Оператор SELECT языка программирования SQL
Резюме: в этой статье вы узнаете, как использовать SQL оператор SELECT для написания запроса выборки данных из одной таблицы.
Содержание
- Введение в оператор SQL SELECT
- Простой выбор данных
- Группировка данных
- Команда HAVING
- Выборка из нескольких таблиц (горизонтальное соединение)
- Вертикальное соединение выборки из разных таблиц
- Упорядочивание
- Копирование в другие таблицы через SELECT
- Исключение дублей
- Примеры использования SELECT в языке программирования SQL
- 1) Пример SQL SELECT — получение информации при выборе данных из всех столбцов.
- 2) SQL SELECT — выбор данных из определенных столбцов
- Сводка
Введение в оператор SQL SELECT
SELECT в SQL позволяет выбрать данные как из одной, так и из нескольких таблиц, но в рамках текущего материала мы рассмотрим выборку только из одной таблицы.
Простой выбор данных
Ниже описан основной синтаксис оператора SELECT, позволяющий выбрать данные из одной таблицы. Он применим как для MySQL так и для других систем.
В этом синтаксисе:
- В первую очередь укажите перечень столбцов таблицы в предложении SELECT. Разделите колонки запятыми.
- После чего следует написать непосредственно имя таблицы после предложения FROM.
При построении плана запроса система баз данных SQL вначале считывает предложение FROM, а уже после этого предложение SELECT.
Это можно читать следующим образом: «выбери мне из таблицы следующие столбцы».
Разделитель в виде точки с запятой (;) не является частью запроса. Сервер баз данных использует ее для разделения нескольких операторов SQL.
К примеру, в случае если выполняются два или более оператора SELECT, следует разграничить их точкой с запятой (;).
При необходимости запросить данные из всех столбцов таблицы, можно применить оператор звездочка (*) вместо перечисления поименно всех столбцов таблицы:
Сиквел не чувствителен к регистру. Поэтому написание команды в виде SELECT или select не теряет смысла запроса.
Поэтому написание команды в виде SELECT или select не теряет смысла запроса.
По конвенции SQL, предлагается использовать заглавные буквы для ключевых слов, таких как SELECT и FROM, и прописные буквы для таких сущностей как имя таблицы или колонки. Это соглашение делает операторы SQL более удобочитаемыми.
Группировка данных
Традиционно в SQL для группировки данных применяется оператор GROUP BY
Группировка или объединение применяется при необходимости сжать какую-то информацию, сгруппировав ее по заданным полям. На картинке выше показан синтаксис применения данной команды. В качестве примера можно рассмотреть продажи фруктов в магазине. Для этого мы группируем записи по колонке fruit, а в качестве второго поля берем агрегатную функцию подсчитывающую количество продаж (в данном случае, независимо от объема). Агрегатные функции (такие как AVG, SUM, COUNT и другие) будут рассмотрены нами позднее в рамках отдельной статьи.
Команда HAVING
Команда HAVING берется обычно как дополнение к группировке используемой в SQL с помощью условия GROUP BY для SELECT.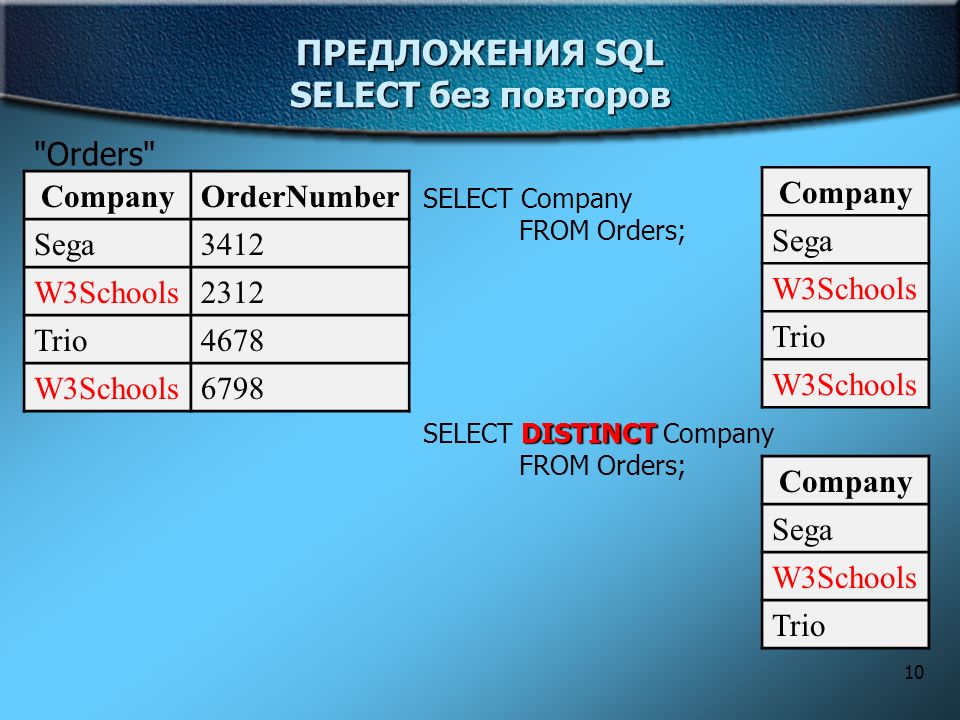
Она может показаться громоздкой, непонятной. Однако спустя несколько удачных или неудачных ее использований приходит понимание синтаксиса. И в дальнейшем она может оказаться вам весьма полезной.
Выборка из нескольких таблиц (горизонтальное соединение)
Эта функция реализована благодаря применению операнда JOIN. Простейшая реализация представлена далее
Здесь таблица A соединяется с таблицей B, поля по которым они соединяются представлены в блоке ON.
Вертикальное соединение выборки из разных таблиц
Бывают ситуации, когда SELECT помогает отобрать записи из нескольких таблиц грубо говоря друг под другом. В подобной ситуации незаменима команда UNION. Ниже продемонстрировано как вывести в один столбец идентификаторы из разных таблиц. Практическое применение такого SELECT‘а сложно представить. А вот в качестве наглядной иллюстрации SQL запроса с применением UNION почему бы и нет.
Упорядочивание
Поменять порядок в выборке можно благодаря добавлению ASC (по алфавиту, от меньшего к большему) и DESC (в обратном порядке) команд. Детали здесь.
Детали здесь.
Копирование в другие таблицы через SELECT
Если позволяет структура таблиц, то имея одинаковую структуру содержимого в SQL допустимо через SELECT производить добавление данных в отдельную таблицу строкой INSERT INTO table:
Обратите пожалуйста внимание, что здесь мы применили условие WHERE в соответствии с которым данные в table2 фильтруются по некоему заданному условию. Включающему операторы сравнения (AND, OR). Подробнее в этой статье.
Чтобы это стало возможно как уже говорилось выше структура у них должна быть одинаковой, для этой цели применим оператор CREATE TABLE name. Он не относится к SELECT, но мы не могли не упомянуть его в этой статье.
Что касается заполнения таблиц, в примере выше не упомянули, однако следует понимать важность использования правильных типов данных в SQL. Также немаловажный вопрос использования NULL и NOT NULL колонок. В зависимости от выбранной опции будет определяться позволит ли вам база данных поместить данные с неопределенным значением (NULL) в табличку или нет. При отсутствии этого указания (как на рисунке выше), считается, что вы такое разрешение дали.
При отсутствии этого указания (как на рисунке выше), считается, что вы такое разрешение дали.
Исключение дублей
Вычленить только неповторяющуюся информацию команде SELECT дает возможность DISTINCT. Именно его применение вы можете увидеть под этим текстом. Подробнее здесь.
Это получение всех возможных вариантов зарплат из сущности со списком сотрудников. Если вы обратили внимание, то безусловно заметили применение в SQL запросе сортировки и указания обратного порядка с помощью DESC.
Примеры использования SELECT в языке программирования SQL
Для демонстрации мы будем использовать таблицу employees.
1) Пример SQL SELECT — получение информации при выборе данных из всех столбцов.
В следующем примере применяется запрос с использованием команды SELECT для выборки всех строк и столбцов таблицы employees:
Далее показан результирующие наборы данных, которые вернул сервер базы данных. Это напоминает некую электронную таблицу, которая имеет свой набор строк и колонки с заголовком:
Команда SELECT * полезна только для специфических запросов и редко применяется профессиональными программистами.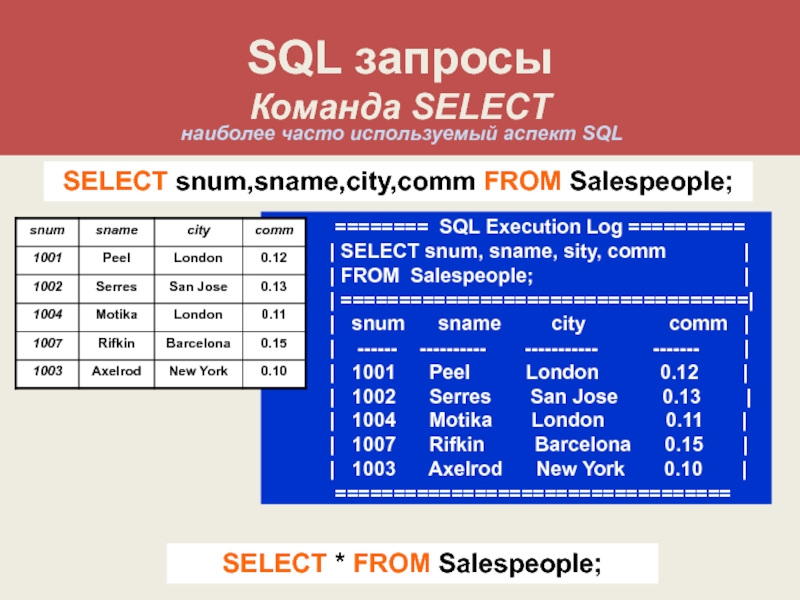 Это обусловлено тем что крайне редко возникают ситуации, когда требуются получить полный набор данных. Обычно он ограничен частью столбцов. Поэтому в процессе разработки рекомендуется избегать использования звездочки select.
Это обусловлено тем что крайне редко возникают ситуации, когда требуются получить полный набор данных. Обычно он ограничен частью столбцов. Поэтому в процессе разработки рекомендуется избегать использования звездочки select.
Если вы используете select *, БД требуется больше времени, чтобы прочитать информацию с диска, нежели если использовать именованную выборку (т.е. перечислить имена всех нужных колонок). Это часто приводит к ухудшению производительности. Особенно это чревато проблемами, если таблица содержит большое количество столбцов со значительным числом строк.
2) SQL SELECT — выбор данных из определенных столбцов
Чтобы выбрать данные из определенных столбцов, можно указать список столбцов после пункта SELECT оператора SELECT.
Например, ниже приведена выборка данных из идентификатора сотрудника, имени, фамилии и даты приема на работу из всех строк таблицы «Сотрудники»:
Теперь набор результатов включает только четыре столбца, указанные в предложении SELECT:
3) SQL SELECT — выполнение простого вычисления
В следующем примере оператор SELECT используется для получения имени, фамилии, зарплаты и новой зарплаты:
Выражение salary * 1. 05 добавляет 5% к зарплате каждого сотрудника. По умолчанию SQL использует выражение в качестве заголовка столбца:
05 добавляет 5% к зарплате каждого сотрудника. По умолчанию SQL использует выражение в качестве заголовка столбца:
Чтобы присвоить выражению или столбцу псевдоним, нужно указать ключевое слово AS, за которым следует псевдоним столбца, как показано ниже:
Например, следующий оператор SELECT использует new_salary в качестве псевдонима столбца для выражения salary * 1.05:
Вывод:
Сводка
Используйте оператор SQL SELECT для выбора данных из таблицы.
Чтобы выбрать данные из таблицы, укажите имя таблицы в предложении FROM и список столбцов в предложении SELECT.
SELECT * — это сокращение от SELECT все столбцы таблицы.
Предыдущая статья: Синтаксис SQL
Следующая статья: Сортировка данных (ORDER BY)
SQL SELECT — что это, примеры использования
Главная » Программирование » SQL
Опубликовано: Рубрика: SQL
SQL SELECT — это команда, которая используется для извлечения информации из базы данных. Она позволяет выбрать нужные данные и отобразить их в виде таблицы или другого формата.
Для использования команды SELECT необходимо знать основные элементы языка SQL, такие как базы данных, таблицы, столбцы и ключевые слова.
Базы данных — это совокупность связанных таблиц, содержащих информацию о конкретной теме. Таблицы состоят из столбцов и строк, где столбцы представляют собой категории информации, а строки — ее конкретные значения.
Для использования команды SELECT необходимо знать структуру таблицы и названия столбцов, из которых вы хотите извлечь данные.
Например, если у вас есть таблица «customers» со столбцами «customer_id», «name», «email» и «phone», вы можете использовать команду SELECT, чтобы извлечь данные из этих столбцов:
SELECT customer_id, name, email, phone
FROM customers;
Эта команда извлекает данные из таблицы «customers» и отображает их в виде таблицы, состоящей из столбцов «customer_id», «name», «email» и «phone».
| customer_id | name | phone | |
|---|---|---|---|
| 1 | Сергей | [email protected] | 555-1234 |
| 2 | Ирина | [email protected] | 555-5678 |
| 3 | Иван | [email protected] | 555-9012 |
| 4 | Алексей | [email protected] | 555-3456 |
| 5 | Екатерина | [email protected] | 555-7890 |
Кроме того, команда SELECT может быть использована для извлечения данных с определенными условиями.
Например, если вы хотите извлечь данные только о клиентах с определенным идентификатором, вы можете использовать команду WHERE:
SELECT customer_id, name, email, phone
FROM customers
WHERE customer_id = 123;
Эта команда извлекает данные только из тех строк таблицы «customers», в которых значение столбца «customer_id» равно 123.
| customer_id | name | phone | |
|---|---|---|---|
| 123 | Мария | mary@example. com com | 555-6789 |
Вы можете использовать команду SELECT для сортировки данных в таблице.
Например, если вы хотите отсортировать данные по значению столбца «name» в алфавитном порядке, вы можете использовать команду ORDER BY:
SELECT customer_id, name, email, phone
FROM customers
ORDER BY name ASC;
Эта команда отображает данные из таблицы «customers» и сортирует их по значению столбца «name» в алфавитном порядке.
| customer_id | name | phone | |
|---|---|---|---|
| 456 | Павел | [email protected] | 555-1234 |
| 123 | Мария | [email protected] | 555-6789 |
| 789 | Светлана | [email protected] | 555-4567 |
Это только несколько примеров использования команды SELECT. SQL имеет множество других команд, которые позволяют выбирать, изменять, удалять и добавлять данные в базу данных. Надеюсь, что эта статья была полезной для вас.
Надеюсь, что эта статья была полезной для вас.
Рейтинг
( 1 оценка, среднее 5 из 5 )
Понравилась статья? Поделиться с друзьями:
sql server — Синтаксис вложенного выбора SQL
Задавать вопрос
спросил
Изменено 2 года, 11 месяцев назад
Просмотрено 9к раз
Я пытаюсь создать запрос, который предоставит мне общее количество агентов (AgentID) для каждого OfficeID. Если кто-то может направить меня в правильном направлении, а также если есть ресурсы, которые дают вам кучу примеров различных типов запросов, которые будут полезны в будущем!
Моя проблема сейчас связана с синтаксисом. Я не уверен, куда нужно идти, чтобы получить желаемый результат выше.
Я не уверен, куда нужно идти, чтобы получить желаемый результат выше.
Вот что у меня есть на данный момент:
Таблицы OFFICE и AGENT:
CREATE TABLE OFFICE
(
OfficeID NVARCHAR(5) УНИКАЛЬНЫЙ,
Адрес офиса NVARCHAR(18) НЕ NULL,
ПЕРВИЧНЫЙ КЛЮЧ(OfficeID)
)
ИДТИ
СОЗДАТЬ ТАБЛИЧНЫЙ АГЕНТ
(
AgentID NVARCHAR(8) УНИКАЛЬНЫЙ,
OfficeID NVARCHAR(5) НЕ NULL,
AgentType NVARCHAR(9) НЕ NULL,
AgentFName NVARCHAR(10) НЕ NULL,
ПЕРВИЧНЫЙ КЛЮЧ (АгентИд),
ВНЕШНИЙ КЛЮЧ (OfficeID) ССЫЛКИ ОФИС
НА УДАЛЕНИЕ КАСКАД
НА КАСКАД ОБНОВЛЕНИЙ
)
ИДТИ
Запрос:
ВЫБЕРИТЕ
OFFICE.OfficeID
ОТ
ОФИС,
(ВЫБЕРИТЕ СЧЕТ(ИД Агента)
ОТ АГЕНТА, ОФИС
ГДЕ OFFICE.OfficeID = АГЕНТ.OfficeID
ГРУППИРОВАТЬ ПО АГЕНТУ.OfficeID)
СОРТИРОВАТЬ ПО
OFFICE.OfficeID
- sql-сервер
- подзапрос
Я бы сделал это с помощью JOIN и GROUP BY, вложение не требуется и не желательно:
SELECT o.OfficeID, COUNT(a.AgentID) NumberOfAgents ИЗ офиса Агенты LEFT JOIN a ON a.OfficeID = o.OfficeID ГРУППИРОВАТЬ ПО o.OfficeID
Что-то вроде этого (желаемый вывод отсутствует):
SELECT O.OfficeID
, (
ВЫБЕРИТЕ КОЛИЧЕСТВО(*)
ОТ АГЕНТА А
ГДЕ A.OfficeID = O.OfficeID
)
ИЗ ОФИС О
ЗАКАЗАТЬ ПО O.OfficeID
Обратите внимание на использование псевдонима таблицы, что рекомендуется для краткости запросов.
0 Вы должны быть конкретными с тем, что вы хотите в соответствии с тем, что я думаю, что в вашем случае не требуется сложный запрос. Например, вы можете получить желаемый результат из приведенного ниже запроса 9.0003выберите officeid, подсчитайте (1) как NoofAgents от агентов группа по officeid
SQL может дать вам желаемый путь во многих отношениях, и вы можете выбрать их на основе оптимизированного решения.
1Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google Зарегистрироваться через Facebook Зарегистрируйтесь, используя адрес электронной почты и парольОпубликовать как гость
Электронная почтаТребуется, но никогда не отображается
Опубликовать как гость
Электронная почтаТребуется, но не отображается
Нажимая «Опубликовать свой ответ», вы соглашаетесь с нашими условиями обслуживания и подтверждаете, что прочитали и поняли нашу политику конфиденциальности и кодекс поведения.
SQL Server SELECT Примеры
Автор: Koen Verbeeck | Обновлено: 12 апреля 2021 г. | Комментарии | Связанный: Подробнее > TSQL
Проблема
При сохранении данных в разных таблицах базы данных SQL в какой-то момент времени вы захочет получить некоторые из этих данных. Здесь оператор SELECT для Появляется язык SQL. Этот учебник научит вас, как использовать SELECT для чтения, агрегирования и сортировать данные из одной или нескольких таблиц базы данных.
Решение
Все запросы в этом руководстве по SQL написаны на Образец базы данных Adventure Works. Вы можете установить его на свой компьютер, чтобы вы могли
выполнить запросы самостоятельно, чтобы увидеть результаты. Вы также можете взять примеры запросов
и замените имена таблиц и имена столбцов именами из вашей собственной базы данных.
Поскольку для чтения данных мы будем использовать только оператор SQL SELECT,
риск изменения или удаления данных.
Примеры операторов SQL SELECT
В самой простой форме предложение SELECT имеет следующий синтаксис SQL для База данных Microsoft SQL Server:
ВЫБЕРИТЕ * ИЗ <ИмяТаблицы>;
Этот запрос SQL выберет все столбцы и все строки из таблицы. Например:
ВЫБЕРИТЕ * ОТ [Человека].[Человека];
Этот запрос выбирает все данные из таблицы Person в схеме Person.
Если нам нужно только подмножество столбцов, мы можем явно перечислить каждый столбец разделенные запятой, вместо использования символа звездочки, который включает все столбцы.
ВЫБЕРИТЕ BusinessEntityID, Имя, Фамилия, Дата изменения ОТ [Человека].[Человека];
Синтаксис для сортировки результатов
Иногда требуется отобразить строки в порядке, отличном от порядка SQL. Сервер возвращает результаты. Вы можете сделать это с помощью ПОРЯДОК SQL пункт ПО.
ВЫБЕРИТЕ столбец1, столбец2, столбец3, … ОТ <имя таблицы> ORDER BY columnX ASC | DESC
Вы можете сортировать по одному или нескольким столбцам, и вы можете выбрать сортировку по возрастанию
(ASC) или по убыванию (DESC). Вернем строки с восходящей датой изменения:
Вернем строки с восходящей датой изменения:
ВЫБЕРИТЕ BusinessEntityID, Имя, Фамилия, Дата изменения ОТ [Человека].[Человека] ЗАКАЗАТЬ ПО [Дата изменения] ASC;
По возрастанию — значение по умолчанию, поэтому явно указывать ASC не нужно.
Теперь с датой изменения по убыванию:
ВЫБЕРИТЕ BusinessEntityID, Имя, Фамилия, Дата изменения ОТ [Человека].[Человека] ЗАКАЗАТЬ ПО [Дата изменения] DESC;
Вы можете сортировать по нескольким столбцам, поэтому давайте сортировать по убыванию даты изменения сначала, затем по возрастанию имени.
ВЫБЕРИТЕ BusinessEntityID, Имя, Фамилия, Дата изменения ОТ [Человека].[Человека] ORDER BY [ModifiedDate] DESC, Имя;
Например, вы можете видеть, как третья и четвертая строки результирующего набора (Carla и Маргарет) поменялись местами.
Фильтрация данных из таблицы
Иногда вам нужно ограничить количество строк, возвращаемых
запрос, особенно если у вас есть таблица с большим количеством строк. Если вы
просто интересно взглянуть на данные, вы можете использовать ТОР пункт. Например, это вернет первые 10 строк таблицы:
Если вы
просто интересно взглянуть на данные, вы можете использовать ТОР пункт. Например, это вернет первые 10 строк таблицы:
ВЫБЕРИТЕ ВЕРХ(10)
[BusinessEntityID]
,[Имя]
,[Фамилия]
,[Дата изменения]
ОТ [Человека].[Человека];
Вместо числа можно также использовать процент. Этот запрос возвращает количество строк, равное (или почти равное) 15% от общего количества строк:
ВЫБЕРИТЕ ВЕРХ(15) ПРОЦЕНТОВ
[BusinessEntityID]
,[Имя]
,[Фамилия]
,[Дата изменения]
ОТ [Человека].[Человека];
В случае с этой таблицей (всего 19 972 строки) запрос возвращает 2 996 ряды.
Если вы хотите отфильтровать строки по условию, Можно использовать предложение WHERE. Обычно он имеет следующую структуру:
ВЫБЕРИТЕ столбец1, столбец2, … ОТ <имя_таблицы> ГДЕ <логическое выражение>;
Каждая строка, в которой выражение возвращает значение true, возвращается запросом. Следующее
запрос возвращает всех людей с именем «Роб».
ВЫБЕРИТЕ
[BusinessEntityID]
,[Имя]
,[Фамилия]
,[Дата изменения]
ОТ [Человека].[Человека]
ГДЕ [Имя] = 'Роб';
В следующем примере три запроса возвращают строки, в которых BusinessEntityID равен меньшему размеру или больше 130.
ВЫБЕРИТЕ
[BusinessEntityID]
,[Имя]
,[Фамилия]
,[Дата изменения]
ОТ [Человека].[Человека]
ГДЕ [BusinessEntityID] = 130;
ВЫБЕРИТЕ
[BusinessEntityID]
,[Имя]
,[Фамилия]
,[Дата изменения]
ОТ [Человека].[Человека]
ГДЕ [BusinessEntityID] < 130;
ВЫБЕРИТЕ
[BusinessEntityID]
,[Имя]
,[Фамилия]
,[Дата изменения]
ОТ [Человека].[Человека]
ГДЕ [BusinessEntityID] > 130;
Вы можете использовать различные функции и операторы, такие как НРАВИТСЯ оператор для более продвинутый поиск строк. В этом примере мы ищем всех людей, у которых имя начинается с «Роб».
ВЫБЕРИТЕ
[BusinessEntityID]
,[Имя]
,[Фамилия]
,[Дата изменения]
ОТ [Человека]. [Человека]
ГДЕ [Имя] НРАВИТСЯ 'Rob%';
[Человека]
ГДЕ [Имя] НРАВИТСЯ 'Rob%';
Дополнительные примеры LIKE см. в совете Синтаксис SQL Server LIKE с подстановочными знаками. Пример с использованием Функция ГОД:
ВЫБЕРИТЕ
[BusinessEntityID]
,[Имя]
,[Фамилия]
,[Дата изменения]
ОТ [Человека].[Человека]
ГДЕ ГОД([Дата изменения]) = 2011;
Теперь возвращаются только строки, в которых строка была изменена в 2011 году:
Вы можете использовать логические операторы И, ИЛИ и НЕ для объединения различных логических выражения друг с другом. Следующий запрос выбирает все строки, в которых имя равно «Роб», а измененная дата была в 2011 году:
ВЫБЕРИТЕ
[BusinessEntityID]
,[Имя]
,[Фамилия]
,[Дата изменения]
ОТ [Человека].[Человека]
ГДЕ [Имя] = 'Роб'
И ГОД([Дата изменения]) = 2011;
Мы получим совершенно другой результирующий набор, если заменим И на ИЛИ. Теперь все ряды
возвращаются, если имя равно Rob или строка была изменена в
2011.
ВЫБЕРИТЕ
[BusinessEntityID]
,[Имя]
,[Фамилия]
,[Дата изменения]
ОТ [Человека].[Человека]
ГДЕ [Имя] = 'Роб'
ИЛИ ГОД([ModifiedDate]) = 2011;
Группировка данных из таблицы SQL Server
Если вы не хотите возвращать отдельные строки сведений из таблицы, а хотите сводные результаты, вы можете использовать Предложение GROUP BY. Запрос имеет следующий формат:
.SELECT столбец 1, столбец 2, <функция агрегации> (столбец 3) ОТ <имя_таблицы> СГРУППИРОВАТЬ ПО столбцу1, столбцу2
В SQL Server существует множество различных функций агрегирования, таких как SUM, AVG, МИН, МАКС и так далее. Вы можете найти список здесь. Если вы используете только агрегации, вам не нужно использовать GROUP BY. пункт. Например, мы можем вернуть количество строк в таблице с помощью Функция СЧЁТ:
ВЫБРАТЬ СЧЕТЧИК(1) КАК RowCnt ОТ [Человека].[Человека];
Новое имя – RowCnt – было присвоено результату с помощью AS
ключевое слово. Это также называется «назначением псевдонима». Добавляя ГРУППУ
BY по имени и предложению WHERE (см. предыдущий раздел), мы можем посчитать
сколько раз имя начинается с «Роб».
Это также называется «назначением псевдонима». Добавляя ГРУППУ
BY по имени и предложению WHERE (см. предыдущий раздел), мы можем посчитать
сколько раз имя начинается с «Роб».
ВЫБЕРИТЕ
[Имя]
,COUNT(1) КАК RowCnt
ОТ [Человека].[Человека]
ГДЕ [Имя] НРАВИТСЯ 'Rob%'
СГРУППИРОВАТЬ ПО [Имя];
Каждый столбец, который не используется внутри функции агрегирования и не константа, должна быть помещена в предложение GROUP BY. Например, если мы добавим Фамилия на SELECT, но не на GROUP BY, мы получаем ошибку:
Фильтрация сводных результатов
Используя предложение WHERE, вы можете отфильтровать отдельные строки. Но что, если вы хотите фильтровать результат агрегированной функции? Это невозможно в ГДЕ предложение, так как эти результаты не существуют в исходной таблице. Мы можем сделать это с предложение HAVING. Используя предыдущий пример, мы хотим вернуть только имена — начиная с «Роб» — где количество строк не менее 20. запрос становится:
ВЫБЕРИТЕ
[Имя]
,COUNT(1) КАК RowCnt
ОТ [Человека]. [Человека]
ГДЕ [Имя] НРАВИТСЯ 'Rob%'
СГРУППИРОВАТЬ ПО [Имя]
ИМЕЕТ СЧЁТ(1) >= 20;
[Человека]
ГДЕ [Имя] НРАВИТСЯ 'Rob%'
СГРУППИРОВАТЬ ПО [Имя]
ИМЕЕТ СЧЁТ(1) >= 20;
Выбор данных из нескольких таблиц SQL Server
Часто вам не нужны данные из одной таблицы, но вам нужно комбинировать разные таблицы, чтобы получить желаемый результат. В SQL вы делаете это, «присоединяясь» столы. Вы берете одну таблицу и определяете, какие столбцы должны совпадать со столбцами другого стола. Они разные типы соединения в SQL:
- INNER JOIN — возвращаются только строки, совпадающие между обеими таблицами.
- LEFT OUTER JOIN – возвращаются все строки из первой таблицы вместе с любыми соответствующими строками из второй таблицы. Также есть ПРАВОЕ СОЕДИНЕНИЕ, что меняет отношения.
- FULL OUTER JOIN — возвращает все строки из обеих таблиц. Если есть нет соответствия, отсутствующая сторона будет иметь значения NULL вместо фактических значений столбца.
- CROSS JOIN – это декартово произведение всех строк обеих таблиц.
Нет соответствия.
 Если у вас есть 100 строк в первой таблице и 10 в
во втором набор результатов будет содержать 100 * 10 = 1000 строк. Этот тип соединения
следует использовать с осторожностью, поскольку потенциально он может возвращать много строк. Мы
не будем обсуждать это дальше в этом совете.
Если у вас есть 100 строк в первой таблице и 10 в
во втором набор результатов будет содержать 100 * 10 = 1000 строк. Этот тип соединения
следует использовать с осторожностью, поскольку потенциально он может возвращать много строк. Мы
не будем обсуждать это дальше в этом совете.
Сообщение в блоге Наглядное объяснение соединений SQL иллюстрирует каждый тип соединения диаграммой Венна. Давайте проиллюстрируем каждый тип соединения на примере запроса.
ВНУТРЕННЕЕ СОЕДИНЕНИЕ
Следующий запрос использует INNER JOIN для возврата всех строк и всех столбцов таблицы. таблицы Person и таблицы Employee, но только если они имеют совпадающие идентификаторы BusinessEntityID. Другими словами, запрос возвращает людей, которые являются сотрудниками AdventureWorks.
ВЫБЕРИТЕ * ОТ [Человека].[Человека] INNER JOIN [HumanResources].[Employee] ON [Employee].[BusinessEntityID] = [Person].[BusinessEntityID];
Если вы не хотите вводить имена таблиц каждый раз, когда ссылаетесь на столбец,
вы также можете использовать псевдонимы. Здесь таблица Person имеет псевдоним «p».
и таблица «Сотрудник» с «e».
Здесь таблица Person имеет псевдоним «p».
и таблица «Сотрудник» с «e».
ВЫБЕРИТЕ * ОТ [Человек].[Человек] p INNER JOIN [HumanResources].[Employee] e ON e.[BusinessEntityID] = p.[BusinessEntityID];
Если между таблицами есть столбцы с одинаковыми именами, необходимо добавить префикс их с именем таблицы или с соответствующим псевдонимом. В следующем запросе мы вернуть BusinessEntityID обеих таблиц, поэтому они должны иметь префикс.
ВЫБЕРИТЕ
стр. [Имя]
,стр.[Фамилия]
,стр.[BusinessEntityID]
,e.[BusinessEntityID]
,e.[Дата найма]
ОТ [Человек].[Человек] p
INNER JOIN [HumanResources].[Employee] e ON e.[BusinessEntityID] = p.[BusinessEntityID];
Рекомендуется добавлять ко всем столбцам в операторе SELECT префикс псевдоним таблицы, так как он покажет, из какой таблицы взят каждый столбец. Этот позволяет избежать путаницы со стороны людей, читающих ваш запрос, особенно если они не знаком со структурой базы данных.
ЛЕВОЕ ВНЕШНЕЕ СОЕДИНЕНИЕ
Когда мы меняем тип соединения на LEFT OUTER JOIN, все строки из таблицы Person
будет возвращен. Неважно, есть ли совпадение с Сотрудником
стол. Если есть совпадение, будет возвращено значение столбца HireDate.
Если нет, вместо этого будет возвращен NULL.
Неважно, есть ли совпадение с Сотрудником
стол. Если есть совпадение, будет возвращено значение столбца HireDate.
Если нет, вместо этого будет возвращен NULL.
ВЫБЕРИТЕ
стр. [Имя]
,стр.[Фамилия]
,стр.[BusinessEntityID]
,e.[BusinessEntityID]
,e.[Дата найма]
ОТ [Человек].[Человек] p
LEFT OUTER JOIN [HumanResources].[Employee] e ON e.[BusinessEntityID] = p.[BusinessEntityID];
В результирующем наборе видно, что HireDate не возвращается для лица, не являющиеся работниками:
RIGHT OUTER JOIN использует точно такой же принцип, но возвращает все строки из вторая таблица и только совпадающие результаты из первой таблицы. Обычно это не часто используется, так как LEFT OUTER JOIN легче читать.
ПОЛНОЕ ВНЕШНЕЕ СОЕДИНЕНИЕ
Чтобы проиллюстрировать концепцию FULL OUTER JOIN, мы используем JobCandidate также стол. Эта таблица содержит 13 строк. Только 2 из этих 13 кандидатов на самом деле
были приняты на работу, и у них BusinessEntityID не равен NULL.
В следующем запросе мы сначала объединяем Person и Employee вместе, чтобы найти всех сотрудников. Затем мы используем FULL OUTER JOIN, чтобы получить всех кандидатов на работу. также в наборе результатов запроса.
ВЫБЕРИТЕ
стр. [Имя]
,стр.[Фамилия]
,стр.[BusinessEntityID]
,e.[BusinessEntityID]
,j.[BusinessEntityID]
,e.[Дата найма]
,j.[JobCandidateID]
ОТ [Человек].[Человек] p
INNER JOIN [HumanResources].[Employee] e ON p.[BusinessEntityID] = e.[BusinessEntityID]
ПОЛНОЕ ВНЕШНЕЕ СОЕДИНЕНИЕ [HumanResources].[JobCandidate] j ON e.[BusinessEntityID] = j.[BusinessEntityID];
290 сотрудников и 13 кандидатов на работу. Принято на работу двух кандидатов, так они тоже наемные работники. Это означает, что общая сумма возвращенных строк должно быть 301 (290 + 13 – 2).
Первые строки — это сотрудники, которых невозможно найти в таблице JobCandidate. Столбец JobCandidateID имеет значение NULL.
В конце набора результатов добавляются кандидаты на работу:
На красной площади у нас 11 кандидатов на работу, которые не были приняты на работу. Все
столбцы равны NULL, за исключением столбца JobCandidateID. В зеленом квадрате имеем
пример кандидата на работу, который был принят на работу. Все столбцы имеют значения в этом
случай.
Все
столбцы равны NULL, за исключением столбца JobCandidateID. В зеленом квадрате имеем
пример кандидата на работу, который был принят на работу. Все столбцы имеют значения в этом
случай.
Наконечник Пример присоединения к SQL Server немного подробнее рассказывает о различных присоединениях. типы.
Заключение
Давайте объединим все предыдущие разделы в один запрос. Этот запрос возвращает количество всех сотрудников, имя которых начинается с «Роб», отсортированы по этому счету по возрастанию.
ВЫБЕРИТЕ
стр. [Имя]
,COUNT(1) КАК RowCnt
ОТ [Человек].[Человек] p
INNER JOIN [HumanResources].[Employee] e ON e.[BusinessEntityID] = p.[BusinessEntityID]
ГДЕ p.[FirstName] LIKE 'Rob%'
СГРУППИРОВАТЬ ПО [p].[Имя]
ЗАКАЗАТЬ ПО [RowCnt] ASC;
Как видно из запроса, вы также можете сортировать по псевдонимам (в данном примере RowCnt) и не только на реальных физических столбцах из таблицы.
Следующие шаги
- В этом совете мы только слегка коснулись того, что делает оператор SELECT.
 сможет сделать. Вот еще несколько сложных конструкций:
сможет сделать. Вот еще несколько сложных конструкций:- Объединение наборов результатов с UNION (ALL): UNION против UNION ALL в SQL Server
- Использование подзапросов - Пример подзапроса SQL Server — и связанные подзапросы: Некоррелированный и коррелированный подзапрос SQL Server.
- Создание коррелированных запросов или использование табличных функций с APPLY: SQL Server ПЕРЕКРЕСТНОЕ ПРИМЕНЕНИЕ и ВНЕШНЕЕ ПРИМЕНЕНИЕ
- Более продвинутая группировка с использованием НАБОРЫ КУБ, РОЛЛАП и ГРУППИРОВКА.
- Дополнительные статьи для обзора:
- Различия между удалением и усечением в SQL Server
- Производительность SQL Server SELECT INTO по сравнению с SQL INSERT INTO
- Примеры таблицы перетаскивания SQL с T-SQL и SQL Server Management Studio
Об авторе
Коэн Вербек — опытный консультант по бизнес-аналитике в AE. Он имеет более чем десятилетний опыт работы с платформой данных Microsoft в различных отраслях.