Диапазоны типов данных | Microsoft Learn
Twitter LinkedIn Facebook Адрес электронной почты
- Статья
- Чтение занимает 2 мин
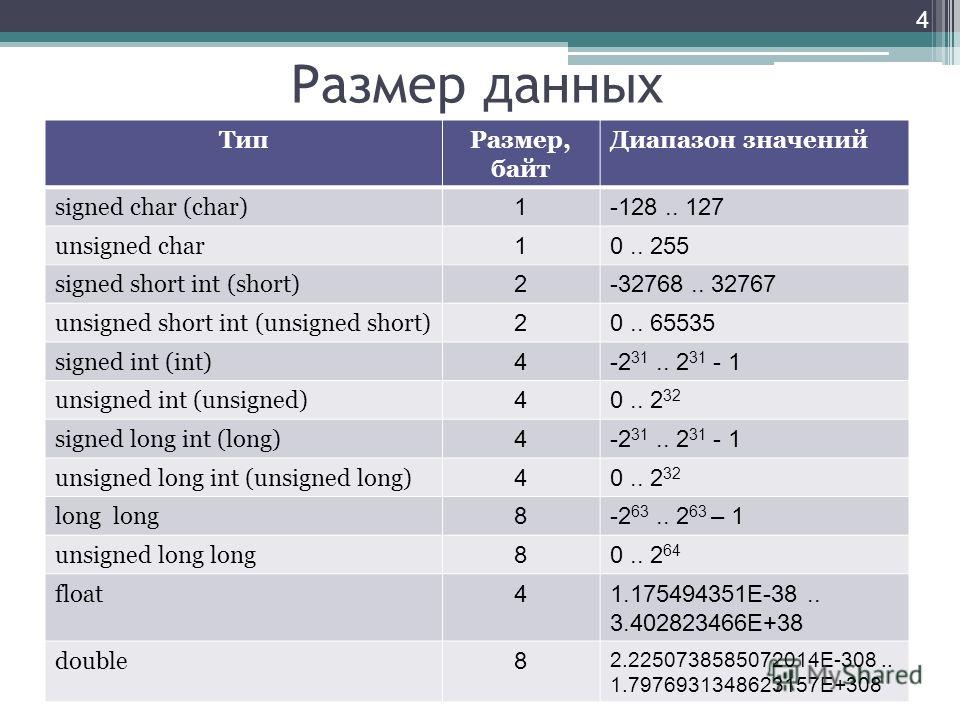
32-разрядные и 64-разрядные компиляторы Microsoft C++ распознают типы в таблице далее в этой статье.
int(unsigned int)__int8(unsigned __int8)__int16(unsigned __int16)__int32(unsigned __int32)__int64(unsigned __int64)short(unsigned short)long(unsigned long)long long(unsigned long long)
Если имя начинается с двух символов подчеркивания (__), тип данных является нестандартным.
Диапазоны, представленные в следующей таблице, включают указанные значения.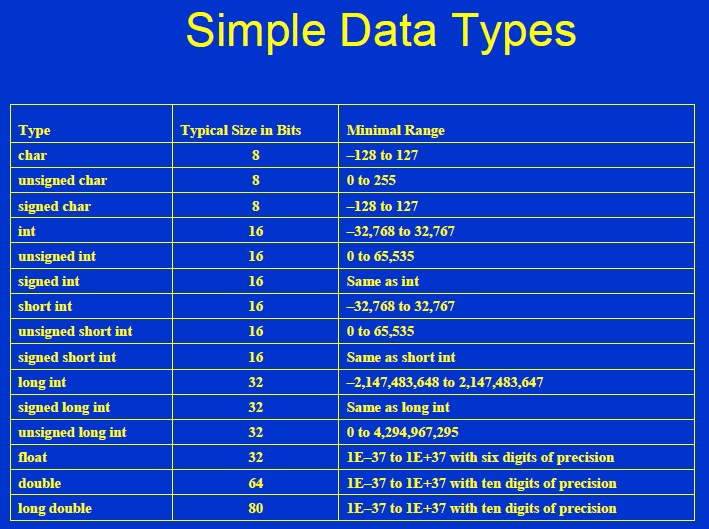
| Имя типа | Байты | Другие имена | Диапазон значений |
|---|---|---|---|
int | 4 | signed | От -2 147 483 648 до 2 147 483 647 |
unsigned int | 4 | unsigned | От 0 до 4 294 967 295 |
__int8 | 1 | char | От -128 до 127 |
unsigned __int8 | 1 | unsigned char | |
__int16 | 2 | short, short int, signed short int | От -32 768 до 32 767 |
unsigned __int16 | 2 | unsigned short, unsigned short int | От 0 до 65 535 |
__int32 | 4 | signed, signed int, int | От -2 147 483 648 до 2 147 483 647 |
unsigned __int32 | 4 | unsigned, unsigned int | От 0 до 4 294 967 295 |
__int64 | 8 | long long, signed long long | От -9 223 372 036 854 775 808 до 9 223 372 036 854 775 807 |
unsigned __int64 | 8 | unsigned long long | От 0 до 18 446 744 073 709 551 615 |
bool | 1 | нет | false или true |
char | 1 | нет | От -128 до 127 по умолчанию От 0 до 255 при компиляции с помощью |
signed char | 1 | нет | От -128 до 127 |
unsigned char | 1 | нет | От 0 до 255 |
short | 2 | short int, signed short int | От -32 768 до 32 767 |
unsigned short | 2 | unsigned short int | От 0 до 65 535 |
long | 4 | long int, signed long int | От -2 147 483 648 до 2 147 483 647 |
unsigned long | 4 | unsigned long int | От 0 до 4 294 967 295 |
long long | 8 | нет (но эквивалентно __int64) | От -9 223 372 036 854 775 808 до 9 223 372 036 854 775 807 |
unsigned long long | 8 | нет (но эквивалентно unsigned __int64) | От 0 до 18 446 744 073 709 551 615 |
enum | непостоянно | нет | |
float | 4 | нет | 3,4E +/- 38 (7 знаков) |
double | 8 | нет | 1,7E +/- 308 (15 знаков) |
long double | то же, что и double | нет | То же, что double |
wchar_t | 2 | __wchar_t | От 0 до 65 535 |
В зависимости от характера использования переменная типа __wchar_t обозначает расширенный символьный или многобайтовый символьный тип. Чтобы указать константу расширенного символьного типа, перед символьной или строковой константой следует использовать префикс
Чтобы указать константу расширенного символьного типа, перед символьной или строковой константой следует использовать префикс
signed и unsigned — это модификаторы, которые можно использовать с любым целочисленным типом, кроме типа bool. Обратите внимание, что char, signed charи unsigned char — это три разных типа, предназначенных для механизмов, подобных перегрузке и шаблонам.
Размер типов int и unsigned int — 4 байта. Однако переносимый код не должен зависеть от размера int , поскольку языковой стандарт позволяет варьировать его в зависимости от реализации.
C и C++ в Visual Studio также поддерживают целочисленные типы с указанием размера. Дополнительные сведения см. в разделах __int8, __int16, __int32, __int64 и Integer Limits.
Дополнительные сведения об ограничениях размеров каждого типа см. в разделе Встроенные типы.
Диапазон перечисляемых типов зависит от контекста языка и указанных флажков компилятора. Дополнительные сведения см. в статьях Объявления перечислений C и Объявления перечислений C++.
Ключевые слова
Встроенные типы
Типы данных — Основы С++
C++ — язык со статической типизацией. У каждой переменной на этапе компиляции должен быть чётко определённый тип данных. Про каждый тип данных заранее известно, сколько места в памяти занимает переменная такого типа.
В этой главе мы познакомимся с некоторыми базовыми типами данных и с понятием области видимости переменных.
Области видимости
В С++ существует понятие области видимости (scope) переменной. Эта область ограничивается блоком кода, в котором переменная определена. Рассмотрим пример:
#include <iostream>
int a = 1; // глобальная переменная
int main() {
int b = 2; // локальная переменная
{
int c = 3; // локальная переменная внутри блока
std::cout << a << " " << b << " " << c << "\n"; // корректно
}
// Эта строчка не скомпилируется,
// так как переменная c не определена в данной области:
std::cout << c << "\n";
}
В этом примере есть три области:
- глобальная, в которой определена переменная
a; - тело функции
main, в которой определена переменнаяb; - внутренний блок, в котором определена переменная
c.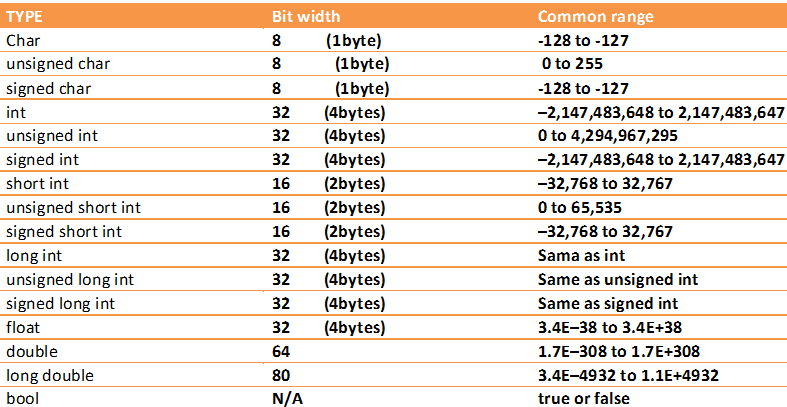
В последней строке примера переменная c недоступна, так как её область видимости уже закончилась. В случае коллизии имён компилятор всегда выбирает самую вложенную область видимости.
Рассмотрим пример:
#include <iostream>
int main() {
int x = 1;
std::cout << x << "\n"; // напечатает 1
{
int x = 2; // новая переменная, к предыдущему x не имеет отношения
std::cout << x << "\n"; // напечатает 2
}
std::cout << x << "\n"; // снова напечатает 1
}
Инициализация локальных переменных
Локальные переменные простых типов, таких как int, не инициализируются по умолчанию нулём. Компилятор просто выделяет для них байты в стековой памяти, но при этом он не обязан как-либо их заполнять. Это один из принципов C++: мы не должны платить за то, что не используем.
Следующий фрагмент кода может напечатать всё что угодно:
#include <iostream>
int main() {
int x;
std::cout << x << "\n"; // неопределённое поведение!
int y;
std::cin >> y; // а это допустимый сценарий
}
Компиляторы g++ и clang++ обычно дают предупреждения о чтении неинициализированных переменных при использовании опции -Wall или -Wuninitialized:
$ clang++ -Wall program.= 0 1 warning generated.
Заметим, что std::string является сложным типом и переменные такого типа всегда по умолчанию инициализируются пустой строкой. Поэтому нет необходимости писать std::string s = "";. Пишите просто std::string s;.
Простые типы данных
С типом int мы уже знакомы. Рассмотрим другие фундаментальные типы данных в С++. Это так называемые интегральные типы и типы для вещественных чисел.
int main() {
char c = '1'; // символ
bool b = true; // логическая переменная, принимает значения false и true
int i = 42; // целое число (занимает, как правило, 4 байта)
short int i = 17; // короткое целое (занимает 2 байта)
long li = 12321321312; // длинное целое (как правило, 8 байт)
long long lli = 12321321312; // длинное целое (как правило, 16 байт)
float f = 2.71828; // дробное число с плавающей запятой (4 байта)
double d = 3. 141592; // дробное число двойной точности (8 байт)
long double ld = 1e15; // длинное дробное (как правило, 16 байт)
}
141592; // дробное число двойной точности (8 байт)
long double ld = 1e15; // длинное дробное (как правило, 16 байт)
}
Обратите внимание, что символы, в отличие от строк (то есть массивов символов), записываются в апострофах, а не в кавычках. В примере выше мы записываем в переменную c символ единицы. Фактически в памяти хранится ASCII-код этого символа, который равен 49.
Напомним, что каждый тип данных занимает заранее известное количество байтов памяти. Стандарт языка С++ не накладывает жёстких ограничений на размеры типов, они могут отличаться для разных платформ и компиляторов.
О том, что делать с этой особенностью, мы расскажем ниже. А пока отметим, что узнать размер переменной или типа на этапе компиляции можно с помощью оператора sizeof.
Например, на 64-битной Linux-системе компилятор clang++ использует такие размеры для типов:
int main() {
std::cout << "char: " << sizeof(char) << "\n"; // 1
std::cout << "bool: " << sizeof(bool) << "\n"; // 1
std::cout << "short int: " << sizeof(short int) << "\n"; // 2 (по стандарту >= 2)
std::cout << "int: " << sizeof(int) << "\n"; // 4 (по стандарту >= 2)
std::cout << "long int: " << sizeof(long int) << "\n"; // 8 (по стандарту >= 4)
std::cout << "long long int: " << sizeof(long long) << "\n"; // 8 (по стандарту >= 8)
std::cout << "float: " << sizeof(float) << "\n"; // 4
std::cout << "double: " << sizeof(double) << "\n"; // 8
std::cout << "long double: " << sizeof(long double) << "\n"; // 16
}
Размеры стандартных типов
По умолчанию числовые типы – знаковые. 32 — 1
}
32 — 1
}
Минимальное и максимальное значение, помещающееся в данный числовой тип, можно получить так:
#include <iostream>
#include <limits> // необходимо для numeric_limits
int main() {
// посчитаем для типа int:
std::cout << "minimum value: " << std::numeric_limits<int>::min() << "\n"
<< "maximum value: " << std::numeric_limits<int>::max() << "\n";
}
Данный пример на 64-битной Linux-системе напечатает:
minimum value: -2147483648 maximum value: 2147483647
Приведённые выше примеры вывода оператора sizeof верны для 64-битных архитектур, которые на сегодняшний день распространены повсеместно. Однако если бы мы скомпилировали и запустили такую программу на компьютере с 32-битной архитектурой, то получили бы другие результаты. Например, sizeof(long int) стал бы равен 4, в то время как на современных компьютерах мы получили бы 8. Также бывают встраиваемые системы, под которые тоже можно писать на С++.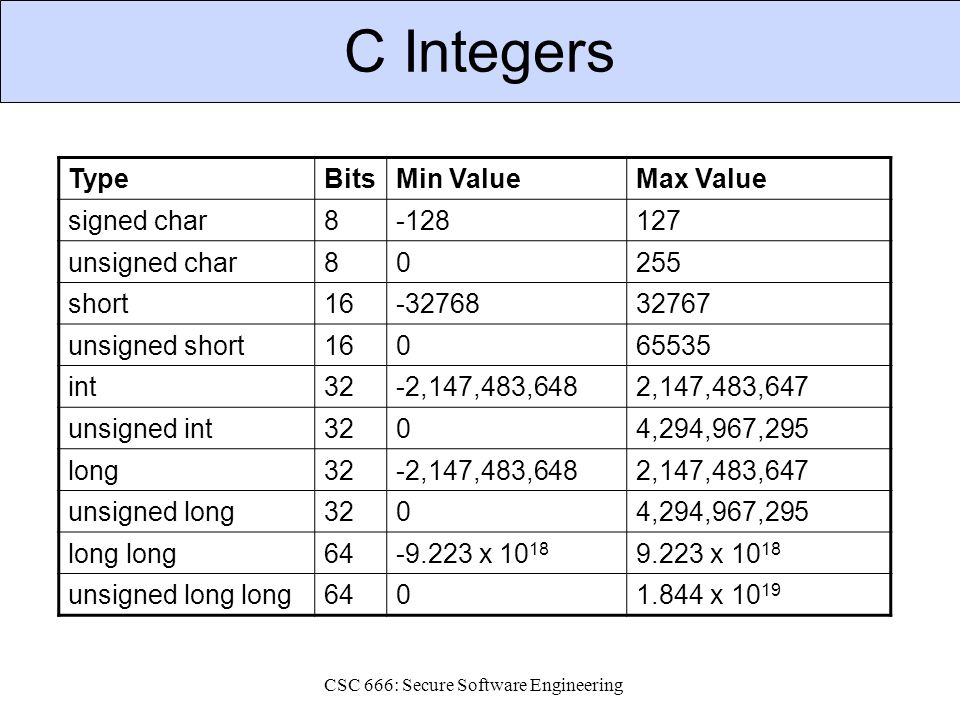 Там битность архитектуры может быть ещё меньше, чем 32.
Там битность архитектуры может быть ещё меньше, чем 32.
В заголовочном файле cstdint стандартной библиотеки имеются целочисленные типы с фиксированным размером:
int8_t/uint8_tint16_t/uint16_tint32_t/uint32_tint64_t/uint64_t
Число в имени типа означает количество бит, используемых для хранения в памяти. Например, int32_t содержит 32 бита (4 байта) и часто соответствует типу int. Если система не поддерживает какой-то тип, то программа с ним просто не скомпилируется.
Переполнение целочисленных типов
Стандартные числовые типы имеют ограниченный размер и ограниченное множество допустимых значений. При арифметических операциях над числами таких типов может возникнуть переполнение — ситуация, когда результат операции не помещается в тип:
#include <iostream>
int main() {
unsigned int a = 123456; // на 64-битной платформе sizeof(a) == 4
// Произведение a * a не помещается в 4 байта, так как оно больше 2^32
std::cout << a * a << "\n";
}
В этом примере выражение a * a будет иметь тот же тип, что и аргументы, поскольку результат не помещается в него целиком. То, что на самом деле будет вычислено, зависит от знаковости типа.
То, что на самом деле будет вычислено, зависит от знаковости типа.
Беззнаковые типы можно спокойно переполнять: вычисления будут производиться по модулю соответствующей степени двойки. Другими словами, будут учтены только младшие биты результата:
int main() {
unsigned int x = 0; // на 64-битной платформе sizeof(x) == 4
unsigned int y = x - 1; // 4294967295, то есть 2**32 - 1
unsigned int z = y + 1; // 0
}
Наоборот, для знаковых типов переполнение приводит к так называемому неопределённому поведению (UB, undefined behavior).
Такая ситуация не считается ошибкой компиляции (в самом деле, на стадии компиляции значения переменных могут быть ещё неизвестны). Но в этом случае стандарт С++ перестаёт что-либо гарантировать по поводу поведения программы. Компиляторы могут использовать такие случаи для оптимизации программ, полагаясь на то, что разработчики пишут код корректно и никогда не допускают неопределённого поведения. Далее нам встретятся и другие случаи неопределённого поведения.
Беззнаковые типы следует использовать, когда вы имеете дело с битовыми наборами. В остальных случаях предпочтительнее использовать знаковые типы.
Арифметические операции
Бинарные операции +, - и * работают для чисел стандартным образом. Результат операции деления /, применённой к целым числам, всегда округляется в сторону нуля. Таким образом, для положительных чисел операция / возвращает неполное частное. Остаток от деления целых чисел можно получить с помощью операции %.
int main() {
int a = 7, b = 3;
int q = a / b; // 2
int r = a % b; // 1
}
Если при делении нужно получить обычное частное, то один из аргументов нужно привести к вещественному типу (например, double) с помощью оператора static_cast:
int main() {
int a = 6, b = 4;
double q = static_cast<double>(a) / b; // 1.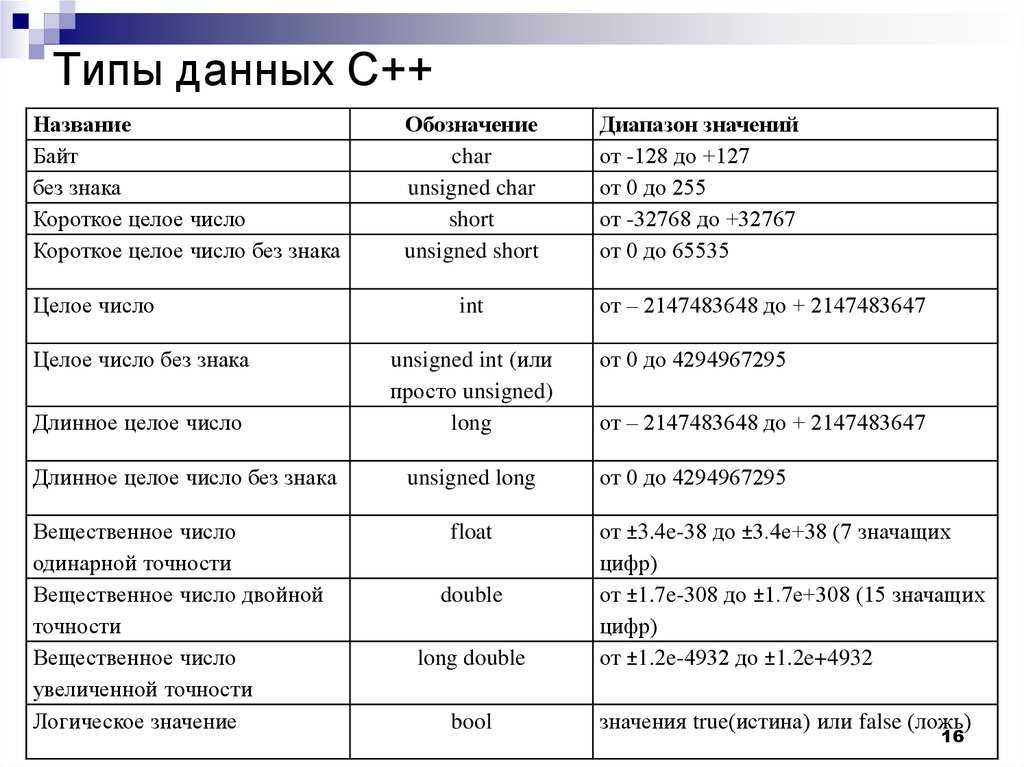 5
}
5
}
Можно было бы написать чуть более кратко: double q = a * 1.0 / b;. Тогда преобразование аргументов произошло бы неявно.
Арифметические операции над символами, а также сравнение символов друг с другом — это фактически операции над их ASCII-кодами:
#include <iostream>
int main() {
char c = 'A';
c += 25; // увеличиваем ASCII-код символа на 25
std::cout << c << "\n"; // Z
}
Таблица ASCII с шестнадцатеричными кодами символов. Слева указана старшая шестнадцатеричная цифра, справа — младшая. Цветом выделены так называемые управляющие символы, обычно не имеющие графического представления.Операция + применительно к строкам означает конкатенирование (то есть склейку). Это пример перегрузки операции: изначальному оператору сложения в стандартной библиотеке для строки придали новый смысл.
#include <string>
int main() {
std::string a = "Hello, ";
std::string b = " world!";
std::string c = a + b; // Hello, world!
}
Для каждой бинарной операции (например, +) есть версия со знаком равенства (+=) для случая, когда левый аргумент совпадает с переменной, которой присваивается результат:
int main() {
int x = 5;
x += 3; // x = x + 3
x *= x; // x = x * x
}
Наконец, имеются операторы ++ и -- для увеличения или уменьшения переменной на единицу.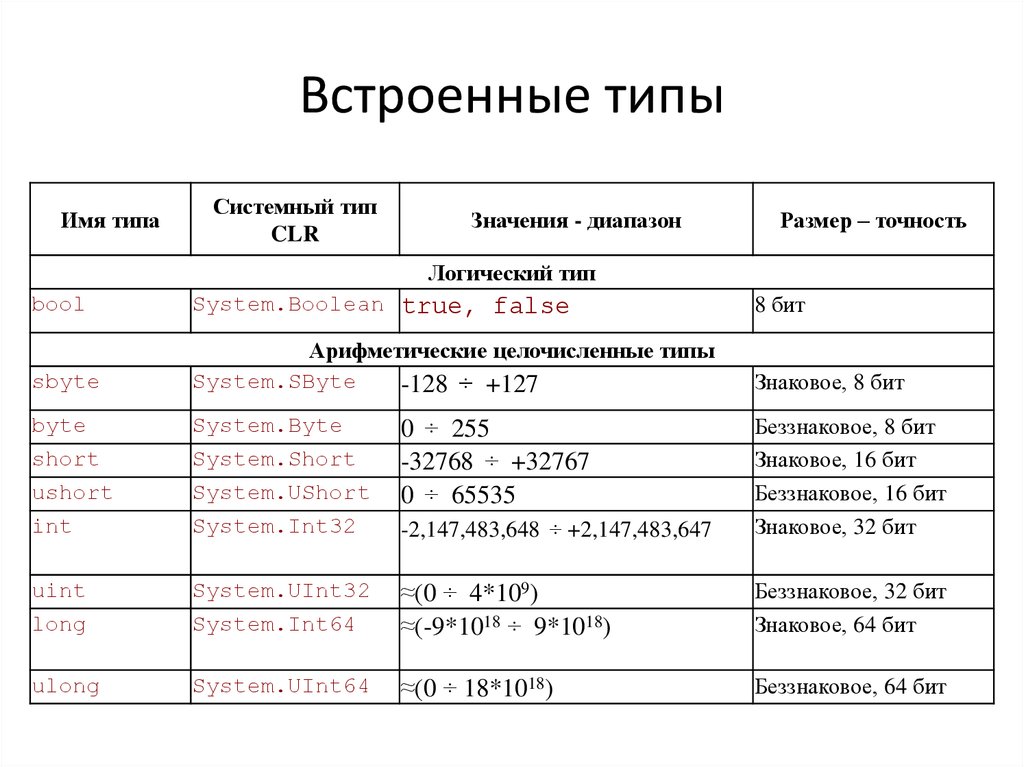 Они бывают префиксные и постфиксные. Отличие состоит в значении выражения, которое будет вычисляться при применении такого оператора. Мы рассмотрим это позже, а пока привыкнем по умолчанию использовать префиксный оператор для обычных чисел:
Они бывают префиксные и постфиксные. Отличие состоит в значении выражения, которое будет вычисляться при применении такого оператора. Мы рассмотрим это позже, а пока привыкнем по умолчанию использовать префиксный оператор для обычных чисел:
int main() {
int x = 5;
++x; // 6
--x; // снова 5
}
Числа с плавающей точкой
В языке C++ существуют три встроенных типа для записи дробных чисел: float (4 байта), double (8 байт) и long double (16 или 8 байт, в зависимости от платформы). В большинстве случаев рекомендуется использовать тип double. Тип float разумно использовать там, где обрабатываются огромные массивы чисел, и возникает необходимость экономить память.
Как правило, хранение дробных чисел в С++ основано на стандарте IEEE 754. Число представляется в виде двоичной дроби в экспоненциальной записи: отдельно хранятся бит знака, порядок и мантисса.
Такое представление выгодно отличается от чисел с фиксированной точкой, где хранится фиксированное количество разрядов. Оно позволяет, хотя и с разной степенью точности, представлять числа, отличающиеся на порядки.
Оно позволяет, хотя и с разной степенью точности, представлять числа, отличающиеся на порядки.
При работе с рациональными числами, знаменатель которых не является степенью двойки, неизбежно возникают погрешности представления. В следующей главе мы разберём как следует сравнивать такие числа.
Автоматический вывод типа
Компилятор C++ умеет автоматически выводить тип переменной по значению, которое ей присваивается. Для этого вместо типа надо написать ключевое слово auto:
int main() {
auto x = 42; // int
auto pi = 3.14159; // double
}
Ключевое слово auto позволяет сократить код и не выписывать сложные типы (нам встретятся дальше монстры вроде std::unordered_multimap<Key, Value>::const_iterator). Важно подчеркнуть, что точный тип переменной всё равно становится известен в момент компиляции.
При использовании auto со строками нужно быть осторожным. Важно знать, что конструкция auto s = "hello" выведет низкоуровневый тип const char * (указатель на неизменяемый набор символов в памяти), а не тип-обёртку std::string.
Точные правила вывода типов похожи на правила вывода шаблонных параметров, с которыми мы познакомимся в главе про шаблоны.
диапазонов типов данных | Microsoft Узнайте
Редактировать
Твиттер LinkedIn Фейсбук Электронная почта
- Статья
- 2 минуты на чтение
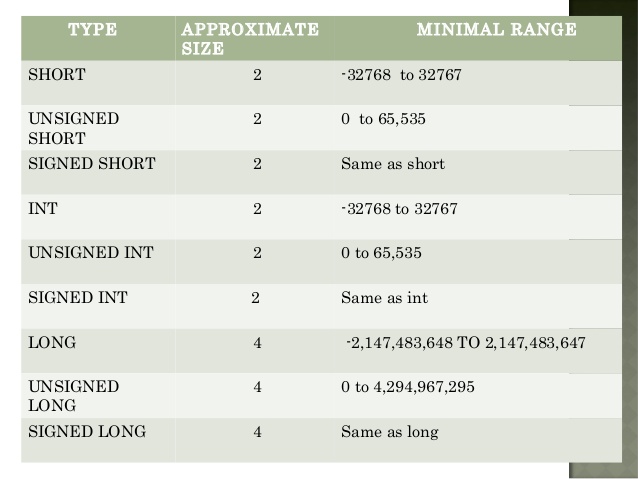
32-разрядные и 64-разрядные компиляторы Microsoft C++ распознают типы, указанные в таблице далее в этой статье.
целое число(целое число без знака)__int8(без знака __int8)__int16(без знака __int16)__int32(без знака __int32)__int64(без знака __int64)короткий(короткий без знака)длинный(длинный без знака)длинный длинный(беззнаковый длинный длинный)
Если его имя начинается с двух знаков подчеркивания ( __ ), тип данных нестандартен.
Диапазоны, указанные в следующей таблице, включают включительно.
| Название типа | байт | Другие названия | Диапазон значений |
|---|---|---|---|
внутр. | 4 | подписанный | -2 147 483 648 до 2 147 483 647 |
целое число без знака | 4 | без знака | от 0 до 4 294 967 295 |
__int8 | 1 | символ | от -128 до 127 |
без знака __int8 | 1 | беззнаковый символ | от 0 до 255 |
__int16 | 2 | короткий , короткий целый , подписанный короткий целый | от -32 768 до 32 767 |
без знака __int16 | 2 | беззнаковое короткое , беззнаковое короткое целое | от 0 до 65 535 |
__int32 | 4 | подписанный , подписанный внутр. , внутр. | -2 147 483 648 до 2 147 483 647 |
без знака __int32 | 4 | без знака , целое число без знака | от 0 до 4 294 967 295 |
__int64 | 8 | длинный длинный , подписанный длинный длинный | -9 223 372 036 854 775 808 до 9 223 372 036 854 775 807 |
без знака __int64 | 8 | без знака длинный длинный | от 0 до 18 446 744 073 709 551 615 |
логический | 1 | нет | ложь или правда |
символ | 1 | нет | от -128 до 127 по умолчанию от 0 до 255 при компиляции с использованием |
знаковый символ | 1 | нет | от -128 до 127 |
беззнаковый символ | 1 | нет | от 0 до 255 |
короткий | 2 | короткое целое , подписанное короткое целое | от -32 768 до 32 767 |
короткий без знака | 2 | короткое целое без знака | от 0 до 65 535 |
длинный | 4 | длинное целое , подписанное длинное целое | -2 147 483 648 до 2 147 483 647 |
длинный без знака | 4 | длинное целое без знака | от 0 до 4 294 967 295 |
длинный длинный | 8 | нет (но эквивалентно __int64 ) | -9 223 372 036 854 775 808 до 9 223 372 036 854 775 807 |
без знака длинный длинный | 8 | нет (но эквивалентно unsigned __int64 ) | от 0 до 18 446 744 073 709 551 615 |
перечисление | варьируется | нет | |
поплавок | 4 | нет | 3. 4E +/- 38 (7 цифр) 4E +/- 38 (7 цифр) |
двойной | 8 | нет | 1.7E +/- 308 (15 цифр) |
длинный двойной | аналогично двойной | нет | То же, что и двойной |
wchar_t | 2 | __wchar_t | от 0 до 65 535 |
В зависимости от того, как она используется, переменная __wchar_t обозначает либо широкосимвольный, либо многобайтовый тип символов. Используйте префикс L перед символьной или строковой константой для обозначения широкосимвольной константы.
signed и unsigned — это модификаторы, которые можно использовать с любым целочисленным типом, кроме bool .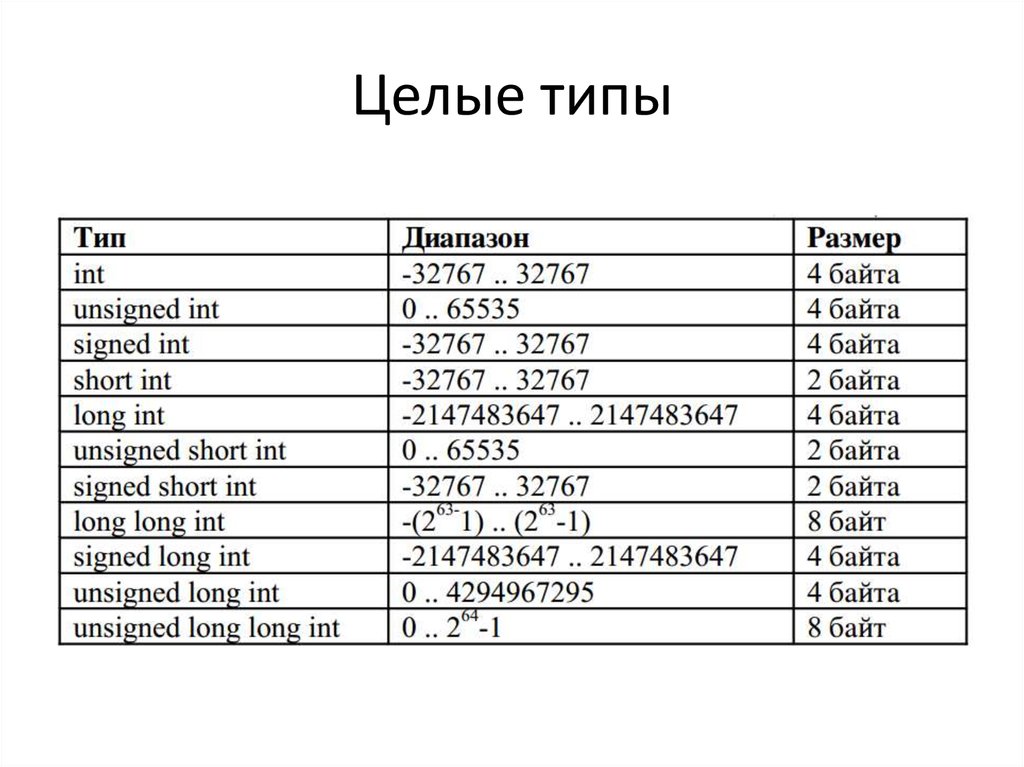 Обратите внимание, что
Обратите внимание, что char , signed char и unsigned char являются тремя различными типами для таких механизмов, как перегрузка и шаблоны.
Типы int и unsigned int имеют размер четыре байта. Однако переносимый код не должен зависеть от размера int , потому что стандарт языка допускает, что это зависит от реализации.
C/C++ в Visual Studio также поддерживает целочисленные типы с размером. Дополнительные сведения см. в разделе __int8, __int16, __int32, __int64 и целочисленные ограничения.
Дополнительные сведения об ограничениях размеров каждого типа см. в разделе Встроенные типы.
Диапазон перечисляемых типов зависит от контекста языка и указанных флагов компилятора. Дополнительные сведения см. в разделе Объявления и перечисления C.
См.
 также
также Ключевые слова
Встраиваемые модели
Обратная связь
Просмотреть все отзывы о странице
Беззнаковые целые типы | Документация Kotlin
Помимо целочисленных типов, Kotlin предоставляет следующие типы для целых чисел без знака:
- 964 — 1
Типы без знака поддерживают большинство операций своих аналогов со знаком.
Числа без знака реализованы как встроенные классы с единственным свойством хранения соответствующего типа аналога со знаком той же ширины. Тем не менее, изменение типа с беззнакового на подписанный аналог (и наоборот) является бинарным изменением , несовместимым с .
Беззнаковые массивы и операции над ними находятся в стадии бета-тестирования. Они могут быть изменены несовместимо в любое время. Требуется согласие (подробности см. ниже).
Same as for primitives, each of unsigned type has corresponding type that represents arrays of that type:
UByteArray: an array of unsigned bytesUShortArray: an array of unsigned shortsUIntArray: массив целых чисел без знакаULongArray: массив длинных чисел без знака0024 Массив класса без накладных расходов.
При использовании массивов без знака вы получите предупреждение о том, что эта функция еще не стабильна. Чтобы удалить предупреждение, включите аннотацию
@ExperimentalUnsignedTypes. Вам решать, должны ли ваши клиенты явно соглашаться на использование вашего API, но имейте в виду, что неподписанные массивы не являются стабильной функцией, поэтому API, который их использует, может быть нарушен из-за изменений в языке. Узнайте больше о требованиях для подписки.Диапазоны и последовательности поддерживаются для
UIntиULongклассамиUIntRange,UIntProgression,ULongRangeиULongProgression. Вместе с целочисленными типами без знака эти классы стабильны.Чтобы упростить использование целых чисел без знака, Kotlin предоставляет возможность пометить целочисленный литерал суффиксом, указывающим на определенный беззнаковый тип (аналогично
FloatилиLong): 9Тег 0003uиUпредназначен для беззнаковых литералов. Точный тип определяется на основе ожидаемого типа. Если ожидаемый тип не указан, компилятор будет использовать
Точный тип определяется на основе ожидаемого типа. Если ожидаемый тип не указан, компилятор будет использовать UIntилиULongв зависимости от размера литерала:val b: UByte = 1u // UByte, указан ожидаемый тип val s: UShort = 1u // UShort, указан ожидаемый тип val l: ULong = 1u // ULong, указан ожидаемый тип val a1 = 42u // UInt: ожидаемый тип не указан, константа вписывается в UInt val a2 = 0xFFFF_FFFF_FFFFu // ULong: ожидаемый тип не указан, константа не помещается в UInt
uLиULявно помечают литерал как unsigned long:val a = 1UL // ULong, несмотря на то, что ожидаемый тип не указан и константа подходит для UInt В случае беззнаковых чисел используется полный битовый диапазон целого числа для представления положительных значений.
Например, для представления шестнадцатеричных констант, которые не подходят для типов со знаком, таких как цвет, в 32-битном форматеAARRGGBB:класс данных Color (представление val: UInt) val yellow = Color(0xFFCC00CCu)
Вы можете использовать числа без знака для инициализации массивов байтов без явного указания
toByte()литеральные приведения:val byteOrderMarkUtf8 = ubyteArrayOf(0xEFu, 0xBBu, 0xBFu) API.