Нереляционные данные и базы данных NoSQL — Azure Architecture Center
Нереляционная база данных — это база данных, в которой в отличие от большинства традиционных систем баз данных не используется табличная схема строк и столбцов. В этих базах данных применяется модель хранения, оптимизированная под конкретные требования типа хранимых данных. Например, данные могут храниться как простые пары «ключ — значение», документы JSON или граф, состоящий из ребер и вершин.
Все эти хранилища данных не используют реляционную модель. Кроме того, они, как правило, поддерживают определенные типы данных. Процесс запроса данных также специфический. Например, хранилища данных временных рядов рассчитаны на запросы к последовательностям данных, упорядоченных по времени. В свою очередь хранилища данных графов рассчитаны на анализ взвешенных связей между сущностями. Ни один из форматов не подходит в полней мере при выполнении задач управления данными о транзакциях.
Термин NoSQL применяется к хранилищам данных, которые не используют язык запросов SQL. Вместо этого они запрашивают данные с помощью других языков программирования и конструкций. На практике NoSQL означает «нереляционная база данных», даже несмотря на то, что многие из этих баз данных под держивают запросы, совместимые с SQL. Однако базовая стратегия выполнения запросов SQL обычно значительно отличается от применяемой в системе управления реляционной базой данных (реляционная СУБД).
Вместо этого они запрашивают данные с помощью других языков программирования и конструкций. На практике NoSQL означает «нереляционная база данных», даже несмотря на то, что многие из этих баз данных под держивают запросы, совместимые с SQL. Однако базовая стратегия выполнения запросов SQL обычно значительно отличается от применяемой в системе управления реляционной базой данных (реляционная СУБД).
В разделах ниже описаны основные категории нереляционных баз данных или баз данных NoSQL.
Хранилища данных документов
Хранилище данных документов управляет набором значений именованных строковых полей и данных объекта в сущности, которая называется документом. Обычно данные в этих хранилищах содержатся в виде документов JSON. Каждое значение поля может представлять собой скалярный элемент, например число, или сложный объект, например список или коллекция типа «родитель — потомок». Данные в полях документа можно закодировать разными способами, например в формате XML, YAML, JSON, BSON, или хранить в виде обычного текста. Поля документов доступны системе управления хранилищем, что позволяет приложению выполнять запросы и применять фильтры, основанные на значениях этих полей.
Поля документов доступны системе управления хранилищем, что позволяет приложению выполнять запросы и применять фильтры, основанные на значениях этих полей.
Как правило, документ содержит все данные для сущности. Элементы, составляющие сущность, зависят от конкретного приложения. Например, сущность может содержать сведения о клиенте, заказе или их сочетание. Один документ может содержать сведения, которые в реляционной СУБД обычно распределяются по нескольким реляционным таблицам. Хранилище документов не требует, чтобы все документы имели одинаковую структуру. Такой свободный подход к форме обеспечивает большую гибкость. Например, приложения могут хранить в документах разные данные в соответствии с текущими требованиями компании.
Приложение может получать документы по ключу документа. Ключ — это уникальный идентификатор документа. Часто к нему применяется хэширование для равномерного распределения данных. Некоторые базы данных документов автоматически создают ключ документа. Другие позволяют указать атрибут документа, который будет использоваться в качестве ключа. Приложение также может запрашивать документы на основе значения одного или нескольких полей. Некоторые базы данных документов поддерживают индексирование, чтобы облегчить быстрый поиск документов по одному или нескольким индексированным полям.
Другие позволяют указать атрибут документа, который будет использоваться в качестве ключа. Приложение также может запрашивать документы на основе значения одного или нескольких полей. Некоторые базы данных документов поддерживают индексирование, чтобы облегчить быстрый поиск документов по одному или нескольким индексированным полям.
Многие базы данных документов поддерживают обновления «на месте», то есть позволяют приложению изменять значения отдельных полей без перезаписи всего документа. Операции чтения и записи в нескольких полях одного документа обычно являются атомарными.
Соответствующие службы Azure:
- Azure Cosmos DB
Столбчатые хранилища данных
Столбчатое хранилище данных или хранилище семейств столбцов упорядочивает данные по столбцам и строкам. Столбчатое хранилище данных в простейшей форме почти неотличимо от реляционной базы данных, по крайней мере организационно. Настоящее преимущество столбчатого хранилища данных заключается в способности денормализованно структурировать разреженные данные, что связано со столбцово-ориентированным методом хранения данных.
Столбчатое хранилище данных можно представить как набор табличных данных со строками и столбцами, в которых столбцы разделяются на определенные группы или семейства столбцов. Каждое семейство столбцов включает набор логически связанных столбцов, которые обычно извлекаются или управляются как единое целое. Другие данные, которые используются в других процессах, хранятся отдельно в других семействах столбцов. В семейство столбцов можно динамически добавить новые столбцы, а строки могут быть разреженными (то есть строки не обязаны иметь значение для каждого столбца).
На следующей диаграмме представлен пример таблицы с двумя семействами столбцов: Identity и Contact Info. Данные одной сущности имеют одинаковые ключи строк во всех семействах столбцов. Такая структура, в которой строки любого объекта в семействе столбцов могут динамически изменяться, определяет важное преимущество этой категории хранилищ. Семейства столбцов очень хорошо подходят для хранения данных с различными схемами.
В отличие от хранилища пар «ключ — значение» и баз данных документов, большинство столбчатых баз данных упорядочивают хранимые данные с помощью самих значений ключей, а не хэш-кодов от них. Ключ строки рассматривается как первичный индекс и обеспечивает доступ на основе определенного ключа или их диапазона. Некоторые реализации позволяют создавать вторичные индексы по определенным столбцам в семействе столбцов. Вторичные индексы позволяют получать данные по значениям столбцов, а не ключам строки.
Все столбцы одного семейства хранятся на диске в одном файле. Каждый файл содержит определенное число строк. При использовании больших наборов данных этот подход позволяет повысить производительность за счет снижения объема данных, которые необходимо считывать с диска, когда отправляется запрос на получение нескольких столбцов за раз.
Чтение и запись строки из одного семейства столбцов — это обычно атомарные операции. Однако некоторые реализации поддерживают атомарность всей строки, распределенной по нескольким семействам столбцов.
Соответствующие службы Azure:
- Azure Cosmos DB для Apache Cassandra
- Использование HBase в HDInsight
Хранилище пар «ключ — значение»
Хранилище пар «ключ — значение» по сути представляет собой большую хэш-таблицу. Каждое значение сопоставляется с уникальным ключом, и хранилище ключей использует этот ключ для хранения данных, применяя к нему некоторую функцию хэширования. Выбор функции хэширования должен обеспечить равномерное распределение хэшированных ключей по хранилищу данных.
Большинство хранилищ пар «ключ — значение» поддерживают только самые простые операции запроса, вставки и удаления. Чтобы частично или полностью изменить значение, приложение всегда перезаписывает существующее значение целиком. В большинстве реализаций атомарной операцией считается чтение или запись одного значения. Запись больших значений занимает относительно долгое время.
Приложение может хранить в наборе значений произвольные данные, но некоторые хранилища пар «ключ — значение» накладывают ограничения на максимальный размер значений. Программное обеспечение хранилища ничего не знает о значениях, которые в нем хранятся. Все сведения о схеме поддерживаются и применяются на уровне приложения. Эти значения по существу являются большими двоичными объектами, которые хранилище извлекает и сохраняет по соответствующему ключу.
Программное обеспечение хранилища ничего не знает о значениях, которые в нем хранятся. Все сведения о схеме поддерживаются и применяются на уровне приложения. Эти значения по существу являются большими двоичными объектами, которые хранилище извлекает и сохраняет по соответствующему ключу.
Хранилища пар «ключ — значение» рассчитаны на приложения, выполняющие простые операции поиска на основе значения ключа или диапазона ключей, но не очень подходят для систем, которым нужно запрашивать данные из нескольких таблиц хранилищ пар «ключ — значение», например присоединенные данные в нескольких таблицах.
Кроме того, хранилища пар «ключ — значение» неудобны в сценариях, где могут выполняться запросы или фильтрация по значению, а не только по ключам. Например, в реляционной базе данных вы можете найти определенную запись с помощью предложения WHERE и отфильтровать ее по неключевым столбцам, но хранилища пар «ключ-значение» обычно не поддерживают такую возможность поиска значений или же этот процесс выполняется медленно.
Одно хранилище пар «ключ — значение» очень легко масштабируется, поскольку позволяет удобно распределить данные среди нескольких узлов на разных компьютерах.
Соответствующие службы Azure:
- Azure Cosmos DB для таблицы
- Кэш Azure для Redis
- хранилище таблиц Azure
Хранилища данных графов
Хранилища данных графов управляют сведениями двух типов: узлами и ребрами. Узлы в этом случае представляют сущности, а ребра определяют связи между ними. Узлы и грани имеют свойства, которые предоставляют сведения о конкретном узле или грани, примерно как столбцы в реляционной таблице. Грани могут иметь направление, указывающее на характер связи.
Хранилища данных графов позволяют приложениям эффективно выполнять запросы, которые проходят через сеть узлов и ребер, а также анализировать связи между сущностями. На схеме ниже представлены данные персонала организации, структурированные в виде графа. Сущностями здесь являются сотрудники и отделы, а грани определяют отношения подчинения и отдел, в котором работает каждый сотрудник. Стрелки на ребрах этого графа показывают направление связей.
Стрелки на ребрах этого графа показывают направление связей.
Такая структура позволяет легко выполнять такие запросы, как «найти всех сотрудников, которые прямо или косвенно подчиняются Светлане» или «найти всех, кто работает в одном отделе с Дмитрием». Процессы сложного анализа выполняются быстро даже на больших графах с большим количеством сущностей и связей. Многие базы данных графов предоставляют язык запросов, который можно использовать для эффективного обхода сети связей.
Соответствующие службы Azure:
- API Graph в Azure Cosmos DB
Хранилища данных временных рядов
Данными временных рядов называются наборы значений, которые упорядочены по времени. Соответственно хранилища данных временных рядов оптимизированы для хранения данных именно такого типа. Хранилища данных временных рядов должны поддерживать очень большое число операций записи, так как обычно в них в режиме реального времени собирается большой объем данных из большого количества источников. Эти хранилища также хорошо подходят для хранения данных телеметрии. Например, для сбора данных от датчиков Интернета вещей или счетчиков в приложениях или системах. Обновления в таких базах данных выполняются редко, а удаление чаще всего является массовой операцией.
Эти хранилища также хорошо подходят для хранения данных телеметрии. Например, для сбора данных от датчиков Интернета вещей или счетчиков в приложениях или системах. Обновления в таких базах данных выполняются редко, а удаление чаще всего является массовой операцией.
Размер отдельных записей в базе данных временных рядов обычно невелик, но их очень много, а значит общий размер данных быстро увеличивается. Хранилища данных временных рядов также обрабатывают данные, полученные вне очереди или несвоевременно, автоматически индексируют точки данных и оптимизируют запросы, полученные в течение определенного промежутка времени. Эта последняя возможность позволяет быстро выполнять запросы к миллионам точек данных и нескольким потокам данных, что, в свою очередь, обеспечивает поддержку визуализации временных рядов (стандартный способ потребления данных временных рядов).
Дополнительные сведения см. в статье Решения для временных рядов.
Соответствующие службы Azure:
- Аналитика временных рядов Azure
- OpenTSDB с HBase в HDInsight
Хранилище данных объектов
Хранилища данных объектов оптимизированы для хранения и извлечения больших двоичных объектов, например изображений, текстовых файлов, видео- и аудиопотоков, объектов данных и документов приложений большого размера, образы дисков виртуальных машин. Объект состоит из сохраненных данных, метаданных и уникального идентификатора доступа к объекту. Хранилища объектов поддерживают отдельные большие файлы, а также позволяют управлять всеми файлами за счет внушительного общего объема хранилища.
Объект состоит из сохраненных данных, метаданных и уникального идентификатора доступа к объекту. Хранилища объектов поддерживают отдельные большие файлы, а также позволяют управлять всеми файлами за счет внушительного общего объема хранилища.
Некоторые хранилища данных объектов реплицируют определенный большой двоичный объект между несколькими узлами кластера, что обеспечивает быстрое параллельное чтение. Этот процесс, в свою очередь, позволяет реализовать масштабируемую архитектуру запроса данных, хранящихся в больших файлах, так как несколько процессов, обычно выполняющихся на разных серверах, могут одновременно запрашивать большие файлы данных.
Часто хранилища данных объектов используют как сетевые общие папки. Доступ к файлам, хранящимся в этих папках, можно получить через компьютерную сеть с использованием стандартных сетевых протоколов, например SMB. Если созданы необходимые механизмы поддержки безопасности и одновременного доступа, такое совместное использование данных позволяет распределенным службам с высокой степенью масштабируемости предоставлять доступ к данным для базовых низкоуровневых операций, то есть для простых запросов на чтение и запись.
Соответствующие службы Azure:
- Хранилище BLOB-объектов Azure
- Azure Data Lake Storage
- Хранилище файлов Azure
Хранилища данных внешних индексов
Хранилища данных внешних индексов позволяют искать информацию, содержащуюся в других хранилищах данных и службах. Внешний индекс выступает в роли вторичного индекса любого хранилища данных. Кроме того, с его помощью можно индексировать большие объемы данных и предоставлять доступ к этим индексам почти в реальном времени.
Например, в файловой системе могут храниться текстовые файлы. По пути файл можно найти быстро, но поиск на основе содержимого выполняется медленно, так как сканируются все файлы. Внешний индекс позволяет создавать вторичные индексы, а затем быстро искать путь к файлам, соответствующим заданным условиям. Рассмотрим еще один пример использования внешнего индекса. Предположим, что хранилища пар «ключ — значение» поддерживают индексирование только по ключу. Вы можете создать вторичный индекс на основе значений данных и быстро найти ключ, однозначно определяющий каждый соответствующий элемент.
Индексы создаются в процессе индексирования, который может выполняться по модели извлечения, то есть по требованию хранилища данных, или по модели передачи, то есть по команде из кода приложения. В некоторых системах поддерживаются многомерные индексы и полнотекстовый поиск по большим объемам текстовых данных.
Часто хранилища данных внешних индексов используют для реализации полнотекстового поиска и поиска в Интернете. В этих случаях поддерживается точный или нечеткий поиск. Нечеткий поиск находит документы, которые соответствуют набору условий, и вычисляет для них коэффициент совпадения с этим набором. Некоторые внешние индексы также поддерживают лингвистический анализ, который возвращает соответствия с учетом синонимов, категорий (например, при поиске по запросу «собаки» соответствием считается «питомцы») и морфологии (например, при поиске по запросу «бег» соответствием считается «бегущий»).
Соответствующие службы Azure:
- Поиск Azure
Стандартные требования
Часто архитектура нереляционных хранилищ данных отличается от архитектуры реляционных баз данных. В частности эти хранилища, как правило, не имеют фиксированной схемы, а также не поддерживают транзакции или ограничивают их область. Из соображений масштабируемости они обычно не включают вторичные индексы.
В частности эти хранилища, как правило, не имеют фиксированной схемы, а также не поддерживают транзакции или ограничивают их область. Из соображений масштабируемости они обычно не включают вторичные индексы.
В таблице ниже приведено сравнение требований каждого нереляционного хранилища данных.
| Требование | Хранилище данных документов | Столбчатое хранилище данных | Хранилище данных пар «ключ — значение» | Хранилище данных графов |
|---|---|---|---|---|
| Нормализация | Денормализированные данные | Денормализированные данные | Денормализированные данные | Нормализированные данные |
| схема | Схема при чтении | Семейства столбцов, определенные при записи, схема столбца при чтении | Схема при чтении | Схема при чтении |
| Согласованность (между параллельными транзакциями) | Настраиваемый уровень согласованности, гарантии на уровне документа | Гарантии на уровне семейства столбцов | Гарантии на уровне ключей | Гарантии на уровне графа |
| Атомарность (область транзакции) | Коллекция | Таблица | Таблица | График |
| Стратегия блокировки | Оптимистичная (без блокировки) | Пессимистичная (блокировка строк) | Оптимистичная (ETag) | |
| Шаблон доступа | Прямой доступ | Статистические выражения на основе данных большого формата | Прямой доступ | Прямой доступ |
| Индексация | Первичный и вторичные индексы | Первичный и вторичные индексы | Только первичный индекс | Первичный и вторичные индексы |
| Форма представления данных | Документ | Таблица с семействами столбцов | Ключ и значение | Граф с ребрами и вершинами |
| разреженные; | Да | Да | Да | Нет |
| Масштабность (большое количество столбцов и атрибутов) | Да | Да | Нет | Нет |
| Размер данных | От малого (КБ) до среднего (несколько МБ) | От среднего (МБ) до большого (несколько ГБ) | Небольшой (КБ) | Небольшой (КБ) |
| Общий максимальный масштаб | Очень большой (ПБ) | Очень большой (ПБ) | Очень большой (ПБ) | Большой (ТБ) |
| Требование | Данные временных рядов | Хранилище данных объектов | Хранилище данных внешних индексов |
|---|---|---|---|
| Нормализация | Нормализированные данные | Денормализированные данные | Денормализированные данные |
| схема | Схема при чтении | Схема при чтении | Схема при записи |
| Согласованность (между параллельными транзакциями) | Н/Д | Н/Д | Н/Д |
| Атомарность (область транзакции) | Н/Д | Объект | Н/Д |
| Стратегия блокировки | Н/Д | Пессимистичная (блокировка больших двоичных объектов) | Н/Д |
| Шаблон доступа | Прямой доступ и агрегирование | Последовательный доступ | Прямой доступ |
| Индексация | Первичный и вторичные индексы | Только первичный индекс | Н/Д |
| Форма представления данных | Таблица | Большой двоичный объект и метаданные | Документ |
| разреженные; | нет | Н/Д | Нет |
| Масштабность (большое количество столбцов и атрибутов) | Нет | Да | Да |
| Размер данных | Небольшой (КБ) | От большого (ГБ) до очень большого (ТБ) | Небольшой (КБ) |
| Общий максимальный масштаб | Большой (несколько ТБ) | Очень большой (ПБ) | Большой (несколько ТБ) |
Соавторы
Эта статья поддерживается Майкрософт. Первоначально она была написана следующими авторами.
Первоначально она была написана следующими авторами.
Основной автор:
- | Зойнер Теджада Генеральный директор и архитектор
Дальнейшие действия
- Реляционные и Данные NoSQL
- Общие сведения о распределенных базах данных NoSQL
- Основы данных в Microsoft Azure: изучение нереляционных данных в Azure
- Реализация нереляционной модели данных
- Разработка архитектуры баз данных
- Основные сведения о моделях хранилищ данных
- Масштабируемая обработка заказов
- Обработка данных Lakehouse практически в реальном времени
Обзор MS SQL Server — База Знаний Timeweb Community
Веб-ресурсы содержат огромное количество данных – от учетных записей пользователей до контента, опубликованного на страницах. То же относится к «облачным» приложениям вроде CRM, программ для бухучета, складского учета и пр. Везде используется один способ хранения информации – база данных. И этой базой необходимо как-то управлять.
Сегодня мы поговорим об одной из самых популярных систем управления реляционными базами данных – MS SQL Server.
Что такое MS SQL Server
Чтобы упростить работу с такими хранилищами данных и повысить эффективность их применения, создаются специализированные системы управления. Одной из наиболее популярных является разработка от Microsoft – SQL Server. Первый релиз платформы опубликован еще в 1989 году, а последняя версия выпущена в 2019 году (проект продолжает развиваться).
Преимущества решения:
- Тесная интеграция с операционной системой Windows.
- Высокая производительность, отказоустойчивость.
- Поддержка многопользовательской среды.
- Расширенные функции резервирования данных.
- Работа с удаленным подключением.
Каждый выпуск включает в себя несколько специализированных редакций. Это снижает сложность внедрения и затраты на процесс разработки собственных решений, адаптированных для «узких» задач. При написании программного кода активно используется интеграция с продуктами Microsoft, например, с платформой Visual Studio.
Прямые конкуренты на рынке – Oracle Database, PostgreSQL. Первый проект коммерческий, он создан для поддержки крупных компаний, поэтому сопоставим по возможностям с MS SQL Server. Второй же распространяется на бесплатной основе и не «блещет» функциональностью, хотя весьма популярен среди многих разработчиков (аналог от Oracle MySQL).
Что такое СУБД
Появление таких продуктов позволило объединить разное понимание БД (баз данных) со стороны пользователей и системных администраторов. Неискушенные в технических деталях люди «видят» таблицы как некий перечень данных с колонками и строками. Системный подход включает файлы с табличными данными, связанными друг с другом согласно определенному алгоритму.
Функции базы данных:
- Постоянное хранение информации.
- Поиск по ключевым критериям.
- Чтение и редактирование по запросу.
Клиентами БД являются прикладные программы, их интерфейс, различные интерактивные модули сайтов вроде калькуляторов и онлайн-редакторов. Но есть еще один компонент системы – СУБД. Он предназначен для ручного доступа к информации и позволяет извлекать данные на диск, работать с ними в памяти сервера, в том числе с применением структурированного языка SQL.
Но есть еще один компонент системы – СУБД. Он предназначен для ручного доступа к информации и позволяет извлекать данные на диск, работать с ними в памяти сервера, в том числе с применением структурированного языка SQL.
Всего различают три типа БД – клиент-серверные, файл-серверные и встраиваемые. MS SQL Server относится к первой категории. Плюс система является реляционной, т.е. адаптированной для хранения данных без избыточности, с минимальными рисками появления аномалий и нарушения целостности внутренних таблиц.
Комьюнити теперь в Телеграм
Подпишитесь и будьте в курсе последних IT-новостей
ПодписатьсяРасширения языка SQL
Язык SQL представляет собой стандарт, унифицирующий обработку данных всеми реляционными базами данных. Такой подход упрощает перекрестные обращения, дает возможность переходить на «иную платформу» без серьезных переделок проекта. Но здесь нужно учитывать, что в каждой БД имеется собственный язык, который называется диалектом (расширением).
Варианты:
- Transact-SQL (T-SQL) – применяется в MS SQL Server.
- PL/SQL (Procedural Language/Structured Query Language) – аналог от Oracle.
- PL/pgSQL (Procedural Language/PostGres Structured Query Language) – язык используется в PostgreSQL.
Обычно от выбранной СУБД зависит, какой язык предстоит использовать (или от навыков человека, который будет администрировать систему). Синтаксис конструкций у них сильно различается, как и формат обращения ко встроенным функциям, поэтому чаще всего тип БД для проекта выбирается раз и навсегда.
Инсталляция MS SQL Server
Подготовительный шаг – скачать установочный пакет SQL Server Enterprise с официальной страницы сайта Microsoft. После нажатия на кнопку «Бесплатная пробная версия» будет предложено выбрать вариант EXE или Azure («облако») и внести свои анкетные данные, при сохранении которых начнется загрузка инсталляционного файла.
Перед запуском установщика нужно создать учетную запись пользователя. Она пригодится для авторизации на сервере при запросе доступа с клиентских компьютеров (даже при условии, что ПК будет один и тот же).
Она пригодится для авторизации на сервере при запросе доступа с клиентских компьютеров (даже при условии, что ПК будет один и тот же).
Последовательность действий:
- В поиске набрать команду lusrmgr.msc и нажать Enter.
- Создать нового пользователя и задать ему пароль доступа.
- Сохранить изменения и перезагрузить компьютер.
Рекомендуется в имени и пароле использовать только буквы латиницы и цифры, кириллица будет привносить риски локальных сбоев из-за особенностей обработки. Теперь можно запускать файл с дистрибутивом MS SQL Server. Программа предложит 3 варианта действий: базовая инсталляция с настройками «по умолчанию», выборочный режим или скачивание файлов «на потом».
В большинстве случаев выбирается первый пункт, при нажатии на который предлагается прочитать и подтвердить лицензионное соглашение. На следующем шаге система позволяет вручную выбрать каталог для установки или согласиться с предложенным значением. Остается нажать на кнопку «Установить» и дождаться завершения процесса.
Остается нажать на кнопку «Установить» и дождаться завершения процесса.
Файлы в основном скачиваются с официального сервера, поэтому понадобится стабильный доступ к интернету. Такой подход обеспечивает установку последнего релиза и проверку легитимности всех модулей (отсутствие вредоносного ПО). Последнее окно сообщает об успешном завершении, после которого можно сразу подключаться к серверу.
Зачем нужен SQL Server Management Studio
Для удобства администрирования также понадобится SQL Server Management Studio (SSMS). Он представляет собой интегрированную среду для управления инфраструктурой БД и поддерживает любые ее варианты – от локальной до Azure. В него встроены инструменты настройки, наблюдения и редактирования экземпляров баз данных.
Последовательность действий:
- Нажать кнопку «Установить SSMS» в окне инсталлятора SQL Server.
- Произойдет автоматическое перенаправление на официальную страницу продукта.
- Скачать последний релиз программного обеспечения на компьютер.
- Запустить инсталлятор и нажать кнопку «Установить».
Программные пакеты приложения также загружаются напрямую из интернета, поэтому требуется стабильный доступ к сети. После завершения установки будет запрошена перезагрузка компьютера. Все, система полностью готова к эксплуатации и созданию первой базы данных.
Хостинг-провайдеры обычно предлагают предустановленный комплект поддержки баз данных на SQL Server. Он не всегда последней версии, зато наверняка работоспособен в рамках как панели управления, так и публикуемых веб-ресурсов. Пользователю фактически предлагается сразу начать с создания БД – запрашивается всего лишь ее название, имя пользователя и пароль.
10 популярных систем управления базами данных (СУБД) [список]
Мы собрали некоторые из самых популярных на сегодняшний день систем управления базами данных (СУБД). Начнем с определения того, что такое система управления базами данных.
Что такое система управления базами данных?
Система управления базами данных (СУБД) — это программное обеспечение, используемое для определения, обработки, извлечения, хранения и управления данными в базах данных.
Подводя итог, системы управления базами данных отвечают за:
- Определение правил для проверки и обработки данных.
- Взаимодействие с базами данных, приложениями и конечными пользователями.
- Получение, хранение и анализ данных.
- Обновление данных.
Популярные системы управления базами данных
MySQL
MySQL — это бесплатная система управления реляционными базами данных (RDBMS) с открытым исходным кодом. Первоначально он принадлежал MySQL AB, а затем был приобретен Sun Microsystems (часть Oracle Corporation с 2010 года). Первоначально MySQL был разработан Ульфом Михаэлем Видениусом, шведами Дэвидом Аксмарком и Алланом Ларссоном, основателями MySQL AB.
Многие веб-приложения, работающие с базами данных, такие как WordPress, Joomla и phpBB, а также многие популярные веб-сайты, такие как MediaWiki, Twitter и Facebook, используют MySQL.
Разработчик : Корпорация Oracle.
Первоначальный автор : MySQL AB.
Последняя версия MySQL : MySQL 8.0.32.
Лицензия MySQL : Стандартная общественная лицензия GNU версии 2 и проприетарная.
MariaDB
MariaDB — это разработанная сообществом бесплатная система управления реляционными базами данных с открытым исходным кодом. Это форк MySQL. Первоначально MariaDB была разработана Ульфом Михаэлем Видениусом, шведами Дэвидом Аксмарком и Алланом Ларссоном, основателями MySQL AB и фонда MariaDB. Ульф Майкл Видениус в настоящее время является ведущим разработчиком и техническим директором MariaDB.
MariaDB также включена во многие дистрибутивы Linux, такие как CentOS, Debian и RHEL. Кроме того, его используют многие организации, такие как Wikipedia, Google или Tumblr.
Разработчик : Корпорация MariaDB Ab и Фонд MariaDB.
Последний выпуск MariaDB : MariaDB 11.1.0.
Лицензия MariaDB : GPL версии 2.
Microsoft SQL Server
Microsoft SQL Server — это коммерческая система управления реляционными базами данных. Он доступен в нескольких версиях, разделенных на три основные категории: основные, специализированные и снятые с производства.
Он доступен в нескольких версиях, разделенных на три основные категории: основные, специализированные и снятые с производства.
Разработчик : Microsoft.
Последняя версия Microsoft SQL Server : Microsoft SQL Server 2022.
Лицензия Microsoft SQL Server : проприетарная лицензия.
СУБД Oracle
СУБД Oracle — коммерческая многомодельная система управления базами данных. Он также известен как база данных Oracle или просто Oracle. Он обычно используется для запуска: онлайн-обработки транзакций (OLTP) и хранилища данных (DW).
Разработчик : Корпорация Oracle.
Последняя долгосрочная версия СУБД Oracle : СУБД Oracle 19c.
Последняя версия СУБД Oracle : бета-версия СУБД Oracle 23c.
Лицензия на СУБД Oracle : проприетарная лицензия.
PostgreSQL
PostgreSQL — это бесплатная система управления реляционными базами данных (RDBMS) с открытым исходным кодом. Первоначально она была разработана как преемник базы данных Ingres, разработанной в Калифорнийском университете в Беркли.
Первоначально она была разработана как преемник базы данных Ingres, разработанной в Калифорнийском университете в Беркли.
Разработчик : Глобальная группа разработчиков PostgreSQL.
Последний выпуск PostgreSQL : PostgreSQL 15.2.
Лицензия PostgreSQL : Лицензия PostgreSQL.
MongoDB
MongoDB — это документно-ориентированная система управления базами данных NoSQL с открытым исходным кодом. MongoDB Inc. предлагает интегрированный набор служб облачных баз данных, а также коммерческую поддержку. Это ориентированное на документ программное обеспечение базы данных обычно используется для хранения больших объемов данных.
Разработчик : MongoDB Inc.
Последний выпуск MongoDB : MongoDB 6.0.4.
Лицензия MongoDB : общедоступная серверная лицензия (SSPL).
Redis
Redis, сокращенно от «Remote Dictionary Server», представляет собой NoSQL систему управления базами данных типа «ключ-значение» с открытым исходным кодом.
Разработчик : Redis.
Автор оригинала : Сальваторе Санфилиппо.
Последний выпуск Redis : Redis 7.0.
Лицензия Redis : BSD 3-пункт.
IBM DB2
IBM DB2 — это продукт управления базами данных, разработанный IBM, ранее известный как DB2 для Linux, UNIX и Windows.
Разработчик : IBM.
Последний выпуск IBM DB2 : IBM DB2 11.5.8.
Лицензия IBM DB2 : проприетарная лицензия.
Elasticsearch
Elasticsearch — это распределенная поисковая и аналитическая система RESTful. Он основан на библиотеке Lucene. Elasticsearch является преемником предыдущей поисковой системы Compass, также разработанной Shay Banon.
Разработчик : Elastic NV.
Автор оригинала : Shay Banon.
Последний выпуск Elasticsearch : Elasticsearch 8. 7.
7.
Лицензия Elasticsearch : лицензия Elastic с двойной лицензией и общедоступная серверная лицензия.
SQLite
SQLite — это ядро базы данных общего пользования, принадлежащее к семейству встроенных систем управления реляционными базами данных. Он имеет привязки ко многим языкам программирования.
Разработчик : Дуэйн Ричард Хипп.
Последний выпуск SQLite : SQLite 3.41.2.
Лицензия SQLite : общественное достояние.
Сравнение систем управления базами данных
| СУБД | Тип | Операционные системы | 9 0207 ЛицензияНаписано на | |
| MySQL | СУРБД | Canonical, FreeBSD, Linux, MacOS, Solaris и Windows | GNU GPL v2 и проприетарные | C и C++ |
| MariaDB | СУРБД | Linux, MacOS и Windows | GNU GPL v2 | Bash, C, C++ и Perl |
| Microsoft SQL Server | СУРБД | Linux и Windows | Собственная | C и C++ |
| СУБД Oracle | Многомодельная система управления базами данных | AIX, BS2000, HP-UX, Linux, MacOS и Windows | Собственный | Язык ассемблера, C и C++ |
| PostgreSQL | СУРБД | 9 0207 FreeBSD, Linux, MacOS, OpenBSD и WindowsЛицензия PostgreSQL | C | |
| MongoDB | Документоориентированная база данных | FreeBSD, Linux, MacOS и Windows | Общественная лицензия на стороне сервера | C++, JavaScript и питон |
| Redis | База данных «ключ-значение» | Unix-подобная | BSD 3-пункт | C |
| РСУБД | Linux, Unix-подобные и Windows | Собственное | Сборка, C, C++ и Java | |
| Elasticsearch | Поиск и индексирование | Linux, MacOS и Windows | Эластичная лицензия с двойной лицензией и общедоступная серверная лицензия | Java |
| SQLite | СУРБД | Android, BSD, iOS, Linux, MacOS, Solaris, VxWorks и Windows | Общественное достояние | 902 07 C
Топ-10 систем управления базами данных
Наконец , согласно рейтингу DB-Engines по состоянию на апрель 2023 года*, это 10 лучших систем управления базами данных:
- Oracle
- MySQL
- Microsoft SQL Server
- Постгрес SQL
- МонгоДБ
- Редис
- IBM DB2
- Эластичный поиск
- SQLite
- Microsoft Access
*Рейтинг DB-Engines обновляется ежемесячно.
6 Управление базой данных
6 Управление базой данных Глава 6Управление базой данных
6.1 Иерархия данных [Рисунок 6.1][Слайд 6-4]
Данные являются основными ресурсами организации. Данные, хранящиеся в компьютерных системах, образуют иерархию, простирающуюся от одного бита до база данных, основная учетная единица фирмы. Каждая высшая ступень этой иерархии организована из компонентов, находящихся под ним.
Данные логически организованы в:
1. Биты (символы)
2. Поля
3. Записи
4. Файлы
5. Базы данных
Бит (Символ) — бит является наименьшей единицей представление данных (значение бита может быть 0 или 1). Восемь бит составляют байт, который может представляют символ или специальный символ в коде символа.
Поле — поле состоит из группы
персонажи. Поле данных представляет атрибут (характеристику или качество) некоторого
сущность (предмет, лицо, место или событие).
Запись — запись представляет собой набор атрибуты, которые описывают реальный объект. Запись состоит из полей, каждое поле описание атрибута объекта.
Файл — группа связанных записей. Файлы часто классифицируются по приложениям, для которых они в основном используются (сотрудники файл). Первичный ключ в файле — это поле (или поля), значение которого идентифицирует запись среди других в файле данных.
База данных – интегрированный набор логически связанные записи или файлы. База данных объединяет записи, ранее хранившиеся в отдельные файлы в общий пул записей данных, который предоставляет данные для многих Приложения. Данные управляются системным программным обеспечением, называемым системами управления базами данных. (СУБД). Данные, хранящиеся в базе данных, не зависят от прикладных программ, использующих их. и типов вторичных запоминающих устройств, на которых он хранится.
904:00 6. 2 Файловая среда и ее ограничения
2 Файловая среда и ее ограничения
Существует три основных метода организации файлов. из которых только два обеспечивают прямой доступ, необходимый в онлайновых системах.
Организация файлов [Рис. 6.2 и 6.3]
Файлы данных организованы таким образом, чтобы облегчить доступ к записей и обеспечить их эффективное хранение. Компромисс между этими двумя требованиями обычно существует: если требуется быстрый доступ, требуется больше памяти, чтобы сделать его возможный.
Доступ к записи для чтения необходимая операция над данными. Есть два типа доступа:
1. Последовательный доступ — выполняется при Доступ к записям осуществляется в порядке их хранения. Последовательный доступ является основным доступом только в пакетных системах, где файлы используются и обновляются через равные промежутки времени.
2. Прямой доступ — оперативная обработка требует прямого доступа, при этом запись может быть доступна без доступ к записям между ним и началом файла.Первичный ключ служит для определить необходимую запись.
Существует три метода организации файлов: [Таблица 6.1]
1. Последовательная организация 2. Индексно-последовательный организация 3. Непосредственная организация
Последовательная организация
В последовательной организации записи физически хранятся в указанном порядке в соответствии с ключевым полем в каждой записи.
Преимущества последовательного доступа:
1. Это быстро и эффективно при работе с большими объемами данных, которые необходимо периодически обрабатывать (пакетная система).
Недостатки последовательного доступа:
1. Требуется, чтобы все новое транзакции должны быть отсортированы в правильной последовательности для обработки последовательного доступа. 2. Размещение, хранение, изменение, удаление или добавление записей в файл требует переупорядочения файла. 3.Этот метод слишком медленный для обработки приложений, требующих немедленного обновления или ответов.
Индексно-последовательная организация
В методе индексированных последовательных файлов записи физически хранится в последовательном порядке на магнитном диске или в другом хранилище с прямым доступом устройство на основе ключевого поля каждой записи. Каждый файл содержит индекс, который ссылается одно или несколько ключевых полей каждой записи данных на адрес места ее хранения.
Прямая организация
Прямая организация файлов обеспечивает самую быструю прямую доступ к записям. При использовании методов прямого доступа записи не обязательно располагать в любую конкретную последовательность на носителе. Характеристики метода прямого доступа включают:
1. Компьютеры должны хранить отслеживание места хранения каждой записи с помощью различных средств прямой организации методы, чтобы данные можно было получить, когда это необходимо.2. Данные о новых транзакциях не надо сортировать. 3. Обработка, которая требует немедленные ответы или обновление легко выполняются.
6.3 Среда базы данных [Рисунок 6.6][Слайд 6-5]
База данных – это организованный набор взаимосвязанных данные, которые обслуживают ряд приложений на предприятии. В базе хранится не только значения атрибутов различных сущностей, но и отношения между ними сущности. База данных управляется системой управления базами данных (СУБД), системным программным обеспечением. который обеспечивает помощь в управлении базами данных, совместно используемыми многими пользователями.
А СУБД:
1. Помогает организовать данные для эффективный доступ различных пользователей с различными потребностями в доступе и для эффективного хранилище. 2. Позволяет создавать, получать доступ, поддерживать и контролировать базы данных. 3. Через СУБД данные могут быть интегрированы и представлены по запросу.
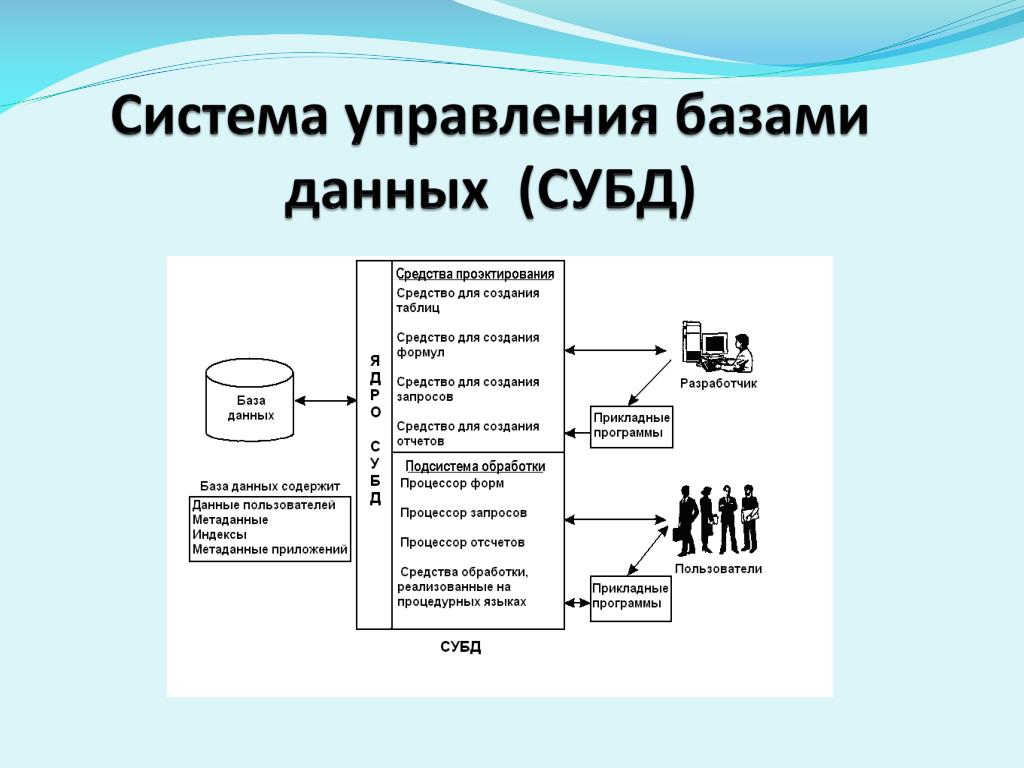
Преимущества подхода к управлению базами данных:
1. Избегайте бесконтрольного избыточность данных и предотвращение несогласованности 2. Данные программы независимость 3. Гибкий доступ к общие данные 4. Преимущества централизованное управление данными
6.4 Уровни определения данных в базах данных [Рисунок 6.7]
Пользовательское представление СУБД становится основой для даты этапы моделирования, на которых идентифицируются отношения между элементами данных. Эти данные модели определяют логические отношения между элементами данных, необходимыми для поддержки базовой бизнес-процесс. СУБД служит логической структурой (схемой, подсхемой и физической) на которых основывается физический дизайн баз данных и разработка приложений программы для поддержки бизнес-процессов организации. СУБД позволяет нам определить базу данных на трех уровнях:
1. Схема — общий логический вид
отношения между данными в базе данных.
СУБД предоставляет язык с именем данные язык определения (DDL) для определения объектов базы данных на трех уровнях. Он также предоставляет язык для манипулирования данными, называемый манипулирование данными. язык (DML), что позволяет получать доступ к записям, изменять значения атрибуты, а также удалять или вставлять записи.
6.5 Модели данных или как их представлять Связь между данными
Модель данных — это метод организации баз данных на
логический уровень, уровень схемы и подсхемы. Основная забота в таком
модель — это то, как представлять отношения между записями базы данных. Отношения между
множество отдельных записей в базах данных основаны на одном из нескольких логических данных
конструкции или модели. СУБД предназначены для предоставления конечным пользователям быстрого и легкого доступа к
информация, хранящаяся в базах данных. Три основные модели включают в себя:
Отношения между
множество отдельных записей в базах данных основаны на одном из нескольких логических данных
конструкции или модели. СУБД предназначены для предоставления конечным пользователям быстрого и легкого доступа к
информация, хранящаяся в базах данных. Три основные модели включают в себя:
1. Иерархическая структура
2. Структура сети
3. Реляционная структура
Иерархический:
Ранние пакеты СУБД для мейнфреймов использовали иерархическую структуру . структура , в которой:
1. Отношения между записями образуют иерархию или древовидная структура.
2. Записи зависимы и расположены многоуровнево структуры, состоящие из одной корневой записи и любого количества подчиненных уровней.
3. Отношения между записями — один ко многим, поскольку каждый элемент данных связан только с одним элементом над ним.
4. Элемент данных или запись на самом высоком уровне иерархия называется корневым элементом.
Доступ к любому элементу данных можно получить, переместив постепенно вниз от корня и вдоль ветвей дерева до желаемого запись находится.
Структура сети:
Структура сети:
1. Может представлять более сложные логические отношения, и до сих пор используется многими пакетами СУБД для мэйнфреймов.
2. Разрешает отношения «многие ко многим» между записями. Что то есть сетевая модель может получить доступ к элементу данных по одному из нескольких путей, потому что любой элемент данных или запись могут быть связаны с любым количеством других элементов данных.
Реляционная структура:
Реляционная структура:
1. Самая популярная из трех структур базы данных.
2. Используется большинством пакетов микрокомпьютерных СУБД, а также многие мини-компьютеры и мейнфреймы.
3. Элементы данных в базе данных хранятся в форма простых таблиц .
Таблицы связаны, если они содержат общие поля.
4. Пакеты СУБД на основе реляционной модели могут компоноваться элементы данных из различных таблиц для предоставления информации пользователям.
Оценка структур базы данных
| МОДЕЛЬ | ПРЕИМУЩЕСТВА | НЕДОСТАТКИ |
| Иерархическая структура данных | Легкость, с которой данные могут
храниться и извлекаться в структурированных рутинных типах транзакций. Простота извлечения данных для целей отчетности. Обработка рутинных транзакций выполняется быстро и эффективно. | Иерархический «один ко многим»
отношения должны быть указаны заранее и не являются гибкими. Не удается легко обрабатывать специальные запросы на информацию. Изменение иерархической структуры базы данных является сложным. Большая избыточность. Требуется знание языка программирования. |
| Структура сети | Более гибкий, чем
иерархическая модель. Способность предоставлять сложные логические отношения между записями | Сеть многие ко многим
отношения должны быть указаны заранее Пользователь ограничен для извлечения данных, к которым можно получить доступ, используя установленные связи между записями. Не может легко обрабатывать специальные запросы на информацию. Требуется знание языка программирования. |
| Реляционная структура | Гибкость в том, что она может
обрабатывать специальные информационные запросы. Программистам легко работать с. Конечные пользователи могут использовать эту модель с небольшим усилием или обучением. Проще в обслуживании, чем иерархическая и сетевая модели. | Не удается обработать большие суммы бизнес-транзакций так же быстро и эффективно, как иерархические и сетевые модели. |

6.6 Реляционные базы данных [Рис. 6.11, 6.13]
Реляционная база данных представляет собой набор таблиц. Такой База данных относительно проста для понимания конечными пользователями. Реляционные базы данных позволяют гибкость в отношении данных и их легко понять и модифицировать.
1. Выберите, который выбирает из указанной таблицы строки, удовлетворяющие заданному условию. 2. Проект, который выбирает из данной таблицы указанные значения атрибутов 3. Присоединяйтесь, что строит новый таблица из двух указанных таблиц.
Сила реляционной модели проистекает из объединения
операция. Именно потому, что записи связаны друг с другом через соединение
операции, а не через ссылки, что нам не нужен предопределенный путь доступа.
операция соединения также занимает много времени, требуя доступа ко многим записям, хранящимся на
диск, чтобы найти нужные записи.
6.7 SQL — реляционный язык запросов
языка структурированных запросов (SQL) стал международный стандартный язык доступа для определения и управления данными в базах данных. Это является языком определения и управления данными большинства известных СУБД, в том числе некоторых нереляционные. SQL может использоваться как независимый язык запросов для определения объектов. в базе данных, введите данные в базу данных и получите доступ к данным. Так называемое встроенный SQL также предоставляется для программирования на процедурных языках (Ahost@ языков), таких как C, COBOL или PL/L, для доступа к базе данных из приложения. программа. В среде конечного пользователя SQL обычно скрыт более удобным для пользователя интерфейсы.
Основные возможности SQL включают:
1. Определение данных 2. Манипуляции с данными
6.8 Проектирование реляционной базы данных
Проектирование базы данных происходит от проектирования
логические уровни схемы и подсхемы для проектирования физического уровня.
Цель логический дизайн , также известный как данные моделирование , заключается в разработке схемы базы данных и всех необходимых подсхемы. Реляционная база данных будет состоять из таблиц (отношений), каждая из которых описывает только атрибуты определенного класса сущностей. Логический дизайн начинается с определением классов сущностей, которые должны быть представлены в базе данных, и установлением отношения между парами этих сущностей. Отношения — это просто взаимодействие между объектами, представленными данными. Эти отношения будут важны для доступ к данным. Часто, диаграммы сущность-связь (E-R) , используются выполнять моделирование данных.
Нормализация — это упрощение
логическое представление данных в реляционных базах данных. Каждая таблица нормализована, что означает, что
все его поля будут содержать одиночные элементы данных, все его записи будут разными, и
каждая таблица будет описывать только один класс сущностей. Цель нормализации
заключается в предотвращении репликации данных со всеми ее негативными последствиями.
Цель нормализации
заключается в предотвращении репликации данных со всеми ее негативными последствиями.
После логического проектирования физический дизайн базы данных. Все поля указаны по длине и характеру данных (чисел, символов и т. д.). Главной целью физического проектирования является чтобы свести к минимуму количество трудоемких обращений к диску, которые будут необходимы для отвечать на типичные запросы к базе данных. Часто индексы предоставляются для обеспечения быстрого доступа. для таких запросов.
6.9 Словарь данных
A словарь данных является программным модулем и база данных, содержащая описания и определения, касающиеся структуры, данных элементы, взаимосвязи и другие характеристики базы данных организации.
Словари данных хранят следующую информацию о данные хранятся в базах данных:
1. Схема, подсхемы и физическая схема 2. Какие приложения и пользователи могут получать определенные данные и какие приложения и пользователи могут изменять данные 3.Перекрестная ссылка информация, например, какие программы используют какие данные и какие пользователи получают какие отчеты 4. Где индивидуальные данные элементы возникают, и кто несет ответственность за поддержание данных 5. Какое стандартное нейминг соглашения предназначены для объектов базы данных. 6. Каковы правила честности для данных 7. Где находятся данные хранятся в географически распределенных базах данных.
Словарь данных:
1. Содержит все данные определения и информация, необходимая для идентификации владельца данных 2. Обеспечивает безопасность и конфиденциальность данных, а также информации, используемой при разработке и обслуживание приложений, использующих базу данных.
6.10 Управление ресурсами данных организации
Использование технологии баз данных позволяет организациям
контролировать свои данные как ресурс, однако автоматически не производит
организационный контроль данных.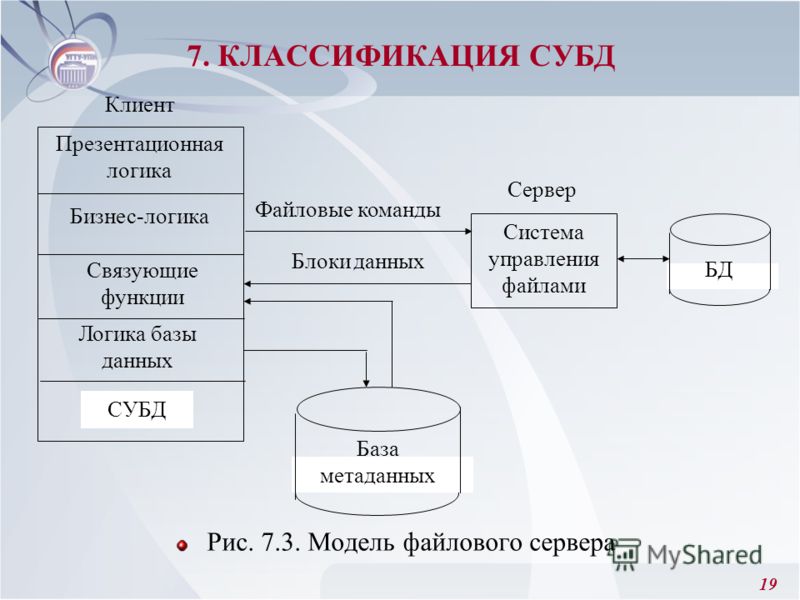
Компоненты управления информационными ресурсами [Рис. 6.17]
И организационные действия, и технологические средства необходимо:
1. Убедитесь, что фирма систематически накапливает данные в своих базах данных 2. Сохраняет данные в течение время 3. Предоставляет соответствующие доступ к данным соответствующим сотрудникам.
Основные компоненты данного информационного ресурса управление:
1. Организационные процессы— Информационное планирование и моделирование данных
2. Вспомогательные технологии— СУБД и словарь данных
3. Организационные функции— администрирование данных и администрирование баз данных
Администрирование баз данных и администрирование баз данных [Рис. 6.18]
Функциональные блоки, отвечающие за управление данными являются:
1. Администратор данных (DA)
2.904:00Администратор базы данных (БД)
Администратор данных – лицо, имеющее центральная ответственность за данные организации.
В обязанности входит:
1. Установление политики и специальные процедуры для сбора, проверки, обмена и инвентаризации данные для хранения в базах данных и для предоставления информации членам организацией и, возможно, лицами вне ее. 2. Администрирование данных — это функция разработки политики, и DA должен иметь доступ к высшему корпоративному руководству. 3. Ключевое лицо, участвующее в стратегическое планирование ресурса данных. 4. Часто определяет основные объекты данных, их атрибуты и отношения между ними.
Администратор баз данных — специалист отвечает за поддержание стандартов разработки, обслуживания и безопасности базы данных организации.
В обязанности входит:
1. Создание баз данных и выполнение политик, установленных администратором данных.2. В крупных организациях функция DBA фактически выполняется группой профессионалов. В небольшой фирме А. программист/аналитик может выполнять функции администратора базы данных, а один из менеджеров выступает в роли администратора базы данных. 3. Схема и подсхемы база данных чаще всего определяется администратором баз данных, обладающим необходимыми техническими знаниями. Они также определяют физическое расположение баз данных с целью оптимизации. производительность системы для ожидаемого шаблона использования базы данных.
Совместная ответственность DA и DBA:
1. Хранение данных словарь 2. Стандартизация имен и другие аспекты определения данных 3. Предоставление резервной копии 4. Обеспечьте безопасность данные, хранящиеся в базе данных, и обеспечить конфиденциальность на основе этой безопасности. 5. Установить катастрофу план восстановления баз данных
6.11 Тенденции развития в управлении базами данных
К трем важным тенденциям в управлении базами данных относятся:
1.Распределенные базы данных 2. Хранилище данных 3. Богатые базы данных (включает в себя объектно-ориентированные базы данных)
Распределенные базы данных [Рис. 6.19][Слайд 6-8]
Распределенные базы данных, которые разбросаны по несколько физических локаций. В распределенных базах данные размещаются там, где они есть. используется чаще всего, но вся база данных доступна каждому авторизованному пользователю. Это базы данных локальных рабочих групп (LAN) и отделов в региональных офисах (WAN), филиал офисы, производственные предприятия и другие рабочие места. Эти базы данных могут включать сегменты как общих операционных, так и общих пользовательских баз данных, а также данных, генерируемых и используемых только на собственном сайте пользователя.
Хранилища данных Базы данных [Рисунок 6.20]
Хранилище данных хранит данные из текущего и предыдущего
лет, которые были извлечены из различных оперативных и управленческих баз данных
организация.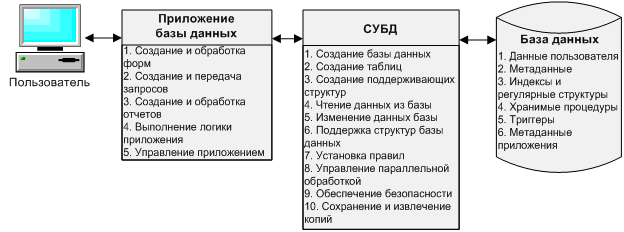 Это центральный источник данных, стандартизированный и интегрированный таким образом.
его могут использовать менеджеры и другие профессионалы, работающие с конечными пользователями, со всего мира.
организация. Целью корпоративного хранилища данных является постоянный отбор данных.
из оперативных баз данных, преобразовать данные в единый формат и открыть
склада конечным пользователям через дружественный и последовательный интерфейс.
Это центральный источник данных, стандартизированный и интегрированный таким образом.
его могут использовать менеджеры и другие профессионалы, работающие с конечными пользователями, со всего мира.
организация. Целью корпоративного хранилища данных является постоянный отбор данных.
из оперативных баз данных, преобразовать данные в единый формат и открыть
склада конечным пользователям через дружественный и последовательный интерфейс.
Хранилища данных также используются для интеллектуального анализа данных — автоматическое обнаружение потенциально значимых взаимосвязей между различными категориями данные.
Системы, поддерживающие хранилище данных, состоят из трех комплектующие:
1. Извлечение и подготовка данных— первая подсистема извлекает данные из операционные системы, многие из которых являются более старыми унаследованными системами, и Ascrubs@ it путем устранения ошибок и несоответствий.
2. Сохранить дату в Склад— второй компонент поддержки — это собственно СУБД который будет управлять данными хранилища.
