Как быстро писать сложные и надежные SQL-запросы на выборку коллекций
Написание SQL-запросов вызывает проблемы даже у опытных программистов, понимающих толк в разделении ответственности, низкой связности и других правильных вещах.
Давайте рассмотрим путь, который обычно проходит программист, а потом предложим альтернативный подход. Здесь и далее я предполагаю, что мы не пишем запросы вручную, а используем какой-то билдер, позволяющий нанизывать на запрос все новые и новые условия и соединения.
Прошу держать в голове, что данные принципы справедливы для относительно небольших систем (миллионы, а не миллиарды записей в таблицах), когда эффект масштаба еще не оказывает значительного влияния на структуру таблиц и запросов. Впрочем к данному размеру можно отнести 90% сайтов в интернете, в том числе и системы автоматизации бизнеса, которыми в основном я занимаюсь.
Изложенные в данной статье подходы справедливы только для выборки данных в рамках некой коллекции. Вычисления же агрегатов будут строиться чуть-чуть по другому.
Итак, традиционный путь
Предположим, у нас есть интернет-магазин и нам необходимо выводить список товаров, используя набор критериев (фильтров). Мы пишем:
SELECT * FROM product WHERE price > :start_price AND price < :end_price;
Все прекрасно, мы сделали покрывающий индекс по цене, радуемся простоте и производительности.
Но что, если нужно выводить рубрики, в которые включены товары из выборки? Отлично, можно добавить соединение с рубриками, потом GROUP BY и агрегатную функцию.
SELECT p.*, GROUP_CONCAT(c.title SEPARATOR ‘, ‘) as categories FROM product p LEFT JOIN product_category pc ON pc.product_id=p.id LEFT JOIN category c ON c.id=pc.category_id WHERE p.price > :start_price AND p.price < :end_price GROUP BY p.id;
Ну.. это работает. А что если нам еще нужен список тегов? И обычно здесь программист добавляет еще JOIN`ов
SELECT p.*, GROUP_CONCAT(c.title SEPARATOR ‘, ‘) as categories, GROUP_CONCAT(t.tag SEPARATOR ‘, ‘) as tags FROM product p LEFT JOIN product_category pc ON pc.product_id=p.id LEFT JOIN category c ON c.id=pc.category_id LEFT JOIN product_tag pt ON pt.product_id=p.id LEFT JOIN tag t ON t.id=pc.tag_id WHERE p.price > :start_price AND p.price < :end_price GROUP BY p.id;

Это уже не работает. Категории и теги начинают задваиваться, ну ладно, мы же можем сделать GROUP_CONCAT(DISTINCT …)! А что если нужно подсчитывать количество отзывов по каждому товару? Еще JOIN? И мы оказываемся в ситуации, когда каждый следующий JOIN начинает мешать предыдущему.
Здесь нужно задуматься.
Альтернативный подход
Каждый запрос следует проанализировать и разделить на небольшие части таким образом, чтобы можно было отнести эти части к одной из двух групп:
- Фильтрация данных (сужение выборки)
- Представление данных (вывод данных и форматирование)
В примере выше все дополнительные соединения (категорий и тегов) играют роли представлений, так как они не накладывают ограничений на выборку (не сужают выборку), а лишь служат инструментом для формирования данных в дополнительных колонках.
Рассмотрим пример соединения с фильтрацией. Например, нам нужно показать только те товары, производители которых зарегистрированы в России:
SELECT p.* FROM product p INNER JOIN manufacturer m ON m.id=p.manufacturer_id AND m.country_key=’RU’ WHERE p.price > :start_price AND p.price < :end_price;
Здесь INNER JOIN не добавляет новые колонки, но сужает выборку. Это явное поведение по типу фильтра.
Распределив части запроса на группы, нужно собрать из них финальный запрос в три простых шага:
- Построить основной запрос на выборку без GROUP BY и по возможности используя покрывающие индексы
- Добавить соединения, обеспечивающие фильтрацию (сужение выборки).
- Добавить соединения, обеспечивающие представление, здесь можно использовать GROUP BY
Соединение с таблицами только по уникальному ключу
Каждое новое соединение следует делать только по уникальному ключу соединяемой таблицы. Если соединяемая таблица не может обеспечить уникальности ключа, то следует использовать подзапрос.
Идея проста — не допустить разрастания выборки по количеству строчек после соединения (и таким образом GROUP BY в основной части запроса не понадобится).
В примере выше с производителями — принцип обеспечен уникальностью ключа manufacturer.id, таким образом соединение с таблицей по этому ключу не приведет к повторению строчек из основной таблицы.
Давайте посмотрим, как же быть с категориями и тегами из первых примеров. Используем подзапрос:
SELECT p.*, pc.categories, pt.tags FROM product LEFT JOIN ( SELECT pc.product_id, GROUP_CONCAT(c.title SEPARATOR ‘, ‘) as categories FROM product_category pc INNER JOIN category c ON c.id=pc.category_id GROUP BY pc.product_id; ) pc ON pc.product_id=p.id LEFT JOIN ( SELECT pt.product_id, GROUP_CONCAT(t.title SEPARATOR ‘, ‘) as tags FROM product_tag pt INNER JOIN tag t ON c.id=pt.tag_id GROUP BY pt.product_id; ) pt ON pt.product_id=p.id WHERE p.price > :start_price AND p.price < :end_price;
Основная проблема этого запроса в том, что при большом количестве товаров в подзапросах может быть большая выборка. Однако, с этим можно работать, привнося в подзапросы дополнительные фильтры из основного запроса, сужая выборку и здесь. Еще есть надежда, что оптимизатор БД, выполняя одни и те же подзапросы, догадается закешировать их результаты.
Давайте добавим фильтр по тем товарам, у которых пользовательская оценка равна 5 звездам:
SELECT p.*, pc.categories, pt.tags FROM product INNER JOIN ( SELECT DISTINCT r.product_id FROM review r WHERE r.starts=5 ) r ON r.product_id=p.id LEFT JOIN ( ... ) pc ON pc.product_id=p.id LEFT JOIN ( ... ) pt ON pt.product_id=p.id WHERE p.price > :start_price AND p.price < :end_price
Обратите внимание, запрос так разбит на части, что мы добавляем этот фильтр, совершенно не беспокоясь о том, что можем повредить остальную часть запроса.
Порядок соединений — от фильтров к представлениям
Часто для выводимой коллекции нужно вычислить пагинацию (сколько страниц займет выборка) и какие-то другие технические данные. В таких случаях те части запроса, которые отвечают за отображение можно просто отбросить.
Таким образом первым делом я обычно собираю запрос из частей, отвечающих за фильтрацию данных. Затем я делаю технические выборки на основе промежуточного состояния запроса, и только потом я дополняю запрос частями, отвечающими за отображение.
Отказ от GROUP BY в основной части запроса
Как только мы начинаем практиковать изложенные выше принципы, GROUP BY из основной части запроса обычно исчезает сам по себе за ненадобностью.
Но если все же он после всех манипуляций остался, то, скорее всего, это обусловлено объективной ситуацией. У вас, скорее всего — агрегатная выборка, а не выборка коллекции.
Изложенный в статье подход помогает мне быстро строить сложные запросы, отлаживая их по частям, и свободно комбинируя логику разных выборок между собой с использованием сборщка запросов.
Многотабличные и вложенные запросы — Проектирование баз данных на SQL (Информатика и программирование)
Лекция 22. Многотабличные и вложенные запросы
Как правило, запросы выполняют обработку данных, расположенных во множестве таблиц. Попытка соединить таблицы по «умолчанию», приведет к декартовому произведению двух таблиц и вернет бессмысленный результат, например, если построить запрос по таблицам 7.3 и 7.4, следующим образом:
SELECT *
FROM А, В
Из раздела реляционной алгебры известно, что под соединением двух таблиц (будем рассматривать экви-соединение) понимается последовательность выполнения операции декартового произведения и выборки, т.е.:
SELECT *
FROM А, В
WHERE А.Код_товара = В.Код_тов
Использование подобного метода возвратит верный результат, приведенный в таблице 7.6. Описанный способ соединения, был единственным в первом стандарте языка SQL.
Стандарт SQL2 расширил возможности соединения до так называемого внешнего соединения (внутренним принято считать соединение с использованием предложения WHERE).
В общем случае синтаксис внешнего соединения выглядит следующим образом:
FROM <Таблица1> <вид соединения> JOIN <Таблица2> ON <Условие соединения>
Вид соединения определяет главную (ведущую) таблицу в соединении и может определяться следующими служебными словами:
§ LEFT – левое внешнее соединение, когда ведущей является таблица слева от вида соединения;
§ RIGHT – правое внешнее соединение, когда ведущей является таблица справа от вида соединения;
§ FULL — полное внешнее соединение, когда обе таблица равны в соединении;
§ INNER – вариант внутреннего соединения.
По правилу внешних соединений, ведущая таблица должна войти в результат запроса всеми своими записями, независимо от наличия соответствующих записей в присоединяемой таблице.
Приведем пример реализации внутреннего соединения для стандарта SQL2:
SELECT *
FROM А INNER JOIN В ON А.Код_товара = В.Код_тов
Вариант внешнего соединения, когда левая таблица является главной (ведущей):
SELECT *
FROM А LEFT JOIN В ON А.Код_товара = В.Код_тов
Продемонстрируем соединение нескольких таблиц на основе проекта «Библиотека». Пусть требуется получить информацию о принадлежности книг к тем или иным предметным областям. Известно, что каталог областей знаний и таблица «Книга» соединяются через промежуточную таблицу «Связь», в этом случае запрос может выглядеть следующим образом:
SELECT Каталог.Наименование as Область_знаний, Книги. ISBN, Книги.Название as Книга
ISBN, Книги.Название as Книга
FROM Книги INNER JOIN (Каталог INNER JOIN Связь ON Каталог.Код_ОЗ = Связь.Код_ОЗ) ON Книги.ISBN = Связь.ISBN;
Группировка по соединяемым таблицам не отличается от группировки по данным одной таблицы. Пусть требуется отобразить перечень читателей библиотеки с указанием количества книг, находящихся у них на руках, тогда запрос может выглядеть следующим образом:
SELECT DISTINCT Читатели.ФИО, Count(*) AS (Количество_книг)
FROM Читатели INNER JOIN Экземпляры ON Читатели.Номер_ЧБ = Экземпляры.Номер_ЧБ
GROUP BY Читатели.ФИО, Читатели.Номер_ЧБ, Экземпляры.Наличие
HAVING Экземпляры.Наличие = No;
Следующий запрос возвращает информацию о должниках и книгах, которые они должны были сдать в библиотеку с сортировкой по дате возврата:
SELECT Книги.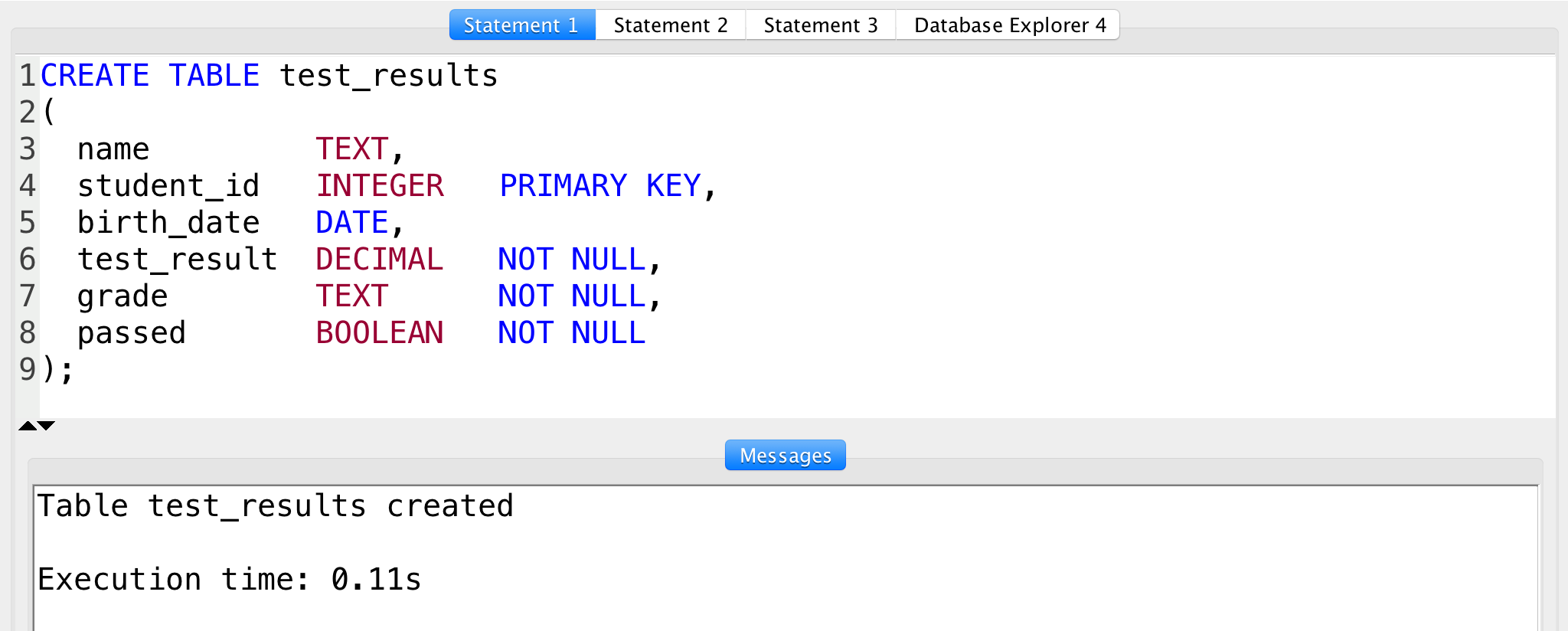 Название, Книги.Автор, Экземпляры.Инв_номер, Экземпляры.Дата_возврата, Читатели.Номер_ЧБ, Читатели.ФИО, Читатели.Тел_дом, Читатели.Тел_раб
Название, Книги.Автор, Экземпляры.Инв_номер, Экземпляры.Дата_возврата, Читатели.Номер_ЧБ, Читатели.ФИО, Читатели.Тел_дом, Читатели.Тел_раб
FROM Книги INNER JOIN (Читатели INNER JOIN Экземпляры ON Читатели.Номер_ЧБ = Экземпляры.Номер_ЧБ) ON Книги.ISBN = Экземпляры.ISBN
WHERE Экземпляры.Дата_возврата < Now() AND Экземпляры.Наличие=No
ORDER BY Экземпляры.Дата_возврата;
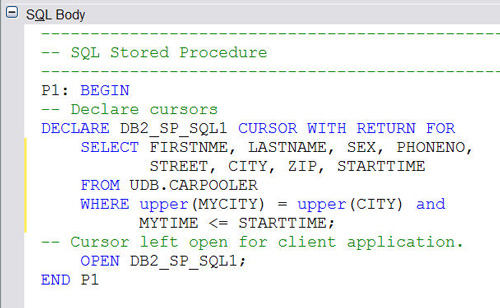
Вложенные запросы
Язык SQL позволяет вкладывать запросы друга в друга, это относится к оператору SELECT. Оператор SELECT, вложенный в другой оператор SELECT, INSERT, UPDATE или DELETE., называется вложенным запросом.
Вложенный оператор SELECT может употребляться в разделах WHERE или HAVING основного запроса и возвращать наборы данных, которые будут использоваться для формирования условий выборки требуемых значений основным запросом.
Средства языка SQL для создания и использования вложенных запросов можно считать избыточными, т.е. вложенность может быть реализована разными способами.
Если вложенный запрос возвращает одно значение (например, агрегат), то оно может использоваться в любом месте, где применяется подобное значение соответствующего типа. Если вложенный запрос возвращает один столбец, то его можно использовать только в директиве WHERE. Во многих случаях вместо вложенного запроса используется оператор объединения, однако некоторые задачи выполняются только с помощью вложенных запросов.
Вложенный запрос всегда заключается в скобки и, если только это не связанный вложенный запрос, завершает выполнение раньше, чем внешний запрос. Вложенный запрос может содержать другой вложенный запрос, который, в свою очередь, тоже может содержать вложенный запрос, и так далее. Глубина вложенности ограничивается только ресурсами системы. Синтаксис вложенного оператора SELECT более короткий и имеет следующий вид:
(SELECT [ALL | DISTINCT] слисок_ столбцов _вложенного_запроса
[FROM список_ таблиц]
[WHERE директива]
[GROUP BY директива]
[HAVING директива])
Приведем пример сложного вложенного запроса. Пусть необходимо получить список читателей имеющих максимальное число книг на руках, при условии, что максимальное количество книг у читателя не ограничено:
Пусть необходимо получить список читателей имеющих максимальное число книг на руках, при условии, что максимальное количество книг у читателя не ограничено:
SELECT Читатели.Номер_ЧБ, Читатели.ФИО, COUNT(*) AS Количество
FROM Читатели INNER JOIN Экземпляры ON Читатели.Номер_ЧБ = Экземпляры.Номер_ЧБ
GROUP BY Читатели.Номер_ЧБ, Читатели.ФИО, Экземпляры.Наличие
HAVING Экземпляры.Наличие = No AND COUNT(*) =
(SELECT MAX(Количество)
FROM
(SELECT COUNT(*) AS Количество
FROM Экземпляры
GROUP BY Экземпляры.Номер_ЧБ, Экземпляры. Наличие
Наличие
HAVING Экземпляры.Наличие = No))
Как и положено вложенным запросом первым выполняется самый «глубокий» по уровню вложенности подзапрос, который определяет количество книг на руках у каждого читателя:
SELECT COUNT(*) AS Количество
FROM Экземпляры
GROUP BY Экземпляры.Номер_ЧБ, Экземпляры.Наличие
HAVING Экземпляры.Наличие = No
Результат работы этого подзапроса список – количество книг по каждому номеру читательского билета. Особенным является то, что результат этого запроса используется в качестве источника строк для запроса более высокого уровня, который находит максимальное значение в этом списке, соответствующее максимальному количеству книг на руках у одного из читателей:
(SELECT MAX(Количество) FROM (SELECT …))
И, наконец, внешний запрос, выполняется в последнюю очередь, подсчитывает количество книг на руках у конкретного читателя и сравнивает его с максимальным количеством книг, полученным в результате работы вложенного запроса. Таким образом, может оказаться несколько читателей имеющих на руках максимальное количество книг.
Таким образом, может оказаться несколько читателей имеющих на руках максимальное количество книг.
В данном примере вложенный запрос возвращает агрегированное значение, полученное в результате итоговой функции MAX, поэтому условное выражение COUNT(*) = (SELECT MAX(Количество)…) имеет смысл. Если вложенный подзапрос может вернуть множество значений, то простое сравнение не подходит, необходимо использование служебных слов ANY или предиката IN, множество значений которого будет формировать вложенный подзапрос. Служебное слово ANY указывает на необходимость использования условного выражения для каждого значения, полученного во вложенном запросе.
Контрольные вопросы
1. Как можно получить декартово произведение двух таблиц?
2. Чем отличается соединение от объединения?
3. Какие виды соединений предусмотрены первым стандартом SQL?
4. Какой синтаксис имеют соединения?
5. Какие виды соединений вы знаете?
6. Для чего необходимы вложенные запросы?
Для чего необходимы вложенные запросы?
7. Какие ограничения налагаются на вложенные запросы?
8. Как можно использовать предикат IN или служебное слово ANY?
Задания для самостоятельной работы
Рекомендуем посмотреть лекцию «3.4. Примеры по прогнозированию инженерной обстановки».
Задание 1. Запишите запрос для определения:
1. к каким предметным областям относится какая-либо книга;
2. какие книги относятся к определенной предметной области.
Задание 2. Дана таблица «Книг_у_читателей», содержащая поля «ФИО_читателя» и «Книг_на_руках». Запишите текст запроса для определения:
1. читателей держащих больше всего книг на руках;
2. читателей держащих меньше всего книг на руках.
5 решенных сложных SQL-запросов
Вектор Sql, созданный freepik — www.freepik.com
SQL (язык структурированных запросов) — очень важный инструмент в наборе инструментов специалиста по данным.
В этой статье я расскажу о 5 найденных мною каверзных вопросах и своих подходах к их решению.
Примечание — Каждый запрос можно записать по-разному. Попробуйте подумать о подходе, прежде чем переходить к моим решениям. Вы также можете предложить различные подходы в разделе ответов.
Нам дана таблица, состоящая из двух столбцов, Имя, и Профессия . Нам нужно запросить все имена, за которыми сразу следует первая буква в столбце профессии, заключенном в круглые скобки 9.0028 .
Мое решение
ВЫБЕРИТЕ
CONCAT (Имя, '(', SUBSTR (Профессия, 1, 1), ')')
С стол; Поскольку нам нужно объединить имя и профессию, мы можем использовать CONCAT . Нам также нужно, чтобы содержала только одну букву внутри скобок. Следовательно, мы будем использовать
Нам также нужно, чтобы содержала только одну букву внутри скобок. Следовательно, мы будем использовать SUBSTR и передавать имя столбца, начальный индекс, конечный индекс. Поскольку нам нужна только первая буква, мы передадим 1,1 (начальный индекс включительно, а конечный индекс не включительно)
Тину попросили вычислить среднюю заработную плату всех сотрудников из созданной ею таблицы EMPLOYEES, но она поняла, что нулевая клавиша на ее клавиатуре не работает после того, как результат показал очень низкий средний показатель. Ей нужна наша помощь в выяснении разницы между неправильно рассчитанным средним значением и фактическим средним значением.
Мы должны написать запрос, обнаруживающий ошибку (Actual AVG — Calculated AVG).
Мое решение
ВЫБЕРИТЕ AVG (Зарплата) - AVG ( ЗАМЕНИТЬ (Зарплата, 0, ’’)) С стол;
Здесь следует отметить, что у нас есть только одна таблица, содержащая фактические значения заработной платы. Чтобы создать сценарий ошибки, мы используем
Чтобы создать сценарий ошибки, мы используем REPLACE для замены нулей. Мы передадим имя столбца, значение, которое нужно заменить, и значение, которым мы заменим метод REPLACE . Затем находим разницу в средних значениях с помощью агрегатной функции СРЕДНЕЕ .
Нам дана таблица, которая представляет собой двоичное дерево поиска, состоящее из двух столбцов
- Корень — если узел является корнем
- Leaf — если узел является листом
- Внутренний — если узел не является ни корневым, ни конечным.
Мое решение
После начального анализа мы можем заключить, что если данный узел N имеет соответствующее значение P как NULL, он является корнем. И для данного узла N, если он существует в столбце P, он не является внутренним узлом. На основе этой идеи напишем запрос.
На основе этой идеи напишем запрос.
ВЫБЕРИТЕ РЕГИСТР
КОГДА P IS NULL THEN CONCAT (N, 'Root')
КОГДА N В (ВЫБЕРИТЕ ОТЛИЧНЫЕ P от BST) ТОГДА CONCAT (N, «внутренний»)
ELSE CONCAT (N, «Лист»)
КОНЕЦ
ИЗ БСТ
ЗАКАЗАТЬ ПО N возр.; Мы можем использовать CASE , которая действует как функция переключения. Как я уже упоминал, если P равно нулю для данного узла N, то N является корнем. Поэтому мы использовали CONCAT для объединения значения узла и метки. Точно так же, если данный узел N находится в столбце P, он является внутренним узлом. Чтобы получить все узлы из столбца P, мы написали подзапрос, который возвращает все отдельные узлы в столбце P. Поскольку нас попросили упорядочить выходные данные по значениям узлов в порядке возрастания, мы использовали
Поскольку нас попросили упорядочить выходные данные по значениям узлов в порядке возрастания, мы использовали
Нам дана таблица транзакций, состоящая из идентификатор_транзакции, идентификатор_пользователя, дата_транзакции, идентификатор_продукта и количество . Нам нужно запросить количество пользователей, которые приобрели продукты в течение нескольких дней (обратите внимание, что данный пользователь может приобрести несколько продуктов в один день).
Мое решение
Чтобы решить этот запрос, мы не можем напрямую подсчитать появление user_id, и если их несколько, мы вернем этот user_id, потому что данный пользователь может иметь более одной транзакции в один день. Следовательно, если с данным user_id связано более одной отдельной даты, это означает, что он покупал продукты в течение нескольких дней. Следуя тому же подходу, я написал запрос. (Внутренний запрос)
SELECT COUNT (user_id) ИЗ ( ВЫБЕРИТЕ user_id ИЗ заказов ГРУППА ПО user_id HAVING COUNT ( ОТЛИЧНАЯ ДАТА (дата)) > 1 ) t1
Поскольку в вопросе задано количество user_id, а не сам user_id, мы используем COUNT во внешнем запросе.
Нам дана таблица подписки, которая состоит из дат начала и окончания подписки для каждого пользователя. Нам нужно написать запрос, который возвращает true/false для каждого пользователя на основе совпадения дат с другими пользователями. Например, если период подписки user1 совпадает с периодом подписки любого другого пользователя, запрос должен вернуть True для пользователя 1.
Мое решение
При первоначальном анализе мы понимаем, что должны сравнивать каждую подписку с любой другой. Давайте рассмотрим даты начала и окончания userA как startA и endA , аналогично для userB , startB 90 016 и endB .
Если startA ≤ endB и endA ≥ startB 9004 8 тогда мы можем сказать, что два диапазона дат перекрываются. Возьмем два примера. Давайте сначала сравним U1 и U3.
Возьмем два примера. Давайте сначала сравним U1 и U3.
startA = 2020–01–01
endA = 2020–01–31
startB = 2020–01–16
endB = 2020–01–26
Здесь мы видим startA (01.01.2020) меньше endB ( 2020–01–26) и аналогично endA (2020–01–31) больше, чем startB (2020–01–16) ) и, следовательно, можно сделать вывод, что даты перекрываются . Точно так же, если вы сравните U1 и U4, вышеуказанное условие не будет выполнено и вернет false.
Мы также должны убедиться, что пользователя не сравнивают с его собственной подпиской. Мы также хотим запустить левое соединение для самого себя, чтобы сопоставить пользователя с другим пользователем, который удовлетворяет нашему условию. Теперь мы создадим две реплики s1 и s2 одной и той же таблицы.
ВЫБЕРИТЕ *
ИЗ подписок AS s1
ЛЕВЫЙ ПРИСОЕДИНЯЙСЯ подписок КАК s2
ВКЛ s1. user_id != s2.user_id
И s1.start_date <= s2.end_date
И s1.end_date >= s2.start_date
user_id != s2.user_id
И s1.start_date <= s2.end_date
И s1.end_date >= s2.start_date Учитывая условное соединение, user_id из s2 должен существовать для каждого user_id в s1 при условии, что существует перекрытие между датами.
Выход
Мы видим, что для каждого пользователя существует другой пользователь на случай, если даты перекрываются. Для user1 есть 2 строки, указывающие, что он соответствует 2 пользователям. Для пользователя 4 соответствующий идентификатор равен нулю, что указывает на то, что он не соответствует ни одному другому пользователю.
Объединив все вместе, мы можем сгруппировать по полю s1.user_id и просто проверить, существует ли какое-либо значение true для пользователя, где s2.user_id НЕ NULL.
Окончательный запрос
ВЫБЕРИТЕ
s1.user_id
, ( CASE WHEN s2.user_id IS NOT NULL THEN 1 ELSE 0 END ) AS перекрытие
ИЗ подписок AS s1
ЛЕВЫЙ ПРИСОЕДИНЯЙСЯ подписок КАК s2
ВКЛ s1. user_id != s2.user_id
И s1.start_date <= s2.end_date
И s1.end_date >= s2.start_date
ГРУППА BY s1.user_id
user_id != s2.user_id
И s1.start_date <= s2.end_date
И s1.end_date >= s2.start_date
ГРУППА BY s1.user_id Мы использовали предложение CASE для обозначения 1 и 0 в зависимости от значения s2.user_id для данного пользователя. Окончательный вывод выглядит следующим образом:
Прежде чем закончить, я хотел бы предложить хорошую книгу по SQL, которая мне очень понравилась и оказалась очень полезной.
Поваренная книга SQL: Решения и методы запросов для разработчиков баз данных (Поваренные книги (O’Reilly))
Освоение SQL требует большой практики. В этой статье я взял 5 каверзных вопросов и объяснил подходы к их решению. Особенность SQL заключается в том, что каждый запрос можно записать разными способами. Не стесняйтесь делиться своими подходами в ответах. Надеюсь, вы сегодня узнали что-то новое!
Если вы хотите связаться со мной, свяжитесь со мной по LinkedIn .
Оригинал. Перепечатано с разрешения.
Сайтея Кура искренняя, дружелюбная и амбициозная, она интересуется веб-разработкой, наукой о данных и НЛП.
Как писать сложные запросы SQL
Содержание
SQL — очень удобный язык для изучения больших наборов данных в нескольких таблицах, а также очень простой для интерпретации, поскольку он похож на базовый английский.
Предоставил: Aadish Jain
Иногда мы можем запутаться, когда есть сложные SQL-запросы, мы в конечном итоге запутались в большом количестве где или присоединиться к условиям. Помимо создания их один раз, мы сталкиваемся с множеством проблем, когда нам нужно их отлаживать или повторно использовать в той же или в другой форме.
Ниже приведены несколько сценариев, когда SQL-запросы становятся довольно сложными для написания:
- Когда есть 3-4 таблицы для объединения по разным атрибутам.

- Когда есть неопределенность в отношении того, какие условия соединения (внутреннее соединение, внешнее соединение, правое соединение, левое соединение) следует использовать в каком случае.
- Когда требуемый столбец не присутствует непосредственно в базе данных, но его необходимо получить из 2-3 столбцов или с помощью математических функций, таких как среднее, максимальное, минимальное и т. д.
- Когда существует неопределенность в отношении использования некоторых необычных условий предложения как groupby, наличие, порядок.
В этой статье я попытаюсь рассказать о «волшебстве» написания сложных операторов SELECT.
Перед тем, как начать писать (сложные) запросы, вы должны понимать, что где находится – какие таблицы хранят какие данные. Кроме того, вы должны понимать природу отношений между этими таблицами. Мы всегда должны иметь в виду схему базы данных и понимать все таблицы и поля с точки зрения бизнеса.
Наличие общей картины базы данных в долгосрочной перспективе сэкономит много времени. Всегда уделяйте некоторое время тому, чтобы получить полное представление о вашей базе данных, прежде чем переходить к созданию запросов. Получив полное представление о схеме базы данных и взаимосвязях между несколькими таблицами, попытайтесь понять бизнес-задачу постановки задачи и подготовьте план на бумаге. Разделите проблему на более мелкие сегменты, а затем начните работать над ними.
Мы должны использовать правильный отступ, потому что только запись и выполнение не важны. Он должен быть легко читаем другим человеком. Поместите каждое выбираемое поле в отдельную строку и поместите каждую новую объединенную таблицу в отдельную строку, а каждый элемент предложения «ГДЕ» — в отдельную строку. Используйте осмысленные псевдонимы для таблиц, чтобы улучшить читаемость. Скорее всего, вам придется ссылаться на свои таблицы несколько раз в запросе, и если вы работаете с чужой базой данных с их соглашением об именах, имена таблиц могут содержать избыточную информацию. Например, «Сведения о сотруднике» — так что вы называете такую таблицу «ED», имя таблицы «Заголовок заказа» может иметь псевдоним «OH» и т. д.
Например, «Сведения о сотруднике» — так что вы называете такую таблицу «ED», имя таблицы «Заголовок заказа» может иметь псевдоним «OH» и т. д.
Рисунок 1: Схема для набора данных заказов
Постановка проблемы заключается в том, что нам необходимо:
Написать запрос для отображения order_id, идентификатора клиента и полного имени клиента вместе с (product_quantity) в качестве общего количества товаров, отгруженных для идентификаторов заказов > 10060, для клиентов, купивших более 15 товаров на отгруженный заказ.
Здесь мы можем понять, что требуются таблицы : online_customer, order_header, order_items, которые могут иметь псевдонимы C, OH и OI соответственно.
Начнем:Выберите запрос, указав необходимые столбцы из каких таблиц.
Итак, orderID можно получить из заголовка заказа или таблицы order_id. Customer_id и имя клиента можно получить из таблицы клиентов.
Количество продукта для каждого заказа доступно в таблице Order Items. Таким образом, запрос будет таким:
. ВЫБЕРИТЕ OI.ORDER_ID,C.CUSTOMER_ID,CONCAT(C.CUSTOMER_FNAME," ",C.CUSTOMER_LNAME) AS 'CUSTOMER_FULL_NAME', SUM(OI.PRODUCT_QUANTITY) AS 'ОБЩЕЕ КОЛИЧЕСТВО'
Теперь мы видим, что нам нужно найти общие порядки из всех трех таблиц, поэтому мы должны использовать здесь INNER JOIN.
Элементы заказа и заголовок заказа имеют общий идентификатор Order_ID, а онлайн-клиенты и заголовок заказа имеют идентификатор клиента в качестве общего ключа поля. Поэтому мы будем использовать условия соединения соответственно.
ВЫБЕРИТЕ OI.ORDER_ID,C.CUSTOMER_ID,CONCAT(C.CUSTOMER_FNAME," ",C.CUSTOMER_LNAME) AS 'CUSTOMER_FULL_NAME', SUM(OI.PRODUCT_QUANTITY) AS 'ОБЩЕЕ КОЛИЧЕСТВО' ОТ online_customer C INNER JOIN ORDER_HEADER OH ON C.CUSTOMER_ID = OH.CUSTOMER_ID INNER JOIN order_items OI ON OH.ORDER_ID = OI.ORDER_ID
Теперь задача состоит в том, чтобы получить все эти данные для идентификаторов заказов> 10060, чтобы мы могли понять, что нам нужно поместить предложение where, чтобы отфильтровать заказы с идентификатором заказа <= 10006. Также статус заказа должен быть Отгружен в заголовке заказа. стол.
Также статус заказа должен быть Отгружен в заголовке заказа. стол.
Таким образом, обновленный запрос будет таким:
ВЫБЕРИТЕ OI.ORDER_ID,C.CUSTOMER_ID,CONCAT(C.CUSTOMER_FNAME," ",C.CUSTOMER_LNAME) AS 'CUSTOMER_FULL_NAME', SUM(OI.PRODUCT_QUANTITY) AS 'ОБЩЕЕ КОЛИЧЕСТВО' ОТ online_customer C INNER JOIN ORDER_HEADER OH ON C.CUSTOMER_ID = OH.CUSTOMER_ID INNER JOIN order_items OI ON OH.ORDER_ID = OI.ORDER_ID ГДЕ OH.ORDER_ID > 10060 И OH.ORDER_STATUS = «Отправлено»
Нам нужно позаботиться о вещах всякий раз, когда нам нужно использовать некоторую агрегацию данных, такую как сумма, среднее, максимальное, минимальное и т. Д., Затем нам нужно указать, на каком основании будет выполняться эта агрегация, и это условие указано в GROUPBY пункт .
Итак, здесь, в нашем примере, мы должны рассчитать сумму количества продуктов для всех продуктов, заказанных с определенным OrderID, поэтому мы будем использовать здесь GROUPBY ORDER_ID.
Таким образом, обновленный запрос будет следующим:
ВЫБЕРИТЕ OI.ORDER_ID,C.CUSTOMER_ID,CONCAT(C.CUSTOMER_FNAME," ",C.CUSTOMER_LNAME) AS 'CUSTOMER_FULL_NAME', SUM(OI.PRODUCT_QUANTITY) AS 'ОБЩЕЕ КОЛИЧЕСТВО' ОТ online_customer C INNER JOIN ORDER_HEADER OH ON C.CUSTOMER_ID = OH.CUSTOMER_ID INNER JOIN order_items OI ON OH.ORDER_ID = OI.ORDER_ID ГДЕ OH.ORDER_ID > 10060 И OH.ORDER_STATUS = ГРУППА «Отправлено» ПО OI.ORDER_ID
Если нам нужно задать условия для агрегированных данных, то они не могут быть обработаны предложением WHERE , и мы должны использовать предложение HAVING для того же.
Как и в нашем примере, нам нужно отфильтровать заказы, для которых общее количество товаров в заказе было меньше 15.
Таким образом, наш обновленный окончательный запрос будет таким:
ВЫБЕРИТЕ OI.ORDER_ID,C.CUSTOMER_ID,CONCAT(C.CUSTOMER_FNAME," ",C.CUSTOMER_LNAME) AS 'CUSTOMER_FULL_NAME', SUM(OI.
