Golang xml encoding=»windows-1251″ — Stack Overflow на русском
Пишу парсер для xml файлов, но проблема в том, что в файле кодировка:
encoding=»windows-1251″.
Когда перевел кодировку в ut8 то следующем кодом смог распарсить документ.
for _, file := range files {
_, filename := utils.Unzip("/Users/farex/upload/"+file.Filename, "/Users/farex/upload/")
_ = filename
///---------- Open our xmlFile-----------------------
for _, file := range filename {
xmlFile, err := os.Open("/Users/farex/upload/" + file)
// if we os.Open returns an error then handle it
if err != nil {
fmt.Println(err)
}
fmt.Println("Successfully Opened " + file)
if utils.Cut(file, 1) == "H" {
defer xmlFile.Close()
byteValue, _ := ioutil.ReadAll(xmlFile)
var zl_list models.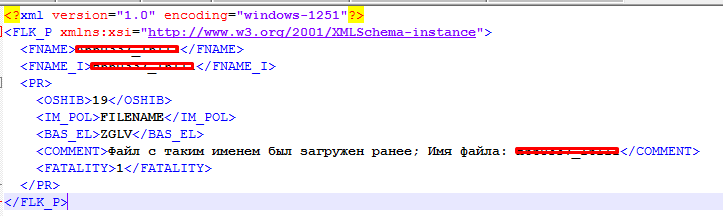
ZL_LIST
xml.Unmarshal(byteValue, &zl_list)
fmt.Println("---ZGLV---")
fmt.Println("VERSION" + zl_list.ZGLV[0].VERSION)
fmt.Println("DATA" + zl_list.ZGLV[0].DATA)
fmt.Println("FILENAME" + zl_list.ZGLV[0].FILENAME)
fmt.Println("SD_z" + zl_list.ZGLV[0].SD_Z)
Это все работает, но задача парсить не Документы в формате utf8 , а в cp-1251.
Как можно «конвертировать» cp-1251 в utf-8 ?
Добавил меторд:
func EncodeWindows1251(ba []uint8) []uint8 {
enc := charmap.Windows1251.NewEncoder()
out, _ := enc.String(string(ba))
return []uint8(out)
}
и соответственно вызываю его:
byteValue, _ := ioutil.ReadAll(xmlFile)
a := EncodeWindows1251(byteValue)
var zl_list models.ZL_LIST
xml.Unmarshal(a, &zl_list)
Тоже не работает…
Но если из документа убрать строку <?xml version="1.0" encoding="windows-1251"?>.
То все работает и документ парсится… Неужели придется регуляркой удалять эту строчку в документе?
Добавил метод наисанный ниже и за импортировал. «golang.org/x/text/encoding/charmap».
Но:
Образец файла xml тут кодировка cp-1251
ruby-on-rails — Разбирать XML в кодировке Windows-1251?
Попытка запустить:
Nokogiri::XML(open("http://my.url.com/any/path.xml"))
Например:
Nokogiri::XML(open("http://bar-navig.yandex.ru/u?ver=2&show=32&url=google.com"))
Но я получаю:
Nokogiri :: XML :: SyntaxError: неподдерживаемая кодировка windows-1251
Но только на сервере. На локальном компьютере работает нормально.
Похоже, iconv поддерживает эту кодировку:
iconv --list | grep 1251
CP1251 MS-CYRL WINDOWS-1251
И даже если я попытаюсь запустить в bash
xmllint 'http://bar-navig.yandex.ru/u?ver=2&show=32&url=google.com'
Работает нормально.
Ruby 1.9.3 Rails 3.2.16 nokogiri 1.6.1 ОС: FreeBSD 8.1
Вот пример кода в строке 16. https://github.com/anoam/seo_params/blob/master /lib/seo_params/yandex.rb
А это образец URL: http://bar-navig.yandex.ru/u?ver = 2 & show = 32 & url = google.com
Как я могу это решить?
0
anoam 22 Апр 2014 в 17:10
2 ответа
Лучший ответ
Nokogiri::XML — это ярлык для Nokogiri::XML::Document.parse(), поэтому просмотрите документацию для Nokogiri::XML::Document.parse()
parse(string_or_io, url = nil, encoding = nil, options = ParseOptions::DEFAULT_XML, &block)
кодировка (необязательно) — это кодировка, которая должна использоваться при обработке документа.
0
the Tin Man 22 Апр 2014 в 21:58
Кодировка в XML документе
XML документы могут содержать символы в различных международных кодировках.
Чтобы не возникало ошибок, необходимо указывать, какая кодировка используется в XML документе, либо сохранять файл в универсальной кодировке UTF-8.
Символьная кодировка
Символьная кодировка определяет уникальный бинарный код для различных символов, используемых в документе.
В компьютерных терминах символьную кодировку также называют символьным набором, символьной раскладкой, кодовым набором и кодом страницы.
Юникод
Юникод — это промышленный стандарт для символьной кодировки текстового документа. Он определяет (почти) все возможные международные символы по именам и числам.
Юникод имеет две разновидности: UTF-8 и UTF-16.
UTF = формат преобразования Юникода (анг. Unicode Transformation Format).
UTF-8 использует один байт (8 бит) для представления общепринятых символов и два (или три) байта для всех остальных символов.
UTF-16 использует два байта (16 бит) для большинства символов и три байта для всего остального.
UTF-8 — Веб-стандарт
UTF-8 — стандартная кодировка символов в сети Интернет.
UTF-8 считается кодировкой по умолчанию в HTML-5, CSS, JavaScript, PHP, SQL и XML.
Кодировка XML документа
Первая строка в XML документе называется прологом:
<?xml version="1.0"?>
Пролог является необязательным и, как правило, содержит номер версии XML.
Кроме этого, он может содержать информацию о кодировке XML документа. Следующий пролог определяет кодировку UTF-8:
<?xml version="1.0" encoding="UTF-8"?>
Стандартизация XML устанавливает, что все приложения XML должны понимать кодировки UTF-8 и UTF-16.
UTF-8 является кодировкой по умолчанию для XML документов без информации о кодировке.
Кроме этого, большинство систем приложений XML работают с такими кодировками, как ISO-8859-1, Windows-1252 и ASCII.
Ошибки XML
Очень часто XML документы создаются на одном компьютере, на сервер выгружается с другого, а в браузере отображаются на третьем компьютере.
Если кодировка некорректно интерпретируется всеми тремя компьютерами, то браузер отобразит бессмысленный набор символов, либо вообще выдаст сообщение об ошибке.
Наилучшим выбором в этом случае будет использование кодировки UTF-8. UTF-8 позволяет отображать практически все международные символы, и, кроме этого, она считается кодировкой по умолчанию, если не указана другая кодировка.
Заключение
Когда вы пишите XML документ:
- Используйте текстовый редактор, который позволяет изменять кодировку документа
- Убедитесь, что редактор настроен на использование нужной кодировки
- Опишите используемую кодировку в соответствующей декларации
- UTF-8 является самой безопасной кодировкой
- UTF-8 является стандартом в сети Интернет
Кодировки в XSLT-преобразованиях. Технология XSLT
Кодировки в XSLT-преобразованиях
Несмотря на то, что в логических деревьях, которыми манипулирует XSLT, текстовые узлы представляются в кодировке Unicode, очень часто в обрабатываемых документах бывает необходимо использовать также другие кодировки. К примеру, большинство русскоязычных документов хранятся в кодировках Windows-1251 и KOI8-R.
Если внимательно присмотреться к преобразованиям, можно заметить, что, как правило, в них участвуют минимум три документа — входящий (преобразовываемый) документ, документ преобразования (преобразующий) и выходящий (преобразованный документ). Соответственно, каждый из них может иметь собственную кодировку.
Кодировка входящего документа указывается в его xml-декларации. Например, документы в кодировке Windows-1251 должны иметь xml-декларацию вида
<?xml version=»1.0″ encoding=»windows-1251″?>
Возможно, небольшим сюрпризом окажется то, что в соответствии со стандартом XML, имена тегов вовсе не обязаны состоять исключительно из латинских букв. В имени элемента можно использовать весь кириллический алфавит, а также множество других символов. Совершенно корректным будет документ
<?xml version=»1.0″ encoding=»windows-1251″?>
<страница>
<содержимое/>
</страница>
Аналогичным образом кириллицу, а также другие наборы символов и алфавиты можно использовать и в самих преобразованиях, поскольку те в свою очередь также являются XML-документами.
Пример
Листинг 8.57. Входящий документ
<?xml version=»1.0″ encoding=»windows-1251″?>
<каждый>
<охотник>
<желает>
<знать>
<где>
<сидит>
<фазан/>
</сидит>
</где>
</знать>
</желает>
</охотник>
</каждый>
Листинг 8.58. Преобразование
<?xml version=»1.0″ encoding=»windows-1251″?>
<xsl:stylesheet
version=»1.0″
xmlns:xsl=»http://www.w3.org/1999/XSL/Transform»>
<xsl:output indent=»yes» encoding=»windows-1251″/>
<xsl:template match=»каждый»>
<редкий>
<xsl:apply-templates/>
</редкий>
</xsl:template>
<xsl:template match=»охотник»>
<рыболов>
<xsl:apply-templates/>
</рыболов>
</xsl:template>
<xsl:template match=»желает/знать»>
<может>
<забыть>
<xsl:apply-templates/>
</забыть>
</может>
</xsl:template>
<xsl:template match=»где»>
<как>
<xsl:apply-templates/>
</как>
</xsl:template>
<xsl:template match=»сидит»>
<плавает>
<xsl:apply-templates/>
</плавает>
</xsl:template>
<xsl:template match=»фазан»>
<щука>
<xsl:apply-templates/>
</щука>
</xsl:template>
</xsl:stylesheet>
Листинг 8.59. Выходящий документ
<?xml version=»1.0″ encoding=»windows-1251″?>
<редкий>
<рыболов>
<может>
<забыть>
<как>
<плавает>
<щука/>
</плавает>
</как>
</забыть>
</может>
</рыболов>
</редкий>
Напомним, что кодировка выходящего документа определяется атрибутом encoding элемента xsl:output и не зависит от кодировок преобразования и обрабатываемых документов. Например, можно легко создать преобразование, которое будет изменять кодировку входящего документа. Это будет идентичное преобразование с элементом xsl:output, определяющим целевой набор символов.
Листинг 8.60. Преобразование, изменяющее кодировку документа на KOI8-R
<xsl:stylesheet version=»1.0″
xmlns:xsl=»http://www.w3.org/1999/XSL/Transform»>
<xsl:output encoding=»KOI8-R»/>
<xsl:template match=»@*|node()»>
<xsl:copy>
<xsl:apply-templates select=»@*|node()»/>
</xsl:copy>
</xsl:template>
</xsl:stylesheet>
Как можно видеть, XSLT довольно гибко поддерживает кодировки — входящие и выходящие документы, а также сами преобразования могут иметь разные наборы символов. Единственным ограничением является множество кодировок, поддерживаемое самим процессором, вернее парсером, который он использует для разбора входящих документов, и сериализатором, который служит для создания физического экземпляра выходящего документа.
Практически во всех процессорах поддерживаются кодировки UTF-8, US- ASCII и ISO-8859-1, но далеко не все могут работать с Windows-1251 или KOI8-R. Поэтому, создавая документы и преобразования в нестандартных кодировках, мы заведомо ограничиваем переносимость решений. В случаях, когда XML/XSLT приложения создаются под конкретный процессор с заведомо известными возможностями, это не является большой проблемой, однако в тех случаях, когда требуется универсальность или точно не известно, каким процессором будет производиться обработка, единственным выходом будет использовать UTF-8 — как во входящих документах, так и в самих преобразованиях.
Импорт данных из XML — k50-docs. Справка K☆50
- Настройка импорта заказов
- Требования к XML файлу
- Пример файла
- Описание тега feed
- Описание тега orders
- Описание тега order
- Описание тега item
К50:Трекер позволяет импортировать данные о заказах в формате XML выгрузки.
XML позволяет передавать информацию о приобретённых товарах в рамках заказа. Данную информацию можно в дальнейшем отправлять в виде транзакции в Google Analytics Для корректного импорта файл должен быть доступен по ссылке для сервиса.
Для создания задачи на импорт данных в формате XML необходимо внутри счетчика перейти в раздел Настройки → Данные → Импорт заказов. Выберите Новое подключение XML:
Для создания задачи на импорт укажите следующие параметры:
1
Наименование задачи, которую вы создаете, например Заказы Активность — если настройка активна, после сохранения будет запущен импорт данных Тип подключения — тип файла с данными, который будет импортироваться в К502
Количество часов, за которое будут импортированы данные в К50, по умолчанию — 1. Зависит от того, как часто обновляется информация о заказах у клиента.3
Ссылка на файл с фидом в формате XML4
Возможные значения: UTF-8 (по умолчанию),Windows-12515
Данная опция необходима в случае, если номер клиента передаётся в виде хеша MD5.XML Выгрузка
Жирным отмечены обязательные поля
| Заголовок | Описание |
|---|---|
| feed | Корневой тег, хранит в себе тег orders |
| Заголовок | Описание |
|---|---|
| orders | Список всех заказов, каждый заказ обрамляется тегом order |
| Тег | Описание |
|---|---|
| date | Дата создания заказа. Формат: YYYY-MM-DD HH:MM:SS. |
| orderId | Идентификатор заказа в системе CRM клиента. |
| callerPhone | Номер телефона, с которого звонил клиент. Формат 7XXXXXXXXXX. Обязательный параметр, если нет тегов uuid и sid |
| sid | Идентификатор сеанса. Обязательный параметр, если не указан callerPhone |
| uuid | Идентификатор пользователя. Обязательный параметр, если не указан callerPhone |
| margin | Суммарная прибыль(маржа) с заказа |
| revenue | Суммарный доход с заказа |
| comment | комментарий к заказу |
| tags | список тегов tag для заказа через запятую |
| type | Тип заказа. Возможные значения: online, offline. |
| items | Перечень приобретенных товаров |
| Тег | Описание |
|---|---|
| id | id товара |
| name | Наименование товара |
| brand | Наименование производителя товара (бренд) |
| category | Категория товара |
| price | Стоимость товара |
| quantity | Количество приобретённых единиц товара |
Нажмите Сохранить. С этого момента информация по настроенным для импорта заказам будет поступать в К50:Трекер.
Наркевич 2 сем / Лабы / ЯП Лабораторные работы / 01-02_Командная строка / 03_Кодировки / ЯП03
Лабораторная работа 3 (4 часа)
Языки программирования
Кодировки ASCII, Windows-1251, UTF-8, UTF-16
Используйте при выполнении лабораторной работы материал лекции 2 [Л2].
Исследуйте таблицы кодировок US—ASCII и Windows-1251 [Л2].
Создайте проект консольного C++-приложения с именем LP_Lab03.
Запишите в строках комментариев три строки:
1) фамилия, имя, год рождения на английском языке, например: IvanovAlex1998;
2) фамилия, имя, год рождения на русском языке, например: ИвановАлексей1998;
3) фамилия (на русском), год рождения, имя (на английском), например: Иванов1998Alex.
Используя таблицы кодировок в [Л2] запишите в комментариях шестнадцатеричное представление 3х строк записанных ранее в кодировке Windows-1251.
Используя таблицы кодировок в [Л2] запишите в комментариях шестнадцатеричное представление трех строк в кодировках UTF-8 и UTF-16.
В программе проекта LP_Lab03 объявите 6 строк: 3 записанные ранее в кодировке Windows-1251 и 3 эти же строки в кодировке UTF-16.
Запустите приложение и с помощью отладчика VS просмотрите области памяти, соответствующие шести объявленным строкам.
Убедитесь, что записанное в комментариях шестнадцатеричное представление строк в кодировках Windows-1251 и Unicode-16 (п.5, 6) идентично полученному с помощью отладчика.
Используя HEX—Editor (обратитесь к преподавателю) определите, в какой кодировке представлены входные файлы (*.cpp и *.h) транслятора C++.
С помощью VS разработайте 3 XML-файла, содержащих 3 строки (п.4):
1) XML1251.xml — в кодировке Windows-1251;
2) XMLUTF8.xml — в кодировке UTF-8;
3) XMLUTF16.xml в кодировке UTF-16.
Используя HEX—Editor проанализируйте XML-файлы (п.11) XML1251.xml, XMLUTF8.xml, XMLUTF16.xml.
Определите символы BOM (Byte order mark) в файлах XML1251.xml, XMLUTF8.xml, XMLUTF16.xml.
Определите в какой кодировке представлены входные файлы (*.cpp и *.h) транслятора C++.
Разработайте XML-файл XMLUTF16BE.xml, применяющий кодировку UTF-16BE.
Используя HEX—Editor, проанализируйте XML-файлы (п.15) XMLUTF16BE.xml, поясните отличие от файла XMLUTF16BE.xml.
Определите разницу значений кодов Windows-1251 символов: F и f, S и s, L и l, Б и б, Г и г, Э и э.
В рамках проекта LP_Lab03 разработайте функцию:
char* UpperW1251(char* destination, char* source)
функция принимает строку символов в кодировке Windows-1251 (параметр source), формирует строку в кодировке Windows-1251 (параметр destination), содержащей буквы только верхнего регистра и возвращает указатель на строку destination.
Ответьте на следующие вопросы:
что такое таблица кодировки?
расшифруйте аббревиатуру ASCII;
поясните структуру кодировки Windows-1251;
что такое UNICODE?
поясните структуру кодировки UNICODE;
что такое UTF-8 и UTF-16?
в каких случаях целесообразно применять кодировку UTF-8?
определите разницу значений кодов UTF-16 символов: F и f, S и s, L и l, Б и б, Г и г, Э и э; каким образом получить из кода буквы нижнего регистра получить букву верхнего регистра.
3
c # — преобразование Unicode в Windows-1251 с помощью XML (HTML) — экранирование
Обратите внимание, что XML является одновременно моделью данных и форматом сериализации. Данные могут использовать другой набор символов, чем сериализация этих данных.
Похоже, что основная причина вашей проблемы заключается в том, что ваш процесс сериализации пытается ограничить набор символов модели данных, в то время как вы хотели бы установить набор символов формата сериализации. Рассмотрим пример: и — это равные XML-документы.У них одинаковая структура и абсолютно одинаковые данные. Из-за умлаута тяжелого металла набор символов данных является Unicode (или чем-то большим, чем ASCII), но из-за использования ссылки на символ & # 246; , набор символов последней формы сериализации документа — ASCII. Чтобы обрабатывать эти данные, ваши инструменты XML по-прежнему должны поддерживать Unicode в обоих случаях, но при использовании последней сериализации инструменты ввода-вывода и передачи файлов не должны поддерживать Unicode.
Я предполагаю, что, сообщая XMLTextWriter использовать кодировку Windows-1251, он, вероятно, на практике пытается ограничить набор символов данных символами, содержащимися в Windows-1251, отбрасывая все символы вне этого набора символов а писать ? символов вместо этого.
Однако, поскольку вы создаете свой XML-документ с помощью XSL-преобразования, вы можете управлять набором символов сериализации прямо в вашем XSLT-документе.Это делается путем добавления атрибута кодировки к элементу xsl: output. Измените его так, чтобы он выглядел так
Теперь процессор XSLT заботится о сериализации в сокращенный набор символов и выводит ссылку на символ для всех символов в данных, которые включены в windows-1251.
Если изменение набора символов данных действительно то, что вам нужно, то вам необходимо обработать данные с помощью подходящей библиотеки преобразования символов, которая может угадать наиболее подходящий заменяющий символ (например, ö -> или ).
Как решить проблему «xml: encoding» windows-1251 «объявлен, но Decoder.CharsetReader равен нулю»? — code-flow.club
Проблема решилась другим способом. Ниже предлагаемый способ. Преобразование мы сделали с помощью команды Linux. DownloadPowerFile func (строка url) * PowerCatalog {list: = PowerCatalog {} // загрузить файл по ссылке и сохранить его в папке с файлами err: = DownloadFilePower ("Powerplant_Talapai.yml", url) if err! = Nil { fmt.Println (err) return & list} var path string path = "/ root / go-workpath / src / stocks / files /" // файл предварительного преобразователя cmd: = exec.Команда ("iconv", "-f", "cp1251", "-t", "utf8", path + "Powerplant_Talapai.yml", "-o", path + "Powerplant_Talapai8.yml") out, err: = cmd.CombinedOutput () if err! = nil {fmt.Printf ("cmd.Run () завершился неудачно с% s \", err)} fmt.Printf ("объединено: \% s \", string (out)) // из файла Powerplant_Talapai8.yml удаляем строку encoding = "windows-1251". Необходимо проверить наличие программы SED cmd2: = exec.Command ("sed", "-i" "s / encoding = \\" windows-1251 \\ "//", path + "Powerplant_Talapai8.yml ") out2, err2: = cmd2.CombinedOutput (), если err2! = Nil {fmt.Printf ("cmd.Run () не удалось с% s \", err2)} fmt.Printf ("объединено: \% s \", string (out2)) // открыть файл соответственно, err: = os.Open (path + "Powerplant_Talapai8.yml") if (err! = nil) {fmt.Println ("файл не может быть найден или открыт") return & list} else {defer resp.Close () body, err: = ioutil.ReadAll (resp) if err! = nil {return & list} newbody: = strings.Replace (string (body), "", "", -1) newbody = strings.Replace (newbody , "", "", -1) err = xml.Unmarshal ([] byte (newbody), & list) if err! = Nil {fmt.Println (err) return & list} return & list}} DownloadFilePower func (строка пути к файлу, строка url) ошибка {// Создаем файл, err: = os.Create ("files /" + filepath) if err! = Nil {return err} defer out.Close () // Получаем данные соответственно, err: = http.Get (url) if err! = nil {return err} defer resp.Body.Close () // Записываем тело в файл _, err = io.Copy (out, соответственно Body) if err! = nil {return err} return nil} Как решить проблему «xml: кодировка» windows-1251 «заявлена но декодером.CharsetReader is nil «? — Разбор
Проблема решилась другим способом. Ниже предложен метод. Преобразование мы выполняли с помощью команды Linux. DownloadPowerFile func (url string) * PowerCatalog {
list: = PowerCatalog {}
// скачиваем файл по ссылке и сохраняем в папке с файлами
err: = DownloadFilePower ("Powerplant_Talapai.yml", URL)
if err! = nil {
fmt.Println (ошибка)
возврат и список
}
строка пути var
путь = "/ root / go-workpath / src / stocks / files /"
// файл предварительного преобразователя
cmd: = exec.Команда («iconv», «-f», «cp1251», «-t», «utf8», путь + «Powerplant_Talapai.yml», «-o», путь + «Powerplant_Talapai8.yml»)
out, err: = cmd.CombinedOutput ()
if err! = nil {
fmt.Printf ("cmd.Run () не удалось с% s \ n", ошибка)
}
fmt.Printf ("объединено: \ n% s \ n", строка (выход))
// из файла Powerplant_Talapai8.yml удаляем строку encoding = "windows-1251". Необходимо проверить наличие программы SED
cmd2: = exec.Command ("sed", "-i" "s / encoding = \" windows-1251 \ "//", путь + "Powerplant_Talapai8.yml")
out2, err2: = cmd2.CombinedOutput ()
if err2! = nil {
fmt.Printf ("cmd.Run () не удалось с% s \ n", err2)
}
fmt.Printf ("объединено: \ n% s \ n", строка (out2))
// открыть файл
resp, err: = os.Open (path + "Powerplant_Talapai8.yml")
if (err! = nil) {
fmt.Println («файл не может быть найден или открыт»)
возврат и список
} еще {
отложить или закрыть ()
body, err: = ioutil.ReadAll (соответственно)
if err! = nil {
возврат и список
}
newbody: = strings.Replace (строка (тело), "<предложения>", "", -1)
newbody = strings.Replace (newbody, "", "", -1)
err = xml.Unmarshal ([] байт (новое тело), & список)
if err! = nil {
fmt.Println (ошибка)
возврат и список
}
возврат и список
}
}
DownloadFilePower func (строка пути к файлу, строка URL) ошибка {
// Создаем файл
out, err: = os.Create ("files /" + путь к файлу)
if err! = nil {
вернуть ошибку
}
отложить out.Close ()
// Получаем данные
соответственно, err: = http.Get (url)
if err! = nil {
вернуть ошибку
}
отложить или Body.Close ()
// Записываем тело в файл
_, err = io.Copy (out, соответственно Body)
if err! = nil {
вернуть ошибку
}
вернуть ноль
} Преобразование Unicode в Windows-1251 с XML (HTML) -Escape-Funktion
Beachten Sie, dass XML sowohl ein Datenmodell as auch ein Serialisierungsformat ist.Die Daten können einen anderen Zeichensatz verwenden als die Serialisierung dieser Daten.
Es sieht so aus, als ob der Hauptgrund für Ihr Problem darin besteht, dass Ihr Serialisierungsprozess versucht, den Zeichensatz des Datenmodells einzuschränken, während Sie den Zeichensatz Desformialisestungs. Nehmen wir ein Beispiel: . sind gleichwertige XML-Dokumente.Sie haben die gleiche Struktur und exakt die gleichen Daten. Wegen der Heavy Metal Umlaute, der Zeichensatz des Datum ist Unicode (oder etwas Größeres als ASCII), aber wegen der Verwendung einer Zeichenreferenz & # 246; , der Zeichensatz des letzteren Serialisierungsformular des Dokuments ist ASCII. Um diese Daten zu verarbeiten, müssen Ihre XML-Tools в beiden Fällen immer noch unicode-fähig sein, aber bei Verwendung der letztgenannten Serialisierung müssen die E / A- und Dateiübertragungs-Tools nähig sein-fähig.
Ich vermute, dass durch das Sagen der XMLTextWriter Um die Windows-1251-Codierung zu verwenden, wird in der Praxis wahrscheinlich versucht, den Zeichensatz der Datum zuden dieseen dieic, windows-1251 Zeichensatzes verwerfen und a. schreiben ? Charakter statt.
Da Sie Ihr XML-Dokument jedoch durch eine XSL-Transformation erzeugen, können Sie den Zeichensatz der Serialisierung direkt in Ihrem XSLT-Dokument steuern.Dies geschieht durch Hinzufügen eines Codierungsattributs zum xsl: output-Element. Ändere es so, dass es so aussieht
Nun übernimmt der XSLT-Prozessor die Serialisierung auf reduzierten Zeichensatz und gibt für all Zeichen in den Daten, die in Windows-1251 enthalten sind, eine Zeichenreferenz aus.
Wenn Sie den Zeichensatz der Daten wirklich ändern möchten, müssen Sie Ihre Daten mit einer geeigneten Zeichenkonvertierungsbibliothek verarbeiten, die das am besten geeignete Ersatzzeichen erraten > 9000 > 0006
Преобразование XML latin1 в UTF-8 и другим способом около
Транскодирование с эффективным использованием памяти, позволяющее обрабатывать файлы любого размера (1 ТБ? Без проблем!):
функция transcodeXML (
[ValidateScript ({Test-Path -Literal $ _})]
[строка] $ source,
[ValidateSet ('IBM037', 'IBM437', 'IBM500', 'ASMO-708', 'DOS-720', 'ibm737', 'ibm775', 'ibm850', 'ibm852', 'IBM855', 'ibm857' , 'IBM00858', 'IBM860', 'ibm861', 'DOS-862', 'IBM863', 'IBM864', 'IBM865', 'cp866', 'ibm869', 'IBM870', 'windows-874', ' cp875 ',' shift_jis ',' gb2312 ',' ks_c_5601-1987 ',' big5 ',' IBM1026 ',' IBM01047 ',' IBM01140 ',' IBM01141 ',' IBM01142 ',' IBM01143 ',' IBM01144 ',' IBM01145 ',' IBM01146 ',' IBM01147 ',' IBM01148 ',' IBM01149 ',' utf-16 ',' utf-16BE ',' windows-1250 ',' windows-1251 ',' Windows-1252 ',' windows-1253 ',' windows-1254 ',' windows-1255 ',' windows-1256 ',' windows-1257 ',' windows-1258 ',' Johab ',' macintosh ',' x-mac-japanese ' , 'x-mac-chinesetrad', 'x-mac-korean', 'x-mac-arabic', 'x-mac-hebrew', 'x-mac-greek', 'x-mac-cyrillic', ' x-mac-chinesesimp ',' x-mac-romanian ',' x-mac-ukrainian ',' x-mac-thai ',' x-mac-ce ',' x-mac-исландский ',' x- mac-turkish ',' x-mac-croatian ',' utf-32 ',' utf-32BE ',' x-Chinese-CNS ',' x-cp20001 ',' x-китайский-Eten ',' x- cp20003 ',' x-cp20004 ',' x-cp20005 ',' x-IA5 ',' x-IA5-German ',' x-IA5-Swedish ',' x-IA5-Norwegian ',' us-ascii ',' x-cp20261 ',' x-cp20269 ',' IBM273 ' , 'IBM277', 'IBM278', 'IBM280', 'IBM284', 'IBM285', 'IBM290', 'IBM297', 'IBM420', 'IBM423', 'IBM424', 'x-EBCDIC-KoreanExtended', ' IBM-Thai ',' koi8-r ',' IBM871 ',' IBM880 ',' IBM905 ',' IBM00924 ',' EUC-JP ',' x-cp20936 ',' x-cp20949 ',' cp1025 ',' koi8-u ',' iso-8859-1 ',' iso-8859-2 ',' iso-8859-3 ',' iso-8859-4 ',' iso-8859-5 ',' iso-8859- 6 ',' iso-8859-7 ',' iso-8859-8 ',' iso-8859-9 ',' iso-8859-13 ',' iso-8859-15 ',' x-Europa ',' iso-8859-8-i ',' iso-2022-jp ',' csISO2022JP ',' iso-2022-jp ',' iso-2022-kr ',' x-cp50227 ',' euc-jp ',' EUC-CN ',' euc-kr ',' hz-gb-2312 ',' GB18030 ',' x-iscii-de ',' x-iscii-be ',' x-iscii-ta ',' x- iscii-te ',' x-iscii-as ',' x-iscii-or ',' x-iscii-ka ',' x-iscii-ma ',' x-iscii-gu ',' x-iscii- pa ',' utf-7 ',' utf-8 ')]
[строка] $ sourceEncoding,
[ValidateScript ({Test-Path -Literal $ _ -IsValid})]
[строка] $ target,
[ValidateSet ('IBM037', 'IBM437', 'IBM500', 'ASMO-708', 'DOS-720', 'ibm737', 'ibm775', 'ibm850', 'ibm852', 'IBM855', 'ibm857' , 'IBM00858', 'IBM860', 'ibm861', 'DOS-862', 'IBM863', 'IBM864', 'IBM865', 'cp866', 'ibm869', 'IBM870', 'windows-874', ' cp875 ',' shift_jis ',' gb2312 ',' ks_c_5601-1987 ',' big5 ',' IBM1026 ',' IBM01047 ',' IBM01140 ',' IBM01141 ',' IBM01142 ',' IBM01143 ',' IBM01144 ',' IBM01145 ',' IBM01146 ',' IBM01147 ',' IBM01148 ',' IBM01149 ',' utf-16 ',' utf-16BE ',' windows-1250 ',' windows-1251 ',' Windows-1252 ',' windows-1253 ',' windows-1254 ',' windows-1255 ',' windows-1256 ',' windows-1257 ',' windows-1258 ',' Johab ',' macintosh ',' x-mac-japanese ' , 'x-mac-chinesetrad', 'x-mac-korean', 'x-mac-arabic', 'x-mac-hebrew', 'x-mac-greek', 'x-mac-cyrillic', ' x-mac-chinesesimp ',' x-mac-romanian ',' x-mac-ukrainian ',' x-mac-thai ',' x-mac-ce ',' x-mac-исландский ',' x- mac-turkish ',' x-mac-croatian ',' utf-32 ',' utf-32BE ',' x-Chinese-CNS ',' x-cp20001 ',' x-китайский-Eten ',' x- cp20003 ',' x-cp20004 ',' x-cp20005 ',' x-IA5 ',' x-IA5-German ',' x-IA5-Swedish ',' x-IA5-Norwegian ',' us-ascii ',' x-cp20261 ',' x-cp20269 ',' IBM273 ' , 'IBM277', 'IBM278', 'IBM280', 'IBM284', 'IBM285', 'IBM290', 'IBM297', 'IBM420', 'IBM423', 'IBM424', 'x-EBCDIC-KoreanExtended', ' IBM-Thai ',' koi8-r ',' IBM871 ',' IBM880 ',' IBM905 ',' IBM00924 ',' EUC-JP ',' x-cp20936 ',' x-cp20949 ',' cp1025 ',' koi8-u ',' iso-8859-1 ',' iso-8859-2 ',' iso-8859-3 ',' iso-8859-4 ',' iso-8859-5 ',' iso-8859- 6 ',' iso-8859-7 ',' iso-8859-8 ',' iso-8859-9 ',' iso-8859-13 ',' iso-8859-15 ',' x-Europa ',' iso-8859-8-i ',' iso-2022-jp ',' csISO2022JP ',' iso-2022-jp ',' iso-2022-kr ',' x-cp50227 ',' euc-jp ',' EUC-CN ',' euc-kr ',' hz-gb-2312 ',' GB18030 ',' x-iscii-de ',' x-iscii-be ',' x-iscii-ta ',' x- iscii-te ',' x-iscii-as ',' x-iscii-or ',' x-iscii-ka ',' x-iscii-ma ',' x-iscii-gu ',' x-iscii- pa ',' utf-7 ',' utf-8 ')]
[строка] $ targetEncoding
) {
$ reader = [IO.>] *? encoding = "") (? i) $ sourceEncoding (? = "") "). Заменить (
[строка] :: new ($ buf, 0, $ nRead),
'$ 1' + $ targetEncoding,
1 # ускорение: только одна замена
)
)
while (! $ reader.EndOfStream) {
$ nRead = $ reader.Read ($ buf, 0, $ buf.Length)
$ writer.Write ($ buf, 0, $ nRead)
}
$ reader.Close ()
$ writer.Close ()
}
использование:
transcodeXML 'r: 1.xml' iso-8859-1 'r: 2.xml' utf-8
Указание набора символов для импорта данных на сервер системы Unicode AR - документация по системе запросов на устранение неисправностей 18.05
При импорте данных до 7.0.00 на сервер Unicode BMC Remedy AR System 7.0.00 или более поздней версии с использованием файлов XML .ARX или .DEF укажите, какой набор символов используется в данных. Указание набора символов позволяет системе BMC Remedy AR System знать, что ей необходимо преобразовать входящие данные из набора символов, отличных от Unicode, в Unicode.
Примечание
При экспорте данных с помощью BMC Remedy AR System 7.0.00 или более поздней версии в выходной файл включается правильный код для набора символов.
Если вы не укажете набор символов, сервер системы AR предполагает, что данные находятся в том же наборе символов, что и сервер системы AR. Если наборы символов не совпадают, ваши данные импортированы, но повреждены.
Важно
Обратите внимание на различия в синтаксисе файлов .ARX и .DEF . Использование неправильного синтаксиса может привести к неожиданным результатам при импорте.
Чтобы указать набор символов в файле XML
Откройте файл XML и убедитесь, что в следующей строке указана правильная кодировка: "?>
Например, чтобы указать традиционный китайский:
Чтобы указать набор символов в файле .ARX
Откройте файл .ARX и введите следующую строку вверху файла: CHAR-SET
Например, чтобы указать традиционный китайский: CHAR-SET big5
Чтобы указать набор символов в файле.DEF файл
Откройте файл .DEF и введите следующую строку вверху файла: char-set:
Например, чтобы указать традиционный китайский: char-set: big5
В следующей таблице содержатся имена кодировок набора символов, которые следует использовать при редактировании файла .ARX или .DEF .
Имена кодировки набора символов
Язык | Кодовое имя |
|---|---|
Традиционный китайский | |
Упрощенный китайский | |
Западноевропейские языки, например английский, французский, немецкий, итальянский, испанский и т. Д. | |
Центральноевропейские языки, такие как польский, чешский, венгерский и т. Д. | |
Кириллица: восточноевропейская - русский, украинский, белорусский, болгарский, сербский, македонский и т. Д. | |
Балтийские языки, такие как латышский, эстонский и литовский. | |
Японский | |
Корейский | |
Perl-XML на uucode.com
Perl-XML на uucode.com Страницасодержит библиотеки и примеры кода для обработки XML в Perl. Я думаю, что Perl не очень удобен для обработки XML.Я не настаиваю на этом, мне просто нужен стандартный DOM для всех модулей и функциональность Balise - мощный язык сценариев SGML / XML. Некоторые из функций реализована в библиотеке утилит DOM.
Я не даю никаких гарантий на код, потому что большая его часть написано под давлением времени. Код следует учитывать альфа-качества. Как бы то ни было, у меня обычно хорошее альфа-качество.
Этот код является публичным доменом. Это означает, что вы можете использовать код для любых целей без каких-либо ограничений.Лучшее, что ты можешь сделать заключается в преобразовании кода в модули или интеграции его в другие модули. По крайней мере, я надеюсь, что мой код окажется для вас полезным.
Пакет русских кодировок для XML :: Parser
Стандартные русские кодировки: windows-1251, cp866 (DOS) и koi8-r (UNIX). Все остальные не стандартные. Примечание для пользователей latin-1: iso-8859-5 является стандартом ISO, а не в России. Если вы хотите добавить поддержку наших кодировок вашего продукта, пожалуйста, добавьте 'windows-1251' и 'koi8-r'. Если вы добавите только iso-8859-5, то ваш продукт не будет поддерживать русский язык.
XML :: Parser поддерживает только iso-8859-5. Языковой пакет Добавлена поддержка всех стандартных русских кодировок. Содержимое пакета enc.zip:
- windows-1251.enc, ibm866.enc, koi8-r.enc
- Эти файлы необходимо скопировать в папку с другими .enc-файлами каталога. установлен XML :: Parser.
- cp1251.txt, cp866.txt, koi8-r.txt
- Текстовые файлы с отображением кодировок в Unicode.
- окна-1251.xml, ibm866.xml, koi8-r.xml
- XML-описание кодировок.Входные данные для модуля XML :: Encoding для создания .enc-файлов.
Следующим шагом после установки кодировок является обновление кода Perl. Вы должны указать желаемую кодировку для XML-парсера. См. Документацию для дополнительной информации.
Последний шаг - самый важный. Подумайте, почему вы используете 8bit файлы вместо UTF8?
Включить функции для синтаксического анализа XML
Этот код демонстрирует, как построить дерево DOM из ряда файлов. Файлы включаются "на лету" во время синтаксического анализа XML.Построитель DOM-дерева (XML :: Handler :: BuildDOM) не знает о включении.
Использую модуль XML :: Filter :: SAXT. Этот модуль является аналогом команд unix cat и tee для событий SAX. Это упрощает построение цепочек ответственности для обработчиков SAX. Например, парсер генерирует события SAX. Первый обработчик в цепочке переименовывает теги para в p, второй обработчик удаляет некоторые теги, третий обработчик может присоединиться к серии символов события для одного события, следующий обработчик может эмулировать push / pull с учетом пространства имен парсер.
Мой код (include-test.zip) собран
поверх XML :: Filter :: SAXT. Я фильтрую теги
Построить дерево DOM в 8-битном формате вместо UTF8
Этот код (8bit-dom.tar.gz) еще один пример расширения XML :: Filter :: SAXT. Я переопределил персонажей обработчик. Обновленный обработчик вызывает XML Parser для оригинала 8-битная строка и передает эту строку в символы обработчик следующего обработчика в цепочке. После обновленных событий SAX обрабатываются в XML :: Handler :: BuildDOM, вы получаете 8-битный DOM вместо UTF8.
Важное примечание: вы НЕ ДОЛЖНЫ строить 8-битное дерево DOM если вы точно не знаете, зачем вы это делаете. Программисты Perl XML считают, что XML :: DOM символьные данные в UTF8.Если вы не примете во внимание это предположение, вы создаете бомбу замедленного действия для своего проекта.
Утилиты DOM
Я обнаружил, что стандарт DOM не подходит для программирования. Как всегда, это только мое мнение. Эта библиотека (domutil.tar.gz) мне помогает сосредоточиться на программировании, а не на чтении XML :: DOM документация. Вот список функций:
- предок, дети, потомок, search_elem_nodes
- Извлечь узлы с заданными именами и / или атрибутами.
- hasAttr, getAttr
- Порядковый стиль доступа к атрибутам узла.
- сканирование SubTree
- Сканировать поддерево. Генерировать события в начале и в конце элемента. Обработчики могут остановить процесс сканирования или запретить сканирование поддерева.
- содержание
- Сгенерировать строку из текстового содержимого дерева.
- from_8bitDOM_to_string
- То же, что XML :: DOM :: toString (преобразование дерева DOM в строку XML), но для 8-битной DOM вместо UTF8 DOM.
Модули Pyxie
Я автор модулей PyxieSax. Эти модули используют текстовую нотацию для представления данных XML. Это обозначение является подмножеством Nsgmls Формат вывода. После публикации Шона МакГрата статья на XML.