Python SQLite: вложенные SQL-запросы
Смотреть материал на видео
На этом занятии поговорим о возможности создавать вложенные запросы к СУБД. Лучше всего это понять на конкретном примере. Предположим, что у нас имеются две таблицы:
Первая students содержит информацию о студентах, а вторая marks – их отметки по разным дисциплинам. Каждый из студентов (кроме четвертого) проходил язык Си. От нас требуется выбрать всех студентов, у которых оценка по языку Си выше, чем у Маши (студент с id = 2). По идее нам тут нужно реализовать два запроса: первый получает значение оценки для Маши по языку Си:
SELECT mark FROM marks WHERE id = 2 AND subject LIKE 'Си'
А второй выбирает всех студентов, у которых оценка по этому предмету выше, чем у Маши:
SELECT name, subject, mark FROM marks JOIN students ON students.rowid = marks.id WHERE mark > 3 AND subject LIKE 'Си'
Так вот, в языке SQL эти два запроса можно объединить, используя идею вложенных запросов:
SELECT name, subject, mark FROM marks JOIN students ON students.rowid = marks.id WHERE mark > (SELECT mark FROM marks WHERE id = 2 AND subject LIKE 'Си') AND subject LIKE 'Си'
 rowid = marks.id
WHERE mark > (SELECT mark FROM marks
WHERE id = 2 AND subject LIKE 'Си')
AND subject LIKE 'Си'
rowid = marks.id
WHERE mark > (SELECT mark FROM marks
WHERE id = 2 AND subject LIKE 'Си')
AND subject LIKE 'Си'Мы здесь во второй запрос вложили первый для определения оценки Маши по предмету Си. Причем, этот вложенный запрос следует записывать в круглых скобках, говоря СУБД, что это отдельная конструкция, которую следует выполнить независимо. То, что будет получено на его выходе и будет фигурировать в качестве Машиной оценки.
Но, что если вложенный запрос вернет несколько записей (оценок), например, если записать его вот так:
SELECT name, subject, mark FROM marks JOIN students ON students.rowid = marks.id WHERE mark > (SELECT mark FROM marks WHERE id = 2 ) AND subject LIKE 'Си'
В этом случае будет использован только первый полученный результат, другие попросту проигнорируются и результат будет тем же (так как первое значение – это оценка Маши по предмету Си).
Если же
вложенный SELECT ничего не
находит (возвращает значение NULL), то внешний запрос не будет возвращать
никаких записей.
Также следует обращать внимание, что подзапросы не могут обрабатывать свои результаты, поэтому в них нельзя указывать, например, оператор GROUP BY. Но агрегирующие функции вполне можно использовать, например, так:
SELECT name, subject, mark FROM marks JOIN students ON students.rowid = marks.id WHERE mark > (SELECT avg(mark) FROM marks WHERE id = 2 ) AND subject LIKE 'Си'
Вложения в команде INSERT
Вложенные запросы можно объявлять и в команде INSERT. Предположим, что у нас имеется еще одна таблица female вот с такой структурой:
Она идентична по структуре таблице students со списком студентов. Наша задача добавить в female всех студентов женского пола.
Для начала запишем запрос выбора девушек из таблицы students:
SELECT * FROM students WHERE sex = 2
А, затем, укажем, что их нужно поместить в таблицу female:
INSERT INTO female SELECT * FROM students WHERE sex = 2
После выполнения этого запроса таблица female будет содержать следующие записи:
Но если
выполнить запрос еще раз, то возникнет ошибка, т.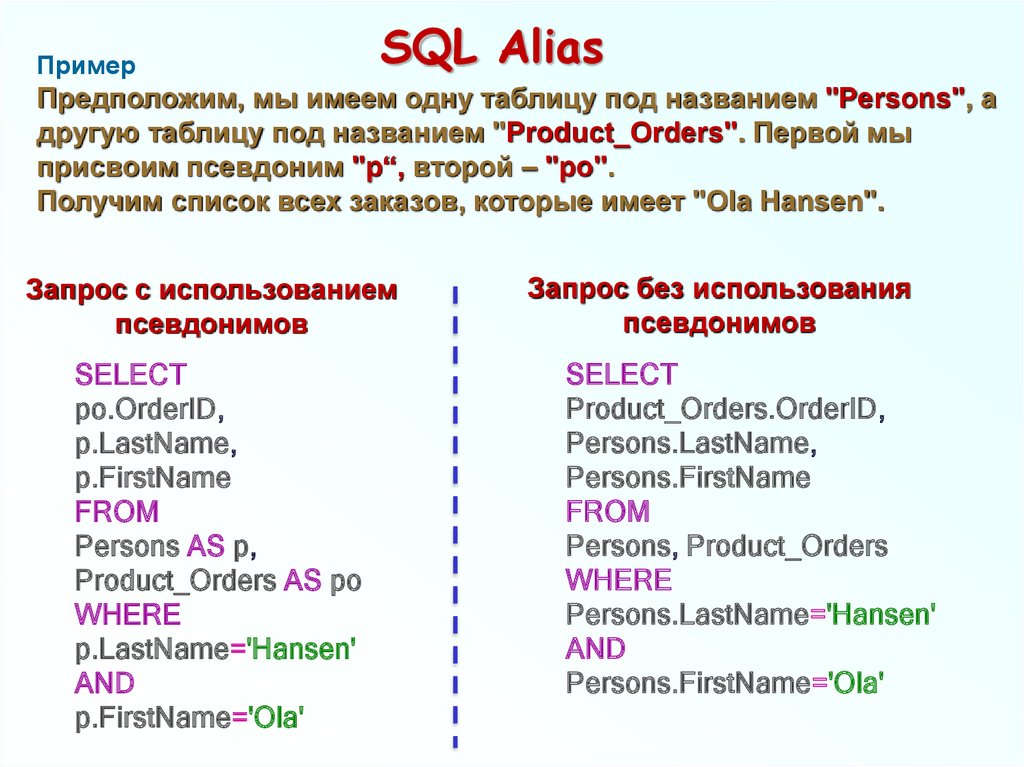 к. мы попытаемся добавить
строки с уже существующими id, что запрещено по структуре этого поля
– оно определено как главный ключ и содержит только уникальные значения.
к. мы попытаемся добавить
строки с уже существующими id, что запрещено по структуре этого поля
– оно определено как главный ключ и содержит только уникальные значения.
Чтобы поправить ситуацию, можно вложенный запрос написать так:
INSERT INTO female SELECT NULL, name, sex, old FROM students WHERE sex = 2
Мы здесь в качестве значения первого поля указали NULL и, соответственно, СУБД вместо него сгенерирует уникальный ключ для добавляемых записей. Теперь таблица female выглядит так:
Вложения в команде UPDATE
Похожим образом можно создавать вложенные запросы и для команды UPDATE. Допустим, мы хотим обнулить все оценки в таблице marks, которые меньше или равны минимальной оценки студента с id = 1. Такой запрос можно записать в виде:
UPDATE marks SET mark = 0 WHERE mark <= (SELECT min(mark) FROM marks WHERE id = 1)
И на выходе получим измененную таблицу:
Как видите,
минимальная оценка у первого студента была равна 3 и все тройки обнулились.
Вложения в команде DELETE
Ну, и наконец, аналогичные действия можно выполнять и в команде DELETE. Допустим, требуется удалить из таблицы students всех студентов, возраст которых меньше, чем у Маши (студента с id = 2). Запрос будет выглядеть так:
DELETE FROM students WHERE old < (SELECT old FROM students WHERE id = 2)
В результате, получим таблицу:
Вот так создаются вложенные запросы в языке SQL. Однако, прибегать к ним следует в последнюю очередь, если никакими другими командами не удается решить поставленную задачу. Так как они создают свое отдельное обращение к БД и на это тратятся дополнительные вычислительные ресурсы.
Конечно, на этом
занятии мы лишь рассмотрели примеры, принцип создания вложенных запросов. На
практике они могут разрастаться и становиться довольно объемными, включать в
себя различные дополнительные операции для выполнения нетривиальных действий с таблицами
БД.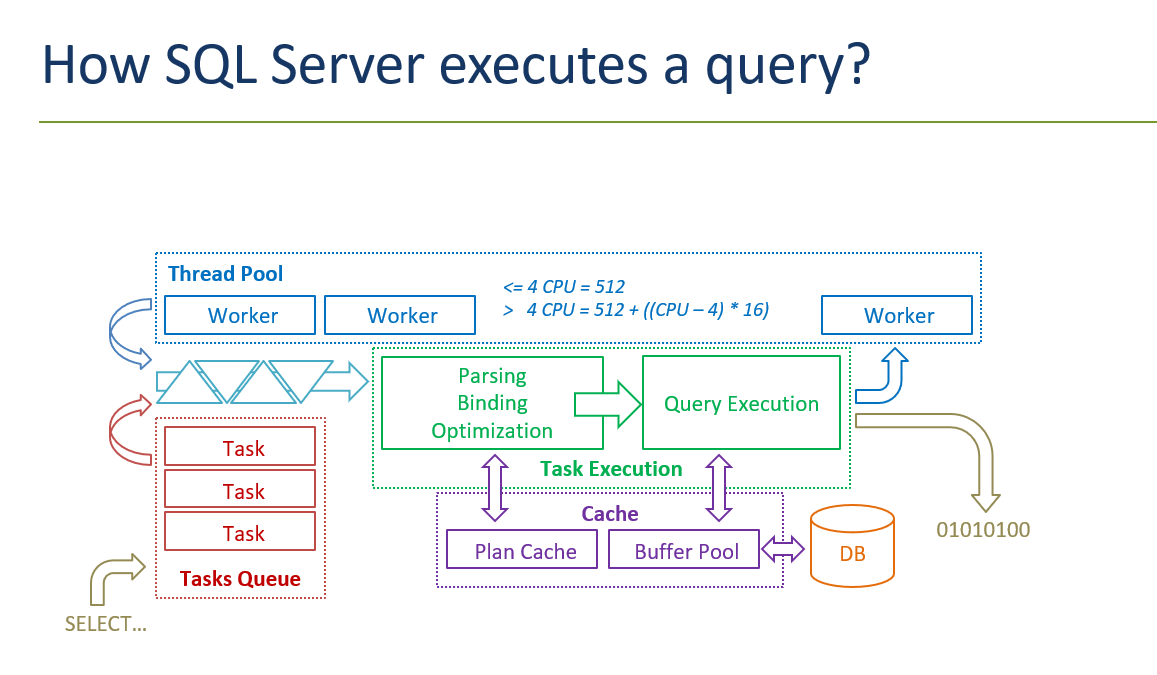
На этом мы завершим обзор SQL-языка. Этого материала вам будет вполне достаточно для начальной работы с БД. По мере развития сможете дальше углубляться в эту тему и узнавать множество новых подходов к реализации различных задач с помощью SQL-запросов.
Видео по теме
Python SQLite #1: что такое СУБД и реляционные БД
Python SQLite #2: подключение к БД, создание и удаление таблиц
Python SQLite #3: команды SELECT и INSERT при работе с таблицами БД
Python SQLite #4: команды UPDATE и DELETE при работе с таблицами
Python SQLite #5: агрегирование и группировка GROUP BY
Python SQLite #6: оператор JOIN для формирования сводного отчета
Python SQLite #7: оператор UNION объединения нескольких таблиц
Python SQLite #8: вложенные SQL-запросы
Python SQLite #9: методы execute, executemany, executescript, commit, rollback и свойство lastrowid
Python SQLite #10: методы fetchall, fetchmany, fetchone, Binary, iterdump
Как быстро писать сложные и надежные SQL-запросы на выборку коллекций
Почему-то написание SQL-запросов часто вызывает проблемы даже у опытных программистов, понимающих толк в разделении ответственности, в низкой связности и других правильных вещах, применение которых в рамках SQL вызывает трудности.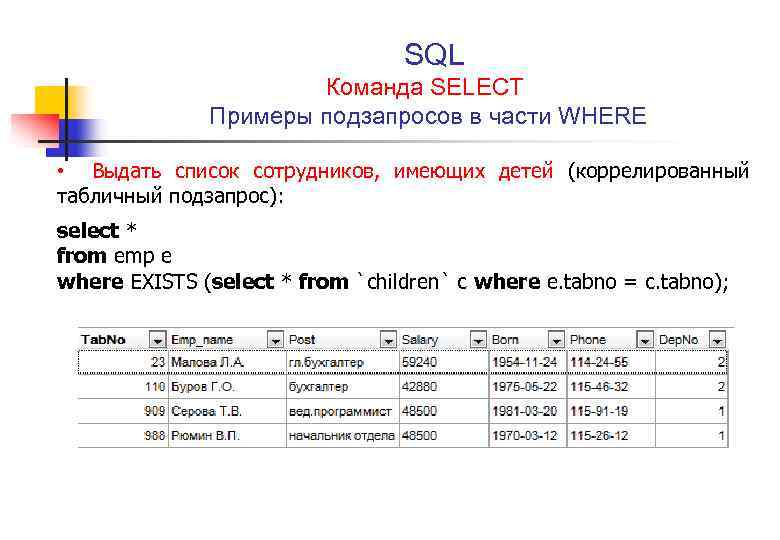
Давайте рассмотрим традиционный путь, который обычно проходит программист, а потом предложим альтернативный подход. Здесь и далее я предполагаю, что мы не пишем запросы вручную, а используем какой-то билдер, позволяющий нанизывать на запрос все новые и новые условия и соединения.
Прошу держать в голове, что данные принципы справедливы для относительно небольших систем (миллионы, а не миллиарды записей в таблицах), когда эффект масштаба еще не оказывает значительного влияния на структуру таблиц и запросов. Впрочем к данному размеру можно отнести 90% сайтов в интернете, в том числе и системы автоматизации бизнеса, которыми в основном я занимаюсь.
Изложенные в данной статье подходы справедливы только для выборки данных в рамках некой коллекции. Вычисления же агрегатов будут строиться чуть-чуть по другому.
Итак, традиционный путь
Предположим, у нас есть интернет-магазин и нам необходимо выводить список товаров, используя набор критериев (фильтров). Мы пишем:
SELECT * FROM product WHERE price > :start_price AND price < :end_price;
Все прекрасно, мы сделали покрывающий индекс по цене, радуемся простоте и производительности.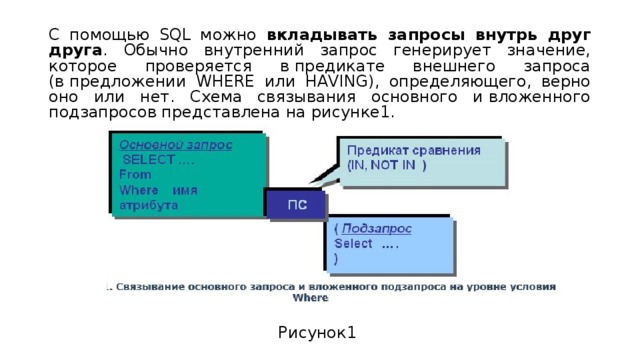
Но что, если нужно выводить рубрики, в которые включены товары из выборки? Отлично, можно добавить соединение с рубриками, потом GROUP BY и какую-нибудь агрегатную функцию.
SELECT p.*, GROUP_CONCAT(c.title SEPARATOR ‘, ‘) as categories FROM product p LEFT JOIN product_category pc ON pc.product_id=p.id LEFT JOIN category c ON c.id=pc.category_id WHERE p.price > :start_price AND p.price < :end_price GROUP BY p.id;
Ну.. это работает. А что если нам еще нужен список тегов? И обычно здесь программист добавляет еще JOIN`ов
SELECT p.*, GROUP_CONCAT(c.title SEPARATOR ‘, ‘) as categories, GROUP_CONCAT(t.tag SEPARATOR ‘, ‘) as tags FROM product p LEFT JOIN product_category pc ON pc.product_id=p.id LEFT JOIN category c ON c.id=pc.category_id LEFT JOIN product_tag pt ON pt.product_id=p.id LEFT JOIN tag t ON t.id=pc.tag_id WHERE p.price > :start_price AND p.price < :end_price GROUP BY p.id;
Это уже не работает. Категории и теги начинают задваиваться, ну ладно, мы же можем сделать GROUP_CONCAT(DISTINCT . ..)! А что если нужно подсчитывать количество отзывов по каждому товару? Еще JOIN? А ничего, когда каждый следующий JOIN начинает мешать предыдущему?
..)! А что если нужно подсчитывать количество отзывов по каждому товару? Еще JOIN? А ничего, когда каждый следующий JOIN начинает мешать предыдущему?
Здесь можно было и призадуматься.
Давайте рассмотрим альтернативный подход
Я постепенно пришел к тому, что каждый запрос разделяю на части. Каждая часть играет одну из двух ролей:
- выборки (фильтра)
- представления (данные)
Такое разделение позволяет мне одной и той же выборке (наборам фильтров) сопоставлять разные представления (данные).
В примере выше все дополнительные соединения (категорий и тегов) играют роли представлений, так как они не накладывают ограничений на выборку (не сужают выборку), а лишь служат инструментом для формирования данных в дополнительных колонках.
Рассмотрим пример соединения с фильтрацией. Например, нам нужно показать только те товары, производители которых зарегистрированы в России:
SELECT p.* FROM product p INNER JOIN manufacturer m ON m.id=p.manufacturer_id AND m.country_key=’RU’ WHERE p.price > :start_price AND p.price < :end_price;
Здесь INNER JOIN не добавляет новые колонки, но сужает выборку. Это явное поведение по типу фильтра.
С типами разобрались. Как же строить запросы? В своей практике для построения запросов я использую три простых принципа:
- Основной запрос на выборку строится без GROUP BY и по возможности использует покрывающие индексы
- Первым делом я добавляю соединения, обеспечивающие фильтрацию (сужение выборки). После, по необходимости, я добавляю соединения, обеспечивающие представление.
- Каждое новое соединение я делаю только уникальному ключу соединяемой таблицы. Если соединяемая таблица не может обеспечить уникальности ключа, то я использую подзапрос.
Давайте рассмотрим принципы с конца.
Соединение с таблицами только по уникальному ключу
Идея проста — не допустить разрастания выборки по количеству строчек после соединения (и таким образом GROUP BY в основной части запроса не понадобится).
В примере выше с производителями — принцип обеспечен уникальностью ключа manufacturer.id, таким образом соединение с таблицей по этому ключу не приведет к повторению строчек из основной таблицы.
Давайте посмотрим, как же быть с категориями и тегами из первых примеров. Используем подзапрос:
SELECT p.*, pc.categories, pt.tags FROM product LEFT JOIN ( SELECT pc.product_id, GROUP_CONCAT(c.title SEPARATOR ‘, ‘) as categories FROM product_category pc INNER JOIN category c ON c.id=pc.category_id GROUP BY pc.product_id; ) pc ON pc.product_id=p.id LEFT JOIN ( SELECT pt.product_id, GROUP_CONCAT(t.title SEPARATOR ‘, ‘) as tags FROM product_tag pt INNER JOIN tag t ON c.id=pt.tag_id GROUP BY pt.product_id; ) pt ON pt.product_id=p.id WHERE p.price > :start_price AND p.price < :end_price;
Основная проблема этого запроса в том, что при большом количестве товаров в подзапросах может быть большая выборка. Однако, с этим можно работать, привнося в подзапросы дополнительные фильтры из основного запроса, сужая выборку и здесь. Также есть надежда, что оптимизатор БД, выполняя одни и те же подзапросы, догадается закешировать их результаты.
Также есть надежда, что оптимизатор БД, выполняя одни и те же подзапросы, догадается закешировать их результаты.
Давайте добавим фильтр по тем товарам, у которых пользовательская оценка равна 5 звездам:
SELECT p.*, pc.categories, pt.tags FROM product INNER JOIN ( SELECT DISTINCT r.product_id FROM review r WHERE r.starts=5 ) r ON r.product_id=p.id LEFT JOIN ( ... ) pc ON pc.product_id=p.id LEFT JOIN ( ... ) pt ON pt.product_id=p.id WHERE p.price > :start_price AND p.price < :end_price
Следуя нашим принципам, мы добавили этот фильтр, совершенно не беспокоясь о том, что повредим остальную часть запроса.
Порядок соединений — от фильтров к представлениям
Часто для выводимой коллекции нужно вычислить пагинацию (сколько страниц займет выборка) и какие-то другие технические данные. В таких случаях те части запроса, которые отвечают за отображение можно просто отбросить.
Таким образом первым делом я обычно собираю запрос из частей, отвечающих за фильтрацию данных. Затем я делаю технические выборки на основе промежуточного состояния запроса, и только потом я дополняю запрос частями, отвечающими за отображение.
Затем я делаю технические выборки на основе промежуточного состояния запроса, и только потом я дополняю запрос частями, отвечающими за отображение.
Отказ от GROUP BY в основной части запроса
Как только мы начинаем практиковать изложенные выше принципы, GROUP BY из основной части запроса обычно исчезает сам по себе за ненадобностью.
Но если все же он после всех манипуляций остался, то, скорее всего, это обусловлено объективной ситуацией. У вас, скорее всего — агрегатная выборка, а не выборка коллекции.
Изложенный в статье подход помогает мне быстро строить сложные запросы, отлаживая их по частям, и свободно комбинируя логику разных выборок между собой с использованием сборщка запросов.
Как писать сложные запросы SQL
Содержание
SQL — очень удобный язык для изучения больших наборов данных в нескольких таблицах, а также очень простой для интерпретации, поскольку он похож на базовый английский.
Предоставил: Aadish Jain
Иногда мы можем запутаться, когда есть сложные SQL-запросы, мы в конечном итоге запутаемся в большом количестве где или присоединяемся к условиям.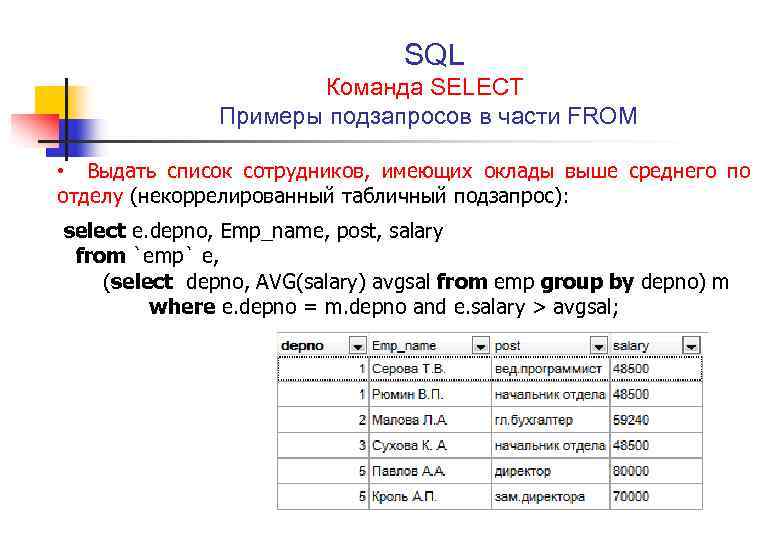 Помимо создания их один раз, мы сталкиваемся с множеством проблем, когда нам нужно их отлаживать или повторно использовать в той же или в другой форме.
Помимо создания их один раз, мы сталкиваемся с множеством проблем, когда нам нужно их отлаживать или повторно использовать в той же или в другой форме.
Ниже приведены несколько сценариев, когда SQL-запросы становятся довольно сложными для написания:
- Когда есть 3-4 таблицы для объединения по разным атрибутам.
- Когда есть неопределенность в отношении того, какие условия соединения (внутреннее соединение, внешнее соединение, правое соединение, левое соединение) мы должны использовать в каком случае.
- Когда требуемый столбец не присутствует непосредственно в базе данных, но его необходимо получить из 2-3 столбцов или с помощью математических функций, таких как среднее, максимальное, минимальное и т. д.
- Когда есть неопределенность в отношении использования некоторых необычных условий предложения, таких как groupby, have, order by.
В этой статье я попытаюсь рассказать о «волшебстве» написания сложных операторов SELECT.
Перед тем, как начать писать (сложные) запросы, вы должны понимать, что где находится – какие таблицы хранят какие данные. Кроме того, вы должны понимать природу отношений между этими таблицами. Мы всегда должны иметь в виду схему базы данных и понимать все таблицы и поля с точки зрения бизнеса.
Наличие общей картины базы данных сэкономит много времени в долгосрочной перспективе. Всегда уделяйте некоторое время тому, чтобы получить полное представление о вашей базе данных, прежде чем переходить к созданию запросов. Получив полное представление о схеме базы данных и взаимосвязях между несколькими таблицами, попытайтесь понять бизнес-задачу постановки задачи и подготовьте план на бумаге. Разделите проблему на более мелкие сегменты, а затем начните работать над ними.
Мы должны использовать правильный отступ, потому что только запись и запуск не важны. Он должен быть легко читаем другим человеком. Поместите каждое выбираемое поле в отдельную строку и поместите каждую новую объединенную таблицу в отдельную строку, а каждый элемент предложения «ГДЕ» — в отдельную строку. Используйте осмысленные псевдонимы для таблиц, чтобы улучшить читаемость. Скорее всего, вам придется ссылаться на свои таблицы несколько раз в запросе, и если вы работаете с чужой базой данных с их соглашением об именах, имена таблиц могут содержать избыточную информацию. Например, «Сведения о сотруднике» — так что вы называете такую таблицу «ED», имя таблицы «Заголовок заказа» может иметь псевдоним «OH» и т. д.
Используйте осмысленные псевдонимы для таблиц, чтобы улучшить читаемость. Скорее всего, вам придется ссылаться на свои таблицы несколько раз в запросе, и если вы работаете с чужой базой данных с их соглашением об именах, имена таблиц могут содержать избыточную информацию. Например, «Сведения о сотруднике» — так что вы называете такую таблицу «ED», имя таблицы «Заголовок заказа» может иметь псевдоним «OH» и т. д.
Рисунок 1: Схема для набора данных заказов
Постановка проблемы заключается в том, что нам необходимо:
Написать запрос для отображения order_id, идентификатора клиента и полного имени клиента вместе с (product_quantity) в качестве общего количества товаров, отгруженных для идентификаторов заказов > 10060, для клиентов, купивших более 15 товаров на отгруженный заказ.
Здесь мы можем понять, что требуются таблицы : online_customer, order_header, order_items, которые могут иметь псевдонимы C, OH и OI соответственно.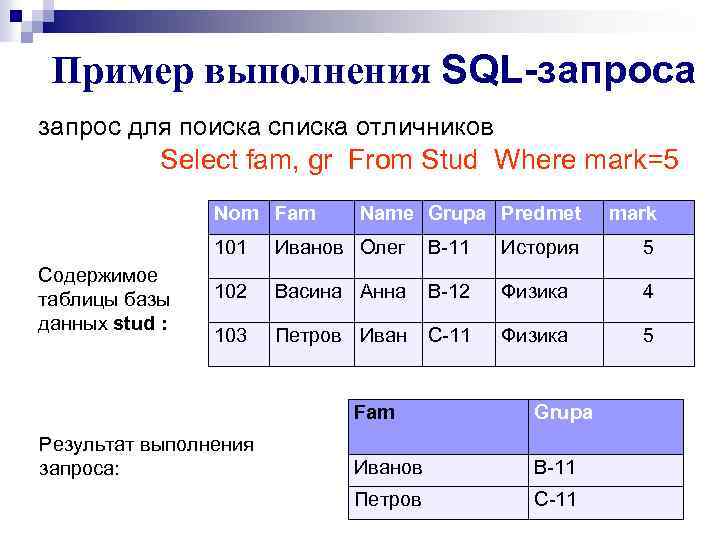
Выберите запрос, указав необходимые столбцы из каких таблиц.
Итак, orderID можно получить из заголовка заказа или таблицы order_id. Customer_id и имя клиента можно получить из таблицы клиентов.
Количество продукта для каждого заказа доступно в таблице Order Items. Таким образом, запрос будет таким:
. ВЫБЕРИТЕ OI.ORDER_ID,C.CUSTOMER_ID,CONCAT(C.CUSTOMER_FNAME," ",C.CUSTOMER_LNAME) AS 'CUSTOMER_FULL_NAME', SUM(OI.PRODUCT_QUANTITY) AS 'ОБЩЕЕ КОЛИЧЕСТВО'
Теперь мы видим, что нам нужно найти общие порядки из всех трех таблиц, поэтому мы должны использовать здесь INNER JOIN.
Элементы заказа и заголовок заказа имеют общий идентификатор Order_ID, а онлайн-клиенты и заголовок заказа имеют идентификатор клиента в качестве общего ключа поля. Поэтому мы будем использовать условия соединения соответственно.
ВЫБЕРИТЕ OI.ORDER_ID,C.CUSTOMER_ID,CONCAT(C.CUSTOMER_FNAME," ",C.CUSTOMER_LNAME) AS 'CUSTOMER_FULL_NAME', SUM(OI.PRODUCT_QUANTITY) AS 'ОБЩЕЕ КОЛИЧЕСТВО' ОТ online_customer C INNER JOIN ORDER_HEADER OH ON C.CUSTOMER_ID = OH.CUSTOMER_ID INNER JOIN order_items OI ON OH.ORDER_ID = OI.ORDER_ID
Теперь задача состоит в том, чтобы получить все эти данные для идентификаторов заказов> 10060, чтобы мы могли понять, что нам нужно поместить предложение where, чтобы отфильтровать заказы с идентификатором заказа <= 10006. Также статус заказа должен быть Отгружен в заголовке заказа. стол.
Таким образом, обновленный запрос будет таким:
ВЫБЕРИТЕ OI.ORDER_ID,C.CUSTOMER_ID,CONCAT(C.CUSTOMER_FNAME," ",C.CUSTOMER_LNAME) AS 'CUSTOMER_FULL_NAME', SUM(OI.PRODUCT_QUANTITY) AS 'ОБЩЕЕ КОЛИЧЕСТВО' ОТ online_customer C INNER JOIN ORDER_HEADER OH ON C.CUSTOMER_ID = OH.CUSTOMER_ID INNER JOIN order_items OI ON OH.ORDER_ID = OI.ORDER_ID ГДЕ OH.ORDER_ID > 10060 И OH.ORDER_STATUS = «Отправлено»
Нам нужно позаботиться о вещах всякий раз, когда нам нужно использовать некоторую агрегацию данных, такую как сумма, среднее, максимальное, минимальное и т. Д., Затем нам нужно указать, на каком основании будет выполняться эта агрегация, и это условие указано в GROUPBY пункт .
Д., Затем нам нужно указать, на каком основании будет выполняться эта агрегация, и это условие указано в GROUPBY пункт .
Итак, здесь, в нашем примере, мы должны вычислить сумму количества продуктов для всех продуктов, заказанных с определенным OrderID, поэтому мы будем использовать здесь GROUPBY ORDER_ID.
Таким образом, обновленный запрос будет следующим:
ВЫБЕРИТЕ OI.ORDER_ID,C.CUSTOMER_ID,CONCAT(C.CUSTOMER_FNAME," ",C.CUSTOMER_LNAME) AS 'CUSTOMER_FULL_NAME', SUM(OI.PRODUCT_QUANTITY) AS 'ОБЩЕЕ КОЛИЧЕСТВО' ОТ online_customer C INNER JOIN ORDER_HEADER OH ON C.CUSTOMER_ID = OH.CUSTOMER_ID INNER JOIN order_items OI ON OH.ORDER_ID = OI.ORDER_ID ГДЕ OH.ORDER_ID > 10060 И OH.ORDER_STATUS = ГРУППА «Отправлено» ПО OI.ORDER_ID
Если нам нужно задать условия для агрегированных данных, то они не могут быть обработаны предложением WHERE , и мы должны использовать предложение HAVING для того же.
Как и в нашем примере, нам нужно отфильтровать заказы, для которых общее количество товаров в заказе было меньше 15.
Таким образом, наш обновленный окончательный запрос будет таким:
ВЫБЕРИТЕ OI.ORDER_ID,C.CUSTOMER_ID,CONCAT(C.CUSTOMER_FNAME," ",C.CUSTOMER_LNAME) AS 'CUSTOMER_FULL_NAME', SUM(OI.PRODUCT_QUANTITY) AS 'TOTAL_QUANTITY' FROM online_customer C INNER JOIN ORDER_HEADER OH ON C.CUSTOMER_ID = OH.CUSTOMER_ID INNER JOIN order_items OI ON OH.ORDER_ID = OI.ORDER_ID ГДЕ OH.ORDER_ID > 10060 AND OH.ORDER_STATUS = 'Отправлено' ГРУППА ПО OI.ORDER_ID HAVING TOTAL_QUANTITY > 15 ;
Таким образом, мы можем легко создавать сложные SQL-запросы, анализируя данные и разбивая запрос на более мелкие фрагменты. Если вы хотите узнать больше о таких концепциях, отправляйтесь в Great Learning Academy и учитесь на бесплатных онлайн-курсах.
Узнайте, как писать SQL-запросы (практиковать сложные SQL-запросы) — techTFQ
Практические SQL-запросы
Написано Thoufiq Mohammed
Изучение синтаксиса SQL очень просто, но научиться писать SQL-запросы, особенно сложные SQL-запросы, может быть сложно и потребуется много практики.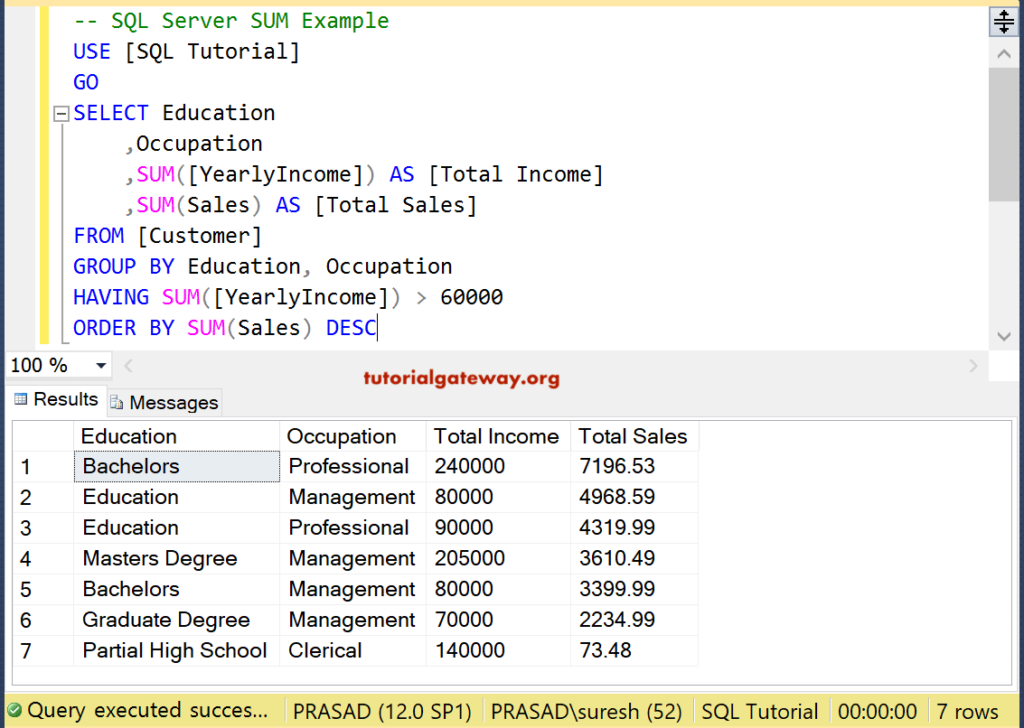
В этом блоге я перечислил ниже 9 SQL-запросов , которые должны помочь вам попрактиковаться в средних и сложных SQL-запросах.
Ниже вы найдете вопросы SQL, а также данные и структуру таблицы, необходимые для решения каждого вопроса SQL. SQL-запрос для решения этих вопросов будет прикреплен к файлу .txt. Вы можете просто загрузить файл для каждого вопроса, чтобы получить решенные SQL-запросы.
*** Примечание. Обратите внимание, что я использовал базу данных PostgreSQL для выполнения всех этих запросов. Я считаю, что эти запросы будут прекрасно работать с любыми другими основными СУБД, такими как Oracle, MySQL, Microsoft SQL Server. Однако, если вы обнаружите, что какой-либо запрос не работает в вашей СУБД, оставьте комментарий ниже, чтобы я мог помочь.
Напишите запрос SQL, чтобы получить все повторяющиеся записи в таблице.
Имя таблицы : ПОЛЬЗОВАТЕЛИ
Примечание : Запись считается дублированной, если имя пользователя присутствует более одного раза.

Подход : Разделите данные на основе имени пользователя, а затем присвойте номер строки каждому из разделенных имен пользователей. Если имя пользователя существует более одного раза, оно будет иметь несколько номеров строк. Используя номер строки, отличный от 1, мы можем идентифицировать повторяющиеся записи.
ПОЛЬЗОВАТЕЛЯ
Ожидаемый результат
Существует несколько способов написать этот запрос. Например, с использованием поля CTID в PostgreSQL или с использованием поля ROWID в Oracle, MySQL, Microsoft SQL Server и т. д., но более простой способ написать этот запрос — использовать оконную функцию.
Попробуйте написать этот запрос самостоятельно, прежде чем искать запрос, который я написал для его решения.
Нажмите кнопку загрузки ниже, чтобы загрузить файл .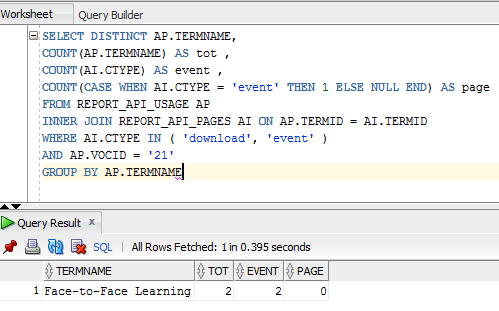 txt, который будет иметь структуру таблицы, данные таблицы и решенный SQL-запрос.
txt, который будет иметь структуру таблицы, данные таблицы и решенный SQL-запрос.
Скачать скрипт — запрос 1
2. Напишите запрос SQL для получения предпоследней записи из таблицы сотрудников.
Имя таблицы : СОТРУДНИК
Подход : Используя оконную функцию, отсортируйте данные в порядке убывания на основе идентификатора сотрудника. Укажите номер строки для каждой записи и выберите запись с номером строки 2.
СЛУЖАЩИЙ
Ожидаемый результат
Опять же, есть несколько способов написать этот запрос, но очень просто использовать оконную функцию.
Попробуйте написать этот запрос самостоятельно, прежде чем искать запрос, который я написал для его решения.
Нажмите кнопку загрузки ниже, чтобы загрузить файл .txt, который будет содержать структуру таблицы, данные таблицы и решенный SQL-запрос.
Скачать скрипт — запрос 2
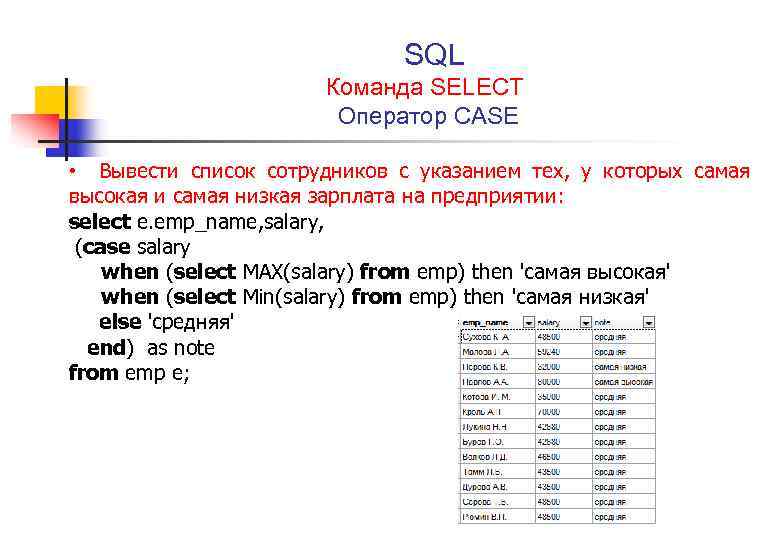
3. Напишите SQL-запрос, чтобы отобразить сведения только о сотрудниках, получающих самую высокую или самую низкую заработную плату в каждом отделе из таблицы сотрудников.
Имя таблицы : EMPLOYEE
Подход : Напишите подзапрос, который разделит данные на основе каждого отдела, а затем определите запись с максимальной и минимальной зарплатой для каждого из разделенных отделов. Наконец, из основного запроса извлеките только те данные, которые соответствуют максимальной и минимальной зарплате, возвращенной из подзапроса.
СЛУЖАЩИЙ
Ожидаемый результат
Опять же, есть много способов сделать это, а также мы можем использовать несколько оконных функций для достижения того же результата. В качестве дополнительной задачи попробуйте решить этот запрос, используя другую оконную функцию, а затем закомментируйте свой запрос.
Нажмите кнопку загрузки ниже, чтобы загрузить файл .txt, который будет содержать структуру таблицы, данные таблицы и решенный SQL-запрос.
Скачать скрипт — запрос 3
4. Из таблицы врачей извлеките информацию о врачах, работающих в той же больнице, но по другой специальности.
Имя таблицы : ВРАЧИ
Подход : Используйте самообъединение для решения этой проблемы. Самосоединение — это когда вы присоединяете таблицу к самой себе.
Дополнительный запрос : Напишите SQL-запрос для получения врачей, работающих в одной больнице, независимо от их специальности.
ВРАЧИ
Ожидаемый результат: Та же больница другой специальности
Ожидаемый результат: Та же больница, независимо от специальности
Нажмите кнопку загрузки ниже, чтобы загрузить файл . txt, который будет содержать структуру таблицы, данные таблицы и решенный SQL-запрос.
txt, который будет содержать структуру таблицы, данные таблицы и решенный SQL-запрос.
Скачать скрипт — запрос 4
5. Из таблицы login_details выберите пользователей, которые вошли в систему 3 или более раз подряд.
Имя таблицы : LOGIN_DETAILS
Подход : Нам нужно получить пользователей, которые появлялись 3 или более раз подряд в таблице сведений для входа. Существует оконная функция, которую можно использовать для извлечения данных из следующей записи. Используйте эту оконную функцию, чтобы сравнить имя пользователя в текущей строке с именем пользователя в следующей строке и в строке, следующей за следующей строкой. Если он совпадает, извлеките эти записи.
LOGIN_DETAILS
Ожидаемый результат
Нажмите кнопку загрузки ниже, чтобы загрузить файл . txt, который будет содержать структуру таблицы, данные таблицы и решенный SQL-запрос.
txt, который будет содержать структуру таблицы, данные таблицы и решенный SQL-запрос.
Скачать скрипт — запрос 5
6. Из таблицы студентов напишите запрос SQL, чтобы поменять местами соседние имена студентов.
Примечание : Если нет соседнего студента, имя студента должно оставаться прежним.
Имя таблицы : СТУДЕНТЫ
Подход : Предполагается, что идентификатор всегда будет порядковым номером. Если id является нечетным числом, извлеките имя студента из следующей записи. Если id — четное число, извлеките имя учащегося из предыдущей записи. Попробуйте выяснить оконную функцию, которую можно использовать для получения данных предыдущей записи.
Если последняя запись является нечетным числом, то она не будет иметь соседнего четного числа, поэтому найдите способ не менять местами данные последней записи.
СТУДЕНТЫ
Ожидаемый результат
Нажмите кнопку загрузки ниже, чтобы загрузить файл . txt, который будет содержать структуру таблицы, данные таблицы и решенный SQL-запрос.
txt, который будет содержать структуру таблицы, данные таблицы и решенный SQL-запрос.
Скачать скрипт — запрос 6
7. Из таблицы погоды выберите все записи, когда в Лондоне были экстремально низкие температуры в течение 3 дней подряд или более.
Примечание : Погода считается очень холодной, когда ее температура ниже нуля.
Имя таблицы : ПОГОДА
Подход : Сначала с помощью подзапроса определите все записи, где температура была очень низкой, а затем используйте основной запрос, чтобы получить только записи, возвращенные как очень низкие из подзапроса. Вам нужно будет не только сравнить записи, следующие за текущей строкой, но также необходимо сравнить записи, предшествующие текущей строке. А также может потребоваться сравнить строки, предшествующие и следующие за текущей строкой. Определите оконную функцию, которая может довольно легко сделать это сравнение.
ПОГОДА
Ожидаемый результат
Нажмите кнопку загрузки ниже, чтобы загрузить файл . txt, который будет содержать структуру таблицы, данные таблицы и решенный SQL-запрос.
txt, который будет содержать структуру таблицы, данные таблицы и решенный SQL-запрос.
Скачать скрипт — запрос 7
8. Из следующих 3 таблиц (event_category, doctor_speciality,patient_treatment) напишите SQL-запрос, чтобы получить гистограмму специальностей уникальных врачей, которые выполняли процедуры, но никогда ничего не назначали.
Название таблицы : СОБЫТИЕ_КАТЕГОРИЯ, ВРАЧ_СПЕЦИАЛИЗАЦИЯ, ПАЦИЕНТ_ЛЕЧЕНИЕ
Подход : Используя таблицу лечения пациента и категории событий, определите всех врачей, которые выписали «Предписание». Запишите это в подзапросе.
Затем в основном запросе объедините лечение пациента, категорию события и таблицу специальности врача, чтобы определить всех врачей, которые выполняли «процедуры». Из этих врачей удалите тех врачей, которых вы получили из подзапроса, чтобы вернуть врачей, которые сделали процедуру, но никогда не делали рецепт.
ЛЕЧЕНИЕ_ПАЦИЕНТА
СОБЫТИЕ_КАТЕГОРИЯ
ВРАЧ_СПЕЦИАЛЬНОСТЬ
Ожидаемый результат
Нажмите кнопку загрузки ниже, чтобы загрузить файл . txt, который будет содержать структуру таблицы, данные таблицы и решенный SQL-запрос.
txt, который будет содержать структуру таблицы, данные таблицы и решенный SQL-запрос.
Скачать скрипт — запрос 8
9. Найдите 2 лучших аккаунта с максимальным количеством уникальных пациентов в месяц.
Примечание : Предпочитайте идентификатор учетной записи с наименьшим значением в случае одинакового количества уникальных пациентов каждый месяц. Затем сгруппируйте все данные на основе каждого месяца и идентификатора учетной записи, чтобы получить общее количество пациентов, принадлежащих каждой учетной записи, в месяц.
Затем ранжируйте эти данные по количеству пациентов в порядке убывания и идентификатору учетной записи в порядке возрастания, поэтому в случае одинакового количества пациентов, присутствующих под несколькими учетными записями, если тогда ранжирование будет предпочтительнее для учетной записи с более низким значением. Наконец, выберите до 2 записей только в месяц, чтобы получить окончательный результат.
ПАЦИЕНТ_ЛОГ
Ожидаемый результат
Нажмите кнопку загрузки ниже, чтобы загрузить файл . txt, который будет содержать структуру таблицы, данные таблицы и решенный SQL-запрос.
txt, который будет содержать структуру таблицы, данные таблицы и решенный SQL-запрос.
Скачать скрипт — запрос 9
10. SQL-запрос для извлечения «N» последовательных записей из таблицы на основе определенного условия
Примечание. Напишите отдельные запросы для выполнения следующих сценариев:
10a. когда таблица имеет первичный ключ
10b. Если в таблице нет первичного ключа
10с. Логика запроса на основе поля данных
10a. когда таблица имеет первичный ключ
Имя таблицы: WEATHER
Данные таблицы ПОГОДЫ
10a: Ожидаемый результат
10б. Если у таблицы нет первичного ключа
Имя таблицы: VW_WEATHER
Данные таблицы VW_WEATHER
10b: Ожидаемый результат
10с.