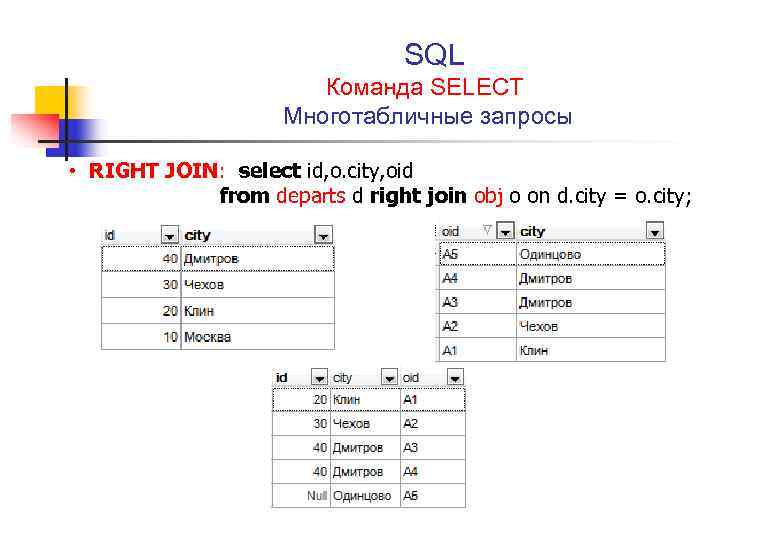
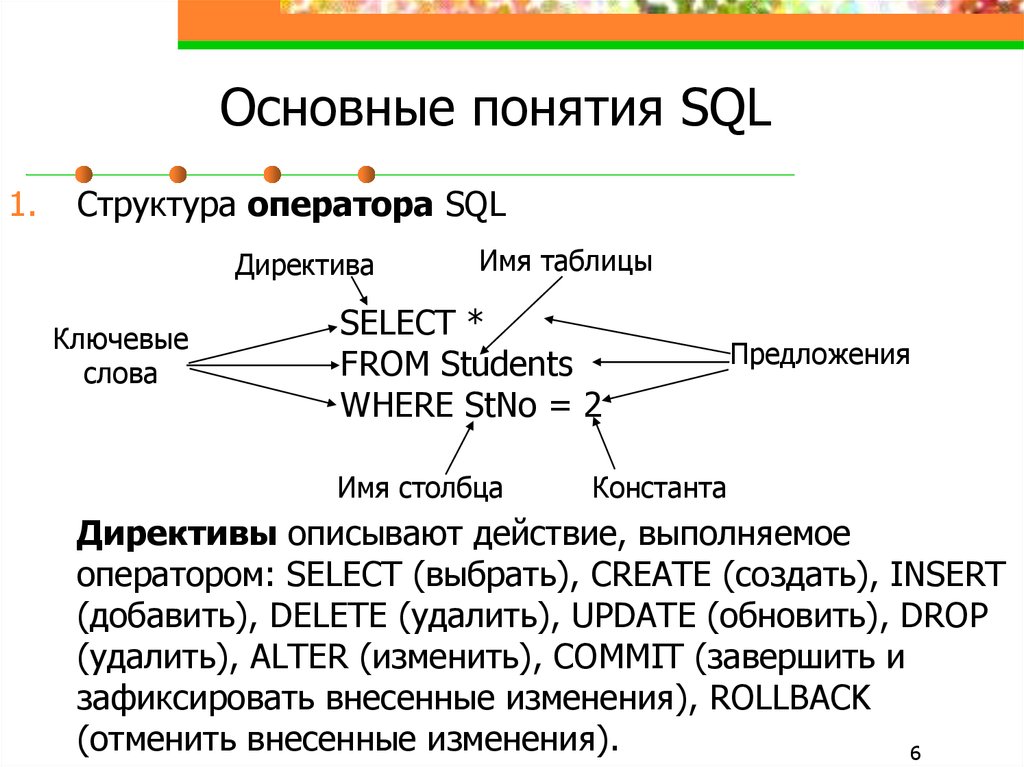
Структура SQL запроса на выборку данных
Простые, или так называемы прямые запросы, строить проще всего. Именно они максимально понятны, точки зрения логики. Как правило, такого рода запросы делаются с одной или нескольких, объединённых таблиц и имеют очень простую структуру.
Самым распространённым действием, при работе с таблицами баз данных является выборка интересующей пользователя информации. Такие процедуры проводиться с целью проанализировать определённого рода информацию. Начинается такая команда Служебным словом Select. Далее идёт перечень колонок, которые нужно выбрать, служебное слово From имя таблицы, с которой нужно сделать выборку данных. Различают две основные схемы запросов к базе данных:
- Простые
- Сложные или вложенные запросы.
Построение простых запросов баз данных
Простые, или так называемы прямые запросы, строить проще всего. Именно они максимально понятны, точки зрения логики. Как правило, такого рода запросы делаются с одной или нескольких, объединённых таблиц и имеют очень простую структуру. Для примера можно рассмотреть три таблицы, а именно: Counterfoil – условия оплаты, Person – сотрудники и таблица Depart – отделы. Из этих таблиц, скажем в первом случае необходимо просто выбрать всю имеющуюся в них информацию. Для этого нужно выполнить скрипт такого плана:
Для примера можно рассмотреть три таблицы, а именно: Counterfoil – условия оплаты, Person – сотрудники и таблица Depart – отделы. Из этих таблиц, скажем в первом случае необходимо просто выбрать всю имеющуюся в них информацию. Для этого нужно выполнить скрипт такого плана:
- Select * from Counterfoil
- Inner join Person on PE_ID = Cou_Person
- Order by PE_ID
Данный скрипт вернёт пользователю все данные из таблиц упорядоченный по сотрудникам. Это самая простая конструкция, которую, при необходимости можно усложнить условиями. Использование условий обозначается служебным словом Where, после которого можно указывать, те поля таблицы, к которым необходимо применить фильтры.
Структура сложных (вложенных) запросов баз данных
Простые запросы не всегда эффективны. Если в таблицах много полей и записей, то выборка может продолжаться от нескольких секунд, до нескольких минут, что не совсем целесообразно. Задача любого программиста баз данных – это максимальная оптимизация работы запросов, не только для получения максимально корректной информации, но и ускорение времени их выполнения.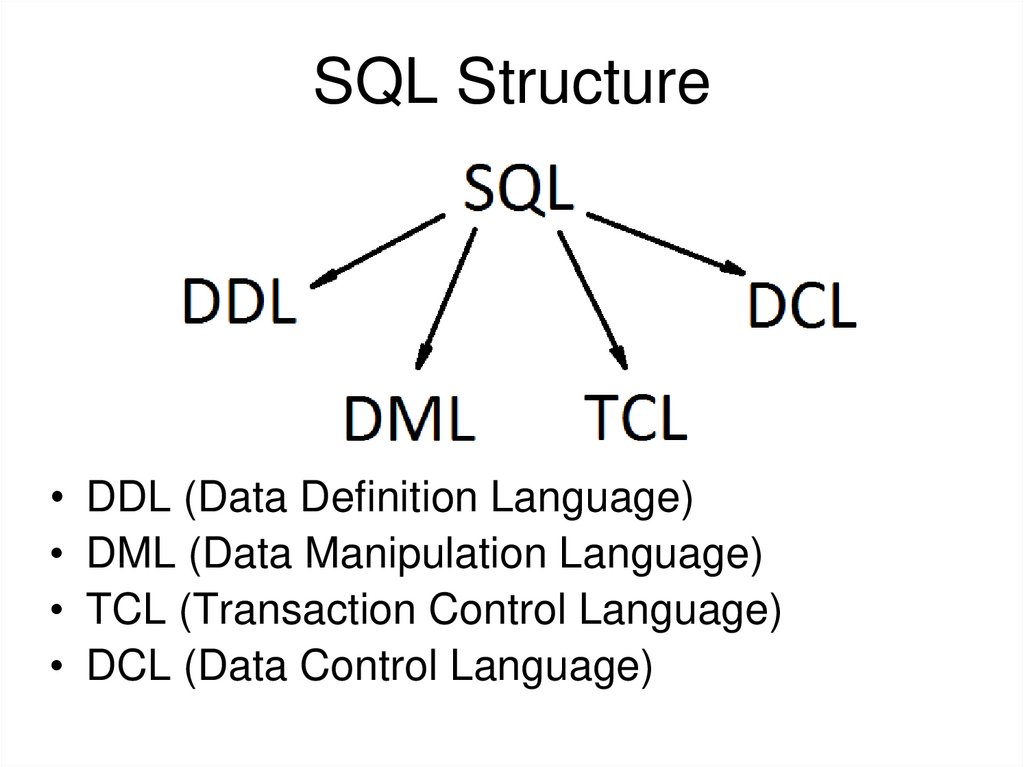 Как раз для этих целей и существую так называемые вложенные запросы.
Как раз для этих целей и существую так называемые вложенные запросы.
Как правило, в таких запросах идёт выборка не по всем полям, а только, по тем, которые необходимы. Можно рассмотреть такой пример. Необходимо вывести номер условия оплаты, сотрудника для которого производится оплата и отдел, где сотрудник работает. Для этого можно воспользоваться вложенным скриптом, который вернёт не все, а только нужные поля таблицы. Такой скрипт будет иметь следующий вид:
- Номер условия
- Наименование
- Код сотрудника
- Сотрудник
- Код отдела
В конце скрипта поставлен фильтр, который выведет информацию только о работающих, на данный момент, сотрудниках компании.
Скрипты на выборку данных с базы могут быть ещё сложнее, но общая структура запросов будет полностью похожа на выше описанные.
Формирование запроса в SQL
SQL символизирует структурированный язык запросов (Structured Query Language). Запросы являются наиболее часто используемым аспектом SQL. Есть категория пользователей SQL, которые используют язык только для формулировки запросов. Поэтому изучение SQL начинается с обсуждения запроса и того, как он выполняется в этом языке. Что такое запрос? Это команда, которая формулируется для СУБД и требует предоставить определенную указанную информацию. Эта информация обычно выводится непосредственно на экран дисплея компьютера или используемый терминал, хотя в ряде случаев ее можно направить на принтер, сохранить в файле или использовать в качестве исходных данных для другой команды или процесса.
Есть категория пользователей SQL, которые используют язык только для формулировки запросов. Поэтому изучение SQL начинается с обсуждения запроса и того, как он выполняется в этом языке. Что такое запрос? Это команда, которая формулируется для СУБД и требует предоставить определенную указанную информацию. Эта информация обычно выводится непосредственно на экран дисплея компьютера или используемый терминал, хотя в ряде случаев ее можно направить на принтер, сохранить в файле или использовать в качестве исходных данных для другой команды или процесса.
Как осуществляется связь запросов?
Запросы являются частью DML. Но так как они совершенно не изменяют информации в таблицах, а лишь показывают ее пользователю, предположим, что запросы являются самостоятельной категорией и определяют команды DML, воздействующие на содержимое базы данных, а не просто показывающие его. Все запросы в SQL конструируются на базе одной команды. Структура этой команды проста, потому что ее можно расширять для того, чтобы выполнить очень сложные вычисления и обработку данных. Эта команда называется SELECT.
Эта команда называется SELECT.
Команда SELECT
В простейшей форме команда SELECT дает инструкцию базе данных для поиска информации в таблице. Например, можно получить таблицу Salespeople, введя с клавиатуры следующее:
SELECT snum, sname, city, comm FROM Salespeople;
Выходные данные для этого запроса представлены на рисунке ниже.
Команда просто выводит все данные из таблицы. Большинство программ, как показано выше, также выводит заголовки столбцов. Некоторые программы допускают тщательное форматирование выходных данных, но это лежит за пределами спецификаций стандарта. Далее приводится объяснение каждой части этой команды:
| SELECT | Ключевое слово, которое сообщает базе данных, что команда является запросом. Все запросы начинаются с этого ключевогослова, за которым следует пробел. |
| snum, sname … | Список столбцов таблицы, которые должны быть представлены в результате выполнения запроса. Столбцы, имена которых не представлены в списке, не включаются в состав выходных данных команды. Это, однако, не приводит к удалению из таблиц таких столбцов или содержащейся в них информации, потому что запрос не воздействует на информацию, представленную в таблицах: он только извлекает данные. Столбцы, имена которых не представлены в списке, не включаются в состав выходных данных команды. Это, однако, не приводит к удалению из таблиц таких столбцов или содержащейся в них информации, потому что запрос не воздействует на информацию, представленную в таблицах: он только извлекает данные. |
| FROM Salespeople | FROM, так же как и SELECT, является ключевым словом, которое должно быть представлено в каждом запросе. Заним следует пробел, а затем — имя таблицы, которая используется как источник информации для запроса. В приведенном примере это таблица Salespeople. Символ «точка с запятой»(;) используется во всех интерактивных командах SQL для сообщения базе данных, что команда сформулирована и готова к выполнению. В некоторых системах этот символ заменен на символ «слэш обратный» («\») в строке, которая непосредственно следует за концом команды. |
Стоит заметить, что запрос по своей природе не обязательно упорядочивает выходные данные каким-либо определенным образом.
Использование клавиши возврата каретки (клавиши Eпter) является произвольным. Можно ввести запрос в одной строке следующим образом:
SELECT snum, sname, city, comm FROM Salespeople;
Поскольку в SQL точка с запятой применяется для того, чтобы пометить конец команды, большинство SQL-пporpaмм использует клавишу «Возврат каретки» (выполняется нажатием клавиши Return или Enter) как пробел.
Выбор чего-либо простейшим способом
Если необходимо увидеть каждую колонку таблицы, существует упрощенный вариант сделать это. Можно использовать символ «*» («звездочка»), который заменяет полный список столбцов.
SELECT * FROM Salespeople;
Результат выполнения этой команды тот же, что и для рассмотренной ранее.
SELECT в общем виде
Обобщая предыдущие рассуждения, следует отметить, что команда SELECT начинается с ключевого слова SELECT, за которым следует пробел. После него следует список разделенных запятыми имен столбцов, которые необходимо увидеть. Если нужно увидеть все столбцы таблицы, то можно заменить список имен столбцов символом (*) (звездочка). За звездочкой следует ключевое слово FROM, за ним — пробел и имя таблицы, к которой направляется запрос. Символ точка с запятой(;) нужно использовать для того, чтобы закончить запрос и показать, что команда готова для выполнения.
Просмотр только определенных столбцов таблицы
Мощность команды SELECT заключается в ее свойстве извлекать из таблицы лишь определенную информацию. Надо отметить возможность просмотра только указанных столбцов таблицы. Для этого достаточно пропустить столбцы, которые нет необходимости просматривать, в части команды SELECT. Например, по запросу
Надо отметить возможность просмотра только указанных столбцов таблицы. Для этого достаточно пропустить столбцы, которые нет необходимости просматривать, в части команды SELECT. Например, по запросу
SELECT sname, comm FROM Salespeople;
получаются выходные данные, представленные на рисунке ниже.
Существуют таблицы, включающие большое количество столбцов, содержащих данные, не все из которых требуются в определенный момент. Следовательно, возможность выбора и указания интересующих колонок весьма полезна.
Перестановка столбцов
Колонки таблицы упорядочены по определению, но это не значит, что их нужно извлекать в том же порядке. Звездочка (*) извлечет столбцы в соответствии с их порядком, но если указать столбцы раздельно, они выстраиваются их в любом желаемом порядке. В таблице Orders зададим такой порядок столбцов: сначала разместим столбец «дата заказа (odate), за ним — столбец «номер продавца» (snum), затем — «номер заказа» (onum) и «количество» (amt):
SELECT odate, snum, onum, amt FROM Orders;
Выходные данные, полученные по этому запросу, представлены на рисунке ниже.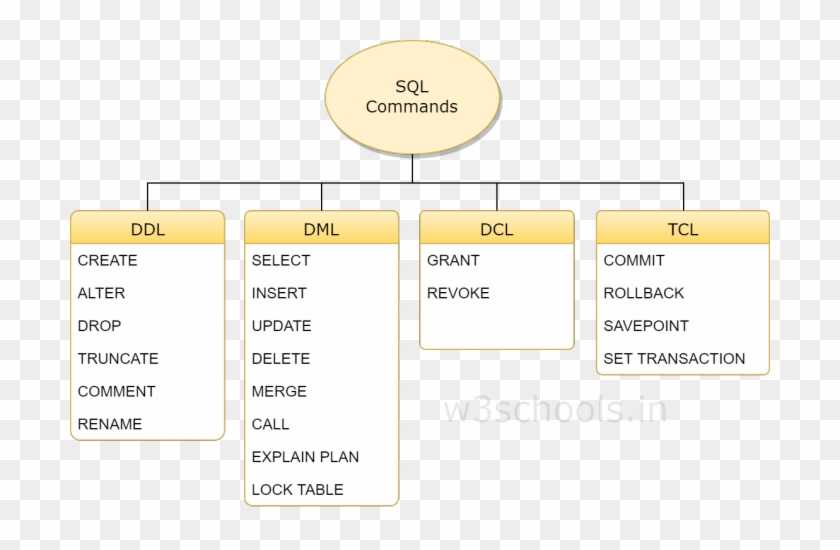
Очевидно, что структура информации таблицах является просто основой для ее реструктуризации средствами SQL.
Устранение избыточных данных
DISТINCT — аргумент, дающий возможность исключить дублирующиеся значения из результата выполнения предложения SELECT. Предположим, необходимо узнать, какие продавцы имеют в настоящее время заказы в таблице Orders. Не имеет значения количество заказов каждого из продавцов, нужен лишь список номеров продавцов (snum). Необходимо ввести:
SELECT snum FROM Orders;
чтобы получить результат, представленный на рисунке ниже.
Для того чтобы получить список без повторений, который легче прочесть, нужно ввести следующую команду:
SELECT DISTINCT snum FROM Orders;
Выходные данные для этого запроса представлены на рисунке ниже.
DISTINCT отслеживает, какие значения появились в списке выходных данных, и исключает из него дублирующиеся значения. Это полезный способ исключить избыточные данные.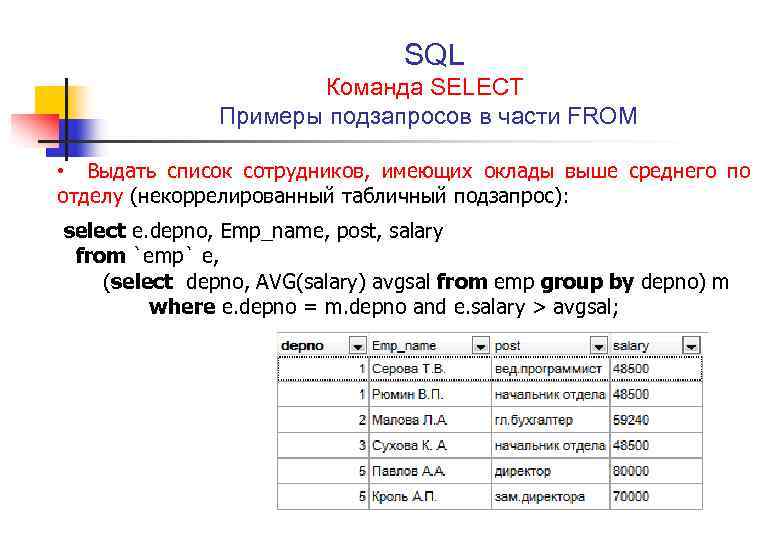 Если таковых нет, не следует использовать DISТINCT, поскольку он может скрыть проблемы. Предположим, все имена покупателей различны. Если кто-то введет второго покупателя с фамилией Clemens в таблицу Customers при использовании SELECT DISТINCT cname, можно не заметить, что имеются дублирующиеся данные. Будут получены ошибочные сведения о Clemens, поскольку в этом случае нет информации об избыточности данных.
Если таковых нет, не следует использовать DISТINCT, поскольку он может скрыть проблемы. Предположим, все имена покупателей различны. Если кто-то введет второго покупателя с фамилией Clemens в таблицу Customers при использовании SELECT DISТINCT cname, можно не заметить, что имеются дублирующиеся данные. Будут получены ошибочные сведения о Clemens, поскольку в этом случае нет информации об избыточности данных.
Параметры DISТINCT. DISТINCT можно задать только один раз для данного предложения SELECT. Если SELECT извлекает множество полей, то он исключает строки, в которых все выбранные поля идентичны. Строки, в которых некоторые значения одинаковы, а другие — различны, включаются в результат. DISТINCT, фактически, действует на всю выходную строку, а не на отдельное поле (исключение составляет его применение внутри агрегатных функций, см. главу 6), исключая возможность их повторения.
DISТINCT в сравнении с ALL. Альтернативой DISTINCT является ALL. Это ключевое слово имеет противоположное действие: повторяющиеся строки включаются в состав выходных данных. Поскольку часто бывает так, что не заданы ни DISТINCT, ни ALL, предполагается ALL; это ключевое слово имеет преимущество перед функциональным аргументом.
Это ключевое слово имеет противоположное действие: повторяющиеся строки включаются в состав выходных данных. Поскольку часто бывает так, что не заданы ни DISТINCT, ни ALL, предполагается ALL; это ключевое слово имеет преимущество перед функциональным аргументом.
Источник: SQL для простых смертных / Мартинн Грабер
С уважением, Артём Санников
Сайт: ArtemSannikov.ru
Метки: MySQL, База данных.
Передовой опыт написания SQL-запросов: как структурировать код
Категории
SQLGuides
удобочитаемость.
Язык структурированных запросов является абсолютно необходимым навыком в отрасли обработки данных. SQL — это не только написание запросов, вы также должны убедиться, что ваши запросы производительны, быстры и удобочитаемы. Таким образом, также необходимо, чтобы вы знали, как эффективно писать SQL-запросы.
Эта статья расскажет вам о лучших методах структурирования SQL-запросов. Даже когда ваш код SQL работает правильно, его все равно можно улучшить, особенно когда речь идет о производительности и удобочитаемости. Это важно, потому что на технических собеседованиях цель состоит не только в том, чтобы проверить, способен ли кандидат предложить работающее решение проблемы, но и в том, может ли он подготовить эффективное и понятное решение. То же самое и в рабочей среде: сделать запросы быстрыми и понятными для других так же важно, как и сделать их правильными.
Это важно, потому что на технических собеседованиях цель состоит не только в том, чтобы проверить, способен ли кандидат предложить работающее решение проблемы, но и в том, может ли он подготовить эффективное и понятное решение. То же самое и в рабочей среде: сделать запросы быстрыми и понятными для других так же важно, как и сделать их правильными.
Давайте воспользуемся реальным примером вопросов для собеседования по науке о данных, которые можно решить с помощью SQL-запроса. У нас будет решение, которое дает правильный вывод, но оно очень неэффективно и чрезвычайно трудно читаемо. Затем мы рассмотрим несколько ключевых рекомендаций по написанию SQL-запросов и применим их к коду, чтобы улучшить его, чтобы его можно было использовать в качестве ответа на вопрос на собеседовании.
Пример вопроса для собеседования по SQL Пример для практики написания эффективных запросов SQL
Вопрос для собеседования Дата: ноябрь 2020 г.
MicrosoftHardInterview QuestionsID 10300
Найдите общее количество загрузок для платных и бесплатных пользователей по дате. Включайте только те записи, в которых неоплачиваемые клиенты имеют больше загрузок, чем платные клиенты. Вывод должен быть сначала отсортирован по самой ранней дате и содержать дату в 3 столбцах, бесплатные загрузки, платные загрузки.
Включайте только те записи, в которых неоплачиваемые клиенты имеют больше загрузок, чем платные клиенты. Вывод должен быть сначала отсортирован по самой ранней дате и содержать дату в 3 столбцах, бесплатные загрузки, платные загрузки.
Таблицы: ms_user_dimension, ms_acc_dimension, ms_download_facts
Ссылка на вопрос: https://platform.stratascratch.com/coding/10300-premium-vs-freemium
Мы будем использовать этот вопрос на собеседовании по SQL в качестве примера, взятого из технических собеседований в Microsoft и озаглавленного «Premium vs Freemium». Задача состоит в том, чтобы найти общее количество загрузок для платных и неплатящих пользователей по дате и включить только те записи, где у неплатящих клиентов больше загрузок, чем у платных. Более того, этот вопрос связан с набором данных, разделенным на три таблицы, которые необходимо объединить.
Исходное решение
Давайте получим исходное решение этой проблемы SQL, которое мы будем использовать в качестве отправной точки. Мы не найдем, как это решение работает или как его можно получить — это не цель этой статьи. Вместо этого мы будем использовать его только как иллюстрацию синтаксических приемов, универсальных для любого SQL-запроса.
Мы не найдем, как это решение работает или как его можно получить — это не цель этой статьи. Вместо этого мы будем использовать его только как иллюстрацию синтаксических приемов, универсальных для любого SQL-запроса.
Это решение, которое можно использовать для получения правильного вывода для этой проблемы:
ВЫБЕРИТЕ дату, "Неоплачиваемый",
оплата
ОТ
(ВЫБЕРИТЕ стр.дату,
p.sum AS платит,
n.nonpaying AS "Неплатежеспособный"
ОТ
(ВЫБЕРИТЕ дату, сумму(загрузки)
ОТ ms_user_dimension a
ВНУТРЕННЕЕ СОЕДИНЕНИЕ ms_acc_dimension b ON a.acc_id = b.acc_id
ВНУТРЕННЕЕ СОЕДИНЕНИЕ ms_download_facts c ON a.user_id=c.user_id
ГДЕ pay_customer = 'да'
СГРУППИРОВАТЬ ПО дате
ЗАКАЗАТЬ ПО дате) стр
ПРИСОЕДИНИТЬСЯ
(ВЫБЕРИТЕ дату, сумму(загрузки) КАК БЕСПЛАТНО
ОТ ms_user_dimension a
ВНУТРЕННЕЕ СОЕДИНЕНИЕ ms_acc_dimension b ON a.acc_id = b.acc_id
ВНУТРЕННЕЕ СОЕДИНЕНИЕ ms_download_facts c ON a.
user_id=c.user_id
ГДЕ pay_customer = 'нет'
СГРУППИРОВАТЬ ПО дате
ORDER BY date) n ON p.date = n.date
ЗАКАЗАТЬ ПО п.дата) с
СГРУППИРОВАТЬ ПО дате, "Неоплачиваемый",
оплата
ИМЕЕТ ("NonPaying" - платит) >0
ЗАКАЗАТЬ ПО дате ASC Не беспокойтесь, если вы не сразу поймете, что здесь происходит. Это на самом деле вещь, это решение намеренно длинное, запутанное и запутанное, и задача будет заключаться в том, чтобы очистить его, используя лучшие практики синтаксиса SQL. Но самое интересное, что это решение работает — мы можем его запустить и посмотреть, сколько загрузок от платных и неплатящих клиентов было в каждую дату. Но даже при том, что это решение правильное, интервьюер, вероятно, не обрадуется такому ответу. Итак, давайте посмотрим, какие лучшие практики написания SQL-запросов нам здесь не хватает и как повысить наши шансы произвести впечатление на интервьюера.
Передовой опыт написания SQL-запросов: как структурировать код
1.
 Удалите несколько вложенных запросов
Удалите несколько вложенных запросовДаже не понимая, что именно делает код, мы видим, что он имеет несколько вложенных запросов. Есть основной запрос, в котором выбираются три столбца, затем в его предложении FROM есть еще один длинный запрос, называемый внутренним запросом. У него есть псевдоним «s». Но тогда сам этот внутренний запрос «s» также имеет два дополнительных и почти идентичных внутренних запроса, «p» и «n», которые объединяются вместе с помощью оператора JOIN. Хотя иметь один внешний запрос и один внутренний запрос абсолютно нормально, более двух запросов, вложенных друг в друга, считаются не очень читабельными, и их следует избегать.
Один из подходов к избавлению от такого количества вложенных запросов состоит в том, чтобы определить некоторые или все из них в форме общих табличных выражений или CTE — конструкций, которые используют ключевое слово WITH и позволяют повторно использовать один запрос несколько раз. Итак, пусть это будет наш первый шаг — мы можем превратить все три вложенных запроса «s», «p» и «n» в CTE.
С р АС
(ВЫБЕРИТЕ дату, сумму(загрузки)
ОТ ms_user_dimension a
ВНУТРЕННЕЕ СОЕДИНЕНИЕ ms_acc_dimension b ON a.acc_id = b.acc_id
ВНУТРЕННЕЕ СОЕДИНЕНИЕ ms_download_facts c ON a.user_id=c.user_id
ГДЕ pay_customer = 'да'
СГРУППИРОВАТЬ ПО дате
ЗАКАЗАТЬ ПО дате),
н КАК
(ВЫБЕРИТЕ дату, сумму(загрузки) КАК БЕСПЛАТНО
ОТ ms_user_dimension a
ВНУТРЕННЕЕ СОЕДИНЕНИЕ ms_acc_dimension b ON a.acc_id = b.acc_id
ВНУТРЕННЕЕ СОЕДИНЕНИЕ ms_download_facts c ON a.user_id=c.user_id
ГДЕ pay_customer = 'нет'
СГРУППИРОВАТЬ ПО дате
ЗАКАЗАТЬ ПО дате),
с АС
(ВЫБЕРИТЕ стр.дату,
p.sum AS платит,
n.nonpaying AS "Неплатежеспособный"
С р
ПРИСОЕДИНЯЙТЕСЬ n ON p.date = n.date
ЗАКАЗАТЬ ПО п.дате)
ВЫБЕРИТЕ дату, "Неоплачиваемый",
оплата
ОТ с
СГРУППИРОВАТЬ ПО дате, "Неоплачиваемый",
оплата
ИМЕЕТ ("NonPaying" - платит) > 0
ЗАКАЗАТЬ ПО дате ASC Теперь этот запрос уже стал немного легче читать. Даже не понимая точно, что происходит, мы можем видеть, что есть два очень похожих шага, «p» и «n», которые должны быть выполнены сначала, чтобы включить «s», а затем результат «s» может быть использован в основной запрос.
2. Обеспечьте согласованность псевдонимов
Псевдонимы в SQL могут быть назначены столбцам, запросам и таблицам для изменения их первоначальных имен. Их необходимо использовать при объединении таблиц с одинаковыми именами столбцов, чтобы избежать двусмысленности в именах столбцов. Псевдонимы также полезны для облегчения понимания кода другими и для замены имен столбцов по умолчанию при использовании аналитических функций (например, СУММ() или СЧЁТ()).
Существует также несколько неписаных правил относительно псевдонимов, которым следует следовать, поскольку неправильно используемый псевдоним может скорее сбить с толку, чем помочь. Начнем с псевдонимов таблицы и запроса. Хорошо, когда это немного больше, чем просто одна буква, и они позволяют нам понять, что находится в таблице или что выдает запрос. В нашем случае первый CTE, который в настоящее время называется «p», используется для подсчета количества загрузок, сделанных платными клиентами, поэтому более информативным названием будет, например, «платный».
Наконец, CTE ‘s’ объединяет два значения: количество загрузок платных и неплатящих клиентов, но еще не фильтрует их, потому что это происходит в основном запросе. Таким образом, его имя может быть, например, «all_downloads». Теперь обратите внимание, что это еще не все таблицы, которым присвоены псевдонимы. Это связано с тем, что в первых двух CTE мы объединяем три таблицы друг с другом, и, поскольку они имеют общие имена столбцов, им нужно дать псевдонимы. В настоящее время это просто «a», «b» и «c», но более информативными названиями будут «users», «accounts» и «downlds» — аббревиатура здесь, потому что в этой таблице уже есть столбец «downloads».
Последнее, что касается псевдонимов таблиц, — это согласованность их использования. Обычно их лучше либо использовать со всеми именами столбцов, либо только в абсолютно необходимых местах (например, только при определении JOIN) или вообще не использовать. Давайте решим использовать псевдонимы таблиц во всех случаях, когда несколько таблиц объединены, то есть во всех CTE, и не использовать их, когда все столбцы поступают только из одной таблицы, как в основном запросе.
Обычно их лучше либо использовать со всеми именами столбцов, либо только в абсолютно необходимых местах (например, только при определении JOIN) или вообще не использовать. Давайте решим использовать псевдонимы таблиц во всех случаях, когда несколько таблиц объединены, то есть во всех CTE, и не использовать их, когда все столбцы поступают только из одной таблицы, как в основном запросе.
С оплатой AS
(ВЫБРАТЬ загрузки.дата, сумма(загрузки.загрузки)
ОТ пользователей ms_user_dimension
ВНУТРЕННЕЕ СОЕДИНЕНИЕ ms_acc_dimension account ON users.acc_id = account.acc_id
INNER JOIN ms_download_facts downlds ON users.user_id=downlds.user_id
ГДЕ account.paying_customer = 'да'
СГРУППИРОВАТЬ ПО downlds.date
ЗАКАЗАТЬ ПО downlds.date),
неплатежный AS
(ВЫБЕРИТЕ загрузки.дата, сумма(загрузки.загрузки) КАК неоплачиваемые
ОТ пользователей ms_user_dimension
ВНУТРЕННЕЕ СОЕДИНЕНИЕ ms_acc_dimension account ON users.acc_id = account.acc_id
INNER JOIN ms_download_facts downlds ON users. user_id=downlds.user_id
ГДЕ account.paying_customer = 'нет'
СГРУППИРОВАТЬ ПО downlds.date
ЗАКАЗАТЬ ПО downlds.date),
all_downloads КАК
(ВЫБЕРИТЕ дату оплаты,
pay.sum КАК платит,
nonpaying.nonpaying AS "Неплатежеспособный"
ОТ оплаты
ПРИСОЕДИНЯЙТЕСЬ к nonpaying ON pay.date = nonpaying.date
ЗАКАЗАТЬ ПО ОПЛАТЕ.ДАТА)
ВЫБЕРИТЕ дату, "Неоплачиваемый",
оплата
ИЗ all_downloads
СГРУППИРОВАТЬ ПО дате, "Неоплачиваемый",
оплата
ИМЕЕТ ("NonPaying" - платит) >0
ЗАКАЗАТЬ ПО дате ASC
user_id=downlds.user_id
ГДЕ account.paying_customer = 'нет'
СГРУППИРОВАТЬ ПО downlds.date
ЗАКАЗАТЬ ПО downlds.date),
all_downloads КАК
(ВЫБЕРИТЕ дату оплаты,
pay.sum КАК платит,
nonpaying.nonpaying AS "Неплатежеспособный"
ОТ оплаты
ПРИСОЕДИНЯЙТЕСЬ к nonpaying ON pay.date = nonpaying.date
ЗАКАЗАТЬ ПО ОПЛАТЕ.ДАТА)
ВЫБЕРИТЕ дату, "Неоплачиваемый",
оплата
ИЗ all_downloads
СГРУППИРОВАТЬ ПО дате, "Неоплачиваемый",
оплата
ИМЕЕТ ("NonPaying" - платит) >0
ЗАКАЗАТЬ ПО дате ASC Это были псевдонимы таблицы и запроса, теперь давайте посмотрим на псевдонимы, присвоенные столбцам. Во-первых, дать псевдонимы результатам аналитических функций. Взгляните на первый запрос. Есть функция SUM(), но к ней не добавляется псевдоним, хотя позже этот столбец используется повторно. Вот почему в CTE all_downloads нам нужно написать pay.sum, чтобы выбрать его. Добавим псевдоним, например n_paying.
Еще одна вещь — поддерживать согласованность псевдонимов столбцов в именах, а также избегать конфликтов с другими псевдонимами. Как и в CTE nonpaying, есть функция SUM(), которая правильно назначается как псевдоним, но этот псевдоним совпадает с псевдонимом CTE, что может сбивать с толку. Давайте придерживаться того же соглашения об именах, что и раньше, и изменим этот псевдоним на n_nonpaying.
Как и в CTE nonpaying, есть функция SUM(), которая правильно назначается как псевдоним, но этот псевдоним совпадает с псевдонимом CTE, что может сбивать с толку. Давайте придерживаться того же соглашения об именах, что и раньше, и изменим этот псевдоним на n_nonpaying.
Теперь в CTE all_downloads происходит много всего. Во-первых, псевдоним «paying», назначенный второму столбцу, совпадает с псевдонимом одного из CTE. И сразу после этого псевдоним третьего столбца — «NonPaying» в кавычках. Хотя SQL позволяет нам назначать такие псевдонимы, использовать такие псевдонимы опасно, потому что каждый раз, когда мы хотим использовать его повторно, нам нужно снова использовать кавычки и сопоставлять все заглавные и строчные буквы в псевдониме. Мы могли бы изменить эти два псевдонима на что-то другое и без кавычек. Но на самом деле даже не обязательно использовать эти алиасы, ведь аналитических функций здесь нет, поэтому имена столбцов из предыдущих, ‘n_paying’ и n_nonpaying’ остаются прежними и на них можно ссылаться в основном запросе, не вызывая проблем.
С оплатой AS
(ВЫБРАТЬ downlds.date, sum(downlds.downloads) AS n_paying
ОТ пользователей ms_user_dimension
ВНУТРЕННЕЕ СОЕДИНЕНИЕ ms_acc_dimension account ON users.acc_id = account.acc_id
INNER JOIN ms_download_facts downlds ON users.user_id=downlds.user_id
ГДЕ account.paying_customer = 'да'
СГРУППИРОВАТЬ ПО downlds.date
ЗАКАЗАТЬ ПО downlds.date),
неплатежный AS
(SELECTdownlds.date, sum(downlds.downloads) AS n_nonpaying
ОТ пользователей ms_user_dimension
ВНУТРЕННЕЕ СОЕДИНЕНИЕ ms_acc_dimension account ON users.acc_id = account.acc_id
INNER JOIN ms_download_facts downlds ON users.user_id=downlds.user_id
ГДЕ account.paying_customer = 'нет'
СГРУППИРОВАТЬ ПО downlds.date
ЗАКАЗАТЬ ПО downlds.date),
all_downloads КАК
(ВЫБЕРИТЕ дату оплаты,
оплата.n_paying,
неоплачиваемый.n_неоплачиваемый
ОТ оплаты
ПРИСОЕДИНЯЙТЕСЬ к nonpaying ON pay.date = nonpaying.date
ЗАКАЗАТЬ ПО ОПЛАТЕ.ДАТА)
ВЫБЕРИТЕ дату, n_nonpaying,
n_paying
ИЗ all_downloads
СГРУППИРОВАТЬ ПО дате, n_nonpaying,
n_paying
ИМЕЕТ (n_nonpaying - n_paying) >0
ЗАКАЗАТЬ ПО дате ASC Не существует особых правил форматирования псевдонимов, но большинство людей используют только строчные буквы и знак подчеркивания, если псевдоним состоит из нескольких слов.
3. Удалите ненужные предложения ORDER BY
Теперь, когда мы позаботились о псевдонимах, давайте начнем сокращать объем кода в нашем решении. Первая вещь довольно второстепенна, но все же способствует удобочитаемости запроса. Речь идет о предложениях ORDER BY. Они, очевидно, используются для сортировки данных в таблице и часто полезны или даже необходимы. В конце концов, иногда необходимо использовать предложение ORDER BY в сочетании с оконной функцией или при выборе верхних строк таблицы с помощью ключевого слова LIMIT. Мы также можем захотеть расположить окончательные результаты в определенном порядке на собеседованиях, иногда это даже может быть требованием.
Но если у нас есть несколько запросов, обычно нет необходимости добавлять одно и то же предложение ORDER BY в каждый из них. Посмотрите на наш запрос, например, мы сортируем результаты по дате, но делаем это во всех возможных запросах и подзапросах. Это не только бесполезно, но и неэффективно, потому что каждое предложение ORDER BY добавляет немного сложности и, следовательно, времени, необходимого для выполнения запроса, особенно при работе с большими наборами данных. Поэтому, если у каждого запроса есть собственное предложение сортировки, хорошо подумать, действительно ли оно необходимо. В нашем случае можно оставить его только в последнем запросе.
Поэтому, если у каждого запроса есть собственное предложение сортировки, хорошо подумать, действительно ли оно необходимо. В нашем случае можно оставить его только в последнем запросе.
С оплатой AS
(ВЫБРАТЬ downlds.date, sum(downlds.downloads) AS n_paying
ОТ пользователей ms_user_dimension
ВНУТРЕННЕЕ СОЕДИНЕНИЕ ms_acc_dimension account ON users.acc_id = account.acc_id
INNER JOIN ms_download_facts downlds ON users.user_id=downlds.user_id
ГДЕ account.paying_customer = 'да'
СГРУППИРОВАТЬ ПО downlds.date),
неплатежный AS
(SELECTdownlds.date, sum(downlds.downloads) AS n_nonpaying
ОТ пользователей ms_user_dimension
ВНУТРЕННЕЕ СОЕДИНЕНИЕ ms_acc_dimension account ON users.acc_id = account.acc_id
INNER JOIN ms_download_facts downlds ON users.user_id=downlds.user_id
ГДЕ account.paying_customer = 'нет'
СГРУППИРОВАТЬ ПО downlds.date),
all_downloads КАК
(ВЫБЕРИТЕ дату оплаты,
оплата.n_paying,
неоплачиваемый.n_неоплачиваемый
ОТ оплаты
ПРИСОЕДИНЯЙТЕСЬ к nonpaying ON pay. date = nonpaying.date)
ВЫБЕРИТЕ дату, n_nonpaying,
n_paying
ИЗ all_downloads
СГРУППИРОВАТЬ ПО дате, n_nonpaying,
n_paying
ИМЕЕТ (n_nonpaying - n_paying) >0
ЗАКАЗАТЬ ПО дате ASC
date = nonpaying.date)
ВЫБЕРИТЕ дату, n_nonpaying,
n_paying
ИЗ all_downloads
СГРУППИРОВАТЬ ПО дате, n_nonpaying,
n_paying
ИМЕЕТ (n_nonpaying - n_paying) >0
ЗАКАЗАТЬ ПО дате ASC 4. Удаление ненужных подзапросов и CTE
Далее, есть гораздо более серьезная тема, чем удаление ненужных предложений ORDER BY — удаление ненужных подзапросов и CTE. Мы говорили о них раньше, когда разбивали вложенные запросы на CTE, но тогда мы просто оставили их как есть, не анализируя, действительно ли они нам нужны.
Оказывается, иногда два запроса делают одно и то же или могут быть объединены в один с помощью других предложений или операторов. В конце концов, каждый запрос увеличивает сложность и время, необходимое для выполнения запроса. В нашем случае четыре разных запроса приводят к тому, что движку четыре раза требуется доступ к таблице для выбора данных из нее. Более того, в трех из этих запросов мы объединяем несколько таблиц, используя JOIN — операции, которые могут занять много времени, особенно если таблицы большие.
Чтобы уменьшить количество запросов в нашем случае, есть два направления. Одной из возможностей было бы объединить запрос all_downloads с основным запросом. В конце концов, эти два запроса почти идентичны, и если бы мы только добавили фильтр, поэтому выражение, говорящее, что разница между n_nonpaying и n_paying должна быть больше 0, к запросу в all_downloads, дало бы те же результаты. Мы могли бы безопасно избавиться от CTE all_downloads и вместо этого объединить платные и неоплачиваемые CTE в основном запросе. Таким образом, мы можем сократить количество запросов до 3. Но можем ли мы добиться большего?
Можем, потому что оказывается, что первые два CTE, а именно «платный» и «неплатный», могут быть выполнены внутри CTE «all_downloads». Это потому, что эти первые два CTE почти идентичны, а главное отличие заключается в предложении WHERE. Мы выбираем одни и те же типы данных из одних и тех же таблиц, но в разных условиях. Но в SQL есть другой способ выбора и даже выполнения арифметических операций над данными с использованием разных условий только в одном запросе: нам нужно использовать CASES.
Мы можем использовать их для преобразования строк «да» и «нет» из столбца «paying_customer» в количество загрузок, а затем суммировать их, чтобы получить общее количество. Это означает, что весь первый CTE можно заменить следующим фрагментом кода:
sum(CASE
КОГДА pay_customer = 'да', ТОГДА загрузки
КОНЕЦ) Это будет очень похоже на неплатящих клиентов. Обе эти инструкции могут быть выполнены прямо в CTE all_downloads, если мы объединим три таблицы, пользователей, учетные записи и загрузки и включим оператор данных GROUP BY также в это CTE.
С all_downloads КАК
(ВЫБЕРИТЕ дату загрузки,
сумма(СЛУЧАЙ
КОГДА account.paying_customer = 'yes', ТО downlds.downloads
КОНЕЦ) КАК n_paying,
сумма(СЛУЧАЙ
КОГДА account.paying_customer = 'no', ТО downlds.downloads
КОНЕЦ) AS n_nonpaying
ОТ пользователей ms_user_dimension
ВНУТРЕННЕЕ СОЕДИНЕНИЕ ms_acc_dimension account ON users. acc_id = account.acc_id
INNER JOIN ms_download_facts downlds ON users.user_id=downlds.user_id
СГРУППИРОВАТЬ ПО downlds.date)
ВЫБЕРИТЕ дату, n_nonpaying,
n_paying
ИЗ all_downloads
СГРУППИРОВАТЬ ПО дате, n_nonpaying,
n_paying
ИМЕЕТ (n_nonpaying - n_paying) >0
ЗАКАЗАТЬ ПО дате ASC
acc_id = account.acc_id
INNER JOIN ms_download_facts downlds ON users.user_id=downlds.user_id
СГРУППИРОВАТЬ ПО downlds.date)
ВЫБЕРИТЕ дату, n_nonpaying,
n_paying
ИЗ all_downloads
СГРУППИРОВАТЬ ПО дате, n_nonpaying,
n_paying
ИМЕЕТ (n_nonpaying - n_paying) >0
ЗАКАЗАТЬ ПО дате ASC С этими изменениями у нас осталось только два запроса, один набор из нескольких JOIN и два случая, когда данные нужно выбирать из таблицы вместо четырех. В то же время мы не можем решить этот вопрос, используя только один запрос, потому что столбцы «n_paying» и «n_nonpaying» должны быть определены в одном запросе, прежде чем использоваться в фильтре в другом запросе.
5. HAVING vs WHERE
Говоря о производительности и эффективности, в нашем запросе есть еще одна деталь, которая излишне замедляет его. Эта деталь — предложение HAVING в основном запросе. Но почему именно ИМЕЕТ, а не ГДЕ? Два пункта очень похожи друг на друга и позволяют фильтровать данные на основе некоторых условий. Как и в этом случае, когда разница между значениями n_nonpaying и n_paying должна быть больше 0. Это условие можно определить как с ключевыми словами WHERE, так и с ключевыми словами HAVING, но одно из них гораздо более подходит в этой ситуации. Ключевое отличие состоит в том, что предложение HAVING может включать агрегатные функции, например. СУММ() или СЧЕТ(). Он позволяет создавать условия на основе суммы, среднего, минимального или максимального значения или количества элементов в наборе данных или в разделах, определенных с помощью предложения GROUP BY. Именно по этой причине предложение HAVING всегда должно сопровождаться оператором GROUP BY.
Как и в этом случае, когда разница между значениями n_nonpaying и n_paying должна быть больше 0. Это условие можно определить как с ключевыми словами WHERE, так и с ключевыми словами HAVING, но одно из них гораздо более подходит в этой ситуации. Ключевое отличие состоит в том, что предложение HAVING может включать агрегатные функции, например. СУММ() или СЧЕТ(). Он позволяет создавать условия на основе суммы, среднего, минимального или максимального значения или количества элементов в наборе данных или в разделах, определенных с помощью предложения GROUP BY. Именно по этой причине предложение HAVING всегда должно сопровождаться оператором GROUP BY.
Многие пользователи SQL не знают, что предложение HAVING следует использовать только тогда, когда необходимо создать условие с помощью агрегатной функции. Во всех остальных случаях предложение WHERE является лучшим выбором? Почему? Все упирается в эффективность. Предложение WHERE выполняется вместе с остальной частью запроса, поэтому, если это более эффективно, механизм SQL может решить ограничить количество экземпляров в наборе данных, используя условие из WHERE, прежде чем выполнять другие операции. С другой стороны, оператор HAVING всегда выполняется после запроса, хотя в коде он является его частью. Это почти всегда приводит к немного большему времени вычислений.
С другой стороны, оператор HAVING всегда выполняется после запроса, хотя в коде он является его частью. Это почти всегда приводит к немного большему времени вычислений.
В нашем примере условие основано на арифметической операции с двумя столбцами, но это не то же самое, что агрегатная функция. По этой причине это условие вполне может быть определено в предложении WHERE. При этом, помимо повышения эффективности, мы также избавляемся от лишнего предложения GROUP BY.
С all_downloads КАК
(ВЫБЕРИТЕ дату загрузки,
сумма(СЛУЧАЙ
КОГДА account.paying_customer = 'yes', ТО downlds.downloads
КОНЕЦ) КАК n_paying,
сумма(СЛУЧАЙ
КОГДА account.paying_customer = 'no', ТО downlds.downloads
КОНЕЦ) AS n_nonpaying
ОТ пользователей ms_user_dimension
ВНУТРЕННЕЕ СОЕДИНЕНИЕ ms_acc_dimension account ON users.acc_id = account.acc_id
INNER JOIN ms_download_facts downlds ON users.user_id=downlds.user_id
СГРУППИРОВАТЬ ПО downlds. date)
ВЫБЕРИТЕ дату, n_nonpaying,
n_paying
ИЗ all_downloads
ГДЕ (n_nonpaying - n_paying) > 0
ЗАКАЗАТЬ ПО дате ASC
date)
ВЫБЕРИТЕ дату, n_nonpaying,
n_paying
ИЗ all_downloads
ГДЕ (n_nonpaying - n_paying) > 0
ЗАКАЗАТЬ ПО дате ASC 6. Форматирование текста
Последнее, что повышает читабельность запросов, — это форматирование кода. Это, по сравнению с другими частицами, о которых мы упоминали, не имеет ничего общего с эффективностью, а связано с простотой понимания кода всеми. Это также та деталь, о которой все забывают при написании SQL-запроса, особенно в стрессовой обстановке собеседования. Или все привыкли к другому стилю форматирования текста и путаются, видя другие подходы.
В SQL нет официальных правил форматирования текста в запросах, но есть некоторые неофициальные рекомендации, которым следуют многие пользователи SQL. Вероятно, наиболее распространенным и известным является то, что все ключевые слова, такие как SELECT, FROM, WHERE, GROUP BY, ORDER BY и т. д., должны быть написаны заглавными буквами. Это также относится к другим встроенным ключевым словам, которые появляются внутри предложений, таких как JOIN, AS, IN, ON или ASC и DESC. Когда дело доходит до названий функций, таких как SUM() или COUNT(), нет единого мнения о том, должны ли они быть написаны полностью заглавными или только строчными буквами, но, вероятно, лучше также использовать их заглавными буквами, чтобы лучше отличать их от столбцов. имена, которые должны быть написаны с маленькой буквы.
Когда дело доходит до названий функций, таких как SUM() или COUNT(), нет единого мнения о том, должны ли они быть написаны полностью заглавными или только строчными буквами, но, вероятно, лучше также использовать их заглавными буквами, чтобы лучше отличать их от столбцов. имена, которые должны быть написаны с маленькой буквы.
Еще одно важное правило заключается в том, что, хотя для работы кода не обязательно, каждое предложение, такое как SELECT, FROM, WHERE, GROUP BY и т. д., должно находиться в новой строке. Для дальнейшего повышения удобочитаемости также рекомендуется иметь новую строку для каждого имени столбца в предложении SELECT. Более того, если мы используем подзапросы или CTE, хорошим подходом является использование таблиц, чтобы визуально отличить внутреннюю часть скобки от остальной части запроса.
Код из нашего примера уже в основном хорошо отформатирован. Но мы по-прежнему можем добавлять новые строки в предложение SELECT основного запроса и использовать заглавные буквы в именах функций SUM().
С all_downloads КАК
(ВЫБЕРИТЕ дату загрузки,
СУММА(СЛУЧАЙ
КОГДА account.paying_customer = 'yes', ТО downlds.downloads
КОНЕЦ) КАК n_paying,
СУММА(СЛУЧАЙ
КОГДА account.paying_customer = 'no', ТО downlds.downloads
КОНЕЦ) AS n_nonpaying
ОТ пользователей ms_user_dimension
ВНУТРЕННЕЕ СОЕДИНЕНИЕ ms_acc_dimension account ON users.acc_id = account.acc_id
INNER JOIN ms_download_facts downlds ON users.user_id=downlds.user_id
СГРУППИРОВАТЬ ПО downlds.date)
ВЫБЕРИТЕ дату,
n_бесплатно,
n_paying
ИЗ all_downloads
ГДЕ (n_nonpaying - n_paying) > 0
ЗАКАЗАТЬ ПО дате ASC Мы знаем, что иногда бывает сложно запомнить все правила форматирования текста или настроить все вручную, например, сделать ключевые слова заглавными или добавить таблицы. Таким образом, полезно иметь привычку использовать эти правила форматирования при написании SQL-запросов, потому что это облегчает понимание кода для нас самих и позволяет писать более читаемый код на собеседованиях.
Заключение
В заключение еще раз приведем список рекомендаций по написанию SQL-запросов:
- Удалить несколько вложенных запросов
- Обеспечить согласованность псевдонимов
- Удалить ненужные предложения ORDER BY
- Удалить ненужные подзапросы
- Если возможно, используйте WHERE, а не HAVING удаляя несколько вложенных запросов, вы можете превратить их в CTE — хорошее эмпирическое правило состоит в том, что один подзапрос в порядке, но несколько подзапросов или подзапрос, повторяющийся несколько раз, должны стать CTE.
Согласованность псевдонимов включает в себя их информативность, длину более 1 буквы, но и не слишком длинные. Будьте последовательны, используете ли вы псевдонимы или нет. Добавляйте псевдонимы к столбцам, созданным аналитическими функциями. Придерживайтесь некоторых соглашений об именах и избегайте столбцов или таблиц, использующих один и тот же псевдоним. Используйте строчные буквы для псевдонимов и символы подчеркивания, если в нем несколько слов.
 Не используйте кавычки для определения псевдонима.
Не используйте кавычки для определения псевдонима.Чтобы удалить предложение ORDER BY, помните, что часто его не нужно повторять в нескольких запросах. Если это так, посмотрите, возможно ли иметь его только в последнем.
Иногда подзапросы или CTE могут быть объединены вместе. Ищите подзапросы, которые выглядят одинаково или приводят к одним и тем же столбцам — часто их проще всего комбинировать. Один из приемов — заменить предложение WHERE на CASE.
Используйте предложение HAVING только в сочетании с агрегатными функциями, почти во всех остальных случаях следует выбирать WHERE.
При форматировании текста запроса не забудьте написать ключевые слова и, возможно, функции заглавными буквами, псевдонимы, имена таблиц и столбцов строчными буквами. Каждое предложение и, возможно, каждый столбец в предложении SELECT должны находиться в новой строке. Используйте табуляцию для отображения подзапросов и CTE.
Если вам интересно, какие вопросы по SQL вам будут задавать на собеседовании, мы написали это исчерпывающее руководство, в котором вы найдете ответы на самые популярные вопросы на собеседованиях по SQL для различных позиций данных и советы по подходу к собеседованиям по SQL.
 Кроме того, ознакомьтесь с некоторыми вопросами для интервью на основе сценариев SQL здесь .
Кроме того, ознакомьтесь с некоторыми вопросами для интервью на основе сценариев SQL здесь . Что такое SQL — узнайте о SQL-запросах, командах и объединениях
Что такое SQL?SQL Значение: это предметно-ориентированный язык. Он используется в языке разработки приложений, чтобы программист мог работать с данными. Данные хранятся в реляционной базе данных. Для управления этими данными у нас есть системы управления реляционными базами данных, такие как SQL Server, MySQL, MS Access и т. д., которые используют SQL в качестве стандартного языка баз данных.
Посмотрите это видео «Введение в SQL и команды SQL»:
В этом учебном пособии «Введение в SQL» вы получите краткий обзор:
- Что означает SQL?
- Что такое данные?
- Что такое база данных?
- Что такое система управления базами данных?
- Типы архитектуры базы данных
- Типы баз данных
- Возможности SQL
- История SQL
- Почему SQL
- SQL-процесс
- Типы команд SQL
- Для чего используется SQL?
- Как использовать SQL
- Типы операторов SQL
- Стандарты SQL
- Элементы языка SQL
- Почему имеет смысл изучать SQL после NoSQL?
- Востребованные навыки SQL
- Какое будущее у баз данных SQL?
- Основы SQL
Распространенный вопрос: «Что такое полная форма SQL».
Что такое данные? SQL расшифровывается как язык структурированных запросов. Первоначальным названием языка было SEQUEL, созданный для исследовательской базы данных IBM System R в 1970, но из-за проблем с авторскими правами они изменили название на SQL.
SQL расшифровывается как язык структурированных запросов. Первоначальным названием языка было SEQUEL, созданный для исследовательской базы данных IBM System R в 1970, но из-за проблем с авторскими правами они изменили название на SQL.Данные — это отдельные фрагменты информации, которые могут быть фактами, цифрами или деталями, которые хранятся в компьютере или используются им. В эту цифровую эпоху, когда данные лежат в основе всего, что мы делаем, освоение того, что такое SQL и как он работает, может занять много времени. Чтобы учиться и стать профессионалом в области SQL, присоединяйтесь к этому полному курсу обучения SQL!
Что такое база данных?База данных — это хорошо организованный набор данных, которые хранятся в электронном формате. Чтобы быть более конкретным, база данных SQL представляет собой электронную систему, которая позволяет пользователям легко получать доступ к данным, манипулировать ими и обновлять их.
Получите 100% повышение!
Осваивайте самые востребованные навыки прямо сейчас!
Что такое система управления базами данных?Рассмотрим школьную базу данных SQL, в которой есть запись о нынешних и ранее изученных учащихся в таблице «Сведения об учащемся». Точно так же он может содержать сведения о факультете, сведения об управлении, сведения о персонале и многое другое в зависимости от требований школы. Поскольку данных очень много, для управления ими нам нужна система управления базами данных.
Почти все современные базы данных управляются системой управления базами данных (СУБД). По сути, это системное программное обеспечение, используемое для систематического создания данных и управления базами данных.
Хотите пройти сертификацию по SQL! Узнайте все о сертификации SQL Server
Как база данных SQL управляет данными?СУБД предоставляет как пользователям, так и программистам фундаментальный способ создания, извлечения, обновления и управления данными.

Рассмотрим сценарий, в котором студент XYZ хочет изменить свой адрес. СУБД ищет сведения о XYZ в таблице «Сведения о студентах» из базы данных «Школьная база данных» и отображает их для пользователя, а затем пользователь редактирует их.
Посмотрите это учебное пособие по полному курсу SQL
Теперь у нас есть четкое представление о базе данных и системе управления ею. Давайте двигаться дальше.
Типы архитектуры базы данныхУ нас есть два типа архитектуры базы данных:
- Файловый сервер
- клиент-сервер
Остались вопросы? Приходите в Intellipaat’s SQL Community , развейте все свои сомнения и преуспейте в своей карьере!
Архитектура файлового сервераВ архитектуре файлового сервера файлы расположены в локальной системе. Это полезно для обмена информацией по сети. Клиент отправляет запрос файла по сети, а файловый сервер пересылает файл клиенту.
 Это считается самым примитивным типом службы данных, используемым для обмена информацией по сети. Файловый сервер также обеспечивает доступ к процессорам удаленного сервера.
Это считается самым примитивным типом службы данных, используемым для обмена информацией по сети. Файловый сервер также обеспечивает доступ к процессорам удаленного сервера.Вот пример для понимания реализации файлового сервера.
Предположим, у вас есть файл Excel, и один из ваших друзей просит вас отправить этот файл для получения некоторой информации. Итак, вы отправляете копию своему другу. Теперь, когда вы вносите какие-либо изменения в свой исходный файл Excel, эти изменения не будут отражаться в файле, который находится у вашего друга.
В этом примере вы — файловый сервер, а ваш друг — устройство, запрашивающее информацию. Мы можем сделать вывод об архитектуре файлового сервера, заметив, что сервер действует как сортировочное устройство, и только один человек в каждый момент времени может иметь к нему доступ.
Хотите узнать больше об администраторах баз данных MS SQL Server, ознакомьтесь с нашим курсом сертификации администраторов баз данных MS SQL Server в Хайдарабаде.
Архитектура клиент-сервер
В архитектуре клиент-сервер база данных является сервером, а любое приложение, использующее данные, является клиентом.
Вот пример, объясняющий работу этого сервера. Рассмотрим три компонента OLE DB или клиентские системы, одновременно обращающиеся к базе данных. Системы вошли на веб-сайт IRCTC, чтобы узнать количество поездов, следующих из пункта назначения X в пункт назначения Y.
Клиентская система отправляет запрос на сетевой сервер. Сетевой сервер отправляет тот же запрос в базу данных, а окончательный результат отправляется в клиентскую систему. Этот процесс проводится, когда одна система отправляет запрос. Но в режиме реального времени будет 90 259 n 90 260 систем, и может быть несколько запросов, которые отправляются одновременно для одних и тех же данных. Сервер базы данных должен будет обрабатывать все запросы одновременно и отправлять запрошенные данные клиентским системам.
Хотите пройти собеседование по SQL? Лучшие вопросы для интервью Intellipaat SQL предназначены только для вас!
Типы баз данныхБазы данных подразделяются на различные базы данных в зависимости от требований к использованию.
- Централизованная база данных.
- Распределенная база данных.
- Персональная база данных.
- База данных конечных пользователей.
- Коммерческая база данных.
- База данных NoSQL.
- Оперативная база данных.
- Реляционная база данных.
- Облачная база данных.
- Объектно-ориентированная база данных.
- Граф базы данных.
Смена карьеры
Возможности SQLТеперь мы готовы работать с SQL! Как обсуждалось ранее, полная форма SQL — это язык структурированных запросов, он помогает вам взаимодействовать с базой данных с помощью команд. Вот некоторые особенности базы данных SQL:
- Позволяет пользователям извлекать данные из реляционной базы данных.
- Позволяет пользователям создавать базы данных и таблицы.
- Позволяет обновлять, вставлять, удалять и изменять базы данных и таблицы.
- Обеспечивает безопасность и позволяет устанавливать разрешения.

- Позволяет людям обрабатывать данные по-новому.
История SQL
IBM Corporation, Inc. создала язык Structured English Query Language (SEQUEL) для реализации модели Кодда. Позже SEQUEL был переименован в SQL (по-прежнему произносится как «sequel»). Первая коммерчески доступная реализация SQL была выпущена в 1979 от Relational Software, Inc. (теперь Oracle). В настоящее время SQL широко признан стандартным языком СУБД.
Почему SQLПоскольку SQL может работать с любой базой данных, это наиболее широко используемый язык для доступа к базе данных. Базы данных, с которыми вы взаимодействуете, представляют собой программы, которые позволяют клиентам логически хранить информацию и управлять ею. С SQL мы можем иметь следующие преимущества.
- SQL предлагает пользователям доступ к данным в реляционных базах данных.
- Пользователи могут использовать эту функцию для определения данных.
- С помощью SQL легко идентифицировать и изменять данные в базе данных.
- Мы можем создавать, удалять, изменять данные в базе данных в любое время.
- Позволяет встраивать модули, библиотеки и предварительные компиляторы SQL в другие языки.
- Представления базы данных, хранимые процедуры и функции могут быть созданы с помощью SQL.
Intellipaat предлагает своим учащимся лучшие курсы по базам данных.
Процесс SQLЕсли вы хотите выполнять SQL-запросы в какой-либо системе СУБД, вы должны сначала выбрать наилучший метод для выполнения вашего запроса, а механизм SQL определит, как интерпретировать эту задачу.
Ниже приведены некоторые важные компоненты процесса SQL:
- Диспетчер запросов . Задача диспетчера — отправить запрос запроса либо в CQE, либо в SQE, в зависимости от атрибутов запроса. Диспетчер отвечает за обработку всех запросов. Этого нельзя избежать.
- Механизмы оптимизации : после рассмотрения нескольких факторов, связанных с объектами, на которые ссылаются, и условиями, определенными в запросе, включая цель оптимизатора, оптимизатор запросов определяет наиболее эффективный способ выполнения выражения SQL.
- Classic Query Engine : для любых пустых полей CQE будет использовать значения по умолчанию для сопоставления данных с буфером записи. Для непустых полей SQE просто сопоставляет данные с буфером записи.
- Механизм запросов SQL : Для доступа к данным в реляционных структурах механизм запросов SQL интерпретирует команды и язык SQL. Многие люди используют механизмы запросов SQL для выполнения операций CRUD (создания, чтения, обновления и удаления) и реализации политик данных, которые требуются реляционными моделями данных и системами управления базами данных.
Интересуетесь SQL? Посетите наш блог о типах данных SQL, чтобы освоить SQL.
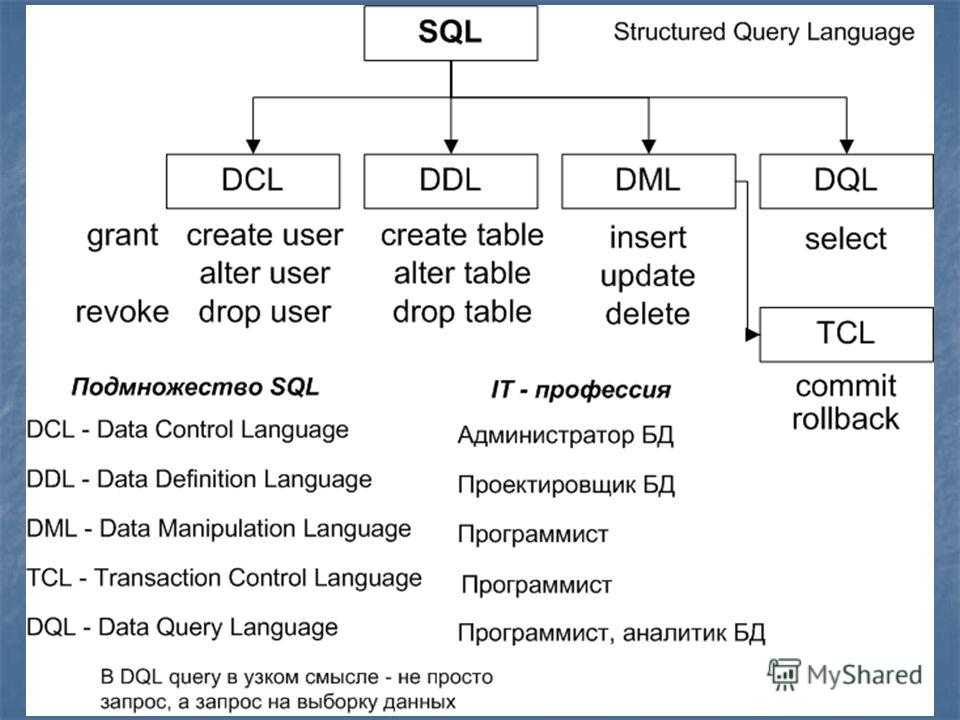
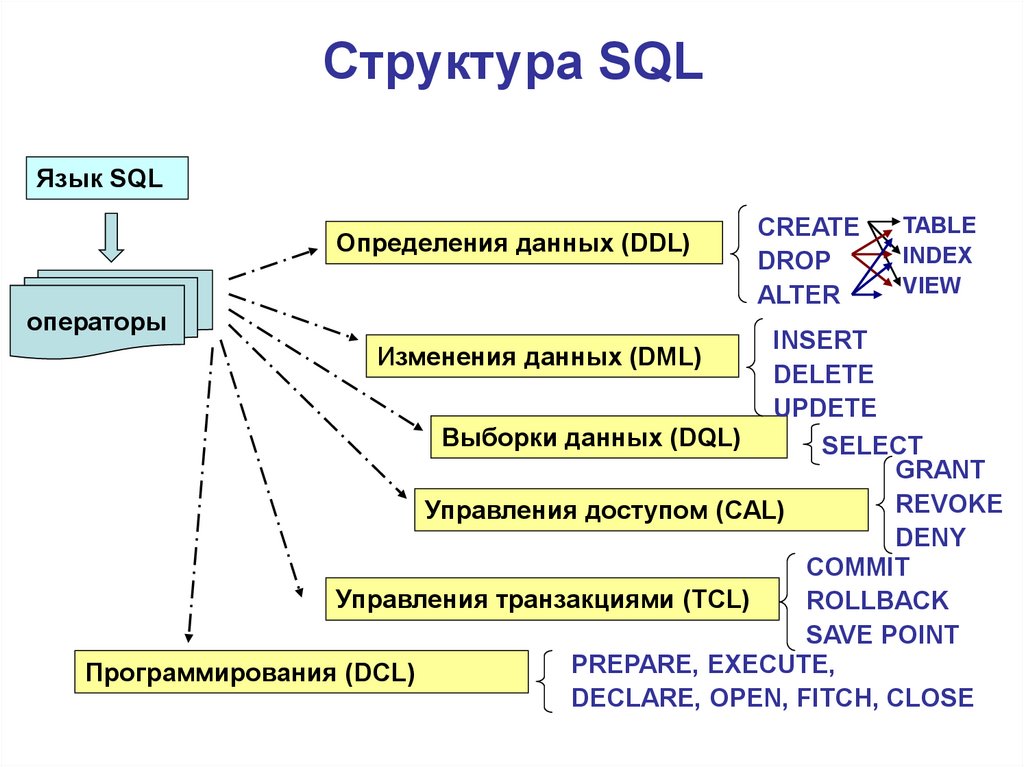
Типы команд SQLКоманды SQL традиционно делятся на четыре категории:
- Язык запроса данных (команды DQL в SQL)
- Язык определения данных (команды DDL в SQL)
- Язык обработки данных (команды DML в SQL)
- Язык управления данными (команды DCL в SQL)
Язык запроса данных содержит только одну команду «выбрать».
Язык определения данных (команды DDL в SQL) Эта команда может сопровождаться множеством других предложений для составления запросов.
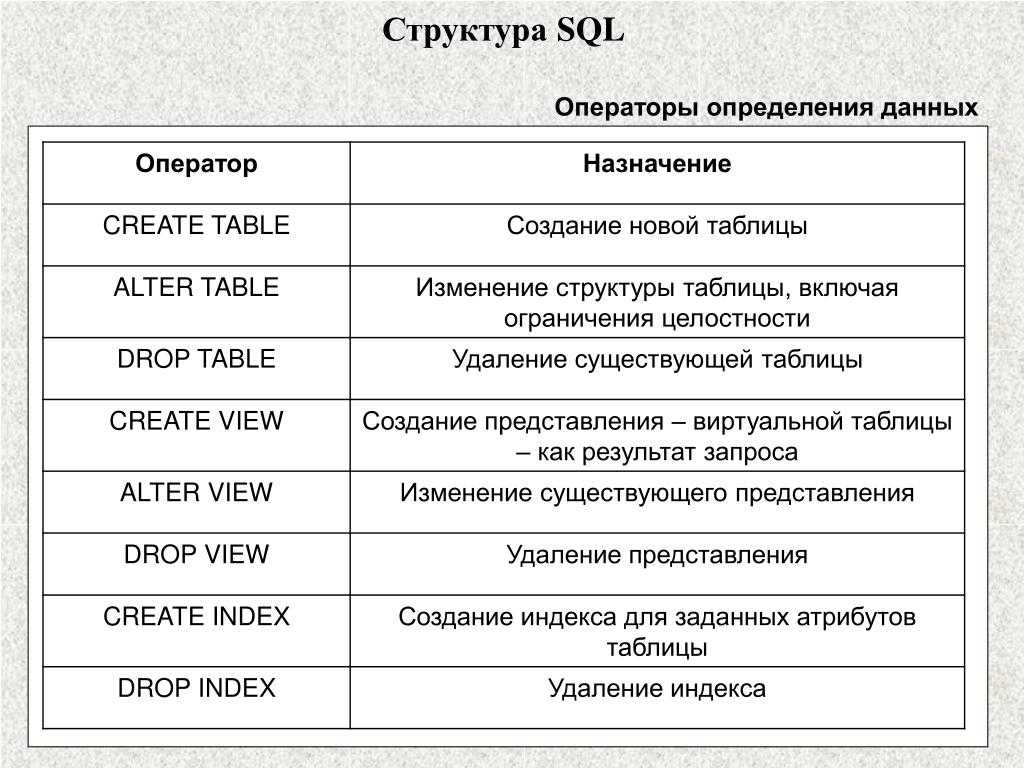
Эта команда может сопровождаться множеством других предложений для составления запросов.Язык определения данных — это мощный инструмент SQL, который позволяет пользователю создавать и реструктурировать объекты базы данных. Основными командами DDL в SQL являются Create Tables, Alter Tables и Drop Tables.
СОЗДАТЬ ТАБЛИЦУ Создает новую таблицу ПОДЪЕМНЫЙ СТОЛ Удаляет ВСЮ таблицу. ИЗМЕНЕНИЕ ТАБЛИЦЫ Изменяет существующую таблицу Курсы, которые могут вам понравиться
Язык манипулирования данными (команды DML в SQL)Язык манипулирования данными используется для манипулирования данными в таблицах. Основными командами DML в SQL являются Insert, Update и Delete.
Язык управления доступом к данным (команды DCL в SQL)ВЫБОР Получить информацию из базы данных ВСТАВКА Добавить новую информацию в базу данных ОБНОВЛЕНИЕ Изменяет информацию, хранящуюся в настоящее время в базе данных УДАЛИТЬ Удалить информацию из базы данных И, наконец, у нас есть доступ к управлению данными, который позволяет пользователю контролировать доступ к данным в базе данных.
 Эти команды DCA обычно используются для управления распределением привилегий между пользователями и создания объектов, связанных с доступом пользователей. Базовыми командами DCL в SQL являются Grant и Revoke.
Эти команды DCA обычно используются для управления распределением привилегий между пользователями и создания объектов, связанных с доступом пользователей. Базовыми командами DCL в SQL являются Grant и Revoke.Это подводит нас к концу введения в SQL. Здесь мы узнали, что такое SQL, полная форма SQL, база данных SQL, все основные команды SQL и их типы — DDL, DCL, DML и DQL с примерами.
Подробнее – Памятка по командам SQL
Для чего используется SQL?В мире технологий базы данных и SQL используются практически в любой среде, где задействованы большие объемы данных. Финансовая индустрия, музыкальные приложения, платформы социальных сетей — вот некоторые из секторов, в которых SQL используется чаще всего.
Например, банковское программное обеспечение и платежные системы, такие как Stripe, хранят и обрабатывают данные о финансовых транзакциях и пользователях в финансовой сфере. В основе этих процедур лежит сложная база данных.
Как использовать SQL Кроме того, системы банковских баз данных имеют дополнительные требования к безопасности, которые требуют строжайшего соблюдения рисков в коде SQL.
Кроме того, системы банковских баз данных имеют дополнительные требования к безопасности, которые требуют строжайшего соблюдения рисков в коде SQL.С помощью SQL мы можем создавать базы данных, таблицы, функции и т. д. Ниже перечислены команды SQL, которые необходимо изучить для работы с базой данных.
- CREATE DATABASE — для создания базы данных
- CREATE TABLE — для создания таблиц
- SELECT — для поиска/извлечения некоторых данных из базы данных
- ОБНОВЛЕНИЕ – для внесения корректировок и редактирования данных
- УДАЛИТЬ – для удаления некоторых данных
Например, если вы хотите создать новую запись в базе данных.
СОЗДАТЬ БАЗУ ДАННЫХ name_of_a_database ; СОЗДАТЬ ТАБЛИЦУ name_of_a_table ( столбец1 тип_данных, столбец2 data_type,)
Типы операторов SQLОператоры SQL в основном подразделяются на следующие.

- Операторы языка определения данных (DDL)
- Операторы языка обработки данных (DML)
- Операторы управления транзакциями
- Операторы управления сеансом
- Заявление об управлении системой
- Встроенные операторы SQL
SQL — это язык управления базами данных. Это влечет за собой формирование базы данных, удаление, поиск строк и модификацию, среди прочего. SQL принят в качестве стандартного языка для реляционных баз данных как ANSI, так и ISO/IEC. Спецификации SQL содержат множество разделов.
Официальные названия этого стандарта:
ANSI/ISO/IEC 9075:2003, «Язык базы данных SQL», Части 1 («SQL/фреймворк»), 2 ("SQL/основа"), 3 ("SQL/CLI"), 4 («SQL/постоянно хранимые модули»), 9 ("SQL/Управление внешними данными"), 10 ("Привязка SQL/объектного языка"), 11 ("SQL/Схемы"), 13 («Подпрограммы и типы SQL/Java»), 14 («SQL/XML») и («SQL/MDA»)Элементы языка SQL
Наиболее часто используемые элементы языка SQL:
Ключевые слова: одно или несколько ключевых слов присутствуют в каждом операторе SQL
Выражения: из элементов, таких как константы, операторы SQL, выражения формируются.

Переменные: существует много переменных, таких как глобальные переменные, Sybase IQ поддерживает локальные переменные и переменные уровня соединения.
Комментарии: для присоединения пояснительного текста к операторам SQL или блокам операторов используется комментарий. Комментарий не выполняется на сервере SQL.
Строки: Строки могут быть литеральными строками или выражениями типов данных VARCHAR/CHAR.
Идентификаторы: имен объектов в базе данных, таких как идентификаторы пользователей, таблицы и столбцы, можно назвать идентификаторами.
Значение NULL: для указания неизвестного, отсутствующего или неприменимого значения используется значение NULL.
Специальные значения: При создании таблиц специальные значения следует использовать в выражениях и в качестве значений по умолчанию для столбцов.
Условия поиска: Условия могут использоваться для выбора подмножества строк таблицы или для управления операторами, такими как оператор IF, для оценки управления потоком.

Хотите стать экспертом по SQL? Пройдите обучение Intellipaat по SQL в Дублине!
Почему имеет смысл изучать SQL после NoSQL?Поскольку базы данных NoSQL представляют собой узкоспециализированные системы с уникальным использованием и ограничениями, мы должны изучать SQL после NoSQL. NoSQL больше подходит тем, кто работает с большими объемами данных. Реляционные базы данных и связанные с ними технологии используются подавляющим большинством людей.
Если сравнивать поддержку безопасности и хранения, у SQL больше преимуществ, чем у NoSQL.
Навыки SQL в спросеБольшинство организаций ищут специалистов по SQL. Некоторые востребованные навыки SQL:
- Структуры баз данных
- Создание базы данных с SQL
- Операторы SQL и предложения
- Управление базой данных SQL
- MySQL и PostgreSQL
- Мастер PHP
Благодаря этим востребованным навыкам SQL вы можете занимать следующие позиции:
- Администраторы баз данных (DBA)
- Инженер по миграции базы данных
- Исследователь данных
- Архитектор больших данных
Хотите узнать больше об SQL, ознакомьтесь с нашим курсом обучения SQL в Малайзии.
Каково будущее баз данных SQL?
В течение многих лет SQL прочно закрепился в базах данных. В будущем базы данных SQL могут быть заменены более распределенными моделями, а NoSQL и Hadoop будут конкурировать за первое место. А согласно опросу разработчиков Stack Overflow, SQL является вторым по распространенности языком программирования, его используют 50% всех разработчиков (веб-, настольных, системных администраторов/DevOps, специалистов по данным/инженеров) и опережает только JavaScript — язык вдвое моложе SQL. Следовательно, базы данных SQL имеют большие возможности в будущем.
Основы SQLТеперь давайте кратко рассмотрим основы SQL, которые мы изучили в этом блоге Что такое SQL.
- SQL-SQL — это язык структурированных запросов.
- История SQL — впервые реализована в 1979 г.
- Почему SQL? — мы можем создавать, изменять, удалять записи данных в базе данных в любое время.