Форматирование строк. Оператор % | Python 3 для начинающих и чайников
Иногда (а точнее, довольно часто) возникают ситуации, когда нужно сделать строку, подставив в неё некоторые данные, полученные в процессе выполнения программы (пользовательский ввод, данные из файлов и т. д.). Подстановку данных можно сделать с помощью форматирования строк. Форматирование можно сделать с помощью оператора %, и метода format.
Метод format является наиболее правильным, но часто можно встретить программный код с форматированием строк в форме оператора %.
Форматирование строк с помощью оператора %
Если для подстановки требуется только один аргумент, то значение — сам аргумент:
>>> 'Hello, %s!' % 'Vasya' 'Hello, Vasya!'
А если несколько, то значением будет являться кортеж со строками подстановки:
>>> '%d %s, %d %s' % (6, 'bananas', 10, 'lemons') '6 bananas, 10 lemons'
Теперь, а почему я пишу то %d, то %s? А всё зависит от того, что мы используем в качестве подстановки и что мы хотим получить в итоге.
| Формат | Что получится |
| ‘%d’, ‘%i’, ‘%u’ | Десятичное число. |
| ‘%o’ | Число в восьмеричной системе счисления. |
| ‘%x’ | Число в шестнадцатеричной системе счисления (буквы в нижнем регистре). |
| ‘%X’ | Число в шестнадцатеричной системе счисления (буквы в верхнем регистре). |
| ‘%e’ | Число с плавающей точкой с экспонентой (экспонента в нижнем регистре). |
| ‘%E’ | Число с плавающей точкой с экспонентой (экспонента в верхнем регистре). |
| ‘%f’, ‘%F’ | Число с плавающей точкой (обычный формат). |
| ‘%g’ | Число с плавающей точкой. с экспонентой (экспонента в нижнем регистре), если она меньше, чем -4 или точности, иначе обычный формат. |
| ‘%G’ | Число с плавающей точкой. с экспонентой (экспонента в верхнем регистре), если она меньше, чем -4 или точности, иначе обычный формат. |
| ‘%c’ | Символ (строка из одного символа или число — код символа). |
| ‘%r’ | Строка (литерал python). |
| ‘%s’ | Строка (как обычно воспринимается пользователем). |
| ‘%%’ | Знак ‘%’. |
Спецификаторы преобразования записываются в следующем порядке:
- %.
- Ключ (опционально), определяет, какой аргумент из значения будет подставляться.
- Флаги преобразования.
- Минимальная ширина поля. Если *, значение берётся из кортежа.
- Точность, начинается с ‘.’, затем — желаемая точность.
- Модификатор длины (опционально).
- Тип (см. таблицу выше).
>>> print ('%(language)s has %(number)03d quote types.' % {"language": "Python", "number": 2})
Python has 002 quote types.Флаги преобразования:
| Флаг | Значение |
| «#» | Значение будет использовать альтернативную форму. |
| «0» | Свободное место будет заполнено нулями. |
| «-« | Свободное место будет заполнено пробелами справа. |
| Свободное место будет заполнено пробелами справа. | |
| «+» | Свободное место будет заполнено пробелами слева. |
>>> '%.2s' % 'Hello!' 'He' >>> '%.*s' % (2, 'Hello!') 'He' >>> '%-10d' % 25 '25 ' >>> '%+10f' % 25 '+25.000000' >>> '%+10s' % 'Hello' ' Hello'
F-строки. Форматированные строки в Python.
«F-строки» обеспечивают краткий, читаемый способ включения значения выражений Python внутри строк. В исходном коде Python форматированная строка или по другому f-string — это буквальная строка с префиксом 'f' или 'F', которая содержит выражения внутри фигурных скобок {}. Выражения заменяются их значениями.
Escape-последовательности декодируются как в обычных строковых литералах, за исключением случаев, когда литерал также помечается как необработанная строка r'string'.
Части строки вне фигурных скобок обрабатываются буквально, за исключением того, что любые двойные фигурные скобки {{ или }} заменяются соответствующей одиночной фигурной скобкой. Одна открывающая фигурная скобка { обозначает поле замены, которое начинается с выражения Python. После выражения может быть поле преобразования, введенное восклицательным знаком !. Спецификатор формата также может быть добавлен, введенный двоеточием :. Поле замены заканчивается закрывающей фигурной скобкой }.
Выражения в форматированных строках рассматриваются как обычные выражения Python, окруженные круглыми скобками, за некоторыми исключениями:
- Пустое выражение недопустимо.
- Как лямбда-выражения, так и выражения присваивания
:=должны быть заключены в явные круглые скобки. - Выражения замены могут содержать разрывы строк, например в строках с тройными кавычками, но они не могут содержать комментарии.

- Каждое выражение вычисляется в контексте, где отображается форматированный строковый литерал, в порядке слева направо.
Если указаны преобразования (!o или !a или !r) , то перед форматированием вычисляется результат преобразования. Затем результат форматируется с помощью протокола str.format(). Спецификатор формата передается в метод __format__() выражения или результата преобразования. Отформатированный результат затем включается в конечное значение всей строки.
Спецификация формата Mini-Language совпадает с языком, используемым во встроенной функции format().
Форматированные строки могут быть объединены, но поля замены не могут быть разделены между литералами.
Спецификатор '=' в f-строках:
Для самостоятельного документирования выражений и отладки в Python-3.8.1 добавлен спецификатор '=' к f-строкам. F-строка, такая как f'{expr=}', расширится до текста выражения и знака равенства, а затем представления вычисляемого выражения. Например:
Например:
>>> user = 'eric_idle'
>>> member_since = date(1975, 7, 31)
>>> f'{user=} {member_since=}'
# "user='eric_idle' member_since=datetime.date(1975, 7, 31)"
Обычные спецификаторы формата f-string
>>> delta = date.today() - member_since
>>> f'{user=!s} {delta.days=:,d}'
# 'user=eric_idle delta.days=16,075'
Спецификатор = будет отображать все выражение, чтобы можно было показать вычисления:
>>> print(f'{theta=} {cos(radians(theta))=:.3f}')
theta=30 cos(radians(theta))=0.866
Общие примеры форматирования вывода f-строкой.
>>> name = 'Fred'
>>> f'He said his name is {name!r}.'
# 'He said his name is 'Fred'.'
# repr() является эквивалентом '!r'
>>> f`He said his name is {repr(name)}.`
# `He said his name is 'Fred'.`
# Вложенные поля
>>> width = 10
>>> precision = 4
>>> value = decimal.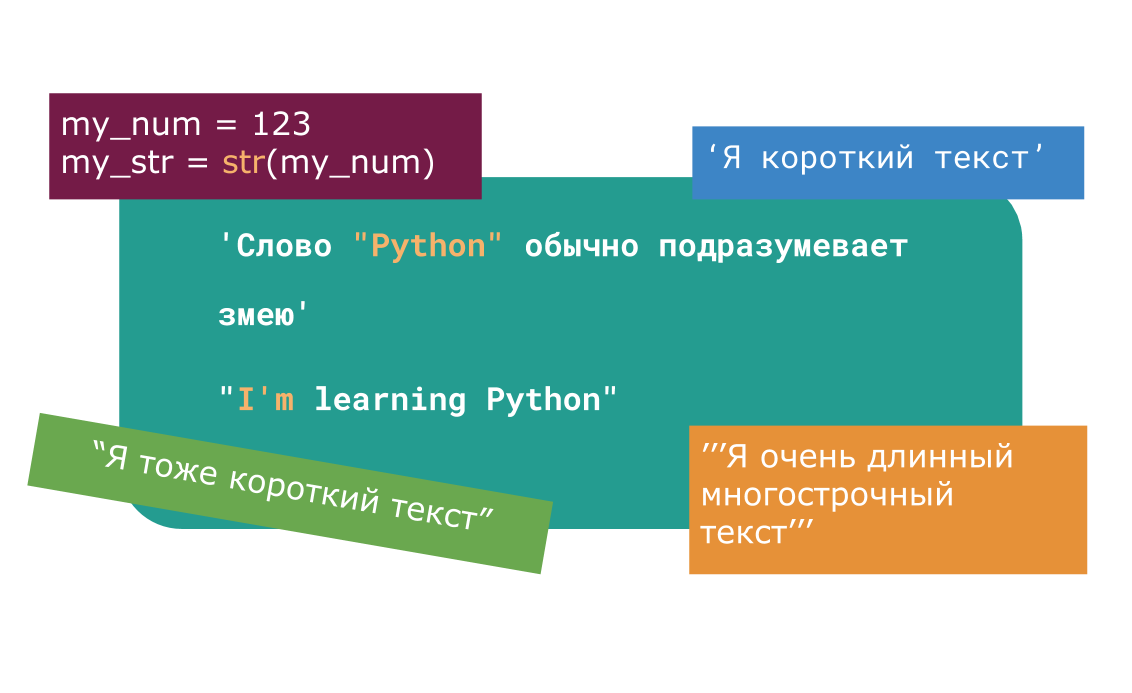 11.2f}'
# 'Pi=3.142, b=**2999.00**'
>>> print("\n".join(f'{a:{a}<{a}}' for a in range(1, 6)))
# 1
# 22
# 333
# 4444
# 55555
11.2f}'
# 'Pi=3.142, b=**2999.00**'
>>> print("\n".join(f'{a:{a}<{a}}' for a in range(1, 6)))
# 1
# 22
# 333
# 4444
# 55555
Использование спецификатора формата даты.
>>> today = datetime(year=2017, month=1, day=27)
>>> f`{today:%B %d, %Y}`
'January 27, 2017'
Использование спецификатора целочисленного формата.
>>> number = 1024
>>> f"{number:#0x}"
'0x400'
Сравнение F-строк с методом str.format():
# метод str.format()
'{},waiters:{}'.format(extra, len(self._waiters))
# F-строка
f'{extra},waiters:{len(self._waiters)}'
# метод str.format()
message.append(" [line {0:2d}]".format(lineno))
# F-строка
message.append(f" [line {lineno:2d}]")
# метод str.format()
methoddef_name = "{}_METHODDEF".format(c_basename.upper())
# F-строка
methoddef_name = f"{c_basename.upper()}_METHODDEF"
# метод str.format()
print("Usage: {0} [{1}]".format(sys.argv[0], '|'.join('--'+opt for opt in valid_opts)), file=sys. stderr)
# F-строка
print(f"Usage: {sys.argv[0]} [{'|'.join('--'+opt for opt in valid_opts)}]", file=sys.stderr)
stderr)
# F-строка
print(f"Usage: {sys.argv[0]} [{'|'.join('--'+opt for opt in valid_opts)}]", file=sys.stderr)
Python | Операции со строками
Операции со строками
Последнее обновление: 23.04.2017
Строка представляет последовательность символов в кодировке Unicode, заключенных в кавычки. Причем в Python мы можем использовать как одинарные, так и двойные кавычки:
name = "Tom" surname = 'Smith' print(name, surname) # Tom Smith
Одной из самых распространенных операций со строками является их объединение или конкатенация. Для объединения строк применяется знак плюса:
name = "Tom" surname = 'Smith' fullname = name + " " + surname print(fullname) # Tom Smith
С объединением двух строк все просто, но что, если нам надо сложить строку и число? В этом случае необходимо привести число к строке с помощью функции str():
name = "Tom" age = 33 info = "Name: " + name + " Age: " + str(age) print(info) # Name: Tom Age: 33
Эскейп-последовательности
Кроме стандартных символов строки могут включать управляющие эскейп-последовательности, которые интерпретируются особым образом.
print("Время пришло в гости отправится\nждет меня старинный друг")На консоль выведет две строки:
Время пришло в гости отправится ждет меня старинный друг
Тоже самое касается и последовательности \t, которая добавляет табляцию.
Кроме того, существуют символы, которые вроде бы сложно использовать в строке. Например, кавычки. И чтобы отобразить кавычки (как двойные, так и одинарные) внутри строки, перед ними ставится слеш:
print("Кафе \"Central Perk\"")Сравнение строк
Особо следует сказать о сравнении строк. При сравнении строк принимается во внимание символы и их регистр. Так, цифровой символ условно меньше, чем любой алфавитный символ. Алфавитный символ в верхнем регистре условно меньше, чем алфавитные символы в нижнем регистре. Например:
str1 = "1a" str2 = "aa" str3 = "Aa" print(str1 > str2) # False, так как первый символ в str1 - цифра print(str2 > str3) # True, так как первый символ в str2 - в нижнем регистре
Поэтому строка «1a» условно меньше, чем строка «aa». Вначале сравнение идет по первому символу. Если начальные символы обоих строк представляют цифры, то
меньшей считается меньшая цифра, например, «1a» меньше, чем «2a».
Вначале сравнение идет по первому символу. Если начальные символы обоих строк представляют цифры, то
меньшей считается меньшая цифра, например, «1a» меньше, чем «2a».
Если начальные символы представляют алфавитные символы в одном и том же регистре, то смотрят по алфавиту. Так, «aa» меньше, чем «ba», а «ba» меньше, чем «ca».
Если первые символы одинаковые, в расчет берутся вторые символы при их наличии.
Зависимость от регистра не всегда желательна, так как по сути мы имеем дело с одинаковыми строками. В этом случае перед сравнением мы можем привести обе строки к одному из регистров.
Функция lower() приводит строку к нижнему регистру, а функция upper() — к верхнему.
str1 = "Tom" str2 = "tom" print(str1 == str2) # False - строки не равны print(str1.lower() == str2.lower()) # True
Про Python — Справочник — str (строка)
Строка — базовый тип представляющий из себя неизменяемую последовательность символов; str от «string» — «строка».
Начиная с +py3.0 имеется в виду последовательность кодовых точек Unicode (соответствует типу unicode в предыдущих версиях Python).
До -py3.0 последовательность представляла из себя строку байт (поддерживает ASCII).
Поскольку в языке нет типа для одиночного символа, то обращение к строке при помощи индекса: my_str[1] — возвращает новую строку с символом по этому индексу.
Строковые литералы могут быть записаны разными способами:
# Одиночные кавычки. Часто встречаемый вариант записи.
my_str = 'а внутри "можно" поместить обычные'# Кавычки.
my_str = "а внутри 'можно' поместить одиночные"
# Три одиночных кавычки. Удобно для записей в несколько строк
my_str = '''В трёх одиночных
кавычках'''
# Тройные кавычки. Общепринятый способ для строк документации.
my_str = """Three double quotes"""
Строковые литералы, содержащие промеж себя только пробел объединяются в единую строку:
('Кот' 'обус') == 'Котобус'Приведение к строке
Другие типы могут быть приведены к строке при помощи конструктора
str(): str(obj).
str(10) # '10'
str(len) # '<built-in function len>'Таким образом можно получить «неформальное» строковое представление объектов. Для пользовательских типов такое представление может быть определено в специализированном методе __str__.
В случае, если получить строковое представление не удалось, производится попытка получить «формальное» представление (см. repr).
Синонимы поиска: str (строка), строки, строковые методы, функции для строк, преобразование в строку, методы строк
Метод String splitlines() в Python возвращает список строк
Сегодня в этом руководстве мы обсудим метод Python string splitlines(). Во-первых, давайте посмотрим на основное определение метода.
Что такое метод String splitlines() в Python?
Python string splitlines() — это встроенный метод, который возвращает список строк в строке с разрывом на границах строк. Разрывы строк не включаются в результирующий список, если keepends не указано как истинное.
Синтаксис.
str.splitlines([keepends])
где,
- str — строковый объект, который нам нужно разбить на список строк,
- keepends, когда установлено
True, границы строк включаются в результирующие элементы списка. В противном случае разрывы строк не включаются.
Таблица для символов границы строки и их соответствующие описания приведены ниже.
Таблица границ линий
| символ | Представление в Python |
| \ п | Перевод строки |
| \р | Возврат каретки |
| \ г \ п | Возврат каретки + перевод строки |
| \ v или \ x0b | Табулирование строк (Python 3.2 и новее) |
| \ f или \ x0c | Подача форм (Python 3.2 и новее) |
| \ x1c | Разделитель файлов |
| \ x1d | Разделитель групп |
| \ x1e | Разделитель записей |
| \ x85 | Следующая строка (контрольный код C1) |
| \ u2028 | Разделитель строк |
| \ u2029 | Разделитель абзацев |
Без остатков
Как упоминалось ранее, без упоминания параметра keepends будет создан список разделенных строк, исключая разрывы строк или граничные символы.
Посмотрите на пример ниже.
#String initialisation string1 = "Tim\nCharlie\nJohn\nAlan" string2 = "Welcome\n\nto\r\nAskPython\t!" string3 = "Keyboard\u2028Monitor\u2029\x1cMouse\x0cCPU\x85Motherboard\x1eSpeakers\r\nUPS" #without keepends print(string1.splitlines()) print(string2.splitlines()) print(string3.splitlines())
Выход:
['Tim', 'Charlie', 'John', 'Alan'] ['Welcome', '', 'to', 'AskPython\t!'] ['Keyboard', 'Monitor', '', 'Mouse', 'CPU', 'Motherboard', 'Speakers', 'UPS']
где,
- Мы объявили три строки, содержащие разные слова, разделенные разными символами переноса строки,
- Мы передаем каждый из них встроенному
splitlines()со значением keepends по умолчанию (false). И распечатываем полученные списки разделенных строк.
Как видно из вывода, поскольку keepends не был установлен, все разделенные строки не содержат границ строк или граничных символов. Для строки 2
Для строки 2 '\t' включается в слово 'Askpython\t' потому что это не граничный символ (его нет в таблице).
Значит, вывод оправдан.
С включением соответствующих переводов строк
Если мы укажем параметр keepends как True , разделенные строки теперь будут включать соответствующие переводы строк.
Давайте изменим наш предыдущий код (без keepends), установив для параметра keepends значение True внутри метода string splitlines() . Внимательно посмотрите на результат и постарайтесь заметить отличие от предыдущего.
#String initialisation string1 = "Tim\nCharlie\nJohn\nAlan" string2 = "Welcome\n\nto\r\nAskPython\t!" string3 = "Keyboard\u2028Monitor\u2029\x1cMouse\x0cCPU\x85Motherboard\x1eSpeakers\r\nUPS" #with keepends print(string1.splitlines(keepends=True)) print(string2.splitlines(keepends=True)) print(string3.splitlines(keepends=True))
Выход:
['Tim\n', 'Charlie\n', 'John\n', 'Alan'] ['Welcome\n', '\n', 'to\r\n', 'AskPython\t!'] ['Keyboard\u2028', 'Monitor\u2029', '\x1c', 'Mouse\x0c', 'CPU\x85', 'Motherboard\x1e', 'Speakers\r\n', 'UPS']
Как и ожидалось, для тех же строк splitlines() включает все граничные символы.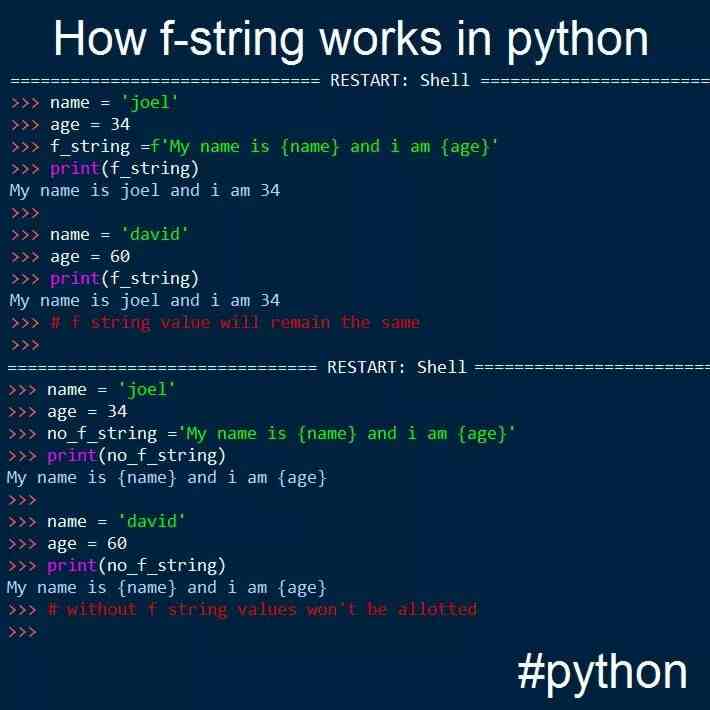
Форматирование строк или «Что означает %s в python?»
- Опубликовано:
- Теги: python
Оглавление
- Примеры
- Как работает оператор ‘%’
- Как работает встроенная функция format()
Для начала несколько примеров
Форматирование строк:>>> name = 'Vasya'
>>> print "My name is %s" % (name)
My name is Vasya
>>> print "My name is %10s. That's my name." % (name)
My name is Vasya. That's my name.
That's my name." % (name)
My name is Vasya. That's my name.
>>> print "My name is %-10s. That's my name." % (name)
My name is Vasya . That's my name.
>>> drinks = {'Long Island': 3, 'Bloody Mary': 2, 'Margarita':4}
>>> print "%-15s%-5s" % ("Name", "Qty")
Name Qty
>>> for k,v in drinks.items():
... print "%-15s%-3s" % (k, v)
...
Bloody Mary 2
Long Island 3
Margarita 4
>>> num = 12.34
>>> print "%d" % (num)
12>>> age = 25
>>> print "My name is %s. I'm %d." % (name, age)
My name is Vasya. I'm 25.Теперь вкратце как работает оператор %
Выражение форматирования можно условно разделить на три части:
определение_формата + % + объект(ы)Обозначения %s, %d, %g и т. п. — это форматы типов данных. Если вы знакомы с языком Си, то это тот же синтаксис, что используется для вывода на печать
п. — это форматы типов данных. Если вы знакомы с языком Си, то это тот же синтаксис, что используется для вывода на печать printf().
Спецификации различных типов данных Python приведены в следующей таблице:
| Формат | Значение |
|---|---|
'd' |
Целое десятичное число. |
'i' |
Целое десятичное число. |
'o' |
Восьмеричное число. |
'u' |
Устаревший тип – то же что 'd'. |
'x' |
Шестнадцатеричное число (нижний регистр). |
'X' |
Шестнадцатеричное число (верхний регистр). |
'e' |
Вещественное число в экспоненциальном виде (нижний регистр). |
'E' |
Вещественное число в экспоненциальном виде (верхний регистр). |
'f' |
Вещественное число в десятичном виде. |
'F' |
Вещественное число в десятичном виде. |
'g' |
Вещественное число. Использует формат 'f' или 'e' в нижнем регистре. |
'G' |
Вещественное число. Использует формат 'F' или 'E' в верхнем регистре. |
'c' |
Один символ (или цифра). |
'r' |
Строка, в которую любой объект Python конвертируется с помощью repr(). |
's' |
Строка, в которую любой объект Python конвертируется с помощью str(). |
'%' |
Аргумент не конвертируется, выводится просто символ '%'. |
Встроенная функция format()
Работает так:str.format()В строке «поля для замены» заключаются в фигурные скобки {}. Все, что не заключено в скобки, воспринимается как обычный текст, которые копируется в неизменном виде. Чтобы передать в тексте символы фигурных скобок, их дублируют: {{ и }}.
Поля для замены форматируются следующим образом:
поле_для_замены ::= "{" [имя_поля] ["!" конверсия] [":" спецификация] "}"
имя_поля ::= имя_аргумента ("." имя_атрибута | "[" номер_элемента "]")*
имя_аргумента ::= [идентификатор | integer]
имя_атрибута ::= идентификатор
индекс_элемента ::= integer | строковый индекс
строковый_индекс ::= <любой символ кроме "]"> +
конверсия ::= "r" | "s" # str или repr
спецификация ::= <описано ниже>спецификация ::= [[заглушка]выравнивание][знак][#][0][ширина][,][. "
знак ::= "+" | "-" | " "
ширина ::= integer # ширина поля
точность ::= integer # знаки после десятичной запятой
тип ::= "b" | "c" | "d" | "e" | "E" | "f" | "F" | "g" | "G" | "n" | "o" | "s" | "x" | "X" | "%"
"
знак ::= "+" | "-" | " "
ширина ::= integer # ширина поля
точность ::= integer # знаки после десятичной запятой
тип ::= "b" | "c" | "d" | "e" | "E" | "f" | "F" | "g" | "G" | "n" | "o" | "s" | "x" | "X" | "%">>> print """\n{0}
... Сидел на стене
... {0}
... Свалился во сне.""".format('Шалтай-Болтай')
Шалтай-Болтай
Сидел на стене
Шалтай-Болтай
Свалился во сне.Как видите, этот способ гораздо гибче оператора ‘%’, так как одни и те же значения мы можем использовать повторно и в любом порядке. Также можно передать именованные аргументы, и тогда обращаться к ним будем не по номерам, а по именам.
Еще пример форматирования:
>>> toc = (
... ('Первая глава', '3'),
... ('Вторая глава', '150')
... )
>>> for line in toc:
... print('{:.Python String format () Метод
❮ Строковые методы
Пример
Вставьте цену внутри заполнителя, цена должна быть с фиксированной точкой, двузначный формат:
txt = «Всего за {price: . 2f} долларов!»
2f} долларов!»
печать (txt.format (цена = 49))
Определение и использование
Метод format () форматирует указанный
значения и вставьте их в заполнитель строки.
Заполнитель определяется с помощью фигурных скобок: {}. Узнать больше о заполнители в разделе заполнителей ниже.
Метод format () возвращает форматированный
строка.
Синтаксис
строка . Формат ( значение1, значение2 … )
Значения параметров
| Параметр | Описание |
|---|---|
| значение1, значение2… | Обязательно. Одно или несколько значений, которые следует отформатировать и вставить в
Струна. Значения могут быть числом, указывающим позицию элемента, который вы хотите
удалять. Значения представляют собой либо список значений, разделенных запятыми, либо
ключ = список значений или их комбинация. Значения могут быть любого типа. |

Заполнители
Заполнители могут быть идентифицированы с помощью именованных индексов {price} , номер
индексы {0} или даже пустые заполнители {} .
Пример
Использование разных значений заполнителя:
txt1 = «Мой
имя {fname}, я {age} «. format (fname =» John «, age = 36)
txt2 =» My
имя: {0}, я {1} «. format (» John «, 36)
txt3 =» Мой
имя {}, я {} «. format (» Джон «, 36)
Типы форматирования
Внутри заполнителей вы можете добавить тип форматирования для форматирования результат:
: < | Попробуй | Выравнивает результат по левому краю (в пределах доступного пространства) |
:> | Попробуйте | Выравнивает результат по правому краю (в пределах доступного пространства) |
: ^ | Попробуй | Центр выравнивает результат (в пределах доступного пространства) |
: = | Попробуй | Помещает знак в крайнее левое положение. |
: + | Попробуй | Используйте знак «плюс», чтобы указать положительный или отрицательный результат. |
: - | Попробуй | Используйте знак минус только для отрицательных значений |
: | Попробуй | Используйте пробел, чтобы вставить дополнительный пробел перед положительными числами (и знак минус перед отрицательными числами) |
:, | Попробуй | Используйте запятую в качестве разделителя тысяч |
: _ | Попробуй | Используйте символ подчеркивания в качестве разделителя тысяч |
: б | Попробуй | Двоичный формат |
: c | Преобразует значение в соответствующий символ Юникода | |
: d | Попробуй | Десятичный формат |
: e | Попробуйте | Научный формат, строчные буквы e |
: E | Попробуйте | Научный формат, с заглавными буквами E |
: f | Попробуй | Исправить формат номера точки |
: F | Попробуйте | Исправить формат номера точки в формате верхнего регистра (показать инф и нан как INF и NAN ) |
: г | Общий формат | |
: G | Общий формат (с использованием заглавной буквы E для научных обозначений) | |
: o | Попробуй | Восьмеричный формат |
: x | Попробуй | Шестнадцатеричный формат, нижний регистр |
: X | Попробуй | Шестнадцатеричный формат, верхний регистр |
: n | Числовой формат | |
:% | Попробуй | Процентный формат |
❮ Строковые методы
Строка Python | strip () - GeeksforGeeks
Строка Python | полоса ()
strip () - это встроенная функция в языке программирования Python, которая возвращает копию строки с удаленными начальными и конечными символами (в зависимости от переданного строкового аргумента).
Синтаксис:
string.strip ([символы]) Параметр: В нем только один необязательный параметр: 1) символов - строка, определяющая набор удаляемых символов. Если необязательный параметр chars не указан, все ведущие и завершающие пробелы удаляются из строки. Возвращаемое значение: Возвращает копию строки с удаленными начальными и конечными символами.
|
вундеркинды для гиков
вундеркинды для гиков
за
|
 полоса (стр2))
полоса (стр2)) вундеркинды для гиков за
Работа с приведенным выше кодом:
Сначала мы создаем строку str1 = «гики для гиков»
Теперь мы вызываем метод полосы над str1 и передаем str2 = «ekgs» в качестве аргумента.
Теперь интерпретатор python отслеживает str1 слева. Он удаляет символ str1, если он присутствует в str2.
В противном случае отслеживание прекращается.
Теперь интерпретатор python отслеживает str1 справа. Удаляет символ str1, если он присутствует в str2.
В противном случае прекращается отслеживание.
Теперь наконец он возвращает результирующую строку.
Когда мы вызываем strip () без аргументов, она удаляет начальные и конечные пробелы.
Струнная полоса Python ()
Метод strip () удаляет символы как слева, так и справа в зависимости от аргумента (строка, определяющая набор символов, которые необходимо удалить).
Синтаксис метода strip () :
string.strip ([символы])
полоса () Параметры
- символов (необязательно) - строка, определяющая набор символов, которые нужно удалить из левой и правой части строки.
Если аргумент символов не указан, все начальные и конечные пробелы удаляются из строки.
Возвращаемое значение из метода strip ()
strip () возвращает копию строки с удаленными начальными и конечными символами.
Обработка полосы () методом
- Когда символ строки слева не совпадает со всеми символами в аргументе
chars, он перестает удалять ведущие символы. - Точно так же, когда символ строки справа не совпадает со всеми символами в аргументе
chars, он перестает удалять завершающие символы.
Пример: Работа метода strip ()
строка = 'xoxo love xoxo'
# Начальные и конечные пробелы удаляются
печать (строка. strip ())
# Все символы <пробел>, x, o, e слева
# и правая часть строки удаляются
печать (строка.стрип ('xoe'))
# Аргумент не содержит пробелов
# Никакие символы не удаляются.печать (строка.стрип ('stx'))
строка = 'Android потрясающий'
print (string.strip ('an'))
strip ())
# Все символы <пробел>, x, o, e слева
# и правая часть строки удаляются
печать (строка.стрип ('xoe'))
# Аргумент не содержит пробелов
# Никакие символы не удаляются.печать (строка.стрип ('stx'))
строка = 'Android потрясающий'
print (string.strip ('an')) Выход
xoxo любовь xoxo любить xoxo любовь xoxo дроид классный
Здесь мы видим, что первое выражение string.strip () без каких-либо аргументов удалило пробелы слева и справа от string .
string.strip ('xoe') удалили все пробелы, x , o и e , ведущие или замыкающие строку.
Поскольку строка имеет пробелы в начале и в конце, выражение string.strip ('stx') не изменяет строку. x не удаляется, так как он находится в середине строки (пробелы ведут и следуют за строкой)
string.strip ('an') удалил и в начале строки.
Python String Exercise с решениями
Как вы знаете, структура данных stings широко используется для хранения данных последовательности символов.Для выполнения любых задач программирования на Python необходимо хорошее понимание операций со строками.
Этот проект упражнений на String призван помочь разработчику Python научиться практиковать операции со строками . Все строковые программы протестированы на Python 3 . Это упражнение содержит 18 строковых программ Python для практики.
Что входит в это упражнение со струнами?
Упражнение содержит 18 вопросов и решений для каждого вопроса.Это упражнение Python String coding - не что иное, как присваивания Python String для решения, где вы можете решать и практиковать различные программы String, вопросы, проблемы и задачи.
Каждый вопрос включает в себя определенную тему, связанную со строками, которую вам нужно практиковать.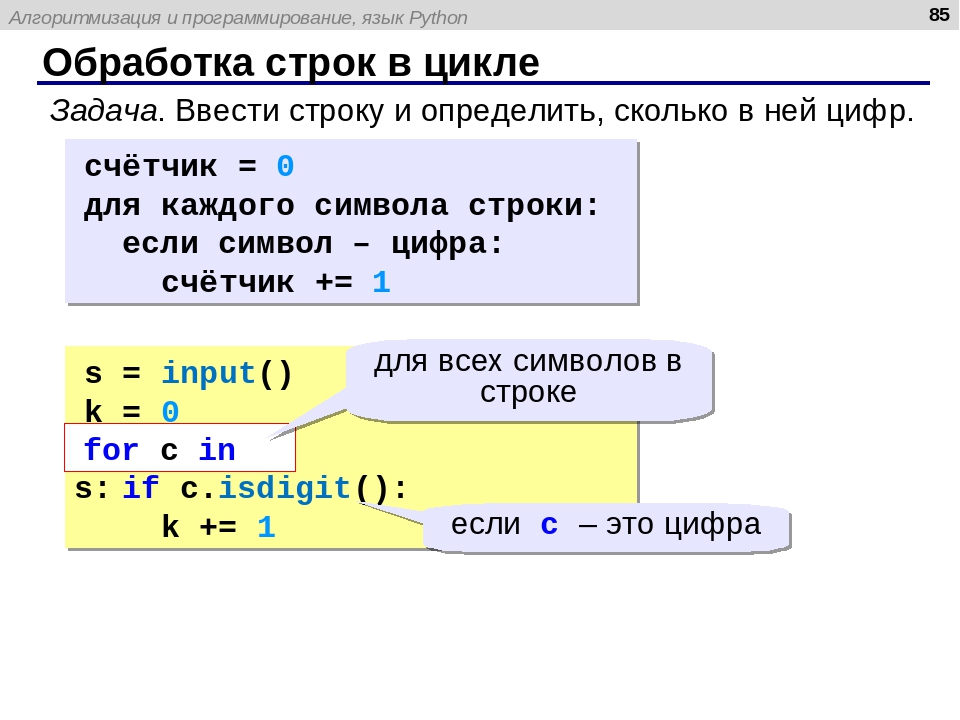 В этом упражнении со строками рассматриваются вопросы по темам , таким как строковые операции, манипуляции, срезы и строковые функции. Эти упражнения Python String подходят для любого разработчика Python. Если вы новичок, после выполнения этого упражнения вы лучше поймете Python String.
В этом упражнении со строками рассматриваются вопросы по темам , таким как строковые операции, манипуляции, срезы и строковые функции. Эти упражнения Python String подходят для любого разработчика Python. Если вы новичок, после выполнения этого упражнения вы лучше поймете Python String.
Используйте Онлайн-редактор кода для решения вопросов упражнения .
Вопрос к упражнению 1. Для строки с нечетной длиной больше 7, вернуть строку, состоящую из трех средних символов данной строки
Корпус 1 :
str1 = "JhonDipPeta"
Ожидаемый результат :
Дип
Корпус 2 :
str2 = "JaSonAy"
Ожидаемый результат :
Сын
Решение :
def getMiddleThreeChars (sampleStr):
middleIndex = int (len (sampleStr) / 2)
print ("Исходная строка", sampleStr)
middleThree = sampleStr [middleIndex-1: middleIndex + 2]
print ("Средние три символа", middleThree)
getMiddleThreeChars ("JhonDipPeta")
getMiddleThreeChars ("Джейсоней") Вопрос к упражнению 2: Даны 2 строки, s1 и s2, создайте новую строку, добавив s2 в середине s1
Дано :
s1 = "Ault"
s2 = "Келли" Ожидаемый результат :
AuKellylt
Решение :
def appendMiddle (s1, s2):
middleIndex = int (len (s1) / 2)
print ("Исходные строки", s1, s2)
middleThree = s1 [: middleIndex:] + s2 + s1 [middleIndex:]
print ("После добавления новой строки посередине", middleThree)
appendMiddle («Олт», «Келли») Вопрос к упражнению 3: даны 2 строки, s1 и s2 возвращают новую строку, состоящую из первого, среднего и последнего символа для каждой входной строки
Дано :
s1 = "Америка"
s2 = "Япония" Ожидаемый результат :
AJrpan
Решение :
def mix_string (s1, s2):
first_char = s1 [: 1] + s2 [: 1]
middle_char = s1 [int (len (s1) / 2): int (len (s1) / 2) + 1] + s2 [int (len (s2) / 2): int (len (s2) / 2) + 1 ]
last_char = s1 [len (s1) - 1] + s2 [len (s2) - 1]
res = first_char + middle_char + last_char
print ("Mix String is", res)
s1 = "Америка"
s2 = "Япония"
mix_string (s1, s2)
Вопрос к упражнению 4. & i5ve"
& i5ve" Ожидаемый результат :
Общее количество знаков, цифр и символов
Chars = 8
Цифры = 3
Символ = 4
Решение :
def findDigitsCharsSymbols (inputString):
charCount = 0
digitCount = 0
symbolCount = 0
для char в inputString:
если char.& i5ve "
print ("общее количество знаков, цифр и символов \ n")
findDigitsCharsSymbols (inputString)
Вопрос к упражнению 6: Для двух строк, s1 и s2, создайте смешанную строку
Примечание : создайте третью строку, состоящую из первого символа s1, затем последнего символа s2, Next, второго символа s1 и второго последнего символа s2 и так далее. Любые оставшиеся символы помещаются в конец результата.
Дано :
s1 = "Abc"
s2 = "Xyz"
Ожидаемый результат :
AzbycX
Решение :
def mixString (s1, s2):
s2 = s2 [:: - 1]
длинаS1 = длина (s1)
длинаS2 = длина (с2)
length = lengthS1, если lengthS1> lengthS2, иначе lengthS2
resultString = ""
для i в диапазоне (длина):
если (i
Упражнение Вопрос 7: Тест баланса строковых символов
Мы скажем, что строки s1 и s2 сбалансированы, если все символы в s1 находятся в s2 . положение символов не имеет значения.
положение символов не имеет значения.
Корпус 1 :
s1 = "Yn"
s2 = "PYnative"
Ожидаемый результат :
Истинно
Корпус 2 :
s1 = "Ynf"
s2 = "PYnative"
Ожидаемый результат :
Ложь
Решение :
def stringBalanceCheck (s1, s2):
flag = True
для char в s1:
если char в s2:
Продолжить
еще:
flag = False
флаг возврата
s1 = "Yn"
s2 = "PYnative"
flag = stringBalanceCheck (s1, s2)
print ("s1 и s2 сбалансированы", флаг)
s1 = "Ynf"
s2 = "PYnative"
flag = stringBalanceCheck (s1, s2)
print ("s1 и s2 сбалансированы", флаг)
Выход:
s1 и s2 сбалансированы True
s1 и s2 сбалансированы Ложь
Упражнение Вопрос 8: Найдите все вхождения «USA» в заданной строке, игнорируя регистр
Дано :
str1 = "Добро пожаловать в США. США круто, не правда ли? "
США круто, не правда ли? "
Ожидаемый результат :
Количество в США: 2
Решение :
inputString = "Добро пожаловать в США. США классные, не правда ли?"
substring = "США"
tempString = inputString.lower ()
count = tempString.count (substring.lower ())
print ("Количество в США:", count)
Вопрос к упражнению 9: Для данной строки вернуть сумму и среднее значение цифр, которые появляются в строке, игнорируя все остальные символы
Дано :
str1 = "Английский = 78 Наука = 83 Математика = 68 История = 65"
Ожидаемый результат :
сумма 294
в среднем 73.5
Решение :
импорт ре
inputStr = "Английский = 78 Наука = 83 Математика = 68 История = 65"
markList = [int (num) вместо num в re.findall (r '\ b \ d + \ b', inputStr)]
totalMarks = 0
для отметки в markList:
totalMarks + = оценка
процент = totalMarks / len (markList)
print («Всего оценок:», totalMarks, «Percentage is», в процентах)
Выход:
Всего оценок: 294 Процент 73,5
Вопрос к упражнению 10: Для входной строки подсчитать вхождения всех символов в строке
Дано :
str1 = "Яблоко"
Ожидаемый результат :
{'A': 1, 'p': 2, 'l': 1, 'e': 1} Решение :
str1 = "Яблоко"
countDict = dict ()
для char в str1:
count = str1. счет (символ)
countDict [char] = count
печать (countDict)
счет (символ)
countDict [char] = count
печать (countDict)
Упражнение 11: перевернуть заданную строку
Дано :
str1 = "PYnative"
Ожидаемый результат :
evitanYP
Решение 1 :
str1 = "PYnative"
print ("Исходная строка:", str1)
str1 = str1 [:: - 1]
print ("Перевернутая строка:", str1)
Решение 2 :
str1 = "PYnative"
print ("Исходная строка:", str1)
str1 = ''.присоединиться (обратное (str1))
print ("Перевернутая строка:", str1)
Вопрос к упражнению 12: Найдите последнюю позицию подстроки «Emma» в заданной строке
Дано :
str1 = "Эмма - специалист по данным, знающий Python. Эмма работает в Google."
Где в строке находится последнее вхождение подстроки «Эмма» ?:
Ожидаемый результат :
Последнее появление Эммы начинается с индекса 43
Решение :
str1 = "Эмма - специалист по данным, знающий Python. Эмма работает в Google ".
print ("Исходная строка:", str1)
index = str1.rfind ("Эмма")
print ("Последнее появление Эммы начинается с", индекс)
Эмма работает в Google ".
print ("Исходная строка:", str1)
index = str1.rfind ("Эмма")
print ("Последнее появление Эммы начинается с", индекс)
Вопрос упражнения 13: Разделить заданную строку по дефисам на несколько подстрок и отобразить каждую подстроку
Дано:
str1 = Эмма-специалист по данным
Ожидаемый результат :
Отображение каждой подстроки
Эмма
является
а
данные
ученый
Решение :
str1 = "Эмма-специалист по данным"
print ("Исходная строка:", str1)
# разделить строку
подстроки = str1.Трещина("-")
print ("Отображение каждой подстроки")
для sub в подстроках:
печать (суб)
Вопрос упражнения 14: Удалить пустые строки из списка строк
Дано :
str_list = ["Эмма", "Джон", "", "Келли", Нет, "Эрик", ""]
Ожидаемый результат :
Оригинальный список укусов
['Эмма', 'Джон', '', 'Келли', Нет, 'Эрик', '']
После удаления пустых строк
[«Эмма», «Джон», «Келли», «Эрик»]
Решение :
str_list = ["Эмма", "Джон", "", "Келли", Нет, "Эрик", ""]
print ("Исходный список жала")
печать (str_list)
# использовать встроенный фильтр функций для фильтрации пустого значения
new_str_list = список (фильтр (Нет, str_list))
print ("После удаления пустых строк")
печать (новый_стр_лист)
Упражнение 15: Удаление специальных символов / знаков препинания из заданной строки
Дано :
str1 = "/ * Джон - @ разработчик и музыкант"
Ожидаемый результат :
«Джон - музыкант-разработчик»
Решение 1 :
строка импорта
str1 = "/ * Джон - @ разработчик и музыкант"
print ("Исходная строка", str1)
# использовать функцию перевода строки
# и функция maketrans класса str
new_str = str1. \ w \ s] ',' ', str1)
print ("Новая строка", str2)
\ w \ s] ',' ', str1)
print ("Новая строка", str2)
Вопрос к упражнению 16. Удаление всех символов, кроме целых, из строки
Дано :
Мне 25 лет и 10 месяцев
Ожидаемый результат :
2510
Решение :
str1 = "Мне 25 лет и 10 месяцев"
print ("Исходная строка", str1)
# Сохранять числа в строке
# Использование понимания списка + join () + isdigit ()
res = "".join ([элемент для элемента в str1, если item.isdigit ()])
печать (разрешение)
Вопрос к упражнению 17: Найдите слова, состоящие из букв и цифр
Дано :
str1 = "Emma25 - специалист по обработке данных50 и эксперт по ИИ"
Ожидаемый результат :
Эмма25
ученый50
Решение :
str1 = "Эмма25 - специалист по данным50 и эксперт в области искусственного интеллекта"
print ("Исходная строка:" + str1)
# Слова с алфавитами и цифрами
# isdigit () для чисел + isalpha () для алфавитов
# используйте any () для проверки каждого символа
res = []
темп = str1. Трещина()
для элемента в темп:
если есть (char.isalpha () для символа в элементе) и любой (char.isdigit () для символа в элементе):
res.append (элемент)
print ("Отображение слов с помощью букв и цифр")
для я в разрешении:
печать (я)
Трещина()
для элемента в темп:
если есть (char.isalpha () для символа в элементе) и любой (char.isdigit () для символа в элементе):
res.append (элемент)
print ("Отображение слов с помощью букв и цифр")
для я в разрешении:
печать (я)
. Вопрос к упражнению 18: В заданной строке замените каждую пунктуацию на #
. Дано :
str1 = '/ * Джон - @ разработчик и музыкант !!'
Ожидаемый результат :
## Джон - # разработчик # музыкант ##
Решение :
из пунктуации импорта строки
str1 = '/ * Джон - @ разработчик и музыкант !!'
print ("Исходная строка:", str1)
# Замените знаки препинания на #
replace_char = '#'
# Использование строки.пунктуация, чтобы получить список всех знаков препинания
# используйте строковую функцию replace (), чтобы заменить каждую пунктуацию на #
для знаков в пунктуации:
str1 = str1.replace (символ, replace_char)
print ("Строки после замены:", str1)
Как дополнить строки нулем, пробелом или другим символом? - thispointer. com
com
В этой статье мы обсудим, как выполнить левое заполнение строк или правое заполнение строк нулем, пробелом или каким-либо другим символом.
Левое заполнение строки в Python
Заполнение строки слева означает добавление заданного символа в левую часть строки, чтобы сделать ее заданной длины. Разберемся на примерах,
Предположим, у нас есть числовая строка, например, «5». Теперь мы хотим преобразовать эту строку длиной 1 в строку длиной 4 на
- Три нуля слева до строки, например «0005»
- Три пробела слева до строки, т. Е. ”5 ″
- Добавляет три символа слева в строку i.е. «–5»
Давайте посмотрим, как это сделать на примерах,
Заполните строку нулями слева, используя string.zfill ()
numStr = "5"
print ('Исходная строка:', numStr)
# Заполните строку слева 0, чтобы она стала длиной 4
numStr = numStr. zfill (4)
print ('Обновленная строка:', numStr)
zfill (4)
print ('Обновленная строка:', numStr)
Вывод: Исходная строка: 5
Обновленная строка: 0005
string.zfill (s, width) дополняет заданную строку слева нулями (0), пока длина строки не достигнет заданной ширины. Здесь 3 нуля добавляются слева от данной строки, чтобы сделать ее длиной 4.
Заполните строку слева пробелом, используя string.rjust ()
string.rjust ()
string.rjust (s, width [, fillchar])
string.rjust () выравнивает данную строку по правому краю, добавляя fillchar слева от строки, чтобы сделать ее длину равной заданной ширине. Давайте использовать его, numStr = "5"
print ('Исходная строка:', numStr)
# Сделать строку длиной 4 выровненной вправо, добавив 3 пробела слева
numStr = numStr. rjust (4, '')
print ('Обновленная строка:', numStr)
rjust (4, '')
print ('Обновленная строка:', numStr)
Вывод: Исходная строка: 5
Обновленная строка: 5
Здесь слева от данной строки добавляются 3 пробела, чтобы ее длина составляла 5. Заполнить строку слева некоторым символом, используя string.rjust ()
Мы можем передать символ заполнения в string.rjust (s, width [, fillchar]) в левую часть заданной строки с помощью этого символа (fillchar), то есть
numStr = "5"
print ('Исходная строка:', numStr)
# Выровнять строку длиной 4 по правому краю, добавив 3 '-' влево
numStr = numStr.rjust (4, '-')
print ('Обновленная строка:', numStr)
Выход: Исходная строка: 5
Обновленная строка: --- 5
Здесь три символа «-» добавляются слева от данной строки, чтобы сделать ее длиной 4.
Правое заполнение строки в Python
Правое заполнение строки означает добавление заданного символа с правой стороны строки, чтобы сделать ее заданной длины. Разберемся на примерах,
Предположим, у нас есть числовая строка, например, «Джон». Теперь мы хотим преобразовать эту строку длиной 4 в строку длиной 7 на
- Три нуля справа от строки, например, «John000»
- Правый отступ на три пробела до строки, например, «John»
- Дополняет строку справа тремя символами, например, «John-»
Давайте посмотрим, как это сделать на примерах,
Заполните строку нулями справа с помощью string.ljust ()
string.ljust (s, width [, fillchar])
строка.ljust () выравнивает данную строку по левому краю, добавляя заданный символ (например, fillchar) слева от строки, чтобы сделать его длину равной заданной ширине. Давайте использовать его,
Давайте использовать его, numStr = "45"
print ('Исходная строка:', numStr)
# Выровнять строку по левому краю длиной 5, добавив 3 0 справа от нее
numStr = numStr.ljust (5; '0')
print ('Обновленная строка:', numStr)
Выход: Исходная строка: 45
Обновленная строка: 45000
Здесь 3 нуля добавляются справа от данной строки, чтобы сделать ее длиной 5. Заполните строку справа пробелом, используя string.ljust ()
userName = "Джон"
print ('Исходная строка:', имя пользователя)
# Выровняйте строку по левому краю длиной 7, добавив 3 пробела справа от нее
userName = userName.ljust (7, '')
print ('Обновленная строка:', userName, 'is')
Выход: Исходная строка: Джон
Обновленная строка: Джон
Здесь справа от данной строки добавлены 3 пробела, чтобы ее длина составила 7.
Заполните строку справа каким-либо символом, используя string.ljust ()
Мы можем передать символ заполнения в string.ljust (s, width [, fillchar]) для правого дополнения данной строки этим символом (то есть fillchar), т.е.
userName = "John"
print ('Исходная строка:', имя пользователя)
# Выровнять строку по левому краю длиной 7, добавив 3 '-' справа от нее
userName = userName.ljust (7, '-')
print ('Обновленная строка:', имя пользователя)
Выход: Исходная строка: Джон
Обновленная строка: John ---
Здесь три символа «-» добавляются справа от данной строки, чтобы сделать ее длиной 7. Полный пример выглядит следующим образом:
def main ():
print ('**** Оставьте строку с 0, используя s.zfill () ****')
numStr = "5"
print ('Исходная строка:', numStr)
# Заполните строку слева 0, чтобы она стала длиной 4
numStr = numStr. zfill (4)
print ('Обновленная строка:', numStr)
print ('**** Оставьте строку с пробелом, используя string.rjust () ****')
numStr = "5"
print ('Исходная строка:', numStr)
# Сделать строку длиной 4 выровненной вправо, добавив 3 пробела слева
numStr = numStr.rjust (4, '')
print ('Обновленная строка:', numStr)
print ('**** Заполните строку слева символом, используя string.rjust () ****')
numStr = "5"
print ('Исходная строка:', numStr)
# Выровнять строку длиной 4 по правому краю, добавив 3 '-' влево
numStr = numStr.rjust (4, '-')
print ('Обновленная строка:', numStr)
print ('**** Право ввести строку с нулями, используя string.rjust () ****')
numStr = "45"
print ('Исходная строка:', numStr)
# Выровнять строку по левому краю длиной 5, добавив 3 0 справа от нее
numStr = numStr.ljust (5; '0')
print ('Обновленная строка:', numStr)
print ('**** Право ввести строку с пробелом, используя string.
zfill (4)
print ('Обновленная строка:', numStr)
print ('**** Оставьте строку с пробелом, используя string.rjust () ****')
numStr = "5"
print ('Исходная строка:', numStr)
# Сделать строку длиной 4 выровненной вправо, добавив 3 пробела слева
numStr = numStr.rjust (4, '')
print ('Обновленная строка:', numStr)
print ('**** Заполните строку слева символом, используя string.rjust () ****')
numStr = "5"
print ('Исходная строка:', numStr)
# Выровнять строку длиной 4 по правому краю, добавив 3 '-' влево
numStr = numStr.rjust (4, '-')
print ('Обновленная строка:', numStr)
print ('**** Право ввести строку с нулями, используя string.rjust () ****')
numStr = "45"
print ('Исходная строка:', numStr)
# Выровнять строку по левому краю длиной 5, добавив 3 0 справа от нее
numStr = numStr.ljust (5; '0')
print ('Обновленная строка:', numStr)
print ('**** Право ввести строку с пробелом, используя string. rjust () ****')
userName = "Джон"
print ('Исходная строка:', имя пользователя)
# Выровняйте строку по левому краю длиной 7, добавив 3 пробела справа от нее
userName = userName.ljust (7, '')
print ('Обновленная строка:', userName, 'is')
print ('**** Правее заполнить строку символом, используя строку.rjust () **** ')
userName = "Джон"
print ('Исходная строка:', имя пользователя)
# Выровнять строку по левому краю длиной 7, добавив 3 '-' справа от нее
userName = userName.ljust (7, '-')
print ('Обновленная строка:', имя пользователя)
если __name__ == '__main__':
главный()
rjust () ****')
userName = "Джон"
print ('Исходная строка:', имя пользователя)
# Выровняйте строку по левому краю длиной 7, добавив 3 пробела справа от нее
userName = userName.ljust (7, '')
print ('Обновленная строка:', userName, 'is')
print ('**** Правее заполнить строку символом, используя строку.rjust () **** ')
userName = "Джон"
print ('Исходная строка:', имя пользователя)
# Выровнять строку по левому краю длиной 7, добавив 3 '-' справа от нее
userName = userName.ljust (7, '-')
print ('Обновленная строка:', имя пользователя)
если __name__ == '__main__':
главный()
Вывод: **** Заполните строку слева 0 с помощью s.zfill () ****
Исходная строка: 5
Обновленная строка: 0005
**** Оставьте строку с пробелом, используя строку.rjust () ****
Исходная строка: 5
Обновленная строка: 5
**** Заполните строку слева символом, используя string.rjust () ****
Исходная строка: 5
Обновленная строка: --- 5
**** Заполните строку нулями справа, используя string.rjust () ****
Исходная строка: 45
Обновленная строка: 45000
**** Заполните строку справа пробелом, используя string.rjust () ****
Исходная строка: John
Обновленная строка: Джон
**** Заполните строку справа символом, используя string.rjust () ****
Исходная строка: John
Обновленная строка: John ---
строка Python - изучение на примере
Что такое строка Python?
Строка - это последовательность символов.Вы, должно быть, использовали строки и на других языках. Строки Python играют ту же роль, что и символьные массивы в таких языках, как C, но они являются инструментами более высокого уровня, чем массивы.
В отличие от таких языков, как C, в Python строки содержат мощный набор инструментов обработки.
Создать строку
Строка Python состоит из нуля или более символов, записанных в одинарных кавычках '' или двойных кавычках ""
S = 'Hello, World!' # одинарные кавычки
S = "Привет, мир!" # двойные кавычки
Многострочные строки
Вы можете создать многострочную строку, используя тройные кавычки: "" "" "" или '' '' '' .
S = "" "Строковые литералы могут
охватывают несколько строк. "" "
печать (S)
# Строковые литералы могут
# охватывают несколько строк.
Конструктор str ()
Вы можете преобразовать практически любой объект в Python в строку, используя конструктор типа str ()
# целое число в строку
S = ул (42)
печать (S)
# Выводит '42'
# комплексное число в строку
S = str (3 + 4j)
печать (S)
# Отпечатки '(3 + 4j)
# список в строку
S = str ([1,1])
печать (S)
# Печатает '[1, 1]'
Доступ к символам по индексу
Вы можете получить доступ к отдельным символам в строке, используя индекс в квадратных скобках.Индексация строки начинается с 0.
Вы также можете получить доступ к строке с помощью отрицательной индексации. Отрицательный строковый индекс отсчитывается от конца строки.
Индексы для элементов в строке показаны ниже:
# Индексирование
S = 'ABCDEFGHI'
print (S [0]) # Печать A
print (S [4]) # Печать E
# Отрицательное индексирование
S = 'ABCDEFGHI'
print (S [-1]) # Печатает I
print (S [-6]) # Печатает D
Нарезка строки
Сегмент строки называется фрагментом , и вы можете извлечь его, используя оператор фрагмента.Отрезок строки также является строкой.
Оператор среза [n: m] возвращает часть строки от «n-го» элемента до «m-го» элемента, включая первую, но исключая последнюю.
S = "ABCDEFGHI"
print (S [2: 5]) # Печать CDE
print (S [5: -1]) # Печать FGH
print (S [1: 6: 2]) # Печать BDF
Возможности нарезки строк, предоставляемые python, обширны и подробно рассматриваются здесь.
Изменить строку
Заманчиво использовать оператор [] в левой части присваивания, чтобы преобразовать символ в строку.например:
S = 'Hello, World!'
S [0] = 'J'
# Triggers TypeError: объект 'str' не поддерживает присвоение элемента
Причина ошибки в том, что строки неизменяемы (неизменяемы), и из-за чего вы не можете изменить существующую строку. Лучшее, что вы можете сделать, это создать новую строку, которая является вариацией оригинала:
S = 'Hello, world!'
new_S = 'J' + S [1:]
печать (new_S)
# Печать Желе, мир!
Конкатенация строк
Вы можете объединить строки с помощью оператора конкатенации + или оператора расширенного присваивания + =
# оператор конкатенации
S = 'Привет' + 'Мир!'
печать (S)
# Привет, мир!
# оператор расширенного присваивания
S = 'Привет'
S + = 'Мир!'
печать (S)
# Печатает Hello, World!
В Python две или более строк, расположенных рядом друг с другом, автоматически объединяются, это называется Неявное объединение .
S = 'Hello,' "World!"
печать (S)
# Печатает Hello, World!
Неявная конкатенация работает только с двумя литералами, но не с переменными или выражениями.
Вы также можете заключить несколько строк в круглые скобки, чтобы соединить их вместе. Эта функция полезна, если вы хотите порвать длинные строки.
S = ('Заключить строки в круглые скобки'
'чтобы соединить их вместе.')
печать (S)
# Поместите строки в круглые скобки, чтобы соединить их вместе.
Вы можете реплицировать подстроки в строке с помощью оператора репликации *
# сложный путь
S = '--------------------'
# легкий путь
S = '-' * 20
Найти длину строки
Чтобы найти количество символов в строке, используйте встроенную функцию len ().
S = 'Supercalifragilisticexpialidocious'
печать (len (S))
# Печатает 34
Заменить текст внутри строки
Иногда вы хотите заменить текст внутри строки, тогда вы можете использовать метод replace ().
S = 'Привет, мир!'
x = S.replace ('Мир', 'Вселенная')
печать (х)
# Печать Привет, Вселенная!
Разделить и объединить строку
Используйте метод split (), чтобы разбить строку на список подстрок вокруг указанного разделителя.
# Разделить строку на запятую
S = 'красный, зеленый, синий, желтый'
х = S.split (',')
печать (х)
# Печать ["красный", "зеленый", "синий", "желтый"]
печать (x [0])
# Печатает красным
И используйте метод join (), чтобы снова объединить список в строку с указанным разделителем между ними.
# Присоединить список подстрок
L = ["красный", "зеленый", "синий", "желтый"]
S = ','. Присоединиться (L)
печать (S)
# Печатает красный, зеленый, синий, желтый
Преобразование регистра в строке
Python предоставляет пять методов для выполнения преобразования регистра в целевой строке, а именно.lower (), upper (), capitalize (), swapcase () и title ()
S = 'Привет, мир!'
печать (S.lower ())
# Привет, мир!
S = 'Привет, мир!'
печать (S.upper ())
# Печатает ПРИВЕТ, МИР!
S = 'Привет, мир!'
печать (S.capitalize ())
# Печать Привет, мир!
S = 'Привет, мир!'
печать (S.swapcase ())
# Печатает привет, мир!
S = 'привет, мир!'
печать (S.title ())
# Печатает Hello, World!
Проверить, содержится ли подстрока в строке
Чтобы проверить, присутствует ли конкретный текст в строке, используйте оператор in. в - это логический оператор, который принимает две строки и возвращает True, если первая появляется как подстрока во второй:
S = 'Hello, World!'
print ('Привет' на S)
# Prints True
Для поиска определенного текста в строке используйте метод find (). Он возвращает самый низкий индекс в строке, в которой найдена подстрока.
# Искать "глупый" в строке
S = 'Оставайся голодным, оставайся глупым'
x = S.find ('Глупый')
печать (х)
# Печать 18
Итерация по строке
Чтобы перебирать символы строки, используйте простой цикл for.
# Печатать каждый символ в строке
S = 'Привет, мир!'
для буквы S:
печать (буква, конец = '')
# Привет, мир !
Python Escape Sequence
Вы можете использовать кавычки внутри строки, если они не совпадают с кавычками, окружающими строку.
S = "Мы открыты" # Выйти из одинарной кавычки
S = "Я сказал 'Вау!'" # Избегайте одинарных кавычек
S = 'Я сказал «Вау!»' # Избегайте двойных кавычек
Это нормально в большинстве случаев, но что, если вы хотите объявить строку как с одинарными, так и с двойными кавычками, например:
Боб сказал мне: «Сэм сказал: «Это не сработает.'”
Python вызовет SyntaxError , поскольку обе кавычки являются специальными символами. Чтобы избежать этой проблемы, используйте escape-символ обратной косой черты \ .
Добавление к специальному символу префикса \ превращает его в обычный символ. Это называется , экранирование .
S = "Боб сказал мне \" Сэм сказал: 'Это не сработает' \ ""
печать (S)
# Печатает Боб сказал мне: «Сэм сказал:« Это не сработает »».
Управляющий символ обратной косой черты используется для представления определенных специальных символов, например: \ n - это новая строка, \ t - это табуляция.Они известны как escape-последовательности .
S = str ('Первая строка. \ N \ t Вторая строка.')
печать (S)
# Первая строка.
# Вторая линия.
Список всех допустимых escape-последовательностей в Python:
Raw String
Предположим, вы сохранили путь к файлу внутри строки. При его выполнении вы получите такой результат:
S = 'C: \ new \ text.txt'
печать (S)
# C:
# ew ext.txt
Здесь \ n интерпретируется как новая строка, а \ t - как табуляция.
Если вы не хотите, чтобы символы с префиксом \ интерпретировались как специальные символы, вы можете объявить строку как необработанную строку , добавив r перед первой кавычкой.
def findDigitsCharsSymbols (inputString):
charCount = 0
digitCount = 0
symbolCount = 0
для char в inputString:
если char.& i5ve "
print ("общее количество знаков, цифр и символов \ n")
findDigitsCharsSymbols (inputString) s1 = "Abc"
s2 = "Xyz" def mixString (s1, s2):
s2 = s2 [:: - 1]
длинаS1 = длина (s1)
длинаS2 = длина (с2)
length = lengthS1, если lengthS1> lengthS2, иначе lengthS2
resultString = ""
для i в диапазоне (длина):
если (i положение символов не имеет значения. s1 = "Yn"
s2 = "PYnative" s1 = "Ynf"
s2 = "PYnative" def stringBalanceCheck (s1, s2):
flag = True
для char в s1:
если char в s2:
Продолжить
еще:
flag = False
флаг возврата
s1 = "Yn"
s2 = "PYnative"
flag = stringBalanceCheck (s1, s2)
print ("s1 и s2 сбалансированы", флаг)
s1 = "Ynf"
s2 = "PYnative"
flag = stringBalanceCheck (s1, s2)
print ("s1 и s2 сбалансированы", флаг)
str1 = "Добро пожаловать в США. США круто, не правда ли? " inputString = "Добро пожаловать в США. США классные, не правда ли?"
substring = "США"
tempString = inputString.lower ()
count = tempString.count (substring.lower ())
print ("Количество в США:", count) str1 = "Английский = 78 Наука = 83 Математика = 68 История = 65" импорт ре
inputStr = "Английский = 78 Наука = 83 Математика = 68 История = 65"
markList = [int (num) вместо num в re.findall (r '\ b \ d + \ b', inputStr)]
totalMarks = 0
для отметки в markList:
totalMarks + = оценка
процент = totalMarks / len (markList)
print («Всего оценок:», totalMarks, «Percentage is», в процентах)
str1 = "Яблоко" str1 = "Яблоко"
countDict = dict ()
для char в str1:
count = str1. счет (символ)
countDict [char] = count
печать (countDict) str1 = "PYnative" evitanYP str1 = "PYnative"
print ("Исходная строка:", str1)
str1 = str1 [:: - 1]
print ("Перевернутая строка:", str1)
str1 = "PYnative"
print ("Исходная строка:", str1)
str1 = ''.присоединиться (обратное (str1))
print ("Перевернутая строка:", str1)
str1 = "Эмма - специалист по данным, знающий Python. Эмма работает в Google ".
print ("Исходная строка:", str1)
index = str1.rfind ("Эмма")
print ("Последнее появление Эммы начинается с", индекс)
str1 = Эмма-специалист по данным str1 = "Эмма-специалист по данным"
print ("Исходная строка:", str1)
# разделить строку
подстроки = str1.Трещина("-")
print ("Отображение каждой подстроки")
для sub в подстроках:
печать (суб)
str_list = ["Эмма", "Джон", "", "Келли", Нет, "Эрик", ""] str_list = ["Эмма", "Джон", "", "Келли", Нет, "Эрик", ""]
print ("Исходный список жала")
печать (str_list)
# использовать встроенный фильтр функций для фильтрации пустого значения
new_str_list = список (фильтр (Нет, str_list))
print ("После удаления пустых строк")
печать (новый_стр_лист)
строка импорта
str1 = "/ * Джон - @ разработчик и музыкант"
print ("Исходная строка", str1)
# использовать функцию перевода строки
# и функция maketrans класса str
new_str = str1. \ w \ s] ',' ', str1)
print ("Новая строка", str2)
str1 = "Мне 25 лет и 10 месяцев"
print ("Исходная строка", str1)
# Сохранять числа в строке
# Использование понимания списка + join () + isdigit ()
res = "".join ([элемент для элемента в str1, если item.isdigit ()])
печать (разрешение)
str1 = "Emma25 - специалист по обработке данных50 и эксперт по ИИ" ученый50
str1 = "Эмма25 - специалист по данным50 и эксперт в области искусственного интеллекта"
print ("Исходная строка:" + str1)
# Слова с алфавитами и цифрами
# isdigit () для чисел + isalpha () для алфавитов
# используйте any () для проверки каждого символа
res = []
темп = str1. Трещина()
для элемента в темп:
если есть (char.isalpha () для символа в элементе) и любой (char.isdigit () для символа в элементе):
res.append (элемент)
print ("Отображение слов с помощью букв и цифр")
для я в разрешении:
печать (я) из пунктуации импорта строки
str1 = '/ * Джон - @ разработчик и музыкант !!'
print ("Исходная строка:", str1)
# Замените знаки препинания на #
replace_char = '#'
# Использование строки.пунктуация, чтобы получить список всех знаков препинания
# используйте строковую функцию replace (), чтобы заменить каждую пунктуацию на #
для знаков в пунктуации:
str1 = str1.replace (символ, replace_char)
print ("Строки после замены:", str1)
com zfill (4)
print ('Обновленная строка:', numStr) rjust (4, '')
print ('Обновленная строка:', numStr)
zfill (4)
print ('Обновленная строка:', numStr)
print ('**** Оставьте строку с пробелом, используя string.rjust () ****')
numStr = "5"
print ('Исходная строка:', numStr)
# Сделать строку длиной 4 выровненной вправо, добавив 3 пробела слева
numStr = numStr.rjust (4, '')
print ('Обновленная строка:', numStr)
print ('**** Заполните строку слева символом, используя string.rjust () ****')
numStr = "5"
print ('Исходная строка:', numStr)
# Выровнять строку длиной 4 по правому краю, добавив 3 '-' влево
numStr = numStr.rjust (4, '-')
print ('Обновленная строка:', numStr)
print ('**** Право ввести строку с нулями, используя string.rjust () ****')
numStr = "45"
print ('Исходная строка:', numStr)
# Выровнять строку по левому краю длиной 5, добавив 3 0 справа от нее
numStr = numStr.ljust (5; '0')
print ('Обновленная строка:', numStr)
print ('**** Право ввести строку с пробелом, используя string. rjust () ****')
userName = "Джон"
print ('Исходная строка:', имя пользователя)
# Выровняйте строку по левому краю длиной 7, добавив 3 пробела справа от нее
userName = userName.ljust (7, '')
print ('Обновленная строка:', userName, 'is')
print ('**** Правее заполнить строку символом, используя строку.rjust () **** ')
userName = "Джон"
print ('Исходная строка:', имя пользователя)
# Выровнять строку по левому краю длиной 7, добавив 3 '-' справа от нее
userName = userName.ljust (7, '-')
print ('Обновленная строка:', имя пользователя)
если __name__ == '__main__':
главный()
'' или двойных кавычках "" S = 'Hello, World!' # одинарные кавычки
S = "Привет, мир!" # двойные кавычки "" "" "" или '' '' '' . S = "" "Строковые литералы могут
охватывают несколько строк. "" "
печать (S)
# Строковые литералы могут
# охватывают несколько строк. # целое число в строку
S = ул (42)
печать (S)
# Выводит '42'
# комплексное число в строку
S = str (3 + 4j)
печать (S)
# Отпечатки '(3 + 4j)
# список в строку
S = str ([1,1])
печать (S)
# Печатает '[1, 1]' # Индексирование
S = 'ABCDEFGHI'
print (S [0]) # Печать A
print (S [4]) # Печать E
# Отрицательное индексирование
S = 'ABCDEFGHI'
print (S [-1]) # Печатает I
print (S [-6]) # Печатает D S = "ABCDEFGHI"
print (S [2: 5]) # Печать CDE
print (S [5: -1]) # Печать FGH
print (S [1: 6: 2]) # Печать BDF S = 'Hello, World!'
S [0] = 'J'
# Triggers TypeError: объект 'str' не поддерживает присвоение элемента S = 'Hello, world!'
new_S = 'J' + S [1:]
печать (new_S)
# Печать Желе, мир! + или оператора расширенного присваивания + = # оператор конкатенации
S = 'Привет' + 'Мир!'
печать (S)
# Привет, мир!
# оператор расширенного присваивания
S = 'Привет'
S + = 'Мир!'
печать (S)
# Печатает Hello, World! S = 'Hello,' "World!"
печать (S)
# Печатает Hello, World! S = ('Заключить строки в круглые скобки'
'чтобы соединить их вместе.')
печать (S)
# Поместите строки в круглые скобки, чтобы соединить их вместе. * # сложный путь
S = '--------------------'
# легкий путь
S = '-' * 20 S = 'Supercalifragilisticexpialidocious'
печать (len (S))
# Печатает 34 S = 'Привет, мир!'
x = S.replace ('Мир', 'Вселенная')
печать (х)
# Печать Привет, Вселенная! # Разделить строку на запятую
S = 'красный, зеленый, синий, желтый'
х = S.split (',')
печать (х)
# Печать ["красный", "зеленый", "синий", "желтый"]
печать (x [0])
# Печатает красным # Присоединить список подстрок
L = ["красный", "зеленый", "синий", "желтый"]
S = ','. Присоединиться (L)
печать (S)
# Печатает красный, зеленый, синий, желтый S = 'Привет, мир!'
печать (S.lower ())
# Привет, мир!
S = 'Привет, мир!'
печать (S.upper ())
# Печатает ПРИВЕТ, МИР!
S = 'Привет, мир!'
печать (S.capitalize ())
# Печать Привет, мир!
S = 'Привет, мир!'
печать (S.swapcase ())
# Печатает привет, мир!
S = 'привет, мир!'
печать (S.title ())
# Печатает Hello, World! в - это логический оператор, который принимает две строки и возвращает True, если первая появляется как подстрока во второй: S = 'Hello, World!'
print ('Привет' на S)
# Prints True # Искать "глупый" в строке
S = 'Оставайся голодным, оставайся глупым'
x = S.find ('Глупый')
печать (х)
# Печать 18 # Печатать каждый символ в строке
S = 'Привет, мир!'
для буквы S:
печать (буква, конец = '')
# Привет, мир ! S = "Мы открыты" # Выйти из одинарной кавычки
S = "Я сказал 'Вау!'" # Избегайте одинарных кавычек
S = 'Я сказал «Вау!»' # Избегайте двойных кавычек SyntaxError , поскольку обе кавычки являются специальными символами. Чтобы избежать этой проблемы, используйте escape-символ обратной косой черты \ . \ превращает его в обычный символ. Это называется , экранирование . S = "Боб сказал мне \" Сэм сказал: 'Это не сработает' \ ""
печать (S)
# Печатает Боб сказал мне: «Сэм сказал:« Это не сработает »». \ n - это новая строка, \ t - это табуляция.Они известны как escape-последовательности . S = str ('Первая строка. \ N \ t Вторая строка.')
печать (S)
# Первая строка.
# Вторая линия. S = 'C: \ new \ text.txt'
печать (S)
# C:
# ew ext.txt \ n интерпретируется как новая строка, а \ t - как табуляция. \ интерпретировались как специальные символы, вы можете объявить строку как необработанную строку , добавив r перед первой кавычкой.