Группировка, оператор GROUP BY
Давайте выполним запрос:
SELECT id, home_type, has_tv, price FROM Rooms;
| id | home_type | has_tv | price |
|---|---|---|---|
| 1 | Private room | 1 | 149 |
| 2 | Entire home/apt | 0 | 225 |
| 3 | Private room | 1 | 150 |
| 4 | Entire home/apt | 1 | 89 |
| 5 | Entire home/apt | 0 | 80 |
| 6 | Entire home/apt | 0 | 200 |
| 7 | Private room | 0 | 60 |
| 8 | Private room | 1 | 79 |
| 9 | Private room | 1 | 79 |
| 10 | Entire home/apt | 1 | 150 |
| 11 | Entire home/apt | 1 | 135 |
| 12 | Private room | 0 | 85 |
| 13 | Private room | 0 | 89 |
| 14 | Private room | 0 | 85 |
| 15 | Entire home/apt | 1 | 120 |
| 40 | Shared room | 1 | 40 |
Так мы получили информацию по каждому сдаваемому жилому помещению. А что если мы хотим получить информацию не о каждой записи отдельно, а о группах, которые они образуют?
А что если мы хотим получить информацию не о каждой записи отдельно, а о группах, которые они образуют?
Например, такими группами могут выступать записи разбитые по типу жилья:
- Shared room (аренда комнаты на несколько человек)
- Private room (аренда целой комнаты)
- Entire home/apt (аренда целой квартиры)
Эти группы включают разные записи в таблице и, соответственно, обладают разными характеристиками, которые нам могут быть весьма полезны.
Такой полезной информацией о группах может быть:
- средняя стоимость аренды комнаты или целого жилого помещения
- количество сдаваемых жилых помещений каждого типа
Для ответов на все эти и многие другие вопросы есть оператор GROUP BY.
SELECT [литералы, агрегатные_функции, поля_группировки] FROM имя_таблицы GROUP BY поля_группировки;
Для того, чтобы записи у нас образовали группы по типу жилья мы должны после GROUP BY указать home_type, т.е. поле, по которому будет происходить группировка.
SELECT home_type FROM Rooms GROUP BY home_type
| home_type |
|---|
| Private room |
| Entire home/apt |
| Shared room |
Следует иметь в виду, что для GROUP BY все значения NULL трактуются как равные, т.е. при группировке по полю, содержащему NULL-значения, все такие строки попадут в одну группу
При использовании оператора GROUP BY мы перешли от работы с отдельными записями на работу с образовавшимися группами. В связи с этим мы не можем просто вывести любое поле из записи (например, has_tv или price), как мы это могли делать раньше. Так как в каждой группе может быть несколько записей и в каждой из них в этом поле может быть разное значение.
При использовании GROUP BY мы можем выводить только:
литералы, т.е. указанное явным образом фиксированные значения.
Мы можем их выводить, так как это фиксированные значения, которые ни от чего не зависят.
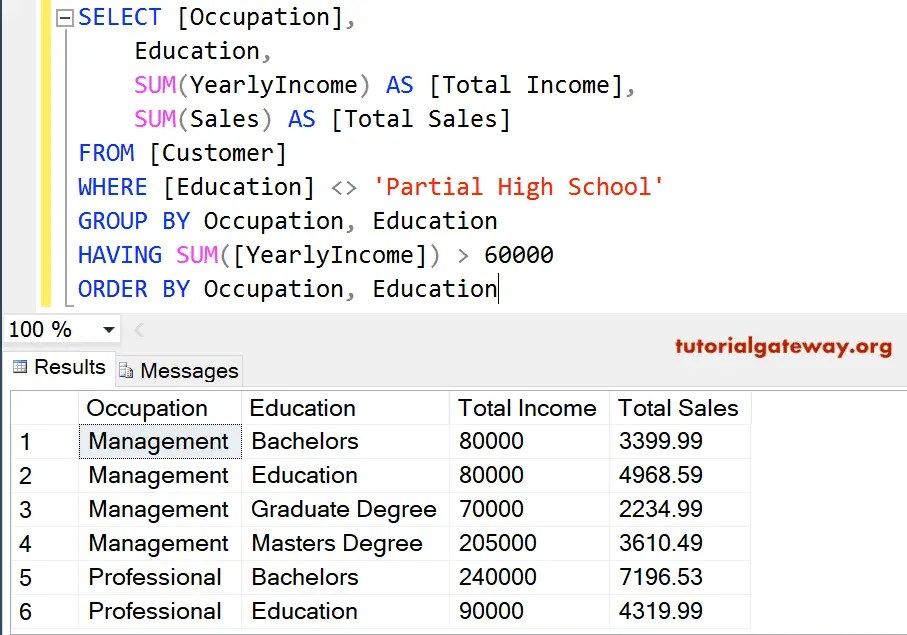
Например,SELECT home_type, "literal" FROM Rooms GROUP BY home_type
home_type literal Private room literal Entire home/apt literal Shared room literal результаты агрегатных функций, т.е. вычисленные значения на основании набора значений.
Более детальную информацию об агрегатных функциях мы затронем на следующем уроке. Но для примера рассмотрим агрегатную функцию AVG.
Функция AVG принимает в качестве аргумента название поля, по которому мы хотим вычислить среднее значение для каждой группы.SELECT home_type, AVG(price) as avg_price FROM Rooms GROUP BY home_type
home_type avg_price Private room 89.4286 Entire home/apt 148.6667 Shared room 40 Так выполненный запрос сначала разбивает все записи из таблицы Rooms на 3 группы, опираясь на поле home_type.
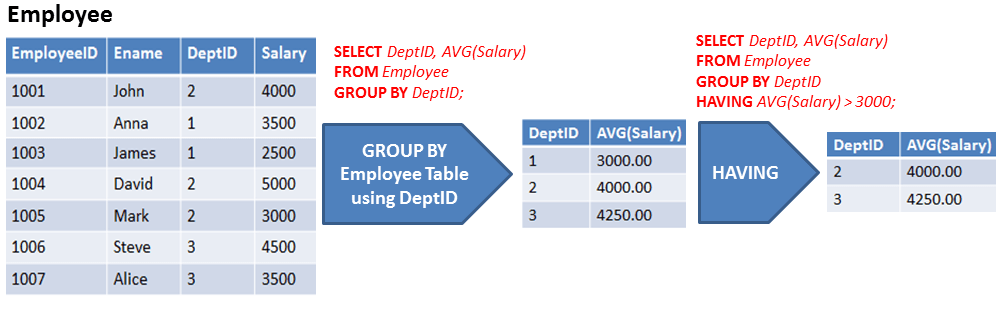 Далее, для каждой группы суммирует все значения, взятые из поля price у каждой записи, входящей в текущую группу, и затем полученный результат
делится на количество записей в данной группе.
Далее, для каждой группы суммирует все значения, взятые из поля price у каждой записи, входящей в текущую группу, и затем полученный результат
делится на количество записей в данной группе.поля группировки.
Мы можем их выводить, так как в рамках одной группы поля, по которым осуществлялась группировка, одинаковые.
Мы уже рассмотрели как записи в таблице группируются по одному полю. Для дополнительной иллюстрации это выглядит примерно так, когда поле группировки home_type:
При группировке по 2 и более полям принцип остается такой же, только теперь образовавшиеся группы дополнительно разбиваются на более мелкие группы в зависимости от второго поля группировки.
Пример группировки по home_type и has_tv:
Давайте проверим себя ? При использовании оператора GROUP BY в SELECT выражение мы можем выводить:
Только литералы, результаты агрегатные функции и поля группировкиВсе те же самые поля, что мы могли выводить по каждой записи в таблицеТолько литералы и результаты агрегатных функцииTransact-SQL группировка данных GROUP BY | Info-Comp.
 ru
ruМы с Вами рассмотрели много материала по SQL, в частности Transact-SQL, но мы не затрагивали такую, на самом деле простую тему как группировка данных GROUP BY. Поэтому сегодня мы научимся использовать оператор group by для группировки данных.
Многие начинающие программисты, когда сталкиваются с SQL, не знают о такой возможности как группировка данных с помощью оператора GROUP BY, хотя эта возможность требуется достаточно часто на практике, в связи с этим наш сегодняшний урок, как обычно с примерами, посвящен именно тому, чтобы Вам было проще и легче научиться использовать данный оператор, так как Вы с этим обязательно столкнетесь. Если Вам интересна тема SQL, то мы, как я уже сказал ранее, не раз затрагивали ее, например, в статьях Язык SQL – объединение JOIN или Объединение Union и union all , поэтому можете ознакомиться и с этим материалом.
И для вступления небольшая теория.
Содержание
- Что такое оператор GROUP BY
- Примеры использования оператора GROUP BY
- Группируем данные с помощью запроса group by
Что такое оператор GROUP BY
GROUP BY – это оператор (или конструкция, кому как удобней) SQL для группировки данных по полю, при использовании в запросе агрегатных функций, таких как sum, max, min, count и других.
Как Вы знаете, агрегатные функции работают с набором значений, например sum суммирует все значения. А вот допустим, Вам необходимо просуммировать по какому-то условию или сразу по нескольким условиям, именно для этого нам нужен оператор group by, чтобы сгруппировать все данные по полям с выводом результатов агрегатных функций.
Как мне кажется, наглядней будет это все разобрать на примерах, поэтому давайте перейдем к примерам.
Примечание! Все примеры будем писать в Management Studio SQL сервера 2008.
Примеры использования оператора GROUP BY
И для начала давайте создадим и заполним тестовую таблицу с данными, которой мы будет посылать наши запросы select с использованием группировки group by. Таблица и данные конечно выдуманные, чисто для примера.
Создаем таблицу
CREATE TABLE [dbo].[test_table](
[id] [int] NULL,
[name] [varchar](50) NULL,
[summa] [money] NULL,
[priz] [int] NULL
) ON [PRIMARY]
GO
Я ее заполнил следующими данными:
Где,
- Id –идентификатор записи;
- Name – фамилия сотрудника;
- Summa- денежные средства;
- Priz – признак денежных средств (допустим 1- Оклад; 2-Премия).

Группируем данные с помощью запроса group by
И в самом начале давайте разберем синтаксис group by, т.е. где писать данную конструкцию:
Синтаксис:
Select агрегатные функции
From источник
Where Условия отбора
Group by поля группировки
Having Условия по агрегатным функциям
Order by поля сортировки
Теперь если нам необходимо просуммировать все денежные средства того или иного сотрудника без использования группировки мы пошлем вот такой запрос:
SELECT SUM(summa)as summa FROM test_table WHERE name='Иванов'
А если нужно просуммировать другого сотрудника, то мы просто меняем условие. Согласитесь, если таких сотрудников много, зачем суммировать каждого, да и это как-то не наглядно, поэтому нам на помощь приходит оператор group by. Пишем запрос:
SELECT SUM(summa)as summa, name FROM test_table GROUP BY name
Как Вы заметили, мы не пишем никаких условий, и у нас отображаются сразу все сотрудники с просуммированным количеством денежных средств, что более наглядно.
Примечание! Сразу отмечу то, что, сколько полей мы пишем в запросе (т.е. поля группировки), помимо агрегатных функций, столько же полей мы пишем в конструкции group by. В нашем примере мы выводим одно поле, поэтому в group by мы указали только одно поле (name), если бы мы выводили несколько полей, то их все пришлось бы указывать в конструкции group by (в последующих примерах Вы это увидите).
Также можно использовать и другие функции, например, подсчитать сколько раз поступали денежные средства тому или иному сотруднику с общей суммой поступивших средств. Для этого мы кроме функции sum будем еще использовать функцию count.
SELECT SUM(summa)as [Всего денежных средств],
COUNT(*) as [Количество поступлений],
Name [Сотрудник]
FROM test_table
GROUP BY name
Но допустим для начальства этого недостаточно, они еще просят, просуммировать также, но еще с группировкой по признаку, т. е. что это за денежные средства (оклад или премия), для этого мы просто добавляем в группировку еще одно поле, и для лучшего восприятия добавим сортировку по сотруднику, и получится следующее:
е. что это за денежные средства (оклад или премия), для этого мы просто добавляем в группировку еще одно поле, и для лучшего восприятия добавим сортировку по сотруднику, и получится следующее:
SELECT SUM(summa)as [Всего денежных средств],
COUNT(*) as [Количество поступлений],
Name [Сотрудник] ,
Priz [Источник]
FROM test_table
GROUP BY name, priz
ORDER BY name
Теперь у нас все отображается, т.е. сколько денег поступило сотруднику, сколько раз, а также из какого источника.
А сейчас для закрепления давайте напишем еще более сложный запрос с группировкой, но еще добавим названия этого источника, так как согласитесь по идентификаторам признака не понятно из какого источника поступили средства. Для этого мы используем конструкцию case.
SELECT SUM(summa) AS [Всего денежных средств],
COUNT(*) AS [Количество поступлений],
Name [Сотрудник],
CASE WHEN priz = 1 then 'Оклад'
WHEN priz = 2 then 'Премия'
ELSE 'Без источника'
END AS [Источник]
FROM test_table
GROUP BY name, priz
ORDER BY name
Вот теперь все достаточно наглядно и не так уж сложно, даже для начинающих.
Также давайте затронем условия по итоговым результатам агрегатных функций (having). Другими словами, мы добавляем условие не по отбору самих строк, а уже на итоговое значение функций, в нашем случае это sum или count. Например, нам нужно вывести все то же самое, но только тех, у которых
SELECT SUM(summa)as [Всего денежных средств],
COUNT(*) as [Количество поступлений],
Name [Сотрудник],
CASE WHEN priz = 1 then 'Оклад'
WHEN priz = 2 then 'Премия'
ELSE 'Без источника'
END AS [Источник]
FROM test_table
GROUP BY name, priz --группируем
HAVING SUM(summa) > 200 --отбираем
ORDER BY name -- сортируем
Теперь у нас вывелись все значения sum(summa), которые больше 200, все просто.
Заметка! Для профессионального изучения языка T-SQL рекомендую посмотреть мои видеокурсы по T-SQL.

Надеюсь, после сегодняшнего урока Вам стало понятно, как и зачем использовать конструкцию group by. Удачи! А SQL мы продолжим изучать в следующих статьях.
GROUP BY в SQL Server
В SQL Server предложение GROUP BY используется для получения сводных данных на основе одной или нескольких групп. Группы могут быть сформированы на одной или нескольких колонках. Например, запрос GROUP BY будет использоваться для подсчета количества сотрудников в каждом отделе или для получения общей заработной платы по отделам.
Вы должны использовать агрегатные функции, такие как COUNT() , MAX() , MIN() , SUM() , AVG() и т. д. в запросе SELECT.
Результат предложения GROUP BY возвращает одну строку для каждого значения столбца GROUP BY.
Синтаксис:
ВЫБЕРИТЕ столбец1, столбец2,... столбецN ИЗ имя_таблицы [ГДЕ] [ГРУППИРОВАТЬ ПО столбцу1, столбцу2...столбцуN] [ИМЕЮЩИЙ] [СОРТИРОВАТЬ ПО]
Предложение SELECT может включать столбцы, которые используются с предложением GROUP BY. Таким образом, чтобы включить другие столбцы в предложение SELECT, используйте агрегатные функции, такие как 9.0005 COUNT() , MAX() , MIN() , SUM() , AVG() с этими столбцами.
- Предложение GROUP BY используется для формирования групп записей.
- Предложение GROUP BY должно стоять после предложения WHERE, если оно присутствует, и перед предложением HAVING.
- Предложение GROUP BY может включать один или несколько столбцов для формирования одной или нескольких групп на основе этих столбцов.
- В предложение SELECT можно включить только столбцы GROUP BY. Чтобы использовать другие столбцы в предложении SELECT, используйте с ними агрегатные функции.
Для демонстрационных целей мы будем использовать следующие таблицы Employee и Department во всех примерах.
Рассмотрим следующий запрос GROUP BY.
ВЫБРАТЬ DeptId, COUNT(EmpId) как «Количество сотрудников» ОТ Сотрудника СГРУППИРОВАТЬ ПО DeptId; --следующий запрос вернет те же данные, что и выше ВЫБЕРИТЕ DeptId, COUNT (*) как «Количество сотрудников» ОТ Сотрудника СГРУППИРОВАТЬ ПО DeptId;
Приведенный выше запрос включает предложение GROUP BY DeptId , поэтому в предложение SELECT можно включить только DeptId . Вам нужно использовать агрегатные функции для включения других столбцов в предложение SELECT, поэтому COUNT(EmpId) включено, потому что мы хотим подсчитать количество сотрудников в том же DeptId . «Количество сотрудников» является псевдонимом столбца COUNT(EmpId) . Запрос отобразит следующий результат.
Следующий запрос получает название отдела вместо DeptId в результате.
SELECT dept.DeptName как «Отдел», count(emp.empid) как «Количество сотрудников» ОТ Сотрудник ип, отдел отдела ГДЕ emp.deptid = dept.DeptId ГРУППА по dept.DeptName
Таким же образом следующий запрос получает общую зарплату по отделам.
SELECT dept.DeptName, sum(emp.salary) as 'Общая зарплата' ОТ Сотрудник ип, отдел отдела ГДЕ emp.deptid = dept.DeptId ГРУППА по dept.DeptName
Следующий запрос вызовет ошибку, поскольку dept.DeptName не включен в предложение GROUP BY или не используется агрегатная функция.
SELECT dept.DeptName, sum(emp.salary) as 'Общая зарплата' ОТ Сотрудник ип, отдел отдела ГДЕ emp.deptid = dept.DeptId ГРУППА по dept.DeptIdХотите проверить, насколько хорошо вы знаете SQL Server?
Запустить тест SQL Server
Работа с оператором SQL GROUP BY
СГРУППИРОВАТЬ ПО… немного сложно явно определить так, чтобы это действительно имело смысл , но он неизбежно будет появляться бесчисленное количество раз в аналитической работе, и он вам часто понадобится.
Проще говоря, оператор GROUP BY позволяет группировать результаты запроса по указанным столбцам и используется в паре с агрегатными функциями, такими как AVG и SUM, для вычисления этих значений в определенных строках.
Оператор GROUP BY появляется в конце запроса после применения любых объединений и фильтров WHERE:
select
my_first_field,
count(id) as cnt --или любая другая агрегатная функция (sum, avg и т.д.)
из my_table
где my_first_field не равно null
group by 1 --grouped by my_first_field
order by 1 desc
Несколько замечаний по поводу реализации GROUP BY:
- Обычно это одна из последних строк в запросе, после любых соединений или выражений where; обычно вы увидите только операторы HAVING, ORDER BY или LIMIT, следующие за ним в запросе
- Вы можете сгруппировать по нескольким полям (например,
сгруппировать по 1,2,3), если вам нужно; в общем, мы рекомендуем выполнять агрегацию и объединение в отдельных CTE, чтобы избежать группировки по слишком большому количеству полей в одном запросе или CTE - .
 имя, которое находится в запросе (например,
имя, которое находится в запросе (например, группа по date_trunc('month', order_date))
Группировка по явному имени столбца (по сравнению с номером столбца в запросе) может быть двоякой: с одной стороны, она потенциально более удобочитаема для конечных бизнес-пользователей; с другой стороны, если имя сгруппированного столбца изменяется, это изменение имени должно быть отражено в операторе group by. Используйте соглашение о группировке, которое подходит вам и вашим данным, но старайтесь придерживаться одного стандартного стиля.
SQL GROUP BY пример
выберите
customer_id,
count(order_id) as num_orders
from {{ ref('orders') }}
group by 1
order by 1
limit 5
Этот простой запрос с использованием примера таблицы Jaffle Shop order вернет клиентов и количество размещенных ими заказов:
| customer_id 9 0144 | количество_заказов |
|---|---|
| 1 | 2 |
| 2 | 1 |
| 3 | 901 51 3|
| 6 | 1 |
| 7 | 1 |
Обратите внимание, что операторы order by и limit находятся после группы на в запросе.
Snowflake, Databricks, BigQuery и Redshift поддерживают возможность группировки по столбцам и используют один и тот же синтаксис.
Агрегаты, агрегаты, и мы уже говорили, агрегаты? Операторы GROUP BY необходимы, когда вы вычисляете агрегаты (средние значения, суммы, подсчеты и т. д.) по определенным столбцам; ваш запрос не будет успешно выполняться без них, если вы пытаетесь использовать агрегатные функции в своем запросе. Вы также можете увидеть операторы GROUP BY, используемые для дедупликации строк или объединения агрегатов с другими таблицами с помощью CTE; в этой статье представлен отличный обзор конкретных областей, которые вы можете увидеть, используя GROUP BY в своих проектах dbt и работе по моделированию данных.
👋Пока, привередливая группа, bys В некоторых сценариях моделирования фиксированных данных вам может понадобиться сгруппировать по многим столбцам, чтобы свернуть таблицу в меньшее количество строк или дедуплицировать строки. В этом сценарии вы можете столкнуться с тем, что пишете group by 1, 2, 3,.