ARMCC. Структуры, обьединение, перечисление, и битовые поля в ARM C и C++
Рассматривается реализация структурных типов данных union, enum, и struct. Так же рассматривается заполнение структур и реализацию битового поля.
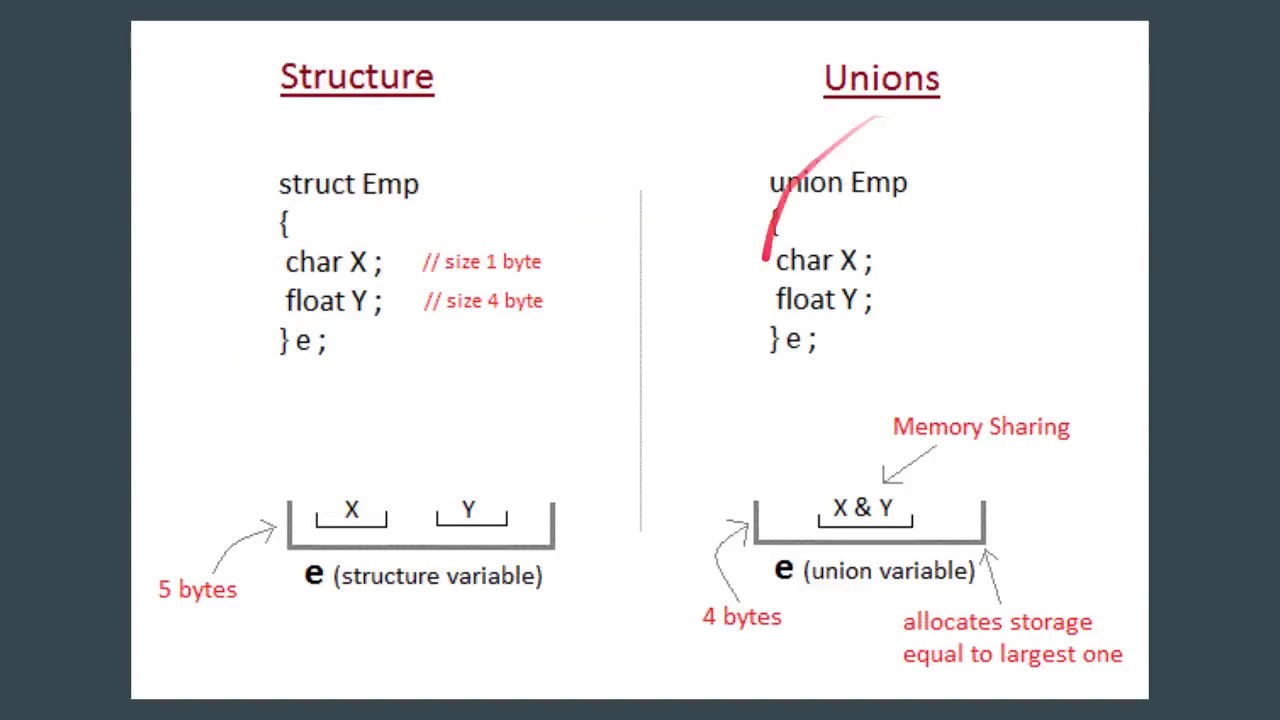
Unions (обьединение)
Когда используется доступ к полюunion другого типа, результат может быть предсказан на основе исходного типа.Enumerations (перечисление)
Обьектenum реализуется наименьшим числовым типом который содержит диапазон перечисления enum.В C режиме, и в C++ режиме без --enum_is_int, если enum перечисление содержит только положительные значения перечислителя, тип хранения перечисления является первым беззнаковым типом из следующего списка в соответствии с диапазоном перечислений в перечислении enum.В других режимах, и в случаях когда enum содержит отрицательные значения перечислителя,тип хранения enum является первым из следующего, согласно диапазону перечисления в перечислителе enum:unsigned charесли не используется--enum_is_intsigned charесли не используется--enum_is_intunsigned shortесли не используется--enum_is_intsigned shortесли не используется--enum_is_intsigned intunsigned intкроме Си с--strictsigned long longкроме Си с--strictunsigned long longкроме Си с--strict.

Примечание
- В RVCT 4.0, тип хранилища
enumявляющийся первым беззнаковым типом из списка применяется только в режиме GNU (--gnu). - В ARM® Compiler 4.1 и выше, тип хранения перечисления
enumтип хранения перечисления, являющийся первым беззнаковым типом из списка, применяется независимо от режима.
enum таким образом может уменьшать размер данных. Опция командной строки --enum_is_int lделает основной тип enum наименьшой шириной int.See the description of C language mappings in the Procedure Call Standard for the ARM® Architecture
specification for more information.Примечание
Care must be taken when mixing translation units that have been compiled with and without the --enum_is_int option, and that share interfaces or data structures.
ints. That is, they must be in the range -2147483648 to +2147483647, inclusive. A warning is issued for out-of-range enumerator values:
That is, they must be in the range -2147483648 to +2147483647, inclusive. A warning is issued for out-of-range enumerator values:#66: enumeration value is out of "int" rangeSuch values are treated the same way as in C++, that is, they are treated as
unsigned
int, long long, or unsigned long
long.To ensure that out-of-range Warnings are reported, use the following command to change them into Errors:
armcc --diag_error=66 ...
Structures (структуры)
Следующие пункты относятся к :
- все структуры Си
Структуры могут содержать заполнение для правильного выравнивания полей и корректного выравнивания структуры.
На графике 1 показан пример классической неупакованной структуры.
Байты 1, 2, и 3 заполняются чтобы обеспечить правильное выравнивание поля.
Байты 11 и 12 заполняются чтобы обеспечить правильное выравнивание структуры.
sizeof() возвращает размер структуры включающая заполнение.График 1 Пример обычной неупакованной структуры
Компилируются структуры одним из способов в зависимости от ее определения:
- Структуры которые определены как
staticилиexternзаполняются нулями. - Структуры в стеке или куче, например которые определены с помощью
malloc()илиauto, заполняются тем что хранилось в памяти ранее. Вы не можете использовать функциюmemcmp()для сравнения содержимого структур определенных таким образом.
--remarks для просмотра сообщений генерируемых компилятором когда он вставляет дополнения в структуру struct.Структуры с пустой инициализацией разрешены в C++:
struct
{
int x;
} X = { };
Однако, если вы компилируете C или C++ с параметрами — cpp и — c90, генерируется ошибка.
Bitfields (битовое поле)
В неупакованных структурах, ARM компилятор выделяет битовые поля в контейнеры.
Контейнер как корректно выравненный обьект декларируемого типа.
Битовые поля распределяются таким образом, чтобы указанное первое поле занимало младшие биты слова в зависимости от конфигурации::
- Little-endian
- Самые низкие адресации являются наименее значимыми.
- Big-endian
- Самые низкие адресации являются наиболее значимыми.
Контейнер битового поля может быть любым целым типом.
Примечание
In strict 1990 ISO Standard C, the only types permitted for a bit field are int, signed int, and unsigned int. For non-int bitfields, the compiler displays an error.
В строгом стандарте ISO стандартного стандарта 1990 года единственными типами, разрешенными для битового поля, являются int, signed int, и unsigned int. Для не —
Для не —int битового поля компилятор отображает ошибку.
signed или unsigned квалификаторов, рассматривается как unsigned. Для примера, int x:10 выделяется как целое число без знака размером 10 бит.Битовое поле присваивается первому контейнеру правильного типа, который имеет достаточное количество нераспределенных битов, например:
struct X
{
int x:10;
int y:20;
};
В первом объявлении создается целочисленный контейнер и выделяется 10 бит в x. Во втором объявлении компилятор находит существующий целочисленный контейнер с достаточным количеством нераспределенных битов и выделяет y в том же контейнере, что и x.
Битовое поле полностью содержится в контейнере. Битовое поле, которое не помещается в контейнер, помещается в следующий контейнер того же типа. Например, декларация z переполняет контейнер, если для структуры объявлено дополнительное битовое поле:
struct X
{
int x:10;
int y:20;
int z:5;
};
Компилятор заполняет оставшиеся два бита для первого контейнера и назначает новый целочисленный контейнер для z.
Контейнеры битого поля могут перекрывать друг друга, например:
struct X
{
int x:10;
char y:2;
};
Первое объявление создает целочисленный контейнер и выделяет 10 бит в x. Эти 10 бит занимают первый байт и два бита второго байта целочисленного контейнера. Во втором объявлении компилятор проверяет контейнер типа char. Не существует подходящего контейнера, поэтому компилятор выделяет новый правильно выровненный контейнерchar.Поскольку естественное выравнивание символа равно 1, компилятор выполняет поиск первого байта, который содержит достаточное количество нераспределенных битов, чтобы полностью содержать бит. В структуре примера второй байт контейнера int имеет два бита, выделенных для x, и 6 бит нераспределены. Компилятор выделяет контейнер char начиная со второго байта предыдущего int контейнера, пропускает первые два бита, которые выделены для x, и выделяет два бита в y.
Если y объявлен char y: 8, компилятор заполняет второй байт и выделяет новый контейнер символов в третий байт, потому что битовое поле не может переполнять его контейнер. На следующем рисунке показано распределение битового поля для следующего примера структуры:
struct X
{
int x:10;
char y:8;
};
Распределение битового поля
Примечение
Те же основные правила применяются к объявлениям битового поля с разными типами контейнеров. Например, добавим битовое поле intstruct X
{
int x:10;
char y:8;
int z:5;
}
Компилятор выделяет контейнер int, начинающийся в том же месте, что и контейнер int x:10, и выделяет байт-выровненный char и 5-битное битовое поле как показано ниже:Распределение битового поля
Вы можете явно помещать контейнер битового поля, объявляя неопределенное битовое поле размером 0. Битовое поле нулевого размера заполняет контейнер до конца, если контейнер не пуст. Последующее объявление битового поля запускает новый пустой контейнер.
Битовое поле нулевого размера заполняет контейнер до конца, если контейнер не пуст. Последующее объявление битового поля запускает новый пустой контейнер.
Примечание
В качестве оптимизации компилятор может перезаписывать биты дополнений в контейнере с неопределенными значениями при записи битового поля. Это не влияет на обычное использование битовых полей.
Packing and alignment of bitfields (упаковка и выравнивание битовых полей)
Использование
__attribute__((aligned(n))) делает битовое поле n-байт выравненным, не только его контейнер, but the bitfield is aligned to the packed alignment at most. It is ignored on bitfields in __packed and __attribute__((packed)) structs.The alignment of a bitfield member’s container is the same as the alignment of that bitfield member. The size of a bitfield container is the least multiple of the alignment that fully covers the bitfield, but no larger than the size of the container-type. The following code examples show this:
The following code examples show this:
#pragma pack(2)
/* Контейнер b должен начинаться с границы выравнивания 2 байта и должен
* иметь размер не больше, чем тип контейнера, в этом случае размер
* короткий. Контейнер b не может начинаться со смещения 0 (перекрывается с a)
*, так как бит b будет начинаться со смещения 2 и не будет полностью лежать
* внутри контейнера. Поэтому контейнер для b должен начинаться со смещения
* 2.
*
* Data layout: 0x11 0x00 0x22 0x22
* Container layout:| a | | b |
*/
struct {
char a;
short b : 16;
} var1 = { 0x11, 0x2222 };
/* контейнер b может быть до 4 байт. Его размер должен быть 2 или 4 байта, так как они являются кратны* ми выравниванию, которые не больше размера контейнера. При использовании 4 байтового контейнера
*, начинающегося с 0, битовое поле b может начинаться со смещения 1 и полностью лежать
* внутри контейнера.
*
* Data layout: 0x11 0x22 0x22 0x00
* Container layout:| a |
* | b |
*/
struct {
char a;
int b : 16;
} var2 = { 0x11, 0x2222 };Упакованные контейнеры битовых полей, включая все контейнеры битовых полей в упакованных структурах, имеют выравнивание 1. Поэтому максимальное битовое дополнение, вставленное для выравнивания упакованного контейнера битовых полей, составляет 7 бит.
Для неупакованного контейнера битового поля, максимальное заполнение битов8*sizeof(container-type)-1.Заполнение хвоста всегда вставляется в структуру по мере необходимости, чтобы гарантировать, что массивы структуры правильно выровнены.
A packed bitfield container is only large enough (in bytes) to hold the bitfield that declared it. Non-packed bitfield containers are the size of their type.
Следующие примеры иллюстрируют эти взаимодействия.
struct A { int z:17; }; // sizeof(A) = 4, alignment = 4
struct A { __packed int z:17; }; // sizeof(A) = 3, alignment = 1
__packed struct A { int z:17; }; // sizeof(A) = 3, alignment = 1struct A { char y:1; int z:31; }; // sizeof(A) = 4, alignment = 4
struct A { char y:1; __packed int z:31; }; // sizeof(A) = 4, alignment = 1
__packed struct A { char y:1; int z:31; }; // sizeof(A) = 4, alignment = 1struct A { char y:1; int z:32; }; // sizeof(A) = 8, alignment = 4
struct A { char y:1; __packed int z:32; }; // sizeof(A) = 5, alignment = 1
__packed struct A { char y:1; int z:32; }; // sizeof(A) = 5, alignment = 1struct A { int x; char y:1; int z:31; }; // sizeof(A) = 8, alignment = 4
struct A { int x; char y:1; __packed int z:31; }; // sizeof(A) = 8, alignment = 4
__packed struct A { int x; char y:1; int z:31; }; // sizeof(A) = 8, alignment = 1struct A { int x; char y:1; int z:32; }; // sizeof(A) = 12, alignment = 4 [1]
struct A { int x; char y:1; __packed int z:32; }; // sizeof(A) = 12, alignment = 4 [2]
__packed struct A { int x; char y:1; int z:32; }; // sizeof(A) = 9, alignment = 1Note that [1] and [2] are not identical; the location of z within the structure and the tail-padding differ.
struct example1
{
int a : 8; /* 4-byte container at offset 0 */
__packed int b : 8; /* 1-byte container at offset 1 */
__packed int c : 24; /* 3-byte container at offset 2 */
}; /* Total size 8 (3 bytes tail padding) */;struct example2
{
__packed int a : 8; /* 1-byte container at offset 0 */
__packed int b : 8; /* 1-byte container at offset 1 */
int c : 8; /* 4-byte container at offset 0 */
}; /* Total size 4 (No tail padding) */struct example3
{
int a : 8; /* 4-byte container at offset 0 */
__packed int b : 32; /* 4-byte container at offset 1 */
__packed int c : 32; /* 4-byte container at offset 5 */
int d : 16; /* 4-byte container at offset 8 */
int e : 16; /* 4-byte container at offset 12 */
int f : 16; /* In previous container */
}; /* Total size 16 (No tail padding) */Структуры в C — темы масштабирования
Обзор
Структура в C — это определяемый пользователем тип данных. Он используется для связывания двух или более похожих или разных типов данных или структур данных вместе в один тип. Структура создается с использованием ключевого слова struct, а структурная переменная создается с использованием ключевого слова struct и имени тега структуры. Тип данных, созданный с использованием структуры в C, может рассматриваться как другие примитивные типы данных C для определения указателя на структуру, передачи структуры в качестве аргумента функции или функции, которая может иметь структуру в качестве возвращаемого типа.
Он используется для связывания двух или более похожих или разных типов данных или структур данных вместе в один тип. Структура создается с использованием ключевого слова struct, а структурная переменная создается с использованием ключевого слова struct и имени тега структуры. Тип данных, созданный с использованием структуры в C, может рассматриваться как другие примитивные типы данных C для определения указателя на структуру, передачи структуры в качестве аргумента функции или функции, которая может иметь структуру в качестве возвращаемого типа.
Область применения статьи
- В этой статье дается основное представление о структуре, о том, как создавать структуру и переменные для структуры.
- Мы также увидим передачу элемента структуры в качестве аргумента функции, указателя на структуру, а также массива структур.
- В этой статье также обсуждалось, как инициализировать структурные переменные и как их выравнивать.
- Также мы увидим ограничения структуры.

Введение
В языке C для хранения целых чисел, символов и десятичных значений у нас есть уже определенные типы данных int, char, float или double (также известные как примитивные типы данных). Кроме того, у нас есть некоторые производные типы данных, такие как массивы и строки, для хранения похожих типов элементов типов данных вместе. Тем не менее, проблема с массивами или строками заключается в том, что они могут хранить только переменные схожих типов данных, а строка может хранить только символы. Что, если нам нужно хранить два разных типа данных вместе в C для многих объектов? Например, есть студенческая переменная, которая может иметь свое имя, класс, раздел и т. д. Поэтому, если мы хотим сохранить всю ее информацию, мы можем создать разные переменные для каждой переменной, такие как массив символов для хранения имени, целочисленная переменная. для хранения класса и символьной переменной для хранения раздела. Но это решение немного запутано, C предоставляет нам лучшее аккуратное и чистое решение, т. е. Structure.
е. Structure.
Зачем использовать структуру?
Представьте, что нам нужно сохранить некоторые свойства, связанные со студентом, такие как имя, класс и раздел. У нас есть один метод для создания массива символов для хранения имени, целочисленной переменной для класса и символьной переменной для раздела, например:
Синтаксис:
Хранить данные для одного ученика легко, но представьте себе создание такого количества переменных. для 50 студентов или даже 500 и более. Таким образом, чтобы справиться с этим типом проблемы, нам нужно создать пользовательский тип данных, который может хранить или связывать разные типы данных вместе, это можно сделать с помощью структуры в C.
Что такое структура?
Структура — это определяемая пользователем структура данных, которая используется для связывания двух или более типов данных или структур данных вместе. Для хранения сведений о студенте мы можем создать структуру для студента, которая имеет следующие типы данных: массив символов для хранения имени, целое число для хранения номера списка, и символ для хранения раздела и т.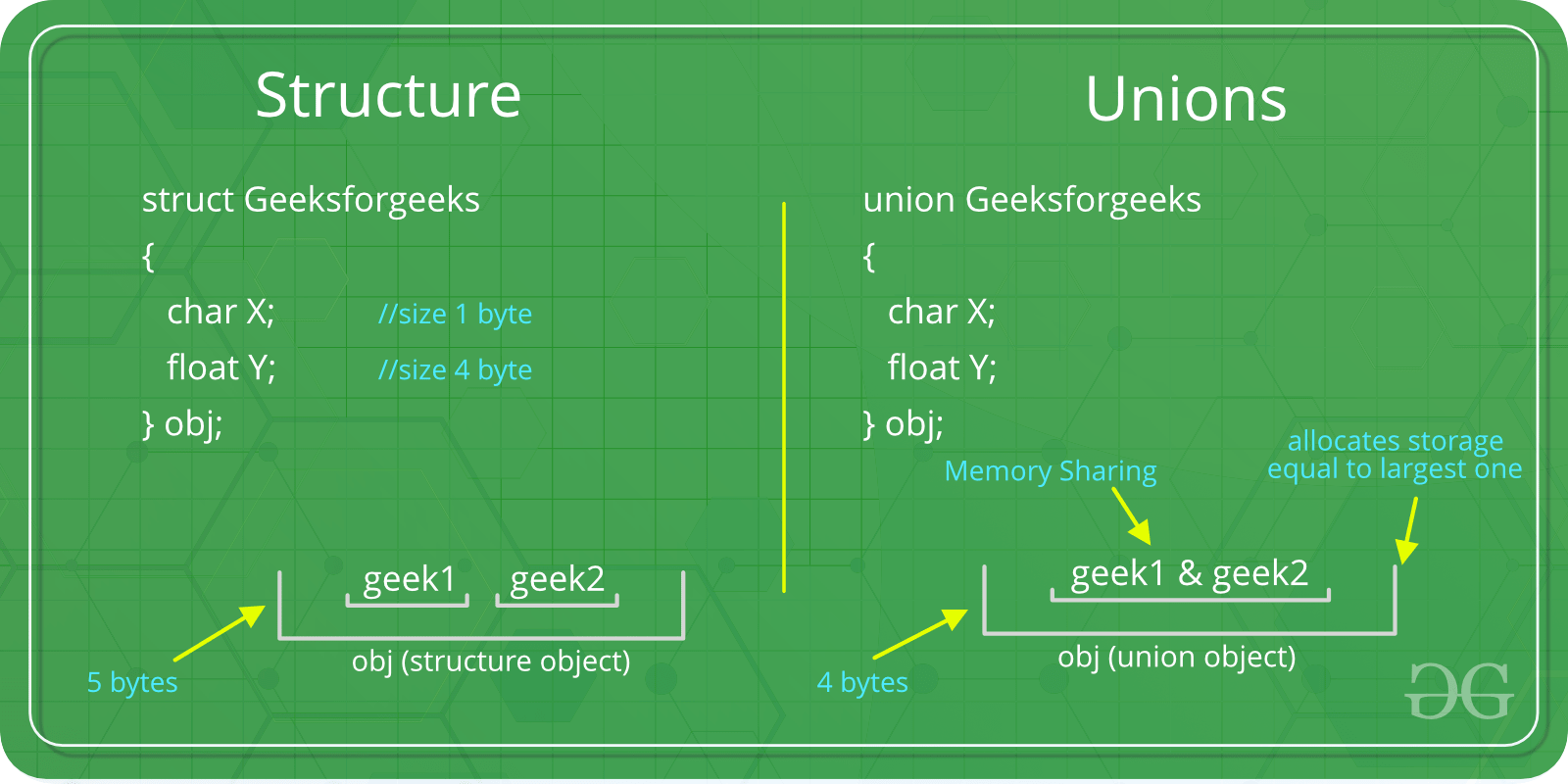 д. Структуры не занимают любое место в памяти до тех пор, пока мы не определим для него некоторые переменные. Когда мы определяем его переменные, они занимают некоторое пространство памяти, которое зависит от типа члена данных и выравнивания (обсуждается ниже).
д. Структуры не занимают любое место в памяти до тех пор, пока мы не определим для него некоторые переменные. Когда мы определяем его переменные, они занимают некоторое пространство памяти, которое зависит от типа члена данных и выравнивания (обсуждается ниже).
Как создать структуру?
Чтобы создать структуру в C, используется ключевое слово struct, за которым следует имя тега структуры. Затем определяется тело структуры, в которое добавляются необходимые элементы данных (примитивные или определяемые пользователем типы данных).
Синтаксис:
В приведенном выше синтаксисе data_members может иметь любой тип данных, такой как int, char, double, array или даже любой другой определяемый пользователем тип данных. data_member_definition для таких типов данных, как массив символов, int и double, — это просто имя переменной, такое как name, class и roll_no. Мы также объявили переменную, т.е. student1 структуры Student. Обратите внимание, что необязательно всегда объявлять структурные переменные таким образом. Мы увидим другие способы в следующих разделах.
Мы увидим другие способы в следующих разделах.
Как объявить структурные переменные?
Если мы создали структуру Student для хранения данных студентов со всеми членами данных, такими как имя студента, класс студента и раздел студента, как мы можем их использовать? Чтобы использовать свойства созданной структуры в C, мы должны создать структурные переменные. Есть два способа объявить переменные для структуры в языке C:
- Первый способ:
Синтаксис:
В приведенном выше примере создается структура Student и для нее объявляется переменная student1 сразу после определения структуры.
- Второй способ:
Создавая структуру на языке C, мы создали пользовательский тип данных. Таким образом, этот тип данных можно рассматривать как примитивный тип данных при объявлении переменной для этой структуры.
Синтаксис:
Какой подход к объявлению структурных переменных лучше?
Если мы объявим структурные переменные с определением структуры, они будут работать как глобальные переменные (это означает, что они могут быть доступны во всей программе). Если нам нужны глобальные переменные, мы можем объявить переменные со структурой, в противном случае объявление с использованием второго подхода является лучшим способом, поскольку переменные легко поддерживать или инициализировать.
Если нам нужны глобальные переменные, мы можем объявить переменные со структурой, в противном случае объявление с использованием второго подхода является лучшим способом, поскольку переменные легко поддерживать или инициализировать.
Как инициализировать элементы структуры?
Инициализация элемента структуры означает присвоение значений элементам структуры в соответствии с их соответствующими типами данных. Но объявление не выделяет память для структуры. Когда мы объявляем переменную для структуры, только тогда память выделяется для этой структурной переменной. Следовательно, придавать ценность тому, что не имеет памяти, — это то же самое, что подавать еду без тарелки, а это не очень хорошая идея! Короче говоря, члены структуры не могут быть инициализированы во время объявления. Например:
Синтаксис:
Эта инициализация структуры даст ошибку. Итак, как мы можем инициализировать элементы? На самом деле существует три способа инициализации элементов структуры:
- Использование точки ‘.
 ‘ оператор
‘ оператор - Использование фигурных скобок «{}»
- Назначенные инициализаторы
- Использование точки ‘.’ оператор
Используя оператор точки (.), мы можем получить доступ к любому элементу структуры, а затем инициализировать или присвоить его значение в соответствии с его типом данных.
Синтаксис:
В приведенном выше синтаксисе сначала мы создали структурную переменную, а затем с помощью оператора точки получили доступ к ее члену для их инициализации.
Давайте рассмотрим пример, чтобы понять приведенный выше синтаксис:
- Пример
- Выход
В приведенном выше коде мы создали структуру Student и объявили в ней некоторые элементы. После этого мы создали экземпляр (переменную или объект структуры Student), чтобы он обращался к членам структуры с помощью оператора точки и присваивал им значение. Кроме того, мы использовали метод строки strcpy, который используется для присвоения значения одной строки другой. В конце мы выводим значения членов структуры с помощью оператора точки.
В конце мы выводим значения членов структуры с помощью оператора точки.
- Использование фигурных скобок ‘{}’
Если мы хотим инициализировать все члены во время объявления структурной переменной, мы можем объявить с помощью фигурных скобок.
Синтаксис:
Чтобы инициализировать элементы данных с помощью этого метода, значения, разделенные запятыми, должны предоставляться в том же порядке, что и элементы, объявленные в структуре. Кроме того, этот метод полезно использовать, когда нам нужно инициализировать все элементы данных.
- Пример
- Выход
В приведенном выше коде сначала мы создали структуру Student. После этого мы создаем переменную для структуры и инициализируем ее элементы с помощью фигурных скобок в том же порядке, в каком члены данных объявляются внутри структуры. В конце выведите присвоенные значения.
- Назначенные инициализаторы
Назначенная инициализация представляет собой простую инициализацию членов структуры и обычно используется, когда мы хотим инициализировать только несколько членов структуры, а не все. Мы обсудим это более подробно в следующем разделе этой статьи.
Мы обсудим это более подробно в следующем разделе этой статьи.
Структуры как аргументы функций
До сих пор мы изучили объявление, инициализацию и печать элементов данных структур. Теперь вы должны задаться вопросом, как мы можем передать всю структуру или ее элементы в функцию. Так что да, мы можем это сделать. При передаче структуры в качестве аргумента функции структурные переменные обрабатываются так же, как переменные примитивных типов данных. Базовый синтаксис для передачи структуры в качестве аргумента функции:
Синтаксис:
Давайте посмотрим на пример для большего понимания:
Пример
Вывод:
В приведенном выше коде мы создали структуру Student и объявили для нее некоторые члены для хранения данных студентов. После этого мы создали экземпляр и инициализировали все члены структуры. Было две функции: в функции printStudent() мы передавали структуру, используя концепцию передачи по значению, а в функции changeStudent() мы передавали структуру по ссылке.
Пока мы передаем значения по ссылке, мы получаем указатель структуры в функции (мы обсудим указатели структуры позже в этой статье).
Битовые поля
В программировании на C память выделяется в битах для хранения каждого типа данных. Например, для целочисленных переменных отводится 32 бита. Битовые поля — это концепция структуры в C, в которой мы можем определить, сколько бит мы должны выделить конкретному члену данных структуры для экономии памяти. Мы можем определить количество битов для конкретного члена, используя двоеточие (:) оператор.
Синтаксис:
Из приведенного выше синтаксиса видно, что мы можем изменить количество битов для элементов данных в соответствии с нашим требованием, используя оператор двоеточия. Давайте рассмотрим пример для лучшего понимания:
В приведенном выше коде мы определили две структуры для хранения дат.
- Первая структура имеет размер 12 байт. Это потому, что есть три целочисленных переменных.
 Каждая целочисленная переменная занимает 4 байта памяти, что дает общий размер 3 * 4 = 12,9.0010
Каждая целочисленная переменная занимает 4 байта памяти, что дает общий размер 3 * 4 = 12,9.0010 - Вторая структура имеет размер 8 байт. Это связано с тем, что во второй структуре мы определили максимальное количество битов, необходимых для представления дня и месяца.
Поскольку мы знаем, что день может иметь максимальное значение 31, его можно легко представить 5 битами (2, возведенные в степень 5, дают нам 32, поэтому мы можем хранить в нем любое число до 31). Точно так же месяц имеет максимальное значение 12. Таким образом, для его представления потребуется максимум 4 бита (2 в степени 4 равно 16, что больше 12). Переменные дня и месяца объединили 9битов, и поскольку они оба являются целыми числами, для них будет выделено 32 бита (4 байта) памяти. Еще 4 байта памяти требуются для переменной года. Следовательно, общий размер 4 + 4 = 8 байт.
Мы можем заметить, что обе структуры имеют одинаковое количество элементов данных, но вторая занимает меньше места. Таким образом, определяя максимальное количество битов, мы можем сэкономить память.
Доступ к элементам структуры
Мы можем получить прямой доступ к элементу структуры с помощью оператора точка (.). Оператор точки используется между именем структурной переменной и именем члена структуры, к которому мы хотим получить доступ. Давайте посмотрим на синтаксис, чтобы понять его лучше.
Синтаксис:
- Пример 1
Результат:
Здесь мы создали простую структуру Complex для определения комплексных чисел. Мы создали структурную переменную var и получили доступ к ее членам структуры: действительным и мнимым с помощью оператора точки и присвоили им некоторое значение. После этого мы снова напечатали значения с помощью оператора точки.
Назначенная инициализация представляет собой простую инициализацию членов структуры и обычно используется, когда мы хотим инициализировать только несколько членов структуры, а не все.
Синтаксис:
Из синтаксиса видно, что мы используем фигурные скобки, а между ними с помощью оператора точки осуществляется доступ и инициализация членов данных. Может быть любое количество членов структуры из одной структуры, которую мы можем инициализировать, и все они разделяются запятыми.
Но самое главное, что мы можем инициализировать члены в любом порядке. Не обязательно поддерживать тот же порядок, в котором члены объявлены в структуре.
Может быть любое количество членов структуры из одной структуры, которую мы можем инициализировать, и все они разделяются запятыми.
Но самое главное, что мы можем инициализировать члены в любом порядке. Не обязательно поддерживать тот же порядок, в котором члены объявлены в структуре.
- Пример
В приведенном выше примере мы видим, что мы инициализировали только два члена структуры. Также обратите внимание, что они не инициализируются в том порядке, в котором они были объявлены в структуре.
- Выход
Что такое массив структур?
Когда мы создаем массив любого примитивного типа данных размером пять, знаете, что происходит? Создается массив, состоящий из 5 блоков памяти, и каждый блок работает так же, как одна переменная того же типа данных. Поскольку структура в C является определяемым пользователем типом данных, мы также можем создать из нее массив, как и другие типы данных.
Синтаксис:
Используя приведенный выше синтаксис, мы создали массив структур, в каждом блоке памяти которого хранится одна структурная переменная.
- Пример
Ввод:
- Выход:
В приведенном выше коде мы создали структуру, а затем массив размером 5 для хранения пяти элементов структуры. После этого мы получили доступ к членам структуры, используя индекс массива для ввода или присвоения значений. Мы также можем передать массив структур в качестве аргумента функции.
Например:
Ввод:
Вывод:
В приведенном выше коде мы создали структуру Student, а затем массив arr размера 5 для хранения пяти элементов структуры. После этого мы получили доступ к членам структуры, используя индекс массива для ввода или присвоения значений. Мы создали функцию print(), которая принимает два параметра: массив структуры и размер массива. В этой функции мы напечатали все значения каждого блока массива.
Вложенные структуры
Вложенное слово означает помещенное или сохраненное одно внутри другого. Поскольку структура в C является определяемым пользователем типом данных, поэтому при создании структуры мы можем определить другую структуру в качестве ее члена данных, что приводит к структуре с другой структурой внутри нее.
Даже вложенная структура может иметь свою вложенную структуру.
Поскольку структура в C является определяемым пользователем типом данных, поэтому при создании структуры мы можем определить другую структуру в качестве ее члена данных, что приводит к структуре с другой структурой внутри нее.
Даже вложенная структура может иметь свою вложенную структуру.
Синтаксис 1:
В приведенном выше синтаксисе сначала определяется структура_1, а затем вкладывается в другую структуру, т. е. структуру_2.
Синтаксис 2:
В приведенном выше синтаксисе мы определили структуру_1 внутри структуры_2. Поскольку мы создаем структуру внутри другой, мы можем определить переменные для этой структуры, как мы обычно определяем для структур.
Чтобы инициализировать переменные структуры, либо мы можем получить доступ к каждому элементу данных с помощью простого оператора точки, либо если мы собираемся инициализировать с помощью фигурных скобок, тогда мы должны поддерживать тот же порядок элементов данных, который был определен в структуре, поэтому для вложенные элементы структуры также сохраняют порядок, поскольку мы инициализировали переменную v1 в приведенном выше примере.
- Пример
Ввод:
Вывод:
В приведенном выше примере мы создали структуру Student с вложенной структурой Address внутри нее. Мы инициализировали элементы данных структурной переменной Student в конце структуры. Создаются еще две структуры: Испытуемый и Учитель . Структура предмета вложена в структуру учителя. В основной функции мы создали переменную для учителя, приняли пользовательский ввод для всех ее членов, а затем распечатали их с помощью операторов printf(). Существует два способа создания вложенных структур. Первый способ — создать структуру (например, Subject) и добавить ее в другую структуру (например, Teacher) в качестве члена данных или определить структуру (например, Address) внутри другой структуры (например, Student).
Использование typedef в структуре
typedef — это ключевое слово в языке C, используемое для присвоения псевдонима типу данных, любому синтаксису или части кода. Основная цель typedef — сделать код коротким, повышая его удобочитаемость. Чтобы объявить структурную переменную, мы пишем сначала ключевое слово struct, затем имя структуры, а затем имя переменной, которое немного длинное. Чтобы дать короткое имя структуре, мы можем использовать typedef. Давайте посмотрим на синтаксис, чтобы точно понять, как это работает:
Основная цель typedef — сделать код коротким, повышая его удобочитаемость. Чтобы объявить структурную переменную, мы пишем сначала ключевое слово struct, затем имя структуры, а затем имя переменной, которое немного длинное. Чтобы дать короткое имя структуре, мы можем использовать typedef. Давайте посмотрим на синтаксис, чтобы точно понять, как это работает:
Синтаксис:
Мы определили два способа использования typedef со структурой в приведенном выше синтаксисе. В первом случае у нас есть typedef структуры после ее объявления, а во втором случае структура была typedef во время объявления. Кроме того, новое_имя может совпадать с имя_структуры . Например:
- Выход:
Мы создали структуру Complex в приведенном выше коде и объявили ее с помощью typedef, используя оба рассмотренных синтаксиса. Итак, по сути, у нас есть два псевдонима для структуры Complex, т. е. Complex и c.
В основной функции мы объявили три структурные переменные для одной и той же структуры тремя разными способами. Во-первых, мы объявили в общем виде. Во-вторых, мы объявляем использование сложного псевдонима и, наконец, используем псевдоним c. Наконец, мы присвоили этому несколько значений, а затем распечатали их все.
Во-первых, мы объявили в общем виде. Во-вторых, мы объявляем использование сложного псевдонима и, наконец, используем псевдоним c. Наконец, мы присвоили этому несколько значений, а затем распечатали их все.
Что такое указатель структуры?
Указатель — это переменная, в которой хранится адрес другой переменной. Поскольку структура состоит из некоторых типов данных или структур данных, для которых память выделяется для переменной структуры, мы можем использовать указатель структуры для хранения адреса этой памяти. Указатель структуры — это, по сути, указатель на структурную переменную. Обратите внимание, что мы используем оператор стрелки (->) для доступа к элементу структуры с помощью указателя.
Синтаксис:
В приведенном выше синтаксисе мы сначала объявили структурную переменную, а затем указатель структуры, указывающий на эту переменную.
Вывод:
В приведенном выше коде мы сначала создали структуру Complex для хранения действительных и мнимых значений комплексного числа. Мы также объявили структурную переменную c и инициализировали ее элементы данных. Затем в функции main() мы создали указатель cptr типа Complex и присвоили ему адрес структурной переменной c.
После этого мы получили доступ к элементам структуры с помощью оператора стрелки и присвоили им значения. В конце мы напечатали значения элементов данных с помощью оператора стрелки.
Мы также объявили структурную переменную c и инициализировали ее элементы данных. Затем в функции main() мы создали указатель cptr типа Complex и присвоили ему адрес структурной переменной c.
После этого мы получили доступ к элементам структуры с помощью оператора стрелки и присвоили им значения. В конце мы напечатали значения элементов данных с помощью оператора стрелки.
Что такое выравнивание элементов конструкции?
Как только структурная переменная объявлена, мы знаем, что ей выделяется память в соответствии с типом данных переменной. Структура состоит из разных элементов данных, поэтому, если они не выровнены должным образом, будет потеря памяти. Чтобы уменьшить потери памяти при случайном объявлении элементов данных, мы придаем им правильное выравнивание (т. е. правильный порядок), определяя их в порядке убывания размера их памяти.
Выход:
В приведенном выше коде мы объявили две структуры, и обе имеют одинаковые элементы данных. Единственное отличие заключается в порядке их объявления. Первая структура имеет размер 32 байта, а вторая имеет размер 24 байта только за счет выравнивания.
Таким образом, чтобы уменьшить потери памяти, при объявлении структуры всегда объявляйте элементы данных в порядке убывания требований к размеру памяти.
Единственное отличие заключается в порядке их объявления. Первая структура имеет размер 32 байта, а вторая имеет размер 24 байта только за счет выравнивания.
Таким образом, чтобы уменьшить потери памяти, при объявлении структуры всегда объявляйте элементы данных в порядке убывания требований к размеру памяти.
Ограничения структур C
Структуры в C имеют много ограничений по сравнению с другими определяемыми пользователем типами данных в других языках. Структуры в C не предоставляют свойство сокрытия данных (с помощью которого мы можем сделать некоторые элементы закрытыми, и к ним нельзя получить доступ извне структуры), и каждый член структуры может быть доступен. Мы не можем определять функции внутри структур в C, поэтому конструктора нет, а структуры не имеют собственной памяти, поэтому мы не можем инициализировать наши элементы данных внутри нее. Если выравнивание элементов структуры неправильное, это может привести к некоторой потере памяти.
Заключение
- Структура в языке C является определяемым пользователем типом данных.
 Он связывает вместе два или более типов данных или структур данных.
Он связывает вместе два или более типов данных или структур данных. - Структура создается с использованием ключевого слова struct, а ее переменные создаются с использованием ключевого слова struct и имени структуры.
- Тип данных, созданный с использованием структуры в C, может рассматриваться как другие примитивные типы данных C для объявления указателя на него, передачи его в качестве аргумента функции или возврата из функции.
- Существует три способа инициализации структурных переменных: с помощью оператора точки, с помощью фигурных скобок или заданной инициализации.
- Одна структура может состоять из другой структуры, или несколько структур могут быть вложенными.
- С помощью typedef мы можем дать короткие или новые имена типу данных структуры.
Структуры в языке C
«В языке C структуры представляют собой инициализацию комбинированного типа данных, которая используется для группировки нескольких переменных в один тип; сгруппированные переменные должны быть связаны друг с другом. Это позволяет получить доступ к этим переменным с помощью одного указателя. Основное различие между структурой и массивом заключается в том, что массив имеет только один тип данных, но, с другой стороны, структура может содержать разные типы данных. Следовательно, мы можем сказать, что структура — это определяемый пользователем тип данных, который используется для хранения нескольких переменных с разными типами данных в одном блоке для хранения определенного типа или записи.
Это позволяет получить доступ к этим переменным с помощью одного указателя. Основное различие между структурой и массивом заключается в том, что массив имеет только один тип данных, но, с другой стороны, структура может содержать разные типы данных. Следовательно, мы можем сказать, что структура — это определяемый пользователем тип данных, который используется для хранения нескольких переменных с разными типами данных в одном блоке для хранения определенного типа или записи.
Предположим, нам нужно сохранить запись человека; этот тип записи будет иметь атрибуты с разными типами данных, такими как число, имя в символе и т. д. Для этой цели мы не можем использовать массив, поскольку он хранит записи с одним и тем же типом данных. Состав нам в этом случае пригодится. Это способ группировать разные типы данных, и его определение означает, что мы создаем новый тип данных».
Синтаксис
Синтаксис объявления структуры следующий:
На приведенном выше рисунке мы написали фрагмент кода для объявления структуры. Структура — это ключевое слово, которое сообщает системе, что мы инициализируем структуру. После этого мы присвоили нашей структуре имя «Structer_Name». Затем открывающая скобка для объявления наших переменных. В разделе переменных мы объявили переменные разных типов данных, чтобы показать вам, как структура может хранить вместе переменные с разными типами данных. Поэтому переменные включены в структуру. Чтобы закончить наш структурный блок, мы используем точку с запятой в качестве разделителя операторов.
Структура — это ключевое слово, которое сообщает системе, что мы инициализируем структуру. После этого мы присвоили нашей структуре имя «Structer_Name». Затем открывающая скобка для объявления наших переменных. В разделе переменных мы объявили переменные разных типов данных, чтобы показать вам, как структура может хранить вместе переменные с разными типами данных. Поэтому переменные включены в структуру. Чтобы закончить наш структурный блок, мы используем точку с запятой в качестве разделителя операторов.
Пример 1
На этом рисунке была построена структура под названием «Сведения об ученике». В блоке переменных мы объявили несколько переменных, описывающих атрибуты студента. Затем мы взяли три характеристики студента, его имя, номер списка и результат или, в нашем примере, процент. Тип данных номеров рулонов — целое число, потому что обычно номер рулона — это число. Полному имени назначается символ, и, наконец, проценту назначается тип данных Float, потому что мы можем получить процент в десятичных точках.
Следует иметь в виду, что структура не может быть объявлена в основном методе. Его можно вызвать, используя его объект в основном методе. После объявления структуры мы перейдем к нашему основному методу, в котором мы объявим объект нашей структуры. С помощью этого объекта мы можем выполнять операции над переменными.
Detail1 — это имя созданного нами объекта. Для каждого ученика мы определим отдельный объект нашей структуры, такой как Detail2, Detail3 и т. д. С помощью Detail1 мы назвали переменные нашей структуры. Теперь Detail1 создаст запись конкретного студента. Мы присвоили нашему ученику Roll_num=100, а также все остальные атрибуты. Чтобы назначить данные определенной записи, мы будем использовать объект, созданный для этой конкретной записи.
После присвоения всех значений переменной в Instance Detail1 нашей структуры мы отобразим эти записи с помощью функции printf. В функции printf %d обозначает десятичные значения, %s представляет строковые значения, а %f сообщает, что будут отображаться значения с плавающей запятой. Мы напечатали все три атрибута «Студент XYZ».
Мы напечатали все три атрибута «Студент XYZ».
После запуска программы мы получим вывод нашего кода, написанного выше. Мы присвоили значения конкретному экземпляру нашей структуры и распечатали значения, и, как вы можете видеть на рисунке ниже, система отобразила нам значения этого экземпляра. С этими значениями могут быть выполнены дополнительные процедуры. Вы также можете определить другой экземпляр структуры Student_Details для создания записей о нескольких учениках с разными именами и другими характеристиками.
Пример 2
В следующем примере была построена структура, называемая таблицей. У таблицы есть длина и ширина, поэтому мы взяли их в качестве параметров этой структуры. Мы уже объяснили в предыдущем примере, как структура хранит различные типы данных. Но в этом примере мы объясним, как мы можем получить доступ к нескольким экземплярам одной структуры. В теле структуры мы объявили две целочисленные переменные.
Теперь, чтобы вызвать структуру, мы перейдем к нашей основной функции. В основной функции мы определили два целых числа как area1 и area2, которые будут хранить площади table1 и table2 соответственно. Мы создали первый объект нашей таблицы как t1, который будет действовать как table1, и мы объявили второй экземпляр нашей структуры как t2, который будет действовать как table2. Длина таблицы 1 равна пяти, а ширина — трем. Переменная Area1 будет хранить значение, которое мы получим, выполнив операцию умножения наших целых чисел t1. Значения, присвоенные таблице 2, равны 7 и 5. Область 2 будет хранить результат умножения этих значений друг на друга. Наконец, мы распечатали вывод, чтобы получить результаты из кода.
В основной функции мы определили два целых числа как area1 и area2, которые будут хранить площади table1 и table2 соответственно. Мы создали первый объект нашей таблицы как t1, который будет действовать как table1, и мы объявили второй экземпляр нашей структуры как t2, который будет действовать как table2. Длина таблицы 1 равна пяти, а ширина — трем. Переменная Area1 будет хранить значение, которое мы получим, выполнив операцию умножения наших целых чисел t1. Значения, присвоенные таблице 2, равны 7 и 5. Область 2 будет хранить результат умножения этих значений друг на друга. Наконец, мы распечатали вывод, чтобы получить результаты из кода.
Система выдаст это в качестве вывода. Мы присвоили 5 и 3 нашему экземпляру t1 и с помощью объекта нашей структуры выполнили математическую операцию над нашими данными.
Мы присвоили 7 и 5 нашему объекту t2, и он также дал нам вывод после операции. Итак, понятно, что с помощью одной структуры и двух переменных мы оперировали несколькими объектами.