Минфин утвердил новую валютную структуру ФНБ с преобладанием юаня
- Финансы
- Ринат Таиров Редакция Forbes
Минфин утвердил новую структуру средств ФНБ: исключается возможность инвестирования в активы, номинированные в долларах, а максимальные доли юаня и золота увеличены до 60% и 40% соответственно. До этого валютная структура ФНБ предполагала также сбережения в евро, фунтах и иенах, но остатки в двух последних валютах уже обнулены
Министерство финансов утвердило новую структуру средств Фонда национального благосостояния (ФНБ) в иностранной валюте и золоте, говорится в сообщении в Telegram-канале Минфина.
Запрещается инвестировать средства ФНБ в активы, номинированные в долларах США. Одновременно в два раза вырастут максимальные доли китайского юаня (60%) и безналичного золота (40%). До этого они составляли 30% и 20% соответственно. Вместе с тем фактические доли каждого из активов в новой структуре теперь могут быть нулевыми. Это уже произошло с фунтом стерлингов и японской иеной: остатки этих валют на счетах ФНБ в Банке России обнулены, сообщил Минфин. Какая доля остается в евро, он не уточнил.
Материал по теме
Новая структура резервов лучше адаптирована к вызовам, которые стоят перед Россией в текущих макроэкономических и геополитических условиях, добавило министерство.
Структура ФНБ не менялась полтора года, с июля 2021-го. Тогда Минфин исключил доллар, до 5% снизил присутствие фунта стерлингов, одновременно доли евро и юаня выросли до 39,7% и 30,4% соответственно. Иена составила 4,7%, безналичное золото — 20,2%. В марте 2022 года примерно половина международных резервов России, включая евро, фунты и иены на счетах Банка России, оказалась замороженной из-за санкций.
Иена составила 4,7%, безналичное золото — 20,2%. В марте 2022 года примерно половина международных резервов России, включая евро, фунты и иены на счетах Банка России, оказалась замороженной из-за санкций.
«Ведомости» ранее, 30 декабря, написали, что предельная разрешенная доля юаня может составить до 80%, а золота — до 40%, то есть фактические размеры активов могут варьироваться в этих пределах. Однако увеличенная доля золота не означает, что Центробанк немедленно начнет его покупать: он может перераспределить в пользу правительства нужные объемы из уже существующих резервов, говорил источник газеты. Депозиты с привязкой к евро, фунтам и иенам перепривяжут к юаням, пояснил другой собеседник издания.
Структура данных. Большая российская энциклопедия
Термины
- Области знаний:
- Теория информации и структур данных
Структу́ра да́нных, организация данных, представляющая собой множество их элементов и множество отношений между ними.
Элементы данных структуры могут быть разной гранулярности. Они могут быть простыми (атомарными) либо агрегированными (составными), включающими другие элементы данных. Примерами атомарных элементов данных являются байты, литеры алфавита, числа разного вида (целые, с фиксированной или плавающей точкой), агрегированных – строки, одномерные и многомерные массивы, таблицы, списки, записи, множества. Элементы данных, входящие в состав агрегированных, сами могут быть агрегированными. Например, запись может включать как атомарные, так и агрегированные элементы данных. Таким образом, структура данных может быть рекурсивной.
Элементы данных структуры данных обладают значением и могут снабжаться в её описании или в тегах языков разметки именами, которые используются для их идентификации при выполнении операций над ними. Для идентификации элементов данных могут использоваться их порядковые номера (индексы) в упорядоченных структурах, например, одномерных или многомерных массивах. Наконец, для цели идентификации может использоваться указание их местоположения, абсолютного или относительного по отношению к другим элементам данных.
Агрегированные элементы данных, например, строки таблиц, могут идентифицироваться совокупностью значений некоторого подмножества составляющих их элементов данных. Эта совокупность называется ключом. Значением ключа является конкатенация значений указанных элементов данных.
Отношения между элементами данных структуры могут быть разнообразными. Например, отношение иерархии, отношение порядка, отношение соседства и другие с различной конкретной семантикой. Они могут быть бинарными различного вида (1:1, 1:N или M:N) или n-арными. В соответствии с этим существуют различные виды структур данных: графовые – деревья или сети, уже упоминавшиеся таблицы, одномерные и многомерные массивы, списки и многие другие.
Со структурой данных в ряде случаев ассоциируются некоторые свойства данных, зависимые от вида отношений между её элементами данных. Так, например, в иерархической древовидной структуре данных объектных моделей данных, используемых в языках программирования и других средствах информационных технологий, в которой вершинам дерева соответствуют типы объектов, поддерживаются отношения наследования свойств типа объектов его подтипами. При этом все свойства, определённые для типа объектов, присущи как экземплярам объектов этого типа, так и объектов его подтипов. Некоторые объектные модели данных используют иерархические структуры более общего вида, в которых подтипы могут иметь несколько родительских типов. В ряде таких моделей допускается отношение множественного наследования экземплярами объектов подтипа свойств экземпляров объектов родительских типов.
При этом все свойства, определённые для типа объектов, присущи как экземплярам объектов этого типа, так и объектов его подтипов. Некоторые объектные модели данных используют иерархические структуры более общего вида, в которых подтипы могут иметь несколько родительских типов. В ряде таких моделей допускается отношение множественного наследования экземплярами объектов подтипа свойств экземпляров объектов родительских типов.
Используются различные способы представления отношений между элементами данных в структуре данных. Так, для представления отношения порядка между соседними элементами списка может использоваться указание из предыдущего элемента на последующий. Строки двух таблиц в реляционной базе данных, содержащие данные об одной и той же сущности реального мира, связываются по критерию совпадения значений их ключей. Отношение между элементами данных столбцов таблицы представляется их принадлежностью одним и тем же строкам таблицы.
В системах программирования, системах баз данных, в веб-браузерах, обеспечивающих просмотр HTML-страниц или XML-документов, а также в других средствах информационных технологий используется многоуровневое представление данных, которыми они оперируют. Отображение представлений данных между смежными уровнями многоуровневого представления обеспечивается механизмами отображения данных.
Отображение представлений данных между смежными уровнями многоуровневого представления обеспечивается механизмами отображения данных.
Системы программирования имеют дело с описанием структуры данных и других их свойств на языке программирования, а также с внутренним представлением этих данных (с их внутренней структурой) на стадии исполнения. Компилятор исходного кода программы, по сути, генерирует описание внутренней структуры данных на основе их описания на языке программирования и «встраивает» его в исполняемый код программы. Интерпретатор формирует и использует внутреннюю структуру данных на стадии исполнения. Средства отображения данных фактически используются при этом, соответственно, на стадии компиляции исходного кода программы или на стадии его интерпретации.
Система управления базами данных (СУБД) генерирует также в своём внутреннем представлении описание структуры хранимых данных, используя схему базы данных, когда она загружается в систему. Механизмы отображения данных являются функциональными компонентами СУБД и работают на стадии функционирования системы.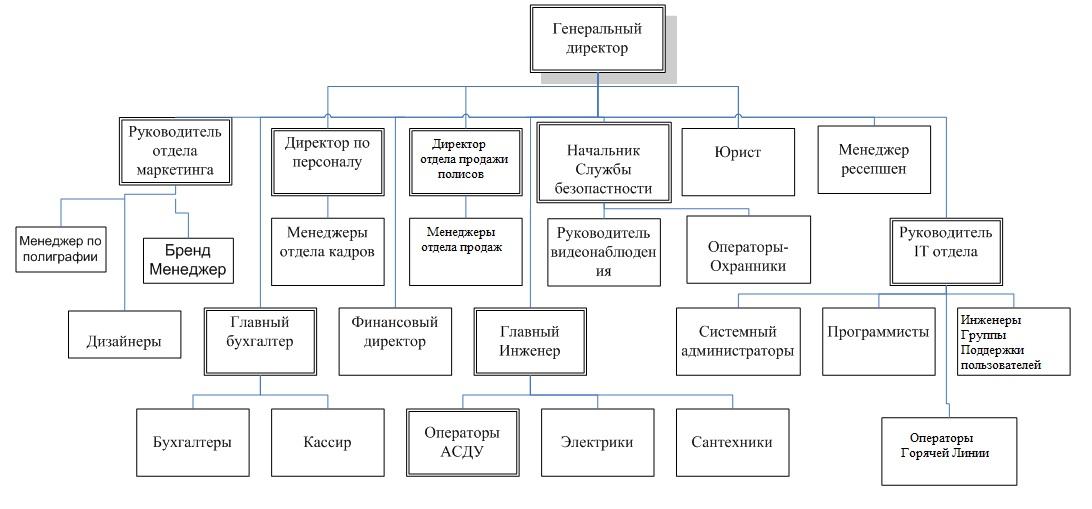 Точно так же механизмы отображения данных встроены в веб-браузеры и функционируют при просмотре страниц веб-сайтов. Эти механизмы генерируют из представления страницы сайта на языке разметки её представление для пользователя, используя информацию тегов разметки.
Точно так же механизмы отображения данных встроены в веб-браузеры и функционируют при просмотре страниц веб-сайтов. Эти механизмы генерируют из представления страницы сайта на языке разметки её представление для пользователя, используя информацию тегов разметки.
Благодаря возможности поддержки многоуровневого представления данных обеспечивается иерархия абстракций данных, позволяющая пользователям СУБД и веб-браузеров, а также программистам при написании программного кода обращаться с данными в понятной им форме, избавляя от необходимости знания, как устроены хранимые данные, – представления их на нижнем уровне иерархии или внутренней структуры данных в исполняемой программе.
Таким образом, указанные программные средства имеют дело с несколькими структурами данных, каждая из которых относится к соответствующему уровню иерархии абстракции данных. Структуры хранимых данных в системах баз данных обладают при этом отличительной особенностью. Наряду с данными, представляющими интерес для пользователей, они могут включать организованные специальным образом вспомогательные структуры данных, обеспечивающие быстрый доступ к пользовательским данным. Примерами могут служить организованные различными способами индексы и хеш-таблицы.
Примерами могут служить организованные различными способами индексы и хеш-таблицы.
В зависимости от вида структуры данных и уровня абстракции данных, к которому она относится, над составляющими её данными возможны различные специфические операции. Так, для данных графовой структуры характерны навигационные операции. Для данных табличной структуры в реляционных системах баз данных свойственны операции селекции (выборки подмножества строк таблицы), проекции (построение новой таблицы, состоящей из заданного подмножества столбцов исходной таблицы), а также соединения таблиц (построение новой таблицы из столбцов двух таблиц-аргументов таким образом, что строки новой таблицы образуются из пар строк, каждая из которых принадлежит одной из таблиц-аргументов; при этом пары образуются из строк, у которых совпадают значения в указанных столбцах). Для структуры хранимых данных специфичны, например, операции актуализации индексов.
Используемые в различных программных системах структуры данных могут иметь или не иметь описание, отчуждённое или не отчуждённое от самих данных. Программный код на языке программирования всегда содержит описание средствами этого языка структуры данных, в нём используемых. СУБД располагает описанием структуры и других свойств данных, содержащихся в базе данных, называемым схемой базы данных. В обоих этих случаях описание структуры данных отчуждено от самих данных. Иная ситуация имеет место для структур данных гипертекстовых HTML-страниц веб-сайтов или для не снабжённых спецификацией соответствующей им XML-схемой XML-документов, содержащихся в веб-сайтах или в системах баз данных. Здесь описание структуры данных не отчуждено от данных и встроено в представление страниц на языке разметки средствами тегов языка. В этом случае структура данных является самоописываемой.
Программный код на языке программирования всегда содержит описание средствами этого языка структуры данных, в нём используемых. СУБД располагает описанием структуры и других свойств данных, содержащихся в базе данных, называемым схемой базы данных. В обоих этих случаях описание структуры данных отчуждено от самих данных. Иная ситуация имеет место для структур данных гипертекстовых HTML-страниц веб-сайтов или для не снабжённых спецификацией соответствующей им XML-схемой XML-документов, содержащихся в веб-сайтах или в системах баз данных. Здесь описание структуры данных не отчуждено от данных и встроено в представление страниц на языке разметки средствами тегов языка. В этом случае структура данных является самоописываемой.
Существует ещё одна особенность структуры хранимых данных в системах баз данных. В современных СУБД отсутствуют средства её описания. Это описание автоматически генерируется из описания структуры данных более высокого уровня многоуровневого представления данных – схемы базы данных. Одним из исключений являются ранние СУБД, основанные на подходе CODASYL (см. Модель данных). В таких СУБД проектировщику баз данных предоставляется специальный язык описания хранимых данных (англ. Data Storage Description Language – DSDL), на котором описывается их структура и другие необходимые свойства.
Одним из исключений являются ранние СУБД, основанные на подходе CODASYL (см. Модель данных). В таких СУБД проектировщику баз данных предоставляется специальный язык описания хранимых данных (англ. Data Storage Description Language – DSDL), на котором описывается их структура и другие необходимые свойства.
Данные, структура которых описана и это описание отчуждено от данных, называются структурированными. В отличие от них, как уже отмечалось, существуют данные со структурой, описание которой встроено в данные (например, страницы веб-сайтов) либо которая описывается схемой, не являющейся строго регламентирующей состояние данных, и некоторые элементы данных структуры могут не соответствовать схеме. Данные с такой структурой называются слабоструктурированными. Такими данными оперируют, например, веб-браузеры и некоторые системы баз данных XML-документов. Наконец, в случае, когда какое-либо описание структуры данных вообще отсутствует, данные называются неструктурированными. Примерами могут служить текстовые документы на естественных языках, аудио- и видеоданные.
Рассмотренные характеристики степеней структурированности обычно не ассоциируют с хранимыми данными и внутренним представлением данных в системах программирования.
Когаловский Михаил Рувимович, Серебряков Владимир АлексеевичДата публикации: 12 августа 2022 г. в 11:49 (GMT+3)
Синтаксис и структура C
Об этом курсе
Этот курс позволит вам начать писать встроенное ПО на языке C для микроконтроллеров. Будет рассмотрено большинство основных конструкций языка C, включая переменные, константы, операторы, выражения и операторы, функции принятия решений, циклы, функции, массивы, многофайловые проекты и указатели данных. Вы изучите все эти темы языка C из неаппаратной среды, чтобы вы могли сосредоточиться на изучении языка C вместо архитектуры микроконтроллера. Презентация будет сопровождаться демонстрацией кода под руководством инструктора, которая будет проводиться с помощью мощного симулятора MPLAB®.
Учебная программа133 мин
Учебный план
- Введение
Обзор 1 мин
- Комментарии
Комментарии 5 мин
- Переменные
Переменные 3 мин
Создание собственных типов 1 мин
-
Заголовочный файл 3 мин
- Литералы и константы
Константы и литералы 2 мин
Типы литералов 4 мин
Буквенные квалификаторы 2 мин
Символьные и строковые литералы 4 мин
- Символические константы
Преобразование типа 3 мин
Операторы присваивания 2 мин
Простой трюк для реляционных операторов 1 мин
Логические операторы 2 мин
-
Побитовые операторы 5 мин
Оператор побитового сдвига 3 мин
Cast Оператор 1 мин
Приоритет и ассоциативность 3 мин
- Решения
Операторы if 3 мин
Заявление о переключении 3 мин
- Петли
Для циклов 4 мин
Пока циклы 2 мин
Делать пока 1 мин
- Перерыв и продолжение 2 мин
- Функции
Функции 4 мин
Параметры 1 мин
Объявления 4 мин
Область действия переменных 8 мин
- Переменные II
Многофайловые проекты 2 мин
Статические переменные 2 мин
Автоматические переменные 1 мин
Внешние переменные 2 мин
Область действия 2 мин
Файлы заголовков 1 мин
- Массивы
Массивы 1 мин
Использование массивов 2 мин
Многомерные массивы 2 мин
Обработка массива 1 мин
Струны 2 мин
- указатели
Введение 3 мин
Почему указатели 1 мин
Объявление указателя 2 мин
Операторы указателя 6 мин
Указатели с иллюстрациями 3 мин
Указатели и массивы 2 мин
Арифметика указателя 2 мин
Прыжки указателя 2 мин
Дополнительная арифметика указателя 4 мин
Приращение указателя до и после 5 мин
Указатели и функции 5 мин
Указатели и строки 2 мин
Массивы указателей 3 мин
- Что дальше?
Следующие шаги 1 мин
- Ваш отзыв
Нам нужен ваш отзыв
Преимущества структуры в программировании на C
В программировании на C структура представляет собой набор различных элементов данных, на которые ссылаются по одному имени. Он также известен как определяемый пользователем тип данных в C.
Он также известен как определяемый пользователем тип данных в C.
Использование структуры в языке C имеет несколько преимуществ. В этой статье мы собираемся перечислить ключевые преимущества структуры при программировании на C.
- Разнородный набор элементов данных: структура позволяет нам создавать определяемый пользователем тип данных, который может хранить элементы с различными типами данных. Например, если мы хотим хранить записи студентов с их номером списка, именем, оценками и адресом, то он содержит элементы с разными типами, т.е. номер списка может быть целым числом, имя — строковым типом, оценки — типом с плавающим числом и адрес строкового типа.
В языке C этого можно добиться, используя следующую структуру:структурировать студента { int рулон_номер; имя персонажа[30]; плавающие метки; адрес символа[50]; };
Теперь структурные переменные можно создавать с помощьюstruct student s1, s2;, и эти переменные могут хранить все данные о двух учениках.
- Уменьшенная сложность: подумайте о хранении студенческих записей пяти разных студентов с номером списка, именем, оценками и адресом, как в приведенном выше примере, без структуры! Что нам здесь нужно? Пять переменных целочисленного типа для хранения списка пяти студентов, пять строковых переменных для хранения имен пяти студентов, пять переменных типа с плавающей запятой для хранения оценок и снова пять строковых переменных для хранения адресов пяти студентов. Ужасный! Не делай так! Просто создайте структуру и создайте массив структуры. Вот и все!
Вот простая установка для этого:структурировать студента { int рулон_номер; имя персонажа[30]; плавающие метки; адрес символа[50]; }; структурировать студента s[5]; - Повышенная производительность: Структура в C устраняет большую нагрузку при работе с записями, которые содержат разнородные элементы данных, тем самым повышая производительность.
- Сопровождаемость кода: Используя структуру, мы представляем сложные записи, используя одно имя, что упрощает сопровождение кода.
