DISTINCT и GROUP BY — в чем магия? | by Roman
4 min read·
Jun 13, 2020SQL-запросDISTINCT является необязательным параметром блока SELECT и применяется сразу ко всем столбцам таблицы, перечисленным в SELECT. Параметр DISTINCT используют, чтобы получить строки таблицы с уникальными значениями. Размещать параметр необходимо сразу после ключевого слова SELECT (в иных случаях появится ошибка синтаксиса. Проверил в базах MySQL, Oracle, PostgreSQL, SQLite, MS SQL SERVER 2017):
Помимо этого, DISTINCT применяется внутри агрегатных функций:
У нас имеется таблица table_test со столбцами category и price. Попробуем получить из нее уникальные значения сначала одного столбца, а затем двух. Результирующие таблицы для удобочитаемости будут отсортированы по возрастанию столбца category.
Исходная таблица test_table:
Работа DISTINCT с одним столбцом таблицы:
Работа DISTINCT с двумя столбцами таблицы:
Но почему же в результирующей таблице существуют повторяющиеся значения столбца category? Ведь их не было в результатах прошлого запроса при работе с одним столбцом.
Дело в том, что значения столбцов проверяются на уникальность не по отдельности, а всей строкой, составленной из столбцов category и price, указанных в блоке SELECT.
Если говорить совсем упрощенно, то в таблице дублировалась строка со значением 12:
Таким образом мы понимаем, что 12 и 21 — это разные строки, поэтому они не были исключены из выборки. Надеюсь, на примере с цифрами стало легче понимать работу DISTINCT.
Сначала примеры.
Работа GROUP BY с одним столбцом таблицы:
Работа GROUP BY с двумя столбцами таблицы:
Да! Результат работы GROUP BY точно такой же, как при использовании DISTINCT в примерах выше. А зачем тогда в SQL два оператора, выполняющих одно и тоже? GROUP BY имеет более широкие возможности, например, позволяет применять агрегатные функции.
А зачем тогда в SQL два оператора, выполняющих одно и тоже? GROUP BY имеет более широкие возможности, например, позволяет применять агрегатные функции.
При помощи GROUP BY мы можем получить количество уникальных строк для каждой категории в test_table. Для этого воспользуемся агрегатной функцией COUNT():
Хм. Тогда получается, раз у GROUP BY такой мощный функционал, то можно всегда его использовать и забыть про DISTINCT? Не стоит так делать. В некоторых случаях DISTINCT выигрывает по скорости выполнения запроса (углубляться не буду, это отдельная тема).
При сравнении скорости получения одинаковых данных из таблицы моего рабочего проекта, содержащей 360 750 строк, DISTINCT оказался в 80 раз быстрее, чем GROUP BY:
Запрос в MySQL с оператором DISTINCTЗапрос в MySQL с оператором GROUP BYСтатья: Синтаксический сахар SQL — функция COALESCE
Если Вы работаете с SQL, то скорее всего Вы сталкивались с выражением COALESCE. Если же Вы с ним не знакомы, то самое время сделать это сейчас — это очень крутая штука, которая пригодится Вам в решении большого количества задач.
Если же Вы с ним не знакомы, то самое время сделать это сейчас — это очень крутая штука, которая пригодится Вам в решении большого количества задач.
Итак, начнем с самого простого — что такое COALESCE?
Определение
COALESCE — это специальное выражение, которое вычисляет по порядку каждый из своих аргументов и на выходе возвращает значение первого аргумента, который был не NULL.
Пример:
SELECT COALESCE(NULL, NULL, 1, 2, NULL, 3)
# 1
Этот запрос вернет 1, потому что первые два аргумента NULL, а третий аргумент принимает значение отличное от NULL. Соответственно, выражение COALESCE даже не будет смотреть дальше — главное, что 3 аргумент не NULL.
Другие примеры:
SELECT COALESCE(1, NULL, 2, NULL)
# 1
или
SELECT COALESCE(NULL, NULL)
# NULL
Наверно, вы поняли основной смысл. Если можно вернуть не
Если можно вернуть не NULL — возвращается первое непустое значение. Если нельзя — возвращается
Стоит отметить, что COALESCE используется во многих популярных СУБД: PostgreSQL, MS SQL Server, Oracle, MySQL и так далее.
Давайте теперь копнем чуть глубже и посмотрим, как же это выражение устроено.
Аналогия с CASE
Мы разобрались, как выражение COALESCE работает, но сможем ли мы написать его с нуля? Допустим, нам дали задание:
Не используя COALESCE, напишите SELECT-запрос, который будет аналогичен запросу SELECT COALESCE(expression1, expression2, expression3, expression4)
Сможете решить такую задачу сходу? На самом деле, еще решение довольно простое: COALESCE — это просто удобная обертка для конструкции CASE. Ее удобно использовать для обработки значений NULL.
Учитывая, что обработка пропусков — типовая задача при написании SQL-запросов, решили выделить эту конструкцию в отдельное выражение COALESCE, чтобы бедные разработчики не мучались каждый раз и не громоздили огромные CASE-выражения.
Давайте же и мы с вами решим эту задачу. Ответ будет такой:
SELECT
CASE
WHEN (expression1 IS NOT NULL) THEN expression1
WHEN (expression2 IS NOT NULL) THEN expression2
WHEN (expression3 IS NOT NULL) THEN expression3
ELSE expression4
END
Вот, собственно, и все премудрости. Согласитесь — не сложно. Но значительно удобней писать COALESCE, чем каждый раз записывать такую объемную конструкцию с CASE.
Боевая задача
Давайте на реальном примере рассмотрим, когда использование COALESCE — не просто желание побаловаться, а реальная необходимость.
Вы можете сказать:
Я столько времени пишу SQL-запросы и ни разу не пользовался COALESCE!
Ну, что же, возможно Вам просто везло… Но с высокой долей вероятности некоторые Ваши запросы начнут выдавать неправильные результаты, если таблицы начнут заполняться «некрасивыми» данными.
Рассмотрим простую задачу. Пусть есть бухгалтерская таблица, в которой содержится информация о имени сотрудника и его ежемесячной премии. В конце года перед нами встала тривиальная задачка (на первый взгляд) — посчитать суммарный заработок каждого сотрудника.
+--------+----------+-----------+--------------+
| ID | name | bonus | date |
+--------+----------+-----------+--------------+
| 1 | Ivan | NULL | 2020-01-01 |
| 1 | Maya | 3500 | 2020-01-03 |
| 1 | Dora | 4500 | 2020-01-02 |
| 1 | Petr | 5750 | 2020-02-01 |
| 1 | Ivan | 3220 | 2020-03-05 |
| ... |
+--------+----------+-----------+--------------+
Так получилось, что у сотрудника Ivan не прогрузился бонус за январь и в таблице стоит значение NULL. Соответственно, приведенный ниже запрос вернет 3220 для этого сотрудника.
SELECT name, SUM(bonus)
FROM table_name
GROUP BY name
Мало того, что результат получился неверным — мы об этом даже не узнаем. А если записей много, то различные расчеты и агреграции постоянно будут приводить к скрытым ошибкам (проверено на практике).
Чтобы такой ситуации избежать, можно заменять значения NULL на очень большое число, например. Тогда мы в качестве результата будем получать премию в несколько миллиардов и понимать, что что-то здесь не так.
Естественно, в зависимости от задачи приемы могут быть разные: этот пример иллюстрирует ручную обработку таблицы с премиями.
В нашем же случае решение можно записать так:
SELECT name, SUM(COALESCE(bonus, 1000000))
FROM table_name
GROUP BY name
Эпилог
Мы рассмотрели выражение COALESCE и показали его важность. Посмотрите на те запросы, которые Вы пишите каждый день — нет ли там места ошибке? Может и у Вас могут возникнуть какие-то ситуации, когда расчет будет неправильным, а Вы даже не сможете этого увидеть? Чтобы избежать таких ситуаций, используйте COALESCE!
Группировать по пункту в SQL Server с примерами
Вернуться к: Учебное пособие по SQL Server для начинающих и профессионалов
В этой статье я собираюсь обсудить Группировать по пункту в SQL Server с примерами. Пожалуйста, прочтите нашу предыдущую статью, в которой мы подробно обсуждали пункт Top n в SQL Server .
Пожалуйста, прочтите нашу предыдущую статью, в которой мы подробно обсуждали пункт Top n в SQL Server .
Группировать по предложению в SQL Server используется для разделения похожих типов записей или данных на группы и последующего возврата. Если мы используем предложение group by в запросе, тогда мы должны использовать функции группировки/агрегации, такие как функции count(), sum(), max(), min() и avg().
Когда мы сначала реализуем предложение group by, данные таблицы будут разделены на отдельные группы в соответствии со столбцом, а затем функция агрегирования будет выполняться для данных каждой группы, чтобы получить результат. Это означает, что первое предложение Group By используется для разделения похожих типов данных на группу, а затем к каждой группе применяется агрегатная функция для получения требуемых результатов.
Синтаксис предложения Group By в SQL Server SELECT выражение1, выражение2, выражение_n,
агрегатная_функция (выражение)
ИЗ столов
[ГДЕ условия]
ГРУППИРОВАТЬ по выражению1, выражению2, выражению_n;
Параметры или аргументы, используемые в предложении Group By в SQL Server: - выражение1, выражение2, выражение_n: Выражения, не инкапсулированные в агрегатной функции, должны быть включены в предложение GROUP BY.
- агрегатная_функция: Агрегатная функция — это не что иное, как функции SUM, COUNT, MIN, MAX или AVG, которые мы должны использовать при использовании предложения Group by в SQL Server.
- Таблиц: Таблицы — это не что иное, как имя таблицы или таблиц, из которых мы хотим получить данные.
- ГДЕ условия: Необязательно. Если вы хотите получить данные на основе некоторых условий, вам необходимо указать такие условия с помощью предложения Where в SQL Server.
Давайте разберемся в группе SQL Server по пункту на примерах. Мы собираемся использовать следующую таблицу сотрудников, чтобы понять предложение Group By в SQL Server с примерами.
Используйте приведенный ниже сценарий SQL, чтобы создать и заполнить таблицу «Сотрудник» образцами данных, которые мы собираемся использовать в этой статье.
-- Создать таблицу сотрудников
СОЗДАТЬ ТАБЛИЦУ Сотрудник
(
ID INT PRIMARY KEY IDENTITY(1,1),
Имя VARCHAR(100),
EmailID VARCHAR(100),
Пол VARCHAR(100),
Кафедра ВАРЧАР(100),
Зарплата ИНТ,
Возраст ИНТ,
ГОРОД ВАРЧАР(100)
)
ИДТИ
--Вставить данные в таблицу сотрудников
ВСТАВЬТЕ В ЗНАЧЕНИЯ СОТРУДНИКОВ('PRANAYA','PRANAYA@G. COM','Male', 'IT', 25000, 30,'MUMBAI')
ВСТАВЬТЕ В ЗНАЧЕНИЯ СОТРУДНИКОВ('TARUN','[email protected]','Мужской', 'Зарплатная ведомость', 30000, 27,'ODISHA')
INSERT INTO Employee VALUES('PRIYANKA','[email protected]','Female', 'IT', 27000, 25,'BANGALORE')
INSERT INTO Employee VALUES('PREETY','[email protected]','Female', 'HR', 35000, 26,'BANGALORE')
ВСТАВЬТЕ В ЗНАЧЕНИЯ СОТРУДНИКОВ('РАМЕШ','РАМЕШ@G.COM','Мужчина','ИТ', 26000, 27,'МУМБАЙ')
INSERT INTO Employee VALUES('PRAMOD','[email protected]','Мужчина','HR', 29000, 28, 'ОДИША')
ВСТАВЬТЕ В ЗНАЧЕНИЯ СОТРУДНИКОВ('ANURAG','[email protected]','Мужчина', 'Зарплата', 27000, 26,'ОДИША')
ВСТАВЬТЕ В ЗНАЧЕНИЯ СОТРУДНИКОВ («HINA», «[email protected]», «Женщина», «HR», 26000, 30, «МУМБАЙ»)
ВСТАВЬТЕ В ЗНАЧЕНИЯ СОТРУДНИКОВ('SAMBIT','[email protected]','Мужской','Зарплатная ведомость', 30000, 25,'ОДИША')
INSERT INTO Employee VALUES('MANOJ','[email protected]','Мужской','HR', 30000, 28,'ODISHA')
ВСТАВЬТЕ В ЗНАЧЕНИЯ СОТРУДНИКОВ («SWAPNA», «[email protected]», «Женщина», «Заработная плата», 28000, 27, «МУМБАЙ»)
INSERT INTO Employee VALUES('LIMA','LIMA@G.
COM','Male', 'IT', 25000, 30,'MUMBAI')
ВСТАВЬТЕ В ЗНАЧЕНИЯ СОТРУДНИКОВ('TARUN','[email protected]','Мужской', 'Зарплатная ведомость', 30000, 27,'ODISHA')
INSERT INTO Employee VALUES('PRIYANKA','[email protected]','Female', 'IT', 27000, 25,'BANGALORE')
INSERT INTO Employee VALUES('PREETY','[email protected]','Female', 'HR', 35000, 26,'BANGALORE')
ВСТАВЬТЕ В ЗНАЧЕНИЯ СОТРУДНИКОВ('РАМЕШ','РАМЕШ@G.COM','Мужчина','ИТ', 26000, 27,'МУМБАЙ')
INSERT INTO Employee VALUES('PRAMOD','[email protected]','Мужчина','HR', 29000, 28, 'ОДИША')
ВСТАВЬТЕ В ЗНАЧЕНИЯ СОТРУДНИКОВ('ANURAG','[email protected]','Мужчина', 'Зарплата', 27000, 26,'ОДИША')
ВСТАВЬТЕ В ЗНАЧЕНИЯ СОТРУДНИКОВ («HINA», «[email protected]», «Женщина», «HR», 26000, 30, «МУМБАЙ»)
ВСТАВЬТЕ В ЗНАЧЕНИЯ СОТРУДНИКОВ('SAMBIT','[email protected]','Мужской','Зарплатная ведомость', 30000, 25,'ОДИША')
INSERT INTO Employee VALUES('MANOJ','[email protected]','Мужской','HR', 30000, 28,'ODISHA')
ВСТАВЬТЕ В ЗНАЧЕНИЯ СОТРУДНИКОВ («SWAPNA», «[email protected]», «Женщина», «Заработная плата», 28000, 27, «МУМБАЙ»)
INSERT INTO Employee VALUES('LIMA','LIMA@G.
COM','Female','HR', 30000, 30,'BANGALORE')
ВСТАВЬТЕ В ЗНАЧЕНИЯ СОТРУДНИКОВ («ДИПАК», «ДИПАК@G.COM», «Мужской», «Заработная плата», 32000, 25, «БАНГАЛОР»)
ИДТИ
WAQ, чтобы узнать общее количество сотрудников в организации.
ВЫБЕРИТЕ COUNT(*) AS TotalEmployee FROM Employee
WAQ, чтобы найти количество сотрудников, работающих в каждом отделе компании.Здесь нам нужно сгруппировать сотрудников по отделам, а затем применить функцию подсчета к каждой группе. Следующий SQL-запрос делает то же самое.
ВЫБЕРИТЕ отдел, COUNT(*) AS TotalEmployee ОТ Сотрудника СГРУППИРОВАТЬ ПО отделам
Когда мы выполняем вышеуказанный запрос, он дает нам следующий результат.
Примечание: Если мы используем предложение Group By в запросе, сначала данные в таблице будут разделены на разные группы на основе столбца, указанного в предложении group by, а затем выполните агрегатную функцию для каждой группы, чтобы получить результаты.
ВЫБЕРИТЕ отдел, общая зарплата = СУММА (зарплата) ОТ Сотрудника СГРУППИРОВАТЬ ПО отделам
Когда мы выполняем вышеуказанный запрос, он дает нам следующий результат.
ВЫБЕРИТЕ отдел, MaxSalary = MAX(SALARY) ОТ Сотрудника СГРУППИРОВАТЬ ПО отделам
Когда мы выполняем приведенный выше запрос, он дает нам следующий результат.
При работе с предложением group by в запросе нам необходимо следовать или учитывать следующее
- Когда агрегатная функция применяется к группе, она возвращает только одно значение, но каждая группа может возвращать значение.
- Используйте предложение Group By только для столбца, содержащего повторяющиеся значения, никогда не применяйте его к уникальным столбцам.

ВЫБЕРИТЕ отдел, пол, количество сотрудников = СЧЁТ (*) ОТ Сотрудника ГРУППА ПО Отделу, Полу ЗАКАЗАТЬ ПО
Когда мы выполняем приведенный выше запрос, он дает нам следующий результат.
Когда мы используем несколько столбцов в предложении group by, сначала данные в таблице делятся на основе первого столбца предложения group by, а затем каждая группа подразделяется на основе второго столбца предложения group by, а затем групповая функция применяется к каждой внутренней группе для получения результата.
Напишите запрос, чтобы получить самую высокую зарплату для организации.ВЫБЕРИТЕ МАКСИМАЛЬНУЮ (зарплату) как максимальную зарплату ОТ сотрудника
Напишите запрос для получения общей суммы зарплат по городам.
Мы применяем агрегатную функцию SUM() к столбцу «Зарплата» и группируем по столбцу «Город». Это эффективно добавляет все зарплаты сотрудников в одном городе.
ВЫБЕРИТЕ ГОРОД, СУММА (Зарплата) как Общая Зарплата ОТ Сотрудника ГРУППА ПО ГОРОДУ
Когда мы выполняем вышеуказанный запрос, он дает нам следующий вывод.
Примечание: Если вы опустите предложение group by и попытаетесь выполнить запрос, вы получите сообщение об ошибке –
Напишите запрос для получения общей суммы заработной платы по городам и полу.Возможна группировка по нескольким столбцам. В этом запросе мы группируем сначала по городу, а затем по полу.
ВЫБЕРИТЕ ГОРОД, Пол, СУММА (Зарплата) как TotalSalary ОТ Сотрудника ГРУППА ПО ГОРОДУ, Пол
Когда мы выполняем вышеуказанный запрос, он дает нам следующий результат.
Напишите запрос для получения общей заработной платы и общего числа сотрудников по городам и полу.
Единственная разница здесь в том, что мы используем агрегатную функцию Count().
ВЫБЕРИТЕ Город, Пол, СУММ(Зарплата) как Общая Зарплата,
COUNT(ID) как TotalEmployees
ОТ Сотрудника
ГРУППА ПО ГОРОДУ, Пол
Напишите запрос, чтобы узнать самую высокую зарплату каждого отдела вместе с именем сотрудника. ВЫБЕРИТЕ Отдел, МАКС(Зарплата) как Зарплата, Имя ОТ Сотрудника ГРУППА ПО Отделу – Неверно
Будет выдано сообщение об ошибке: Столбец «Employee.Name» недействителен в списке выбора, поскольку он не содержится ни в агрегатной функции, ни в предложении GROUP BY.
Примечание. Приведенный выше запрос не будет выполнен, поскольку при использовании предложения group by в операторе список выбора может содержать только три элемента:
- Столбцы, связанные с предложением GROUP BY.
- Агрегатные или групповые функции
- Константы
В приведенном выше запросе столбец Name не попадает ни под один из трех, поэтому его нельзя использовать в списке выбора.
ВЫБЕРИТЕ Отдел, МАКС(Зарплата) как Зарплата, Имя ОТ Сотрудника ГРУППА ПО Отделу -- Недействительно ВЫБЕРИТЕ отдел, МАКС(ЗАРПЛАТА), ПОЛУЧИТЬДАТА() ОТ Сотрудника ГРУППА ПО Отделу --Действительно ВЫБЕРИТЕ отдел, пол, MAX (зарплата), «Здравствуйте» как FixedValue ОТ Сотрудника ГРУППА ПО Отделу, полу --Действительно
В следующей статье я собираюсь обсудить Наличие пункта в SQL Server с примерами. Здесь, в этой статье, я пытаюсь объяснить пункт Group By в SQL Server на нескольких примерах. Я надеюсь, что эта статья поможет вам с вашими потребностями. Я хотел бы получить ваш отзыв. Оставьте свой отзыв, вопрос или комментарий к этой статье.
Как использовать операторы GROUP BY, HAVING и ORDER BY SQL
SQL дает вам возможность извлекать, анализировать и отображать необходимую информацию с помощью предложений GROUP BY, HAVING и ORDER BY. Вот несколько примеров того, как вы можете их использовать.
GROUP BY пункты
Иногда вместо того, чтобы извлекать отдельные записи, вы хотите узнать что-то о группе записей. Предложение GROUP BY — это инструмент, который вам нужен.Предположим, вы являетесь менеджером по продажам в другом месте и хотите посмотреть на эффективность работы вашего отдела продаж. Если вы выполняете простой SELECT, такой как следующий запрос:
SELECT InvoiceNo, SaleDate, Продавец, TotalSale ОТ ПРОДАЖ;
Этот результат дает вам некоторое представление о том, насколько хорошо работают ваши продавцы, потому что в них задействовано очень мало общих продаж. Однако в реальной жизни у компании было бы намного больше продаж, и было бы не так просто сказать, были ли достигнуты цели продаж.
Чтобы провести реальный анализ, вы можете объединить предложение GROUP BY с одной из агрегатных функций (также называемых функциями набора ), чтобы получить количественную картину эффективности продаж. Например, вы можете увидеть, какой продавец продает больше прибыльных дорогостоящих товаров, используя функцию среднего (AVG) следующим образом:
ВЫБЕРИТЕ Продавца, AVG(TotalSale) ОТ ПРОДАЖ ГРУППА ПО ПРОДАВЦАМ;Выполнение запроса с другой системой управления базами данных даст тот же результат, но может немного отличаться.
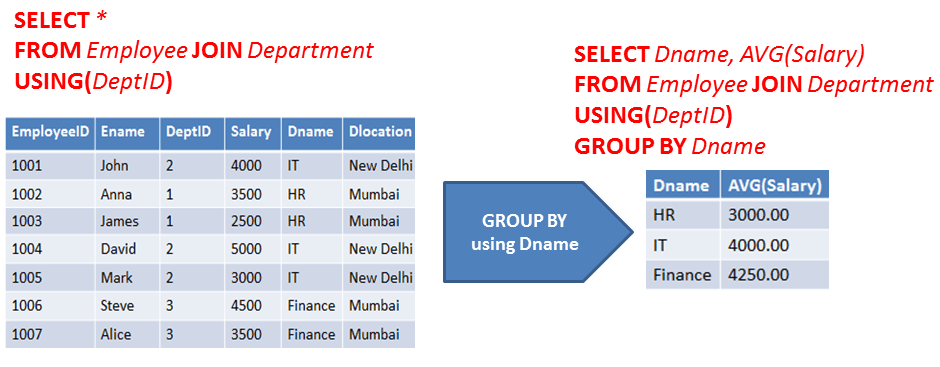
Средняя стоимость продаж Беннета значительно выше, чем у двух других продавцов. Вы сравниваете общий объем продаж с аналогичным запросом:
ВЫБЕРИТЕ Продавец, СУММ(ОбщаяПродажа) ОТ ПРОДАЖ ГРУППА ПО ПРОДАВЦАМ;
Bennett также имеет самый высокий общий объем продаж, что согласуется с самым высоким средним объемом продаж.
ИМЕЮЩИЕ пункты
Вы можете дополнительно проанализировать сгруппированные данные, используя предложение HAVING. Предложение HAVING — это фильтр, который действует аналогично предложению WHERE, но в отношении групп строк, а не отдельных строк. Чтобы проиллюстрировать функцию предложения HAVING, предположим, что менеджер по продажам считает, что Беннет сам находится в классе.Его работа искажает общие данные для других продавцов. (Ага — разрушитель кривых.) Вы можете исключить продажи Bennett из сгруппированных данных, используя предложение HAVING следующим образом:
ВЫБЕРИТЕ Продавец, СУММ(ОбщаяПродажа) ОТ ПРОДАЖ СГРУППИРОВАТЬ ПО ПРОДАВЦАМ ИМЕЕТ Продавца <> «Беннетт»;Учитываются только строки, в которых продавцом не является Беннет.

Пункты ORDER BY
Используйте предложение ORDER BY для отображения выходной таблицы запроса в возрастающем или убывающем алфавитном порядке. В то время как предложение GROUP BY собирает строки в группы и сортирует группы в алфавитном порядке, предложение ORDER BY сортирует отдельные строки. Предложение ORDER BY должно быть последним предложением, которое вы указываете в запросе.Если запрос также содержит предложение GROUP BY, это предложение сначала упорядочивает выходные строки в группы. Затем предложение ORDER BY сортирует строки в каждой группе. Если у вас нет предложения GROUP BY, тогда инструкция рассматривает всю таблицу как группу, а предложение ORDER BY сортирует все ее строки в соответствии со столбцом (или столбцами), указанными в предложении ORDER BY.
Чтобы проиллюстрировать это, рассмотрим данные в таблице SALES. Таблица SALES содержит столбцы для InvoiceNo, SaleDate, Salesperson и TotalSale. Если вы используете следующий пример, вы увидите все данные в таблице SALES, но в произвольном порядке:
ВЫБЕРИТЕ * ИЗ ПРОДАЖ ;В одной реализации это может быть порядок вставки строк в таблицу; в другой реализации порядок может быть порядком самых последних обновлений.
 Порядок также может неожиданно измениться, если кто-то физически реорганизует базу данных. Это одна из причин, по которой обычно рекомендуется указывать порядок, в котором вам нужны строки.
Порядок также может неожиданно измениться, если кто-то физически реорганизует базу данных. Это одна из причин, по которой обычно рекомендуется указывать порядок, в котором вам нужны строки.Вы можете, например, захотеть увидеть строки, упорядоченные по дате продажи следующим образом:
ВЫБРАТЬ * ИЗ ЗАКАЗА НА ПРОДАЖУ ПО дате продажи ;В этом примере возвращаются все строки таблицы SALES, упорядоченные по дате продажи. Для строк с одинаковым значением SaleDate порядок по умолчанию зависит от реализации. Однако вы можете указать, как сортировать строки, имеющие одинаковую дату продажи. Вы можете просмотреть продажи для каждой даты продажи в порядке по номеру счета-фактуры следующим образом:
ВЫБРАТЬ * ИЗ ЗАКАЗА НА ПРОДАЖУ ПО дате продажи, номеру счета-фактуры;В этом примере продажи сначала упорядочиваются по дате продажи; затем для каждой даты продажи он упорядочивает продажи по номеру счета-фактуры. Но не путайте этот пример со следующим запросом:
ВЫБРАТЬ * ИЗ ЗАКАЗА НА ПРОДАЖУ ПО № счета-фактуры, Дата продажи ;Этот запрос сначала упорядочивает продажи по INVOICE_NO.
