СУБД: что это, виды, структура, функции
Разбираемся с тем, как устроены эти системы и какие примеры использования СУБД существуют.
- Что такое СУБД
- Для чего нужны СУБД
- Из чего состоят системы управления базами данных
- Основные виды СУБД
- Примеры современных СУБД
- Что нужно запомнить о СУБД
Что такое СУБД
СУБД — это система управления базами данных. Первые СУБД появились ещё в 1970-х, и сегодня их используют в каждой второй компании: от небольших интернет-магазинов до Facebook, Google и Amazon.
Чтобы управлять базами данных и находить нужную информацию, запросы к ним пишут на специальных языках. Самый популярный из них — SQL (от англ. Structured Query Language — «язык структурированных запросов»).
Так СУБД применяют на практике: пользователи отправляют через них SQL-запросы к базам данных и в ответ получают нужные данные
База без СУБД — просто набор данных, с которым ничего нельзя сделать, как КамАЗ без кабины. Технически это машина: можно заливать бензин и масло, менять детали. Но водитель с таким камазом не сможет ничего делать. Стоит только добавить кабину, то есть систему управления, и всё меняется: можно ехать, рулить и поворачивать. Так и СУБД позволяет управлять и пользоваться данными.
Технически это машина: можно заливать бензин и масло, менять детали. Но водитель с таким камазом не сможет ничего делать. Стоит только добавить кабину, то есть систему управления, и всё меняется: можно ехать, рулить и поворачивать. Так и СУБД позволяет управлять и пользоваться данными.
Материал по теме:
Что такое DevOps: зачем он нужен, где применяется и в чём его плюсы и минусы
Для чего нужны СУБД
При помощи СУБД можно создавать, объединять, удалять информацию в базах данных, предоставлять к ним доступ определённым пользователям и защищать от взлома.
Основные функции СУБД:
● Создание баз данных, изменение, удаление и объединение их по определённым признакам.
● Хранение данных, в том числе больших массивов, в структурированном виде и нужном формате.
● Защита данных от взлома и нежелательных изменений при помощи распределённого доступа: когда разным группам пользователей доступны разный объём и сегменты данных.
● Выгрузка и сортировка данных по заданным фильтрам при помощи SQL-запросов.
● Поддержка целостности баз данных, резервное копирование и восстановление после сбоёв.
Системы управления БД нужны специалистам, которые работают с данными в IT:
● Разработчикам приложений и сайтов, чтобы хранить и обрабатывать данные о пользователях, транзакциях и содержимом каталога.
Например, при разработке приложения для фитнес-клуба данные пользователей складывают в огромную таблицу типа Excel, где указаны имя, дата рождения, данные об абонементе, записи и отмены тренировок и так далее. Если БД организована правильно, то будет намного проще «расшарить» приложение при открытии нового филиала фитнес-клуба или — в случае блокировки приложения — создать новое без потери данных клиентов, а значит, и без потери денег для бизнеса.
● Аналитикам данных и специалистам по Data Science, чтобы извлекать нужные данные для исследований, формировать отчёты и строить прогнозы. В любом смартфоне система способна узнавать лица людей на фотографиях и группировать изображения. Это происходит благодаря обучению компьютеров на миллионах изображений, данные о которых хранятся в СУБД.
Это происходит благодаря обучению компьютеров на миллионах изображений, данные о которых хранятся в СУБД.
● DevOps-инженерам, чтобы автоматизировать процесс разработки и внедрения продукта на основе данных и отчётов. Агрегировать и анализировать отчёты пользователей вручную практически невозможно, а СУБД позволяют автоматизировать, например, разработку новой версии ПО или собирать данные об ошибках при разработке нового приложения.
Разобраться, как устроены СУБД и какими они бывают, можно на курсе «SQL для работы с данными и аналитики». Специалисты-практики научат составлять простейшие запросы и пользоваться популярными СУБД для бизнеса и аналитики.
Научитесь работать с SQL
Попробуйте себя в роли аналитика, даже если нет опыта работы с базами данных и html, и сделайте 2 бизнес-проекта по реальным требованиям заказчика за 1,5 месяца обучения. Начните с бесплатной вводной части курса «SQL для работы с данными и аналитики».
Из чего состоят системы управления базами данных
Вот главные элементы, которые есть в каждой СУБД, и их функции:
● Ядро.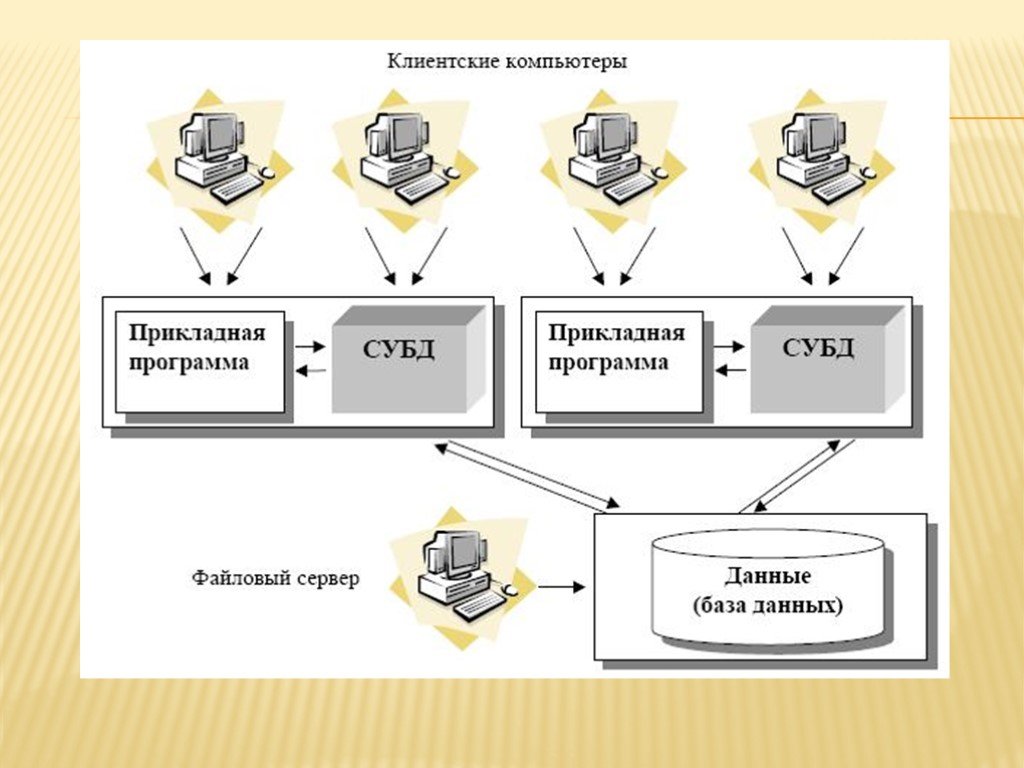 Это основа всей системы, которая отвечает за хранение и обработку баз данных. В ядре фиксируются все изменения: добавление, удаление или исправление целых баз и отдельных ячеек.
Это основа всей системы, которая отвечает за хранение и обработку баз данных. В ядре фиксируются все изменения: добавление, удаление или исправление целых баз и отдельных ячеек.
Так выглядит структура СУБД: когда кто-то отправляет запрос к базе данных, он проходит через специальное ПО, процессор языка запросов и ядро, а потом тот же путь проходят результаты в виде данных
● Процессор, или компилятор. Обрабатывает запросы к базам данных на внутренних языках и SQL, преобразуя их в нужные команды и передавая результаты.
● Программные средства, или утилиты. С их помощью пользователи вводят запросы, а администраторы баз данных настраивают доступ и другие параметры.
● Базы данных. То, где хранятся данные, организованные особым образом, иногда — в зашифрованном виде. Если это реляционные базы, то данные представлены в виде таблиц, связанных с друг другом. Если объектные — в виде объектов: блоков информации с определёнными свойствами и параметрами.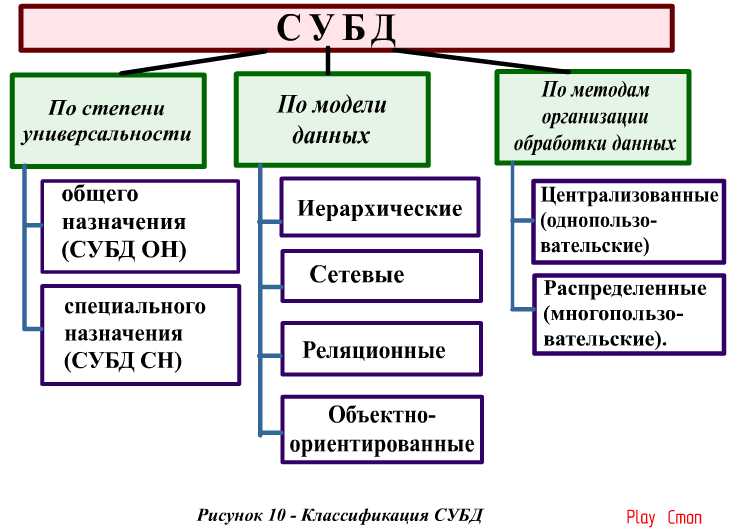
К примеру, чтобы составить меню собственной кофейни, для начала нужно изучить, что продают конкуренты и откуда заказывают продукты, а потом собрать все данные в одном месте. На выходе получатся базы данных:
— С напитками и их ингредиентами: например, миндальный капучино состоит из кофе, молока и миндального сиропа.
— С поставщиками, которые поставляют продукты и расходные материалы: стаканчики, трубочки, салфетки.
Если эти базы структурировать нужным образом, будет легко рассчитать, во сколько обойдётся кокосовый латте, у кого выгоднее брать сырьё и расходные материалы и по какой цене продавать готовый кофе. Как работают базы данных и где используются в бизнесе, наглядно и на примерах объяснили в статье.
Узнайте больше про работу с базами данных и SQL
Скачайте нашу памятку с основными SQL-командами, чтобы они всегда были под рукой
Основные виды СУБД
СУБД можно классифицировать по разным параметрам:
Хранение баз данных:
● Локальные.
Все элементы системы и баз данных находятся на одном сервере, как правило внутри компании.
● Распределённые.
Элементы находятся на разных серверах, в том числе облачных.
Многие современные СУБД поддерживают как локальное, так и распределённое применение или позволяют подключить дополнительные модули для распределённого доступа.
Хранение и обработка данных и запросов:
● Клиент-серверные.
СУБД и базы данных размещены на одном сервере, к которому обращаются с запросами разные пользователи. Получить доступ к данным через этот сервер можно с любого компьютера, специального ПО для этого не требуется. Например, если это база данных интернет-магазина, где покупатели ищут разные товары.
Примеры: Firebird, MS SQL Server, Oracle, PostgreSQL.
● Файл-серверные.
Базы данных хранятся на одном файл-сервере, а СУБД — на каждом устройстве, с которого отправляются запросы к БД. Чтобы пользователь мог получить доступ к данным, у него на компьютере должна быть установлена и настроена СУБД. Такие системы используют для локальных корпоративных сервисов: например, CRM, где хранятся данные о клиентах компании и документообороте.
Такие системы используют для локальных корпоративных сервисов: например, CRM, где хранятся данные о клиентах компании и документообороте.
Примеры: Microsoft Access, Paradox, dBase, FoxPro, Visual FoxPro.
● Встраиваемые.
Локальные СУБД, которые встраиваются в приложение как отдельный модуль и используются для управления данными только внутри него.
Примеры: OpenEdge, SQLite, Microsoft SQL Server Compact.
Язык запросов:
● СУБД с поддержкой SQL — самого распространённого и универсального языка структурированных запросов к базам данных.
Примеры: MySQL, Microsoft SQL Server, PostgreSQL.
● NoSQL — нереляционные СУБД, которые поддерживают другие языки запросов, основанные на языках программирования: например, JavaScript. Такие СУБД встречаются там, где нужно работать с большими данными или архивами документов с огромным количеством разных связей.
Примеры: Oracle NoSQL Database.
Структура и организация данных:
● Реляционные.
Данные представлены в виде таблиц, связанных между собой сквозными параметрами. У каждой строки есть уникальный идентификатор, или ключ. Это позволяет легко находить нужные данные и связывать их между собой.
Примеры: MySQL, PostgreSQL.
● Ключ-значение.
Те, где для хранения данных используют уникальный идентификатор из двух частей — ключ и значение, — который присваивается каждой единице данных.
Примеры: Redis, Memcached.
● Документные.
СУБД для баз данных, где хранятся документы со структурированным текстом и особым синтаксисом. Это могут быть архивы, каталоги или журналы действий, логи для сайтов и приложений.
Примеры: Amazon DocumentDB, CouchDB, MongoDB.
● Графовые.
СУБД, которые работают с базами данных, где в качестве единицы информации выступают взаимосвязи, аналогичные тем, что есть между родственниками или людьми со схожими интересами. Такие базы часто используют в соцсетях или рекомендательных сервисах.
Примеры: Amazon Neptune, Neo4j, InfoGrid.
● Колоночные.
Эти СУБД похожи на реляционные, только данные здесь представлены в виде колонок, каждая из которых аналогична отдельной таблице.
Примеры: SAP IQ, Google Bigtable, Vertica.
Примеры современных СУБД
PostgreSQL
Клиент-серверная реляционная СУБД, которая обладает значительной функциональностью и производительностью, при этом доступна бесплатно. Она также подходит для масштабных проектов с большими массивами данных и высокой нагрузкой.
В качестве основного языка запросов используется SQL, но СУБД также поддерживает его расширения на базе языков программирования: PL/Perl, PL/Python и PL/Java. Одно из главных преимуществ PostgreSQL в том, что здесь нет ограничений по размеру баз данных и числу записей в таблицах.
Интерфейс СУБД PostgreSQL
На курсе «SQL для работы с данными и аналитики» студенты учатся решать рабочие задачи с помощью популярных СУБД, чтобы принимать решения на основе данных и структурировать их в больших массивах.
Реляционная СУБД клиент-серверного типа, которая подходит для средних и небольших команд или проектов. Программа для работы с базами данных обладает простым и удобным интерфейсом и доступна для свободного пользования, поддерживает множество разных форматов таблиц и постоянно расширяет свои возможности.
СУБД работает онлайн с высокой скоростью и позволяет хранить до 50 млн единиц данных. Однако её функциональность всё же уже, чем у PostgreSQL. MySQL используют для хранения и управления данными сайтов и интернет-магазинов, среди которых Facebook, Twitter, Alibaba, Wikipedia. Она также может работать в комбинации с другими популярными СУБД.
Интерфейс MySQL
Microsoft SQL Server
Реляционная СУБД, расширенную платную версию которой используют в крупных компаниях. Бесплатная версия Express подходит для небольших проектов с объёмом данных до 10 Гб.
Система позволяет автоматизировать рутинные задачи: например, изменить размер файла или управлять памятью. Здесь удобно хранить данные со сложной структурой и быстро находить нужное за счёт простого поиска.
Здесь удобно хранить данные со сложной структурой и быстро находить нужное за счёт простого поиска.
В систему можно выгружать данные из других программ Microsoft (например, Access и Excel), а также вносить изменения в режиме онлайн. Для запросов в СУБД используется расширение SQL T-SQL (Transact-SQL).
Интерфейс MS SQL Server
MongoDB
Документная система управления NoSQL, где данные хранятся в виде JSON-файлов (от англ. JavaScript Object Notation), то есть текстовых документов в формате, основанном на JavaScript. Его же СУБД поддерживает в качестве языка запросов вместо SQL.
Вместо таблиц, как это принято в реляционных СУБД, в MongoDB данные хранятся в виде коллекций, то есть групп документов. Это бесплатная программа для работы с БД с открытым кодом, которая позволяет хранить любые данные, если их перевести в формат JSON. Такие свойства делают её практически универсальной и легко масштабируемой.
Эта СУБД подходит для работы с большими данными разных типов и из множества разных источников. Данные автоматически распределяются между разными базами так, чтобы оптимизировать нагрузку и ускорить обработку запросов. MongoDB используют для хранения локальных данных такие компании, как Google, Facebook, Twitter, IBM, Forbes, а также многие интернет-магазины.
Данные автоматически распределяются между разными базами так, чтобы оптимизировать нагрузку и ускорить обработку запросов. MongoDB используют для хранения локальных данных такие компании, как Google, Facebook, Twitter, IBM, Forbes, а также многие интернет-магазины.
Интерфейс MongoDB
SQLite
Компактная СУБД, которая подходит для небольших проектов. Она состоит из одного файла и встраивается в IT-инфраструктуру в виде библиотеки, не задействуя серверы и специальные службы. Все базы данных хранятся на одном устройстве.
SQLite подходит для небольших сайтов и приложений с ограниченным трафиком и объёмом данных, а также сервисов, где нужно прочитать или сохранить файлы на диск. СУБД работает на компьютерах, смартфонах, ТВ, приставках и беспилотниках, не требует администрирования и поддержки. В качестве языка запросов здесь используется С.
Интерфейс SQLIte
Что нужно запомнить о СУБД
● При помощи СУБД можно собирать, хранить, защищать базы данных, управлять ими. А ещё предоставлять распределённый доступ: чтобы разным группам пользователей были доступны разные объёмы данных и операции с ними.
А ещё предоставлять распределённый доступ: чтобы разным группам пользователей были доступны разные объёмы данных и операции с ними.
● СУБД нужны всем, кто работает с данными: интернет-магазинам, банкам, маркетологам, исследователям, разработчикам игр и приложений.
● Чтобы работать с СУБД, нужно освоить основы языка запросов (самый популярный и универсальный — SQL). Для некоторых СУБД пригодятся также языки программирования: JavaScript, Python, C++.
● Есть разные виды и классификации СУБД: по структуре баз данных, формату файлов, языку запросов и способу размещения системы.
● На рынке десятки различных СУБД, но самых популярных не больше десяти. Среди них можно выбрать ту, которая отвечает задачам, условиям и бюджету: по масштабу проекта и объёму данных, способу установки и размещения, доступности (платная или бесплатная). Чем масштабнее и дороже СУБД, тем больше у неё возможностей и выше уровень защиты данных.
Статью подготовили:
Поделиться
Читать также:
Как работают базы данных в IT: разбор на примерах
Читать статью
Как устроен язык SQL и почему он так востребован
Читать статью
Система управления базами данных.
 Microsoft Office Access
Microsoft Office AccessВопросы:
· Что такое СУБД?
· Элементы баз данных, такие как таблица, форма, запрос и многое другое.
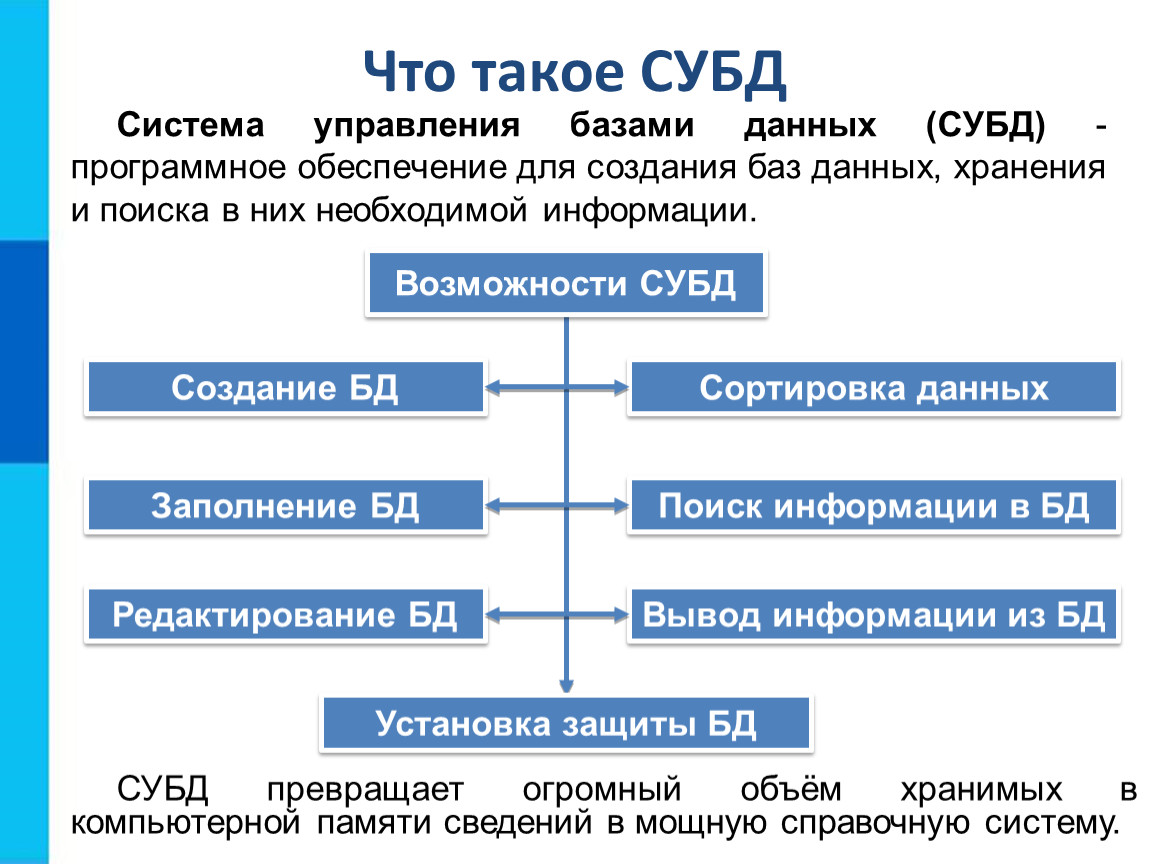
СУБД – система управления базами данных – это программное обеспечение, которое предназначено для создания, хранения и обработки баз данных. Системы управления базами данных позволяют создавать структуру базы данных, заполнять ее информацией, редактировать структуру и содержание, выполнять сортировку данных, осуществлять поиск информации в базе данных, выводить нужную информацию на экран монитора, в файл и на бумажный носитель, устанавливать защиту баз данных. СУБД помогает работать с большими объёмами информации, собирая все данные в большую справочную систему, при помощи которой можно быстро искать и выбирать нужную информацию.
В настоящее время существует большое
количество различных СУБД. По способу доступа к базам данных их можно разделить
на две группы: настольные и серверные.
Настольные СУБД ориентированы на обслуживание одного пользователя, работающего на определённом компьютере с базами данных в любой момент времени. К настольным СУБД относятся:
· Microsoft Access;
· Paradox;
· OpenOffice.org Base;
· FoxPro.
Недостатки настольных СУБД стали очевидными, когда возникла необходимость одновременной работы с ними большого числа пользователей. Поэтому следующим этапом развития СУБД стало создание серверных СУБД.
Серверные СУБД используют принцип централизованного хранения и обработки данных, который основан на архитектуре клиент-сервер.
СУБД, хранящая данные, и прикладная программа, интерпретирующая эти данные, являются разными приложениями, то есть существуют приложение-сервер и приложение-клиент. К серверным СУБД относятся:
· Microsoft SQL;
· Informix;
· Sybase.
Итак, более простыми и распространёнными настольными базами данных являются Microsoft Access и OpenOffice.org Base. На данном уроке мы с вами познакомимся с программой создания баз данных OpenOffice.org Base.
Для начала запустим эту программу и познакомимся с её интерфейсом.
Открываем приложение OpenOffice Base. В появившемся окне выбираем пункт “Создать новую базу данных”. Нажимаем кнопку готово и в появившемся окне указываем имя базы данных и путь для сохранения. В нашем случае назовём базу данных «Сведения о четвертных оценках учащихся» и укажем путь к своей рабочей папке.
Появится окно программы. Вверху находится строка заголовка, где указано название нашей базы данных и программы, в которой оно открыто. Чуть ниже находится строка меню, панель инструментов, рабочая область и строка состояния.
Основными объектами базы данных являются таблицы, формы, запросы и отчёты.
Таблицы — главный объект
базы данных. Он предназначен для хранения данных. На основе таблицы создаются
остальные объекты базы данных. Реляционная база данных может состоять из множества
взаимосвязанных таблиц.
Он предназначен для хранения данных. На основе таблицы создаются
остальные объекты базы данных. Реляционная база данных может состоять из множества
взаимосвязанных таблиц.
Следующий объект – формы. Формы являются вспомогательными объектами. Их создают для того, чтобы работа пользователя при вводе, просмотре и редактировании данных в таблице была более удобной.
Запросы – это команды и их параметры, с которыми пользователь обращается к СУБД для поиска данных, сортировки, добавления, удаления и обновления записей.
Отчёты – это документы, которые формируются на основе таблиц и запросов. Они предназначены для вывода на печать.
Давайте создадим базу данных «Сведения о
четвертных оценках учащихся», которая будет содержать сведения об учащихся:
номер, фамилию, имя, отчество, пол, дату рождения и класс; и оценки за первую
четверть по учебным предметам: математика, русский язык, биология, химия,
физика и английский язык.
Данная база данных будет состоять из двух таблиц. Первая таблица будет содержать поля: номер, фамилия, имя, отчество, пол, дата рождения и класс. Вторая: номер, оценки по математике, русскому языку, биологии, химии, физике и английскому языку за первую четверть.
Итак, создадим первую таблицу и назовём ее «Сведения об учащихся». Для этого в рабочей области слева выберем объект Таблицы и справа Создать таблицу в режиме дизайна. В появившемся окне в столбце имя поля укажем название первого поля: номер и укажем его тип: числовой. Далее имена второго, третьего, четвёртого и пятого полей будут фамилия, имя, отчество, пол, а их тип будет текстовым. Поле дата рождения будет типа дата, а класс – числовой.
Прежде чем сохранить таблицу, необходимо
указать поле – ключ. Вспомним, что ключ – это поле или совокупность
полей, значения которых в записях не повторяются, то есть являются уникальными.
В нашем случае это будет поле с именем «Номер».
Теперь сохраним нашу таблицу при помощи команды Файл далее сохранить как. Указываем имя таблицы «Сведения об учащихся» и нажимаем окей. Закрываем нашу таблицу.
Обратите внимание, что в рабочей области Таблицы появилась наша сохранённая таблица. Для редактирования/изменения данной таблицы необходимо выделить её левой кнопкой мыши и на панели инструментов нажать кнопку «редактировать». Снова откроется наша таблица в режиме дизайна. Здесь мы можем добавлять и удалять поля, изменять их тип и многое другое.
Аналогичным образом создаём и сохраняем ещё одну таблицу с именем «Оценки первая четверть».
Полем-ключом в этой таблице будет поле с
именем «Номер». Поля с именами номер и Оценки по математике, русскому языку,
биологии, химии, физике и английскому языку в данной таблице будут относится к
числовому типу.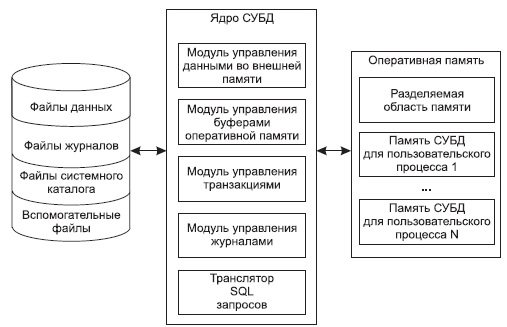
Для заполнения таблицы можно использовать несколько способов: первый непосредственно вводить данные в таблицу – и второй создать форму для ввода информации.
Давайте таблицу «Сведения об учащихся» заполним методом ввода данных в неё. Для этого откроем её двойным щелчком мыши по ней. И введём необходимые данные. Первая запись будет содержать следующее: Номер: 1; Фамилия: Иванов, Имя: Андрей; Отчество: Игоревич; Пол будем обозначать буквами м или ж. В данном случае м. Дата рождения 3.06.2000. Класс 11.
Для перехода к следующей ячейке можно использовать клавишу Tab или стрелку на клавиатуре «Вправо». Аналогично заполним все ячейки данной таблицы.
Есть ячейки, в которых данные отображаются
не полностью, то есть не вмещаются в размер поля. Для того, чтобы расширить
размер поля необходимо подвести курсор к правой границе названия поля, курсор
изменится на стрелку. Теперь нажимаем левую кнопку мыши и растягиваем поле до
нужного размера.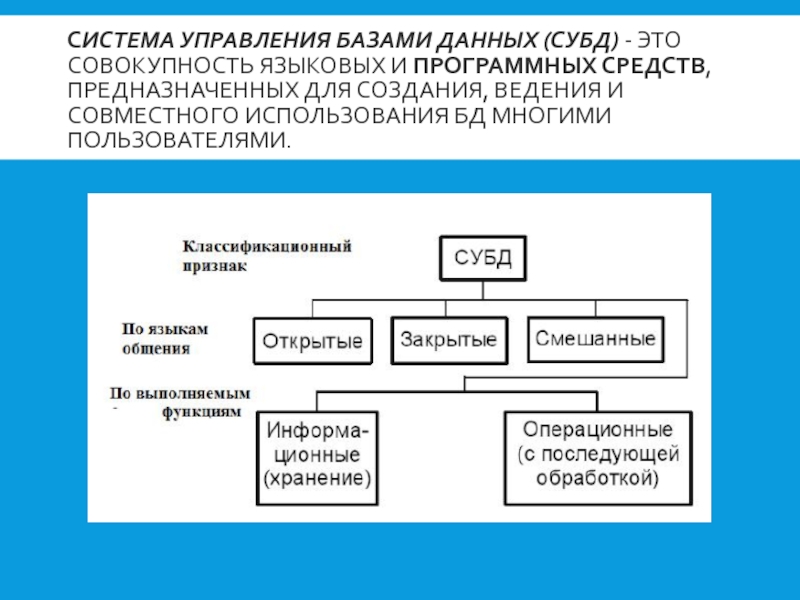 После заполнения нажимаем кнопку cохранить и
закрываем нашу таблицу.
После заполнения нажимаем кнопку cохранить и
закрываем нашу таблицу.
Вторую таблицу «Оценки первая четверть» заполним с помощью форм. Для этого в объектах таблицы выберем формы, затем будем использовать мастер для создания форм. В появившемся окне выбираем необходимую таблицу, затем выбираем нужные для заполнения поля путём перемещения из левого окна в правое. Одинарная стрелка для перемещения по одному полю, двойная – для перемещения всех полей сразу. Так как нам нужно заполнить всю таблицу – выберем все.
Нажимаем дважды кнопку дальше. На пятом
шаге выбираем оформление нашей формы. Обратите внимание, что при выборе формы
можно просмотреть, что в итоге получится. Выберем первую. Можно выбрать
расположение текста по отношению к ячейкам для заполнения: слева или справа.
Переходим к седьмому шагу путем нажатия на кнопку дальше дважды. На данном шаге
выбираем цвет оформления формы. Например, светло-синий. И на последнем, восьмом
шаге зададим имя форме «Первая четверть». Нажимаем кнопку готово.
И на последнем, восьмом
шаге зададим имя форме «Первая четверть». Нажимаем кнопку готово.
Откроется форма для заполнения. Вводим необходимые данные о первом учащемся. Номер — 1. Для перехода к следующей ячейке можно использовать левую кнопку мыши, щелкнув в нужном месте или клавишу Tab. Далее математика – 5, русский язык – 4, биология – 4, химия – 5, физика – 4 и английский язык – 5.
Чтобы перейти к заполнению данных о втором учащемся необходимо нажать на кнопку следующий или клавишу Tab. Заполняем сведения о данном учащемся и остальных аналогичным образом.
После заполнения данной формы просто ее закрываем. Для просмотра данных таблицы можно перейти к объектам таблицы и открыть «Оценки первая четверть».
Данная база данных может быть в дальнейшем
изменена путём редактирования (исправление, удаление) старых или внесения новых
данных, изменения содержимых отдельных полей и структуры всей таблицы.
К таблице можно применять такое действие как сортировка. Сортировка – это упорядочение данных по возрастанию или убыванию. Давайте отсортируем данные в таблице сведения об учащихся. Будем сортировать поле фамилия в алфавитном порядке, то есть по возрастанию. Для этого откроем таблицу, поставим курсор в поле – фамилия и нажмем на кнопку сортировка на панели инструментов. Обратите внимание, что все фамилии упорядочились по алфавиту.
На данном уроке нам также необходимо познакомиться с таким объектом как запросы.
Запрос (справка) – это таблица, которая содержит интересующие пользователя сведения, извлечённые из базы данных. Таблица содержит записи и поля, которые содержатся в запросах на выборку данных, удовлетворяющих заданным условиям (условиям выбора).
Условия выбора записываются в форме
логических выражений, сформированных из высказываний на естественном языке. Для
задания условий выбора используются простые и сложные логические
выражения.
В данной таблице приведены простые логические выражения и их значения.
|
= |
равно |
> |
больше |
|
<> |
не равно |
<= |
меньше или равно |
|
< |
меньше |
<= |
больше или равно |
К сложным относятся следующие логические операции: и, или, не. И говорит о том, что должны выполняться оба условия, или – хотя бы одно из двух, не означает отрицание условия.
|
и |
Оба условия |
|
или |
Хотя бы одно из двух |
|
не |
Отрицание |
Давайте
разберёмся на примере. Необходимо создать запрос, который выведет на экран
номер, фамилию и имя учащихся, оценки которых выше 3 по математике и выше 4 по
биологии.
Необходимо создать запрос, который выведет на экран
номер, фамилию и имя учащихся, оценки которых выше 3 по математике и выше 4 по
биологии.
Для этого откроем нашу базу данных «Сведения о четвертных оценках учащихся».
Прежде чем создавать запросы, давайте свяжем наши таблицы между собой. В реляционной базе данных связи создаются для сохранения синхронизации. Они позволяют избежать избыточности данных, то есть, например, при создании нашего запроса, если мы не свяжем таблицы между собой, то оценки выше трёх по математике и выше четырёх по биологии будут повторяться для каждого учащегося. Связи с обеспечением целостности данных позволяют следить за тем, чтобы данные в одной таблице соответствовали данным в другой.
Для этого в строке меню выбираем
сервис в появившемся окне связи. У нас отображаются две наших таблицы.
Будем связывать два поля с именами номер в первой и второй таблицах. Связать
таблицы очень просто. Подведём курсор к названию поля «Номер» в таблице «Оценки
первая четверть», нажимаем и удерживаем левую кнопку мыши и переносим ее к полю
«Номер» в таблице «Сведения об учащихся» и отпускаем левую кнопку мыши. В
результате связь отобразится в виде линии между полями.
Подведём курсор к названию поля «Номер» в таблице «Оценки
первая четверть», нажимаем и удерживаем левую кнопку мыши и переносим ее к полю
«Номер» в таблице «Сведения об учащихся» и отпускаем левую кнопку мыши. В
результате связь отобразится в виде линии между полями.
Нажимаем кнопку сохранить и закрываем окно «Связи».
Теперь мы можем создать запрос. Для этого
выбираем объект запросы и создание запроса в режиме дизайна. В появившемся окне
выбираем таблицу «Сведения об учащихся» и нажимаем кнопку добавить, затем
аналогичным образом добавляем таблицу «Оценки первая четверть». Закрываем окно.
Теперь в поле таблица выбираем название таблицы из которой будут взяты данные,
а в строке поле выбираем название поля. Например, нам нужен номер. В поле
таблица выбираем имя таблицы «Оценки первая четверть», а в имени поля выбираем
номер. Далее выбираем имя таблицы «Сведения об учащихся» и имя поля – фамилия.
Все остальные поля выбираем аналогичным образом.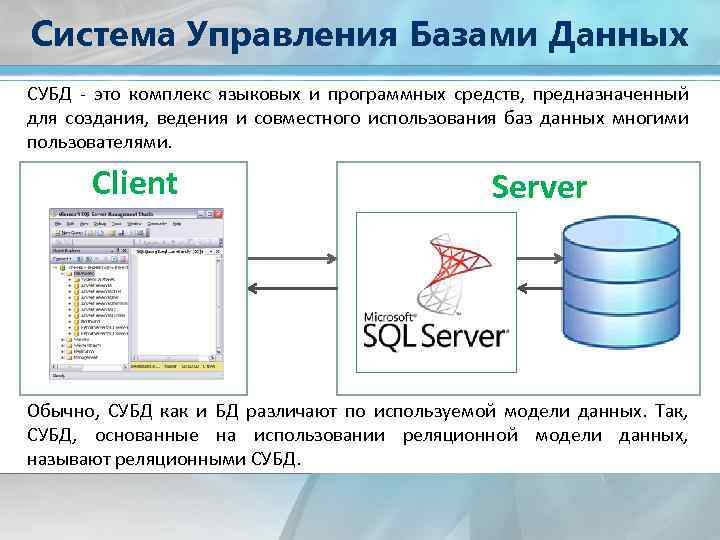
Теперь нам необходимо осуществить выборку данных по полям математика и биология. Для этого в строке критерий поля математика ставим знак больше и цифру 3, а в поле биология больше 4.
Сохраняем данный запрос под именем «Оценки по математике и биологии». Закрываем запрос.
Для просмотра результатов открываем наш запрос двойным нажатием левой кнопки мыши на нём. Перед нами сформировалась таблица, в которой указаны учащиеся с оценками выше трёх по математике и выше четырёх по биологии.
При помощи запросов пользователь может быстро найти в базе данных и вывести на экран компьютера необходимую информацию. Но в некоторых случаях найденную информацию необходимо представить в определённой форме и подготовить к выводу на печать. Данный этап работы называется подготовкой отчётов.
Важно запомнить:
·
СУБД
–
это программное обеспечение, которое предназначено для создания, хранения и
обработки баз данных.
· По способу доступа к базам данных СУБД можно разделить на две группы: настольные и серверные.
· Таблицы – главный объект базы данных. Он предназначен для хранения данных.
· Формы являются вспомогательными объектами. Их создают для того, чтобы работа пользователя при вводе, просмотре и редактировании данных в таблице была более удобной.
· Запросы – это команды и их параметры, с которыми пользователь обращается к СУБД для поиска данных, сортировки, добавления, удаления и обновления записей.
· Отчёты – это документы, которые формируются на основе таблиц и запросов. Они предназначены для вывода на печать.
· Рассмотрели интерфейс программы OpenOffice Base и научились создавать такие объекты как таблицы, формы и запросы.
Что такое управление данными и почему это важно?
Управление данными — это процесс приема, хранения, организации и обслуживания данных, созданных и собранных организацией.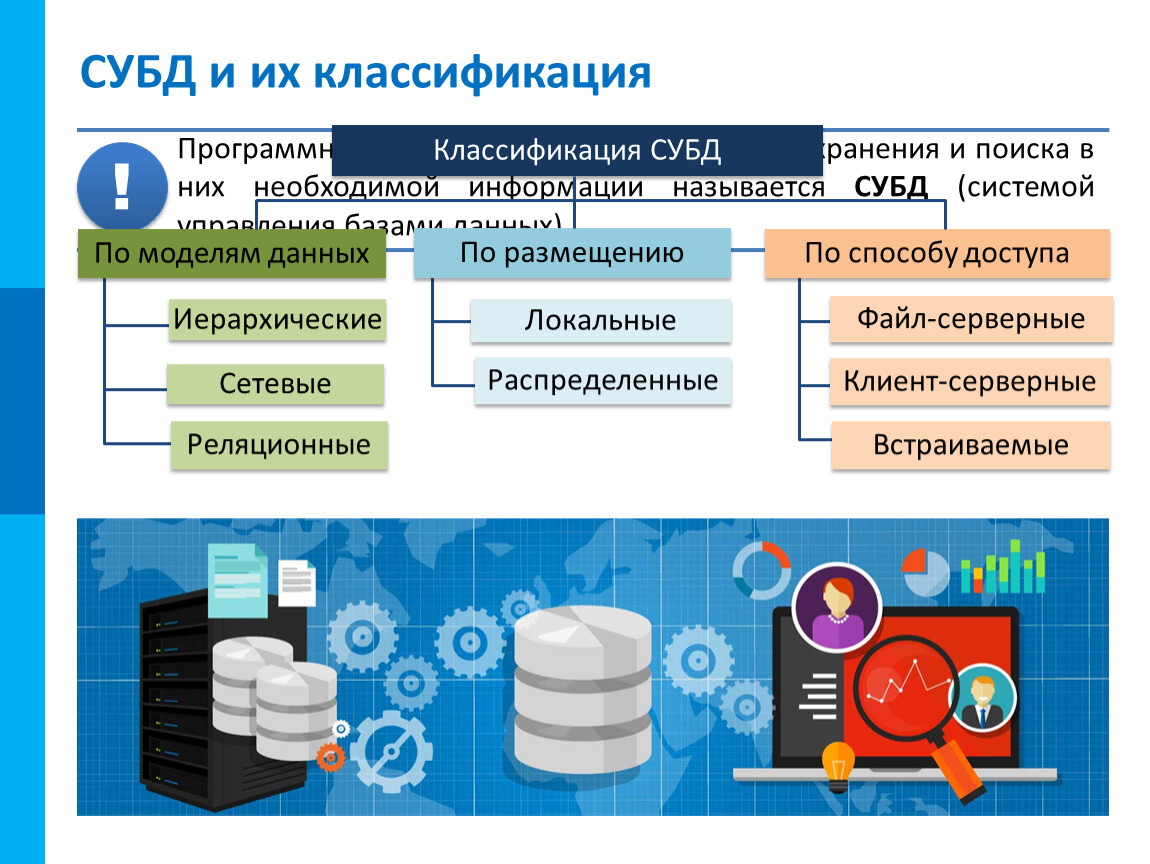 Эффективное управление данными является важнейшей частью развертывания ИТ-систем, которые запускают бизнес-приложения и предоставляют аналитическую информацию, помогающую руководителям корпораций, бизнес-менеджерам и другим конечным пользователям принимать оперативные решения и осуществлять стратегическое планирование.
Эффективное управление данными является важнейшей частью развертывания ИТ-систем, которые запускают бизнес-приложения и предоставляют аналитическую информацию, помогающую руководителям корпораций, бизнес-менеджерам и другим конечным пользователям принимать оперативные решения и осуществлять стратегическое планирование.
Процесс управления данными включает в себя сочетание различных функций, которые в совокупности направлены на то, чтобы данные в корпоративных системах были точными, доступными и доступными. Большая часть необходимой работы выполняется ИТ-специалистами и группами управления данными, но бизнес-пользователи обычно также участвуют в некоторых частях процесса, чтобы убедиться, что данные соответствуют их потребностям, и вовлечь их в политики, регулирующие их использование.
В этом подробном руководстве по управлению данными подробно объясняется, что это такое, и дается представление об отдельных дисциплинах, которые оно включает, передовых методах управления данными, проблемах, с которыми сталкиваются организации, и бизнес-преимуществах успешной стратегии управления данными. Вы также найдете обзор инструментов и методов управления данными. Перейдите по гиперссылкам на странице, чтобы прочитать больше статей о тенденциях в области управления данными и получить советы экспертов по управлению корпоративными данными.
Вы также найдете обзор инструментов и методов управления данными. Перейдите по гиперссылкам на странице, чтобы прочитать больше статей о тенденциях в области управления данными и получить советы экспертов по управлению корпоративными данными.
Данные все чаще рассматриваются как корпоративный актив, который можно использовать для принятия более обоснованных бизнес-решений, улучшения маркетинговых кампаний, оптимизации бизнес-операций и сокращения затрат, и все это с целью увеличения доходов и прибыли. Но отсутствие надлежащего управления данными может обременить организации несовместимыми хранилищами данных, непоследовательными наборами данных и проблемами качества данных, которые ограничивают их возможности запуска бизнес-аналитики (BI) и аналитических приложений или, что еще хуже, приводят к ошибочным выводам.
Важность управления данными также возросла, поскольку предприятия подчиняются все большему числу нормативных требований, включая законы о конфиденциальности и защите данных, такие как GDPR и Закон штата Калифорния о конфиденциальности потребителей (CCPA). Кроме того, компании собирают все большие объемы данных и все большее разнообразие типов данных — и то, и другое является отличительной чертой систем больших данных, которые развернуты многими. Без хорошего управления данными такие среды могут стать громоздкими и сложными для навигации.
Кроме того, компании собирают все большие объемы данных и все большее разнообразие типов данных — и то, и другое является отличительной чертой систем больших данных, которые развернуты многими. Без хорошего управления данными такие среды могут стать громоздкими и сложными для навигации.
Отдельные дисциплины, которые являются частью общего процесса управления данными, охватывают ряд шагов, от обработки и хранения данных до управления тем, как данные форматируются и используются в операционных и аналитических системах. Разработка архитектуры данных часто является первым шагом, особенно в крупных организациях с большим количеством данных для управления. Архитектура данных обеспечивает схему управления данными и развертывания баз данных и других платформ данных, включая специальные технологии для отдельных приложений.
Базы данных являются наиболее распространенной платформой, используемой для хранения корпоративных данных. Они содержат набор данных, организованных таким образом, чтобы к ним можно было обращаться, обновлять и управлять ими. Они используются как в системах обработки транзакций, которые создают оперативные данные, такие как записи клиентов и заказы на продажу, так и в хранилищах данных, в которых хранятся консолидированные наборы данных из бизнес-систем для бизнес-аналитики и аналитики.
Они содержат набор данных, организованных таким образом, чтобы к ним можно было обращаться, обновлять и управлять ими. Они используются как в системах обработки транзакций, которые создают оперативные данные, такие как записи клиентов и заказы на продажу, так и в хранилищах данных, в которых хранятся консолидированные наборы данных из бизнес-систем для бизнес-аналитики и аналитики.
Это делает администрирование базы данных основной функцией управления данными. После настройки баз данных необходимо выполнить мониторинг производительности и настройку, чтобы поддерживать приемлемое время отклика на запросы к базе данных, которые пользователи запускают для получения информации из хранящихся в них данных. Другие административные задачи включают разработку, настройку, установку и обновление базы данных; безопасность данных; резервное копирование и восстановление базы данных; и применение обновлений программного обеспечения и исправлений безопасности.
Управление данными включает множество взаимосвязанных функций.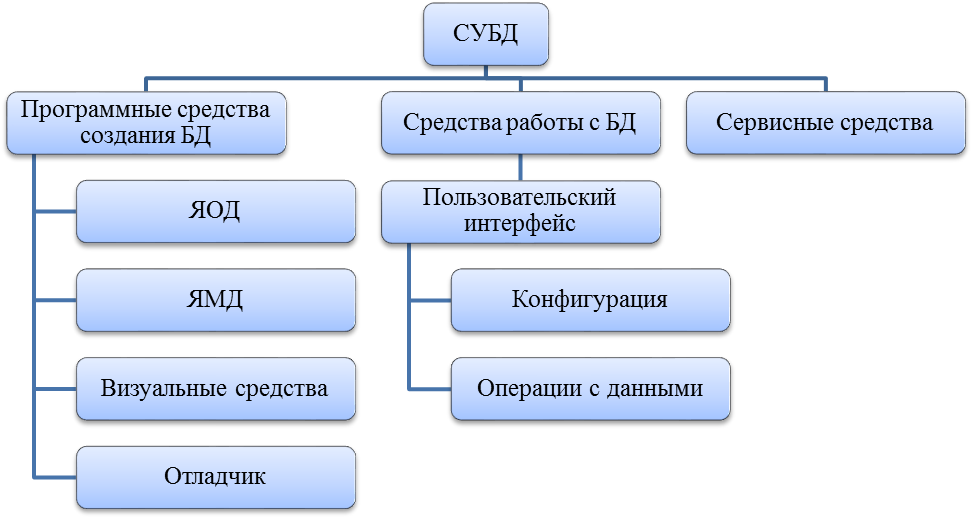
Основной технологией, используемой для развертывания и администрирования баз данных, является система управления базами данных (СУБД), представляющая собой программное обеспечение, выступающее в качестве интерфейса между управляемыми ею базами данных и администраторами баз данных (DBA), конечными пользователями и приложениями, которые к ним обращаются. Платформы данных, альтернативные базам данных, включают файловые системы и облачные службы хранения объектов, которые хранят данные менее структурированным образом, чем обычные базы данных, предлагая большую гибкость в отношении типов данных, которые можно хранить, и способов форматирования данных. Однако в результате они не подходят для транзакционных приложений.
Другие фундаментальные дисциплины управления данными включают следующее:
- моделирование данных, которое отображает отношения между элементами данных и то, как данные проходят через системы; интеграция данных
- , которая объединяет данные из разных источников данных для оперативного и аналитического использования;
- управление данными, которое устанавливает политики и процедуры для обеспечения согласованности данных во всей организации;
- управление качеством данных, целью которого является исправление ошибок и несоответствий в данных; и
- Управление основными данными (MDM), которое создает общий набор справочных данных о таких вещах, как клиенты и продукты.

Широкий спектр технологий, инструментов и методов может использоваться как часть процесса управления данными. Следующие параметры доступны для различных аспектов управления данными.
Системы управления базами данных. Наиболее распространенным типом СУБД являются системы управления реляционными базами данных. Реляционные базы данных организуют данные в таблицы со строками и столбцами, которые содержат записи базы данных. Связанные записи в разных таблицах могут быть связаны с помощью первичных и внешних ключей, что позволяет избежать необходимости создания повторяющихся записей данных. Реляционные базы данных строятся на основе языка программирования SQL и жесткой модели данных, которая лучше всего подходит для структурированных данных транзакций. Это, а также их поддержка свойств транзакций ACID — атомарности, непротиворечивости, изоляции и надежности — сделали их лучшим выбором базы данных для приложений обработки транзакций.
Однако другие типы технологий СУБД появились как жизнеспособные варианты для различных типов рабочих нагрузок данных. Большинство из них относится к категории баз данных NoSQL, которые не предъявляют жестких требований к моделям данных и схемам баз данных. В результате они могут хранить неструктурированные и полуструктурированные данные, такие как данные датчиков, записи посещений в Интернете, а также журналы сети, сервера и приложений.
Существует четыре основных типа систем NoSQL:
- базы данных документов, которые хранят элементы данных в структурах, подобных документам; Базы данных
- типа «ключ-значение», которые объединяют уникальные ключи и связанные значения;
- хранилища с широкими столбцами и таблицами с большим количеством столбцов; и Базы данных графов
- , которые соединяют связанные элементы данных в графическом формате.
Название NoSQL стало несколько неправильным — хотя базы данных NoSQL не полагаются на SQL, многие из них теперь поддерживают его элементы и предлагают определенный уровень совместимости с ACID.
Дополнительные параметры базы данных и СУБД включают базы данных в оперативной памяти, в которых данные хранятся в памяти сервера, а не на диске, для повышения производительности ввода-вывода, а также столбцовые базы данных, предназначенные для аналитических приложений. Иерархические базы данных, работающие на мэйнфреймах и предшествующие разработке реляционных систем и систем NoSQL, также по-прежнему доступны для использования. Пользователи могут развертывать базы данных в локальных или облачных системах. Кроме того, различные поставщики баз данных предлагают услуги управляемых облачных баз данных, в которых они занимаются развертыванием, настройкой и администрированием баз данных для пользователей.
Управление большими данными. Базы данных NoSQL часто используются в развертываниях больших данных из-за их способности хранить и управлять различными типами данных. Среды больших данных также обычно строятся на основе технологий с открытым исходным кодом, таких как Hadoop, распределенная среда обработки с файловой системой, которая работает в кластерах стандартных серверов; связанная с ним база данных HBase; процессор обработки Spark; и платформы обработки потоков Kafka, Flink и Storm. Все чаще системы больших данных развертываются в облаке с использованием объектного хранилища, такого как Amazon Simple Storage Service (S3).
Все чаще системы больших данных развертываются в облаке с использованием объектного хранилища, такого как Amazon Simple Storage Service (S3).
Хранилища данных и озера данных. Двумя наиболее широко используемыми репозиториями для управления данными аналитики являются хранилища данных и озера данных. Хранилище данных — более традиционный метод — обычно основано на реляционной или столбчатой базе данных и хранит структурированные данные, собранные из разных операционных систем и подготовленные для анализа. Основными вариантами использования хранилища данных являются BI-запросы и корпоративная отчетность, которые позволяют бизнес-аналитикам и руководителям анализировать продажи, управление запасами и другие ключевые показатели эффективности.
Хранилище данных предприятия включает данные из бизнес-систем организации. В крупных компаниях отдельные дочерние компании и бизнес-подразделения с автономией управления могут создавать свои собственные хранилища данных. Витрины данных — это еще один вариант хранилища — это уменьшенные версии хранилищ данных, которые содержат подмножества данных организации для определенных отделов или групп пользователей. В одном подходе к развертыванию существующее хранилище данных используется для создания различных киосков данных; в другом сначала создаются витрины данных, а затем они используются для заполнения хранилища данных.
Витрины данных — это еще один вариант хранилища — это уменьшенные версии хранилищ данных, которые содержат подмножества данных организации для определенных отделов или групп пользователей. В одном подходе к развертыванию существующее хранилище данных используется для создания различных киосков данных; в другом сначала создаются витрины данных, а затем они используются для заполнения хранилища данных.
, с другой стороны, хранят пулы больших данных для использования в прогнозном моделировании, машинном обучении и других приложениях расширенной аналитики. Первоначально они чаще всего строились на кластерах Hadoop, но S3 и другие службы хранения облачных объектов все чаще используются для развертывания озера данных. Иногда они также развертываются в базах данных NoSQL, и различные платформы могут быть объединены в среде распределенного озера данных. Данные могут быть обработаны для анализа при их приеме, но озеро данных часто содержит необработанные данные, хранящиеся как есть.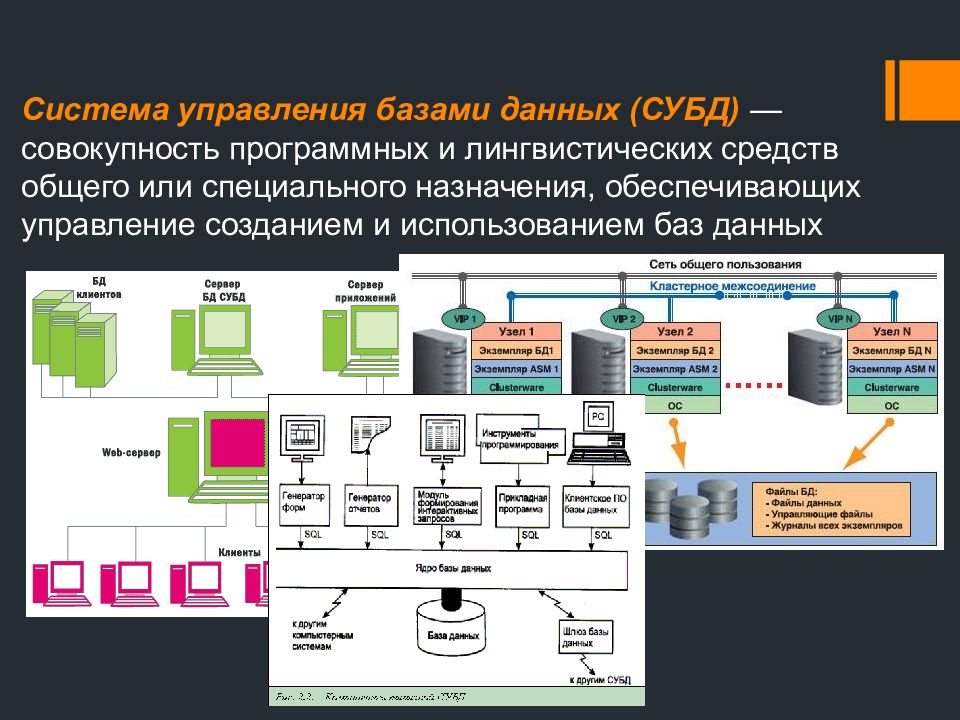 В этом случае специалисты по данным и другие аналитики обычно выполняют свою собственную работу по подготовке данных для конкретных аналитических целей.
В этом случае специалисты по данным и другие аналитики обычно выполняют свою собственную работу по подготовке данных для конкретных аналитических целей.
Также появился третий вариант платформы для хранения и обработки аналитических данных: хранилище данных. Как следует из названия, оно сочетает в себе элементы озер и хранилищ данных, объединяя гибкое хранилище данных, масштабируемость и более низкую стоимость озера данных с возможностями запросов и более строгой структурой управления данными хранилища данных.
Интеграция данных. Наиболее широко используемым методом интеграции данных является извлечение, преобразование и загрузка (ETL), при котором данные извлекаются из исходных систем, преобразуются в согласованный формат, а затем загружаются интегрированные данные в хранилище данных или другую целевую систему. Однако платформы интеграции данных теперь также поддерживают множество других методов интеграции. Это включает в себя извлечение, загрузку и преобразование (ELT), вариант ETL, который оставляет данные в их исходной форме при загрузке на целевую платформу. ELT — это распространенный выбор для интеграции данных в озерах данных и других системах больших данных.
ELT — это распространенный выбор для интеграции данных в озерах данных и других системах больших данных.
ETL и ELT — это процессы пакетной интеграции, которые запускаются с запланированными интервалами. Группы управления данными также могут выполнять интеграцию данных в режиме реального времени, используя такие методы, как сбор данных об изменениях, который применяет изменения к данным в базах данных в хранилище данных или другом репозитории, и интеграцию потоковых данных, которая объединяет потоки данных в реальном времени на непрерывная основа. Виртуализация данных — еще один вариант интеграции, использующий уровень абстракции для создания виртуального представления данных из разных систем для конечных пользователей вместо физической загрузки данных в хранилище данных.
Здесь показаны различные подходы, которые можно использовать для интеграции данных. Моделирование данных. Разработчики моделей данных создают серию концептуальных, логических и физических моделей данных, которые документируют наборы данных и рабочие процессы в визуальной форме и сопоставляют их с бизнес-требованиями для обработки транзакций и аналитики. Общие методы моделирования данных включают разработку диаграмм отношений сущностей, сопоставлений данных и схем в различных типах моделей. Модели данных часто необходимо обновлять при добавлении новых источников данных или изменении информационных потребностей организации.
Общие методы моделирования данных включают разработку диаграмм отношений сущностей, сопоставлений данных и схем в различных типах моделей. Модели данных часто необходимо обновлять при добавлении новых источников данных или изменении информационных потребностей организации.
Управление данными, качество данных и MDM. Управление данными — это прежде всего организационный процесс; программные продукты, которые могут помочь управлять программами управления данными, доступны, но они являются необязательным элементом. Хотя программами управления могут управлять специалисты по управлению данными, они обычно включают совет по управлению данными, состоящий из руководителей предприятий, которые коллективно принимают решения в отношении общих определений данных и корпоративных стандартов для создания, форматирования и использования данных.
Еще одним ключевым аспектом инициатив по управлению является управление данными, которое включает в себя надзор за наборами данных и обеспечение соблюдения конечными пользователями утвержденных политик данных. Распорядитель данных может работать как полный, так и неполный рабочий день, в зависимости от размера организации и объема ее программы управления. Распорядители данных также могут приходить как из бизнес-операций, так и из ИТ-отдела; в любом случае, хорошее знание данных, за которыми они наблюдают, обычно является необходимым условием.
Распорядитель данных может работать как полный, так и неполный рабочий день, в зависимости от размера организации и объема ее программы управления. Распорядители данных также могут приходить как из бизнес-операций, так и из ИТ-отдела; в любом случае, хорошее знание данных, за которыми они наблюдают, обычно является необходимым условием.
Управление данными тесно связано с усилиями по улучшению качества данных. Обеспечение высокого уровня качества данных является ключевой частью эффективного управления данными, а показатели, документирующие улучшения качества данных организации, играют центральную роль в демонстрации ценности программ управления для бизнеса. Ключевые методы обеспечения качества данных, поддерживаемые различными программными инструментами, включают следующее:
- профилирование данных, которое сканирует наборы данных для выявления значений выбросов, которые могут быть ошибками; очистка данных
- , также известная как очистка данных, которая исправляет ошибки данных путем изменения или удаления неверных данных; и Проверка данных
- , которая проверяет данные на соответствие заданным правилам качества.

Управление основными данными также связано с управлением данными и управлением качеством данных, хотя MDM не получило такого широкого распространения, как они. Отчасти это связано со сложностью программ MDM, которые в основном ограничивают их использование крупными организациями. MDM создает центральный реестр основных данных для выбранных доменов данных, который часто называют золотая пластинка . Основные данные хранятся в концентраторе MDM, который передает данные в аналитические системы для согласованной корпоративной отчетности и анализа. При желании концентратор также может передавать обновленные основные данные обратно в исходные системы.
Наблюдаемость данных — это новый процесс, который может улучшить качество данных и инициативы по управлению данными, предоставляя более полную картину состояния данных в организации. Адаптированный из методов наблюдения в ИТ-системах, наблюдаемость данных отслеживает конвейеры данных и наборы данных, выявляя проблемы, которые необходимо решить. Инструменты наблюдения за данными можно использовать для автоматизации процедур мониторинга, оповещения и анализа первопричин, а также для планирования и определения приоритетов работы по устранению проблем.
Инструменты наблюдения за данными можно использовать для автоматизации процедур мониторинга, оповещения и анализа первопричин, а также для планирования и определения приоритетов работы по устранению проблем.
Вот некоторые рекомендации, которые помогут поддерживать процесс управления данными в организации на правильном пути.
Сделать управление данными и качество данных главными приоритетами. Надежная программа управления данными является важнейшим компонентом эффективных стратегий управления данными, особенно в организациях с распределенными средами данных, включающими разнообразный набор систем.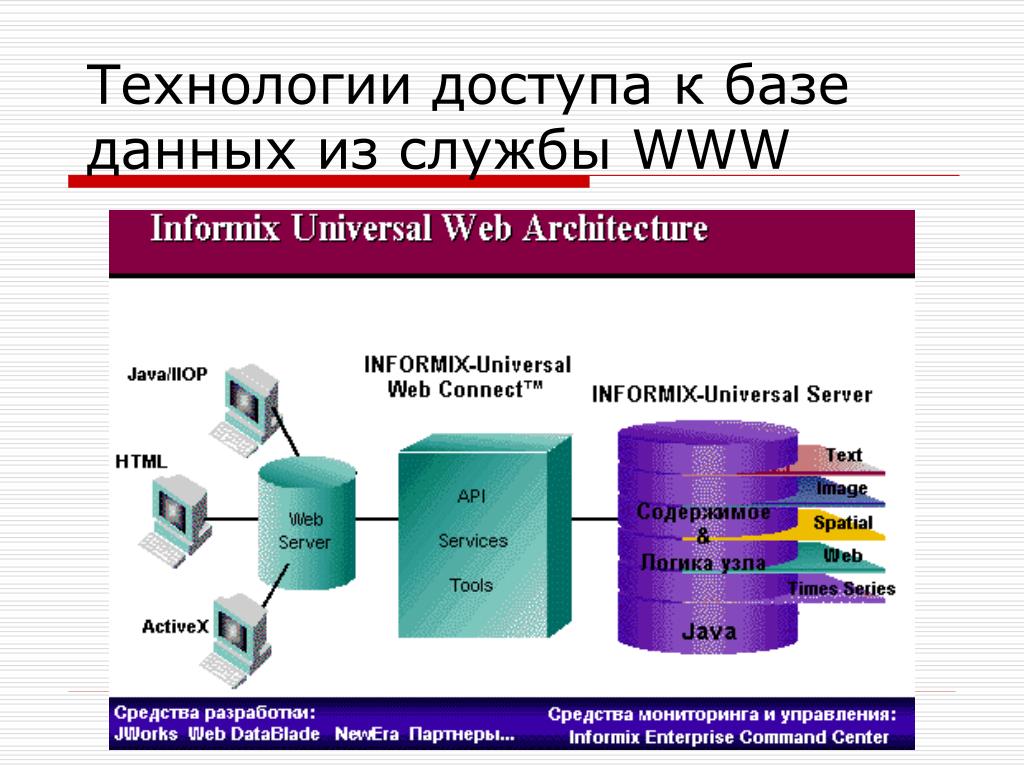 Также необходимо уделять большое внимание качеству данных. Однако в обоих случаях ИТ-специалисты и группы управления данными не могут действовать в одиночку. Руководители предприятий и пользователи должны быть вовлечены, чтобы убедиться, что их потребности в данных удовлетворены, а проблемы с качеством данных не увековечены. То же самое относится и к проектам моделирования данных.
Также необходимо уделять большое внимание качеству данных. Однако в обоих случаях ИТ-специалисты и группы управления данными не могут действовать в одиночку. Руководители предприятий и пользователи должны быть вовлечены, чтобы убедиться, что их потребности в данных удовлетворены, а проблемы с качеством данных не увековечены. То же самое относится и к проектам моделирования данных.
Продумывайте развертывание платформ управления данными. Множество доступных для использования баз данных и других платформ данных требует тщательного подхода при проектировании архитектуры, оценке и выборе технологий. ИТ-менеджеры и менеджеры по данным должны быть уверены, что внедряемые ими системы управления данными подходят для намеченной цели и обеспечивают возможности обработки данных и аналитическую информацию, необходимые для бизнес-операций организации.
Убедитесь, что вы можете удовлетворить потребности бизнеса и пользователей сейчас и в будущем. Среды данных не статичны — добавляются новые источники данных, изменяются существующие наборы данных и развиваются потребности бизнеса в данных. Чтобы не отставать, управление данными должно быть способно адаптироваться к изменяющимся требованиям. Например, группам данных необходимо тесно сотрудничать с конечными пользователями при создании и обновлении конвейеров данных, чтобы гарантировать, что они включают все необходимые данные на постоянной основе. Может помочь процесс DataOps — это совместный подход к разработке систем данных и конвейеров, основанный на сочетании DevOps, гибкой разработки программного обеспечения и методологий бережливого производства. DataOps объединяет менеджеров данных и пользователей для автоматизации рабочих процессов, улучшения связи и ускорения доставки данных.
Чтобы не отставать, управление данными должно быть способно адаптироваться к изменяющимся требованиям. Например, группам данных необходимо тесно сотрудничать с конечными пользователями при создании и обновлении конвейеров данных, чтобы гарантировать, что они включают все необходимые данные на постоянной основе. Может помочь процесс DataOps — это совместный подход к разработке систем данных и конвейеров, основанный на сочетании DevOps, гибкой разработки программного обеспечения и методологий бережливого производства. DataOps объединяет менеджеров данных и пользователей для автоматизации рабочих процессов, улучшения связи и ускорения доставки данных.
DAMA International, Организация специалистов по управлению данными и другие отраслевые группы также предлагают передовые практические рекомендации и образовательные ресурсы по дисциплинам управления данными. Например, DAMA опубликовало справочник DAMA-DMBOK: Data Management Body of Knowledge , в котором делается попытка определить стандартное представление функций и методов управления данными. Обычно называемый DMBOK, он был впервые опубликован в 2009 г., а второе издание, DMBOK2, было выпущено в 2017 г.
Обычно называемый DMBOK, он был впервые опубликован в 2009 г., а второе издание, DMBOK2, было выпущено в 2017 г.
Постоянно растущие объемы данных усложняют процесс управления данными, особенно когда речь идет о сочетании структурированных, полуструктурированных и неструктурированных данных. Кроме того, если в организации нет хорошо спроектированной архитектуры данных, она может столкнуться с разрозненными системами, которые трудно интегрировать и управлять ими скоординированным образом. Это затрудняет обеспечение точности и согласованности наборов данных на всех платформах данных.
Даже в хорошо спланированных средах предоставление специалистам по данным и другим аналитикам возможности находить нужные данные и получать к ним доступ может быть проблемой, особенно когда данные распределены по различным базам данных и системам больших данных. Чтобы сделать данные более доступными, многие группы управления данными создают каталоги данных, которые документируют то, что доступно в системах, и обычно включают бизнес-глоссарии, словари данных на основе метаданных и записи о происхождении данных.
Ускоренный переход к облаку может упростить некоторые аспекты работы по управлению данными, но также создает новые проблемы. Например, миграция в облачные базы данных может быть сложной для организаций, которым необходимо перенести данные и рабочие нагрузки по обработке из существующих локальных систем. Затраты — еще одна серьезная проблема в облаке: использование облачных систем и управляемых сервисов должно тщательно контролироваться, чтобы счета за обработку данных не превышали суммы, предусмотренные в бюджете.
Многие команды по управлению данными теперь входят в число сотрудников, которые несут ответственность за защиту безопасности корпоративных данных и ограничение потенциальной юридической ответственности за утечку данных или неправомерное использование данных. Менеджеры данных должны помочь обеспечить соблюдение как государственных, так и отраслевых норм в отношении безопасности, конфиденциальности и использования данных.
Это стало более серьезной проблемой в связи с принятием GDPR, закона Европейского союза о конфиденциальности данных, вступившего в силу в мае 2018 г. , и CCPA, который был подписан в 2018 г. и вступил в силу в начале 2020 г. Положения Позже CCPA был расширен Законом о правах на неприкосновенность частной жизни штата Калифорния, который был одобрен избирателями штата в ноябре 2020 года и вступил в силу 1 января 2023 года.
, и CCPA, который был подписан в 2018 г. и вступил в силу в начале 2020 г. Положения Позже CCPA был расширен Законом о правах на неприкосновенность частной жизни штата Калифорния, который был одобрен избирателями штата в ноябре 2020 года и вступил в силу 1 января 2023 года.
Процесс управления данными включает в себя широкий спектр задач, обязанностей и навыков. В небольших организациях с ограниченными ресурсами отдельные работники могут выполнять несколько ролей. Но в более крупных командах по управлению данными обычно есть архитекторы данных, специалисты по моделированию данных, администраторы баз данных, разработчики баз данных, администраторы данных, аналитики и инженеры по качеству данных, а также разработчики ETL. Другая роль, которую чаще всего замечают, — это аналитик хранилища данных, который помогает управлять данными в хранилище данных и создает аналитические модели данных для бизнес-пользователей.
Вот некоторые основные сведения о профессии управления данными.
Специалисты по данным, другие аналитики данных и инженеры данных, которые помогают создавать конвейеры данных и подготавливать данные для анализа, также могут входить в состав группы управления данными. В других случаях они входят в отдельную группу по науке о данных или аналитике. Однако даже в этом случае они обычно сами решают некоторые задачи по управлению данными, особенно в озерах данных с необработанными данными, которые необходимо фильтровать и подготавливать для конкретных аналитических целей.
Точно так же разработчики приложений иногда помогают развертывать платформы больших данных и управлять ими, что в целом требует новых навыков по сравнению с системами реляционных баз данных. В результате организациям может потребоваться нанять новых сотрудников или переобучить традиционных администраторов баз данных, чтобы удовлетворить свои потребности в управлении большими данными.
Менеджеры по управлению данными и распорядители данных также квалифицируются как специалисты по управлению данными. Но обычно они входят в состав отдельной группы по управлению данными.
Но обычно они входят в состав отдельной группы по управлению данными.
Хорошо реализованная стратегия управления данными может принести организациям различные преимущества:
- Это может помочь компаниям получить потенциальные конкурентные преимущества по сравнению с их бизнес-конкурентами, как за счет повышения операционной эффективности, так и за счет более эффективного принятия решений.
- Организации с хорошо управляемыми данными могут стать более гибкими, что позволит им выявлять рыночные тенденции и быстрее использовать новые возможности для бизнеса.
- Эффективное управление данными также может помочь компаниям избежать утечек данных, ошибок при сборе данных и других проблем с безопасностью и конфиденциальностью данных, которые могут нанести ущерб их репутации, привести к непредвиденным расходам и поставить их под юридическую угрозу.
- В конечном счете, надежный подход к управлению данными может повысить эффективность бизнеса, помогая улучшить бизнес-стратегии и процессы.
Первый расцвет управления данными был в значительной степени обусловлен ИТ-специалистами, которые сосредоточились на решении проблемы мусора на первых компьютерах после того, как признали, что машины делают ложные выводы, потому что им подаются неточные или неадекватные данные. Иерархические базы данных на основе мэйнфреймов стали доступны в 1960-х годов, привнося больше формальностей в развивающийся процесс управления данными.
Реляционная база данных появилась в 1970-х годах и закрепила за собой место в центре экосистемы управления данными в 1980-х годах. Идея хранилища данных возникла в конце того же десятилетия, и первые сторонники этой концепции начали развертывание хранилищ данных в середине 1990-х годов. К началу 2000-х реляционное программное обеспечение было доминирующей технологией с виртуальной блокировкой развертывания баз данных.
Но первый выпуск Hadoop стал доступен в 2006 году, за ним последовал механизм обработки Spark и различные другие технологии обработки больших данных. В то же время стал доступен ряд баз данных NoSQL. Хотя реляционные платформы по-прежнему являются наиболее широко используемым хранилищем данных, распространение больших данных и альтернатив NoSQL, а также сред озер данных, которые они позволяют, предоставили организациям более широкий набор вариантов управления данными. Добавление концепции Data Lakehouse в 2017 году еще больше расширило возможности.
В то же время стал доступен ряд баз данных NoSQL. Хотя реляционные платформы по-прежнему являются наиболее широко используемым хранилищем данных, распространение больших данных и альтернатив NoSQL, а также сред озер данных, которые они позволяют, предоставили организациям более широкий набор вариантов управления данными. Добавление концепции Data Lakehouse в 2017 году еще больше расширило возможности.
Но все эти варианты сделали многие среды данных более сложными. Это стимулирует разработку новых технологий и процессов, призванных облегчить управление ими. В дополнение к наблюдаемости данных они включают структуру данных, архитектурную структуру, которая направлена на лучшую унификацию активов данных за счет автоматизации процессов интеграции и обеспечения их повторного использования, а также сетку данных, децентрализованную архитектуру, которая дает ответственность за владение данными и управление ими отдельным доменам бизнеса, с федеративное управление для согласования организационных стандартов и политик.
Однако ни один из этих трех подходов пока не используется широко. В своем отчете Hype Cycle за 2022 год о новых технологиях управления данными консалтинговая фирма Gartner сообщила, что каждая из них была принята менее чем 5% целевой аудитории пользователей. Gartner предсказал, что структура данных и наблюдаемость данных находятся в пределах от пяти до 10 лет до достижения полной зрелости и массового внедрения, но в конечном итоге они могут быть очень полезными для пользователей. Это было менее оптимистично в отношении сетки данных, что дало рейтинг потенциальной выгоды «Низкий».
Ниже приведены некоторые другие заметные тенденции управления данными:
Технологии управления облачными данными становятся все более распространенными. Gartner прогнозирует, что облачные базы данных будут приносить 50% общего дохода от СУБД в 2022 году. В отчете Hype Cycle говорится, что организации также «быстро продвигаются» к развертыванию новых технологий управления данными в облаке. Для компаний, которые не готовы к полной миграции, гибридные облачные архитектуры, сочетающие облачные и локальные системы, например гибридные среды хранения данных, также являются вариантом.
Для компаний, которые не готовы к полной миграции, гибридные облачные архитектуры, сочетающие облачные и локальные системы, например гибридные среды хранения данных, также являются вариантом.
Расширенные возможности управления данными также направлены на оптимизацию процессов. Поставщики программного обеспечения добавляют расширенные функции для качества данных, управления базами данных, интеграции данных и каталогизации данных, которые используют технологии искусственного интеллекта и машинного обучения для автоматизации повторяющихся задач, выявления проблем и предложения действий.
Рост периферийных вычислений создает новые потребности в управлении данными. Поскольку организации все чаще используют удаленные датчики и устройства IoT для сбора и обработки данных в рамках сред периферийных вычислений, некоторые поставщики также разрабатывают возможности управления периферийными данными для конечных устройств.
Последнее обновление: декабрь 2022 г.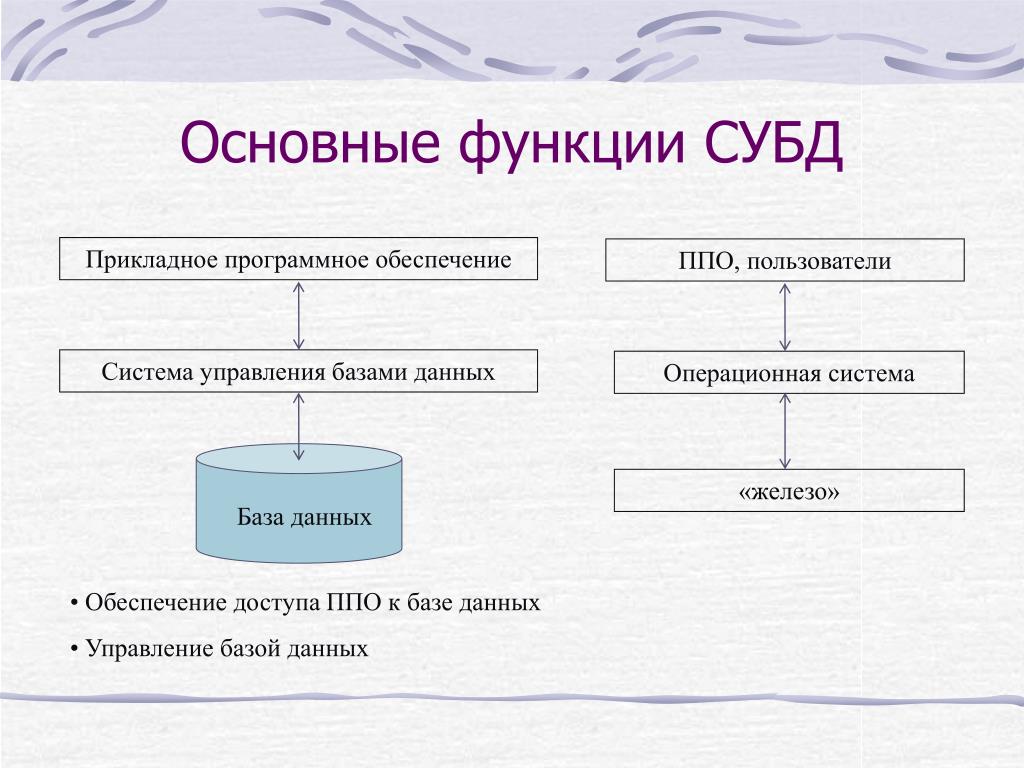
- 8 упреждающих шагов для улучшения качества данных
- Локальные и облачные хранилища данных: плюсы и минусы
- 7 лучших практик для успешных программ управления данными
- Cloud DBA: как облако меняет роль администратора базы данных
- Что такое родословная данных? Методы, лучшие практики и инструменты
Что такое схема?
Управление данными- Эндрю Золя
В компьютерном программировании схема (произносится как SKEE-мах) — это организация или структура базы данных, а в искусственном интеллекте (ИИ) схема — это формальное выражение правила вывода.
В первом случае деятельность по моделированию данных ведет к схеме. В последнем схема выводится из математики и представляет собой, по существу, обобщенную аксиому или выражение, в котором конкретные значения или случаи заменяются символами в гипотезе для получения конкретного вывода.
В последнем схема выводится из математики и представляет собой, по существу, обобщенную аксиому или выражение, в котором конкретные значения или случаи заменяются символами в гипотезе для получения конкретного вывода.
Слово «схема» происходит от греческого слова «форма» или «фигура». Однако то, как именно вы определяете схему, зависит от контекста. Существуют разные типы схем, и их значения тесно связаны с такими областями, как наука о данных, образование, маркетинг, SEO (поисковая оптимизация) и психология.
Что такое схема в базе данных?Схема базы данных похожа на скелетную структуру, представляющую логическое представление всей базы данных. Он разрабатывает все ограничения, применяемые к данным в конкретной базе данных. Всякий раз, когда организации занимаются моделированием данных, это приводит к схеме.
Люди часто используют схему, говоря как о реляционных базах данных, так и об объектно-ориентированных базах данных. Иногда это также относится к визуализации структуры или формального текстового описания.
Архитектура или план того, как будут отображаться данные, схема базы данных описывает форму данных и то, как они соотносятся с другими моделями, таблицами и базами данных. В этом сценарии запись базы данных является экземпляром схемы базы данных, содержащей все свойства, описанные в схеме.
Схема базы данных (обычно) широко делится на две категории: физическая схема базы данных, которая определяет, как на самом деле хранятся файлы, подобные данным; и логическая схема базы данных, которая описывает все логические ограничения, включая целостность, таблицы и представления, применяемые к хранимым данным.
Некоторые общие примеры схемы базы данных включают следующее:
- схема звезда
- схема снежинки
- схема созвездия фактов (или схема галактики)
Схема «звезда» — это простая схема хранилища данных, напоминающая звезду. Часто используемая для создания хранилищ данных схема «звезда» включает одну или несколько таблиц фактов и таблиц измерений. Он использует денормализованные данные.
Он использует денормализованные данные.
Как следует из названия, схема снежинки более сложна. Несмотря на это, схема «снежинка» является популярной схемой базы данных, поскольку в ней таблицы измерений нормализованы, что позволяет сэкономить место для хранения и свести к минимуму избыточность данных.
Схема созвездия фактов намного сложнее, чем схема звезды и схема снежинки. Он может похвастаться несколькими таблицами фактов, которые совместно используют несколько таблиц измерений.
Схема Snowflake использует нормализованные данные для организации данных таким образом, чтобы устранить избыточность и помочь уменьшить объем данных.Дальнейшее изучение различий между схемами «снежинка» и «звезда».
Что такое схема в SQL? База данных SQL включает в себя функции, индексы, таблицы и представления, и нет никаких ограничений, когда речь идет о количестве объектов, хранящихся в любой отдельной базе данных. Схемы SQL помогают определить эти объекты на логическом уровне. Пользователь, которому принадлежит эта схема, называется владельцем схемы.
Схемы SQL помогают определить эти объекты на логическом уровне. Пользователь, которому принадлежит эта схема, называется владельцем схемы.
Представление в SQL — это виртуальная таблица, состоящая из столбцов и строк на основе набора результатов инструкции. Внешние ключи и первичные ключи представляют отношения между одной таблицей и другой.
Что такое схема в SEO?Когда дело доходит до поисковой оптимизации (SEO), схемы играют решающую роль в определении различных объектов на веб-сайте. Это означает, что схемы помогают ясно объяснить поисковым роботам отношения между людьми, продуктами и вещами. Предоставляя этот дополнительный контент, сайты могут помочь поисковым роботам успешно сопоставить намерение поиска с контентом.
Схемы определяют тип ресурсов, которые поисковые роботы могут быстро просматривать без какой-либо дополнительной видимости или дополнительного контекста, который часто приводит к задержке. Этот подход также помогает улучшить видимость страницы результатов поисковой системы (SERP) для изображений, видео, часто задаваемых вопросов и многого другого.
Разметка Schema или метки, закодированные в HTML, добавляют контекст и делят важную информацию о страницах веб-сайта. По сути, он действует как HTML-указатель для пауков, которые просматривают ваш контент и предоставляют расширенные фрагменты в результатах поиска.
Хотя конкретное определение схемы зависит от контекста, в котором она используется, термин всегда восходит к своему греческому происхождению, означающему фигуру или форму. Что такое схема API?API (интерфейсы прикладного программирования) позволяют разрозненным частям программного обеспечения, службам и платформам обмениваться информацией и взаимодействовать. Вдохновленная схемой базы данных, схема API направлена на предоставление программистам и их API такого же рода руководств/коннекторов/дескрипторов для различных аспектов разработки приложений.
Создание языков описания API (API DL) сначала включило схему API, которая позже привела к сегодняшнему стандарту OpenAPI. Схема API, читаемая как людьми, так и машинами, описывает операции RESTful API и методы взаимодействия с API.
Схема API, читаемая как людьми, так и машинами, описывает операции RESTful API и методы взаимодействия с API.
Думайте о схеме API как о виртуальном руководстве по эксплуатации, расширяющем процессы программирования. Это упрощает использование API и делает его более доступным для обнаружения, а при правильном выполнении позволяет создавать SDK и документацию по API, созданную машиной.
Узнайте больше о схемах API, их истории и о том, как одна компания, занимающаяся разработкой облачных приложений, ориентированная на API, эффективно их использует.
Дополнительные виды схемыОбразование
В образовании схема — формы множественного числа — это схемы или схемы (часто используемые в академической письменной форме) — обычно представляет собой схему, план или диаграмму. Это общая идея о чем-то, что помогает студентам учиться.
Это общая идея о чем-то, что помогает студентам учиться.
Психология
Схема в психологии и других социальных науках описывает ментальное понятие. Он предоставляет информацию человеку о том, чего ожидать от различных переживаний и обстоятельств. Эти схемы разработаны и основаны на жизненном опыте и служат руководством для когнитивных процессов и поведения.
В психологии существует несколько видов схем, в том числе следующие:
- схемы событий
- схемы объектов
- человека схемы
- самосхемы
- социальные схемы
Социальные науки также используют слово схемы для классификации событий и объектов на основе общих характеристик и элементов, которые помогают интерпретировать и предсказывать мир.
Последнее обновление: май 2021 г.
Продолжить чтение О схеме- Краткий обзор трехуровневых стилей архитектуры
- Новый дизайн схемы хранилища данных приносит пользу бизнес-пользователям
- Руководство по переносу базы данных с открытым исходным кодом: переход
- Инструменты и советы по модернизации среды хранилища данных
Как получить структуру из неструктурированных данных
Автор: Энтони АдсхедStarRocks переносит базу данных OLAP с открытым исходным кодом в облако
Автор: Шон КернерMinIO расширяет возможности анализа Snowflake до любого местоположения данных
Автор: Адам АрмстронгКак создать схему базы данных в MySQL
Автор: Кэмерон Маккензи
- Alteryx представляет генеративный движок искусственного интеллекта, обновление Analytics Cloud
Давний поставщик управления данными разработал новый механизм искусственного интеллекта, который включает в себя генеративный искусственный интеллект.
 Он также представил новые возможности …
Он также представил новые возможности … - Microsoft представляет AI Boost для Power BI, новую Fabric для данных
Технический гигант представил инструмент, который дополнит его основную аналитическую платформу генеративным искусственным интеллектом, а также новый пакет SaaS …
- ThoughtSpot представляет новый инструмент, интегрирующий LLM OpenAI
Поставщик аналитики представил множество новых возможностей, в том числе Sage, которая объединяет технологию генеративного искусственного интеллекта OpenAI …
- AWS Control Tower стремится упростить управление несколькими учетными записями
Многие организации изо всех сил пытаются управлять своей огромной коллекцией учетных записей AWS, но Control Tower может помочь. Сервис автоматизирует …
- Разбираем модель ценообразования Amazon EKS
В модели ценообразования Amazon EKS есть несколько важных переменных.
 Покопайтесь в цифрах, чтобы убедиться, что вы развернули службу…
Покопайтесь в цифрах, чтобы убедиться, что вы развернули службу… - Сравните EKS и самоуправляемый Kubernetes на AWS
Пользователи
AWS сталкиваются с выбором при развертывании Kubernetes: запустить его самостоятельно на EC2 или позволить Amazon выполнить тяжелую работу с помощью EKS. См…
- 8 программных инструментов для обмена знаниями и совместной работы
Обмен знаниями и совместная работа являются основными элементами современного рабочего места благодаря удаленной и гибридной работе. Эти восемь инструментов могут …
- Каковы преимущества базы знаний?
Поскольку база знаний позволяет клиентам и сотрудникам быстро находить ответы, она может повысить оценку удовлетворенности клиентов организации…
- Как создать базу знаний WordPress
База знаний позволяет клиентам быстро находить ответы на свои вопросы, что приносит пользу CX.
 Организации могут использовать WordPress…
Организации могут использовать WordPress…
- Oracle ставит перед собой высокие национальные цели в области ЭУЗ с приобретением Cerner
Приобретя Cerner, Oracle нацелилась на создание национальной анонимной базы данных пациентов — дорога, заполненная …
- Благодаря Cerner Oracle Cloud Infrastructure получает импульс
Oracle планирует приобрести Cerner в рамках сделки на сумму около 30 миллиардов долларов. Второй по величине поставщик электронных медицинских карт в США может вдохнуть новую жизнь …
- Верховный суд встал на сторону Google в иске о нарушении авторских прав на Oracle API
Верховный суд постановил 6-2, что API-интерфейсы Java, используемые в телефонах Android, не подпадают под действие американского закона об авторском праве, в связи с чем …
- Обзор ERP: партнеры SAP представляют новые продукты на выставке Sapphire
На SAP Sapphire 2023 партнеры SAP и независимые поставщики программного обеспечения представили продукты и услуги, направленные на автоматизацию процессов, повышение безопасности и.
