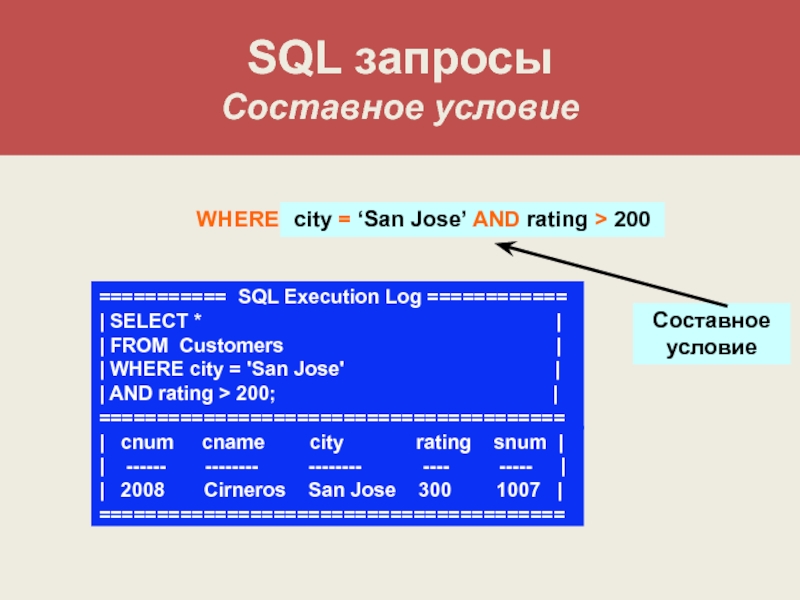
Оператор SQL WHERE — Примеры и синтаксис
ВВЕРХ❮ ❯
В большинстве случаев необходимо получать не все записи, а только те, которые соответствуют определенным критериям. Поэтому для осуществления фильтрации выборки в SQL есть специальный оператор WHERE.
1. Простое фильтрование оператором WHERE.
Давайте из нашей таблицы, например, отберем записи, относящиеся только к определенному товару. Для этого мы укажем дополнительный параметр отбора, который будет фильтровать значение по колонке Product.
Пример запроса для отбора текстовых значений:
SELECT * FROM Sumproduct WHERE Product = 'Bikes'
Как видим, условие отбора взято в одинарные кавычки, что является обязательным при фильтровании текстовых значений. При фильтровании числовых значений кавычки не нужны.
Пример запроса для отбора числовых значений:
SELECT * FROM Sumproduct WHERE Amount > 40000 ORDER BY Amount
В этом примере мы отобрали записи, в которых выручка от реализации составила более 40 тыс. $ и, дополнительно, все записи посортировали по возрастанию по полю Amount.
$ и, дополнительно, все записи посортировали по возрастанию по полю Amount.
В таблице ниже указан перечень условных операторов, поддерживаемых SQL:
| Знак операции | Значение |
|---|---|
| = | Равно |
| <> | Не равно |
| < | Меньше |
| <= | Меньше или равно |
| > | Больше |
| >= | Больше или равно |
| BETWEEN | Между двумя значениями |
| IS NULL | Отсутствует запись |
2. Фильтрация по диапазону значений (
BETWEEN). Для отбора данных, которые лежат в определенном диапазоне, используется оператор BETWEEN. В следующем запросе будут отобраны все значения, лежащие в пределах от 1000 $ в 2000 $ включительно, в поле Amount.
SELECT * FROM Sumproduct WHERE Amount BETWEEN 1000 AND 2000
Очередность сортировки будет зависеть от порядка расположения полей в запросе. То есть, в нашем случае сначала данные будут посортированы по колонке Amount, а затем по City.
3. Выборка пустых записей (
IS NULL).В SQL существует специальный оператор для выборки пустых записей (називаеьбся NULL). Пустой записью считается любая ячейка в таблице, в которую не введены какие-либо символы. Если в ячейку введен 0 или пробел, то считается, что поле заполнено.
SELECT * FROM Sumproduct WHERE Amount IS NULL
В примере выше, мы нарочно удалили два значения в поле Amount, чтобы продемонстрировать работу оператора NULL.
4. Расширенное фильтрации (
AND, OR). Язык SQL не ограничивается фильтрацией по одному условию, для собственных целей вы можете использовать достаточно сложные конструкции для выборки данных одновременно по многим критериям. Для этого в SQL есть дополнительные операторы, которые расширяют возможности оператора WHERE. Такими операторами являются: AND, OR, IN, NOT. Приведем несколько примеров работы данных операторов.
Для этого в SQL есть дополнительные операторы, которые расширяют возможности оператора WHERE. Такими операторами являются: AND, OR, IN, NOT. Приведем несколько примеров работы данных операторов.
SELECT * FROM Sumproduct WHERE Amount > 40000 AND City = 'Toronto'
SELECT * FROM Sumproduct WHERE Month = 'April' OR Month = 'March'
Давайте объединим операторы AND и OR. Для этого сделаем выборку велосипедов (Bikes) и коньков (Skates), которые были проданы в марте (March).
SELECT * FROM Sumproduct WHERE Product = 'Bikes' OR Product = 'Skates' AND Month = 'March'
Видим, что в нашу выборку попало за много значений (кроме марта (March), также январь (January), февраль (February) и апрель (April)). В чем же причина? А в том, что SQL имеет приоритеты выполнения команд. То есть оператор AND имеет более высокий приоритет, чем оператор OR, поэтому сначала были отобраны записи с коньками, которие проданные в марте, а потом все записи, касающиеся велосипедов.
В чем же причина? А в том, что SQL имеет приоритеты выполнения команд. То есть оператор AND имеет более высокий приоритет, чем оператор OR, поэтому сначала были отобраны записи с коньками, которие проданные в марте, а потом все записи, касающиеся велосипедов.
Итак, чтобы получить правильную выборку, нам нужно изменить приоритеты выполнения команд. Для этого используем скобки, как в математике. Тогда, сначала будут обработаны операторы в скобках, а затем — все остальные.
SELECT * FROM Sumproduct WHERE (Product = 'Bikes' OR Product = 'Skates') AND Month = 'March'
5. Расширенная фильтрация (
оператор IN).SELECT * FROM Sumproduct WHERE ID IN (4, 12, 58, 67)
Оператор IN выполняет ту же функцию, что и OR, однако имеет ряд преимуществ:

6. Расширенная фильтрация (
оператор NOT).SELECT *
FROM Sumproduct
WHERE NOT City IN ('Toronto', 'Montreal')
Ключевое слово NOT позволяет убрать ненужные значения из выборки. Также его особенностью является то, что оно проставляется перед названием столбца, участвующего в фильтровании, а не после.
Статьи по теме:
Запрос с полнотекстовым поиском — SQL Server
- Статья
Применимо к:База данныхSQL Server Azure SQL Управляемый экземпляр SQL Azure
Пишите полнотекстовые запросы с помощью предикатов  В этой статье приведены примеры предикатов и функций, из которых вы сможете выбрать самые подходящие.
В этой статье приведены примеры предикатов и функций, из которых вы сможете выбрать самые подходящие.
- Для сопоставления слов и фраз используйте функции CONTAINS и CONTAINSTABLE.
- Для поиска совпадений по смыслу, а не буквального совпадения, используйте функции FREETEXT и FREETEXTTABLE.
Примеры предикатов и функций
Ниже приводятся примеры базы данных AdventureWorks. Окончательный выпуск AdventureWorks см. в разделе Базы данных и сценарии AdventureWorks для SQL Server 2016 CTP3. Чтобы запустить примеры запросов, нужно также настроить полнотекстовый поиск. Дополнительные сведения см. в разделе Начало работы с полнотекстовым поиском.
Пример CONTAINS
В следующем примере выполняется поиск всех продуктов с ценой $80.99, которые содержат слово "Mountain":
USE AdventureWorks2012 GO SELECT Name, ListPrice FROM Production.Product WHERE ListPrice = 80.99 AND CONTAINS(Name, 'Mountain') GO
Пример FREETEXT
В следующем примере выполняется поиск всех документов, содержащих слова, связанные с vital safety components:
USE AdventureWorks2012 GO SELECT Title FROM Production.Document WHERE FREETEXT (Document, 'vital safety components') GO
Пример CONTAINSTABLE
В следующем примере возвращается идентификатор описания и описание всех продуктов, для которых столбец Описание содержит слово «алюминий» рядом со словом «light» или «lightweight». Возвращаются только строки с рангом 2 или выше.
USE AdventureWorks2012
GO
SELECT FT_TBL.ProductDescriptionID,
FT_TBL.Description,
KEY_TBL.RANK
FROM Production.ProductDescription AS FT_TBL INNER JOIN
CONTAINSTABLE (Production.ProductDescription,
Description,
'(light NEAR aluminum) OR
(lightweight NEAR aluminum)'
) AS KEY_TBL
ON FT_TBL.ProductDescriptionID = KEY_TBL.
[KEY]
WHERE KEY_TBL.RANK > 2
ORDER BY KEY_TBL.RANK DESC;
GO
Пример FREETEXTTABLE
В следующем примере запрос FREETEXTTABLE расширяется таким образом, чтобы он возвратил первыми строки с самыми высокими ранжирующими значениями и добавил ранг каждой строки к списку выбора. Чтобы написать аналогичный запрос, необходимо знать, что столбец ProductDescriptionID является уникальным ключевым столбцом для таблицы ProductDescription.
USE AdventureWorks2012
GO
SELECT KEY_TBL.RANK, FT_TBL.Description
FROM Production.ProductDescription AS FT_TBL
INNER JOIN
FREETEXTTABLE(Production.ProductDescription, Description,
'perfect all-around bike') AS KEY_TBL
ON FT_TBL.ProductDescriptionID = KEY_TBL.[KEY]
ORDER BY KEY_TBL.RANK DESC
GO
Ниже приведено расширение того же запроса, которое возвращает только строки с рангом 10 или выше.
USE AdventureWorks2012 GO SELECT KEY_TBL.RANK, FT_TBL.Description FROM Production.ProductDescription AS FT_TBL INNER JOIN FREETEXTTABLE(Production.ProductDescription, Description, 'perfect all-around bike') AS KEY_TBL ON FT_TBL.ProductDescriptionID = KEY_TBL.[KEY] WHERE KEY_TBL.RANK >= 10 ORDER BY KEY_TBL.RANK DESC GO
Сопоставление слов или смысла
CONTAINS/CONTAINSTABLE и FREETEXT/FREETEXTTABLE полезны для различных типов сопоставления. Следующая информация поможет выбрать самый подходящий предикат или функцию для запроса:
CONTAINS/CONTAINSTABLE
- Поиск точных и неточных соответствий отдельных слов и фраз.
- Вы сможете также делать следующее:
- указывать уровень сходства похожих слов;
- возвращать взвешенные совпадения;
- объединять условия поиска с логическими операторами. Дополнительные сведения см. в разделе Использование логических операторов (AND, OR и NOT) далее в этой статье.

FREETEXT/FREETEXTTABLE
- Поиск совпадений по смыслу, а не по буквальному совпадению задаваемых слов, фраз или предложений (текст в свободной форме).
- Соответствие регистрируется, если в полнотекстовом индексе указанного столбца найден любой из терминов в любой форме.
Сравнение предикатов и функций
Синтаксис и параметры предикатов CONTAINS/FREETEXT, а также функций, возвращающих наборы строк, CONTAINSTABLE/FREETEXTTABLE отличаются. Следующая информация поможет выбрать самый подходящий предикат или функцию для запроса:
Предикаты CONTAINS и FREETEXT
Использование. Полнотекстовые предикаты CONTAINS и FREETEXT используются в предложении WHERE или HAVING инструкции SELECT.
Результаты. Предикаты CONTAINS и FREETEXT возвращают значение TRUE или FALSE, которое указывает, соответствует ли данная строка полнотекстовому запросу. Совпадающие строки возвращаются в результирующем наборе.
Совпадающие строки возвращаются в результирующем наборе.
Дополнительные параметры. Вы можете объединить предикаты с любым другим предикатом Transact-SQL, например LIKE и BETWEEN.
Вы можете указать, следует ли искать один столбец, список столбцов или все столбцы в таблице.
Вы также можете указать язык, ресурсы на котором используются данным полнотекстовым запросом для разбиения на слова и выделения корней, поиска в тезаурусе и удаления пропускаемых слов.
Четырехкомпонентное имя может использоваться в предикате CONTAINS или FREETEXT для запроса по столбцам полнотекстового индекса целевых таблиц на связанном сервере. Чтобы подготовить удаленный сервер к приему полнотекстовых запросов, сначала необходимо создать полнотекстовые индексы для целевых таблиц и столбцов на удаленном сервере, а затем добавить удаленный сервер в качестве связанного сервера.
Дополнительные сведения. Дополнительные сведения о синтаксисе и аргументах этих предикатов см. в статьях о CONTAINS и FREETEXT.
в статьях о CONTAINS и FREETEXT.
Функции со значениями набора строк CONTAINSTABLE и FREETEXTTABLE
Использование. Полнотекстовые функции CONTAINSTABLE и FREETEXTTABLE можно использовать в предложении FROM инструкции SELECT, как обычное имя таблицы.
Вам нужно указать базовую таблицу для поиска при использовании любой из этих функций. Как и для предикатов, в таблице, где выполняется поиск, можно задавать один столбец, список столбцов или все столбцы, а также при необходимости язык, ресурсы которого будут использоваться данным полнотекстовым запросом.
Обычно результат функций CONTAINSTABLE или FREETEXTTABLE необходимо соединять с базовой таблицей. Для присоединения таблиц необходимо знать уникальное имя ключевого столбца. Этот столбец, имеющийся в каждой таблице с поддержкой полнотекстового поиска, используется для принудительного применения уникальных строк в таблице (уникальный**ключевой столбец). Дополнительные сведения о ключевом столбце см. в статье Создание полнотекстовых индексов и управление ими.
в статье Создание полнотекстовых индексов и управление ими.
Результаты. Эти функции возвращают пустую таблицу, либо таблицу с одной или несколькими строками, соответствующими полнотекстовому запросу. Возвращаемая таблица содержит только строки базовой таблицы, которые соответствуют критерию выбора, задаваемому в условии полнотекстового поиска функции.
Запросы, использующие одну из этих функций, также возвращают ранжирующие по релевантности значения (RANK) и полнотекстовый ключ (KEY) для каждой строки:
- Столбец KEY. Столбец KEY возвращает уникальные значения возвращаемых строк. С помощью столбца KEY можно задавать критерии выбора.
- Столбец RANK. Столбец RANK содержит ранжирующее значение для каждой строки, указывающее степень соответствия этой строки критериям выбора. Чем выше ранжирующее значение текста или документа в строке, тем больше она релевантна данному полнотекстовому запросу. Разные строки могут ранжироваться одинаково.
 Можно ограничить число возвращаемых совпадений. Для этого нужно задать необязательный параметр top_n_by_rank . Дополнительные сведения см. в разделе Ограничение количества результатов поиска с использованием функции RANK.
Можно ограничить число возвращаемых совпадений. Для этого нужно задать необязательный параметр top_n_by_rank . Дополнительные сведения см. в разделе Ограничение количества результатов поиска с использованием функции RANK.
Дополнительные сведения. Дополнительные сведения о синтаксисе и аргументах этих функций см. в статьях о CONTAINSTABLE и FREETEXTTABLE.
Определенные типы поиска
Поиск конкретного слова или фразы (простое выражение)
Для поиска конкретного слова или фразы в таблице можно использовать запросы CONTAINS, CONTAINSTABLE, FREETEXT или FREETEXTTABLE. Например, для поиска в таблице ProductReview базы данных AdventureWorks2022 всех комментариев о продукции, содержащих фразу «learning curve», можно использовать предикат CONTAINS следующим образом:
USE AdventureWorks2012 GO SELECT Comments FROM Production.ProductReview WHERE CONTAINS(Comments, '"learning curve"') GO
Условие поиска (в этом случае «learning curve») может быть сложным и включать одно выражение или несколько.
Дополнительные сведения о простых условиях поиска
В полнотекстовом поиске слово (или токен) представляет собой строку, границы которой определяются соответствующими словами согласно лингвистическим правилам указанного языка. Допустимая фраза состоит из нескольких слов со знаками препинания между ними или без них.
Например, «круассан» — это слово, а «кофе с молоком» — фраза. Такие слова и фразы называются простыми выражениями.
ФункцииCONTAINS и CONTAINSTABLE выполняют поиск точного соответствия для фразы. ФункцииFREETEXT и FREETEXTTABLE разбивают фразу на отдельные слова.
Поиск слова по префиксу (префиксное выражение)
Для поиска слов и фраз с указанным префиксом можно использовать функции CONTAINS или CONTAINSTABLE . Будут возвращены все записи в столбце, содержащие текст, который начинается с заданного префикса. Например, чтобы найти все строки, содержащие префикс top-, как в top``ple, top``pingи top. Запрос выглядит следующим образом:
Запрос выглядит следующим образом:
USE AdventureWorks2012 GO SELECT Description, ProductDescriptionID FROM Production.ProductDescription WHERE CONTAINS (Description, '"top*"' ) GO
При выполнении этого запроса будут возвращены все фрагменты текста, соответствующие тексту, указанному перед звездочкой (*). Если текст и звездочка не ограничены двойными кавычками (например, CONTAINS (DESCRIPTION, 'top*')), звездочка не считается символом-шаблоном.
Если префиксный терм является фразой, каждый токен, составляющий фразу, считается отдельным префиксным термом. При выполнении такого запроса будут возвращены все строки со словами, начинающимися на префиксные термы. Например, если запрос включает префиксное выражение «белый хлеб*», будут возвращены строки с текстом «белый хлебец», «белый хлебный» и «белый хлеб», но не «белый поджаренный хлеб».
Дополнительные сведения о поиске префиксов
Для создания производного слова или словоформ префиксное выражение обращается к строке, прикрепленной к началу слова.
Для единственного префиксного выражения частью результирующего набора будет любое слово, начинающееся с указанного выражения. Например, для префиксного выражения «авто *» совпадениями будут «автоматический», «автомобиль» и т. д.
Внутри фразы каждое слово считается префиксным выражением. Например, термин «auto tran*» соответствует «автоматической коробке передач» и «автомобильному преобразователю», но не соответствует «автоматической моторной коробке передач».
Поиск префиксов поддерживается CONTAINS и CONTAINSTABLE.
Поиск словоформ конкретного слова (производное выражение)
С помощью функций CONTAINS, CONTAINSTABLE, FREETEXTили FREETEXTTABLE можно найти все грамматические формы глаголов и существительных (поиск словоформ) или синонимы указанного слова (поиск по тезаурусу).
В следующем примере выполняется поиск любых форм слова «foot» («foot», «feet» и т. д.) в столбце Comments таблицы ProductReview в базе данных AdventureWorks.
USE AdventureWorks2012 GO SELECT Comments, ReviewerName FROM Production.ProductReview WHERE CONTAINS (Comments, 'FORMSOF(INFLECTIONAL, "foot")') GO
В полнотекстовом поиске используются парадигматические модули, которые позволяют найти глагол в различных временах и лицах или существительное в формах единственного или множественного числа. Дополнительные сведения о парадигматических модулях см. в разделе Настройка и управление средством разбиения на слова и парадигматические модули для поиска.
Дополнительные сведения о создании условий поиска
Словоформы — это глаголы в различных временах и лицах или существительные в формах единственного или множественного числа.
Например, выполните поиск по форме слова «диск». Если в разных строках таблицы содержатся слова «drive», «drive», «drive», «driving» и «driven», все они будут включены в результирующий набор, так как каждый из них может быть сформирован из слова drive.
ЗапросыFREETEXT и FREETEXTTABLE по умолчанию ищут словоформы всех указанных слов. Запросы CONTAINS и CONTAINSTABLE поддерживают необязательный аргумент
Запросы CONTAINS и CONTAINSTABLE поддерживают необязательный аргумент INFLECTIONAL.
Поиск синонимов конкретного слова
В тезаурусе определяются пользовательские синонимы терминов. Дополнительные сведения о файлах тезауруса см. в статье Настройка файлов тезауруса для полнотекстового поиска и управление ими.
Например, если в тезаурус добавляется запись «{автомобиль, автомобиль, грузовик, фургон}», можно выполнить поиск по форме тезауруса слова «автомобиль». Все строки в запрашиваемой таблице, содержащие слова «автомобиль», «грузовик», «фургон» или «автомобиль», отображаются в результирующем наборе, так как каждое из этих слов принадлежит к набору синонимов, содержащим слово «car».
По умолчанию тезаурус используется в запросахFREETEXT и FREETEXTTABLE . Запросы CONTAINS и CONTAINSTABLE поддерживают необязательный аргумент THESAURUS.
Поиск слова ОКОЛО другого слова
Выражение с учетом расположения означает слова или фразы, которые находятся рядом друг с другом. Также можно указать максимальное количество слов, которые не включаются в поиск и разделяют первое и последнее из искомых слов. Кроме того, можно искать два слова или две фразы в любом порядке или в порядке, в котором они указаны.
Также можно указать максимальное количество слов, которые не включаются в поиск и разделяют первое и последнее из искомых слов. Кроме того, можно искать два слова или две фразы в любом порядке или в порядке, в котором они указаны.
Примером может служить поиск строк, в которых слово «лед» находится рядом со словом «хоккей» или фраза «хоккей на льду» — рядом с фразой «катание на коньках».
CONTAINS и CONTAINSTABLE
Дополнительные сведения о поиске похожих слов см. в разделе Поиск слов близких к другим с использованием оператора NEAR.
Поиск слов или фраз с использованием взвешенных величин (взвешенное выражение)
Для поиска слов и фраз можно использовать функцию CONTAINSTABLE с взвешенными значениями. Вес, измеряемый числом от 0,0 до 1,0, обозначает степень важности каждого слова и фразы в наборе слов или фраз. Значение веса 0,0 является самым низким, значение 1,0 — самым высоким.
В следующем примере показан запрос, который ищет все адреса клиентов с использованием весов, в котором любой текст, начинающийся со строки «Bay», имеет значение «Street» или «View». Результаты дают более высокий ранг тем строкам, которые содержат больше указанных слов.
Результаты дают более высокий ранг тем строкам, которые содержат больше указанных слов.
USE AdventureWorks2012
GO
SELECT AddressLine1, KEY_TBL.RANK
FROM Person.Address AS Address INNER JOIN
CONTAINSTABLE(Person.Address, AddressLine1, 'ISABOUT ("Bay*",
Street WEIGHT(0.9),
View WEIGHT(0.1)
) ' ) AS KEY_TBL
ON Address.AddressID = KEY_TBL.[KEY]
ORDER BY KEY_TBL.RANK DESC
GO
Взвешенное выражение можно использовать в сочетании с любым простым выражением, префиксным выражением, производным выражением или выражением с учетом расположения.
Дополнительные сведения о взвешенных условиях поиска
Во взвешенных условиях поиска взвешенное значение показывает уровень важности каждого слова и фразы в наборе слов и фраз. Значение веса 0,0 является самым низким, значение 1,0 — самым высоким.
Например, в запросе для поиска нескольких выражений можно задать вес для каждого искомого слова, обозначающий его значимость по сравнению с другими словами в условии поиска. Результат выполнения такого типа запроса будет в начале содержать наиболее релевантные строки, исходя из соответствующего веса, присвоенного искомым словам. В результирующих наборах содержатся документы или строки с любыми из указанных выражений (или содержимым, которое находится между ними), однако некоторые из результатов будут считаться важнее остальных ввиду разницы во взвешенных значениях, связанных с различными выражениями, по которым выполнялся поиск.
Результат выполнения такого типа запроса будет в начале содержать наиболее релевантные строки, исходя из соответствующего веса, присвоенного искомым словам. В результирующих наборах содержатся документы или строки с любыми из указанных выражений (или содержимым, которое находится между ними), однако некоторые из результатов будут считаться важнее остальных ввиду разницы во взвешенных значениях, связанных с различными выражениями, по которым выполнялся поиск.
Поиск взвешенных условий поиска поддерживается CONTAINSTABLE.
Использование операторов AND, OR и NOT (логические операторы)
Функция CONTAINSTABLE и предикат CONTAINS используют одинаковые условия поиска. Они поддерживают объединение нескольких искомых терминов (с помощью логических операторов AND, OR и NOT) для выполнения логических операций. Например, можно использовать И для поиска строк, содержащих как «латте», так и «бублик в стиле Нью-йорка». Например, можно использовать функцию AND NOT, чтобы найти строки, содержащие «бублики», но не содержащие «сливочный сыр».
Предикаты FREETEXT и FREETEXTTABLE, напротив, обрабатывают логические термины как слова, которые следует искать.
Сведения об объединении CONTAINS с другими предикатами, которые используют логические операторы AND, OR и NOT, см. в разделе Условие поиска (Transact-SQL).
Пример
В следующем примере используется предикат CONTAINS для поиска описаний, в которых идентификатор описания не равен 5, а описание содержит как слово «Алюминий», так и слово «шпиндель». Условие поиска использует логический оператор AND. В следующем примере используется таблица ProductDescription базы данных AdventureWorks2022.
USE AdventureWorks2012 GO SELECT Description FROM Production.ProductDescription WHERE ProductDescriptionID <> 5 AND CONTAINS(Description, 'aluminum AND spindle') GO
Регистр, стоп-слова, язык и тезаурус
При написании полнотекстовых запросов можно также указать следующие параметры.
Учет регистра букв.
 В запросах полнотекстового поиска не учитывается регистр букв. Однако в японском языке есть несколько фонетических орфографий, в которых концепция орфографической нормализации аналогична нечувствительности к регистру (например, японская азбука = нечувствительность). Этот тип орфографической нормализации не поддерживается.
В запросах полнотекстового поиска не учитывается регистр букв. Однако в японском языке есть несколько фонетических орфографий, в которых концепция орфографической нормализации аналогична нечувствительности к регистру (например, японская азбука = нечувствительность). Этот тип орфографической нормализации не поддерживается.Стоп-слова. При определении полнотекстового запроса следует иметь в виду, что средство полнотекстового поиска не учитывает стоп-слова (также известные как пропускаемые слова), указанные в критерии поиска. Стоп-слова — это часто встречающиеся слова, которые не повышают эффективность поиска конкретного текста. Примерами могут служить слова «и», «или», «о» и «в». Стоп-слова перечислены в списке стоп-слов. Каждый полнотекстовый индекс связан с конкретным списком стоп-слов, который определяет, какие стоп-слова не указываются в запросе или в индексе во время индексирования. Дополнительные сведения см. в статье Настройка стоп -слов и списков стоп-слов для полнотекстового поиска и управление ими.

Язык с помощью параметра LANGUAGE. Многие выражения запроса в значительной степени зависят от поведения средства разбиения по словам. Чтобы гарантировать использование правильного средства разбиения по словам (и парадигматического модуля) и файла тезауруса, рекомендуется указывать параметр LANGUAGE. Дополнительные сведения см. в разделе Выбор языка при создании полнотекстового индекса.
Тезаурус. По умолчанию тезаурус используется в запросах FREETEXT и FREETEXTTABLE. Предикат CONTAINS и функция CONTAINSTABLE поддерживают необязательный аргумент THESAURUS. Дополнительные сведения см. в статье Настройка файлов тезауруса для полнотекстового поиска и управление ими.
Проверка результатов разметки
После применения сочетания заданного средства разбивки текста на слова, тезауруса и списка стоп-слов в запросе итоговый результат разметки полнотекстового поиска можно просмотреть с помощью динамического административного представления sys. dm_fts_parser. Дополнительные сведения см. в разделе sys.dm_fts_parser (Transact-SQL).
dm_fts_parser. Дополнительные сведения см. в разделе sys.dm_fts_parser (Transact-SQL).
См. также
CONTAINS (Transact-SQL)
CONTAINSTABLE (Transact-SQL)
FREETEXT (Transact-SQL)
FREETEXTTABLE (Transact-SQL)
Создание запросов полнотекстового поиска (визуальные инструменты для баз данных)
Улучшение производительности полнотекстовых запросов
1. Изучите SQL SELECT/FROM/WHERE
Если вы уже закончили загрузку QueryPie и подключение к базе данных, пришло время управлять данными и находить их. Давайте рассмотрим, что мы можем сделать с запросом SELECT, FROM и WHERE.
📌Содержание
Запрос 1. Использование SELECT для ВСЕХ столбцов
SELECT * FROM film;
Запрос 2. Использование SELECT для столбца SPECIFIC
SELECT film_id, title, rating, special_features FROM film;
Запрос 3. Использование WHERE
SELECT film_id, title, rating, special_features FROM film WHERE rating='R';
# SELECT, FROM, WHERE
Самые основные «Вопросы», которые мы можем задать в SQL, это SELECT , FROM и WHERE . Они имеют интуитивно понятное значение, поэтому довольно легко догадаться о функции, прочитав их. Давайте быстро пробежимся по ним.
Они имеют интуитивно понятное значение, поэтому довольно легко догадаться о функции, прочитав их. Давайте быстро пробежимся по ним.
📌 SELECT : вы говорите базе данных, что вам показать
📌 из : вы предоставляете базе данных место для поиска
📌 , где : вы сузите/указываете местоположение
🔑 Начиная сейчас, мы будем называть наши «вопросы» как
Запросы .Итак, давайте рассмотрим наш первый запрос.
Q1. Какие данные содержатся в таблице «фильм»? Покажите мне!
SELECT(нужные столбцы) FROM(в конкретной таблице)
Это самый простой запрос. Мы можем начать диалог с любой базой данных
, просто используя это предложение.
В этом примере мы будем использовать данные из таблицы Film в Sample Database sakila .
Применив эту идею к запросу 1, мы можем прочитать его как «ВЫБЕРИТЕ «столбцы» ИЗ таблицы «фильм». Нам не нужно слово «таблица» после названия таблицы. SQL уже знает, что слово, следующее за запросом
Нам не нужно слово «таблица» после названия таблицы. SQL уже знает, что слово, следующее за запросом FROM , будет именем таблицы. Так и пиши ИЗ плёнки .
Если вы хотите увидеть сразу все доступные данные каждого столбца в указанной таблице, используйте символ звездочки ( *). Символ * здесь означает все данные всех столбцов. Допустим, мы хотим, чтобы отображал все столбцы, содержащие информацию внутри таблицы фильмов . В SQL это примерно переводится как « SELECT (показать) * (все столбцы, содержащие информацию) FROM (внутри) фильм (таблица ) ». Удалите все скобки, и вы получите простой SQL-запрос:
SELECT * FROM film;
Обязательно используйте точку с запятой ( ; ) в конце предложения, чтобы сообщить SQL, что это конец вашего запроса и вы готовы увидеть результаты.
✦ Нажмите SQL Запустите в левом верхнем углу, чтобы попробовать ваш запрос
Вы должны увидеть что-то похожее на изображение, показанное ниже.
В результате тонна колонок загружена информацией о фильмах!
Но, допустим, мы хотим видеть только информацию о самом фильме без лишнего беспорядка в виде ставки проката или продолжительности фильма.
Q2. Здесь слишком много столбцов!! Давайте посмотрим только на идентификатор, название, рейтинг и специальные функции в таблице фильмов.
SELECT(конкретные желаемые «столбцы») FROM(в конкретной «таблице»)
рейтинг , и специальные функции . Просто введите точное имя нужного столбца после SELECT , чтобы отфильтровать информацию. В этом случае вы можете использовать это:
ВЫБЕРИТЕ фильм_идентификатор, название, рейтинг, специальные_функции ИЗ фильма;
Q3. Хорошо, теперь давайте сузим его еще больше. Давайте посмотрим только на идентификатор фильма, название, рейтинг и особенности фильмов с рейтингом R.
SELECT(показать этот столбец) FROM(конкретная таблица) WHERE(соответствует условию)
Если условие числовое: WHERE film_id=5
Если условие символьное: 9 0027 ГДЕ рейтинг= ‘PG’ — ( Добавить одинарные кавычки!! )
Теперь, когда мы знаем, как находить конкретные данные, давайте еще немного сузим круг поиска. Допустим, нам нужна информация только о фильмах с определенным рейтингом (R, PG-13, PG и т. д.). Для этого нам нужно начать использовать SQL-запрос
Допустим, нам нужна информация только о фильмах с определенным рейтингом (R, PG-13, PG и т. д.). Для этого нам нужно начать использовать SQL-запрос WHERE .
Просто добавьте ГДЕ в конец запроса после желаемого рейтинга. В этом примере мы будем искать фильмы с рейтингом R. Почему бы и нет?
Плагин ГДЕ рейтинг='R' в конце заявления. Обратите внимание, что мы добавили одинарные кавычки вокруг буквы R ( ‘’ ). Это связано с тем, что SQL нуждается в этой дополнительной скобке, когда условие не является числом. Есть способы обойти это, но для начинающих хорошо иметь прочную основу. Итак, давайте использовать эти одинарные кавычки! Ваш окончательный запрос должен выглядеть примерно так:
SELECT film_id, title, rating, special_features FROM film WHERE rating='R';
✦ Не забудьте нажать SQL Run в левом верхнем углу, чтобы выполнить запрос
# Время практики Попробуйте использовать SELECT , FROM и WHERE в этом примерном сценарии:
📰 Покупатель в вашем киномагазине подходит к вам и просит список всех фильмов, срок проката которых составляет 3 дня. Она также интересуется ценой (арендной ставкой). Как можно посмотреть эту информацию? Не забудьте также найти идентификационный номер, чтобы вы могли легко найти фильмы на полках.
Она также интересуется ценой (арендной ставкой). Как можно посмотреть эту информацию? Не забудьте также найти идентификационный номер, чтобы вы могли легко найти фильмы на полках.
Вот ответ:
ВЫБЕРИТЕ фильм_идентификатор, название, ставка_проката, продолжительность_проката ИЗ фильма, ГДЕ прокат_длительность=3;
SQLBolt — Learn SQL — SQL Урок 12: Порядок выполнения запроса
Теперь, когда у нас есть представление обо всех частях запроса, мы можем теперь поговорить о том, как они все сочетаются друг с другом в контексте полного запроса.
Полный запрос SELECT
SELECT DISTINCT column, AGG_FUNC( column_or_expression ), …
ОТ моей таблицы
ПРИСОЕДИНЯЙТЕСЬ к другой_таблице
ON mytable.column = другая_таблица.column
ГДЕ выражение_ограничения СГРУППИРОВАТЬ ПО столбцу
НАЛИЧИЕ выражение_ограничения ПОРЯДОК ПО столбец ASC/DESC
ПРЕДЕЛ счет СМЕЩЕНИЕ счет ; Каждый запрос начинается с поиска необходимых данных в базе данных, а затем фильтрации этих данных. во что-то, что может быть обработано и понято как можно быстрее. Поскольку каждая часть
запрос выполняется последовательно, важно понимать порядок выполнения, чтобы знать
какие результаты доступны где.
во что-то, что может быть обработано и понято как можно быстрее. Поскольку каждая часть
запрос выполняется последовательно, важно понимать порядок выполнения, чтобы знать
какие результаты доступны где.
1.
FROM и JOIN s Предложение FROM и последующие JOIN сначала выполняются для определения общего рабочего набора
данные, которые запрашиваются. Это включает в себя подзапросы в этом предложении и может привести к тому, что временные таблицы
должен быть создан под капотом, содержащим все столбцы и строки соединяемых таблиц.
2.
ГДЕ Когда у нас есть полный рабочий набор данных, первый проход ГДЕ ограничения применяются к
отдельные строки и строки, не удовлетворяющие этому ограничению, отбрасываются. Каждое из ограничений
может обращаться только к столбцам непосредственно из таблиц, запрошенных в предложении FROM . Псевдонимы в SELECT части запроса недоступны в большинстве баз данных, поскольку они могут включать
выражения, зависящие от частей запроса, которые еще не выполнены.
3.
ГРУППИРОВАТЬ ПО Остальные строки после WHERE ограничения затем группируются на основе общих значений
в столбце, указанном в предложении GROUP BY . В результате группировки останется только как
много строк, так как в этом столбце есть уникальные значения. Неявно это означает, что вам нужно только
чтобы использовать это, когда у вас есть агрегатные функции в вашем запросе.
4.
HAVING Если в запросе есть предложение GROUP BY , то ограничения в HAVING 9Затем применяется пункт 0069.
к сгруппированным строкам, отбросить сгруппированные строки, которые не удовлетворяют ограничению. Как ГДЕ пункт, псевдонимы также недоступны с этого шага в большинстве баз данных.
5.
SELECT Все выражения в части SELECT запроса вычисляются окончательно.
6.
DISTINCT Из оставшихся строк строки с повторяющимися значениями в столбце, отмеченном как DISTINCT , будут отброшены.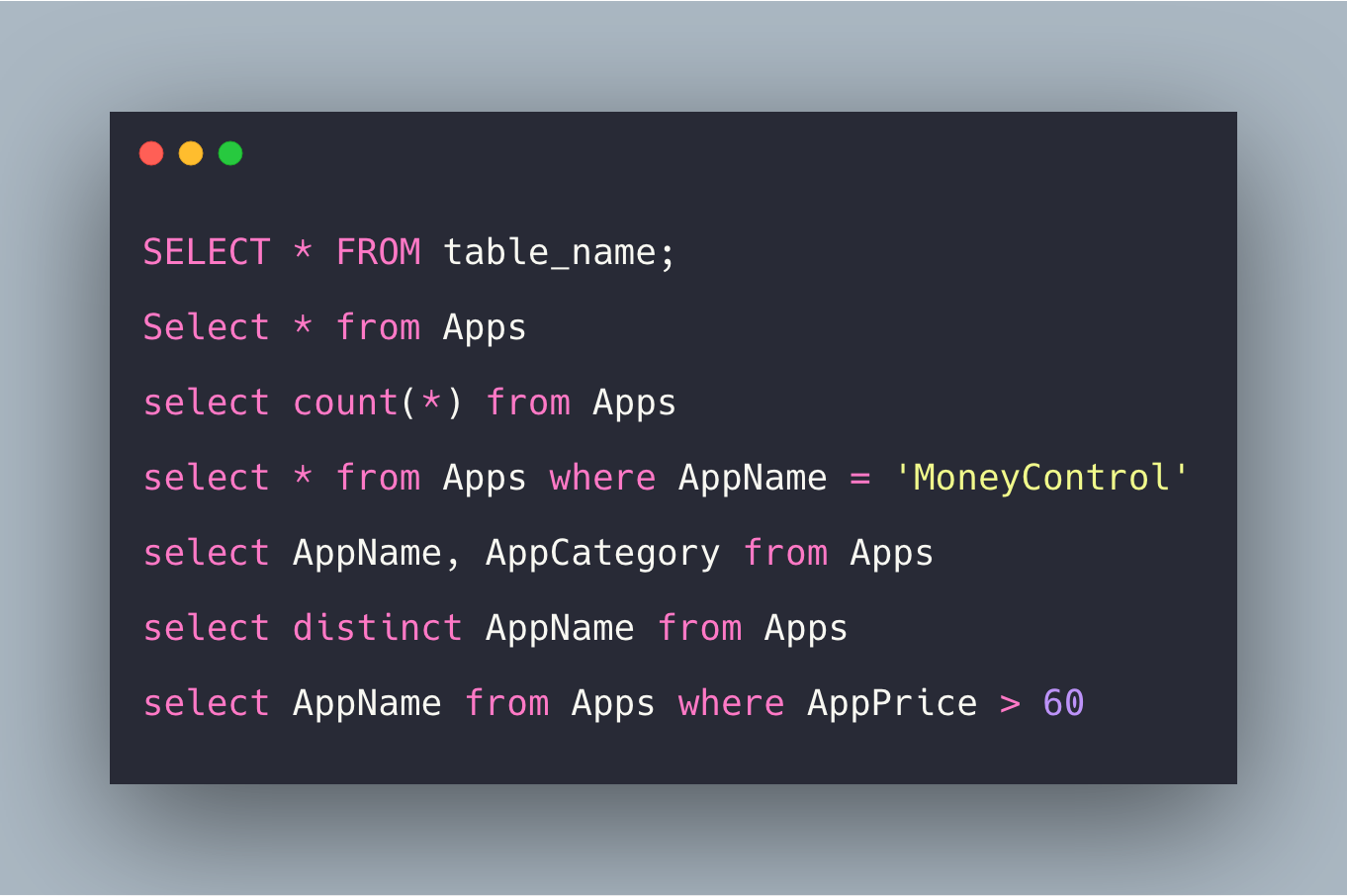
7.
ORDER BY Если порядок указан в предложении ORDER BY , строки затем сортируются по указанным данным в
либо по возрастанию, либо по убыванию. Поскольку все выражения в части SELECT запроса
были вычислены, вы можете ссылаться на псевдонимы в этом предложении.
8.
LIMIT / OFFSET Наконец, строки, выходящие за пределы диапазона, заданного LIMIT и OFFSET отбрасываются,
оставляя окончательный набор строк, которые должны быть возвращены из запроса.
Заключение
Не каждый запрос должен содержать все части, перечисленные выше, но одна из причин гибкости SQL заключается в следующем. что он позволяет разработчикам и аналитикам данных быстро манипулировать данными без необходимости писать дополнительные код, просто используя приведенные выше пункты.
На этом наши уроки по запросам SELECT заканчиваются, поздравляем, вы дошли до этого момента! Это упражнение попытается
и проверьте свое понимание запросов, поэтому не расстраивайтесь, если они кажутся вам сложными.