Сравнение строк Python 3 | Timeweb Cloud
В Python сравнение строк — это сравнение их символов по отдельности, которое происходит последовательно. Сначала сравниваются первые символы, затем — вторые, дальше — третьи и так далее, пока не закончатся обе строки. При этом учитываются не сами символы, а их значения Unicode.
Простое сравнениеЧтобы выполнить в Python сравнение строк на похожесть, используют операторы == (равно) и != (не равно).
Оператор == вернёт True в том случае, если строки совпадают, и False — если они не совпадают. Оператор != работает наоборот: он возвращает True, если значения отличаются.
В качестве примера сравните название хостера. Выполните следующий код:
hoster = 'cloud'
print(hoster == 'cloud')
print(hoster != 'cloud')
В первом случае вы получите ответ True, во втором — False.
Теперь попробуйте изменить значение переменной. Напишите название с большой буквы, а при сравнении используйте название с маленькой буквы:
hoster = 'Cloud'
print(hoster == 'cloud')
print(hoster != 'cloud')
Результат будет противоположный. Первый print() вернёт False, а второй – True. Всё потому, что ‘Cloud’ != ‘cloud’.
Первый print() вернёт False, а второй – True. Всё потому, что ‘Cloud’ != ‘cloud’.
Чтобы понять, как здесь сработало сравнение символов в строке Python, используйте функцию ord(). Она показывает значение Unicode, переданное в качестве аргумента символа.
Выполните:
print(ord('C'))В ответ вы получите число 67. Это значение Unicode большой буквы ‘C’.
Затем проделайте то же самое с маленькой буквой:
print(ord('c'))В ответ вы получите число 99.
Важность регистраРазница в значениях Unicode в посимвольном сравнении строк на Python очень важна. Например, вы хотите создать квиз. Пользователь должен вводить ответы на вопросы в поля формы. Задача программы — обработать полученные ответы и сравнить их с данными, которые хранятся в базе. Если ответ совпадает, пользователь получает 1 балл.
В нашем примере сравнение останавливается после проверки первых символов. Интерпретатор Python видит, что в последовательности Unicode буква ‘С’ встречается раньше, чем буква ‘с’. Значит, строка, которая начинается с неё, будет меньше.
Значит, строка, которая начинается с неё, будет меньше.
Пользователи могут вводить одни и те же слова по-разному — писать с маленькой буквы, с большой, через Caps Lock. Хранить подходящие значения нереально. И не нужно. Гораздо проще приводить всё к единому виду. Например, с помощью метода lower().
Проверьте, как выполнится в Python сравнение строк без учёта регистра:
hoster1 = 'Cloud'
hoster2 = 'cloud'
print(hoster1 == hoster2)
Вернётся False, потому что значения разные.
С методом lower():
hoster1 = 'Cloud'
hoster2 = 'cloud'
print(hoster1.lower() == hoster2.lower())
Вернётся True. Метод lower() приводит все символы к нижнему регистру. Теперь не имеет значения, в каком виде передана строка. Программа приведет ее к заданному вами стандарту и сравнит с тем ответом, который хранится в базе данных.
Сравнение двух строк Python можно выполнить не только на равенство, но и на больше или меньше. Возьмём тот же пример, но используем другие операторы.
Код:
hoster1 = 'Cloud'
hoster2 = 'cloud'
print(hoster1 > hoster2)
вернёт False, потому что значение Unicode у буквы ‘С’ меньше, чем у ‘с’ — 67 против 99. Если же поменять оператор:
hoster1 = 'Cloud'
hoster2 = 'cloud'
print(hoster1 < hoster2)
то вернётся True. Так работает лексикографическое сравнение строк на Python — каждый символ в одной строке по очереди сравнивается с символом в другой строке.
Сравнение с помощью isВ Python всё — это объект. Строки не исключение. Поэтому их можно сравнивать не только по фактическому значению, но и по идентификатору экземпляра объекта.
Проще разобраться на примере. Задайте две переменные с одинаковым значением. Пусть это тоже будет название хостера.
hoster1 = cloud’
hoster2 = ‘cloud’
Напишите короткую программу, которая будет сравнивать фактические значения обеих строк и печатать в ответ, совпадают они или нет.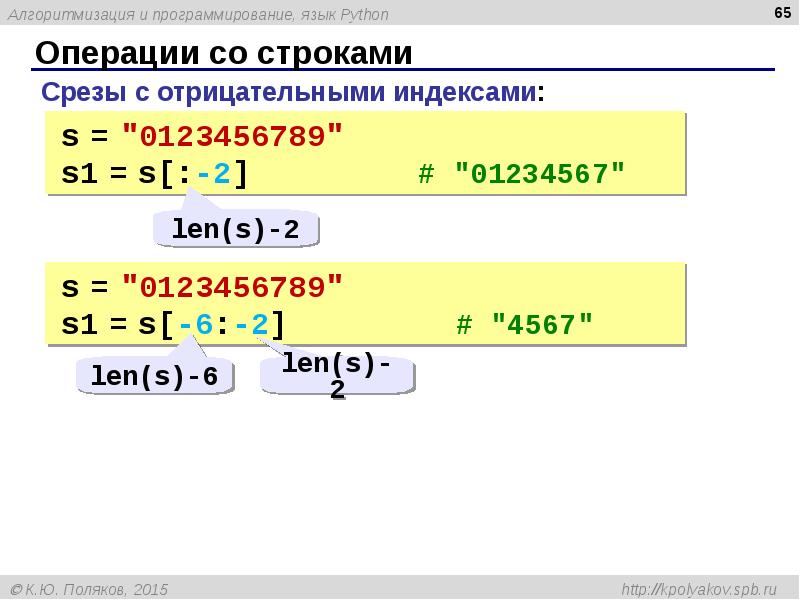
if hoster1 == hoster2:
print(‘Это один и тот же хостер’)
else:
print(‘Это разные хостеры’)
В ответ вы получите, что это один и тот же хостер. Здесь всё логично, фактические значения у переменных одинаковые.
Теперь проверьте, одинаковые ли идентификаторы у обоих экземпляров объекта. Используйте для этого оператор ‘is’. Если обе переменные указывают на один объект, он возвращает True. В противном случае — False.
Проблема в том, что даже если строки имеют одинаковое значение, в ответ вы можете получить False, потому что переменные указывают на разные экземпляры объекта.
Чтобы оптимизировать работу со строками, Python выполняет интернирование. Суть метода проста. Для некоторых неизменяемых объектов в памяти хранится только один экземпляр. Когда вы пишете в двух или более переменных одинаковые значения, они обычно ссылаются на одну ячейку памяти. Поэтому в некоторых случаях оператор is возвращает True.
Но важно помнить об одной особенности. Интернирование происходит до выполнения кода. Поэтому, например, такая программа вернёт False:
Интернирование происходит до выполнения кода. Поэтому, например, такая программа вернёт False:
hoster1 = 'cloud'
hoster2 = 'cl'
print(hoster1, 'и', hoster2 + 'oud', 'это один и тот же хостер:', hoster1 is hoster2)
#Output:
cloud и cloud это один и тот же хостер: False
Здесь вы изначально задали переменным разные значения. Поэтому они стали ссылаться на разные экземпляры объекта.
Чтобы избежать проблем в больших программах, при сравнении по идентификаторам необходимо явно интернировать строки. Для этого в Python используется метод intern.
import sys
a = sys.intern(‘string’)
b = sys.intern(‘string’)
a is b
True
Возможно, вы никогда не встретитесь с необходимостью сравнивать строки по ссылкам. Но если вдруг такая задача попадётся, теперь вы знаете, как решить её и обезопасить себя от неверных результатов.
Нечёткое сравнениеДопустим, вы хотите сделать программу с парсером и RSS, которая будет собирать новости из разных источников. Чтобы новости не дублировались, нужно сравнивать заголовки. Делать это посимвольно бессмысленно — каждое новостное агентство придумывает свой заголовок. Здесь на помощь приходит нечёткое сравнение.
Чтобы новости не дублировались, нужно сравнивать заголовки. Делать это посимвольно бессмысленно — каждое новостное агентство придумывает свой заголовок. Здесь на помощь приходит нечёткое сравнение.
Нечёткое сравнение строк на Python реализовано в библиотеке thefuzz. Алгоритм сравнения основан на расстоянии Левенштейна, которое показывает разность между двумя последовательностями символов.
Установите библиотеки thefuzz и python-Levenshtein:
pip install thefuzz
pip install python-Levenshtein
Импортируйте библиотеку в файл:
from thefuzz import fuzz as f
Выполните простое сравнение:
f.ratio(‘Хостер Cloud’, ‘Cloud хостер’)
Максимально возможный результат— 100. Вы увидите его, если передадите идентичные значения.
Библиотеку thefuzz также можно использовать для поиска подстрок без регулярных выражений. Например:
from thefuzz import fuzz as f
f.partial_ratio(‘Здесь будем искать упоминание Cloud’, ‘Cloud’)
В ответ вы получите 100 — подстрока встречается точно в таком виде.
Ещё один мощный метод — WRatio. Он обрабатывает разные регистры, а также знаки препинания и некоторые другие параметры. Например, такое сравнение:
f.WRatio(‘Хостер Компания CLOUD!!!’, ‘КоМпАнИя,,, ClouD Хостер’)
вернёт совпадение 95 из 100.
Мы рассмотрели основные методы библиотеки thefuzz, которые помогают выполнить сравнение строк в Python 3. Посмотреть другие примеры вы можете в репозитории библиотеки на GitHub.
Кстати, в официальном канале Timeweb Cloud мы собрали комьюнити из специалистов, которые говорят про IT-тренды, делятся полезными инструкциями и даже приглашают к себе работать.
Индексация и разделение строк в Python 3
Умение работать со строками очень важно в любом языке программирования. Сегодня мы расскажем про строки в Python: что это такое, как найти индекс в строке python, какие есть методы работы с индексами.
СтрокиСтроки – это последовательности символьных данных, которые, как и любые другие типы данных в языке python на основе последовательностей, могут быть проиндексированы. Чтобы задать строку, надо заключить последовательность символов (буквы, цифры, пробелы, знаки препинания и т.д.) в одинарные, двойные или тройные кавычки. Индексирование символов начинается с нуля, и каждый символ в строке имеет собственный индекс. Индекс последнего символа на единицу меньше длины строки.
Чтобы задать строку, надо заключить последовательность символов (буквы, цифры, пробелы, знаки препинания и т.д.) в одинарные, двойные или тройные кавычки. Индексирование символов начинается с нуля, и каждый символ в строке имеет собственный индекс. Индекс последнего символа на единицу меньше длины строки.
string = 'We love Python!'
Если мы проверим тип переменной string, то получим: str.
Числовые индексы могут быть положительными и отрицательными. Чтобы обратиться к символу по индексу, надо указать его в квадратных скобках []. Если ссылаться на конкретный индекс, то можно получить символ, которому он соответствует:
print('4-й символ: ', string[4])
4-й символ: oВ нашей строке символ «o» имеет индекс 4.
Если мы попытаемся обратиться к символу по индексу, которого в строке нет, то получим ошибку:
print('15-й символ: ', string[15])
IndexError: string index out of rangeЧтобы узнать максимальный индекс в строке можно отнять 1 от длины строки так как индексация начинается с 0:
print('Максимальный индекс в строке: ',len(string) - 1)
Максимальный индекс в строке: 14При использовании индексы могут быть не только положительными, но и отрицательными. В этом случае индексация в Python идет с конца:
В этом случае индексация в Python идет с конца:
print('-1-й символ в строке: ', string[-1])
-1-й символ: !Индекс -1 имеет последний символ строки.
Срезы строкМожно выводить не только символ с конкретным индексом, но и диапазон символов в строке – подстроку. Для этого используется оператор нарезки, а фрагмент строки, который получается в итоге, называется срезом.
print('Символы с 1 по 6: ', string[1:6])
Символы с 1 по 6: e lovВ данном примере 1 – индекс начала среза, а 6 – индекс окончания среза. В подстроку входят символы с 1 по 5 включительно.
В случае, если требуется получить подстроку с 0 символа, то индекс начала среза можно опустить:
print('Символы с 0 по 6: ', string[:6])
Символы с 0 по 6: We lovАналогично в случае, если мы хотим получить срез до конца строки, мы можем опустить индекс окончания среза.
При разделении строк в Python 3 на срезы также можно использовать индексы с отрицательными значениями. Отрицательные индексы начинаются с -1 и уменьшаются при отдалении от конца строки:
Отрицательные индексы начинаются с -1 и уменьшаются при отдалении от конца строки:
print('Символы с -1 по -7: ', string[-7:-1])
Символы с -1 по -7: PythonЕсли не указывать индексы начала и конца среза, то мы получим всю строку:
print('Строка: ', string[:])
Строка: We love Python!В случае с получением среза допускается указывать индексы, которые выходят за пределы строки:
print('Символы с 6 по 100: ', string[6:100])
Символы с 6 по 100: e Python!При создании срезов также можно использовать еще один параметр – шаг. Шаг показывает, на сколько элементов требуется сдвинуться после получения символа. В примерах, рассмотренных выше, мы не указывали шаг, в таких случае используется значение по умолчанию, равное 1.
print('Подстрока с шагом 3: ', string[0:10:3])
Подстрока с шагом 3: WleyМы получили каждый третий элемент: We love Python!
Мы можем использовать шаг без указания начала и конца среза – в таком случае подстрока будет составляться из каждого n-ого элемента по всей строке.
print('Подстрока с шагом 3: ', string[::3])
Подстрока с шагом 3: WleyoЗначение шага также может быть отрицательным.
МетодыСуществует несколько методов, которые позволяют вести подсчет строк и выводить индексы строки python. Один из таких методов был рассмотрен выше: len(string) – длина строки.
Помимо длины строки мы можем также подсчитать количество вхождения какого либо символа или подстроки с помощью метода count():
print('Количество вхождений символа e:', string.count('e'))
Количество вхождений символа e: 2Следующий метод позволяет определить индекс символа или подстроки в исходной строке:
print('Индекс символа e:', string.find('e'))
Индекс символа e: 1Первый символ «e» появляется на позиции с индексом 1. В случае если такой элемент не найден, метод вернет -1. Если мы находим индекс подстроки, мы получаем индекс ее первого символа:
print('Индекс подстроки love:', string. find('love'))
find('love'))
Индекс подстроки love: 3Если нам нужно найти подстроку с определенного индекса, мы можем указать диапазон символов, в котором следует искать:
print('Индекс символа e:', string.find('e', 4,9))
Индекс символа e: 6В случае необходимости получить максимальный индекс элемента в строке мы можем воспользоваться методом rfind(). Он работает аналогично find(), с той разницей, что find() находит минимальный индекс элемента (первое вхождение элемента в строку).
Для поиска подстроки можно воспользоваться методами index() и rindex(). Они работают аналогично find() и rfind(), однако в случае если подстрока не найдена возвращают ошибку:
ValueError: substring not foundЗаключение
В этот раз мы рассмотрели особенности типов данных строки, индексацию и срез строк в Python 3. Эти базовые знания пригодятся при выполнении самых разных задач с одним из самых популярных языков программирования.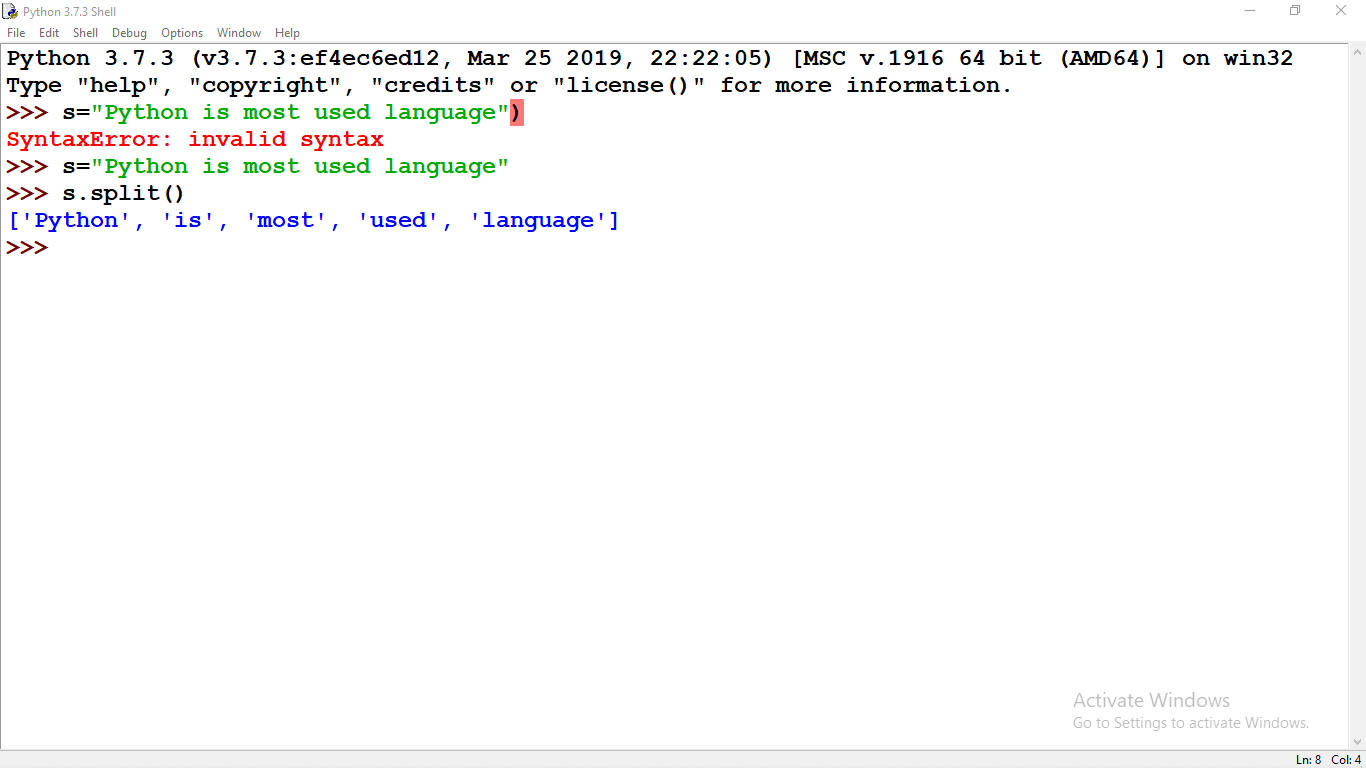 Дополнительную информацию вы можете найти в документации, а также в статьях о Python в блоге cloud.timeweb.com.
Дополнительную информацию вы можете найти в документации, а также в статьях о Python в блоге cloud.timeweb.com.
Работа со строками в Python 3
В Python последовательности символов называются строками . Он используется в Python для записи текстовой информации, такой как имена. Строки Python являются «неизменяемыми», что означает, что их нельзя изменить после создания.
Создание строки
Строки можно создавать с использованием одинарных, двойных или даже тройных кавычек. Python обрабатывает одинарные кавычки так же, как двойные кавычки.
Python3
Строка = 'Hello Geek' print ( "Создание строки с одинарными кавычками:" 90 018 |
Создание строки с одинарными кавычками: Hello Geek Создание строки с двойными кавычками: да, я гик Создание строки с тройными кавычками: да, я гик
Примечание: Будьте осторожны с кавычками!
Python3
| 9SyntaxError: неверный синтаксис Причиной указанной выше ошибки является одинарная кавычка в Да, я остановил строку. Пример: Python3
'WithQuotes' Привет "Питон" "С цитатами" Привет "Питон" Примечание: Для получения дополнительной информации см. Одинарные и двойные кавычки | Python Индексирование строк Строки представляют собой последовательность символов, что означает, что Python может использовать индексы для вызова частей последовательности.
Положительная индексация Python3
1-й элемент: G 2-й элемент: E 3-й элемент: E 4-й элемент: K Отрицательная индексация Python3
4-й элемент: K 3-й элемент: E 2-й элемент: E 1-й элемент: G Обновление строк В Python не допускается обновление или удаление символов из строки. Python3
Выходные данные
Обновление всей строки Python3
Перед обновлением: Привет, компьютерщики После обновления: Geeksforgeeks Обновленная строка: - Привет, Python Нарезка струн Нарезка Python заключается в получении подстроки из заданной строки путем ее разрезания соответственно от начала до конца. Нарезка Python может быть выполнена двумя способами.
Python3
Ну и дела Гикфо искать Нарезка с отрицательным индексом. Python3
Geekforgeek Geekforge Мы можем использовать [ : : ] для указания частоты печати элементов. Python3
Geekforgeeks эфрек СкигрофкиГ Примечание: Дополнительную информацию см. в разделе Разделение строк в Python. печатные строковые операторы. Метод string format() форматирует заданную строку. Python3
Geeksforgeeks, Портал информатики для гиков. Привет знатоки, как дела? Я хочу 2 бургера! Примечание: Для получения дополнительной информации см. Отформатированные f-строки литералы имеют префикс «f» и фигурные скобки { }, содержащие выражения, которые будут заменены их значениями. Python3
GeekForGeeks: компьютерные науки портал для гиков Да, я гик Всего 36 книг Geeksforgeeks — портал информатики для гиков. Примечание: Для получения дополнительной информации см. f-строки в Python 3 – Форматированные строковые литералы Как соединять строки в Python 3Программистам суждено работать с большим количеством строковых данных. Отчасти это связано с тем, что компьютерные языки привязаны к человеческому языку, мы используем один для создания другого, и наоборот. По этой причине рекомендуется заранее освоить все тонкости работы со строками. В Python это включает в себя изучение того, как соединять строки. Манипуляции со строками могут показаться сложными, но в языке Python есть инструменты, облегчающие эту сложную задачу. Прежде чем погрузиться в набор инструментов Python, давайте рассмотрим свойства строк в Python. Немного теории строкКак вы помните, в Python строки представляют собой массив символьных данных. Важным моментом в отношении строк является то, что они неизменяемы в языке Python. Это означает, что после создания строки Python ее нельзя изменить. Мы можем проверить эту функцию Python, создав новую строковую переменную. Если мы попытаемся изменить символ в строке, Python выдаст нам ошибку трассировки. >>> my_string = "Python для начинающих" >>> моя_строка[0] 'П' >>> my_string[0] = 'p' Traceback (последний последний вызов): Файл " При написании кода Python рекомендуется помнить о неизменном качестве строк. Хотя вы не можете изменять строки в Python, вы можете соединять их или добавлять к ним. Python поставляется со многими инструментами, облегчающими работу со строками. В этом уроке мы рассмотрим различные методы соединения строк, включая конкатенацию строк. Когда дело доходит до соединения строк, мы можем использовать как операторы Python, так и встроенные методы. По мере продвижения учащихся они, вероятно, так или иначе будут использовать каждую из этих техник. Соединение строк с помощью оператора «+»Конкатенация — это действие по объединению двух или более строк для создания одной новой строки. В Python строки могут быть объединены с помощью оператора «+». Подобно математическому уравнению, этот способ соединения строк является прямым, позволяя «складывать» несколько строк вместе. Рассмотрим несколько примеров: # объединение строк с помощью оператора '+'
first_name = "Бильбо"
last_name = "Бэггинс"
# соединить имена, разделенные пробелом
полное_имя = первое_имя + " " + фамилия
print("Hello, " + full_name + ".") В нашем первом примере мы создали две строки, first_name и last_name, а затем соединили их с помощью оператора «+». Для ясности мы добавили пробел между именами. Запустив файл, видим в командной строке следующий текст: Привет, Бильбо Бэггинс. Оператор печати в конце примера показывает, как объединение строк может генерировать более разборчивый текст. Давайте посмотрим на другой пример. На этот раз мы воспользуемся циклом for, чтобы соединить наши строковые данные. # некоторые персонажи из Властелина колец
символы = ["Фродо", "Гэндальф", "Сэм", "Арагорн", "Эовин"]
сюжетная линия = ""
# перебираем каждого персонажа и добавляем его в сюжетную линию
для i в диапазоне (len (символы)):
# включить "и" перед последним символом в списке
если я == len(символов)-1:
сюжетная линия += "и" + персонажи[i]
еще:
сюжетная линия += персонажи[i] + ", "
сюжетная линия += «Идут в Мордор, чтобы уничтожить кольцо».
распечатать (сюжет)
В этом более сложном примере показано, как можно использовать конкатенацию для создания удобочитаемого текста из списка Python. С помощью цикла for список персонажей (взятых из романов «Властелин колец») один за другим присоединяется к строке сюжетной линии. В этот цикл был включен условный оператор, чтобы проверить, достигли ли мы последнего объекта в списке символов. Если у нас есть, добавляется дополнительное «и», чтобы окончательный текст был более разборчивым. Мы также обязательно включим наши оксфордские запятые для большей разборчивости. Вот окончательный результат: Фродо, Гэндальф, Сэм, Арагорн и Эовин направляются в Мордор, чтобы уничтожить кольцо. Этот метод НЕ будет работать, если оба объекта не являются жалом. Например, попытка соединить строку с числом приведет к ошибке. >>> строка = "один" + 2 Traceback (последний последний вызов): Файл " Как видите, Python позволяет нам только конкатенировать строку с другой строкой. Наша работа как программистов — понимать ограничения языков, с которыми мы работаем. В Python нам нужно убедиться, что мы объединяем правильные типы объектов, если мы хотим избежать ошибок. Присоединение к спискам с оператором «+»Оператор «+» также может использоваться для объединения одного или нескольких списков строковых данных. Например, если бы у нас было три списка, каждый со своей уникальной строкой, мы могли бы использовать оператор «+», чтобы создать новый список, объединяющий элементы из всех трех. хоббитов = ["Фродо", "Сэм"] эльфы = ["Леголас"] люди = ["Арагорн"] печать (хоббиты + эльфы + люди) Как видите, у оператора «+» много применений. С его помощью программисты Python могут легко комбинировать строковые данные и списки строк. Соединение строк с помощью метода .join()Если вы имеете дело с итерируемым объектом в Python, скорее всего, вы захотите использовать метод .join() . Итерируемый объект , такой как строка или список, может быть легко объединен с помощью метода .join() . Любая итерация или последовательность Python может быть объединена с помощью метода . string_name.join(iterable) Вот пример использования метода .join() для объединения списка строк: numbers = ["one", "two" , «три», «четыре», «пять»]
печать (','. Присоединиться (числа))
Запустив программу в командной строке, мы увидим следующий вывод: один, два, три, четыре, пять Метод .join() вернет новую строку, которая включает все элементы в итерируемый объект, к которому присоединяется сепаратор . В предыдущем примере разделителем была запятая, но для соединения данных можно использовать любую строку. числа = ["один", "два", "три", "четыре", "пять"]
print(' and '.join(numbers)) Мы также можем использовать этот метод для объединения списка буквенно-цифровых данных, используя пустую строку в качестве разделителя. title = ['L','o','r','d',' ','o','f',' ','t','h','e',' ', «р», «и», «н», «г», «с»] печать («». Присоединиться (название)) Метод .join() также можно использовать для получения строки с содержимым словаря. При использовании .join() таким образом, метод будет возвращать только ключи в словаре, а не их значения. number_dictionary = {"один":1, "два":2, "три":3,"четыре":4,"пять":5}
print(', '.join(number_dictionary))
При объединении последовательностей методом .join() результатом будет строка с элементами обеих последовательностей. Копирование строк с помощью оператора «*»Если вам нужно соединить две или более одинаковых строк, можно использовать оператор «*». С помощью оператора «*» вы можете повторять строку любое количество раз. фрукт = «яблоко» print(fruit * 2) Оператор «*» можно комбинировать с оператором «+» для объединения строк. Комбинация этих методов позволяет нам воспользоваться многими расширенными функциями Python. fruit1 = "яблоко" Fruit2 = "апельсин" фрукты1 += " " фрукты2 += " " print(фрукты1 * 2 + " " + фрукты2 * 3) Разделение и воссоединение строкПоскольку строки в Python неизменяемы, довольно часто их разделяют и воссоединяют. . Метод split() — это еще один метод экземпляра строки. Это означает, что мы можем вызывать его с конца любого строкового объекта. Подобно методу .join() , метод .split() использует разделитель для анализа строковых данных. По умолчанию в качестве разделителя для этого метода используется пробел. Давайте посмотрим на метод .split() в действии. имён = "Фродо Сэм Гэндальф Арагорн" печать (имена.split()) Этот код выводит список строк. ['Фродо', 'Сэм', 'Гэндальф', 'Арагорн'] На другом примере мы увидим, как разбить предложение на отдельные части. story = "Фродо взял кольцо силы на гору рока. Использование файла . Метод split() возвращает новый итерируемый объект. Поскольку объект является итерируемым, мы можем использовать метод .join() , о котором мы узнали ранее, чтобы «склеить» строки вместе. original = "Фродо взял кольцо силы на гору рока." слова = оригинал.split() переделать = ' '.join(слова) печать (ремейк) Используя строковые методы в Python, мы можем легко разделять и соединять строки. Эти методы имеют решающее значение для работы со строками и итерируемыми объектами. Подведение итоговК настоящему моменту вы должны иметь более глубокие знания о строках и их использовании в Python 3. Работа с примерами, представленными в этом руководстве, станет отличным началом вашего пути к освоению Python. Однако ученик не может добиться успеха в одиночку. Вот почему мы составили список дополнительных ресурсов, предоставляемых Python For Beginners, чтобы помочь вам завершить обучение. Оставить комментарий
|
 Если вы хотите напечатать ‘WithQuotes’ в python, это нельзя сделать только с помощью одинарных (или двойных) кавычек, это требует одновременного использования обоих. Лучший способ избежать этой ошибки — использовать двойные кавычки.
Если вы хотите напечатать ‘WithQuotes’ в python, это нельзя сделать только с помощью одинарных (или двойных) кавычек, это требует одновременного использования обоих. Лучший способ избежать этой ошибки — использовать двойные кавычки. Есть два способа индексации.
Есть два способа индексации.

 Он указывает шаг, после которого каждый элемент будет напечатан, начиная с заданного индекса. Если ничего не указано, то он начинается с 0-го индекса.
Он указывает шаг, после которого каждый элемент будет напечатан, начиная с заданного индекса. Если ничего не указано, то он начинается с 0-го индекса.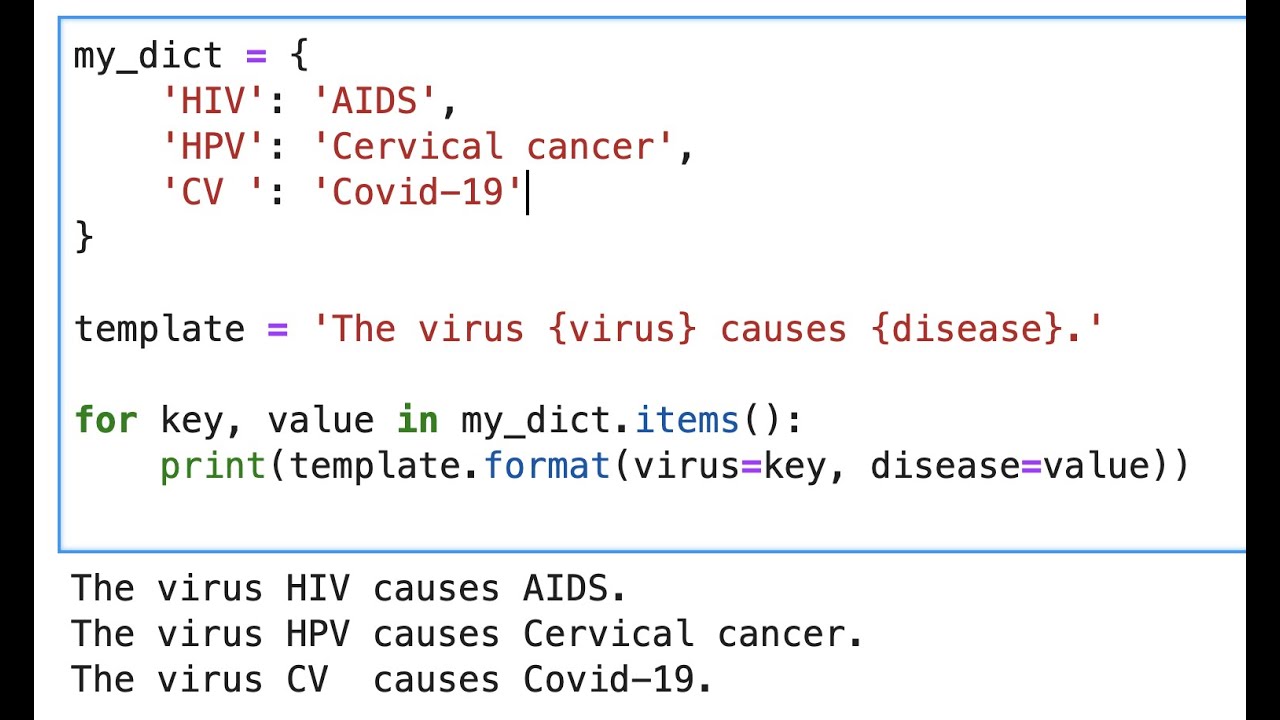 Он допускает множественные замены и форматирование значений.
Он допускает множественные замены и форматирование значений. Python | функция format()
Python | функция format()
 Для изменения строки потребуется создать совершенно новую строку или перезаписать старую.
Для изменения строки потребуется создать совершенно новую строку или перезаписать старую. У каждого есть свое предназначение.
У каждого есть свое предназначение. Добавляя знаки препинания с помощью конкатенации, мы можем создавать программы Python, которые легче понять, легче обновлять и с большей вероятностью будут использовать другие.
Добавляя знаки препинания с помощью конкатенации, мы можем создавать программы Python, которые легче понять, легче обновлять и с большей вероятностью будут использовать другие.

 join() . Это включает в себя, списки и словари.
join() . Это включает в себя, списки и словари.

 "
слова = история.split()
печать (слова)
"
слова = история.split()
печать (слова)
