история, виды, примеры, применение Big Data
NoSQL – это подход к реализации масштабируемого хранилища (базы) информации с гибкой моделью данных, отличающийся от классических реляционных СУБД. В нереляционных базах проблемы масштабируемости (scalability) и доступности (availability), важные для Big Data, решаются за счёт атомарности (atomicity) и согласованности данных (consistency) [1].
Зачем нужны нереляционные базы данных в Big Data: история появления и развития
NoSQL-базы оптимизированы для приложений, которые должны быстро, с низкой временной задержкой (low latency) обрабатывать большой объем данных с разной структурой [2]. Таким образом, нереляционные хранилища непосредственно ориентированы на Big Data. Однако, идея баз данных такого типа зародилась гораздо раньше термина «большие данные», еще в 80-е годы прошлого века, во времена первых компьютеров (мэйнфреймов) и использовалась для иерархических служб каталогов. Современное понимание NoSQL-СУБД возникло в начале 2000-х годов, в рамках создания параллельных распределённых систем для высокомасштабируемых интернет-приложений, таких как онлайн-поисковики [1].
Современное понимание NoSQL-СУБД возникло в начале 2000-х годов, в рамках создания параллельных распределённых систем для высокомасштабируемых интернет-приложений, таких как онлайн-поисковики [1].
Вообще термин NoSQL обозначает «не только SQL» (Not Only SQL), характеризуя ответвление от традиционного подхода к проектированию баз данных. Изначально так называлась опенсорсная база данных, созданная Карло Строззи, которая хранила все данные как ASCII-файлы, а вместо SQL-запросов доступа к данным использовала шелловские скрипты [3]. В начале 2000-х годов Google построил свою поисковую систему и приложения (GMail, Maps, Earth и прочие сервисы), решив проблемы масштабируемости и параллельной обработки больших объёмов данных. Так была создана распределённые файловая и координирующая системы, а также колоночное хранилище (column family store), основанное на вычислительной модели MapReduce. После того, как корпорация Google опубликовала описание этих технологий, они стали очень популярны у разработчиков открытого программного обеспечения. В результате этого был создан Apache Hadoop и запущены основные связанные с ним проекты. Например, в 2007 году другой ИТ-гигант, Amazon.com, опубликовав статьи о своей высокодоступной базе данных Amazon DynamoDB. Далее в эту гонку NoSQL- технологий для управления большими данными включилось множество корпораций: IBM, Facebook, Netflix, eBay, Hulu, Yahoo! и другие ИТ-компаний со своими проприетарными и открытыми решениями [1].
В результате этого был создан Apache Hadoop и запущены основные связанные с ним проекты. Например, в 2007 году другой ИТ-гигант, Amazon.com, опубликовав статьи о своей высокодоступной базе данных Amazon DynamoDB. Далее в эту гонку NoSQL- технологий для управления большими данными включилось множество корпораций: IBM, Facebook, Netflix, eBay, Hulu, Yahoo! и другие ИТ-компаний со своими проприетарными и открытыми решениями [1].
Какие бывают NoSQL-СУБД: основные типы нереляционных баз данных
Все NoSQL решения принято делить на 4 типа:
- Ключ-значение (Key-value) – наиболее простой вариант хранилища данных, использующий ключ для доступа к значению в рамках большой хэш-таблицы [4]. Такие СУБД применяются для хранения изображений, создания специализированных файловых систем, в качестве кэшей для объектов, а также в масштабируемых Big Data системах, включая игровые и рекламные приложения, а также проекты интернета вещей (Internet of Things, IoT), в т.

- Документно-ориентированное хранилище, в котором данные, представленные парами ключ-значение, сжимаются в виде полуструктурированного документа из тегированных элементов, подобно JSON, XML, BSON и другим подобным форматам [4]. Такая модель хорошо подходит для каталогов, пользовательские профилей и систем управления контентом, где каждый документ уникален и изменяется со временем [2]. Поэтому чаще всего документные NoSQL-СУБД используются в CMS-системах, издательском деле и документальном поиске. Самые яркие примеры документно-ориентированных нереляционных баз данных – это CouchDB, Couchbase, MongoDB, eXist, Berkeley DB XML [1].

- Колоночное хранилище, которое хранит информацию в виде разреженной матрицы, строки и столбцы которой используются как ключи. В мире Big Data к колоночным хранилищам относятся базы типа «семейство столбцов» (Column Family). В таких системах сами значения хранятся в столбцах (колонках), представленных в отдельных файлах. Благодаря такой модели данных можно хранить большое количество атрибутов в сжатом виде, что ускоряет выполнение запросов к базе, особенно операции поиска и агрегации данных [4]. Наличие временных меток (timestamp) позволяет использовать такие СУБД для организации счётчиков, регистрации и обработки событий, связанных со временем: системы биржевой аналитики, IoT/IIoT-приложения, систему управления содержимым и т.д. Самой известной колоночной базой данных является Google Big Table, а также основанные на ней Apache HBase и Cassandra. Также к этому типу относятся менее популярные ScyllaDB, Apache Accumulo и Hypertable

- Графовое хранилище представляют собой сетевую базу, которая использует узлы и рёбра для отображения и хранения данных [4]. Поскольку рёбра графа являются хранимыми, его обход не требует дополнительных вычислений (как соединение в SQL). При этом для нахождения начальной вершины обхода необходимы индексы. Обычно графовые СУБД поддерживают ACID-требования и специализированные языки запросов (Gremlin, Cypher, SPARQL, GraphQL и т.д.) [1]. Такие СУБД используются в задачах, ориентированных на связи: социальные сети, выявление мошенничества, маршруты общественного транспорта, дорожные карты, сетевые топологии [3]. Примеры графовых баз: InfoGrid, Neo4j, Amazon Neptune, OrientDB, AllegroGraph, Blazegraph, InfiniteGraph, FlockDB, Titan, ArangoDB. О том, как проанализировать граф в Neo4j средствами языка запросов Cypher, читайте в нашей отдельной статье.
Чем хороши и плохи нереляционные базы данных: главные достоинства и недостатки
По сравнению с классическими SQL-базами, нереляционные СУБД обладают следующими преимуществами:
- линейная масштабируемость – добавление новых узлов в кластер увеличивает общую производительность системы [1];
- гибкость, позволяющая оперировать полуструктирированные данные, реализуя, в.
 т.ч. полнотекстовый поиск по базе [2];
т.ч. полнотекстовый поиск по базе [2]; - возможность работать с
- высокая доступность за счет репликации данных и других механизмов отказоустойчивости, в частности, шаринга – автоматического разделения данных по разным узлам сети, когда каждый сервер кластера отвечает только за определенный набор информации, обрабатывая запросы на его чтение и запись. Это увеличивает скорость обработки данных и пропускную способность приложения [5].
- производительность за счет оптимизации для конкретных видов моделей данных (документной, графовой, колоночной или «ключ‑значение») и шаблонов доступа [2];
- широкие функциональные возможности – собственные SQL-подобные языки запросов, RESTful-интерфейсы, API и сложные типы данных, например, map, list и struct, позволяющие обрабатывать сразу множество значений [2].

Обратной стороной вышеуказанных достоинств являются следующие недостатки:
- ограниченная емкость встроенного языка запросов [5]. Например, HBase предоставляет всего 4 функции работы с данными (Put, Get, Scan, Delete), в Cassandra отсутствуют операции Insert и Join, несмотря на наличие SQL-подобного языка запросов. Для решения этой проблемы используются сторонние средства трансляции классических SQL-выражений в исполнительный код для конкретной нереляционной базы. Например, Apache Phoenix для HBase или универсальный Drill.
- сложности в поддержке всех ACID-требований к транзакциям (атомарность, консистентность, изоляция, долговечность) из-за того, что NoSQL-СУБД вместо CAP-модели (согласованность, доступность, устойчивость к разделению) скорее соответствуют модели BASE (базовая доступность, гибкое состояние и итоговая согласованность)
 Аналогичным образом Riak позволяет настраивать требуемые характеристики доступности-согласованности даже для отдельных запросов за счет задания количества узлов, необходимых для подтверждения успешного завершения транзакции [1]. Подробнее о CAP-и BASE-моделях мы расскажем в отдельной статье.
Аналогичным образом Riak позволяет настраивать требуемые характеристики доступности-согласованности даже для отдельных запросов за счет задания количества узлов, необходимых для подтверждения успешного завершения транзакции [1]. Подробнее о CAP-и BASE-моделях мы расскажем в отдельной статье. - сильная привязка приложения к конкретной СУБД из-за специфики внутреннего языка запросов и гибкой модели данных, ориентированной на конкретный случай [5];
- недостаток специалистов по NoSQL-базам по сравнению с реляционными аналогами [5].
Подводя итог описанию основных аспектов нереляционных СУБД, стоит отметить некоторую некорректность запроса «NoSQL vs SQL» в связи с разными архитектурными подходами и прикладными задачами, на которые ориентированы эти ИТ-средства. Традиционные SQL-базы отлично справляются с обработкой строго типизированной информации не слишком большого объема. Например, локальная ERP-система или облачная CRM. Однако, в случае обработки большого объема полуструктурированных и неструктурированных данных, т.е. Big Data, в распределенной системе следует выбирать из множества NoSQL-хранилищ, учитывая специфику самой задачи. В частности, для самостоятельных решений интернета вещей (Internet of Things), в т.ч. промышленного, отлично подходит Cassandra, о чем мы рассказывали здесь. А в случае многоуровневой ИТ-инфраструктуры на базе Apache Hadoop стоит обратить внимание на HBase, которая позволяет оперативно, практически в режиме реального времени, работать с данными, хранящимися в HDFS.
Например, локальная ERP-система или облачная CRM. Однако, в случае обработки большого объема полуструктурированных и неструктурированных данных, т.е. Big Data, в распределенной системе следует выбирать из множества NoSQL-хранилищ, учитывая специфику самой задачи. В частности, для самостоятельных решений интернета вещей (Internet of Things), в т.ч. промышленного, отлично подходит Cassandra, о чем мы рассказывали здесь. А в случае многоуровневой ИТ-инфраструктуры на базе Apache Hadoop стоит обратить внимание на HBase, которая позволяет оперативно, практически в режиме реального времени, работать с данными, хранящимися в HDFS.
Источники
- https://ru.wikipedia.org/wiki/NoSQL
- https://aws.amazon.com/ru/nosql/
- https://ru.bmstu.wiki/NoSQL
- https://tproger.ru/translations/types-of-nosql-db/
- https://habr.com/ru/sandbox/113232/
Related Entries
Блокировки в 1С и СУБД.
 Виды блокировок в 1С
Виды блокировок в 1СЧто такое блокировки в 1С и СУБД?
ПОЛЕЗНЫЕ ССЫЛКИ:
Из-за чего возникают избыточные блокировки в 1С? Выбор сервера для 1С 8.3 Выбор СУБД для 1С В нашей статье расскажем про блокировки на следующих уровнях: в 1С 8.3 и 8.2; в СУБД. Разберем принцип их действия, и разновидности. Если в системе работает более одного пользователя, то обязательно нужна опция «Блокировка данных».Блокировка демонстрирует, что системными ресурсами завладел «чужой» пользователь. Некоторые приравнивают ее к ошибке. Но это не так. Блокировка предназначена для разделения ресурсов, она является вынужденной и крайне необходимой мерой для работы в многопользовательском режиме.
На ряду с положительными действиями, из-за избыточного количества блокировок вполне может произойти и отрицательный эффект для системы. Их порою называют «лишними» за то, что они своим влиянием слишком много информации охватывают. Такие блокировки надо убирать, т.к. они способны сделать систему малоэффективной.
Такие блокировки надо убирать, т.к. они способны сделать систему малоэффективной.
 В нем действуют блокировки на уровне СУБД.
В нем действуют блокировки на уровне СУБД.Применять их следует с осторожностью, чтобы не было проблемных моментов на разных уровнях изоляции транзакций.Автоматические транзакционные блокировки 1С и СУБД В этом режиме все блокировки осуществляет СУБД. Программисты не могут никак повлиять на процесс. При этом разработчикам несколько проще выполнять свои действия, но пользователям не рекомендуется создавать здесь информационную систему (в особенности для СУБД PostgreSQL, Oracle BD, т.к. в процессе модификации сведений они заблокируют всю табличную часть).
Для различных СУБД в автоматическом режиме применяют такие степени изоляции:
1. SERIALIZABLE целиком на таблицу – файловый режим 1С, PostgreSQL, Oracle.
2. SERIALIZABLE на записи – MS SQL, IBM DB2 (работая с не объектными сущностями).
3. REPEATABLE READ на записи – MS SQL, IBM DB2 (с объектными).
Управляемые режимы транзакционных блокировок 1С и СУБД При таком варианте вся ответственность должна ложиться на производителя программного продукта 1С. Отметим, что СУБД назначает повышенный уровень изоляции для транзакций — READ COMMITED.
Отметим, что СУБД назначает повышенный уровень изоляции для транзакций — READ COMMITED.Взаимодействуя с БД, менеджер блокировок 1С проводит анализ – возможен ли «захват» ресурса. Важно понимать, что блокировки, проведенные одним исполнителем совместимы в любом случае.
Но существует ситуация, при которой две блокировки НЕ состыкуются ни при каких обстоятельствах:
1. Их сделали разные пользователи.
2. Несовместимые виды.
3. Установили на один ресурс.
Физическая реализация блокировок в СУБД Мы говорим о таблице, находящейся в БД под именем «master». А таблица блокировок обозначается словом «syslockinfo».В таблице есть четыре ячейки:
1. ИД блокирующей сессии SPID.
2. Что конкретно захвачено RES ID.
3. Типы блокировки — S, U или X MODE (их, конечно же, значительно больше, но в 1С применяют лишь эти три).
4. Состояние блокировки — есть два понятия: GRANT (установлена) и WAIT (в очереди).
Чтобы завершить транзакции на уровне SQL как правило применяют команду KILL и указывают идентификатор сессии: KILL SPID/
Какие типы блокировок 1С совместимы?|
S |
U |
X |
|
|
S |
+ |
+ |
— |
|
U |
+ |
— |
— |
|
X |
— |
— |
- |
Обозначения:
S — разделяемая блокировка (чтение).
U — блокировка обновления (которая установлена в запросе конструкцией «ДЛЯ ИЗМЕНЕНИЯ»).
X — исключительная блокировка (на запись).
Вернуться в блогНОВОСТИ
Перейти в Блог22.05
Базовые программы «1С» со скидкой 50%
26.04
XXIX Всероссийская студенческая научно-теоретическая конференция
17.04
Интервью со студенткой Оренбургского филиала РЭУ им. Г.В. Плеханова Анастасией Кужбаевой
Отзывы о компании
Сивелькина С. В.
ПАО «НИКО-БАНК» выражает свою благодарность за оперативную и грамотную работу.
В условиях постоянно меняющегося законодательства Банк заинтересован иметь полную и актуальную номативную базу. Это обеспечивается использованием Банком справочно-нормативной системы «Гарант».
Безусловным плюсом в работе компании «МастерСофт» является быстрое реагирование сотрудников при предоставлении документов по запросу Банка, принятых до обновления справочно-правовой системы.
Мордвинцев С. П.
Коллектив компании «АЭРОПОРТ ОРЕНБУРГ» выражает благодарность за взаимовыгодное сотрудничество с МастерСофт-ИТ. Оперативная поставка антивирусных программ Dr. Web обеспечила надежную защиту нашей компьтерной сети.
Особая благодарность сотрудникам Департамента продаж СЦ ИТ за профессиональный подход в решении всех возникающих задач.Ряховская Н. А.
ООО «Орский Вагонный Завод» выражает искреннюю благодраность за качество обслуживания вашими специалистами. Консультации и поставка антивирусов всегда проходят оперативно и на высоком профессиональном уровне.
Уверены, что и в дальнейшем наше сотрудничество на взаимовыгодных условиях продолжится.Кетерер Т.
 М.
М.Главный бухгалтер муниципального бюджетного учреждения дополнительного образования «Дворец творчества детей и молодёжи» Кетерер Татьяна Михайловна выражает благодарность специалистам МастерСофт:
«Я хотела бы объявить благодарность вашим сотрудникам. Работает с нами по программе «1С: Бухгалтерия бюджетного учреждения 8» непосредственно Шевлягина Юлия.
Так же огромная благодарность за отзывчивость, терпение и квалифицированную, своевременную помощь Набокиной Олесе и Ерёменко Татьяне (они нас сопровождают по программе «Зарплата и Кадры»).
Им очень с нами тяжело, но они терпеливо продолжают сотрудничать. С вами очень надёжно. Конечно же наши ошибки есть и без вас мы бы вообще о них не знали и в суде, наверное, судились бы. А сейчас мы решаем вопросы…».
Типы элементов в сцене
Поиск
Существует несколько типов элементов, которые могут сосуществовать в сцене: Mesh , Curve , Particle и Basis . Эти типы могут взаимодействовать для определения сложного поведения и дальнейшего использования возможностей моделей вещества.
Эти типы могут взаимодействовать для определения сложного поведения и дальнейшего использования возможностей моделей вещества.
Сетка представляет собой группу частиц в трехмерном пространстве (вершины), соединенных сегментами (ребрами) для создания поверхностей (полигонов).
Расположение вершин и способ их соединения называется топологией , и сетка будет по-разному реагировать на определенные операции в зависимости от ее топологии. Например, деформация скручивания требует достаточного количества вершин, соединенных вместе таким образом, чтобы перетекала с ориентацией скручивания, чтобы обеспечить плавный результат.
На сетки может отрицательно влиять топология, которая ставит под угрозу ее целостность , например, перекрывающиеся вершины, дыры, неоднородность или полигоны с более чем 4 ребрами (NGons).
То, как поверхности меша реагируют на свет, определяется Нормалью его вершин. Нормаль — это вектор, который определяет направление вершины/поверхности , обращенной к и по умолчанию перпендикулярной поверхности меша.
Нормаль — это вектор, который определяет направление вершины/поверхности , обращенной к и по умолчанию перпендикулярной поверхности меша.
Для любой вершины, которая «связывает» два полигона вместе, будет одна нормаль вершины, определенная для каждого полигона . Если эти нормали выровнены по , затенение от одного полигона к другому будет равно гладкий . Если нормали невыровненные , затенение будет разбитым на части , что приведет к видимой разнице в затенении между полигонами.
Сетки с базовыми формами можно создавать с помощью узла Primitive 3D, или вы можете загружать свои собственные пользовательские сетки с помощью узла ресурсов сцены.
Сетка подразделения (SubD)
Существует определенный тип сетки, который может быть подразделен на более плотную, более гладкую версию динамически: подразделение ( SubD ) сетки. Сетки
SubD позволяют вам моделировать геометрию без влияния на производительность обработки очень плотных сеток из тысяч/миллионов полигонов, сохраняя редактируемую версию сетки, то есть управляющую сетку , достаточно легкой, а затем процедурно подразделяя ее.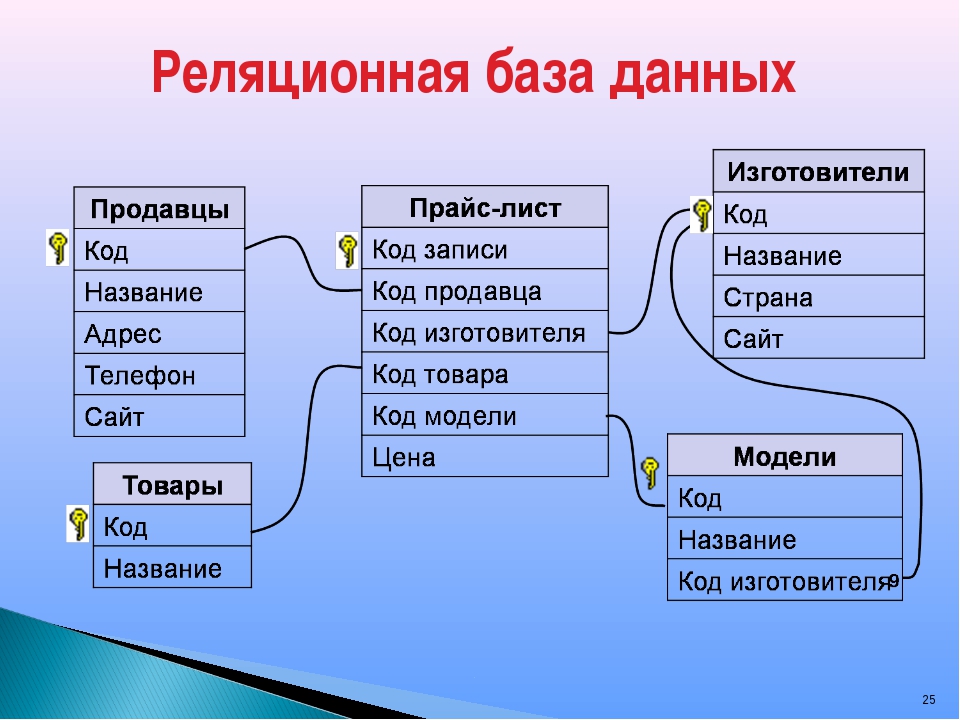
Управляющая сетка — это базовая геометрия, которая используется для управления формой разделенной/сглаженной сетки. Плоскость Subdivision и поле Subdivision создают сетки SubD и позволяют настраивать свойства их управляющей сетки, такие как размеры и количество граней на каждой оси.
В примере справа он представлен с прозрачной поверхностью и красными вершинами. Непрозрачная сетка представляет собой сглаженный результат SubD со значением резкости 0.
Вы можете использовать прямое подразделение (т.е. бесконечно резкое ), которое не влияет на силуэт (например, для скульптинга) или сгладить жесткие углы сетки, поскольку она подразделяется. Поскольку сглаживание полностью динамическое, резкость углов можно настроить на лету.
В графах модели Substance эти сетки обрабатываются иначе, чем стандартные сетки, поэтому сетки должны быть явно установлены как сетки SubD . Это делается с помощью узлов примитивов подразделения, упомянутых выше, или путем установки свойства As Subd узла ресурсов сцены на True для пользовательских сеток.
Кривая — это описание пути через точки в трехмерном пространстве.
Кривая имеет определенную ориентацию, т. е. для двух точек A и B отношение A к B отличается от B к A. Кривые также могут быть замкнутыми, и в этом случае у вас может быть путь, идущий от A к B и C и снова к А.
В дополнение к положению каждая точка кривой имеет нормаль . Нормаль определяет «поворот» кривой в данной точке. Все кривые в графах модели Substance представляют собой полилиний , что означает, что кривые, проходящие от узла к другому, на самом деле являются списками небольших сегментов, каждый из которых идеально прямой .
Мы используем такие узлы, как примитив Curve, которые используют различные стили интерполяции для создания этих сегментов, чтобы аппроксимировать идеально гладкую кривую в пространстве. Чем выше разрешение, тем больше сегментов, тем плавнее криво выглядит.
Типы интерполяции, поддерживаемые во время создания:
- Полилиния строится из нескольких прямых сегментов, соединенных вершинами, и может быть разделена на большее количество точек.
 Этот режим позволяет напрямую использовать математические функции, такие как эллипсы или спирали, и каждая точка идеально выровнена.
Этот режим позволяет напрямую использовать математические функции, такие как эллипсы или спирали, и каждая точка идеально выровнена. - Кубическая кривая Безье следует траектории, определяемой математической операцией. Интерполяция кривой между заданными «Контрольными точками» управляется этой математикой. Большинство кривых Photoshop и Illustrator внутренне полагаются на этот тип интерполяции.
- B-сплайн (базисный сплайн) и NURBS (неоднородный рациональный базисный сплайн) также следуют траекториям, определенным математическими операциями, но эти кривые не проходят через каждую точку, которая их описывает, если только несколько точек не перекрываются в то же место. Каждая точка имеет вес, определяющий величину ее влияния на траекторию кривой. Эти кривые разделены на сегменты одинаковой длины для B-сплайнов и неравной длины для NURBS.
Дополнительные функции и возможности кривых в разработке .
Мы также планируем изначально поддерживать эти интерполяции, чтобы их контрольные точки по-прежнему были доступны для использования другими узлами в будущем. Однако на данный момент все результаты запекаются до полилиний.
Частица
A Частица представляет собой объект, представляющий уникальное местоположение в трехмерном пространстве с заданным ориентация . Мы обычно называем набор сгенерированных и рассеянных Частиц Облаком Частиц .
Базис представляет собой локальное координатное пространство , которое может служить более простой точкой отсчета для новых преобразований, деформаций и создания экземпляров Элементов. Основа может адаптировать к свойствам других Элементов, например. опираясь на сетку по мере изменения ее высоты.
Например, если вы хотите переместить сетку вдоль стены, проще создать новую основу, выровненную с этой поверхностью, и использовать эту новую опорную основу для перемещения сетки, как если бы она находилась на «полу». Если стена изменит размеры, Основа последует за ней, и все Предметы, использующие эту Основу, будут перемещаться соответственно, чтобы опираться на стену.
Если стена изменит размеры, Основа последует за ней, и все Предметы, использующие эту Основу, будут перемещаться соответственно, чтобы опираться на стену.
Все узлы в графе модели вещества, которые принимают сцену в качестве входных данных, будут изменять сцену, используя ее глобальную выровненную по миру ограничивающую рамку в качестве опорного пространства, если иное не указано явно в параметре. Пользовательский базис — это один из методов указания этого эталонного пространства.
Подробнее читайте в описании базового узла.
Взаимодействие между типами элементов
Перечисленные выше типы элементов следует использовать в сочетании, чтобы использовать все возможности графов модели вещества. Вот несколько примеров таких комбинаций:
- Сети могут быть созданы вдоль кривой
- Частицы могут быть отобраны на поверхности сетки, чтобы затем создавать другие сетки на их позициях
- Кривые могут быть извлечены из сегментов сетки
- Сетки могут использоваться для все сетки, с которыми они перекрываются
- Преобразование (положение, ориентация, масштаб) сетки может использоваться в качестве основы для других сеток или кривых
В примере справа Кривые, Частицы и Базы были показаны только в демонстрационных целях. Вы можете отобразить эти элементы в конечном результате для проверки поведения вашей сцены, включив их в слияния сцен .
Вы можете отобразить эти элементы в конечном результате для проверки поведения вашей сцены, включив их в слияния сцен .
Войдите в свою учетную запись
Войти
Управление учетной записьюУпражнение по моделированию подразделения
Создание полигональной сетки вручную обычно приводит к грубой и блочной модели, непригодной для производства. На самом деле генерировать каждый полигон нужного для производства размера было бы утомительно, поэтому мы будем использовать поверхности подразделения. Основная идея поверхности подразделения заключается в том, что пользователь предоставляет «контур» модели в виде входной полигональной сетки, а затем компьютер подразделяет или «сглаживает» входную сетку для создания сетки гораздо более высокого разрешения.
Примечание: В Maya есть тип объекта, называемый Subdiv Surface, который представляет собой адаптивный тип поверхности подразделения. Мы не будем использовать Subdiv Surfaces в этом классе по разным причинам. Когда мы говорим о поверхностях подразделения, мы всегда будем иметь в виду полигональную сетку, созданную командой Smooth .
Мы не будем использовать Subdiv Surfaces в этом классе по разным причинам. Когда мы говорим о поверхностях подразделения, мы всегда будем иметь в виду полигональную сетку, созданную командой Smooth .
Существует два типа поверхностей подразделения: интерполяционная и аппроксимирующая. В первом случае поверхность подразделения будет проходить через точки, указанные во входной сетке. Во втором случае входная сетка информирует, но не полностью ограничивает форму поверхности подразделения. Maya использует аппроксимирующий метод подразделения, поэтому хорошо иметь в виду, что сглаженная сетка не всегда будет похожа на исходную сетку. См. куб ниже для демонстрации этого.
Клавиши 1 , 2 и 3 обеспечивают различные режимы просмотра поверхности подразделения. Клавиша 1 покажет только входную сетку, клавиша 2 покажет каркас входной сетки и поверхность подразделения, а клавиша 3 покажет только поверхность подразделения. Попробуйте создать различные полигональные примитивы и посмотрите, как они выглядят в разных режимах сглаживания.
Попробуйте создать различные полигональные примитивы и посмотрите, как они выглядят в разных режимах сглаживания.
Следует отметить, что различные режимы сглаживания не влияют на саму базовую геометрию. Они обеспечивают только предварительный просмотр того, как будет выглядеть разделенная поверхность. Это быстро станет очевидным, когда вы попытаетесь отрендерить свою модель и увидите только входную сетку. Чтобы на самом деле разделить сетку, вам нужно будет использовать Гладкая (Сетка → Гладкая) .
Насколько гладкой будет разделенная поверхность, зависит от того, сколько раз она была разделена. Вы можете указать это в Smooth (Options) или, если Smooth уже применено, то вы можете отредактировать атрибут Divisions узла polySmoothFace в Channel Box.
Как правило, вам нужно всего лишь дважды разделить сетку, чтобы создать сетку, готовую к рендерингу. Если вы все еще можете различить отдельные полигоны в силуэте разделенной сетки, вам, вероятно, нужно добавить больше деталей к входной сетке. Вы можете изменить количество делений, которые вы видите, когда в 2 и 3 режимы сглаживания нажатием Page Up и Page Down . Чтобы установить уровень разделения в предварительном просмотре на два, нажимайте Page Down до тех пор, пока сетка больше не будет подразделяться, затем дважды нажмите Page Up .
Вы можете изменить количество делений, которые вы видите, когда в 2 и 3 режимы сглаживания нажатием Page Up и Page Down . Чтобы установить уровень разделения в предварительном просмотре на два, нажимайте Page Down до тех пор, пока сетка больше не будет подразделяться, затем дважды нажмите Page Up .
Как вы, наверное, заметили, разделение сетки приводит к сглаживанию всех жестких краев. Сглаженный куб практически выглядит как сфера. Хотя обычно это желаемое поведение, иногда мы хотим сохранить четкую кромку на разделенной поверхности. Есть два основных способа сохранить четкие края: добавить больше петель края или использовать инструмент Crease Tool.
Самый простой способ укрепить края — добавить больше петель. Форма поверхности подразделения зависит от особенностей локальной геометрии области. Добавляя больше ребер, вы делаете геометрию более плотной и, таким образом, уменьшаете влияние поверхности подразделения. Как правило, достаточно иметь дополнительную кромочную петлю с каждой стороны, чтобы создать достаточно жесткую кромку. Попробуйте укрепить различные края, добавив к кубу контуры краев.
Как правило, достаточно иметь дополнительную кромочную петлю с каждой стороны, чтобы создать достаточно жесткую кромку. Попробуйте укрепить различные края, добавив к кубу контуры краев.
Одним из быстрых способов добавить дополнительные ребра является использование 9Команда 0005 Bevel ( Edit Mesh → Bevel ). Это создаст красивый изогнутый край с таким количеством дополнительных краев, которое вы выберете. В зависимости от того, на каких краях вы используете Bevel , он может создать несколько треугольников, поэтому будьте осторожны при его использовании.
Добавление дополнительных реберных петель — это простой метод, который легко использовать и понимать. Однако это немного неэффективно, так как требует усложнения сетки, которая не дает много информации. Обычно это не проблема, поскольку рендеринг геометрии обходится дешево, но если вы хотите свести к минимуму количество геометрии, которая у вас есть, или усилить жесткость очень определенного края, используйте Crease Tool (Edit Mesh → Crease Tool) .
Чтобы сделать край более жестким, выберите нужные края активным инструментом Crease Tool. Как только края выбраны, щелкните средней кнопкой мыши и перетащите мышь влево и вправо, чтобы отрегулировать твердость краев. Вам следует избегать слишком сильного сгибания края, так как обычно это приводит к неправильной нормали вдоль сгиба. Если вам больше не нужны складки, их можно легко убрать с объекта (Редактировать сетку → Удалить все) . Попробуйте инструмент Crease Tool на разных краях прямо сейчас.
Что-то не так с самолетом на изображении ниже. Он выглядит нормально, когда не разделен, но когда он разделен, центральная грань ведет себя странно. Выбор объекта и включение Face Normals показывает проблему ( Display → Polygons → Face Normals ). Нормали центральной грани не указывают в том же направлении, что и остальные грани, что вызывает странное поведение. Прежде чем мы рассмотрим, как решить эту проблему, давайте кратко коснемся того, что такое норма.
Нормаль — это вектор, обычно ортогональный плоскости многоугольника. Он используется в освещении и подразделении, но интуитивно вы можете думать о нем как о описании того, какое направление на сетке является «наружу». Все многоугольники имеют две стороны, поэтому каждая нормаль может указывать двумя способами. Большинство сеток, с которыми вы будете иметь дело, являются «водонепроницаемыми», то есть образуют одну непрерывную замкнутую поверхность. Сфера и куб являются примерами водонепроницаемых моделей, а одна плоскость — нет. Для водонепроницаемых сеток, если камера видит полигон, нормаль должна быть направлена примерно в сторону камеры, а не внутрь, в сторону закрытой области.
Если вы правильно смоделировали свою сетку, то исправить обычные проблемы будет легко. Самый быстрый способ — выбрать вашу сетку и Conform нормалей ( Normals → Conform ). Это сделает все нормали согласованными. Это не значит, что они правильные, просто последовательные. Если соответствие выбирает неправильное направление, вы можете изменить их, используя Reverse (Normals → Reverse) . Если вам нужно настроить размер нормалей, отображаемых в Maya, вы можете использовать Отображение → Полигоны → Размер нормалей… .
Если соответствие выбирает неправильное направление, вы можете изменить их, используя Reverse (Normals → Reverse) . Если вам нужно настроить размер нормалей, отображаемых в Maya, вы можете использовать Отображение → Полигоны → Размер нормалей… .
При создании сложной поверхности подразделения, такой как грань, небольшие изменения в положении вершин могут привести к неприемлемым искажениям поверхности подразделения. Одним из инструментов для решения этой проблемы является Sculpt Geometry Tool (Mesh → Sculpt Geometry Tool) . Вместо того, чтобы воздействовать на одну вершину за раз, этот инструмент воздействует на область вершин в соответствии с установленной операцией. В настройках инструмента есть различные операции, такие как Push, Pull, Smooth, Relax и Erase. Smooth и Relax хороши для устранения проблем, вызванных неровными вершинами, однако Smooth имеет тенденцию сглаживать поверхность, поэтому Relax лучше подходит для искривленных поверхностей.