CLIP: Соединение текста и изображений
Мы представляем нейронную сеть под названием CLIP, которая эффективно изучает визуальные концепции на основе наблюдения за естественным языком. CLIP можно применить к любому эталону визуальной классификации, просто указав имена визуальных категорий, которые необходимо распознать, аналогично возможностям «нулевого выстрела» GPT-2 и GPT-3.
Прочитать документПросмотреть код Хотя глубокое обучение произвело революцию в компьютерном зрении, у современных подходов есть несколько серьезных проблем: типичные наборы данных о зрении трудоемки и дорогостоящи для создания при обучении только узкому набору визуальных понятий; стандартные модели зрения хорошо справляются с одной задачей и только с одной задачей и требуют значительных усилий для адаптации к новой задаче; и модели, которые хорошо работают в тестах, имеют разочаровывающе низкую производительность в стресс-тестах, что ставит под сомнение весь подход глубокого обучения к компьютерному зрению.
Мы представляем нейронную сеть, которая призвана решить эти проблемы: она обучается на самых разных изображениях с широким спектром контроля естественного языка, которые в изобилии доступны в Интернете. По своему замыслу сеть может быть проинструктирована на естественном языке для выполнения большого количества тестов классификации без прямой оптимизации производительности теста, аналогично возможностям «нулевого выстрела» GPT-2 и GPT-3. Это ключевое изменение: не проводя прямую оптимизацию для эталонного теста, мы показываем, что он становится гораздо более репрезентативным: наша система закрывает этот «пробел в надежности» до 75%, при этом обеспечивая производительность оригинального ResNet-50 на ImageNet Zero- снят без использования каких-либо оригинальных образцов с маркировкой 1.28M.
Хотя обе модели имеют одинаковую точность на тестовом наборе ImageNet, производительность CLIP гораздо более репрезентативна для наборов данных, которые измеряют точность в других настройках, не относящихся к ImageNet. Например, ObjectNet проверяет способность модели распознавать объекты в разных позах и с разным фоном внутри дома, в то время как ImageNet Rendition и ImageNet Sketch проверяют способность модели распознавать более абстрактные изображения объектов.
Например, ObjectNet проверяет способность модели распознавать объекты в разных позах и с разным фоном внутри дома, в то время как ImageNet Rendition и ImageNet Sketch проверяют способность модели распознавать более абстрактные изображения объектов.
ЗАЖИМ ( Contrastive Language–Image Pre-training ) основан на большом объеме работы по переносу нулевого выстрела, контролю естественного языка и мультимодальному обучению. Идея обучения с нулевыми данными возникла более десяти лет назад, но до недавнего времени в основном изучалась в области компьютерного зрения как способ обобщения невидимых категорий объектов. Важным открытием было использование естественного языка в качестве гибкого пространства предсказаний, позволяющего обобщать и передавать данные. В 2013 году Ричер Сочер и его соавторы из Стэнфорда разработали доказательство концепции, обучив модель на CIFAR-10 делать прогнозы в пространстве встраивания векторов слов, и показали, что эта модель может предсказывать два невидимых класса. В том же году DeVISE расширил этот подход и продемонстрировал, что можно точно настроить модель ImageNet, чтобы она могла обобщаться для правильного прогнозирования объектов за пределами исходного обучающего набора из 1000.
В том же году DeVISE расширил этот подход и продемонстрировал, что можно точно настроить модель ImageNet, чтобы она могла обобщаться для правильного прогнозирования объектов за пределами исходного обучающего набора из 1000.
Наибольшее вдохновение для CLIP послужила работа Анга Ли и его соавторов из FAIR, которые в 2016 году продемонстрировали использование контроля над естественным языком для обеспечения нулевой передачи в несколько существующих наборов данных классификации компьютерного зрения, таких как канонический набор данных ImageNet. Они достигли этого, настроив ImageNet CNN для предсказания гораздо более широкого набора визуальных понятий (визуальных n-грамм) из текста заголовков, описаний и тегов 30 миллионов фотографий Flickr, и смогли достичь точности 11,5% на ImageNet. нулевой выстрел.
Наконец, CLIP является частью группы статей, посвященных изучению визуальных представлений с помощью контроля естественного языка, опубликованных в прошлом году. Это направление работы использует более современные архитектуры, такие как Transformer, и включает в себя VirTex, который исследовал авторегрессивное языковое моделирование, ICMLM, который исследовал моделирование маскированного языка, и ConVIRT, который изучал ту же цель сравнения, которую мы используем для CLIP, но в области медицинской визуализации.
Подход
Мы показываем, что масштабирования простой задачи предварительного обучения достаточно для достижения конкурентоспособной нулевой производительности на большом количестве наборов данных классификации изображений. Наш метод использует широко доступный источник наблюдения: текст в сочетании с изображениями, найденными в Интернете. Эти данные используются для создания следующей прокси-задачи обучения для CLIP: по заданному изображению предсказать, какой из набора из 32 768 случайно выбранных текстовых фрагментов фактически был связан с ним в нашем наборе данных.
Наша интуиция подсказывает, что для решения этой задачи модели CLIP должны научиться распознавать широкий спектр визуальных понятий в изображениях и ассоциировать их со своими именами. В результате модели CLIP можно применять практически к любым задачам визуальной классификации. Например, если задачей набора данных является классификация фотографий собак и кошек, мы проверяем для каждого изображения, предсказывает ли модель CLIP текстовое описание «фото собаки » или «фото кота ».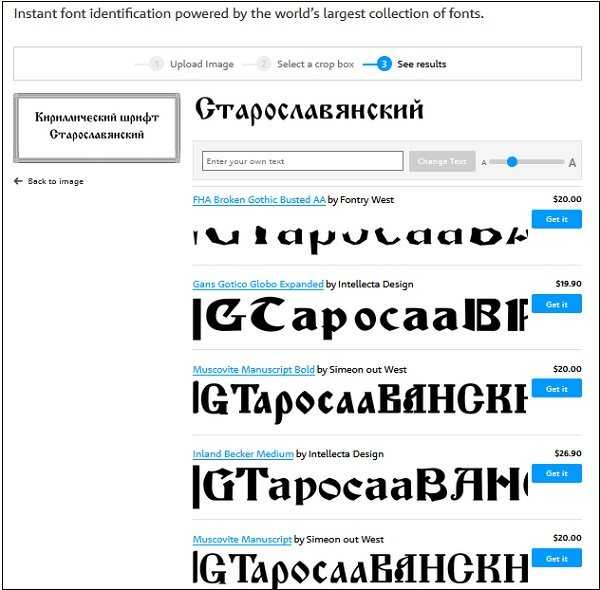 скорее всего в паре с ним.
скорее всего в паре с ним.
CLIP предварительно обучает кодировщик изображений и кодировщик текста, чтобы предсказать, какие изображения были соединены с какими текстами в нашем наборе данных. Затем мы используем это поведение, чтобы превратить CLIP в нулевой классификатор. Мы конвертируем все классы набора данных в подписи, такие как «фотография собаки », и предсказываем класс подписи CLIP оценивает лучшие пары с данным изображением.
CLIP был разработан для смягчения ряда серьезных проблем в стандартном подходе к компьютерному зрению на основе глубокого обучения:
Дорогостоящие наборы данных : Для глубокого обучения требуется много данных, а модели зрения традиционно обучались на размеченных вручную наборах данных, которые дорого создавать и обеспечивают только наблюдение за ограниченным числом заранее определенных визуальных концепций. Набор данных ImageNet, один из крупнейших проектов в этой области, потребовал более 25 000 рабочих для аннотирования 14 миллионов изображений для 22 000 категорий объектов.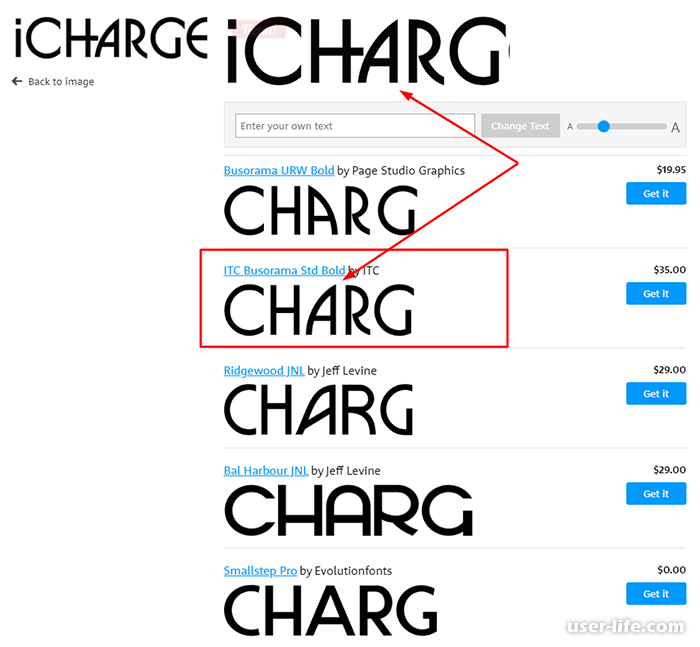 Напротив, CLIP учится на парах текст-изображение, которые уже общедоступны в Интернете. Снижение потребности в дорогостоящих больших помеченных наборах данных было тщательно изучено в предыдущих работах, в частности, в обучении с самоконтролем, контрастных методах, подходах к самообучению и генеративном моделировании.
Напротив, CLIP учится на парах текст-изображение, которые уже общедоступны в Интернете. Снижение потребности в дорогостоящих больших помеченных наборах данных было тщательно изучено в предыдущих работах, в частности, в обучении с самоконтролем, контрастных методах, подходах к самообучению и генеративном моделировании.
Узкий : Модель ImageNet хорошо предсказывает 1000 категорий ImageNet, но это все, что она может сделать «из коробки». Если мы хотим выполнить какую-либо другую задачу, специалисту по машинному обучению необходимо создать новый набор данных, добавить выходную головку и точно настроить модель. Напротив, CLIP можно адаптировать для выполнения широкого круга задач визуальной классификации без дополнительных обучающих примеров. Чтобы применить CLIP к новой задаче, все, что нам нужно сделать, это «сообщить» текстовому кодировщику CLIP имена визуальных понятий задачи, и он выведет линейный классификатор визуальных представлений CLIP. Точность этого классификатора часто конкурентоспособна с полностью контролируемыми моделями.
Мы показываем случайные прогнозы классификаторов CLIP с нулевым выстрелом на примерах из различных наборов данных ниже. [1] быть намного ниже ожиданий, установленных эталоном. Другими словами, существует разрыв между «эталонной производительностью» и «реальной производительностью». Мы предполагаем, что этот разрыв возникает из-за того, что модели «обманывают», оптимизируя только производительность в тесте, как студент, который сдал экзамен, изучая только вопросы экзаменов прошлых лет. Напротив, модель CLIP можно оценивать на бенчмарках без необходимости обучения на их данных, поэтому она не может «мошенничать» таким образом. Это приводит к тому, что его эталонная производительность намного лучше отражает его производительность в дикой природе. Чтобы проверить «гипотезу мошенничества», мы также измеряем, как изменяется производительность CLIP, когда он может «обучаться» для ImageNet. Когда линейный классификатор устанавливается в дополнение к функциям CLIP, он повышает точность CLIP на тестовом наборе ImageNet почти на 10%. Однако этот классификатор делает не лучше в среднем по оценочному набору из 7 других наборов данных, измеряющих «надежную» производительность.
Однако этот классификатор делает не лучше в среднем по оценочному набору из 7 других наборов данных, измеряющих «надежную» производительность.
Основные выводы
1. CLIP очень эффективен
CLIP учится на нефильтрованных, сильно различающихся и сильно зашумленных данных и предназначен для использования в режиме нулевого выстрела. Из GPT-2 и 3 мы знаем, что модели, обученные на таких данных, могут достигать убедительных результатов с нулевым выстрелом; однако такие модели требуют значительных обучающих вычислений. Чтобы сократить объем необходимых вычислений, мы сосредоточились на алгоритмических способах повышения эффективности обучения нашего подхода.
Мы сообщаем о двух вариантах алгоритма, которые привели к значительной экономии вычислительных ресурсов. Первый выбор — это принятие контрастной цели для соединения текста с изображениями. Первоначально мы исследовали подход преобразования изображения в текст, аналогичный VirTex, но столкнулись с трудностями при его масштабировании для достижения современной производительности. В экспериментах малого и среднего масштаба мы обнаружили, что контрастный объектив, используемый CLIP, в 4-10 раз эффективнее при классификации ImageNet с нулевым выстрелом. Вторым вариантом было использование Vision Transformer, что дало нам еще 3-кратный прирост эффективности вычислений по сравнению со стандартным ResNet. В конце концов, наша самая производительная модель CLIP обучается на 256 графических процессорах в течение 2 недель, что аналогично существующим крупномасштабным моделям изображений.
В экспериментах малого и среднего масштаба мы обнаружили, что контрастный объектив, используемый CLIP, в 4-10 раз эффективнее при классификации ImageNet с нулевым выстрелом. Вторым вариантом было использование Vision Transformer, что дало нам еще 3-кратный прирост эффективности вычислений по сравнению со стандартным ResNet. В конце концов, наша самая производительная модель CLIP обучается на 256 графических процессорах в течение 2 недель, что аналогично существующим крупномасштабным моделям изображений.
Первоначально мы изучали обучающие языковые модели преобразования изображений в титры, но обнаружили, что этот подход не справляется с нулевой передачей. В этом 16-дневном эксперименте с графическим процессором языковая модель достигла точности только 16% в ImageNet после обучения на 400 миллионах изображений. CLIP намного эффективнее и обеспечивает ту же точность примерно в 10 раз быстрее.
2. CLIP является гибким и общим
Поскольку они изучают широкий спектр визуальных понятий непосредственно из естественного языка, модели CLIP являются значительно более гибкими и общими, чем существующие модели ImageNet. Мы обнаруживаем, что они способны с нуля выполнять множество различных задач. Чтобы подтвердить это, мы измерили нулевую производительность CLIP на более чем 30 различных наборах данных, включая такие задачи, как детальная классификация объектов, географическая локализация, распознавание действий в видео и оптическое распознавание символов. [2] В частности, обучение OCR является примером захватывающего поведения, которое не встречается в стандартных моделях ImageNet. Выше мы визуализируем случайный прогноз, не являющийся лучшим, из каждого классификатора с нулевым выстрелом.
Мы обнаруживаем, что они способны с нуля выполнять множество различных задач. Чтобы подтвердить это, мы измерили нулевую производительность CLIP на более чем 30 различных наборах данных, включая такие задачи, как детальная классификация объектов, географическая локализация, распознавание действий в видео и оптическое распознавание символов. [2] В частности, обучение OCR является примером захватывающего поведения, которое не встречается в стандартных моделях ImageNet. Выше мы визуализируем случайный прогноз, не являющийся лучшим, из каждого классификатора с нулевым выстрелом.
Этот вывод также отражен в стандартной оценке обучения представлению с использованием линейных датчиков. Лучшая модель CLIP превосходит лучшую общедоступную модель ImageNet, Noisy Student EfficientNet-L2, в 20 из 26 различных наборов данных передачи, которые мы тестировали.
В наборе из 27 наборов данных, измеряющих такие задачи, как детальная классификация объектов, оптическое распознавание символов, распознавание действий в видео и геолокация, мы обнаружили, что модели CLIP изучают более широко полезные представления изображений. Модели CLIP также более эффективны с точки зрения вычислений, чем модели из 10 предыдущих подходов, с которыми мы сравниваем.
Модели CLIP также более эффективны с точки зрения вычислений, чем модели из 10 предыдущих подходов, с которыми мы сравниваем.
Ограничения
В то время как CLIP обычно хорошо справляется с распознаванием обычных объектов, он испытывает затруднения при выполнении более абстрактных или систематических задач, таких как подсчет количества объектов на изображении, и более сложных задач, таких как предсказание, насколько близко ближайший автомобиль находится на фотографии. . В этих двух наборах данных CLIP с нулевым выстрелом лишь немного лучше, чем случайное угадывание. Zero-shot CLIP также борется по сравнению с моделями для конкретных задач при очень тонкой классификации, например, в определении различий между моделями автомобилей, вариантами самолетов или видами цветов.
CLIP также по-прежнему плохо обобщает изображения, не включенные в его набор данных для предварительной подготовки. Например, хотя CLIP изучает способную систему OCR, при оценке рукописных цифр из набора данных MNIST нулевая точность CLIP достигает только 88% точности, что намного ниже 99,75% людей в наборе данных. Наконец, мы заметили, что классификаторы нулевого выстрела CLIP могут быть чувствительны к формулировкам или формулировкам и иногда требуют проб и ошибок «быстрой разработки» для хорошей работы.
Наконец, мы заметили, что классификаторы нулевого выстрела CLIP могут быть чувствительны к формулировкам или формулировкам и иногда требуют проб и ошибок «быстрой разработки» для хорошей работы.
Более широкое воздействие
CLIP позволяет людям разрабатывать свои собственные классификаторы и устраняет необходимость в обучающих данных для конкретных задач. Способ проектирования этих классов может сильно повлиять как на производительность модели, так и на ее погрешности. Например, мы обнаруживаем, что при наличии набора ярлыков, включающего ярлыки расы Fairface [3] и нескольких вопиющих терминов, таких как «преступник», «животное» и т. д., модель имеет тенденцию классифицировать изображения людей в возрасте 0 лет. –20 в категории вопиющих при уровне ~ 32,3%. Однако, когда мы добавляем класс «дочерний» в список возможных классов, это поведение снижается до ~8,7%.
Кроме того, учитывая, что CLIP не требует специальных данных для обучения, он может с большей легкостью разблокировать определенные нишевые задачи. Некоторые из этих задач могут создавать риски, связанные с конфиденциальностью или слежкой, и мы изучаем эту проблему, изучая эффективность CLIP в отношении идентификации знаменитостей. CLIP имеет первую точность 59,2% для классификации изображений знаменитостей «в дикой природе» при выборе из 100 кандидатов и первую точность 43,3% при выборе из 1000 возможных вариантов. Хотя достижение этих результатов с помощью предобучения, не зависящего от задачи, заслуживает внимания, эта производительность неконкурентоспособна по сравнению с широко доступными моделями производственного уровня. Мы дополнительно исследуем проблемы, которые ставит CLIP в нашей статье, и мы надеемся, что эта работа мотивирует будущие исследования по характеристике возможностей, недостатков и предубеждений таких моделей. Мы рады взаимодействовать с исследовательским сообществом по таким вопросам.
Некоторые из этих задач могут создавать риски, связанные с конфиденциальностью или слежкой, и мы изучаем эту проблему, изучая эффективность CLIP в отношении идентификации знаменитостей. CLIP имеет первую точность 59,2% для классификации изображений знаменитостей «в дикой природе» при выборе из 100 кандидатов и первую точность 43,3% при выборе из 1000 возможных вариантов. Хотя достижение этих результатов с помощью предобучения, не зависящего от задачи, заслуживает внимания, эта производительность неконкурентоспособна по сравнению с широко доступными моделями производственного уровня. Мы дополнительно исследуем проблемы, которые ставит CLIP в нашей статье, и мы надеемся, что эта работа мотивирует будущие исследования по характеристике возможностей, недостатков и предубеждений таких моделей. Мы рады взаимодействовать с исследовательским сообществом по таким вопросам.
Заключение
С помощью CLIP мы проверили, можно ли использовать независимое от задач предварительное обучение естественному языку в масштабе Интернета, которое привело к недавнему прорыву в НЛП, для повышения эффективности глубокого обучения в других областях. Мы в восторге от результатов, которые мы уже видели, применяя этот подход к компьютерному зрению. Как и семейство GPT, CLIP изучает широкий спектр задач во время предварительной подготовки, которую мы демонстрируем с помощью переноса с нулевым выстрелом. Нас также обнадеживают наши результаты на ImageNet, которые предполагают, что нулевая оценка является более репрезентативной мерой возможностей модели.
Мы в восторге от результатов, которые мы уже видели, применяя этот подход к компьютерному зрению. Как и семейство GPT, CLIP изучает широкий спектр задач во время предварительной подготовки, которую мы демонстрируем с помощью переноса с нулевым выстрелом. Нас также обнадеживают наши результаты на ImageNet, которые предполагают, что нулевая оценка является более репрезентативной мерой возможностей модели.
Как определить шрифты в изображениях. Бывают ситуации, когда хочется… | by Icons8
Бывают ситуации, когда хочется узнать название неизвестного шрифта. Найти его можно разными способами, но некоторые из них более эффективны. Я говорю об инструментах, созданных специально для идентификации шрифтов.
В этой статье мы рассмотрим три решения для идентификации шрифтов.
Чтобы выяснить, какой шрифт лучше, я сделал следующее:
- Пробовал решения, найденные в Интернете
- Вопросы в таких местах, как Reddit, Quora и форумы
- Получение рекомендаций от дизайнеров
Объединив приведенные выше результаты, я обнаружил три лучших идентификатора шрифта: WhatFontIs, MyFonts, FontsNinja.
WhatFontIs был создан с нуля, чтобы стать самым лучшим идентификатором шрифта, очень простым в использовании и эффективным. С его помощью вы определите шрифты с любого изображения и любого веб-сайта.
Pros
- Программное обеспечение имеет самую обширную базу данных в отрасли, насчитывающую более 790k шрифтов, как бесплатных, так и платных
- Работает со всеми производителями шрифтов, включая Google Fonts
- Поиск как с бесплатными, так и с платными шрифтами
- Для каждого идентифицированного шрифта вы получаете более 60 бесплатных и платных альтернатив шрифтов
- Инструмент на 100% бесплатное использование независимо от того, сколько шрифтов вы хотите идентифицировать
- Регистрация не требуется
Минусы
- Чтобы идентифицировать шрифты с веб-сайтов, вам необходимо установить расширение Google Chrome
MyFonts — дистрибьютор шрифтов с большой библиотекой шрифтов. Он имеет простой в использовании инструмент идентификации шрифтов под названием WhatTheFont.
Он имеет простой в использовании инструмент идентификации шрифтов под названием WhatTheFont.
Pros
- Работа Fast
- Сервис предлагает много аналогичных шрифтов
- Бесплатно для использования
- Без регистрации
- Вы можете проконсультироваться с онлайн -сообщество определяет в основном платные шрифты
- Интернет-сообщество не отвечает на все вопросы
- Довольно небольшая база данных шрифтов — 130 тыс. шрифтов
- Отсутствие идентификации шрифтов с веб-сайтов
FontsNinja — мощное приложение и расширение для браузера, которое поможет вам идентифицировать шрифты с веб-сайтов.
- Бесплатно для использования с расширением для браузера и пробной версией приложения
- Вы можете найти шрифт, его размер, межбуквенный интервал, высоту строки и цвет
- Попробуйте шрифты на своем компьютере в один клик
- Приятный интерфейс
- Нет идентификации шрифта по изображениям
- Только 20 шрифтов в бесплатной пробной версии
- Небольшая база данных
Теперь давайте посмотрим, как идентифицировать шрифты с помощью одного из этих инструментов.