРОТИВ БАЗ ДАННЫХ)
Большинство материалов в библиотечных базах данных либо прошли рецензирование, либо рецензировались профессиональным редактором.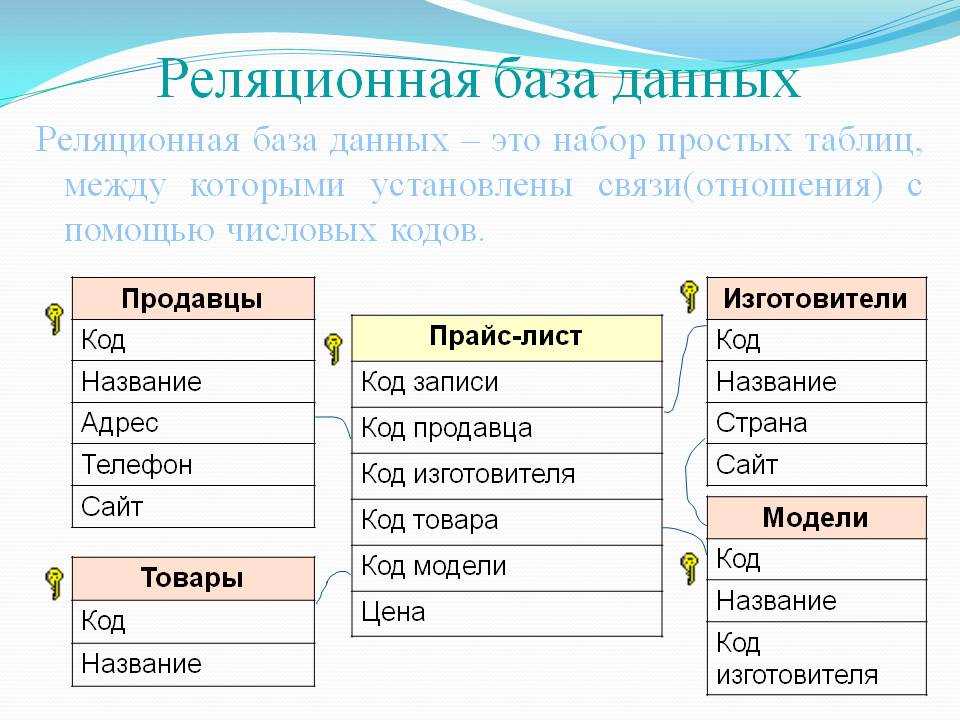 Посетите наше руководство по рецензированию , чтобы узнать больше. Однако информация и изображения в бесплатной сети (Интернет) могут быть размещены кем угодно, поскольку нет обязательного процесса проверки. Некоторые материалы в бесплатном Интернете могли быть проверены редактором, но большинство из них никогда не рецензировались.
Посетите наше руководство по рецензированию , чтобы узнать больше. Однако информация и изображения в бесплатной сети (Интернет) могут быть размещены кем угодно, поскольку нет обязательного процесса проверки. Некоторые материалы в бесплатном Интернете могли быть проверены редактором, но большинство из них никогда не рецензировались.
Кроме того, может быть трудно найти то, что вам нужно, в Интернете с миллионами результатов. Базы данных библиотек ориентированы на определенную аудиторию, часто касаются конкретных тем, таких как сельское хозяйство или музыкальные записи, и собирают связанные материалы в одном месте. Это позволяет более эффективно искать.
В бесплатном Интернете вы можете найти актуальную информацию, начиная от сплетен о знаменитостях и заканчивая сатирой и мнениями. Но когда дело доходит до надежных фактических источников, историческая информация часто не бесплатна. Баз данных таких JSTOR может содержать как старую, так и текущую информацию; публикации могут вернуться к первому номеру журнала.
ДОСТУП К ИНФОРМАЦИИ
Большая часть научной информации не находится в свободном доступе. Бесплатная сеть обычно предоставляет только краткую информацию о цитировании основных документов, такую как имя автора, дата публикации и название публикации. В то время как бесплатная сеть обычно ограничивает доступ к информации через платный доступ, базы данных библиотек часто содержат полные тексты материалов.
Библиотеки оплачивают годовую подписку, чтобы получить доступ к материалам через базы данных, дающие больше, чем просто цитаты. Многие базы данных библиотек содержат полный текст элемента; вы можете просматривать и загружать целые статьи, книги, статистические таблицы или изображения. Они также проверяют наличие альтернативных способов доступа к элементу, например к другим библиотечным базам данных. В качестве дополнительного бонуса библиотечные базы данных часто предлагают получить элемент через межбиблиотечный абонемент, если он не доступен немедленно.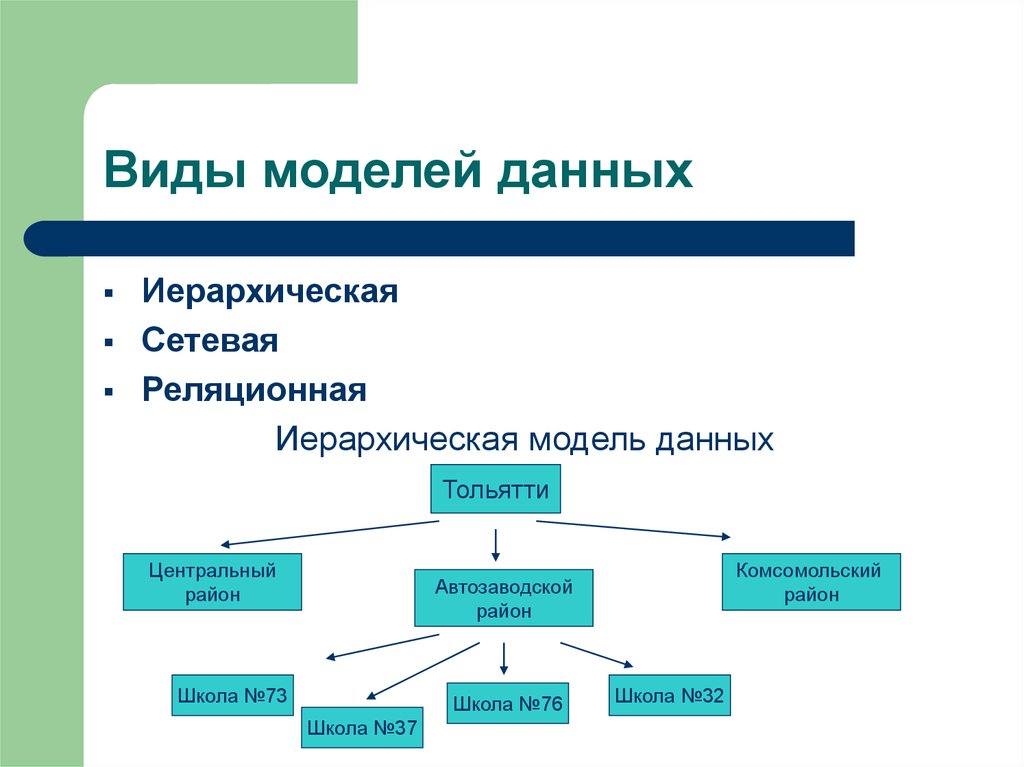
ПРЕИМУЩЕСТВА БАЗ ДАННЫХ
Для многих людей поиск в Интернете является первым шагом к проведению любого исследования. Но Интернет может быстро перегрузить вас потоком информации. И нет никакой проверки на надежность.
| БАЗЫ ДАННЫХ… | ПРЕИМУЩЕСТВА… |
|---|---|
| Специально для конкретных тем или аудиторий. | Исследования намного проще и экономят время. |
| Рецензировано экспертами или проверено профессиональными редакторами. | Высококачественная информация, более надежная. |
| Предоплата библиотеки через подписку. | Нет необходимости в платежах из кармана. |
| Доступен как в кампусе, так и за его пределами. | Доступ 24/7 из любого интернет-соединения. |
| В основном сборники статей и отчетов. | Обычно указывают типы литературы. |
Часто специализированные.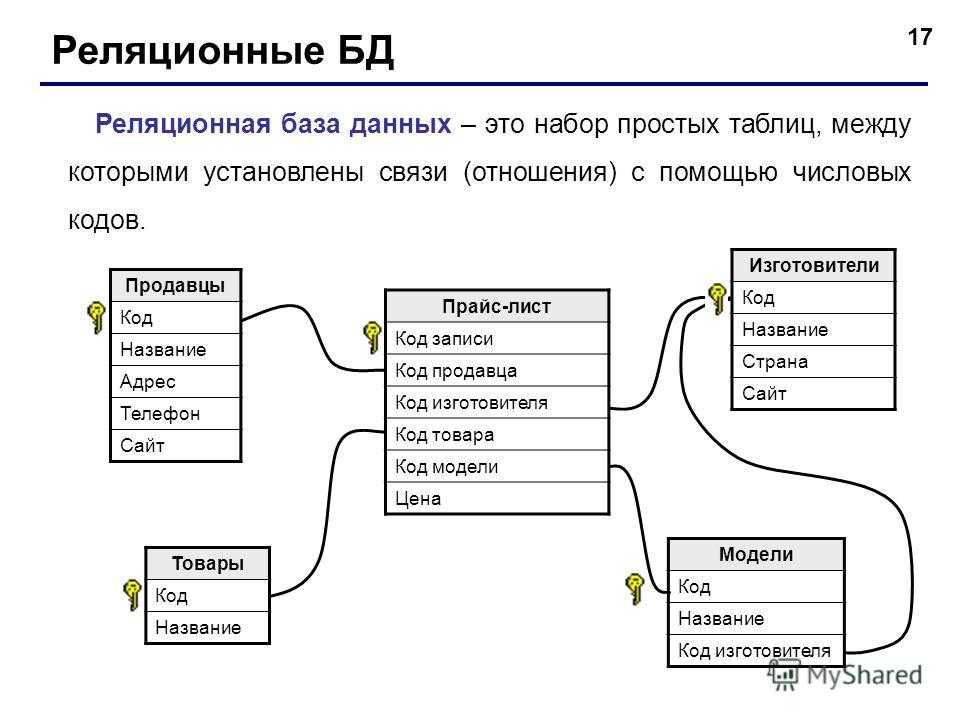 | Может включать газеты, журналы или главы книг. |
| Цитаты обычно сопровождаются аннотациями. | Предлагает краткий обзор базового документа. |
| Ссылка на каталог библиотеки для дальнейшего доступа. | Быстро проверьте, есть ли у библиотеки доступ, или отправьте запрос на межбиблиотечный абонемент, если у нас его нет. |
ШИРОКИЙ ПРОТИВ. SPECIFIC
Большинство библиотечных баз данных предназначены для определенной аудитории, которая диктует тип материала в них. Academic Search Complete , например, охватывает научные журналы по академическим темам, и целевой аудиторией являются студенты бакалавриата. GreenFile , с другой стороны, предназначен для всех, от средней школы до докторских степеней, но фокусируется только на экологических проблемах.
Что такое база данных? Определение, типы, примеры
следующий → ← предыдущая Что такое данные? Данные — это набор отдельных небольших единиц информации. Слово «данные» произошло от слова «датум», что означает «единая часть информации». Это множественное число слова datum. В вычислительной технике данные — это информация, которую можно преобразовать в форму для эффективного перемещения и обработки. Данные взаимозаменяемы. Что такое база данных?База данных представляет собой организованный набор данных, так что к ним можно легко получить доступ и управлять ими. Вы можете организовать данные в таблицы, строки, столбцы и проиндексировать их, чтобы упростить поиск нужной информации. Обработчики базы данных создают базу данных таким образом, что только один набор программного обеспечения обеспечивает доступ к данным для всех пользователей. Основная цель базы данных состоит в том, чтобы оперировать большим объемом информации путем хранения, извлечения и управления данными. В настоящее время во всемирной паутине существует множество динамических веб-сайтов , которые управляются через базы данных. Например, модель, проверяющая наличие номеров в гостинице. Это пример динамического веб-сайта, использующего базу данных. Доступно множество баз данных , таких как MySQL, Sybase, Oracle, MongoDB, Informix, PostgreSQL, SQL Server и т. д. Современные базы данных управляются системой управления базами данных (СУБД). SQL или язык структурированных запросов используется для работы с данными, хранящимися в базе данных. SQL зависит от реляционной алгебры и реляционного исчисления кортежей. Цилиндрическая структура используется для отображения образа базы данных. Эволюция баз данных База данных завершила более чем 50-летний путь эволюции от системы с плоскими файлами к реляционным и объектно-реляционным системам. Он прошел через несколько поколений. ЭволюцияФайловыйВ 1968 году была введена файловая база данных. В файловых базах данных данные хранились в плоском файле. Хотя у файлов есть много преимуществ, есть несколько ограничений. Одним из основных преимуществ является то, что файловая система имеет различные методы доступа, например, последовательный, индексированный и случайный. Требуется обширное программирование на языке третьего поколения, таком как COBOL, BASIC. Иерархическая модель данных1968-1980 годы были эпохой иерархической базы данных. Выдающаяся иерархическая модель базы данных была первой СУБД IBM. Она называлась IMS (система управления информацией). В этой модели файлы связаны родительским/дочерним образом. На приведенной ниже диаграмме представлена иерархическая модель данных. Маленький круг представляет объекты. Как и файловая система, эта модель также имела некоторые ограничения, такие как сложная реализация, отсутствие структурной независимости, неспособность легко обрабатывать отношения «многие-многие» и т. Сетевая модель данныхЧарльз Бахман разработал первую СУБД в компании Honeywell под названием Integrated Data Store (IDS). Он был разработан в начале 1960-х годов, но стандартизирован в 1971 году группой CODASYL (Конференция по языкам систем данных). В этой модели файлы связаны как владельцы и члены, как и в общей сетевой модели. Сетевая модель данных идентифицировала следующие компоненты:
Эта модель также имела некоторые ограничения, такие как сложность системы и сложность проектирования и обслуживания. Реляционная база данных1970 — настоящее время: Это эпоха реляционных баз данных и управления базами данных. В 1970 году реляционная модель была предложена Э. Ф. Коддом. Модель реляционной базы данных имеет два основных термина: экземпляр и схема. Экземпляр представляет собой таблицу со строками или столбцами Схема определяет структуру, такую как имя отношения, тип каждого столбца и имя. В этой модели используются некоторые математические концепции, такие как теория множеств и логика предикатов. Первое приложение для работы с базами данных в Интернете было создано в 1995 году. В эпоху реляционных баз данных было введено гораздо больше моделей, таких как объектно-ориентированная модель, объектно-реляционная модель и т. д. Облачная база данныхОблачная база данныхпозволяет хранить, управлять и извлекать структурированные и неструктурированные данные через облачную платформу. Эти данные доступны через Интернет. Облачные базы данных также называют базой данных как услугой (DBaaS), поскольку они предлагаются как управляемая услуга. Некоторые лучшие облачные варианты:
Преимущества облачной базы данных Снижение затрат Как правило, компании-провайдеру не нужно вкладывать средства в базы данных. Автоматизированный Облачные базы данныхобогащены различными автоматизированными процессами, такими как восстановление, отработка отказа и автоматическое масштабирование. Повышенная доступность Вы можете получить доступ к своей облачной базе данных из любого места и в любое время. Все, что вам нужно, это просто подключение к Интернету. База данных NoSQLБаза данных NoSQL — это подход к разработке таких баз данных, которые могут поддерживать широкий спектр моделей данных. NoSQL означает «не только SQL». Это альтернатива традиционным реляционным базам данных, в которых данные размещаются в таблицах, а схема данных идеально разрабатывается до создания базы данных. Базы данныхNoSQL полезны для большого набора распределенных данных. Некоторые примеры системы баз данных NoSQL с их категорией:
Преимущество NoSQLВысокая масштабируемость Благодаря масштабируемости NoSQL может обрабатывать большие объемы данных. Высокая доступность NoSQL поддерживает автоматическую репликацию. Автоматическая репликация делает его высокодоступным, поскольку в случае любого сбоя данные реплицируются в предыдущее согласованное состояние. Недостаток NoSQLОткрытый код NoSQL — это база данных с открытым исходным кодом, поэтому для NoSQL пока нет надежного стандарта. Задача управления Управление данными в NoSQL намного сложнее, чем в реляционных базах данных. Это очень сложно установить и еще более беспокойно управлять ежедневно. Графический интерфейс недоступен Инструменты с графическим интерфейсомдля базы данных NoSQL не так легко доступны на рынке. Резервное копирование Резервное копирование — большое слабое место для баз данных NoSQL. Объектно-ориентированные базы данныхОбъектно-ориентированные базы данных содержат данные в виде объектов и классов. Объекты — это сущности реального мира, а типы — это коллекции объектов. Объектно-ориентированная база данных представляет собой комбинацию функций реляционной модели с объектно-ориентированными принципами. Это альтернативная реализация реляционной модели. Объектно-ориентированные базы данных содержат правила объектно-ориентированного программирования. Объектно-ориентированная система управления базами данных представляет собой гибридное приложение. Объектно-ориентированная модель базы данных содержит следующие свойства. Свойства объектно-ориентированного программирования
Свойства реляционной базы данных
Графические базы данных База данных графа — это база данных NoSQL. Базы данных графов удобны для поиска взаимосвязей между данными, поскольку они подчеркивают взаимосвязь между релевантными данными. Базы данных Graph очень полезны, когда база данных содержит сложные отношения и динамическую схему. Он в основном используется в управлении цепочками поставок , определяя источник IP-телефонии . СУБД (система управления базами данных)Система управления базой данных — это программное обеспечение, которое используется для хранения и извлечения базы данных. Например, Oracle, MySQL и т. д.; это некоторые популярные инструменты СУБД.
Преимущество СУБДУправление резервированием Он хранит все данные в одном файле базы данных, поэтому он может контролировать избыточность данных. Обмен данными Авторизованный пользователь может обмениваться данными между несколькими пользователями. Резервное копирование Обеспечивает резервное копирование и подсистему восстановления. Эта система восстановления автоматически создает данные после сбоя системы и восстанавливает данные при необходимости. Несколько пользовательских интерфейсов Предоставляет различные типы пользовательских интерфейсов, такие как графический интерфейс, интерфейсы приложений. Недостаток СУБДРазмер Занимает много места на диске и памяти для эффективной работы. Стоимость СУБД требует высокоскоростного процессора данных и большего объема памяти для запуска программного обеспечения СУБД, поэтому она является дорогостоящей. Сложность СУБД создает дополнительные сложности и требования. РСУБД (система управления реляционными базами данных)Слово РСУБД обозначается как «система управления реляционными базами данных». Он представлен в виде таблицы, содержащей строки и столбцы. СУРБД основана на реляционной модели; он был введен Э. Ф. Коддом. Реляционная база данных содержит следующие компоненты:
РСУБД — это табличная СУБД, обеспечивающая безопасность, целостность, точность и непротиворечивость данных. Оставить комментарий
|
 Его можно использовать в различных формах, таких как текст, числа, мультимедиа, байты и т. д., его можно хранить на листах бумаги или в электронной памяти и т. д.
Его можно использовать в различных формах, таких как текст, числа, мультимедиа, байты и т. д., его можно хранить на листах бумаги или в электронной памяти и т. д.
 д.
д.
 Он может обслуживать и поддерживать один или несколько центров обработки данных.
Он может обслуживать и поддерживать один или несколько центров обработки данных.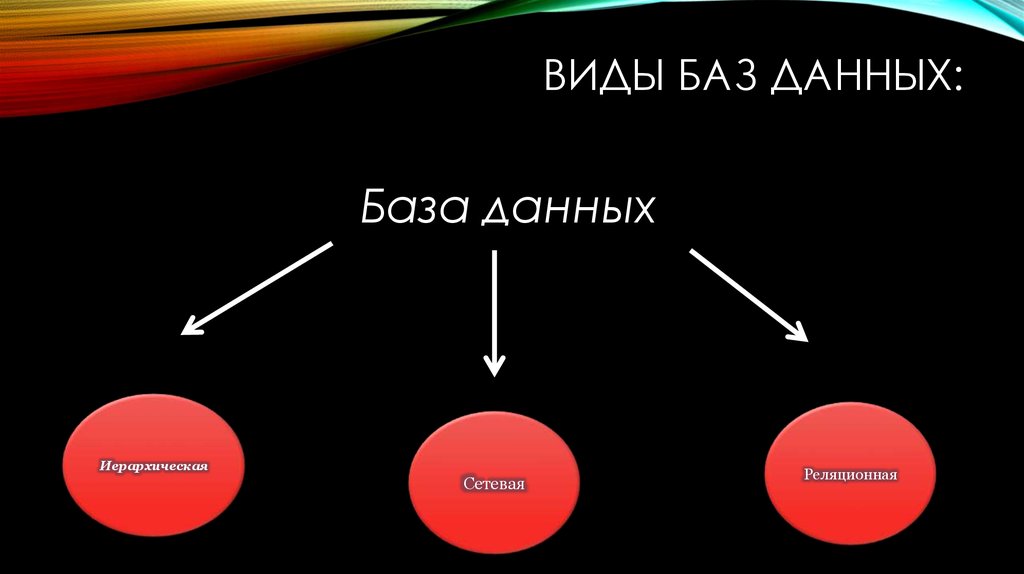 Если объем данных растет, база данных NoSQL масштабирует ее для эффективной обработки этих данных.
Если объем данных растет, база данных NoSQL масштабирует ее для эффективной обработки этих данных. Некоторые базы данных, такие как MongoDB, не имеют эффективных подходов к резервному копированию данных.
Некоторые базы данных, такие как MongoDB, не имеют эффективных подходов к резервному копированию данных.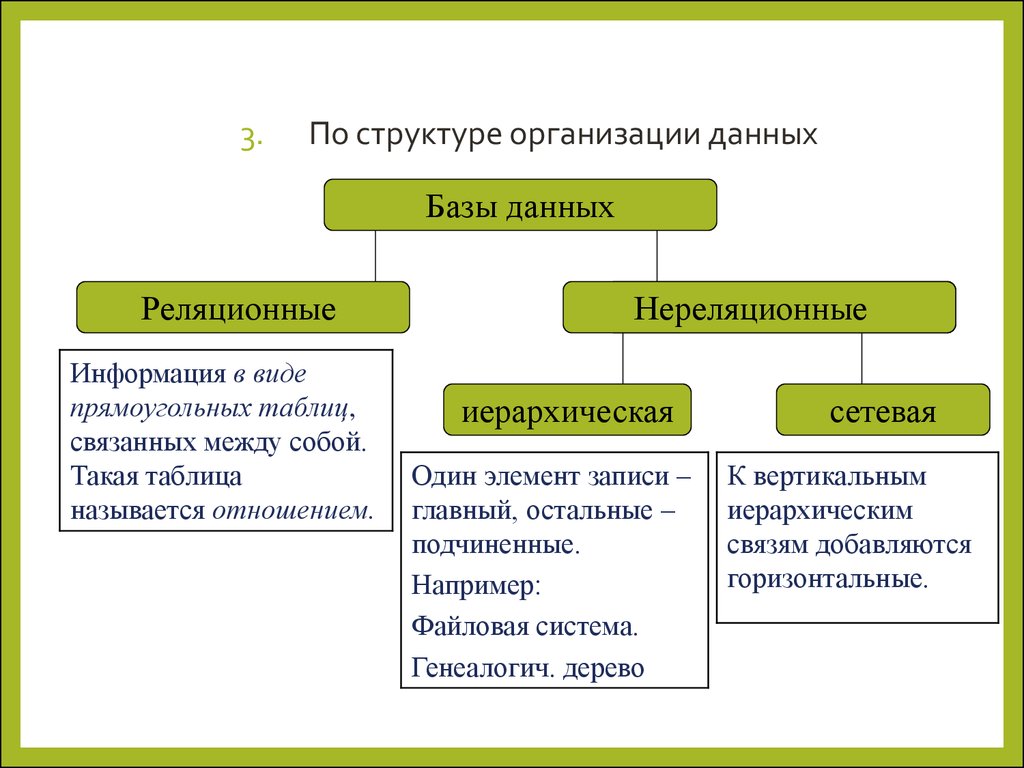 Это графическое представление данных. Он содержит узлы и ребра. Узел представляет сущность, а каждое ребро представляет отношение между двумя ребрами. Каждый узел в базе данных графа представляет собой уникальный идентификатор.
Это графическое представление данных. Он содержит узлы и ребра. Узел представляет сущность, а каждое ребро представляет отношение между двумя ребрами. Каждый узел в базе данных графа представляет собой уникальный идентификатор. д.
д.