Какие бывают типы | C#
В этом уроке мы рассмотрим систему типов в C# с высоты птичьего полета, не погружаясь в детали. Но сначала ответим на вопрос, зачем вообще про них знать? В коде программ мы все время оперируем данными. Эти данные имеют разную природу, могут быть по разному организованы, что влияет и на удобство работы с ними и эффективность этой работы. Типы преследуют нас буквально на каждом шагу, поэтому без их изучения программирование на C# возможно только на очень базовом уровне.
С другой стороны не пытайтесь запомнить всю эту информацию про типы наизусть (иначе можно приуныть). Она дается лишь для общего представления. Все что надо знать про типы вы и так выучите в процессе программирования.
Глобально, типы данных в C# можно разделить на две большие группы: встроенные и пользовательские.
Встроенные типы данных – типы которые определены в самом языке. Некоторыми встроенными типами мы уже пользовались: int, float и string.
Всего в языке 18 встроенных типов данных. Полный список вы сможете найти в документации к языку. Тут же мы проведем краткий обзор.
10 из 18 типов используются для представления целых чисел. Это типы byte, sbyte, short, ushort, int, uint, nint, nuint, long, ulong. Отличаются они прежде всего количеством занимаемой памяти и, как следствие, диапазоном возможных значений. Например byte занимает в памяти, как ни трудно догадаться, один байт, а значит может хранить числа от 0 до 255 (здесь мы не погружаемся в основы двоичной системы счисления, просто поверьте на слово). short и ushort – 2 байта, int и uint – 4 байта и long и ulong – 8 байт. nint и nuint
могут иметь как 4 так и 8 байт в зависимости от разрядности системы.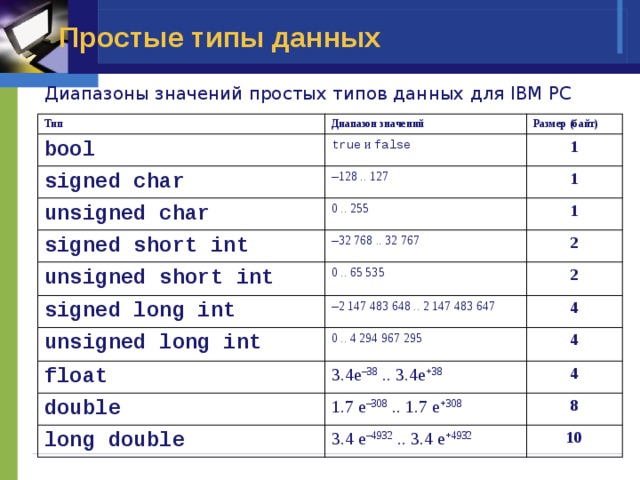 Приставка u означает что это беззнаковый (unsigned) тип – он может хранить только целые числа без знака.
Приставка u означает что это беззнаковый (unsigned) тип – он может хранить только целые числа без знака.byte x = 3; // Отработает без проблем // error CS0031: Constant value '270' cannot be converted to a 'byte' byte y = 270;
Определение переменной y завершилось с ошибкой, потому что мы указали тип byte, но присвоили переменной значение 270, которое выходит за множество возможных значений.
Возникает закономерный вопрос. Зачем аж 10 типов для хранения чисел? Почему бы не сделать один, в который влезает почти любое большое число? Технически так сделать можно, но мы находимся в мире инженерных решений. Это значит, что у любого решения всегда есть обратная сторона, поэтому невозможно сделать идеально, придется чем-то пожертвовать. В данном случае, объемом занимаемой памяти. Если оставить только 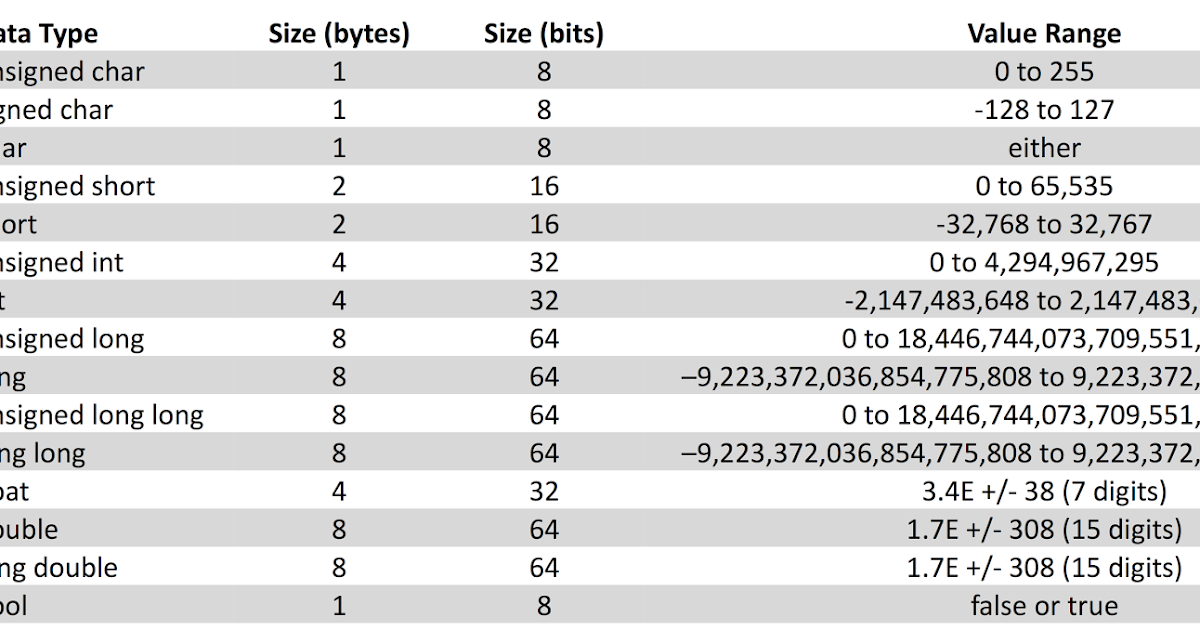
Такая же логика использовалась для типов float и double. Они оба отвечают за рациональные числа, разница лишь в том, что double это «двойной» float, то есть в памяти он занимает в два раза больше места.
Создатели C# полагаются на разумность программистов. На их способность правильно подобрать нужные типы в зависимости от задачи. Для каких-то экстремальных приложений так и происходит, но в типичной разработке все просто. Программисты выбирают int для целых чисел и double для рациональных.
Тип boolean отвечает за логические значения true
false. Впереди им посвящен целый раздел, там мы про него и поговорим.Все числовые типы являются значимыми. Это значит, что при передаче они копируются целиком, и что в них нельзя записать значение null. В следующем уроке мы поговорим про это.
Строка сама по себе тоже является базовым типом. В отличие от предыдущих базовых типов, строка является ссылочным типом. Это означает что при передаче она передает лишь ссылку на себя, а не копируется целиком.
Это означает что при передаче она передает лишь ссылку на себя, а не копируется целиком.
Особняком стоит тип char (символ). Символ это не строка, у него другой способ определения, через одиночные кавычки:
char ch = 'a'; // error CS0029: Cannot implicitly convert type 'string' to 'char' char ch3 = "b";
Строка состоящая из одного символа это не символ. С точки зрения здравого смысла кажется не логично, но, с точки зрения типов, все так и должно быть, со временем вы это прочувствуете.
Извлечение символа из строки извлекает как раз символ, а не строку состоящую из одного символа.
// операция [] извлекает из строки символ с нужным номером. Нумерация начинается с 0 "hexlet"[1]; // 'e'
object – это базовый тип для всех остальных типов. Дальше в уроках про объектно-ориентированное программирование мы разберем что это значит.
dynamic – это очень особенный тип в языке C#. Он даже является скорее «анти-типом», так как позволяет писать в себя любые данные без проверки компилятором. Изучение dynamic выходит за рамки этого курса, но и в реальном коде его использование можно увидеть не часто. Если интересно, можете почитать статью.
Изучение dynamic выходит за рамки этого курса, но и в реальном коде его использование можно увидеть не часто. Если интересно, можете почитать статью.
Задание
Выведите на экран результат конкатенации слова hexlet
, символа ‘—‘ и числа 7Упражнение не проходит проверку — что делать? 😶Если вы зашли в тупик, то самое время задать вопрос в «Обсуждениях». Как правильно задать вопрос:
- Обязательно приложите вывод тестов, без него практически невозможно понять что не так, даже если вы покажете свой код. Программисты плохо исполняют код в голове, но по полученной ошибке почти всегда понятно, куда смотреть.
Тесты устроены таким образом, что они проверяют решение разными способами и на разных данных. Часто решение работает с одними входными данными, но не работает с другими. Чтобы разобраться с этим моментом, изучите вкладку «Тесты» и внимательно посмотрите на вывод ошибок, в котором есть подсказки.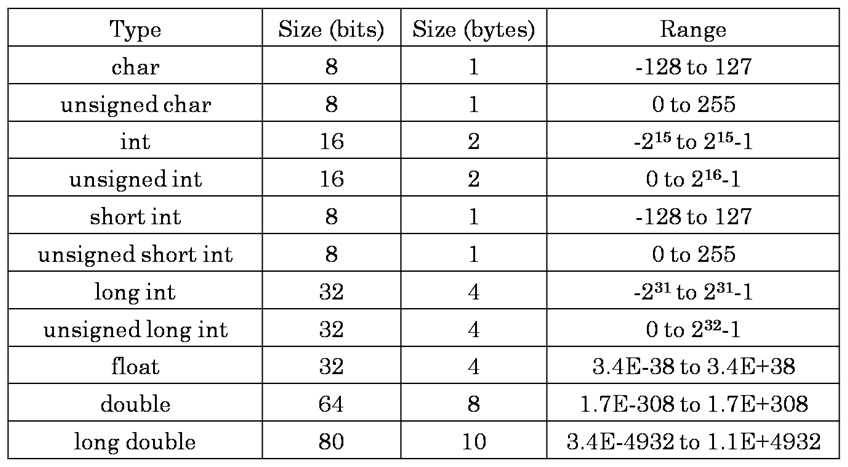
Это нормально 🙆, в программировании одну задачу можно выполнить множеством способов. Если ваш код прошел проверку, то он соответствует условиям задачи.
В редких случаях бывает, что решение подогнано под тесты, но это видно сразу.
Прочитал урок — ничего не понятно 🙄Создавать обучающие материалы, понятные для всех без исключения, довольно сложно. Мы очень стараемся, но всегда есть что улучшать. Если вы встретили материал, который вам непонятен, опишите проблему в «Обсуждениях». Идеально, если вы сформулируете непонятные моменты в виде вопросов. Обычно нам нужно несколько дней для внесения правок.
Кстати, вы тоже можете участвовать в улучшении курсов: внизу есть ссылка на исходный код уроков, который можно править прямо из браузера.
Определения
Тип данных — множество данных в коде (разновидность информации). Тип определяет, что можно делать с элементами конкретного множества. Например, целые числа, рациональные числа, строки — это разные типы данных.
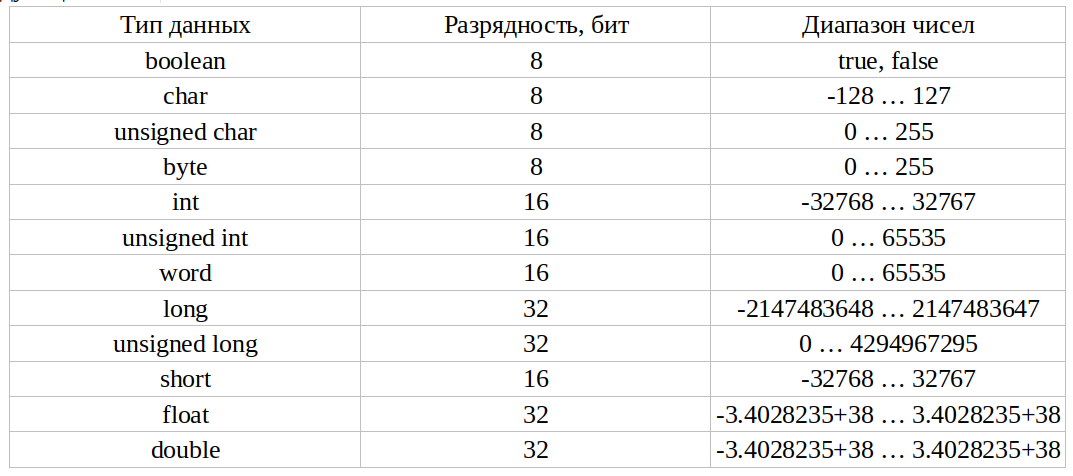
Встроенные типы данных — простые типы, встроенные в сам язык программирования.
←Предыдущий
Следующий→
Нашли ошибку? Есть что добавить? Пулреквесты приветствуются https://github.com/hexlet-basics
C++ — Типы данных
При написании программы на любом языке вам нужно использовать различные переменные для хранения различной информации. Переменные — это не что иное, как зарезервированные ячейки памяти для хранения значений. Это означает, что при создании переменной вы сохраняете некоторое пространство в памяти.
Вы можете хранить информацию различных типов данных, таких как символ, широкий символ, целое число, плавающая точка, двойная плавающая точка, логическое значение и т. Д. На основе типа данных переменной операционная система выделяет память и решает, что можно сохранить в зарезервированная память.
Примитивные встроенные типы
C ++ предлагает программисту богатый набор встроенных, а также пользовательских типов данных.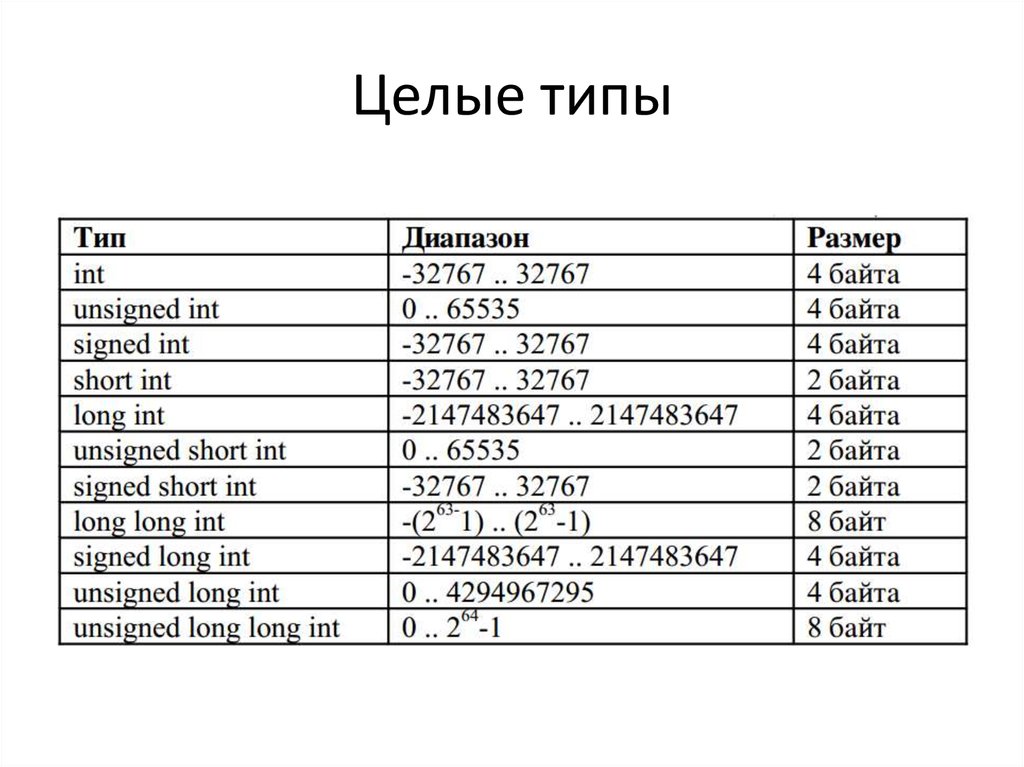 В следующих таблицах перечислены семь основных типов данных C ++:
В следующих таблицах перечислены семь основных типов данных C ++:
| Type | Keyword |
|---|---|
| Boolean | bool |
| Character | char |
| Integer | int |
| Floating point | float |
| Double floating point | double |
| Valueless | void |
| Wide character | wchar_t |
Некоторые из основных типов могут быть изменены с использованием одного или нескольких модификаторов этого типа:
- signed
- unsigned
- short
- long
В следующей таблице показан тип переменной, объем памяти, который требуется для хранения значения в памяти, и то, что является максимальным и минимальным значением, которое может быть сохранено в таких переменных.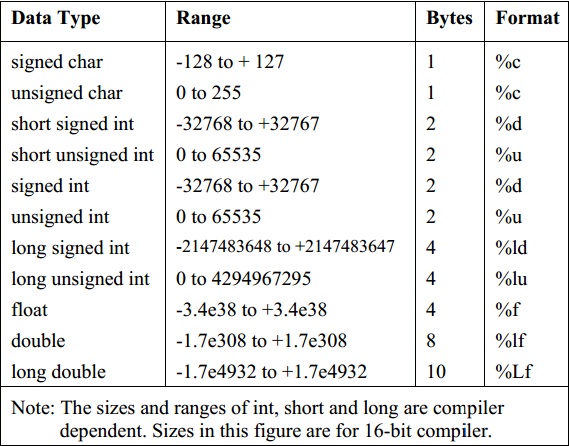
| Type | Typical Bit Width | Typical Range |
|---|---|---|
| char | 1byte | -127 to 127 or 0 to 255 |
| unsigned char | 1byte | 0 to 255 |
| signed char | 1byte | -127 to 127 |
| int | 4bytes | -2147483648 to 2147483647 |
| unsigned int | 4bytes | 0 to 4294967295 |
| signed int | 4bytes | -2147483648 to 2147483647 |
| short int | 2bytes | -32768 to 32767 |
| unsigned short int | Range | 0 to 65,535 |
| signed short int | Range | -32768 to 32767 |
| long int | 4bytes | -2,147,483,648 to 2,147,483,647 |
| signed long int | 4bytes | same as long int |
| unsigned long int | 4bytes | 0 to 4,294,967,295 |
| float | 4bytes | +/- 3.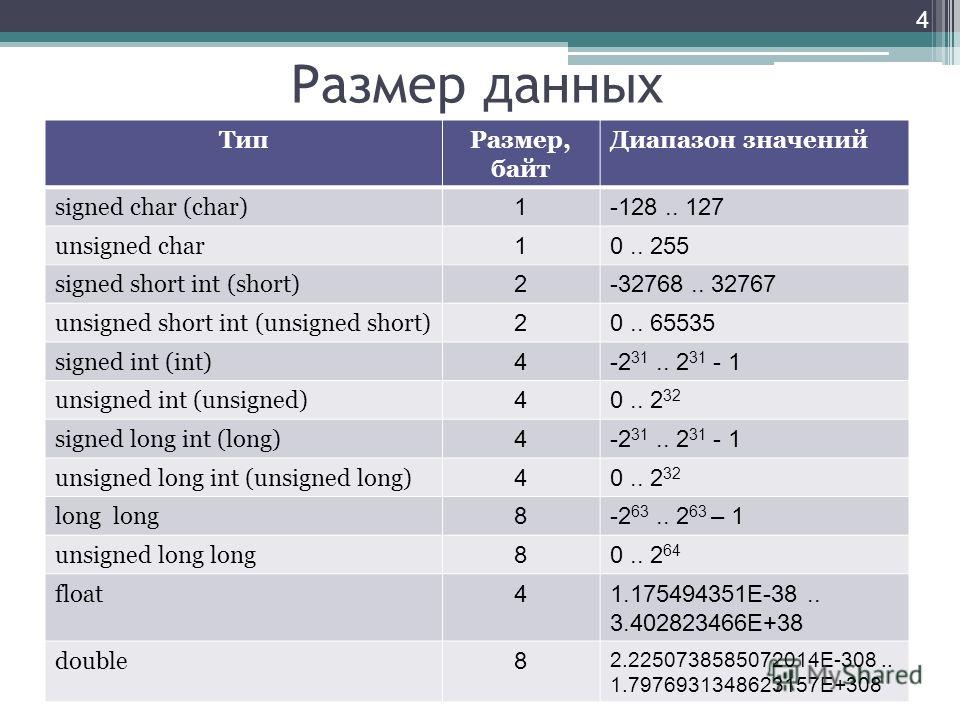 4e +/- 38 (~7 digits) 4e +/- 38 (~7 digits) |
| double | 8bytes | +/- 1.7e +/- 308 (~15 digits) |
| long double | 8bytes | +/- 1.7e +/- 308 (~15 digits) |
| wchar_t | 2 or 4 bytes | 1 wide character |
Размер переменных может отличаться от размера, указанного в приведенной выше таблице, в зависимости от компилятора и компьютера, который вы используете. Ниже приведен пример, который даст правильный размер различных типов данных на вашем компьютере.
#include <iostream>
using namespace std;
int main() {
cout << "Size of char : " << sizeof(char) << endl;
cout << "Size of int : " << sizeof(int) << endl;
cout << "Size of short int : " << sizeof(short int) << endl;
cout << "Size of long int : " << sizeof(long int) << endl;
cout << "Size of float : " << sizeof(float) << endl;
cout << "Size of double : " << sizeof(double) << endl;
cout << "Size of wchar_t : " << sizeof(wchar_t) << endl;
return 0;
}В этом примере используется endl , который вводит символ новой строки после каждой строки, а оператор << используется для передачи нескольких значений на экран. Мы также используем оператор sizeof () для получения размера различных типов данных.
Мы также используем оператор sizeof () для получения размера различных типов данных.
Когда приведенный выше код компилируется и выполняется, он производит следующий результат, который может варьироваться от машины к машине:
Size of char : 1
Size of int : 4
Size of short int : 2
Size of long int : 4
Size of float : 4
Size of double : 8
Size of wchar_t : 4Декларации typedef
Вы можете создать новое имя для существующего типа с помощью typedef. Ниже приведен простой синтаксис для определения нового типа с использованием typedef:
typedef type newname; Например, следующее говорит компилятору, что ногами является другое имя для int:
typedef int feet;Теперь следующая декларация совершенно легальна и создает целочисленную переменную, называемую расстоянием:
feet distance;Перечисленные типы
Перечислимый тип объявляет необязательное имя типа и набор из нуля или более идентификаторов, которые могут использоваться как значения типа. Каждый перечислитель является константой, тип которой является перечислением. Для создания перечисления требуется использование ключевого слова enum . Общий вид типа перечисления:
Каждый перечислитель является константой, тип которой является перечислением. Для создания перечисления требуется использование ключевого слова enum . Общий вид типа перечисления:
enum enum-name { list of names } var-list; Здесь enum-name — это имя типа перечисления. Список имен разделяется запятой. Например, следующий код определяет перечисление цветов, называемых цветами, и переменной c цвета типа. Наконец, c присваивается значение «blue».
enum color { red, green, blue } c;
c = blue;По умолчанию значение первого имени равно 0, второе имя имеет значение 1, а третье — значение 2 и т. Д. Но вы можете указать имя, определенное значение, добавив инициализатор. Например, в следующем перечислении зеленый будет иметь значение 5.
enum color { red, green = 5, blue };Здесь blue будет иметь значение 6, потому что каждое имя будет больше, чем предыдущее.
С++ — Как я могу использовать 6-байтовый целочисленный тип данных в C?
спросил
Изменено 2 года, 8 месяцев назад
Просмотрено 3к раз
Я хочу использовать 6-байтовый тип данных в c, но не могу найти, как это сделать.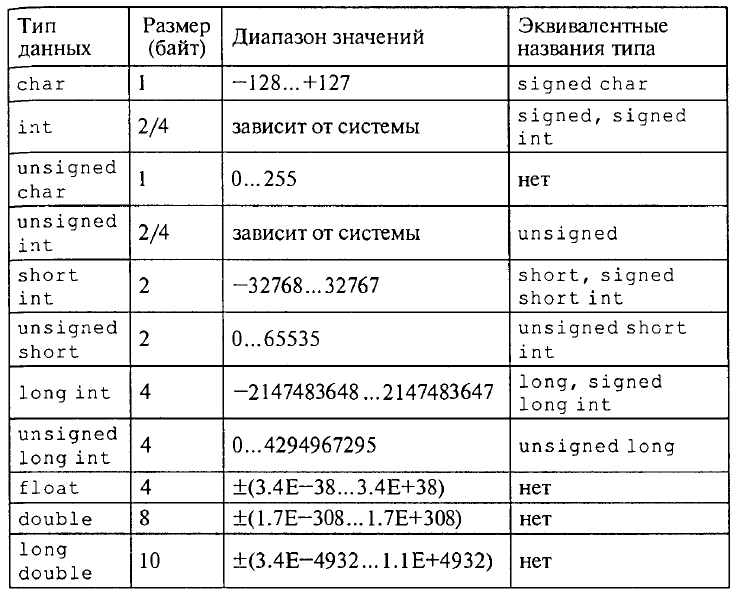 Можете ли вы научить меня, как использовать 6-байтовый целочисленный тип данных в c?
Можете ли вы научить меня, как использовать 6-байтовый целочисленный тип данных в c?
Я использую dev C++ и кодовые блоки.
Я хочу использовать C, но я также могу использовать C++. Windows 64-bit
- c++
- c
- типы
- целое число
- пользовательский тип данных
8
Есть способ получить точное количество битов для чего-то в C, так что теоретически это выполнимо, но это займет больше 48 бит в памяти.
Для этого вы можете использовать битовые поля из C, для этого вы можете:
структура your_type {
uint64_t ваше_значение: 48;
};
С помощью этого вы можете создать такую структуру и получить доступ к your_value, который будет иметь 48-битное представление. Под капотом он будет рассматриваться как uint64_t.
Говоря, что я настоятельно рекомендую прочитать Ansi C или любую другую книгу по основам C, чтобы лучше узнать основы.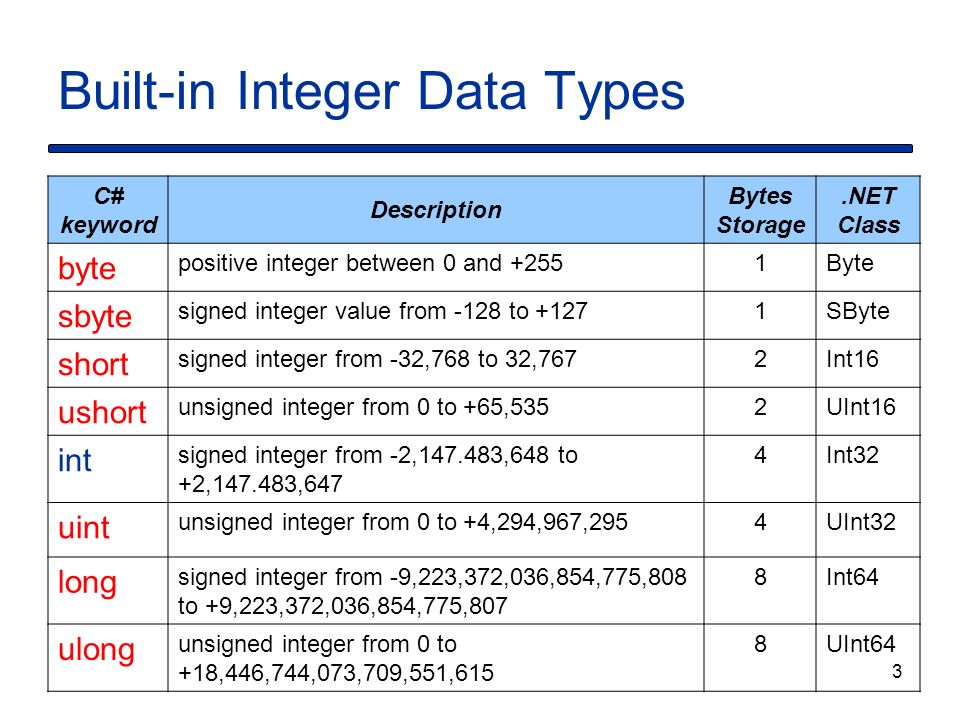
Имейте в виду, что создание парсеров с битовыми полями, как правило, плохая идея из-за проблем с заполнением, упаковкой и порядком байтов. Если вам нужен какой-либо протокол, обратите внимание на пакет сообщений или любую другую библиотеку протоколов.
1
Чтение стандарта C11 n1570 и стандарта C++11 n3337.
C и C++ — это
различных языков программированияСм. также этот справочный веб-сайт C и C++.
Прочтите также хорошие книги по программированию на C ( Modern C ) и хорошую книгу по программированию на C++ (и документацию вашего компилятора).
6-байтовые целые числа здесь не упоминаются.
(за исключением теоретически странных реализаций C или C++; я не могу назвать ни одной существующей в 2020 году)
Вы можете использовать битовые поля в структуре или (вместо этого) 64-битные числа std::int64_t ) в сочетании с побитовыми операциями (например, побитовые или 09 или 04 или
|
| не ~ или операции побитового сдвига << или >> ) Вы можете создавать процедуры сериализации, например. используйте SWIG. Остерегайтесь проблем с порядком байтов. Для простоты отладки вы можете предпочесть текстовые форматы, такие как JSON, вместо отправки двоичных пакетов.
используйте SWIG. Остерегайтесь проблем с порядком байтов. Для простоты отладки вы можете предпочесть текстовые форматы, такие как JSON, вместо отправки двоичных пакетов.
Типичным примером 48-битных чисел являются MAC-адреса кадра Ethernet. См. пример кода, упомянутый в вики OSDEV.
5
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя адрес электронной почты и пароль
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Размер типов данных в C
Типы данных — одна из важнейших функций языка программирования C. Мы используем типы данных с функциями и переменными для определения того, какие данные они обычно содержат. Эти данные могут быть символом или значением некоторого типа. Также могут быть различные наборы символов или наборы значений. Язык C предлагает очень широкий спектр всех типов данных, и каждый из них может содержать уникальный тип данных с некоторым заранее определенным диапазоном.
Мы используем типы данных с функциями и переменными для определения того, какие данные они обычно содержат. Эти данные могут быть символом или значением некоторого типа. Также могут быть различные наборы символов или наборы значений. Язык C предлагает очень широкий спектр всех типов данных, и каждый из них может содержать уникальный тип данных с некоторым заранее определенным диапазоном.
В этой статье мы более подробно рассмотрим размер типов данных в C в соответствии с программой GATE для CSE (Computer Science Engineering). Читайте дальше, чтобы узнать больше.
Содержание
- Типы типов данных в C
- Первичные типы данных
- Размер первичных типов данных
- Размер символа
- Размер короткого целого числа
- Размер длинного целого числа
- Что отличает диапазон для беззнаковых и знаковых типов?
- Дополнение 1S
- Дополнение 2S
- Типы данных с плавающей запятой
- Нормализованная форма
- Денормализованная форма
- Резюме
- Производные типы данных
- Практические проблемы с размером типов данных в C
- Часто задаваемые вопросы
Типы типов данных в C
Язык программирования C имеет два основных типа данных:
- Первичный
- Производный
Первичные типы данных
Первичные типы данных в основном являются стандартными типами данных, которые определяет язык C.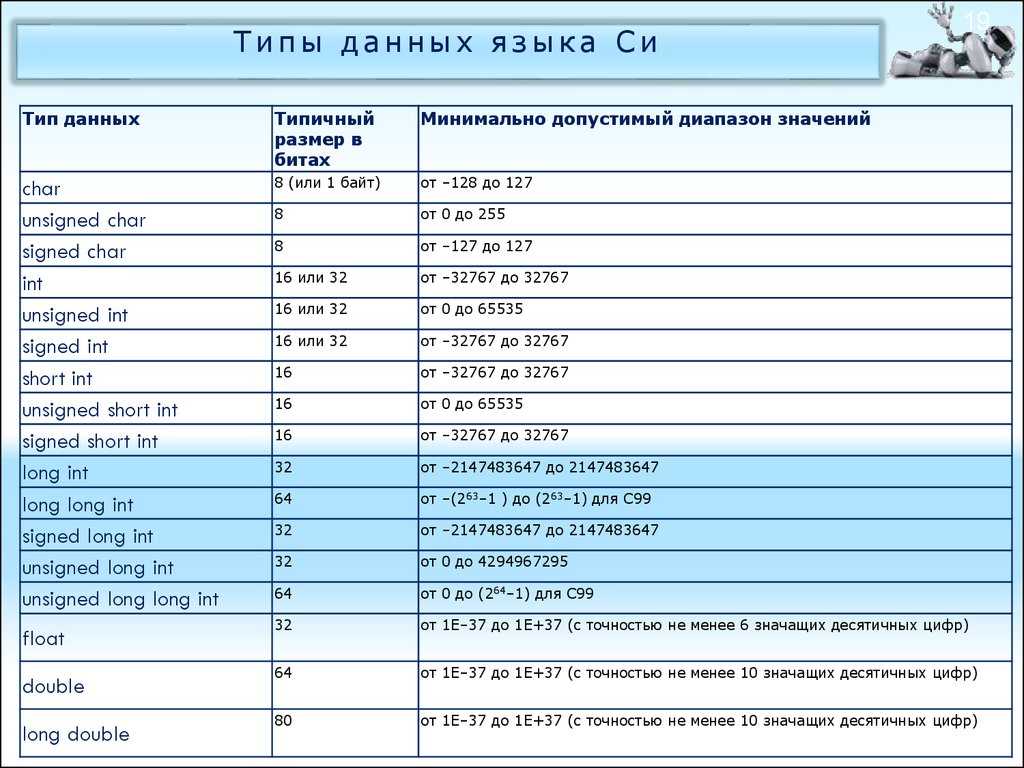 Язык определяет четыре основных типа данных в программировании. Это:
Язык определяет четыре основных типа данных в программировании. Это:
char – по своей природе являются однобайтовыми. Тип данных char может содержать один символ в локальном наборе символов.
float – это типы одинарной точности с плавающей запятой.
int – это целые числа. Обычно они отражают естественный размер целого числа на хост-компьютере.
double – это типы двойной точности с плавающей запятой.
Кроме того, к базовым типам данных можно применять различное количество квалификаторов. Длинные и короткие квалификаторы, примененные к целым числам, окажутся:
счетчик длинных чисел;
короткий инт ш;
*Обратите внимание, что мы можем опустить слово int в объявлениях такого типа.
Размер первичных типов данных
Вот список всех первичных типов данных:
| Тип | Ассортимент | Размер (в байтах) |
| беззнаковый символ | от 0 до 255 | 1 |
| знаковый символ или символ | от -128 до +127 | 1 |
| Целое число без знака | 0 до 65535 | 2 |
| знаковое целое число или целое число | -32 768 до +32767 | 2 |
| короткое целое без знака | 0 до 65535 | 2 |
| со знаком короткое целое или короткое целое | -32 768 до +32767 | 2 |
| длинное целое без знака | 0 до +4 294 967 295 | 4 |
| со знаком long int или long int | -2 147 483 648 до +2 147 483 647 | 4 |
| длинный двойной | 3.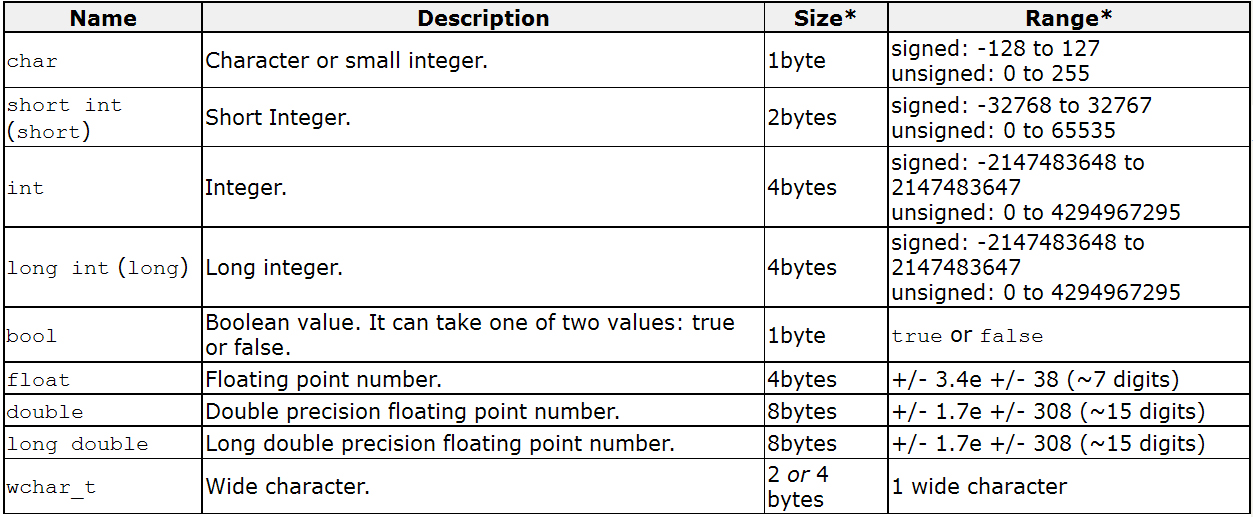 4E-4932 до 1.1E+4932 4E-4932 до 1.1E+4932 | 10 |
| двойной | 1.7E-308 до 1.7E+308 | 8 |
| поплавок | 3.4E-38 до 3.4E+38 | 4 |
Размер и диапазон типов данных во многом зависят от компилятора. Однако код, компилируемый компилятором, предназначен для некоторых конкретных типов микроконтроллеров или микропроцессоров. Один единственный компилятор может обеспечить поддержку нескольких целей или процессоров. Затем компилятор определяет размер доступных типов данных на основе выбранной цели. Проще говоря, размер любого типа данных напрямую зависит от компилятора вместе с целевым процессором (для которого генерация кода происходит с помощью компилятора).
В приведенной выше таблице предполагается 16-битный компилятор. Это означает, что генерация кода компилятора будет для 16-битного целевого процессора. Целое число, как правило, является естественным размером для любого процессора или машины. В таблице, упомянутой выше, целое число имеет ширину 16 бит или 2 байта. Таким образом, компилятор также имеет ширину 16 бит или 2 байта. Если бы компилятор был 32-битным, размер типа int был бы примерно 32-битным или 4 байта. Однако это может происходить не каждый раз. Также возможно, что размер целого числа составляет 32 бита или 4 байта для 64-битного процессора. Это полностью зависит от типа компилятора.
В таблице, упомянутой выше, целое число имеет ширину 16 бит или 2 байта. Таким образом, компилятор также имеет ширину 16 бит или 2 байта. Если бы компилятор был 32-битным, размер типа int был бы примерно 32-битным или 4 байта. Однако это может происходить не каждый раз. Также возможно, что размер целого числа составляет 32 бита или 4 байта для 64-битного процессора. Это полностью зависит от типа компилятора.
Давайте рассмотрим пример целочисленного типа данных:
внутр.темп.; // переменная «temp» способна хранить целочисленные значения
(как отрицательный, так и положительный)
темп = 50;
темп = -50;
подписанный временный интервал; // переменная «temp» способна хранить целочисленные значения
(как отрицательный, так и положительный)
темп = 987654;
темп = -987654;
беззнаковый интервал времени; // переменная «temp» способна хранить целочисленные значения
(только положительный)
темп = 87654;
темп = -8; // Данное присвоение неверно
Размер символа
Размер как беззнакового, так и подписанного char всегда равен 1 байту, независимо от того, какой компилятор мы используем. Здесь знаковый символ может содержать отрицательные значения. Таким образом, определенный диапазон здесь составляет от -128 до +127. Но беззнаковый символ может содержать только положительные значения. Таким образом, диапазон таких символов составляет от 0 до 255. Эти типы символьных данных могут хранить символы ASCII или числа, эквивалентные символам ASCII.
Здесь знаковый символ может содержать отрицательные значения. Таким образом, определенный диапазон здесь составляет от -128 до +127. Но беззнаковый символ может содержать только положительные значения. Таким образом, диапазон таких символов составляет от 0 до 255. Эти типы символьных данных могут хранить символы ASCII или числа, эквивалентные символам ASCII.
Размер короткого целого числа
В большинстве компиляторов размер как целых чисел без знака, так и целых чисел со знаком составляет около 2 байт.
Размер длинного целого числа
Размер длинных целых чисел без знака и со знаком зависит от типа используемого компилятора. Размер обычно составляет около 32 бит или 4 байта для 16/32-битного компилятора. Тем не менее, это зависит от того, какой компилятор мы используем.
Нет спецификации размеров типов данных в соответствии со стандартом C, кроме символьных. По определению C:
Каждый компилятор может выбрать подходящий размер для собственного оборудования. Он подвергается только одному ограничению: длинные должны быть не менее 32 бит, целые и короткие — не менее 16 бит, короткие не длиннее, чем целые, а целые не длиннее, чем длинные.
Он подвергается только одному ограничению: длинные должны быть не менее 32 бит, целые и короткие — не менее 16 бит, короткие не длиннее, чем целые, а целые не длиннее, чем длинные.
Чем отличается диапазон для беззнаковых и знаковых типов?
Хотя размер любого типа данных без знака и знака одинаков, они оба имеют разные диапазоны значений для хранения в любой переменной. Почему? Это связано с тем, что числа со знаком представлены в форме дополнения до 2 в любом процессоре или машине. Например, представление числа -23 в виде дополнения до 2 будет выглядеть так:
(десятичный) 23 <-> (двоичный) 10111
Дополнение до 1
Дополнение числа 10111 до 1 будет:
Здесь общее количество единиц, добавляемых перед фактическим числом, во многом зависит от размера машины или целевого процессора. Поскольку машина, с которой мы здесь имеем дело, является 64-битной машиной, мы добавили столько единиц, чтобы итоговое число также стало 64-битным числом.
Проще говоря, дополнение до единицы — это, по сути, инвертированная версия фактического числа. 0 преобразуются в 1, а 1 в 0.
0 преобразуются в 1, а 1 в 0.
Дополнение до двойки
Дополнение до 2 в основном является дополнением до 1 + 1, то есть
111111111111111111111111111111111111111111111111111111111101000 + 1:
111111111111111111111111111111111111111111111111111111111101001 <-> (десятичный) -23
Некоторые расчеты на компьютере помогут вам проверить этот результат здесь.
Давайте рассмотрим пример знакового символа, способного хранить числа в диапазоне от -128 до +127. Теперь мы все знаем, что и беззнаковые, и подписанные char могут хранить в себе всего 8 бит данных.
Итак, если мы предположим, что пытаемся сохранить число -190 в 8-битном переменном символе, то процессор будет обрабатывать это число следующим образом:
(десятичный) 190 <-> (двоичный) 10111110 : 8 бит
Дополнение до 1 для значения 190: (Двоичный) 01000001 : 8 бит
Дополнение до 2 для значения 190: (Двоичный) 01000010 : 8 бит
(Двоичный) 01000010 <-> (Десятичный) 66
Интерпретация номеров символов компьютером будет следующей:
(1) MSB бит: Знак числа [0: Положительный, 1: Отрицательный], 7-0 Биты: 1000010: [66] Фактические данные
Это означает, что всякий раз, когда мы пытаемся сохранить число, превышающее определенный диапазон, это число в конечном итоге будет округлено в меньшую сторону. Таким образом, мы получили результат 256-19.0 равно 66. Здесь 256 — это, по сути, максимальное значение, которое может хранить беззнаковое число символов.
Таким образом, мы получили результат 256-19.0 равно 66. Здесь 256 — это, по сути, максимальное значение, которое может хранить беззнаковое число символов.
Теперь давайте рассмотрим еще один пример того, как мы можем сохранить число -126 в переменной типа данных char.
(десятичный) 126 <-> (двоичный) 01111110
Дополнение до 1 126: (Двоичный) 10000001 : 8-бит
Дополнение до 2 от 126: (Двоичный) 10000010 : 8-бит
(Двоичный) 10000010 <-> (Десятичный) -126
Если вы хотите проверить полученные результаты, вы можете выполнить обратные вычисления. Здесь число отрицательное, так как старший бит равен 1. Кроме того, 0000010 — это остальные 7 бит. Таким образом, дополнение числа до 2 будет: ~0000010 = 1111101 = (десятичное) 126
Если мы объединим число и знак здесь, мы получим результат: (Десятичный) -126
Та же самая концепция подходит как для беззнаковых, так и для целых типов данных со знаком.
В заключение, как беззнаковые, так и знаковые числа имеют одинаковое определение размера данных в C. Однако представление чисел со знаком осуществляется в форме дополнения до 2, а старший бит двоичного числа представляет знак этого числа. Поскольку двоичная 1 (дополнительный 1 бит) предназначена для идентификации данного числа как отрицательного, общий диапазон чисел со знаком намного меньше, чем диапазон чисел без знака.
Однако представление чисел со знаком осуществляется в форме дополнения до 2, а старший бит двоичного числа представляет знак этого числа. Поскольку двоичная 1 (дополнительный 1 бит) предназначена для идентификации данного числа как отрицательного, общий диапазон чисел со знаком намного меньше, чем диапазон чисел без знака.
Ваш процессор обрабатывает отрицательные числа, поэтому вам не нужно заботиться о них отдельно. Просто убедитесь, что вы присваиваете допустимое число переменной со знаком, которая попадает в определенный диапазон. Если вы этого не сделаете, назначенный номер в конечном итоге будет усечен.
Типы данных с плавающей запятой
Язык C определяет два основных типа данных для хранения дробных чисел или чисел с плавающей запятой. Это двойной или с плавающей запятой . Можно легко применить длинные квалификаторы к двойнику. Таким образом, мы получаем еще один тип — long double.
В компьютерной системе формат IEEE-754 представляет числа с плавающей запятой. -3 = 1,375D.
-3 = 1,375D.
Здесь бит знака в основном представляет знак числа, где S=1 — отрицательное число, а S=0 — положительное число. В упомянутом выше примере S=1. Таким образом, число отрицательное. Это означает, что число будет -1,375D.
Фактический показатель степени в нормализованной форме будет равен E-127 (это так называемое смещение-127 или превышение-127). Это потому, что человек должен представлять как отрицательные, так и положительные показатели. В случае 8-битного E, который находится в диапазоне от 0 до 255, фактическая экспонента чисел от -127 до 128 может быть обеспечена избыточной схемой -127. Например, в упомянутом примере E-127=129-127=2D.
2. Денормализованная форма
У нормализованной формы есть серьезные проблемы. Например, он использует неявное значение, которое приводит к 1 вместо дроби. Таким образом, нормализованная форма не может представлять ноль как число, начинающееся с 1. Денормализованная форма в основном предназначена для представления числа ноль, а также других чисел.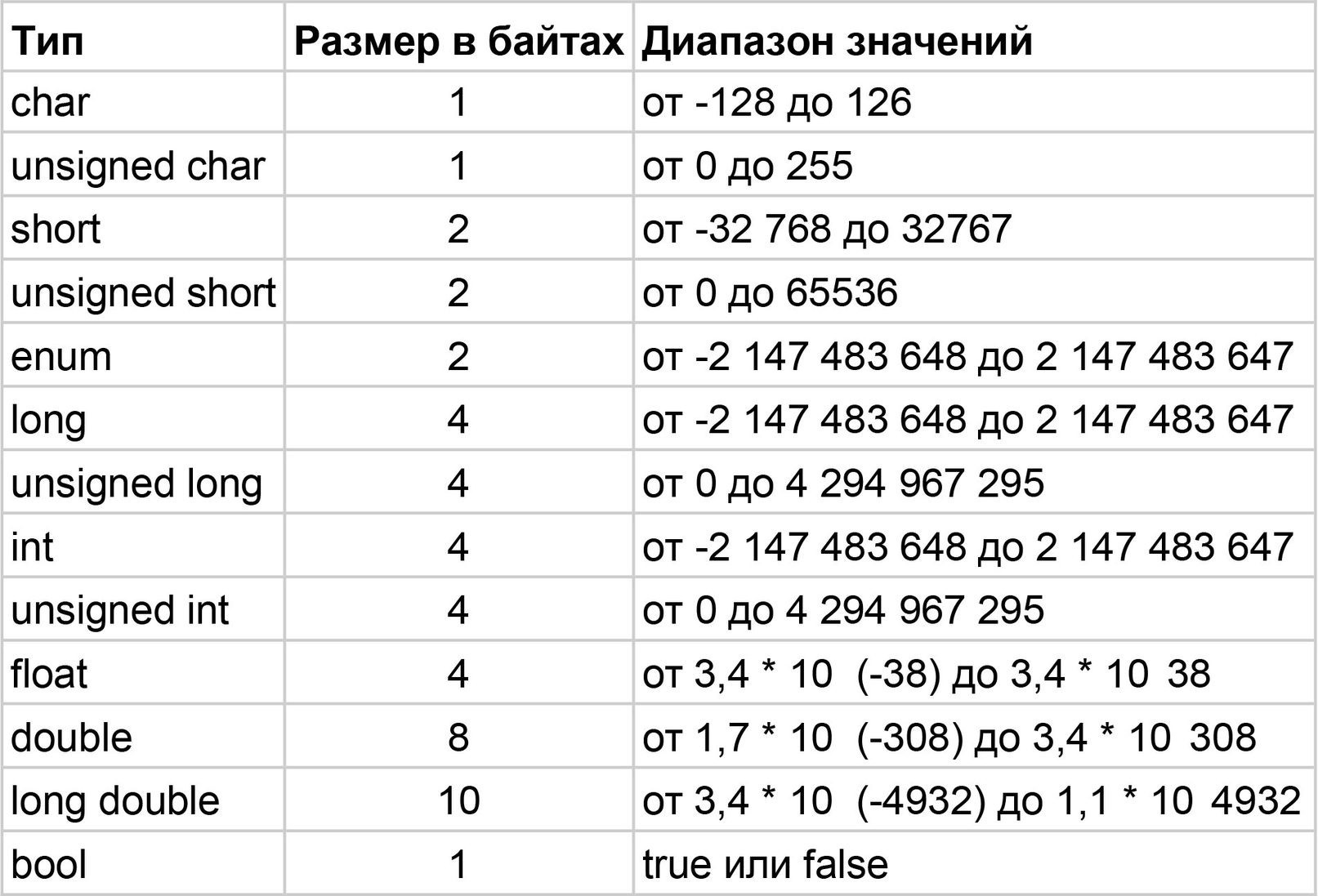 -126 = 0,9-126 тогда будет оцениваться как очень маленькое число. Нам нужно представить денормализованную форму, используя E=0 и F=0. Они также могут представлять чрезвычайно отрицательные и положительные числа, близкие к нулевому значению.
-126 = 0,9-126 тогда будет оцениваться как очень маленькое число. Нам нужно представить денормализованную форму, используя E=0 и F=0. Они также могут представлять чрезвычайно отрицательные и положительные числа, близкие к нулевому значению.
(c) В случае E = 255 будут представлены некоторые специальные значения, например, NaN (относится не к числу) и ±INF (отрицательная и положительная бесконечность).
Производные типы данных
Они также известны как определяемые пользователем типы. Этот тип данных является производным от первичного типа данных, поэтому он известен как производные типы данных. Но они способны хранить набор различных значений вместо хранения одного единственного значения. Объединения, структуры, массивы и перечисления являются одними из наиболее распространенных в языке C.
Практические задачи по размеру типов данных в C
1. Размер char равен 1 байту, если char:
А. Подпись
Б. Без знака
Без знака
С. Оба
Д. Нет. Это больше 1 байта.
Ответ – C. Оба
2. Тип данных int отражает естественный размер _________ на ___________.
А. целое число, программа
B. Целое число , хост-компьютер
C. с плавающей запятой, главная машина
D. с плавающей запятой, программа
Ответ – B. Целое число , хост-компьютер
3. Диапазон и размер типа данных варьируются между различными:
А. Компиляторы
B. Операционные системы
С. Оба
Д. Нет
Ответ – C. Оба
Часто задаваемые вопросы
Что отличает диапазон для беззнаковых и подписанных типов?
Хотя размер любого типа данных без знака и знака одинаков, они оба имеют разные диапазоны значений, которые можно сохранить в любой переменной. Почему? Это связано с тем, что числа со знаком представлены в форме дополнения до 2 в любом процессоре или машине. Например, представление числа -23 в виде дополнения до 2 будет выглядеть так:
Почему? Это связано с тем, что числа со знаком представлены в форме дополнения до 2 в любом процессоре или машине. Например, представление числа -23 в виде дополнения до 2 будет выглядеть так:
(Десятичный) 23 <-> (Двоичный) 10111
Почему мы используем плавающие типы данных?
Язык C определяет два основных типа данных для хранения дробных чисел или чисел с плавающей запятой. Они бывают двойными или плавающими. Можно легко применить длинные квалификаторы к двойнику. Таким образом, мы получаем еще один тип — long double.
В компьютерной системе формат IEEE-754 представляет числа с плавающей запятой. Большинство современных процессоров и процессоров принимают этот формат. Он имеет два основных представления:
1. 32-битная одинарная точность
2. 64-битная двойная точность
Продолжайте учиться и следите за обновлениями, чтобы получать последние обновления об экзамене GATE, а также о критериях приемлемости GATE, GATE 2023, допускной карточке GATE, программе GATE для CSE (компьютерная инженерия), примечаниях GATE CSE, вопроснике GATE CSE и многом другом.