Введение в базы данных / Хабр
Прежде чем начать рассказывать о базах данных, скажу, для кого эта статья. Если вы бывалый разработчик, то смело пропускайте статью, ничего нового вы с ней не найдете. Статья для тех, кто только планирует начать карьеру в дата-аналитике или data science, кто много раз слышал словосочетание «база данных», но не до конца понимает, что это.
Я решила написать эту статью, потому что именно такой статьи мне очень не хватало несколько лет назад, когда я только начала карьеру в аналитике данных. Тогда я часто слышала слова «база данных», «реляционная база», «primary key», примерно понимала, что они означают, но единую картину в голове у меня сложить не получалось.
Что такое база данных и зачем она?
Компании часто собирают информацию о своих клиентах, сотрудниках, операциях, финансах и т. д. Потом эту информацию можно выгодно использовать. Например, можно ее проанализировать и понять, какими способами можно увеличить прибыль. Можно на ее основе построить хитрые MLмодели, которые помогут улучшить продукт. Или, в конце концов, эту информацию можно просто перепродать другим компаниям.
Или, в конце концов, эту информацию можно просто перепродать другим компаниям.
Чтоб собирать и анализировать информацию, надо уметь ее сохранять. Конечно, можно сохранять информацию в печатном виде в обычных папках или в Excel-файлах. И многие компании до сих пор так сохраняют информацию. Однако, такое подойдет только для маленьких компаний с небольшим количеством данных. Когда компания вырастает, то и данных становится много, такие варианты сохранения информации становятся непригодны. Тогда на помощь приходят базы данных.
Базы данных помогают справиться с большим количеством проблем, решить которые папкам и Excel-файлам не под силу:
В базе данных можно хранить очень огромное количество данных – миллиарды и триллионы записей;
Базы помогают защищать данные — они позволяют давать доступ к данным только определенному кругу лиц. При этом можно ставить ограничения, кому к каким данным можно давать доступ и какого типа доступ, только чтение или редактирование тоже;
Базы данных могут помогать следить за правильностью данных с помощью различного вида проверок;
Также, базы данных могут позволять большому количеству людей одновременно взаимодействовать с данными.

Так что же такое база данных? Если говорить коротко, то это определенная структура, в которой хранится информация. Я понимаю, что из этого определения пока мало что понятно. Однако, более конкретное определение дать сложно, потому что существует много типов баз данных, и все они совершенно разные.
Я думаю, это определение станет понятнее, когда я далее опишу наиболее популярные типы баз данных на конкретных примерах.
Типы баз данных
Существует много разных типов баз данных. Наиболее популярные типы:
Реляционные базы данных
Key-value базы данных
Документно-ориентированные базы данных
Графовые базы данных
Колоночные базы данных
Далее я расскажу о каждом из этих типов. Однако, начну я реляционных баз данных и больше всего буду рассказывать о них, потому что именно этим типом баз данных чаще всего пользуются аналитики данных и data scientist-ы.
Реляционные базы данных (MySQL, PostgreSQL, Oracle DB)
Реляционная база данных – это база данных, которая состоит из таблиц. У реляционной базы данных 2 очень важные характеристики:
У реляционной базы данных 2 очень важные характеристики:
Рассмотрим пример реляционной базы. Допустим, у нас есть сервис доставки еды. Тогда, если мы построим реляционную базу данных для этого сервиса, то она, скорее всего, будет содержать следующие таблицы:
Рис 1. Пример реляционной базы данныхНа рисунке 1 я попыталась изобразить графически реляционную базу данных. Мы видим таблицы, из которых состоит база, и также видим, какие столбцы содержит каждая из таблиц.
Как я отметила выше, второй важной характеристикой реляционных баз данных является то, что между таблицами существуют отношения. Отношения между таблицами определяются с помощью primary key и foreign key.
Primary key – это столбец (или группа столбцов) таблицы, который содержит уникальные значения для каждой строки. На примере выше primary key каждой таблицы я выделила зеленым цветом. То есть, например, в таблице с заказами каждая строка будет описывать отдельный заказ. Не будет 2 строк, которые описывают один и тот же заказ, потому ID заказа будет разный для каждой строки.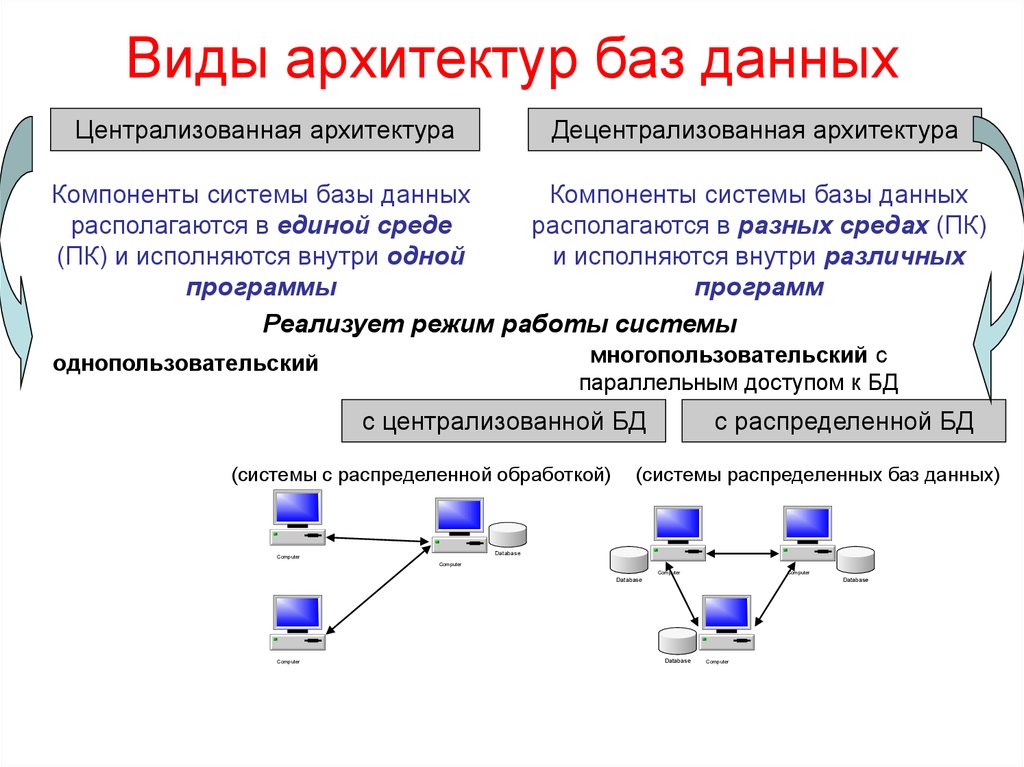
Foreign key – это столбец в таблице, который содержит primary key другой таблицы. На рисунке foreign key отмечены желтым. То есть, таблица с заказами содержит ID клиента, который является primary key в таблице с клиентами, но в таблице с заказами он будет foreign key.
Primary key и foreign key помогают не только связывать между собой таблицы реляционной базы данных отношениями. Они еще помогают следить за целостностью и правильностью данных в базе. Например, если мы ошибемся в ID клиента, добавляя новый заказ в таблицу с заказами, то база выдаст ошибку, так как не найдет соответствующий ID клиента в таблице с клиентами.
Для взаимодействия с реляционными базами данных чаще всего используется SQL (Structured QueryLanguage). Это специальный язык программирования, на котором пишутся запросы к реляционной базе. SQL-запросами можно создавать и удалять таблицы в реляционной базе, изменять данные в существующих таблицах и доставать из таблиц необходимую информацию.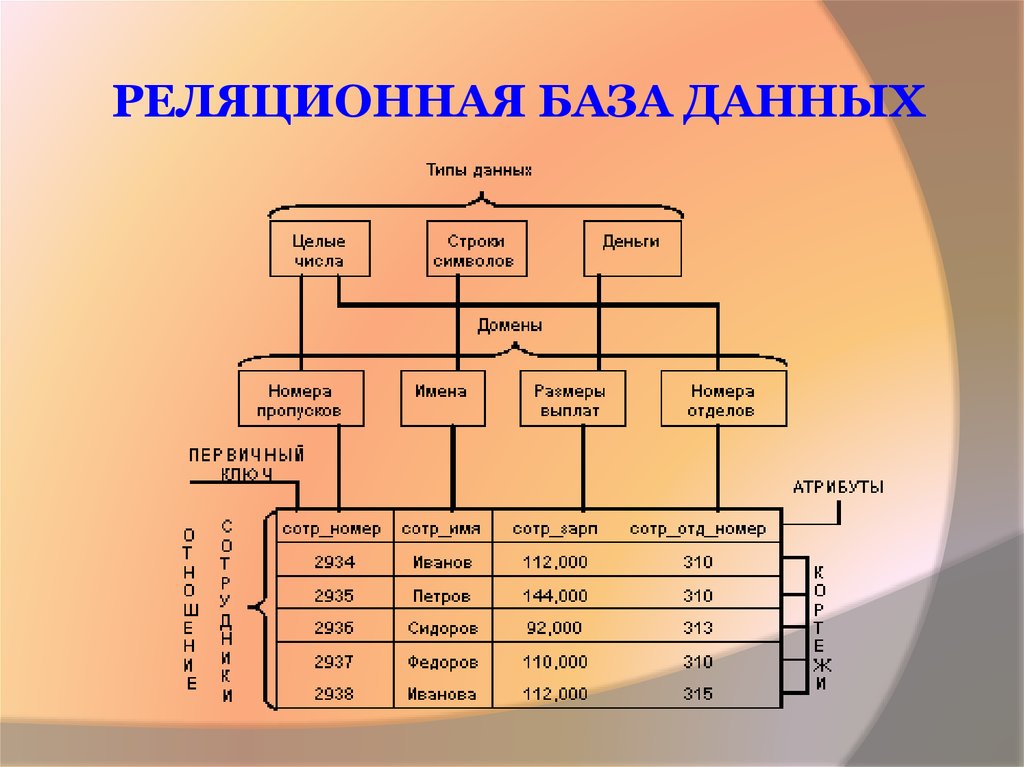
Как я уже говорила выше, реляционные базы данных удобно использовать в аналитике, так как информация в них структурирована и распределена по смыслу, что, конечно, мечта любого аналитика. Однако, аналитики часто пишут сложные и не очень эффективные SQL-запросы, потому важно придумывать способы ускорения обработки запросов к реляционной базе.
Одним из наиболее популярных методов ускорения работы запросов к реляционным базам данных является индексирование таблиц. Индекс – это определенный столбец в таблице, по которому осуществляется поиск.
Приведу пример работы индекса. Например, мы хотим найти все заказы клиента 007 из ресторана 1. Тогда, если у нас в таблице с заказами нет индекса, то мы будем перебирать все заказы пока не найдем нужные. Если же у нас есть индекс в таблице с заказами, то ситуация будет иной. Допустим, что индексом является столбец ID ресторана. Тогда наши данные в таблице с заказами будут сгруппированы по ID ресторана. И тогда при поиске заказов клиента 007 из ресторана 1, мы не будем перебирать всю таблицу с заказами, а найдем группу заказов из ресторана 1 и будем искать необходимые данные внутри этой группы.
Из примера выше с индексом выше понятно, что индексом удобно выбирать такой столбец, в разрезе которого часто ищутся данные.
Также, одним из важных свойств реляционных баз данных является соответствие требованиям ACID. Я не буду углубляться в детали этих требований, только отмечу, что эти требования гарантируют целостность и корректность данных, несмотря на ошибки, системные сбои, перебои в питании, изменение данных несколькими пользователями одновременно и прочие необычные ситуации.
Выглядит так, что реляционная база данных идеальная база, и непонятно, почему бы постоянно ее не использовать. Однако, у реляционной базы данных есть и недостатки, и потому данный тип не всегда подходит для нужд бизнеса. Например, реляционная база данных не подходит для данных без четкой структуры, потому что мы не сможем разложить эти данные в отдельные таблицы по смыслу. А данных без четкой структуры гораздо больше, чем данных с четкой структурой.
Какие еще есть типы баз данных?
Прочие типы баз данных, которые не реляционные, часто называются noSQL базы данных.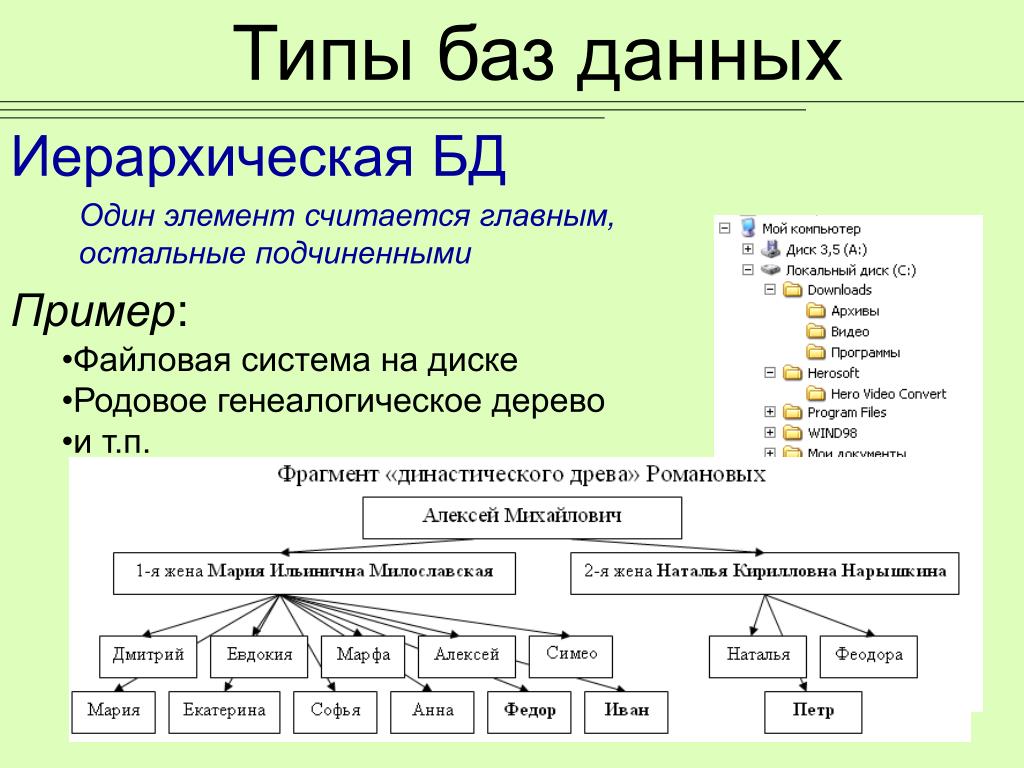 Обсудим наиболее популярные типы нереляционных баз данных.
Обсудим наиболее популярные типы нереляционных баз данных.
Key-value базы данных (пример — Redis)
Название говорит о том, какие данные удобно хранить в Key-value базе – в такой базе хранят данные, которые удобно представить в виде пары ключ-значение. Основное преимущество таких баз – это очень быстрый поиск значения по ключу. При этом значение может содержать какие угодно типы данных.
Такие базы данных удобно применять в проектах, где необходимо выдавать быстрый результат по ключу, например, для онлайн торгов или сделок.
Рис 2. Пример key-value базы данныхДокументно-ориентированные (пример — Mongo DB)
В документно-ориентированной базе данных единицей хранения является документ (который может быть в формате json, или xml, или в каком-нибудь еще формате). Удобство таких баз в том, что в них быстро и легко записывать любые типы данных, при этом эти данные не обязаны обладать четкой структурой. Минус таких баз в том, что данные в них неудобно анализировать.
В моей предыдущей компании такой тип баз данных служил базой для реляционных баз. То есть сначала все данные попадали и сохранялись в документно-ориентированной базе. Потом команда дата инженеров обрабатывала эти огромные полотна информации, структурировала и складывала в реляционную базу данных, которую уже могла использовать команда аналитиков и Data Science.
Рис 3. Пример документно-ориентированной базы данныхГрафовые базы данных (пример — Orient DB)
Как следует из названия, в графовой базе данных данные хранятся в виде графов. Данный тип баз удобен, когда надо находить информацию не только о каком-то объекте, но и доставать информации о связах этого объекта с другими.
Например, в моей текущей компании данный тип баз используется для нахождения куки конкретного юзера и всех взаимосвязанных с этой кукой идентификаторов. Также, такой тип данных часто используется социальными сетями для сохранения информации не только о пользователях, но и о связях каждого пользователя с другими.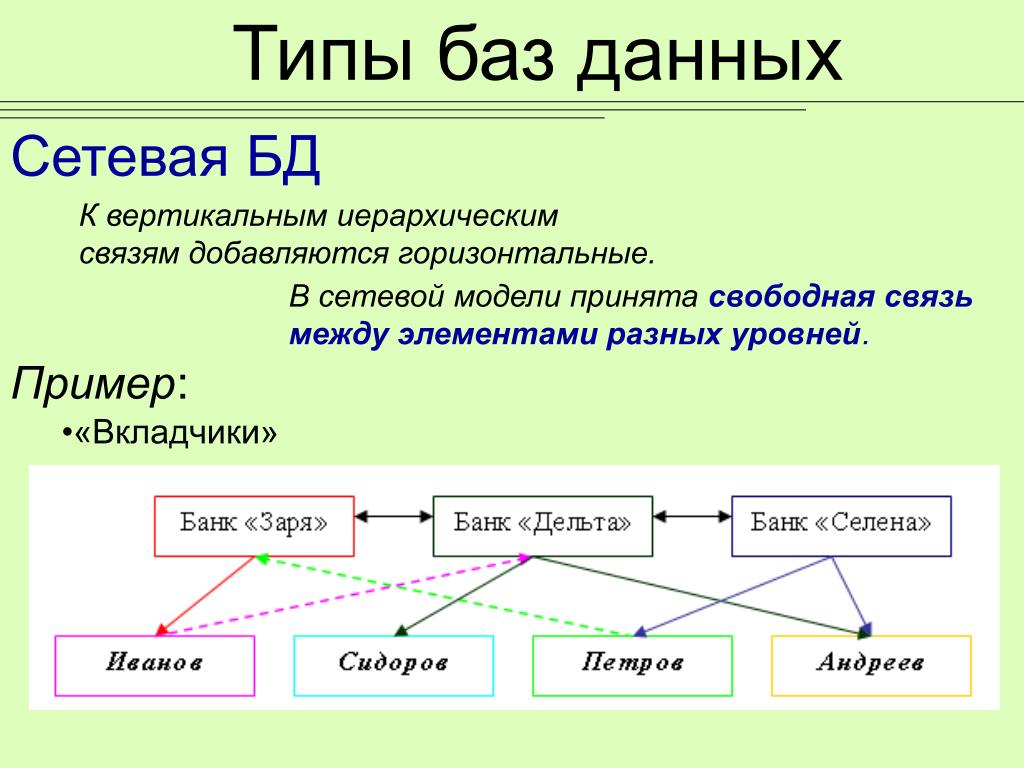
Колоночные (столбцовые) базы данных (примеры — Cassandra, Clickhouse)
В реляционных базах данных данные записаны в виде строк. Что же касается колоночных баз данных, то тут данные записываются в виде столбцов. Потому поиск данных в колоночной базе данных осуществляется не перебором всех строк, как это происходит в реляционной базе данных, а поиском необходимого значения в тех столбцах таблицы, которые нас интересуют.
Преимущество колоночных баз данных в том, что они могут быстро находить определенные значения в столбцах, которые нас интересуют.
Ну и напоследок
В заключение скажу, что типов баз данных великое множество. Какие-то типы приобретают популярность, какие-то больше не используются. У каждого типа свои преимущества и недостатки. И, выбирая тот или иной тип баз данных, надо исходить в первую очередь от вида вашего бизнеса и его потребностей.
Классификации, виды, типы баз данных
480 auto
Администрирование
Какие существуют варианты классификаций баз данных? Приводим наиболее полный список всех типологий БД. По различным критериям.
По различным критериям.
IT GIRL 12
Post Views: 2 469
Классификации, виды, типы баз данных | Boodet.online Блог 2020-07-19 ru Классификации, виды, типы баз данных | Boodet.online
Boodet Online
+7 (499) 649 09 90
123022,
Москва,
ул. Рочдельская, дом 15, строение 15
Рочдельская, дом 15, строение 15
Классификации, виды, типы баз данных | Boodet.online
286 104
Boodet Online +7 499 649 09 90 123022, Москва, ул. Рочдельская, дом 15, строение 15
Поделиться
Твинтнуть
Поделиться
Запинить
Отправить
Классификации баз данных
Любой человек или компания генерируют данные в большом количестве. Эти сведения нужно где-то хранить и обрабатывать. Для этого используют базы данных, которые упорядочивают, систематизируют информацию. От того, какую именно БД использует разработчик, зависит, как будет работать приложение.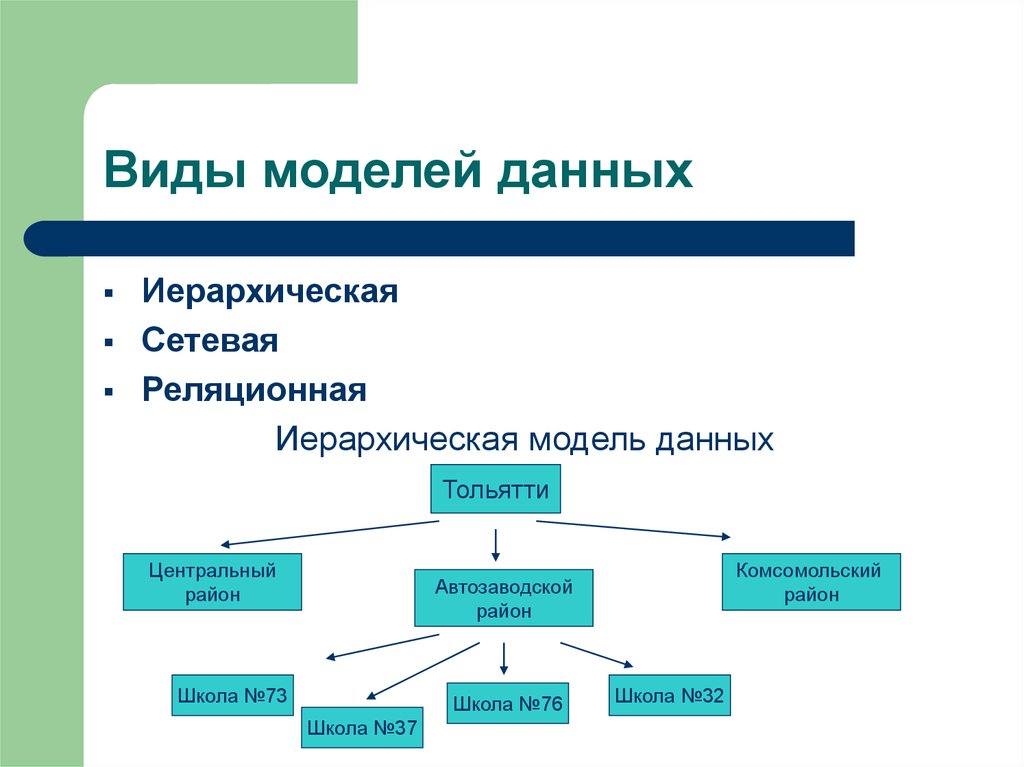
БД делятся на несколько видов: по типу, структуре и обращению к данным. Какая существует классификация баз данных, в чем их различие и в каких случаях использовать — рассказывают специалисты Boodet.Online.
По типу данных
Если базы данных объединяют разные документы в зависимости, их называют документальными. Они также делятся на реферативные, библиографические (не требуют хранения) и полнотекстовые (полный текст документа хранится на носителе). Документы можно хранить в их изначальном виде (текст) или в виде ссылки. Соответственно, когда пользователь делает запрос, то получает либо полный текст или абзац, либо ссылку. Несмотря на простую структуру, документальные базы данных до сих пор активно используют, например, в библиотеках и архивах.
Кстати, в таких БД можно искать не только информацию, но и критерии документов. Например, если задать поиск по критериям «дата создания» и «автор», можно будет посмотреть, сколько файлов создал определенный сотрудник за год.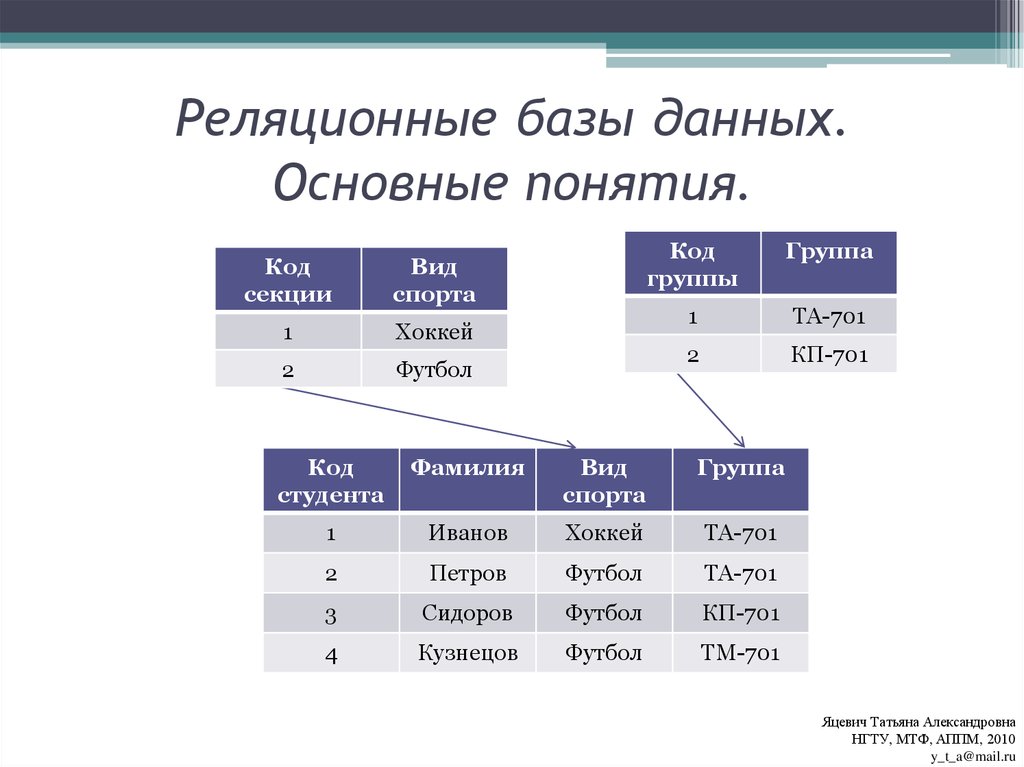 Этим же методом ищут официальные формы, например «Ф9»
Этим же методом ищут официальные формы, например «Ф9»
Фактографические базы данных включают в себя информацию об объекте исследования, например, количество «больничных дней» у сотрудников. Классификаторы и словари относятся к лексикографическим БД.
По структуре данных
Базы данных классифицируются на:
структурированные — заполнять их можно только после того, как структура БД описана и спроектирована;
частично структурированные — обычный или гипертекст;
неструктурированные — семантические сети.
Структурированные бывают:
смешанными;
иерархическими;
реляционными;
мультимодальными;
сетевыми.
По обращению к данным
В зависимости от характера обращения к информации БД классифицируют на:
общие:
локальные;
распределенные.
Общие интегрированные и распределенные базы позволяют многим пользователям получать доступ к данным одновременно. Это реализовано с помощью параллельного или многопользовательского режимов доступа. Локальный вид такой возможности не дает — информацией может пользоваться только один пользователь.
Это реализовано с помощью параллельного или многопользовательского режимов доступа. Локальный вид такой возможности не дает — информацией может пользоваться только один пользователь.
Иерархические БД
Архитектура иерархических баз данных похожа на дерево. Информация каждого объекта хранится в виде сущности, к которой есть свои элементы (дочерние и родительские). Такой вид организации хорошо подходит для чтения и плохо — для поиска информации из-за высокого уровня вложенности.
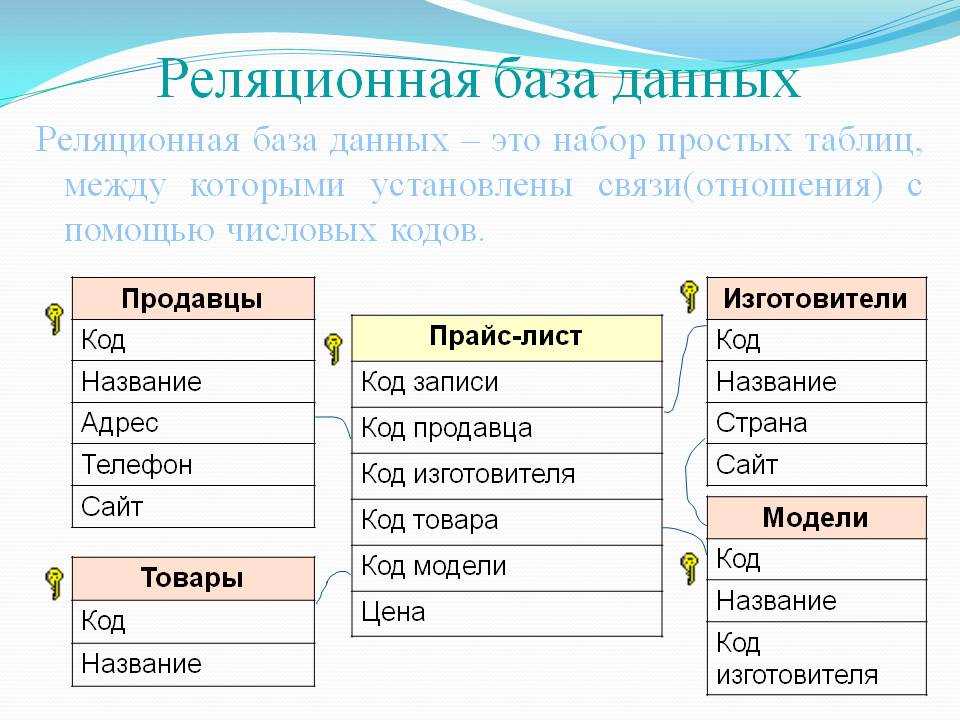
Реляционные
Реляционная модель основана на математической теории множеств — «relation». В парадигме базы данных это означает визуальное представление информации в виде таблицы, где у ячеек есть свойства, описания, взаимосвязи. При этом сами отношения между сведениями не обязательно должны быть линейными (как в таблицах), они могут быть абстрактными.
В таблицах, где хранятся объекты, всегда фиксированное количество столбцов. То есть структура реляционных БД заранее известна и описана. В столбцах указывают название и вид данных. Чтобы таблицы стали базой, надо логически их связать. А чтобы управлять таким набором таблиц понадобится СУБД.
В столбцах указывают название и вид данных. Чтобы таблицы стали базой, надо логически их связать. А чтобы управлять таким набором таблиц понадобится СУБД.
Запросы в реляционных базах данных классифицируются на структурированные и неструктурированные:
Структурированные — SQL. Гибкие и хорошо организованные, можно адаптировать практически под любые типы данных. К структурированным относятся:
MariaDB;
SQLite;
MySQL;
PostgreSQL.
Неструктурированные — NoSQL. Благодаря согласованности информации повышают доступность и масштабируемость приложений. Относятся к реляционным базам данных, хотя и работают не по классическому реляционному шаблону. При этом в ряде случаев поддерживают запросы SQL. NoSQL СУБД:
Зачем нужны NoSQL? Неструктурированные базы подходят для обработки больших данных. Для Big Data нужны аппаратные платформы из серверных кластеров — это создает сложности в работе с традиционными программами.
Это не значит, что NoSQL — единственный вариант для компаний, которые работают с Big Data. Современный подход заключается в одновременном использовании нескольких БД для одного приложения. Это позволяет предположить, что архитектура популярных баз данных будет меняться, чтобы унифицировать подход к хранению, поиску и обработке информации.
Сетевые БД
Сетевые модели решают некоторые недостатки иерархических, но плохо справляются с простыми запросами. Это приводит к тому, что если меняется структура организации информации, вместе с ней меняется и приложение.
Архитектура похожа на иерархическую, есть и дочерние, и родительские элементы. Единственное отличие — связываться элементы могут в любых направлениях. То есть каждый элемент может быть связан с любым другим, независимо от иерархии.
Многомодельные и комбинированные БД и СУБД
Чтобы можно было применять различные представления для разного вида данных, используют многомодельные базы. Это значит, что несколько БД размещают в одной системе и настраивают взаимосвязи. Это очень удобно — можно выполнять запрос из одной БД, просматривать информацию в другой и вносить изменения в третьей. Благодаря многомодельному подходу уменьшается нагрузка на СУБД, исчезает необходимость менять основную инфраструктуру. Линейное масштабирование сокращает расходы и время разработки приложений.
Это значит, что несколько БД размещают в одной системе и настраивают взаимосвязи. Это очень удобно — можно выполнять запрос из одной БД, просматривать информацию в другой и вносить изменения в третьей. Благодаря многомодельному подходу уменьшается нагрузка на СУБД, исчезает необходимость менять основную инфраструктуру. Линейное масштабирование сокращает расходы и время разработки приложений.
К многомодельным относятся:
Couchbase;
ArangoDB.
Комбинированные базы данных (NewSQL) относятся к семейству распределенных. Они сочетают в себе реляционный и нереляционных подход. Основное отличие от традиционных реляционных БД — масштабируемая конструкция и высокий уровень согласованности. Основной минус: чтобы внедрить такой подход, нужен специалист не ниже Senior. Зато в итоге повысится доступность приложения, появится горизонтальное масштабирование и увеличится гибкость.
NewSQL:
Spanner;
yugabyteDB;
VoltDB;
CockroachDB;
MemSQL.
Заключение
Нельзя однозначно сказать, что одна БД лучше другой. Это, скорее, способы решать различные задачи работы с информацией. Какую вид баз данных использовать в компании — зависит от рабочих процессов и программ, которыми пользуются сотрудники. Чтобы решить проблему размещения информации и доступа к ней, можно воспользоваться современными облачными технологиями. Например, компания Boodet.Online предлагает услугу по аренде облачного сервера SQL — пригодится тем, кто хочет сделать работу с 1С более быстрой и стабильной.
Поделиться
Твинтнуть
Поделиться
Запинить
Отправить
Facebook
YouTube
Telegram
: типы, примеры и преимущества
Дата публикации
Автор Джули Полито
Наличие правильной схемы является ключевым фактором, поддерживающим современный анализ данных. Схемы баз данных могут сбивать с толку, но эта статья поможет вам спроектировать правильную схему для ваших хранилищ данных, начиная с самого определения «схемы базы данных».
Схемы баз данных могут сбивать с толку, но эта статья поможет вам спроектировать правильную схему для ваших хранилищ данных, начиная с самого определения «схемы базы данных».
Что такое схема базы данных?
В контексте моделей данных «схема» означает общую модель данных и дизайн структур данных. Процесс разработки схемы известен как моделирование данных.
Частично структурированные данные — это быстрорастущая часть постоянно растущего разнообразия данных в современной аналитике данных. «Схема» — это логическая схема, существующая в полуструктурированном документе.
Однако слово «схема» может также означать физическую часть базы данных. Многие платформы облачных данных, в том числе Amazon Redshift, Snowflake и Azure Synapse Analytics, используют концепцию «базы данных» в качестве основной структурной единицы. Одна база данных может содержать множество схем, а схемы содержат объекты схемы, такие как таблицы, столбцы и ключи данных.
Типы моделей схемы базы данных
Самый простой тип схемы базы данных — это плоская модель . Плоская модель содержит отдельные таблицы, не связанные друг с другом. Это также означает, что все столбцы представляют собой простые строки и числа, а не полуструктурированные. Наиболее широко используемыми схемами плоской базы данных являются файлы CSV.
Иерархическая модель базы данных содержит отношения родитель-потомок, точно так же, как генеалогическое древо. Иерархические модели используются уже более 50 лет, особенно для высокопроизводительных систем OLTP, таких как Adabas. Каждый документ JSON или XML содержит иерархическую модель данных.
В модели графа точки данных, известные как узлы, связаны друг с другом с помощью «ребер». Как и в реальном мире, нет никаких ограничений на то, какие узлы могут быть связаны. Это делает графовые модели идеальными для кодирования знаний в виде RDF, например, с использованием Neo4j или Gremlin. Модели Network представляют собой подмножество графовых моделей, в которых схема определяет четкую иерархию. Например, одна учетная запись содержит много транзакций, а не наоборот.
Реляционные модели имеют таблицы, которые связаны друг с другом с помощью столбцов первичного и внешнего ключа. В графическом виде схема реляционной базы данных называется диаграммой отношений сущностей (ERD). Если у вас есть ERD, у вас есть реляционная модель данных.
Для целей представления данных ничто не сравнится с простотой наличия одной таблицы транзакционных фактов, связанной со многими таблицами измерений «по» критериям. При рисовании в виде ERD такая модель имеет форму звезды и поэтому известна как 9.0039 звездная схема .
В звездообразной схеме может быть значительное количество повторений. Например, в измерении даты каждый отдельный атрибут уровня года повторяется 365 раз. Вы можете каскадировать их в подтаблицы, например, день – месяц – год. Это делает ERD более похожим на снежинку, поэтому она известна как схема снежинки .
Примеры диаграмм взаимосвязей сущностей
В реляционных моделях наиболее распространенной связью является связь «один ко многим». Например, если одна группа может содержать много проектов, она будет отображаться следующим образом:
Иногда отношения более сложные. Например, один студент посещает много классов, а в одном классе много студентов. Отношение «многие ко многим» обычно заменяется сущностью-пересечением, подобной следующей:
В качестве схемы «звезда» с таблицей фактов о посещаемости занятий она может выглядеть так:
6
6
66
66
И, наконец, схема снежинки, вот так. Обратите внимание на добавление подтаблиц, что приводит к меньшему повторению данных, но большему количеству объединений:
Как обрабатывать полуструктурированные данные
Основная особенность полуструктурированных данных, таких как JSON, заключается в том, что это наиболее удобный формат для записи данных.
На самом деле полуструктурированные данные хорошо структурированы, но гибким образом, что оставляет бесконечное пространство для маневра для изменений — известное как «дрейф схемы ». ” Строки в полуструктурированной таблице могут не иметь абсолютно одинаковых атрибутов, и нет никакого способа выяснить это, кроме как продолжить и прочитать их. Это называется «9Схема 0039 при чтении. »
Целью интеграции данных является повышение пригодности данных при сохранении их качества на первоначально высоком уровне. Обычно это означает «выравнивание» полуструктурированных данных путем преобразования их в реляционную модель.
- Иерархии → Несколько таблиц
- Схема при чтении → Именованные столбцы
Однако полуструктурированные форматы все же могут быть полезным способом отложить интеграцию данных, например, в таблицах Data Vault Satellite.
Что такое нормализация данных и почему она так важна?
Нормализация данных — это процесс моделирования данных (разработка схемы). Это гарантирует, что реляционная модель придерживается основных средств контроля качества. Основной стандарт известен как третья нормальная форма (3NF) и имеет следующие требования:
- Таблицы имеют уникальный идентификатор, исключающий дублирование
- Отношения представляют собой отношения один ко многим, а не многие ко многим, что уменьшает путаницу
- Столбцы имеют определенные типы данных, что позволяет избежать несогласованности
- Столбцы содержат отдельные значения, такие как строки и числа, что открывает путь для эффективной интеграции, которая решает проблемы децентрализации
На самом деле звездообразные схемы, используемые почти в каждом хранилище данных, намеренно несколько денормализованы . Они часто содержат дублирование, чтобы сделать запросы проще и быстрее. Ключом к успешной реализации звездообразной схемы является использование преобразованного и нормализованного уровня данных в качестве источника. Таким образом, осуществляется контроль качества данных, чтобы гарантировать, что данные сохранят свою ценность.
Важность и преимущества хорошего дизайна базы данных
Наличие архитектуры данных с четко определенной — и, в идеале, нормализованной — схемой помогает поддерживать качество данных за счет использования ограничений базы данных, таких как согласованное форматирование и обеспечение ссылочной целостности во время поиска. Это также помогает свести к минимуму дублирование данных. Обе эти вещи лежат в основе надежной аналитики.
С точки зрения безопасности наличие схемы помогает управлять доступом к данным. Это особенно актуально при защите информации, позволяющей установить личность (PII), которая обычно требует дополнительных уровней защиты, таких как токенизация.
Узнайте о различиях между моделированием предметной области, физическим моделированием и логическим моделированием.
Понимание модели данных базы данных
Лучший способ понять систему интеграции данных на верхнем уровне — это посмотреть, какие модели данных или схемы использовались в различных логических слоях данных.
По мере того, как потребление данных проходит через бронзовую, серебряную и золотую стадии, модели данных также меняются. По этой причине вы должны знать все о том, как сравнивать хранилище данных, звездообразную схему и 3NF.
- На ранних этапах, на бронзовой стадии, модели данных диктуются источниками и могут быть полуструктурированными или даже неструктурированными. Это место для плоских, иерархических, графических и сетевых моделей.
- На промежуточном, серебряном уровне преобладают реляционные модели, такие как 3NF и Data Vault
- Для представления пользователям наилучшим выбором являются схемы «звезда» или «снежинка»
Как лучше всего перемещать данные между этими слоями? Короткий ответ — процесс извлечения, загрузки и преобразования (ELT).
Схемы баз данных и их связь с хранилищами данных
От бронзы к серебру главная проблема заключается в поиске нужных данных среди реально доступных данных. ELT — это процесс получения необработанных данных и преобразования их в стандартизированный формат.
При переходе от серебра к золоту основная проблема заключается в выборе данных, необходимых потребителям, и представлении их в наиболее удобном виде.
Следующие шаги
Прочтите о том, как использовать схемы для поддержания высокого качества данных при одновременном улучшении использования.
Узнайте больше о том, как Matillion предоставляет комплексное решение для интеграции и преобразования данных, созданное для облака и имеющее многочисленные соединители баз данных для репликации ваших данных в облаке.
Получить демонстрацию
СУБД | Типы баз данных
следующий →
← предыдущая
Существуют различные типы баз данных, используемых для хранения различных типов данных:
1) Централизованная база данных
Это тип базы данных, в которой данные хранятся в централизованной системе баз данных. Пользователям удобно получать доступ к сохраненным данным из разных мест через несколько приложений. Эти приложения содержат процесс аутентификации, позволяющий пользователям безопасно получать доступ к данным. Примером централизованной базы данных может быть Центральная библиотека, содержащая центральную базу данных каждой библиотеки колледжа/университета.
Преимущества централизованной базы данных
- Снижен риск управления данными, т. е. манипулирование данными не повлияет на основные данные.
- Поддерживается согласованность данных, так как он управляет данными в центральном репозитории.
- Обеспечивает более высокое качество данных, что позволяет организациям устанавливать стандарты данных.
- Это менее затратно, поскольку для обработки наборов данных требуется меньше поставщиков.
Недостатки централизованной базы данных
- Размер централизованной базы данных велик, что увеличивает время отклика на выборку данных.
- Обновлять такую обширную базу данных непросто.
- Если произойдет какой-либо сбой сервера, все данные будут потеряны, что может привести к огромным потерям.
2) Распределенная база данных
В отличие от централизованной системы баз данных, в распределенных системах данные распределяются между различными системами баз данных организации. Эти системы баз данных связаны через каналы связи. Такие ссылки помогают конечным пользователям легко получить доступ к данным. Примерами распределенной базы данных являются Apache Cassandra, HBase, Ignite и т. д.
Мы можем дополнительно разделить систему распределенной базы данных на:
- Однородная DDB: Те системы баз данных, которые работают в одной и той же операционной системе, используют один и тот же прикладной процесс и используют одни и те же аппаратные устройства.
- Гетерогенная DDB: Те системы баз данных, которые выполняются в разных операционных системах с использованием разных прикладных процедур и содержат разные аппаратные устройства.
Преимущества распределенной базы данных
- В распределенной базе данных возможна модульная разработка, т.е. система может быть расширена за счет включения новых компьютеров и подключения их к распределенной системе.
- Один сбой сервера не повлияет на весь набор данных.
3) Реляционная база данных
Эта база данных основана на реляционной модели данных, в которой данные хранятся в виде строк (кортежа) и столбцов (атрибутов), которые вместе образуют таблицу (отношение). Реляционная база данных использует SQL для хранения, обработки и обслуживания данных. Э. Ф. Кодд изобрел базу данных в 1970. Каждая таблица в базе данных имеет ключ, который делает данные уникальными по сравнению с другими. Примерами реляционных баз данных являются MySQL, Microsoft SQL Server, Oracle и т. д.
Свойства реляционной базы данных
Существуют следующие четыре общеизвестных свойства реляционной модели, известных как свойства ACID, где:
A означает атомарность: Это гарантирует, что операция с данными завершится либо успешно, либо неудачно. Он следует стратегии «все или ничего». Например, транзакция будет либо зафиксирована, либо прервана.
C означает Согласованность: Если мы выполняем какую-либо операцию над данными, ее значение до и после операции должно быть сохранено. Например, баланс счета до и после транзакции должен быть правильным, то есть он должен сохраняться.
I означает Изоляция: Могут быть одновременные пользователи для одновременного доступа к данным из базы данных. Таким образом, изоляция между данными должна оставаться изолированной. Например, когда несколько транзакций происходят одновременно, эффекты одной транзакции не должны быть видны другим транзакциям в базе данных.
D означает Долговечность: Он гарантирует, что после завершения операции и фиксации данных изменения данных останутся постоянными.
4) База данных NoSQL
Non-SQL/Not Only SQL — это тип базы данных, который используется для хранения широкого спектра наборов данных. Это не реляционная база данных, поскольку она хранит данные не только в табличной форме, но и несколькими различными способами. Он появился, когда возрос спрос на создание современных приложений. Таким образом, NoSQL представил широкий спектр технологий баз данных в ответ на спрос.
Далее мы можем разделить базы данных NoSQL на следующие четыре типа:
- Хранилище «ключ-значение»: Это простейший тип хранилища базы данных, в котором каждый отдельный элемент хранится в виде ключа (или имени атрибута), вместе содержащего его значение.
- База данных, ориентированная на документы: Тип базы данных, используемый для хранения данных в виде документов в формате JSON. Это помогает разработчикам хранить данные, используя тот же формат модели документа, который используется в коде приложения.
- Базы данных графов: Используется для хранения огромных объемов данных в графообразной структуре. Чаще всего сайты социальных сетей используют графовую базу данных.
- Хранилища с широким столбцом: Аналогично данным, представленным в реляционных базах данных. Здесь данные хранятся в больших столбцах вместе, а не в строках.
Преимущества базы данных NoSQL
- Обеспечивает хорошую производительность при разработке приложений, поскольку не требуется хранить данные в структурированном формате.
- Это лучший вариант для управления и обработки больших наборов данных.
- Обеспечивает высокую масштабируемость.
- Пользователи могут быстро получить доступ к данным из базы данных через ключ-значение.
5) Облачная база данных
Тип базы данных, в которой данные хранятся в виртуальной среде и выполняются на платформе облачных вычислений. Он предоставляет пользователям различные сервисы облачных вычислений (SaaS, PaaS, IaaS и т. д.) для доступа к базе данных. Существует множество облачных платформ, но лучшие варианты:
.- Веб-сервисы Amazon (AWS)
- Microsoft Azure
- Каматера
- PhonixNAP
- НаукаСофт
- Google Cloud SQL и т. д.
6) Объектно-ориентированные базы данных
Тип базы данных, использующий подход объектной модели данных для хранения данных в системе баз данных. Данные представляются и хранятся в виде объектов, аналогичных объектам, используемым в объектно-ориентированном языке программирования.
7) Иерархические базы данных
Это тип базы данных, в которой данные хранятся в виде узлов отношений родитель-потомок. Здесь он организует данные в виде древовидной структуры.
Данные сохраняются в виде записей, связанных ссылками. Каждая дочерняя запись в дереве будет содержать только одного родителя. С другой стороны, у каждой родительской записи может быть несколько дочерних записей.
8) Сетевые базы данных
Это база данных, которая обычно соответствует сетевой модели данных. Здесь представление данных осуществляется в виде узлов, связанных между собой связями. В отличие от иерархической базы данных, она позволяет каждой записи иметь несколько дочерних и родительских узлов для формирования обобщенной структуры графа.
9) Персональная база данных
Сбор и хранение данных в системе пользователя определяет личную базу данных. Эта база данных в основном предназначена для одного пользователя.
Преимущество личной базы данных
- Он прост и удобен в обращении.
- Занимает меньше места для хранения, так как имеет небольшой размер.
10) Оперативная база данных
Тип базы данных, которая создает и обновляет базу данных в режиме реального времени. Он в основном предназначен для выполнения и обработки ежедневных операций с данными в нескольких компаниях. Например, организация использует оперативные базы данных для управления ежедневными транзакциями.
11) Корпоративная база данных
Крупные организации или предприятия используют эту базу данных для управления огромным объемом данных. Это помогает организациям повышать и улучшать свою эффективность. Такая база данных обеспечивает одновременный доступ пользователей.
Преимущества корпоративной базы данных:
- Несколько процессов поддерживаются базой данных Enterprise. Оставить комментарий
6
И, наконец, схема снежинки, вот так. Обратите внимание на добавление подтаблиц, что приводит к меньшему повторению данных, но большему количеству объединений:
Как обрабатывать полуструктурированные данные
Основная особенность полуструктурированных данных, таких как JSON, заключается в том, что это наиболее удобный формат для записи данных.
На самом деле полуструктурированные данные хорошо структурированы, но гибким образом, что оставляет бесконечное пространство для маневра для изменений — известное как «дрейф схемы ». ” Строки в полуструктурированной таблице могут не иметь абсолютно одинаковых атрибутов, и нет никакого способа выяснить это, кроме как продолжить и прочитать их. Это называется «9Схема 0039 при чтении. »
Целью интеграции данных является повышение пригодности данных при сохранении их качества на первоначально высоком уровне. Обычно это означает «выравнивание» полуструктурированных данных путем преобразования их в реляционную модель.
- Иерархии → Несколько таблиц
- Схема при чтении → Именованные столбцы
Однако полуструктурированные форматы все же могут быть полезным способом отложить интеграцию данных, например, в таблицах Data Vault Satellite.
Что такое нормализация данных и почему она так важна?
Нормализация данных — это процесс моделирования данных (разработка схемы). Это гарантирует, что реляционная модель придерживается основных средств контроля качества. Основной стандарт известен как третья нормальная форма (3NF) и имеет следующие требования:
- Таблицы имеют уникальный идентификатор, исключающий дублирование
- Отношения представляют собой отношения один ко многим, а не многие ко многим, что уменьшает путаницу
- Столбцы имеют определенные типы данных, что позволяет избежать несогласованности
- Столбцы содержат отдельные значения, такие как строки и числа, что открывает путь для эффективной интеграции, которая решает проблемы децентрализации
На самом деле звездообразные схемы, используемые почти в каждом хранилище данных, намеренно несколько денормализованы . Они часто содержат дублирование, чтобы сделать запросы проще и быстрее. Ключом к успешной реализации звездообразной схемы является использование преобразованного и нормализованного уровня данных в качестве источника. Таким образом, осуществляется контроль качества данных, чтобы гарантировать, что данные сохранят свою ценность.
Важность и преимущества хорошего дизайна базы данных
Наличие архитектуры данных с четко определенной — и, в идеале, нормализованной — схемой помогает поддерживать качество данных за счет использования ограничений базы данных, таких как согласованное форматирование и обеспечение ссылочной целостности во время поиска. Это также помогает свести к минимуму дублирование данных. Обе эти вещи лежат в основе надежной аналитики.
С точки зрения безопасности наличие схемы помогает управлять доступом к данным. Это особенно актуально при защите информации, позволяющей установить личность (PII), которая обычно требует дополнительных уровней защиты, таких как токенизация.
Узнайте о различиях между моделированием предметной области, физическим моделированием и логическим моделированием.
Понимание модели данных базы данных
Лучший способ понять систему интеграции данных на верхнем уровне — это посмотреть, какие модели данных или схемы использовались в различных логических слоях данных.
По мере того, как потребление данных проходит через бронзовую, серебряную и золотую стадии, модели данных также меняются. По этой причине вы должны знать все о том, как сравнивать хранилище данных, звездообразную схему и 3NF.
- На ранних этапах, на бронзовой стадии, модели данных диктуются источниками и могут быть полуструктурированными или даже неструктурированными. Это место для плоских, иерархических, графических и сетевых моделей.
- На промежуточном, серебряном уровне преобладают реляционные модели, такие как 3NF и Data Vault
- Для представления пользователям наилучшим выбором являются схемы «звезда» или «снежинка»
Как лучше всего перемещать данные между этими слоями? Короткий ответ — процесс извлечения, загрузки и преобразования (ELT).
Схемы баз данных и их связь с хранилищами данных
От бронзы к серебру главная проблема заключается в поиске нужных данных среди реально доступных данных. ELT — это процесс получения необработанных данных и преобразования их в стандартизированный формат.
При переходе от серебра к золоту основная проблема заключается в выборе данных, необходимых потребителям, и представлении их в наиболее удобном виде.
Следующие шаги
Прочтите о том, как использовать схемы для поддержания высокого качества данных при одновременном улучшении использования.
Узнайте больше о том, как Matillion предоставляет комплексное решение для интеграции и преобразования данных, созданное для облака и имеющее многочисленные соединители баз данных для репликации ваших данных в облаке.
Получить демонстрацию
СУБД | Типы баз данных
следующий → ← предыдущая Существуют различные типы баз данных, используемых для хранения различных типов данных: 1) Централизованная база данных Это тип базы данных, в которой данные хранятся в централизованной системе баз данных. Преимущества централизованной базы данных
Недостатки централизованной базы данных
2) Распределенная база данныхВ отличие от централизованной системы баз данных, в распределенных системах данные распределяются между различными системами баз данных организации. Эти системы баз данных связаны через каналы связи. Такие ссылки помогают конечным пользователям легко получить доступ к данным. Примерами распределенной базы данных являются Apache Cassandra, HBase, Ignite и т. д. Мы можем дополнительно разделить систему распределенной базы данных на:
Преимущества распределенной базы данных
3) Реляционная база данныхЭта база данных основана на реляционной модели данных, в которой данные хранятся в виде строк (кортежа) и столбцов (атрибутов), которые вместе образуют таблицу (отношение). Реляционная база данных использует SQL для хранения, обработки и обслуживания данных. Э. Ф. Кодд изобрел базу данных в 1970. Каждая таблица в базе данных имеет ключ, который делает данные уникальными по сравнению с другими. Примерами реляционных баз данных являются MySQL, Microsoft SQL Server, Oracle и т. д. Свойства реляционной базы данныхСуществуют следующие четыре общеизвестных свойства реляционной модели, известных как свойства ACID, где: A означает атомарность: Это гарантирует, что операция с данными завершится либо успешно, либо неудачно. C означает Согласованность: Если мы выполняем какую-либо операцию над данными, ее значение до и после операции должно быть сохранено. Например, баланс счета до и после транзакции должен быть правильным, то есть он должен сохраняться. I означает Изоляция: Могут быть одновременные пользователи для одновременного доступа к данным из базы данных. Таким образом, изоляция между данными должна оставаться изолированной. Например, когда несколько транзакций происходят одновременно, эффекты одной транзакции не должны быть видны другим транзакциям в базе данных. D означает Долговечность: Он гарантирует, что после завершения операции и фиксации данных изменения данных останутся постоянными. 4) База данных NoSQL Non-SQL/Not Only SQL — это тип базы данных, который используется для хранения широкого спектра наборов данных.
Преимущества базы данных NoSQL
5) Облачная база данныхТип базы данных, в которой данные хранятся в виртуальной среде и выполняются на платформе облачных вычислений. Он предоставляет пользователям различные сервисы облачных вычислений (SaaS, PaaS, IaaS и т. д.) для доступа к базе данных. Существует множество облачных платформ, но лучшие варианты: .
6) Объектно-ориентированные базы данныхТип базы данных, использующий подход объектной модели данных для хранения данных в системе баз данных. Данные представляются и хранятся в виде объектов, аналогичных объектам, используемым в объектно-ориентированном языке программирования. 7) Иерархические базы данныхЭто тип базы данных, в которой данные хранятся в виде узлов отношений родитель-потомок. Здесь он организует данные в виде древовидной структуры. Данные сохраняются в виде записей, связанных ссылками. Каждая дочерняя запись в дереве будет содержать только одного родителя. С другой стороны, у каждой родительской записи может быть несколько дочерних записей. 8) Сетевые базы данных Это база данных, которая обычно соответствует сетевой модели данных. Здесь представление данных осуществляется в виде узлов, связанных между собой связями. В отличие от иерархической базы данных, она позволяет каждой записи иметь несколько дочерних и родительских узлов для формирования обобщенной структуры графа. 9) Персональная база данныхСбор и хранение данных в системе пользователя определяет личную базу данных. Эта база данных в основном предназначена для одного пользователя. Преимущество личной базы данных
10) Оперативная база данныхТип базы данных, которая создает и обновляет базу данных в режиме реального времени. Он в основном предназначен для выполнения и обработки ежедневных операций с данными в нескольких компаниях. Например, организация использует оперативные базы данных для управления ежедневными транзакциями. 11) Корпоративная база данныхКрупные организации или предприятия используют эту базу данных для управления огромным объемом данных. Это помогает организациям повышать и улучшать свою эффективность. Такая база данных обеспечивает одновременный доступ пользователей. Преимущества корпоративной базы данных:
|