Кодирование символов : кодовая страница, ASCII
Кодировка символов (часто называемая также кодовой страницей) – это набор числовых значений, которые ставятся в соответствие группе алфавитно-цифровых символов, знаков пунктуации и специальных символов.
Для кодировки символов в Windows используется таблица ASCII (American Standard Code for Interchange of Information).
В ASCII первые 128 символов всех кодовых страниц состоят из базовой таблицы символов. Первые 32 кода базовой таблицы, начиная с нулевого, размещают управляющие коды.
| Символ | Код | Клавиши | Значение |
| nul | 0 | Ctrl + @ | Нуль |
| soh | 1 | Ctrl + A | Начало заголовка |
| stx | 2 | Ctrl + B | Начало текста |
| etx | 3 | Ctrl + C | Конец текста |
| eot | 4 | Ctrl + D | Конец передачи |
| 5 | Ctrl + E | Запрос | |
| ack | 6 | Ctrl + F | Подтверждение |
| bel | 7 | Ctrl + G | Сигнал (звонок) |
| bs | 8 | Ctrl + H | Забой (шаг назад) |
| ht | 9 | Ctrl + I | Горизонтальная табуляция |
| lf | 10 | Ctrl + J | Перевод строки |
| vt | 11 | Ctrl + K | Вертикальная табуляция |
| ff | 12 | Ctrl + L | Новая страница |
| cr | 13 | Ctrl + M | Возврат каретки |
| so | 14 | Ctrl + N | Выключить сдвиг |
| si | 15 | Ctrl + O | Включить сдвиг |
| dle | 16 | Ctrl + P | Ключ связи данных |
| dc1 | 17 | Ctrl + Q | Управление устройством 1 |
| dc2 | 18 | Ctrl + R | Управление устройством 2 |
| dc3 | 19 | Ctrl + S | Управление устройством 3 |
| dc4 | 20 | Ctrl + T | Управление устройством 4 |
| nak | 21 | Ctrl + U | Отрицательное подтверждение |
| syn | 22 | Ctrl + V | Синхронизация |
| etb | 23 | Ctrl + W | Конец передаваемого блока |
| can | 24 | Ctrl + X | Отказ |
| em | 25 | Ctrl + Y | Конец среды |
| sub | 26 | Ctrl + Z | Замена |
| esc | 27 | Ctrl + [ | Ключ |
| fs | 28 | Ctrl + \ | Разделитель файлов |
| gs | 29 | Ctrl + ] | Разделитель группы |
| rs | 30 | Ctrl + ^ | Разделитель записей |
| us | 31 | Ctrl + _ | Разделитель модулей |
Базовая таблица кодировки ASCII
| 32 пробел | 48 0 | 64 @ | 80 P | 96 ` | 112 p |
| 33 ! | 49 1 | 65 A | 81 Q | 97 a | 113 q |
| 34 “ | 50 2 | 66 B | 82 R | 98 b | 114 r |
| 35 # | 51 3 | 67 C | 83 S | 99 c | 115 s |
| 36 $ | 52 4 | 68 D | 84 T | 100 d | 116 t |
| 37 % | 53 5 | 69 E | 85 U | 101 e | 117 u |
| 38 & | 54 6 | 70 F | 86 V | 102 f | 118 v |
| 39 ‘ | 55 7 | 71 G | 87 W | 103 g | 119 w |
| 40 ( | 56 8 | 72 H | 88 X | 104 h | 120 x |
| 41 ) | 57 9 | 73 I | 89 Y | 105 i | 121 y |
| 42 * | 58 : | 74 J | 90 Z | 106 j | 122 z |
| 43 + | 59 ; | 75 K | 91 [ | 107 k | 123 { |
| 44 , | 60 < | 76 L | 92 \ | 108 l | 124 | |
| 45 — | 61 = | 77 M | 93 ] | 109 m | 125 } |
46 . | 110 n | 126 ~ | |||
| 47 / | 63 ? | 79 O | 95 _ | 111 o | 127 |
Символы с номерами от 128 до 255 представляют собой таблицу расширения и варьируются в зависимости от набора скриптов, представленных кодировкой символов. Набор символов таблицы расширения различается в зависимости от выбранной кодовой страницы:
1251 – кодовая страница Windows
| 128 Ђ | 144 Ђ | 160 | 176 ° | 192 А | 208 Р | 224 а | 240 р |
| 129 Ѓ | 145 ‘ | 161 Ў | 177 ± | 193 Б | 209 С | 225 б | 241 с |
| 130 ‚ | 146 ’ | 162 ў | 178 I | 194 В | 210 Т | 226 в | 242 т |
| 131 ѓ | 147 “ | 163 J | 179 i | 195 Г | 211 У | 227 г | 243 у |
| 132 „ | 148 ” | 164 ¤ | 180 ґ | 196 Д | 212 Ф | 228 д | 244 ф |
| 133 … | 149 • | 165 Ґ | 181 μ | 197 Е | 213 Х | 229 е | 245 х |
| 134 † | 150 – | 166 ¦ | 182 ¶ | 198 Ж | 214 Ц | 230 ж | 246 ц |
| 135 ‡ | 151 — | 167 § | 183 · | 215 Ч | 231 з | 247 ч | |
| 136 € | 152 □ | 168 Ё | 184 ё | 200 И | 216 Ш | 232 и | 248 ш |
| 137 ‰ | 153 ™ | 169 © | 185 № | 201 Й | 217 Щ | 233 й | 249 щ |
| 138 Љ | 154 љ | 170 Є | 186 є | 202 К | 218 Ъ | 234 к | 250 ъ |
| 139 < | 155 > | 171 « | 187 » | 203 Л | 219 Ы | 235 л | 251 ы |
| 140 Њ | 156 њ | 172 ¬ | 188 j | 204 М | 220 Ь | 236 м | 252 ь |
| 141 Ќ | 157 ќ | 173 | 189 S | 205 Н | 221 Э | 237 н | 253 э |
| 142 Ћ | 158 ћ | 174 ® | 190 s | 206 О | 222 Ю | 238 о | 254 ю |
| 143 Џ | 159 џ | 175 Ï | 191 ї | 207 П | 223 Я | 239 п | 255 я |
866 – кодовая страница DOS
| 128 А | 144 Р | 160 а | 176 ░ | 192 └ | 208 ╨ | 224 р | 240 ≡Ё |
| 129 Б | 145 С | 161 б | 177 ▒ | 193 ┴ | 209 ╤ | 225 с | 241 ±ё |
| 130 В | 146 Т | 162 в | 178 ▓ | 194 ┬ | 210 ╥ | 226 т | 242 ≥ |
| 131 Г | 147 У | 163 г | 179 │ | 195 ├ | 211 ╙ | 227 у | 243 ≤ |
| 132 Д | 148 Ф | 164 д | 180 ┤ | 196 ─ | 212 ╘ | 228 ф | 244 ⌠ |
| 133 Е | 149 Х | 165 е | 181 ╡ | 197 ┼ | 213 ╒ | 229 х | 245 ⌡ |
| 134 Ж | 150 Ц | 166 ж | 182 ╢ | 198 ╞ | 230 ц | 246 ¸ | |
| 135 З | 151 Ч | 167 з | 183 ╖ | 199 ╟ | 215 ╫ | 231 ч | 247 » |
| 136 И | 152 Ш | 168 и | 184 ╕ | 200 ╚ | 216 ╪ | 232 ш | 248 ° |
| 137 Й | 153 Щ | 169 й | 185 ╣ | 201 ╔ | 217 ┘ | 233 щ | 249 · |
| 138 К | 154 Ъ | 170 к | 186 ║ | 202 ╩ | 218 ┌ | 234 ъ | 250 ∙ |
| 139 Л | 155 Ы | 171 л | 187 ╗ | 203 ╦ | 219 █ | 235 ы | 251 √ |
| 140 М | 156 Ь | 172 м | 188 ╝ | 204 ╠ | 220 ▄ | 236 ь | 252 ⁿ |
| 141 Н | 157 Э | 173 н | 189 ╜ | 205 ═ | 221 ▌ | 237 э | 253 ² |
| 142 О | 158 Ю | 174 о | 190 ╛ | 206 ╬ | 222 ▐ | 238 ю | 254 ■ |
| 143 П | 159 Я | 175 п | 191 ┐ | 207 ╧ | 223 ▀ | 239 я | 255 |
Русские названия основных спецсимволов:
| Символ | Название |
| ` | гравис, кавычка, обратный машинописный апостроф |
| ` | гравис, кавычка, обратный машинописный апостроф |
| ~ | тильда |
| ! | восклицательный знак |
| @ | эт, коммерческое эт, «собака» |
| # | октоторп, решетка, диез |
| $ | знак доллара |
| % | процент |
| ^ | циркумфлекс, знак вставки |
| & | амперсанд |
| * | астериск, звездочка, знак умножения |
| ( | левая открывающая круглая скобка |
| ) | правая закрывающая круглая скобка |
| — | минус, дефис |
| _ | знак подчеркивания |
| = | знак равенства |
| + | плюс |
| [ | левая открывающая квадратная скобка |
| ] | правая закрывающая квадратная скобка |
| { | левая открывающая фигурная скобка |
| } | правая закрывающая фигурная скобка |
| ; | точка с запятой |
| : | двоеточие |
| ‘ | машинописный апостроф, одинарная кавычка |
| « | двойная кавычка |
| , | запятая |
. | точка |
| / | слэш, косая черта, знак дроби |
| < | левая открытая угловая скобка, знак меньше |
| > | правая закрытая угловая скобка, знак больше |
| \ | обратный слэш, обратная косая черта |
| | | вертикальная черта |
Кодировка UNICODE
Юникод (Unicode) — стандарт кодирования символов, позволяющий представить знаки практически всех письменных языков. Стандарт предложен в 1991 году некоммерческой организацией «Консорциум Юникода».
В Unicode используются 16-битовые (2-байтовые) коды, что позволяет представить 65536 символов.
Применение стандарта Unicode позволяет закодировать очень большое число символов из разных письменностей: в документах Unicode могут соседствовать китайские иероглифы, математические символы, буквы греческого алфавита, латиницы и кириллицы, при этом становится ненужным переключение кодовых страниц.
Для представления символьных данных в кодировке Unicode используется символьный тип wchar_t.
| ASCII | UNICODE |
| char | wchar_t |
| 1 байт | 2 байта |
Тип кодировки задается в свойствах проекта Microsoft Visual Studio:
Многобайтовая кодировка предполагает использование кодировки ASCII.
При этом при построении проекта используется директива условной компиляции, переопределяющая тип TCHAR:
#ifdef _UNICODE
typedef wchar_t TCHAR;
#else
typedef char TCHAR;
#endif
Для перекодирования строки в формат Unicode без изменения кодировки файла используется макроопределение
_T(«строка»)
Прототип макроса содержится в файле tchar.h.
Назад: Представление данных и архитектура ЭВМ
Кодирование текстовой информации — Кодирование информации
Кодирование текстовой информации
Одна и та же информация может быть представлена (закодирована) в нескольких
формах. C появлением компьютеров возникла необходимость кодирования всех видов
информации, с которыми имеет дело и отдельный человек, и человечество в целом.
Но решать задачу кодирования информации человечество начало задолго до
появления компьютеров. Грандиозные достижения человечества — письменность и
арифметика — есть не что иное, как система кодирования речи и числовой
информации. Информация никогда не появляется в чистом виде, она всегда как-то
представлена, как-то закодирована.
C появлением компьютеров возникла необходимость кодирования всех видов
информации, с которыми имеет дело и отдельный человек, и человечество в целом.
Но решать задачу кодирования информации человечество начало задолго до
появления компьютеров. Грандиозные достижения человечества — письменность и
арифметика — есть не что иное, как система кодирования речи и числовой
информации. Информация никогда не появляется в чистом виде, она всегда как-то
представлена, как-то закодирована.
Двоичное кодирование – один из распространенных способов представления информации. В вычислительных машинах, в роботах и станках с числовым программным управлением, как правило, вся информация, с которой имеет дело устройство, кодируется в виде слов двоичного алфавита.
Начиная с конца 60-х годов, компьютеры все больше стали использоваться для
обработки текстовой информации, и в настоящее время основная доля персональных
компьютеров в мире (и большая часть времени) занята обработкой именно текстовой
информации. Все эти виды информации в компьютере представлены в двоичном коде,
т. е. используется алфавит мощностью два (всего два символа 0 и 1). Связано это
с тем, что удобно представлять информацию в виде последовательности
электрических импульсов: импульс отсутствует (0), импульс есть (1).
Все эти виды информации в компьютере представлены в двоичном коде,
т. е. используется алфавит мощностью два (всего два символа 0 и 1). Связано это
с тем, что удобно представлять информацию в виде последовательности
электрических импульсов: импульс отсутствует (0), импульс есть (1).
Такое кодирование принято называть двоичным, а сами логические последовательности нулей и единиц — машинным языком.
С точки зрения ЭВМ текст состоит из отдельных символов. К числу символов принадлежат не только буквы (заглавные или строчные, латинские или русские), но и цифры, знаки препинания, спецсимволы типа «=», «(«, «&» и т.п. и даже (обратите особое внимание!) пробелы между словами.
Тексты вводятся в память компьютера с помощью клавиатуры. На клавишах
написаны привычные нам буквы, цифры, знаки препинания и другие символы. В
оперативную память они попадают в двоичном коде. Это значит, что каждый символ
представляется 8-разрядным двоичным кодом.
Рис.1 Представление символа в виде двоичного кода.
Традиционно для кодирования одного символа используется количество информации, равное 1 байту, т. е. I = 1 байт = 8 бит. При помощи формулы, которая связывает между собой количество возможных событий К и количество информации I, можно вычислить сколько различных символов можно закодировать (считая, что символы — это возможные события): К = 2I = 28 = 256, т. е. для представления текстовой информации можно использовать алфавит мощностью 256 символов.
Такое количество символов вполне достаточно для представления текстовой информации, включая прописные и строчные буквы русского и латинского алфавита, цифры, знаки, графические символы и пр.
Кодирование заключается в том, что каждому символу ставится в соответствие
уникальный десятичный код от 0 до 255 или соответствующий ему двоичный код от
00000000 до 11111111. Таким образом, человек различает символы по их
начертанию, а компьютер — по их коду.
Удобство побайтового кодирования символов очевидно, поскольку байт — наименьшая адресуемая часть памяти и, следовательно, процессор может обратиться к каждому символу отдельно, выполняя обработку текста. С другой стороны, 256 символов – это вполне достаточное количество для представления самой разнообразной символьной информации.
В процессе вывода символа на экран компьютера производится обратный процесс — декодирование, то есть преобразование кода символа в его изображение. Важно, что присвоение символу конкретного кода — это вопрос соглашения, которое фиксируется в кодовой таблице.
Теперь возникает вопрос, какой именно восьмиразрядный двоичный код поставить в соответствие каждому символу. Понятно, что это дело условное, можно придумать множество способов кодировки.
Все символы компьютерного алфавита пронумерованы от 0 до 255. Каждому
номеру соответствует восьмиразрядный двоичный код от 00000000 до 11111111. Этот
код просто порядковый номер символа в двоичной системе счисления.
Этот
код просто порядковый номер символа в двоичной системе счисления.
Виды таблиц кодировок
Таблица, в которой всем символам компьютерного алфавита поставлены в соответствие порядковые номера, называется таблицей кодировки.
Для разных типов ЭВМ используются различные таблицы кодировки.
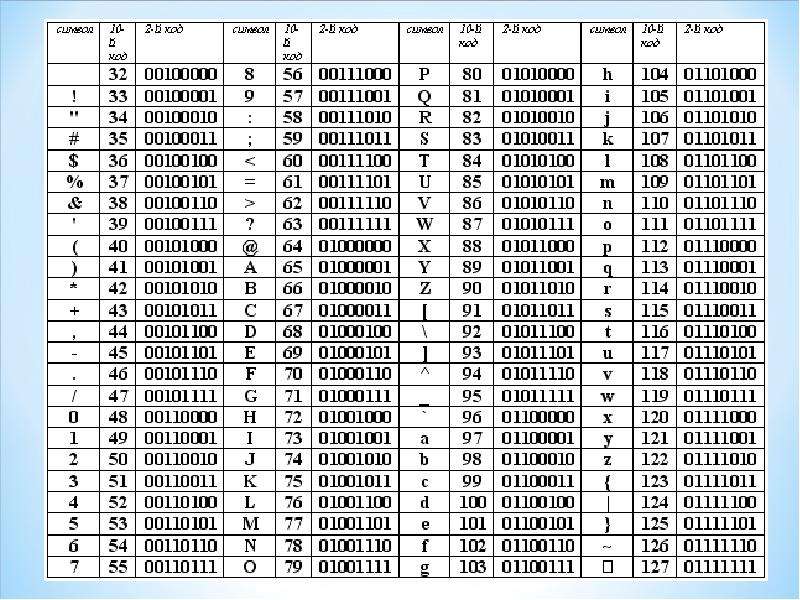
В качестве международного стандарта принята кодовая таблица ASCII (American Standard Code for Information Interchange — Американский стандартный код для информационного обмена), кодирующая первую половину символов с числовыми кодами от 0 до 127 ( коды от 0 до 32 отведены не символам, а функциональным клавишам).
Таблица кодов ASCII делится на две части.
Международным стандартом является лишь первая половина таблицы, т.е. символы с номерами от 0 (00000000), до 127 (01111111).
Структура таблицы кодировки ASCII
Порядковый номер | Код | Символ |
0 — 31 | 00000000 — 00011111 | Символы с номерами от 0 до 31 принято называть
управляющими. Их функция – управление процессом вывода текста на экран или печать, подача звукового сигнала, разметка текста и т.п. |
32 — 127 | 0100000 — 01111111 | Стандартная часть таблицы (английский). Сюда входят строчные и прописные буквы латинского алфавита, десятичные цифры, знаки препинания, всевозможные скобки, коммерческие и другие символы. Символ 32 — пробел, т.е. пустая позиция в тексте. Все остальные отражаются определенными знаками. |
128 — 255 | 10000000 — 11111111 | Альтернативная часть таблицы (русская). Вторая половина кодовой таблицы ASCII, называемая кодовой страницей (128 кодов, начиная с 10000000 и кончая 11111111), может иметь различные варианты, каждый вариант имеет свой номер. Кодовая страница в первую очередь
используется для размещения национальных алфавитов, отличных от латинского. |

 В
русских национальных кодировках в этой части таблицы размещаются символы
русского алфавита.
В
русских национальных кодировках в этой части таблицы размещаются символы
русского алфавита.Рис. 2 Первая половина таблицы кодировки ASCII.
Обращается внимание на то, что в таблице кодировки буквы (прописные и строчные) располагаются в алфавитном порядке, а цифры упорядочены по возрастанию значений. Такое соблюдение лексикографического порядка в расположении символов называется принципом последовательного кодирования алфавита.
Для букв русского алфавита также соблюдается принцип последовательного кодирования.
Рис.3 Вторая половина таблицы кодировки ASCII.
К сожалению, в настоящее время существуют пять различных кодировок кириллицы (КОИ8-Р, Windows. MS-DOS, Macintosh и ISO). Из-за этого часто возникают проблемы с переносом русского текста с одного компьютера на другой, из одной программной системы в другую.
Хронологически одним из первых стандартов кодирования русских букв на
компьютерах был КОИ8 («Код обмена информацией, 8-битный»). Эта
кодировка применялась еще в 70-е годы на компьютерах серии ЕС ЭВМ, а с
середины 80-х стала использоваться в первых русифицированных версиях
операционной системы UNIX.
Эта
кодировка применялась еще в 70-е годы на компьютерах серии ЕС ЭВМ, а с
середины 80-х стала использоваться в первых русифицированных версиях
операционной системы UNIX.
Рис.4 Кодировка КОИ8.
От начала 90-х годов, времени господства операционной системы MS DOS, остается кодировка CP866 («CP» означает «Code Page», «кодовая страница»).
Рис.5 Кодировка CP866 .
Компьютеры фирмы Apple, работающие под управлением операционной системы Mac OS, используют свою собственную кодировку Mac.
Рис.6 Кодировка Mac.
Кроме того, Международная организация по стандартизации (International Standards Organization, ISO) утвердила в качестве стандарта для русского языка еще одну кодировку под названием ISO 8859-5.
Рис. 7 Кодировка ISO 8859-5.
Наиболее распространенной в настоящее время является кодировка Microsoft
Windows, обозначаемая сокращением CP1251. Введена компанией Microsoft; с учетом
широкого распространения операционных систем (ОС) и других программных
продуктов этой компании в Российской Федерации она нашла широкое
распространение.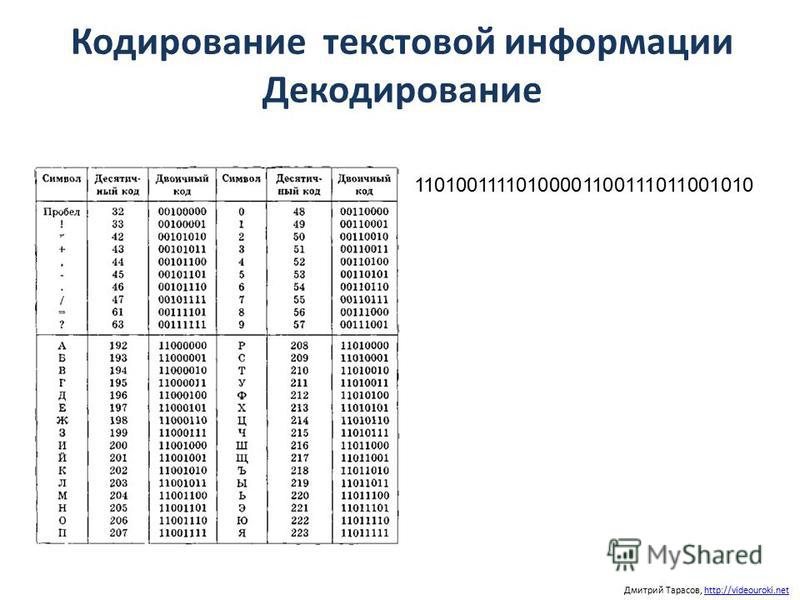
Рис. 8 Кодировка CP1251.
С конца 90-х годов проблема стандартизации символьного кодирования решается введением нового международного стандарта, который называется Unicode.
Рис.9 Кодировка Unicode.
Это 16-разрядная кодировка, т.е. в ней на каждый символ отводится 2 байта памяти. Конечно, при этом объем занимаемой памяти увеличивается в 2 раза. Но зато такая кодовая таблица допускает включение до 65536 символов. Полная спецификация стандарта Unicode включает в себя все существующие, вымершие и искусственно созданные алфавиты мира, а также множество математических, музыкальных, химических и прочих символов.
Внутреннее представление слов в памяти компьютера
с помощью таблицы ASCII
Слова | Память |
file | 01100110 01101001 01101100 01100101 |
disk | 01100100 01101001 01110011 01101011 |
Иногда бывает так, что текст, состоящий из букв русского алфавита,
полученный с другого компьютера, невозможно прочитать — на экране монитора
видна какая-то «абракадабра». Это происходит оттого, что на
компьютерах применяется разная кодировка символов русского языка.
Это происходит оттого, что на
компьютерах применяется разная кодировка символов русского языка.
Рис. 10.
Таким образом, каждая кодировка задается своей собственной кодовой таблицей. Как видно из таблицы, одному и тому же двоичному коду в различных кодировках поставлены в соответствие различные символы.
Например, последовательность числовых кодов 221, 194, 204 в кодировке СР1251 образует слово «ЭВМ» (Рис. 10), тогда как в других кодировках это будет бессмысленный набор символов.
К счастью, в большинстве случаев пользователь не должен заботиться о перекодировках текстовых документов, так как это делают специальные программы-конверторы, встроенные в приложения.
Проверка кодировки символов используя валидатор
Проверка кодировки символов используя валидаторIntended audience:
пользователи, шифровальщики XHTML/HTML (используя редакторы или скрипты), разработчики скриптов (PHP, JSP, и т.д.), Менеджеры веб-проектов, и каждый, кто хочет узнать, как проверить кодировку символов документа.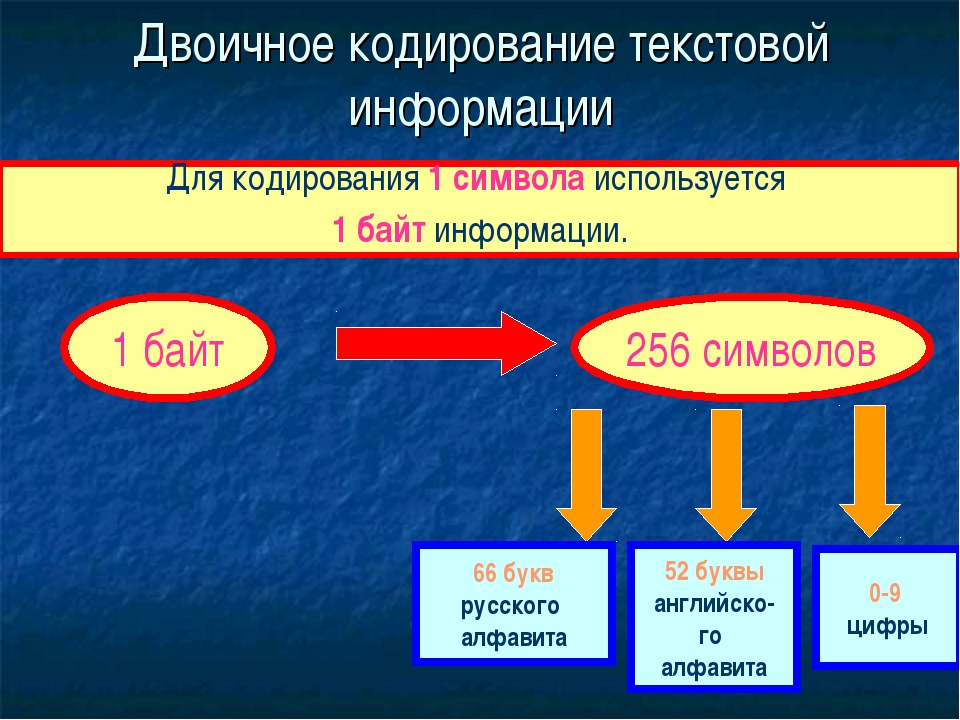
Как я могу проверить правильно ли кодирование символов моего документа используя W3C HTML Валидатор?
Чтобы убедиться, что все получатели документа могут его правильно отобразить и интерпретировать, очень важно правильно указать кодировку символов (‘charset’). Один из способов это проверить — использовать W3C Сервис Проверки Разметки. Валидатор обычно определяет кодировку символов с HTTP заголовков и информации в документе. Если валидатор не в состоянии обнаружить кодировку, то её можно будет выбрать на странице результатов валидатора с помощью раскрывающегося меню ‘Кодировка’ (пример).
Но часто, валидатор не жалуется, даже если обнаруженное или избранное неправильное кодирование. Причина этого в том, что много кодировок очень похожи, а валидатор проверяет только синтаксис разметки и не может решить имеет ли смысл декодированный текст или нет. Чтобы убедиться, что вы имеете правильное кодирование, которое означает, что документ будет корректно отображаться для читателей, используйте следующие пункты:
Если выбранные или обнаруженые кодирования:
US-ASCII,UTF-8,UTF-16, илиiso-2022-jp(Japanese JIS), и валидатор не жалуется на проблемы с кодировкой, то есть очень высокая вероятность того, что кодирование избранное правильно. Обратите внимание, что
Обратите внимание, что US-ASCIIявляется строгим подмножеством кодировкиUTF-8, и поэтому, еслиUS-ASCIIработает, тоUTF-8также будет работать.Для любого другого кодирования необходим визуальный контроль. Выберите опцию Show Source (показать источник) с Extended Interface (Расширенного интерфейса) валидатора, и проверьте правильно ли отображаются в тексте non-ASCII символы. Для страниц на иностранных языках, это, как правило, можно сделать достаточно быстро. Для страниц на Английском языке со всего несколькими non-ASCII символамы, это может быть более сложной задачей.
Например, если вы пытались интерпретировать главную страницу W3C как iso-8859-1, вам, возможно, придется пересмотреть источник почти до конца для того, чтобы найти такой текст, как ‘©’ и ‘®’ и увидеть, что это неправильный выбор. (Конечно, та страница, с самого начала указывает валидатору, что она закодирована в UTF-8, и поэтому на самом деле вам не нужно что-то еще проверять.
 )
)В некоторых случаях более чем одна кодировка будет адекватно представлять символы в документе. Например, есть некоторое перекрытие между
iso-8859-1(Latin-1, Западная Европа) иiso-8859-2(Latin-2, Восточная Европа), и другие кодировки в этой серии. Если после тщательной проверки, вы не можете найти разницу, то любой выбор будет подходящим. Близкое сходство этих кодировок с точки зрения моделей байтов и с точки зрения фактически закодированных символов объясняет почему только визуальный осмотр может помочь убедиться правильное ли кодирование.Если ни одна из предложенных валидатором кодировок не работает, то вы либо имеете страницу в кодировке, которую валидатор (пока) не поддерживает, или как-то, текст в нескольких различных кодировках смешался на странице. В первом случае, напишите на validator mailing list (список рассылки валидатора) (public archive (общественный архив)), чтобы вашу кодировку символов добавили.
 В последнем случае, вы должны исправить свою страницу, так как каждая Веб-страница может использовать только одну кодировку символов.
В последнем случае, вы должны исправить свою страницу, так как каждая Веб-страница может использовать только одну кодировку символов.
Валидатор не может работать без информации о кодировке потому что SGML или XML проверка основана на проверке последовательностей символов в документе, но то, что валидатор принимает в качестве входных данных — просто последовательность байтов. Знание кодирования символов позволяет валидатору превращать байты в символы. В общем, все то же самое действительно для всех других видов приемников, включая браузеры. Если символы определены не правильно, то Веб браузер будет отображать некорректную информацию.
Валидатор делает это путем преобразования из указанного кодирования в UTF-8, и использует UTF-8 внутренне. Если преобразование в UTF-8 не удается
потому, что отдельная последовательность байтов не может появиться во входной кодировоке, то валидатор выдает сообщение об ошибке. В UTF-8 для информации на входе, валидатор
проверяет действительно ли только UTF-8 последовательности байтов используются.
Обратите внимание, что визуальная проверка веб-страницы с помощью браузера без использования валидатор может провалиться, поскольку:
- Некоторые браузеры используют нестандартные способы выявления кодирования символов.
- Каждый браузер имеет настройки, которые используются для неотмеченных страниц, а если те настройки случайно будут правильной кодировкой страницы, то вы не увидите, что страница с должной информацией о кодировке не доходит.
- Кроме текста на странице, есть еще текст в атрибутах (например текст атрибута alt в
<img>), который нужно проверить.
HTML кодировки-W3Docs
Для того, чтобы браузер смог правильно отобразить текст на веб-странице, необходимо указать ее кодировку. В противном случае вместо текста на веб-странице будут отображаться непонятные символы.
Кодировку указывают в теге <meta> который находится в блоке <head>.
Пример
<head>
<meta charset="utf-8">
</head>В HTML 5 для указания кодировки используется атрибут charset: <meta charset=»utf-8″>
Рассмотрим основные виды кодировок
Кодировка ASCII¶
ASCII (American Standard Code for Information Interchange), американский стандартный кодекс для обмена информацией между компьютерными и аппаратными устройствами был придуман в 60 годах прошлого века. ASCII — 7-битная кодовая таблица, которая содержит 128 символов (цифры от 1 до 9, прописные и строчные латинские буквы, специальные символы). Современные системы кодировки, такие как ISO-8859 и UTF-8, разработаны на основе ASCII.
ASCII — 7-битная кодовая таблица, которая содержит 128 символов (цифры от 1 до 9, прописные и строчные латинские буквы, специальные символы). Современные системы кодировки, такие как ISO-8859 и UTF-8, разработаны на основе ASCII.
Печатные символы ASCII
ANSI ¶
Со временем стандарт кодировки ASCII расширялся, появилась возможность использовать не 128, а 256 символов, которые можно закодировать в одном байте информации. Одной из расширенных версий ASCII является ANSI (American National Standards Institute). Примером ANSI-кодировки является Windows-1251, которая включает типографические символы, а также буквы алфавитов славянских народов.
ISO-8859-1¶
Организация Международных стандартов (International Standards Organization) ввела диапазон кодировок для разных языков, от ISO 8859-1 до ISO 8859-16.
В большинстве браузеров по умолчанию используется кодировка ISO-8859-1. Кодировка символов от 0 до 127 в ISO-8859-1 соответствует кодировке ASCII (цифры от 1 до 9, заглавные и строчные буквы английского алфавита и несколько спецсимволов).
В HTML 4 любая кодировка, отличная от стандарта ISO-8859-1, должна быть указана в теге <meta> .
Таблица кодов символов ISO-8859-1
<meta http-equiv="Content-Type" content="text/html;charset=ISO-8859-8">Кодировка Unicode ¶
В 1991 году был разработан универсальный стандарт кодирования Unicode Transformation Format (UTF), благодаря которому стало возможным представить знаки практически всех известных письменных языков. Разработчиками стандарта была некоммерческая организация Unicode Consortium.
Первой была разработана кодировка UTF-32, затем UTF-16, и наконец появился стандарт UTF-8.
В UTF-32 для кодирования одного символа использовалось 32 бита (4 байта), что увеличивало вес конечного файла в 4 раза. В UTF-16 вес снизился вдвое, так как для кодирования использовалось уже 16 бит, но и это было далеко не оптимальным решением. Разработанный впоследствии стандарт UTF-8 на сегодняшний день считается самым оптимальным. Для кодирования одного символа в UTF-8 используется от 1 до 4 байт. Он идеально совмещается с системами, которые используют 8-битные символы.
Для кодирования одного символа в UTF-8 используется от 1 до 4 байт. Он идеально совмещается с системами, которые используют 8-битные символы.
UTF-8 унаследовал базовую часть кодировки ASCII (128 символов), то есть для кодировки латинских символов используется 8 бит (1 байт). Все последующие символы кодируются двумя байтами и более.
HTML4 поддерживает только кодировку UTF-8. В HTML5 поддерживаются как UTF-8, так и UTF-16.
Таблица кодов символов UTF-8
Знаки с кодами от U+0400 до U+052F, от U+2DE0 до U+2DFF, от U+A640 до U+A69F кодируют символы кириллицы.
Кодирование текстовой информации
Чаще всего кодированию подвергаются тексты, написанные на естественных языках (русском, немецком и др.).
Основные способы кодирования текстовой информации
Существует несколько основных способов кодирования текстовой информации:
- графический, в котором текстовая информация кодируется путем использования специальных рисунков или знаков;
- символьный, в котором тексты кодируются с использованием символов того же алфавита, на котором написан исходник;
- числовой, в котором текстовая информация кодируется с помощью чисел.

Процесс чтения текста представляет собой процесс, обратный его написанию, в результате которого письменный текст преобразуется в устную речь. Чтение – это ничто иное, как декодирование письменного текста.
А сейчас обратите внимание на то, что существует много способов кодирования одного и того же текста на одном и том же языке.
Пример 1
Поскольку мы русские, то и текст привыкли записывать с помощью алфавита своего родного языка. Однако тот же самый текст можно записать, используя латинские буквы. Иногда это приходится делать, когда мы отправляем SMS по мобильному телефону, клавиатура которого не содержит русских букв, или же электронное письмо на русском языке за границу, если у адресата нет русифицированного программного обеспечения. Например, фразу «Здравствуй, дорогой Саша!» можно записать как: «Zdravstvui, dorogoi Sasha!».
Стенография
Определение 1
Стенография — это один из способов кодирования текстовой информации с помощью специальных знаков. Она представляет собой быстрый способ записи устной речи. Навыками стенографии могут владеть далеко не все, а лишь немногие специально обученные люди, которых называют стенографистами. Эти люди успевают записывать текст синхронно с речью выступающего человека, что, на наш взгляд, достаточно сложно. Однако для них это не проблема, поскольку в стенограмме целое слово или сочетание букв могут обозначаться одним знаком. Скорость стенографического письма превосходит скорость обычного в $4-7$ раз. Расшифровать (декодировать) стенограмму может только сам стенографист.
Она представляет собой быстрый способ записи устной речи. Навыками стенографии могут владеть далеко не все, а лишь немногие специально обученные люди, которых называют стенографистами. Эти люди успевают записывать текст синхронно с речью выступающего человека, что, на наш взгляд, достаточно сложно. Однако для них это не проблема, поскольку в стенограмме целое слово или сочетание букв могут обозначаться одним знаком. Скорость стенографического письма превосходит скорость обычного в $4-7$ раз. Расшифровать (декодировать) стенограмму может только сам стенографист.
Пример 2
На рисунке представлен пример стенографии, в которой написано следущее: «Говорить умеют все люди на свете. Даже у самых примитивных племен есть речь. Язык — это нечто всеобщее и самое человеческое, что есть на свете»:
Рисунок 1.
Стенография позволяет не только вести синхронную запись устной речи, но и рационализировать технику письма.
Замечание 1
Приведёнными примерами мы проиллюстрировали важное правило: для кодирования одной и той же информации можно использовать разные способы, при этом их выбор будет зависеть от цели кодирования, условий и имеющихся средств.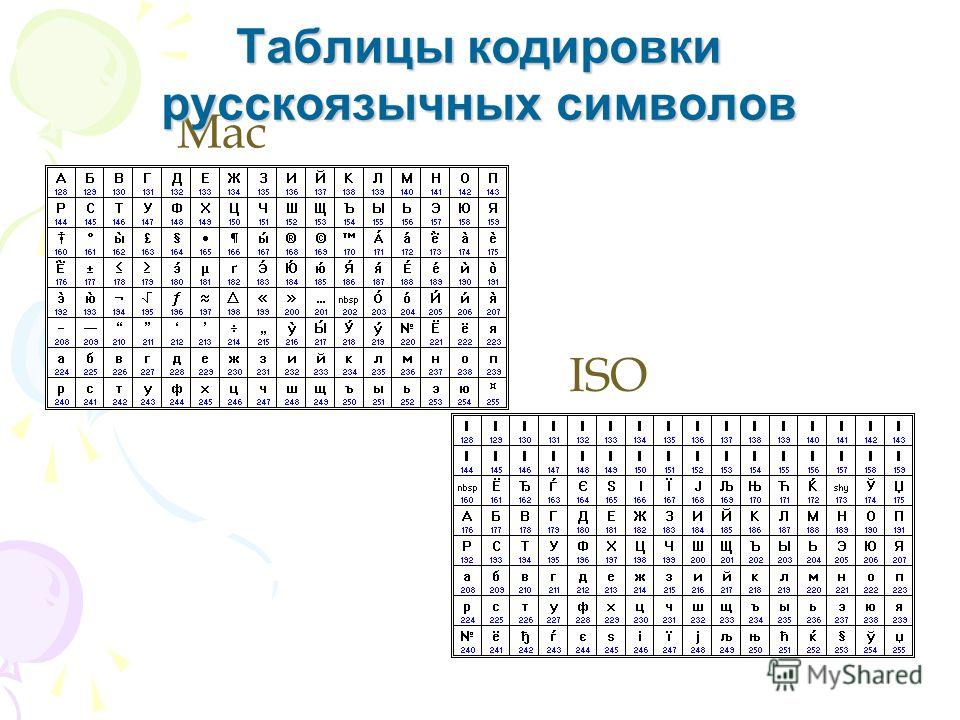
Если нам нужно записать текст в темпе речи, сделаем это с помощью стенографии; если нужно передать текст за границу, воспользуемся латинским алфавитом; если необходимо представить текст в виде, понятном для грамотного русского человека, запишем его по всем правилам грамматики русского языка.
Также немаловажен выбор способа кодирования информации, который, в свою очередь, может быть связан с предполагаемым способом её обработки.
Пример 3
Рассмотрим пример представления чисел количественной информации. Используя буквы русского алфавита, можно записать число «тридцать пять». Используя же алфавит арабской десятичной системы счисления, запишем: $35$. Допустим нам необходимо произвести вычисления. Естественно, что для выполнения расчётов мы выберем удобную для нас запись числа арабскими цифрами, хотя можно примеры описывать и словами, но это будет довольно громоздко и не практично.
Замечание 2
Заметим, что приведенные выше записи одного и того же числа используют разные языки: первая — естественный русский язык, вторая — формальный язык математики, не имеющий национальной принадлежности. Переход от представления на естественном языке к представлению на формальном языке можно также рассматривать как кодирование.
Переход от представления на естественном языке к представлению на формальном языке можно также рассматривать как кодирование.
Криптография
В некоторых случаях возникает потребность засекречивания текста сообщения или документа, для того чтобы его не смогли прочитать те, кому не положено. Это называется защитой от несанкционированного доступа. В таком случае секретный текст шифруется. В давние времена шифрование называлось тайнописью.
Определение 2
Шифрование представляет собой процесс превращения открытого текста в зашифрованный, а дешифрование — процесс обратного преобразования, при котором восстанавливается исходный текст. Шифрование — это тоже кодирование, но с засекреченным методом, известным только источнику и адресату. Методами шифрования занимается наука криптография.
Определение 3
Криптография — это наука о методах и принципах передачи и приема зашифрованной с помощью специальных ключей информации. Ключ — секретная информация, используемая криптографическим алгоритмом при шифровании/расшифровке сообщений.
Ключ — секретная информация, используемая криптографическим алгоритмом при шифровании/расшифровке сообщений.
Числовое кодирование текстовой информации
В каждом национальном языке имеется свой алфавит, который состоит из определенного набора букв, следующих друг за другом, а значит и имеющих свой порядковый номер.
Каждой букве сопоставляется целое положительное число, которое называют кодом символа. Именно этот код и будет хранить память компьютера, а при выводе на экран или бумагу преобразовывать в соответствующий ему символ. Помимо кодов самих символов в памяти компьютера хранится и информация о том, какие именно данные закодированы в конкретной области памяти. Это необходимо для различия представленной информации в памяти компьютера (числа и символы).
Используя соответствия букв алфавита с их числовыми кодами, можно сформировать специальные таблицы кодирования. Иначе можно сказать, что символы конкретного алфавита имеют свои числовые коды в соответствии с определенной таблицей кодирования.
Однако, как известно, алфавитов в мире большое множество (английский, русский, китайский и др.). Соответственно возникает вопрос, каким образом можно закодировать все используемые на компьютере алфавиты.
Чтобы ответить на данный вопрос, нам придется заглянуть назад в прошлое.
В $60$-х годах прошлого века в американском национальном институте стандартизации (ANSI) была разработана специальная таблица кодирования символов, которая затем стала использоваться во всех операционных системах. Эта таблица называется ASCII (American Standard Code for Information Interchange, что означает в переводе с английского «американский стандартный код для обмена информацией»).
В данной таблице представлен $7$-битный стандарт кодирования, при использовании которого компьютер может записать каждый символ в одну $7$-битную ячейку запоминающего устройства. При этом известно, что в ячейке, состоящей из $7$ битов, можно сохранять $128$ различных состояний. В стандарте ASCII каждому из этих $128$ состояний соответствует какая-то буква, знак препинания или же специальный символ.
В процессе развития вычислительной техники стало ясно, что $7$-битный стандарт кодирования достаточно мал, поскольку в $128$ состояниях $7$-битной ячейки нельзя закодировать буквы всех письменностей, имеющихся в мире.
Чтобы решить эту проблему, разработчики программного обеспечения начали создавать собственные 8-битные стандарты кодировки текста. За счет дополнительного бита диапазон кодирования в них был расширен до $256$ символов. Во избежание путаницы, первые $128$ символов в таких кодировках, как правило, соответствуют стандарту ASCII. Оставшиеся $128$ — реализуют региональные языковые особенности.
Замечание 3
Как мы знаем национальных алфавитов огромное количество, поэтому и расширенные таблицы ASCII-кодов представлены множеством вариантов. Так для русского языка существует также несколько вариантов, наиболее распространенные Windows-$1251$ и Koi8-r. Большое количество вариантов кодировочных таблиц создает определенные трудности. К примеру, мы отправляем письмо, представленное в одной кодировке, а получатель при этом пытается прочесть его в другой. В результате на экране у него появляется непонятная абракадабра, что говорит о том, что получателю для прочтения письма требуется применить иную кодировочную таблицу.
В результате на экране у него появляется непонятная абракадабра, что говорит о том, что получателю для прочтения письма требуется применить иную кодировочную таблицу.
Существует и другая проблема, которая заключается в том, что алфавиты некоторых языков содержат слишком много символов, которые не позволяют помещаться им в отведенные позиции с $128$ до $255$ однобайтовой кодировки.
Следующая проблема возникает тогда, когда в тексте используют несколько языков (например, русский, английский и немецкий). Нельзя же использовать обе таблицы сразу.
Для решения этих проблем в начале $90$-х годов прошлого столетия был разработан новый стандарт кодирования символов, который назвали Unicode. С помощью этого стандарта стало возможным использование в одном тексте любых языков и символов.
Данный стандарт для кодирования символов предоставляет $31$ бит, что составляет $4$ байта за минусом $1$ бита. Количество возможных комбинаций при использовании данной кодировочной таблицы очень велико: $231 = 2 \ 147 \ 483 \ 684$ (т. е. более $2$ млрд.). Это возможно стало в связи с тем, что Unicode описывает алфавиты всех известных языков, даже «мертвых» и выдуманных, включает многие математические и другие специальные символы. И все-таки информационная емкость $31$-битового Unicode слишком велика, И как следствие, наиболее часто используют именно сокращенную $16$-битовую версию ($216 = 65 \ 536$ значений), в которой представлены все современные алфавиты.
В Unicode первые $128$ кодов совпадают с таблицей ASCII.
е. более $2$ млрд.). Это возможно стало в связи с тем, что Unicode описывает алфавиты всех известных языков, даже «мертвых» и выдуманных, включает многие математические и другие специальные символы. И все-таки информационная емкость $31$-битового Unicode слишком велика, И как следствие, наиболее часто используют именно сокращенную $16$-битовую версию ($216 = 65 \ 536$ значений), в которой представлены все современные алфавиты.
В Unicode первые $128$ кодов совпадают с таблицей ASCII.
Проблема с текстом в письмах на Mac – Наши инструкции
Неверная кодировка писем в клиенте Mail в OS X
Иногда, в процессе почтовой переписки, пользователи Mac сталкиваются с проблемой, так как и текст, и даже тема письма могут быть полностью искажены, например:
ОНДПНАМЕЕ — KOI8-R
ŽŽŽāŽÝŽÝŽÖŽÔŽÚ — SO-8859-10
¬â¬ض¬ف¬ض — CP1256
Коды, обозначенные справа от нечитаных символов — это виды кодировок, с помощью которых зашифрован текст.
Причина такого отображения — искажение кодировки, которое может возникнуть в процессе переписки между двумя пользователями.
Например, вы ведете переписку с другим человеком, использующим почтовый клиент Outlook, в котором по умолчанию выставлена кодировка CP1251, в то время как почтовый клиент Mail по умолчанию использует кодировку UTF-8.
Или же отправитель копирует информацию из какого-либо другого письма или каталога, вставляет ее в свое сообщение (при этом автоматически применяется кодировка скопированного текста) и после этого начинает писать сообщение.
Текст письма можно расшифровать с помощью сервиса Декодер.
Но, чтобы избежать таких проблем в будущем, рекомендуется минимизировать возможность искажения кодировки хотя бы со своей стороны.
Есть несколько советов:
A. используйте в новых сообщениях (ответах) формат оригинала. В этом случае вы будете отправлять письма в той же кодировке, в которой они были присланы вам.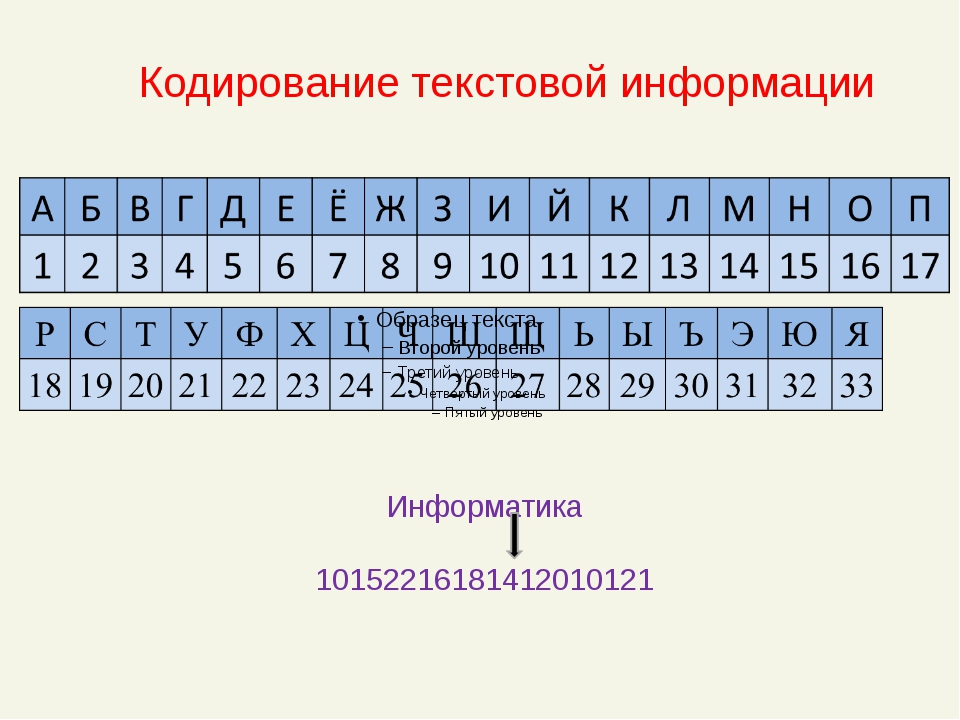
1. Откройте клиент Mail.
2. в Строке меню Apple выберите Mail > Настройки.
3. В новом окне выберите вкладку Формат.
Укажите формат сообщения как Простой текст — это отключит Rich Text форматирование и все новые сообщения по умолчанию будут составляться как простой текст (Palin Text).
Поставьте галочку напротив Использовать в сообщении формат оригинала — при ответе, ваше сообщение будет использовать ту же кодировку и тот же формат (Rich Text или Palin Text).
B. Используйте для всех писем, отправленных через почтовый клиент, кодировку UTF-8 по умолчанию.
Чтобы отправлять все письма в формате UTF-8 — достаточно вставить в вашу подпись, которую вы используете, любой специальный символ Unicode, например ✉ или ©.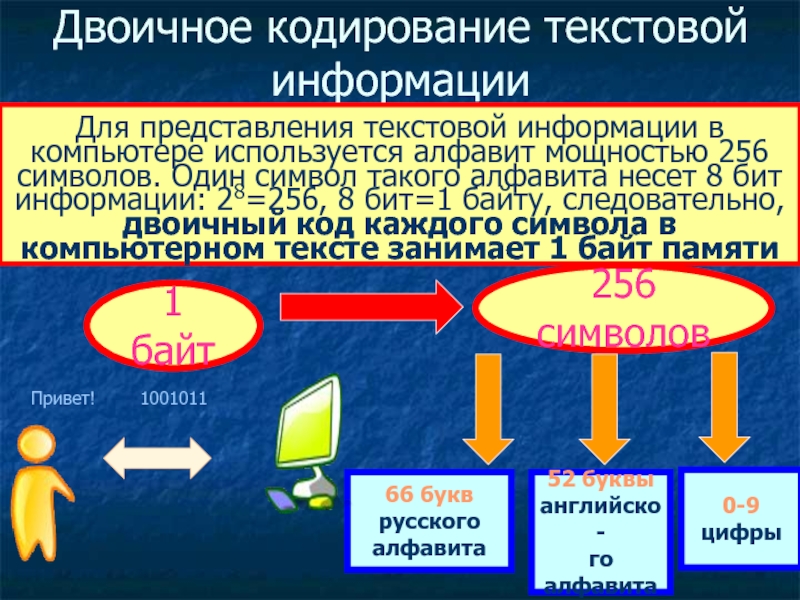 В таком случае для письма всегда будет применять кодировка UTF-8.
В таком случае для письма всегда будет применять кодировка UTF-8.
Посмотреть список символов и выбрать тот, который вам больше нравится, на следующей странице: http://unicode-table.com/ru/
Чтобы отредактировать вашу подпись в почтовом клиенте Mail — вы можете воспользоваться следующей инструкцией: http://help.shortcut.ru/entries/82074997-Как-добавить-подпись-в-программе-Mail-app
C. Попросите получателя проверить настройки своего почтового клиента.
Вполне вероятно, что сложности в переписке получателя могут возникать не только с вами. Вы можете выслать ему ссылку на эту инструкцию — https://shortcut.zendesk.com/hc/admin/articles/206142038
PHP: Поддерживаемые кодировки символов — Manual
В настоящее время модулем mbstring поддерживаются
следующие кодировки символов. Любая из этих кодировок символов
может быть указаны в параметре encoding функций mbstring.
Следующие кодировки символов поддерживаются в этом расширении PHP:
- UCS-4*
- UCS-4BE
- UCS-4LE*
- UCS-2
- UCS-2BE
- UCS-2LE
- UTF-32*
- UTF-32BE*
- UTF-32LE*
- UTF-16*
- UTF-16BE*
- UTF-16LE*
- UTF-7
- UTF7-IMAP
- UTF-8*
- ASCII*
- EUC-JP*
- SJIS*
- eucJP-win*
- SJIS-win*
- ISO-2022-JP
- ISO-2022-JP-MS
- CP932
- CP51932
- SJIS-mac (alias: MacJapanese)
- SJIS-Mobile#DOCOMO (alias: SJIS-DOCOMO)
- SJIS-Mobile#KDDI (alias: SJIS-KDDI)
- SJIS-Mobile#SOFTBANK (alias: SJIS-SOFTBANK)
- UTF-8-Mobile#DOCOMO (alias: UTF-8-DOCOMO)
- UTF-8-Mobile#KDDI-A
- UTF-8-Mobile#KDDI-B (alias: UTF-8-KDDI)
- UTF-8-Mobile#SOFTBANK (alias: UTF-8-SOFTBANK)
- ISO-2022-JP-MOBILE#KDDI (alias: ISO-2022-JP-KDDI)
- JIS
- JIS-ms
- CP50220
- CP50220raw
- CP50221
- CP50222
- ISO-8859-1*
- ISO-8859-2*
- ISO-8859-3*
- ISO-8859-4*
- ISO-8859-5*
- ISO-8859-6*
- ISO-8859-7*
- ISO-8859-8*
- ISO-8859-9*
- ISO-8859-10*
- ISO-8859-13*
- ISO-8859-14*
- ISO-8859-15*
- ISO-8859-16*
- byte2be
- byte2le
- byte4be
- byte4le
- BASE64
- HTML-ENTITIES (alias: HTML)
- 7bit
- 8bit
- EUC-CN*
- CP936
- GB18030
- HZ
- EUC-TW*
- CP950
- BIG-5*
- EUC-KR*
- UHC (alias: CP949)
- ISO-2022-KR
- Windows-1251 (alias: CP1251)
- Windows-1252 (alias: CP1252)
- CP866 (alias: IBM866)
- KOI8-R*
- KOI8-U*
- ArmSCII-8 (alias: ArmSCII8)
* обозначает кодировки, которые также могут использоваться в регулярных выражениях.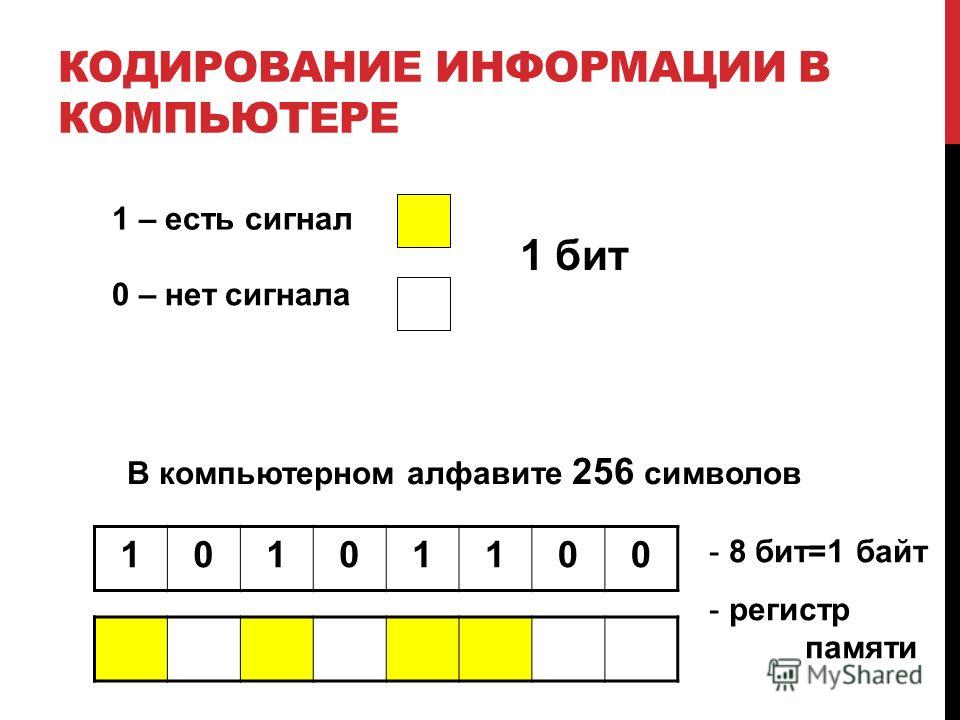
Любая запись в php.ini, которая принимает имя кодировки,
может также использовать значения «auto» и
«pass«.
Функции mbstring, которые принимают имя
кодировки, также могут использовать значение «auto«.
Если установлено значение «pass«,
преобразование кодировки не производится.
Если установлено значение «auto«, оно расширяется
списком кодировок, определённым в
NLS (настройках национального языка).
Например, если NLS установлен в Japanese,
предполагается, что значение будет из списка
«ASCII,JIS,UTF-8,EUC-JP,SJIS«.
Смотрите также mb_detect_order()
Определение кодировки символов
В то время как мы рассматриваем текстовые документы как строки текста, компьютеры на самом деле видят их как двоичные данные или серию нулей и единиц. Следовательно, символы в текстовом документе должны быть представлены числовыми кодами. Для этого текст сохраняется с использованием одного из нескольких типов кодировки символов.
Для этого текст сохраняется с использованием одного из нескольких типов кодировки символов.
Самыми популярными типами кодировки символов являются ASCII и Unicode. Хотя ASCII по-прежнему поддерживается почти всеми текстовыми редакторами, Unicode используется чаще, потому что он поддерживает больший набор символов.Юникод часто определяется как UTF-8, UTF-16 или UTF-32, которые относятся к различным стандартам Unicode. UTF означает «Формат преобразования Unicode», а число указывает количество битов, используемых для представления каждого символа. С первых дней вычислений символы были представлены как минимум одним байтом (8 бит), поэтому различные стандарты Unicode сохраняют символы в количестве, кратном 8 битам.
Хотя ASCII и Unicode являются наиболее распространенными типами кодировки символов, другие стандарты кодирования также могут использоваться для кодирования текстовых файлов.Например, существует несколько типов стандартов кодировки символов для конкретных языков, таких как западные, латиноамериканские, японские, корейские и китайские.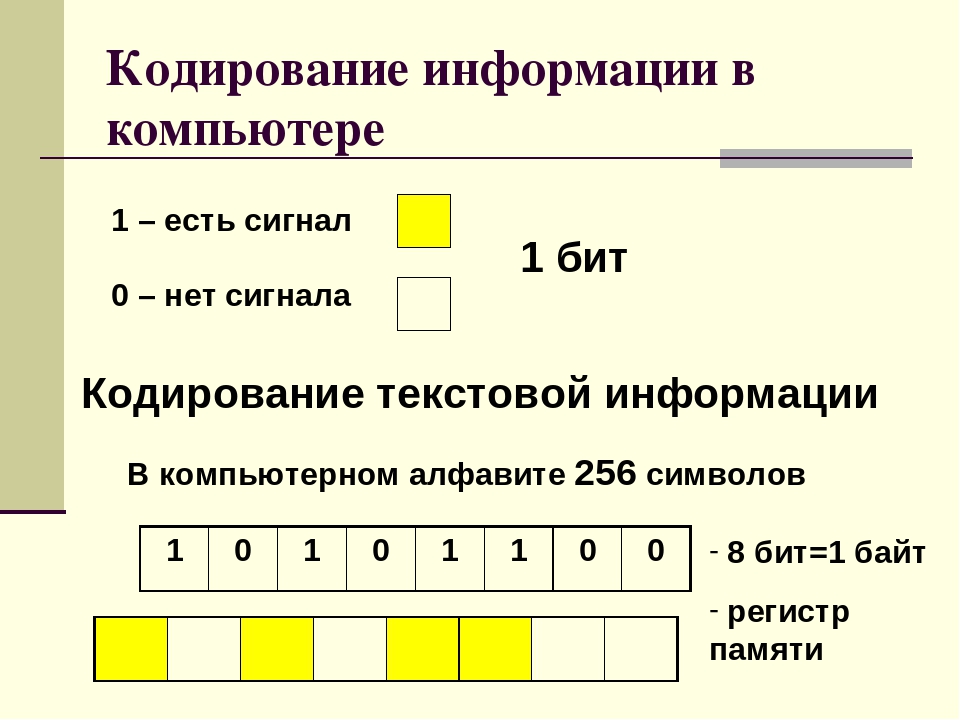 В то время как западные языки используют похожие символы, восточные языки требуют совершенно другого набора символов. Следовательно, латинская кодировка не поддерживает символы, необходимые для представления текстовой строки на китайском языке. К счастью, современные стандарты, такие как UTF-16, поддерживают достаточно большой набор символов для представления как западных, так и восточных букв и символов.
В то время как западные языки используют похожие символы, восточные языки требуют совершенно другого набора символов. Следовательно, латинская кодировка не поддерживает символы, необходимые для представления текстовой строки на китайском языке. К счастью, современные стандарты, такие как UTF-16, поддерживают достаточно большой набор символов для представления как западных, так и восточных букв и символов.
Обновлено: 24 сентября 2010 г.
TechTerms — Компьютерный словарь технических терминов
Эта страница содержит техническое определение кодировки символов. Он объясняет в компьютерной терминологии, что означает кодирование символов, и является одним из многих программных терминов в словаре TechTerms.
Все определения на веб-сайте TechTerms составлены так, чтобы быть технически точными, но также простыми для понимания. Если вы сочтете это определение кодировки символов полезным, вы можете сослаться на него, используя приведенные выше ссылки для цитирования. Если вы считаете, что термин следует обновить или добавить в словарь TechTerms, отправьте электронное письмо в TechTerms!
Если вы считаете, что термин следует обновить или добавить в словарь TechTerms, отправьте электронное письмо в TechTerms!
Подпишитесь на информационный бюллетень TechTerms, чтобы получать избранные термины и тесты прямо в свой почтовый ящик. Вы можете получать электронную почту ежедневно или еженедельно.
Подписаться
Что такое кодировка символов
Кодировка символов
Кодировка символов сообщает компьютеру, как интерпретировать необработанные нули и единицы в реальные символы. Обычно это делается путем соединения цифр с символами.Слова и предложения в тексте состоят из символов, и эти символы сгруппированы в набор символов. В настоящее время существует множество различных типов кодировок символов, но чаще всего мы имеем дело с ASCII, 8-битными кодировками и кодировками на основе Unicode.
ASCII
Американский стандартный код для обмена информацией (ASCII) — это схема кодирования символов, и это был первый стандарт кодирования символов. Это код для представления английских символов в виде чисел, где каждой букве присвоен номер от 0 до 127.Большинство современных схем кодирования символов основаны на ASCII, хотя они поддерживают множество дополнительных символов. Это однобайтовая кодировка с использованием только нижних 7 бит. В файле ASCII каждый буквенный, цифровой или специальный символ представлен 7-битным двоичным числом
Это код для представления английских символов в виде чисел, где каждой букве присвоен номер от 0 до 127.Большинство современных схем кодирования символов основаны на ASCII, хотя они поддерживают множество дополнительных символов. Это однобайтовая кодировка с использованием только нижних 7 бит. В файле ASCII каждый буквенный, цифровой или специальный символ представлен 7-битным двоичным числом
ANSI
Коды ANSI (Американский национальный институт стандартов) — это стандартизированные цифровые или буквенные коды, выпущенные Американским национальным институтом стандартов для обеспечения единообразной идентификации географических объектов во всех федеральных правительственных учреждениях.Он служил координатором системы добровольной стандартизации частного сектора США более 90 лет. По сути, это расширение набора символов ASCII, поскольку оно включает все символы ASCII с дополнительными 128 кодами символов. ASCII просто определяет 7-битную кодовую страницу со 128 символами. ANSI расширяет это значение до 8 бит, и существует несколько различных кодовых страниц для символов от 128 до 255.
ANSI расширяет это значение до 8 бит, и существует несколько различных кодовых страниц для символов от 128 до 255.
Юникод
Unicode — это стандарт, который определяет внутреннюю систему кодирования текста почти во всех операционных системах, используемых в компьютерах в настоящее время, будь то Windows, Unix, Macintosh, Linux или что-то еще, потому что Unicode может обрабатывать символы практически для всех современных языков и даже некоторых древних. языков одновременно, если в системе клиента установлены шрифты для конкретного языка.
UTF
Unicode присваивает каждому символу уникальный номер или кодовую точку. Он определяет два метода сопоставления: кодировки UTF (формат преобразования Unicode) и кодировки UCS (универсальный набор символов). Кодировки на основе Unicode реализуют стандарт Unicode и включают UTF-8, UTF-16 и UTF-32 / UCS-4. Они выходят за рамки 8-битных и поддерживают почти все языки мира. UTF-8 набирает обороты как доминирующая международная кодировка в Интернете. UTF-8, UTF-16 и UTF-32, вероятно, являются наиболее часто используемыми кодировками.
UTF-8, UTF-16 и UTF-32, вероятно, являются наиболее часто используемыми кодировками.
UTF-8 — использует 1 байт для представления символов в наборе ASCII, два байта для символов в нескольких алфавитных блоках и три байта для остальной части BMP. Дополнительные символы занимают 4 байта.
UTF-16 — использует 2 байта для любого символа в BMP и 4 байта для дополнительных символов.
UTF-32 — использует 4 байта для всех символов.
Кодовая единица
Для Unicode конкретная последовательность битов называется кодовой единицей.Кодовая единица — это битовая последовательность, используемая для кодирования каждого символа репертуара.
В US-ASCII кодовая единица составляет 7 бит. В UTF-8 кодовая единица составляет 8 бит. В EBCDIC кодовая единица составляет 8 бит. В UTF-16 кодовая единица составляет 16 бит. В UTF-32 кодовая единица составляет 32 бита.
ДАЛЕЕ ….. Подключение C # к MySQL
Понимание различных типов кодирования | by Gaurav Gupta
Прежде всего, зачем нужна кодировка символов?
Кодировка символов используется, чтобы сообщить компьютеру, как интерпретировать необработанные нули и единицы в реальные символы, буквы и символы. Обычно это делается путем соединения цифр с символами. Это способ создания программного обеспечения для всех, кто использует другой язык, чем вы.
Обычно это делается путем соединения цифр с символами. Это способ создания программного обеспечения для всех, кто использует другой язык, чем вы.
Существуют различные типы кодирования, такие как ASCII, UNICODE, BASE64 и многие другие.
Обычно мы знаем, как получить двоичные числа для любого имеющегося у нас десятичного числа. Например, если мы хотим преобразовать 55 в двоичный формат, тогда это будет 110111, но как насчет символов, таких как A до Z и от a до Z, и других вещей, таких как *, (,) и $,%, которые мы используем ежедневно, как компьютер понимает все? этих персонажей? Ответ — кодировка.Кодирование гарантирует, что каждый символ представлен на компьютере.
На нашей клавиатуре каждому символу присвоено десятичное число, даже всем специальным символам, которые мы обсуждали выше. Например, A присваивается номер 65, а маленькому a — 97 и т. Д. Для всех других символов в алфавите.
Это назначение было выполнено в одном из ранее согласованных форматов 60-х, который называется форматом ASCII. Поскольку у нас есть 8 бит (1 байт) для представления всего, в ASCII у нас есть 7 бит.Это делает его до 127 символов, которые мы можем закодировать с помощью ASCII.
Поскольку у нас есть 8 бит (1 байт) для представления всего, в ASCII у нас есть 7 бит.Это делает его до 127 символов, которые мы можем закодировать с помощью ASCII.
64 32 16 8 4 2 1
Итак, если вы хотите показать капитал, которому присвоено 65, как вы представляете его в двоичном формате? Простой
1000001
и C? 1000011
Вы можете увидеть список полной таблицы ASCII здесь. Таблица ASCII
Это упрощает кодирование и представление английских и других специальных символов, потому что теперь вы можете преобразовать любой символ в понятный компьютеру двоичный код, который представлен с использованием ASCII. символы.
По мере того, как люди стали больше пользоваться компьютерами и захотели общаться, этого было недостаточно, чтобы каждый во всем мире представлял своих персонажей на компьютере. ASCII представлял только английские символы.
Проблема действительно началась, когда вы хотели сказать закодировать арабский, японский, китайский и многие другие языки.
Затем появился UNICODE, который мог представлять гораздо больше символов, или вы могли произносить все возможные символы на всех языках мира.UNICODE может использовать больше бит, чем ASCII (всего 6 бит). В UNICODE у вас есть 8, 16 и 32 бит. Это дает нам возможность использовать около миллиарда символов и отображать их в компьютере. UNICODE обратно совместим, например, если он использует символы ASCII до 127. Если вы используете кодировку UNICODE и используете букву A, тогда это будет десятичное число 65 или 1000001 в двоичном формате.
Base64 — это способ кодирования двоичных данных в набор символов ASCII, известный практически каждой компьютерной системе. Примеры почтовых систем не могут работать с двоичными данными, потому что они ожидают текстовые данные ASCII.Поэтому, если вы хотите передать изображение или другой файл, он будет поврежден из-за способа обработки данных.
Большая часть компьютерных систем хранит данные в байтах, что составляет 8 бит на байт, поэтому ASCII становится непригодным для передачи такого рода данных. Эти данные могут быть повреждены. Система может стереть 8-й бит, что может повредить все данные, которые вы хотите отправить. Для решения этих проблем была введена кодировка Base64. Это позволяет вам кодировать произвольные байты в байты, которые, как известно, безопасно отправлять без повреждения.
Эти данные могут быть повреждены. Система может стереть 8-й бит, что может повредить все данные, которые вы хотите отправить. Для решения этих проблем была введена кодировка Base64. Это позволяет вам кодировать произвольные байты в байты, которые, как известно, безопасно отправлять без повреждения.
Если мы хотим закодировать этот пример теста в base64:
Строка: «Это тест кодирования в base64»
Кодировка Base64: VGhpcyBpcyBlbmNvZGluZyB0ZXN0IGluIGJhc2U2NA ==
Кодировка Base64 разбивает поток двоичных данных на 6-битный поток из 3 полных байтов и представляет их как печатаемые символы ASCII в стандарте ASCII.
Таблица кодировки base64 начинается с A-Z, a-z, 0–9 и +, / и дополнения, которое составляет =
26 + 26 + 10 + 2 = 64 символа, поэтому это называется кодировкой base64.
Предположим, что у нас есть строка с именем «Dog», и нам нужно преобразовать ее в строку в кодировке base64.
- Необходимо преобразовать строку ASCII «Собака» в числа ASCII
- Необходимо преобразовать эти числа в двоичное, которое становится
- Эти двоичные потоки единиц и нулей делятся на подмножество по 6 бит каждый.

- Шестизначный двоичный поток преобразуется между двоичными символами или основанием 2 в десятичные символы основанием 10 путем возведения в квадрат каждого значения, представленного 1 в двоичной последовательности, с его позиционным квадратом. Это в основном то же самое, что и преобразование двоичных 8 битов в десятичные, но здесь масштаб равен 6 битам. Таким образом, мы будем рассматривать только следующие
Таким образом, представление ASCII Dog в base64 — это RG9n.
Помните, что Base64 кодирует 24 бита кусками по 6 бит, что равняется 6 символам base64.Группа, в которой 4 символа не завершаются, мы будем использовать = для завершения набора символов из 4
различных типов схем кодирования — Праймер
Как разработчик программного обеспечения и особенно как веб-разработчик, вы, вероятно, каждый день видите / используете разные типы кодирования. Я знаю, что постоянно сталкиваюсь с самыми разными кодировками. Однако, поскольку кодирование никогда не является центральным понятием, его часто замалчивают, и иногда может возникнуть путаница, какая кодировка какая и когда каждая из них актуальна. Что ж, чтобы избавиться от путаницы раз и навсегда, вот краткое руководство по различным типам схем кодирования, с которыми вы, вероятно, столкнетесь, и о том, когда каждая из них актуальна.
Что ж, чтобы избавиться от путаницы раз и навсегда, вот краткое руководство по различным типам схем кодирования, с которыми вы, вероятно, столкнетесь, и о том, когда каждая из них актуальна.
Кодировка HTML
КодировкаHtml в основном используется для представления различных символов, чтобы их можно было безопасно использовать в документе HTML (как следует из названия). Как вы знаете, существуют различные символы, которые являются частью самой разметки HTML (например, <,> и т. Д.). Чтобы использовать их в документе в качестве содержимого, вам необходимо закодировать их в HTML.Есть два способа кодирования символов HTML.
Кодировка HTML определяет несколько объектов для представления символов, которые могут быть частью разметки, например:
”-” ‘- ' > -> <- < & - &
Вы также можете кодировать HTML любой символ, используя его код ASCII, добавив к нему префикс & #, а затем используя десятичное значение ASCII или добавив к нему префикс & # x и используя шестнадцатеричное значение ASCII, например:
’- ' <- < > -> ‘-"
Итак, каждый раз, когда вам нужно закодировать символы в самом html-документе, это способы сделать это. Иногда его путают с кодировкой URL, которая несколько отличается.
Иногда его путают с кодировкой URL, которая несколько отличается.
Кодировка URL
При работе с URL-адресами они могут содержать только печатаемые символы ASCII (это символы с кодами ASCII от 32 до 126 в десятичной системе, т.е. шестнадцатеричные 0x20 - 0x7E). Однако некоторые символы в этом диапазоне могут иметь особое значение в URL-адресе или в протоколе HTTP. Кодирование URL-адресов вступает в игру, когда мы либо имеем в URL-адресе некоторые символы со специальным значением, либо хотим, чтобы символы выходили за пределы диапазона печати.Чтобы URL-адрес закодировал символ, мы просто префикс его шестнадцатеричного значения с помощью%, например:
% -% 25 пробел -% 20 вкладка -% 09 = -% 3D
Обратите внимание, что как часть схемы кодирования URL-адреса вы также можете представить пробел с помощью +. Это часто путают с кодировкой Unicode из-за того, что обе начинаются с%, однако кодировка Unicode немного сложнее.
Кодировка Unicode
Кодировку Unicode можно использовать для кодирования символа из любого языка или системы письма в мире. Кодирование Unicode включает в себя несколько схем кодирования.
Кодирование Unicode включает в себя несколько схем кодирования.
16-битная кодировка Unicode в чем-то похожа на кодировку URL (поэтому их иногда можно спутать). Чтобы закодировать символ в 16-битном Unicode, вы начинаете с% u, а затем добавляете кодовую точку символа Unicode, который вы хотите кодировать. Кодовая точка - это, по сути, всего лишь 4-значное шестнадцатеричное число, которое соответствует определенному символу, который вы пытаетесь представить в соответствии со стандартом Unicode (как вы можете себе представить, их много, посмотрите) e.грамм.:
@ -% u0040 ∞ (бесконечность) -% u221E
UTF-8 - это еще один тип кодировки Unicode, в котором для представления каждого символа используется один или несколько байтов. Когда нам нужно кодировать символы UTF-8 для передачи по HTTP, мы просто добавляем к каждому байту представления UTF-8 префикс%. Вы можете найти представления различных символов в кодировке UTF-8, перейдя по той же ссылке, что и выше.

± (плюс минус) -% c2% b1 © (авторское право) -% c2% a9
Как вы понимаете, о Unicode можно сказать гораздо больше, но это лишь краткое руководство, так что я оставлю это на ваше усмотрение, чтобы вы узнали больше сами.
Кодировка Base64
Это весело, и о нем всегда полезно знать. Base64 используется для представления двоичных данных с использованием только печатаемых символов. Обычно он используется в базовой HTTP-аутентификации для кодирования учетных данных пользователя, он также используется для кодирования вложений электронной почты для передачи по SMPT. Кроме того, кодировка Base64 иногда используется для передачи двоичных данных внутри файлов cookie и других параметров, а также часто просто используется для того, чтобы сделать различные данные нечитаемыми (или менее легко читаемыми), чтобы предотвратить легкое вмешательство.
Base64 рассматривает данные в блоках по 3 байта, что составляет 24 бита. Эти 24 бита затем делятся на 4 фрагмента по 6 бит в каждом, и каждый из этих фрагментов затем преобразуется в соответствующее ему значение base64. Поскольку он имеет дело с 6-битными фрагментами, каждый фрагмент может отображать 64 возможных символа (отсюда и название). Если конец кодируемой строки содержит менее 3 символов (что означает, что мы можем сделать 4 символа base64), то мы создаем столько символов base64, сколько можем, и дополняем остальные символы =.Вы можете ознакомиться с алфавитом с основанием 64 здесь, а также во многих других местах. Давайте посмотрим на быстрый пример.
Поскольку он имеет дело с 6-битными фрагментами, каждый фрагмент может отображать 64 возможных символа (отсюда и название). Если конец кодируемой строки содержит менее 3 символов (что означает, что мы можем сделать 4 символа base64), то мы создаем столько символов base64, сколько можем, и дополняем остальные символы =.Вы можете ознакомиться с алфавитом с основанием 64 здесь, а также во многих других местах. Давайте посмотрим на быстрый пример.
Если мы хотим преобразовать слово «торт» в основание 64, мы просто преобразуем каждый из символов в его десятичное значение ASCII, а затем получаем двоичное значение каждого десятичного значения. В нашем случае:
торт = 01100011011000010110101101100101
Теперь нам нужно разбить нашу двоичную строку на блоки по 6 бит каждый, и, поскольку каждые 3 символа должны составлять 4 символа base64, мы можем дополнить его нулями, если нам не хватает:
011000 110110 000101 101011 011001 010000 000000 000000
Теперь мы конвертируем каждое из 6-битных двоичных значений в соответствующий ему символ, а в случае нулевого значения мы используем символ заполнения (=).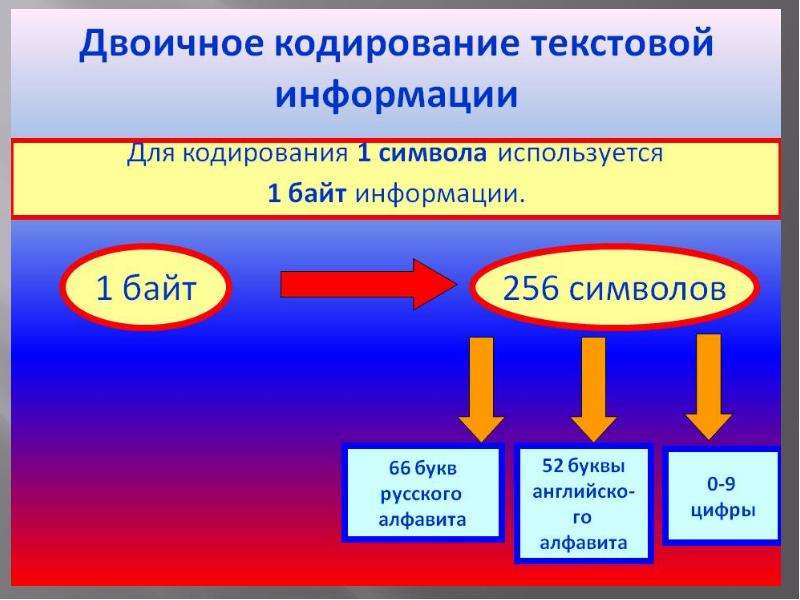 В нашем случае получаем:
В нашем случае получаем:
Y2FrZQ ==
Значение слова «торт» в кодировке base64.
КодировкуBase64 обычно довольно легко обнаружить, поскольку она выглядит довольно характерно, особенно когда она содержит символы-заполнители (=) в конце строки.
Шестнадцатеричное кодирование
Этот простой, вроде как :). В основном с шестнадцатеричным кодированием мы просто используем шестнадцатеричное значение каждого символа для представления набора символов. Итак, если бы мы хотели представить слово «привет», это было бы:
68656C6C6F
Довольно просто, правда? Что ж, это просто, когда мы кодируем печатаемые символы ASCII (я уже упоминал о них выше).Как только нам нужно кодировать какие-то международные символы, это становится более сложным, поскольку мы должны вернуться к Unicode. Я бы не стал особо беспокоиться об этом, у вас гораздо меньше шансов столкнуться с ним в повседневной веб-разработке, и теперь вы знаете, что это может быть, если вы увидите кучу шестнадцатеричных чисел, склеенных вместе.
Надеюсь, это было полезно, и вы можете ссылаться на это - как на отправную точку - всякий раз, когда у вас есть проблемы с кодировкой; чтобы разобраться в путанице. Если вы думаете, что есть другие схемы кодирования (актуальные для нашей повседневной жизни как разработчиков программного обеспечения), о которых я должен был упомянуть, дайте мне знать в комментариях.
Encoding 101 - Часть 1: Что такое кодирование? Блог Bizbrains
Итак, вы можете подумать, что текст - это просто текст. Ну подумай еще раз. В этой серии сообщений в блоге мы перейдем к байтовому уровню, изучим, как текст на самом деле представлен компьютерами, и обсудим, как это влияет на ваши интеграционные решения.
Что такое кодировка?
Кодирование - это способ, которым компьютер сохраняет текст как необработанные двоичные данные. Чтобы правильно читать текстовые данные, вы должны знать, какая кодировка использовалась для их хранения, а затем использовать ту же кодировку для интерпретации двоичных данных, чтобы получить исходный текст.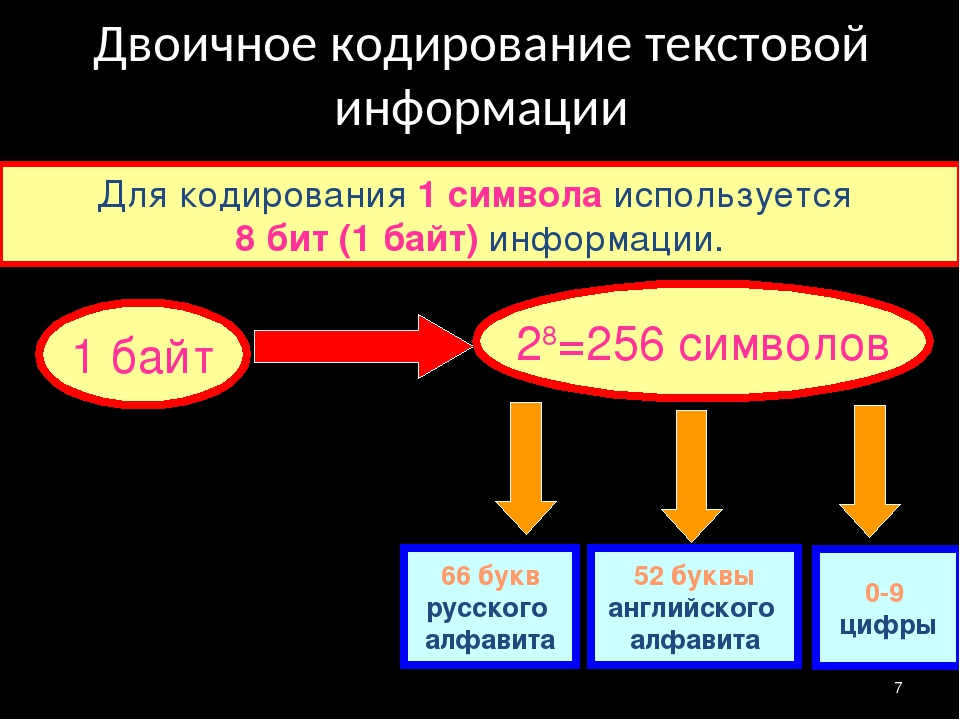 Теперь вы, вероятно, думаете: «Звучит не так уж плохо, конечно, есть всего пара разных кодировок, и наверняка все текстовые данные содержат информацию о том, какая кодировка используется, не так ли?» Что ж, ответы на эти вопросы, к сожалению, не так просты, поэтому кодирование может быть таким кошмаром для разработчиков.
Теперь вы, вероятно, думаете: «Звучит не так уж плохо, конечно, есть всего пара разных кодировок, и наверняка все текстовые данные содержат информацию о том, какая кодировка используется, не так ли?» Что ж, ответы на эти вопросы, к сожалению, не так просты, поэтому кодирование может быть таким кошмаром для разработчиков.
Что такое текст?
Фактический текст зависит от контекста. Когда текст хранится или куда-то передается, это просто часть двоичных данных, таких же, как и любые другие данные.На самом базовом уровне это длинный ряд нулей и единиц. Когда он активно обрабатывается компьютером, это все еще двоичные данные, но они интерпретируются системой как отдельные символы и во многих случаях преобразуются в другое двоичное представление во время обработки. Это представление называется Unicode.
Краткое введение в Unicode
Еще в 1988 году цифровая обработка данных становилась все более и более распространенной, но рынок все еще был крайне фрагментирован, и каждый поставщик использовал свои собственные нестандартные решения для большинства задач. В результате взаимная совместимость между различными компьютерными системами практически отсутствовала, и отправка данных из одной системы в другую часто была очень сложной задачей. В это время была предпринята попытка остановить поток возникающих проблем с кодировкой путем введения стандартного общего набора символов, известного как Unicode. Таким образом, все различные используемые кодировки можно было, по крайней мере, сопоставить с общим набором символов, поэтому не было бы никаких сомнений относительно того, какой символ должен представлять данный код.
В результате взаимная совместимость между различными компьютерными системами практически отсутствовала, и отправка данных из одной системы в другую часто была очень сложной задачей. В это время была предпринята попытка остановить поток возникающих проблем с кодировкой путем введения стандартного общего набора символов, известного как Unicode. Таким образом, все различные используемые кодировки можно было, по крайней мере, сопоставить с общим набором символов, поэтому не было бы никаких сомнений относительно того, какой символ должен представлять данный код.
Из статьи Википедии для Unicode:
«Unicode - это стандарт компьютерной индустрии для согласованного кодирования, представления и обработки текста, выраженного в большинстве мировых систем письма. Стандарт поддерживается Консорциумом Unicode, и по состоянию на май 2019 года самая последняя версия Unicode 12.1 содержит набор из 137 994 символа, охватывающий 150 современных и исторических сценариев, а также несколько наборов символов и эмодзи.
При обработке текста Unicode обеспечивает уникальную кодовую точку - число, а не глиф - для каждого символа.Другими словами, Unicode представляет символ абстрактным образом, а визуальную визуализацию (размер, форму, шрифт или стиль) оставляет другому программному обеспечению, например веб-браузеру или текстовому процессору ».
Набор символов Unicode сам по себе не является кодировкой, а представляет собой просто стандартизованный набор всех символов, с которыми кто-либо может встретиться в файле данных. Стандарт Unicode также содержит ряд актуальных кодировок. Общим для всех этих форм, в отличие от большинства других форм кодирования текста, является то, что они поддерживают весь набор символов Unicode.
XKCD # 1953 - История Unicode
Хотя Unicode действительно устранил некоторые проблемы, связанные с избытком сосуществующих кодировок символов, он не решил все из них. Во-первых, внедрение сопутствующих систем кодирования было медленным и все еще далеко не универсальным. С другой стороны, даже при том, что наличие общего набора символов для сопоставления кодировок, безусловно, было полезным, это не изменило тот досадный факт, что многие типы текстовых данных не содержат никакой информации о том, какая система кодирования использовалась для их создания.
С другой стороны, даже при том, что наличие общего набора символов для сопоставления кодировок, безусловно, было полезным, это не изменило тот досадный факт, что многие типы текстовых данных не содержат никакой информации о том, какая система кодирования использовалась для их создания.
Итак, как работает кодирование?
Хорошо, давайте перейдем к мельчайшим деталям. Что на самом деле сохраняется при сохранении текстового файла? Сначала мы рассмотрим одну из самых старых и простых кодировок - ASCII. Вот выдержка из статьи Википедии для ASCII:
«Первоначально основанный на английском алфавите, ASCII кодирует 128 заданных символов в семибитовые целые числа, как показано в таблице ASCII выше. Можно напечатать девяносто пять закодированных символов: это цифры от 0 до 9, строчные буквы от a до z, прописные буквы от A до Z и символы пунктуации.Кроме того, исходная спецификация ASCII включала 33 непечатаемых управляющих кода, которые были созданы с помощью телетайпов; большинство из них уже устарели, хотя некоторые из них все еще широко используются, например, коды возврата каретки, перевода строки и табуляции ».
Поскольку ASCII был разработан в США и основан на английском алфавите, он содержит только стандартные английские символы. Это означает, что текст, содержащий неанглийские символы (например, буквы с диакритическими знаками или специальные буквы, используемые в других языках), не может быть точно закодирован в ASCII без замены специальных символов на стандартные английские.ASCII был разработан с использованием 7-битных кодов для представления закодированных символов, но поскольку все современные компьютеры используют байты (8 бит) в качестве наименьшей единицы памяти, символы ASCII теперь хранятся с использованием 8 бит на символ. Первый бит просто не используется.
Весь стандарт кодирования ASCII выглядит так:
Теперь давайте рассмотрим пример, чтобы увидеть, как эти тексты будут закодированы в стандарте ASCII. Вместо того, чтобы полностью писать двоичные представления более длинных текстов, мы будем использовать шестнадцатеричную нотацию для двоичных данных.
Когда вы открываете текстовый файл в кодировке ASCII в текстовом редакторе, программа считывает каждый байт файла и ищет значение в таблице ASCII, чтобы определить, какой символ отображать для этого байта.
ОднакоASCII - это очень ограниченная кодировка. Он содержит только 95 печатных символов и поэтому может использоваться только для кодирования этих символов. Если у вас есть текстовые данные, которые содержат больше символов, чем эти 95 печатных символов, вам придется использовать другую кодировку.
Это основы работы кодирования. В следующей части серии мы рассмотрим несколько различных кодировок и их отличия друг от друга, которые вы можете найти здесь. Кодировка 101 - часть 2.
Безболезненное руководство - Настоящий Python
Обработка кодировок символов в Python или любом другом языке временами может показаться болезненной. В таких местах, как Stack Overflow, есть тысячи вопросов, возникающих из-за путаницы с исключениями, такими как UnicodeDecodeError и UnicodeEncodeError .Это руководство предназначено для устранения тумана Exception и демонстрации того, что работа с текстовыми и двоичными данными в Python 3 может быть удобной. Поддержка Unicode в Python сильна и надежна, но для ее освоения требуется время.
Это руководство отличается тем, что оно не зависит от языка, а вместо этого намеренно ориентировано на Python. Вы все равно получите учебник, не зависящий от языка, но затем вы погрузитесь в иллюстрации на Python с минимальным количеством текстовых абзацев.Вы увидите, как использовать концепции кодировок символов в живом коде Python.
К концу этого руководства вы будете:
- Получите концептуальные обзоры кодировок символов и систем нумерации
- Узнайте, как кодирование вступает в игру с помощью Python
strибайт - Знайте о поддержке в Python систем нумерации с помощью различных форм
intлитералов - Ознакомьтесь со встроенными функциями Python, связанными с кодировками символов и системами нумерации.
Системы кодирования и нумерации символов настолько тесно связаны, что их нужно рассматривать в одном учебном пособии, иначе обработка любой из них будет совершенно неадекватной.
Примечание : эта статья ориентирована на Python 3. В частности, все примеры кода в этом руководстве были сгенерированы из оболочки CPython 3.7.2, хотя все второстепенные версии Python 3 должны вести себя (в основном) одинаково при обработке текста.
Если вы все еще используете Python 2 и вас пугают различия в том, как Python 2 и Python 3 обрабатывают текстовые и двоичные данные, то, надеюсь, это руководство поможет вам сделать переход.
Что такое кодировка символов?
Существуют десятки, если не сотни кодировок символов.Лучший способ понять, что это такое, - рассмотреть одну из простейших кодировок символов - ASCII.
Независимо от того, являетесь ли вы самоучкой или имеете формальное образование в области информатики, скорее всего, вы видели таблицу ASCII один или два раза. ASCII - хорошее место для начала изучения кодировки символов, потому что это небольшая и ограниченная кодировка. (Как оказалось, слишком мало.)
Включает:
- Строчные английские буквы : a от до z
- Заглавные английские буквы : A от до Z
- Некоторые знаки препинания и символы :
"$"и"!", чтобы назвать пару - Пробельные символы : фактический пробел (
""), а также перевод строки, возврат каретки, горизонтальная табуляция, вертикальная табуляция и некоторые другие - Некоторые непечатаемые символы : символы, такие как backspace,
"\ b", которые не могут быть напечатаны буквально так, как буква A может
Итак, какое более формальное определение кодировки символов?
На очень высоком уровне это способ преобразования символов (таких как буквы, знаки препинания, символы, пробелы и управляющие символы) в целые числа и, в конечном итоге, в биты.Каждый символ может быть закодирован в уникальную последовательность битов. Не волнуйтесь, если вы не уверены в концепции битов, потому что мы скоро к ним вернемся.
Различные обозначенные категории представляют собой группы персонажей. Каждому одиночному символу соответствует код , который можно рассматривать как целое число. В таблице ASCII символы разбиты на разные диапазоны:
| Диапазон кодовой точки | Класс |
|---|---|
| от 0 до 31 | Управляющие / непечатаемые символы |
| 32-64 | Пунктуация, символы, числа и пробел |
| 65-90 | Заглавные буквы английского алфавита |
| 91–96 | Дополнительные графемы, например [ и \ |
| 97–122 | Строчные буквы английского алфавита |
| от 123 до 126 | Дополнительные графемы, например { и | |
| 127 | Управляющий / непечатаемый символ ( DEL ) |
Вся таблица ASCII содержит 128 символов.В этой таблице содержится полный набор символов , разрешенный ASCII. Если вы не видите здесь символа, вы просто не можете выразить его как печатный текст в схеме кодировки ASCII.
| Кодовая точка | Персонаж (Имя) | Кодовая точка | Персонаж (Имя) |
|---|---|---|---|
| 0 | NUL (Нуль) | 64 | @ |
| 1 | SOH (начало заголовка) | 65 | А |
| 2 | STX (начало текста) | 66 | В |
| 3 | ETX (конец текста) | 67 | К |
| 4 | EOT (конец передачи) | 68 | Д |
| 5 | ENQ (Запрос) | 69 | E |
| 6 | ACK (подтверждение) | 70 | Ф. |
| 7 | BEL (Звонок) | 71 | G |
| 8 | BS (Backspace) | 72 | H |
| 9 | HT (горизонтальный выступ) | 73 | я |
| 10 | LF (перевод строки) | 74 | Дж |
| 11 | VT (вертикальный выступ) | 75 | К |
| 12 | FF (подача формы) | 76 | л |
| 13 | CR (возврат каретки) | 77 | м |
| 14 | SO (сдвиг) | 78 | N |
| 15 | SI (сдвиг внутрь) | 79 | О |
| 16 | DLE (выход из канала передачи данных) | 80 | п. |
| 17 | DC1 (Управление устройством 1) | 81 | Q |
| 18 | DC2 (Управление устройством 2) | 82 | R |
| 19 | DC3 (Управление устройством 3) | 83 | S |
| 20 | DC4 (Управление устройством 4) | 84 | т |
| 21 | NAK (отрицательное подтверждение) | 85 | U |
| 22 | SYN (синхронный холостой ход) | 86 | В |
| 23 | ETB (конец блока передачи) | 87 | Вт |
| 24 | CAN (Отмена) | 88 | X |
| 25 | EM (конец среднего) | 89 | Y |
| 26 | SUB (Заменитель) | 90 | Z |
| 27 | ESC (выход) | 91 | [ |
| 28 | FS (Разделитель файлов) | 92 | \ |
| 29 | GS (Разделитель групп) | 93 | ] |
| 30 | RS (Разделитель записей) | 94 | ^ |
| 31 | США (разделитель единиц) | 95 | _ |
| 32 | SP (Космос) | 96 | ` |
| 33 | ! | 97 | |
| 34 | " | 98 | б |
| 35 | # | 99 | с |
| 36 | $ | 100 | д |
| 37 | % | 101 | e |
| 38 | и | 102 | f |
| 39 | ' | 103 | г |
| 40 | ( | 104 | ч |
| 41 | ) | 105 | и |
| 42 | * | 106 | j |
| 43 | + | 107 | к |
| 44 | , | 108 | л |
| 45 | – | 109 | м |
| 46 | . | 110 | n |
| 47 | / | 111 | или |
| 48 | 0 | 112 | п. |
| 49 | 1 | 113 | q |
| 50 | 2 | 114 | р |
| 51 | 3 | 115 | с |
| 52 | 4 | 116 | т |
| 53 | 5 | 117 | u |
| 54 | 6 | 118 | v |
| 55 | 7 | 119 | w |
| 56 | 8 | 120 | x |
| 57 | 9 | 121 | y |
| 58 | : | 122 | z |
| 59 | ; | 123 | { |
| 60 | < | 124 | | |
| 61 | = | 125 | } |
| 62 | > | 126 | ~ |
| 63 | ? | 127 | DEL (удалить) |
Строка
Модуль Модуль Python string представляет собой удобный универсальный инструмент для строковых констант, которые попадают в набор символов ASCII._` {|} ~ "" "
printable = цифры + ascii_letters + знаки препинания + пробел
Большинство этих констант должны самодокументироваться в своих именах идентификаторов. Вскоре мы рассмотрим, что такое шестнадцатеричных цифр и восьмицифровых цифр .
Эти константы можно использовать для повседневных операций со строками:
>>> >>> импортная строка
>>> s = "Что не так с ASCII?!?!?"
>>> s.rstrip (строка. пунктуация)
"Что не так с ASCII"
Примечание : строка .printable включает в себя все string.whitespace . Это немного не согласуется с другим методом проверки того, считается ли символ пригодным для печати, а именно str.isprintable () , который сообщит вам, что ни один из {'\ v', '\ n', '\ r', '\ f ',' \ t '} считаются пригодными для печати.
Тонкое различие связано с определением: str.isprintable () считает что-то пригодным для печати, если «все его символы считаются печатаемыми в repr () .”
Немного освежить
Сейчас хорошее время для краткого освежения информации о bit , наиболее фундаментальной единице информации, которую знает компьютер.
Бит — это сигнал, который имеет только два возможных состояния. Есть разные способы символического представления бита, которые означают одно и то же:
- 0 или 1
- «да» или «нет»
-
ВерноилиЛожно - «включено» или «выключено»
В нашей таблице ASCII из предыдущего раздела используется то, что мы с вами называем числами (от 0 до 127), но более точно называемые числами с основанием 10 (десятичными).
Вы также можете выразить каждое из этих чисел с основанием 10 последовательностью битов (основание 2). Вот двоичные версии от 0 до 10 в десятичном виде:
| Десятичное число | Двоичный (компактный) | Двоичный (заполненная форма) |
|---|---|---|
| 0 | 0 | 00000000 |
| 1 | 1 | 00000001 |
| 2 | 10 | 00000010 |
| 3 | 11 | 00000011 |
| 4 | 100 | 00000100 |
| 5 | 101 | 00000101 |
| 6 | 110 | 00000110 |
| 7 | 111 | 00000111 |
| 8 | 1000 | 00001000 |
| 9 | 1001 | 00001001 |
| 10 | 1010 | 00001010 |
Обратите внимание, что по мере увеличения десятичного числа n вам потребуется больше значащих битов для представления набора символов до этого числа включительно.
Вот удобный способ представления строк ASCII как последовательности битов в Python. Каждый символ из строки ASCII получает псевдокодирование в 8 бит с пробелами между 8-битными последовательностями, каждая из которых представляет один символ:
>>> >>> def make_bitseq (s: str) -> str:
... если не s.isascii ():
... поднять ValueError ("Допускается только ASCII")
... return "" .join (f "{ord (i): 08b}" для i в s)
>>> make_bitseq ("биты")
'01100010 01101001 01110100 01110011'
>>> make_bitseq ("ЗАГЛАВКИ")
'01000011 01000001 01010000 01010011'
>>> make_bitseq ("25 долларов.43 ")
'00100100 00110010 00110101 00101110 00110100 00110011'
>>> make_bitseq ("~ 5")
'01111110 00110101'
Примечание : .isascii () был введен в Python 3.7.
Строка f f "{ord (i): 08b}" использует мини-язык спецификации формата Python, который является способом указания форматирования для полей замены в строках формата:
Левая часть двоеточия,
ord (i), представляет собой фактический объект, значение которого будет отформатировано и вставлено в вывод.Использование функции Pythonord ()дает вам кодовую точку base-10 для одного символаstr.Правая часть двоеточия — это спецификатор формата.
08означает шириной 8, 0 с дополнением , аbфункционирует как знак для вывода результирующего числа с основанием 2 (двоичное).
Этот трюк предназначен в основном для развлечения, и он очень плохо подойдет для любого символа, которого вы не видите в таблице ASCII.Позже мы обсудим, как другие кодировки решают эту проблему.
Нам нужно больше бит!
Есть критически важная формула, связанная с определением бита. Учитывая количество битов, n , количество различных возможных значений, которые могут быть представлены в n битах, равно 2 n :
def n_possible_values (nbits: int) -> int:
вернуть 2 ** нбит
Вот что это значит:
- 1 бит позволит вам выразить 2 1 == 2 возможных значений.
- 8 бит позволят вам выразить 2 8 == 256 возможных значений.
- 64 бита позволят вам выразить 2 64 == 18,446,744,073,709,551,616 возможных значений.
Из этой формулы следует следствие: учитывая диапазон различных возможных значений, как мы можем найти количество битов, n , которое требуется для полного представления диапазона? Вы пытаетесь найти n в уравнении 2 n = x (где вы уже знаете x ).
Вот что из этого получается:
>>> >>> from math import ceil, log
>>> def n_bits_required (nvalues: int) -> int:
... вернуть ceil (log (nvalues) / log (2))
>>> n_bits_required (256)
8
Причина, по которой вам нужно использовать потолок в n_bits_required () , состоит в том, чтобы учесть значения, которые не являются чистыми степенями 2. Скажем, вам нужно сохранить набор символов из 110 символов. Наивно, это должно занять log (110) / log (2) == 6.781 бит, но нет такого понятия, как 0,781 бит. 110 значений потребуют 7 бит, а не 6, причем последние слоты не нужны:
>>> n_bits_required (110)
7
Все это служит доказательством одной концепции: ASCII, строго говоря, является 7-битным кодом. Таблица ASCII, которую вы видели выше, содержит 128 кодовых точек и символов, от 0 до 127 включительно. Для этого требуется 7 бит:
>>> >>> n_bits_required (128) # от 0 до 127
7
>>> n_possible_values (7)
128
Проблема в том, что современные компьютеры почти ничего не хранят в 7-битных слотах.Они передают данные в единицах по 8 бит, обычно известных как байт .
Примечание : В этом руководстве я предполагаю, что байт относится к 8 битам, как это было с 1960-х годов, а не к какой-либо другой единице хранения. Вы можете позвонить по этому номеру: октет , , если хотите.
Это означает, что дисковое пространство, используемое ASCII, наполовину пусто. Если неясно, почему это так, вспомните приведенную выше таблицу преобразования десятичных чисел в двоичные. Вы можете, , выразить числа 0 и 1 всего одним битом, или вы можете использовать 8 бит, чтобы выразить их как 00000000 и 00000001, соответственно.
Вы, , можете выразить числа от 0 до 3 всего двумя битами или от 00 до 11, или вы можете использовать 8 битов, чтобы выразить их как 00000000, 00000001, 00000010 и 00000011, соответственно. Самая высокая кодовая точка ASCII, 127, требует только 7 значащих битов.
Зная это, вы можете видеть, что make_bitseq () преобразует строки ASCII в представление байтов str , где каждый символ занимает один байт:
>>> make_bitseq ("биты")
'01100010 01101001 01110100 01110011'
Недостаточное использованиеASCII 8-битных байтов, предлагаемых современными компьютерами, привело к семейству конфликтующих, неформальных кодировок, каждая из которых определяла дополнительные символы, которые должны использоваться с оставшимися 128 доступными кодовыми точками, разрешенными в схеме кодирования 8-битных символов.
Эти разные кодировки не только конфликтовали друг с другом, но и каждая из них сама по себе оставалась крайне неполным представлением персонажей мира, несмотря на то, что в них использовался один дополнительный бит.
Спустя годы одна мега-схема кодирования символов стала управлять всеми ими. Однако, прежде чем мы перейдем к делу, давайте поговорим на минутку о системах нумерации, которые являются фундаментальной основой схем кодирования символов.
Покрытие всех баз: другие системы счисления
При обсуждении ASCII выше вы видели, что каждый символ отображается на целое число в диапазоне от 0 до 127.
Этот диапазон чисел выражается в десятичной системе счисления (основание 10). Это способ, которым вы, я и остальные из нас, людей, привыкли считать, и нет более сложной причины, чем то, что у нас 10 пальцев.
Но есть и другие системы нумерации, которые особенно распространены в исходном коде CPython. Хотя «базовое число» одно и то же, все системы нумерации — это просто разные способы выражения одного и того же числа.
Если бы я спросил вас, какое число представляет строка "11" , вы были бы правы, бросив на меня странный взгляд, прежде чем ответить, что оно представляет собой одиннадцать.
Однако это строковое представление может выражать разные базовые числа в разных системах нумерации. В дополнение к десятичной системе счисления альтернативы включают следующие общепринятые системы нумерации:
- Двоичный : базовый 2
- Восьмеричное : основание 8
- Шестнадцатеричный (шестнадцатеричный) : основание 16
Но что для нас означает утверждение, что в определенной системе счисления числа представлены в базе N ?
Вот лучший из известных мне способов сформулировать, что это означает: это количество пальцев, на которые вы рассчитываете в этой системе.
Если вам нужно гораздо более полное, но все же мягкое введение в системы нумерации, то книга Чарльза Петцольда Code — невероятно крутая книга, в которой подробно исследуются основы компьютерного кода.
Один из способов продемонстрировать, как разные системы нумерации интерпретируют одно и то же, — использовать конструктор Python int () . Если вы передадите str в int () , Python по умолчанию будет считать, что строка выражает число в базе 10, если вы не укажете иное:
>>> int ('11 ')
11
>>> int ('11 ', base = 10) # 10 уже по умолчанию
11
>>> int ('11 ', base = 2) # Двоичный
3
>>> int ('11 ', base = 8) # Восьмеричный
9
>>> int ('11 ', base = 16) # Шестнадцатеричный
17
Существует более распространенный способ сообщить Python, что ваше целое число набрано с основанием, отличным от 10.Python принимает буквальных форм каждой из трех альтернативных систем нумерации, указанных выше:
| Тип литерала | Префикс | Пример |
|---|---|---|
| н / д | н / д | 11 |
| Двоичный литерал | 0b или 0B | 0b11 |
| Восьмеричный литерал | 0o или 0O | 0o11 |
| Буквенный шестигранник | 0x или 0X | 0x11 |
Все это подформы целочисленных литералов .Вы можете видеть, что они дают те же результаты, соответственно, что и вызовы int () с нестандартными значениями base . Все они просто от до Python:
>>> 11
11
>>> 0b11 # Двоичный литерал
3
>>> 0o11 # Восьмеричный литерал
9
>>> 0x11 # шестнадцатеричный литерал
17
Вот как вы можете ввести двоичный, восьмеричный и шестнадцатеричный эквиваленты десятичных чисел от 0 до 20. Любой из них совершенно допустим в оболочке интерпретатора Python или в исходном коде, и все они имеют тип int :
| Десятичное число | двоичный | восьмеричное | шестигранник |
|---|---|---|---|
0 | 0b0 | 0o0 | 0x0 |
1 | 0b1 | 0o1 | 0x1 |
2 | 0b10 | 0o2 | 0x2 |
3 | 0b11 | 0o3 | 0x3 |
4 | 0b100 | 0o4 | 0x4 |
5 | 0b101 | 0o5 | 0x5 |
6 | 0b110 | 0o6 | 0x6 |
7 | 0b111 | 0o7 | 0x7 |
8 | 0b1000 | 0o10 | 0x8 |
9 | 0b1001 | 0o11 | 0x9 |
10 | 0b1010 | 0o12 | 0xa |
11 | 0b1011 | 0o13 | 0xb |
12 | 0b1100 | 0o14 | 0xc |
13 | 0b1101 | 0o15 | 0xd |
14 | 0b1110 | 0o16 | 0xe |
15 | 0b1111 | 0o17 | 0xf |
16 | 0b10000 | 0o20 | 0x10 |
17 | 0b10001 | 0o21 | 0x11 |
18 | 0b10010 | 0o22 | 0x12 |
19 | 0b10011 | 0o23 | 0x13 |
20 | 0b10100 | 0o24 | 0x14 |
Удивительно, насколько распространены эти выражения в стандартной библиотеке Python.Если вы хотите в этом убедиться, перейдите туда, где находится ваш каталог lib / python3.7 / , и проверьте использование шестнадцатеричных литералов, например:
$ grep -nri --include "* \. Py" -e "\ b0x" lib / python3.7
Это должно работать в любой системе Unix, имеющей grep . Вы можете использовать «\ b0o» для поиска восьмеричных литералов или «\ b0b» для поиска двоичных литералов.
Каков аргумент в пользу использования этих альтернативных синтаксисов литералов int ? Короче говоря, это потому, что 2, 8 и 16 — это степени двойки, а 10 — нет.Эти три альтернативные системы счисления иногда предлагают способ выражения значений в удобной для компьютера манере. Например, число 65536 или 2 16 — это всего лишь 10000 в шестнадцатеричном формате или 0x10000 в шестнадцатеричном формате Python.
Введите Unicode
Как вы видели, проблема с ASCII заключается в том, что это недостаточно большой набор символов, чтобы вместить мировой набор языков, диалектов, символов и глифов. (Его даже недостаточно для одного английского.)
Unicode в основном служит той же цели, что и ASCII, но он просто охватывает в некотором смысле способ большего набора кодовых точек. Есть несколько кодировок, которые возникли в хронологическом порядке между ASCII и Unicode, но на самом деле о них пока не стоит упоминать, потому что Unicode и одна из его схем кодирования, UTF-8, стали широко использоваться.
Думайте о Юникоде как об огромной версии таблицы ASCII, имеющей 1114 112 возможных кодовых точек. Это от 0 до 1,114,111 или от 0 до 17 * (2 16 ) — 1 или 0x10ffff в шестнадцатеричном формате.Фактически, ASCII — идеальное подмножество Unicode. Первые 128 символов в таблице Unicode в точности соответствуют символам ASCII, которые, как вы разумно ожидали, от них будут.
Для обеспечения технической точности сам код Unicode является , а не кодировкой . Скорее, Unicode — это , реализованный с помощью различных кодировок символов, которые вы скоро увидите. Unicode лучше рассматривать как карту (что-то вроде dict ) или таблицу базы данных с двумя столбцами.Он отображает символы (например, "a" , "" или даже "ቈ" ) в различные положительные целые числа. Кодировка символов должна предлагать немного больше.
Unicode содержит практически все символы, которые вы можете себе представить, включая дополнительные непечатаемые. Один из моих любимых — надоедливый знак с написанием справа налево, который имеет кодовую точку 8207 и используется в тексте с языковыми алфавитами как слева направо, так и справа налево, например в статье, содержащей абзацы на английском и арабском языках .
Примечание: Мир кодировок символов — одна из многих мелких технических деталей, над которыми некоторые люди любят придираться. Одна из таких деталей заключается в том, что фактически можно использовать только 1111998 кодовых точек Unicode по нескольким архаичным причинам.
Unicode против UTF-8
Людям не потребовалось много времени, чтобы понять, что все символы мира не могут быть упакованы в один байт каждый. Из этого очевидно, что современные, более полные кодировки должны использовать несколько байтов для кодирования некоторых символов.
Вы также видели выше, что Unicode технически не является полноценной кодировкой символов. Это почему?
Есть одна вещь, о которой Unicode не говорит вам: он не говорит вам, как получить фактические биты из текста, а только кодовые точки. В нем недостаточно информации о том, как преобразовать текст в двоичные данные и наоборот.
Unicode — это абстрактный стандарт кодирования, а не кодирование. Вот где в игру вступают UTF-8 и другие схемы кодирования. Стандарт Unicode (карта символов для кодовых точек) определяет несколько различных кодировок из своего единственного набора символов.
UTF-8, а также его менее используемые родственники, UTF-16 и UTF-32, являются форматами кодирования для представления символов Unicode в виде двоичных данных из одного или нескольких байтов на символ. Мы обсудим UTF-16 и UTF-32 чуть позже, но UTF-8, безусловно, занял самую большую долю пирога.
Это подводит нас к давно назревшему определению. Что формально означает кодировать и декодировать ?
Кодирование и декодирование в Python 3
Тип Python 3 str предназначен для представления удобочитаемого текста и может содержать любой символ Юникода.
Тип байт , наоборот, представляет двоичные данные или последовательности необработанных байтов, которые по сути не имеют прикрепленной к нему кодировки.
Кодирование и декодирование — это процесс перехода от одного к другому:
Кодирование и декодирование (Изображение: Real Python) В .encode () и .decode () параметр кодировки по умолчанию равен «utf-8» , хотя, как правило, более безопасно и однозначно указывать это:
>>> "резюме".кодировать ("utf-8")
b'r \ xc3 \ xa9sum \ xc3 \ xa9 '
>>> "Эль-Ниньо" .encode ("utf-8")
b'El Ni \ xc3 \ xb1o '
>>> b "r \ xc3 \ xa9sum \ xc3 \ xa9" .decode ("utf-8")
'резюме'
>>> b "Эль-Нинь \ xc3 \ xb1o" .decode ("utf-8")
'Эль-Ниньо'
Результатом str.encode () является объект байта байт. Оба байтовых литерала (например, b "r \ xc3 \ xa9sum \ xc3 \ xa9" ) и представления байтов допускают только символы ASCII.
Вот почему при вызове «Эль-Ниньо».encode ("utf-8") , ASCII-совместимый "El" может быть представлен как есть, но n с тильдой заменяется на "\ xc3 \ xb1" . Эта запутанная последовательность представляет собой два байта, 0xc3 и 0xb1 в шестнадцатеричном формате:
>>> "" .join (f "{i: 08b}" для i in (0xc3, 0xb1))
'11000011 10110001'
То есть для символа - требуется два байта для его двоичного представления в UTF-8.
Примечание . Если вы наберете help (str.encode) , вы, вероятно, увидите значение по умолчанию: encoding = 'utf-8' . Будьте осторожны, исключая это и просто используйте "резюме" .encode () , потому что значение по умолчанию может быть другим в Windows до Python 3.6.
Python 3: все на Unicode
Python 3 полностью использует Unicode и UTF-8. Вот что это значит:
Исходный код Python 3 по умолчанию считается UTF-8.Это означает, что вам не нужна кодировка
# - * -: UTF-8 - * -в верхней частифайлов .pyв Python 3.Весь текст (
str) по умолчанию - Unicode. Закодированный текст Unicode представлен в виде двоичных данных (байт,). Типstrможет содержать любой буквальный символ Юникода, например«Δv / Δt», все из которых будут сохранены как Юникод.Python 3 принимает множество кодовых точек Unicode в идентификаторах, что означает
résumé = "~ / Documents / resume.pdf "действителен, если это вам нравится.- Модуль
Python
reпо умолчанию использует флагre.UNICODE, а неre.ASCII. Это означает, например, чтоr "\ w"соответствует символам слова Unicode, а не только буквам ASCII. По умолчанию
кодируетвstr.encode ()ибайт. Decode ()- UTF-8.
Есть еще одно свойство, которое является более тонким: кодировка по умолчанию для встроенного open () зависит от платформы и значения локали .getpreferredencoding () :
>>> # Mac OS X High Sierra
>>> импортировать локаль
>>> locale.getpreferredencoding ()
'UTF-8'
>>> # Windows Server 2012; другие сборки Windows могут использовать UTF-16
>>> импортировать локаль
>>> locale.getpreferredencoding ()
'cp1252'
Опять же, урок здесь состоит в том, чтобы быть осторожным, делая предположения, когда дело доходит до универсальности UTF-8, даже если это преобладающая кодировка. Никогда не помешает быть явным в вашем коде.
Один байт, два байта, три байта, четыре
Важнейшей особенностью является то, что UTF-8 представляет собой кодировку с переменной длиной . Заманчиво замалчивать, что это означает, но стоит вникнуть.
Вернитесь к разделу, посвященному ASCII. Все в расширенной области ASCII требует не более одного байта пространства. Вы можете быстро доказать это с помощью следующего выражения генератора:
>>> >>> all (len (chr (i) .encode ("ascii")) == 1 для i в диапазоне (128))
Правда
UTF-8 совсем другой.Данный символ Unicode может занимать от одного до четырех байтов. Вот пример одного символа Юникода, занимающего четыре байта:
>>> >>> ibrow = "🤨"
>>> len (ibrow)
1
>>> ibrow.encode ("utf-8")
б '\ xf0 \ x9f \ xa4 \ xa8'
>>> len (ibrow.encode ("utf-8"))
4
>>> # Calling list () для байтового объекта дает вам
>>> # десятичное значение для каждого байта
>>> список (b '\ xf0 \ x9f \ xa4 \ xa8')
[240, 159, 164, 168]
Это тонкая, но важная особенность len () :
- Длина одного символа Unicode в Python
strбудет всегда равной 1, независимо от того, сколько байтов он занимает. - Длина одного и того же символа, закодированного до
байтов,будет где-то между 1 и 4.
В таблице ниже приведены общие типы символов, которые помещаются в каждый сегмент длины байта:
| Десятичный диапазон | Hex Диапазон | Что включено | Примеры |
|---|---|---|---|
| от 0 до 127 | "\ u0000" от до "\ u007F" | США ASCII | "A" , "\ n" , "7" , "&" |
| 128 до 2047 | "\ u0080" от до "\ u07FF" | Большинство латинских алфавитов * | "ñ" , "±" , "" , "ñ" |
| 2048 до 65535 | "\ u0800" от до "\ uFFFF" | Дополнительные детали многоязычного самолета (БМП) ** | "" , "" , "ᮈ" , "‰" |
| 65536 до 1114111 | "\ U00010000" от до "\ U0010FFFF" | Другое *** | "" , "𐀀" , "😓" , "🂲" , |
* Например, английский, арабский, греческий и ирландский
** Огромный набор языков и символов - в основном китайский, японский и корейский по объему (также ASCII и латинский алфавиты)
*** Дополнительный китайский , Японские, корейские и вьетнамские символы, а также другие символы и смайлы
Примечание : Чтобы не упустить из виду общую картину, существует дополнительный набор технических функций UTF-8, которые здесь не рассматриваются, поскольку они редко видны пользователю Python.
Например, UTF-8 фактически использует коды префикса, которые указывают количество байтов в последовательности. Это позволяет декодеру определять, какие байты принадлежат друг другу в кодировке переменной длины, и позволяет первому байту служить индикатором количества байтов в предстоящей последовательности.
В статьеWikipedia, посвященной UTF-8, не обойтись без технических подробностей, и всегда есть официальный стандарт Unicode, который поможет вам при чтении.
А как насчет UTF-16 и UTF-32?
Вернемся к двум другим вариантам кодировки, UTF-16 и UTF-32.
На практике разница между ними и UTF-8 существенна. Вот пример того, насколько велика разница при двустороннем преобразовании:
>>> >>> letter = "αβγδ"
>>> rawdata = letter.encode ("utf-8")
>>> rawdata.decode ("utf-8")
'αβγδ'
>>> rawdata.decode ("utf-16") # 😧
'뇎닎 돎듎'
В этом случае кодирование четырех греческих букв с помощью UTF-8 и последующее декодирование обратно в текст в UTF-16 приведет к получению текста str на совершенно другом языке (корейском).
Совершенно неверные результаты, подобные этому, возможны, если одна и та же кодировка не используется в двух направлениях. Два варианта декодирования одного и того же объекта размером байт могут привести к результатам, даже на разных языках.
В этой таблице указаны диапазон или количество байтов в UTF-8, UTF-16 и UTF-32:
| Кодировка | байт на символ (включительно) | переменной длины |
|---|---|---|
| UTF-8 | от 1 до 4 | Есть |
| UTF-16 | от 2 до 4 | Есть |
| UTF-32 | 4 | № |
Еще одним любопытным аспектом семейства UTF является то, что UTF-8 не будет всегда занимать меньше места, чем UTF-16.Это может показаться математически нелогичным, но вполне возможно:
>>> >>> text = "記者 鄭啟源 羅智堅"
>>> len (text.encode ("utf-8"))
26 год
>>> len (text.encode ("utf-16"))
22
Причина этого в том, что кодовые точки в диапазоне от U + 0800 до U + FFFF (от 2048 до 65535 в десятичной форме) занимают три байта в UTF-8 по сравнению с двумя в UTF-16.
Я ни в коем случае не рекомендую вам садиться в поезд UTF-16, независимо от того, работаете ли вы на языке, символы которого обычно находятся в этом диапазоне.Среди других причин один из веских аргументов в пользу использования UTF-8 заключается в том, что в мире кодирования отличная идея - сливаться с толпой.
Не говоря уже о том, что это 2019 год: память компьютера дешевая, поэтому экономия 4 байтов за счет использования UTF-16, вероятно, не стоит того.
Встроенные функции Python
Вы прошли через трудную часть. Пришло время использовать то, что вы уже видели в Python.
Python имеет группу встроенных функций, которые так или иначе связаны с системами нумерации и кодировкой символов:
Их можно логически сгруппировать в зависимости от их назначения:
ascii (),bin (),hex ()иoct ()предназначены для получения другого представления ввода.Каждый производитstr. Первый,ascii (), создает представление объекта только в формате ASCII с экранированными символами, отличными от ASCII. Остальные три дают двоичное, шестнадцатеричное и восьмеричное представление целого числа соответственно. Это всего лишь представлений , а не фундаментальное изменение ввода.байтов (),str ()иint ()являются конструкторами классов для своих соответствующих типов,байтов,strиint.Каждый из них предлагает способы принуждения ввода к желаемому типу. Например, как вы видели ранее, хотяint (11.0), вероятно, более распространен, вы также можете увидетьint ('11 ', base = 16).ord ()иchr ()являются инверсиями друг друга в том смысле, что функция Pythonord ()преобразует символstrв его кодовую точку base-10, аchr ()делает противоположный.
Вот более подробный взгляд на каждую из этих девяти функций:
| Функция | Подпись | Принимает | Тип возврата | Назначение |
|---|---|---|---|---|
ascii () | ascii (obj) | Зависит от | ул. | Представление объекта только в формате ASCII с экранированными символами, отличными от ASCII |
бункер () | бин (номер) | номер: внутренний | ул. | Двоичное представление целого числа с префиксом «0b» |
байт () | байт (iterable_of_ints) | Зависит от | байт | Преобразование входных данных в байтов , сырые двоичные данные |
chr () | chr (i) | i: int | ул. | Преобразование целочисленной кодовой точки в один символ Юникода |
шестигранник () | шестнадцатеричный (номер) | номер: внутренний | ул. | Шестнадцатеричное представление целого числа с префиксом «0x» |
внутр () | int ([x]) | Зависит от | внутренний | Привести (преобразовать) вход в int |
окт. () | окт (номер) | номер: внутренний | ул. | Восьмеричное представление целого числа с префиксом "0o" |
ord () | орд (в) | c: str | внутренний | Преобразование одиночного символа Юникода в его целочисленную кодовую точку |
ул. () | str (object = ’‘) | Зависит от | ул. | Привести (преобразовать) вход в str , текст |
Вы можете развернуть раздел ниже, чтобы увидеть несколько примеров каждой функции.
ascii () дает представление объекта только в формате ASCII с экранированными символами, отличными от ASCII:
>>> ascii ("abcdefg")
"'abcdefg'"
>>> ascii ("халепеньо")
"'Джалепе \\ xf1o'"
>>> ascii ((1, 2, 3))
'(1, 2, 3)'
>>> ascii (0xc0ffee) # Шестнадцатеричный литерал (int)
"12648430"
bin () дает двоичное представление целого числа с префиксом «0b» :
>>> корзина (0)
'0b0'
>>> корзина (400)
'0b110010000'
>>> bin (0xc0ffee) # Шестнадцатеричный литерал (int)
'0b110000001111111111101110'
>>> [bin (i) for i in [1, 2, 4, 8, 16]] # `int` + понимание списка
['0b1', '0b10', '0b100', '0b1000', '0b10000']
байт () приводит к байтам ввода, представляя необработанные двоичные данные:
>>> # Итерация целых чисел
>>> байты ((104, 101, 108, 108, 111, 32, 119, 111, 114, 108, 100))
привет мир
>>> bytes (range (97, 123)) # Итерация целых чисел
b'abcdefghijklmnopqrstuvwxyz '
>>> bytes ("real 🐍", "utf-8") # Строка + кодировка
б'реал \ xf0 \ x9f \ x90 \ x8d '
>>> байтов (10)
б '\ x00 \ x00 \ x00 \ x00 \ x00 \ x00 \ x00 \ x00 \ x00 \ x00'
>>> байтов.fromhex ('c0 ff ee')
б '\ xc0 \ xff \ xee'
>>> bytes.fromhex ("72 65 61 6c 70 79 74 68 6f 6e")
b 'альпифон'
chr () преобразует целочисленную кодовую точку в один символ Юникода:
>>> chr (97)
'а'
>>> chr (7048)
'ᮈ'
>>> chr (1114111)
'\ U0010ffff'
>>> chr (0x10FFFF) # Шестнадцатеричный литерал (int)
'\ U0010ffff'
>>> chr (0b01100100) # Двоичный литерал (int)
'd'
hex () дает шестнадцатеричное представление целого числа с префиксом «0x» :
>>> шестнадцатеричный (100)
'0x64'
>>> [hex (i) для i в [1, 2, 4, 8, 16]]
['0x1', '0x2', '0x4', '0x8', '0x10']
>>> [hex (i) для i в диапазоне (16)]
['0x0', '0x1', '0x2', '0x3', '0x4', '0x5', '0x6', '0x7',
'0x8', '0x9', '0xa', '0xb', '0xc', '0xd', '0xe', '0xf']
int () принуждает ввод к int , опционально интерпретируя ввод в заданной базе:
>>> int (11.0)
11
>>> int ('11 ')
11
>>> int ('11 ', основание = 2)
3
>>> int ('11 ', основание = 8)
9
>>> int ('11 ', основание = 16)
17
>>> int (0xc0ffee - 1.0)
12648429
>>> int.from_bytes (b "\ x0f", "маленький")
15
>>> int.from_bytes (b '\ xc0 \ xff \ xee', "большой")
12648430
Функция Python ord () преобразует одиночный символ Юникода в его целочисленный код:
>>> ord ("а")
97
>>> ord ("ę")
281
>>> ord ("ᮈ")
7048
>>> [ord (i) вместо i в "привет, мир"]
[104, 101, 108, 108, 111, 32, 119, 111, 114, 108, 100]
str () приводит к вводу str , представляя текст:
>>> str ("строка строки")
'строка строки'
>>> str (5)
'5'
>>> str ([1, 2, 3, 4]) # Как [1, 2, 3, 4].__str __ (), но используйте str ()
'[1, 2, 3, 4]'
>>> str (b "\ xc2 \ xbc чашка муки", "utf-8")
Стакана муки
>>> str (0xc0ffee)
"12648430"
Строковые литералы Python: способы снять шкуру с кошки
Вместо того, чтобы использовать конструктор str () , принято вводить str буквально:
>>> еда = "креветки и крупа"
Это может показаться достаточно простым. Но интересная сторона дела заключается в том, что, поскольку Python 3 полностью ориентирован на Unicode, вы можете «набирать» символы Unicode, которые вы, вероятно, даже не найдете на своей клавиатуре.Вы можете скопировать и вставить это прямо в оболочку интерпретатора Python 3:
>>> >>> алфавит = 'αβγδεζηθικλμνξοπρςστυφχψ'
>>> печать (алфавит)
αβγδεζηθικλμνξοπρςστυφχψ
Помимо размещения фактических, неэкранированных символов Unicode в консоли, есть и другие способы ввода строк Unicode.
Один из самых плотных разделов документации Python - это раздел, посвященный лексическому анализу, в частности раздел, посвященный строковым и байтовым литералам.Лично мне пришлось прочитать этот раздел один, два или, может быть, девять раз, чтобы он действительно проникся.
Отчасти он говорит о том, что Python позволяет вводить один и тот же символ Unicode шестью способами.
Первый и самый распространенный способ - буквально набрать сам символ, как вы уже видели. Сложная часть этого метода - это нахождение фактических нажатий клавиш. Вот здесь и вступают в игру другие методы получения и представления персонажей. Вот полный список:
| Последовательность выхода | Значение | Как выразить "a" |
|---|---|---|
"\ ooo" | Знак с восьмеричным числом ooo | "\ 141" |
"\ xhh" | Символ с шестнадцатеричным значением hh | "\ x61" |
"\ N {name}" | Персонаж с именем имя в базе данных Unicode | "\ N {СТРОЧНАЯ ЛАТИНСКАЯ БУКВА A}" |
"\ uxxxx" | Символ с 16-битным (2-байтовым) шестнадцатеричным значением xxxx | "\ u0061" |
"\ Uxxxxxxxx" | Символ с 32-битным (4-байтовым) шестнадцатеричным значением xxxxxxxx | "\ U00000061" |
Вот некоторые доказательства и подтверждения вышеизложенного:
>>> >>> (
... "а" ==
... "\ x61" ==
... "\ N {СТРОЧНАЯ ЛАТИНСКАЯ БУКВА A}" ==
... "\ u0061" ==
... "\ U00000061"
...)
Правда
Теперь есть два основных предостережения:
Не все эти формы подходят для всех персонажей. Шестнадцатеричное представление целого числа 300:
0x012c, что просто не подходит для 2-значного escape-кода"\ xhh". Наивысшая кодовая точка, которую вы можете втиснуть в эту escape-последовательность, - это"\ xff"("ÿ").Аналогично для"\ ooo", он будет работать только до"\ 777"("ǿ").Для
\ xhh,\ uxxxxи\ Uxxxxxxxxтребуется ровно столько цифр, сколько показано в этих примерах. Это может вызвать зацикливание из-за того, что в таблицах Unicode обычно отображаются коды символов с ведущимиU +и переменным количеством шестнадцатеричных символов. Ключевым моментом является то, что таблицы Unicode чаще всего не заполняют эти коды нулями.
Например, если вы обратитесь на unicode-table.com за информацией о готической букве faihu (или fehu), "𐍆" , вы увидите, что она указана как имеющая код U + 10346 .
Как поместить это в "\ uxxxx" или "\ Uxxxxxxxx" ? Ну, вы не можете поместить его в "\ uxxxx" , потому что это 4-байтовый символ, и чтобы использовать "\ Uxxxxxxxx" для представления этого символа, вам нужно будет ввести последовательность слева:
>>> "\ U00010346"
'𐍆'
Это также означает, что форма "\ Uxxxxxxxx" является единственной escape-последовательностью, которая может содержать любой символ Unicode.
Примечание : Вот короткая функция для преобразования строк, которые выглядят как "U + 10346" , во что-то, с чем может работать Python. Он использует str.zfill () :
>>> def make_uchr (код: str):
... return chr (int (code.lstrip ("U +"). zfill (8), 16))
>>> make_uchr ("U + 10346")
'𐍆'
>>> make_uchr ("U + 0026")
'&'
Другие кодировки, доступные в Python
На данный момент вы видели четыре кодировки символов:
- ASCII
- UTF-8
- UTF-16
- UTF-32
Есть масса других.
Одним из примеров является Latin-1 (также называемый ISO-8859-1), который технически является значением по умолчанию для протокола передачи гипертекста (HTTP) согласно RFC 2616. Windows имеет свой собственный вариант Latin-1, называемый cp1252.
Примечание : ISO-8859-1 все еще широко распространен в дикой природе. Библиотека запросов следует RFC 2616 «в буквальном смысле» в использовании ее в качестве кодировки по умолчанию для содержимого ответа HTTP или HTTPS. Если слово «текст» найдено в заголовке Content-Type , и никакая другая кодировка не указана, тогда запросы будут использовать ISO-8859-1.
Полный список принятых кодировок скрыт в документации для модуля кодеков , который является частью стандартной библиотеки Python.
Есть еще одна полезная распознаваемая кодировка, о которой следует знать, это «unicode-escape» . Если у вас есть декодированный str и вы хотите быстро получить представление его экранированного литерала Unicode, вы можете указать эту кодировку в .encode () :
>>> alef = chr (1575) # Или "\ u0627"
>>> alef_hamza = chr (1571) # Или "\ u0623"
>>> алеф, алеф_хамза
('ا', 'أ')
>>> алеф.кодировать ("unicode-escape")
б '\\ u0627'
>>> alef_hamza.encode ("unicode-escape")
б '\\ u0623'
Вы знаете, что они говорят о предположениях…
Тот факт, что Python делает допущение о кодировке UTF-8 для файлов и кода, который генерирует вы, , не означает, что вы, программист, должны работать с тем же допущением для внешних данных.
Давайте повторим это снова, потому что это правило, по которому следует жить: когда вы получаете двоичные данные (байты) из стороннего источника, будь то из файла или по сети, лучше всего проверить, что данные указывают кодировку .Если нет, то спросите сами.
Все операции ввода-вывода происходят в байтах, а не в тексте, и байты для компьютера - это только единицы и нули, пока вы не укажете иное, сообщив ему кодировку.
Вот пример того, где что-то может пойти не так. Вы подписаны на API, который отправляет вам рецепт дня, который вы получаете в байтах и всегда без проблем декодировали с помощью .decode ("utf-8") . В этот день часть рецепта выглядит так:
>>> data = b "\ xbc чашка муки"
Похоже, рецепт требует немного муки, но мы не знаем, сколько:
>>> >>> данные.декодировать ("utf-8")
Отслеживание (последний вызов последний):
Файл "", строка 1, в
UnicodeDecodeError: кодек utf-8 не может декодировать байт 0xbc в позиции 0: недопустимый начальный байт
Эээ . Есть эта надоедливая ошибка UnicodeDecodeError , которая может укусить вас, когда вы делаете предположения о кодировании. Вы уточняете у хоста API. И вот, данные на самом деле отправляются в кодировке Latin-1:
>>> data.decode ("латиница-1")
Стакана муки
Ну вот.В Latin-1 каждый символ помещается в один байт, тогда как символ «¼» занимает два байта в UTF-8 ( "\ xc2 \ xbc" ).
Урок здесь в том, что может быть опасно предполагать кодировку любых данных, которые передаются вам. В наши дни это , обычно это UTF-8, но это небольшой процент случаев, когда это не приведет к взрыву.
Если вам действительно нужно отказаться от поставки и угадать кодировку, взгляните на библиотеку chardet , которая использует методологию Mozilla, чтобы сделать обоснованное предположение о неоднозначно закодированном тексте.Тем не менее, такой инструмент, как chardet , должен быть вашим последним средством, а не первым.
Шансы и окончания:
unicodedata Было бы упущением не упомянуть unicodedata из стандартной библиотеки Python, которая позволяет вам взаимодействовать и выполнять поиск в базе данных символов Unicode (UCD):
>>> импортировать unicodedata
>>> unicodedata.name ("€")
«ЗНАК ЕВРО»
>>> unicodedata.lookup («ЗНАК ЕВРО»)
'€'
Заключение
В этой статье вы раскрыли обширную и впечатляющую тему кодировки символов в Python.
Здесь вы много узнали:
- Основные понятия кодировок символов и систем нумерации
- Целочисленные, двоичные, восьмеричные, шестнадцатеричные, строковые и байтовые литералы в Python
- Встроенные функции Python, связанные с системами кодировки и нумерации символов
- Обработка текста в Python 3 по сравнению с двоичными данными
Теперь идите и закодируйте!
ресурса
Чтобы получить более подробную информацию о затронутых здесь темах, посетите эти ресурсы:
В документации Python есть две страницы по теме:
Кодировка HTML
Чтобы правильно отображать HTML-страницу, веб-браузер должен знать какой набор символов использовать.
Из ASCII в UTF-8
ASCII был первым стандартом кодировки символов. ASCII определяет 128 различных символов, которые могут использоваться в Интернете: цифры (0-9), английские буквы (A-Z) и некоторые специальные персонажи нравятся! $ + - () @ <>.
ISO-8859-1 был набором символов по умолчанию для HTML 4. Этот набор символов поддерживает 256 различных кодов символов. HTML 4 также поддерживает UTF-8.
ANSI (Windows-1252) был исходным набором символов Windows.ANSI идентичен согласно ISO-8859-1, за исключением того, что ANSI содержит 32 дополнительных символа.
Спецификация HTML5 поощряет веб-разработчиков использовать символ UTF-8. набор, который охватывает почти все персонажи и символы в мире!
Атрибут кодировки HTML
Для правильного отображения HTML-страницы веб-браузер должен знать набор символов, используемый на странице.
Это указано в теге :
Различия между наборами символов
В следующей таблице показаны различия между наборами символов, описанными выше:
| Число | ASCII | ANSI | 8859 | UTF-8 | Описание | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 32 | пространство | |||||||||||||||
| 33 | ! | ! | ! | ! | восклицательный знак | |||||||||||
| 34 | " | " | " | " | кавычка | |||||||||||
| 35 | # | # | 9039 9039 знак 36$ | $ | $ | $ | знак доллара | |||||||||
| 37 | % | % | % | % | знак процента | и | и | амперсанд | ||||||||
| 39 | ' | ' | ' | ' | апостроф | |||||||||||
| 40 | ( | |||||||||||||||
| 41 | ) | ) | ) | ) | правая скобка | |||||||||||
| 42 | 9 0394 ** | * | * | звездочка | ||||||||||||
| 43 | + | + | + | + | плюс знак | |||||||||||
| 9039, 9039 9039 9039, 9039 | , | запятая | ||||||||||||||
| 45 | - | - | - | - | дефис-минус | |||||||||||
| 46 | . | . | . | . | до упора | |||||||||||
| 47 | / | / | / | / | солидус | |||||||||||
| 48 | 0 | 0 | 0 | 9039 01 | 1 | 1 | 1 | цифра один | ||||||||
| 50 | 2 | 2 | 2 | 2 | 51 цифра два | 3 | цифра три | |||||||||
| 52 | 4 | 4 | 4 | 4 | цифра четыре | |||||||||||
| 53 | 5 | 5 | ||||||||||||||
| 54 | 6 | 6 | 6 | 6 | цифра шесть | |||||||||||
| 55 | 7 | 7 | 903 94 77 | цифра семь | ||||||||||||
| 56 | 8 | 8 | 8 | 8 | цифра восемь | |||||||||||
| 57 | 9 | 9 | девять||||||||||||||
| 58 | : | : | : | : | двоеточие | |||||||||||
| 59 | ; | ; | ; | ; | точка с запятой | |||||||||||
| 60 | < | < | < | < | знак «меньше» | |||||||||||
| 61 | = | = | = | = | = | = | = | 62 | > | > | > | > | знак больше | |||
| 63 | ? | ? | ? | ? | вопросительный знак | |||||||||||
| 64 | @ | @ | @ | @ | коммерческий в | |||||||||||
| 65 | A | A | A 9039 заглавная буква | |||||||||||||
| 66 | B | B | B | B | Заглавная латинская буква B | |||||||||||
| 67 | C | C | C | C 9038 | Заглавная латинская буква | D | D | D | D | Заглавная латинская буква D | ||||||
| 69 | E | E | E | E | Заглавная латинская буква E | F | F | Заглавная латинская буква F | ||||||||
| 71 | G | G | G | G | 903 94 Заглавная латинская буква G||||||||||||
| 72 | H | H | H | H | Заглавная латинская буква H | |||||||||||
| 73 | I | I | I | заглавная буква I | ||||||||||||
| 74 | J | J | J | J | Заглавная латинская буква J | |||||||||||
| 75 | K | K | K | K | заглавная буква KK | 76 | L | L | L | L | Заглавная латинская буква L | |||||
| 77 | M | M | M | M | латинская заглавная буква M | NN | N | N | Заглавная латинская буква N | |||||||
| 79 | O | O | O | O 90 395 | Заглавная латинская буква O | |||||||||||
| 80 | P | P | P | P | Заглавная латинская буква P | |||||||||||
| 81 | Q | Q | Q | Q | Q | Q | Q | Q | Q 9039 буква Q | |||||||
| 82 | R | R | R | R | Заглавная латинская буква R | |||||||||||
| 83 | S | S | S | S | S | заглавная буква | ||||||||||
| 84 | T | T | T | T | Заглавная латинская буква T | |||||||||||
| 85 | U | U | U | U | Заглавная латинская буква | V | V | V | V | Заглавная латинская буква V | ||||||
| 87 | W | W | W | 90 394 WЗаглавная латинская буква W | ||||||||||||
| 88 | X | X | X | X | Заглавная латинская буква X | |||||||||||
| 89 | Y | Y | Y | Y | 9039 Латинская заглавная буква Y||||||||||||
| 90 | Z | Z | Z | Z | Латинская заглавная буква Z | |||||||||||
| 91 | [ | [ | [ | [ | [ | левая квадратная скобка] | ||||||||||
| 92 | \ | \ | \ | \ | обратный солидус | |||||||||||
| 93 | ] | ] | ] | ] | правый квадрат | ^ | ^ | ^ | акцент с циркумфлексом | |||||||
| 95 | _ | _ | _ | _ 903 95 | нижняя линия | |||||||||||
| 96 | ` | ` | ` | ` | серьезный акцент | |||||||||||
| 97 | a | a | a | a | a | 9039|||||||||||
| 98 | b | b | b | b | Строчная латинская буква b | |||||||||||
| 99 | c | c | c | c | Строчная латинская буква | d | d | d | d | Строчная латинская буква d | ||||||
| 101 | e | e | e | e | Строчная латинская буква e | f | f | Строчная латинская буква f | ||||||||
| 103 | g | g | g | g | Строчная латинская le tter g | |||||||||||
| 104 | h | h | h | h | Строчная латинская буква h | |||||||||||
| 105 | i | i | маленькая букваi | i4 | ||||||||||||
| 106 | j | j | j | j | Строчная латинская буква j | |||||||||||
| 107 | k | k | k | k 9038 | латинская строчная буква k90 | l | l | l | l | Строчная латинская буква l | ||||||
| 109 | m | m | m | m | Строчная латинская буква m | 903 1104|||||||||||
| n | n | Строчная латинская буква n | ||||||||||||||
| 111 | o | o | o | o | Строчная латинская буква le tter o | |||||||||||
| 112 | p | p | p | p | Строчная латинская буква p | |||||||||||
| 113 | q | q | маленькаяq | q | q | q | q | |||||||||
| 114 | r | r | r | r | Строчная латинская буква r | |||||||||||
| 115 | s | s | s | s | латинская строчная буква | t | t | t | t | Строчная латинская буква t | ||||||
| 117 | u | u | u | u | Строчная латинская буква u | |||||||||||
| v | v | Строчная латинская буква v | ||||||||||||||
| 119 | w | w | w | w | Строчная латинская буква le tter w | |||||||||||
| 120 | x | x | x | x | Строчная латинская буква x | |||||||||||
| 121 | y | y | маленькая букваy | y | y | y | ||||||||||
| 122 | z | z | z | z | Строчная латинская буква z | |||||||||||
| 123 | { | { | { | { | левая фигурная скоба | | | | | | | | вертикальная линия | |||||||
| 125 | } | } | } | } | правая фигурная скоба | |||||||||||
| 126 | ~ | ~ | ~ | 9039 127 | DEL | |||||||||||
| 128 | € | евро знак | евро знак | |||||||||||||
| 129 | ||||||||||||||||
| 130 | ‚ | одинарная кавычка с малым числом 9 | ||||||||||||||
| 131 | ƒ | строчная буква латинского алфавита 9039 | „ | двойные низкие 9 кавычки | ||||||||||||
| 133 | … | двойной эллипс | ||||||||||||||
| 134 | † | 9039 9039 9039 9039 9039 9039 кинжал | ||||||||||||||
| 136 | ˆ | модификатор буквы с циркумфлексом с акцентом | ||||||||||||||
| 137 | ‰ | 9039 9039 9039 9039 9039 9039 | Заглавная латинская буква S с кароном | |||||||||||||
| 139 | ‹ | кавычка с одинарным левым углом | ||||||||||||||
| 140 | 9039 | латиница c апитальная лигатура OE | ||||||||||||||
| 141 | НЕ ИСПОЛЬЗУЕТСЯ | |||||||||||||||
| 142 | Ž | заглавная заглавная | НЕ ИСПОЛЬЗУЕТСЯ | |||||||||||||
| 144 | НЕ ИСПОЛЬЗУЕТСЯ | |||||||||||||||
| 145 | 9039 9039 9039 9039 9039левая одинарная кавычка | |||||||||||||||
| 146 | ’ | правая одинарная кавычка | ||||||||||||||
| 147 | “ | “ | ” | правый двойная кавычка | ||||||||||||
| 149 | • | bullet | ||||||||||||||
| 150 | - | 9039 9039 9039 9039 9039 9039 9039 9039 9039 9039 9039 9039 | длинное тире | |||||||||||||
| 152 | ˜ | маленькая тильда | ||||||||||||||
| 153 | ||||||||||||||||
| š | Строчная латинская буква s с кароном | |||||||||||||||
| 155 | › | кавычка с одинарным прямым углом | Латинская маленькая лигатура oe | |||||||||||||
| 157 | НЕ ИСПОЛЬЗУЕТСЯ | |||||||||||||||
| 158 | ž | Latin | Ÿ | Заглавная латинская буква Y с диэрезисом | ||||||||||||
| 160 | без разрыва пространства | |||||||||||||||
| перевернутый восклицательный знак | ||||||||||||||||
| 162 | ¢ | ¢ | ¢ | знак центов | ||||||||||||
| 163 | £ | 9039 9039¤ | ¤ | ¤ | знак валюты | 90 390|||||||||||
| 165 | ¥ | ¥ | ¥ | знак йены | ||||||||||||
| 166 | ¦ | ¦ | 9039 9039 9039 9039 9039§ | § | знак раздела | |||||||||||
| 168 | ¨ | ¨ | ¨ | диэрезис | ||||||||||||
| 169 | 9039 9039 9039 © авторское право | |||||||||||||||
| 170 | ª | ª | ª | женский порядковый указатель | ||||||||||||
| 171 | « | « | « | двойная метка¬ | ¬ | ¬ | без знака | |||||||||
| 173 | 903 94мягкий дефис | |||||||||||||||
| 174 | ® | ® | ® | зарегистрированный знак | ||||||||||||
| 175 | mac4 9039 9039 mac | 9039 | ||||||||||||||
| 176 | ° | ° | ° | знак градуса | ||||||||||||
| 177 | ± | ± | 90 знак394 ± минус² | ² | ² | надстрочный два | ||||||||||
| 179 | ³ | ³ | ³ | 90´39 90´39 | 90´39 | 9039 острый акцент | ||||||||||
| 181 | µ | µ | µ | 9 0394 микро знак|||||||||||||
| 182 | ¶ | ¶ | ¶ | знак пилкроу | ||||||||||||
| 183 | · | 9039 средний | 9039¸ | ¸ | ¸ | седилла | ||||||||||
| 185 | ¹ | ¹ | ¹ | 9039 9039 9039 9039 9039 9039 мужской порядковый номер | ||||||||||||
| 187 | » | » | » | кавычки с двойным углом вправо | ||||||||||||
| 188 | ¼ | vul | 9039 | |||||||||||||
| 189 | ½ | ½ | ½ | vulga r дробь одна половина | ||||||||||||
| 190 | ¾ | ¾ | ¾ | вульгарная фракция три четверти | ||||||||||||
| 191 | ¿ | |||||||||||||||
| 192 | À | À | À | Заглавная латинская буква A с тупым шрифтом | ||||||||||||
| 193 | Á | Á | Á | Á | Á 9039 заглавная буква A 9039 9039 | Â | Â | Â | Заглавная латинская буква A с циркумфлексом | |||||||
| 195 | à | à | à | à | à | 9039 t49039 9039 A 9039 9039 9039 латинская заглавная букваÄ | Ä | Ä | Заглавная латинская буква A с тремой | |||||||
| 197 | Å | Å | Å | Заглавная латинская буква A с кольцом сверху | ||||||||||||
| 198 | Æ | Æ | Æ | Æ | Æ | 9039 9039 заглавная буква | Ç | Ç | Ç | Заглавная латинская буква C с седилем | ||||||
| 200 | È | È | È | заглавная 9039 9039 латинская заглавная буква E с тупым шрифтом 9039 | É | É | É | Заглавная латинская буква E с острым ударением | ||||||||
| 202 | Ê | Ê | Ê | Заглавная латинская буква E с циркумфлексом | 9039 | Ë | Ë | Заглавная латинская буква E с тремой | ||||||||
| 204 | 9 0395 | Ì | Ì | Ì | Заглавная латинская буква I с тупым ударением | |||||||||||
| 205 | Í | Í | Í | Заглавная латинская буква I с острым углом 9039 Î | Î | Î | Заглавная латинская буква I с циркумфлексом | |||||||||
| 207 | Ï | Ï | Ï | Заглавная латинская буква I с диэрезисом | 9039 9039ì | ì | Заглавная латинская буква Eth | |||||||||
| 209 | Ñ | Ñ | Ñ | Заглавная латинская буква N с тильдой | ||||||||||||
| 21039 | ||||||||||||||||
| 21039 | Ò | Латинская заглавная буква O с тупиком | ||||||||||||||
| 211 | Ó | Ó | Ó | Заглавная латинская буква O с острым ударением | ||||||||||||
| 212 | Ô | Ô | Ô | Заглавная латинская буква O с циркумфлексом | ||||||||||||
| 213 | 9039 | Заглавная латинская буква O с тильдой | ||||||||||||||
| 214 | Ö | Ö | Ö | Заглавная латинская буква O с диэрезисом | ||||||||||||
| 215 | 215 | 9039 знак умножения | ||||||||||||||
| 216 | Ø | Ø | Ø | Заглавная латинская буква O со штрихом | ||||||||||||
| 217 | Ù | 90Ù395 90Ù395 | 5 латинская заглавная | |||||||||||||
| 218 | Ú | Ú | Ú | Заглавная латинская буква l etter U с острым углом | ||||||||||||
| 219 | Û | Û | Û | Заглавная латинская буква U с циркумфлексом | ||||||||||||
| 220 | Ü | заглавная | с диэрезисом | |||||||||||||
| 221 | Ý | Ý | Ý | Заглавная латинская буква Y с острым ударением | ||||||||||||
| 222 | ||||||||||||||||
| 9039 | ||||||||||||||||
| 223 | ß | ß | ß | Строчная латинская буква, резкая s | ||||||||||||
| 224 | à | à | à | à | à | aá | á | á | Строчная латинская буква a с острым ударением | |||||||
| â | â | â | Строчная латинская буква a с циркумфлексом | |||||||||||||
| 227 | ã | ã | ã | ã | ã | ä | ä | ä | Строчная латинская буква a с диэрезисом | |||||||
| 229 | å | å | ||||||||||||||
| Latin 9039 | æ | æ | æ | Строчная латинская буква ae | ||||||||||||
| 231 | ç | ç | ç | è | è | Строчная латинская буква e с тупым ударением | ||||||||||
| 233 | é | é | é | Строчная латинская буква e с острым ударением | ||||||||||||
| 234 | ê | ê | ê | Латинская строчная буква e с флексом | ||||||||||||
| ë | Строчная латинская буква e с тремой | |||||||||||||||
| 236 | ì | ì | ì | Строчная латинская буква i с тупым шрифтом | ||||||||||||
| 237 | ||||||||||||||||
| 237 | ||||||||||||||||
| 237 | ||||||||||||||||
| 237 | ||||||||||||||||
| 237 9039 í | Строчная латинская буква i с острым ударением | |||||||||||||||
| 238 | î | î | î | Строчная латинская буква i с циркумфлексом | ||||||||||||
| 239 | 9039 | Строчная латинская буква i с тремой | ||||||||||||||
| 240 | ð | ð | ð | Строчная латинская буква eth | ||||||||||||
| 241 | ñ | ñ | ñ | Строчная латинская буква n с тильдой | ||||||||||||
| 242 | 242 | ò4 9039 ò394 9039 ò394 9039 o с могилой | ||||||||||||||
| 243 | - | - | - | латинская строчная буква o с острым углом | ||||||||||||
| 244 | ô | ô | 9039 с циркумфлексом | |||||||||||||
| 245 | x | x | x | латинская строчная буква o с тильдой | ||||||||||||
| 246 | ö | small 90is | ||||||||||||||
| 247 | ÷ | ÷ | ÷ | знак деления | ||||||||||||
| 248 | ø | ø | ø | Строчная латинская буква o со штрихом | ||||||||||||
| 249 | ù | ù | ù | ù | Latin 9038 | ú | ú | ú | Строчная латинская буква u с острым ударением | |||||||
| 251 | û | û | û | ú | ü | ü | ü | Строчная латинская буква u с диэрезисом | ||||||||
| 253 | ý | ý | ý | Строчная латинская буква y с острым углом | 9039 9039 9039þ | þ | Строчная латинская шип | |||||||||
| 255 | 4 | ÿ | ÿ | Строчная латинская буква y с тремой |
Набор символов ASCII
ASCII использует значения от 0 до 31 (и 127) для управляющих символов.
ASCII использует значения от 32 до 126 для букв, цифр и символов.
ASCII не использует значения от 128 до 255.
Набор символов ANSI (Windows-1252)
ANSI идентичен ASCII для значений от 0 до 127.
ANSI имеет собственный набор символов для значений от 128 до 159.
ANSI идентичен UTF-8 для значений от 160 до 255.
Набор символов ISO-8859-1
ISO-8859-1 идентичен ASCII для значений от 0 до 127.
ISO-8859-1 не использует значения от 128 до 159.
ISO-8859-1 идентичен UTF-8 для значений от 160 до 255.
Набор символов UTF-8
UTF-8 идентичен ASCII для значений от 0 до 127.
UTF-8 не использует значения от 128 до 159.
UTF-8 идентичен ANSI и 8859-1 для значений от 160 до 255.
UTF-8 продолжает значение 256 с более чем 10 000 различных символы.
Для более детального ознакомления ознакомьтесь с полным справочником по набору символов HTML.