Юникод в Python | Введение в Python
Зарегистрируйтесь для доступа к 15+ бесплатным курсам по программированию с тренажером
Видео может быть заблокировано из-за расширений браузера. В статье вы найдете решение этой проблемы.
Unicode in Python
Before the Unicode
- Memory consists of bytes
- A string is a chain of bytes
- One byte can have up to 256 values
- One byte can mark one of 256 symbols
- To print a byte, you should find a symbol that it marks…
- … with a special table, named
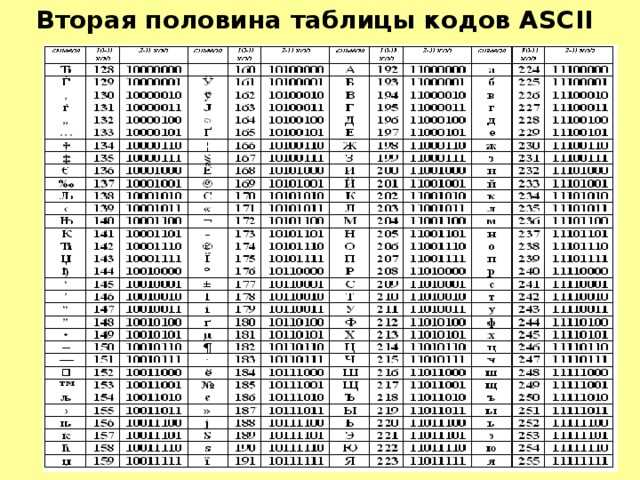
Code page
ASCII Code page
- a special table that compares bytes with symbols
- ASCII table as a standard
- 0..127 for latin and system symbols
- 128..255 for extended symbols
How about foreign languages?
- 0..127 for latin and system symbols anyway
- 128.
 .255 for realm-specific symbols
.255 for realm-specific symbols - One realm — one code page
cp866DOS-Cyrilliccp1251Windows-Cyrilliccp1253Windows-Creek- etc
Encoding hell
- Lots of code pages
- Every message should declare the code page
- Remember your inbox 10 years ago
How does it fail
- User A types
"Привет"on Linux (utf-8) - The bytes are
\xd0\x9f\xd1\x80\xd0\xb8\xd0\xb2\xd0\xb5\xd1\x82 - The program should send a header with encoding, but it doesn’t
- User B receives the message without header on Windows (cp1251)
- So default code page becomes cp1251
- Decoded message is
Привет - :—(
The solution is Unicode
- It’s a common unlimited alphabet
- Every symbol has its own number
- Unicode is growing
U+XXXXto refer a specific code
U+0031 1 U+00A9 © U+20AC € U+266B ♫ U+4E64 乤 U+45B4 䖴
What is UTF?
- An algorithm how turn Unicode into bytes and read it back
- There are
UTF-8,-16and-32encodings UTF-8uses 1 byte for latin and 2 bytes for non-latinUTF-8is compatible with english text- Can encode large subset of Unicode
Still have problems with Unicode?
- Try to use
UTF-8encoding everywhere - Read Joel Spolsky «About Unicode and Character Sets»
Unicode in Python 2. x
x
- Unicode strings are declared with
u'...'prefix - The should be coding directive in your file
- Use
\uXXXXto refer unicode symbols0..FFFF \UXXXXXXXXto refer0..FFFFFFFFsymbols (rare)
# coding=utf-8 # -*- coding: utf-8 -*- name = u'Иван' name = u'Ιαννης' name = u'João' greet = u'\u041f\u0440\u0438\u0432\u0435\u0442' print greet >>> Привет print u'\U0000041f\U00000440\U00000438\U00000432\U00000435\U00000442' >>> Привет data = u""" Any string in english Любая строка на русском 任何字符串在中國""" print data Any string in english Любая строка на русском 任何字符串在中國 repr(data) u'\nAny string in english\n\u041b\u044e\u0431\u0430\u044f \u0441\u0442\u0440\u043e\u043a\u0430 \u043d\u0430 \u0440\u0443\u0441\u0441\u043a\u043e\u043c\n\u4efb\u4f55\u5b57\u7b26\u4e32\u5728\u4e2d\u570b\n'
How to turn an object into Unicode
unicode([1, 2, True, {"test": 42}])
>>> u"[1, 2, True, {'test': 42}]"
unicode(obj) == obj. __unicode__()
class User(object):
def __unicode__(self):
return u'%s %s' % (self.name, self.surname)
user = User(...)
unicode(user) # u'Михаил Паниковский'
__unicode__()
class User(object):
def __unicode__(self):
return u'%s %s' % (self.name, self.surname)
user = User(...)
unicode(user) # u'Михаил Паниковский'
How to turn a 8-bit string into Unicode
message = '\xcf\xf0\xe8\xe2\xe5\xf2'
decoded = message.decode('cp1251')
repr(decoded)
>>> u'\u041f\u0440\u0438\u0432\u0435\u0442'
print decoded
Привет
message = '\x8f\xe0\xa8\xa2\xa5\xe2'
decoded = unicode(message, 'cp866')
>>> Привет
How to turn a Unicode into 8-bit string
udata = u'Сообщение'
udata.encode('cp1251')
>>> '\xd1\xee\xee\xe1\xf9\xe5\xed\xe8\xe5'
udata.encode('utf-8')
>>> '\xd0\xa1\xd0\xbe\xd0\xbe\xd0\xb1\xd1\x89\xd0\xb5\xd0\xbd\xd0\xb8'
Encode/decode chaining
u'Иван'.encode('cp866').decode('cp866')
>>> u'\u0418\u0432\u0430\u043d'
'\x88\xa2\xa0\xad'.decode('cp866').encode('utf-8')
>>> '\xd0\x98\xd0\xb2\xd0\xb0\xd0\xbd'
Encode/Decode errors
>>> u'Ivan'.encode('cp1251') 'Ivan' >>> u'Иван'.encode('cp1251') '\xc8\xe2\xe0\xed' >>> u'任何字符串在中國'.decode('cp1251') UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-7: ordinal not in range(128)
The meaning of strings
- Unicode is a human string
- 8-bit string is just bytes
- Avoid printing bytes
- The result depends on locale, code page, etc
Don’t mix unicode and 8-bit strings!
u'Привет, ' + 'Ivan'
Привет, Ivan
u'Привет, ' + 'Иван'
>>> UnicodeDecodeError: 'ascii' codec can't decode byte 0xd0 in position 0: ordinal not in range(128)
name = '\xd0\x98\xd0\xb2\xd0\xb0\xd0\xbd'
u'Привет, ' + name.decode('utf-8')
>>> Привет, Иван
Methods are same
data = u'Юникод и Ко' data.upper() # ЮНИКОД И КО data.lower() # юникод и ко data.split(u' ') >>> [u'\u042e\u043d\u0438\u043a\u043e\u0434', u'\u0438', u'\u041a\u043e'] data.replace(u'Ко', u'Компания') # Юникод и Компания
Остались вопросы? Задайте их в разделе «Обсуждение»
Вам ответят команда поддержки Хекслета или другие студенты.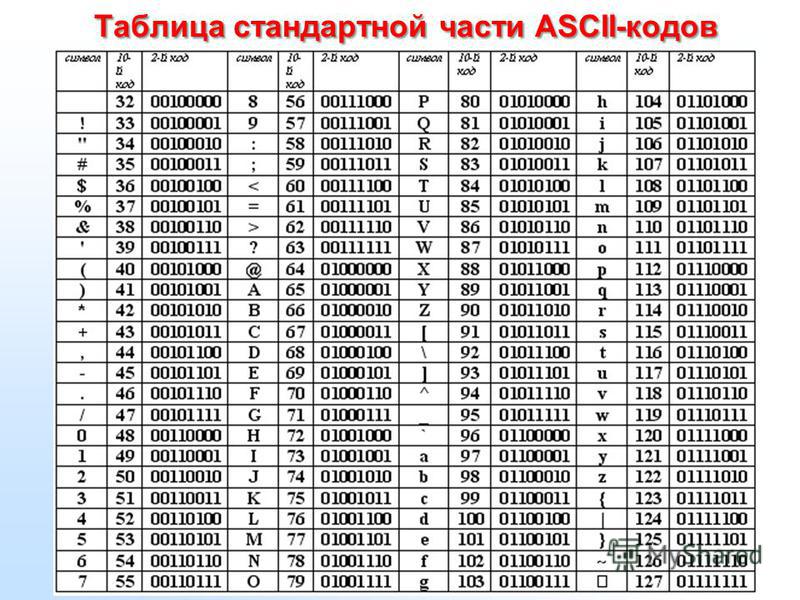
Обмен данными по протоколу HTTP
>>> from http.client import HTTPConnection
>>> con = HTTPConnection(«test1.ru»)
>>> con2 = HTTPConnection(«test1.ru», 80)
>>> con3 = HTTPConnection(«test1.ru:80»)
Листинг 21.9. Отправка данных методом GET
>>> from http.client import HTTPConnection
>>> from urllib.parse import urlencode
>>> data = urlencode({«color»: «Красный», «var»: 15}, encoding=»cp1251″)
>>> headers = { «User-Agent»: «MySpider/1.0»,
«Accept»: «text/html, text/plain, application/xml»,
«Accept-Language»: «ru, ru-RU»,
«Accept-Charset»: «windows-1251»,
«Referer»: «/index.php» }
>>> con = HTTPConnection(«test1.ru»)
>>> con.request(«GET», «/testrobots.php?%s» % data, headers=headers)
>>> result = con.getresponse() # Создаем объект результата
>>> print(result.read().decode(«cp1251»)) # Читаем данные
. .. Фрагмент опущен …
.. Фрагмент опущен …
>>> con.close() # Закрываем объект соединения
Листинг 21.10. Отправка данных методом POST
>>> from http.client import HTTPConnection
>>> from urllib.parse import urlencode
>>> data = urlencode({«color»: «Красный», «var»: 15}, encoding=»cp1251″)
>>> headers = { «User-Agent»: «MySpider/1.0»,
«Accept»: «text/html, text/plain, application/xml»,
«Accept-Language»: «ru, ru-RU»,
«Accept-Charset»: «windows-1251»,
«Content-Type»: «application/x-www-form-urlencoded»,
«Referer»: «/index.php» }
>>> con = HTTPConnection(«test1.ru»)
>>> con.request(«POST», «/testrobots.php», data, headers=headers)
>>> result = con.getresponse() # Создаем объект результата
>>> print(result.read().decode(«cp1251»))
… Фрагмент опущен …
>>> con.close()
>>> result.getheader(«Content-Type»)
‘text/plain; charset=windows-1251’
>>> print(result.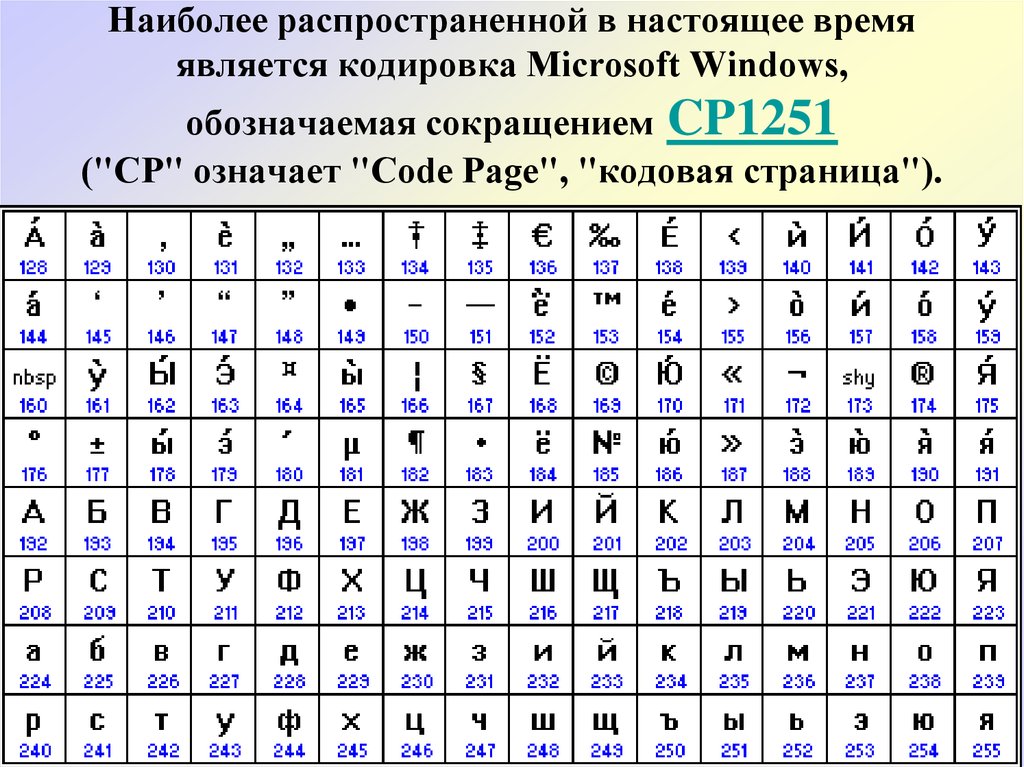 getheader(«Content-Types»))
getheader(«Content-Types»))
None
>>> result.getheader(«Content-Types», 10)
>>> result.getheaders()
[(‘Date’, ‘Mon, 27 Apr 2015 13:33:21 GMT’), (‘Server’, ‘Apache/2.2.4
(Win32) mod_ssl/2.2.4 OpenSSL/0.9.8d PHP/5.2.4′), (‘X-Powered-By’,
‘PHP/5.2.4’), (‘Content-Length’, ‘422’), (‘Content-Type’,
‘text/plain; charset=windows-1251’)]
>>> dict(result.getheaders())
{‘Date’: ‘Mon, 27 Apr 2015 13:33:21 GMT’, ‘Content-Length’: ‘422’,
‘X-Powered-By’: ‘PHP/5.2.4’, ‘Content-Type’: ‘text/plain;
charset=windows-1251′, ‘Server’: ‘Apache/2.2.4 (Win32)
mod_ssl/2.2.4 OpenSSL/0.9.8d PHP/5.2.4′}
>>> result.status
>>> result.reason # При коде 200
‘OK’
>>> result.reason # При коде 302
‘Moved Temporarily’
>>> result.version # Протокол HTTP/1.1
>>> print(result.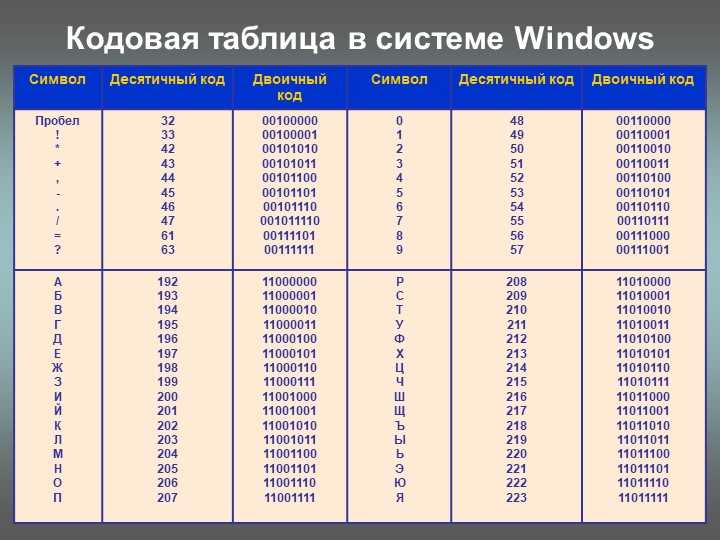 msg)
msg)
Date: Mon, 27 Apr 2015 13:33:21 GMT
Server: Apache/2.2.4 (Win32) mod_ssl/2.2.4 OpenSSL/0.9.8d PHP/5.2.4
X-Powered-By: PHP/5.2.4
Content-Length: 422
Content-Type: text/plain; charset=windows-1251
>>> result.msg.as_string()
‘Date: Mon, 27 Apr 2015 13:33:21 GMT\nServer: Apache/2.2.4 (Win32)
mod_ssl/2.2.4 OpenSSL/0.9.8d PHP/5.2.4\nX-Powered-By:
PHP/5.2.4\nContent-Length: 422\nContent-Type: text/plain;
charset=windows-1251\n\n’
>>> result.msg.items()
[(‘Date’, ‘Mon, 27 Apr 2015 13:33:21 GMT’), (‘Server’, ‘Apache/2.2.4
(Win32) mod_ssl/2.2.4 OpenSSL/0.9.8d PHP/5.2.4′), (‘X-Powered-By’,
‘PHP/5.2.4’), (‘Content-Length’, ‘422’), (‘Content-Type’,
‘text/plain; charset=windows-1251’)]
>>> result.msg.keys()
[‘Date’, ‘Server’, ‘X-Powered-By’, ‘Content-Length’, ‘Content-Type’]
>>> result.msg.values()
[‘Mon, 27 Apr 2015 13:33:21 GMT’, ‘Apache/2.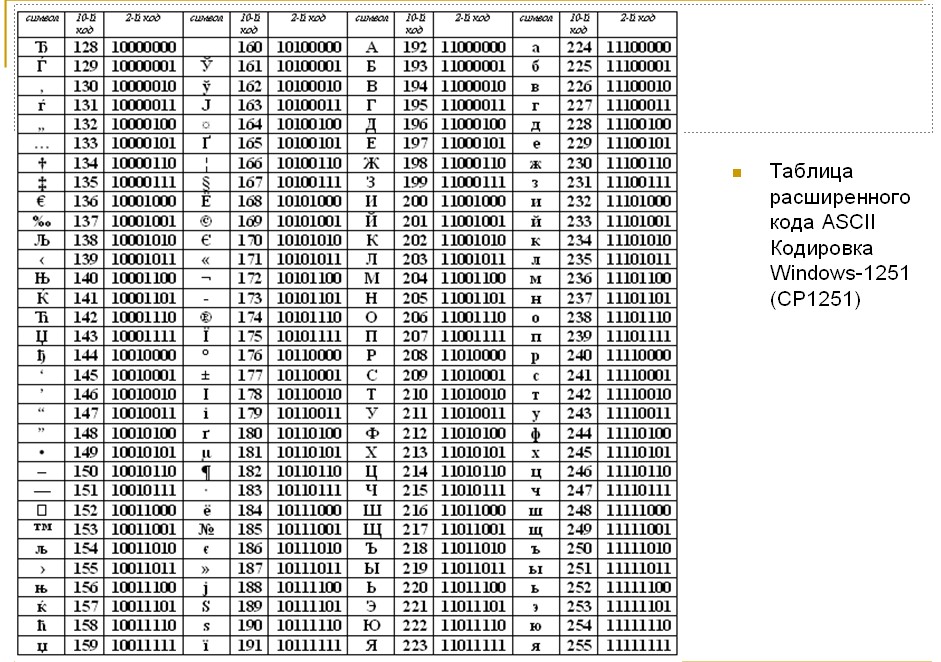 2.4 (Win32) mod_ssl/2.2.4
2.4 (Win32) mod_ssl/2.2.4
OpenSSL/0.9.8d PHP/5.2.4′, ‘PHP/5.2.4’, ‘422’, ‘text/plain;
charset=windows-1251′]
>>> result.msg.get(«X-Powered-By»)
‘PHP/5.2.4’
>>> print(result.msg.get(«X-Powered-By2»))
None
>>> result.msg.get(«X-Powered-By2», failobj=10)
>>> result.msg.get_all(«X-Powered-By»)
[‘PHP/5.2.4’]
>>> result.msg.get_content_type()
‘text/plain’
>>> result.msg.get_content_maintype()
‘text’
>>> result.msg.get_content_subtype()
‘plain’
>>> result.msg.get_content_charset()
‘windows-1251’
Листинг 21.11. Отправка запроса методом HEAD
>>> from http.client import HTTPConnection
>>> headers = { «User-Agent»: «MySpider/1.0»,
«Accept»: «text/html, text/plain, application/xml»,
«Accept-Language»: «ru, ru-RU»,
«Accept-Charset»: «windows-1251»,
«Referer»: «/index. php» }
php» }
>>> con = HTTPConnection(«test1.ru»)
>>> con.request(«HEAD», «/testrobots.php», headers=headers)
>>> result = con.getresponse() # Создаем объект результата
>>> print(result.msg)
Date: Mon, 27 Apr 2015 13:39:54 GMT
Server: Apache/2.2.4 (Win32) mod_ssl/2.2.4 OpenSSL/0.9.8d PHP/5.2.4
X-Powered-By: PHP/5.2.4
Content-Type: text/plain; charset=windows-1251
>>> result.read() # Данные не передаются, только заголовки!
b»
>>> con.close()
21.6. Обмен данными с помощью модуля urllib.request
>>> from urllib.request import urlopen
>>> res = urlopen(«http://test1.ru/testrobots.php»)
>>> print(res.read(34).decode(«cp1251»))
Название робота: Python-urllib/3.4
>>> print(res.read().decode(«cp1251»))
… Фрагмент опущен …
>>> res.read()
b»
>>> res = urlopen(«http://test1. ru/testrobots.php»)
ru/testrobots.php»)
>>> print(res.readline().decode(«cp1251»))
Название робота: Python-urllib/3.4
>>> res = urlopen(«http://test1.ru/testrobots.php»)
>>> res.readlines(3)
[b’\xcd\xe0\xe7\xe2\xe0\xed\xe8\xe5 \xf0\xee\xe1\xee\xf2\xe0:
Python-urllib/3.4\n’]
>>> res.readlines()
… Фрагмент опущен …
>>> res.readlines()
[]
>>> res = urlopen(«http://test1.ru/testrobots.php»)
>>> for line in res: print(line)
>>> res = urlopen(«http://test1.ru/testrobots.php»)
>>> info = res.info()
>>> info.items()
[(‘Date’, ‘Mon, 27 Apr 2015 13:55:25 GMT’), (‘Server’, ‘Apache/2.2.4
(Win32) mod_ssl/2.2.4 OpenSSL/0.9.8d PHP/5.2.4′), (‘X-Powered-By’,
‘PHP/5.2.4’), (‘Content-Length’, ‘288’), (‘Connection’, ‘close’),
(‘Content-Type’, ‘text/plain; charset=windows-1251’)]
>>> info. get(«Content-Type»)
get(«Content-Type»)
‘text/plain; charset=windows-1251’
>>> info.get_content_type(), info.get_content_charset()
(‘text/plain’, ‘windows-1251’)
>>> info.get_content_maintype(), info.get_content_subtype()
(‘text’, ‘plain’)
>>> res.code, res.msg
(200, ‘OK’)
Листинг 21.12. Отправка данных методами GET и POST
>>> from urllib.request import urlopen
>>> from urllib.parse import urlencode
>>> data = urlencode({«color»: «Красный», «var»: 15}, encoding=»cp1251″)
>>> # Отправка данных методом GET
>>> url = «http://test1.ru/testrobots.php?» + data
>>> res = urlopen(url)
>>> print(res.read(34).decode(«cp1251»))
Название робота: Python-urllib/3.4
>>> res.close()
>>> # Отправка данных методом POST
>>> url = » http://test1.ru/testrobots.php»
>>> res = urlopen(url, data. encode(«cp1251»))
encode(«cp1251»))
>>> print(res.read().decode(«cp1251»))
… Фрагмент опущен …
>>> res.close()
Листинг 21.13. Использование класса Request
>>> from urllib.request import urlopen, Request
>>> from urllib.parse import urlencode
>>> headers = { «User-Agent»: «MySpider/1.0»,
«Accept»: «text/html, text/plain, application/xml»,
«Accept-Language»: «ru, ru-RU»,
«Accept-Charset»: «windows-1251»,
«Referer»: «/index.php» }
>>> data = urlencode({«color»: «Красный», «var»: 15}, encoding=»cp1251″)
>>> # Отправка данных методом GET
>>> url = «http://test1.ru/testrobots.php?» + data
>>> request = Request(url, headers=headers)
>>> res = urlopen(request)
>>> print(res.read(29).decode(«cp1251»))
Название робота: MySpider/1.0
>>> res.close()
>>> # Отправка данных методом POST
>>> url = «http://test1.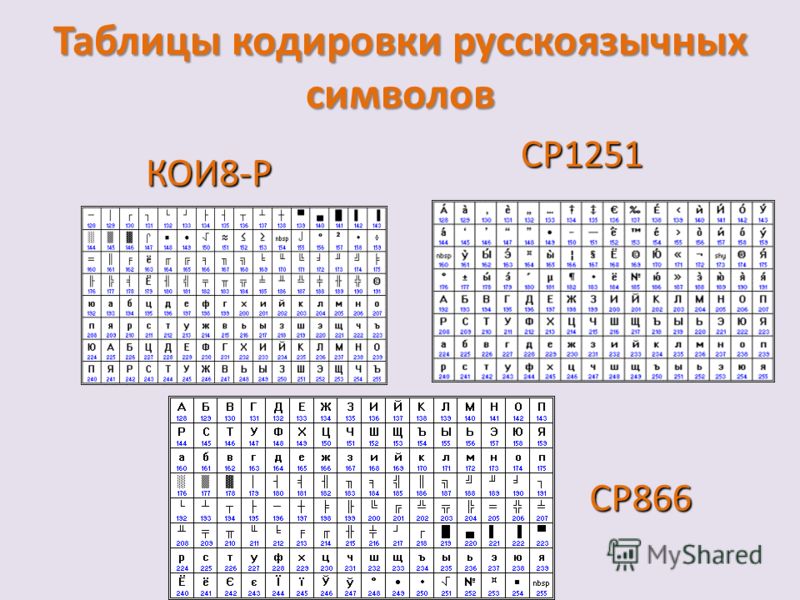 ru/testrobots.php»
ru/testrobots.php»
>>> request = Request(url, data.encode(«cp1251»), headers=headers)
>>> res = urlopen(request)
>>> print(res.read().decode(«cp1251»))
… Фрагмент опущен …
>>> res.close()
Определение кодировки
<meta http-equiv=»Content-Type»
content=»text/html; charset=windows-1251″>
c:\python34\scripts\pip install chardet
>>> import chardet
>>> chardet.__version__
‘2.3.0’
Листинг 21.14. Пример определения кодировки
>>> import chardet
>>> chardet.detect(bytes(«Строка», «cp1251»))
{‘confidence’: 0.99, ‘encoding’: ‘windows-1251’}
>>> chardet.detect(bytes(«Строка», «koi8-r»))
{‘confidence’: 0.99, ‘encoding’: ‘KOI8-R’}
>>> chardet.detect(bytes(«Строка», «utf-8»))
{‘confidence’: 0.99, ‘encoding’: ‘utf-8’}
Листинг 21. 15. Пример использования класса UniversalDetector
15. Пример использования класса UniversalDetector
from chardet.universaldetector import UniversalDetector
ud = UniversalDetector() # Создаем объект
for line in open(«file.txt», «rb»):
ud.feed(line) # Передаем текущую строку
if ud.done: break # Прерываем цикл, если done == True
ud.close() # Закрываем объект
print(ud.result) # Выводим результат
input()
Сжатие данных
Поддержка «плохих» кодировок — ftfy: исправляет текст для вас
Модуль ftfy.bad_codecs дает Python возможность декодировать некоторые распространенные,
некорректные кодировки.
Python не хочет, чтобы вы писали текст небрежно. Его кодеры и декодеры
(«кодеки») по возможности следуют соответствующим стандартам, а это означает, что
когда вы получите сообщение о том, что не соответствует этим стандартам, вы, вероятно, потерпите неудачу
расшифровать его. Или вы можете успешно расшифровать его для конкретной реализации
причин, что, пожалуй, хуже.
Существуют некоторые кодировки, которых Python не желает, чтобы существовали. широко используется за пределами Python:
«варианты utf-8», семейство кодировок не совсем UTF-8, включая всегда популярный CESU-8 и «Java модифицированный UTF-8».
«Неаккуратные» версии кодировок карт символов, где байты, которые не соответствуют вместо этого все будет отображаться в символ Unicode с тем же номером.
Простой импорт этого модуля или фактически любой части ftfy.bad_codecs .
Однако, если вы хотите вызвать что-то, потому что на этом настаивает программа проверки кода,
вы можете вызвать ftfy.bad_codecs.ok() .
Краткий пример декодирования текста, закодированного в CESU-8:
>>> импортировать ftfy.bad_codecs >>> print(b'\xed\xa0\xbd\xed\xb8\x8d'.decode('utf-8-варианты')) 😍
«Небрежные» кодировки
ftfy.bad_codecs.sloppy предоставляет кодировки карт символов, которые заполняют свои «дыры»
запутанным, но распространенным способом: путем вывода кодовых точек Unicode с одинаковыми
числа.
Это невероятно уродливо, и это также соответствует стандарту HTML5.
Однобайтовая кодировка сопоставляет каждый байт с символом Unicode, за исключением некоторых байты остаются неотображенными. В широко используемой кодировке Windows-1252 для например, байты 0x81 и 0x8D, среди прочего, не имеют значения.
Python, желая сохранить некоторое чувство приличия, будет обрабатывать эти байты как ошибки. Но Windows знает, что 0x81 и 0x8D являются возможными байтами, и они отличаются друг от друга. Он просто не определил, что они представляют собой с точки зрения Юникод.
Программное обеспечение, которое должно взаимодействовать с Windows-1252 и Unicode, например все
обычные веб-браузеры — выберут некоторые символы Unicode для сопоставления
к, и символы, которые они выбирают, являются символами Unicode с тем же самым
номера: U+0081 и U+008D. Это то же самое, что и Latin-1, и
результирующие символы, как правило, попадают в диапазон Unicode, отведенный для
в любом случае устаревшие управляющие символы Latin-1.
Это то же самое, что и Latin-1, и
результирующие символы, как правило, попадают в диапазон Unicode, отведенный для
в любом случае устаревшие управляющие символы Latin-1.
Эти небрежные кодеки позволяют Python делать то же самое, взаимодействуя, таким образом, с другое программное обеспечение, которое работает таким образом. Он определяет небрежную версию многих однобайтовые кодировки с дырками. (Нет необходимости в неряшливой версии кодировка без дырок: например, не существует такой вещи, как sloppy-iso-8859-2 или sloppy-macroman.)
Будут определены следующие кодировки:
sloppy-windows-1250 (Центральноевропейская, вроде на основе ISO-8859-2)
sloppy-windows-1251 (кириллица)
sloppy-windows-1252 (западноевропейский, на основе латиницы-1)
sloppy-windows-1253 (греч., вроде на основе ISO-8859-7)
sloppy-windows-1254 (турецкий, на основе ISO-8859-9)
sloppy-windows-1255 (иврит, на основе ISO-8859-8)
sloppy-windows-1256 (арабский)
sloppy-windows-1257 (Балтийский, на базе ISO-8859-13)
sloppy-windows-1258 (вьетнамский)
sloppy-cp874 (тайский, на основе ISO-8859-11)
sloppy-iso-8859-3 (наверное, мальтийский и эсперанто)
sloppy-iso-8859-6 (другой арабский)
sloppy-iso-8859-7 (греческий)
неаккуратный-iso-8859-8 (иврит)
sloppy-iso-8859-11 (тайский)
Псевдонимы, такие как «sloppy-cp1252» для «sloppy-windows-1252», также будут
определенный.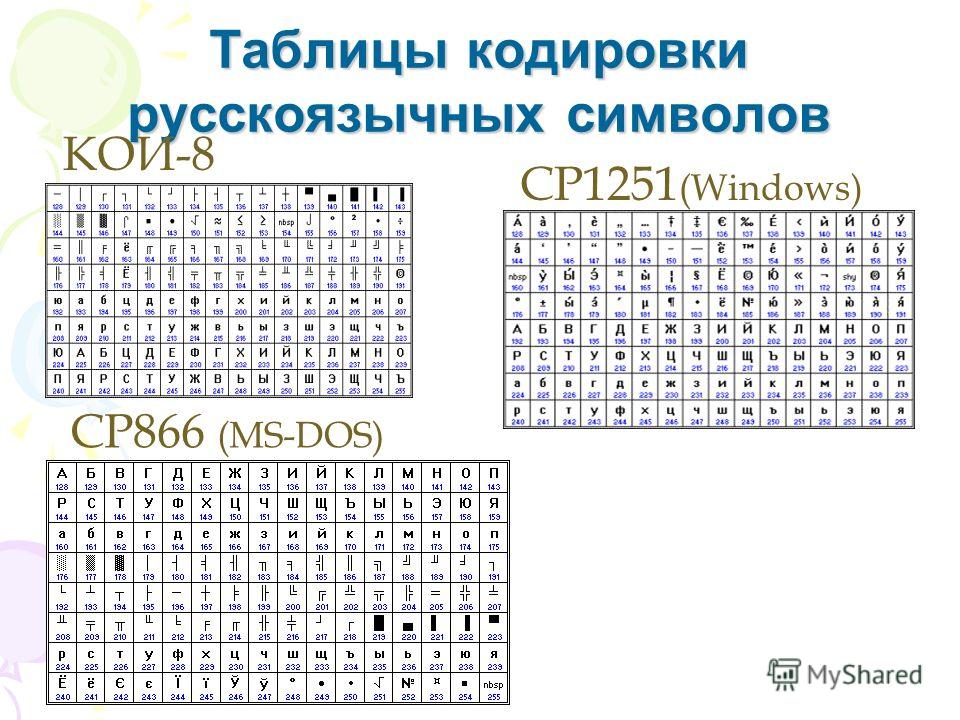
Пять из этих кодировок (от sloppy-windows-1250 до sloppy-windows-1254 )
используются внутри ftfy.
Вот несколько примеров использования ftfy.explain_unicode() для иллюстрации того, как
sloppy-windows-1252 объединяет Windows-1252 с Latin-1:
>>> импорт из ftfy, объяснение_юникода
>>> некоторые_байты = b'\x80\x81\x82'
>>> объясните_юникод (некоторые_байты. декодировать ('латиница-1'))
U+0080 \x80 [Копия] <неизвестно>
U+0081 \x81 [Копия] <неизвестно>
U+0082 \x82 [Копия] <неизвестно>
>>> объясните_юникод (некоторые_байты.декодировать ('windows-1252', 'заменить'))
U+20AC € [Sc] ЗНАК ЕВРО
U+FFFD � [So] ЗАМЕНЯЮЩИЙ СИМВОЛ
U + 201A ‚ [Ps] ОДИНАРНАЯ МЛАДШАЯ-9 КАВАТЫ
>>> объясните_юникод (некоторые_байты. декодировать ('sloppy-windows-1252'))
U+20AC € [Sc] ЗНАК ЕВРО
U+0081 \x81 [Копия] <неизвестно>
U + 201A ‚ [Ps] ОДИНАРНАЯ МЛАДШАЯ-9 КАВАТЫ
Варианты UTF-8
Этот файл определяет кодек под названием «utf-8-variants» (или «utf-8-var»), который может
декодировать текст, закодированный популярной нестандартной версией UTF-8. Это включает в себя CESU-8, случайное кодирование, созданное путем наложения UTF-8 поверх
UTF-16, а также вариант Java с CESU-8, который содержит двухбайтовую кодировку для
кодовая точка 0.
Это включает в себя CESU-8, случайное кодирование, созданное путем наложения UTF-8 поверх
UTF-16, а также вариант Java с CESU-8, который содержит двухбайтовую кодировку для
кодовая точка 0.
Это особенно актуально для Python 3, который не предоставляет другого способа расшифровка ЦЭСУ-8 1.
Самый простой способ использовать кодек — просто импортировать ftfy.bad_codecs :
>>> импортировать ftfy.bad_codecs
>>> результат = b'а вот и ноль! \xc0\x80'.decode('utf-8-var')
>>> print(repr(result).lstrip('u'))
'а вот и ноль! \x00'
Кодек совсем не обеспечивает «правильность» CESU-8. Например, Юникод Не совсем стандартное описание консорциума CESU-8 требует наличия только одна возможная кодировка любого символа, поэтому она не позволяет смешивать действительные УТФ-8 и ЦЕСУ-8. Этот кодек допускает ли это , точно так же, как UTF-8 Python 2 декодер делает.
Символы в базовой многоязычной плоскости по-прежнему имеют только одну кодировку.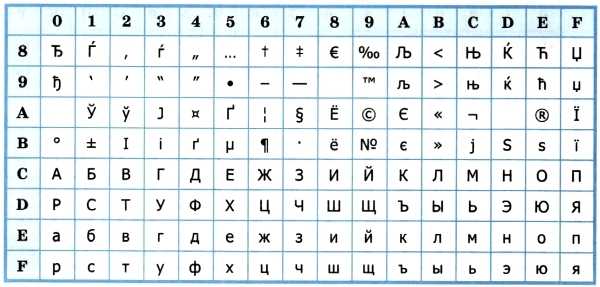 Этот
кодек по-прежнему применяет правило внутри BMP, согласно которому символы должны отображаться в
их кратчайшая форма. Есть одно исключение: последовательность байтов
Этот
кодек по-прежнему применяет правило внутри BMP, согласно которому символы должны отображаться в
их кратчайшая форма. Есть одно исключение: последовательность байтов 0xc0 0x80 ,
вместо 0x00 может использоваться для кодирования нулевого символа U+0000 , например
в Яве.
Если вы кодируете с помощью этого кодека, вы получаете легитимный кодек UTF-8. Расшифровка с помощью этого кодек и затем перекодирование не является идемпотентным, хотя кодирование и затем расшифровка есть. Так что этот модуль вам CESU-8 производить не будет. Ищите это функциональность родственного модуля «Разрыв текста для вас» появится примерно никогда.
- 1
В крайнем случае вы можете декодировать CESU-8 в Python 2, используя кодек UTF-8: сначала декодировать байты (неправильно), потом кодировать их, потом декодировать опять же, каждый раз используя UTF-8 в качестве кодека. Но Python 2 мертв, поэтому используйте вместо этого ftfy.
Проблема 16444: Используйте support.
 TESTFN_UNDECODABLE в UNIX
TESTFN_UNDECODABLE в UNIXIssue16444
➜
Это средство отслеживания проблем было перенесено на GitHub ,
а сейчас только для чтения .
Для получения дополнительной информации,
см. часто задаваемые вопросы GitHub в Руководстве разработчика Python.
Создано 08.11.2012, 22:52 автором vstinner , последнее изменение 11.04.2022 14:57 автором admin . Эта проблема закрыта .
| Имя файла | Загружено | Описание | Редактировать |
|---|---|---|---|
| support_undecodedable.patch | встиннер, 2012-11-08 22:52 | рассмотрение |
| msg175200 — (просмотреть) | Автор: STINNER Виктор (vstinner) * | Дата: 2012-11-08 22:52 | |
|---|---|---|---|
Прикрепленное исправление изменяет способ вычисления support. | |||
| msg175201 — (просмотреть) | Автор: STINNER Виктор (vstinner) * | Дата: 2012-11-08 22:53 | |
Патч содержит два вывода, чтобы облегчить отладку самого патча, эти операторы печати необходимо удалить позже. | |||
| msg175202 — (просмотреть) | Автор: STINNER Виктор (vstinner) * | Дата: 2012-11-08 23:04 | |
> Мы также можем использовать support.TESTFN_UNDECODABLE > в test_cmd_line_script.test_non_ascii() в Windows О, подпроцесс больше не поддерживает передачу байтовых аргументов в программу (начиная с Python 3.0). http://bugs.python.org/issue4036#msg100376 Поэтому для этого теста лучше использовать TESTFN_NONASCII ;-) Это подтверждает, что нам нужны две константы в зависимости от контекста. Это зависит от платформы и способа чтения/записи данных: иногда некодируемые символы поддерживаются на любой платформе (например, кодировщик base64), иногда недекодируемые символы не поддерживаются (например, distutils ожидает действительные метаданные), иногда это зависит от платформы ( пример: этот тест). | |||
| msg175209 — (просмотреть) | Автор: STINNER Виктор (vstinner) * | Дата: 2012-11-08 23:50 | |
> Пожалуйста, протестируйте патч на UNIX, Windows и Mac OS X. Полный набор тестов проходит: * Linux с кодировкой локали UTF-8 * Linux с кодировкой локали ASCII * Windows с кодовой страницей cp932 ANSI * Mac OS 10.8 с кодировкой локали ASCII (и utf-8/surrogateescape для кодировки файловой системы) ($LANG, $LC_ALL, $LC_CTYPE не установлены) | |||
| msg175221 — (просмотреть) | Автор: Сергей Сторчака (serhiy.storchaka) * | Дата: 2012-11-09 11:00 | |
Попробуйте b'\x81', b'\x98', b'\xae', b'\xd5', b'\xff'. Они не декодируются во всех 1-байтовых кодировках. b'\x81' : shift_jis_2004 shift_jis shift_jisx0213 cp869 cp874 cp932 cp1250 cp1252 cp1253 cp1254 cp1255 cp1257 cp1258 b'\x98' : shift_jis_2004 shift_jis shift_jisx0213 cp874 cp932 cp1250 cp1251 cp1253 cp1257 b'\xae' : iso8859-3 iso8859-6 iso8859-7 cp424 b'\xd5' : iso8859-8 cp856 cp857 b'\xff' : hp-roman8 iso8859-6 iso8859-7 iso8859-8 iso8859-11 shift_jis_2004 shift_jis shift_jisx0213 tis-620 cp864 cp874 cp1253 cp1255 | |||
| msg175222 — (просмотреть) | Автор: Сергей Сторчака (serhiy.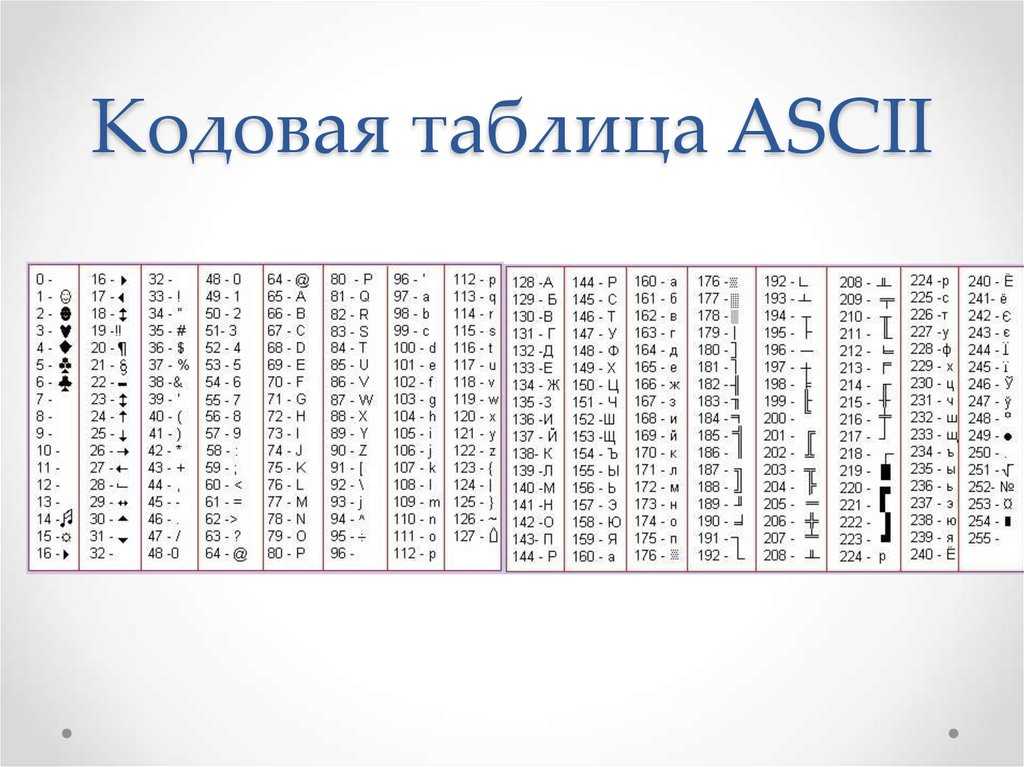 storchaka) * storchaka) * | Дата: 2012-11-09 11:09 | |
Попробуйте b'\xed\xb2\x80' и b'\xed\xb4\x80' для UTF-8 (в Unix и Mac OS X).
b'\xed\xb2\x80' равно b'\x80'.decode('utf-8', 'surrogateescape').encode('utf-8', 'surrogatepass').
b'\xed\xb4\x80' равно '\udd00'.encode('utf-8', 'surrogatepass') и '\udd00' не могут быть закодированы с помощью surrogateescape. | |||
| msg175223 — (просмотреть) | Автор: Сергей Сторчака (serhiy.storchaka) * | Дата: 2012-11-09 11:14 | |
> Прохождение полного набора тестов: Дело не только в том, что испытания прошли. Они должны потерпеть неудачу, если исходная ошибка повторится. Вы пытались восстановить ошибки? | |||
| msg175271 — (просмотреть) | Автор: STINNER Виктор (vstinner) * | Дата: 10.11.2012 10:50 | |
> Дело не только в том, что тесты прошли. | |||
| msg175272 — (просмотреть) | Автор: Roundup Robot (python-dev) | Дата: 2012-11-10 11:07 | |
Новый набор изменений 6b8a8bc6ba9c Виктора Стиннера в ветке «по умолчанию»: Проблема № 16444, № 16218: использование TESTFN_UNDECODABLE в UNIX http://hg. | |||
| msg175275 — (просмотреть) | Автор: Сергей Сторчака (serhiy.storchaka) * | Дата: 10.11.2012 12:21 | |
TESTFN_UNDECODABLE не обнаружен для cp1250, cp1251, cp1252, cp1254, cp1257 и cp1258. Просто добавьте b'\x81\x98\xae\xd5\xff', хотя бы один из этих байтов недекодируется в какой-то кодировке, в которой есть недекодируемые байты. | |||
| msg175291 — (просмотреть) | Автор: Антуан Питру (pitrou) * | Дата: 2012-11-10 18:24 | |
Я полагаю, вы заметили, что сломали кучу билдботов :) | |||
| msg175296 — (просмотреть) | Автор: Roundup Robot (python-dev) | Дата: 2012-11-10 21:31 | |
Новый набор изменений 398f8770bf0d Виктора Стиннера в ветке «по умолчанию»: Проблема № 16444: отключить недекодируемые символы в тесте test_non_ascii() до тех пор, пока http://hg. | |||
| msg175396 — (просмотреть) | Автор: STINNER Виктор (vstinner) * | Дата: 2012-11-11 21:51 | |
> TESTFN_UNDECODABLE не обнаружен для cp1250, cp1251, cp1252, cp1254, cp1257 и cp1258. Кодировка Python и реальный кодек, используемый Windows, различаются: Python не может декодировать байты 0x80-0x9f, но Windows их декодирует. Я предпочитаю избегать этих байтов, чтобы не слишком полагаться на кодек Python. | |||
| msg175399 — (просмотреть) | Автор: Сергей Сторчака (serhiy.storchaka) * | Дата: 2012-11-11 22:08 | |
Эти кодировки используются не только в Windows. | |||
| msg175402 — (просмотреть) | Автор: STINNER Виктор (vstinner) * | Дата: 2012-11-11 22:15 | |
> Я полагаю, вы заметили, что сломали кучу билдботов :) Сбои возникают на FreeBSD, OpenIndiana и некоторых других сборочных роботах, которые не устанавливают локаль и поэтому используют локаль «C». | |||
| msg175406 — (просмотреть) | Автор: STINNER Виктор (vstinner) * | Дата: 2012-11-11 23:12 | |
> Эти кодировки используются не только в Windows. Вы можете явно использовать кодировку cpXXX для чтения или записи файла, но эти кодировки не используются для sys. | |||
| msg175413 — (просмотреть) | Автор: Roundup Robot (python-dev) | Дата: 2012-11-12 00:24 | |
Новый набор изменений 6017f09ead53 Виктора Стиннера в ветке «3.3»: Проблема № 16218, № 16444: Улучшение обратного порта в тестах для символов, отличных от ASCII. http://hg.python.org/cpython/rev/6017f09ead53 | |||
| msg175423 — (просмотреть) | Автор: Сергей Сторчака (serhiy.storchaka) * | Дата: 2012-11-12 08:05 | |
> Вы можете явно использовать кодировку cpXXX для чтения или записи файла, но эти > кодировки не используются для sys.getfilesystemencoding() (или > sys.stdout.encoding). По крайней мере, CP1251 использовался для многих кириллических локалей в эпоху до UTF8 (я иногда использую его до сих пор). На данный момент CP1251 является кодировкой по умолчанию для белорусского и болгарского языков: $ grep CP /usr/share/i18n/ПОДДЕРЖИВАЕТСЯ be_BY CP1251 bg_BG CP1251 ru_RU. | |||
| msg176893 — (просмотр) | Автор: Сергей Сторчака (serhiy.storchaka) * | Дата: 2012-12-04 10:40 | |
Пинг. | |||
| msg176955 — (просмотреть) | Автор: Roundup Robot (python-dev) | Дата: 2012-12-04 20:42 | |
Новый набор изменений ed0ff4b3d1c4 Виктора Стиннера в ветке «по умолчанию»: Проблема № 16444: проверьте больше байтов в support.TESTFN_UNDECODABLE для поддержки большего количества кодовых страниц Windows. http://hg.python.org/cpython/rev/ed0ff4b3d1c4 | |||
| msg176958 — (просмотр) | Автор: STINNER Виктор (vstinner) * | Дата: 2012-12-04 20:53 | |
Оооо, все оставшиеся проблемы с недекодируемыми байтами теперь должны быть исправлены (пока кто-нибудь не откроет новую? :-)) | |||
| msg178868 — (просмотр) | Автор: Roundup Robot (python-dev) | Дата: 2013-01-03 00:59 | |
Новый набор изменений 41658a4fb3cc Виктора Стиннера в ветке «3. | |||
 TESTFN_UNDECODABLE в UNIX: используйте кодировку файловой системы в *строгом* режиме, без использования обработчика ошибок суррогатного перехода.
Таким образом, мы можем использовать support.TESTFN_UNDECODABLE, чтобы проверить, правильно ли функция использует обработчик ошибок surrogateescape и/или проверить, правильно ли она ведет себя с символами, отличными от ASCII.
Патч также использует support.TESTFN_UNDECODABLE (только в UNIX) в test_cmd_line_script.test_non_ascii(), чтобы также проверить, что исправление для #16218 работает с кодировкой локали UTF-8.
Пожалуйста, протестируйте патч на UNIX, Windows и Mac OS X.
Мы также можем использовать support.TESTFN_UNDECODABLE в test_cmd_line_script.test_non_ascii() в Windows, я проверю.
У Windows какое-то странное поведение с недекодируемыми символами: некоторые из них заменены символом на аналогичный глиф.
TESTFN_UNDECODABLE в UNIX: используйте кодировку файловой системы в *строгом* режиме, без использования обработчика ошибок суррогатного перехода.
Таким образом, мы можем использовать support.TESTFN_UNDECODABLE, чтобы проверить, правильно ли функция использует обработчик ошибок surrogateescape и/или проверить, правильно ли она ведет себя с символами, отличными от ASCII.
Патч также использует support.TESTFN_UNDECODABLE (только в UNIX) в test_cmd_line_script.test_non_ascii(), чтобы также проверить, что исправление для #16218 работает с кодировкой локали UTF-8.
Пожалуйста, протестируйте патч на UNIX, Windows и Mac OS X.
Мы также можем использовать support.TESTFN_UNDECODABLE в test_cmd_line_script.test_non_ascii() в Windows, я проверю.
У Windows какое-то странное поведение с недекодируемыми символами: некоторые из них заменены символом на аналогичный глиф. 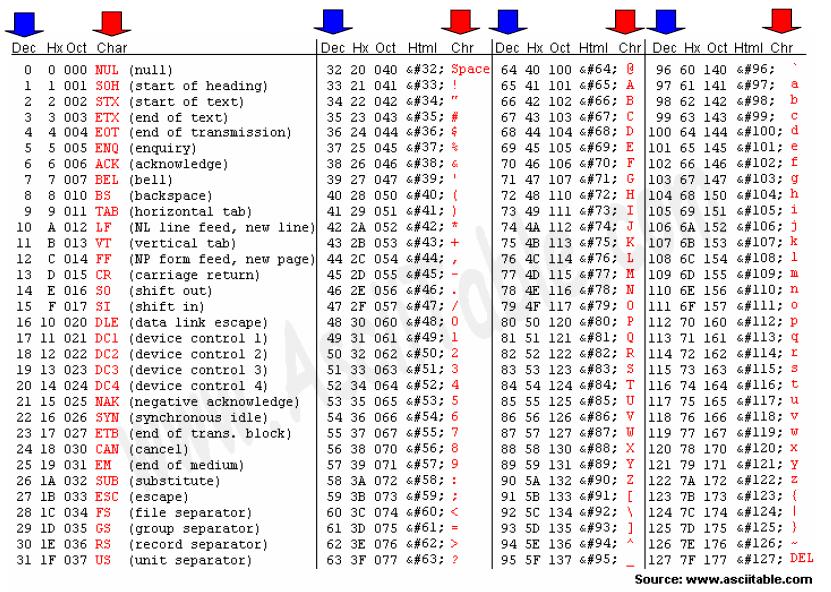 +print("TESTFN_UNDECODABLE = %a" % TESTFN_UNDECODABLE)
+print("TESTFN_NONASCII = %a" % TESTFN_NONASCII)
+print("TESTFN_UNDECODABLE = %a" % TESTFN_UNDECODABLE)
+print("TESTFN_NONASCII = %a" % TESTFN_NONASCII) 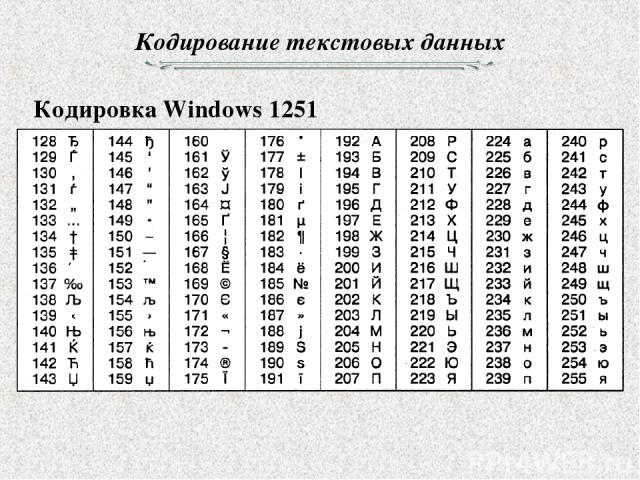
 Верно, но я не хочу вводить регрессию :-)
> Они должны дать сбой, если первоначальная ошибка повторится. Вы пытались восстановить ошибки?
test_cmd_line_script.test_non_ascii() происходит из выпуска № 16218, набор изменений 23ebe277e982. Я проверил эту проблему: support_undecodedable.patch проверяет отсутствие регрессии с UTF-8 (и ASCI и ISO-8859-1) кодировка локали в UNIX.
test_genericpath.test_non_ascii() исходит из проблемы № 3426, это исправление исходит из проблемы № 3187, набор изменений 8a7c930abab6. Я не хочу тратить время на то, чтобы попробовать новый тест по этой проблеме, потому что это 8a7c930abab6 является серьезным изменением, я не вижу, как отменить его, просто чтобы проверить проблему. Считаю, что проблема исправлена, и новый тест должен не уменьшать тестовое покрытие, а лишь увеличивать его ;-)
Верно, но я не хочу вводить регрессию :-)
> Они должны дать сбой, если первоначальная ошибка повторится. Вы пытались восстановить ошибки?
test_cmd_line_script.test_non_ascii() происходит из выпуска № 16218, набор изменений 23ebe277e982. Я проверил эту проблему: support_undecodedable.patch проверяет отсутствие регрессии с UTF-8 (и ASCI и ISO-8859-1) кодировка локали в UNIX.
test_genericpath.test_non_ascii() исходит из проблемы № 3426, это исправление исходит из проблемы № 3187, набор изменений 8a7c930abab6. Я не хочу тратить время на то, чтобы попробовать новый тест по этой проблеме, потому что это 8a7c930abab6 является серьезным изменением, я не вижу, как отменить его, просто чтобы проверить проблему. Считаю, что проблема исправлена, и новый тест должен не уменьшать тестовое покрытие, а лишь увеличивать его ;-) 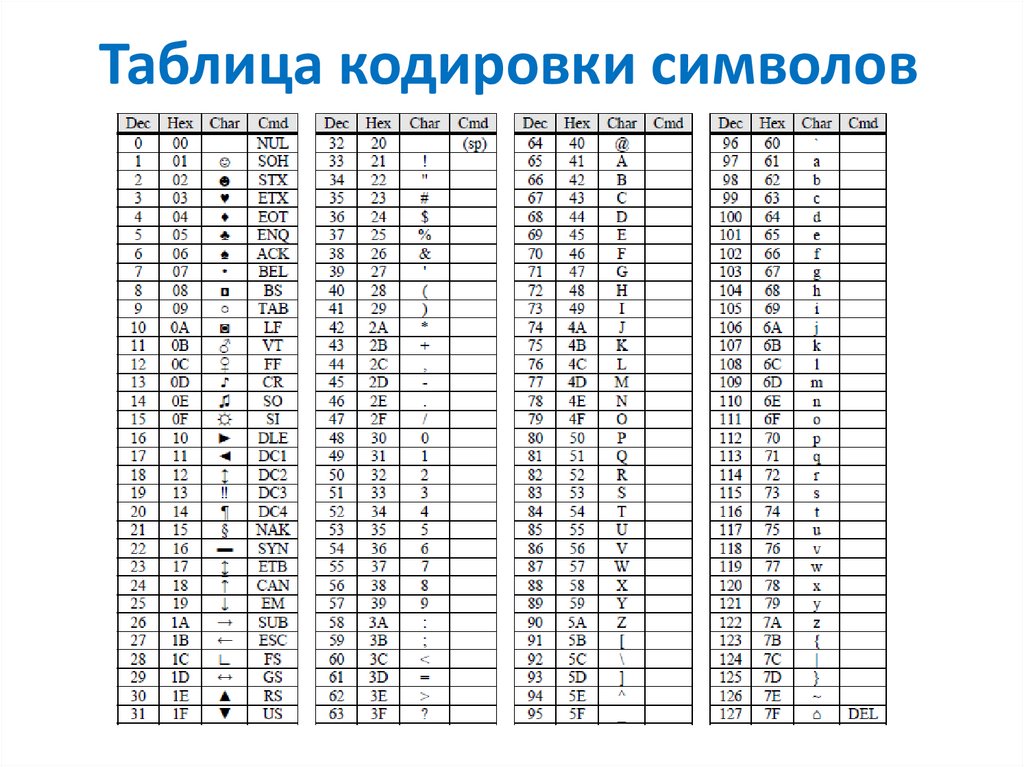 python.org/cpython/rev/6b8a8bc6ba9c
python.org/cpython/rev/6b8a8bc6ba9c  python.org/cpython/rev/398f8770bf0d
python.org/cpython/rev/398f8770bf0d 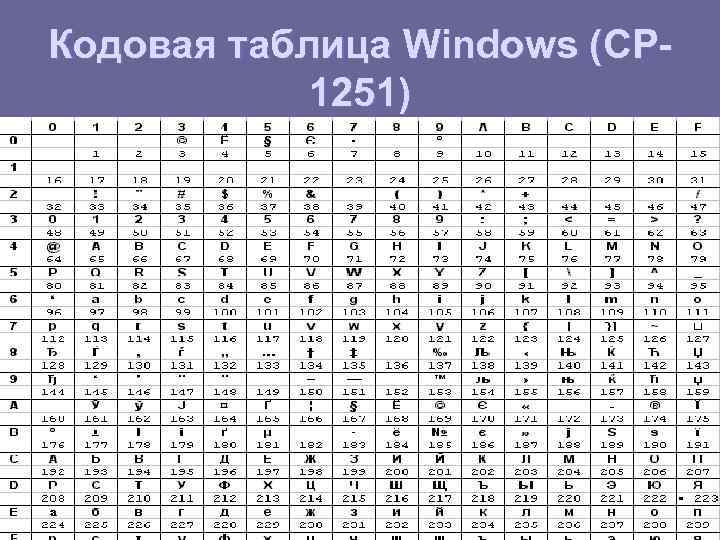 main() декодирует аргументы командной строки из кодировки локали, используя _Py_char2wchar(). В этих ОС локаль "C" использует ISO-8859.-1, но проблема в том, что nl_langinfo(CODESET) объявляет ASCII :-/ test_cmd_line.test_undecodable_code() обрабатывает этот случай. Выдержка из комментария:
# _Py_char2wchar() декодирует b'\xff' как '\xff', даже если локаль
# C и кодировка локали - ASCII. Встречается на FreeBSD, Solaris
# и Mac OS X.
Mac OS X теперь использует UTF-8 для декодирования аргументов командной строки.
Я только что создал проблему № 16455, чтобы исправить FreeBSD и OpenIndiana.
Предлагаю закрыть эту проблему, так как считаю ее исправленной (#16455 повторно активирует TESTFN_UNDECODABLE в test_cmd_line_script).
main() декодирует аргументы командной строки из кодировки локали, используя _Py_char2wchar(). В этих ОС локаль "C" использует ISO-8859.-1, но проблема в том, что nl_langinfo(CODESET) объявляет ASCII :-/ test_cmd_line.test_undecodable_code() обрабатывает этот случай. Выдержка из комментария:
# _Py_char2wchar() декодирует b'\xff' как '\xff', даже если локаль
# C и кодировка локали - ASCII. Встречается на FreeBSD, Solaris
# и Mac OS X.
Mac OS X теперь использует UTF-8 для декодирования аргументов командной строки.
Я только что создал проблему № 16455, чтобы исправить FreeBSD и OpenIndiana.
Предлагаю закрыть эту проблему, так как считаю ее исправленной (#16455 повторно активирует TESTFN_UNDECODABLE в test_cmd_line_script). 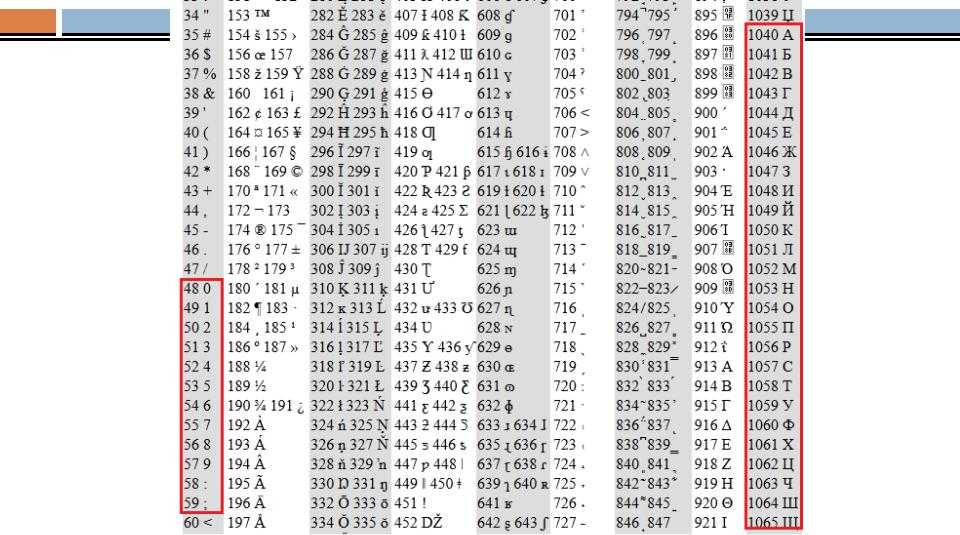 getfilesystemencoding() (или sys.stdout.encoding).
getfilesystemencoding() (или sys.stdout.encoding). 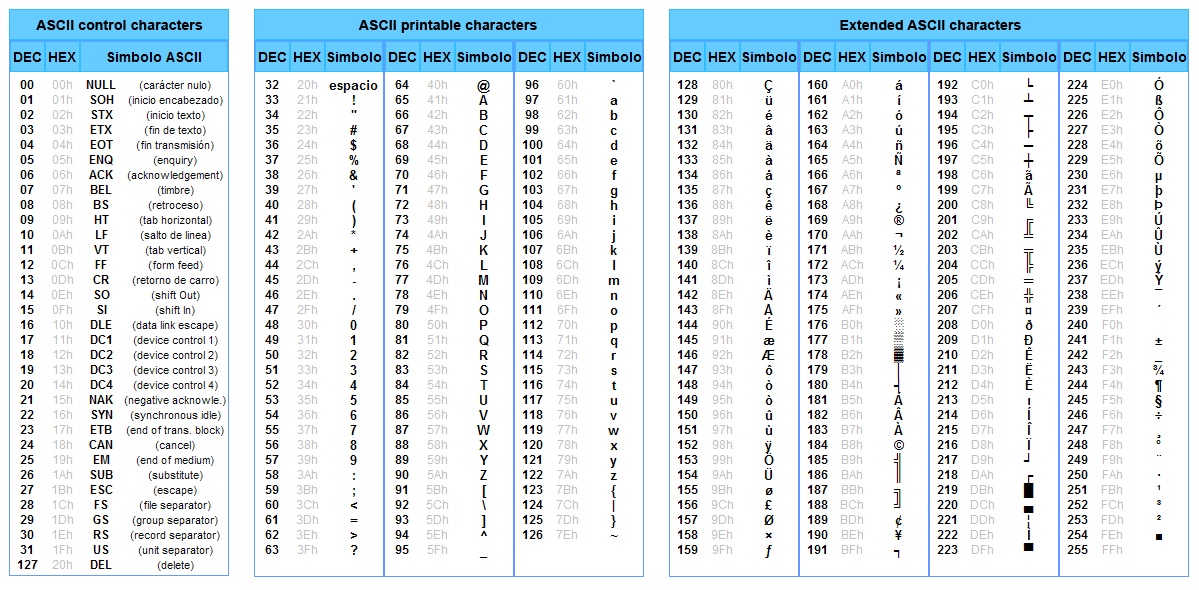 CP1251 CP1251
yi_US CP1255
CP1251 CP1251
yi_US CP1255  2»:
Проблема № 16218, № 16414, № 16444: Бэкпорт FS_NONASCII, TESTFN_UNDECODABLE,
http://hg.python.org/cpython/rev/41658a4fb3cc
Новый набор изменений 4d40c1ce8566 Виктора Стиннера в ветке 3.3:
(Объединение 3.2) Проблема № 16218, № 16414, № 16444: Backport FS_NONASCII,
http://hg.python.org/cpython/rev/4d40c1ce8566
2»:
Проблема № 16218, № 16414, № 16444: Бэкпорт FS_NONASCII, TESTFN_UNDECODABLE,
http://hg.python.org/cpython/rev/41658a4fb3cc
Новый набор изменений 4d40c1ce8566 Виктора Стиннера в ветке 3.3:
(Объединение 3.2) Проблема № 16218, № 16414, № 16444: Backport FS_NONASCII,
http://hg.python.org/cpython/rev/4d40c1ce8566 | Дата | Пользователь | Действие | Аргументы |
|---|---|---|---|
| 2022-04-11 14:57:38 | admin | set | github: 60648 |
| 2013-01-03 01:07:37 | vstinner | set | versions: + Python 3.2, Python 3.3 |
| 2013-01-03 00:59:43 | python-dev | set | сообщения: + msg178868 |
| 2012-12-04 20:53:30 | vstinner | набор | статус: открыто -> закрыто разрешение: исправлено сообщения: + msg176958 |
| 2012-12-04 20:42:00 | python-dev | set | сообщения: + msg176955 |
| 2012-12-04 10:40:07 | serhiy.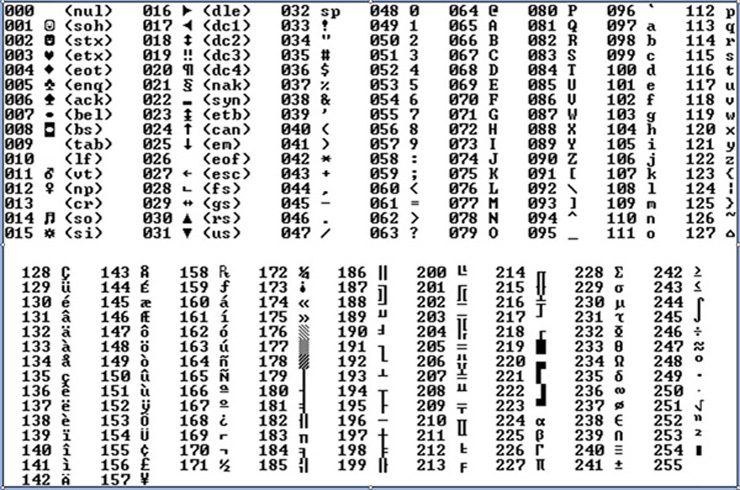 storchaka storchaka | набор | тип: улучшение сообщения: + msg176893 stage: patch review |
| 2012-11-15 15:53:18 | asvetlov | set | nosy:
+ асветлов |
| 12.11.2012 08:05:43 | сергий.сторчака | набор | сообщения: + msg175423 |
| 2012-11-12 00:24:14 | python-dev | set | сообщения: + msg175413 |
| 2012-11-11 23:12:16 | vstinner | set | сообщения: + msg175406 |
| 2012-11-11 22:15:48 | vstinner | set | сообщения: + msg175402 |
| 11.11.2012 22:08:49 | сергий.сторчака | набор | сообщения: + msg175399 |
| 2012-11-11 21:51:52 | vstinner | set | сообщения: + msg175396 |
| 2012-11-10 21:31:49 | python-dev | set | сообщения: + msg175296 |
| 2012-11-10 18:24:50 | pitrou | набор | любопытный:
+ pitrou сообщения: + сообщение 175291 |
| 2012-11-10 12:21:27 | сергий.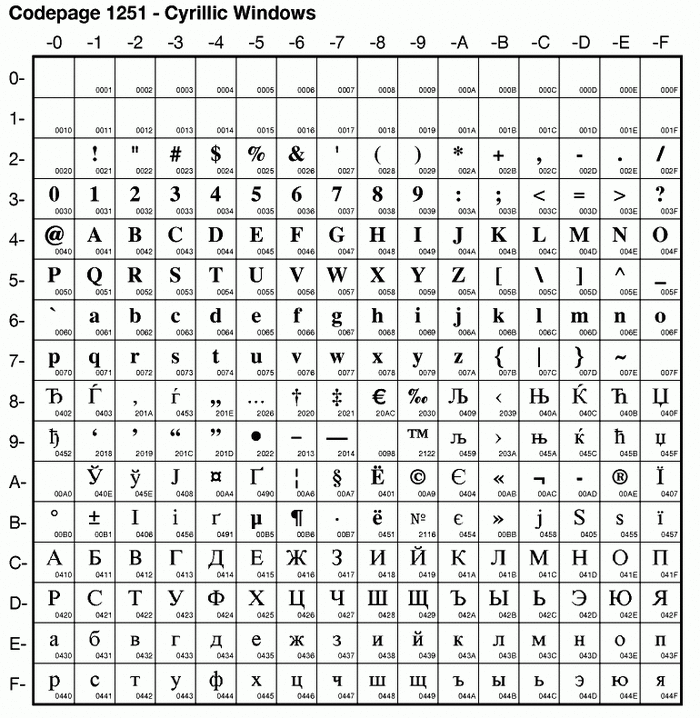 Оставить комментарий
|