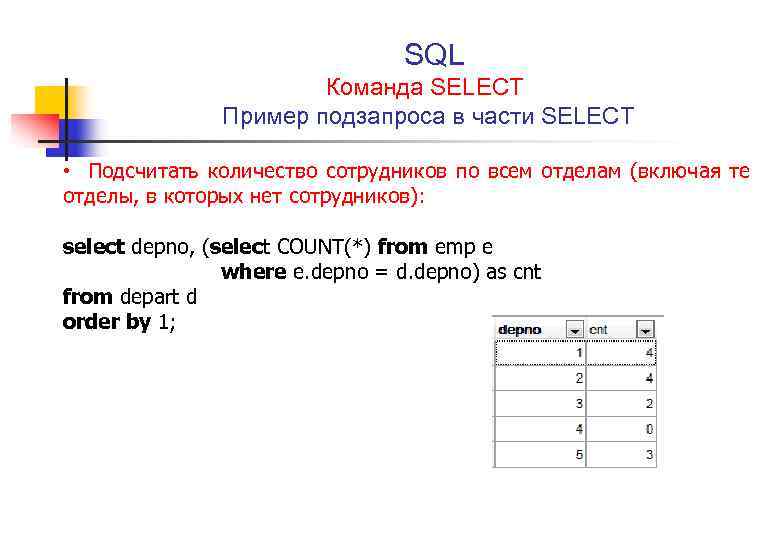
Оптимизация сложных запросов MySQL / Хабр
Введение
MySQL — весьма противоречивый продукт. С одной стороны, он имеет несравненное преимущество в скорости перед другими базами данных на простейших операциях/запросах. С другой стороны, он имеет настолько неразвитый (если не сказать недоразвитый) оптимизатор, что на сложных запросах проигрывает вчистую.
Прежде всего хотелось бы ограничить круг рассматриваемых проблем оптимизации «широкими» и большими таблицами. Скажем до 10m записей и размером до 20Gb, с большим количеством изменяемых запросов к ним. Если в вашей в таблице много миллионов записей, каждая размером по 100 байт, и пять несложных возможных запросов к ней — это статья не для Вас. NB: Рассматривается движок MySQL innodb/percona — в дальнейшем просто MySQL.
Большинство запросов не являются очень сложными. Поэтому очень важно знать как построить индекс для использования нужным запросом и/или модифицировать запрос таким образом, чтобы он использовал уже имеющиеся индексы.
Отбросим простейшие случаи для очень небольших таблиц, для которых оптимизатор зачастую использует type=all (полный просмотр) вне зависимости от наличия индексов — к примеру, классификатор с 40-ка записями. MySQL имеет алгоритм использования нескольких индексов (index merge), но работает этот алгоритм не очень часто, и только без order by. Единственный разумный способ пытаться использовать index merge — случаи выборки по разным столбцам с OR.
Еще одно отступление: подразумевается что читатель уже знаком с explain. Часто сам запрос немного модифицируется оптимизатором, поэтому для того, чтобы понять, почему использовался или нет тот или иной индекс, следует вызвать
explain extended select xxx;
а затем
show warnings;
который и покажет измененный оптимизатором запрос.
Покрывающий индекс — от толстых таблиц к индексам
Итак задача: пусть у нас есть довольно простой запрос, который выполняется довольно часто, но для такого частого вызова относительно медленно. Рассмотрим стратегию приведения нашего запроса к using index, как к наиболее быстрому выбору.
Почему using index? Да, MySQL используют только B-tree индексы, но тем не менее MySQL старается по возможности держать индексы целиком в памяти (и при этом может даже добавить поверх них адаптивные хеш-индексы) — собственно все это и дает сказочный прирост производительности MySQL по отношению к другим базам данных. К тому же оптимизатор зачастую предпочтет использовать хоть и не лучший, но уже загруженный в память индекс, нежели более лучший, но на диске (для
- слишком тяжелые индексы — зло. Либо они не будут использоваться потому что они еще не в памяти, либо их не будут грузить в память потому что при этом вытеснятся другие индексы.

- если размер индекса сопоставим с размером таблицы, либо совокупность используемых индексов для разных частых запросов существенно превышает размер памяти сервера — существенной оптимизации не добиться.
- Нюанс — индексировать/сортировать по TEXT — обрекать себя на постоянный using filesort.
Один тонкий момент, про который иногда забываешь — MySQL создает только кластерные индексы. Кластерный — по сути указывающий не на абсолютное положение записи в таблице, а (условно) на запись первичного ключа, который в свою очередь позволяет извлечь саму искомую запись. Но MySQL, не мудрствуя лукаво, для того чтобы обойтись без второго лукапа, поступает просто — расширяя любой ключ на ширину первичного ключа. Таким образом если у вас в таблице primary key (ID), key (A,B,C), то в реальности у вас второй ключ не (A,B,C), а (A,B,C,ID). Отсюда мораль — толстый первичный ключ суть зло.
Следует указать на разницу в кешировании запросов в разных базах. Если PostgreSQL/Oracle кешируют планы запросов (как бы prepare for some timeout), то MySQL просто кеширует СТРОКУ запроса (включая значение параметров) и сохраняет результат запроса. То есть если последовательно селектировать
Если PostgreSQL/Oracle кешируют планы запросов (как бы prepare for some timeout), то MySQL просто кеширует СТРОКУ запроса (включая значение параметров) и сохраняет результат запроса. То есть если последовательно селектировать
select AAA from BBB where CCC=DDD
несколько раз — то, если DDD не содержит изменяющихся функций, и таблица AAA не изменилась (в смысле используемой изоляции), результат будет взят прямо из кеша. Довольно спорное улучшение.
Таким образом, считаем, что мы не просто вызываем один и тот же запрос несколько раз. Параметры запроса меняются, данные таблицы меняются. Наилучший вариант — использование покрывающего индекса. Какой же индекс будет покрывающим?
- Во-первых, смотрим на клоз order by. Используемый индекс должен начинаться с тех же столбцов что упомянуты в order by, в той же или в полностью обратной сортировке. Если сортировка не прямая и не обратная — индекс не может быть использован.
 Здесь есть одно но… MySQL до сих пор не поддерживает индексов со смешанными сортировками. Индекс всегда asc. Так что если у вас есть order by A asc, B desc — распрощайтесь с using index.
Здесь есть одно но… MySQL до сих пор не поддерживает индексов со смешанными сортировками. Индекс всегда asc. Так что если у вас есть order by A asc, B desc — распрощайтесь с using index. - Столбцы, которые извлекаются, должны присутствовать в покрывающем индексе. Очень часто это невыполнимое условие в связи с бесконечным ростом индекса, что, как известно, зло. Поэтому существует способ обойти этот момент — использование self join‘а. То есть разделение запроса на выбор строк и извлечение данных. Во-первых, выбираем по заданному условию только столбцы первичного ключа (который всегда присутствует в кластером индексе), и во-вторых, полученный результат джойним к селекту всех требуемых столбцов, используя этот самый первичный ключ. Таким образом у нас будет чистый using index в первом селекте, и eq_ref (суть множественный const) для второго селекта. Итак, мы получаем что-то похожее на:
select AAA,BBB,CCC,DDD from tableName as a join tableName as b using (PK) «where over table b»
- Далее клоз where.
 Здесь в худшем случае мы можем перебрать весь индекс (type=index), но по возможности стоит стремиться использовать функции, не выводящие за рамки
Здесь в худшем случае мы можем перебрать весь индекс (type=index), но по возможности стоит стремиться использовать функции, не выводящие за рамки
Собственно, это все, что можно сделать для случая, когда мы имеем только один вид запроса. К сожалению, оптимизатор MySQL не всегда при наличии покрывающего индекса может выбрать именно его для выполнения запроса. Что ж, в таком случае приходится помогать оптимизатору с помощью стандартных хинтов use/force index.
Вычленение толстых полей из покрывающего индекса — от толстых индексов к тонким
Но что делать, если у нас запросы бывают нескольких видов, или требуются разные сортировки и при этом используются толстые поля (varchar)? Просто посчитайте размер индекса поля varchar(100)
в миллионе записей. А если это поле используется в разных видах запросов — для которых у нас разные покрывающие индексы? Возможно ли иметь в памяти только ОДИН индекс по этому толстому полю, сохранив при этом ту же (или почти ту же) производительность в разных запросах? Итак — последний пункт.
А если это поле используется в разных видах запросов — для которых у нас разные покрывающие индексы? Возможно ли иметь в памяти только ОДИН индекс по этому толстому полю, сохранив при этом ту же (или почти ту же) производительность в разных запросах? Итак — последний пункт.- Толстые и тонкие поля. Очевидно, что иметь несколько РАЗНЫХ вариантов ключей с использованием толстых полей — непозволительная роскошь. Поэтому по возможности мы должны пытаться иметь только один ключ начинающийся на толстое поле. И здесь уместно использовать некоторый искусственный алгоритм замены условий. То есть заменить условие по толстому полю на джойн по результатам этого условия. К примеру:
select A from tableName where A=1 or fatB='test'
вместо создания ключа key(fatB, A) мы создадим тонкий ключ key(A) и толстый key(fatB). И перепишем условие след образом.create temporary table tmp as select PK from tableName where fatB='test'; select A from tableName left join tmp using (PK) where A=1 or tmp.

Следовательно, мы можем иметь много тонких ключей, для разных запросов и только один толстый по полю fatB. Реальная экономия памяти, при почти полном сохранении производительности.
Задание для самостоятельного разбора
Требуется создать минимальное количество ключей (с точки зрения памяти) и оптимизировать запросы вида:
select A,B,C,D from tableName where A=1 and B=2 or C=3 and D like 'test%'; select A,C,D from tableName where B=3 or C=3 and D ='test' order by B;
Допустим запросы не сводимы к type=range.
Список используемой литературы
- High Performance MySQL, 2nd Edition
Optimization, Backups, Replication, and More
By Baron Schwartz, Peter Zaitsev, Vadim Tkachenko, Jeremy D. Zawodny, Arjen Lentz, Derek J. Balling
Publisher: O’Reilly Media
Released: June 2008
Pages: 712 - www.
 mysqlperformanceblog.com
mysqlperformanceblog.com
MySQL — сложные запросы — подробное описание (личный опыт)
Привет. Стал я тут писать одно Web-приложение и столкнулся с тем что на вывод одной таблице у меня получается около 4 запрос в БД. Если делать мини сервис с мелкой посещаемостью, то нагрузка как бы не о чем. А вот если людей будет уже около 2000 тысяч хотя бы в сутки, то запросы растут с геометрической прогрессией.
Чтобы не нагружать мой сервер, решил я более глубоко погрузится в MySQL и выяснил, что можно составлять сложные запросы к Базе Данных(БД). Т.е. было 4 select к БД, а стал один с вложенными запросами и join`ами.
К тому же сложные запросы MySQL помогут сократить код логики. Раньше было 4 запроса и соответственно получали 4 массива, каждый нужно было обойти, придать ему нужный вид, дальше объединить его с другими. А сейчас получается один запрос и один массив, все.
Задача
Возьмем абстрактную задачу: Вывести курс ЦБ на страницу.
Выводим следующее:
- Даллар США (это название валюты на русском).
- USD (это название валюты на английском).
- Текущая дата.
- Значение валюты.
- Вчерашняя дата.
- Значение валюты.
- Колонка разность (отянть вчера от сегодня).
И так представим, что БД у нас построена по правилам «Трех нормальных форм». Т.е. 1 и 2 пункт из списка выше хранится в одной таблице, 3-6 хранятся данные в другой таблице. А 7 пункт вообще вычисляется средствами MySql.
Сам код запроса
Запрос будет выглядеть следующем образом.
SELECT
r.id_name_currency,
r.value,
yesterday.value,
r.date,
yesterday.date,
pc.name_currency_en,
pc.name_currency_ru,
(yesterday.value - r.value)
FROM
parser_all_exchange_rates r
JOIN
(
SELECT
rr.date,
rr.value,
rr.id_name_currency
FROM
parser_all_exchange_rates rr
WHERE
rr. id_name_banks = 233 AND
rr.date = CURRENT_DATE() - INTERVAL 1 DAY
) yesterday
JOIN parser_name_currencies pc ON r.id_name_currency = pc.id
WHERE
r.id_name_banks = 233 AND
r.date = CURRENT_DATE() AND
yesterday.id_name_currency = r.id_name_currency
id_name_banks = 233 AND
rr.date = CURRENT_DATE() - INTERVAL 1 DAY
) yesterday
JOIN parser_name_currencies pc ON r.id_name_currency = pc.id
WHERE
r.id_name_banks = 233 AND
r.date = CURRENT_DATE() AND
yesterday.id_name_currency = r.id_name_currencyВ начале для легкости понимания лучше разбить задачу на блоки.
Пишем отдельные селекты для получения тех данных, которые нужны из разных таблиц, и только после этого начинаем их объединять. В дальнейшем с приобретением опыта, вы сами поймете когда это случится, будите уже писать сразу сложный запрос без разбивания его на блоки.
Нюансы
А как же без них.
FROM
parser_all_exchange_rates r,
(
SELECT
rr.date,
rr.value,
rr.id_name_currency
FROM
parser_all_exchange_rates rr
WHERE
rr.id_name_banks = 233 AND
rr. date = CURRENT_DATE() - INTERVAL 1 DAY
) yesterday
INNER JOIN parser_name_currencies pc ON r.id_name_currency = pc.id
date = CURRENT_DATE() - INTERVAL 1 DAY
) yesterday
INNER JOIN parser_name_currencies pc ON r.id_name_currency = pc.idЕсли посмотреть на код выше, то после from идет указатель на имя таблицы, в которой мы ищем информацию, затем идет в скобках следующая таблица, после скобок ей присваивается имя yesterday и затем указываем join. Если написать так, то будет синтаксическая ошибка.
Join можно перенести на верх и вставить его перед скобками и поставить запятую, то все отработает, но это все равно не верно. Нужно писать более универсально. Т.е. т.к. в первом примере.
Необязательно писать INNER JOIN, можно просто JOIN. СУБД по умолчанию выполнить именно внутреннее соединение.
Будут вопросы пишите в комментариях.
Предыдущая
База данныхУстановка Redis Centos 8
Сложный запрос MySQL с несколькими операторами выбора
Задать вопрос
спросил
Изменено 9 лет, 10 месяцев назад
Просмотрено 19 тысяч раз
У меня есть три таблицы в Mysql, которые связаны друг с другом:
Профиль (ID, Name, Stuff. .)
.)
Контакт (ID, ProfileID, desc, Ord)
Адрес (ID, ProfileID, desc, Ord)
Теперь мне нужно выбрать все profile из таблицы профилей, с полем «desc» из Contact и Address, где Ord = 1. (это для функции поиска, где в таблице я буду отображать имя, основную контактную информацию и основной адрес клиента
В настоящее время я могу сделать это с помощью трех отдельных SQL-запросов:
ВЫБЕРИТЕ Имя, ИДЕНТИФИКАТОР ИЗ ПРОФИЛЯ, ГДЕ name="bla"
Затем в цикле foreach я выполню два других запроса:
SELECT ProfileID, desc FROM Contact WHERE ProfileID=MyProfileID AND Ord=1 SELECT ProfileID, desc FROM Address WHERE ProfileID=MyProfileID AND Ord=1
Я знаю, что вы можете сделать несколько SELECT в одном запросе, есть ли способ сгруппировать все три SELECT в один запрос?
- mysql
- выберите
- несколько таблиц
Вы должны иметь возможность ПРИСОЕДИНЯТЬСЯ к таблицам profile. и 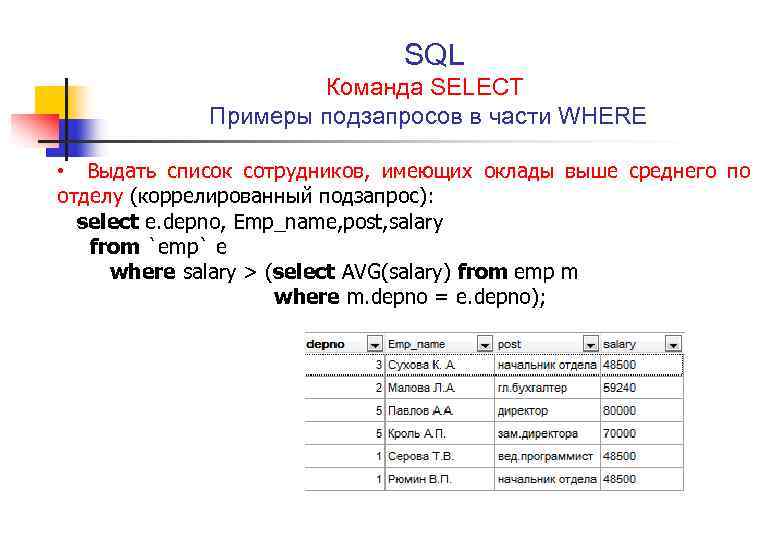 id
id profileid в других таблицах.
Если вы уверены, что profileid существует во всех трех таблицах, вы можете использовать INNER JOIN . INNER JOIN возвращает совпадающие строки во всех таблицах:
select p.id, имя, c.desc ContactDesc, a.desc AddressDesc из профиля р контакт внутреннего соединения c на p.id = c.profileid адрес внутреннего соединения a на p.id = a.profileid где p.name = 'бла' и корд = 1 и a.ord = 1
Если вы не уверены, что у вас будут совпадающие строки, вы можете использовать LEFT JOIN :
select p.id, имя, c.desc ContactDesc, a.desc AddressDesc из профиля р левый присоединиться к контакту c на p.id = c.profileid и корд = 1 левый адрес присоединения a на p.id = a.profileid и a.ord = 1 где p.name = 'бла'
Если вам нужна помощь в изучении синтаксиса JOIN , вот отличное наглядное объяснение соединений
1
Этот запрос ниже выбирает столбец только тогда, когда ID из таблицы Profile имеет хотя бы одно совпадение в таблицах: Contact и Address . Если один или оба из них являются обнуляемыми , используйте
Если один или оба из них являются обнуляемыми , используйте LEFT JOIN вместо INNER JOIN , потому что LEFT JOIN отображает все записи из боковой таблицы Left-hand независимо от того, имеет ли она совпадение с другими таблицами или нет. .
ВЫБЕРИТЕ a.*,
b.desc как BDESC,
c.desc как CDESC
ИЗ Профиля а
ВНУТРЕННЕЕ СОЕДИНЕНИЕ Контакты b
ON a.ID = b.ProfileID
ВНУТРЕННЕЕ СОЕДИНЕНИЕ Адрес c
ON a.ID = c.ProfileID
ГДЕ b.ORD = 1 И
c.ORD = 1 И
a.Name = 'имя ЗДЕСЬ'
LEFT JOIN версия:
SELECT a.*,
b.desc как BDESC,
c.desc как CDESC
ИЗ Профиля а
ВНУТРЕННЕЕ СОЕДИНЕНИЕ Контакты b
ON a.ID = b.ProfileID И b.ORD = 1
ВНУТРЕННЕЕ СОЕДИНЕНИЕ Адрес c
ON a.ID = c.ProfileID И c.ORD = 1
ГДЕ a.Name = 'nameHERE'
Для получения дополнительной информации о соединениях перейдите по ссылке ниже:
- Визуальное представление соединений SQL
1
Я создал рабочую демонстрацию по вашему требованию:
Приведенный ниже запрос извлечет все соответствующие записи из базы данных. Его идентификатор профиля, имя и описание контактных таблиц
Его идентификатор профиля, имя и описание контактных таблиц
выберите p.id,p.name,p. stauff,c.descr,a.descr из профиля как p контакт внутреннего соединения как c на c.profileid=p.id внутренний адрес соединения как a.profileid=p.id где p.name="bla" и c.ord=1 и a.ord=1
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя электронную почту и пароль
Опубликовать как гость
Электронная почта
Обязательно, но не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
mysql - Сложный SQL-запрос с двумя таблицами и группировкой по количеству
Задать вопрос
спросил
Изменено 2 года, 7 месяцев назад
Просмотрено 85 раз
Мне нужно написать сложный запрос, включающий две таблицы, и я не могу понять, как правильно составить запрос.
Структура таблицы вместе с примерами данных следующая:
Таблица 1: ID | Тип | Размер А123 | Блок | Середина С368 | площадь | Большой Х634 | Треугольник | Небольшой К623 | площадь | Небольшой
Таблица 2: ID | код | Описание | Цена А123 | С06 | чувствительный материал | 99,99 А123 | Н66 | Тяжелый класс | 12,76 А123 | U74 | Розовый оттенок | 299,99 С368 | Н66 | Тяжелый класс | 12,76 С368 | G66 | Зеленый оттенок | 499,99 С368 | С06 | чувствительный материал | 99,99 С368 | К79 | Прозрачное стекло | 59,99 Х634 | G66 | Зеленый оттенок | 499,99 Х634 | К79 | Прозрачное стекло | 59,99 Х634 | Z63 | корпоративный класс | 999,99 К623 | К79 | Прозрачное стекло | 59,99 К623 | G66 | Зеленый оттенок | 499,99 К623 | Х57 | Дополнительный трубопровод | 199,99
Запрос должен основываться в первую очередь на столбце «Тип» из таблицы 1, а затем суммировать значения из таблицы 2 на основе совпадающих идентификаторов.
Конечным результатом должно быть число, которое выглядит следующим образом: Тип = Квадрат:
Код | Описание | Считать Н66 | Тяжелый класс | 1 G66 | Зеленый оттенок | 2 С06 | чувствительный материал | 1 К79| Прозрачное стекло | 2 Х57 | Дополнительный трубопровод | 1
Как мне собрать этот результат, используя эти две таблицы? Вот первоначальный запрос, который я написал - это выглядит правильно? Это дает результат, аналогичный приведенному выше примеру, однако я не уверен, что он на 100% правильный и охватывает все крайние случаи.
выберите код, описание, количество (*) как общее из ( ВЫБЕРИТЕ код, описание ИЗ db.options_list операций ВНУТРЕННЕЕ СОЕДИНЕНИЕ db.obj_list ON ops.ID = db.obj_list.ID ГДЕ db.obj_list.type="Квадрат" ) источник группировать по коду упорядочить по общему убыванию
Спасибо
- mysql
- sql
- присоединиться
- группировать по
- количество
1
Если я правильно понимаю, это просто присоединиться к группе / по запросу :
SELECT ops.code, max(ops.description), count(*) как итог
ИЗ db.options_list ops ПРИСОЕДИНЯЙТЕСЬ
db.obj_list ол
ON опс.ID = ol.ID
ГДЕ ol.type = 'Квадрат'
СГРУППИРОВАТЬ ПО ops.code
ЗАКАЗАТЬ ПО общее описание;
Примечания:
- Все таблицы используют псевдонимы таблиц.
- Все ссылки на столбцы квалифицированы.
- Разделителем для сравнения строк является стандартная одинарная кавычка, а не нестандартная двойная кавычка.