Как сравнить строки в Python? Операторы сравнения строк
Строка в Python представляет собой набор символов, находящихся в кавычках. При этом сравнение строк отличается от сравнения чисел и имеет свои особенности. В этой статье мы кратко и простым языком расскажем о сравнении строк в Python и посмотрим, какие операторы для этого есть, и как эти операторы используются.
Основные операторы сравнения в Python
Итак, в языке программирования Python для сравнения строк используют следующие операторы:
- оператор <, «меньше»;
- оператор <=, «меньше или равно;
- оператор ==, «равно»;
- оператор !=, «не равно»;
- оператор >, «больше»;
- оператор >=, «больше или равно».
Использование оператора «больше/меньше»
Ниже вы увидите простейший пример сравнения строк в Python с помощью соответствующих операторов: > и <. Давайте сравним строки со словами banana и apple:
print("apple" > "banana")
False
print("apple" < "banana")
True
Так как буква «a» находится перед «b», слово apple будет находиться перед словом banana, что логично (то есть banana больше, чем apple). Однако всё сложнее, чем может показаться на первый взгляд. Давайте для наглядности сравним, равны ли слова Apple и apple:
Однако всё сложнее, чем может показаться на первый взгляд. Давайте для наглядности сравним, равны ли слова Apple и apple:
print("apple" == "Apple")
False
print("apple" > "Apple")
True
Мы увидим отсутствие равенства, а всё потому, что в Python одинаковые буквы, имеющие разный регистр, считаются разными символами, и компьютер их различает по присвоенным им уникальным значениям.
Что касается нашей ситуации, то здесь латинская «А» имеет значение 65, в то время как значение строчной «а» равно 97.
Кстати, если хотите узнать уникальное значение какого-нибудь символа, используйте функцию ord:
print(ord("A"))
65
При сравнении символов или строк, Python конвертирует символы в их соответствующие порядковые значения, после чего сравнивает слева направо.
Существует функция chr, преобразовывающая порядковое значение в символ. Пример:
print(chr(1040)) А
Например, кириллическая А соответствует значению 1040. Есть свои значения у цифр, а также вспомогательных знаков, включая «?», «=», пробел.
Есть свои значения у цифр, а также вспомогательных знаков, включая «?», «=», пробел.
В принципе, вы всегда можете выполнить сравнение строк в Python, предварительно конвертировав строки в один формат, к примеру, в нижний регистр (используем метод lower):
str1 = "apple" str2 = "Apple" str2.lower() print(str1 == str1) True
Применение оператора «равенство»
Мы можем проверить, равны ли строки, посредством оператора ==:
print("строка1" == "строка2")
False
Естественно, строки не являются равными, т. к. выполняется точное сравнение в Python. Неравными будут и те строки, которые содержат одинаковые, но переставленные местами символы. В последнем случае есть выход: превратить нашу строку в список, отсортировать, сравнить и вывести содержимое:
strA = "abcde" strB = "abdec" print(sorted(list(strA)) == sorted(list(strB))) print(sorted(list(strA))) print(sorted(list(strB))) True ['a', 'b', 'c', 'd', 'e'] ['a', 'b', 'c', 'd', 'e']
Использование оператора «не равно»
Оператор != выполняет проверку неравенства:
print("abc" != "zxc") True
Разумеется, результат True, ведь abc не равно zxc.
Применение операторов «больше или равно/меньше или равно»
Если при использовании оператора <= одна строка будет меньше или равна другой, мы получим True.
print("abc" <= "bcd")
True
В нашем случае «abc» меньше.
Аналогично работает и оператор >=:
print("abc" >= "abc")
True
В этой ситуации очевидно, что строки равны.
Сравнение строк в Python
В Python строка – это последовательность символов, причем отдельный символ тоже считается строкой. Все символы имеют разные значения Unicode или ASCII.
Строки в Python можно сравнивать. При этом, по сути, сравниваются их символы. Сравнение происходит последовательно: первый символ одной строки сравнивается с первым символом другой. Если они равны, сравниваются символы на следующей позиции.
Следует учитывать, что компьютер сравнивает не символы как таковые, а их значения в Unicode. Чем больше это значение, тем «больше» символ.
Сравнение строк осуществляется так же, как и сравнение чисел, т. е. для этого нет каких-то специальных методов. Для прямого сравнения значений строк используется оператор
е. для этого нет каких-то специальных методов. Для прямого сравнения значений строк используется оператор ==. Если строки идентичны, возвращается True, в противном случае – False.
Для сравнения строк в Python используются разные операторы. Давайте начнем с операторов == и !=, а затем разберем остальные.
Сравнение строк при помощи == и !=
Сравнение двух строк можно эффективно выполнить с помощью операторов == и !=. Оператор == возвращает True, если строки идентичны, и False в противном случае. Оператор != действует наоборот.
Рассмотрим следующий пример:
language = 'chinese' print(language == 'chinese') print(language != 'chinese') # Output: # True # False
В данном коде language – это переменная, содержащая строку «chinese». Сравнение выполняется путем поочередного сравнения символов одной строки с символами другой строки.
Сравнение выполняется путем поочередного сравнения символов одной строки с символами другой строки.
В качестве результата оператор == возвращает True, а оператор != возвращает False, потому что сравниваемые строки одинаковые.
Теперь давайте сравним символы верхнего и нижнего регистра. Чтобы показать разницу между одинаковыми буквами в разных регистрах мы выведем их значения Unicode при помощи функции ord(). Символы с меньшим значением Unicode имеют меньший размер, а символы с большим значением Unicode – больший.
print('chinese' == 'Chinese') # False print('chinese' > 'Chinese') # True print(ord('c')) # 99 print(ord('C')) # 67
Итак, в данном случае мы сравниваем символ «c» в слове «chinese» с символом «C» в слове «Chinese».
Как мы видим, строки «chinese» и «Сhinese» – не одно и то же. Поэтому после сравнения этих строк с помощью оператора
Поэтому после сравнения этих строк с помощью оператора == оператор print() возвращает False . Выведя значения Unicode для «c» и «C», мы видим, что значение «C» (67) меньше, чем значение «c» (99). На этом сравнение прекращается, и выражение print('chinese' > 'Chinese') возвращает True.
Мы получаем результат: «chinese» больше, чем «Сhinese», потому что первый символ в одном слове больше первого символа во втором.
Python задачи
Наш телеграм канал с тестами по Python, задачами с собеседований и разбором решений.
Подробнее
×
Сравнение строк другими операторами
Для сравнения строк в Python используются не только == и !=. Как и при сравнении чисел, мы можем использовать операторы <, >, <= и >=.
string = 'chinese' string1 = 'china' print(string < string1) # False print(string > string1) # True print(string <= string1) # False print(string >= string1) # True
Мы присваиваем значение «chinese» для string и «china» для string1.
<, >, <=, >=.После сравнения string и string1 оператором < мы получаем False. Первые четыре символа «chinese» и «china» идентичны. Однако пятый символ переменной string – «е», в то время как пятый символ string1 – «а». Значение «e» в Юникоде равно 101, а «a» – 97. Таким образом, в результате сравнения этих переменных «chinese» оказывается больше, чем «china».
Сравнение строк с помощью is
Теперь давайте поговорим про сравнение строк с помощью оператора is. Он работает следующим образом. Если две переменные указывают на один объект, оператор возвращает True, иначе — False.
Обратите внимание, что даже если обе строки имеют одинаковое значение, все равно может вернуться False — если у сравниваемых объектов разные id. Подробнее про разницу между операторами == и is можно почитать в статье «Чем == отличается от is?».
Итак, рассмотрим следующий пример. Мы берем три строки: string1, string2, string3. Переменной string1 мы присваиваем значение ['u', 'v', 'w']. Переменную string2 приравниваем к string1. string3 приравниваем к string1, но не просто, а преобразовав в список string3 = list(string1), хотя, по сути, это и так список, т.е. значения не поменяются. А далее мы сравниваем строки операторами == и is.
string1 = ['u', 'v', 'w'] string2 = string1 string3 = list(string1) print(string1 == string2) # True print(string1 == string3) # True print(string1 is string2) # True print(string1 is string3) # False print(id(string1)) # 139879412641216 print(id(string2)) # 139879412641216 print(id(string3)) # 139879412022144
Переменные string1 и string2 абсолютно идентичны и ссылаются на одни и те же объекты. Однако для
Однако для string3 мы создали новый объект, и хотя значение string3 совпадает со значением string1, они ссылаются на разные объекты.
Адреса объектов определяются с помощью функции id(). Мы видим, что адреса объектов string3 и string1 действительно разные, в то время как адреса string2 и string1 совпадают.
Именно поэтому сравнение string1 и string2 обоими операторами возвращает True, поскольку они имеют не только одинаковое значение, но и одинаковый адрес.
Сравнение string1 и string3 оператором == дает True, а оператором is дает False, так как значения совпадают, но объекты и их адреса — разные.
Сравнение введенных пользователем строк
Теперь рассмотрим ситуацию, когда мы получаем ввод от пользователя и выполняем различные операции сравнения с полученными данными .
Здесь мы берем три строковые переменные с именами str_1, str_2, str_3. Значения
Значения str_1 и str_2 вводятся пользователем. Значение str_3 приравнивается к значению str_1. Дальше мы сравниваем строки разными операторами сравнения: !=, <= ,>=.
str_1 = input('Enter the value of str_1: ')
# Enter the value of str_1: chinese
str_2 = input('Enter the value of str_2: ')
# Enter the value of str_2: china
str_3 = str_1
print(str_1 == str_2)
# False
print(str_1 != str_2)
# True
print(str_1 <= str_2)
# False
print(str_1 >= str_2)
# True
print(str_1 is str_2)
# False
print(str_1 is str_3)
# TrueКогда мы запускаем нашу программу, пользователя просят ввести значения str_1 и str_2. После присвоения значений переменным эти строки сравниваются разными операторами.
Введенное значение str_1 – «chinese», а str_2 – «china». Сначала мы сравниваем эти строки с помощью оператора ==. Поскольку значения не совпадают, мы получаем результат False. Затем мы сравниваем наши строки с помощью оператора !=. Поскольку значения не совпадают, мы получаем результат True.
Дальше мы сравниваем строки с помощью оператора <=. Поскольку str_1 больше str_2, мы получаем True. И, в конце, мы используем is для сравнения строк. str_1 и str_2 имеют разные значения и ссылаются на разные объекты, поэтому результат будет False. Значения str_2 и str_3 идентичны, а переменные ссылаются на один объект, поэтому мы получим True.
Заключение
В этой статье мы поговорили про сравнение строк в Python с помощью различных операторов: ==, !=, >, <, >= и <=. Вы узнали, как именно происходит сравнение, какие строки считаются большими, а какие — меньшими. Мы также разобрали, чем отличается применение
Вы узнали, как именно происходит сравнение, какие строки считаются большими, а какие — меньшими. Мы также разобрали, чем отличается применение == и is, и показали разницу на примерах.
Надеемся, эта статья была вам полезна. Успехов в написании кода!
Перевод статьи «Python string comparison».
Python задачи
Наш телеграм канал с тестами по Python, задачами с собеседований и разбором решений.
Подробнее
×
Как сравнить строку в Python? (Сравнение строк 101)
В этой статье мы узнаем, что такое строки в языке программирования, как их создавать и как их использовать. Далее мы изучим различные операторы для сравнения строк в python. Наконец, мы кратко изучим сравнение некоторых строк Python вместе с его примером кода Python и выводом. Итак, приступим!
Что такое строки? Строка обычно представляет собой последовательность символов. Символ — это простой символ. Например, в английском языке у нас есть 26 символов. Компьютерная система не понимает символы и, следовательно, имеет дело с двоичными числами. Несмотря на то, что мы можем видеть символы на экранах наших мониторов, внутри они хранятся и управляются как комбинация нулей и единиц. Преобразование символов и двоичного числа называется кодированием, а обратное — декодированием. Некоторые из популярных кодировок — ASCII и Unicode. В языке программирования Python строка представляет собой последовательность символов Unicode.
Символ — это простой символ. Например, в английском языке у нас есть 26 символов. Компьютерная система не понимает символы и, следовательно, имеет дело с двоичными числами. Несмотря на то, что мы можем видеть символы на экранах наших мониторов, внутри они хранятся и управляются как комбинация нулей и единиц. Преобразование символов и двоичного числа называется кодированием, а обратное — декодированием. Некоторые из популярных кодировок — ASCII и Unicode. В языке программирования Python строка представляет собой последовательность символов Unicode.
В языке Python мы можем сравнивать две строки, например, определять, эквивалентны ли две строки друг другу или нет, или даже какая строка больше или меньше друг друга. Давайте проверим некоторые операторы сравнения строк, используемые для этой цели ниже:
- == : Этот оператор проверяет, равны ли две строки.
- !=: Этот оператор проверяет, не равны ли две строки.

- <: Этот оператор проверяет, меньше ли строка слева, чем строка справа.
- <=: Этот оператор проверяет, является ли строка слева меньше или равна строке справа.
- >: Этот оператор проверяет, больше ли строка слева, чем строка справа.
- >=: Этот оператор проверяет, больше ли строка слева, чем строка справа.
В программировании на Python мы можем проверить, равны строки или нет, используя «==» или функцию «.__eq__».
Пример:
s1 = 'Строка'
s2 = 'Строка'
s3 = 'строка'
# проверка равенства с учетом регистра
если s1 == s2:
print('s1 и s2 равны.')
если s1.__eq__(s2):
print('s1 и s2 равны.')
Здесь мы проверяем строки s1 и s2, равны они или нет, а затем используем условный оператор «если» с комбинацией оператора равенства.
Вывод приведенного выше кода выглядит следующим образом:
s1 и s2 равны.
s1 и s2 равны.
Как насчет сравнения без учета регистра?При проверке на равенство строк иногда хочется игнорировать регистр строк при сравнении. Таким образом, в качестве решения этой проблемы мы можем использовать функцию case fold(), lower() или upper() для игнорирования нечувствительного к регистру сравнения строк на равенство.
s1 = 'Строка'
s2 = 'Строка'
s3 = 'строка'
если s1.casefold() == s3.casefold():
печать (s1.casefold())
печать (s3.casefold())
print('s1 и s3 равны при сравнении без учета регистра')
если s1.lower() == s3.lower():
печать (s1.lower())
печать (s3.lower())
print('s1 и s3 равны при сравнении без учета регистра')
если s1.upper() == s3.upper():
печать (s1.upper())
печать (s3.upper())
print('s1 и s3 равны при сравнении без учета регистра')
Вывод приведенного выше кода выглядит следующим образом:
строка
строка
s1 и s3 равны при сравнении без учета регистра
STRING
STRING
s1 и s3 равны при сравнении без учета регистра. Также мы изучили некоторые операторы сравнения строк и проверку равенства строк. Даже мы проверили сравнение строк без учета регистра.
Также мы изучили некоторые операторы сравнения строк и проверку равенства строк. Даже мы проверили сравнение строк без учета регистра.
Как сравнить две строки в Python (8 простых способов)
Сравнение строк — фундаментальная задача, характерная для любого языка программирования.
Когда дело доходит до Python, есть несколько способов сделать это. Лучший из них всегда будет зависеть от варианта использования, но мы можем сузить их до нескольких, которые лучше всего подходят для этой цели.
В этой статье мы сделаем именно это.
К концу этого урока вы узнаете:
- как сравнивать строки с помощью
==и!=операторы - как использовать оператор
isдля сравнения двух строк - как сравнивать строки с помощью операторов
<,>,<=и>= - как сравнить две строки без учета регистра
- как игнорировать пробелы при сравнении строк
- как определить, похожи ли две строки, выполнив нечеткое сопоставление
- как сравнить две строки и вернуть разницу
- как отлаживать, когда сравнение строк не работает
Поехали!
Сравнение строк с помощью операторов
== и != Самый простой способ проверить, равны ли две строки в Python, — использовать оператор == . А если вы ищете обратное, то
А если вы ищете обратное, то != — это то, что вам нужно. Вот и все!
== и != являются логическими операторами, то есть они возвращают True или Ложь . Например, == возвращает True , если две строки совпадают, и False в противном случае.
>>> имя = 'Карл' >>> другое_имя = 'Карл' >>> имя == другое_имя Истинный >>> имя != другое_имя ЛОЖЬ >>> Yet_another_name = 'Джош' >>> имя == еще_другое_имя ЛОЖЬ
Эти операторы также чувствительны к регистру , что означает, что прописные буквы обрабатываются по-разному. Пример ниже показывает именно это, город начинается с прописной буквы L , тогда как заглавная буква начинается со строчной буквы l . В результате Python возвращает False при сравнении их с == .
>>> имя = 'Карл' >>> Yet_another_name = 'карл' >>> имя == еще_другое_имя ЛОЖЬ >>> имя != еще_другое_имя Истинный
Сравнение строк с использованием оператора
is Другой способ сравнения двух строк в Python — использование оператора это оператор . Однако тип сравнения, который он выполняет, отличается от
Однако тип сравнения, который он выполняет, отличается от == . Оператор сравнения – это оператор , если две строки совпадают. instance .
В Python и во многих других языках мы говорим, что два объекта являются одним и тем же экземпляром, если они являются одним и тем же объектом в памяти.
>>> имя = 'Джон Джейбокс Ховард' >>> другое_имя = имя >>> имя другое_имя Истинный >>> Yet_another_name = 'Джон Джейбокс Ховард' >>> имя еще_другое_имя ЛОЖЬ >>> идентификатор (имя) 140142470447472 >>> id(другое_имя) 140142470447472 >>> id(еще_еще_имя) 140142459568816
На изображении ниже показано, как этот пример будет представлен в памяти.
Как видите, мы сравниваем личности , , а не контент. Объекты с одним и тем же идентификатором обычно имеют одни и те же ссылки и совместно используют одно и то же место в памяти. Имейте это в виду при использовании оператора is .
Сравнение строк с помощью операторов
<, >, <= и >=Третий способ сравнения строк — по алфавиту. Это полезно, когда нам нужно определить лексикографический порядок двух строк.
Давайте посмотрим на пример.
>>> имя = 'Мария' >>> другое_имя = 'маркус' >>> имя < другое_имя ЛОЖЬ >>> имя > другое_имя Истинный >>> имя <= другое_имя ЛОЖЬ >>> имя >= другое_имя Истинный
Чтобы определить порядок, Python сравнивает строки char за char. В нашем примере первые три буквы одинаковые mar , а следующая нет, c от marcus стоит перед я от Мария .
Важно иметь в виду, что эти сравнения чувствительны к регистру . Python обрабатывает верхний и нижний регистр по-разному. Например, если мы заменим "Мария" на "Мария" , то результат будет другим, потому что M предшествует m .
>>> имя = 'Мария'
>>> другое_имя = 'маркус'
>>> имя < другое_имя
Истинный
>>> Орд('М') < Орд('М')
Истинный
>>> Орд('М')
77
>>> орд('м')
109⚠️ ПРЕДУПРЕЖДЕНИЕ ⚠️ Избегайте сравнения строк, представляющих числа, с использованием этих операторов.
Сравнение выполняется на основе алфавитного порядка, в результате чего
"2" < "10"оценивается какFalse.
>>> а = '2' >>> б = '10' >>> а < б ЛОЖЬ >>> а <= б ЛОЖЬ >>> а > б Истинный >>> а >= б Истинный
Сравнение двух строк без учета регистра
Иногда нам может понадобиться сравнить две строки — список строк или даже словарь строк — независимо от случая.
Достижение этого будет зависеть от алфавита, с которым мы имеем дело. Для строк ASCII мы можем преобразовать обе строки в нижний регистр с помощью str.lower() или в верхний регистр с помощью str.upper() и сравнить их.
Для других алфавитов, таких как греческий или немецкий, преобразование в нижний регистр, чтобы сделать строки нечувствительными к регистру, не всегда работает. Давайте посмотрим на некоторые примеры.
Предположим, у нас есть строка на немецком языке с названием 'Straße' , что означает "Улица" . Вы также можете написать это же слово без
Вы также можете написать это же слово без ß , в этом случае слово станет Strasse . Если мы попытаемся сделать это строчными или прописными буквами, посмотрите, что произойдет.
>>> a = 'Атрассе' >>> a = 'Штрассе' >>> b = 'штрассе' >>> a.нижний() == b.нижний() ЛОЖЬ >>> a.lower() улица >>> б.нижний() 'штрассе'
Это происходит потому, что простой вызов str.lower() ничего не сделает с ß . Его строчная форма эквивалентна ss , но ß имеет одинаковую форму и вид в нижнем или верхнем регистре.
Лучший способ игнорировать регистр и обеспечить эффективное сравнение строк без учета регистра — использовать str.casefold . Согласно документам:
Сворачивание регистра похоже на преобразование нижнего регистра, но более агрессивно, поскольку оно предназначено для удаления всех различий между регистрами в строке.
Давайте посмотрим, что произойдет, если мы используем str.. casefold вместо
casefold вместо
>>> a = 'Штрассе' >>> b = 'штрассе' >>> a.casefold() == b.casefold() Истинный >>> a.casefold() 'штрассе' >>> b.casefold() 'штрассе'
Как сравнить две строки и игнорировать пробелы
Иногда вам может понадобиться сравнить две строки, игнорируя символы пробела. Лучшее решение этой проблемы зависит от того, где находятся пробелы, есть ли в строке несколько пробелов и так далее.
Первый пример, который мы рассмотрим, предполагает, что единственная разница между строками состоит в том, что одна из них имеет начальные и/или конечные пробелы. В этом случае мы можем обрезать обе строки, используя метод str.strip , и использовать == оператор для их сравнения.
>>> s1 = 'Эй, мне очень нравится этот пост.' >>> s2 = 'Эй, мне очень нравится этот пост. ' >>> s1.strip() == s2.strip() Истинный
Однако иногда у вас есть строка с пробелами повсюду, включая несколько пробелов внутри нее. Если это так, то стр. недостаточно. полосы
полосы
>>> s2 = ' Эй, мне очень нравится этот пост. ' >>> s1 = 'Эй, мне очень нравится этот пост.' >>> s1.strip() == s2.strip() ЛОЖЬ
Альтернативой является удаление повторяющихся пробелов с помощью регулярного выражения. Этот метод возвращает только повторяющиеся символы, поэтому нам все равно нужно удалить начальные и конечные символы.
>>> s2 = ' Эй, мне очень нравится этот пост. '
>>> s1 = 'Эй, мне очень нравится этот пост.'
>>> re.sub('\s+', ' ', s1.strip())
«Эй, мне очень нравится этот пост».
>>> re.sub('\s+', ' ', s2.strip())
«Эй, мне очень нравится этот пост».
>>> re.sub('\s+', ' ', s1.strip()) == re.sub('\s+', ' ', s2.strip())
Истинный
Или, если вам плевать на дубликаты и вы хотите удалить все, просто передайте пустую строку в качестве второго аргумента в re.sub .
>>> s2 = ' Эй, мне очень нравится этот пост. '
>>> s1 = 'Эй, мне очень нравится этот пост.'
>>> re.sub('\s+', '', s1.strip())
«Эй, мне очень нравится этот пост». >>> re.sub('\s+', '', s2.strip())
«Эй, мне очень нравится этот пост».
>>> re.sub('\s+', '', s1.strip()) == re.sub('\s+', '', s2.strip())
Истинный
>>> re.sub('\s+', '', s2.strip())
«Эй, мне очень нравится этот пост».
>>> re.sub('\s+', '', s1.strip()) == re.sub('\s+', '', s2.strip())
Истинный
Последний и окончательный метод заключается в использовании таблицы перевода. Это решение является интересной альтернативой регулярному выражению.
>>> table = str.maketrans({' ': Нет})
>>> таблица
{32: Нет}
>>> s1.translate(таблица)
«Эй, мне очень нравится этот пост».
>>> s2.translate(таблица)
«Эй, мне очень нравится этот пост».
>>> s1.translate(таблица) == s2.translate(таблица)
Истинный
Преимущество этого метода в том, что он позволяет удалять не только пробелы, но и другие символы, такие как знаки препинания.
>>> строка импорта >>> table = str.maketrans(dict.fromkeys(строка.пунктуация + ' ')) >>> s1.translate(таблица) «Эй, мне очень нравится этот пост» >>> s2.translate(таблица) «Эй, мне очень нравится этот пост» >>> s1.translate(таблица) == s2.translate(таблица) Истинный
Как сравнить две строки на предмет сходства (нечеткое сопоставление строк)
Другим популярным вариантом использования сравнения строк является проверка того, почти ли две строки равны. В этой задаче нам интересно узнать, насколько они похожи, а не сравнивать их равенство.
В этой задаче нам интересно узнать, насколько они похожи, а не сравнивать их равенство.
Чтобы упростить понимание, рассмотрим ситуацию, когда у нас есть две строки, и мы готовы игнорировать ошибки в написании. К сожалению, это невозможно с оператором == .
Мы можем решить эту задачу двумя способами:
- используя
difflibиз стандартной библиотеки - с использованием внешней библиотеки, такой как
jellysifh
Использование
difflib difflib в стандартной библиотеке имеет класс SequenceMatcher , который предоставляет метод ratio() , который возвращает меру сходства строки в процентах.
Предположим, у вас есть две похожие строки, скажем, a = "preview" и b = "previeu" . Единственная разница между ними заключается в последней букве. Давайте представим, что эта разница для вас достаточно мала и вы хотите ее игнорировать.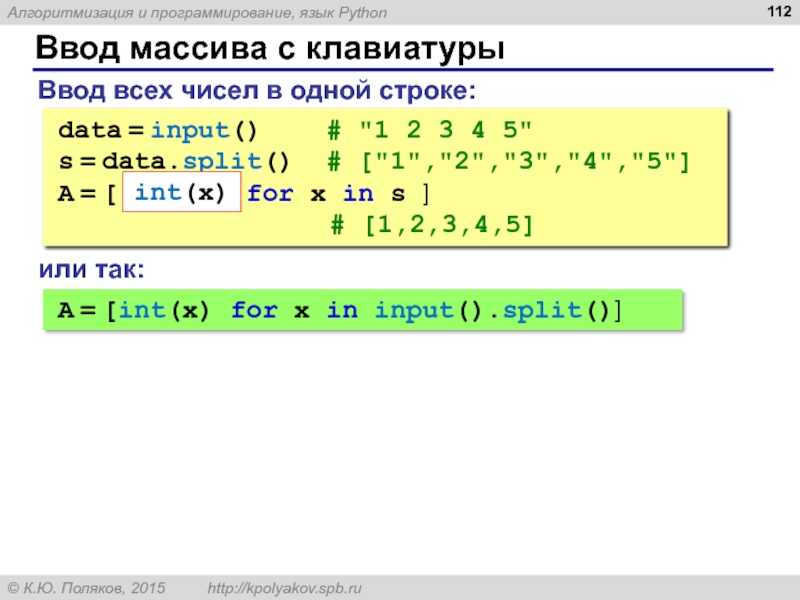
С помощью SequenceMatcher.ratio() мы можем получить процент, в котором они похожи, и использовать это число, чтобы утверждать, достаточно ли похожи две строки.
из difflib импорт SequenceMatcher >>> а = "предварительный просмотр" >>> б = "предыдущий" >>> SequenceMatcher(a=a, b=b).ratio() 0,8571428571428571
В этом примере SequenceMatcher говорит нам, что две строки похожи на 85%. Затем мы можем использовать это число в качестве порога и игнорировать разницу.
>>> def is_string_similar (s1: str, s2: str, threshold: float = 0.8) -> bool
...: :
...: вернуть SequenceMatcher(a=s1, b=s2).ratio() > порог
...:
>>> is_string_similar(s1="предварительный просмотр", s2="предварительный просмотр")
Истинный
>>> is_string_similar(s1="предварительный просмотр", s2="предварительный просмотр")
Истинный
>>> is_string_similar(s1="предварительный просмотр", s2="предварительный просмотрjajdj")
ЛОЖЬ
Но есть одна проблема.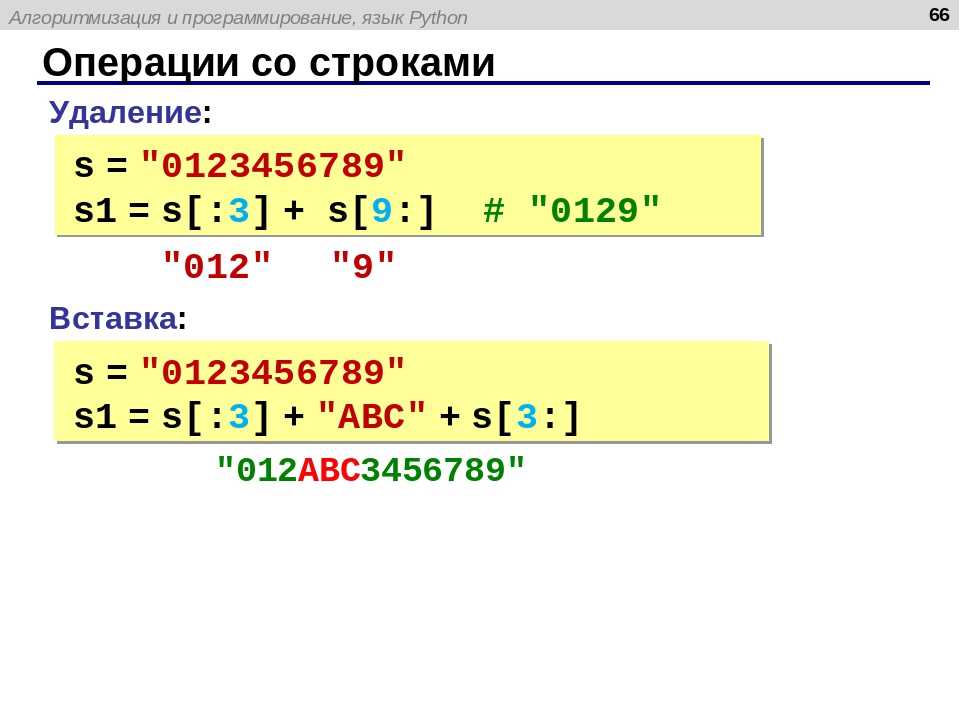 Порог зависит от длины строки. Например, две очень маленькие строки, скажем,
Порог зависит от длины строки. Например, две очень маленькие строки, скажем, a = "ab" и b = "ac" , будут отличаться на 50%.
>>> SequenceMatcher(a="ab", b="ac").ratio() 0,5
Таким образом, установка приемлемого порога может оказаться сложной задачей. В качестве альтернативы мы можем попробовать другой алгоритм, который подсчитывает перестановки букв в строке. И хорошая новость в том, что такой алгоритм существует, и это то, что мы увидим дальше.
Использование расстояния Дамерау-Левенштейна
Алгоритм Дамерау-Левенштейна подсчитывает минимальное количество операций, необходимых для преобразования одной строки в другую.
Другими словами, он сообщает, сколько вставок, удалений или замен одного символа; или перестановку двух соседних символов, которые нам нужно выполнить, чтобы две строки стали равными.
В Python мы можем использовать функцию damerau_levenshtein_distance из jellysifh библиотека.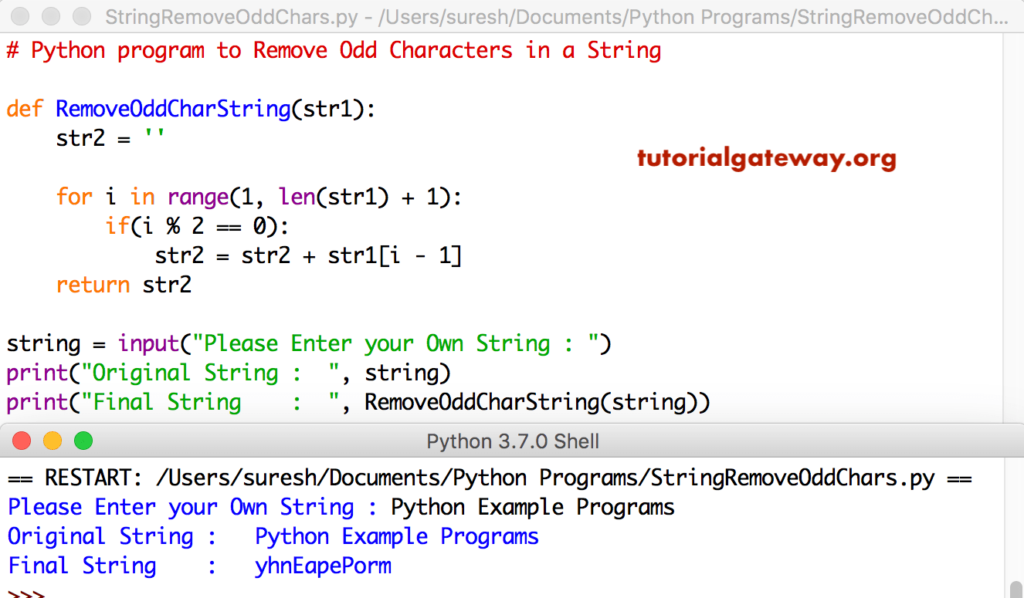
Посмотрим, что такое расстояние Дамерау-Левенштейна для последнего примера из предыдущего раздела.
>>> медуза импортная
>>> jellyfish.damerau_levenshtein_distance('ab', 'ac')
1
Это 1! Значит, чтобы преобразовать "ac" в "ab" , нам нужно 1 изменение. А первый пример?
>>> s1 = "предварительный просмотр" >>> s2 = "предыдущий" >>> jellyfish.damerau_levenshtein_distance(s1, s2) 1
Это тоже 1! И это имеет большой смысл, в конце концов, нам просто нужно отредактировать последнюю букву, чтобы сделать их равными.
Таким образом, мы можем установить порог на основе количества изменений, а не соотношения.
>>> def are_strings_similar (s1: str, s2: str, threshold: int = 2) -> bool:
...: вернуть jellyfish.damerau_levenshtein_distance(s1, s2) <= порог
...:
>>> are_strings_similar("ab", "ac")
Истинный
>>> are_strings_similar("ab", "ackiol")
ЛОЖЬ
>>> are_strings_similar("ab", "cb")
Истинный
>>> are_strings_similar("abcf", "abcd")
Истинный
# эти не очень похожи, но порог по умолчанию равен 2
>>> are_strings_similar("abcf", "acfg")
Истинный
>>> are_strings_similar("abcf", "acyg")
ЛОЖЬ
Как сравнить две строки и вернуть разницу
Иногда мы заранее знаем, что две строки различны, и хотим знать, чем они отличаются.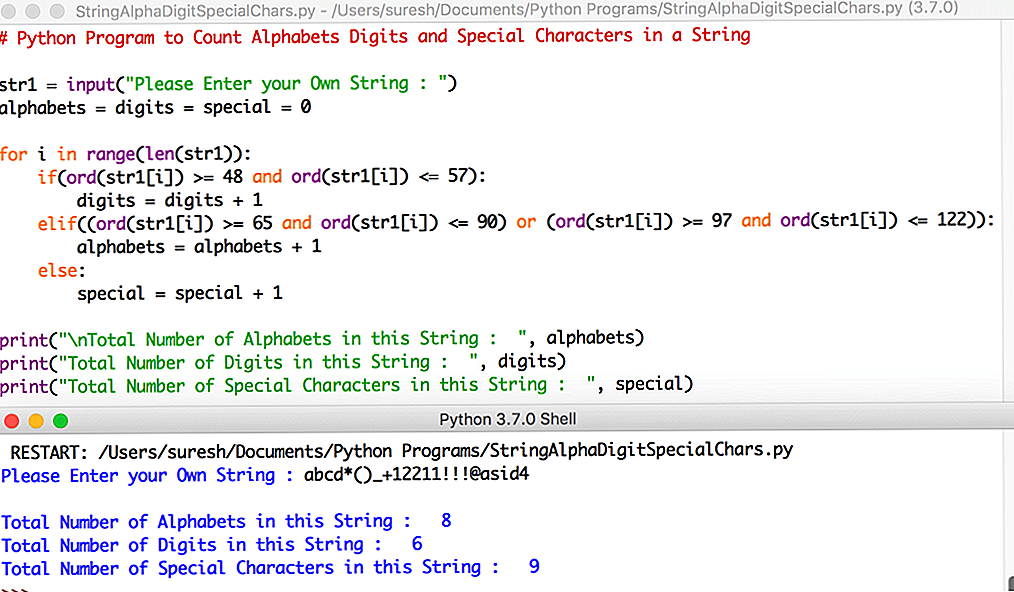 Другими словами, мы хотим получить их «diff».
Другими словами, мы хотим получить их «diff».
В предыдущем разделе мы использовали difflib , чтобы определить, достаточно ли похожи две строки. Этот модуль на самом деле более мощный, и мы можем использовать его для сравнения строк и отображения их различий.
Раздражает то, что вместо одной строки требуется список строк. Затем он возвращает генератор, который можно использовать для объединения в одну строку и вывода разницы.
>>> импортировать difflib
>>> d = difflib.Differ()
>>> diff = d.compare(['моя строка для теста'], ['моя строка для теста'])
>>> разница
<объект-генератор Differ.compare по адресу 0x7f27703250b0>
>>> список(разн.)
['- моя строка для теста', '? ---\n', '+ моя ул для теста']
>>> print('\n'.join(diff))
- моя строка для теста
? ---
+ моя ул для теста
Сравнение строк не работает?
В этом разделе мы обсудим причины, по которым ваше сравнение строк не работает, и как это исправить. Две основные причины, основанные на моем опыте:
- использование неверного оператора
- с пробелом в конце или новой строкой
Сравнение строк с использованием
равно вместо == Это очень распространено среди начинающих разработчиков Python. Легко использовать неправильный оператор, особенно при сравнении строк.
Легко использовать неправильный оператор, особенно при сравнении строк.
Как мы обсуждали в этой статье, используйте только оператор is , если вы хотите проверить, совпадают ли две строки экземпляра .
Наличие завершающего пробела новой строки (
\n ) Это очень распространено при чтении строки из функции ввода . Всякий раз, когда мы используем эту функцию для сбора информации, пользователь может случайно добавить пробел в конце.
Если вы сохраните результат ввода в переменную, вы не сразу увидите проблему.
>>> а = 'привет'
>>> b = input('Введите слово:')
Введите слово: привет
>>> а == б
ЛОЖЬ
>>> а
'привет'
>>> б
'привет '
>>> a == b.strip()
Истинный
Решение здесь состоит в том, чтобы удалить пробелы из строки, которую вводит пользователь, и затем сравнить ее. Вы можете сделать это с любым источником ввода, которому вы не доверяете.
Заключение
В этом руководстве мы увидели 8 различных способов сравнения строк в Python и две наиболее распространенные ошибки. Мы увидели, как можно использовать различные операции для сравнения строк и как использовать внешние библиотеки для нечеткого сопоставления строк.
Ключевые выводы:
- Используйте
==и!=операторы для сравнения двух строк на равенство - Используйте оператор
is, чтобы проверить, являются ли две строки одним и тем же экземпляром - Используйте операторы
<,>,<=и>=для сравнения строк по алфавиту - Используйте
str.casefold()для сравнения двух строк без учета регистра - Обрезать строки с помощью собственных методов или регулярных выражений, чтобы игнорировать пробелы при сравнении строк
- Используйте
difflibилиjellyfish, чтобы проверить, почти ли две строки равны (нечеткое соответствие) - Используйте
difflibдля сравнения двух строк и возврата разницы - Сравнение строк не работает? Проверьте наличие пробелов в конце или начале или узнайте, используете ли вы подходящего оператора для задания .
