Что такое SQL, как работает язык SQL
Поделиться:
SQL, Structured Query Language — язык структурированных запросов, с помощью которого из базы данных извлекаются, записываются, группируются данные. База данных или БД — это набор файлов, в которых записаны контент, логины, пароли, настройки личных кабинетов, данные о посетителях и клиентах. Другими словами — массивы всевозможных, разнообразных данных.
Кто и для чего использует язык SQL
SQL нужен, чтобы работать с базой данных: записывать в неё новую информацию, менять или удалять старую. Для этого IT-специалисты пишут специальные команды — SQL-запросы.
Среди программистов есть отдельные специалисты, которые знают, как создать базу данных и использовать SQL для работы с ней. К ним относятся:
- Администратор базы данных. С помощью SQL администратор даёт или отнимает у других пользователей доступ к БД. Ещё настраивает резервное копирование базы, чтобы в случае ошибки или бага данные не стерлись.
- Разработчик.
 Создаёт программы, у которых много собственных данных: текста, картинок, анимаций, сведений, паролей, телефонов клиентов. Эти данные разработчик сохраняет в БД через язык SQL.
Создаёт программы, у которых много собственных данных: текста, картинок, анимаций, сведений, паролей, телефонов клиентов. Эти данные разработчик сохраняет в БД через язык SQL. - Тестировщик. Тестировщик проверяет код. А если в коде есть часть, связанная с БД, он использует язык SQL, чтобы проверить, как он работает..
- Бизнес-аналитик. Работает с SQL, чтобы получить из базы данные для изучения, поиска закономерностей и составления отчётов.
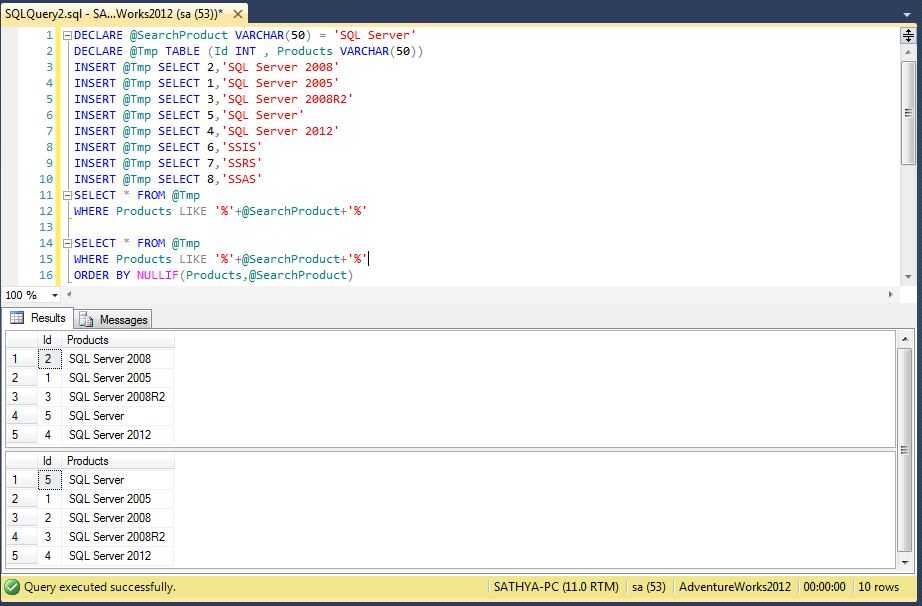
 Создаёт программы, у которых много собственных данных: текста, картинок, анимаций, сведений, паролей, телефонов клиентов. Эти данные разработчик сохраняет в БД через язык SQL.
Создаёт программы, у которых много собственных данных: текста, картинок, анимаций, сведений, паролей, телефонов клиентов. Эти данные разработчик сохраняет в БД через язык SQL.Как работает SQL-запрос
SQL-запрос — это команда, через которую айтишники работают с БД: выгружают из них данные, заменяют, сортируют, удаляют. Работает запрос по следующей схеме:
- Программист пишет SQL-запрос — команду, в которой зашифровано, что надо сделать с данными в базе.
- СУБД или система управления базой данных — специальная программа, которая управляет БД — принимает и расшифровывает запрос.
- Если команда написана верно, СУБД выполняет запрос.
Читайте также
Как использовать Microsoft SQL для отчётов в Power BI.На примере Mindbox
Операторы в SQL
Оператор SQL — это команда, которая выполняет конкретную операцию в БД. Выглядит оператор как слово, но само по себе не работает. Чтобы работало, его надо вписать в конкретный SQL-запрос.
К примеру, оператор «SELECT» означает, что нужно выбрать из БД данные, которые соответствуют какому-то условию. Если нужно найти в БД информацию о клиенте Семенове Михаиле Александровиче, то SQL-запрос с оператором «SELECT» будет выглядеть так:
SELECT * FROM clients WHERE name = Семенов Михаил Александрович,
Где:
- SELECT — отобрать;
- FROM clients — из таблицы «Клиенты»;
- WHERE name — имя Семенов Михаил Александрович.
Все операторы поделены на группы в зависимости от действий, которые они выполняют.
- Data Definition Language. Или DDL — это операторы для работы с таблицами БД. Они нужны, когда пользователь хочет создать новую, изменить или удалить существующую таблице.
Оператор Действие CREATE Создать таблицу ALTER Изменить таблицу DROP Удалить таблицу - Data Manipulation Language. Или DML — это операторы, которые позволяют редактировать все данные в таблицах или некоторые по определённым условиям. Например, пользователь может изменить название какого-то одного клиента в базе.
Оператор Действие SELECT Отсортировать INSERT Создать запись UPDATE Изменить или обновить значение DELETE Удалить значение - Data Control Language. Или DCL — это операторы, которые выдают или отнимают права у пользователей для работы с БД.
Оператор Действие GRANT Дать пользователю права доступа REVOKE Забрать у пользователя права доступа
- SQL — это язык программирования для работы с базами данных.

- В SQL есть операторы — команды, через которые управляют самой базой и данными внутри её. И запросы: строчки кода, в которых указывают оператора, чтобы он сработал.
- SQL используют администраторы, разработчики, тестировщики и аналитики.
Поделиться:
🗄️ ✔️ 10 лучших практик написания SQL-запросов
Статья является переводом. Оригинал доступен по ссылке.
Я работаю с данными уже 3 года, и меня до сих пор удивляет, что есть люди, которые хотят стать аналитиками, практически не зная SQL. Хочу особо подчеркнуть, что SQL является фундаментальным языком независимо от того, кем вы будете работать в сфере анализа данных.
Конечно, я видел исключения, когда люди, обладающие впечатляющими знаниями в других областях, помимо SQL, получают работу, но при этом после получения оффера им все равно приходится изучать SQL. Я думаю, что почти невозможно быть профессионалом в сфере анализа данных без знаний SQL.
Данные советы предназначены для всех специалистов, независимо от опыта. Я перечислил самые распространенные случаи в моей практике, разместив в порядке возрастания сложности.
Для примеров я буду использовать базу данных SQLite: sql-practice.com
1. Проверка уникальных значений в таблице
SELECT count(*), count(distinct patient_id) FROM patients
В этом примере показано, как проверить, является ли ваш столбец первичным ключом в таблице. Конечно, это обычно используется в создаваемых вами таблицах, поскольку в большинстве баз данных есть возможность указать первичный ключ в метаданных информационной схемы.
Если числа из двух столбцов равны, то столбец, который вы подсчитали во второй части запроса, может быть первичным ключом. Это не всегда является гарантией, но иногда может помочь разобраться.
Однако становится немного сложнее, когда у вас есть несколько столбцов, которые создают первичный ключ. Чтобы решить эту проблему, просто объедините столбцы, составляющие первичный ключ, после ключевого слова
SELECT count(*), count(distinct first_name || last_name) FROM patients
2. Поиск повторяющихся записей
SELECT
first_name
, count(*) as ct
FROM patients
GROUP BY
first_name
HAVING
count(*) > 1
ORDER BY
COUNT(*) DESC
;
Таблица из примера — это упрощенная версия баз данных, которые вы будете использовать в своей работе. В большинстве случаев вы захотите выяснить причины дублирования значений в базе данных. Для этого вам пригодится данный запрос.
Вы можете использовать ключевое слово HAVING для сортировки повторяющихся значений.
Джон. Затем вы запустите еще один запрос, чтобы увидеть причину повторяющихся значений, и увидите, что все пациенты имеют разные фамилии и ID.Больше полезных материалов вы найдете на нашем телеграм-канале «Библиотека программиста»
Интересно, перейти к каналу
3. Обработка NULL с DISTINCT
with new_table as (
select patient_id from patients
UNION
select null
)
select
count(*)
, count(distinct patient_id)
, count(patient_id)
from new_table
Результатом запроса будет значение 4531 для столбца COUNT(*) и 4530 для двух оставшихся столбцов. Когда вы указываете столбец, ключевое слово COUNT исключает нулевые значения. Однако, при использовании звездочки в подсчет включаются значения NULL. Это может сбивать с толку при проверке, является ли столбец первичным ключом, поэтому я посчитал нужным упомянуть об этом.
4. CTE > Подзапросы
-- Use of CTE
with combined_table as (
select
*
FROM patients p
JOIN admissions a
on p.patient_id = a.patient_id
)
, name_most_admissions as (
select
first_name || ' ' || last_name as full_name
, count(*) as admission_ct
FROM combined_table
)
select * from name_most_admissions
;
-- Use of sub-queries :(
select * from
(select
first_name || ' ' || last_name as full_name
, count(*) as admission_ct
FROM (select
*
FROM patients p
JOIN admissions a
on p.patient_id = a.patient_id
) combined_table
) name_most_admissions
;
Когда я впервые начал работать аналитиком данных 3 года назад, я писал SQL-запросы с большим количеством подзапросов, чем это было необходимо. Я быстро понял, что это не приводит к читабельному коду. В большинстве ситуаций вы хотите использовать общее табличное выражение вместо подзапроса.
5. Использование SUM и CASE WHEN вместе
select
sum(case when allergies = 'Penicillin' and city = 'Burlington' then 1 else 0 end) as allergies_burl
, sum(case when allergies = 'Penicillin' and city = 'Oakville' then 1 else 0 end) as allergies_oak
from patients
Предложение WHERE может работать, если вы хотите суммировать количество пациентов, отвечающих определенным условиям. Но если вы хотите проверить несколько условий, вы можете использовать ключевые слова SUM
CASE WHEN вместе. Это делает код лаконичным и легко читаемым.Данную комбинацию также можно использовать в выражении WHERE, как в примере ниже.
select
*
FROM patients
WHERE TRUE
and 1 = (case when allergies = 'Penicillin' and city = 'Burlington' then 1 else 0 end)
6.
 Будьте осторожны с датами
Будьте осторожны с датамиwith new_table as (
select
patient_id
, first_name
, last_name
, time(birth_date, '+1 second') as birth_date
from patients
where TRUE
and patient_id = 1
UNION
select
patient_id
, first_name
, last_name
, birth_date
from patients
WHERE TRUE
and patient_id != 1
)
select
birth_date
from new_table
where TRUE
and birth_date between '1953-12-05' and '1953-12-06'
В этой базе данных все даты сокращены до дня. Это означает, что все значения времени столбца Birthday_date в этом примере равны 00:00:00
В зависимости от среды разработки SQL ваши настройки могут скрыть отображение времени. Но то, что время скрыто, не означает, что оно не является частью данных.
В приведенном выше примере я искусственно добавил секунду к пациенту №1. Как видите, этой 1-й секунды было достаточно, чтобы исключить пациента из результатов при использовании ключевого слова
Как видите, этой 1-й секунды было достаточно, чтобы исключить пациента из результатов при использовании ключевого слова BETWEEN.
Еще один распространенный пример, который чаще всего упускают из вида специалисты по работе с данными, — это присоединение к датам, в которых все еще есть временной компонент. В большинстве случаев они действительно пытаются присоединиться к столбцам с сокращенной датой и, в конечном итоге, не получают желаемого результата или, что еще хуже, они не осознают, что получили неправильный результат.
7. Не забывайте об оконных функциях
select
p.*
, MAX(weight) over (partition by city) as maxwt_by_city
from patients p
Оконные функции — отличный способ сохранить все строки данных, а затем добавить еще один столбец с важными агрегатными сведениями. В этом случае мы смогли сохранить все данные и добавить максимальный вес по столбцу города.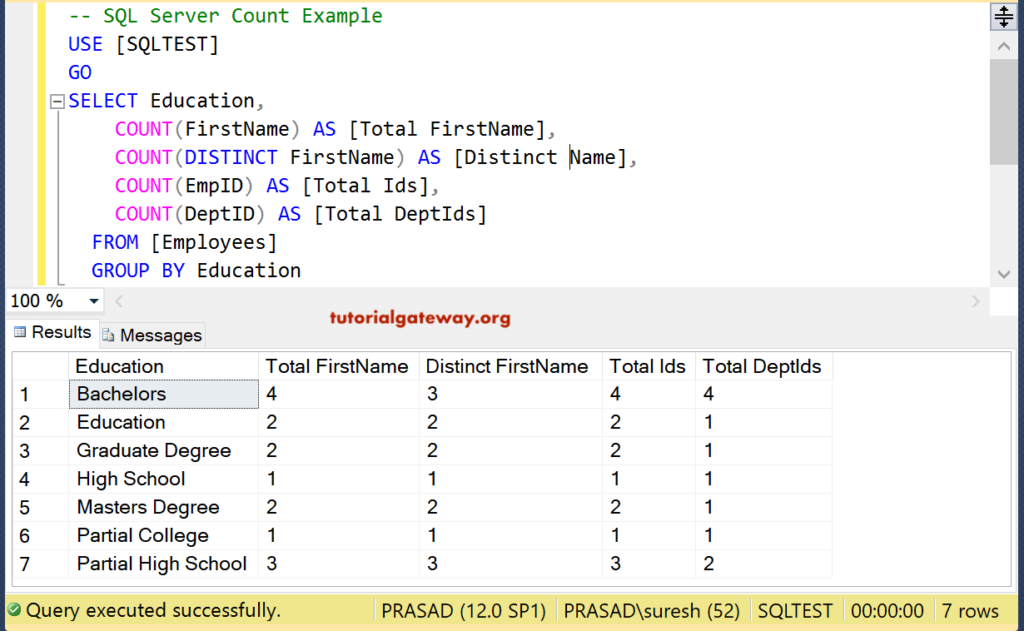
Я видел, как некоторые аналитики пробовали обходные пути, когда оконная функция делала код короче и читабельнее и, скорее всего, также экономила им время.
Существует множество различных оконных функций, но приведенный выше пример является распространенным и простым вариантом использования.
8. По возможности избегайте DISTINCT
Последние 3 совета не содержат примеров программного кода, но они так же важны, как и приведенные выше. По моему опыту, специалисты по работе с данными слишком часто используют distinct, чтобы предотвратить дублирование, не разбираясь в причине.
Это ошибка. Если вы не можете с самого начала объяснить, почему в данных есть дубликаты, возможно, вы исключили из своего анализа какую-то полезную информацию. Вы всегда должны быть в состоянии объяснить, почему вы помещаете distinct в таблицу и почему есть дубликаты. Использование
Использование WHERE обычно предпочтительнее, так как вы можете увидеть то, что исключается.
9. Форматирование SQL
Об этом сказано довольно много, но стоит повторить. Обязательно отформатируйте SQL. Лучше создать больше строк с хорошим форматированием, чем пытаться сжать весь код всего в несколько строк. Это позволит ускорить разработку.
Вы можете заметить, что в примерах я использовал TRUE в WHERE выражении. Это было сделано для того, чтобы все аргументы в выражении WHERE начинались с AND. Таким образом, аргументы начинаются с одного и того же места.
Еще один быстрый совет — добавить запятые в начале столбца в выражении SELECT. Это позволяет легко найти пропущенные запятые, поскольку все они будут упорядочены.
10. Совет по отладке
Некоторые SQL-запросы могут быть очень сложными для отладки. Что мне больше всего помогло, когда я сталкивался с этим в прошлом, так это то, что я очень усердно документировал свои шаги.
Что мне больше всего помогло, когда я сталкивался с этим в прошлом, так это то, что я очень усердно документировал свои шаги.
Чтобы задокументировать шаги, я пронумерую часть кода в комментариях перед запросом. Комментарий описывает, что я пытаюсь сделать в этом разделе запроса. Затем я напишу свой ответ под заголовком комментария после выполнения запроса.
Во время отладки действительно легко увидеть варианты, которые вы уже попробовали, и я обещаю, что с таким подходом вы решите эту проблему быстрее.
***
Надеюсь, вы узнали что-то полезное из приведенных выше советов. Какие из них вы нашли наиболее полезными? Мы также с нетерпением ждем ваших советов и, пожалуйста, дайте ссылки на любые другие полезные статьи в комментариях, спасибо!
Материалы по теме
- 📜 Основные SQL-команды и запросы с примерами, которые должен знать каждый разработчик
- 🐘 Руководство по SQL для начинающих.
 Часть 1: создание базы данных, таблиц и установка связей между таблицами
Часть 1: создание базы данных, таблиц и установка связей между таблицами - 🐘 Руководство по SQL для начинающих. Часть 2: фильтрация данных, запрос внутри запроса, работа с массивами
- 🐘 Руководство по SQL для начинающих. Часть 3: усложняем запросы, именуем вложенные запросы, анализируем скорость запроса
Инструкция SELECT: как выбрать конкретные значения
Поиск
Оператор select используется для запроса базы данных и извлечения выбранных данных, соответствующих заданным вами критериям. Вот формат простого оператора select:
select "column1" ["столбец2" и т.д.] из "имя таблицы" [где "условие"]; [] = необязательно
Имена столбцов, следующие за ключевым словом select, определяют, какие столбцы будут возвращены в результатах. Вы можете выбрать столько имен столбцов, сколько хотите, или вы можете использовать «*», чтобы выбрать все столбцы.
Имя таблицы, которое следует за ключевым словом из , указывает таблицу, которая будет запрошена для получения желаемых результатов.
Предложение where (необязательное) указывает, какие значения данных или строки будут возвращены или отображены на основе критериев, описанных после ключевого слова 9.0005 где .
Условный выбор, используемый в , где пункт :
| = | Равно |
| > | Больше |
| < | Менее |
| >= | Больше или равно |
| <= | Меньше или равно |
| <> | Не равно |
| НРАВИТСЯ | *См. примечание ниже примечание ниже |
Оператор сопоставления с образцом LIKE также может использоваться при условном выборе предложения where. Like — очень мощный оператор, который позволяет вам выбирать только те строки, которые «похожи» на то, что вы укажете. Знак процента «%» можно использовать в качестве подстановочного знака для соответствия любому возможному символу, который может появиться до или после указанных символов. Например:
выбрать первый, последний, город из эмпинфо где сначала НРАВИТСЯ 'Er%';
Эта инструкция SQL будет соответствовать любым именам, начинающимся с «Er». Строки должны быть заключены в одинарные кавычки.
Или можно указать,
выбрать первый, последний из эмпинфо где последний НРАВИТСЯ '%s';
Этот оператор будет соответствовать любым фамилиям, оканчивающимся на «s».
выберите * из empinfo где сначала = 'Эрик';
Будут выбраны только те строки, где имя в точности равно «Эрик».
| Образец таблицы: empinfo | |||||
|---|---|---|---|---|---|
| первый | последний | идентификатор | возраст | город | состояние |
| Джон | Джонс | 99980 | 45 | Пейсон | Аризона |
| Мэри | Джонс | 99982 | 25 | Пейсон | Аризона |
| Эрик | Эдвардс | 88232 | 32 | Сан-Диего | Калифорния |
| Мэри Энн | Эдвардс | 88233 | 32 | Феникс | Аризона |
| Имбирь | Хауэлл | 98002 | 42 | Коттонвуд | Аризона |
| Себастьян | Смит | 92001 | 23 | Гила Бенд | Аризона |
| Гас | Серый | 22322 | 35 | Багдад | Аризона |
| Мэри Энн | май | 32326 | 52 | Тусон | Аризона |
| Эрика | Уильямс | 32327 | 60 | Показать низкий уровень | Аризона |
| Лерой | Коричневый | 32380 | 22 | Сосновая вершина | Аризона |
| Элрой | Тесак | 32382 | 22 | Глобус | Аризона |
Введите следующие примеры операторов выбора в форму интерпретатора SQL внизу этой страницы. Прежде чем нажать «отправить», запишите ожидаемые результаты. Нажмите «отправить» и сравните результаты.
Прежде чем нажать «отправить», запишите ожидаемые результаты. Нажмите «отправить» и сравните результаты.
выбрать первый, последний, город из empinfo;
выбрать последний, город, возраст из empinfo
где возраст > 30;
выберите первый, последний, город, штат из empinfo
где сначала НРАВИТСЯ 'J%';
выберите * из empinfo;
выбрать первый, последний, из empinfo
где последний НРАВИТСЯ '%s';
выберите первый, последний, возраст из empinfo
где последний НРАВИТСЯ '%illia%';
выберите * из empinfo, где first = 'Eric'; Упражнения с операторами выбора
Введите операторы выбора для:
- Отображение имени и возраста всех участников таблицы.
Показать ответ
- Отображать имя, фамилию и город для всех, кто не из Payson.
Показать ответ
- Показать все столбцы для всех, кому больше 40 лет.
Показать ответ
- Показать имена и фамилии всех, чьи фамилии заканчиваются на «ау».

Показать ответ
- Показать все столбцы для всех, чье имя равно «Мэри».
Показать ответ
- Показать все столбцы для всех, чье имя содержит «Мэри».
Показать ответ
Введите оператор SQL здесь:
Здесь будут отображаться результаты
Памятка по SQL
Памятка по SQLУзнайте о некоторых передовых методах работы с SQL.
Каждая база данных SQL имеет несколько иной способ обработки массивов. Поскольку ресурсы SQL в Retool по умолчанию настроены на преобразование запросов в подготовленные операторы, это может иметь более сложные взаимодействия с несколькими значениями внутри одного параметра. Вот лучшие практики для некоторых из наших наиболее распространенных баз данных без необходимости отключать подготовленные операторы.
выбрать
*
от
пользователи
где идентификатор = ЛЮБОЙ ({{ [1, 2, 3] }})
ВЫБОР
*
ОТ
пользователи
ГДЕ
идентификатор IN (
ВЫБИРАТЬ
конвертировать (целое число, значение)
ОТ
string_split({{ [1, 2, 3] }}, ',')
)
ВЫБОР
*
ОТ
пользователи
ГДЕ
идентификатор IN (
ВЫБИРАТЬ
Split. a.value('.', 'NVARCHAR(MAX)') ДАННЫЕ
ОТ
(
ВЫБИРАТЬ
БРОСАТЬ(
'
a.value('.', 'NVARCHAR(MAX)') ДАННЫЕ
ОТ
(
ВЫБИРАТЬ
БРОСАТЬ(
'' + REPLACE({{ [1,2,3,4,5,5,6].join(',') }}, ',', ' ') + ' ' КАК XML
) как строка
) КАК
ПЕРЕКРЕСТНОЕ ПРИМЕНЕНИЕ String.nodes('/X') AS Split(a)
)
выбрать
*
от
пользователи
где
идентификатор IN ({{ [1, 2, 3] }})
выбрать
*
от
пользователи
где id IN UNNEST({{ [1, 2, 3] }})
ВЫБОР
*
ОТ
c --c — идентификатор контейнера, вводимый в пользовательском интерфейсе редактора запросов.
ГДЕ
array_contains( {{ [1,2,3] }}, c.id )
Базы данных с уникальными структурами массивов
SELECT
*
ОТ
ПУБЛИЧНЫЕ ПОЛЬЗОВАТЕЛИ
ГДЕ
ARRAY_CONTAINS(ID::variant, SPLIT( '{{[123,224].join()}}', ',')) )
выбрать
*
от
пользователи
где
идентификатор IN ({{ [1, 2, 3]. join() }})
join() }})
выбрать
*
от
пользователи
где
СОДЕРЖИТ({{','+'Джордж,Фред,Крис'+',' }}, ',' || user.name || ',')
В качестве последнего запасного варианта, еще один умный способ заставить это работать в базах данных SQL, поддерживающих сопоставление подстрок, состоит в преобразовании вашего массива в строку, разделенную запятыми, начинающуюся и заканчивающуюся запятой. Если ваш столбец соответствует запятой, добавленной до и после (с использованием оператора || ), это будет уникальное совпадение.
Обычный вариант использования — наличие раскрывающегося списка, позволяющего пользователю фильтровать пользователей по статусу. Однако, если вы хотите отобразить все статусы, когда статус не выбран, вам нужно будет использовать следующий шаблон для достижения своей цели.
выбрать
*
от
пользователи
где
( {{ !select1.value }} ИЛИ users.status = {{ select1. value }} )
value }} )
выбрать
*
от
пользователи
где
( {{!select1.value ? 1 : 0}} = 1 ИЛИ users.status = {{ select1.value }} )
При написании запросов со сложной или специальной условной логикой следует помнить о трех подходах.
Избегайте написания избыточной логики внутри предложения WHERE и комбинируйте условия, чтобы сделать запросы более быстрыми и понятными.
выбрать элемент, категория от еда где (категория = «Фрукты») И (элемент = «Апельсин» ИЛИ элемент = «Яблоко»)
Этот пункт WHERE содержит избыточное условие AND , поскольку и Orange , и Apple уже являются частью категории Fruit . Удаление ненужных условий ускоряет запросы и снижает сложность.
Используйте скобки () для организации условий.