Предикаты поиска / Хабр
По материалам статьи Craig Freedman
Перед тем, как SQL Server приступит к поиску по индексу, он должен определить, являются ли ключи индекса подходящими для оценки предиката запроса.
Индексы по одному столбцу
С индексами по одному столбцу всё довольно просто. SQL Server может их использовать для самых простых сравнений, например, равенства и неравенства (больше чем, меньше чем, и т.д.). Более сложные выражения, такие как функции по столбцу и предикаты «LIKE» с символами подстановки, будут в таких случаях создавать трудности для использования поиска по индексу.
Например, предположим, что мы имеем индекс по одному столбцу, созданный по полю «a». Этот индекс может использоваться для поиска при следующих предикатах:
a = 3.14 a > 100 a between 0 and 99 a like 'abc%' a in (2, 3, 5, 7)
Однако, поиск по индексу не будет задействован если использовать вот такие предикаты:
ABS(a) = 1 a + 1 = 9 a like '%abc'
Индексы по нескольким столбцам
С индексами по нескольким столбцам дело обстоит сложнее. Для таких индексов важен порядок ключей. Этим определяется порядок сортировки индекса, и от порядка ключей зависит набор предикатов поиска, которые SQL Server сможет использовать для этого индекса.
Для таких индексов важен порядок ключей. Этим определяется порядок сортировки индекса, и от порядка ключей зависит набор предикатов поиска, которые SQL Server сможет использовать для этого индекса.
Для того, чтобы проще понять важность порядка ключей, представьте себе телефонную книгу. Для телефонной книги походит индекс с ключами: «фамилия» и «имя». Содержание телефонной книги отсортировано по фамилии, что упрощает поиск кого-нибудь, если мы знаем его фамилию. Однако, если мы знаем только имя, очень трудно получить список людей с необходимым нам именем. В таком случае, нам бы лучше подошла другая телефонная книга, в которой абоненты отсортированы по имени.
Точно также обстоит дело, если мы имеем индекс по двум столбцам, т.е. мы сможем использовать индекс только для предиката по второму столбцу, если указан предикат равенства для первого столбца. Даже если мы не сможем использовать индекс для удовлетворения условия предиката второго столбца, мы сможем использовать его для первого столбца. В этом случае, вводится остаточный предикат для предиката второго столбца, который будет тем же самым предикатом, который используется для просмотра.
В этом случае, вводится остаточный предикат для предиката второго столбца, который будет тем же самым предикатом, который используется для просмотра.
Например, предположим, что у нас есть индекс по двум столбцам «a» и «b». Мы можем его использовать для поиска по любому из предикатов, которые применимы для индексов по одному столбцу. Кроме того, можно использовать это индекс и для поиска со следующими дополнительными предикатами:
a = 3.14 and b = 'pi' a = 'xyzzy' and b <= 0
Для следующих ниже примеров, мы можем использовать индекс для удовлетворения условий предиката для столбца «a», но не для столбца «b». В этих случаях потребуется остаточный предикат:
a > 100 and b > 100 a like 'abc%' and b = 2
И, наконец, невозможно использовать индекс для поиска со следующим ниже набором предикатов, поскольку поиск невозможен даже по столбцу «a». В таких случаях, оптимизатор вынужден использовать другой индекс (например, такой индекс, у которого столбец «b» указан первым), или он будет использовать просмотр с остаточным предикатом.
b = 0 a + 1 = 9 and b between 1 and 9 a like '%abc' and b in (1, 3, 5)
Добавим в пример немного конкретики.
Рассмотрим следующую схему:
create table person (id int, last_name varchar(30), first_name varchar(30)) create unique clustered index person_id on person (id) create index person_name on person (last_name, first_name)
Ниже представлены три запроса с соответствующими им текстовыми планами исполнения. Первый запрос осуществляет поиск по обоим столбцам индекса person_name. Второй запрос ищет только по первому столбцу и использует остаточный предикат, для оценки first_name. Третий запрос не может использовать поиск и использует просмотр с остаточным предикатом.
select id from person where last_name = 'Doe' and first_name = 'John' |--Index Seek(OBJECT:([person].[person_name]), SEEK:([person].[last_name]='Doe' AND [person].[first_name]='John')) select id from person where last_name > 'Doe' and first_name = 'John' |--Index Seek(OBJECT:([person].[person_name]), SEEK:([person].[last_name] > 'Doe'), WHERE:([person].[first_name]='John')) select id from person where last_name like '%oe' and first_name = 'John' |--Index Scan(OBJECT:([person].[person_name]), WHERE:([person].[first_name]='John' AND [person].[last_name] like '%oe'))
Внимание: Если Вы пробуете воспроизвести эти планы для этих и некоторых следующих примеров, учтите, что я использовал подсказки индексов (которые не указаны), позволяющие гарантировать получение необходимого плана запроса, поскольку я хотел проиллюстрировать эти примеры без необходимости вставки данных в таблицу.
Дополнение о ключах индекса
Очень часто ключи индекса являются набором столбцов, которые были указаны в инструкции по созданию этого индекса. Однако, когда создается некластеризованный уникальный индекс для таблицы с кластеризованным индексом, в ключ некластеризованного индекса добавляется ключ кластеризованного индекса, если он не является частью ключей некластеризованного индекса.
Например, рассмотрим такую схему:
create table T_heap (a int, b int, c int, d int, e int, f int) create index T_heap_a on T_heap (a) create index T_heap_bc on T_heap (b, c) create index T_heap_d on T_heap (d) include (e) create unique index T_heap_f on T_heap (f) create table T_clu (a int, b int, c int, d int, e int, f int) create unique clustered index T_clu_a on T_clu (a) create index T_clu_b on T_clu (b) create index T_clu_ac on T_clu (a, c) create index T_clu_d on T_clu (d) include (e) create unique index T_clu_f on T_clu (f)
Столбцы ключей и покрываемые столбцы для каждого из индексов:
Индекс | Столбцы ключа | Покрываемые столбцы |
T_heap_a | a | a |
T_heap_bc | b, c | b, c |
T_heap_d | d | d, e |
T_heap_f | f | f |
T_clu_a | a | a, b, c, d, e |
T_clu_b | b, a | a, b |
T_clu_ac | a, c | a, c |
T_clu_d | d, a | a, d, e |
T_clu_f | f | a, f |
Обратите внимание, что каждый некластеризованный индекс таблицы T_clu включает ключевой столбец кластеризованного индекса, за исключением уникального индекса T_clu_f.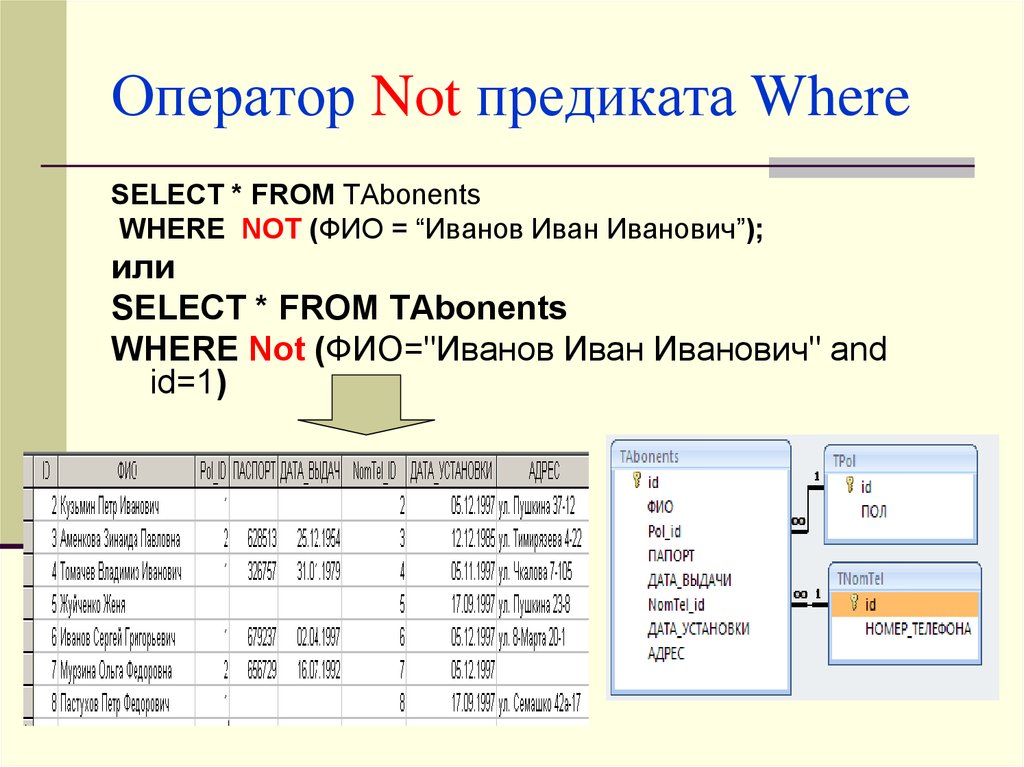
Описанное в этой статье поведение оптимизатора не изменилось и в SQL Server 2005. Уникальные некластеризованные индексы не включают ключи кластеризованного индекса в свой набор ключевых столбцов, но делают их покрываемыми столбцами. То есть Вы не можете искать по кластеризованному ключу, но Вы можете выбирать значения по индексу. Это происходит потому, что ключ кластеризованного индекса хранится только на страницах листового уровня сбалансированного дерева; он не хранится на страницах не листового уровня. Ключ кластеризованного индекса необходим для поиска закладок. Нет нужды искать по ключу кластеризованного индекса, поскольку поиск по ключу уникального индекса обычно возвращает одну строку. В SQL Server 2000, фактически может использоваться поиск по ключу кластеризованного индекса, но это относится к внутренней реализации в виде остаточного предиката, а не в виде поиска.
Postgres Pro Enterprise : Документация: 9.6: 9.2. Функции и операторы сравнения : Компания Postgres Professional
Набор операторов сравнения включает обычные операторы, перечисленные в Таблице 9. 1.
1.
Таблица 9.1. Операторы сравнения
| Оператор | Описание |
|---|---|
< | меньше |
> | больше |
<= | меньше или равно |
>= | больше или равно |
= | равно |
<> или != | не равно |
Примечание
Оператор != преобразуется в <> на стадии разбора запроса. Как следствие, реализовать операторы != и <> по-разному невозможно.
Операторы сравнения определены для всех типов данных, для которых они имеют смысл. Все операторы сравнения представляют собой бинарные операторы, возвращающие значения типа boolean; при этом выражения вида <, который бы сравнивал булево значение с 3).
Существует также несколько предикатов сравнения; они приведены в Таблице 9.2. Они работают подобно операторам, но имеют особый синтаксис, установленный стандартом SQL.
Таблица 9.2. Предикаты сравнения
| Предикат | Описание |
|---|---|
a BETWEEN x AND y | между |
a NOT BETWEEN x AND y | не между |
a BETWEEN SYMMETRIC x AND y | между, после сортировки сравниваемых значений |
a NOT BETWEEN SYMMETRIC x AND y | не между, после сортировки сравниваемых значений |
a IS DISTINCT FROM b | не равно, при этом NULL воспринимается как обычное значение |
a IS NOT DISTINCT FROM b | равно, при этом NULL воспринимается как обычное значение |
выражение IS NULL | эквивалентно NULL |
выражение IS NOT NULL | не эквивалентно NULL |
выражение ISNULL | эквивалентно NULL (нестандартный синтаксис) |
выражение | не эквивалентно NULL (нестандартный синтаксис) |
логическое_выражение IS TRUE | истина |
логическое_выражение IS NOT TRUE | ложь или неопределённость |
логическое_выражение IS FALSE | ложь |
логическое_выражение IS NOT FALSE | истина или неопределённость |
логическое_выражение IS UNKNOWN | неопределённость |
логическое_выражение IS NOT UNKNOWN | истина или ложь |
Предикат BETWEEN упрощает проверки интервала:
aBETWEENxANDy
равнозначно выражению
a>=xANDa<=y
Заметьте, что BETWEEN считает, что границы интервала также включаются в интервал.
NOT BETWEEN выполняет противоположное сравнение:
aNOT BETWEENxANDy
равнозначно выражению
a<xORa>y
Предикат BETWEEN SYMMETRIC аналогичен BETWEEN, за исключением того, что аргумент слева от AND не обязательно должен быть меньше или равен аргументу справа. Если это не так, аргументы автоматически меняются местами, так что всегда подразумевается непустой интервал.
Обычные операторы сравнения выдают NULL (что означает «неопределённость»), а не true или false, когда любое из сравниваемых значений NULL. Например, 7 = NULL выдаёт NULL, так же, как и 7 <> NULL. Когда это поведение нежелательно, можно использовать предикаты IS [ NOT ] DISTINCT FROM:
aIS DISTINCT FROMbaIS NOT DISTINCT FROMb
Для значений не NULL условие IS DISTINCT FROM работает так же, как оператор <>. Однако если оба сравниваемых значения NULL, результат будет false, и только если одно из значений NULL, возвращается true. Аналогично, условие
Однако если оба сравниваемых значения NULL, результат будет false, и только если одно из значений NULL, возвращается true. Аналогично, условие IS NOT DISTINCT FROM равносильно = для значений не NULL, но возвращает true, если оба сравниваемых значения NULL, и false в противном случае. Таким образом, эти предикаты по сути работают с NULL, как с обычным значением, а не с «неопределённостью».
Для проверки, содержит ли значение NULL или нет, используются предикаты:
выражениеIS NULLвыражениеIS NOT NULL
или равнозначные (но нестандартные) предикаты:
выражениеISNULLвыражениеNOTNULL
Заметьте, что проверка выражение = NULLNULL считается не «равным» NULL. (Значение NULL представляет неопределённость, и равны ли две неопределённости, тоже не определено. )
)
Подсказка
Некоторые приложения могут ожидать, что выражение = NULLвыражения является NULL. Такие приложения настоятельно рекомендуется исправить и привести в соответствие со стандартом SQL. Однако в случаях, когда это невозможно, это поведение можно изменить с помощью параметра конфигурации transform_null_equals. Когда этот параметр включён, Postgres Pro преобразует условие x = NULL в x IS NULL.
Если выражение возвращает табличную строку, тогда IS NULL будет истинным, когда само выражение — NULL или все поля строки — NULL, а IS NOT NULL будет истинным, когда само выражение не NULL, и все поля строки так же не NULL. Вследствие такого определения, IS NULL и IS NOT NULL не всегда будут возвращать взаимодополняющие результаты для таких выражений; в частности такие выражения со строками, одни поля которых NULL, а другие не NULL, будут ложными одновременно. В некоторых случаях имеет смысл написать
В некоторых случаях имеет смысл написать строка IS DISTINCT FROM NULL или строка IS NOT DISTINCT FROM NULL, чтобы просто проверить, равно ли NULL всё значение строки, без каких-либо дополнительных проверок полей строки.
Логические значения можно также проверить с помощью предикатов
логическое_выражениеIS TRUEлогическое_выражениеIS NOT TRUEлогическое_выражениеIS FALSEлогическое_выражениеIS NOT FALSEлогическое_выражениеIS UNKNOWNлогическое_выражениеIS NOT UNKNOWN
Они всегда возвращают true или false и никогда NULL, даже если какой-любо операнд — NULL. Они интерпретируют значение NULL как «неопределённость». Заметьте, что IS UNKNOWN и IS NOT UNKNOWN по сути равнозначны IS NULL и IS NOT NULL, соответственно, за исключением того, что выражение может быть только булевого типа.
Также имеется несколько связанных со сравнениями функций; они перечислены в Таблице 9.3.
Таблица 9.3. Функции сравнения
| Функция | Описание | Пример | Результат примера |
|---|---|---|---|
num_nonnulls(VARIADIC "any") | возвращает число аргументов, отличных от NULL | num_nonnulls(1, NULL, 2) | 2 |
num_nulls(VARIADIC "any") | возвращает число аргументов NULL | num_nulls(1, NULL, 2) | 1 |
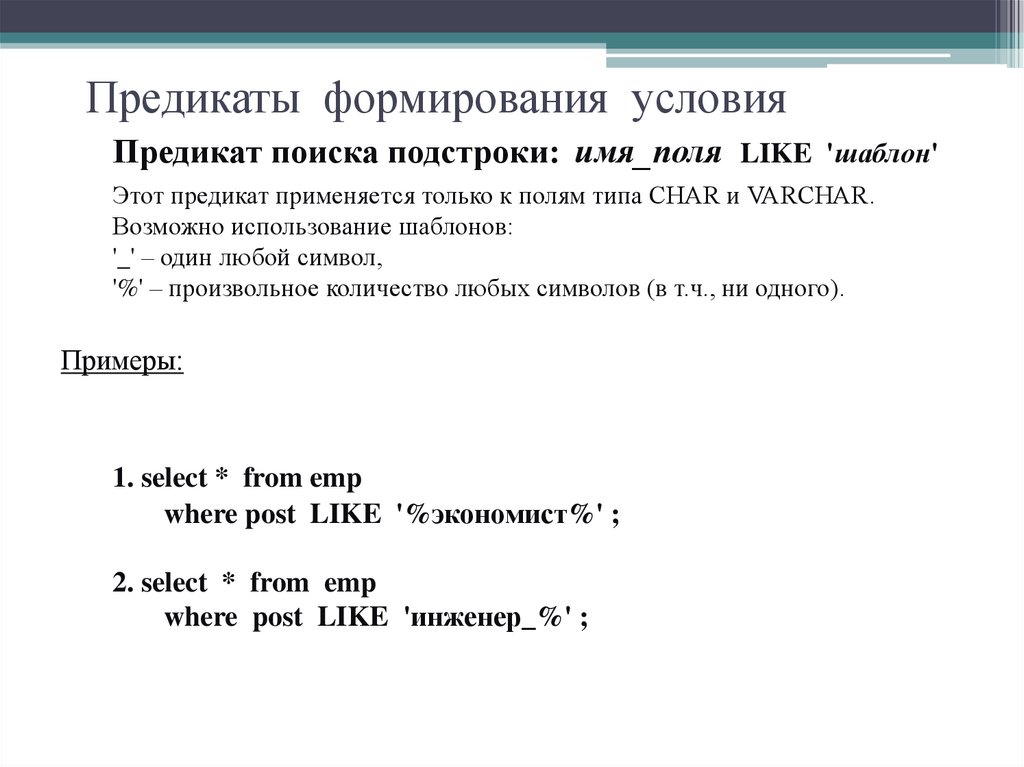
Предикаты в SQL
Предикаты в SQL3 мая 2022 г. by Robert Gravelle
На этой неделе мы ненадолго нажмем кнопку «Пауза» из серии «Некоторые основные ошибки SQL-запросов», чтобы поговорить о предикатах в SQL. Причина в том, что предикаты будут учитываться в части 3 серии «Основные ошибки SQL-запросов».
Предикат — это просто выражение, результатом которого является ИСТИНА, ЛОЖЬ или НЕИЗВЕСТНО. Предикаты обычно используются в условиях поиска предложений WHERE и HAVING, условиях соединения предложений FROM, а также в любой другой части запроса, где требуется логическое значение.
Существует множество типов предикатов, в том числе:
- Сравнение
- КАК
- МЕЖДУ
- В
- СУЩЕСТВУЕТ
- IS NULL (/INTEGER/DECIMAL/FLOAT…)
В оставшейся части этой статьи мы рассмотрим несколько примеров вышеупомянутых типов предикатов.
Каждый раз, когда мы используем оператор сравнения в выражении, таком как WHERE employee_salary > 100000 , мы создаем предикат, который оценивается как ИСТИНА, ЛОЖЬ или НЕИЗВЕСТНО. Операторы сравнения включают:
- = равно
- > Больше
- < Меньше
- >= Больше или равно
- <= Меньше или равно
- <> Не равно
Следовательно, предикат сравнения принимает вид:
выражение_1 оператор сравнения выражение_2
В предикате сравнения выражение2 также может быть подзапросом. Если подзапрос не возвращает ни одной строки, предикат сравнения оценивается как FALSE.
Если подзапрос не возвращает ни одной строки, предикат сравнения оценивается как FALSE.
В SQL предикатом сопоставления с шаблоном номер один является оператор LIKE, поскольку он сравнивает значения столбца с указанным шаблоном. Like работает с любым символьным или датовым типом данных. Вот пример:
Оператор BETWEEN задает диапазон, который определяет нижнюю и верхнюю границы определяемых значений. Например, в Предикате доход МЕЖДУ 5000 И 20000 выбранные данные представляют собой диапазон больше или равный 5000 и меньше или равный 20000. Оператор Между может использоваться с числовыми, текстовыми типами данных и датами. Вот пример:
Оператор IN позволяет использовать два или более выражений для поиска запроса. Результатом условия является TRUE, если значение соответствующего столбца равно одному из выражений, заданных предикатом IN:
Предикат EXISTS принимает подзапрос в качестве аргумента. Он возвращает TRUE, если подзапрос возвращает одну или несколько строк, и возвращает FALSE, если он возвращает ноль строк.
Вот пример:
Используйте IS NULL, чтобы определить, является ли выражение пустым, потому что вы не можете проверить его с помощью оператора сравнения =. При применении к выражениям значений строк все элементы должны проверяться одинаково.
Предикат IS NULL принимает следующую форму:
ЯВЛЯЕТСЯ [НЕ]НУЛЬНЫМ
Например, выражение x IS NULL равно TRUE, если x равно NULL.
IS UNKNOWN является синонимом IS NULL, когда выражение имеет тип BOOLEAN.
Вот запрос, который использует предикат IS NOT NULL для получения всех участников, чья фамилия не равна NULL:
В этом блоге мы прервали регулярно запланированный блог, чтобы показать вам этот важный урок о предикатах SQL. Обычно используемые в условиях поиска предложений WHERE и HAVING, условиях соединения предложений FROM, предикаты — это выражения, которые оцениваются как TRUE, FALSE или UNKNOWN. В следующие недели мы снова увидим предикаты в продолжении серии «Основные ошибки SQL-запросов».
Предикаты | ENT
Полевые предикаты
- BOOL :
- = ,! =
- NUMERIC :
- = ,!,>, <,> =, <=,
- в in,!,>, <,> =, <=,
- in, не в том, что не в
- Время :
- =, !=, >, <, >=, <=
- В, НЕ В
- Строка , < = , >3 : 9001 =, <=
- IN, NOT IN
- Содержит, HasPrefix, HasSuffix
- ContainsFold, EqualFold ( SQL специфично)
- =, !=
- =, !=, >, <, >=, <= для вложенных значений (путь JSON).
- Содержит вложенные значения (путь JSON).
- HasKey, Len
-
nullпроверяет наличие вложенных значений (путь JSON).
- IsNil, NotNil
Edge Predicates
HasEdge .
 Например, для ребра с именем
Например, для ребра с именем ownerтипаPetиспользуйте:client.Pet.
Запрос().
Где(pet.HasOwner()).
Все(ctx)
HasEdgeWith . Добавьте список предикатов для предиката края.
клиент.Пэт.
Запрос().
Где(pet.HasOwnerWith(user.Name("a8m"))).
Все(ctx)
Отрицание (НЕ)
client.Pet.
Запрос().
Где(pet.Not(pet.NameHasPrefix("Ари"))).
Все(ctx)
Разъединение (OR)
client.Pet.
Запрос().
Где(
pet.Or(
pet.HasOwner(),
pet.Not(pet.HasFriends()),
)
).
Все(ctx)
Соединение (И)
клиент.Пэт.
Запрос().
Где(
pet.And(
pet.HasOwner(),
pet.Not(pet.HasFriends()),
)
).
All(ctx)
Пользовательские предикаты
Пользовательские предикаты могут быть полезны, если вы хотите написать собственную логику для конкретного диалекта или контролировать выполняемые запросы.
Получить всех питомцев пользователей 1, 2 и 3
питомцев := client.Pet.
Запрос().
Where(func(s *sql.Selector) {
s.Where(sql.InInts(pet.FieldOwnerID, 1, 2, 3))
}).
AllX(ctx)
Приведенный выше код выдаст следующий запрос SQL:
SELECT DISTINCT `pets`.`id`, `pets`.`owner_id` FROM `pets` WHERE `owner_id` IN (1, 2 , 3)
Подсчитайте количество пользователей, чье поле JSON с именем
URL содержит ключ схемы количество := клиент.Пользователь.
Запрос().
Where(func(s *sql.Selector) {
s.Where(sqljson.HasKey(user.FieldURL, sqljson.Path("Scheme")))
}).
CountX(ctx)
Приведенный выше код создаст следующий запрос SQL:
-- PostgreSQL
SELECT COUNT(DISTINCT "users"."id") FROM "users" WHERE "url"->'Scheme' IS NOT NULL-- SQLite и MySQL
SELECT COUNT(DISTINCT `users`.`id`) FROM `users` WHERE JSON_EXTRACT(`url`, "$.Scheme") НЕ NULL
Получить всех пользователей с автомобилем
"Tesla" Рассмотрим энт-запрос, например:
пользователей := client.User.Query().
Где(пользователь.HasCarWith(car.Model("Tesla"))).
AllX(ctx)
Этот запрос можно перефразировать в 3 различных формах: IN , EXISTS и JOIN .
// Версия `IN`.
пользователей := client.User.Query().
Where(func(s *sql.Selector) {
t := sql.Table(car.Table)
s.Where(
sql.In(
s.C(user.FieldID),
sql.Select(t.C(user.FieldID)).From(t).Where(sql.EQ(t.C(car.FieldModel), "Tesla")),
),
)
}).
AllX(ctx)// версия `JOIN`.
пользователей := client.User.Query().
Where(func(s *sql.Selector) {
t := sql.Table(car.Table)
s.Join(t).On(s.C(user.FieldID), t.C(car.FieldOwnerID))
s .Where(sql.EQ(t.C(car.FieldModel), "Tesla"))
}).
AllX(ctx)// `СУЩЕСТВУЕТ` версия.

пользователей := client.User.Query().
Where(func(s *sql.Selector) {
t := sql.Table(car.Table)
p := sql.And(
sql.EQ(t.C(car.FieldModel), "Tesla"),
sql.ColumnsEQ(s.C(user.FieldID), t.C(car.FieldOwnerID)),
)
s.Where(sql.Exists(sql.Select().From(t).Where(p)))
}) .
AllX(ctx)
Приведенный выше код создаст следующий SQL-запрос:
-- Версия `IN`.
SELECT DISTINCT `users`.`id`, `users`.`age`, `users`.`name` FROM `users` WHERE `users`.`id` IN (SELECT `cars`.`id` FROM ` cars` ГДЕ `cars`.`model` = 'Tesla')-- Версия `JOIN`.
SELECT DISTINCT `users`.`id`, `users`.`age`, `users`.`name` FROM `users` ПРИСОЕДИНЯЙТЕСЬ к `cars` НА `users`.`id` = `cars`.`owner_id` ГДЕ `cars`.`model` = 'Tesla'-- `СУЩЕСТВУЕТ` версия.
SELECT DISTINCT `users`.`id`, `users`.`age`, `users`.`name` FROM `users` WHERE EXISTS (SELECT * FROM `cars` WHERE `cars`.`model` = 'Tesla ' AND `users`.`id` = `cars`.`owner_id`)
Получить всех питомцев, имя которых содержит определенный шаблон
Сгенерированный код обеспечивает HasPrefix , HasSuffix , Содержит предикаты и ContainsFold для сопоставления с образцом. Однако, чтобы использовать оператор
Однако, чтобы использовать оператор LIKE с пользовательским шаблоном, используйте следующий пример.
домашних животных := client.Pet.Query().
Where(func(s *sql.Selector){
s.Where(sql.Like(pet.Name,"_B%"))
}).
AllX(ctx)
Приведенный выше код выдаст следующий SQL-запрос:
SELECT DISTINCT `pets`.`id`, `pets`.`owner_id`, `pets`.`name`, `pets`. `возраст`, `домашние животные`.`виды` ОТ `домашних животных` ГДЕ `имя` НРАВИТСЯ '_B%'
Пользовательские функции SQL
Чтобы использовать встроенные функции SQL, такие как DATE() , используйте один из следующих вариантов:
1. Передайте функцию предиката с учетом диалекта, используя sql.P вариант:
пользователей := client.User.Query().
Выберите(user.FieldID).
Where(sql.P(func(b *sql.Builder) {
b.WriteString("DATE(").Ident("last_login_at").WriteByte(')').WriteOp(OpGTE).Arg(значение)
})).
AllX(ctx)
Приведенный выше код создаст следующий SQL-запрос:
ВЫБЕРИТЕ `id` ИЗ `users` ГДЕ ДАТА(`last_login_at`) >= ?
2. Встроить выражение предиката с помощью опции ExprP() :
пользователей := client.User.Query().
Выберите(user.FieldID).
Where(func(s *sql.Selector) {
s.Where(sql.ExprP("DATE(last_login_at) >=?", value))
}).
AllX(ctx)
Приведенный выше код выдаст тот же запрос SQL:
SELECT `id` FROM `users` WHERE DATE(`last_login_at`) >= ?
Предикаты JSON
Предикаты JSON не генерируются по умолчанию как часть генерации кода. Тем не менее, ent предоставляет официальный пакет
с именем sqljson для применения предикатов к столбцам JSON с использованием
опция пользовательских предикатов.
Сравните значение JSON , контент, sqljson.DotPath(«атрибуты[1].body.content»))
sqljson.ValueGTE(user.FieldData, status. StatusBadRequest, sqljson.Path(«response», «status»))
StatusBadRequest, sqljson.Path(«response», «status»))
Проверить наличие ключа JSON
sqljson.HasKey(user.FieldData, sqljson.Path("атрибуты", "[1]", "тело")) sqljson.HasKey(user.FieldData, sqljson.DotPath("атрибуты[1].body"))
Обратите внимание, что key с литералом null в качестве значения также соответствует этой операции.
Проверить JSON
null литералыsqljson.ValueIsNull (user.FieldData)sqljson.ValueIsNull (user.FieldData, sqljson.Path («атрибуты»))
sqljson.ValueIsNull (user.FieldData, sqljson.DotPath («атрибуты [1]»). ))
Обратите внимание, что ValueIsNull возвращает true, если значение равно JSON null ,
но не база данных NULL .
Сравните длину массива JSON0169 sqljson.LenLT(user.FieldData, 20, sqljson.Path(«attributes»)),
)
Проверить, содержит ли значение JSON другое значение
sqljson.
