UTF-8 — что это и зачем нужна кодировка символов
Автор: RuWeb
Время чтения: 7 минут
Поделиться:
Машины и люди говорят «на разных языках», однако пользователи видят на экране компьютера понятный им текст, даже если в памяти устройства он хранится в виде чисел. При создании веб-сайта разработчику необходимо помнить, что возможность его использовать должна быть не только у сервера, но и у конечного пользователя. Для преобразования числового представления информации в ее символьный вид используют кодировки. Долгое время разработчики использовали разные схемы для трансформации текста, и если на другом устройстве работала иная кодировка, часть информации не могла быть распознана и терялась. Ситуация исправилась с появлением Юникода. В нашем материале отвечаем на вопросы: UTF-8 — что это? Для чего служит? Какие преимущества и недостатки имеет стандарт?
Что такое UTF-8
UTF-8 (Unicode Transformation Format, 8-bit) — это система кодирования, работающая по стандарту Unicode.
UTF-8 входит в семейство кодировок Unicode, каждая из которых уникальна. Особенность UTF-8 заключается в том, что она представляет символы в однобайтовых единицах. Один байт содержит в самом простом виде восемь бит информации, что нашло отражение в названии кодировки.
Для чего нужна кодировка символов
Компьютеры обрабатывают информацию в двоичной системе. Чтобы разобраться в текстовом сообщении, им необходимо обработать последовательность нулей и единиц. Например, английская литера А — это 01000001. Человеку для понимания текста этого недостаточно, он воспринимает данные, записанные с помощью букв, цифр и других символов, кроме того ему потребуется знание языка, на котором написано сообщение.
Компьютер говорит на языке битов и байтов. Информация в двоичной системе измеряется с помощью битов. Если объем данных достигает 8 битов, то для удобства подсчетов используют большую единицу измерения — байт, далее следуют килобайты, мега- и гигабайты. Каждый символ текста записывается в компьютерной системе в виде строки битов.
Человек говорит на языке символов. Одним из первых наиболее универсальных стандартов кодирования является ASCII. Он имеет библиотеки, в которых систематизированы элементы двух языков — байтового и символьного. Буквам, знакам пунктуации, цифрам присваиваются индивидуальные числовые коды. Например, литере «B» в верхнем регистре по стандарту кодирования ASCII присваивается код «066».
Стандарт ASCII содержит данные о самых востребованных символах и работает для передачи текста, написанного латинскими буквами. Однако пользователи веб-ресурсов, приложений, программного обеспечения и других ИТ-продуктов рассредоточены по всему миру. Поэтому для кодирования всех языков человечества и вообще любого символа, который когда-либо использовался, включая эмотиконы, появился стандарт с более широкими возможностями по хранению символов и соответствующих им кодов — Unicode. Его понимают большинство компьютеров на планете и носители основных мировых языков. Юникод хранит результаты преобразования информации, выполненного через систему кодирования UTF-8, UTF-16 или UTF-32.
Преимущества и недостатки
Юникод — это набор символов, взятых из всех языков мира, глифов и эмодзи. Семейство кодировок UTF определяет, как символ будет представлен в двоичной системе. UTF-8 позволяет пользователям работать в совместимой со всеобщими стандартами и принятой по всему миру многоязычной среде.
Семейство кодировок UTF определяет, как символ будет представлен в двоичной системе. UTF-8 позволяет пользователям работать в совместимой со всеобщими стандартами и принятой по всему миру многоязычной среде.
Языки программирования (ЯП) по-разному поддерживают и используют кодировки. Иногда они могут искажать Unicode. Недостатки Юникода для разных ЯП и программ:
- PHP. Данный язык программирования поддерживает 256 символов, то есть воспринимает 1 символ в строке за 1 байт информации. Так происходит, даже если символ в строке весит больше одного байта. Например, смайл может весить четыре байта, а для PHP все равно один. Однако это можно исправить, настроив многобайтовые функции. Тогда при подсчете длины строки PHP будет обращаться к памяти, а не считать символ за байт.
- JavaScript. Работает с кодировкой UTF-16. Сложные символы требуют две кодовых точки для ссылки.

- MySQL. Система управления базами данных не поддерживает UTF-8 в его стандартном виде. MySQL недостаточно 24 битов, чтобы представить один символ. СУБД поддерживает расширенную версию кодировки — UTF-8mb4.
Максимальный потенциал
С помощью UTF-8 можно записать код любой длины. Однако, для того чтобы работа алгоритма была эффективной и надежной, лучше ограничить размер кода. Unicode 6.х является действующим стандартом и предполагает использование кода до четырех байт в UTF-8.
Сравнение UTF-8 и UTF-16
UTF-8 и UTF-16 — две самые широко используемые кодировки в стандарте Unicode. Они обе обладают переменной длинной кодирования. Один символ в них может быть представлен разным количеством байт. В Юникоде все данные хранятся в таблице и отсортированы по количеству байт, которое они имеют в двоичной системе. В начале стандарта символы могут занимать всего 1 байт, поэтому и UTF-8 зашифрует их с помощью 1 байта. Если данные требуют двух байтов, то и в UTF-8 они будут весить два байта. UTF-8 кодирует символ в двоичную строку от одного до четырех байтов. Так, для шифрования латинских символов достаточно одного байта, а для кириллических — двух. Для данных языков максимального потенциала UTF-8 достаточно.
Если данные требуют двух байтов, то и в UTF-8 они будут весить два байта. UTF-8 кодирует символ в двоичную строку от одного до четырех байтов. Так, для шифрования латинских символов достаточно одного байта, а для кириллических — двух. Для данных языков максимального потенциала UTF-8 достаточно.
UTF-16 оперирует данными из двух и четырех байт. Кодировка подходит для восточных языков.
Заключение
UTF-8 является самым распространенным методом кодирования в Сети, поскольку позволяет хранить текст, содержащий любой символ. Он способен перевести символы, содержащиеся в библиотеке Юникода, в байты, а затем выполнить обратный процесс.
Автор: RuWeb
Время чтения: 7 минут
Поделиться:
другие полезные статьи
09.01.
 2023
Автор: RuWeb
2023
Автор: RuWebWordPress (WP) — самая популярная бесплатная система управления контентом. Поэтому пользователи со всего мира ежедневно создают сайты на этой платформе.
16.01.2023 Автор: RuWeb
Регистрация доменного имени — задача, с которой рано или поздно сталкивается каждый веб-мастер, поскольку без этого пункта полноценно запустить сайт в интернете не получится.
23.01.2023 Автор: RuWeb
Доменное имя является важной частью продвижения сайта в интернете. Оно упрощает поиск ресурса для пользователей, влияет на его оптимизацию в поисковых системах и формирует первое впечатление о проекте — еще до того, как человек его посетит.
Чем UTF-8 отличается от Unicode?
Программирование › PHP › Прочее › Как поставить кодировку utf 8 в PHP?
UTF-8 — это кодировка, которая используются для перевода двоичных данных в числа.
- Что такое UTF-8 простыми словами?
- Что такое Unicode простыми словами?
- Чем отличаются кодировки UTF?
- Для чего используется Юникод?
- Как использовать Юникод?
- Как кодируется Юникод?
- Что входит в UTF-8?
- Сколько символов в кодировке UTF-8?
- Как поставить UTF-8?
- Какая кодировка поддерживает русский?
- Как выбрать кодировку UTF-8?
- Какая кодировка используется в Windows 10?
- Какой шрифт поддерживает Юникод?
- Какая из кодировок наиболее часто используется в настоящее время?
- Какую кодировку использует стандарт Unicode?
- Сколько байт занимает символ Юникода?
- Как понять что за кодировка?
- Для чего нужны разные кодировки?
- Зачем нужен UTF-16?
- Что такое UTF-8 в Python?
- Что такое Unicode C++?
- Чем отличается кодировка ASCII от кодировки Unicode?
- Как добавить кодировку UTF-8?
- Какой тег устанавливает кодировку UTF-8?
- Почему вместо стандарта кодировки символов ASCII стали использовать UTF-8?
- Что такое Unicode Java?
- Какие есть виды кодировки?
- Сколько байт в UTF-8?
- Сколько байт кодируют один символ в кодировке UTF-8?
- Как настроить UTF-8?
- Как включить UTF-8?
Что такое UTF-8 простыми словами?
Unicode Transformation Format, 8-bit — «формат преобразования Юникода, 8-бит») — распространённый стандарт кодирования символов, позволяющий более компактно хранить и передавать символы Юникода, используя переменное количество байт (от 1 до 4), и обеспечивающий полную обратную совместимость с 7-битной кодировкой ASCII.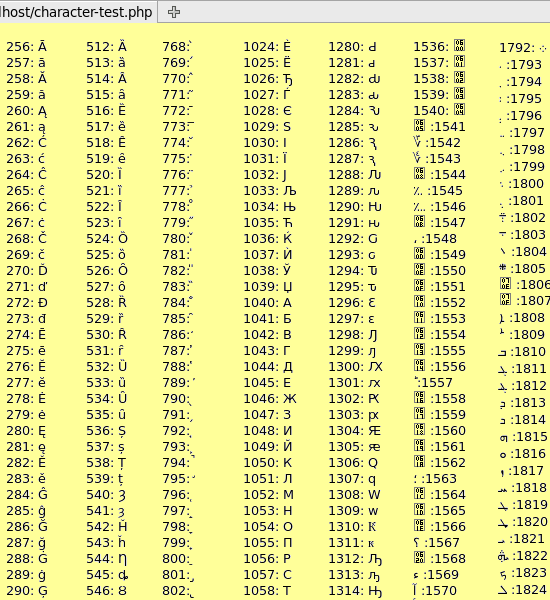
Что такое Unicode простыми словами?
Юнико́д (англ. Unicode) — стандарт кодирования символов, включающий в себя знаки почти всех письменных языков мира. В настоящее время стандарт является преобладающим в Интернете.
Чем отличаются кодировки UTF?
UTF-8 — стандарт кодирования, преобразующий номера ячеек таблицы Юникод в бинарные коды с использованием переменного количества бит: 8, 16, 24 или 32. UTF-16 — стандарт кодирования, преобразующий номера ячеек таблицы Юникод в бинарные коды с использованием переменного количества бит:16 или 32.
Для чего используется Юникод?
Поскольку Unicode содержит кодовые знаки для большинства символов во всех современных языках, то использование кодировки символов Unicode позволит вашему компьютеру интерпретировать практически каждый известный символ. Существует три основных схемы Юникод для кодирования символов: UTF-8, UTF-16 и UTF-32.
Как использовать Юникод?
Чтобы вставить символ Юникода, введите код символа, затем последовательно нажмите клавиши ALT и X. Например, чтобы вставить символ доллара ($), введите 0024 и последовательно нажмите клавиши ALT и X. Все коды символов Юникода см.
Например, чтобы вставить символ доллара ($), введите 0024 и последовательно нажмите клавиши ALT и X. Все коды символов Юникода см.
Как кодируется Юникод?
В рамках Юникода кодирование происходит дважды. Первый раз кодируется набор символов Юникода (character set), в том смысле, что каждому юникод-символу ставится с соответствие кодовая позиция. В рамках этого процесса набор символов Юникода превращается в кодированный набор символов (coded character set).
Что входит в UTF-8?
UTF-8 является лишь представлением Юникода в 8-битном виде. Символы с кодами меньше 128 представляются одним байтом, а так как в Юникоде они повторяют ASCII, то текст написанный только этими символами будет являться текстом в ASCII.
Сколько символов в кодировке UTF-8?
В кодировке UTF-8 унаследованы однобайтные (точнее, 7-битные) коды символов ASCII-7 (коды от 0 до 127), т. е. одним байтом кодируются латинские буквы, цифры и специальные символы.
Как поставить UTF-8?
Откройте меню «Вид» в верхней части браузера. Нажмите «Кодировка текста». Выберите Unicode (UTF-8) в раскрывающемся меню.
Нажмите «Кодировка текста». Выберите Unicode (UTF-8) в раскрывающемся меню.
Какая кодировка поддерживает русский?
Наиболее распространёнными кодировками с поддержкой Русского языка (с использованием символов Кириллицы) являются: UTF-8, Windows-1251, CP-866, KOI-8R, ISO-8859-5.
Как выбрать кодировку UTF-8?
Сменить кодировку файла на UTF-8 в Excel:
- Переходим на вкладку «Данные», выбираем «Получение внешних данных», а далее — «Из текста».
- Открывается мастер импорта текста.
- В поле «Формат файла» перебираем кодировки, пока не найдём ту, в которой текст отображается правильно.
- Выбираем символы-разделители.
Какая кодировка используется в Windows 10?
Windows-1251 — набор символов и кодировка, являющаяся стандартной 8-битной кодировкой для русских версий Microsoft Windows до 10-й версии.
Какой шрифт поддерживает Юникод?
Шрифты, поддерживающие Unicode 15.0
Шрифт | Версия шрифта | Количество глифов |
|---|---|---|
Annapurna SIL | 1. | 977 |
Arial Unicode MS | 1.01 | 50377 |
BabelStone Han | 15.0.3; October 26, 2022 | 64535 |
BabelStone Khitan Small Linear | 13.003 | 598 |
 204
204Какая из кодировок наиболее часто используется в настоящее время?
В настоящее время в основном используются кодировки трёх типов: совместимые с ASCII, совместимые с EBCDIC и основанные на Юникоде 16-битные, с подавляющим преобладанием первых. Представление UTF-8 Юникода совместимо с ASCII.
Какую кодировку использует стандарт Unicode?
UTF-32 — один из способов кодирования символов из Юникод, использующий для кодирования любого символа ровно бита. Остальные кодировки, UTF-8 и UTF-16, используют для представления символов переменное число байт. Символ UTF-32 является прямым представлением его кодовой позиции (англ. code point).
Сколько байт занимает символ Юникода?
В кодировке Unicode один символ занимает 16 бит памяти, что соответствует 2 байтам (1 байт = 8 бит).
Как понять что за кодировка?
Открыть искомый текстовый файл в Блокноте Windows и выбрать пункт меню «Файл» -> «Сохранить как». Пример текстового файла, в котором русский текст задан в формате UTF, но это не очевидно при открытии. 2. В открывшемся диалоговом окне вы сразу видите, в какой кодировке был сохранён текст в текстовом файле.
Для чего нужны разные кодировки?
Кодирование информации — процесс преобразования сигнала из формы, удобной для непосредственного использования информации, в форму, удобную для передачи, хранения или автоматической переработки.
Зачем нужен UTF-16?
UTF-16 (англ. Unicode Transformation Format) в информатике — один из способов кодирования символов из Юникода в виде последовательности 16-битных слов. Данная кодировка позволяет записывать символы Юникода в диапазонах U+0000..
Что такое UTF-8 в Python?
UTF-8 — кодировка символов юникод в двоичном виде. Использует от 1 до 4 байт. Так как наиболее часто используемые символы занимают 1 байт (в частности, аски-символы), то UTF-8 оптимальна для английского текста, но не для азиатского. UTF-16 используется для кодирования 2-мя или 4-мя байтами.
UTF-16 используется для кодирования 2-мя или 4-мя байтами.
Что такое Unicode C++?
Unicode является стандартом де-факто для представления текста на любых языках в современном программном обеспечении.
Чем отличается кодировка ASCII от кодировки Unicode?
Отличия от Unicode
ASCII появилась раньше и включает в себя меньше символов. В стандартной таблице их всего 128, если не считать расширений для других языков. А в «Юникоде», который реализуют кодировки UTF-8 и UTF-32, сейчас 2²¹ символов — это больше чем два миллиона.
Как добавить кодировку UTF-8?
Модификации => Свойства страницы => Заголовок/Кодировка и выставляем кодировку UTF-8. Нажимаем «перезагрузить», убрали галочку с Подключить Юникод Сигнатуры (BOM). Применить и OK.
Какой тег устанавливает кодировку UTF-8?
Кодировка в meta-теге
Данный тег говорит о том, что документ использует кодировку UTF-8, или так называемый Юникод. Наиболее распространенными кодировками являются UTF-8 и Windows-1251.
Почему вместо стандарта кодировки символов ASCII стали использовать UTF-8?
Первый байт UTF-8 используется для кодирования ASCII, что означает, что данный набор символов полностью обратно совместим с ASCII. UTF-8 означает, что символы ASCII и Latin полностью взаимозаменяемы с небольшим увеличением размера данных, так как используется только первый байт.
Что такое Unicode Java?
В Java используется продвинутая разновидность кодировки Unicode — UTF-16: каждый символ в которой кодировался 16 битами (2 байтами). Она способна вместить до 65,536 символов! В этой кодировке можно найти почти все символы всех алфавитов мира.
Какие есть виды кодировки?
Существуют три основных метода химического кодирования:
- Горячий укол или химзащита. На практике для пациента это болезненный укол в вену.
- «Подшиться» или поставить «торпедо». При этом методе капсула с препаратом подшивается пациенту под кожу.
- Эспераль гель. Это внутримышечная инъекция под лопатку.

Сколько байт в UTF-8?
Требования UTF-8
Число байтов в кодировке | Число битов в code point | Минимальное значение |
|---|---|---|
1 | 1..7 | U+0000 = 00000000 |
2 | 8..11 | U+0080 = 11000010 10000000 |
3 | 12..16 | U+0800 = 11100000 10100000 10000000 |
4 | 17..21 | U+010000 = 11110000 10010000 10000000 10000000 |
Сколько байт кодируют один символ в кодировке UTF-8?
Каждый байт содержит 8 бит, таким образом каждый символ русского алфавита кодируется 2 байтами (16/8).
Как настроить UTF-8?
Установка параметра в Visual Studio или программными средствами:
- Откройте диалоговое окно Окна свойств проекта.
- Выберите страницу свойств Свойства> конфигурацииC/C++>Командная строка.
- В окне Дополнительные параметрыдобавьте /utf-8 параметр, чтобы указать предпочтительную кодировку.
Как включить UTF-8?
Откройте меню «Вид» в верхней части браузера. Нажмите «Кодировка текста». Выберите Unicode (UTF-8) в раскрывающемся меню.
Как работает кодировка Unicode UTF-8
UTF-8 — это умный способ кодирования текста Unicode. Я упоминал об этом пару раз в последнее время, но я не писал в блоге об UTF-8 как таковой. Вот оно.
Проблема, которую решает UTF-8
Американские клавиатуры часто могут отображать 101 символ, что означает, что 101 символа будет достаточно для большинства текстов на английском языке. Семи бит будет достаточно, чтобы закодировать эти символы, поскольку 2 7 = 128, а именно это и делает ASCII . Он представляет каждый символ с помощью 8 бит, поскольку компьютеры работают с битами в группах размеров, которые являются степенью двойки, но первый бит всегда равен 0, потому что он не нужен.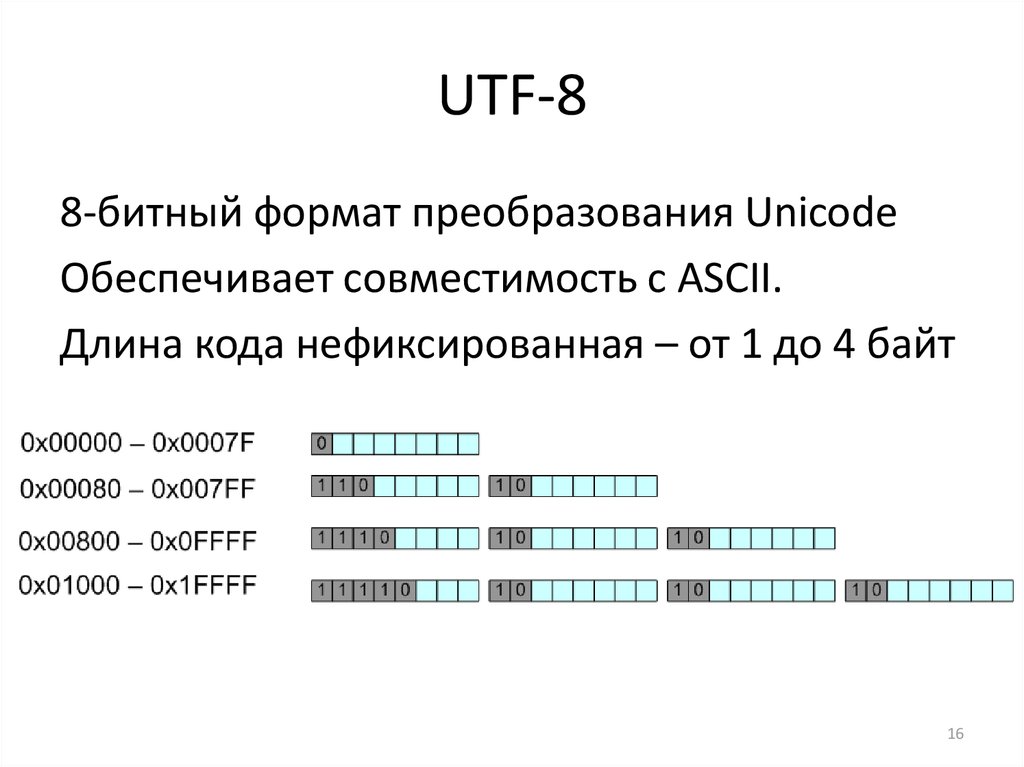 Расширенный ASCII использует оставшееся пространство в ASCII для кодирования дополнительных символов.
Расширенный ASCII использует оставшееся пространство в ASCII для кодирования дополнительных символов.
В общей сложности 256 символов могут быть полезны некоторым пользователям, но они не позволят вам представлять, например, китайский язык. Первоначально Unicode хотел использовать два байта вместо одного байта для представления символов, что дало бы 2 16 = 65 536 возможностей, что было бы достаточно для охвата многих систем письма в мире. Но не все, и поэтому Юникод расширен до четырех байт.
Если бы вы хранили текст на английском языке, используя два байта для каждой буквы, половина пространства была бы потеряна для хранения нулей. И если бы вы использовали четыре байта на букву, три четверти пространства были бы потрачены впустую. Без какой-либо кодировки каждый файл, содержащий английский тест, был бы в два-четыре раза больше необходимого . И не только английский, но и все языки, которые могут быть представлены с помощью ASCII.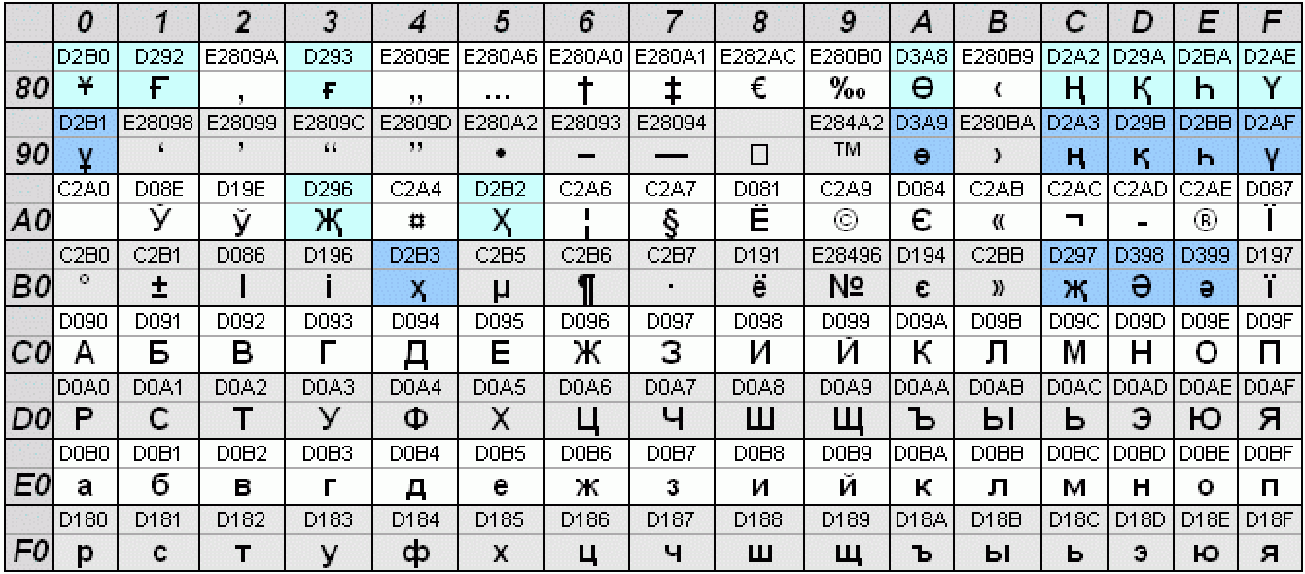
UTF-8 — это способ кодирования Unicode, при котором текстовый файл ASCII кодирует сам себя. Никакого лишнего пространства, кроме начального бита каждого байта, который ASCII не использует. И если ваш файл в основном представляет собой текст ASCII с добавлением нескольких символов, отличных от ASCII, символы, отличные от ASCII, просто сделают ваш файл немного длиннее. Вам не нужно внезапно заставлять каждый символ занимать в два или четыре раза больше места только потому, что вы хотите использовать, скажем, знак евро € (U+20AC).
Как это делает UTF-8
Поскольку первый бит символов ASCII установлен в ноль, байты с первым битом, установленным в 1, не используются и могут использоваться специально.
Когда программное обеспечение, читающее кодировку UTF-8, встречает байт, начинающийся с 1, оно подсчитывает, сколько единиц следует за ним, прежде чем встретится с 0. Например, в байте вида 110xxxxx за начальной 1 следует одна 1. Пусть n — количество единиц между начальным 1 и первым 0. Оставшиеся биты в этом байте и некоторые биты в следующих n байт будут представлять символ Unicode. Нет необходимости, чтобы n было больше 3 по причинам, к которым мы вернемся позже. То есть для представления символа Unicode с использованием UTF-8 требуется не более четырех байтов.
Оставшиеся биты в этом байте и некоторые биты в следующих n байт будут представлять символ Unicode. Нет необходимости, чтобы n было больше 3 по причинам, к которым мы вернемся позже. То есть для представления символа Unicode с использованием UTF-8 требуется не более четырех байтов.
Таким образом, байт вида 110xxxxx говорит о том, что первые пять битов символа Юникода хранятся в конце этого байта, а остальные биты идут в следующем байте.
Байт вида 1110xxxx содержит четыре бита символа Unicode и говорит о том, что остальные биты приходятся на следующие два байта.
Байт вида 11110xxx содержит три бита символа Unicode и говорит о том, что остальные биты приходятся на следующие три байта.
После начального байта, уведомляющего о начале символа, распределенного по нескольким байтам, биты сохраняются в байтах формы 10xxxxxx. Поскольку начальные байты многобайтовой последовательности начинаются с двух битов 1, двусмысленности нет: байт, начинающийся с 10, не может обозначать начало новой многобайтовой последовательности. То есть UTF-8 является самопунктуирующим.
То есть UTF-8 является самопунктуирующим.
Итак, многобайтовые последовательности имеют одну из следующих форм.
110ххххх 10ххххххх
1110хххх 10хххххх 10хххххх
11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
Если посчитать крестики в нижнем ряду, их 21. Таким образом, эта схема может представлять только числа длиной до 21 бита. Разве нам не нужны 32 бита? Оказывается, нет.
Хотя символ Unicode якобы является 32-битным числом, на самом деле для кодирования символа Unicode требуется не более 21 бита по причинам, описанным здесь. Вот почему n , количество единиц, следующих за начальной 1 в начале многобайтовой последовательности, должно быть только 1, 2 или 3. Схема кодирования UTF-8 может быть расширена, чтобы разрешить n = 4, 5, или 6, но это необязательно.
Эффективность
UTF-8 позволяет вам взять обычный файл ASCII и считать его файлом Unicode, закодированным с помощью UTF-8. Таким образом, UTF-8 так же эффективен, как ASCII, с точки зрения пространства. Но не по времени. Если программа знает, что файл на самом деле является ASCII, она может принять каждый байт по номинальному значению, не проверяя, является ли он первым байтом многобайтовой последовательности.
Но не по времени. Если программа знает, что файл на самом деле является ASCII, она может принять каждый байт по номинальному значению, не проверяя, является ли он первым байтом многобайтовой последовательности.
И хотя обычный ASCII допустим в UTF-8, расширенный ASCII — нет. Таким образом, расширенные символы ASCII теперь будут занимать два байта вместо одного. Мой предыдущий пост был о путанице, которая может возникнуть из-за того, что программное обеспечение интерпретирует файл в кодировке UTF-8 как расширенный файл ASCII.
Похожие сообщения
- Безнадежная задача консорциума Unicode
- Сколько символов Unicode возможно?
- Примеры кода префикса
Unicode, UTF-8 объясняется примерами с использованием Go | Автор: Пандула Вирасурия
Unicode и utf-8 — это две темы, над которыми у меня всегда было много проблем. Хотя я могу запомнить указание схемы кодирования для utf-8 при чтении и записи файлов, это всегда казалось черным ящиком.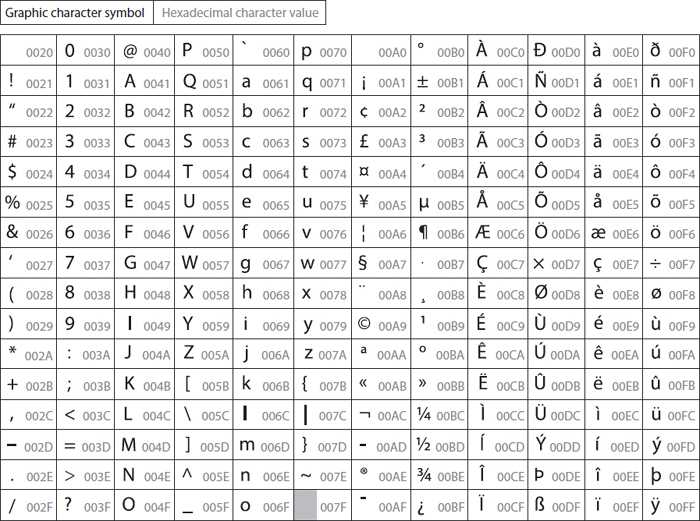 И всякий раз, когда я пытался что-то прочитать об этом, это всегда указывало на ссылки, которые были слишком краткими или слишком сложными. Поэтому я надеюсь, что эта статья станет хорошей ступенькой для всех, кто хочет получить практические знания в области кодирования текста.
И всякий раз, когда я пытался что-то прочитать об этом, это всегда указывало на ссылки, которые были слишком краткими или слишком сложными. Поэтому я надеюсь, что эта статья станет хорошей ступенькой для всех, кто хочет получить практические знания в области кодирования текста.
Я разделил эту статью на следующие подтемы.
- Стандарт ASCII
- Другие схемы, основанные на ASCII, и проблемы, с которыми они связаны in Go
Короче говоря, кодирование символов относится к процессу преобразования символов в их двоичные представления, понятные компьютеру. отображение того, как это делается, называется схемой кодирования .
Прародители этих схем кодирования известны как ASCII (американский стандартный код для обмена информацией). Это 7-битная схема кодирования, разработанная и получившая известность в лабораториях Белла в 70-х годах. В то время программам требовались только строчные и прописные буквы английского алфавита с цифрами, пунктуацией, управляющими символами и несколькими другими специальными символами.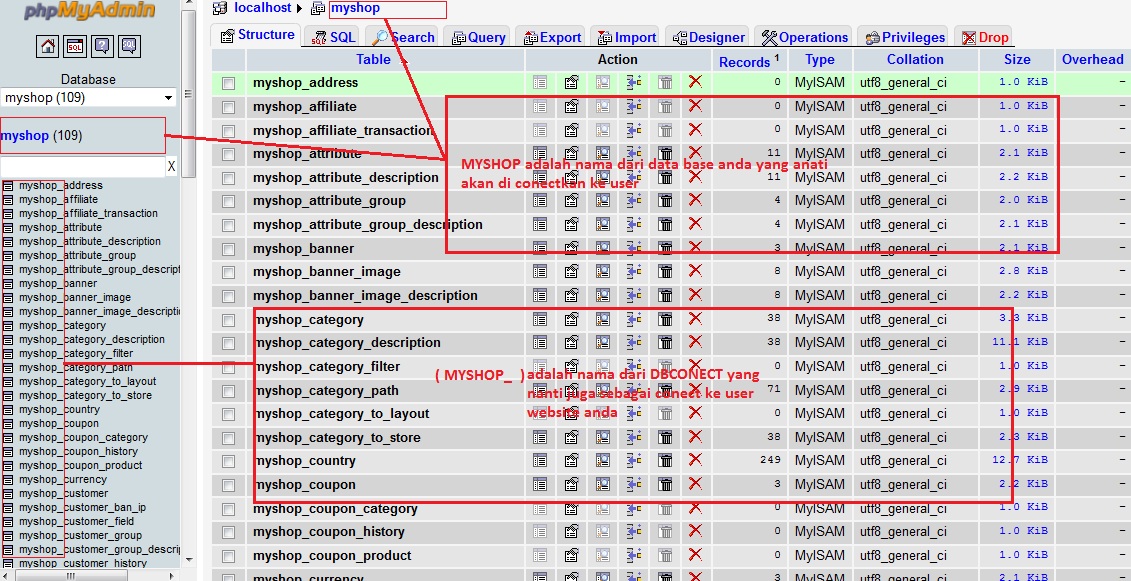 Поскольку это 7-битное отображение, оно поддерживает только 2⁷ == 128 символов.
Поскольку это 7-битное отображение, оно поддерживает только 2⁷ == 128 символов.
Другие схемы, основанные на ASCII
Поскольку в то время в большинстве языков для сохранения символа использовалось 8 бит, один бит всегда оставался впустую. Это означает, что 2⁸ — 2⁷ = еще 128 символов могли быть сопоставлены с чем-то.
Таким образом, многие компании придумали свои собственные схемы кодирования, основанные на ASCII, которые иногда назывались расширенными ASCII, включающими 256 различных символов. Например, схема кодирования Latin-1 расширяет ASCII для поддержки большинства западноевропейских языков. Windows поддерживала схему кодирования, известную как 9.0009 CP-1252 (известный как ANSI ), в то время как Mac-OS поддерживала схему, известную как Mac-OS Roman .
CP-1252 Набор латинских символов SchemeMac-OS Если вы сравните два вышеуказанных набора символов, вы увидите, что они имеют общие символы. Однако эти символы кодируются по-разному в каждой схеме.
Однако эти символы кодируются по-разному в каждой схеме.
Между тем, страны с большим количеством символов, такие как Япония, Китай и Корея, придумали свои собственные наборы символов, которые также не включали ASCII.
Необходимость Unicode
Теперь давайте разберемся, зачем нам понадобилась универсальная кодировка символов. Представьте, что вы записываете текстовый файл в операционной системе Windows, которая поддерживает схему кодирования CP-1252 и содержит несколько греческих символов. Допустим, вы прочитали этот файл в системе Mac OS, используя схему кодирования по умолчанию Mac-OS Roman. Текст, который вы написали, будет иметь другое значение, поскольку неанглийские символы будут сопоставлены с нежелательными другими символами. В то время этот пример казался немного надуманным, и существовали способы обойти его, не забывая читать и писать по общей схеме.
Однако в 90-е годы Интернет начал набирать обороты, и внезапно у вас появились документы, написанные по разным схемам по всему миру, которые стали распространяться повсюду. Это в значительной степени подчеркнуло необходимость единого стандарта.
Это в значительной степени подчеркнуло необходимость единого стандарта.
Стандарт Unicode
В начале 90-х годов родился стандарт Unicode, который обеспечивает последовательное кодирование, представление и обработку текста, выраженного в большинстве мировых систем письма. Стандарт поддерживается обществом, известным как Консорциум Unicode, и по состоянию на март 2020 года его репертуар составляет 143 859символов с Unicode 13.0. Эти символы состоят из 143 696 графических символов и 163 символов формата, охватывающих 154 современных и исторических шрифта, а также несколько наборов символов и смайликов.
Unicode использует простую схему кодирования беззнаковых (положительных) целых чисел. Каждому символу присваивается целочисленное значение в диапазоне от 0 до 1 114 111. Эти целые числа известны как кодовые точки. Первые несколько символов стандарта Unicode такие же, как и в стандарте ASCII (например, A равно 65). И каждому добавленному новому символу присваивается увеличенное значение кодовой точки. Кодовые точки нескольких символов языка хинди приведены ниже.
Кодовые точки нескольких символов языка хинди приведены ниже.
ऒ — 2322, ओ — 2323, औ — 2324, क — 2325
Как правило, набор символов неанглийского языка соответствует его алфавиту.
Если есть что-то, что вы хотите вынести из этой статьи, то это должно быть ниже.
Unicode не указывает, как кодовые точки должны быть закодированы (преобразование в биты). Он не зависит от каких-либо двоичных представлений, поскольку это просто числа.
Он просто дает кодовую точку каждому символу. То, как эти кодовые точки сохраняются в памяти или записываются на диск, полностью зависит от конечного пользователя. По этой причине у нас есть много схем кодирования для Unicode. Давайте сначала посмотрим на UTF-32, так как он более интуитивно понятен.
UTF-32
UTF-32 просто использует 4 байта для сохранения каждого символа. Это означает, что 2³²= 4 294 967 296 символов Юникода (считайте символы кодовыми точками) можно закодировать. Однако недостатком этой схемы является то, что по существу каждый символ занимает 4 байта памяти. Это может быть большой потерей, поскольку документ, содержащий только английские символы, закодированные с помощью UTF-32, займет до 4 раз больше места по сравнению с тем же документом, закодированным с помощью ASCII, поскольку ASCII занимает всего 1 байт. Итак, давайте посмотрим, можем ли мы сделать лучше.
Однако недостатком этой схемы является то, что по существу каждый символ занимает 4 байта памяти. Это может быть большой потерей, поскольку документ, содержащий только английские символы, закодированные с помощью UTF-32, займет до 4 раз больше места по сравнению с тем же документом, закодированным с помощью ASCII, поскольку ASCII занимает всего 1 байт. Итак, давайте посмотрим, можем ли мы сделать лучше.
UTF-16
UTF-16 использует 2 байта для сохранения каждого символа в стандарте Unicode. Для символов, заданных в шестнадцатеричном диапазоне (ux0000 — uxFFFF), каждая кодовая точка хранится непосредственно в 16-битном формате. Более того, для кодовых точек, которые не помещаются в диапазоне 16 бит (больше 2¹⁶ == 65536), используются две 16-битные кодовые точки с методом, называемым суррогатами, в который я не стал бы углубляться, поскольку это сложный процесс. . Однако UTF-16 также потребует 2 байта для хранения символов ASCII, и это оставляет больше возможностей для улучшения.
UTF-8
UTF-8 — это последняя часть головоломки, известная как один из лучших способов взлома эпохи Интернета. Несмотря на то, что название предполагает, что UTF-8 может использовать всего 1 байт (8 бит), это не совсем так. UTF-8 использует так называемую схему кодирования переменной длины.
Для символов в диапазоне от 0 до 127 (от 0x0 до 0x7F) используется только 8 бит, а первый бит остается равным 0. Это точное представление стандарта ASCII. Поэтому известно, что UTF-8 обратно совместим со стандартом ASCII. Это означает, что документ, закодированный по стандарту ASCII, будет легко читаться с использованием UTF-8 и наоборот при условии, что он содержит только символы ASCII.
Для символов от 128 до 2047 (от 0x80 до 0x7FF) используется 2 байта для кодирования. Это кодирование осуществляется особым образом. Возьмем, к примеру, символ Ѱ (кодовая точка = 1136). Это будет представлено в двоичном виде, как показано ниже:
Ѱ = 1136 = U+0470 = 110 10001 | 10 110000
В приведенном выше примере курсивные буквы представляют фактическое двоичное преобразование целочисленной кодовой точки. В первом байте первые 3 бита будут всегда будет 110 для представления символа как 2 байта , закодированного кодовой точкой Unicode, в то время как во втором байте первые 2 бита будут всегда будут 10 для представления его как байта продолжения . Таким образом, технически только 11 бит из 16 фактически используются для представления кодовой точки.
В первом байте первые 3 бита будут всегда будет 110 для представления символа как 2 байта , закодированного кодовой точкой Unicode, в то время как во втором байте первые 2 бита будут всегда будут 10 для представления его как байта продолжения . Таким образом, технически только 11 бит из 16 фактически используются для представления кодовой точки.
Наглядное представление об этом дано в таблице ниже. Вы также можете увидеть, как кодируются 3-байтовые и 4-байтовые символы.
Типы последовательностей байтов UTF-8Для большей ясности давайте выберем 3-байтовый символ и посмотрим его двоичное представление. Давайте рассмотрим представление римской цифры Ⅲ в кодировке UTF-8.
Ѱ = 8546 = U+2162 = 1110 0010 | 10 000101 | 10 100010
Единственное отличие от 2 байтов в том, что на этот раз используются 3 байта и в первом байте первые 4 бита всегда будут 1110, а в последующих байтах первые два бита всегда будут 10. Остальные биты используются для фактического двоичного представления.
Остальные биты используются для фактического двоичного представления.
Теперь, когда у нас есть краткое представление о Unicode и различных схемах кодирования, давайте рассмотрим несколько примеров. Я использовал Go в качестве языка программирования, так как Go изначально поддерживает Unicode и UTF-8. Скорее всего, из-за того, что соучредители Go Роб Пайк и Кен Томпсон также разработали UTF-8. Кроме того, игровая площадка Go — это отличный способ попрактиковаться в Unicode, поскольку он не требует никаких настроек.
Игровая площадка для го: https://play.golang.org/
В го символы представлены в виде типа данных, называемого рун, , который является псевдонимом для типа данных Int32. Не вдаваясь в специфические подробности Go, вы можете написать символьную переменную с приведенным ниже синтаксисом.
‘A’ — двоичное, десятичное и символьное представление с типом переменной Output вышеприведенного кода Теперь посмотрим, как символы представлены в строковом формате, байтовом массиве и в двоичном формате. Мы можем использовать различные глаголы форматирования, унаследованные от языка Си.
Мы можем использовать различные глаголы форматирования, унаследованные от языка Си.
Вы можете видеть, как массив байтов продолжает увеличиваться, когда представлен символом с более высоким значением кодовой точки. Давайте посмотрим, как мы можем напечатать список сингальских символов (мой родной язык), если мы начнем с основного сингальского символа.
Печать каждого успешного символа Unicode после заданного сингальского символа. Затем, используя это как базовую кодовую точку, он напечатал следующие 20 значений кодовой точки.Полный код указан в приведенной выше ссылке на игровую площадку.
С 4 байтами UTF-8 может использовать до 21 бита для хранения любых возможных кодовых точек. Этого достаточно для всех персонажей, существующих сейчас. А если в будущем символов станет больше, то UTF-8 легко можно будет расширить до 5, 6 байт и так далее. Элегантность этого решения заключается в том, что оно решает проблему необходимости дополнительных байтов для хранения повседневных символов ASCII, а также обратно совместимо с ASCII.