НОУ ИНТУИТ | Лекция | Типы данных в языке С++
< Лекция 1 || Лекция 2: 1234 || Лекция 3 >
Аннотация: В лекции рассматриваются понятие типов данных в языках программирования, приводится классификация типов данных в С++, излагаются особенности представления базовых типов и операций над ними, рекомендации и правила выполнения операции преобразования базовых типов в С++.
Ключевые слова: представление, пользовательский тип, переменная, вычисление выражения, тип данных, объект, проверка допустимости, язык программирования, базовый тип, стандарт языка, сложный тип, производный тип, спецификатор, диапазон, short, sign, unsigned, базовый тип данных, integer, описание переменной, время выполнения, определение, асимметрия, целочисленный тип, значение, операции, декремент, инкремент, целый тип, восьмеричная система счисления, точность, бит, экспонента, мантисса, таблица кодировки, таблица символов, ASCII, байт, Unicode, константы, слово, истина, ложь, единица, логический тип, синтаксис, именованная константа, память, параметр функции, нетипизированный указатель, определение функции, операция приведения, ENUM, сообщение об ошибке, операнд, приведение типов, тип переменной, явное преобразование, потеря информации, hour, автоматическое преобразование, знаковый бит, потеря точности, производный тип данных, управляющая последовательность, входные данные, числовой тип, вещественное число, линейная программа, высказывание, mx/s, символьные типы
Основная цель любой программы состоит в обработке каких-либо данных, например, чисел или текстов. Данные могут быть различного вида или типа и, в зависимости от этого, с ними можно выполнять разные действия.
В любом языке программирования каждая константа, переменная, результат вычисления выражения или функции должны иметь определенный тип данных.
Тип данных – это множество допустимых значений, которые может принимать тот или иной объект, а также множество допустимых операций, которые применимы к нему. В современном понимании тип также зависит от внутреннего представления информации.
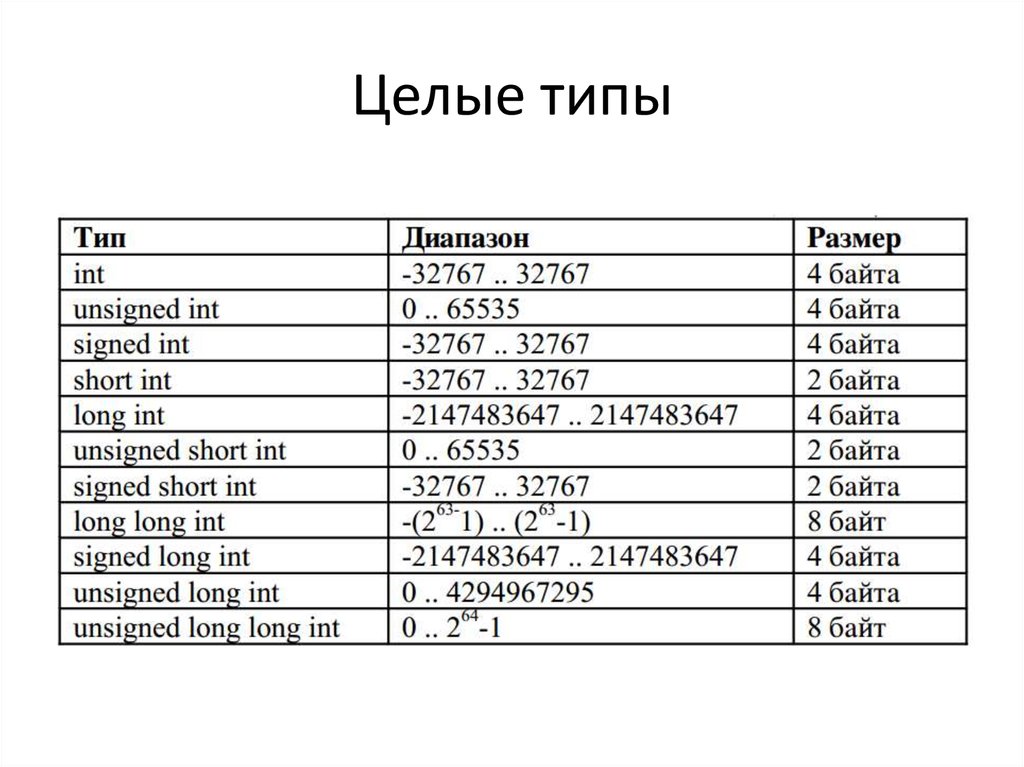 Тип данных определяет:
Тип данных определяет:- внутреннее представление данных в памяти компьютера;
- объем памяти, выделяемый под данные;
- множество (диапазон) значений, которые могут принимать величины этого типа;
- операции и функции, которые можно применять к данным этого типа.
Исходя из данных характеристик, необходимо определять тип каждой величины, используемой в программе для представления объектов. Обязательное описание типа позволяет компилятору производить проверку допустимости различных конструкций программы. От выбора типа величины зависит последовательность машинных команд, построенная компилятором.
Классификация типов данных в С++
Современные языки программирования, как правило, могут иметь набор простых типов, являющихся встроенными в данный язык программирования, и средства для создания производных типов.
Объектно-ориентированные языки программирования позволяют определять типы класса.
Реализация простых типов данных заключается в способе представления значений данного типа в компьютере и в наборе операций, поддерживаемых для данного типа.
Тип данных определяет размер памяти, выделяемой под переменную данного типа при ее создании. Язык программирования C++ поддерживает следующие типы данных (рис. 1.1).
- Производные типы.
 Производные типы задаются пользователем, и переменные этих типов создаются как с использованием базовых типов, так и типов классов.
Производные типы задаются пользователем, и переменные этих типов создаются как с использованием базовых типов, так и типов классов. - Типы класса. Экземпляры этих типов называются объектами.
Существует четыре спецификатора типа данных, уточняющих внутреннее представление и диапазон базовых типов:
| short (короткий) | длина |
| long (длинный) | |
| signed (знаковый) | знак (модификатор) |
| unsigned (беззнаковый) |
 intuit.ru/2010/edi»>Рассмотрим более подробно базовые типы данных.
intuit.ru/2010/edi»>Рассмотрим более подробно базовые типы данных.
Целочисленный (целый) тип данных (тип int)
Переменные данного типа применяются для хранения целых чисел (integer). Описание переменной, имеющей тип int, сообщает компилятору, что он должен связать с идентификатором (именем) переменной количество памяти, достаточное для хранения целого числа во время выполнения программы.
Границы диапазона целых чисел, которые можно хранить в переменных типа int, зависят от конкретного компьютера, компилятора и операционной системы (от реализации). Для 16-разрядного процессора под него отводится 2 байта, для 32-разрядного – 4 байта.
Для внутреннего представления знаковых целых чисел характерно определение знака по старшему биту (0 – для положительных, 1 – для отрицательных). Поэтому число 0 во внутреннем представлении относится к положительным значениям. Следовательно, наблюдается асимметрия границ целых промежутков.
Следовательно, наблюдается асимметрия границ целых промежутков.
В целочисленных типах для всех значений определены следующий и предыдущий элементы. Для максимального следующим значением будет являться минимальное в этом же типе, предыдущее для минимального определяется как максимальное значение. То есть целочисленный диапазон условно можно представить сомкнутым в кольцо. Поэтому определены операции декремента для минимального и инкремента для максимального значений в целых типах.
От количества отводимой под объект памяти зависит множество допустимых значений, которые может принимать объект:
- short int – занимает 2 байта, следовательно, имеет диапазон от –32 768 до +32 767;
- int – занимает 4 байта, следовательно, имеет диапазон от –2 147 483 648 до +2 147 483 647;
 intuit.ru/2010/edi»>
long int – занимает 4 байта, следовательно, имеет диапазон от –2 147 483 648 до +2 147 483 647;
intuit.ru/2010/edi»>
long int – занимает 4 байта, следовательно, имеет диапазон от –2 147 483 648 до +2 147 483 647;
Модификаторы signed и unsigned также влияют на множество допустимых значений, которые может принимать объект:
- unsigned short int – занимает 2 байта, следовательно, имеет диапазон от 0 до 65 535;
- unsigned int – занимает 4 байта, следовательно, имеет диапазон от 0 до 4 294 967 295;
- unsigned long int – занимает 4 байта, следовательно, имеет диапазон от 0 до 4 294 967 295;
- unsigned long long int – занимает 8 байтов, следовательно, имеет диапазон от 0 до 18 446 744 073 709 551 615.

Например:
unsigned int b; signed int a; int c; unsigned d; signed f;
Приведем несколько правил, касающихся записи целочисленных значений в исходном тексте программ.
- Нельзя пользоваться десятичной точкой. Значения 26 и 26.0 одинаковы, но 26.0 не является значением типа int.
- Нельзя пользоваться запятыми в качестве разделителей тысяч. Например, число 23,897 следует записывать как 23897.
- Целые значения не должны начинаться с незначащего нуля. Он применяется для обозначения восьмеричных или шестнадцатеричных чисел, так что компилятор будет рассматривать значение 011 как число 9 в восьмеричной системе счисления.
На практике рекомендуется использовать основной целый тип, то есть тип int.
Вещественный (данные с плавающей точкой) тип данных (типы float и double)
Для хранения вещественных чисел применяются типы данных float (с одинарной точностью) и double (с двойной точностью). Смысл знаков «+» и «-» для вещественных типов совпадает с целыми. Последние незначащие нули справа от десятичной точки игнорируются. Поэтому варианты записи +523.5, 523.5 и 523.500 представляют одно и то же значение.
Для представления вещественных чисел используются два формата:
В большинстве случаев используется тип double, он обеспечивает более высокую точность, чем тип float. Максимальную точность и наибольший диапазон чисел достигается с помощью типа long double.
Максимальную точность и наибольший диапазон чисел достигается с помощью типа long double.
Величина с модификатором типа float занимает 4 байта. Из них 1 бит отводится для знака, 8 бит для избыточной экспоненты и 23 бита для мантиссы. Отметим, что старший бит мантиссы всегда равен 1, поэтому он не заполняется, в связи с этим диапазон модулей значений переменной с плавающей точкой приблизительно равен от 3.14E–38 до 3.14E+38.
Величина типа double занимает 8 байтов в памяти. Ее формат аналогичен формату float. Биты памяти распределяются следующим образом: 1 бит для знака, 11 бит для экспоненты и 52 бита для мантиссы. С учетом опущенного старшего бита мантиссы диапазон модулей значений переменной с двойной точностью равен от 1.7E–308 до 1.7E+308.
Величина типа long double аналогична типу double.
Например:
float a, b; double x, y; long double z;
Дальше >>
< Лекция 1 || Лекция 2: 1234 || Лекция 3 >
Использование памяти в Python / Хабр
Сколько памяти занимает 1 миллион целых чисел?
Меня часто донимали размышление о том, насколько эффективно Python использует память по сравнению с другими языками программирования. Например, сколько памяти нужно, чтобы работать с 1 миллионом целых чисел? А с тем же количеством строк произвольной длины?
Например, сколько памяти нужно, чтобы работать с 1 миллионом целых чисел? А с тем же количеством строк произвольной длины?Как оказалось, в Python есть возможность получить необходимую информацию прямо из интерактивной консоли, не обращаясь к исходному коду на C (хотя, для верности, мы туда все таки заглянем).
Удовлетворив любопытство, мы залезем внутрь типов данных и узнаем, на что именно расходуется память.
Все примеры были сделаны в CPython версии 2.7.4 на 32 битной машине. В конце приведена таблица для потребности в памяти на 64 битной машине.
Необходимые инструменты
sys.getsizeof и метод __sizeof__()
Первый инструмент, который нам потребуется находится в стандартной библиотеки sys. Цитируем официальную документацию:sys.getsizeof(объект[, значение_по_умолчанию])Возвращает размер объекта в байтах.
Если указано значение по умолчанию, то оно вернется, если объект не предоставляет способа получить размер.В противном случае возникнет исключение TypeError.
Getsizeof() вызывает метод объекта __sizeof__ и добавляет размер дополнительной информации, которая хранится для сборщика мусора, если он используется.
Алгоритм работы getsizeof(), переписанной на Python, мог бы выглядеть следующем образом:
Py_TPFLAGS_HAVE_GC = 1 << 14 # константа. в двоичным виде равна 0b100000000000000
def sys_getsizeof(obj, default = None)
if obj.hasattr('__sizeof__'):
size = obj.__sizeof__()
elif default is not None:
return default
else:
raise TypeError('Объект не имеет атрибута __sizeof__')
# Если у типа объекта установлен флаг HAVE_GC
if type(obj).__flags__ & Py_TPFLAGS_HAVE_GC:
size = size + размер PyGC_Head
return size
Где PyGC_Head — элемент двойного связанного списка, который используется сборщиком мусора для обнаружения кольцевых ссылок. В исходном коде он представлен следующей структурой:
typedef union _gc_head {
struct {
union _gc_head *gc_next;
union _gc_head *gc_sourcev;
Py_ssize_t gc_refs;
} gc;
long double dummy;
} PyGC_Head;
Размер PyGC_Head будет равен 12 байт на 32 битной и 24 байта на 64 битной машине.
Попробуем вызвать getsizeof() в консоли и посмотрим, что получится:
>>> import sys
>>> GC_FLAG = 1 << 14
>>> sys.getsizeof(1)
12
>>> (1).__sizeof__()
12
>>> bool(type(1).__flags__ & GC_FLAG)
False
>>> sys.getsizeof(1.1)
16
>>> (1.1).__sizeof__()
16
>>> bool(type(1.1).__flags__ & GC_FLAG)
False
>>> sys.getsizeof('')
21
>>> ''.__sizeof__()
21
>>> bool(type('').__flags__ & GC_FLAG)
False
>>> sys.getsizeof('hello')
26
>>> sys.getsizeof(tuple())
24
>>> tuple().__sizeof__()
12
>>> bool(type(tuple()).__flags__ & GC_FLAG)
True
>>> sys.getsizeof(tuple((1, 2, 3)))
36
За исключением магии с проверкой флагов, все очень просто.
Как видно из примера, int и float занимают 12 и 16 байт соответственно. Str занимает 21 байт и еще по одному байту на каждый символ содержимого. Пустой кортеж занимает 12 байт, и дополнительно 4 байта на каждый элемент. Для простых типов данных (которые не содержат ссылок на другие объекты, и соответственно, не отслеживаются сборщиком мусора), значение sys.getsizeof равно значению, возвращаемого методом __sizeof__().
Для простых типов данных (которые не содержат ссылок на другие объекты, и соответственно, не отслеживаются сборщиком мусора), значение sys.getsizeof равно значению, возвращаемого методом __sizeof__().
id() и ctypes.string_at
Теперь выясним, на что именно расходуется память.Для этого нужно нам нужны две вещи: во-первых, узнать, где именно хранится объект, а во-вторых, получить прямой доступ на чтение из памяти. Несмотря на то, что Python тщательно оберегает нас от прямого обращения к памяти, это сделать все таки возможно. При этом нужно быть осторожным, так как это может привести к ошибке сегментирования.
Встроенная функция id() возвращает адрес памяти, где храниться начала объекта (сам объект является C структурой)
>>> obj = 1 >>> id(obj) 158020320
Чтобы считать данные по адресу памяти нужно воспользоваться функцией string_at из модуля ctypes. Ее официальное описание не очень подробное:
ctypes.string_at(адрес[, длина])
Это функция возвращает строку, с началом в ячейки памяти «адрес». Если «длина» не указана, то считается что строка zero-terminated,
Теперь попробуем считать данные по адресу, который вернул нам id():
>>> import ctypes >>> obj = 1 >>> sys.getsizeof(obj) 12 >>> ctypes.string_at(id(obj), 12) 'u\x01\x00\x00 \xf2&\x08\x01\x00\x00\x003\x01\x00\x00 \xf2&\x08\x00\x00\x00\x001\x00\x00\x00'
Вид шестнадцатеричного кода не очень впечатляет, но мы близки к истине.
Модель Struct
Для того чтобы представить вывод в значения, удобные для восприятия, воспользуемся еще одним модулем. Здесь нам поможет функция unpack() из модуля struct.struct
Этот модуль производит преобразование между значениями Python и структурами на C, представленными в виде строк.struct.unpack(формат, строка)
Разбирает строку в соответствие с данным форматов.Всегда возвращает кортеж, даже если строка содержит только один элемент. Строка должна содержать в точности то количество информации, как описано форматом.
Форматы данных, которые нам потребуются.
| символ | Значение C | Значение Python | Длина на 32битной машине |
| c | char | Строка из одного символа | 1 |
| i | int | int | 4 |
| l | long | int | 4 |
| L | unsigned long | int | 4 |
| d | double | float | 8 |
Теперь собираем все вместе и посмотрим на внутреннее устройство некоторых типов данных.
Int
>>> obj = 1
>>> sys.getsizeof(obj), obj.__sizeof__()
(12, 12)
>>> struct.unpack('LLl', ctypes. string_at(id(obj), 12))
(373, 136770080, 1)
string_at(id(obj), 12))
(373, 136770080, 1)
О формате значений несложно догадаться.
Первое число (373) — количество указателей, на объект.
>>> obj2 = obj
>>> struct.unpack('LLl', ctypes.string_at(id(obj), 12))
(374, 136770080, 1)
Как видно, число увеличилось на единицу, после того как мы создали еще одну ссылку на объект.Второе число (136770080) — указатель (id) на тип объекта:
>>> type(obj) <type 'int'> >>> id(type(obj) ) 136770080
Третье число (1) — непосредственно содержимое объекта.
>>> obj = 1234567
>>> struct.unpack('LLl', ctypes.string_at(id(obj), 12))
(1, 136770080, 1234567)
Наши догадки можно подтвердить, заглянув в исходный код CPythontypedef struct {
PyObject_HEAD
long ob_ival;
} PyIntObject;
Здесь PyObject_HEAD — макрос, общий для всех встроенных объектов, а ob_ival — значение типа long. Макрос PyObject_HEAD добавляет счетчик количества указателей на объект и указатель на родительский тип объекта — как раз то, что мы и видели.
Макрос PyObject_HEAD добавляет счетчик количества указателей на объект и указатель на родительский тип объекта — как раз то, что мы и видели.Float
Число с плавающей запятой очень похоже на int, но представлено в памяти C значением типа double.typedef struct {
PyObject_HEAD
double ob_fval;
} PyFloatObject;
В этом легко убедиться:
>>> obj = 1.1
>>> sys.getsizeof(obj), obj.__sizeof__()
(16, 16)
>>> struct.unpack('LLd', ctypes.string_at(id(obj), 16)
(1, 136763968, 1.1)
Строка (Str)
Строка представлена в виде массива символов, оканчивающимся нулевым байтом. Также в структуре строки отдельного сохраняется ее длина, хэш от ее содержания и флаг, определяющий, хранится ли она во внутреннем кэше interned.typedef struct {
PyObject_VAR_HEAD
long ob_shash; # хэш от строки
int ob_sstate; # находится ли в кэше?
char ob_sval[1]; # содержимое строки + нулевой байт
} PyStringObject;
Макрос PyObject_VAR_HEAD включает в себя PyObject_HEAD и добавляет значение long ob_ival, в котором хранится длина строки.
>>> obj = 'hello world'
>>> sys.getsizeof(obj), obj.__sizeof__()
(32, 32)
>>> struct.unpack('LLLli' + 'c' * (len(obj) + 1), ctypes.string_at(id(obj), 4*5 + len(obj) + 1))
(1, 136790112, 11, -1500746465, 0, 'h', 'e', 'l', 'l', 'o', ' ', 'w', 'o', 'r', 'l', 'd', '\x00')
Четвертое значение соответствует хэшу от строки, в чем нетрудно убедиться.
>>> hash(obj) -1500746465
Как видно, значение sstate равно 0, так что строка сейчас не кэшируется. Попробуем ее добавить в кэш:
>>> intern(obj)
'hello world'
>>> struct.unpack('LLLli' + 'c' * (len(obj) + 1), ctypes.string_at(id(obj), 4*5 + len(obj) + 1))
(2, 136790112, 11, -1500746465, 1, 'h', 'e', 'l', 'l', 'o', ' ', 'w', 'o', 'r', 'l', 'd', '\x00') Кортеж (Tuple)
Кортеж представлен в виде массива из указателей. Так как его использование может приводить к возникновению кольцевых ссылок, он отслеживается сборщиком мусора, на что расходуется дополнительная память (об этом нам напоминает вызов sys. getsizeof())
getsizeof())Структура tuple похоже на строку, только в ней отсутствуют специальные поля, кроме длины.
typedef struct {
PyObject_VAR_HEAD
PyObject *ob_item[1];
} PyTupleObject;
>>> obj = (1,2,3)
>>> sys.getsizeof(obj), obj.__sizeof__()
(36, 24)
>>> struct.unpack('LLL'+'L'*len(obj), ctypes.string_at(id(obj), 12+4*len(obj)))
(1, 136532800, 3, 146763112, 146763100, 146763088)
>>> for i in obj: print i, id(i)
1 146763112
2 146763100
3 146763088
Как видим из примера, последние три элементы кортежа являются указателями на его содержимое.Остальные базовые типы данных (unicode, list, dict, set, frozenset) можно исследовать аналогичным образом.
Что в итоге?
| Тип | Имя в CPython | формат | Формат, для вложенных объектов | Длина на 32bit | Длина на 64bit | Память для GC* |
| Int | PyIntObject | LLl | 12 | 24 | ||
| float | PyFloatObject | LLd | 16 | 24 | ||
| str | PyStringObject | LLLli+c*(длина+1) | 21+длина | 37+длина | ||
| unicode | PyUnicodeObject | LLLLlL | L*(длина+1) | 28+4*длина | 52+4*длина | |
| tuple | PyTupleObject | LLL+L*длина | 12+4*длина | 24+8*длина | Есть | |
| list | PyListObject | L*5 | L*длину | 20+4*длина | 40+8*длина | Есть |
| Set/ frozenset |
PySetObject | L*7+(lL)*8+lL | LL* длина | (<=5 элементов) 100 (>5 элементов) 100+8*длина |
(<=5 элементов) 200 (>5 элементов) 200+16*длина |
Есть |
| dict | PyDictObject | L*7+(lLL)*8 | lLL*длина | (<=5 элементов) 124 (>5 элементов) 124+12*длина |
(<=5 элементов) 248 (>5 элементов) 248+24*длина |
Есть |
Мы видим, что простые типы данных в Python в два-три раза больше своих прототипов на C. 6 байт) на кортеж, которых будет хранить на них ссылки.
6 байт) на кортеж, которых будет хранить на них ссылки.
UPD: Опечатки.
UPD: В подзаголовке «1 миллион целых чисел», вместо «1 миллион простых чисел»
Java — выделение памяти для значения int 1 против 2 147 483 647
спросил
Изменено 9 лет, 1 месяц назад
Просмотрено 846 раз
Java выделяет 4 байта памяти для целого числа. Но происходит ли это для всех значений int независимо от того, какое это значение? 931-1 бит.
Когда JVM выделяет память для целого числа, она вслепую выделяет 4 байта для каждой отдельной целой переменной или выделяет больше памяти по мере увеличения числа?
- java
- управление памятью
- типы
- целочисленные
Переменная типа int всегда занимает 4 байта.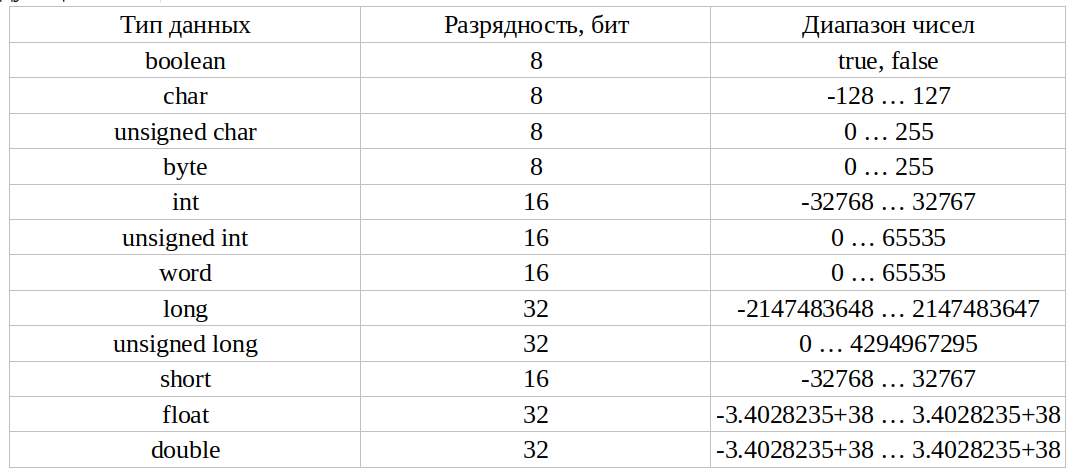 Было бы пустой тратой времени пытаться оптимизировать используемое пространство в зависимости от фактического значения. Программист несет ответственность за принятие решения о том, сколько байтов ему нужно для переменной. 963-1 , и его хранилище растет вместе со значением внутри него.
Было бы пустой тратой времени пытаться оптимизировать используемое пространство в зависимости от фактического значения. Программист несет ответственность за принятие решения о том, сколько байтов ему нужно для переменной. 963-1 , и его хранилище растет вместе со значением внутри него.
Размер BigInteger зависит от виртуальной машины, потому что размер ссылки на объект в Java неодинаков на разных платформах, а размер заголовка объекта даже не всегда одинаков в течение жизненного цикла объекта. . На 64-битной виртуальной машине это может быть 16 (заголовок объекта) + 20 (заголовок массива) + 5*4 (целые поля в BigInteger) + 8 (ссылка на массив) = 64 байта занимаемой площади плюс необходимое количество байтов держать номер.
1Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google Зарегистрироваться через Facebook Зарегистрируйтесь, используя электронную почту и парольОпубликовать как гость
Электронная почтаТребуется, но не отображается
Опубликовать как гость
Электронная почтаТребуется, но не отображается
Нажимая «Опубликовать свой ответ», вы соглашаетесь с нашими условиями обслуживания и подтверждаете, что прочитали и поняли нашу политику конфиденциальности и кодекс поведения.
c++ — сколько бит выделяется для целого числа при размещении в куче
спросил
Изменено 1 год, 7 месяцев назад
Просмотрено 274 раза
В последнее время я возился с C++ и выделил память для целого числа следующим образом:
int* p = новое целое число;
Как я и думал, целое число обычно 4/3 бита в зависимости от архитектуры системы, но при печати размера памяти, выделяемой этим указателем:
cout << sizeof p << " - это размер int" << endl; // вывод: 8 — это размер int
Почему так? Помощь будет высоко оценена.
- С++
- указатели
Здесь вы ошибаетесь в нескольких вещах: sizeof p дает вам размер p , который не является int , а int* , то есть УКАЗАТЕЛЬ на целое число. Насколько велико целое число или указатель на целое число, зависит от машины, т.е. от реализации, над которой вы сейчас работаете, в основном от функции компилятора, архитектуры, операционной системы, режима работы и т. д. Также я думаю, что вы имеете в виду байты, то есть октеты, а не биты.
Насколько велико целое число или указатель на целое число, зависит от машины, т.е. от реализации, над которой вы сейчас работаете, в основном от функции компилятора, архитектуры, операционной системы, режима работы и т. д. Также я думаю, что вы имеете в виду байты, то есть октеты, а не биты.
Также размер любого типа не зависит от того, что когда-либо было выделено в «куче», т.е. с динамическим хранением/новым/malloc или в «стеке», т.е. с автоматической продолжительностью хранения.
В конце: размер int независимо от того, находится ли он в куче, гарантированно будет не менее 16 бит или 2 октета. Поскольку байт обычно состоит, но не обязательно, из 8 бит, это также 2 байта. Чтобы на самом деле напечатать размер в вашем примере кода, вы должны взять sizeof (*p)
Количество битов, занимаемых int , равно CHAR_BIT*sizeof(int) . #include , чтобы определить константу CHAR_BIT .
Хотя в современном мире вы, скорее всего, найдете CHAR_BIT равно 8, за исключением некоторых специализированных аппаратных средств. На некоторых устройствах цифровой обработки сигналов это может быть даже 64.
Я думаю, вы могли перепутать «бит» (двоичная цифра 0 или 1) и «байт».
Вы также перепутали int и указатель на int в своем примере.
Однако будьте осторожны. Логически new int выделяет столько места для вы можете использовать , но обычно больше памяти выделяется «за кулисами» для «обслуживания» и, возможно, «выравнивания».
Я не буду вдаваться в подробности, но вы можете обнаружить, что выделение int потребляет около 32 или даже 64 байт памяти компьютера, пока вы не вызовете удалить на нем.
sizeof p выводит размер указателя. sizeof p=8 указывает на 64-битную архитектуру. В большинстве современных архитектур значение int составляет 4 байта или 32 бита. Вы можете вывести размер int либо с помощью sizeof(int), либо sizeof(var), где var является переменной. Кроме того, вы уверены, что вам нужно выделить int? Часто вы можете просто поместить его в стек, откуда он будет удален автоматически, просто написав
Вы можете вывести размер int либо с помощью sizeof(int), либо sizeof(var), где var является переменной. Кроме того, вы уверены, что вам нужно выделить int? Часто вы можете просто поместить его в стек, откуда он будет удален автоматически, просто написав
инт п = 0;1
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google Зарегистрироваться через Facebook Зарегистрируйтесь, используя электронную почту и парольОпубликовать как гость
Электронная почтаТребуется, но никогда не отображается
Опубликовать как гость
Электронная почтаТребуется, но не отображается
Нажимая «Опубликовать свой ответ», вы соглашаетесь с нашими условиями обслуживания и подтверждаете, что прочитали и поняли нашу политику конфиденциальности и кодекс поведения.