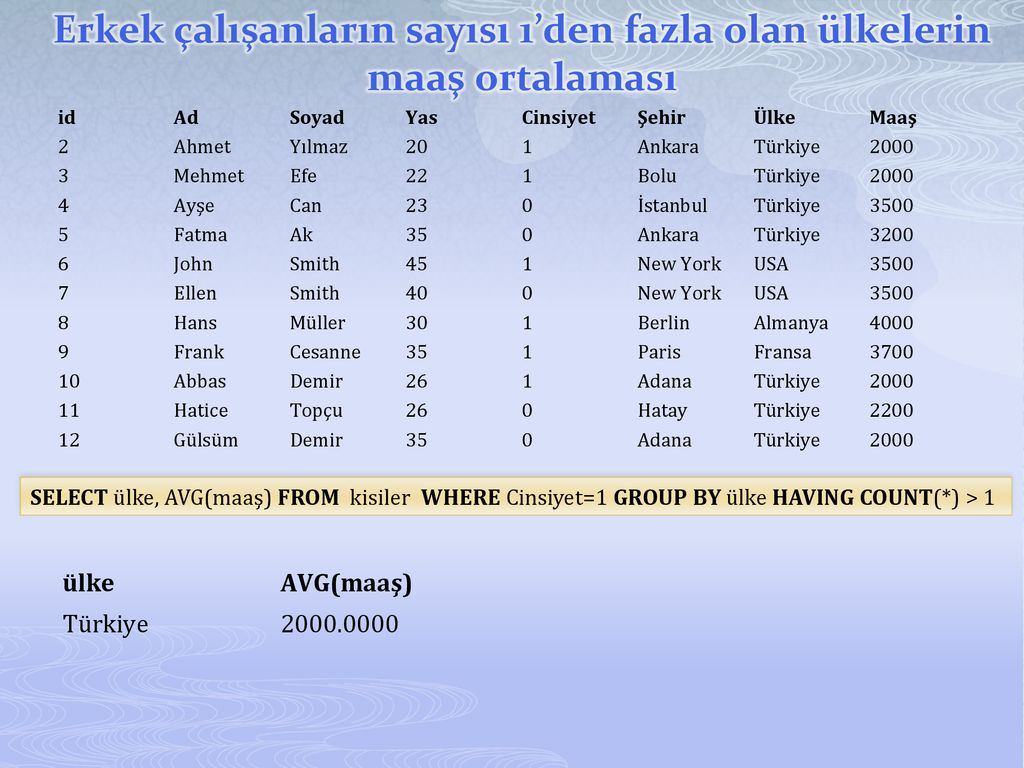
Оператор SQL GROUP BY: синтаксис, примеры
Оператор SQL GROUP BY используется для объединения результатов выборки по одному или нескольким столбцам.
Оператор SQL GROUP BY имеет следующий синтаксис:
GROUP BY column_name
С использованием оператора SQL GROUP BY тесно связано использование агрегатных функций и оператор SQL HAVING
Примеры оператора SQL GROUP BY. Имеется следующая таблица Artists:
| Singer | Album | Year | Sale |
| The Prodigy | Invaders Must Die | 2008 | 1200000 |
| Drowning Pool | Sinner | 2001 | |
| Massive Attack | Mezzanine | 1998 | 2300000 |
| The Prodigy | Fat of the Land | 1997 | 600000 |
| The Prodigy | Music For The Jilted Generation | 1994 | 1500000 |
| Massive Attack | 100th Window | 2003 | 1200000 |
| Drowning Pool | Full Circle | 2007 | 800000 |
| Massive Attack | Danny The Dog | 2004 | 1900000 |
| Drowning Pool | Resilience | 2013 | 500000 |
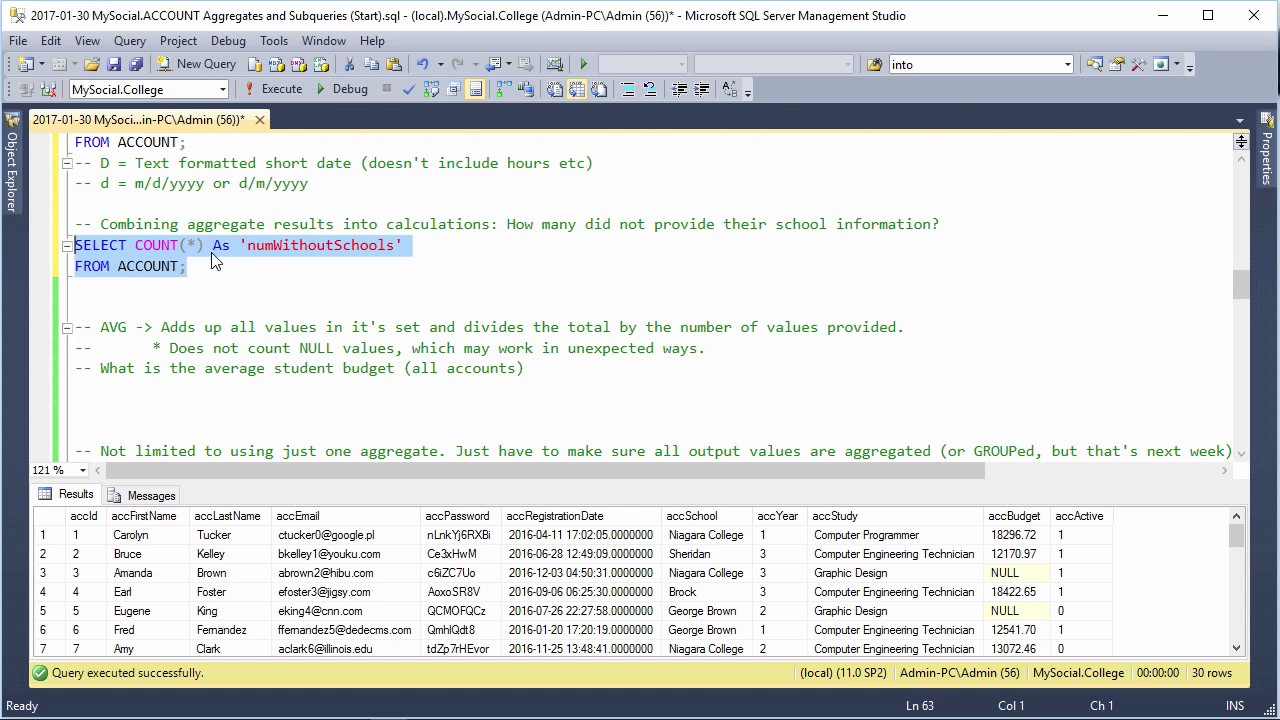
Пример 1. Используя оператор SQL GROUP BY найти сумму продаж альбомов (Sale) всех исполнителей (Singer):
Используя оператор SQL GROUP BY найти сумму продаж альбомов (Sale) всех исполнителей (Singer):
SELECT Singer, SUM(Sale) AS AllSales FROM Artists GROUP BY Singer
Результат:
| Singer | AllSales |
| Drowning Pool | 1700000 |
| Massive Attack | 5400000 |
| The Prodigy | 3300000 |
В данном запросе используется оператор SQL AS, позволяющий задать новое имя столбца AllSales на выходе. В нашем случае это сделано для наглядности.
Пример 2. Узнать в каком году был выпущен последний альбом каждой из групп используя оператор SQL GROUP BY:
SELECT Singer, MAX(Year) AS LastAlbumYear FROM Artists GROUP BY Singer
Результат:
| Singer | LastAlbumYear |
| Drowning Pool | 2013 |
| Massive Attack | 2004 |
| The Prodigy | 2008 |
GROUPING (Transact-SQL) — SQL Server
- Чтение занимает 2 мин
В этой статье
Применимо к: SQL Server (все поддерживаемые версии) База данных SQL Azure Управляемый экземпляр SQL Azure Azure Synapse Analytics
Указывает, является ли указанное выражение столбца в списке GROUP BY статистическим или нет. В результирующем наборе функция GROUPING возвращает 1 (статистическое выражение) или ноль (нестатистическое выражение). Функция GROUPING может использоваться только в списке SELECT <select>, предложениях HAVING и ORDER BY, если указано предложение GROUP BY.
Синтаксические обозначения в Transact-SQL
Синтаксис
GROUPING ( <column_expression> )
Аргументы
<column_expression>
Столбец или выражение, которое содержит столбец в предложении GROUP BY.
Типы возвращаемых данных
tinyint
Remarks
GROUPING используется, чтобы различать значения NULL, возвращаемые операторами ROLLUP, CUBE или GROUPING SETS, и стандартные значения NULL. Возвращение NULL в качестве результата операции ROLLUP, CUBE или GROUPING SETS является особым случаем использования NULL. Значение служит заполнителем столбца в результирующем наборе и означает «все».
Возвращение NULL в качестве результата операции ROLLUP, CUBE или GROUPING SETS является особым случаем использования NULL. Значение служит заполнителем столбца в результирующем наборе и означает «все».
Примеры
В следующем примере производится группирование SalesQuota и статистическая обработка сумм SaleYTD в базе данных AdventureWorks2012. Функция SalesQuota.
SELECT SalesQuota, SUM(SalesYTD) 'TotalSalesYTD', GROUPING(SalesQuota) AS 'Grouping'
FROM Sales.SalesPerson
GROUP BY SalesQuota WITH ROLLUP;
GO
В результирующем наборе показаны два значения NULL в SalesQuota. Первый NULL представляет группу значений NULL из этого столбца в таблице. Второй NULL находится в строке итогов, добавленной операцией ROLLUP. Строка итогов содержит суммы TotalSalesYTD для всех групп SalesQuota и обозначается с помощью 1 в столбце Grouping.
Результирующий набор:
SalesQuota TotalSalesYTD Grouping
------------ ----------------- --------
NULL 1533087.5999 0
250000.00 33461260.59 0
300000.00 9299677.9445 0
NULL 44294026.1344 1
(4 row(s) affected)
См. также:
GROUPING_ID (Transact-SQL)
GROUP BY (Transact-SQL)
Что означает SQL пункт «GROUP BY 1»?
Кто-то прислал мне запрос SQL, где предложение GROUP BY состояло из утверждения: GROUP BY 1 .
Это, должно быть, опечатка, верно? Ни один столбец не имеет псевдонима 1. Что это может означать? Правильно ли я предполагаю, что это должно быть опечатка?
mysql sql group-byПоделиться Источник Spencer 12 сентября 2011 в 19:10
6 ответов
- «group by» требуется в операторе count(*) SQL?
Следующее утверждение работает в моей базе данных: select column_a, count(*) from my_schema.

- SQL Оптимизировать Group By Запрос
У меня здесь есть таблица со следующими полями: Удостоверение личности, имя, вид. дата Данные: id name kind date 1 Thomas 1 2015-01-01 2 Thomas 1 2015-01-01 3 Thomas 2 2014-01-01 4 Kevin 2 2014-01-01 5 Kevin 2 2014-01-01 5 Kevin 2 2014-01-01 5 Kevin 2 2014-01-01 6 Sasha 1 2014-01-01 У меня есть…
239
Это означает group by первый столбец, независимо от того, как он называется. Вы можете сделать то же самое с ORDER BY .
Поделиться Yuck 12 сентября 2011 в 19:12
76
SELECT account_id, open_emp_id
^^^^ ^^^^
1 2
FROM account
GROUP BY 1;
В приведенном выше запросе GROUP BY 1 относится к first column in select statement , который является account_id .
Вы также можете указать в ORDER BY .
Примечание: число в порядке BY и GROUP BY всегда начинается с 1, а не с 0.
Поделиться Vishwanath Dalvi 12 сентября 2011 в 19:18
25
В дополнение к группировке по имени Поля, вы также можете group by порядковый номер или положение поля в таблице. 1 соответствует первому полю (независимо от имени), 2-второму и так далее.
Это, как правило, не рекомендуется, если вы группируетесь по чему-то конкретному, так как структура таблицы/представления может измениться. Кроме того, может быть трудно быстро понять, что делает ваш запрос SQL, если вы не запомнили поля таблицы.
Если вы возвращаете уникальный набор или быстро выполняете временный поиск, это хороший сокращенный синтаксис для уменьшения набора текста. Если вы планируете запустить запрос снова в какой-то момент, я бы рекомендовал заменить их, чтобы избежать будущей путаницы и неожиданных осложнений (из-за изменений схемы).
Поделиться vol7ron 12 сентября 2011 в 19:19
- SQL «Distinct» и Group By пункт
ищу по всему этому сайту, но не вижу никакой похожей и помогающей темы. Пример: у меня есть данные, как показано ниже Col1 Col2 aaaa 1111 aaaa 2222 bbbb 4444 bbbb 3333 Как я могу запросить таблицу, подобную приведенной ниже ? Col1 Col2 aaaa 1111 2222 bbbb 4444 3333 Мой текущий запрос для проверки…
- SQL использование GROUP BY и COUNT
Я создал таблицу MariaDB(10.1.21) с именем ‘group_test’ и сохранил некоторые данные, как показано ниже. Group Item Value1 Value2 Value3 A a1 1 0 0 A a2 1 1 1 A a3 1 1 2 B b1 1 1 0 B b2 1 1 1 B b3 1 0 0 B b4 1 1 3 C c1 1 1 0 C c2 1 1 1 Используя запрос, я хочу сразу же получить результат, как…
11
Это будет group by первое поле в предложении select
Поделиться Daan Geurts 12 сентября 2011 в 19:13
5
Это означает sql group by 1-й столбец в вашем предложении select, мы всегда используем этот GROUP BY 1 вместе с ORDER BY 1, кроме того, вы также можете использовать этот GROUP BY 1,2,3., конечно, это удобно для нас, но вы должны обратить внимание на это условие результат может быть не таким, как вы хотите, если кто-то изменил ваши столбцы select, и он не визуализируется. .
.
Поделиться 张艳军 15 мая 2017 в 08:23
4
Это будет group by позиция столбца, которую вы ставите после предложения group by.
например, если вы запустите ‘ SELECT SALESMAN_NAME, SUM(SALES) FROM SALES GROUP BY 1 ‘
, это будет group by SALESMAN_NAME .
Один из рисков при этом заключается в том, что если вы запустите ‘ Select * ‘ и по какой-то причине воссоздадите таблицу со столбцами в другом порядке, это даст вам другой результат, чем вы ожидали.
Поделиться wdoering 19 декабря 2014 в 18:32
Похожие вопросы:
Является ли предложение GROUP BY в SQL избыточным?
Всякий раз, когда мы используем агрегатную функцию в SQL ( MIN , MAX , AVG и т. д.), Мы всегда должны GROUP BY все неагрегированные столбцы, например: SELECT storeid, storename, SUM(revenue),…
д.), Мы всегда должны GROUP BY все неагрегированные столбцы, например: SELECT storeid, storename, SUM(revenue),…
GROUP BY с Максом (дата)
Например , я пытаюсь перечислить последний пункт назначения (время отправления MAX) для каждого поезда в таблице : Train Dest Time 1 HK 10:00 1 SH 12:00 1 SZ 14:00 2 HK 13:00 2 SH 09:00 2 SZ 07:00…
что это значит, когда мы используем «group by 1» в запросе SQL
Я наткнулся на запрос, где он указан select concat(21*floor(diff/21), ‘-‘, 21*floor(diff/21) + 20) as `range`, count(*) as `number of users` from new_table group by 1 order by diff; вот что именно…
«group by» требуется в операторе count(*) SQL?
Следующее утверждение работает в моей базе данных: select column_a, count(*) from my_schema.my_table group by 1; но это не так: select column_a, count(*) from my_schema.my_table; Я получаю ошибку:…
SQL Оптимизировать Group By Запрос
У меня здесь есть таблица со следующими полями: Удостоверение личности, имя, вид. дата Данные: id name kind date 1 Thomas 1 2015-01-01 2 Thomas 1 2015-01-01 3 Thomas 2 2014-01-01 4 Kevin 2…
дата Данные: id name kind date 1 Thomas 1 2015-01-01 2 Thomas 1 2015-01-01 3 Thomas 2 2014-01-01 4 Kevin 2…
SQL «Distinct» и Group By пункт
ищу по всему этому сайту, но не вижу никакой похожей и помогающей темы. Пример: у меня есть данные, как показано ниже Col1 Col2 aaaa 1111 aaaa 2222 bbbb 4444 bbbb 3333 Как я могу запросить таблицу,…
SQL использование GROUP BY и COUNT
Я создал таблицу MariaDB(10.1.21) с именем ‘group_test’ и сохранил некоторые данные, как показано ниже. Group Item Value1 Value2 Value3 A a1 1 0 0 A a2 1 1 1 A a3 1 1 2 B b1 1 1 0 B b2 1 1 1 B b3 1…
SQL — GROUP BY пункт
У меня есть таблица, в которой мне нужны были последние 2 строки из каждого type записей. используя GROUP BY . Например, на рисунке ниже я хочу получить последние 2 записи в зависимости от столбца…
SQL SELECT — GROUP BY
Очень много, начиная с SQL. Я пытаюсь собрать данные из нескольких таблиц, чтобы получить сводку, где значения из первой таблицы сгруппированы по полю, повторному коду и суммируются. И в…
И в…
SQL GROUP BY 1 2 3 и SQL порядок исполнения
Это может быть глупый вопрос, но я действительно запутался. Таким образом, в соответствии с порядком выполнения запроса SQL предложение GROUP BY будет выполнено до предложения SELECT . Однако это…
Команда SELECT Раздел GROUP BY — Группировка записей по полям
Раздел GROUP BY
Если в табличном выражении присутствует раздел GROUP BY SQL, то следующим выполняется GROUP BY.
Если обозначить через R таблицу, являющуюся результатом предыдущего раздела (FROM или WHERE), то результатом раздела GROUP BY является разбиение R на множество групп строк, состоящего из минимального числа групп таких, что для каждого столбца из списка столбцов раздела GROUP BY во всех строках каждой группы, включающей более одной строки, значения этого столбца равны. Для обозначения результата раздела GROUP BY в стандарте используется термин “сгруппированная таблица”.
Если утверждение SELECT содержит предложение GROUP BY(SELECT GROUP BY), список выбора может содержать только следующие типы выражений:
- Константы.
- Агрегатные функции.
- Функции USER, UID, и SYSDATE.
- Выражения, соответствующие перечисленным в предложении GROUP BY.
- Выражения, включающие вышеперечисленные выражения.
Пример 1. Вычислить общий объем покупок для каждого товара:
SELECT stock, SUM(quant) FROM ordsale GROUP BY stock;
Фраза GROUP BY не предполагает упорядочивания строк. Для упорядочивания результата этого примера по кодам товаров, следует поместить фразу ORDER BY stock следом за фразой GROUP BY.
Пример 2. Можно использовать группировки данных GROUP BY совместно с условием. Например, выбрать для каждого покупаемого товара его код и общий объем покупок, за исключением покупок покупателя с кодом 23:
SELECT stock, SUM(quant) FROM ordsale WHERE customerno<>23 GROUP BY stock;
Строки, не удовлетворяющие условию WHERE, исключаются перед группированием данных.
Строки таблицы можно группировать по любой комбинации ее полей. Если поле, по значениям которого осуществляется группирование, содержит какие-либо неопределенные значения, то каждое из них порождает отдельную группу.
Допустим, есть задача на вычисление количества какого-либо продукта. Поставщик поставляет нам продукцию по определённой цене. Вычислим общее количество каждого из продуктов. В этом нам поможет фраза GROUP BY.
Transact-SQL группировка данных GROUP BY | Info-Comp.ru
Мы с Вами рассмотрели много материала по SQL, в частности Transact-SQL, но мы не затрагивали такую, на самом деле простую тему как 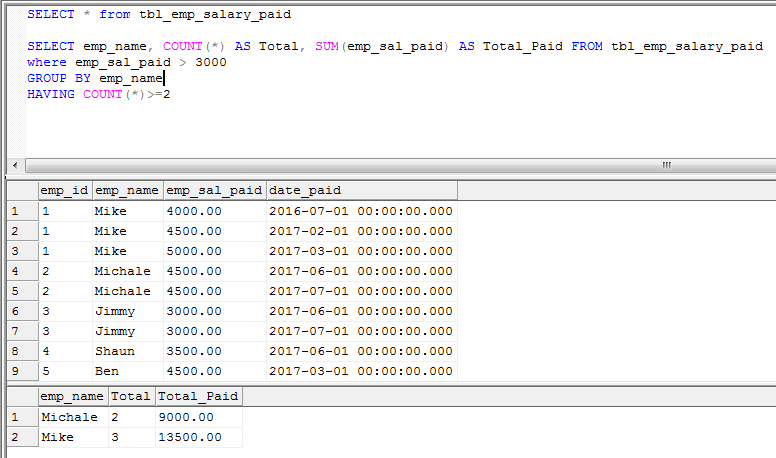 Поэтому сегодня мы научимся использовать оператор group by для группировки данных.
Поэтому сегодня мы научимся использовать оператор group by для группировки данных.
Многие начинающие программисты, когда сталкиваются с SQL, не знают о такой возможности как группировка данных с помощью оператора GROUP BY, хотя эта возможность требуется достаточно часто на практике, в связи с этим наш сегодняшний урок, как обычно с примерами, посвящен именно тому, чтобы Вам было проще и легче научиться использовать данный оператор, так как Вы с этим обязательно столкнетесь. Если Вам интересна тема SQL, то мы, как я уже сказал ранее, не раз затрагивали ее, например, в статьях Язык SQL – объединение JOIN или Объединение Union и union all , поэтому можете ознакомиться и с этим материалом.
И для вступления небольшая теория.
Что такое оператор GROUP BY
GROUP BY – это оператор (или конструкция, кому как удобней) SQL для группировки данных по полю, при использовании в запросе агрегатных функций, таких как sum, max, min, count и других.
Как Вы знаете, агрегатные функции работают с набором значений, например sum суммирует все значения. А вот допустим, Вам необходимо просуммировать по какому-то условию или сразу по нескольким условиям, именно для этого нам нужен оператор group by, чтобы сгруппировать все данные по полям с выводом результатов агрегатных функций.
Как мне кажется, наглядней будет это все разобрать на примерах, поэтому давайте перейдем к примерам.
Примечание! Все примеры будем писать в Management Studio SQL сервера 2008.
Примеры использования оператора GROUP BY
И для начала давайте создадим и заполним тестовую таблицу с данными, которой мы будет посылать наши запросы select с использованием группировки group by. Таблица и данные конечно выдуманные, чисто для примера.
Создаем таблицу
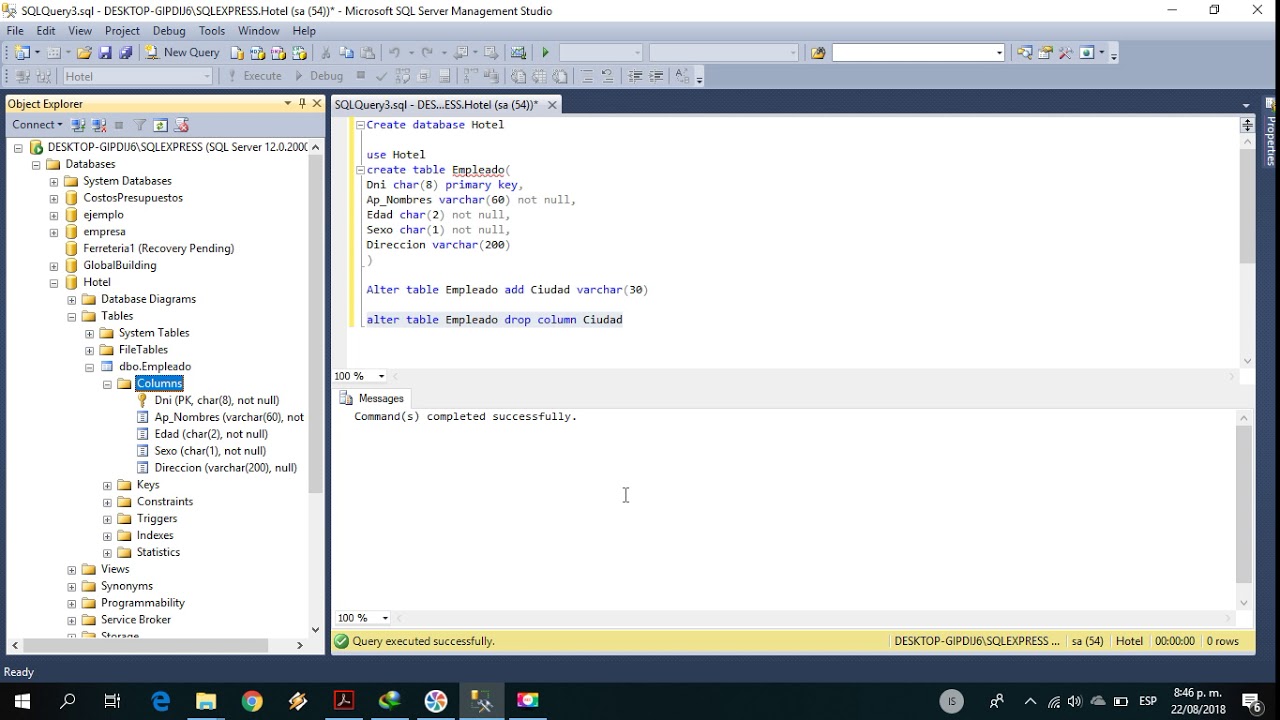
CREATE TABLE [dbo].[test_table](
[id] [int] NULL,
[name] [varchar](50) NULL,
[summa] [money] NULL,
[priz] [int] NULL
) ON [PRIMARY]
GO
Я ее заполнил следующими данными:
Где,
- Id –идентификатор записи;
- Name – фамилия сотрудника;
- Summa- денежные средства;
- Priz – признак денежных средств (допустим 1- Оклад; 2-Премия).
Группируем данные с помощью запроса group by
И в самом начале давайте разберем синтаксис group by, т.е. где писать данную конструкцию:
Синтаксис:
Select агрегатные функции
From источник
Where Условия отбора
Group by поля группировки
Having Условия по агрегатным функциям
Order by поля сортировки
Теперь если нам необходимо просуммировать все денежные средства того или иного сотрудника без использования группировки мы пошлем вот такой запрос:
SELECT SUM(summa)as summa FROM test_table WHERE name='Иванов'
А если нужно просуммировать другого сотрудника, то мы просто меняем условие. Согласитесь, если таких сотрудников много, зачем суммировать каждого, да и это как-то не наглядно, поэтому нам на помощь приходит оператор group by. Пишем запрос:
SELECT SUM(summa)as summa, name FROM test_table GROUP BY name
Как Вы заметили, мы не пишем никаких условий, и у нас отображаются сразу все сотрудники с просуммированным количеством денежных средств, что более наглядно.
Примечание! Сразу отмечу то, что, сколько полей мы пишем в запросе (т.е. поля группировки), помимо агрегатных функций, столько же полей мы пишем в конструкции group by. В нашем примере мы выводим одно поле, поэтому в group by мы указали только одно поле (name), если бы мы выводили несколько полей, то их все пришлось бы указывать в конструкции group by (в последующих примерах Вы это увидите).
Также можно использовать и другие функции, например, подсчитать сколько раз поступали денежные средства тому или иному сотруднику с общей суммой поступивших средств. Для этого мы кроме функции sum будем еще использовать функцию count.
SELECT SUM(summa)as [Всего денежных средств],
COUNT(*) as [Количество поступлений],
Name [Сотрудник]
FROM test_table
GROUP BY name
Но допустим для начальства этого недостаточно, они еще просят, просуммировать также, но еще с группировкой по признаку, т. е. что это за денежные средства (оклад или премия), для этого мы просто добавляем в группировку еще одно поле, и для лучшего восприятия добавим сортировку по сотруднику, и получится следующее:
е. что это за денежные средства (оклад или премия), для этого мы просто добавляем в группировку еще одно поле, и для лучшего восприятия добавим сортировку по сотруднику, и получится следующее:
SELECT SUM(summa)as [Всего денежных средств],
COUNT(*) as [Количество поступлений],
Name [Сотрудник] ,
Priz [Источник]
FROM test_table
GROUP BY name, priz
ORDER BY name
Теперь у нас все отображается, т.е. сколько денег поступило сотруднику, сколько раз, а также из какого источника.
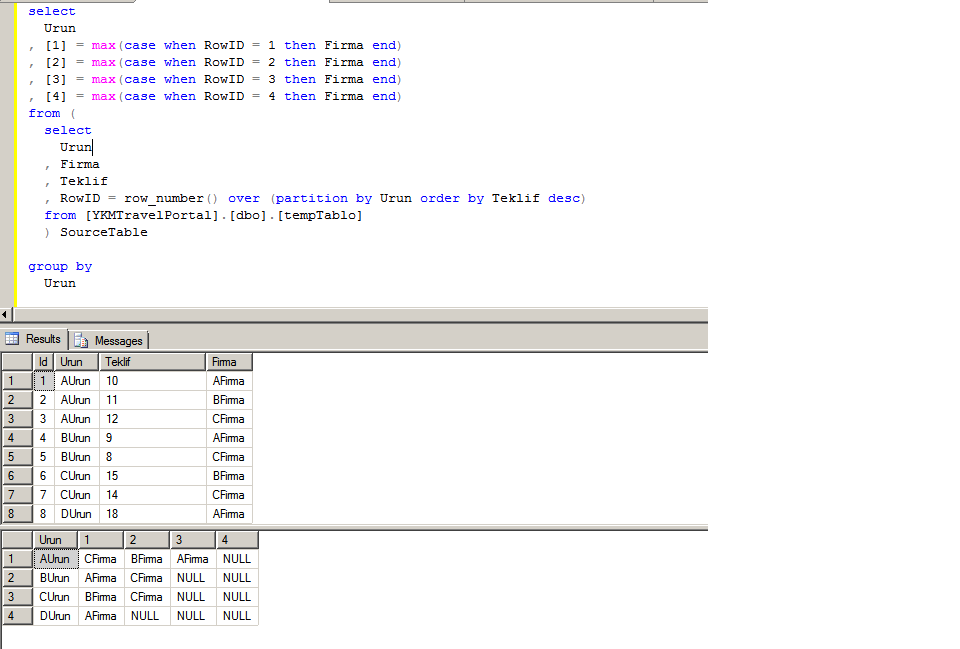
А сейчас для закрепления давайте напишем еще более сложный запрос с группировкой, но еще добавим названия этого источника, так как согласитесь по идентификаторам признака не понятно из какого источника поступили средства. Для этого мы используем конструкцию case.
SELECT SUM(summa) AS [Всего денежных средств],
COUNT(*) AS [Количество поступлений],
Name [Сотрудник],
CASE WHEN priz = 1 then 'Оклад'
WHEN priz = 2 then 'Премия'
ELSE 'Без источника'
END AS [Источник]
FROM test_table
GROUP BY name, priz
ORDER BY name
Вот теперь все достаточно наглядно и не так уж сложно, даже для начинающих.
Также давайте затронем условия по итоговым результатам агрегатных функций (having). Другими словами, мы добавляем условие не по отбору самих строк, а уже на итоговое значение функций, в нашем случае это sum или count. Например, нам нужно вывести все то же самое, но только тех, у которых «всего денежных средств» больше 200. Для этого добавим условие having:
SELECT SUM(summa)as [Всего денежных средств],
COUNT(*) as [Количество поступлений],
Name [Сотрудник],
CASE WHEN priz = 1 then 'Оклад'
WHEN priz = 2 then 'Премия'
ELSE 'Без источника'
END AS [Источник]
FROM test_table
GROUP BY name, priz --группируем
HAVING SUM(summa) > 200 --отбираем
ORDER BY name -- сортируем
Теперь у нас вывелись все значения sum(summa), которые больше 200, все просто.
Заметка! Для профессионального изучения языка T-SQL рекомендую посмотреть мои видеокурсы по T-SQL.
Надеюсь, после сегодняшнего урока Вам стало понятно, как и зачем использовать конструкцию group by. Удачи! А SQL мы продолжим изучать в следующих статьях.
Нравится4Не нравится2.12. Группировка – Group By
Очень интересных эффектов можно добиться, если использовать математику вместе с GROP_BY. Что если нужно посчитать, количество различных имен в таблице tbPeoples. Как же это можно сделать?
Если использовать только ту информацию, которую мы уже знаем, то проблема решается достаточно сложно. Для начала мы должны определить уникальные имена, которые существуют в таблице:
SELECT DISTINCT vcName FROM tbPeoples
После этого нужно определить количество каждого имени в таблице. Например, количество Андреев можно узнать следующим образом:
SELECT count(*) FROM tbPeoples WHERE vcName='Андрей'
Но это сложно и требует ручного вмешательства. Конечно же, можно было бы использовать подзапросы для определения количества без вмешательства, но это будет сложно, и подзапросы мы еще не рассматривали. Самое простое решение кроется как раз в операторе GROUP BY. Рассмотрим эту возможность на примере:
Самое простое решение кроется как раз в операторе GROUP BY. Рассмотрим эту возможность на примере:
SELECT vcName, count(*) FROM tbPeoples GROUP BY vcName
Оператор GROUP BY группирует записи по указанным после оператора через запятую именам колонок. После оператора SELECT нужно перечислить те же имена колонок и математическую функцию, которую вы хотите использовать. В данном случае используется функция COUNT для подсчета количества строк в группе. Итак, в нашей таблице несколько Андреев, в запросе они объединяются в группу и в результате выводиться на экран количество строк в этой группе.
Результат выполнения запроса:
АНДРЕЙ 5 БОЛИК 1 ВЛАД 1 ИВАН 3 ЛЕЛИК 1 СЕРГЕЙ 2 СЛАВИК 1 ...
В первой колонке показано имя работника, а во второй колонке количество записей с таким именем.
Посмотрим еще пример, давайте посчитаем, сколько раз встречаются в таблице одинаковые записи в поля имени и фамилии
SELECT vcFamil, vcName, count(*) FROM tbPeoples GROUP BY vcFamil, vcName
Результат – количество повторений из сочетания полей фамилия и имя. В моей тестовой таблице содержимое этих двух полей образуют уникальное значение, поэтому в колонке количества будет всегда единица.
В моей тестовой таблице содержимое этих двух полей образуют уникальное значение, поэтому в колонке количества будет всегда единица.
Прежде чем рассматривать еще примеры, давайте узнаем, как можно сортировать строки по колонке количества записей:
SELECT vcName, count(*) FROM tbPeoples GROUP BY vcName ORDER BY count(*) DESC
В операторе ORDER BY без проблем можно писать функции. Чтобы сценарий был более красивым, лучше будет задать псевдоним для поля количества записей:
SELECT vcName, count(*) AS ct FROM tbPeoples GROUP BY vcName ORDER BY ct DESC
Чтобы лучше понять работу этого оператора, необходимо рассмотреть еще несколько примеров. Я сам не сразу же понял, как ей пользоваться, поэтому постараюсь вам показать максимум разных запросов, чтобы вы на практике увидели смысл их работы. Следующий запрос определяет количество повторений фамилий:
SELECT vcSurName, count(*) FROM tbPeoples GROUP BY vcSurName
Обратите внимание, что поля, которые указываются в группировке, обязательно присутствуют в операторе SELECT. Другие поля там не могут присутствовать. Например, следующий запрос будет неверен:
Другие поля там не могут присутствовать. Например, следующий запрос будет неверен:
SELECT vcFamil, vcSurName, count(*) FROM tbPeoples GROUP BY vcSurName
Чтобы лучше понять почему, давайте разберем его работу. Допустим, что у нас есть таблица из двух колонок – фамилии и отчества:
ИВАНОВ ИВАНЫЧ ПЕТРОВ ПАЛЫЧ СИДОРОВ ПАЛЫЧ
Во время группировки по отчеству, вторая и третья строка должны восприниматься как одно целое, но какую из двух фамилий вывести в результате: Петров или Сидоров? Вот из-за этого в разделе SELECT должны быть только те поля, по которым происходит группировка.
Давайте посмотрим пример связанных таблиц. Допустим, что нам нужно определить, количество номеров телефонов для каждого пользователя. В этом случае, должно быть подсчитано, сколько записей в таблице tbPhoneNumbers соответствует каждой записи в таблице tbPeoples. Лучше будет сгруппировать по первичному ключу таблицы tbPeoples, потому что он обеспечивает уникальность строк, для которых нужно определить количество записей в другой таблице. Так как у нас группировка происходит по одной таблице, а количество считается по другой таблице, в группировку можно добавлять любые поля помимо ключевого. Например:
Так как у нас группировка происходит по одной таблице, а количество считается по другой таблице, в группировку можно добавлять любые поля помимо ключевого. Например:
SELECT pl.idPeoples, vcFamil, vcSurName, COUNT(vcPhoneNumber) FROM tbPeoples pl, tbPhoneNumbers pn WHERE pl.idPeoples *= pn.idPeoples GROUP BY pl.idPeoples, vcFamil, vcSurName ORDER BY COUNT(vcPhoneNumber) DESC
Рассмотрим этот запрос. Я решил вывести на экран помимо первичного ключа еще и фамилию и имя. Все эти поля перечислены в разделе SELECT и GROUP BY. Можно взять и другие поля из таблицы tbPeoples, но только из этой таблицы. В разделе WHERE наводиться связь между таблицами, а в разделе ORDER BY мы сортируем количество найденных телефонов.
С помощью GROUP BY можно не только определять количество записей с помощью оператора COUNT, но и суммы. Вспомним, что в нашей базе данных есть еще таблица товаров из следующих полей: Дата покупки, Название товара, Цена, Количество. Давайте сгруппируем таблицу по названию и определим количество каждого товара:
Давайте сгруппируем таблицу по названию и определим количество каждого товара:
SELECT [Название товара], SUM(Количество) FROM Товары GROUP BY [Название товара]
В этом примере с помощью группировки мы определили сумму по колонке с помощью оператора SUM.
С помощью секции HAVING очень удобно ограничивать вывод. Например, вам нужно вывести сумму количества товаров, но при этом должны отражаться только те записи, в которых количество более 1. Просто GROUP BY тут уже не поможет. Нужно добавить секцию HAVING, с нужным условием:
SELECT [Название товара], SUM(Количество) FROM Товары GROUP BY [Название товара] HAVING SUM(Количество)>1
В секции HAVING мы написали, что сумма товара (SUM(Количество)) должна быть более 1.
Теперь посмотрим, как с помощью HAVING можно решить классическую задачу поиска двойных записей. Допустим, что нужно вывести на экран фамилии, которые повторяются в таблице более одного раза. Просто для подсчета фамилий достаточно использовать секцию GROUP BY, но если добавить еще и HAVING, то можно будет отобразить только двойные записи:
Просто для подсчета фамилий достаточно использовать секцию GROUP BY, но если добавить еще и HAVING, то можно будет отобразить только двойные записи:
SELECT vcFamil, count(*) FROM tbPeoples GROUP BY vcFamil HAVING count(*)>1
Где бы я не работал, и как бы хорошо не строилась база данных, приходится регулярно выявлять и избавляться от двойных записей, потому что они портят отчетность. В таких случаях группировка оказывается незаменимой. Да, можно вводить ограничения уникальности по тем полям, которые не должны двоиться, но не всегда это может оказаться эффективным решением.
SQL — Group By — CoderLessons.com
Предложение SQL GROUP BY используется в сотрудничестве с оператором SELECT для объединения идентичных данных в группы. Это предложение GROUP BY следует за предложением WHERE в инструкции SELECT и предшествует предложению ORDER BY.
Синтаксис
Основной синтаксис предложения GROUP BY показан в следующем блоке кода. Предложение GROUP BY должно соответствовать условиям в предложении WHERE и должно предшествовать предложению ORDER BY, если оно используется.
Предложение GROUP BY должно соответствовать условиям в предложении WHERE и должно предшествовать предложению ORDER BY, если оно используется.
SELECT column1, column2 FROM table_name WHERE [ conditions ] GROUP BY column1, column2 ORDER BY column1, column2
пример
Предположим, что таблица CUSTOMERS содержит следующие записи:
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 6 | Komal | 22 | MP | 4500.00 | | 7 | Muffy | 24 | Indore | 10000.00 | +----+----------+-----+-----------+----------+
Если вы хотите узнать общую сумму заработной платы по каждому клиенту, запрос GROUP BY будет выглядеть следующим образом.
SQL> SELECT NAME, SUM(SALARY) FROM CUSTOMERS GROUP BY NAME;
Это даст следующий результат —
+----------+-------------+ | NAME | SUM(SALARY) | +----------+-------------+ | Chaitali | 6500.00 | | Hardik | 8500.00 | | kaushik | 2000.00 | | Khilan | 1500.00 | | Komal | 4500.00 | | Muffy | 10000.00 | | Ramesh | 2000.00 | +----------+-------------+
Теперь давайте посмотрим на таблицу, в которой таблица CUSTOMERS содержит следующие записи с повторяющимися именами:
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 2 | Ramesh | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 4 | kaushik | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 6 | Komal | 22 | MP | 4500.00 | | 7 | Muffy | 24 | Indore | 10000.00 | +----+----------+-----+-----------+----------+
Опять же, если вы хотите узнать общую сумму заработной платы по каждому клиенту, запрос GROUP BY будет выглядеть следующим образом:
SQL> SELECT NAME, SUM(SALARY) FROM CUSTOMERS GROUP BY NAME;
Это даст следующий результат —
SQL | GROUP BY — GeeksforGeeks
Оператор GROUP BY в SQL используется для организации идентичных данных в группы с помощью некоторых функций. то есть, если конкретный столбец имеет одинаковые значения в разных строках, он организует эти строки в группу.
Важные моменты:
- Предложение GROUP BY используется с оператором SELECT.
- В запросе предложение GROUP BY помещается после предложения WHERE.
- В запросе предложение GROUP BY помещается перед предложением ORDER BY, если оно используется.
Синтаксис :
ВЫБРАТЬ столбец1, имя_функции (столбец2) FROM table_name ГДЕ условие ГРУППА ПО столбцу 1, столбцу 2 ЗАКАЗАТЬ столбец1, столбец2; имя_функции : имя используемой функции, например SUM (), AVG ().имя_таблицы : Имя таблицы. состояние : Состояние использованное.
Пример таблицы:
Сотрудник
Студент
Пример:
- Группировать по одному столбцу : Группировать по одному столбцу означает, чтобы разместить все строки с одинаковым значением только этот конкретный столбец в одной группе.Рассмотрим запрос, как показано ниже:
ВЫБЕРИТЕ ИМЯ, СУММУ (ЗАРПЛАТА) ОТ сотрудника ГРУППА ПО ИМЕНИ;
Вышеупомянутый запрос выдаст следующий результат:
Как вы можете видеть в вышеприведенном выводе, строки с повторяющимися ИМЕНАМИ сгруппированы под одним ИМЯ, а их соответствующая ЗАРПЛАТА является суммой ЗАРПЛАТЫ повторяющихся строк. Здесь для вычисления суммы используется функция SQL SUM (). - Группировать по нескольким столбцам : Группировать по нескольким столбцам, например, GROUP BY column1, column2 .
 Это означает размещение всех строк с одинаковыми значениями обоих столбцов column1 и column2 в одной группе. Рассмотрим следующий запрос:
Это означает размещение всех строк с одинаковыми значениями обоих столбцов column1 и column2 в одной группе. Рассмотрим следующий запрос:SELECT SUBJECT, YEAR, Count (*) ОТ Студента ГРУППА ПО ПРЕДМЕТАМ, ГОД;
Выходные данные :
Как вы можете видеть в выходных данных выше, учащиеся с одинаковыми ПРЕДМЕТАМИ и ГОДОМ помещаются в одну группу. И те, у которых один и тот же ТЕМА, но не ГОД, принадлежат к разным группам. Итак, здесь мы сгруппировали таблицу по двум или более чем одному столбцу.
Пункт HAVING
Мы знаем, что предложение WHERE используется для размещения условий в столбцах, но что, если мы хотим разместить условия в группах?
Здесь используется условие HAVING. Мы можем использовать предложение HAVING для размещения условий, чтобы решить, какая группа будет частью окончательного набора результатов. Также мы не можем использовать агрегатные функции, такие как SUM (), COUNT () и т. Д., С предложением WHERE. Поэтому нам нужно использовать предложение HAVING, если мы хотим использовать любую из этих функций в условиях.
Д., С предложением WHERE. Поэтому нам нужно использовать предложение HAVING, если мы хотим использовать любую из этих функций в условиях.
Синтаксис :
ВЫБРАТЬ столбец1, имя_функции (столбец2) FROM table_name ГДЕ условие ГРУППА ПО столбцу 1, столбцу 2 ИМЕЮЩИЕ условие ЗАКАЗАТЬ столбец1, столбец2; имя_функции : имя используемой функции, например SUM (), AVG (). имя_таблицы : Имя таблицы. состояние : Состояние использованное.
Пример :
ВЫБЕРИТЕ ИМЯ, СУММУ (ЗАРПЛАТУ) ОТ сотрудника ГРУППА ПО ИМЕНИ ИМЕЕТ СУММУ (ЗАРПЛАТУ)> 3000;
Выходные данные :
Как видно из вышеприведенных выходных данных, только одна группа из трех появляется в наборе результатов, поскольку это единственная группа, в которой сумма SALARY больше 3000.Таким образом, мы использовали здесь предложение HAVING, чтобы разместить это условие, поскольку условие требуется размещать в группах, а не в столбцах.
Автор статьи: Harsh Agarwal . Если вам нравится GeeksforGeeks, и вы хотели бы внести свой вклад, вы также можете написать статью с помощью provide.geeksforgeeks.org или отправить ее по электронной почте на [email protected]. Посмотрите, как ваша статья появляется на главной странице GeeksforGeeks, и помогите другим гикам.
Пожалуйста, напишите комментарий, если вы обнаружите что-то неправильное, или если вы хотите поделиться дополнительной информацией по теме, обсуждаемой выше.
Вниманию читателя! Не прекращайте учиться сейчас. Ознакомьтесь со всеми важными концепциями теории CS для собеседований SDE с помощью курса CS Theory Course по доступной для студентов цене и подготовьтесь к работе в отрасли.
Предложение SQL GROUP BY и HAVING с примерами
Что такое предложение SQL Group by?
Предложение GROUP BY — это команда SQL, которая используется для группировки строк с одинаковыми значениями . Предложение GROUP BY используется в операторе SELECT.При желании он используется вместе с агрегатными функциями для создания сводных отчетов из базы данных.
Предложение GROUP BY используется в операторе SELECT.При желании он используется вместе с агрегатными функциями для создания сводных отчетов из базы данных.
Это то, что он делает, суммирует данные из базы данных.
Запросы, содержащие предложение GROUP BY, называются сгруппированными запросами и возвращают только одну строку для каждого сгруппированного элемента.
Синтаксис SQL GROUP BY
Теперь, когда мы знаем, что такое предложение SQL GROUP BY, давайте посмотрим на синтаксис для базовой группы по запросу.
операторов SELECT... GROUP BY имя_столбца1 [, имя_столбца2, ...] [условие HAVING];
ЗДЕСЬ
- «Операторы SELECT …» — это стандартный запрос команды SQL SELECT.
- « GROUP BY имя_столбца1 » — это предложение, которое выполняет группировку на основе имя_столбца1.
- «[, имя_столбца2, …]» не является обязательным; представляет имена других столбцов, когда группировка выполняется более чем по одному столбцу.

- «[HAVING condition]» не является обязательным; он используется для ограничения строк, затронутых предложением GROUP BY.Это похоже на предложение WHERE.
Группирование с использованием одного столбца
Чтобы помочь понять эффект предложения SQL Group By, давайте выполним простой запрос, который возвращает все записи пола из таблицы members.
ВЫБЕРИТЕ `пол` ИЗ` members`;
| пол |
|---|
| женский |
| женский |
| мужской |
| женский |
| мужской |
| 9016 мужской мужской мужской Мужской |
Предположим, мы хотим получить уникальные значения для полов.Мы можем использовать следующий запрос —
SELECT `пол` ИЗ` members` GROUP BY `пол`;
Выполнение вышеуказанного сценария в рабочей среде MySQL для Myflixdb дает следующие результаты.
Обратите внимание, что было возвращено только два результата. Это потому, что у нас есть только два гендерных типа — Мужской и Женский. Предложение GROUP BY в SQL сгруппировало все «мужские» члены вместе и вернуло для него только одну строку. То же самое и с участницами «Женского».
Группировка с использованием нескольких столбцов
Предположим, что мы хотим получить список фильмов category_id и соответствующие годы, в которые они были выпущены.
Давайте посмотрим на вывод этого простого запроса
SELECT `category_id`,` year_released` FROM `movies`;
| category_id | year_released | |||
|---|---|---|---|---|
| 1 | 2011 | |||
| 2 | 2008 | |||
| NULL | 9017ULL1 2008 9017 9017 9017 9017 9017 9017 9017 9017 9017 9017 9017||||
| 6 | 2007 | |||
| 6 | 2007 | |||
| 8 | 2005 | |||
| NULL | 2012 | |||
| 1920 | 8 | 1920 |
Приведенный выше результат имеет много дубликатов.
Давайте выполним тот же запрос, используя group by в SQL —
SELECT `category_id`,` year_released` FROM `movies` GROUP BY` category_id`, `year_released`;
Выполнение вышеуказанного сценария в рабочей среде MySQL для myflixdb дает нам следующие результаты, показанные ниже.
| category_id | year_released | |||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| NULL | 2008 | |||||||||||||||||||||||||||
| NULL | 2010 | |||||||||||||||||||||||||||
| NULL | 2012 | 2012 | 2012 | |||||||||||||||||||||||||
| 6 | 2007 | |||||||||||||||||||||||||||
| 7 | 1920 | |||||||||||||||||||||||||||
| 8 | 1920 | |||||||||||||||||||||||||||
| 8 | 2005 | |||||||||||||||||||||||||||
| 8 | пункт GROUP BY 900 как идентификатор категории, так и год выпуска для идентификации уникальных строк в нашем примере выше. Если идентификатор категории тот же, но год выпуска отличается, тогда строка рассматривается как уникальная. Группирующие и агрегатные функцииПредположим, нам нужно общее количество мужчин и женщин в нашей базе данных. Для этого мы можем использовать следующий сценарий, показанный ниже. ВЫБЕРИТЕ `пол`, COUNT (` членство_число`) ИЗ `members` GROUP BY` пол`; Выполнение вышеуказанного сценария в рабочей среде MySQL для myflixdb дает следующие результаты.
Результаты, показанные ниже, сгруппированы по каждому уникальному значению гендерной группы и номерам количество строк подсчитывается с помощью агрегатной функции COUNT. Ограничение результатов запроса с помощью предложенияHAVING Не всегда нам нужно выполнять группировку всех данных в данной таблице. Предположим, мы хотим знать все годы выпуска для категории фильмов с идентификатором 8. Для достижения наших результатов мы будем использовать следующий сценарий. ВЫБРАТЬ * ИЗ `movies` ГРУППА ПО` category_id`, `year_released` HAVING` category_id` = 8; Выполнение вышеуказанного сценария в рабочей среде MySQL для Myflixdb дает следующие результаты, показанные ниже.
Обратите внимание, что наше предложение GROUP BY затронуло только фильмы с идентификатором категории 8. Сводка
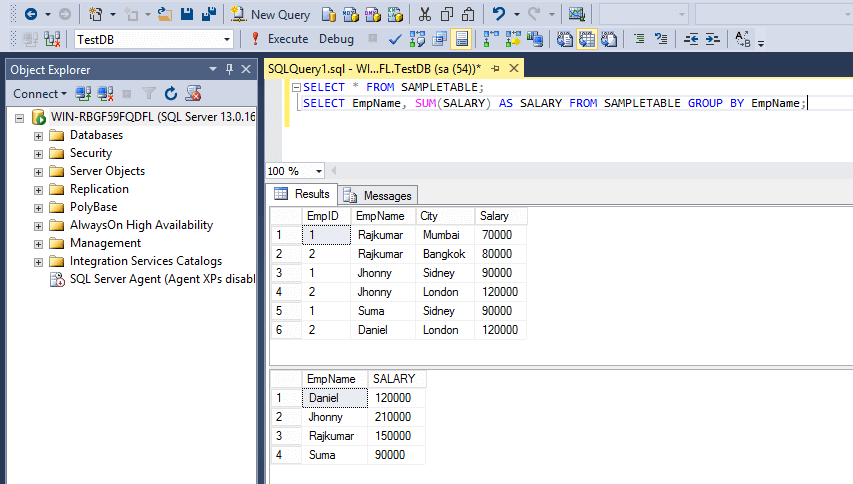
sql - Использование группы по нескольким столбцамЗдесь я собираюсь объяснить не только использование предложения GROUP, но также использование функций Aggregate. Предложение Запомните этот заказ:
Вы можете использовать все это, если используете агрегатные функции, и это порядок, в котором они должны быть установлены, иначе вы можете получить ошибку. Агрегатные функции:
Примеры сценариев SQL об использовании агрегатных функций: Допустим, нам нужно найти заказы на продажу, общая сумма продаж которых превышает 950 долларов.Мы объединяем предложение Подсчет всех заказов и их группировка по идентификатору клиента и сортировка результата по возрастанию. Получите категорию, у которой средняя цена за единицу превышает 10 долларов США, используя функцию Получение менее дорогого продукта по каждой категории с помощью функции Следующий оператор группирует строки с одинаковыми значениями в столбцах categoryId и productId : SQL ГРУППА ПО | Средний уровень SQLНачиная с этого места? Этот урок является частью полного руководства по использованию SQL для анализа данных. Проверьте начало. В этом уроке мы рассмотрим: Предложение SQL GROUP BYАгрегатные функции SQL, такие как В подобных ситуациях вам нужно использовать предложение Вы можете группировать по нескольким столбцам, но вы должны разделять имена столбцов запятыми - как в случае с Практическая задачаПодсчитайте общее количество акций, торгуемых каждый месяц. Отсортируйте результаты в хронологическом порядке. Попробуй это Посмотреть ответGROUP BY номера столбцов Как и в случае с Примечание: эта функция (нумерация столбцов вместо использования имен) поддерживается Mode, но не всеми разновидностями SQL, поэтому, если вы используете другую систему или подключены к определенным типам баз данных, она может не работать. Использование GROUP BY с ORDER BY Порядок имен столбцов в предложении Использование GROUP BY с LIMIT При группировке по нескольким столбцам следует помнить об одном: SQL оценивает агрегаты до предложения На самом деле это хороший способ делать что-то, потому что вы знаете, что получите правильные агрегаты. Если SQL сокращает таблицу до 100 строк, а затем выполняет агрегирование, ваши результаты будут существенно другими. Результаты приведенного выше запроса превышают 100 строк, так что это прекрасный пример. Попробуйте снять ограничение и запустить его снова, чтобы увидеть, что изменится. Отточите свои навыки работы с SQLПрактическая задача Напишите запрос для расчета среднесуточного изменения цен на акции Apple, сгруппированных по годам. Практическая задачаНапишите запрос, который вычисляет самые низкие и самые высокие цены, достигнутые акциями Apple за каждый месяц. Попробуй это Посмотреть ответSQL GROUP BYСводка : в этом руководстве вы узнаете, как с помощью предложения SQL GROUP BY группировать строки в набор сводных строк по значениям столбцов или выражений. Введение в предложение SQL GROUP BY Предложение Предложение Типичный синтаксис
Примеры SQL GROUP BY Давайте посмотрим на продукты SQL GROUP BY с функцией SUM, пример Чтобы получить общее количество единиц на складе для каждой категории продуктов, вы используете
Механизм базы данных выполняет следующие шаги:
SQL GROUP BY с функцией COUNT, пример Следующий запрос выбирает количество продуктов в каждой категории продуктов с помощью предложения
SQL GROUP BY с функцией AVG Вы можете проверить среднее количество единиц на складе для каждой категории продуктов, используя предложение
Функция SQL GROUP BY с функциями MIN и MAXПримените тот же метод, вы можете выбрать минимальное и максимальное количество единиц на складе для каждой категории продукта следующим образом:
SQL GROUP BY с ORDER BY, пример Предложение
SQL GROUP BY по нескольким столбцамВы можете сгруппировать набор результатов не только по одному столбцу, но и по нескольким столбцам.Например, если вы хотите узнать, сколько заказов на продажу было заказано покупателем и продано продавцом, вы можете сгруппировать набор результатов как по клиенту, так и по продавцу. Схема базы данных связанных таблиц выглядит следующим образом: Следующий запрос иллюстрирует идею:
В этом руководстве вы узнали, как использовать предложение SQL Было ли это руководство полезным? SQL - ГРУППА ПОПоследнее изменение: 3 мая 2021 г. До сих пор наши функции агрегирования обрабатывали все данные, но часто бывает полезно разбить агрегирование на группы. Допустим, мы хотели получить не количество всех треков, а количество треков в каждом жанре. Один из способов сделать это - написать отдельный запрос для каждого жанра, например: Но нам нужно знать, что такое все genre_id, и использовать какой-нибудь другой инструмент, чтобы снова объединить все результаты.Не идеально. К счастью, у нас есть предложение GROUP BY, которое делает это намного проще. Предложение GROUP BY сообщает базе данных, как сгруппировать набор результатов, поэтому мы можем более просто написать запросы выше как: Как это круто ?! Можете ли вы подсчитать все треки по композитору? Здесь полезно отсортировать результаты этого запроса по количеству, чтобы мы могли видеть, какие композиторы создали наибольшее количество треков (по крайней мере, в нашей базе данных). Выше указано, что композитор NULL считается имеющим наибольшее количество треков.Это просто шум. Используя то, что мы только что узнали об операторах NULL, можете ли вы изменить запрос, чтобы отфильтровать составители NULL? Несколько GROUP BY Вы можете группировать по нескольким параметрам, и это просто создает второй набор групп внутри первого набора. Приоритет / порядок групп такой же, как и в списке. Вы можете видеть, что переключение порядка genre_id и composer в предложении GROUP BY приводит к совершенно другому запросу: Обратите внимание, что я также добавил предложения ORDER BY, чтобы сделать вывод немного более понятным.ORDER BY довольно полезны и распространены при использовании GROUP BY. Правила GROUP BYПри использовании GROUP BY следует соблюдать несколько правил. Самая большая проблема заключается в том, что все данные, которые не указаны в качестве параметра для GROUP BY, требуют применения к ним функции агрегирования. Подумайте, что такое следующий запрос: Выдает ошибку, потому что база данных не знает, что делать с unit_price .Хотя для каждой группы есть только один genre_id, есть много unit_prices. Можете ли вы исправить приведенный выше запрос, чтобы получить среднее значение unit_price на genre_id ? GROUP BY ОшибкиЭто правило легко забыть, и в этом случае вы увидите ошибку, подобную следующей Просто помните, что это означает, что вам нужно либо добавить этот столбец в GROUP BY, либо применить к нему функцию агрегирования, чтобы база данных знала, что делать. В следующем примере возникает эта ошибка, потому что база данных не знает, что делать со всеми ценами за единицу. Можете ли вы изменить его, чтобы вернуть среднее значение unit_price на genre_id ? Написано:
Дэйв Фаулер SQL GROUP BY - w3resourceGROUP BY пунктПредложение SQL GROUP BY используется для разделения строк в таблице на более мелкие группы. Предложение GROUP BY используется с оператором SQL SELECT. Группировка может произойти после извлечения строк из таблицы. Когда некоторые строки извлекаются из сгруппированного результата по какому-либо условию, это возможно с помощью предложения HAVING. Предложение GROUP BY используется с оператором SELECT для создания группы строк на основе значений определенного столбца или выражения. Функцию SQL AGGREGATE можно использовать для получения сводной информации для каждой группы, и они применяются к отдельной группе. Предложение WHERE используется для извлечения строк на основе определенного условия, но его нельзя применить к сгруппированному результату. Предположим, что в операторе SQL вы используете GROUP BY, при необходимости вы можете использовать HAVING вместо WHERE после GROUP BY. Синтаксис: SELECT <список_столбцов> FROM <имя таблицы> ГДЕ <условие> ГРУППА ПО <столбцы> [ИМЕЕТ] <условие>; Параметры:
Графическое представление групп данных Использование GROUP BY с агрегатными функциями - Возможности агрегатных функций выше в сочетании с предложением GROUP BY. SQL GROUP BY с функцией COUNT () Следующий запрос отображает количество сотрудников, работающих в каждом отделе. Примерная таблица: сотрудники Код SQL: Пример вывода: Код отдела № сотрудников
--------------- ---------------
100 6
30 6
1
90 3
20 2
70 1
110 2
50 45
80 34
40 1
60 5
10 1
SQL GROUP BY с функцией SUM ()Следующий запрос отображает общую заработную плату, выплачиваемую сотрудникам, работающим в каждом отделе. Примерная таблица: сотрудники Код SQL: Пример вывода: СУММА DEPARTMENT_ID (ЗАРПЛАТА)
------------- -----------
100 51608
30 24900
7000
90 58000
20 19000
70 10000
110 20308
50 156400
80 304500
40 6500
60 28800
10 4400
|
 Если идентификатор категории и год выпуска совпадают для более чем одной строки, то она считается дубликатом и отображается только одна строка.
Если идентификатор категории и год выпуска совпадают для более чем одной строки, то она считается дубликатом и отображается только одна строка.  Бывают моменты, когда мы захотим ограничить наши результаты определенными критериями. В таких случаях мы можем использовать предложение HAVING
Бывают моменты, когда мы захотим ограничить наши результаты определенными критериями. В таких случаях мы можем использовать предложение HAVING

 Мы объединяем функцию
Мы объединяем функцию  categoryId = p1.categoryId)
categoryId = p1.categoryId)
 Обычно рекомендуется делать это только тогда, когда вы группируете много столбцов или если что-то еще вызывает чрезмерно длинный текст в предложении
Обычно рекомендуется делать это только тогда, когда вы группируете много столбцов или если что-то еще вызывает чрезмерно длинный текст в предложении  aapl_historical_stock_price
ГРУППА ПО году, месяцу
ЗАКАЗАТЬ ПО месяцу, году
aapl_historical_stock_price
ГРУППА ПО году, месяцу
ЗАКАЗАТЬ ПО месяцу, году
 Поэтому вы часто обнаруживаете, что предложение
Поэтому вы часто обнаруживаете, что предложение 
 Например, вы можете отсортировать категории продуктов по количеству продуктов следующим образом:
Например, вы можете отсортировать категории продуктов по количеству продуктов следующим образом: customerid = b.customerid
INNER JOIN сотрудники e ON e.employeeid = a.employeeid
ГРУППА ПО b.customerid,
a.employeeid
ЗАКАЗ ОТ b.customerid ASC,
DESC «Количество заказов»;
customerid = b.customerid
INNER JOIN сотрудники e ON e.employeeid = a.employeeid
ГРУППА ПО b.customerid,
a.employeeid
ЗАКАЗ ОТ b.customerid ASC,
DESC «Количество заказов»;  .
.
ВЫБРАТЬ СЧЕТЧИК (*) ИЗ треков ГДЕ genre_id = n;
.
.
ВЫБРАТЬ СЧЕТЧИК (*) ИЗ треков ГДЕ genre_id = n;
 Попробуйте запустить следующий пример, в котором сначала группируются по жанрам, а затем по композиторам.
Попробуйте запустить следующий пример, в котором сначала группируются по жанрам, а затем по композиторам.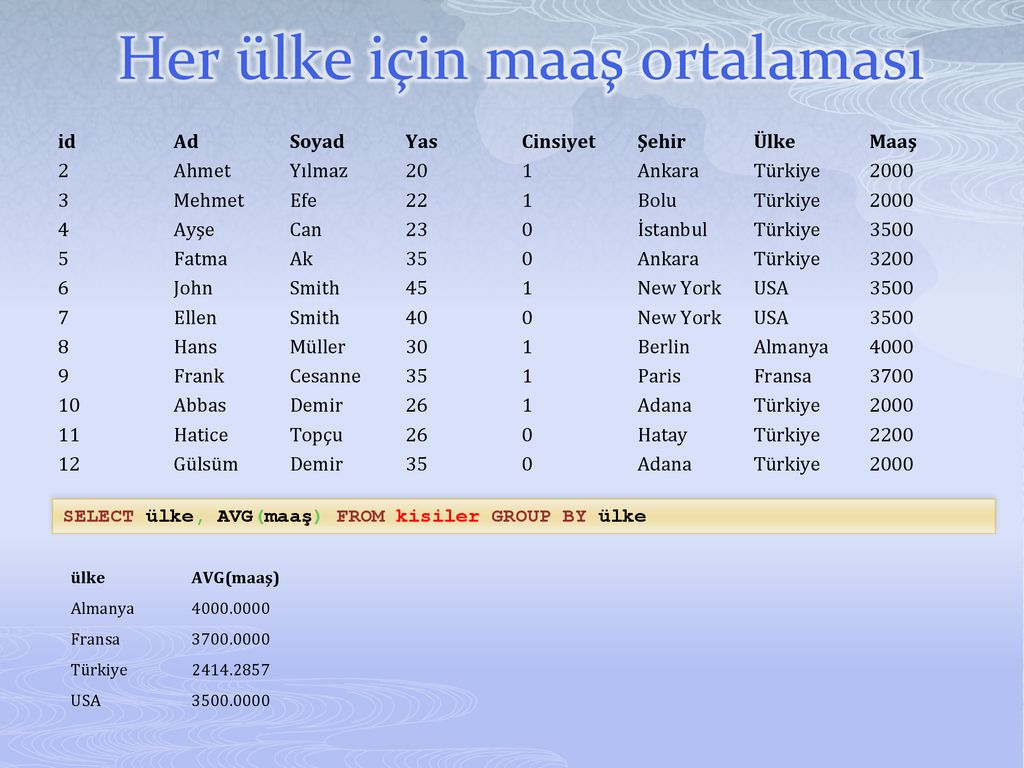 Все они не могут быть просто выведены как значение без какой-либо функции агрегирования.
Все они не могут быть просто выведены как значение без какой-либо функции агрегирования.
 org/WebPageElement/Heading"> SQL GROUP BY с функцией COUNT () и SUM ()
org/WebPageElement/Heading"> SQL GROUP BY с функцией COUNT () и SUM ()  org/WebPageElement/Heading"> SQL GROUP BY с предложением WHERE
org/WebPageElement/Heading"> SQL GROUP BY с предложением WHERE