Выполнение объединений с помощью SQL Access
- Чтение занимает 5 мин
В этой статье
В реляционной системе баз данных, такой как доступ, часто требуется извлекать данные из нескольких таблиц за раз.In a relational database system like Access, you often need to extract information from more than one table at a time. Для этого можно использовать инструкцию SQL Join , которая позволяет извлекать записи из таблиц с определенными связями независимо от того, являются ли они одними, одними и многими.This can be accomplished by using an SQL JOIN statement, which enables you to retrieve records from tables that have defined relationships, whether they are one-to-one, one-to-many, or many-to-many.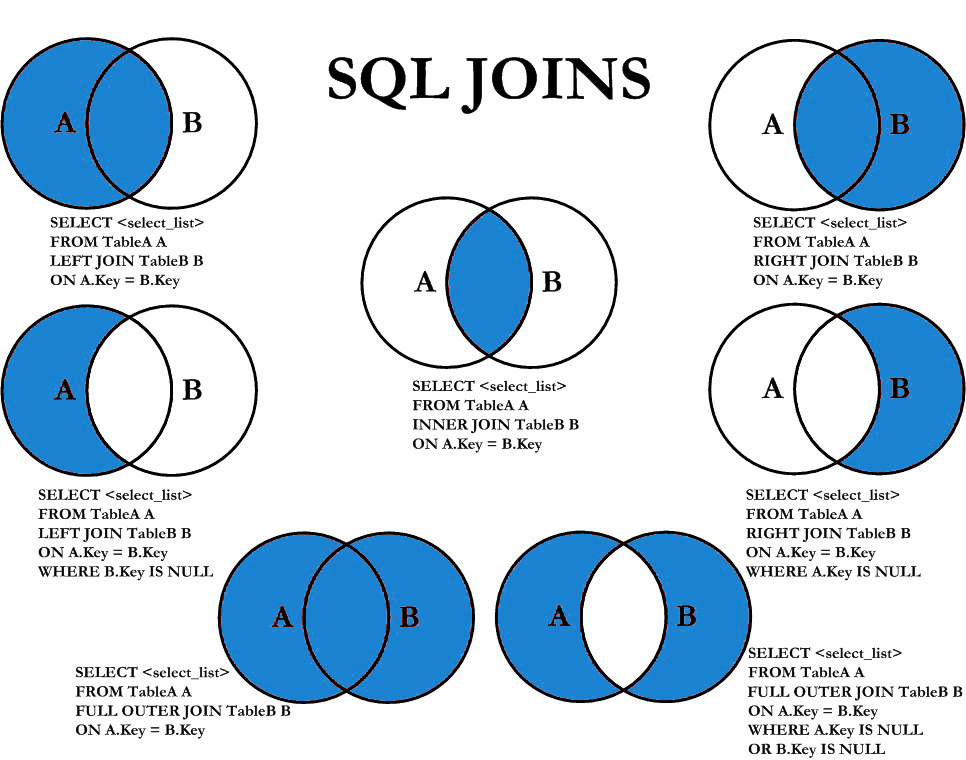
ВНУТРЕННИЕ соединенияINNER JOINs
Внутреннее соединение, которое также называется эквивалентным объединением, является наиболее часто используемым типом объединения.The INNER JOIN, also known as an equi-join, is the most commonly used type of join. Это соединение используется для получения строк из двух или более таблиц, сопоставляя значение поля, которое является общим для таблиц.This join is used to retrieve rows from two or more tables by matching a field value that is common between the tables. Объединяемые поля должны иметь похожие типы данных, и вы не можете присоединиться к типам данных мемо или OLEOBJECT.The fields you join on must have similar data types, and you cannot join on MEMO or OLEOBJECT data types.
Чтобы создать оператор inner join , используйте ключевые слова inner join в предложении from инструкции SELECT
.To build an INNER JOIN statement, use the INNER JOIN keywords in the FROM clause of a SELECT statement.
В этом примере используется внутреннее соединение для создания набора результатов всех клиентов, у которых есть счета, а также даты и суммы этих счетов.This example uses the INNER JOIN to build a result set of all customers who have invoices, in addition to the dates and amounts of those invoices.
SELECT [Last Name], InvoiceDate, Amount
FROM tblCustomers INNER JOIN tblInvoices
ON tblCustomers.CustomerID=tblInvoices.CustomerID
ORDER BY InvoiceDate
Обратите внимание на то, что имена таблиц делятся на ключевые слова inner join и что реляционное сравнение выполняется после ключевого слова On .Be aware that the table names are divided by the  For the relational comparisons, you can also use the <, >, <=, >=, or <> operators, and you can also use the BETWEEN keyword. Кроме того, обратите внимание, что поля ID из обеих таблиц используются только в реляционном сравнении; они не являются частью результирующего набора.Also note that the ID fields from both tables are used only in the relational comparison; they are not part of the final result set.
For the relational comparisons, you can also use the <, >, <=, >=, or <> operators, and you can also use the BETWEEN keyword. Кроме того, обратите внимание, что поля ID из обеих таблиц используются только в реляционном сравнении; они не являются частью результирующего набора.Also note that the ID fields from both tables are used only in the relational comparison; they are not part of the final result set.
Для дальнейшей квалификации оператора SELECT можно использовать предложение WHERE после сравнения JOIN в предложении On
.To further qualify the SELECT statement, you can use a WHERE clause after the join comparison in the ON clause.В приведенном ниже примере набор результатов сужается, чтобы включить только счета, выпущенные после 1 января 1998 г.The following example narrows the result set to include only invoices dated after January 1, 1998.
SELECT [Last Name], InvoiceDate, Amount
FROM tblCustomers INNER JOIN tblInvoices
ON tblCustomers.CustomerID=tblInvoices.CustomerID
WHERE tblInvoices.InvoiceDate > #01/01/1998#
ORDER BY InvoiceDate
Если необходимо присоединиться к нескольким таблицам, можно вложить условия inner join .When you must join more than one table, you can nest the INNER JOIN clauses. Следующий пример строится на предыдущем операторе SELECT
SELECT [Last Name], InvoiceDate, Amount, City, State
FROM (tblCustomers INNER JOIN tblInvoices
ON tblCustomers. CustomerID=tblInvoices.CustomerID)
INNER JOIN tblShipping
ON tblCustomers.CustomerID=tblShipping.CustomerID
ORDER BY InvoiceDate
CustomerID=tblInvoices.CustomerID)
INNER JOIN tblShipping
ON tblCustomers.CustomerID=tblShipping.CustomerID
ORDER BY InvoiceDate
Обратите внимание, что первое предложение Join заключено в круглые скобки, чтобы оно было логически отделено от второго предложения Join .Be aware that the first JOIN clause is enclosed in parentheses to keep it logically separated from the second JOIN clause. Кроме того, можно присоединить таблицу к самой себе с помощью псевдонима для имени второй таблицы в предложении from .It is also possible to join a table to itself by using an alias for the second table name in the FROM clause. Предположим, вы хотите найти все записи клиентов, содержащие повторяющиеся фамилии.Suppose that you want to find all customer records that have duplicate last names. Это можно сделать, создав псевдоним «A» для второй таблицы и проверив имена, которые отличаются. You can do this by creating the alias «A» for the second table and checking for first names that are different.
You can do this by creating the alias «A» for the second table and checking for first names that are different.
SELECT tblCustomers.[Last Name], tblCustomers.[First Name] FROM tblCustomers INNER JOIN tblCustomers AS A ON tblCustomers.[Last Name]=A.[Last Name] WHERE tblCustomers.[First Name]<>A.[First Name] ORDER BY tblCustomers.[Last Name]
ВНЕШНИЕ соединенияOUTER JOINs
Внешнее объединение используется для получения записей из нескольких таблиц, сохраняя записи из одной из таблиц, даже если в другой таблице нет соответствующей записи.An OUTER JOIN is used to retrieve records from multiple tables while preserving records from one of the tables, even if there is no matching record in the other table. Существует два типа внешних объединений , поддерживаемых ядром баз данных Access: левые внешние соединения и правая внешние соединения.There are two types of OUTER JOINs that the Access database engine supports: LEFT OUTER JOINs and RIGHT OUTER JOINs.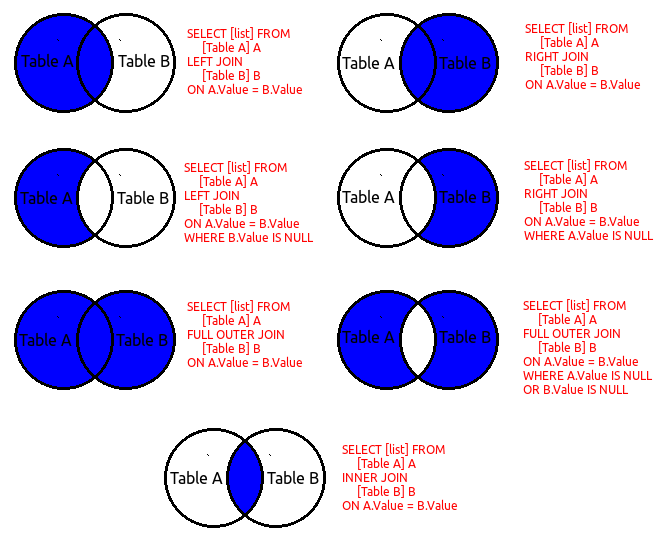
Вспомните две таблицы, расположенные рядом друг с другом, таблица слева и таблица справа.Think of two tables that are beside each other, a table on the left and a table on the right. Левое внешнее соединение выбирает все строки в правой таблице, которые совпадают с условиями реляционного сравнения, а также выбирает все строки из левой таблицы, даже если в правой таблице нет соответствия.The LEFT OUTER JOIN selects all rows in the right table that match the relational comparison criteria, and also selects all rows from the left table, even if no match exists in the right table. Правое внешнее соединение просто является обратным по отношению к левому внешнему соединению; Вместо этого сохраняются все строки в правой таблице.The RIGHT OUTER JOIN is simply the reverse of the LEFT OUTER JOIN; all rows in the right table are preserved instead.
Например, предположим, что вы хотите определить общую сумму выставленных счетов для каждого клиента, но если у клиента нет накладных, вы хотите отобразить его, отображая слово «нет».
SELECT [Last Name] & ', ' & [First Name] AS Name,
IIF(Sum(Amount) IS NULL,'NONE',Sum(Amount)) AS Total
FROM tblCustomers LEFT OUTER JOIN tblInvoices
ON tblCustomers.CustomerID=tblInvoices.CustomerID
GROUP BY [Last Name] & ', ' & [First Name]
В предыдущей инструкции SQL возникают некоторые события.Several things occur in the previous SQL statement. Первый — использование оператора сцепления строк «&».The first is the use of the string concatenation operator «&». Этот оператор позволяет объединить два поля вместе с одной строкой.This operator allows you to join two or more fields together as one string. Второй оператор — непосредственный оператор if ( IIf), который проверяет, имеет ли значение значение null.The second is the immediate if (IIf) statement, which checks to see if the total is null.
Внешние соединения могут быть вложены в внутренние соединения при объединении с несколькими таблицами, но внутренние соединения не могут быть вложены в внешние соединения.OUTER JOINs can be nested inside INNER JOINs in a multi-table join, but INNER JOINs cannot be nested inside OUTER JOINs.
Декартово произведениеThe Cartesian product
Термин, с которым часто приходится обсуждать соединения, это декартово произведение.A term that often comes up when discussing joins is the Cartesian product. Декартово-продукт определяется как «все возможные сочетания всех строк во всех таблицах».A Cartesian product is defined as «all possible combinations of all rows in all tables.» Например, если вы присоединяетесь к двум таблицам без какого бы то ни было какого типа квалификации или присоединения, вы получите декартово произведение.For example, if you were to join two tables without any kind of qualification or join type, you would get a Cartesian product.
SELECT *
FROM tblCustomers, tblInvoices
Это не хорошая вещь, особенно с таблицами, содержащими сотни или тысячи строк.This is not a good thing, especially with tables that contain hundreds or thousands of rows. Не создавайте декартово продукты, всегда выполняя присоединение.You should avoid creating Cartesian products by always qualifying your joins.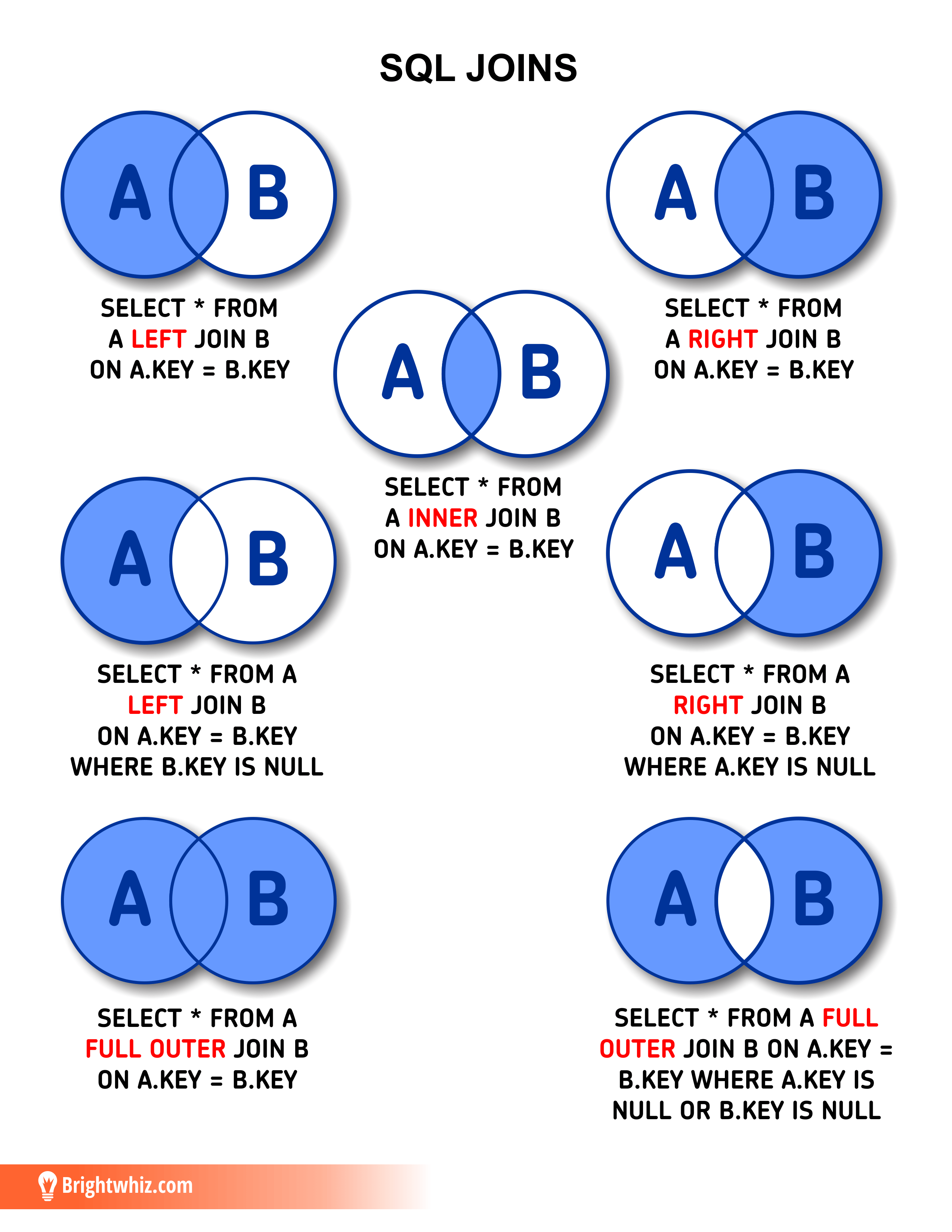
Оператор UNIONThe UNION operator
Несмотря на то, что оператор Union , также называемый запросом на объединение, не является объединением, он включается здесь, так как он включает в себя объединение данных из нескольких источников данных в один набор результатов, что аналогично некоторым типам соединений.Although the UNION operator, also known as a union query, is not technically a join, it is included here because it does involve combining data from multiple sources of data into one result set, which is similar to some types of joins. Оператор Union используется для объединения данных в таблицах, инструкциях SELECT или запросах, при этом не удаляются повторяющиеся строки.The UNION operator is used to splice together data from tables, SELECT statements, or queries, while leaving out any duplicate rows. Оба источника данных должны иметь одинаковое число полей, но эти поля не обязательно должны иметь одинаковый тип данных.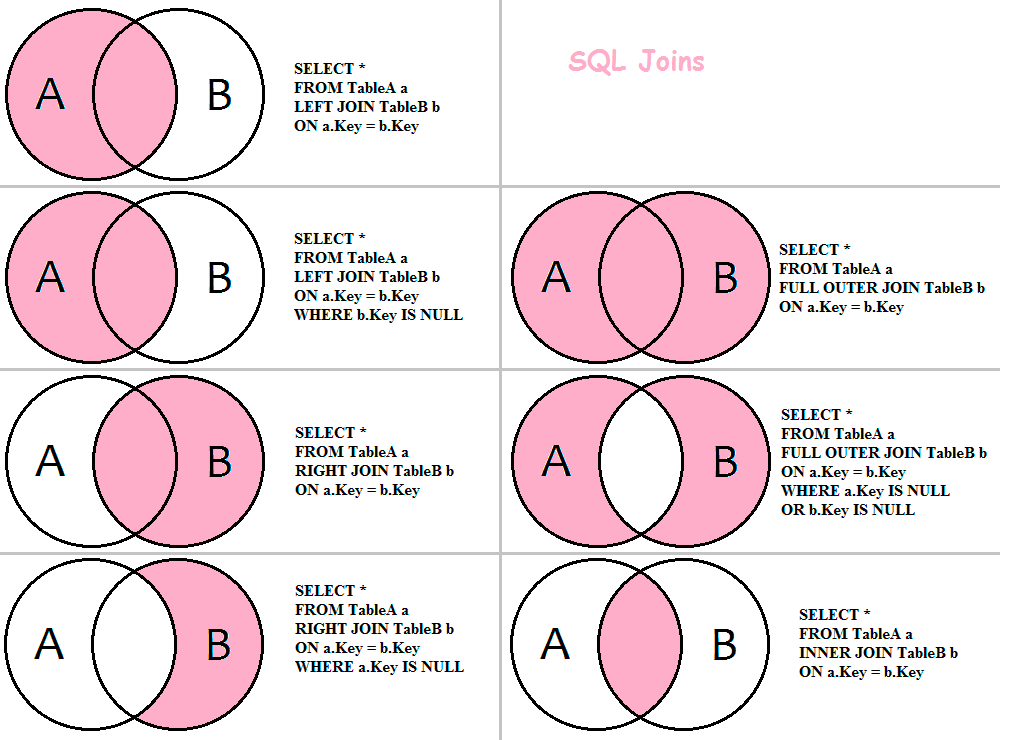 Both data sources must have the same number of fields, but the fields do not have to be the same data type. Предположим, у вас есть таблица Employees, имеющая ту же структуру, что и таблица Customers, и вы хотите создать список имен и адресов электронной почты, объединив обе таблицы.Suppose that you have an Employees table that has the same structure as the Customers table, and you want to build a list of names and email addresses by combining both tables.
Both data sources must have the same number of fields, but the fields do not have to be the same data type. Предположим, у вас есть таблица Employees, имеющая ту же структуру, что и таблица Customers, и вы хотите создать список имен и адресов электронной почты, объединив обе таблицы.Suppose that you have an Employees table that has the same structure as the Customers table, and you want to build a list of names and email addresses by combining both tables.
SELECT [Last Name], [First Name], Email
FROM tblCustomers
UNION
SELECT [Last Name], [First Name], Email
FROM tblEmployees
Чтобы получить все поля из обеих таблиц, можно использовать ключевое слово Table , как показано ниже.To retrieve all fields from both tables, you could use the TABLE keyword, like this.
TABLE tblCustomers
UNION
TABLE tblEmployees
Оператор Union не будет отображать записи, которые являются точными дубликатами в обеих таблицах, но их можно переопределить с помощью предиката ALL после ключевого слова Union , как показано ниже:The UNION operator will not display any records that are exact duplicates in both tables, but this can be overridden by using the ALL predicate after the UNION keyword, like this:
SELECT [Last Name], [First Name], Email
FROM tblCustomers
UNION ALL
SELECT [Last Name], [First Name], Email
FROM tblEmployees
Оператор TRANSFORMThe TRANSFORM statement
Несмотря на то, что инструкция Transform , также называемая перекрестным запросом, также не считается присоединением, она включается здесь, так как она включает в себя объединение данных из нескольких источников данных в один набор результатов, что аналогично некоторым типам соединений. Although the TRANSFORM statement, also known as a crosstab query, is also not technically considered a join, it is included here because it does involve combining data from multiple sources of data into one result set, which is similar to some types of joins.
Although the TRANSFORM statement, also known as a crosstab query, is also not technically considered a join, it is included here because it does involve combining data from multiple sources of data into one result set, which is similar to some types of joins.
Оператор Transform используется для вычисления суммы, среднего, количества или другого типа итогового значения для записей.A TRANSFORM statement is used to calculate a sum, average, count, or other type of aggregate total on records. Затем сведения отображаются в сетке или электронном формате с данными, сгруппированными по вертикали (строкам) и горизонтали (столбцам).It then displays the information in a grid or spreadsheet format with data grouped both vertically (rows) and horizontally (columns). Ниже приведена общая форма для оператора Transform .The general form for a TRANSFORM statement is the following.
TRANSFORM aggregating function
SELECT statement
PIVOT column heading field
Примером может служить создание таблицы, отображающей итоговые значения по счетам для каждого клиента на основе года. An example scenario could be if you want to build a datasheet that displays the invoice totals for each customer on a year-by-year basis. В качестве вертикальных заголовков будут использоваться имена клиентов, а для горизонтальных заголовков — годы.The vertical headings will be the customer names, and the horizontal headings will be the years. Вы можете изменить предыдущую инструкцию SQL, чтобы она соответствовала оператору Transform.You can modify a previous SQL statement to fit the transform statement.
An example scenario could be if you want to build a datasheet that displays the invoice totals for each customer on a year-by-year basis. В качестве вертикальных заголовков будут использоваться имена клиентов, а для горизонтальных заголовков — годы.The vertical headings will be the customer names, and the horizontal headings will be the years. Вы можете изменить предыдущую инструкцию SQL, чтобы она соответствовала оператору Transform.You can modify a previous SQL statement to fit the transform statement.
TRANSFORM
IIF(Sum([Amount]) IS NULL,'NONE',Sum([Amount]))
AS Total
SELECT [Last Name] & ', ' & [First Name] AS Name
FROM tblCustomers LEFT JOIN tblInvoices
ON tblCustomers.CustomerID=tblInvoices.CustomerID
GROUP BY [Last Name] & ', ' & [First Name]
PIVOT Format(InvoiceDate, 'yyyy')
IN ('1996','1997','1998','1999','2000')
Обратите внимание, что функция статистической обработки является функцией Sum , вертикальными заголовками являются предложение Group By оператора SELECT , а горизонтальные заголовки определяются полем, указанным после ключевого слова Pivot . Be aware that the aggregating function is the Sum function, the vertical headings are in the GROUP BY clause of the SELECT statement, and the horizontal headings are determined by the field listed after the PIVOT keyword.
Be aware that the aggregating function is the Sum function, the vertical headings are in the GROUP BY clause of the SELECT statement, and the horizontal headings are determined by the field listed after the PIVOT keyword.
Поддержка и обратная связьSupport and feedback
Есть вопросы или отзывы, касающиеся Office VBA или этой статьи?Have questions or feedback about Office VBA or this documentation? Руководство по другим способам получения поддержки и отправки отзывов см. в статье Поддержка Office VBA и обратная связь.Please see Office VBA support and feedback for guidance about the ways you can receive support and provide feedback.
Операторы Inner Join и Outer (left, right, full) Join в SQL (Oracle)
2006-01-06 Базы данных и язык запросов SQLКлючевое слово join в SQL используется при построении select выражений.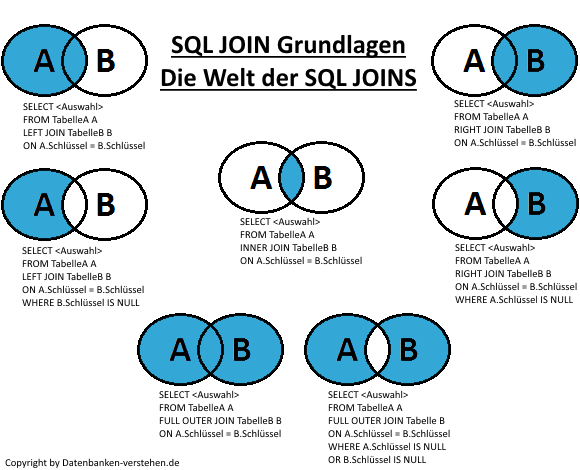 Инструкция Join позволяет объединить колонки из нескольких таблиц в одну. Объединение происходит временное и целостность таблиц не нарушается. Существует три типа join-выражений:
Инструкция Join позволяет объединить колонки из нескольких таблиц в одну. Объединение происходит временное и целостность таблиц не нарушается. Существует три типа join-выражений:
- inner join;
- outer join;
- cross join;
В свою очередь, outer join может быть left, right и full (слово outer обычно опускается).
В качестве примера (DBMS Oracle) создадим две простые таблицы и сконструируем для них SQL-выражения с использованием join.
В первой таблице будет хранится ID пользователя и его nick-name, а во второй — ID ресурса, имя ресурса и ID пользователя, который может этот ресурс администрировать.
create table t_users ( t_id number(11, 0), t_nick varchar(16), primary key (t_id) ) create table t_resources ( t_id number(11, 0), t_name varchar(16), t_userid number (11, 0), primary key (t_id) )
Содержимое таблиц пусть будет таким:
T_ID T_NICK 1 user1 3 user3 4 user4 T_ID T_NAME T_USERID 1 res1 3 2 res2 1 3 res3 2 5 res5 3
Конструкция join выглядит так:
... join_type join table_name on condition ...
Где join_type — тип join-выражения, table_name — имя таблицы, которая присоединяется к результату, condition — условие объединения таблиц.
Кострукция join располагается сразу после select-выражения. Можно использовать несколько таких конструкций подряд для объединения соответствующего кол-ва таблиц. Логичнее всего использовать join в том случае, когда таблица имеет внешний ключ (foreign key).
Inner join необходим для получения только тех строк, для которых существует соответствие записей главной таблицы и присоединяемой. Иными словами условие condition должно выполняться всегда. Пример:
select t_resources.t_name, t_users.t_nick from t_resources inner join t_users on t_users.t_id = t_resources.t_userid
Результат будет таким:
T_NAME T_NICK res2 user1 res1 user3 res5 user3
В случае с left join из главной таблицы будут выбраны все записи, даже если в присоединяемой таблице нет совпадений, то есть условие condition не учитывает присоединяемую (правую) таблицу. Пример:
Пример:
select t_resources.t_name, t_users.t_nick from t_resources left join t_users on t_users.t_id = t_resources.t_userid
Результат выполнения запроса:
T_NAME T_NICK res1 user3 res2 user1 res3 (null) res5 user3
Результат показывает все ресурсы и их администраторов, вне зависимотсти от того есть они или нет.
Right join отображает все строки удовлетворяющие правой части условия condition, даже если они не имеют соответствия в главной (левой) таблице:
select t_resources.t_name, t_users.t_nick from t_resources right join t_users on t_users.t_id = t_resources.t_userid
А результат будет следующим:
T_NAME T_NICK res2 user1 res1 user3 res5 user3 (null) user4
Результирующая таблица показывает ресурсы и их администраторов.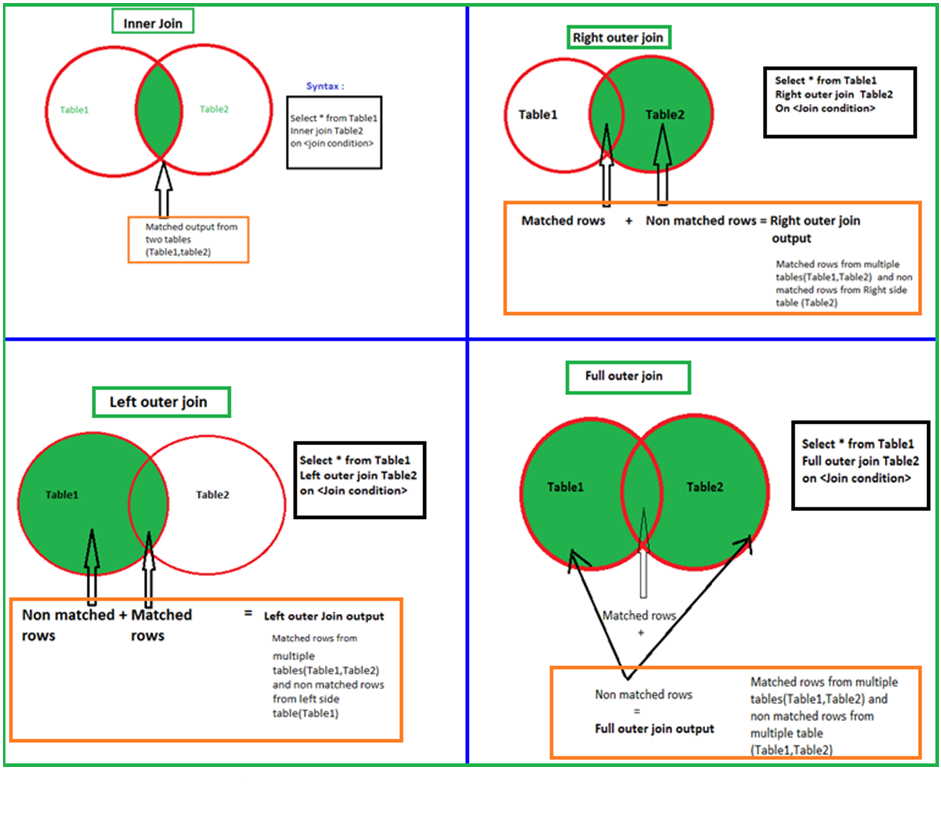 Если адмнистратор не задействован, эта запись тоже будет отображена. Такое может случиться, например, если ресурс был удален.
Если адмнистратор не задействован, эта запись тоже будет отображена. Такое может случиться, например, если ресурс был удален.
Full outer join (ключевое слово outer можно опустить) необходим для отображения всех возможных комбинаций строк из нескольких таблиц. Иными словами, это объединение результатов left и right join.
select t_resources.t_name, t_users.t_nick from t_resources full join t_users on t_users.t_id = t_resources.t_userid
А результат будет таким:
T_NAME T_NICK res1 user3 res2 user1 res3 (null) res5 user3 (null) user4
Некоторые СУБД не поддерживают такую функциональность (например, MySQL), в таких случаях обычно используют объединение двух запросов:
select t_resources.t_name, t_users.t_nick from t_resources left join t_users on t_users.t_id = t_resources.t_userid union select t_resources.t_name, t_users.t_nick from t_resources right join t_users on t_users.t_id = t_resources.t_userid
Наконец, cross join. Этот тип join еще называют декартовым произведением (на английском — cartesian product). Настоятельно рекомендую использовать его с умом, так как время выполнения запроса с увеличением числа таблиц и строк в них растет нелинейно. Вот пример запроса, который аналогичен cross join:
select t_resources.t_name, t_users.t_nick from t_resources, t_users
Конструкция Join (в сочетании с другими SQL конструкциями, например, group by) часто встречается при программировании под базы данных. Думаю, эта статья будет вам полезна.
Кстати, для проверки своих знаний в области баз данных (и в частности Oracle) рекомендую воспользоваться этим сайтом онлайн тестирования — Тесты по базам данных.
MySQL: оператор JOIN — Индустрия веб разработки
Большинство начинающих веб программистов начинает свое изучение MySQL с простейших операторов SELECT, UPDATE и DELETE. Данными операторами вполне можно описать весь необходимый функционал простого сайта, но, как можно догадаться, на этом возможности языка SQL далеко не заканчиваются. В процессе разработки обязательно потребуется объединение данных из нескольких таблиц. И для этих целей существует оператор JOIN. Данный оператор является основным оператором стандарта SQL92 и поддерживается большинством СУБД.
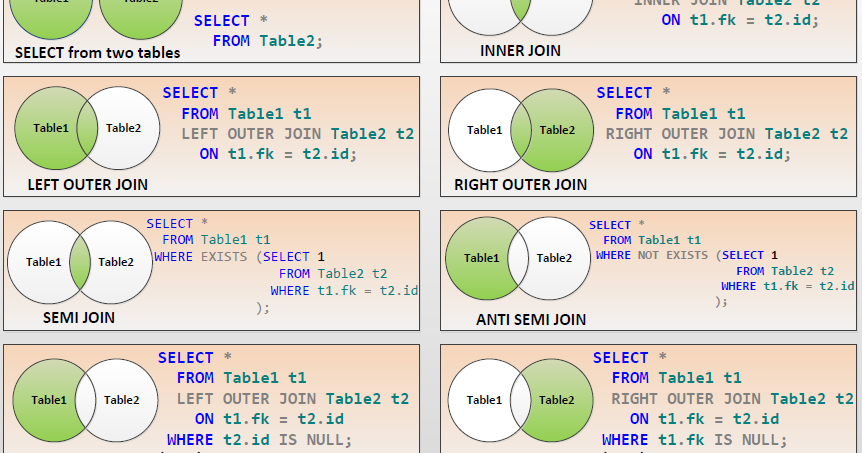
Общий синтаксис JOIN выглядит следующим образом:SELECT FIELD [,... n]
FROM MainTable
{INNER | {LEFT | RIGHT | FULL} OUTER | CROSS } JOIN JoinTable ON <conditions>Однако, сразу следует отметить, что СУБД MySQL поддерживает только два наиболее популярных выражения: INNER JOIN и LEFT JOIN.
Рассмотрим как работает каждый из операторов, для этого создадим две таблицы: TableA и TableB.![]()
id name id name -- ---- -- ---- 1 Pirate 1 Rutabaga 2 Monkey 2 Pirate 3 Ninja 3 Darth Vader 4 Spaghetti 4 Ninja
Попробуем объединить данные из этих таблиц используя различные варианты конструкции оператора JOIN.
1. INNER JOIN – внутреннее соединение. Объединяет две таблицы, где каждая строка обоих таблиц в точности соответствует условию. Если для строки одной таблицы не найдено соответствия в другой таблице, строка не включается в набор.
SELECT * FROM TableA INNER JOIN TableB ON TableA.name = TableB.name
id name id name -- ---- -- ---- 1 Pirate 2 Pirate 3 Ninja 4 Ninja
INNER JOIN
Выбор по первичному ключу и индексу положительно сказывается на скорости выборки.
2. OUTER JOIN – внешнее объединение.
Присоединение таблицы с необязательным присутствием записи в таблице.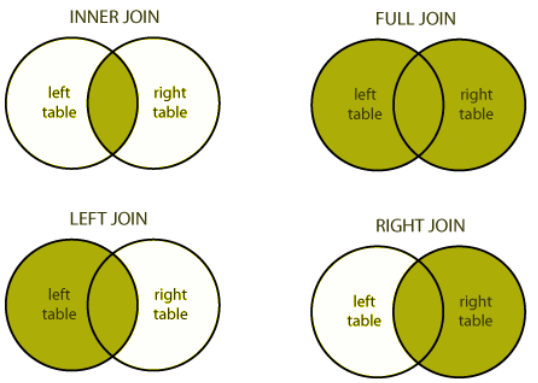 Также как и в случае с inner join, условие по индексированным полям и первичному ключу ускоряет все виды outer join’ов.
Также как и в случае с inner join, условие по индексированным полям и первичному ключу ускоряет все виды outer join’ов.
2.1 LEFT OUTER JOIN или LEFT JOIN-левое внешнее объединения. Левосторонние объединения позволяют извлекать данные из левой таблицы, дополняя их по возможности данными из правой таблицы, поля правой таблицы заполняются значениями NULL.
SELECT * FROM TableA LEFT OUTER JOIN TableB ON TableA.name = TableB.name
id name id name -- ---- -- ---- 1 Pirate 2 Pirate 2 Monkey null null 3 Ninja 4 Ninja 4 Spaghetti null null
LEFT OUTER JOIN
Если дополнить предыдущий запрос условием на проверку несуществования, то можно получить список записей, которые не имеют пары в таблице TableB:
SELECT * FROM TableA LEFT OUTER JOIN TableB ON TableA.name = TableB.name WHERE TableB.id IS null
id name id name -- ---- -- ---- 2 Monkey null null 4 Spaghetti null null
LEFT OUTER JOIN
2. 2 RIGHT OUTER JOIN или RIGHT JOIN — Правостороннее внешнее объединение
2 RIGHT OUTER JOIN или RIGHT JOIN — Правостороннее внешнее объединение
Этот вид объединений практически ничем не отличается от левостороннего объединения, за тем исключением, что данные берутся из второй таблицы, которая находится справа от конструкции JOIN, и сравниваются с данными, которые находятся в таблице, указанной перед конструкцией.
2.3 FULL OUTER JOIN – комбинация правого и левого объединений. К левой таблице присоединяются все записи из правой, соответствующие условию (по правилам inner join), плюс все не вошедшие записи из правой таблицы, поля левой таблицы заполняются значениями NULL и плюс все не вошедшие записи из левой таблицы, поля правой таблицы заполняются значениями NULL.
SELECT * FROM TableA FULL OUTER JOIN TableB ON TableA.name = TableB.name
id name id name -- ---- -- ---- 1 Pirate 2 Pirate 2 Monkey null null 3 Ninja 4 Ninja 4 Spaghetti null null null null 1 Rutabaga null null 3 Darth Vader
FULL OUTER JOIN
SELECT * FROM TableA FULL OUTER JOIN TableB ON TableA.name = TableB.name WHERE TableA.id IS null OR TableB.id IS null
id name id name -- ---- -- ---- 2 Monkey null null 4 Spaghetti null null null null 1 Rutabaga null null 3 Darth Vader
FULL OUTER JOIN
3. CROSS JOIN – перекрестное объединение (декартово произведение), выводятся все возможные сочетания из обеих таблиц. Для этого типа оператора JOIN условия не указывается.
SELECT * FROM TableA CROSS JOIN TableB
id name id name -- ---- -- ---- 1 Pirate 1 Rutabaga 2 Monkey 2 Rutabaga 3 Ninja 3 Rutabaga 4 Spaghetti 4 Rutabaga 1 Pirate 1 Pirate 2 Monkey 2 Pirate 3 Ninja 3 Pirate 4 Spaghetti 4 Pirate 1 Pirate 1 Darth Vader 2 Monkey 2 Darth Vader 3 Ninja 3 Darth Vader 4 Spaghetti 4 Darth Vader 1 Pirate 1 Ninja 2 Monkey 2 Ninja 3 Ninja 3 Ninja 4 Spaghetti 4 Ninja
Данная конструкция, по причине своей не нужности, не поддерживается почти ни в одной БД
SQL Server: присоединяется к
В этом руководстве по SQL Server объясняется, как использовать JOINS , как INNER, так и OUTER JOINS, в SQL Server (Transact-SQL) с синтаксисом, наглядными иллюстрациями и примерами.
Описание
SQL Server (Transact-SQL) СОЕДИНЕНИЯ используются для извлечения данных из нескольких таблиц. SQL Server JOIN выполняется всякий раз, когда две или более таблиц объединяются в операторе SQL.
Существует 4 различных типа соединений SQL Server:
- SQL Server ВНУТРЕННЕЕ СОЕДИНЕНИЕ (или иногда называемое простым соединением)
- SQL Server LEFT OUTER JOIN (или иногда его называют LEFT JOIN)
- SQL Server RIGHT OUTER JOIN (или иногда называется RIGHT JOIN)
- ПОЛНОЕ ВНЕШНЕЕ СОЕДИНЕНИЕ SQL Server (или иногда его называют ПОЛНОЕ СОЕДИНЕНИЕ)
Итак, давайте обсудим синтаксис SQL Server JOIN, посмотрим на визуальные иллюстрации SQL Server JOINS и рассмотрим примеры SQL Server JOIN.
INNER JOIN (простое соединение)
Скорее всего, вы уже написали оператор, использующий INNER JOIN SQL Server. Это наиболее распространенный тип соединения. SQL Server INNER JOINS возвращает все строки из нескольких таблиц, в которых выполнено условие соединения.
Синтаксис
Синтаксис INNER JOIN в SQL Server (Transact-SQL):
ВЫБРАТЬ столбцы ИЗ table1 INNER JOIN table2 НА table1.column = table2.column;
Визуальная иллюстрация
На этой визуальной диаграмме SQL Server INNER JOIN возвращает заштрихованную область:
SQL Server INNER JOIN вернет записи, в которых пересекаются table1 и table2 .
Пример
Вот пример INNER JOIN в SQL Server (Transact-SQL):
ВЫБЕРИТЕ поставщиков.id_supplier_id, поставщиков.supplier_name, orders.order_date ОТ поставщиков INNER JOIN заказы ON поставщиков.supplier_id = orders.supplier_id;
В этом примере SQL Server INNER JOIN будут возвращены все строки из таблиц поставщиков и заказов, в которых есть совпадающее значение supplier_id как в таблицах поставщиков, так и в таблицах заказов.
Давайте посмотрим на некоторые данные, чтобы объяснить, как работают INNER JOINS:
У нас есть таблица поставщиков с двумя полями (supplier_id и supplier_name).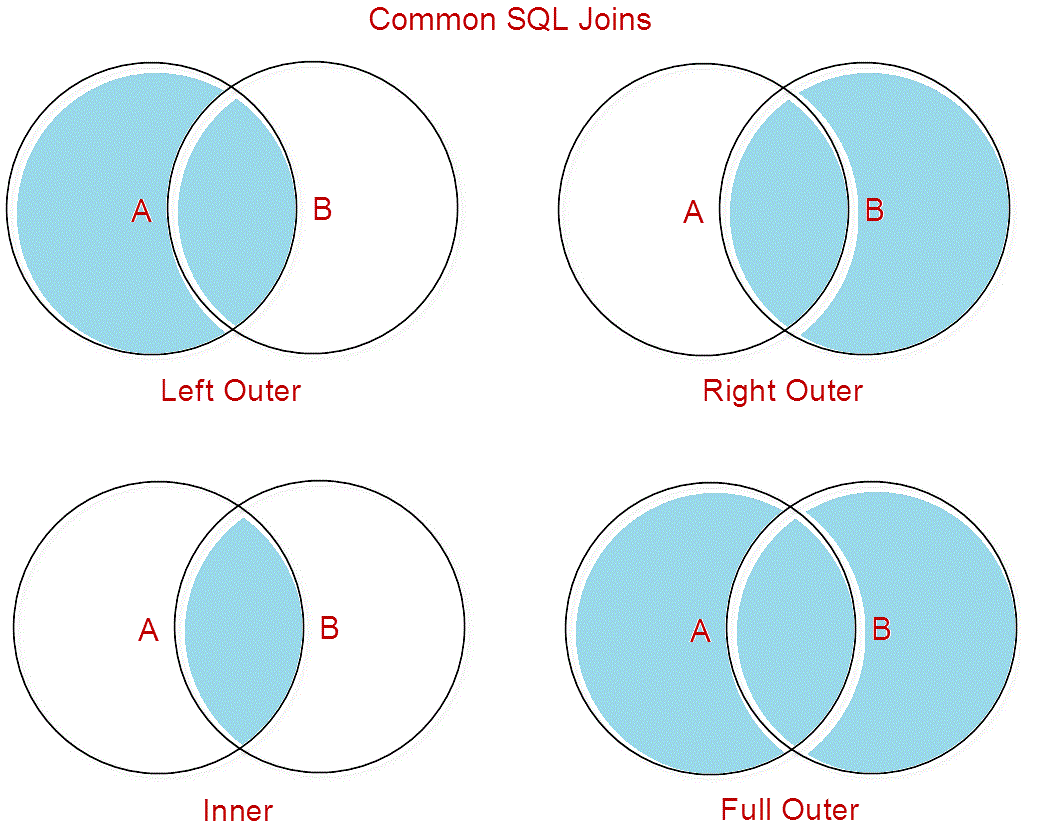 Он содержит следующие данные:
Он содержит следующие данные:
| идентификатор_ поставщика | имя_поставщика |
|---|---|
| 10000 | IBM |
| 10001 | Hewlett Packard |
| 10002 | Microsoft |
| 10003 | NVIDIA |
У нас есть еще одна таблица под названием orders с тремя полями (order_id, supplier_id и order_date).Он содержит следующие данные:
| идентификатор заказа | provider_id | дата заказа |
|---|---|---|
| 500125 | 10000 | 12.05.2003 |
| 500126 | 10001 | 13.05.2003 |
| 500127 | 10004 | 14.05.2003 |
Если мы запустим инструкцию SQL Server SELECT (которая содержит INNER JOIN) ниже:
ВЫБЕРИТЕ поставщиков.идентификатор_ поставщика, имя_поставщика.имя_поставщика, заказ_дата_поставщика ОТ поставщиков INNER JOIN заказы ON поставщиков.supplier_id = orders.supplier_id;
Наш набор результатов будет выглядеть так:
| идентификатор_ поставщика | название | дата заказа |
|---|---|---|
| 10000 | IBM | 12.05.2003 |
| 10001 | Hewlett Packard | 13.05.2003 |
Строки для Microsoft и NVIDIA из таблицы поставщиков будут опущены, так как 10002 и 10003 поставщика_id не существуют в обеих таблицах.Строка для 500127 (идентификатор_заказа) из таблицы заказов будет опущена, поскольку идентификатор поставщика 10004 не существует в таблице поставщиков.
Старый синтаксис
В заключение стоит упомянуть, что приведенный выше пример INNER JOIN SQL Server может быть переписан с использованием старого неявного синтаксиса как
SQL Joins — CodeProject
Введение
Первое, что мы учимся делать с SQL, — это писать команду SELECT оператор для получения данных из одной таблицы. Такое заявление кажется
прямолинейно и очень близко к языку, на котором мы говорим.
Такое заявление кажется
прямолинейно и очень близко к языку, на котором мы говорим.
Но реальные запросы часто намного сложнее, чем
эти простые инструкции SELECT .
Прежде всего, обычно нужные нам данные разбиваются на несколько разные таблицы. Это естественное следствие нормализации данных, которое важная особенность любой хорошо спроектированной модели базы данных. И SQL дает вам возможность собрать эти данные воедино.
В прошлом администраторы баз данных и разработчики ставили все необходимое
таблицы и / или представления в предложении FROM, а затем используйте предложение WHERE для определения
как записи из каждой таблицы будут сочетаться с другими записями. (Сделать
этот текст стал более читабельным, с этого момента я упрощу и скажу
«таблица» вместо «таблица и / или представление»).
Но прошло много времени с тех пор, как у нас есть стандарт для
объединяя эти данные. И это делается с помощью оператора JOIN (ANSI-SQL 92). К сожалению, есть некоторые подробности об операторах JOIN, которые
остаются непонятными для многих.
К сожалению, есть некоторые подробности об операторах JOIN, которые
остаются непонятными для многих.
Ниже я покажу различные синтаксисы объединений, поддерживаемых T-SQL. (это SQL Server 2008). Я выделю несколько концепций, которые, как мне кажется, не следует забывать каждый раз, когда мы объединяем данные из двух или более таблиц.
Начало работы: 1 Таблица , нет Присоединиться
Когда у вас есть только один объект для запроса, синтаксис будет довольно
простой и без соединения.Заявление будет старым и добрым
« ВЫБРАТЬ поля ИЗ объекта » плюс любые другие необязательные
предложение, которое вы, возможно, захотите использовать (то есть WHERE , GROUP BY , ИМЕЮЩИЙ , или ЗАКАЗАТЬ ПО ).
Конечные пользователи не знают, что мы, администраторы баз данных, обычно скрываем
множество сложных объединений под одним красивым и простым в использовании представлением. Это сделано для
несколько причин, начиная от безопасности данных и заканчивая производительностью базы данных. За
Например, администраторы баз данных могут предоставлять конечным пользователям разрешения на доступ к одному единственному представлению.
вместо нескольких производственных таблиц, что явно увеличивает безопасность данных.Или же
учитывая производительность, администраторы баз данных могут создать представление, используя правильные параметры для
объединить записи из нескольких таблиц, правильно используя индексы базы данных и тем самым
повышение производительности запросов.
Это сделано для
несколько причин, начиная от безопасности данных и заканчивая производительностью базы данных. За
Например, администраторы баз данных могут предоставлять конечным пользователям разрешения на доступ к одному единственному представлению.
вместо нескольких производственных таблиц, что явно увеличивает безопасность данных.Или же
учитывая производительность, администраторы баз данных могут создать представление, используя правильные параметры для
объединить записи из нескольких таблиц, правильно используя индексы базы данных и тем самым
повышение производительности запросов.
В общем, объединения могут присутствовать в базе данных, даже если конечные пользователи их не видят.
Логика Объединение таблиц
Много лет назад, когда я начал работать с SQL, я узнал там
Было несколько типов соединений.Но мне потребовалось время, чтобы понять, что
именно я это делал, когда собирал эти таблицы. Может потому что люди
настолько боятся математики, что не часто говорят, что вся идея
за объединением столов — это набор
Теория. Несмотря на причудливое название, концепция настолько проста, что нас учат
это в начальной школе.
Несмотря на причудливое название, концепция настолько проста, что нас учат
это в начальной школе.
Чертеж на Рисунке 1 очень похож на те, что были в моем детские книги от первого класса. Идея состоит в том, чтобы найти соответствующие объекты в разные наборы.Что ж, это именно то, что мы делаем с SQL JOINs!
Как только вы поймете эту аналогию, все начнется смысл.
Считайте, что 2 набора — это таблицы и числа, которые мы видим ключи, которые мы будем использовать для объединения таблиц. Так что в каждом наборе вместо представляя все записи, мы видим только ключевые поля из каждого стол. Набор результатов этой комбинации будет определяться типом присоединяйтесь, мы рассматриваем, и это тема, которую я сейчас покажу.Чтобы проиллюстрировать наши Например, у нас есть 2 таблицы, показанные ниже:
Таблица 1
ключ1 | поле1 | поле2 | ключ2 | ключ3 |
3 | Эрик | 8 | 1 | 6 |
4 | Джон | 3 | 4 | 4 |
6 | Марка | 3 | 7 | 1 |
7 | Петр | 6 | 8 | 5 |
8 | Гарри | 0 | 9 | 2 |
Таблица 2
ключ2 | поле1 | поле2 | поле3 |
1 | Нью-Йорк | А | N |
2 | Сан-Паулу | Б | N |
4 | Париж | К | Y |
5 | Лондон | К | Y |
6 | Рим | К | Y |
9 | Мадрид | К | Y |
0 | Бангалор | Д | N |
Скрипт для создания и заполнения этих таблиц доступен как
один прикрепленный файл ( SQLServerCentral.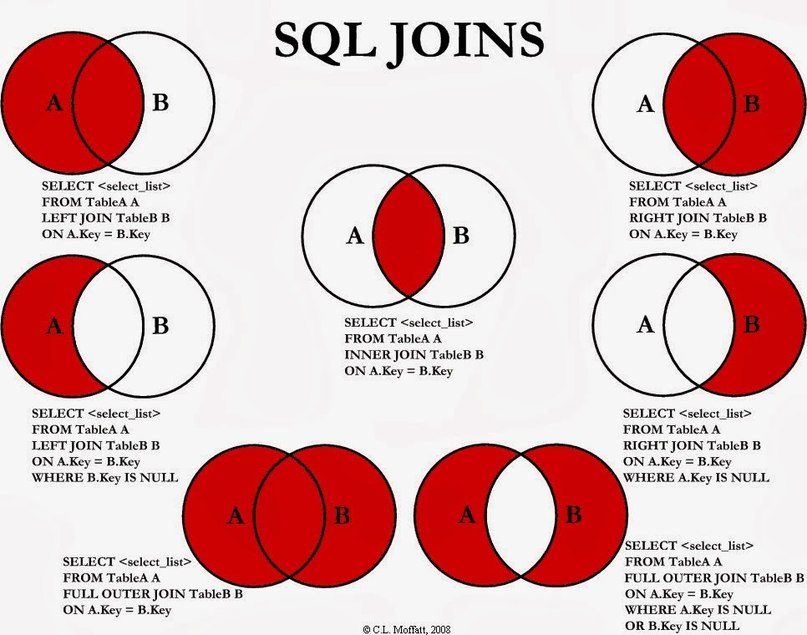 com_JOIN.sql ) в ресурсах
раздел ниже.
com_JOIN.sql ) в ресурсах
раздел ниже.
Вы заметите, что этот скрипт не полностью реализует ссылочную целостность. Я намеренно оставил таблицы без внешних ключей, чтобы лучше объясните функциональность различных типов соединений. Но я сделал это для Только в дидактических целях. Внешние ключи чрезвычайно полезны для гарантии данных согласованность, и их нельзя исключать из реальной базы данных.
Что ж, теперь мы готовы к работе.Давайте проверим, какие типы соединений мы может использовать в T-SQL соответствующий синтаксис и набор результатов, каждый из которых будет генерировать.
Внутреннее соединение
Это наиболее распространенное соединение, которое мы используем в SQL. Он возвращает пересечение двух множеств. Или, если говорить о таблицах, приносит только записи из обеих таблиц, соответствующих заданному критерию.
На Рисунке 2 мы видим диаграмму Венна, иллюстрирующую внутреннюю
соединение двух таблиц. Набор результатов операции — это область красного цвета.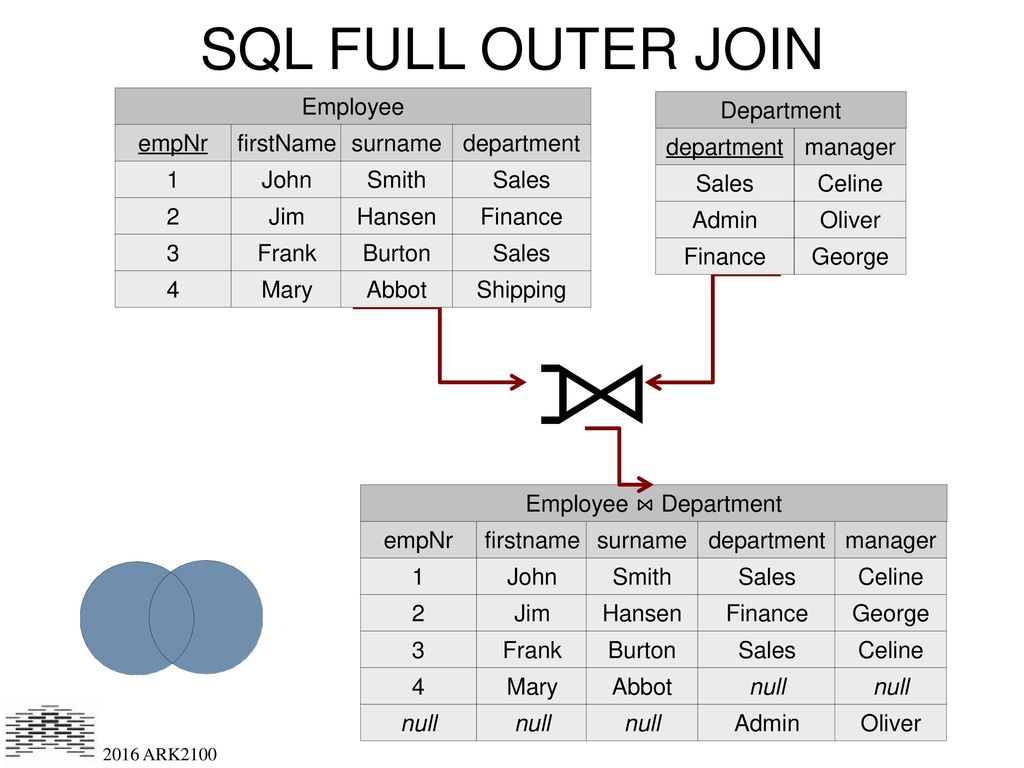
Рисунок 2: Представление INNER JOIN
Теперь проверьте синтаксис, чтобы объединить данные из Table1 и Table2 , используя ВНУТРЕННЕЕ СОЕДИНЕНИЕ.
ВЫБЕРИТЕ t1.key1, t1.field1 как имя, t1.key2 как T1Key,
t2.key2 как T2Key, t2.field1 как City
ИЗ Table1 t1
INNER JOIN Table2 t2 ON t1.key2 = t2.key2; Набор результатов этого оператора будет:
ключ1 | Имя | T1Key | T2Key | Городской |
3 | Эрик | 1 | 1 | Нью-Йорк |
4 | Джон | 4 | 4 | Париж |
6 | Гарри | 9 | 9 | Мадрид |
Обратите внимание, что он вернул только данные из записей, которые имеют
одинаковое значение для key2 для Table1 и Table2 .
В отличие от INNER JOIN существует также OUTER JOIN. Там — это три типа ВНЕШНИХ СОЕДИНЕНИЙ: полное, левое и правое. Мы рассмотрим каждый один подробно ниже.
ПОЛНОЕ СОЕДИНЕНИЕ
Это также известно как FULL OUTER JOIN (зарезервированное слово OUTER не является обязательным). ПОЛНЫЕ СОЕДИНЕНИЯ работают как объединение двух наборов. Теперь у нас есть Рисунок 3 Диаграмма Венна, иллюстрирующая ПОЛНОЕ СОЕДИНЕНИЕ двух таблиц. Набор результатов операция — снова область красного цвета.
Рисунок 3: Представление ПОЛНОГО СОЕДИНЕНИЯ
Синтаксис почти такой же, как мы видели раньше.
ВЫБЕРИТЕ t1.key1, t1.field1 как имя, t1.key2 как T1Key,
t2.key2 как T2Key, t2.field1 как City
ИЗ Table1 t1
FULL JOIN Table2 t2 ON t1.key2 = t2.key2; Набор результатов этого оператора будет:
ключ1 | Имя | T1Key | T2Key | Городской |
3 | Эрик | 1 | 1 | Нью-Йорк |
4 | Джон | 4 | 4 | Париж |
6 | Марка | 7 | null | null |
7 | Петр | 8 | null | null |
8 | Гарри | 9 | 9 | Мадрид |
null | null | null | 2 | Сан-Паулу |
null | null | null | 5 | Лондон |
null | null | null | 6 | Рим |
null | null | null | 0 | Бангалор |
FULL JOIN возвращает все записи из Table1 и Table2 ,
без дублирования данных.
ЛЕВОЕ СОЕДИНЕНИЕ
Также известный как LEFT OUTER JOIN, это частный случай ПОЛНОЕ СОЕДИНЕНИЕ. Он приносит все запрошенные данные из таблицы, которая появляется слева. оператора JOIN, плюс данные из правой таблицы, которая пересекается с первый. Ниже представлена диаграмма Венна, иллюстрирующая ЛЕВОЕ СОЕДИНЕНИЕ двух таблицы на рисунке 4.
Рисунок 4: Представление LEFT JOIN
См. Синтаксис ниже.
ВЫБРАТЬ t1.key1, t1.field1 как имя, t1.key2 как T1Key,
t2.key2 как T2Key, t2.field1 как City
ИЗ Table1 t1
LEFT JOIN Table2 t2 ON t1.key2 = t2.key2; Набор результатов этого оператора будет:
ключ1 | Имя | T1Key | T2Key | Городской |
3 | Эрик | 1 | 1 | Нью-Йорк |
4 | Джон | 4 | 4 | Париж |
6 | Марка | 7 | null | null |
7 | Петр | 8 | null | null |
8 | Гарри | 9 | 9 | Мадрид |
Третья и четвертая записи ( key1 равно
до 6 и 7) отображать NULL значений в последних полях, потому что нет информации
быть принесенным со второго стола.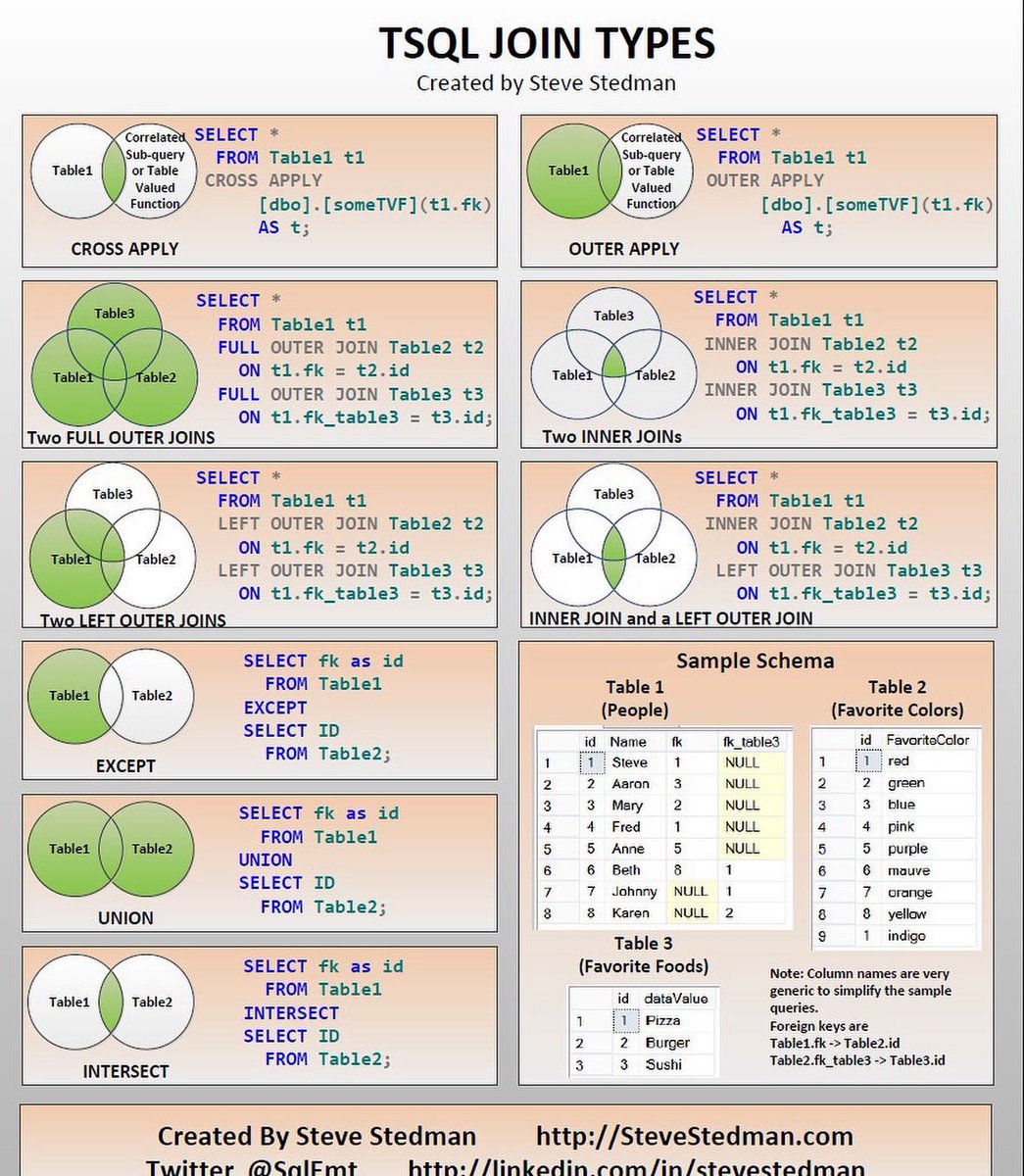 Это означает, что у нас есть значение в поле key2 в Table1 без
Соответствующее значение в Table2 . Мы могли бы избежать этой «несогласованности данных» в
случае у нас был внешний ключ в поле key2 в Table1 .
Это означает, что у нас есть значение в поле key2 в Table1 без
Соответствующее значение в Table2 . Мы могли бы избежать этой «несогласованности данных» в
случае у нас был внешний ключ в поле key2 в Table1 .
ПРАВИЛЬНОЕ ПРИСОЕДИНЕНИЕ
Также известен как RIGHT OUTER JOIN, это еще один частный случай. ПОЛНОГО СОЕДИНЕНИЯ. Он приносит все запрошенные данные из таблицы, которая появляется в справа от оператора JOIN, плюс данные из левой таблицы, которая пересекается с правым.Диаграмма Венна для ПРАВИЛЬНОГО СОЕДИНЕНИЯ двух Таблицы представлены на Рисунке 5.
Рисунок 5: Представление ПРАВОГО СОЕДИНЕНИЯ
Как видите, синтаксис очень похож.
ВЫБЕРИТЕ t1.key1, t1.field1 как имя, t1.key2 как T1Key,
t2.key2 как T2Key, t2.field1 как City
ИЗ Table1 t1
RIGHT JOIN Table2 t2 ON t1.key2 = t2.key2; Набор результатов этого оператора будет:
ключ1 | Имя | T1Key | T2Key | Городской |
null | null | null | 0 | Бангалор |
3 | Эрик | 1 | 1 | Нью-Йорк |
null | null | null | 2 | Сан-Паулу |
4 | Джон | 4 | 4 | Париж |
null | null | null | 5 | Лондон |
null | null | null | 6 | Рим |
8 | Гарри | 9 | 9 | Мадрид |
Обратите внимание, что записи с ключом key1 равны
до 6 и 7 больше не появляются в наборе результатов.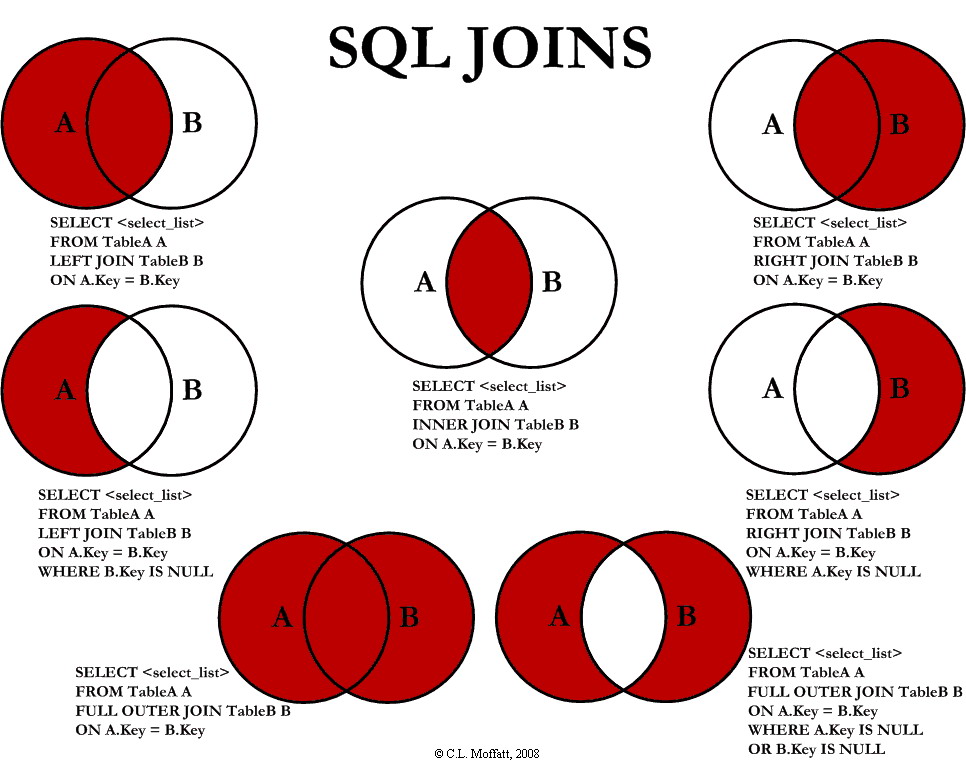 Это потому, что у них нет
соответствующая запись в правой таблице. Есть 4 записи, показывающие NULL
значения в первых полях, потому что они недоступны в левой таблице.
Это потому, что у них нет
соответствующая запись в правой таблице. Есть 4 записи, показывающие NULL
значения в первых полях, потому что они недоступны в левой таблице.
КРЕСТ СОЕДИНЕНИЕ
CROSS JOIN на самом деле декартово произведение. Использование CROSS JOIN генерирует точно такой же вывод при вызове двух таблиц (разделенных запятой) вообще без JOIN. Это означает, что мы получим огромный набор результатов, где каждый запись Table1 будет продублирована для каждой записи в Table2 .Если Table1 имеет N1 записей и Таблица 2 имеет N2 записей, на выходе будет N1 умноженное на N2 записей.
Я не верю, что есть способ представить этот результат в виде Диаграмма Венна. Думаю, это будет трехмерное изображение. Если это действительно В этом случае диаграмма будет больше сбивать с толку, чем объяснять.
Синтаксис CROSS JOIN будет:
ВЫБЕРИТЕ t1.key1, t1.field1 как имя, t1. key2 как T1Key,
t2.key2 как T2Key, t2.field1 как Город
ИЗ Table1 t1
CROSS JOIN Table2 t2;
key2 как T1Key,
t2.key2 как T2Key, t2.field1 как Город
ИЗ Table1 t1
CROSS JOIN Table2 t2; Как Таблица1 имеет 5 записей, а Таблица2 имеет еще 7, на выходе этого запроса будет 35 записей (5 x 7).
Проверьте прикрепленный файл ( SQLServerCentral.com_JOIN_CrossJoin.rpt ).
Если честно, я сейчас не припомню, чтобы единственная реальная ситуация, в которой мне действительно нужно создать декартово произведение два стола. Но когда вам нужно, CROSS JOIN все равно есть.
Кроме того, стоит позаботиться о производительности. Скажи тебе случайно запустить на рабочем сервере запрос с CROSS JOIN более двух таблицы с 1 миллионом записей. Это, безусловно, то, что даст вам Головная боль. Вероятно, ваш сервер начнет показывать проблемы с производительностью, так как ваш запрос может выполняться в течение некоторого времени, занимая значительную часть сервера Ресурсы.
САМОСОЕДИНЕНИЕ
Оператор JOIN может использоваться для объединения любой пары таблиц,
в том числе совмещение таблицы с собой. Это «самостоятельное присоединение».
Самостоятельное присоединение может использовать любой оператор JOIN.
Это «самостоятельное присоединение».
Самостоятельное присоединение может использовать любой оператор JOIN.
Например, посмотрите этот классический пример возврата начальник сотрудника (на основании Table1 ). В этом примере мы считайте, что значение в поле 2 на самом деле является боссом ‘ кодовый номер, поэтому относится к key1 .
ВЫБЕРИТЕ t1.key1, t1.field1 как имя,
t1.field2, mirror.field1 как босс
ИЗ Table1 t1
LEFT JOIN Table1 mirror ON t1.field2 = mirror.key1; И это результат этого запроса.
ключ1 | Имя | поле2 | Бобышка |
3 | Эрик | 8 | Гарри |
4 | Джон | 3 | Эрик |
6 | Марка | 3 | Эрик |
7 | Петр | 8 | Гарри |
8 | Гарри | 0 | null |
В этом примере последняя запись показывает, что у Гарри нет босса,
или, другими словами, он №1 в иерархии компании.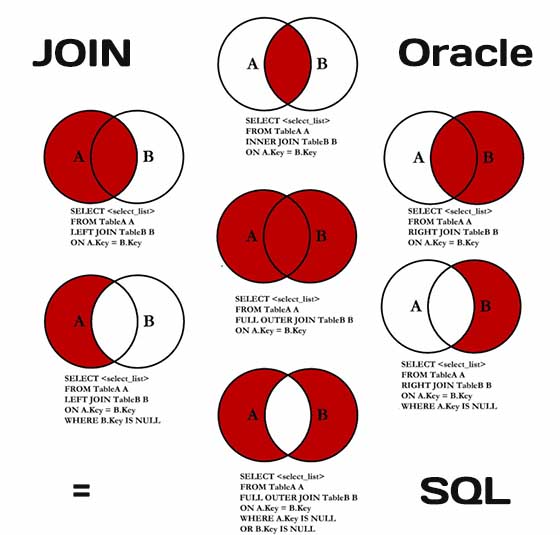
Без пересечения множеств
Проверяя предыдущие диаграммы Венна, которые я только что показал выше, можно приходят к простому вопросу: что, если мне нужно получить все записи из Table1 , кроме для тех, которые соответствуют записям в Table2 . Хорошо, это очень полезно в повседневной работе, но, очевидно, нам не нужен специальный оператор JOIN для этого.
Посмотрите на наборы результатов выше, и вы увидите, что вам нужно только
добавьте в оператор SQL предложение WHERE , ища записи, которые имеют ПУСТО значение для ключа Table2 .Итак, набор результатов, который мы ищем, представляет собой показанную красную область.
на диаграмме Венна ниже (Рисунок 6).
Рисунок 6: Несовпадающие записи из Table1 .
Мы можем написать LEFT JOIN для этого запроса, например:
ВЫБЕРИТЕ t1.key1, t1.field1 как имя, t1. key2 как T1Key,
t2.key2 как T2Key, t2.field1 как City
ИЗ Table1 t1
LEFT JOIN Table2 t2 ON t1.key2 = t2.key2
ГДЕ t2.key2 ЕСТЬ NULL;
key2 как T1Key,
t2.key2 как T2Key, t2.field1 как City
ИЗ Table1 t1
LEFT JOIN Table2 t2 ON t1.key2 = t2.key2
ГДЕ t2.key2 ЕСТЬ NULL; И, наконец, результат будет:
ключ1 | Имя | T1Key | T2Key | Городской |
6 | Марка | 7 | null | null |
7 | Петр | 8 | null | null |
Когда мы делаем такой запрос, мы должны обращать внимание на то, какие
поле, которое мы выбираем для предложения WHERE .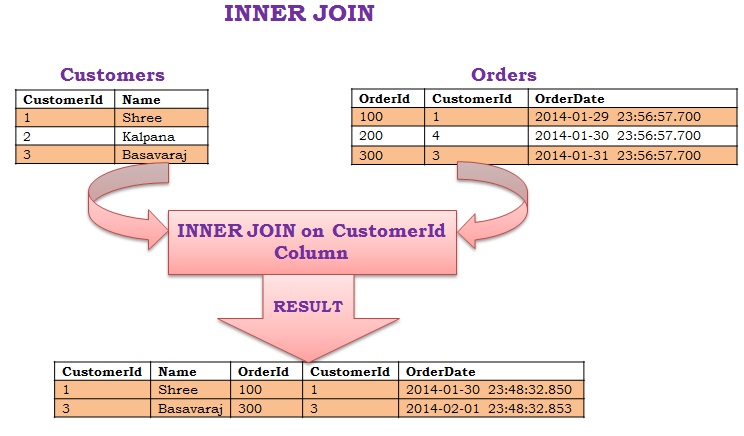 Мы должны использовать поле, которое не позволяет
Мы должны использовать поле, которое не позволяет NULL значений. В противном случае результирующий набор может включать нежелательные записи. Поэтому
Я предложил использовать ключ второй таблицы. В частности, его первичный ключ.
Поскольку первичные ключи не принимают значения NULL, они обеспечат наш набор результатов
будет именно то, что нам нужно.
Одно слово о планах выполнения
Эти комментарии приводят нас к важному выводу. Мы обычно не
перестаньте думать об этом, но обратите внимание, что план выполнения SQL-запросов
сначала вычислит набор результатов для предложения FROM и оператора JOIN
(если есть), и тогда будет выполнено предложение WHERE .
Это верно как для SQL Server, так и для любой другой СУБД.
Базовое понимание того, как работает SQL, важно для любой администратор базы данных или разработчик. Это поможет вам добиться цели. Быстро и надежный способ. Если вам это интересно, просто посмотрите на исполнение план для запроса выше, показан
Объединения и индексы
Взгляните еще раз на план выполнения этого запроса. Заметьте это
использовали кластерные индексы обеих таблиц.Использование индексов — лучший способ
сделайте ваш запрос быстрее. Но нужно обратить внимание на некоторые детали.
Заметьте это
использовали кластерные индексы обеих таблиц.Использование индексов — лучший способ
сделайте ваш запрос быстрее. Но нужно обратить внимание на некоторые детали.
Когда мы пишем наши запросы, мы ожидаем, что запрос SQL Server Оптимизатор для использования индексов таблиц для повышения производительности запросов. Мы также можем помогите оптимизатору запросов выбрать проиндексированные поля, которые будут частью вашего запроса.
Например, при использовании оператора JOIN идеальный подход заключается в том, чтобы основать условие соединения на индексированных полях. Снова проверяем выполнение План, мы замечаем, что кластерный индекс на Table2 был используемый.Этот индекс был автоматически построен на key2 , когда эта таблица была создана, так как key2 является первичным ключом к ней стол.
С другой стороны, Table1 не имел
индекс по полю key2 . Из-за этого оптимизатор запросов старался быть достаточно умным.
Вспомнив немного о ссылочной целостности, вы увидите key2 должен быть внешним ключом в Table1 , потому что он связан с другим полем в другой таблице (которая это Table2.key2 ).
Лично я считаю, что внешние ключи должны существовать во всех реальных модели баз данных. И неплохо создавать некластеризованные индексы для всех внешние ключи.Вы всегда будете запускать множество запросов, а также использовать JOIN оператор на основе вашего первичного и внешнего ключей.
( Важно : SQL Server автоматически создает кластерный
индекс по первичным ключам. Но по умолчанию он ничего не делает с внешними ключами.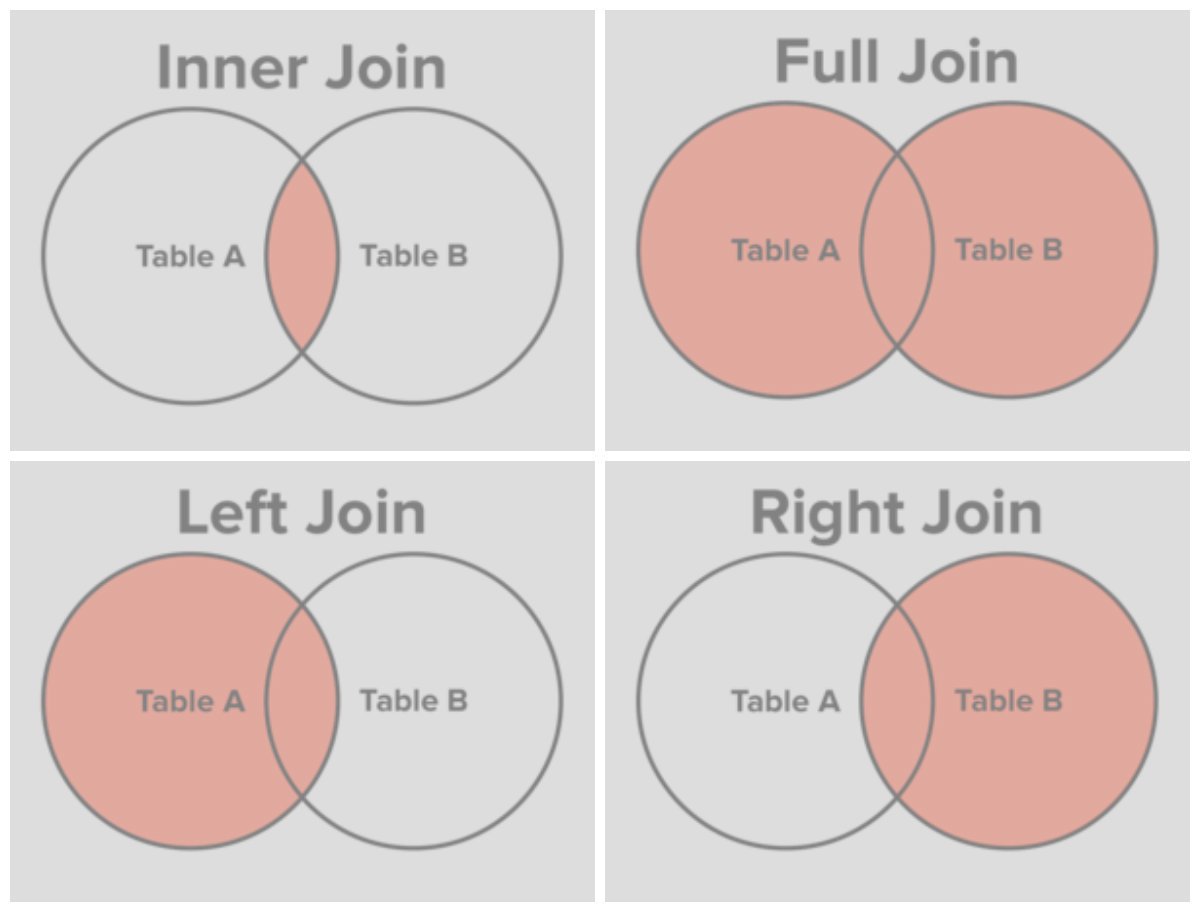 Так
убедитесь, что у вас есть правильные настройки в вашей базе данных).
Так
убедитесь, что у вас есть правильные настройки в вашей базе данных).
Неравные сравнения
Когда мы пишем операторы SQL с помощью оператора JOIN, мы обычно сравните, если одно поле в одной таблице равно другому полю в другой таблице.Но это не обязательный синтаксис. Мы могли бы использовать любой логический оператор, например отличается от (<>), больше (>), меньше (<) и т. д.
Хотя эта причудливая штука может создать впечатление, что SQL дает столько силы, что я чувствую, что это скорее косметическая особенность. Учти это пример. См. Таблицу 1 выше, где у нас есть 5 записей. Теперь рассмотрим следующий оператор SQL.
ВЫБЕРИТЕ t1.key1, t1.field1 как имя, t1.key2 как T1Key,
t2.key2 как T2Key, t2.field1 как City
ИЗ Table1 t1
INNER JOIN Table2 t2 ON t1.key2 <= t2.key2
ГДЕ t1.key1 = 3; Обратите внимание, что здесь используется внутреннее соединение, и мы специально выбираем
одна запись из Table1 , та, где key1 -
равно 3. Проблема только в том, что есть 6 записей и Table2 , которые
удовлетворяют условию соединения. Взгляните на результат этого запроса.
Проблема только в том, что есть 6 записей и Table2 , которые
удовлетворяют условию соединения. Взгляните на результат этого запроса.
ключ1 | Имя | T1Key | T2Key | Городской |
3 | Эрик | 1 | 1 | Нью-Йорк |
3 | Эрик | 1 | 2 | Сан-Паулу |
3 | Эрик | 1 | 4 | Париж |
3 | Эрик | 1 | 5 | Лондон |
3 | Эрик | 1 | 6 | Рим |
3 | Эрик | 1 | 9 | Мадрид |
Проблема с неравными объединениями в том, что они обычно дублируют
записи.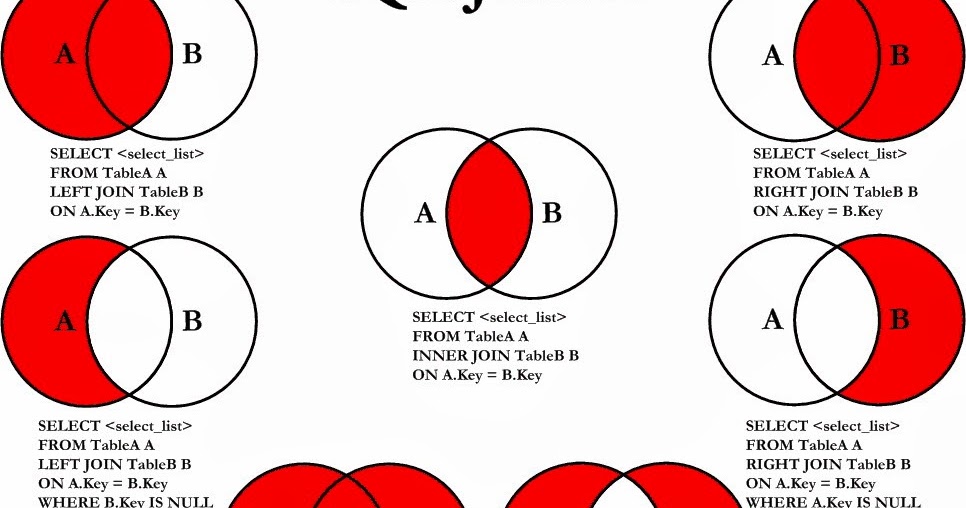 И это не то, что вам нужно регулярно. Так или иначе,
теперь вы знаете, что можете это сделать.
И это не то, что вам нужно регулярно. Так или иначе,
теперь вы знаете, что можете это сделать.
Несколько СОЕДИНЕНИЙ
SQL JOIN всегда сводятся к объединению пары таблиц и поиск связанных объектов, которые подчиняются заданному правилу (обычно, но не ограничиваясь этим, равные значения). Мы можем присоединиться к нескольким столам. Например, чтобы объединить 3 таблицы, вам понадобится 2 соединения. И для каждой новой таблицы потребуется новое соединение. Если вы используете соединение на каждом шаге, чтобы объединить N таблиц, вы будете использовать соединения N-1.
Важно то, что SQL позволяет использовать разные типы соединений в одном операторе.
Но администраторы баз данных и разработчики должны быть осторожны, присоединяясь к слишком многим
таблицы. Несколько раз я встречал ситуации, когда запросы требовали 10, 20
столы или даже больше. По соображениям производительности не рекомендуется делать
единый запрос для объединения всех данных. Оптимизатор запросов будет работать лучше
если вы разбиваете свой запрос на несколько более мелких и простых запросов.
Оптимизатор запросов будет работать лучше
если вы разбиваете свой запрос на несколько более мелких и простых запросов.
Теперь представьте, что у нас есть третья таблица с названием Table3 , показанная ниже.
Таблица 3
ключ3 | поле1 |
1 | Инженер |
2 | Хирург |
3 | DBA |
4 | Юрист |
5 | Учитель |
6 | Актер |
Теперь давайте напишем заявление, чтобы указать имя сотрудника,
город, в котором он живет и по профессии. Это потребует от нас присоединиться ко всем
3 таблицы. Просто помните, что объединения записываются парами. Итак, сначала мы соединим Table1 с Table2 . И
затем мы присоединимся к Table1 и Table3 . Итоговый сценарий показан ниже.
Это потребует от нас присоединиться ко всем
3 таблицы. Просто помните, что объединения записываются парами. Итак, сначала мы соединим Table1 с Table2 . И
затем мы присоединимся к Table1 и Table3 . Итоговый сценарий показан ниже.
ВЫБЕРИТЕ t1.key1, t1.field1 как Сотрудник,
t2.key2, t2.field1 как Город,
t3.key3, t3.field1 как профессия
ИЗ Table1 t1
INNER JOIN Table2 t2 ON t1.key2 = t2.key2
INNER JOIN Table3 t3 ON t1.key3 = t3.key3; Поскольку у нас работают только ВНУТРЕННИЕ СОЕДИНЕНИЯ, у нас будут только записи которые соответствуют комбинации 3 таблиц. См. Вывод ниже.
div clkey1 | Имя | ключ2 | Городской | ключ3 | Профессия |
3 | Эрик | 1 | Нью-Йорк | 6 | Актер |
4 | Джон | 4 | Париж | 4 | Юрист |
6 | Гарри | 9 | Мадрид | 2 | Хирург |
Помимо операторов SELECT
Использование операторов JOIN не ограничивается SELECT заявления. В T-SQL вы можете использовать объединения в операторах
В T-SQL вы можете использовать объединения в операторах INSERT , DELETE и UPDATE .
также. Но имейте в виду, что в большинстве современных СУБД объединения не выполняются.
поддерживается в операторах DELETE и UPDATE . Так что я бы посоветовал вам ограничить
использование объединений только с операторами SELECT и INSERT , даже в коде SQL Server.
Это важно, если вы хотите, чтобы ваши скрипты было легче переносить на
разные платформы.
Как избежать условных соединений в T-SQL
То, что некоторые SQL JOIN возможны, не означает, что они являются хорошим вариантом. «Условное СОЕДИНЕНИЕ» - одно из них.
Так что же такое условное соединение? Здесь один ключ в таблице используется для соединения либо с одной таблицей, либо с другими, в зависимости от какого-либо критерия. Звучит необычно, но такое бывает, особенно в очень сложных, иногда автоматически сгенерированных запросах. Обычно он представляет собой попытку использовать полиморфную связь между таблицами и представляет собой запах кода SQL.
Обычно он представляет собой попытку использовать полиморфную связь между таблицами и представляет собой запах кода SQL.
Термин «Условное СОЕДИНЕНИЕ» несколько неоднозначен, поскольку люди обращаются к различным проблемам, когда используют его. Кажется, что программисты хотят либо СОЕДИНЯТЬ таблицу с несколькими другими таблицами, либо СОЕДИНЯТЬ столбец в таблице с разными столбцами второй таблицы, выбирая столбец СОЕДИНЕНИЕ на основе условия.
Поскольку T-SQL не имеет синтаксиса, который позволял бы поместить имя таблицы в оператор CASE, первое определение условного JOIN действительно не имеет никаких других средств разрешения, кроме как просто JOIN всех таблиц (вероятно, как LEFT OUTER JOINs) и используйте операторы CASE для извлечения определенных элементов данных, требуемых из вторичных таблиц, при необходимости.
Недавно я писал запрос, который можно разрешить, используя второй случай. Хотя я думал о нескольких других способах сделать это, с точки зрения кодирования использование оператора CASE в предложении ON JOIN привело к простейшему синтаксису, чтобы запрос работал. Однако был ли синтаксис, который выглядел простым, самым эффективным способом сделать это?
Однако был ли синтаксис, который выглядел простым, самым эффективным способом сделать это?
Давайте посмотрим правде в глаза, иногда в программировании вы не можете позволить себе роскошь отступить и перепроектировать систему, чтобы избежать требования, но всегда лучше, если мы можем оптимизировать производительность SQL, который соответствует требованиям.
Пример данных
Начнем с простого примера, иллюстрирующего условное соединение. Этот код создает две таблицы с одним миллионом строк тестовых данных во вторичной таблице, к которой мы будем выполнять условное JOIN.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 14 18 19 20 21 22 23 24 25 26 27 28 29 31 34 35 36 37 38 39 40 41 42 43 44 45 46 47 51 52 53 54 55 56 57 58 59 60 61 62 63 9 0003 6465 66 67 | СОЗДАТЬ ТАБЛИЦУ dbo. ( ID INT IDENTITY PRIMARY KEY , num INT NOT NULL ); INSERT INTO dbo.SampleLeftTable (num) VALUES (21), (44), (53), (78); CREATE TABLE dbo.ConditionalJoinExample ( ID INT IDENTITY PRIMARY KEY , N1 INT NOT NULL , N2 INT NOT NULL , N3 INTULL NOT NULL , N3 INTULL NOT NULL , N3 INTULL NOT NULL ) ; WITH Tally (n) AS ( SELECT ROW_NUMBER () OVER (ORDER BY (SELECT NULL)) FROM (VALUES (0), (0), (0), (0), ( 0), (0), (0), (0), (0), (0)) a (n) - 10 строк CROSS JOIN (VALUES (0), (0), (0), ( 0), (0), (0), (0), (0), (0), (0)) b (n) - x10 строк CROSS JOIN (VALUES (0), (0), ( 0), (0), (0), (0), (0), (0), (0), (0)) c (n) - x10 строк CROSS JOIN (VALUES (0), ( 0), (0), (0), (0), (0), (0), (0), (0), (0)) d (n) - x10 строк CROSS JOIN (VALUES ( 0), (0), (0), (0), (0), (0), (0), (0), (0), (0)) e (n) - x10 строк КРЕСТ ПРИСОЕДИНЯЙТЕСЬ (ЗНАЧЕНИЯ (0), (0), (0), (0), (0), (0), (0), (0), (0), (0)) f (n) - x10 строк ) - = 1 млн строк INSERT INTO dbo. ( N1, N2, N3, N4 ) - заполнить каждый столбец случайным числом в диапазоне {1,100} SELECT N1 = 1 + ABS (CHECKSUM (NEWID ()))% 100 , N2 = 1 + ABS (CHECKSUM (NEWID ()))% 100 , N3 = 1 + ABS (CHECKSUM (NEWID ()))% 100 , N4 = 1 + ABS (CHECKSUM (NEWID ( )))% 100 ОТ ТАЛИ; GO --DROP TABLE dbo.SampleLeftTable; --СКАЛЬНАЯ ТАБЛИЦА dbo.ConditionalJoinExample; Вот результаты. ВЫБРАТЬ * ИЗ dbo.SampleLeftTable; ID номер 1 21 2 44 3 53 4 78 SELECT TOP 10 * FROM dbo.ConditionalJoinExample; ID N1 N2 N3 N4 1 19 30 1 66 2 61 92 69 51 3 9 1 20 74 4 81 78 76 79 5 62100 37 75 6 59 83 58 43 7 89 70 76 30 8 40 11 85 91 9 97 16 67 84 10 22 50 74 30 |
 SampleLeftTable
SampleLeftTable ConditionalJoinExample
ConditionalJoinExample Вы можете видеть, что четыре столбца данных (N1, N2, N3 и N4) содержат случайные числа в диапазоне от 1 до 100.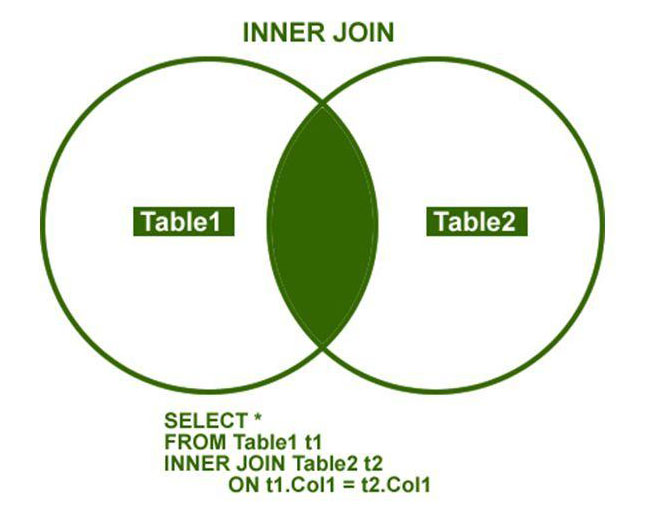 Мы выбрали ТОП-10 строк только для иллюстрации, и если вы будете следовать по тексту, вы получите другие, но похожие результаты во втором наборе результатов. Закомментированные DROP предоставляются для очистки вашей песочницы позже, если вы хотите запустить эти примеры на своем сервере. Обратите внимание, что мы будем запускать их с использованием SQL 2012, но также можно использовать SQL 2008 или SQL 2005.
Мы выбрали ТОП-10 строк только для иллюстрации, и если вы будете следовать по тексту, вы получите другие, но похожие результаты во втором наборе результатов. Закомментированные DROP предоставляются для очистки вашей песочницы позже, если вы хотите запустить эти примеры на своем сервере. Обратите внимание, что мы будем запускать их с использованием SQL 2012, но также можно использовать SQL 2008 или SQL 2005.
Сценарий 1: Условное соединение на основе данных в левой таблице
Теперь предположим, что у нас есть бизнес-требование, в котором говорится, что мы хотим выполнить JOIN из левой таблицы (4 строки) во вторичную таблицу на основе диапазона, в который попадает значение в левой таблице.Такое СОЕДИНЕНИЕ может выглядеть так.
ВЫБРАТЬ a.ID, num, b.ID, N1, N2, N3, N4 FROM dbo.SampleLeftTable a JOIN dbo.ConditionalJoinExample b ON num = CASE WHEN num BETWEEN 1 AND 25 .N1 КОГДА НОМЕР МЕЖДУ 26 И 50 ТОГДА b.N2 КОГДА НОМЕР МЕЖДУ 51 И 75 ТОГДА b.N3 ДРУГОЕ b.N4 КОНЕЦ; |
И он отображает результаты, которые выглядят следующим образом (показаны только первые пять строк из примерно 40 000 возвращенных).
ID номер ID N1 N2 N3 N4 3 53 23 52 70 53 4 3 53 72 48 49 53 3 3 53 227 89 81 53 1 3 53 269 19 28 53 77 3 53 393 83 72 53 78 |
Вы можете видеть, что, поскольку значение Num в строке в левой таблице равно 53, оно соответствует третьему столбцу N (N3) в таблице, к которой присоединилась.
Меня интересовали ВРЕМЯ и СТАТИСТИКА ВХОДА-ВЫВОДА, поэтому я запустил этот запрос с ними, и мы получили эти результаты.
(затронуты 40104 строки) Таблица SampleLeftTable. Счетчик сканирования 1, логических чтений 2, физических чтений 0, опережающих чтений 0, логических чтений lob 0, физических чтений lob 0, упреждающих чтений lob 0. Таблица 'ConditionalJoinExample'. Счетчик сканирования 4, логических чтений 14400, физических чтений 0, упреждающих чтений 0, логических чтений lob 0, физических чтений lob 0, упреждающих чтений lob 0. Стол "Рабочий стол". Счетчик сканирования 0, логических чтений 11676892, физических чтений 0, упреждающих чтений 0, lob логических чтений 0, lob физических чтений 0, упреждающих чтений lob 0. Таблица «Рабочая таблица». Счетчик сканирований 0, логических чтений 0, физических чтений 0, упреждающих чтений 0, логических чтений lob 0, физических чтений lob 0, упреждающих чтений lob 0. Время выполнения SQL Server: Процессорное время = 20015 мс, затраченное время = 5617 мс. |
Хотя для выполнения запроса потребовалось всего пять с половиной секунд, он выглядел подозрительно дорогим с точки зрения ЦП.План запроса для этого был такой.
Во-первых, мы не должны удивляться, увидев в планах оператор параллелизма, потому что из наших результатов по времени мы видим, что используемое процессорное время намного превышает время, прошедшее для запроса.
Мы также видим, что в обеих таблицах используется оператор сканирования кластерного индекса, но если мы посмотрим немного глубже на то, что происходит с правой таблицей (развернув детали операторов спула таблиц и сканирования кластерного индекса), мы увидим, что они пытаются работать с четырьмя миллионами (фактическими) строками данных, когда в таблице всего один миллион строк данных!
Наша первая мысль, конечно, заключается в том, что, возможно, мы сможем создать ИНДЕКС, чтобы немного ускорить работу этого плохого парня.Так что давай попробуем.
CREATEINDEX ix5ON dbo.ConditionalJoinExample (N1, N2, N3, N4); |
Когда мы снова запускаем тот же запрос, мы получаем эти временные результаты.
Время синтаксического анализа и компиляции SQL Server: Время ЦП = 0 мс, прошедшее время = 2 мс. (затронуты 40104 строки) Таблица SampleLeftTable.Счетчик сканирования 1, логических чтений 2, физических чтений 0, опережающих чтений 0, логических чтений lob 0, физических чтений lob 0, упреждающих чтений lob 0. Таблица 'ConditionalJoinExample'. Счетчик сканирования 4, логических чтений 12928, физических чтений 0, упреждающих чтений 0, логических чтений lob 0, физических чтений lob 0, упреждающих чтений lob 0. Таблица «Рабочая таблица». Счетчик сканирования 0, логических чтений 11676892, физических чтений 0, упреждающих чтений 0, lob логических чтений 0, lob физических чтений 0, упреждающих чтений lob 0. Таблица «Рабочая таблица».Счетчик сканирований 0, логических чтений 0, физических чтений 0, упреждающих чтений 0, логических чтений lob 0, физических чтений lob 0, упреждающих чтений lob 0. Время выполнения SQL Server: Процессорное время = 20279 мс, затраченное время = 5949 мс. |
И они не особо впечатляющие, примерно того же порядка, что и первые. По плану запроса:
Мы видим, что пока используется созданный нами ИНДЕКС, он, похоже, мало помог.Если вы повторите этот запрос и наведите курсор на операторы Index Scan (NonClustered) и Table Spool в графическом плане запроса, вы обнаружите, что в запросе использовались те же четыре миллиона фактических строк.
Определенно пора переписать этот запрос и ускорить его выполнение, найдя альтернативу условному соединению.
Вместо нашего условного JOIN мы можем разделить большую таблицу на четыре части, выполняя последовательные JOINs на каждом из разделов, а затем повторно объединяя части, как это (используя UNION ALL):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 14 18 19 20 21 22 23 24 25 26 | - Отбросьте досадно бесполезный INDEX DROP INDEX ix5 ON dbo.ConditionalJoinExample; ВЫБЕРИТЕ a.ID, num, b.ID, N1, N2, N3, N4 FROM dbo.SampleLeftTable a JOIN dbo.ConditionalJoinExample b ON num = b.N1 WHERE AND 25 UNION ALL SELECT a.ID, num, b.ID, N1, N2, N3, N4 FROM dbo.SampleLeftTable a JOIN dbo.ConditionalJoinExample b ON num = WHERE num BETWEEN 26 AND 50UNION ALL SELECT a.ID, num, b.ID, N1, N2, N3, N4 FROM dbo.SampleLeftTable a JOIN dbo.ConditionalJoinExample b ON num = b.N3 WHERE num BETWEEN 51 И UN 75 ВСЕХВЫБЕРИТЕ a.ID, num, b.ID, N1, N2, N3, N4 FROM dbo.SampleLeftTable a JOIN dbo.ConditionalJoinExample b ON num = b.N4 WHERE num 100ETWEEN; |
Хотя этот запрос кажется намного более сложным (он определенно занимает намного больше времени, чтобы написать даже с использованием копирования и вставки), мы очень впечатлены результатами по времени:
(затронуты 40104 строки) Таблица SampleLeftTable.Число сканирований 4, логических чтений 8, физических чтений 0, упреждающих чтений 0, логических чтений lob 0, физических чтений lob 0, упреждающих чтений lob 0. Таблица «Рабочая таблица». Счетчик сканирования 0, логических чтений 0, физических чтений 0, упреждающих чтений 0, логических чтений lob 0, физических чтений lob 0, упреждающих чтений lob 0. Таблица 'ConditionalJoinExample'. Счетчик сканирований 20, логических чтений 14600, физических чтений 0, упреждающих чтений 0, lob логических чтений 0, lob физических чтений 0, упреждающих чтений lob 0. Таблица «Рабочая таблица».Количество сканирований 0, логических чтений 0, физических чтений 0, упреждающих чтений 0, логических чтений lob 0, физических чтений lob 0, упреждающих чтений lob 0. Время выполнения SQL Server: Процессорное время = 249 мс, затраченное время = 389 мс. |
Хотя этот запрос сейчас выполняется менее чем за полсекунды (с уменьшением времени ЦП на два порядка), он действительно создает гораздо более (казалось бы) сложный план запроса.
Несмотря на то, что SQL выполняет четыре сканирования кластерного индекса большой таблицы, результаты в подавляющем большинстве случаев в пользу этого запроса по сравнению с условным JOIN.
SQL 2012 несколько ворчал, что отсутствует ИНДЕКС, который мог бы немного улучшить запрос, поэтому давайте продолжим и создадим ИНДЕКС, который он рекомендует, и попробуем еще раз.
- Добавить рекомендуемый ИНДЕКС СОЗДАТЬ НЕКЛАСТЕРНЫЙ ИНДЕКС ix1 НА dbo.ConditionalJoinExample (N4) INCLUDE (ID, N1, N2, N3); |
Теперь мы получаем эти временные результаты:
(затронуты 40104 строки) Таблица SampleLeftTable.Число сканирований 4, логических чтений 8, физических чтений 0, упреждающих чтений 0, логических чтений lob 0, физических чтений lob 0, упреждающих чтений lob 0. Таблица «Рабочая таблица». Счетчик сканирования 0, логических чтений 0, физических чтений 0, упреждающих чтений 0, логических чтений lob 0, физических чтений lob 0, упреждающих чтений lob 0. Таблица 'ConditionalJoinExample'. Счетчик сканирования 16, логических чтений 9807, физических чтений 0, упреждающих чтений 0, lob логических чтений 0, lob физических чтений 0, упреждающих чтений lob 0. Таблица «Рабочая таблица».Счетчик сканирований 0, логических чтений 0, физических чтений 0, упреждающих чтений 0, логических чтений lob 0, физических чтений lob 0, упреждающих чтений lob 0. Время выполнения SQL Server: Процессорное время = 265 мс, затраченное время = 398 мс. |
Мне кажется, что рекомендуемый ИНДЕКС нисколько не помог! И я действительно проверил план запроса и обнаружил, что оптимизатор использовал рекомендуемый ИНДЕКС.
С моей точки зрения, я бы сказал, что переписывание сработало достаточно, чтобы я, не колеблясь, использовал его в производстве без рекомендованного ИНДЕКСа, тем самым сэкономив пространство, которое потребовало бы создание ИНДЕКСа, не говоря уже о накладных расходах, связанных с этим ИНДЕКСОМ. в операторах INSERT, UPDATE и DELETE.
Я также должен отметить, что в нашей первой (условной JOIN) попытке мы работали со столбцами (N1,…, N4), которые все были одного типа данных. Если в вашем случае это не так, то, вероятно, есть дополнительные противники производительности в переводе их на тот же тип данных, на которые вы должны обратить внимание и принять во внимание.
Давайте отбросим этот ИНДЕКС, прежде чем приступить к следующему сценарию.
DROP INDEXix1 ONdbo.ConditionalJoinExample; |
Сценарий 2: Условное соединение на основе внешнего параметра
Иногда у вас может быть проблема SQL, которая заставляет вас думать, что вам нужно управлять столбцом условного ключа JOIN каким-либо переключателем, возможно, тем, который передается в качестве параметра в хранимой процедуре. Давайте посмотрим на упрощенный пример, в котором не используется хранимая процедура:
DECLARE @Switch INT = 1; ВЫБРАТЬ a.ID, num, b.ID, N1, N2, N3, N4 FROM dbo.SampleLeftTable a JOIN dbo.ConditionalJoinExample b ON num = CASE @Switch КОГДА 1 ТО b.N1 КОГДА b.N2 КОГДА 3 ТО b.N3 ELSE b.N4 КОНЕЦ; |
Здесь локальная переменная @Switch управляет столбцом, к которому мы присоединяемся. Результаты по времени выглядят подозрительно похожими на первый случай, который мы исследовали.
(затронуто 40156 строк) Таблица SampleLeftTable. Счетчик сканирования 1, логических чтений 2, физических чтений 0, опережающих чтений 0, логических чтений lob 0, физических чтений lob 0, упреждающих чтений lob 0. Таблица 'ConditionalJoinExample'. Счетчик сканирований 4, логических чтений 14400, физических чтений 0, упреждающих чтений 0, lob логических чтений 0, lob физических чтений 0, упреждающих чтений lob 0. Таблица «Рабочая таблица».Счетчик сканирования 0, логических чтений 11676892, физических чтений 0, упреждающих чтений 0, lob логических чтений 0, lob физических чтений 0, упреждающих чтений lob 0. Таблица «Рабочая таблица». Счетчик сканирований 0, логических чтений 0, физических чтений 0, опережающих чтений 0, логических чтений lob 0, физических чтений lob 0, упреждающих чтений lob 0. Время выполнения SQL Server: Время ЦП = 19297 мс, затраченное время = 5284 мс. |
Действительно, план запроса, который мы здесь не будем показывать, очень похож на первый план запроса, который мы показали, вплоть до четырех миллионов фактических строк в операторах Clustered Index Scan и Table Spool.
Использование идентичного подхода к рефакторингу:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 14 18 19 20 21 22 23 24 25 | DECLARE @Switch INT = 1; ВЫБРАТЬ a.ID, num, b.ID, N1, N2, N3, N4 FROM dbo.SampleLeftTable a JOIN dbo.ConditionalJoinExample b ON num = b.N1 WHERE @Switch = 1 UNION ALL3 ВЫБЕРИТЕ a.ID, num, b.ID, N1, N2, N3, N4 ИЗ dbo.SampleLeftTable a JOIN dbo.ConditionalJoinExample b ON num = b.N2 WHERE @Switch = 2 ВСЕВЫБЕРИТЕ a.ID, num, b.ID, N1, N2, N3, N4 FROM dbo.SampleLeftTable a JOIN dbo.ConditionalJoinExample b ON num = b.N3 WHERE @Switch = 3 UNION ALL SELECT a.ID, num, b.ID, N1, N2, N3, N4 FROM dbo.SampleLeftTable JOIN dbo.ConditionalJoinExample bON num = b.N4 WHERE @Switch NOT IN (1,2,3); |
В результате мы получаем гораздо более сложный запрос (с похожим, гораздо более сложным планом запроса), который выполняет быстрое разделение!
(затронуто 40156 строк) Таблица SampleLeftTable. Оставить комментарий
|