Характеристика технологии «клиент-сервер»
По дисциплине обслуживания сети современные компьютерные сети используют технологию «клиент-сервер» (client-server) или одноранговую (peer-to-peer) технологию.
В одноранговых сетях все компьютеры, как правило, имеют доступ к ресурсам других компьютеров, то есть все компьютеры в сети являются равноправными. Одноранговая локальная сеть предоставляет возможность такой организации работы компьютерной сети, при которой каждая рабочая станция одновременно может быть и сервером.
Преимущество одноранговых сетей заключается в том, что разделяемыми ресурсами могут являться ресурсы всех компьютеров в сети и нет необходимости копировать все используемые сразу несколькими пользователями файлы на сервер. В принципе, любой пользователь сети имеет возможность использовать все данные, хранящиеся на других компьютерах сети, и устройства, подключенные к ним.
Затраты на организацию одноранговых
вычислительных сетей относительно
небольшие.
«Клиент-сервер» — это модель
взаимодействия компьютеров в сети. Как
правило, компьютеры не являются
равноправными. Каждый из них имеет свое,
отличное от других, назначение, играет
определенную роль. Некоторые компьютеры
в сети владеют и распоряжаются
информационновычислительными ресурсами,
такими как процессоры, файловая система,
почтовая служба, служба печати, база
данных.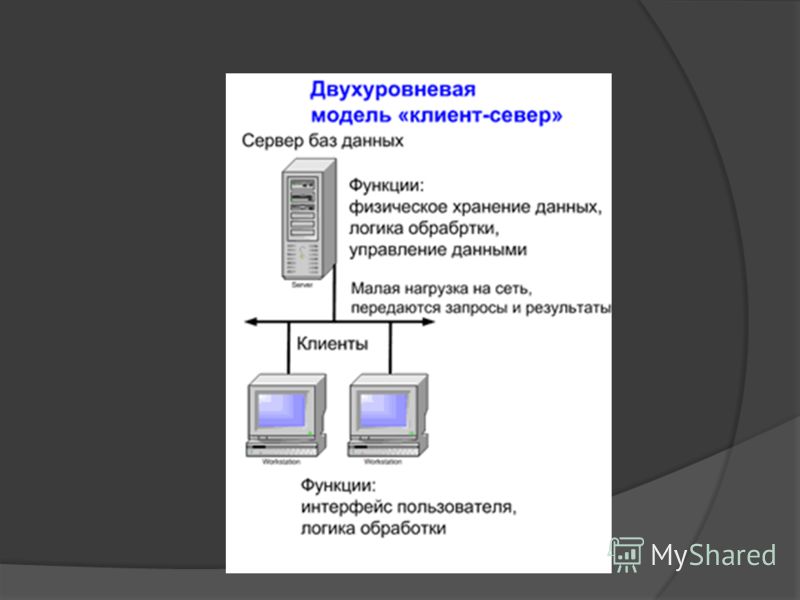
Компьютер, управляющий тем или иным ресурсом, принято называть сервером этого ресурса, а компьютер, желающий им воспользоваться, — клиентом. Конкретный сервер определяется видом ресурса, которым он владеет. Так, если ресурсом являются базы данных, то речь идет о сервере баз данных, назначение которого — обслуживать запросы клиентов, связанные с обработкой данных; если ресурс — это файловая система, то говорят о файловом сервере или файл-сервере.
В сети один и тот же компьютер может выполнять как роль клиента, так и роль сервера.
Если предполагается, что проектируемая
информационная система будет построена
по технологии «клиент-сервер», то
это означает, что прикладные программы,
реализованные в ее рамках, будут иметь
распределенный характер. Иными словами,
часть функций прикладной программы
(или, проще, приложения) будет реализована
в программеклиенте, другая — в
программе-сервере, причем для их
взаимодействия будет определен некоторый
протокол.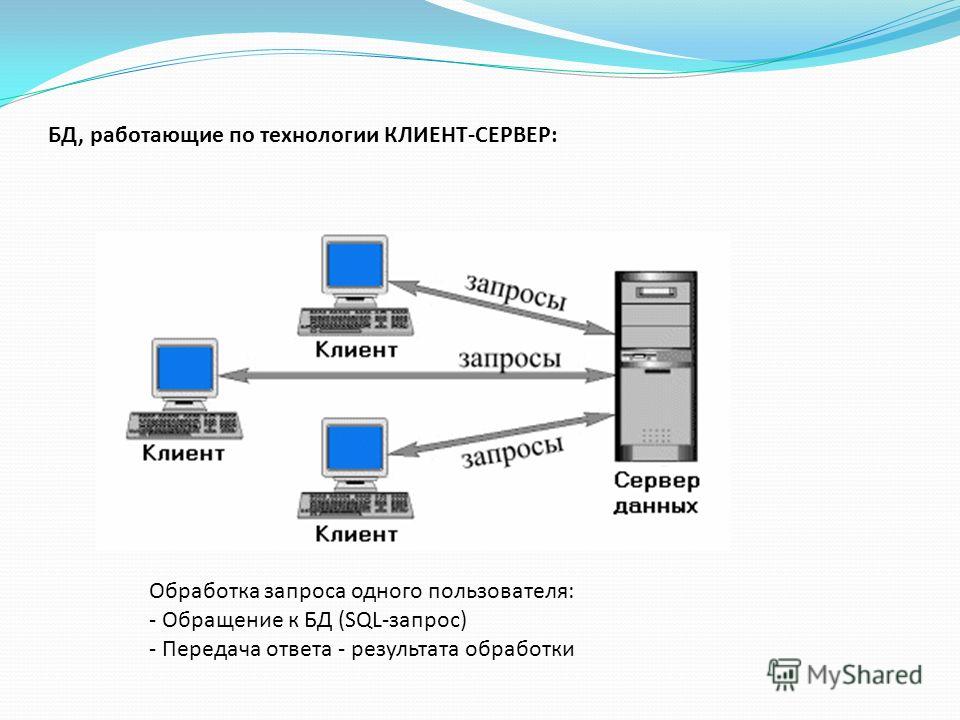
Рис. 5 — Сеть по принципу «клиент-сервер» и одноранговая сеть
КРАТКАЯ ИСТОРИЯ И ПРИНЦИП РАБОТЫ INTERNET
Internet представляет собой глобальную компьютерную сеть. Само ее название означает «между сетей». Это сеть, соединяющая отдельные сети.
Сеть Интернет возникла в 60-е годы как проект американского министерства обороны. Роль компьютеров возрастала, возникали все новые и новые потребности в сфере совместного использования информации в территориально распределенных неоднородных (то есть включающих компьютеры разных моделей и производительности) системах, а также необходимость защиты информационных потоков во время возможных перебоев на отдельных станциях сети.
Сеть Интернет опирается на семейство
протоколов, созданных для обеспечения
независимой маршрутизации и передачи
информации в глобальных сетях, чтобы в
случае отключения одной из станций сети
информацию можно было передать в пункт
назначения, направив ее через другие
станции. Разработанный для этой цели
протокол назвали протоколом межсетевого
обмена (Internetworking Protocol — IP). Протокол IP
получил широкое распространение в
военно-технической сфере. Ученые
использовали его для передачи
научно-технической информации.
Министерство обороны США секретно
курировало огромное количество научных
проектов во многих университетах страны
и сумело найти эффективный способ
передачи информации через разнородные
сети. Именно из-за того, что в обмен
информацией оказались вовлечены широкие
научные круги, этот протокол быстро
вышел из-под контроля военных. Его начали
использовать и в исследовательских
институтах NATO и в университетах Европы.
Сегодня протокол IP, а значит, и Интернет,
стали всемирном достоянием.
Разработанный для этой цели
протокол назвали протоколом межсетевого
обмена (Internetworking Protocol — IP). Протокол IP
получил широкое распространение в
военно-технической сфере. Ученые
использовали его для передачи
научно-технической информации.
Министерство обороны США секретно
курировало огромное количество научных
проектов во многих университетах страны
и сумело найти эффективный способ
передачи информации через разнородные
сети. Именно из-за того, что в обмен
информацией оказались вовлечены широкие
научные круги, этот протокол быстро
вышел из-под контроля военных. Его начали
использовать и в исследовательских
институтах NATO и в университетах Европы.
Сегодня протокол IP, а значит, и Интернет,
стали всемирном достоянием.
Итак, кратко охарактеризуем рождение
и развитие Internet. В 1960-е годы, после
Карибского кризиса, фирма RAND Corporation,
один из исследовательских центров
Соединенных Штатов, впервые предложила
создать децентрализованную компьютерную
сеть, покрывающую всю страну.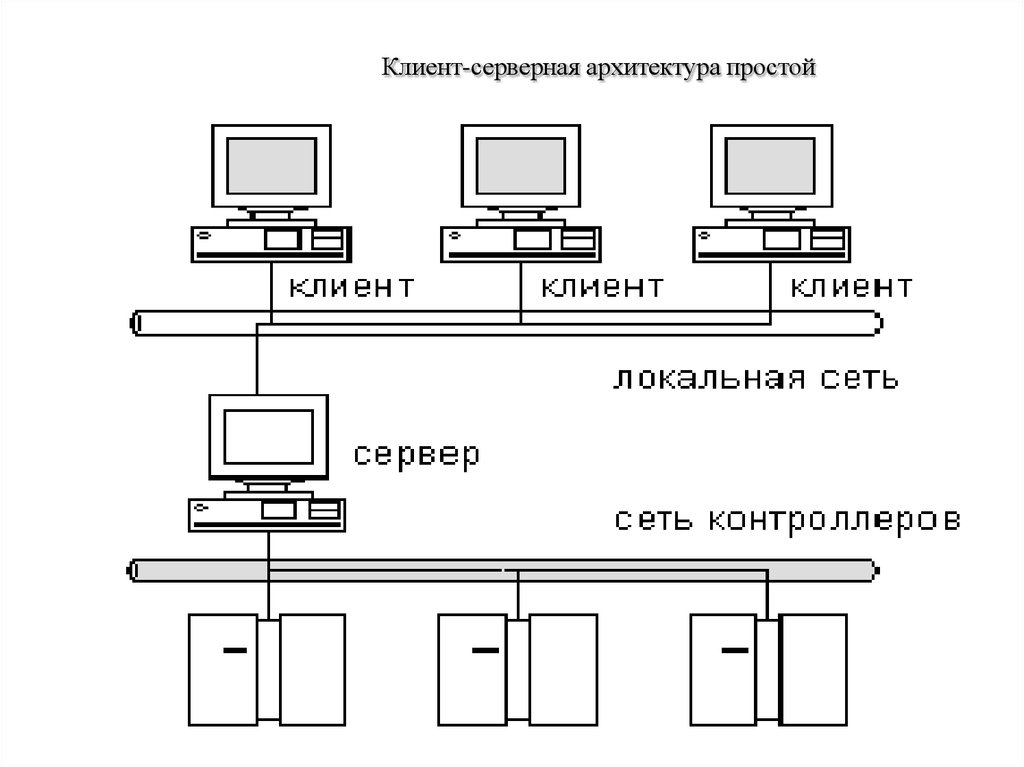 Проект
включал в себя объединение компьютеров
военных, научных и образовательных
учреждений в сеть, которая могла бы
сохранить работоспособность в условиях
ядерной атаки. Это был ответ США на
запуск 4 октября 1957 года Советским Союзом
первого искусственного спутника Земли.
Основной идеей проекта была децентрализация
управления и подчинения, чтобы выход
из строя одного или нескольких сегментов
сети оставлял бы ее работоспособной.
Это требование дает ключ к пониманию
принципов построения и структуры
Internet. В проектируемой модели сети всегда
была связь между компьютером-источником
и компьютеромприемником (станцией
назначения). Сеть изначально предполагалась
ненадежной: любая часть сети может
исчезнуть в любой момент. Такая структура
может быть осуществлена только в том
случае, если между узлами сети существуют
множественные связи.
Проект
включал в себя объединение компьютеров
военных, научных и образовательных
учреждений в сеть, которая могла бы
сохранить работоспособность в условиях
ядерной атаки. Это был ответ США на
запуск 4 октября 1957 года Советским Союзом
первого искусственного спутника Земли.
Основной идеей проекта была децентрализация
управления и подчинения, чтобы выход
из строя одного или нескольких сегментов
сети оставлял бы ее работоспособной.
Это требование дает ключ к пониманию
принципов построения и структуры
Internet. В проектируемой модели сети всегда
была связь между компьютером-источником
и компьютеромприемником (станцией
назначения). Сеть изначально предполагалась
ненадежной: любая часть сети может
исчезнуть в любой момент. Такая структура
может быть осуществлена только в том
случае, если между узлами сети существуют
множественные связи.
В первом варианте идеи подобной сети
(1964 год, сотрудник RAND П. Бэран (Paul
Baran)), просто утверждалось, что все узлы (компьютеры) сети должны иметь одинаковый
статус.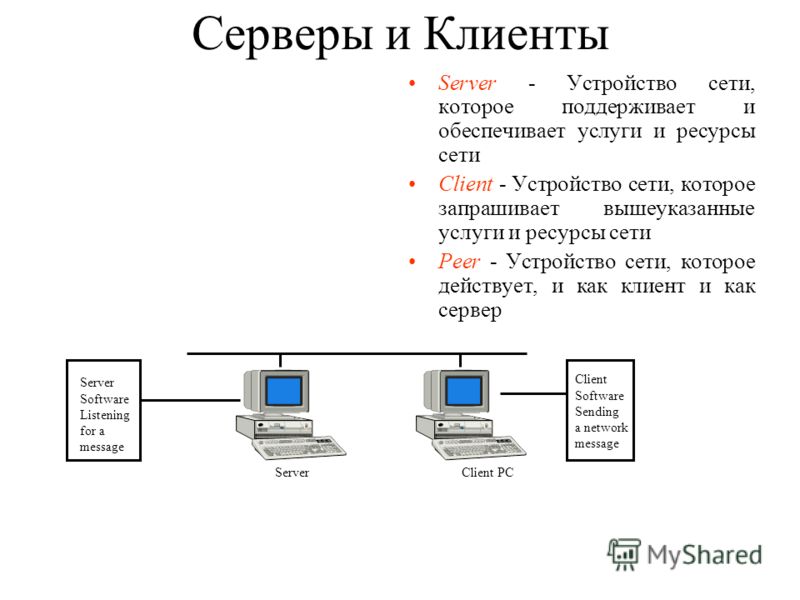 Каждый узел уполномочен порождать,
передавать и получать сообщения от
любого другого. Сообщения для передачи
разбиваются на небольшие стандартизированные
элементы, называемые пакетами
Каждый узел уполномочен порождать,
передавать и получать сообщения от
любого другого. Сообщения для передачи
разбиваются на небольшие стандартизированные
элементы, называемые пакетами
В конце 1960-х годов, корпорация RAND, Массачусетский технологический институт и Калифорнийский университет Лос-Анджелеса начали экспериментировать с концепцией децентрализованной сети с пересылкой пакетов. В Великобритании подобные эксперименты проводились NPL (National Physical Laboratory , Национальной физической лабораторией). В 1968 году подразделение Пентагона — ARPA (Advanced
Research Projects Agency) — Агентство по работе с исследовательскими проектами в области перспективных исследований — открыло финансирование этого проекта в США.
К осени 1969 года появилась на свет сеть ARPANET, состоящая к тому времени из четырех узлов, а именно:
Анджелеса,
институте,
Барбары,
Первые испытаний ARPANET оказались крайне
успешными.
К 1971 году ARPANET разрослась до 15 узлов, включая Массачусетский технологический институт, RAND, Гарвард, Питтсбургский университет Каренги-Меллона, Case Western Reserve и центр NASA в Эймсе.
К 1972 году сеть ARPANET насчитывала уже 37 узлов, а в 1973 году впервые были подключены и зарубежные узлы – Университетский колледж в Лондоне и Королевская лаборатория радиолокации в Норвегии. Ответственность за администрирование сети взяло на себя DCA (Defence Communication Agency, Оборонное агенство по коммуникациям), в настоящее время называемое DISA (Defence Information Systems Agency, Оборонное агенство по информационным системам).
Несмотря на то, что изначально ARPANET
состояла из соединений между самыми
престижными исследовательскими
институтами США, и что первые обоснования
создания ARPANET подчеркивали ее важность
как средства удаленного доступа к
компьютерам, основной поток информации
по сети не соответствовал своему
первоначальному предназначению.
Несмотря на то, как в реальности
использовались новые возможности,
создание ARPANET и концепции децентрализованной
сети с пакетной передачей данных в
целом означали огромный успех. В течение
1970-х годов эта легко расширяемая система
претерпела гигантский рост. Её
децентрализованная структура, существенно
отличающаяся от структур существовавших
в то время корпоративных сетей, позволяла
подключать к сети компьютеры практически
любого типа, — при одном лишь условии,
что эти компьютеры «понимали» протокол (соглашение о стандарте) пакетной
передачи данных NCP (Network Control Protocol, Протокол
сетевого управления). Этот протокол
стал предшественником ныне используемого
TCP/IP (Transmission Control Protocol/Internet Protocol, Протокол
управления передачей/Протокол Intenet, или
Межсетевой Протокол).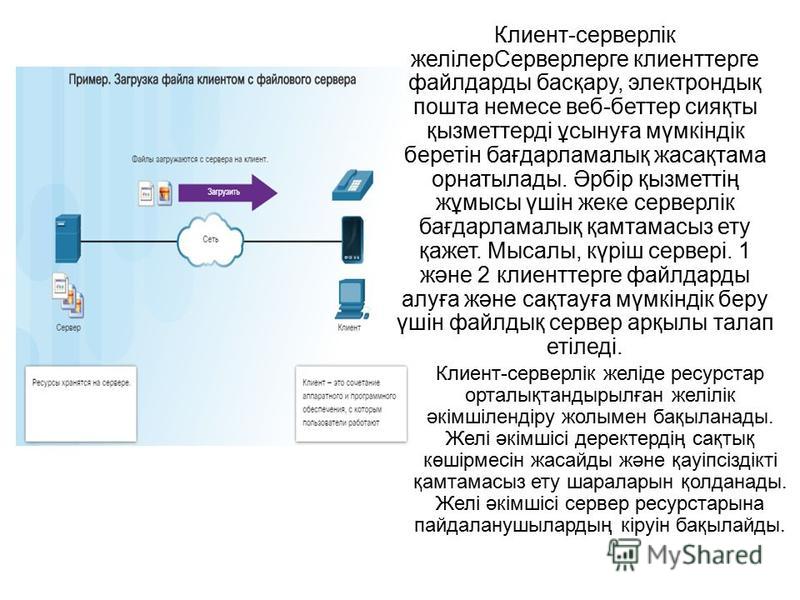
Уже в 1974 году В. Серф и Б. Кан, сотрудники NSF (National Science Foundation, Государственный фонд научных исследований — аналог нашего Министерства Науки), опубликовали свои первые спецификации нового протокола управления передачей данных TCP/IP, который до 1977 года использовался при подключении к ARPANET других компьютерных сетей.
Протокол TCP/IP, открытый для общего использования, отличался от NCP тем, что сообщение разбивались, и преобразовывались в пакеты на узле отправки, обратное преобразование со сборкой сообщения из пакетов происходило на узле назначения. Протокол IP устанавливал адресацию пакетов, которая позволяла пакетам достичь места назначения, проходя через многочисленные узлы, или даже сети, стандарты которых отличались от стандарта NCP для ARPANET.
Эти решения могут показаться странными, как и предположение о «ненадежной» сети, но уже имеющийся опыт показал, что большинство этих решений вполне разумно и верно. Пока ISO (Organization for International
Standartization, Международная Организация по
Стандартизации) тратила годы, создавая
окончательный стандарт для компьютерных
сетей, активисты Internet начали устанавливать
IP-программное обеспечение на все
возможные типы компьютеров. Вскоре это
стало единственным приемлемым способом
для связи разнородных компьютеров.
Такая схема понравилась правительству
и университетам, которые проводят
политику покупки компьютеров у различных
производителей. Каждый покупал тот
компьютер, который ему нравился и вправе
был ожидать, что сможет работать по сети
совместно с другими компьютерами.
Вскоре это
стало единственным приемлемым способом
для связи разнородных компьютеров.
Такая схема понравилась правительству
и университетам, которые проводят
политику покупки компьютеров у различных
производителей. Каждый покупал тот
компьютер, который ему нравился и вправе
был ожидать, что сможет работать по сети
совместно с другими компьютерами.
Протокол TCP/IP послужил толчком для дальнейшего расширения ARPANET, поскольку он легко устанавливался на практически любой компьютер и позволял сети с легкостью развиваться вширь от любого существующего узла.
К 1983 году ARPANET, которая к тому времени уже получила общепринятое имя Internet, отражающее ее структуру мощной совокупности связанных между собой компьютеров и сетей, официально отказалась от использования протокола NCP в пользу более развитого и распространенного протокола TCP/IP.
В этом же году из ARPANET выделилась MILNET,
которая стала относиться к Defence Data
Network (DDN, Оборонная сеть обмена данными)
министерства обороны США.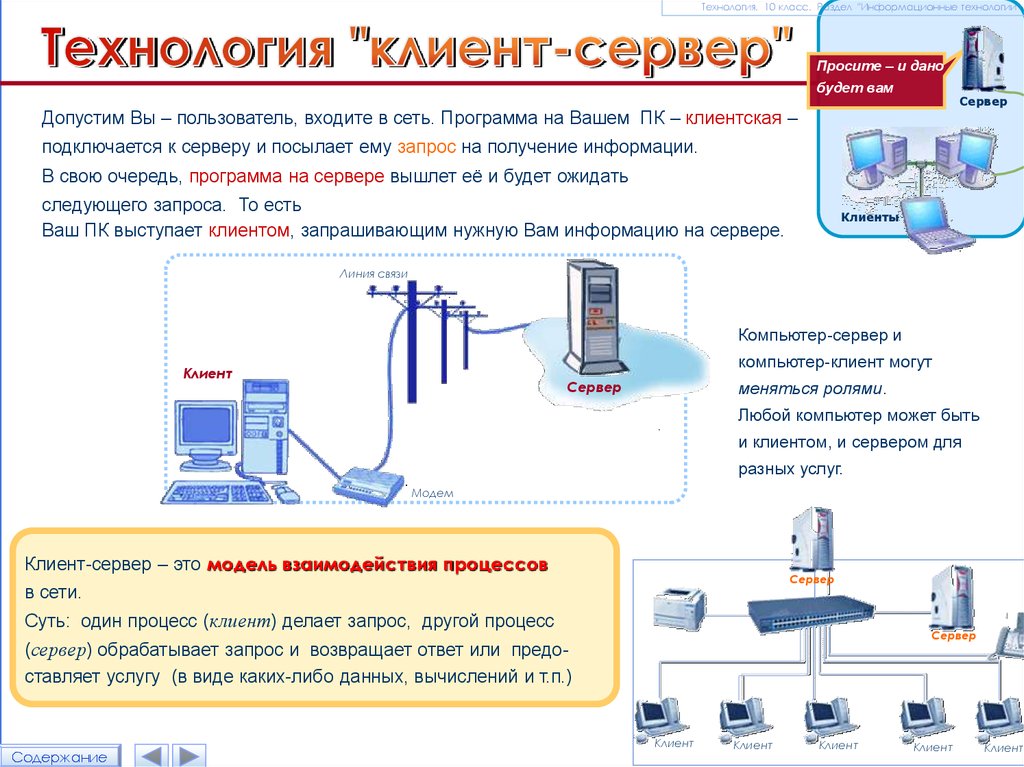 Термин Internet
стал использоваться для обозначения
единой сети: MILNET и ARPANET. И хотя в 1991 году
ARPANET прекратила свое существование,
название Internet продолжило свое
существование, так как Сеть стала
объединять в себе уже и международные
сети.
Термин Internet
стал использоваться для обозначения
единой сети: MILNET и ARPANET. И хотя в 1991 году
ARPANET прекратила свое существование,
название Internet продолжило свое
существование, так как Сеть стала
объединять в себе уже и международные
сети.
Это решение было официально поддержано Министерством Обороны США, – протокол вошел в MIL STD (Military Standarts, Военные стандарты), и все, кто работал в сети, обязаны были перейти к этим новым протоколам.
Для облегчения этого перехода ARPA обратилась с предложением к руководителям фирмы Berkley Software Design — внедрить протоколы TCP/IP в Berkley (BSD) UNIX. С этого и начался союз UNIX и TCP/IP. UNIX – это одна из наиболее популярных операционных систем для серверов Internet. 1980-е годы стали периодом бурного роста Internet.
В то время начали появляться Локальные
Вычислительные Сети (LAN), например, такие
как Ethernet и др. Одновременно появились
компьютеры, которые стали называть рабочими станциями. На большинстве
рабочих станций была установлена
операционная система UNIX. Эта ОС имела
возможность работы в сети с Протоколом
Internet (IP). В связи с возникновением
принципиально новых задач и методов их
решения появилась новая потребность:
организации желали подключиться к
ARPANET своей локальной сетью.
На большинстве
рабочих станций была установлена
операционная система UNIX. Эта ОС имела
возможность работы в сети с Протоколом
Internet (IP). В связи с возникновением
принципиально новых задач и методов их
решения появилась новая потребность:
организации желали подключиться к
ARPANET своей локальной сетью.
Охват мирового сообщества Internet существенно расширился благодаря включению следующих сетей:
1982.
EARN – Европейская сеть учебных и научно-исследовательских учреждений, год подключения – 1983.
JUNET – Японская сеть UNIX-машин, год подключения – 1984.
JANET – Объединенная академическая сеть Великобритании, год подключения – 1984.
В конце 80-х годов наиболее влиятельные учереждения США на средства, выделенные NSF, основали NSFNET – пять суперкомпьютерных центров в Принстоне, Питтсбурге, Калифорнийском университете Санта-
Барбары и университете Корнели. Сеть
из этих пяти центров обычно называется
«магистральных хребтом Internet в США»
(Internet Backbone).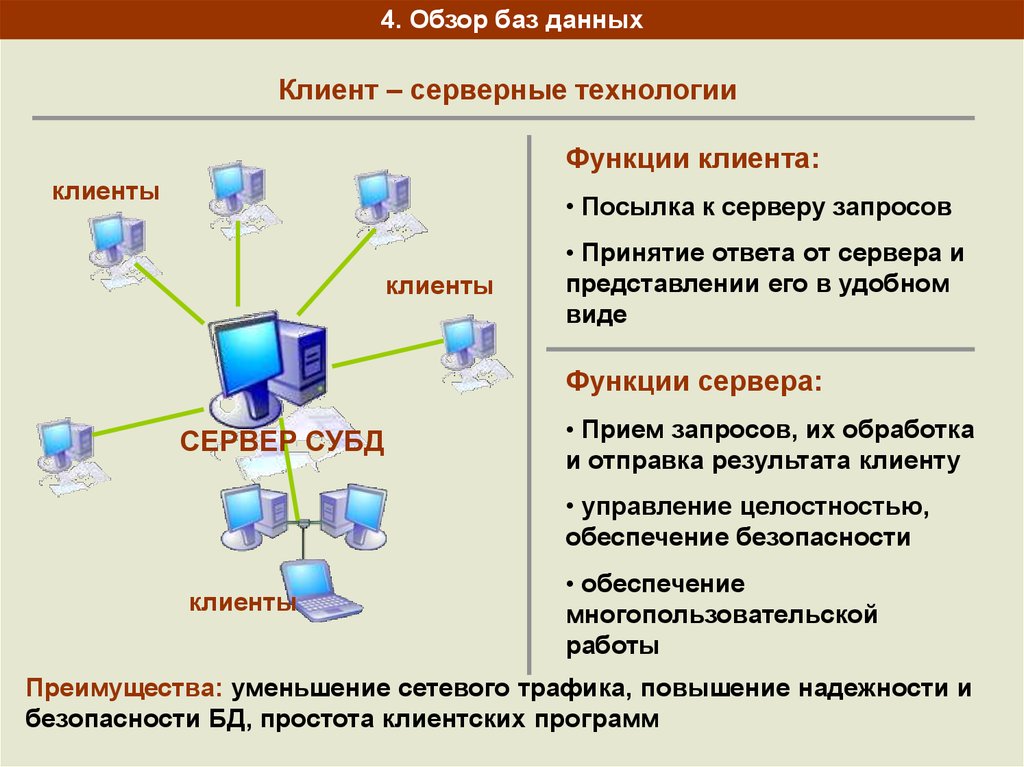 Эта сеть была доступна
для использования в любых научных
учреждениях. Было создано всего лишь
пять центров потому, что они очень дороги
даже для богатой Америки. Именно поэтому
их и следовало использовать кооперативно.
Эта сеть была доступна
для использования в любых научных
учреждениях. Было создано всего лишь
пять центров потому, что они очень дороги
даже для богатой Америки. Именно поэтому
их и следовало использовать кооперативно.
Возникла проблема связи: требовался способ соединить эти центры и предоставить доступ к ним различным пользователям. Сначала была сделана попытка использовать коммуникации ARPANET, но это решение потерпело крах, столкнувшись с бюрократией оборонной отрасли и проблемой обеспечения персоналом. Тогда NSF решил построить свою собственную сеть, основанную на IP технологии ARPANET. Центры были соединены специальными телефонными линиями с пропускной способностью 56
Кбит/сек.
Однако, было очевидно, что не стоит даже
и пытаться соединить все университеты
и исследовательские организации
непосредственно с центрами, т.к. проложить
такое количество кабеля — не только
очень дорого, но практически невозможно.
Поэтому решено было создавать сети по
региональному принципу. В каждой части
страны заинтересованные учреждения
должны были соединиться со своими
ближайшими соседями.
В каждой части
страны заинтересованные учреждения
должны были соединиться со своими
ближайшими соседями.
Получившиеся цепочки подсоединялись к суперкомпьютеру в одной из своих точек, таким образом, суперкомпьютерные центры были соединены вместе. В такой топологии любой компьютер мог связаться с любым другим, передавая сообщения через соседей.
Это решение было успешным, но настала пора, когда сеть уже более не справлялась с возросшими потребностями. Совместное использование суперкомпьютеров позволяло подключенным общинам использовать и множество других вещей, не относящихся к суперкомпьютерам. Неожиданно университеты, школы и другие организации осознали, что заимели под рукой море данных и мир пользователей. Поток сообщений в сети нарастал все быстрее и быстрее пока, в конце концов, не перегрузил управляющие сетью компьютеры и связывающие их телефонные линии.
В 1987 г. контракт на управление и развитие
сети был передан компании Merit Network Inc.,
которая занималась образовательной
сетью Мичегана совместно с фирмами IBM
и MCI. Менее чем за два года, продолжающееся
расширение Internet и растущие потребности
в вычислительных мощностях привели к
модернизации в 1988 году магистрали
NSFNET, сетевые управляющие машины были
также заменены на более быстрые.
Менее чем за два года, продолжающееся
расширение Internet и растущие потребности
в вычислительных мощностях привели к
модернизации в 1988 году магистрали
NSFNET, сетевые управляющие машины были
также заменены на более быстрые.
Важно отметить то, что усилия NSF по развитию сети привели к тому, что любой желающий может получить доступ к сети. Прежде Internet была доступна только для исследователей в области информатики, государственным служащим. В 1987 году число компьютеров, подключенных к Intenet составило более 10 000. К 1989 году это число достигло 100 000. В 1992 году число компьютеров в сети превысило миллион.
Однако, наиболее серьезным развитием Internet в 1990-х годах стало создание WWW (World Wide Web, Всемирная паутина).
Итак, логическая структура Internet представляет собой некое виртуальное объединение, имеющее свое собственное информационное пространство.
Internet обеспечивает обмен информацией
между всеми компьютерами, которые входят
в сети, подключенные к ней. Тип компьютера
и используемая им операционная система
значения не имеют. Соединение сетей
обладает громадными возможностями. С
собственного компьютера любой абонент
Internet может передавать сообщения в другой
город, просматривать каталог библиотеки
Конгресса в Вашингтоне, знакомиться с
картинами на последней выставке в музее
Метрополитен в Нью-Йорке, участвовать
в конференции IEEE и даже в играх с
абонентами сети из разных стран. Internet
предоставляет в распоряжение своих
пользователей множество всевозможных
ресурсов.
Тип компьютера
и используемая им операционная система
значения не имеют. Соединение сетей
обладает громадными возможностями. С
собственного компьютера любой абонент
Internet может передавать сообщения в другой
город, просматривать каталог библиотеки
Конгресса в Вашингтоне, знакомиться с
картинами на последней выставке в музее
Метрополитен в Нью-Йорке, участвовать
в конференции IEEE и даже в играх с
абонентами сети из разных стран. Internet
предоставляет в распоряжение своих
пользователей множество всевозможных
ресурсов.
Основные ячейки Internet — локальные вычислительные сети. Это значит, что Internet не просто устанавливает связь между отдельными компьютерами, а создает пути соединения для более крупных единиц — групп компьютеров.
Если некоторая локальная сеть
непосредственно подключена к Internet, то
каждая рабочая станция этой сети также
может подключаться к Internet. Существуют
также компьютеры, самостоятельно
подключенные к Internet. Они называются
хост-компьютерами (host — хозяин). Каждый
подключенный к сети компьютер имеет
свой адрес, по которому его может найти
абонент из любой точки света.
Каждый
подключенный к сети компьютер имеет
свой адрес, по которому его может найти
абонент из любой точки света.
Важной особенностью Internet является то, что она, объединяя различные сети, не создает при этом никакой иерархии — все компьютеры, подключенные к сети, равноправны. Internet самостоятельно осуществляет передачу данных. К адресам станций предъявляются специальные требования. Адрес должен иметь формат, позволяющий вести его обработку автоматически, и должен нести некоторую информацию о своем владельце.
С этой целью для каждого компьютера устанавливаются два адреса:
цифровой IP-адрес (IP — Internetwork Protocol — межсетевой протокол) и доменный адрес.
Оба эти адреса могут применяться равноценно. Цифровой адрес удобен для обработки на компьютере, а доменный адрес — для восприятия пользователем.
Цифровой адрес имеет длину 32 бита. Для
удобства он разделяется на четыре блока
по 8 бит, которые можно записать в
десятичном виде. Адрес содержит полную
информацию, необходимую для идентификации
компьютера.
Адрес содержит полную
информацию, необходимую для идентификации
компьютера.
Два блока определяют адрес сети, а два другие — адрес компьютера внутри этой сети. Существует определенное правило для установления границы между этими адресами. Поэтому IP-адрес включает в себя три компонента: адрес сети, адрес подсети, адрес компьютера в подсети.
Например: В двоичном коде цифровой адрес записывается следующим образом: 10000000001011010000100110001000. В десятичном коде он имеет вид: 192.45.9.200. Адрес сети — 192.45; адрес подсети — 9; адрес компьютера — 200.
Доменный адрес определяет область, представляющую ряд хосткомпьютеров. В отличие от цифрового адреса он читается в обратном порядке. Вначале идет имя компьютера, затем имя сети, в которой он находится.
В системе адресов Internet приняты домены, представленные географическими регионами. Они имеют имя, состоящее из двух букв.
Компьютерное имя включает, как минимум,
два уровня доменов. Каждый уровень
отделяется от другого точкой. Слева от
домена верхнего уровня располагаются
другие имена. Все имена, находящиеся
слева, — поддомены для общего домена.
Слева от
домена верхнего уровня располагаются
другие имена. Все имена, находящиеся
слева, — поддомены для общего домена.
Например, географические домены некоторых стран: Франция — fr; Канада- са; США — us; Россия – ru, Украина — ua.
Существуют и домены, разделенные по тематическим признакам. Такие домены имеют трехбуквенное сокращенное название. Так, учебные заведения — edu. Правительственные учреждения — gov. Коммерческие организации — com.
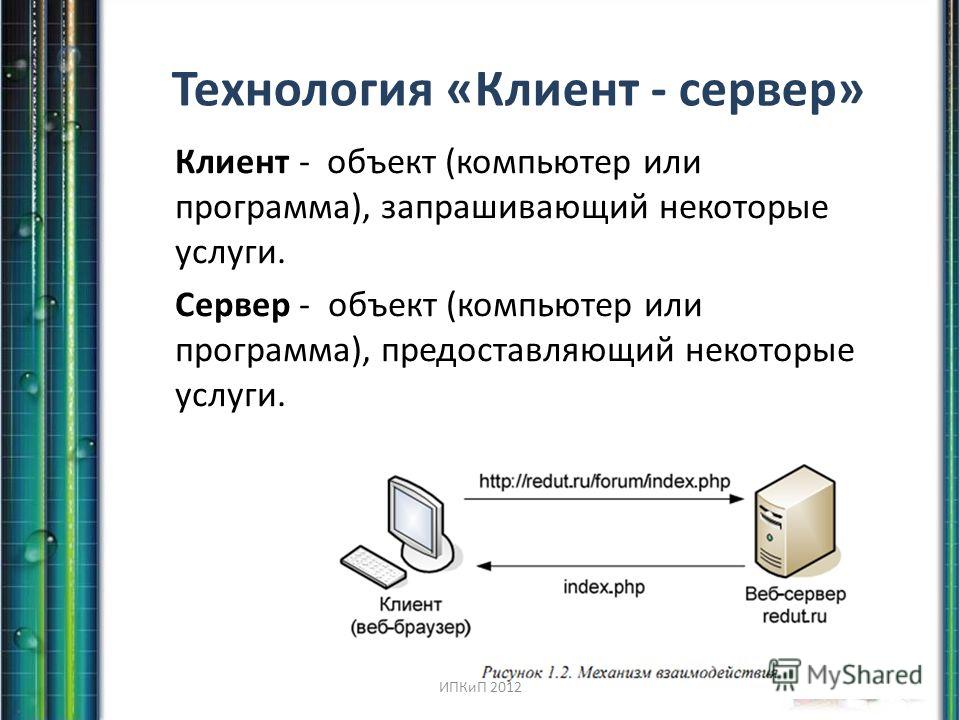
Построение клиент-серверных баз данных в Delphi » DelphiComponent.ru
До настоящего момента мы рассматривали только локальные базы данных, не затрагивая многопользовательского доступа. Целью данного занятия является обсуждение особенностей, присущих удаленным базам данных.
Напомним, что при использовании технологии «клиент-сервер» база данных располагается на удаленном компьютере (сервере) и называется удаленной базой данных.
ПРИМЕЧАНИЕ: Сервером называется не только компьютер (сервер сети), но и специализированная программа, которая в нашем случае управляет базой данных.
Приложение, обеспечивающее доступ к базе данных с компьютера пользователя, называется приложением-клиентом.
В основе взаимодействия клиента и сервера лежит язык SQL. Именно поэтому сервер базы данных называют еще и SQL-сервером, а базу данных — базой данных SQL. К SQL-серверам относятся:
Есть еще множество программ SQL-серверов. Каждая из них имеет свои особенности, которые необходимо учитывать при разработке приложения-клиента. Некоторые из них мы рассмотрим на следующем, десятом занятии.
Далее в книге сервер будет называться программой SQL-сервера. Установленную на компьютере-сервере базу данных будем именовать удаленной базой данных.
В изложенной простой схеме взаимодействия приложения-клиента н сервера мы еще не упомянули несколько важных функций, которые должно выполнять приложение-клиент. Вот эти функции (включая и упомянутые ранее):
Удаленная база данных представляет собой совокупность взаимосвязанных таблиц. Отличие ее от локальной заключается в том, что данные связанных таблиц содержатся в одном общем файле. В остальном структуры практически идентичны.
В остальном структуры практически идентичны.
Для управления базой данных сервер может задействовать следующие механизмы:
- триггеры;
- генераторы;
- хранимые процедуры;
- функции, определяемые пользователем;
- транзакции;
- кэшированные изменения;
- события.
Многие из этих механизмов зависят от установленного SQL-сервера и его языка. Далее на этом занятии мы рассмотрим некоторые из перечисленных средств на примере их использования в InterBase.
Хранимая процедура — это небольшая программа, которая расположена на сервере базы данных и которую можно вызвать из приложения-клиента.
Хранимые процедуры позволяют ускорить работу с данными на сервере базы данных благодаря следующим преимуществам:
- при использовании хранимых процедур вместо длинного текста SQL-запроса серверу отправляется короткое обращение к хранимой процедуре. Таким образом уменьшается сетевой график;
- хранимая процедура выполняется непосредственно на сервере.
 В результате скорость доступа к данным не зависит от производительности машины-клиента;
В результате скорость доступа к данным не зависит от производительности машины-клиента; - хранимая процедура, в отличие от SQL-запроса, не фебует предварительной проверки синтаксиса;
- хранимые процедуры являются общими для всех приложений-клиентов и реализуют единые правила работы с базой данных.
Для выполнения хранимой процедуры в Delphi был введен компонент TStoredProc. Рассмотрим его основные свойства.
Свойство DatabaseName типа String указывает на компонент TDatabase, используемый для установления соединения с базой данных. Это свойство аналогично одноименному свойству компонентов ТTable и TQuery.
Свойство StoredProcName типа String определяет хранимую процедуру, которая должна вызываться. Имя хранимой процедуры выбирается н выггядяющрм списке с помощью инспектора объектов.
ПРИМЕЧАНИЕ: Если при попытке выбора хранимой процедуры соединение с базой данных отсутствует, будет выдан запрос на его установление.
После выбора хранимой процедуры можно устанавливать два других свойства. Свойство РагатэтипаТРагатзопределяет массив параметров компонента TStoredProc.
Свойство ParamBindMode типа TParamBindMode определяет, как будет установлено соответствие между параметрамикомпонента TStoredProc и параметрами процедуры, и может принимать одно из следующих значений:
- pbByName — соответствие будет установлено по именам, то есть имена параметров компонента TStoredProc и соответствующих параметров процедуры должны совпадать. Данное значение принимается по умолчанию;
- pbByNumber — соответствие будет установлено в порядке перечисления, то есть первый параметр компонентаTStoredProc сопоставлен первому параметру процедуры и т. д.
Выполнение выбранной хранимой процедуры осуществляется с помощью вызовов методов Prepare и ЕхесРгос:
- метод Prepare осуществляет подготовку хранимой процедуры, которая заключается в связывании параметров процедуры п компонента TStoredProc в соответствии с установленным значением свойства ParamBindMode;
- метод ЕхесРгос непосредственно выполняет хранимую процедуру.
Листинг 9.1 иллюстрирует вызов хранимой процедуры из приложения при нажатии кнопки Buttonl.
Листинг 9.1. Вызов хранимой процедуры
Показать / Скрыть текст
Для написания хранимых процедур и триггеров используется специальный язык хранимых процедур. Разные серверы используют разные диалекты. Мы не будем изучать их все, а кратко рассмотрим язык хранимых процедур, использующийся сервером InterBase, который имеет много общего с языком Pascal. Язык хранимых процедур включает в себя операторы для управления ходом вычислительного процесса (ветвления, цикла), а также некоторые функциональные возможности языка SQL.
Хранимая процедура создается оператором
Показать / Скрыть текст
После имени процедуры следует необязательный список входных параметров, с помощью которых из приложения в процедуру могут передаваться исходные данные. Список выходных параметров, посредством которых в приложение возвращаются результаты выполнения процедуры, указывается после слова RETURNS. Каждый параметр описывается своим именем и типом, разделенными пробелом. Между различными параметрами должны стоять запятые.
Список выходных параметров, посредством которых в приложение возвращаются результаты выполнения процедуры, указывается после слова RETURNS. Каждый параметр описывается своим именем и типом, разделенными пробелом. Между различными параметрами должны стоять запятые.
При использовании параметра в теле процедуры перед его именем необходимо ставить двоеточие.
В текст хранимой процедуры допускается вставлять комментарии. Для вставки комментариев используются комбинации символов /* и */.
Вновь созданную процедуру можно удалить или изменить. Для удаления процедуры служит оператор
DROP PROCEDURE <Имя процедуры>Для изменения существующей процедуры используется оператор
ALTER PROCEDUREЕго список параметров идентичен списку параметров оператора
CREATE PROCEDUREРассмотрим некоторые из основных элементов языка хранимых процедур. Заметим, что все операторы обязательно должны заканчиваться точкой с запятой (кроме составного оператора).
Оператор объявления переменных имеет следующий вид:
Показать / Скрыть текст
Переменные могут быть только того типа, который допускается в InterBase.
Объявленные переменные являются локальными, то есть видимы исключительно внутри процедуры, в которой они были объявлены. Приведем пример объявления переменных:
Показать / Скрыть текст
Оператор присваивания описывается следующим образом: <Имя переменной> <Выражение>;
Перед знаком равенства двоеточие не ставится!
Переменная и выражение должны иметь одинаковый или совместимый тип, иначе возможна ошибка.
ВНИМАНИЕ: Ошибка возникает не при создании хранимой процедуры, а во время ее выполнения.
Проиллюстрируем сказанное несколькими примерами:
Показать / Скрыть текст
Оператор ветвления имеет вид:
Показать / Скрыть текст
Этот оператор аналогичен оператору ветвления, использующемуся в Delphi. Оператор цикла оформляется аналогично такому же оператору в Delphi:
Оператор цикла оформляется аналогично такому же оператору в Delphi:
Показать / Скрыть текст
Оператор выбора записи похож на инструкцию SELECT языка SQL, но дополнен следующим операндом:
Каждое имя после двоеточия указывает переменную или выходной параметр, которому должно быть присвоено значение столбцов строки, полученной в результате выполнения команды SELECT.
Например:
Показать / Скрыть текст
Здесь создается хранимая процедура pSelect, в которой для сотрудников из таблицы MyTable подсчитываются общая сумма заработной платы (по полю Zarplata) и среднее значение по организации. Полученные в результате выполнения процедуры значения будут присвоены выходным параметрам opSum и opSred. Входных параметров процедура не имеет.
Оператор выхода из процедуры служит для досрочного выхода из процедуры и передачи управления вызывающей программе млн процедуре. Оператор выхода представляет собой ключевое слово EXIT
Оператор вызова процедуры применяется для вызова из одной хранимой процедуры другой хранимой процедуры и записывается в общем виде так:
Показать / Скрыть текст
Оператор вызывает хранимую процедуру с указанным именем и параметрами. Приведем пример вызова хранимой процедуры:
Приведем пример вызова хранимой процедуры:
Показать / Скрыть текст
Оператор посылки сообщения предназначен для уведомления о событии всех приложений-клиентов, связанных с сервером. Данный оператор имеет следующий вид:
POSTJVENT <Имя события>;Триггер представляет собой процедуру, которая постоянно размещена на сервере базы данных (как и хранимая процедура) и вызывается автоматически при изменении записей базы данных.
В отличие от хранимых процедур, триггеры нельзя вызывать из приложений-клиентов, а также передавать им параметры и получать от них результаты.
По определению триггер похож на обработчик событий BeforeEdit, AfterEdit, Before-Delete, AfterDelete, Beforelnsert и Afterlnsert.
Триггеры в основном используются для программной реализации бизнес-правил. С помощью триггеров накладываются различные ограничения (например, иа значения столбцов).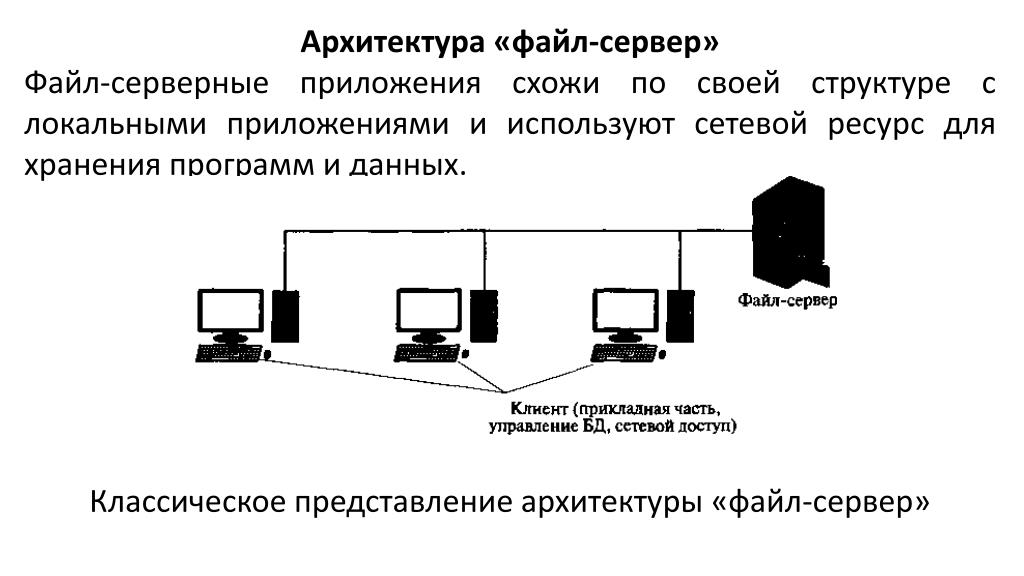
Для создания триггера применяется оператор CREATE TRIGGER, который имеет следующий вид:
Показать / Скрыть текст
Операнды ACTIVE и INACTIVE определяют, будет ли триггер активен сразу после его создания. По умолчанию ои будет активен (ACTIVE), то есть при наступлении определенного события триггер будет выполняться. Неактивный триггер (INACTIVE) при наступлении определенного события выполняться не будет. Таким образом, созданный триггер можно включать или выключать.
Операнды BEFORE и AFTER указывают, когда будет выполняться триггер: до наступления определенного события (BEFORE) или после (AFTER).
Операнды UPDATE, INSERT и DELETE определяют тип события, при возникновении которого будет выполняться триггер. Это такие типы событий, как изменение (UPDATE), добавление (INSERT) и удаление (DELETE) записей.
Для каждого события можно создать несколько триггеров, которые будут выполняться (если они активны). Порядок их выполнения определяется операндом POSITION. Триггеры будут срабатывать в порядке возрастания чисел, указанных в данном операнде.
Порядок их выполнения определяется операндом POSITION. Триггеры будут срабатывать в порядке возрастания чисел, указанных в данном операнде.
Созданный триггер можно изменить или удалить. Удаление триггера осуществляется оператором
DROP TRIGGER <Имя триггера>
Изменить уже существующий триггер можно с помощью оператора ALTER TRIGGER, который имеет такой же формат, что и оператор CREATE TRIGGER.
Тело триггера программируется так же, как и тело хранимой процедуры.
В таблицах InterBase отсутствует автоинкрементный тип. Для обеспечения уникальности значений ключевых столбцов совместно с триггерами используются генераторы.
Генератор применяется для создания уникальных целочисленных значений. Генератор можно создать с помощью приведенного ниже оператора:
CREATE GENERATOR <Имя генератора>
Кроме непосредственного создания генератора, необходимо присвоить ему начальное значение. Для этого используется следующий оператор:
Для этого используется следующий оператор:
SET GENERATOR <Имя генератора> ТО «Начальное значение>
Начальное значение — это число, начиная с которого будут генерироваться уникальные значения.
К созданному генератору можно обращаться с помощью функции
GEN_ID (<Имя генератора>, <Шаг>)
Данная (функция возвращает значение, увеличенное на целочисленный шаг относительно последнего сгенерированного значения.
ВНИМАНИЕ: После определения начального значения и шага их изменять нельзя. В противном случае уникальность генерируемых значений может быть нарушена.
Приведем пример создания генератора:
CREATE GENERATOR MyGen: SET GENERATOR MyGen TO2:
Здесь создается генератор с именем MyGen, начальное значение которого равно 2. Пример обращения к этому генератору может быть таким:
GENJD(MyGen.
1):
Все операции, выполняемые приложением-клиентом с данными на SQL-сервере, происходят в виде транзакций.
Транзакцией называется группа из нескольких операции над данными из таблиц удаленной базы данных.
Основным принципом транзакций является «либо все, либо ничего». Если во время выполнения набора действий (транзакции) па каком-то этапе невозможно произвести очередное действие, то нужно выполнить возврат базы данных к начальному состоянию (произвести откат транзакции). Таким образом (при правильном планировании транзакций) обеспечивается целостность базы данных. Далее мы расскажем, как начинать, завершать транзакции п управлять ими с помощью SQL-выражений. А также рассмотрим вопрос об использовании транзакций в приложениях, разработанных в Delphi. Вся приведенная информация относится к InterBase.
Для управления транзакциями в Delphi имеются три основные команды:
- SET TRANSACTION — начинает транзакцию и определяет се поведение;
- COMMIT — сохраняет изменения, внесенные транзакцией, в базе данных и завершает транзакцию;
- ROLLBACK — отменяет изменения, внесенные транзакцией, и завершает транзакцию.
 Рассмотрим эти команды более подробно.
Рассмотрим эти команды более подробно.
Команда для запуска транзакции в общем виде выглядит следующим образом:
SET TRANSACTION [Access mode] [Lock Resolution] [Isolation Level] [Table Reservation]
Команда содержит четыре необязательных параметра (перечисленные в квадратных скобках). Если эти параметры опустить, то получившаяся инструкция SET TRANSACTION равносильна выражению
SET TRANSACTION READ WRITE WAIT ISOLATION LEVEL SNAPSHOT
Перечислим параметры команды и их возможные значения.
- Параметр Access mode (тип доступа) определяет тип доступа к данным. Он может принимать одно из двух значении:
- READ ONLY — транзакция может только читать данные н не в состоянии модифицировать их;
- READ WRITE — указывает, что транзакция может читать и модифицировать данные. Это значение устанавливается по умолчанию.

- Параметр Isolation Level (уровень изоляции) определяет порядок взаимодействия данной транзакции с другими в рабочей базе данных. Может принимать значения:
- SNAPSHOT — значение по умолчанию. Внутри транзакции будут доступны данные в том состоянии, в каком они находились на момент начала транзакции. Если по ходу дела в базе данных появилисьнзменепия, внесенные другими завершенными транзакциями, то начатая транзакция их не увидит. При попытке модифицировать такие записи будет выдано сообщение о конфликте;
- SNAPSHOT TABLE STABILITY — предоставляет транзакции исключительный доступ к таблицам, которые она использует. Другие транзакции смогут только читать данные из этих таблиц;
- READ COMMlT — позволяеттранзакцин видеть текущее состояние базы данных.
ВНИМАНИЕ: Обратите особое внимание на уровень изоляции транзакции. При неправильно установленном уровне могут возникать проблемы.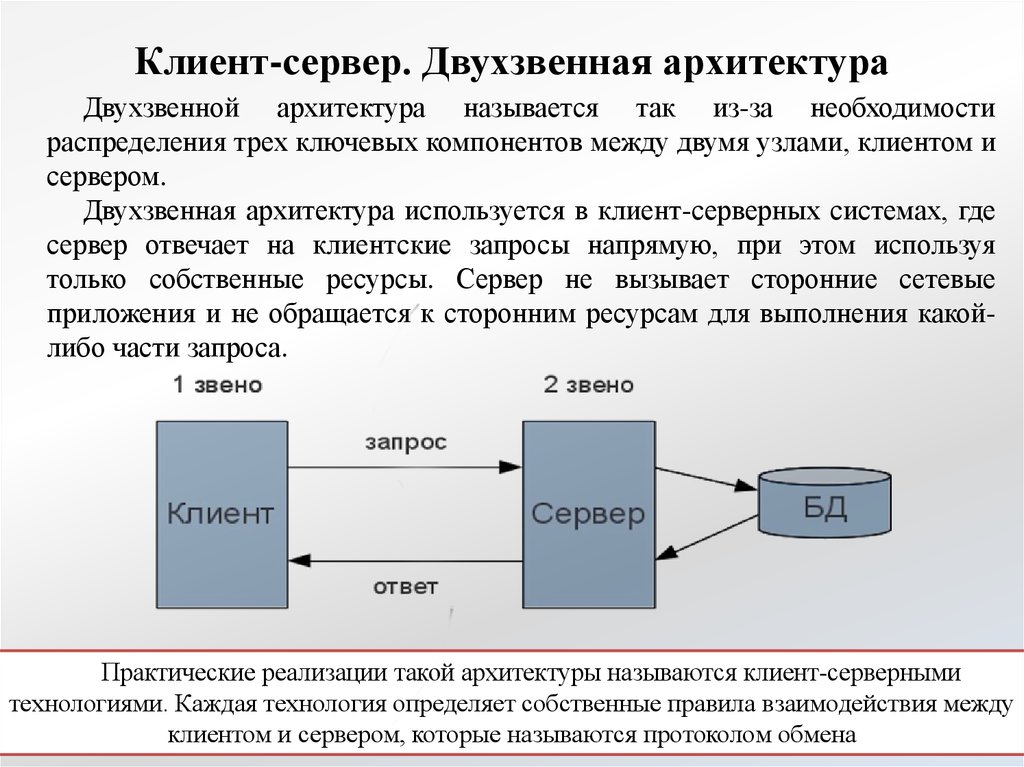 Эти проблемы имеют место в одном из двух случаев: транзакция пытается модифицировать запись, которая была изменена или удалена уже после ее старта; транзакция пытается модифицировать таблицу, заблокированную другой транзакцией с уровнем изоляции SNAPSHOT TABLE STABILITY.
Эти проблемы имеют место в одном из двух случаев: транзакция пытается модифицировать запись, которая была изменена или удалена уже после ее старта; транзакция пытается модифицировать таблицу, заблокированную другой транзакцией с уровнем изоляции SNAPSHOT TABLE STABILITY.
- Параметр Lock Resolution (разрешение блокировки) управляет интерпретацией событий при обнаружении конфликта блокировки. Может принимать одно из двух значений:
- WAIT — значение по умолчанию. Ожидает разблокирования требуемой записи. После этого пытается продолжить работу;
- NO WATT — немедленно возвращает ошибку блокировки записи и прекращает выполнение транзакции.
- Параметр Table Reservation (уровень доступа к таблице) позволяет транзакции получить гарантированный доступ необходимого уровня к указанным таблицам. Существует четыре уровня доступа:
- PROTECTED READ — запрещает обновление таблицы другими транзакциями, но позволяет им выбирать данные из таблицы;
- PROTECTED WRITE — блокируетобновление таблицы другими транзакциями, читать данные из таблицы могут только транзакции типа SNAPSHOT пли READ COMMITTED;
- SHARED READ — самый либеральный уровень.
 Читать могут все, модифицировать — транзакции типа READ WRITE;
Читать могут все, модифицировать — транзакции типа READ WRITE; - SHARED WRITE — транзакции типа SNAPSHOT или READ COMMITTED и READ WRITE могут модифицировать таблицу, остальные способны только выбирать данные.
Если все действия, составляющие транзакцию, успешно выполнены или возникла ошибка, транзакция должна быть завершена, для того чтобы база данных оказалась в непротиворечивом состоянии. Для этого в Delphi есть две SQL-команды:
- COMMIT — сохраняет внесенные транзакцией изменения в базу данных. Это означает, что транзакция завершена успешно;
- ROLLBACK — откат транзакции. Транзакция завершается и никаких изменений в базу данных не вносится. Операция выполняется в случае возникновения ошибки при выполнении операции (например, при невозможности обновить запись).
Все транзакции в Delphi можно условно разделить на явные и неявные.
Явная транзакция — это транзакция, начатая и завершенная с помощью методов компонента TDataBase: StartTransaction, Commit и RollBack. После начала явной транзакции все изменения, вносимые в данные, относятся к этой транзакции.
После начала явной транзакции все изменения, вносимые в данные, относятся к этой транзакции.
Другого способа начать явную транзакцию, кроме использования компонента TDataBase, нет. Следовательно, в рамках одного соединения нельзя начать две транзакции.
ПРИМЕЧАНИЕ: На самом деле такая возможность есть, но это потребует обращения к функциям API InterBase. В данной книге мы не будем останавливаться на вопросах программирования на низком уровне с использованием API.
Неявная транзакция стартует при модификации данных, если в текущий момент нет явной транзакции. Неявная транзакция возникает, например, при выполнении метода Post для компонентов наборов данных ТТаblе и TQuery. Например, если вы отредактировали запись в TDBGrid и переходите на другую запись, то это влечет за собой выполнение метода Post, что, в свою очередь, приводит к началу неявной транзакции, обновлению данных внутри транзакции и ее завершению. Важно отметить, что неявная транзакция, начатая с помощью методов Post, Delete, Insert, Append и т. д., заканчивается автоматически.
д., заканчивается автоматически.
Что такое клиент-серверная архитектура? Все, что вы должны знать
Сегодня компьютерами пользуется больше людей, чем когда-либо, и они полагаются на эти устройства и сети, к которым они подключены, для решения многих задач, от критически важных до несерьезных. Неудивительно, что огромное количество пользователей и еще более значительное количество запросов создают нагрузку на серверы и сети.
Как будто этих проблем недостаточно, ИТ-специалисты должны иметь дело с постоянным потоком новых технологий, которые необходимо внедрить в сеть. Развитие в этой быстро меняющейся среде имеет решающее значение для поддержания организации в актуальном состоянии и конкурентоспособности. Проще говоря, альтернативы нет.
ИТ-специалисты справляются с этой нагрузкой, внедряя клиент-серверную архитектуру или клиент-серверную архитектуру. Но вам может быть интересно: «Что такое сеть клиент-сервер?» Что ж, вы попали в нужное место. В этой статье будет объяснена архитектура клиент-сервер, показана модель клиент-сервер и проиллюстрированы преимущества архитектуры клиент-сервер.
Давайте сначала рассмотрим некоторые основы, а затем перейдем к сути вопроса.
Основы терминологии
Клиент — это лицо или организация, использующая в качестве услуги. В контексте ИТ клиент — это компьютер/устройство, также называемое хостом, который фактически использует службу или принимает информацию. К клиентским устройствам относятся ноутбуки, рабочие станции, устройства IoT и аналогичные сетевые устройства.
Сервер в мире ИТ — это удаленный компьютер, обеспечивающий доступ к данным и службам. Серверы обычно представляют собой физические устройства, такие как стоечные серверы, хотя рост облачных вычислений привел к появлению виртуальных серверов. Сервер обрабатывает такие процессы, как электронная почта, размещение приложений, подключение к Интернету, печать и многое другое.
Объяснение архитектуры клиент-сервер
Архитектура клиент-сервер относится к системе, которая размещает, предоставляет и управляет большинством ресурсов и служб, запрашиваемых клиентом.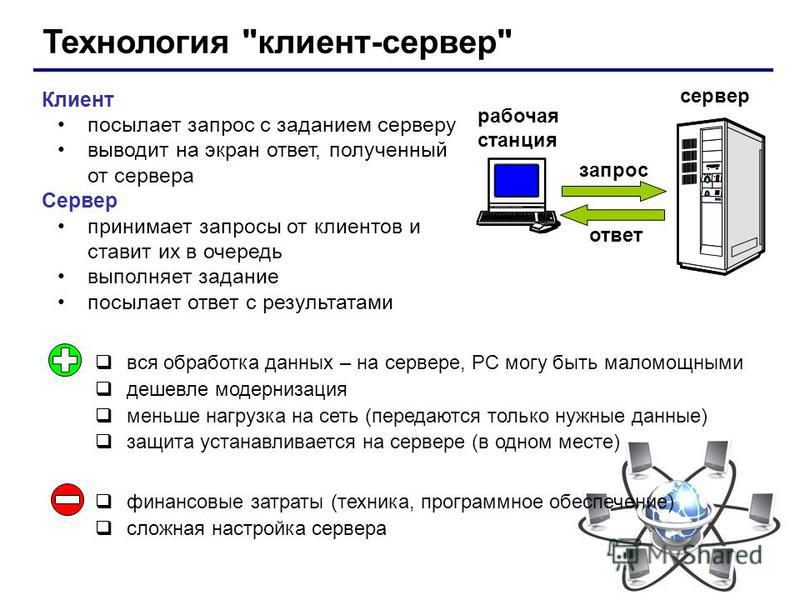 В этой модели все запросы и услуги доставляются по сети, и ее также называют моделью сетевых вычислений или сетью клиент-сервер.
В этой модели все запросы и услуги доставляются по сети, и ее также называют моделью сетевых вычислений или сетью клиент-сервер.
Архитектура клиент-сервер, также называемая моделью клиент-сервер, представляет собой сетевое приложение, которое распределяет задачи и рабочие нагрузки между клиентами и серверами, которые находятся в одной системе или связаны компьютерной сетью.
Архитектура клиент-сервер обычно включает несколько пользовательских рабочих станций, ПК или других устройств, подключенных к центральному серверу через Интернет-соединение или другую сеть. Клиент отправляет запрос данных, а сервер принимает и обрабатывает запрос, отправляя пакеты данных обратно тому пользователю, который в них нуждается.
Эта модель также называется сетью клиент-сервер или моделью сетевых вычислений.
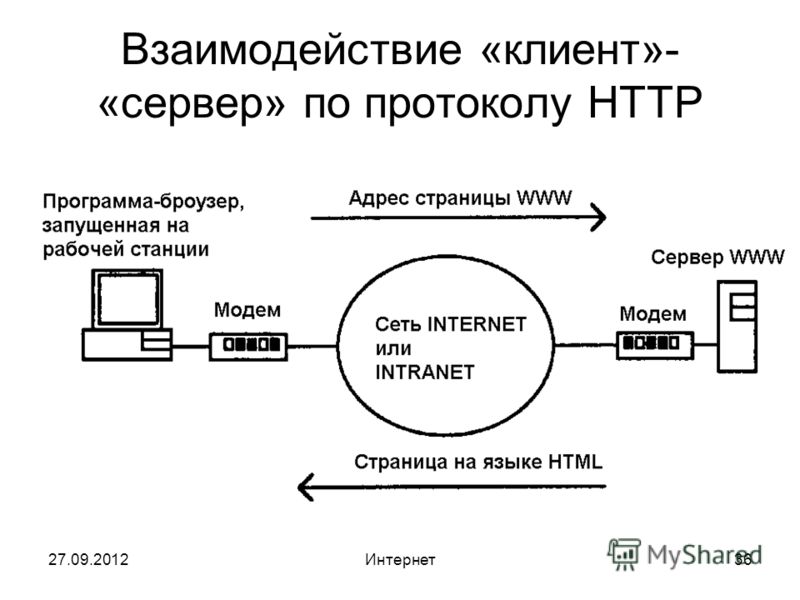
Если коротко:
- Сначала клиент отправляет запрос через сетевое устройство
- Затем сетевой сервер принимает и обрабатывает запрос пользователя
- Наконец, сервер доставляет ответ клиенту
Какова цель архитектуры клиент-сервер?
Мы уже установили, что технологии постоянно развиваются и совершенствуются, часто очень быстрыми темпами. В результате сегодняшние предприятия все больше полагаются на технологии, особенно ИТ, чтобы процветать и оставаться конкурентоспособными в среде «развивайся или умри».
В результате сегодняшние предприятия все больше полагаются на технологии, особенно ИТ, чтобы процветать и оставаться конкурентоспособными в среде «развивайся или умри».
Таким образом, современным организациям нужна система, упрощающая сбор, обработку и действия с корпоративными данными, что повышает эффективность бизнес-процессов и обеспечивает выживаемость на современных мировых рынках.
Сетевая модель клиент-сервер обеспечивает более высокий уровень обработки, что повышает эффективность мощности рабочих станций, расширение возможностей рабочих групп, удаленное управление сетью, ориентированный на рынок бизнес и сохранение существующих инвестиций.
Подводя итоги, можно сказать, что архитектура «клиент-сервер» обеспечивает именно ту структуру, которая необходима современным организациям для решения задач быстро развивающегося ИТ-мира.
Характеристики клиент-серверной архитектуры
Архитектура клиент-сервер обычно имеет следующие характеристики:
- Клиентские и серверные машины обычно требуют разных аппаратных и программных ресурсов и поставляются другими поставщиками.
- Сеть имеет горизонтальную масштабируемость, которая увеличивает количество клиентских машин и вертикальную масштабируемость, а затем перемещает весь процесс на более мощные серверы или в многосерверную конфигурацию.
- Один компьютер-сервер может одновременно предоставлять несколько служб, хотя для каждой службы требуется отдельная серверная программа.
- И клиентские, и серверные приложения напрямую взаимодействуют с протоколом транспортного уровня. Этот процесс устанавливает связь и позволяет объектам отправлять и получать информацию.
- И клиентскому, и серверному компьютерам необходим полный стек протоколов. Транспортный протокол использует протоколы нижнего уровня для отправки и получения отдельных сообщений.
Визуализация клиент-серверной архитектуры
На следующей диаграмме клиент-сервер показаны основы архитектуры:
Источник: Serverwatch.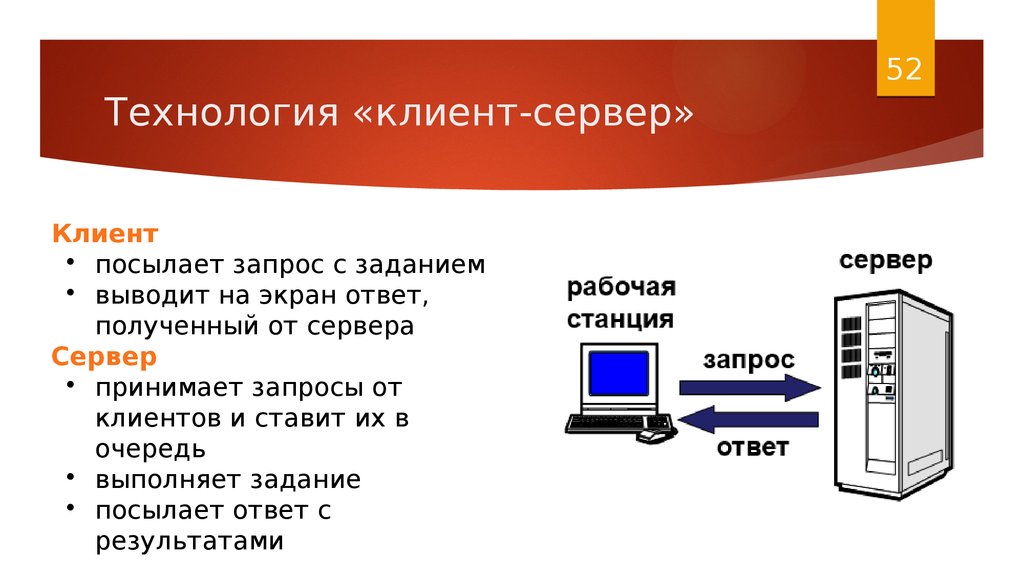
Какие примеры клиент-серверной архитектуры?
Вы можете задаться вопросом, что представляет собой реальное приложение архитектуры клиент-сервер. Вот три примера того, как вы используете архитектуру клиент-сервер, возможно, чаще, чем вы думаете!
- Серверы электронной почты. Благодаря простоте и скорости электронная почта вытеснила традиционную почтовую почту в качестве основной формы корпоративного общения. Серверы электронной почты, поддерживаемые различными брендами специального программного обеспечения, отправляют и получают электронные письма между сторонами.
- Файловые серверы. Если вы храните файлы в облачных службах, таких как Google Docs или Microsoft Office, вы используете файловый сервер. Файловые серверы — это централизованные хранилища файлов, к которым обращаются многие клиенты.
- Веб-серверы: на этих высокопроизводительных серверах размещено множество различных веб-сайтов, и клиенты получают к ним доступ через Интернет.
 Вот пошаговая разбивка:
Вот пошаговая разбивка: - Клиент/пользователь использует свой веб-браузер для ввода нужного URL-адреса
- Браузер запрашивает у системы доменных имен (DNS) IP-адрес
- DNS-сервер находит IP-адрес нужного сервера и отправляет его в веб-браузер
- Браузер создает запрос HTTPS или HTTP
- Сервер/производитель отправляет пользователю правильные файлы
- Клиент/пользователь получает файлы, отправленные сервером, и процесс повторяется по мере необходимости
Преимущества и недостатки клиент-серверной архитектуры
Архитектура клиент-сервер имеет свои положительные и отрицательные стороны для современных цифровых потребителей. Начнем со списка преимуществ:
- Это централизованная система, которая хранит все данные и элементы управления в одном месте
- Обеспечивает высокий уровень масштабируемости, организации и эффективности
- Позволяет ИТ-персоналу отдельно изменять мощности клиента и сервера
- Экономичен, особенно в плане обслуживания
- Позволяет восстановить данные
- Позволяет выполнять балансировку нагрузки, что оптимизирует производительность
- Позволяет различным платформам совместно использовать ресурсы
- Пользователям не нужно входить в терминал или другой процессор для доступа к корпоративной информации или настольным инструментам, таким как программы для презентаций PowerPoint или утилиты для работы с электронными таблицами
- Установка снижает частоту репликации данных
Естественно, клиент-серверная архитектура — это не только солнышко и леденцы.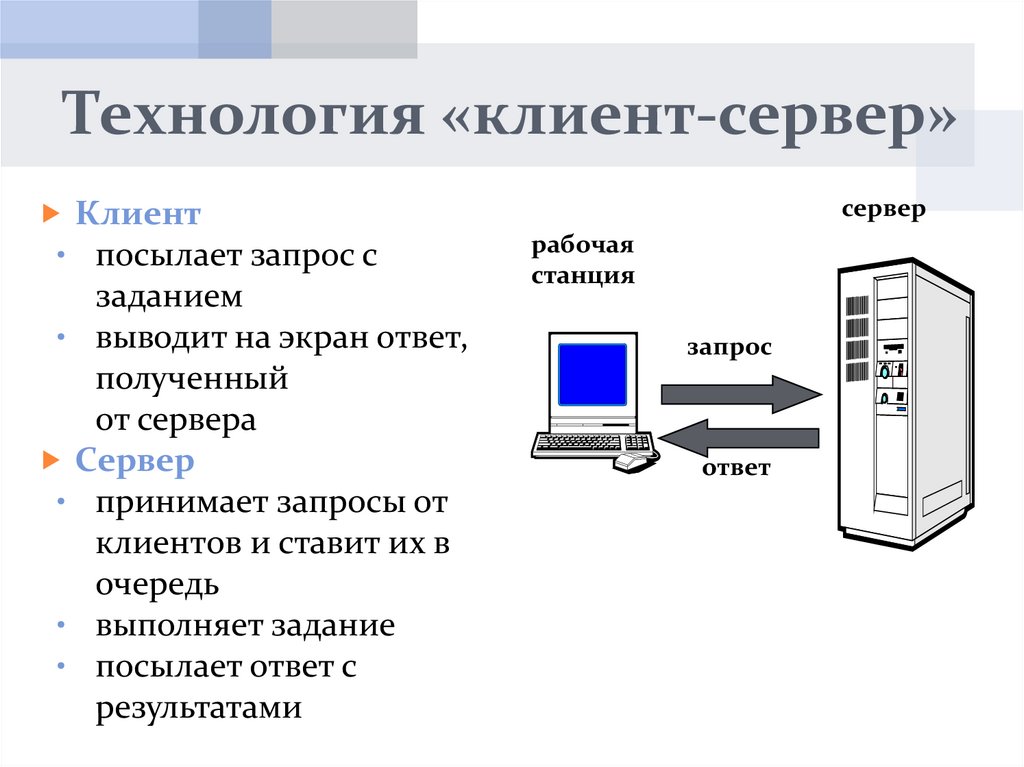 Вот минусы:
Вот минусы:
- Если на сервере есть червь, вирус или троян, пользователи, скорее всего, поймают его, поскольку сеть состоит из связанных клиентов и серверов
- Сервер уязвим для атак типа «отказ в обслуживании» (DoS).
- Пакеты данных могут быть подделаны или изменены во время передачи
- Запускать и первоначально внедрять дорого
- Если критический сервер выходит из строя, клиенты мертвы в воде
- Установка подвержена фишингу и атакам «Человек посередине» (MITM)
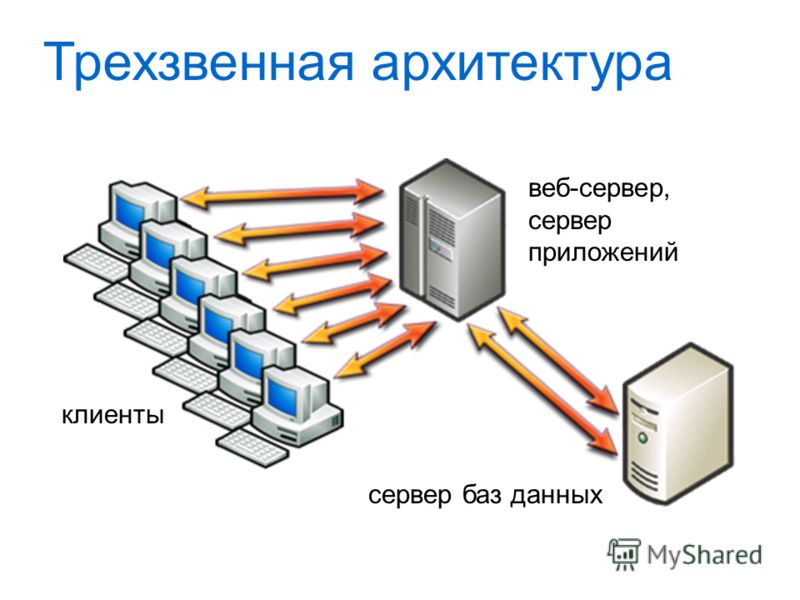
Что такое трехуровневая архитектура клиент-сервер?
Трехуровневая архитектура клиент-сервер состоит из уровня представления, известного как уровень пользовательского интерфейса, уровня приложений, называемого уровнем службы, и уровня данных, включающего сервер базы данных. Трехуровневую архитектуру можно разделить на три части:
- Уровень представления (или уровень клиента): этот уровень отвечает за пользовательский интерфейс.
- Прикладной уровень (или бизнес-уровень): этот уровень выполняет детальную обработку.
- Уровень базы данных (или уровень данных): на этом уровне хранится информация.
Клиентская система управляет уровнем представления; Сервер приложений следит за уровнем приложений, а серверная система контролирует уровень базы данных.
Вот модель трехуровневой клиент-серверной архитектуры:
Источник: Thecrazyprogrammer
Клиент-сервер против одноранговой сети: сравнение
Одноранговые сети, также называемые P2P-сетями, состоят из групп компьютеров (также называемых узлами или одноранговыми узлами), объединенных в сеть, где одноранговые узлы действуют как клиент и сервер. Пиры имеют равные обязанности и разрешения для работы с данными. Эта установка радикально отличается от модели клиент-сервер, которая имеет очень определенные группы пользователей и серверов.
Если вы зашли в ресторан быстрого питания, подошли к стойке и заказали бургер у продавца, это будут отношения клиент-сервер. Однако, если вы вошли в это заведение на следующий день и обнаружили, что они убрали персонал, вы могли закричать: «Кто-нибудь, пожалуйста, принесите мне гамбургер!» и другой клиент вставал, приносил вам гамбургер и звонил в продажу. Это одноранговая сеть!
Однако, если вы вошли в это заведение на следующий день и обнаружили, что они убрали персонал, вы могли закричать: «Кто-нибудь, пожалуйста, принесите мне гамбургер!» и другой клиент вставал, приносил вам гамбургер и звонил в продажу. Это одноранговая сеть!
Если вы слышали о блокчейне, поздравляем, вы знаете о одноранговой сети!
Вот основные различия между двумя сетевыми моделями:
- Сети клиент-сервер нуждаются в центральном файловом сервере и, следовательно, стоят дороже; у одноранговой сети нет этого сервера.
- Сети клиент-сервер разграничивают пользователей и провайдеров; партнеры действуют как потребители и поставщики.
- Сети клиент-сервер предлагают больше уровней безопасности, что делает их более безопасными. Конечные пользователи несут ответственность за безопасность одноранговой сети.
- Чем больше активных узлов в одноранговой сети, тем больше страдает ее производительность.
 Сети клиент-сервер обеспечивают лучшую стабильность и масштабируемость. Идеальный диапазон для P2P-сетей — от двух до восьми пользователей.
Сети клиент-сервер обеспечивают лучшую стабильность и масштабируемость. Идеальный диапазон для P2P-сетей — от двух до восьми пользователей. - Одноранговые пользователи могут обмениваться файлами быстрее и проще, чем в сети клиент-сервер.
- При сбое сервера сети клиент-сервер все останавливается, но если один узел в сети P2P выходит из строя, остальные продолжают работать.
Осмысление мира ИТ
Быстро развивающийся мир информационных технологий постоянно развивается и меняется. И не только предприятия и организации должны идти в ногу со временем — ИТ-специалисты, которые хотят оставаться впереди всех и повышать свои шансы на найм или продвижение в своей компании, должны расширять и повышать свои технологические навыки.
К счастью, в Simplilearn есть все ресурсы, необходимые для повышения квалификации и повышения вашей конкурентоспособности в перспективной компании. Будь то ИТ-услуги и архитектура, искусственный интеллект и машинное обучение, кибербезопасность или многие другие области, Simplilearn предлагает программы, учебные курсы, учебные пособия и другие ресурсы, необходимые для того, чтобы стать авторитетом в области ИТ.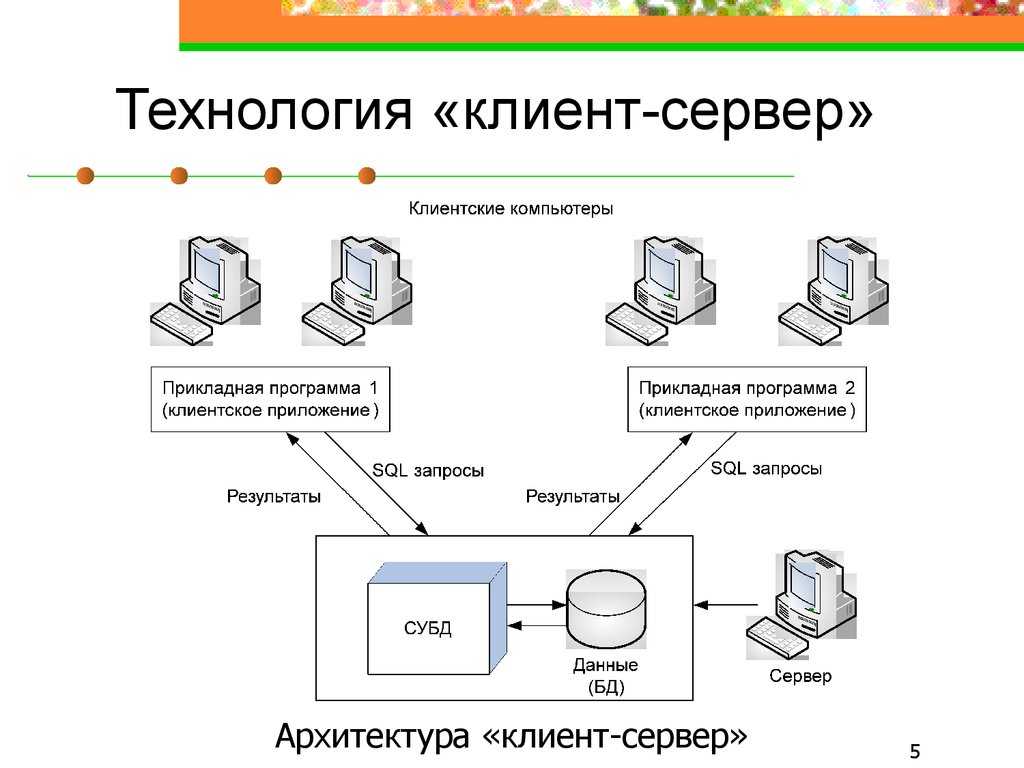
Попробуйте Simplilearn сегодня и поднимите свою карьеру на новый уровень!
Как работает ИТ: клиент-серверная модель
22 ноября 2016 г.
ИТ-отрасль прилагает постоянные усилия, чтобы сделать большие объемы информации, устройств и соединений максимально управляемыми. Даже сегодня многие из новых технологий, выпущенных Cisco, VMware, Citrix и другими разработчиками, предназначены для облегчения повседневных задач ИТ-специалистов. Это необходимо для дальнейшего успеха бизнеса.
С каждым годом компьютерные системы становятся все более и более сложными, и в результате вместе с ними усложняется и наша ИТ-среда. Нам нужен , чтобы продолжать оптимизировать наши операции и повышать эффективность управления, прежде чем мы все будем по уши в управленческих задачах.
Попутно технологи разработали модель клиент-сервер, чтобы немного облегчить жизнь ИТ-директорам, и она до сих пор широко используется.
Краткий обзор: Модель клиент-сервер
Модель клиент-сервер на практике является фундаментальным принципом работы всех центров обработки данных, включая облачные.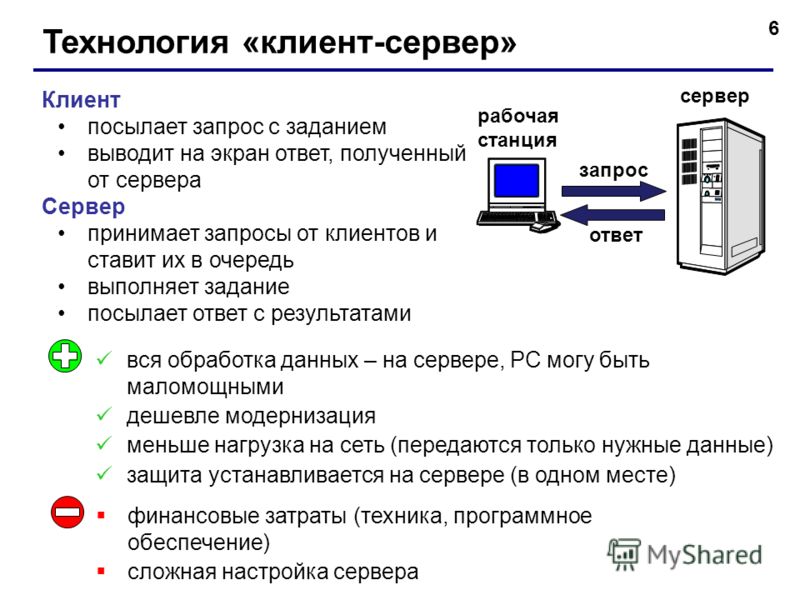 Термин «модель клиент-сервер» просто описывает стратегию, при которой не все необходимые приложения и файлы устанавливаются непосредственно на конечную точку. Вместо этого некоторые или все эти файлы или приложения устанавливаются на сервер, расположенный в другом месте. Клиенты, имеющие форму ноутбуков, настольных компьютеров, планшетов или смартфонов, затем запрашивают файл или приложение с удаленного сервера. Сервер слышит запрос, проверяет учетные данные и, если все проверено, передает клиенту запрошенный файл.
Термин «модель клиент-сервер» просто описывает стратегию, при которой не все необходимые приложения и файлы устанавливаются непосредственно на конечную точку. Вместо этого некоторые или все эти файлы или приложения устанавливаются на сервер, расположенный в другом месте. Клиенты, имеющие форму ноутбуков, настольных компьютеров, планшетов или смартфонов, затем запрашивают файл или приложение с удаленного сервера. Сервер слышит запрос, проверяет учетные данные и, если все проверено, передает клиенту запрошенный файл.
Связь между клиентами и серверами — улица с двусторонним движением. Серверы могут связываться с клиентами, чтобы убедиться, что у клиента есть соответствующие исправления, обновления, или узнать, нужно ли клиенту что-то еще. После того, как сервер выполнил свою работу, он закрывает соединение с клиентом, чтобы сохранить пропускную способность в сети.
Централизованные вычисления
В этом описании есть одна оговорка. Хотя централизованные вычисления могут использовать модель клиент-сервер, это не совсем одно и то же.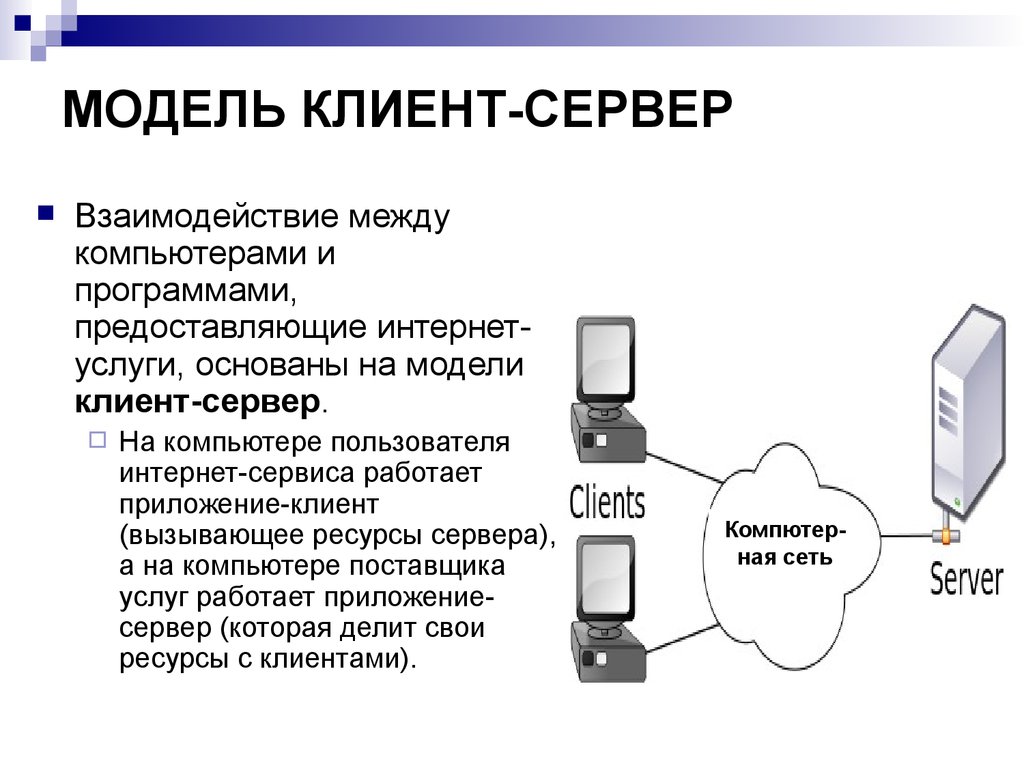 Модель клиент-сервер не обязательно требует, чтобы сервер обладал большими вычислительными ресурсами, чем клиент. Однако централизованные вычисления, в частности, означают, что большинство вычислительных ресурсов консолидированы в одном серверном пространстве.
Модель клиент-сервер не обязательно требует, чтобы сервер обладал большими вычислительными ресурсами, чем клиент. Однако централизованные вычисления, в частности, означают, что большинство вычислительных ресурсов консолидированы в одном серверном пространстве.
Преимущества клиент-сервера: централизованное управление
Преимущества этого подхода довольно очевидны. Предположим, компания использует определенную цифровую форму в качестве ключевой части своего бизнес-процесса. Сотни сотрудников используют его десятки раз в день, и существуют юридические требования и деловая политика, связанные с правильным заполнением формы. Теперь предположим, что принят новый закон и его форму нужно немного изменить.
Без клиент-серверной системы
Компания должна будет раздать файл каждому сотруднику и надеяться, что теперь они будут использовать этот новый файл вместо старой версии, уже сохраненной на их устройствах.
С системой клиент-сервер
Этот процесс довольно прост. Сотрудники уже обращались к форме удаленно с сервера. Для распространения и обновления файла ИТ-администратору достаточно заменить файл новой версией на сетевом диске. Файл никогда не устанавливался на отдельные компьютеры, поэтому обновление для всей компании выполняется одним окончательным действием.
Сотрудники уже обращались к форме удаленно с сервера. Для распространения и обновления файла ИТ-администратору достаточно заменить файл новой версией на сетевом диске. Файл никогда не устанавливался на отдельные компьютеры, поэтому обновление для всей компании выполняется одним окончательным действием.
Простая концепция, огромное влияние
Сегодня мы видим, что модель клиент-сервер еще больше расширяется до облака. По сути, облако — это просто более крупный и взаимосвязанный сервер, который вы арендуете у облачного провайдера. Клиент — ваша конечная точка — по-прежнему отправляет запросы и получает файлы с сервера почти таким же образом. Модель «клиент-сервер» настолько эффективна для поддержания согласованности между большими коллекциями клиентов, что трудно представить, чтобы передовые ИТ-практики перешли на другую альтернативу.
Нравится то, что вы читаете?
О Mindsight
Mindsight, чикагский поставщик ИТ-консалтинга и услуг, является продолжением вашей команды.