c — Что есть ANSI и ASCII
Я бы хотел, наконец, разобраться, как правильно называть строки 8-ми битных символов.
Что такое строка символов UTF-8 мне хорошо понятно — это строка, каждый символ которой представлен переменным количеством 8-ми битных блоков (байтов).
Что такое строки UTF-16/UTF-32 мне тоже ясно.
Но я не могу понять, как корректно называть восьмибитные кодировки, где первые 128 знаков строго определены, а последующие — меняются в зависимости от используемой кодовой страницы.
Кто-то их называет ascii, кто-то ansi, или просто CP1251, если подразумевается конкретная кодировка.
Помогите разобраться. Гугл только запутал.
- c
- utf-8
- ascii
- ansi
ASCII (читается аски́) — это первая кодировка применявшаяся еще в пору когда 99% юзеров SO еще даже не родились (1963 год).
Далее со временем стало понятно, что для других языков можно использовать 8-й бит для отображения национальных символов — то есть использовать 256 символов. Эту расширенную 8-битовую кодировку условно называют ANSI (читается анси́) по названию американского института стандартов в рамках которого и была предложена 8-битовая кодировка. Соответственно, для каждого национального языка была предложена своя раскладка второй половины таблицы (от 128 до 255 символа), а первая половина таблицы от 0 до 127 — изначальные символы ASCII. KOI-8, CP-1251, 1252 и проч. — это различные инкарнации ANSI
Далее когда дело дошло до иероглифов стало понятно, что в 256 символов не уместиться и появилась UNICODE (читается юникод
) — где на 1 символ отводится 2 байта, то есть 65536 символов, где таблица была жестко поделена между национальными символами, например таблица ASCII осталась в интервалеU+0000 до U+007F, а наша с вами кириллица в интервале U+A640 до U+A69F ну и т.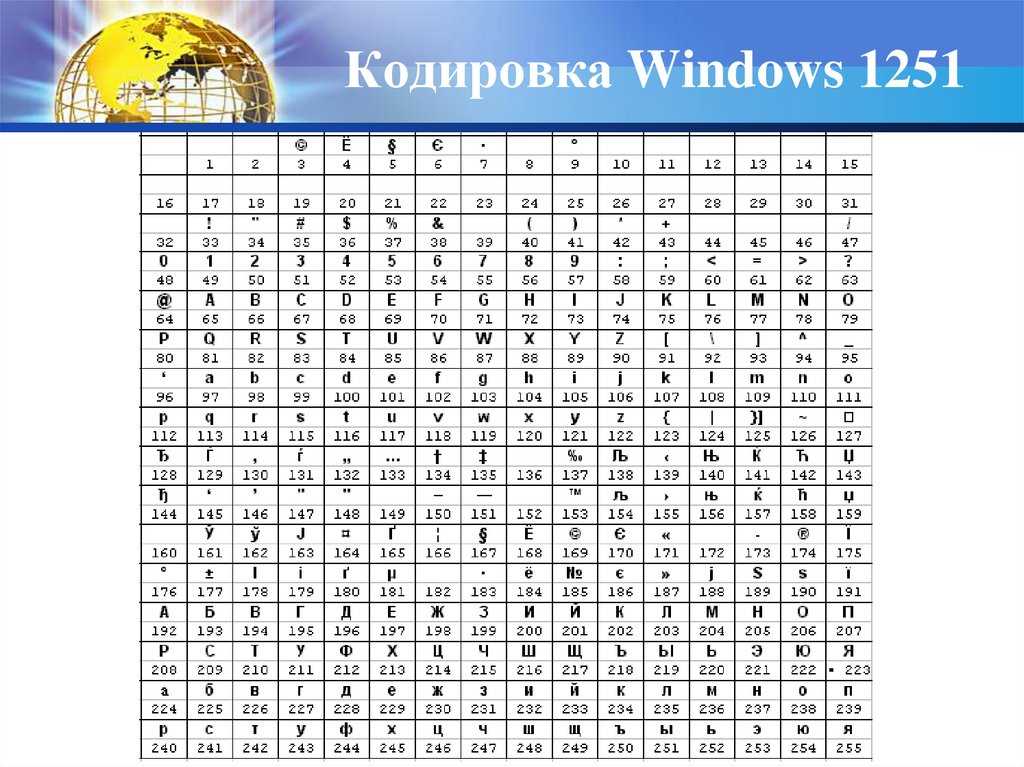 д.
д.С нарастанием угара стало ясно что 65536 символов также не хватает, потому что появились эмодзи, стали поднимать голову другие национальные символы справедливо указывавшие на нехватку места в таблице UNICODE, тогда был предложен UTF-8 (читается ютиэф 8), где количество байтов в символе имеет разную длину и может быть от 1-го до 4 байт, что дает 1 112 064 символов.
Вот, как то так.
3
ASCII (American Standard Code for Information Interchange) — первый вариант кодировки.
Потом появились CP866, KOI8-R, Windows 1251 и вот это всё.
Так что, CP1251 — это расширенная версия ASCII.
ANSI — это расширения ASCII, в которых были удалены псевдографические элементы и добавлены символы типографики.
CP1251 — это пример ANSI кодировки.
Если на диаграмме Эйлера показать:
2
Считаю название «восьмибитные» или «однобайтовые кодировки» вполне корректным общим названием для подобных вещей.
Само собой, если подразумевается какая-то конкретная кодовая страница/кодировка, то она и указывается: «KOI8-R», «CP1251» «CP1250», «ISO8859-5».
ASCII как стандарт (а это действительно стандарт — American standard code for information interchange) определяет, если я правильно помню, только первые 127 кодов символов. Поэтому формально символы типа «я», «č», «њ», «Ḱ» не принадлежат ASCII.
«ANSI» — это вообще исключительно русскоязычный (sic!) термин для CP1251, т.к. вообще-то это сокращение обозначает американский национальный институт стандартизации (а «OEM» — original equipment manufacturer).
Зарегистрируйтесь или войдите
Регистрация через Google
Регистрация через Facebook
Регистрация через почту
Отправить без регистрации
Почта
Необходима, но никому не показывается
Отправить без регистрации
Почта
Необходима, но никому не показывается
Нажимая на кнопку «Отправить ответ», вы соглашаетесь с нашими пользовательским соглашением, политикой конфиденциальности и политикой о куки
Windows-1251 — Wikipedia
From Wikipedia, the free encyclopedia
Jump to navigationJump to search
Windows-1251 is an 8-bit character encoding, designed to cover languages that use the Cyrillic script such as Russian, Ukrainian, Belarusian, Bulgarian, Serbian Cyrillic, Macedonian and other languages.
On the web, it is the second most-used single-byte character encoding (or third most-used character encoding overall), and most used of the single-byte encodings supporting Cyrillic. As of March 2022, 0.5% of all websites use Windows-1251.[1][2] However, it is used by 6.4% of Russian (.ru) websites,[3][4][5] where it is the second most popular choice after UTF-8. In Linux, the encoding is known as cp1251.[6]IBM uses code page 1251 (CCSID 1251 and euro sign extended CCSID 5347) for Windows-1251.[7][8][9][10][11][12][13]
Windows-1251 and KOI8-R (or its Ukrainian variant KOI8-U) are much more commonly used than ISO 8859-5 (which is used by less than 0.0004% of websites).[14] In contrast to Windows-1252 and ISO 8859-1, Windows-1251 is not closely related to ISO 8859-5.
Unicode is preferred to Windows-1251 or other Cyrillic encodings in modern applications, especially on the Internet, making UTF-8 the dominant encoding for web pages.
Contents
- 1 Character set
- 2 Kazakh variant
- 3 Amiga variant
- 4 See also
- 5 References
- 6 Further reading
- 7 External links
Character set[edit]
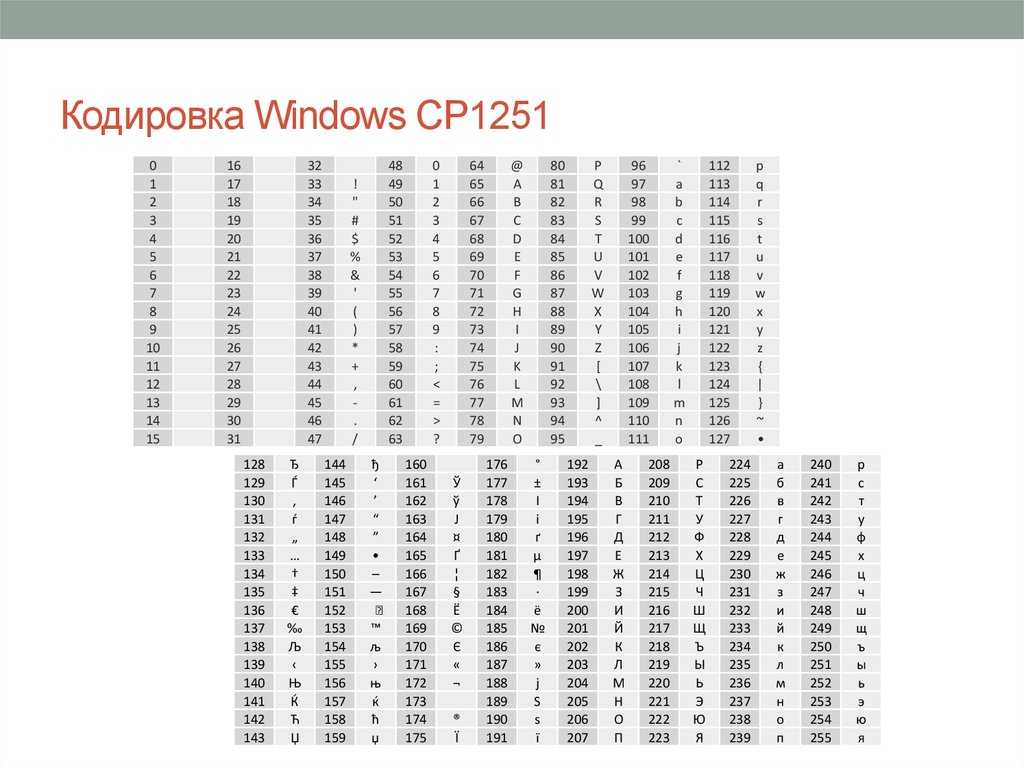
The following table shows Windows-1251. Each character is shown with its Unicode equivalent and its Alt code.
| Windows-1251[15] | ||||||||||||||||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| 0x | NUL | SOH | STX | ETX | EOT | ENQ | ACK | BEL | BS | HT | LF | VT | FF | CR | SO | SI |
| 1x | DLE | DC1 | DC2 | DC3 | DC4 | NAK | SYN | ETB | CAN | EM | SUB | ESC | FS | GS | RS | US |
| 2x | SP | ! | » | # | $ | % | & | ‘ | ( | ) | * | + | , | — | . | / |
| 3x | 0 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | : | ; | < | = | > | ? | |
| 4x | @ | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O |
| 5x | P | Q | R | S | T | U | V | W | X | Y | Z | [ | \ | ] | ^ | _ |
| 6x | ` | a | b | c | d | e | f | g | h | i | j | k | l | m | n | o |
| 7x | p | q | r | s | t | u | v | w | x | y | z | { | | | } | ~ | DEL |
| 8x | Ђ | Ѓ | ‚ | ѓ | „ | … | † | ‡ | € | ‰ | Љ | ‹ | Њ | Ќ | Ћ | Џ |
| 9x | ђ | ‘ | ’ | “ | ” | • | – | — | ™ | љ | › | њ | ќ | ћ | џ | |
| Ax | NBSP | Ў | ў | Ј | ¤ | Ґ | ¦ | § | Ё | © | Є | « | ¬ | SHY | ® | Ї |
| Bx | ° | ± | І | і | ґ | µ | ¶ | · | ё | № | є | » | ј | Ѕ | ѕ | ї |
| Cx | А | Б | В | Г | Д | Е | Ж | З | И | Й | К | Л | М | Н | О | П |
| Dx | Р | С | Т | У | Ф | Х | Ц | Ч | Ш | Щ | Ъ | Ы | Ь | Э | Ю | Я |
| Ex | а | б | в | г | д | е | ж | з | и | й | к | л | м | н | о | п |
| Fx | р | с | т | у | ф | х | ц | ч | ш | щ | ъ | ы | ь | э | ю | я |
Differences from Windows-1252
Kazakh variant[edit]
An altered version of Windows-1251 was standardised in Kazakhstan as Kazakh standard STRK1048, and is known by the label KZ-1048. It differs in the rows shown below:
It differs in the rows shown below:
| KZ-1048 (STRK1048-2002)[16] | ||||||||||||||||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| 8x | Ђ | Ѓ | ‚ | ѓ | „ | … | † | ‡ | € | ‰ | Љ | ‹ | Њ | Қ | Һ | Џ |
| 9x | ђ | ‘ | ’ | “ | ” | • | – | — | ™ | љ | › | њ | қ | һ | џ | |
| Ax | NBSP | Ұ | ұ | Ә | ¤ | Ө | ¦ | § | Ё | © | Ғ | « | ¬ | SHY | ® | Ү |
| Bx | ° | ± | І | і | ө | µ | ¶ | · | ё | № | ғ | » | ә | Ң | ң | ү |
Differences from Windows-1251
Amiga variant[edit]
Russian Amiga OS systems used a version of code page 1251 which matches Windows-1251 for the Russian subset of the Cyrillic letters, but otherwise mostly follows ISO-8859-1. This version is known as Amiga-1251,[17] under which name it is registered with the IANA.[18]
This version is known as Amiga-1251,[17] under which name it is registered with the IANA.[18]
| Amiga-1251[17] | ||||||||||||||||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| 8x | XXX | XXX | BPH | NBH | IND | NEL | SSA | ESA | HTS | HTJ | VTS | PLD | PLU | RI | SS2 | SS3 |
| 9x | DCS | PU1 | PU2 | STS | CCH | MW | SPA | EPA | SOS | XXX | SCI | CSI | ST | OSC | PM | APC |
| Ax | NBSP | ¡ | ¢ | £ | €[a] | ¥ | ¦ | § | Ё | © | №[b] | « | ¬ | SHY | ® | ¯ |
| Bx | ° | ± | ² | ³ | ´ | µ | ¶ | · | ё | ¹ | º | » | ¼ | ½ | ¾ | ¿ |
Different from Windows-1251 to match ISO-8859-1
Different from both Windows-1251 and ISO-8859-1
- ^ Matching ISO-8859-15; at a different location than in Windows-1251
- ^ Present in Windows-1251, but in a different location (absent from ISO-8859-1/15)
See also[edit]
- Latin script in Unicode
- Unicode
- Universal Character Set
- European Unicode subset (DIN 91379)
- UTF-8
References[edit]
- ^ «Historical trends in the usage of character encodings, March 2022».
 «Character Sets». IANA.
«Character Sets». IANA.
Further reading[edit]
- Kornai, Andras; Birnbaum, David J.; da Cruz, Frank; Davis, Bur; Fowler, George; Paine, Richard B.; Paperno, Slava; Simonsen, Keld J.; Thobe, Glenn E.; Vulis, Dimitri; van Wingen, Johan W. (1993-03-13). «CYRILLIC ENCODING FAQ Version 1.3». Retrieved 2020-06-24.
External links[edit]
- Windows 1251 reference chart
- IANA Charset Name Registration
- Unicode mappings of windows 1251 with «best fit»
- Universal Cyrillic decoder, an online program that may help recovering unreadable Cyrillic texts with broken Windows-1251 or other character encodings.
mysql — html страница отображает кириллицу нормально, если содержит charset=windows-1251, но не utf-8
Задавать вопрос
спросил
Изменено 10 лет, 6 месяцев назад
Просмотрено 4к раз
Ну. .. Страницы html и таблицы mysql содержат кириллицу.
Для отображения кириллического текста Барысаў2000 я использую
.. Страницы html и таблицы mysql содержат кириллицу.
Для отображения кириллического текста Барысаў2000 я использую
на сайте. Для хранения этого слова в таблице MySQL используется сортировка utf8_unicode_ci (я читал некоторые темы и, как я понял, для хранения кириллических символов рекомендуется utf8_unicode_ci). Но то, что я на самом деле вижу с помощью phpMyAdmin, текст Барысаў2000 хранится в БД как Áàðûñà¢2000, и это проблема, которую я хочу решить. (Метод POST + экранирование опасных символов используются для сохранения пользовательского текста в БД). Но когда вы выбираете эти данные и отображаете их на html-странице, все выглядит нормально: Барысаў2000.
Проблема с отображением phpMyAdmin не беспокоила меня до сегодняшнего дня. Сегодня пытался решить.
Я догадался, что везде должен использовать utf-8, поэтому я переключился с
до
Теперь на моих страницах вместо кириллицы отображаются вопросы и вопрос с отображением кириллицы в моей БД так и не решился. Кто может сказать мне, в чем проблема?
P.S. Я без проблем читаю сербские и белорусские (кириллица) веб-сайты и могу печатать кириллические тексты на своем локальном хосте.
Кто может сказать мне, в чем проблема?
P.S. Я без проблем читаю сербские и белорусские (кириллица) веб-сайты и могу печатать кириллические тексты на своем локальном хосте.
Спасибо.
- mysql
- utf-8
- кодировка символов
- интернационализация
- cp1251
1
Проблема с phpMyAdmin, вероятно, вызвана неправильным подбором кодировки символов. Если вы закодируете текст Барысаў2000 , используя кодировку windows 1251 , вы получите поток байтов C1 E0 F0 FB F1 E0 A2 32 30 30 30 0D 0A . Если этот поток байтов интерпретируется как текст, который с ISO-8859-1 или кодировка windows-1252, результат отображается как Áàðûñà¢2000 .
Это говорит о том, что строки в вашей базе данных действительно хранятся в кодировке windows-1251. Затем, если вы выведете эти строки и только заявите, что он использует кодировку UTF-8 (без какой-либо перекодировки), результатом будет мусорный текст, потому что этот поток байтов содержит недопустимые последовательности байтов UTF-8.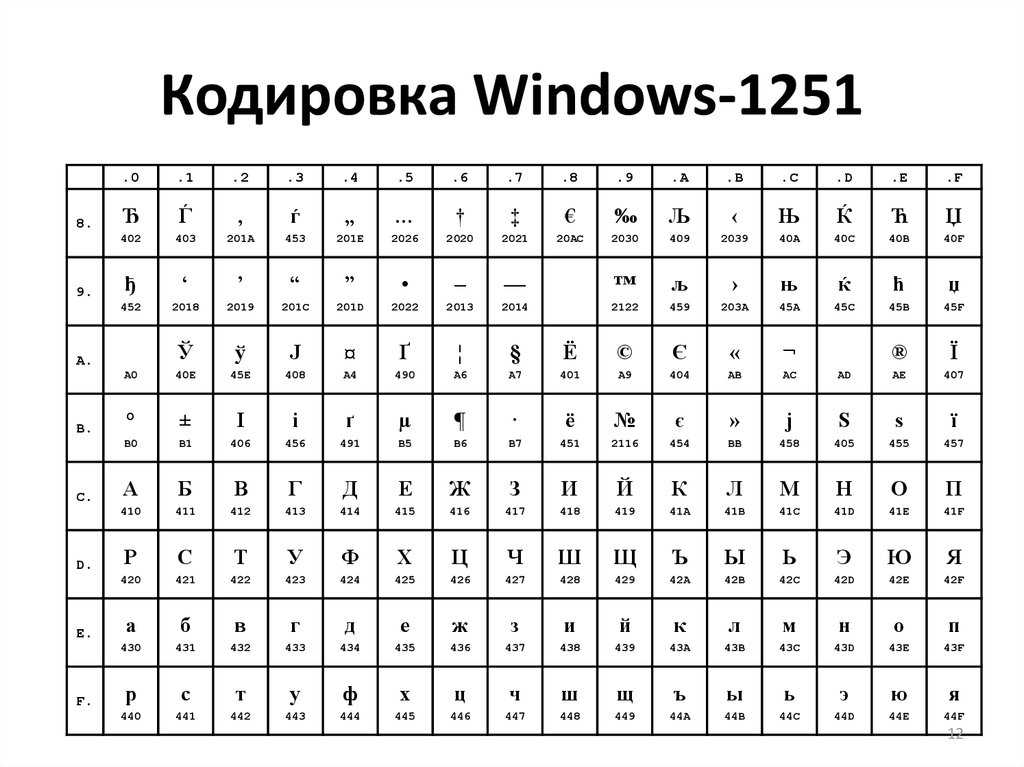
Вы должны либо продолжать обслуживать свои страницы с кодировкой Windows-1251 и указать phpMyAdmin использовать эту кодировку, либо вам следует переключиться на юникод везде (также внутри, в базе данных). Чем меньше преобразований символов и угадывания правильной кодировки вам нужно, тем проще будет поддерживать вашу систему.
4
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя электронную почту и пароль
Опубликовать как гость
Электронная почта
Требуется, но никогда не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Является ли CP-1251 расширением для ASCII?
спросил
Изменено 9 лет, 5 месяцев назад
Просмотрено 776 раз
Если мне нужны символы кириллицы в формате ASCII, это будет означать, что мне понадобится расширенная таблица ASCII, верно? Я хочу знать, является ли cp-1251 расширением ASCII, и если нет, то чем оно считается.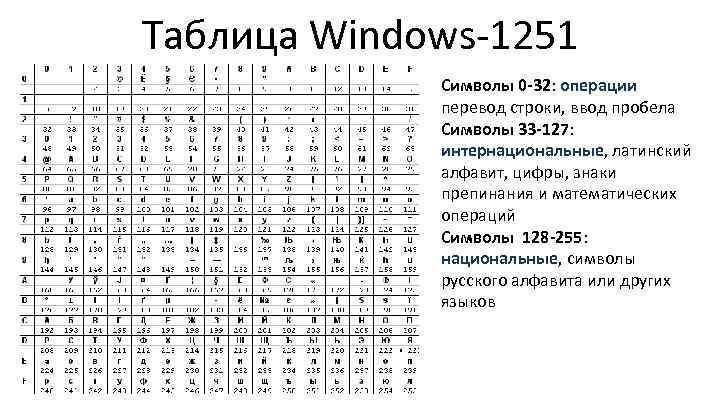 Я немного запутался с поиском в гугле. В некоторых местах говорят, что это кодовая страница в другом расширении.
Я немного запутался с поиском в гугле. В некоторых местах говорят, что это кодовая страница в другом расширении.
Также, если у меня есть символ O cp-1251 с кодом 206, тогда значение UTF-8 того же символа будет 041E, верно?
«Расширенный ASCII» — неоднозначный термин.
US-ASCII поддерживает 128 значений (8-й бит зарезервирован) и не поддерживает коды кириллицы. Первая половина Windows 1251 сопоставляет кодовые точки с одним и тем же диапазоном значений. То же самое верно и для UTF-8. Таким образом, любые документы, закодированные как ASCII, являются допустимыми для Windows 1252, Windows 1251, UTF-8, ISO-8859-1, и некоторых других кодировок .
U+004F (ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА O), закодированные как ASCII, Windows-1251 или UTF-8, будут иметь одно и то же значение октета ( 4F ) при просмотре с помощью шестнадцатеричного редактора.
Для данных на естественном языке большинство кодировок, отличных от Unicode, следует считать устаревшими.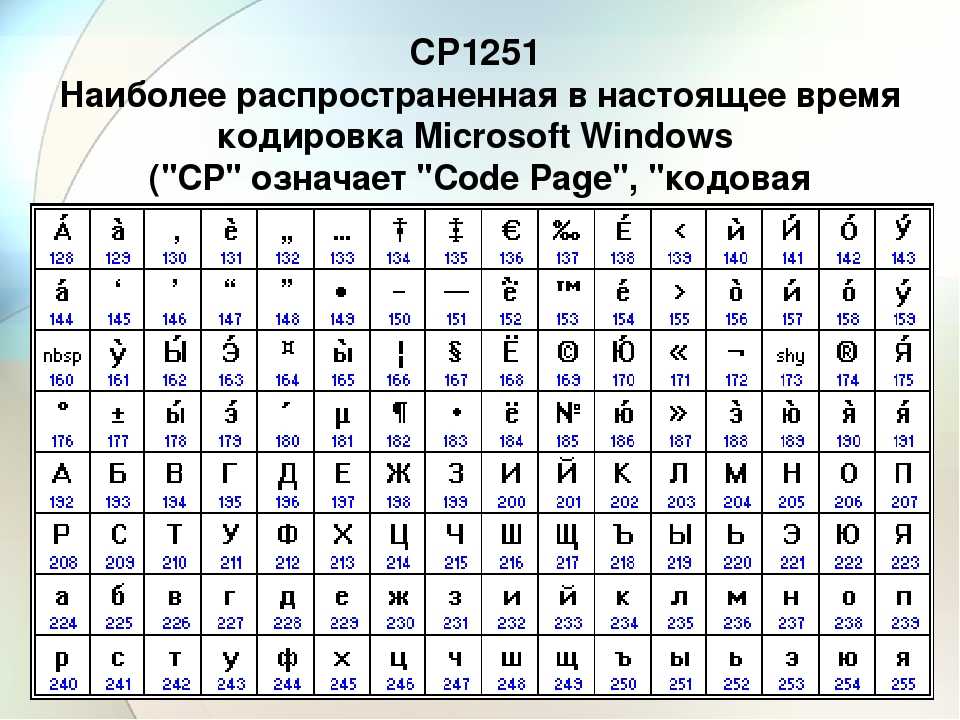
ASCII является стандартом. Это 7-битный код. Он содержит значения в диапазоне 0 .. 127. Все остальное не ASCII.
На ПК можно работать с кодовыми страницами. Вы можете выбрать кодовую страницу, содержащую интересующие вас символы.
Возможно, будет полезно взглянуть на Unicode, который может поддерживать ASCII и практически любой другой символ, когда-либо изобретенный.
Технически ASCII — это 7-битный формат, не содержащий символов кириллицы. Учитывая это, нельзя иметь кириллические символы в подлинном формате ASCII.
CP-1251 — это 8-битная кодировка, включающая символы кириллицы. Первые 128 символов CP-1251 совпадают с ASCII, поэтому в этом смысле это расширение ASCII. Однако в конечном итоге CP-1251 — это просто кодировка символов, т. е. сопоставление между символами и числовыми значениями.
В настоящее время семейство кодировок Unicode имеет наибольшую популярность для современных интернационализированных приложений, при этом UTF-8 является наиболее популярным из-за компактного представления основных символов ASCII.