что это за нереляционная база данных, примеры СУБД
Скопировано
Содержание
NoSQL (от англ. not only SQL) — категория, объединяющая системы управления базами данных, отличающимися от реляционных БД, для работы с которыми используется язык SQL. Такие СУБД появились в 2000-х годах как попытка решить проблемы масштабируемости при сохранении простоты и гибкости.
Впервые термин NoSQL был использован еще в 90-х годах как название конкретной системы, разработанной Карло Стрози. С современными СУБД, объединенными понятием «not only SQL», она не имела ничего общего, кроме того, что для управления данными в ней не использовался язык SQL. В своем смысле термин NoSQL стал применяться с 2009 года — с одноименной IT-конференции, посвященной новым опенсорсным продуктам на рынке обработки и хранения данных. Несмотря на то что организаторы мероприятия просто хотели придумать емкое и звучное название «на один раз», оно мгновенно завирусилось в твиттере и стало названием для целого направления в IT-индустрии.
История NoSQL
Хотя понятие появилось только в конце девяностых годов прошлого века, а широко стало использоваться через десять лет, нереляционные базы данных применяются с начала компьютерной эры. Первый пик их популярности пришелся на эпоху мейнфреймов, затем они были вытеснены реляционными БД и заняли нишу специализированных хранилищ — например, электронных каталогов.
Новый виток популярности нереляционных баз данных начался с появлением интернета и его главного инструмента — поисковых систем. Для работы было нужно обеспечивать параллельную обработку больших массивов данных и масштабируемость. Первой в направлении стала работать компания Google, создавшая крупнейшую поисковую систему и комплекс других сервисов и приложений, работавших с большими объемами информации. Наработки подстегнули создателей открытого программного обеспечения и другие коммерческие компании разрабатывать похожие или альтернативные продукты, основанные на тех же принципах доступности, простоты и масштабируемости.
Как работают нереляционные базы данных
Отличие NoSQL от реляционных баз данныхВ реляционных базах данных информация хранится в таблицах — наборах связанных друг с другом (поэтому реляционных) записей, организованных в столбцах и строках. При этом для них заранее должна быть определена схема, по которой приложения будут записывать информацию в БД. Связь имеется и между таблицами с помощью ключей, которые позволяют, например, извлечь определенную строку для проверки или изменения.
В нереляционных БД строго определенной схемы взаимосвязи между данными нет. То есть информационная модель определяется СУБД «по ходу дела» в процессе работы приложения. Это позволяет быстро адаптировать базу данных в зависимости от того, с каким типом информации в конкретный момент времени работает приложение. Для решения аналогичной задачи с помощью реляционных БД пришлось бы подключать дополнительную базу данных.
Особенности NoSQL
Термин объединяет множество СУБД, имеющих различную архитектуру и характеристики. Однако, можно выделить несколько присущих им всем особенностей:
Однако, можно выделить несколько присущих им всем особенностей:
- Неструктурированность. В NoSQL-базах структура данных не регламентирована вообще или лишь в малой степени. Если нужно внести изменения в поля отдельного документа, для этого не потребуется декларативно менять всю структуру таблицы. При необходимости поменять модель данных потребуется просто указать изменения в коде приложения.
- Использование альтернатив SQL. В нереляционных базах данных не применяется именно SQL, утвержденный Американским национальным институтом стандартов. В то же время разработчики многих NoSQL-СУБД применяют языки управления данными, в той или иной мере похожие на него по синтаксису.
- Агрегация данных. В то время как реляционные БД сохраняют данные в виде таблиц, в нереляционных они представляют собой целостные объекты. Например, в базе данных электронного магазина заказ и позиции заказа объединяются в один логический объект, причем позиции содержат ссылку на товар и его характеристики, которые регулярно демонстрируются пользователю.
 Если же вместе с заказом регулярно извлекаются платежи, то имеет смысл объединить их в один объект. То есть агрегация данных адаптируется под модель работы конкретного приложения.
Если же вместе с заказом регулярно извлекаются платежи, то имеет смысл объединить их в один объект. То есть агрегация данных адаптируется под модель работы конкретного приложения. - Распределенность. В нереляционных базах данных реализована горизонтальная масштабируемость. Она достигается за счет соединения быстрым подключением нескольких независимых друг от друга серверов, каждый из которых обрабатывает только часть данных, а не весь массив. Соответственно, нет необходимости наращивать мощность каждого сервера (тем более что есть физический предел) — достаточно просто добавить в систему новый.
- Открытость. Эта характеристика свойственна не всем, но большинству NoSQL-базам данных. На это повлияло и то, что их появление совпало с развитием движения за свободное (и открытое) ПО, и то, что опенсоурсные СУБД проще адаптировать под разное железо и задачи, они более доступны для изменения, проверки и т.
 д.
д.
Виды NoSQL-баз данных
- Ключ-значение. В таких БД для доступа к значению используется ключ. Они применяются в качестве хранилищ изображений, специализированных файловых систем, кэшей, информационных платформ для онлайн-игр и т.д. — везде, где главными требованиями являются высокая масштабируемость и минимальная задержка обработки запроса.
- Матричные. В таких БД данные хранятся в виде разреженных матриц, где строки и столбцы используются как ключи доступа к значению. Чаще всего такие СУБД применяют в индексировании веб-страниц и других задачах, связанных с обработкой больших данных.
- Документо-ориентированные. В базах данных этого типа данные записываются в специальный документ в формате JSON или близком к нему. Таким БД свойственны одновременно иерархичность и гибкость. Чаще всего они применяются в системах управления контентом, каталогах, специализированных поисковых системах (например, в электронных архивах).

- Графовые. Такие БД сохраняют информацию в виде сложно связанных друг с другом графов. Связанность данных упрощает их хранение, навигацию и поиск. Типичными примерами использования графовых БД являются социальные сети, системы выявления мошенничества.
Преимущества NoSQL
- Горизонтальная масштабируемость — для увеличения производительности достаточно добавить новый сервер в систему, а не наращивать мощности уже имеющихся.
- Высокая устойчивость — так как NoSQL-БД размещаются на независимых серверах, выход одного из них из строя не обрушит всю базу данных и, следовательно, не приведет к полному отказу приложения.
- Производительность — с одной стороны, каждый сервер обрабатывает только свои запросы, не растрачивая свои мощности на все; с другой — информационные модели таких СУБД адаптируются под специфику каждого приложения.
- Гибкость — нереляционные БД могут работать с неструктурированными данными и различными моделями представления информации.

- Широкая применимость — горизонтальная масштабируемость и производительность позволяют применять нереляционные БД в обработке больших данных, онлайн-играх, интернете вещей, электронной коммерции, научной деятельности, издательском бизнесе и т.д.
Недостатки NoSQL
- Ограниченность языка — встроенные языковые возможности нереляционных баз данных, из-за чего в работе с ними часто приходится использовать сторонние инструменты для трансляции стандартных SQL-команд.
- Недостаточная надежность транзакций — из-за того, что NoSQL-БД заточены под высокую производительность и масштабируемость, в них страдает согласованность данных, критически важная для таких сфер, как денежные переводы.
NoSQL-базы данных появились в эпоху больших объемов информации и широкополосного интернета. Они имеют преимущества перед классическими реляционными БД, но полностью заменить их не могут, особенно в таких областях, где требуется высокая надежность транзакций.
Скопировано
индексы, понятие транзакции, уровни изоляции на простых примерах
Данная статья является переводом. Ссылка на оригинал.
Часто бывает неожиданным, как мало мы знаем о том, как работают базы данных, учитывая, что они хранят почти все состояния наших приложений. Тем не менее они являются фундаментом успеха большинства систем. Итак, сегодня я объясню две наиболее важные темы при работе с индексами и транзакциями РСУБД.
Не вдаваясь в подробности особенностей базы данных, я расскажу все, что вы должны понимать об индексах РСУБД. Я кратко коснусь транзакций и уровней изоляции и того, как они могут повлиять на ваше мнение о конкретных транзакциях.
Что такое РСУБД?
Реляционная база данных – это цифровая база данных, основанная на модели реляционных данных, предложенной Э.Ф. Коддом в 1970 году. Для обслуживания реляционных баз данных используется система управления реляционными базами данных (СУБД). Многие системы реляционных баз данных имеют возможность использовать SQL (Язык структурированных запросов) для запроса и сопровождения базы данных. Примерами могут служить MySQL и PostgreSQL.
Что такое индекс?
Индексы — это структура данных, которая помогает сократить время поиска запрошенных данных. Индексы достигают этого за счет дополнительных затрат на хранение, память и поддержание их в актуальном состоянии (более медленная запись), что позволяет нам пропустить утомительную проверку каждой строки таблицы.
Подобно указателю в конце учебника он помогает вам попасть на нужную страницу.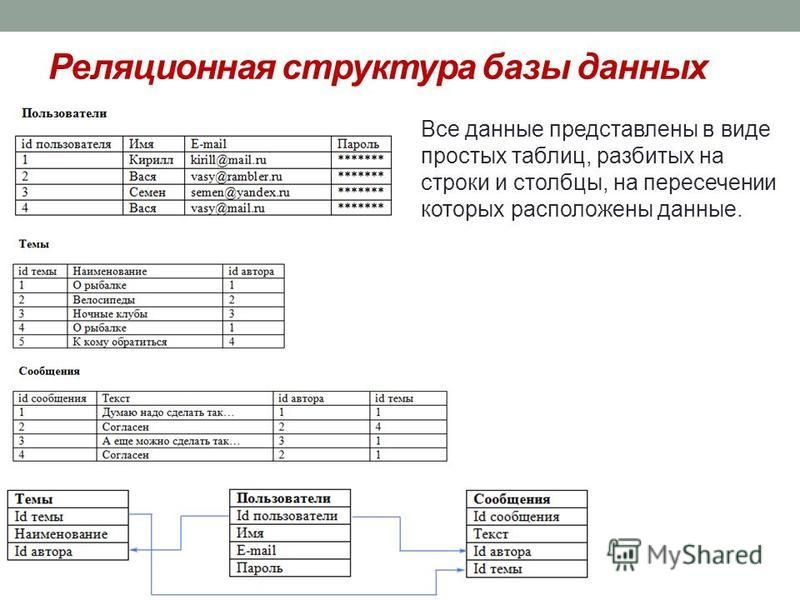 Я не большой поклонник аналогии с книгой, так как сравнение быстро перестает быть корректным, когда мы углубляемся в индексы базы данных, но тем не менее аналогия позволяет отлично понять тему.
Я не большой поклонник аналогии с книгой, так как сравнение быстро перестает быть корректным, когда мы углубляемся в индексы базы данных, но тем не менее аналогия позволяет отлично понять тему.
Зачем нужны индексы?
Небольшие объемы данных поддаются управлению (подумайте о списке посещаемости для небольшого класса), но когда они становятся больше (подумайте о реестре рождений для большого города), они становятся менее управляемыми. Все, что раньше было быстрым, становится медленным, слишком медленным.
Подумайте, как изменилась бы ваша стратегия, если бы вам пришлось искать что-то на одной странице, а не на тысяче страниц имен. Нет, серьезно, остановитесь на секунду и подумайте.
По мере роста, системы собирают и хранят больше данных, что в конечном итоге приводит к описанной выше проблеме.
Нам нужны индексы, чтобы помочь получить как можно быстрее релевантные данные, которые нам нужны.
Как работают индексы?
Производительность чтения (Read performance) увеличивается по мере индексации данных, но это происходит за счет производительности записи (write performance), поскольку вам необходимо поддерживать индекс в актуальном состоянииТаким образом, ответ на вопрос, который часто задается выше, заключается в том, чтобы логически хранить эти данные в зависимости от того, как вы будете их искать. Это означает, что если вы хотите искать в списке по имени, вы должны отсортировать список по имени. Есть несколько проблем с этой стратегией. Я озвучу их в виде вопросов для читателей:
- Что делать, если вы хотите искать данные несколькими способами?
- Как бы вы справились с добавлением новых данных в список? Данный способ быстрый?
- Что бы вы сделали с обновлениями?
- Что такое O-нотация в этих задачах?
Есть о чем подумать. Независимо от вашей первоначальной стратегии, нам определенно нужен способ поддерживать порядок, чтобы мы могли быстро получать релевантные неупорядоченные данные (подробнее об этом позже).
Независимо от вашей первоначальной стратегии, нам определенно нужен способ поддерживать порядок, чтобы мы могли быстро получать релевантные неупорядоченные данные (подробнее об этом позже).
Возьмем пример ниже.
Небольшая таблица, которая легко считывается с диска.+─────+─────────+──────────────+
| id | name | city |
+─────+─────────+──────────────+
| 1 | Mahdi | Ottawa |
| 2 | Elon | Mars |
| 3 | Jeff | Orbit |
| 4 | Klay | Oakland |
| 4 | Klay | Oakland |
| 5 | Lebron | Los Angeles |
+─────+─────────+──────────────+
Базовые данные распределяются по хранилищу беспорядочно и распределяются явно случайным образом. В настоящее время большинство производственных серверов поставляются с твердотельными накопителями, но в некоторых случаях вам понадобятся вращающиеся диски (жесткие диски), но, честно говоря, их становится все меньше и меньше, поскольку цены на твердотельные накопители значительно снижаются.
Больше полезных материалов вы найдете на нашем телеграм-канале «Библиотека программиста»
Интересно, перейти к каналу
SSD vs. HDD
Основное различие между твердотельным накопителем (SSD) и жестким диском (HDD) заключается в том, как данные хранятся и как к ним осуществляется доступ. Жесткие диски используют механические вращающиеся диски и движущуюся головку чтения/записи для доступа к данным (задержка), в то время как твердотельные накопители используют гораздо более быстрые чипы памяти, особенно при чтении большого количества небольших файлов. Поэтому, если цена не является проблемой, твердотельные накопители — лучший вариант, тем более что современные твердотельные накопители почти так же надежны, как и жесткие диски.
Теперь чтение этого небольшого объема данных в памяти выполняется довольно быстро и относительно легко сканируется. Что, если данные, которые мы ищем, не могут быть полностью кэшированы в памяти? или время чтения всех данных с диска занимает слишком много времени?

+──────────+─────────+───────────────────+
| id | name | city |
+──────────+─────────+───────────────────+
| 1 | Mahdi | Ottawa |
| 2 | Elon | Mars |
| 3 | Jeff | Orbit |
| 4 | Klay | Oakland |
| 5 | Lebron | Los Angeles |
| ... | ... | ... |
| 1000000 | Steph | San Francisco |
| 1001000 | Linus | Portland |
+───────+─────────+──────────────────────+
Итак, я видел эту проблему раньше. Вот как действует большинство разработчиков: нам нужен словарь (хеш-мэп) и способ добраться до конкретной строки, которую мы ищем, без необходимости сканировать медленный диск, считывая тонны блоков, чтобы увидеть, есть ли нужные нам данные.
Это так называемые листовые узлы индекса, которым дается определенный столбец для индексации и которые могут хранить расположение соответствующих строк.
Эти конечные узлы индекса представляют собой сопоставление между индексированным столбцом и тем местом, где на диске находится соответствующая строка. Это дает нам быстрый способ добраться до определенной строки, если вы ссылаетесь на нее по индексированному столбцу. Сканирование индекса может быть намного быстрее, так как это компактное представление (меньше байтов) столбца, по которому вы ищете. Это экономит ваше время на чтение множества блоков в поисках запрошенных данных и гораздо удобнее кэшируется, что еще больше ускоряет весь процесс.
Масштаб данных часто работает против вас, и сбалансированные деревья — первый инструмент в вашем арсенале против него.
Листовые узлы этих индексов имеют одинаковый размер, и мы пытаемся сохранить как можно больше таких конечных узлов в каждом блоке. Поскольку эта структура требует сортировки (логически, а не физически на диске), нам нужно решить проблему быстрого добавления и удаления данных. Старый добрый связанный список управляет этим точнее, чем двусвязный список.
Старый добрый связанный список управляет этим точнее, чем двусвязный список.
Блоки
В вычислительной технике блоки представляют собой группу байтов, которые обычно содержат фиксированное количество записей, которые ограничены общей длиной (длиной блока). Таким образом, если бы мы рассчитали количество байт, которое потребуется для хранения строки, деленное на длину блока, результат показал бы нам, сколько строк можно прочитать из определенного блока.
На очень низком уровне вы можете использовать это, чтобы рассуждать о том, насколько производительными могут быть ваши системы. Quick Maths™ может быть очень эффективным при планировании производственных мощностей.
Преимуществ здесь в два раза больше: это позволяет нам читать конечные узлы индекса как вперед, так и назад, и быстро перестраивать структуру индекса, когда мы удаляем или добавляем новые строки, поскольку мы просто модифицируем указатели — короче, мощная штука.
Связанный список
Связанный список – это линейный набор элементов данных, порядок которых не определяется их физическим размещением в памяти. Вместо этого каждый фрагмент указывает на следующий. Это структура данных, состоящая из набора узлов, представляющих последовательность вместе. В своей самой простой форме каждый узел содержит данные и ссылку на следующий узел в ряду.
Поскольку эти конечные узлы физически не расположены на диске по порядку (помните, что указатели поддерживают сортировку в двусвязном списке), нам нужен способ добраться до нужных конечных узлов индекса.
Сбалансированные деревья (B-Tree)
Структурное отличие BTree от B+TreeТаким образом, вы можете задаться вопросом, где вы сделали серьезную ошибку, читая о B-деревьях, которые вы ненавидели со школы. Я понимаю, что эти вещи скучны, но они высокоэффективны и заслуживают вашего внимания.
B+Tree позволяет нам построить древовидную структуру, в которой каждый промежуточный узел указывает на наивысшее значение узла соответствующих конечных узлов. Это дает нам четкий путь для поиска конечного узла индекса, который будет указывать на необходимые данные.
Эта структура строится снизу вверх так, что промежуточный узел покрывает все конечные узлы, пока мы не достигнем корневого узла наверху. Эта древовидная структура получила название «сбалансированная», потому что глубина одинакова по всему дереву.
B-Tree vs. B+Tree
Основное отличие, которое демонстрируют деревья B+, заключается в том, что промежуточные узлы не хранят на них никаких данных. Вместо этого, все ссылки на данные связаны с конечными узлами, что позволяет улучшить кэширование древовидной структуры.
Во-вторых, конечные узлы связаны, поэтому, если вам нужно выполнить сканирование индекса, вы можете выполнить один линейный проход, а не обходить все дерево вверх и вниз и загружать больше индексных данных с диска.
Логарифмическая масштабируемость
Я хочу сделать здесь небольшое отступление, чтобы показать всю мощь этой структуры. Конечно, большинство разработчиков знают об экспоненциальном росте данных и, в идеале, об оценках вашей компании. Но к сожалению, масштаб данных часто работает против вас, и сбалансированные деревья — первый инструмент в вашем арсенале.
В зависимости от количества элементов, на которые могут ссылаться промежуточные узлы (M), плюс общая глубина дерева (N), мы можем ссылаться M на N объектов.
Вот таблица, иллюстрирующая концепцию со значением M, равным 5.
Так как количество конечных узлов индекса увеличивается экспоненциально, высота дерева растет невероятно медленно (логарифмически) относительно количества конечных узлов индекса. Это в сочетании со сбалансированной высотой дерева позволяет почти мгновенно идентифицировать соответствующие конечные узлы индекса, которые указывают на фактические данные на диске.
Это в сочетании со сбалансированной высотой дерева позволяет почти мгновенно идентифицировать соответствующие конечные узлы индекса, которые указывают на фактические данные на диске.
Разве это не потрясающе!
Что такое транзакция?
Транзакция – это группа последовательных операций, которая представляет собой логическую единицу работы с данными. Поэтому операция должна либо произойти в полной мере, либо не произойти вовсе. Я бы сказал, что большинству систем не нужно управлять транзакциями вручную, но бывают ситуации, когда повышенная гибкость играет важную роль в достижении желаемого эффекта. Транзакции в основном касаются I в ACID – Isolation (изолированности).
Что такое ACID?
В информатике ACID (атомарность, согласованность, изолированность, надежность) – это набор свойств транзакций базы данных, предназначенных для обеспечения достоверности данных, несмотря на ошибки, сбои питания и другие сбои.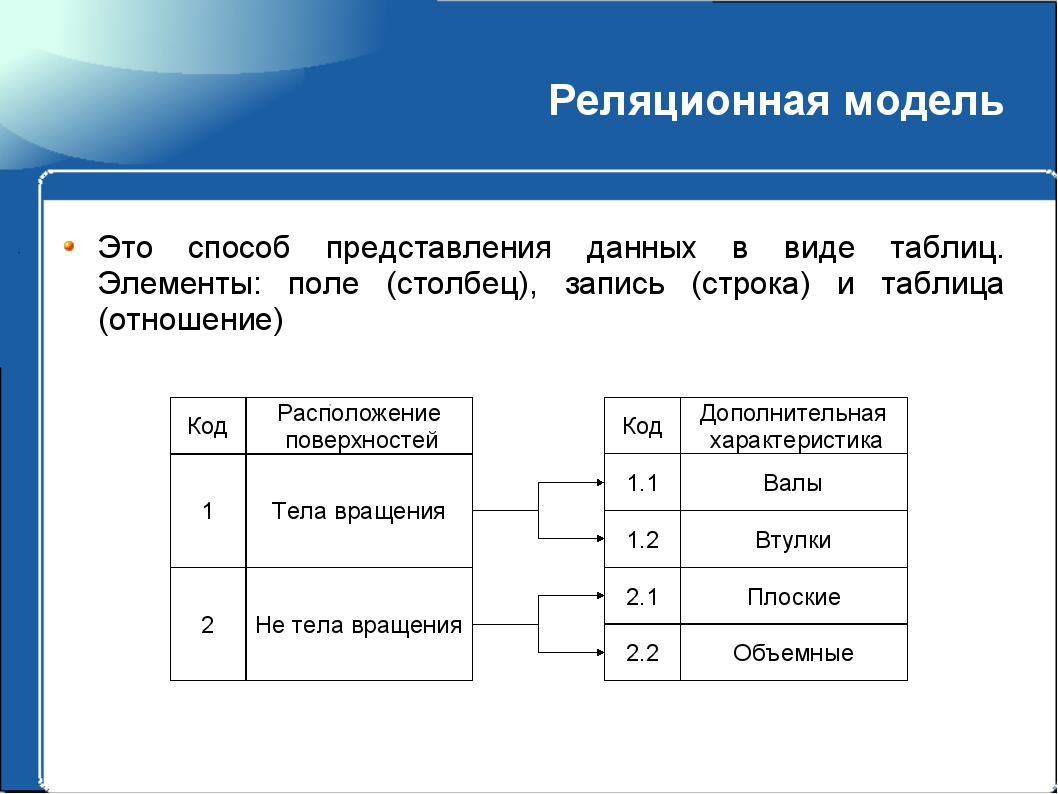
- Атомарность предотвращает частичное обновление базы данных, что может вызвать более серьезные проблемы, чем полное исключение всей серии.
- Согласованность гарантирует, что транзакция может перемещать базу данных из одного допустимого состояния в другое. Это позволяет соответствовать всем определенным правилам базы данных, а также предотвращать сбои в результате некорректных транзакций.
- Изолированность определяет, как конкретное действие отображается другим пользователям системы.
- Надежность – это свойство, которое гарантирует, что транзакции, которые были совершены, будут сохраняться постоянно.
Эти свойства, как правило, хорошо понятны, но их определения могут не совпадать от системы к системе в зависимости от системы базы данных. Поэтому обязательно ознакомьтесь с каждым из них для вашей производственной базы данных.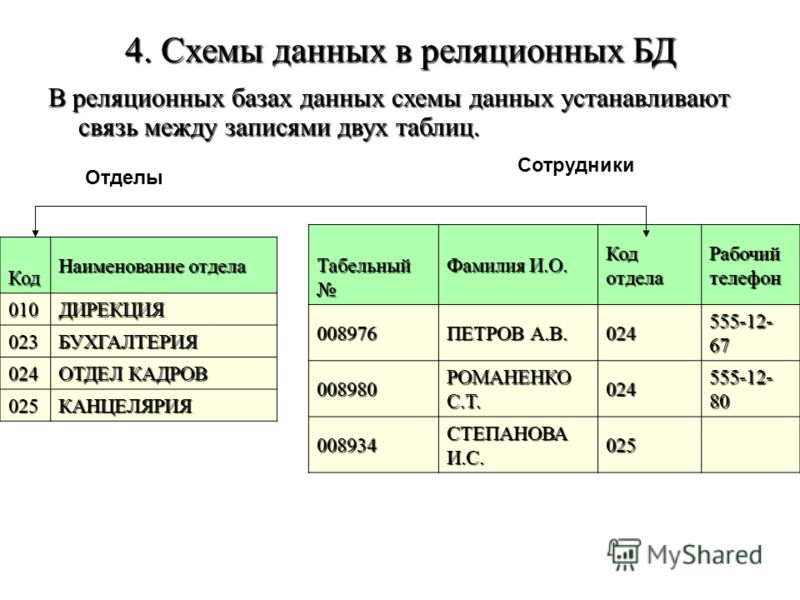
Это может быть сделано автоматически, чтобы вы даже не знали, что они совершаются, или вы можете создать их вручную следующим образом:
Как создать ручную транзакцию-- Manual transaction with commit.
BEGIN;
SELECT * FROM people WHERE id =1;
COMMIT or ROLLBACK;
Мы сосредоточимся на времени между BEGIN и COMMIT или ROLLBACK и на том, что происходит с различными другими транзакциями, воздействующими на те же данные.
COMMIT/ROLLBACK
Все транзакции, выполняемые вручную, заканчиваются либо успешным COMMIT, либо ROLLBACK.
COMMITсохраняет изменения (надежность), внесенные текущей транзакцией.ROLLBACKотменяет изменения, внесенные текущей транзакцией.
Для случая, когда вы не управляете транзакциями вручную, если все запросы в транзакции завершены успешно, они фиксируются (COMMIT). Если происходит какой-либо сбой, изменения во время этой транзакции откатываются (
Если происходит какой-либо сбой, изменения во время этой транзакции откатываются (ROLLBACK), чтобы обеспечить атомарность всего действия.
О феноменах
В этих изоляциях могут возникать некоторые феномены чтения, и их понимание важно для отладки ваших систем и поиска несоответствий, которые ваша система может допустить.
Неповторяемые чтения
Пример неповторяемого чтенияКак показано на изображении выше, неповторяемые чтения происходят, если вы не можете получить согласованное представление данных между двумя последовательными чтениями во время транзакции. В определенных режимах возможна одновременная модификация базы данных, и могут быть сценарии, в которых значение, которое вы только что прочитали, может быть изменено, что приведет к неповторяемому чтению.
«Грязные» чтения
Пример «грязного» чтенияТочно так же «грязное» чтение происходит, когда вы выполняете чтение, а другая транзакция обновляет ту же строку, но не фиксирует работу, вы выполняете другое чтение и можете получить доступ к незафиксированному («грязному») значению, которое не является устойчивым изменением состояния и несовместимо с состоянием базы данных.
Фантомное чтение
Пример фантомного чтенияФантомные чтения — это еще один феномен чтения фиксированных данных (committed read), который чаще всего возникает, когда вы имеете дело с агрегатами. Например, вы запрашиваете количество клиентов в конкретной транзакции. Между двумя последующими чтениями другой клиент регистрируется или удаляет свою учетную запись (committed), в результате чего вы получаете два разных значения, если ваша база данных не поддерживает блокировки диапазона для этих транзакций.
Range Locks (блокировки диапазона) лучше всего описывать, иллюстрируя все возможные уровни блокировки:
- Сериализованный доступ к базе данных — заставляет базу данных выполнять запросы один за другим — ужасный параллелизм, однако высочайший уровень согласованности.
- Блокировка таблицы — блокировка таблицы для вашей транзакции с немного лучшим параллелизмом, но одновременная запись в таблицу по-прежнему замедляется.

- Блокировка строк — блокирует строку, над которой вы работаете, даже лучше, чем при блокировкe таблиц, но если эта строка нужна нескольким транзакциям, им придется подождать.
Блокировки диапазона находятся между двумя последними уровнями блокировок. Они блокируют диапазон значений, захваченных транзакцией, и не позволяют вставлять или обновлять в пределах диапазона, захваченного транзакцией.
4 уровня изоляции
4 уровня изоляции для SQL StandardСтандарт SQL определяет 4 стандартных уровня изоляции, которые могут и должны быть настроены глобально (могут произойти неприятные вещи, если мы не отнесемся внимательно к уровням изоляции).
REPEATABLE READ (Повторяемое чтение)
Начнем с REPEATABLE READ. Здесь относительно просто понять и установить таблицу для остальных уровней изоляции. Этот уровень изоляции обеспечивает согласованное чтение в рамках транзакции, установленной первым чтением. Эта изоляция поддерживается несколькими способами. Некоторые из них влияют на общую производительность системы, другие нет, но это выходит за рамки этого поста.
Этот уровень изоляции обеспечивает согласованное чтение в рамках транзакции, установленной первым чтением. Эта изоляция поддерживается несколькими способами. Некоторые из них влияют на общую производительность системы, другие нет, но это выходит за рамки этого поста.
Как только мы делаем наше первое чтение (см. рисунок выше.), это представление блокируется на время транзакции, поэтому все, что происходит вне контекста этой транзакции, не имеет значения — committed или нет.
Этот уровень изоляции защищает нас от нескольких известных проблем с изоляцией, в основном от неповторяющихся и грязных чтений. У него есть небольшая несогласованность данных, хотя он привязан к конкретному представлению базы данных. Здесь выгодно сохранять краткосрочные транзакции.
SERIALIZABLE (Упорядочиваемость)
Этот режим работы может быть наиболее строгим и последовательным, поскольку он позволяет выполнять только один запрос за раз.
Все типы феномена чтения больше невозможны, поскольку база данных выполняет запросы один за другим, переходя из одного стабильного состояния в другое. Здесь больше нюансов, но зато все происходит более-менее точно.
Важно отметить, что в этом режиме должен быть некоторый механизм повторных попыток, поскольку запросы могут завершаться ошибкой из-за проблем с параллелизмом.
Более новые распределенные базы данных используют преимущества этого уровня изоляции для обеспечения согласованности. CockroachDB — пример такой базы данных.
READ COMMITTED (Чтение фиксированных данных)
Этот режим изоляции отличается от REPEATABLE READ тем, что каждое чтение создает свой собственный непротиворечивый (зафиксированный) моментальный снимок времени. В результате этот режим изоляции подвержен фантомным чтениям, если мы выполняем несколько операций чтения в рамках одной и той же транзакции.
READ UNCOMMITTED (Чтение незафиксированных данных)
В качестве альтернативы уровень изоляции READ UNCOMMITTED не поддерживает блокировку транзакций и может видеть незафиксированные данные по мере их возникновения, что приводит к «грязным» чтениям. В общем, действительно ночной кошмар для некоторых систем.
***
Материалы по теме
- 🗄️ ✔️ 10 лучших практик написания SQL-запросов
- 📜 Основные SQL-команды и запросы с примерами, которые должен знать каждый разработчик
- 🐘 Руководство по SQL для начинающих. Часть 1: создание базы данных, таблиц и установка связей между таблицами
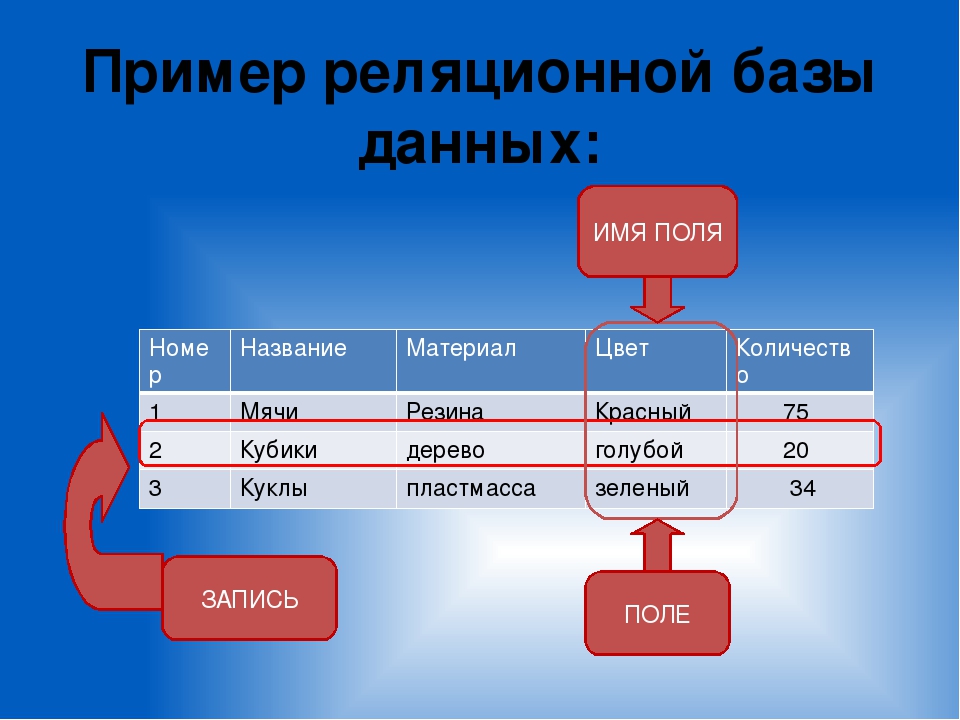
Что такое реляционная база данных? Возможности и использование
Реляционная база данных — это тип базы данных, в которой хранятся и систематизируются связанные точки данных. Данные организованы в таблицы, связанные на основе общих данных.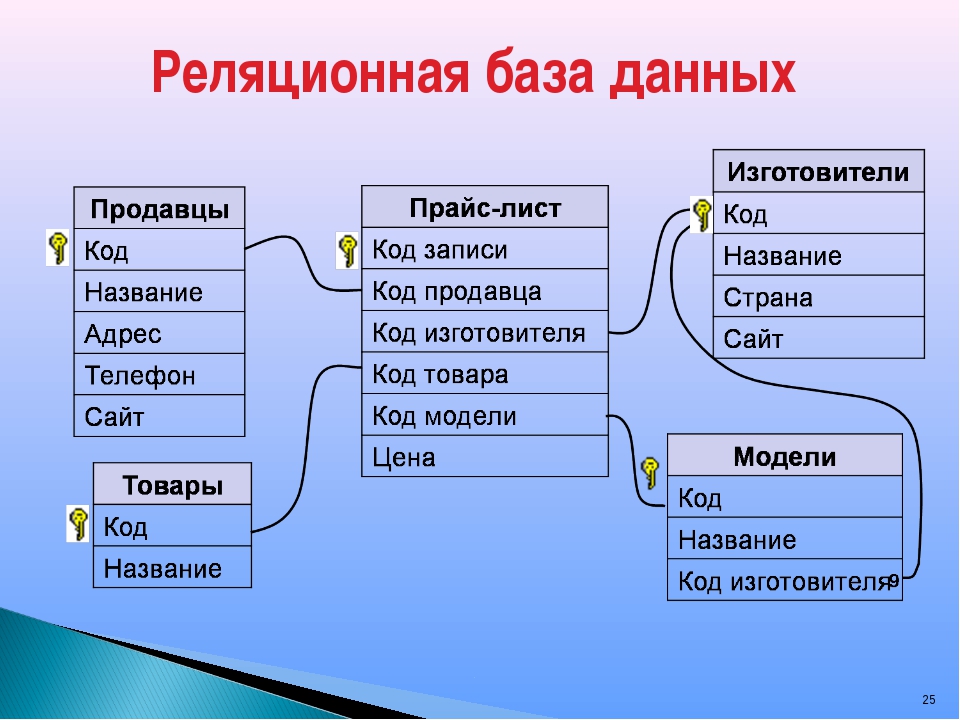 Сегодня они являются наиболее распространенным типом баз данных, используемых предприятиями.
Сегодня они являются наиболее распространенным типом баз данных, используемых предприятиями.
Такая база данных позволяет выполнять поиск в одной или нескольких таблицах с помощью одного запроса. Это также поможет вам понять связи между вашими данными, чтобы вы могли принимать более обоснованные бизнес-решения.
Реляционные базы данных идеально подходят для комплексного анализа данных и операций. В нереляционной базе данных таблицы могут совместно использовать одни и те же данные, но они не могут «связываться» друг с другом. С реляционной базой данных они могут.
Одним из способов использования реляционной базы данных является соединение таблиц для данных клиентов и транзакций. У бизнеса будут оба набора данных, но они могут быть разрозненными. Реляционная база данных объединяет их.
Например, в таблице клиентов могут быть поля для:
В таблице транзакций могут быть такие поля, как:
Поскольку обе таблицы содержат идентификатор клиента, таблицы могут быть связаны. Это означает, что команда склада может найти адрес клиента, соответствующий идентификатору клиента, без записи этой информации в качестве отдельной точки данных для каждой транзакции. Связывание этих наборов данных также можно использовать для создания отчетов, таких как отчет о клиентах.
Это означает, что команда склада может найти адрес клиента, соответствующий идентификатору клиента, без записи этой информации в качестве отдельной точки данных для каждой транзакции. Связывание этих наборов данных также можно использовать для создания отчетов, таких как отчет о клиентах.
Ниже мы рассмотрим особенности, использование и преимущества реляционной базы данных. Кроме того, мы описываем функции реляционных данных Salesforce.
Особенности реляционной базы данных
Реляционным базам данных необходимы характеристики ACID.
ACID относится к четырем основным свойствам: атомарность, согласованность, изоляция и долговечность.
Эти функции являются основным отличием реляционной базы данных от нереляционной базы данных.
Атомарность
Атомарность обеспечивает точность данных. Это гарантирует, что все данные соответствуют правилам, положениям и политикам бизнеса.
Также требуется, чтобы все задачи завершились успешно, иначе транзакция будет откатана.
Атомарность определяет все элементы полной транзакции базы данных.
Непротиворечивость
Состояние базы данных должно оставаться согласованным на протяжении всей транзакции.
Непротиворечивость определяет правила сохранения точек данных. Это гарантирует, что они останутся в правильном состоянии после транзакции.
Реляционные базы данных имеют согласованность данных, поскольку информация обновляется в приложениях и копиях базы данных (также называемых «экземплярами»). Это означает, что несколько экземпляров всегда имеют одни и те же данные.
Изоляция
В реляционной базе данных каждая транзакция является отдельной и не зависит от других. Это стало возможным благодаря изоляции.
Изоляция делает эффект транзакции невидимым до тех пор, пока она не будет зафиксирована. Это снижает риск путаницы.
Надежность
Надежность означает, что вы можете восстановить данные после неудачной транзакции.
Это также гарантирует, что изменения данных будут постоянными.
Использование и преимущества реляционной базы данных
Реляционные базы данных часто являются основой системы управления взаимоотношениями с клиентами (CRM), такой как Salesforce.
Но отслеживание транзакций клиентов — это только один вариант использования реляционной базы данных. Есть много других. Некоторые из них мы даже используем в повседневной жизни. Например, когда вы снимаете деньги в банкомате, ваш банковский баланс может мгновенно обновляться в вашем мобильном приложении, если оно использует реляционную базу данных. Это связано с тем, что точка данных этого сценария («Баланс счета») постоянно обновляется на всех платформах.
Существует множество преимуществ использования реляционной базы данных по сравнению с нереляционной базой данных. И многие из них влияют на другие системы, включая Salesforce.
Некоторые из основных преимуществ реляционной базы данных:
Непротиворечивость данных
Как упоминалось, когда мы говорили о ACID, основной частью реляционной базы данных является согласованность.
Модель реляционной базы данных гарантирует, что все пользователи всегда будут видеть одни и те же данные.
Это улучшает понимание в бизнесе, поскольку все видят одну и ту же информацию. Это гарантирует, что никто не будет принимать бизнес-решения на основе устаревшей информации.
Данные, работающие вместе
Все данные в реляционной базе данных имеют «отношения» с другими данными. Столбцы построены таким образом, что легко установить отношения между точками данных.
Совместная работа с данными дает более целостное представление обо всех ваших данных, в том числе о ваших клиентах.
Гибкость данных
Реляционные базы данных обеспечивают гибкость. Пользователи могут изменить то, что они видят. И легко добавить дополнительные данные позже.
Реляционная база данных также позволяет просматривать подмножество данных. Это означает, что вы можете скрыть определенные данные, если некоторым пользователям нужен доступ только к определенному набору столбцов или строк.
Функции реляционных данных в Salesforce CRM
CRM Salesforce построена на реляционной базе данных.
Salesforce называет свои таблицы «объектами». И эти объекты могут относиться друг к другу. Эти отношения можно использовать для обмена информацией и создания подключенных представлений данных.
В Salesforce существует два типа взаимосвязей:
Отношения поиска
Это самая простая реляционная связь в Salesforce.
Отношение поиска связывает два объекта, так что вы можете «искать» один объект среди связанных элементов другого объекта. Отношения поиска могут быть «один к одному» или «один ко многим».
Стандартное отношение «один ко многим» — это отношение «Организация к контакту». Это позволяет подключить несколько контактов к одному аккаунту.
Связь «один к одному» — это когда необходимо связать только один набор данных. Например, если вы занимаетесь недвижимостью, у вас может быть объект «Недвижимость» и объект «Продавец жилья». У собственности есть только один продавец жилья, поэтому необходимо связать только один набор данных.
У собственности есть только один продавец жилья, поэтому необходимо связать только один набор данных.
Отношения родитель-потомок
Отношения родитель-потомок сложнее, чем отношения поиска.
При этом один объект является родительским, а другой — дочерним. Родительский объект контролирует некоторые действия дочернего объекта, например, кто может просматривать его данные. Это также означает, что если вы удаляете родительский объект, вы удаляете все связанные с ним дочерние объекты.
Например, у вас может быть отношение родитель-потомок между Собственностью и Предложением. Все предложения эксклюзивны для одного объекта. Если имущество будет снято с продажи, вы можете удалить объект Property, чтобы удалить все связанные предложения из вашей системы.
Родительско-дочерние отношения используются, когда объекты всегда связаны. Когда объекты иногда связаны, это отношение поиска.
Зачем выбирать Salesforce
Salesforce предоставляет вам все преимущества реляционной базы данных с расширенными функциями CRM. Кроме того, Salesforce выводит CRM на новый уровень благодаря таким инновациям, как Salesforce Einstein, в которой используется искусственный интеллект.
Кроме того, Salesforce выводит CRM на новый уровень благодаря таким инновациям, как Salesforce Einstein, в которой используется искусственный интеллект.
Salesforce Customer 360 — CRM-система №1 в мире. Он объединяет продажи, обслуживание, маркетинг, коммерцию, ИТ и аналитику. И все это стало возможным благодаря реляционной базе данных.
Преимущества реляционной базы данных | 8 Преимущества реляционной базы данных
Реляционная база данных состоит из правильно организованных таблиц, из которых данные можно администрировать и управлять ими различными способами без необходимости реорганизации всего набора таблиц базы данных. Запросы SQL применяются как для интерактивных запросов для извлечения информации, так и для сбора данных для целей отчетности и анализа. Это помогает сделать важные процессы принятия бизнес-решений удобными.
Одним из основных преимуществ использования реляционной базы данных является то, что этот тип базы данных позволяет пользователю просто классифицировать данные по различным категориям и эффективно их хранить. Это расположение может быть получено с помощью запросов и фильтров. После создания новой базы данных любой набор данных различных категорий может быть включен в базу данных без внесения каких-либо изменений в существующую систему. Система реляционной базы данных имеет множество других преимуществ по сравнению с любым другим типом базы данных.
Это расположение может быть получено с помощью запросов и фильтров. После создания новой базы данных любой набор данных различных категорий может быть включен в базу данных без внесения каких-либо изменений в существующую систему. Система реляционной базы данных имеет множество других преимуществ по сравнению с любым другим типом базы данных.
Основные преимущества реляционной базы данных
Система реляционной базы данных имеет множество других преимуществ по сравнению с любым другим типом базы данных. Ниже приведены несколько существенных преимуществ:
1. Простая модель
Система реляционной базы данных является самой простой моделью, поскольку она не требует каких-либо сложных процессов структурирования или запросов. Он не включает утомительные архитектурные процессы, такие как иерархическое структурирование или определение базы данных. Поскольку структура проста, ее достаточно обрабатывать простыми SQL-запросами и не требуется разрабатывать сложные запросы.
2. Точность данных
В системе реляционной базы данных может быть несколько таблиц, связанных друг с другом с использованием концепций первичного ключа и внешнего ключа. Это делает данные неповторяющимися. Нет возможности для дублирования данных. Следовательно, точность данных в реляционной базе данных выше, чем в любой другой системе баз данных.
3. Легкий доступ к данным
В системе реляционных баз данных нет шаблона или пути для доступа к данным, так как к другим типам баз данных можно получить доступ только путем навигации по дереву или иерархической модели. Любой, кто обращается к данным, может запросить любую таблицу в реляционной базе данных. Используя запросы на соединение и условные операторы, можно объединить все или любое количество связанных таблиц для получения необходимых данных. Результирующие данные могут быть изменены на основе значений из любого столбца, любого количества столбцов, что позволяет пользователю легко восстановить соответствующие данные в результате. Это позволяет выбрать нужные столбцы для включения в результат, чтобы отображались только соответствующие данные.
Это позволяет выбрать нужные столбцы для включения в результат, чтобы отображались только соответствующие данные.
4. Целостность данных
Целостность данных является важнейшей характеристикой системы реляционных баз данных. Надежные вводы данных и проверки легитимности гарантируют, что все данные в базе данных находятся в рамках подходящих механизмов, а данные, необходимые для создания отношений, присутствуют. Эта реляционная надежность между таблицами в базе данных помогает избежать несовершенства, изоляции или несвязанности записей. Целостность данных помогает обеспечить другие важные характеристики реляционной базы данных, такие как простота использования, точность и стабильность данных.
5. Гибкость
Система реляционной базы данных сама по себе обладает качествами для выравнивания, расширения на большую длину, поскольку она наделена гибкой структурой для удовлетворения постоянно меняющихся требований. Это облегчает увеличение входящего объема данных, а также обновление и удаление там, где это необходимо.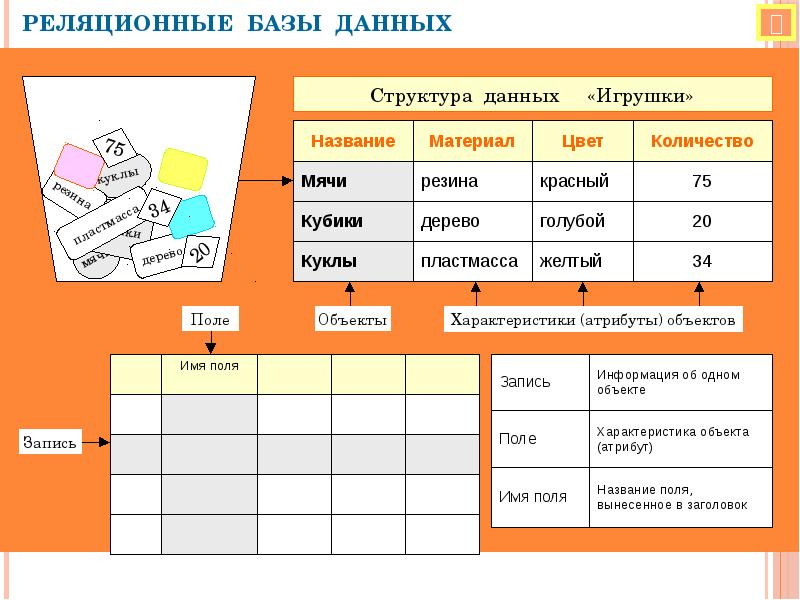 Эта модель также допускает изменения, внесенные в конфигурацию базы данных, которые могут быть применены без труда, без сбоя данных или других частей базы данных.
Эта модель также допускает изменения, внесенные в конфигурацию базы данных, которые могут быть применены без труда, без сбоя данных или других частей базы данных.
Аналитик данных может быстро и легко вставлять, обновлять или удалять таблицы, столбцы или отдельные данные в данной системе баз данных, чтобы удовлетворить потребности бизнеса. Предположительно не существует ограничений на количество строк, столбцов или таблиц, которые может содержать реляционная база данных. В любом практическом приложении разработка и преобразование ограничиваются системой управления реляционными базами данных и оборудованием, содержащимся на серверах. Таким образом, эти изменения могут привести к изменениям в других периферийных функциональных устройствах, подключенных к конкретной системе реляционной базы данных.
6. Нормализация
Выдерживается методический стиль для обеспечения того, чтобы структура реляционной базы данных была освобождена от любых отклонений, которые могут повлиять на целостность и точность таблиц в базе данных. Процесс нормализации обеспечивает набор правил, характеристик и целей для структуры базы данных и оценки модели реляционной базы данных.
Процесс нормализации обеспечивает набор правил, характеристик и целей для структуры базы данных и оценки модели реляционной базы данных.
Нормализация направлена на иллюстрацию нескольких уровней разбивки данных. Ожидается, что любой уровень нормализации будет выполнен на одном и том же уровне, то есть до перехода к следующим уровням. Реляционная модель базы данных обычно считается нормализованной только тогда, когда она удовлетворяет необходимым условиям третьей формы нормализации. Нормализация создает впечатление уверенности в плане базы данных, чтобы она была очень прочной и надежной.
7. Высокий уровень безопасности
Поскольку данные разделены между таблицами системы реляционной базы данных, можно сделать несколько таблиц помеченными как конфиденциальные, а другие нет. Это разделение легко реализуется с помощью системы управления реляционными базами данных, в отличие от других баз данных. Когда аналитик данных пытается войти в систему с именем пользователя и паролем, база данных может установить границы его уровня доступа, предоставляя доступ только к тем таблицам, с которыми ему разрешено работать, в зависимости от его уровня доступа.
8. Возможность будущих модификаций
Поскольку система реляционной базы данных хранит записи в отдельных таблицах в зависимости от их категорий, можно легко вставлять, удалять или обновлять записи, соответствующие последним требованиям. Эта особенность модели реляционной базы данных допускает самые новые требования, предъявляемые бизнесом. Любое количество новых или существующих таблиц или столбцов данных может быть вставлено или изменено в зависимости от предоставленных условий, сохраняя основные качества системы управления реляционной базой данных.
Заключение
Суммируя все преимущества использования реляционной базы данных по сравнению с любым другим типом базы данных, реляционная база данных помогает поддерживать целостность данных, точность данных, снижает избыточность данных до минимума или нуля, масштабируемость данных, гибкость данных и облегчает реализацию методов безопасности. Прежде всего, система управления реляционными базами данных представляет собой более простую модель базы данных как для проектирования, так и для реализации.